

Automated Reconstruction of Existing Building Interior Scene BIMs Using a Feature-Enhanced Point Transformer and an Octree



Abstract
:1. Introduction
2. Literature Review
2.1. Semantic Segmentation
2.2. Object Segmentation
2.3. Reconstruction of an Existing Building BIM
3. Methodology
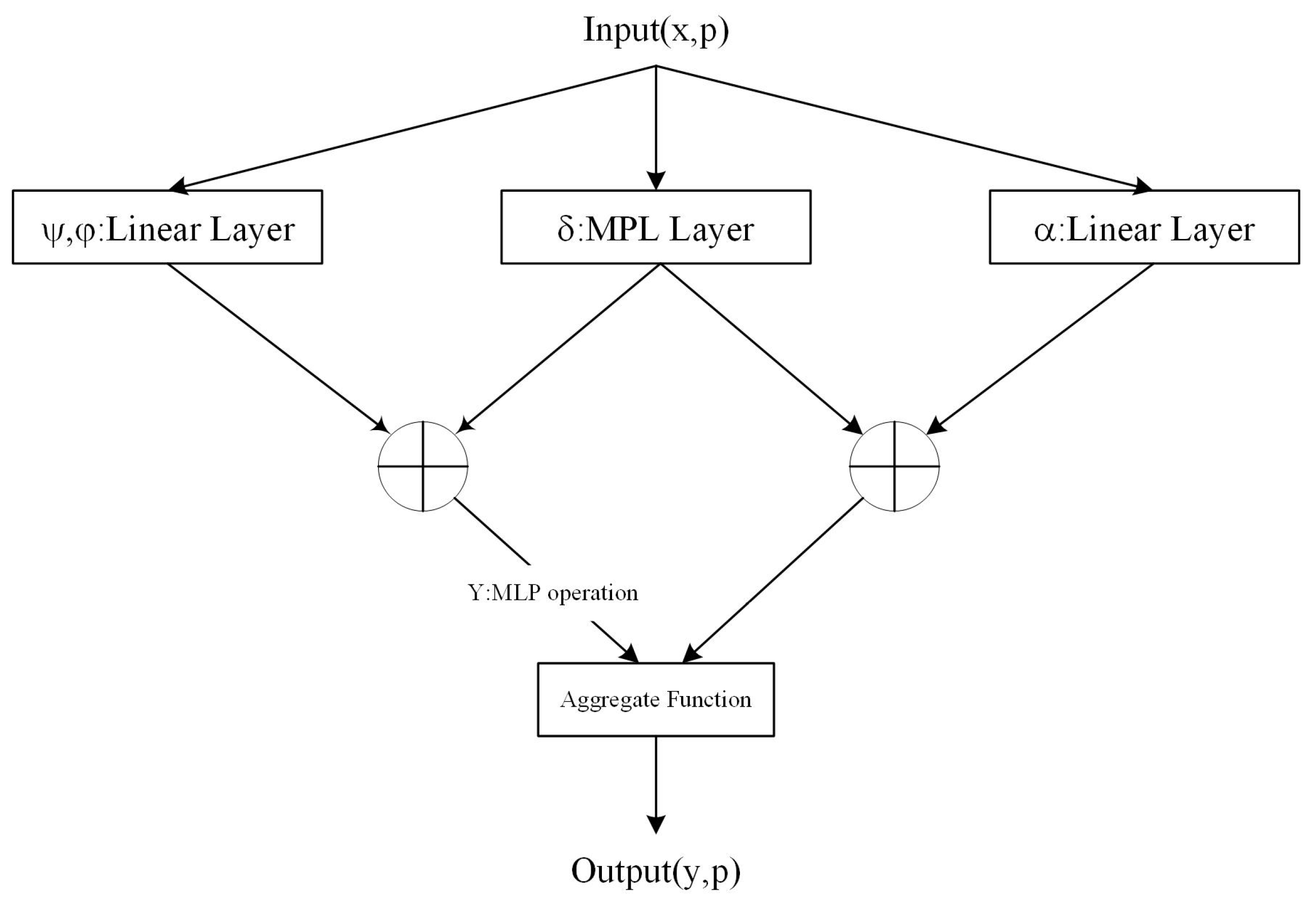
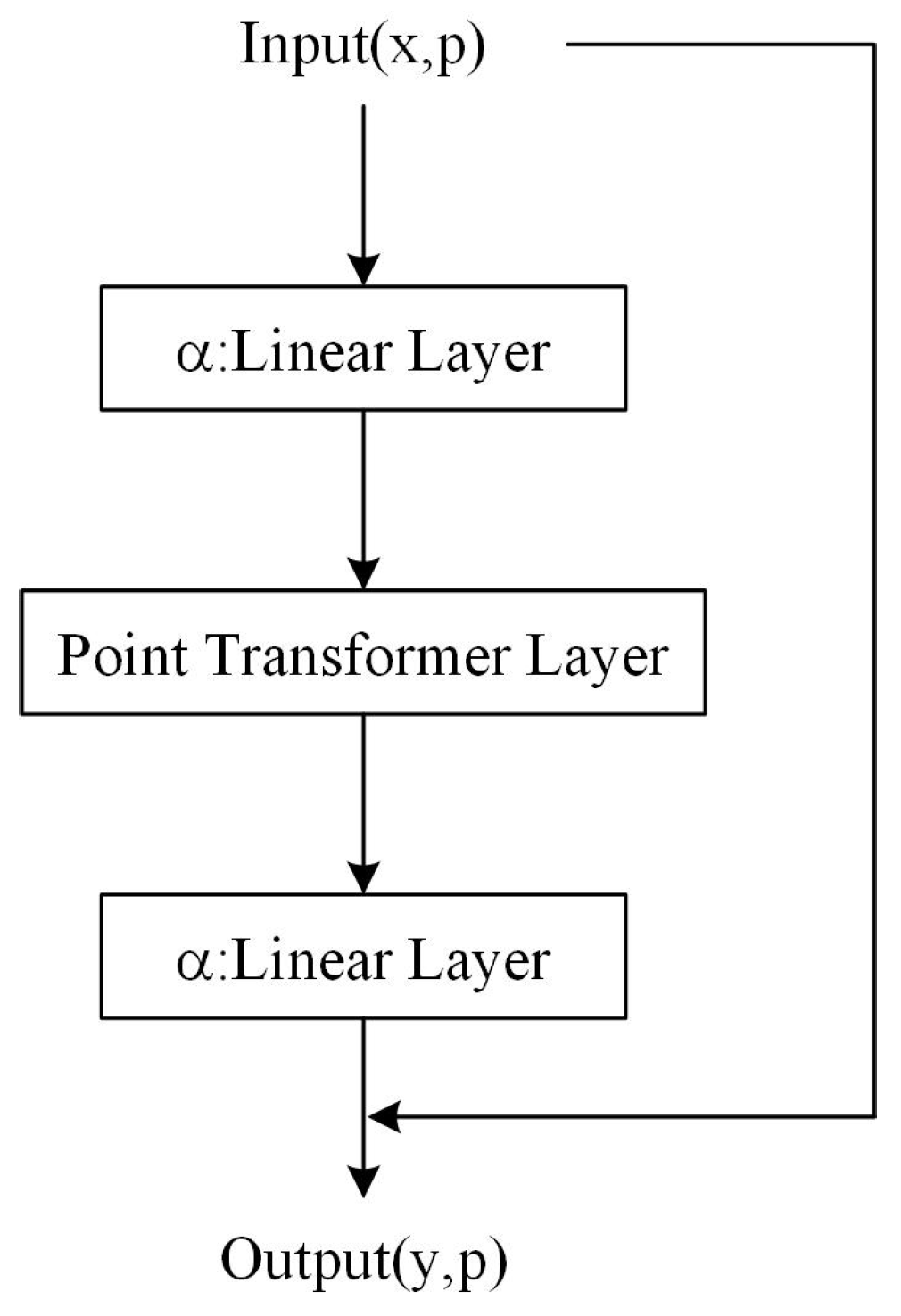
3.1. Feature-Enhanced Point Transformer
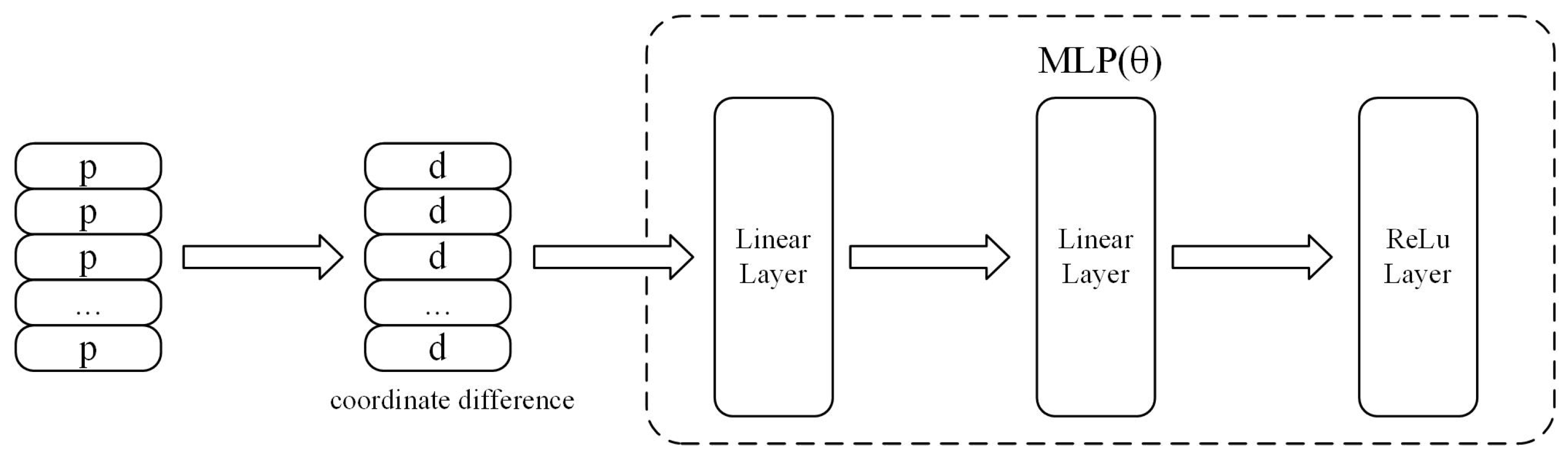
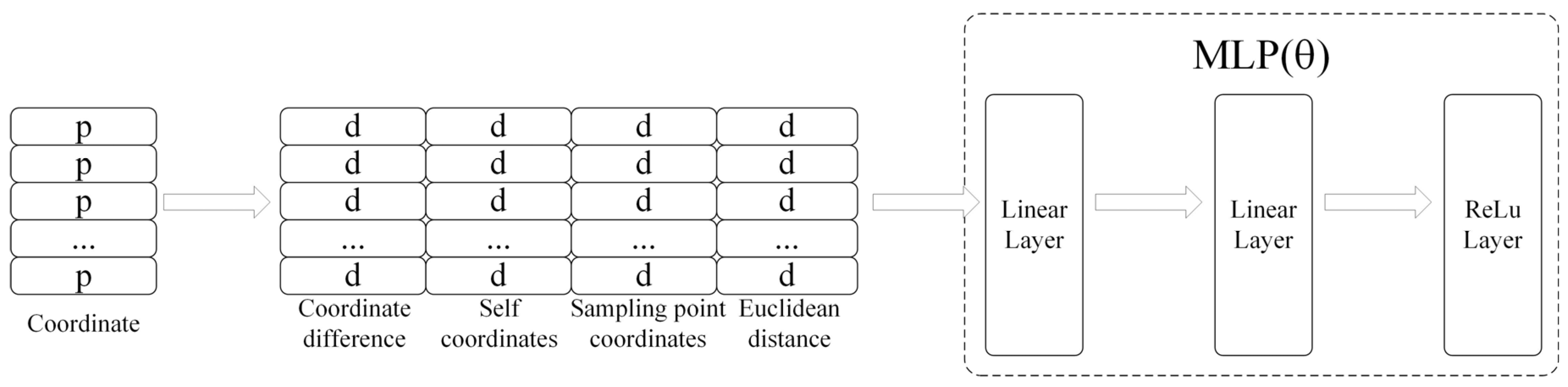
3.1.1. Feature Position Enhancement
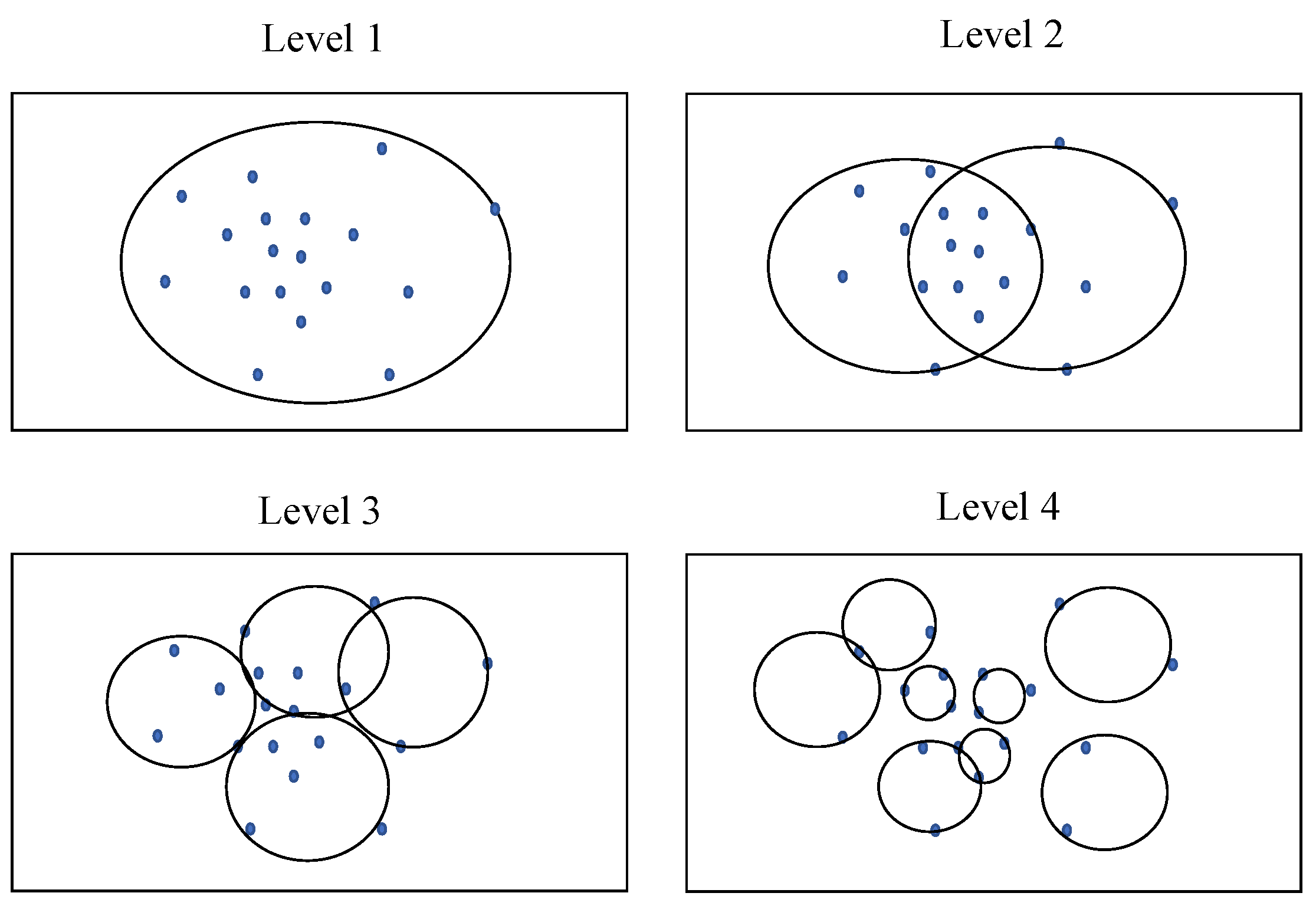
3.1.2. Ball Tree Downsampling Module
| Algorithm 1: Ball Tree Search Algorithm. |
| Function ball_tree_search is |
| Global: Q—Cache of k nearest neighbors (initially containing a point at infinity), q—Corresponding to Q, storing distances between points in Q and the test point |
| Input: k—Search for k nearest neighbors, t—Test point, node—Current node |
| Output: None |
| If distance(t, node.pivot) − node.radius ≥ max(q) then |
| Return |
| End if |
| If node is a leaf node, then |
| Add node.p to Q and update q accordingly |
| If there are more k nearest neighbors in Q, remove the point in Q that is farthest from the test point and update q accordingly |
| Otherwise |
| Recursively search the two child nodes of the current node |
| ball_tree_search(k, t, node.s1) |
| ball_tree_search(k, t, node.s2) |
| End if |
| End function |
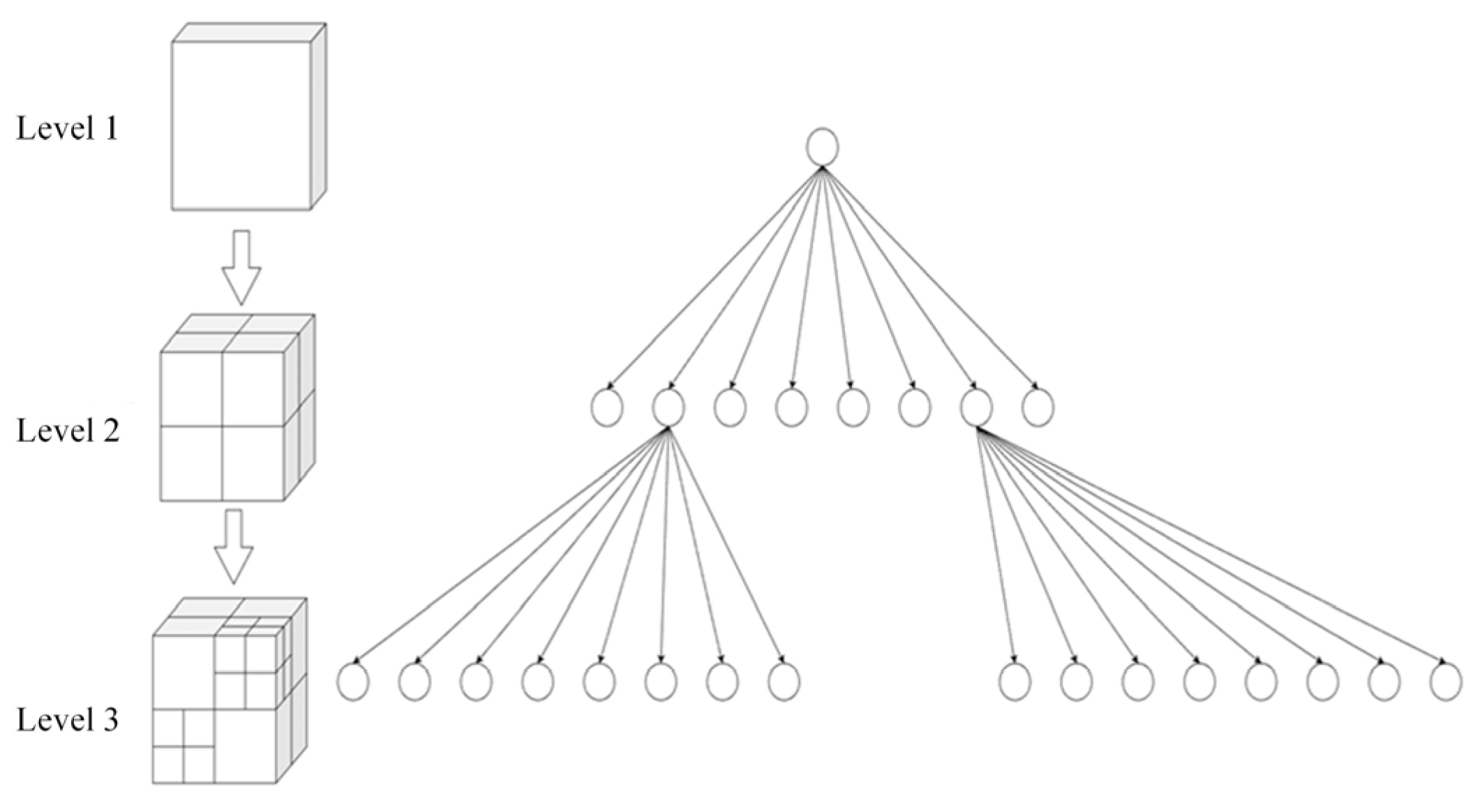
3.2. Octree Algorithm
- Set a maximum recursion depth to prevent infinite recursion and performance issues caused by excessive subdivisions;
- Determine the maximum size of the scene, which serves as the initial size of the cubic region;
- Add individual elements successively to the cubic regions that can contain them and do not have child nodes;
- If the current cubic region has not reached the maximum recursion depth, divide it into eight equal parts and allocate all individual elements to the child cubic regions;
- If the number of individual elements assigned to a child cubic region is the same as that of its parent cubic region, an additional subdivision is considered meaningless, and the subdivision process stops;
- Repeat steps 3–5 until the maximum recursion depth is reached.
4. Experimental Results and Analysis
4.1. Experimental Configuration
4.2. Feasibility Verification of the Feature-Enhanced Point Transformer
4.3. Results and Analysis
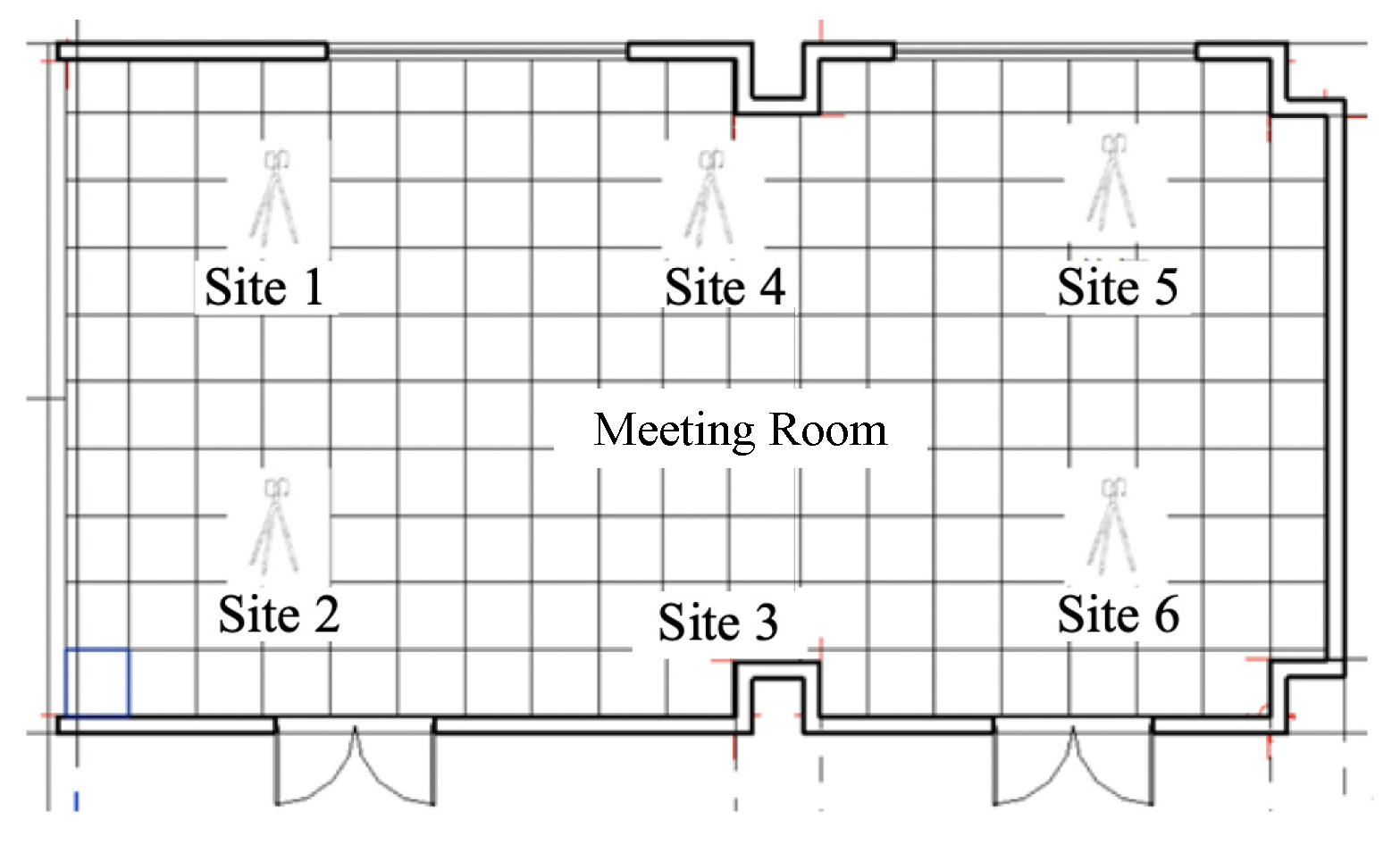
4.3.1. Data Collection
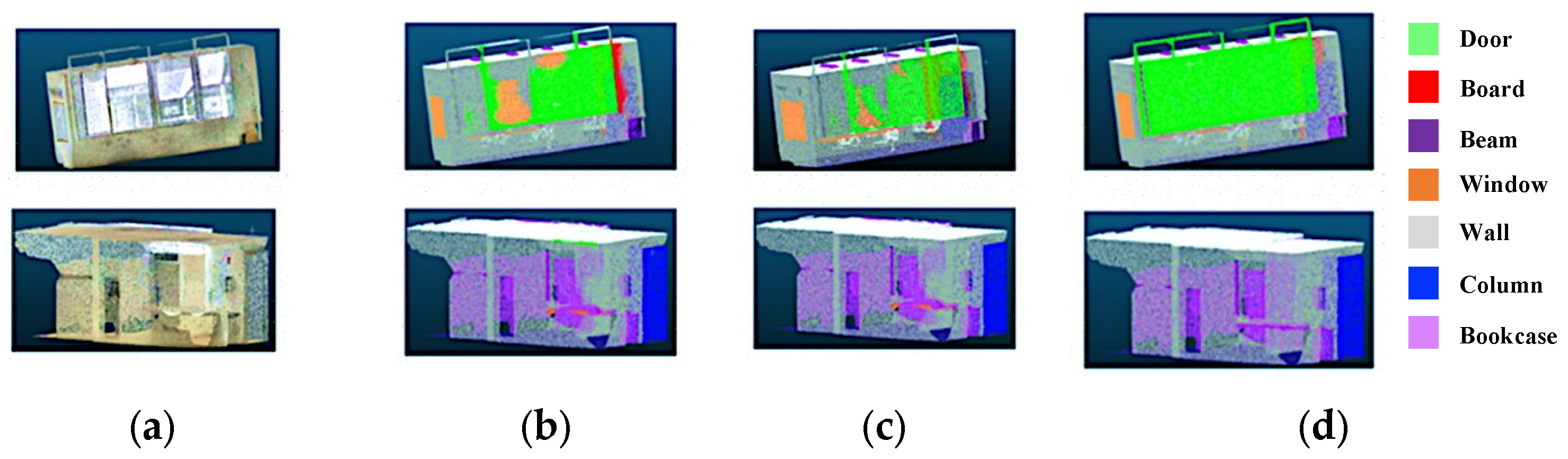
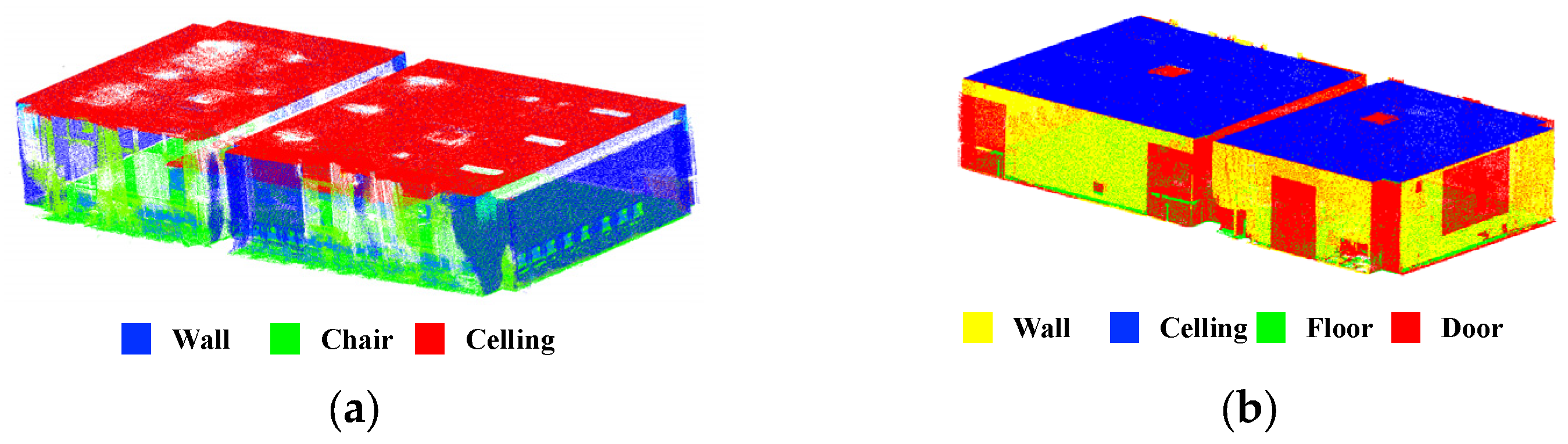
4.3.2. Semantic Segmentation
4.3.3. Object Segmentation
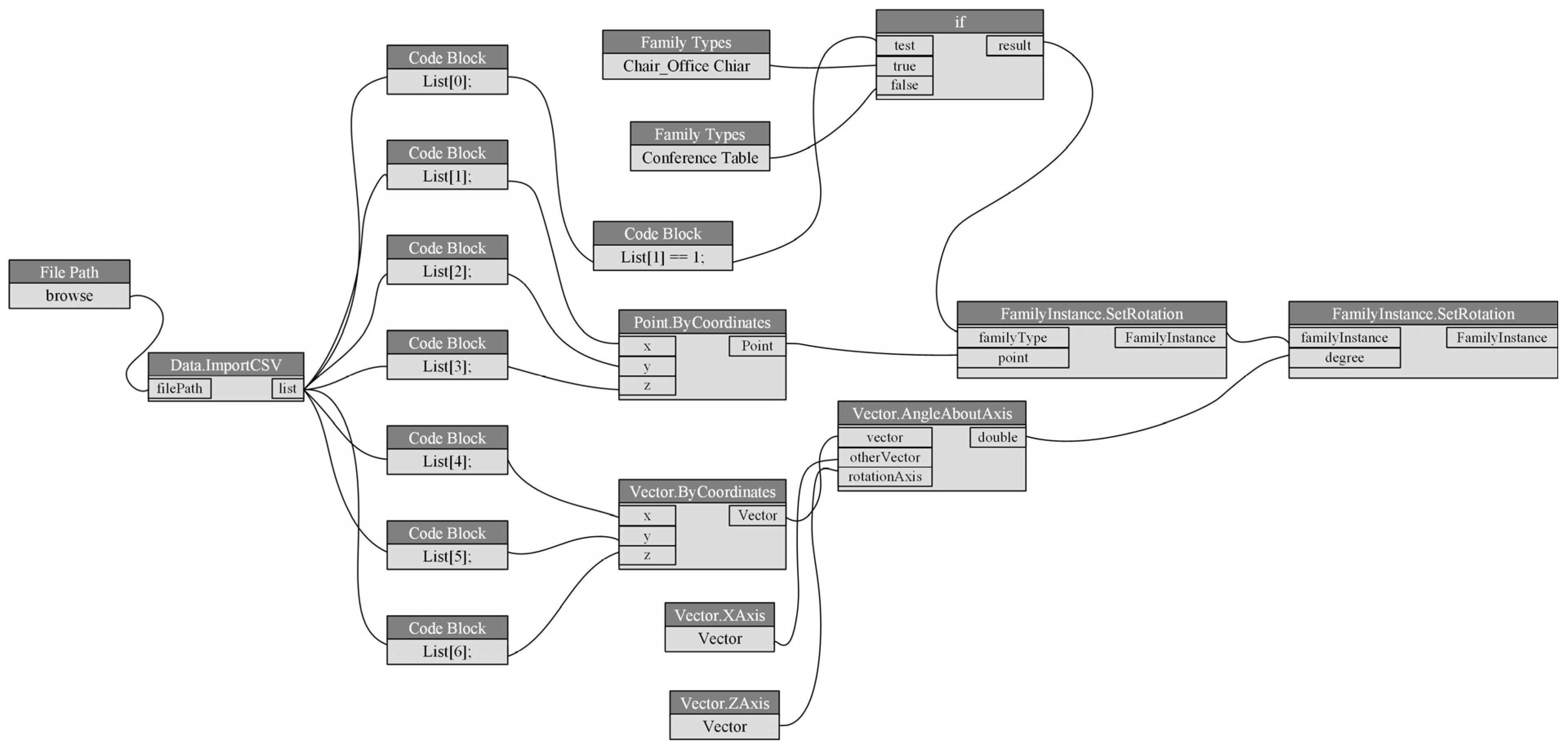
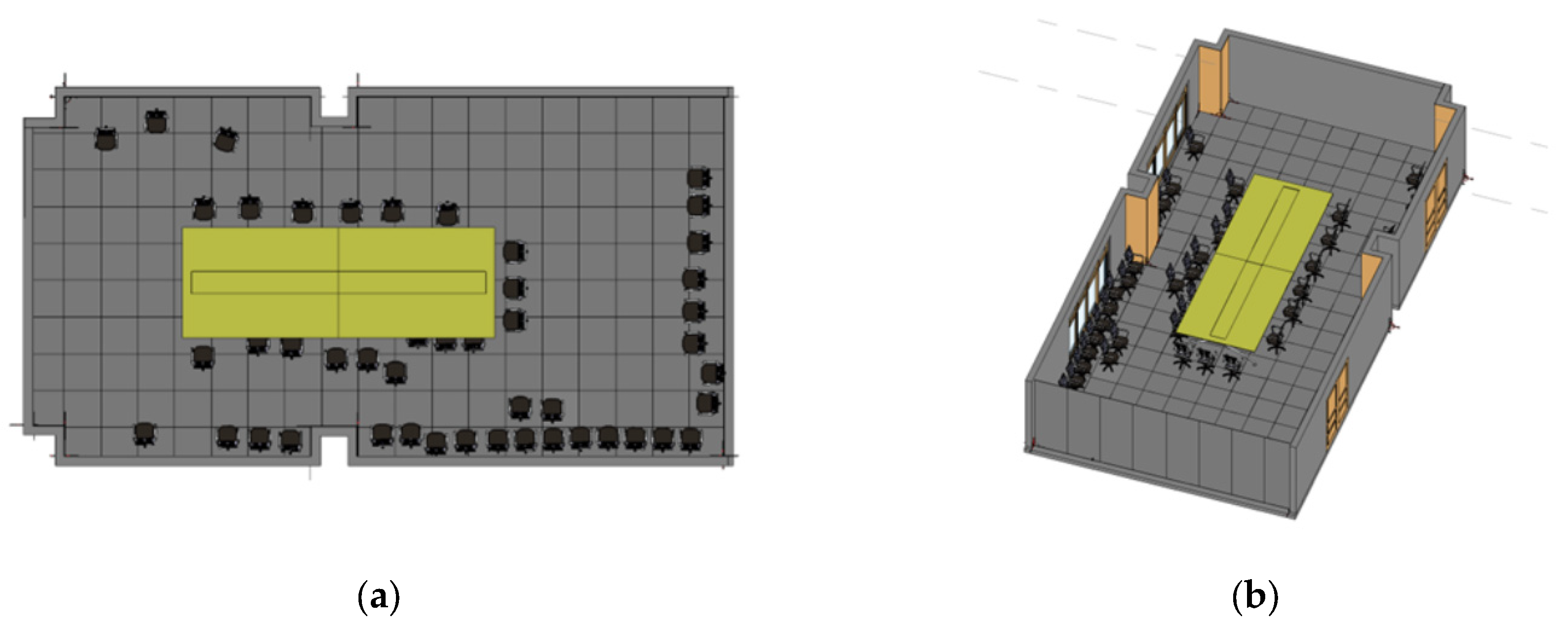
4.3.4. Automatic Reconstruction of the BIM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meyer, T.; Brunn, A.; Stilla, U. Change detection for indoor construction progress monitoring based on BIM, point clouds and uncertainties. Autom. Constr. 2022, 141, 104442. [Google Scholar] [CrossRef]
- Utkucu, D.; Sözer, H. Interoperability and data exchange within BIM platform to evaluate building energy performance and indoor comfort. Autom. Constr. 2020, 116, 103225. [Google Scholar] [CrossRef]
- Cao, Y.; Kamaruzzaman, S.; Aziz, N. Green Building Construction: A Systematic Review of BIM Utilization. Buildings 2022, 12, 1205. [Google Scholar] [CrossRef]
- Tang, S.; Shelden, D.R.; Eastman, C.M.; Pishdad-Bozorgi, P.; Gao, X. A review of building information modeling (BIM) and the internet of things (IoT) devices integration: Present status and future trends. Autom. Constr. 2019, 101, 127–139. [Google Scholar] [CrossRef]
- Hou, G.; Li, L.; Xu, Z.; Chen, Q.; Liu, Y.; Qiu, B. A BIM-Based Visual Warning Management System for Structural Health Monitoring Integrated with LSTM Network. KSCE J. Civ. Eng. 2021, 25, 2779–2793. [Google Scholar] [CrossRef]
- Farnsworth, C.B.; Beveridge, S.; Miller, K.R.; Christofferson, J.P. Application, Advantages, and Methods Associated with Using BIM in Commercial Construction. Int. J. Construct. Educ. Res. 2014, 11, 218–236. [Google Scholar] [CrossRef]
- Murali, S.; Speciale, P.; Oswald, M.R.; Pollefeys, M. Indoor Scan2BIM: Building information models of house interiors. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6126–6133. [Google Scholar] [CrossRef]
- Hichri, N.; Stefani, C.; De Luca, L.; Veron, P. Review of the “AS-BUILT BIM” Approaches. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-5/W1, 107–112. [Google Scholar] [CrossRef]
- Han, X.F.; Laga, H.; Bennamoun, M. Image-Based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1578–1604. [Google Scholar] [CrossRef]
- Hong, K.; Wang, H.; Zhu, B. Small Defect Instance Reconstruction Based on 2D Connectivity-3D Probabilistic Voting. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; pp. 1448–1453. [Google Scholar] [CrossRef]
- Garrido, M.; Paraforos, D.; Reiser, D.; Vázquez Arellano, M.; Griepentrog, H.; Valero, C. 3D Maize Plant Reconstruction Based on Georeferenced Overlapping LiDAR Point Clouds. Remote Sens. 2015, 7, 17077–17096. [Google Scholar] [CrossRef]
- Fan, B.; Kong, Q.; Wang, X.; Wang, Z.; Xiang, S.; Pan, C.; Fua, P. A Performance Evaluation of Local Features for Image-Based 3D Reconstruction. IEEE Trans. Image Process. 2019, 28, 4774–4789. [Google Scholar] [CrossRef]
- Asadi, K.; Ramshankar, H.; Noghabaei, M.; Han, K. Real-Time Image Localization and Registration with BIM Using Perspective Alignment for Indoor Monitoring of Construction. J. Comput. Civ. Eng. 2019, 33, 04019031. [Google Scholar] [CrossRef]
- Mahmood, B.; Han, S.; Lee, D.-E. BIM-Based Registration and Localization of 3D Point Clouds of Indoor Scenes Using Geometric Features for Augmented Reality. Remote Sens. 2020, 12, 2302. [Google Scholar] [CrossRef]
- Wang, B.; Wang, Q.; Cheng, J.C.P.; Song, C.; Yin, C. Vision-assisted BIM reconstruction from 3D LiDAR point clouds for MEP scenes. Autom. Constr. 2022, 133, 103997. [Google Scholar] [CrossRef]
- Yang, K.; Hu, X.; Bergasa, L.M.; Romera, E.; Huang, X.; Sun, D.; Wang, K. Can we pass beyond the field of view? Panoramic annular semantic segmentation for real-world surrounding perception. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 446–453. [Google Scholar] [CrossRef]
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16259–16268. [Google Scholar] [CrossRef]
- Guo, M.-H.; Cai, J.-X.; Liu, Z.-N.; Mu, T.-J.; Martin, R.R.; Hu, S.-M. PCT: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Du, R.; Ma, Z.; Xie, P.; He, Y.; Cen, H. PST: Plant segmentation transformer for 3D point clouds of rapeseed plants at the podding stage. ISPRS J. Photogramm. Remote Sens. 2023, 195, 380–392. [Google Scholar] [CrossRef]
- Ando, A.; Gidaris, S.; Bursuc, A.; Puy, G.; Boulch, A.; Marlet, R. RangeViT: Towards Vision Transformers for 3D Semantic Segmentation in Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5240–5250. [Google Scholar] [CrossRef]
- Ibrahim, M.; Akhtar, N.; Anwar, S.; Mian, A. SAT3D: Slot Attention Transformer for 3D Point Cloud Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5456–5466. [Google Scholar] [CrossRef]
- Schult, J.; Engelmann, F.; Hermans, A.; Litany, O.; Tang, S.; Leibe, B. Mask3D: Mask Transformer for 3D Semantic Instance Segmentation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 8216–8223. [Google Scholar] [CrossRef]
- Zhao, B.; Hua, X.; Yu, K.; Xuan, W.; Chen, X.; Tao, W. Indoor Point Cloud Segmentation Using Iterative Gaussian Mapping and Improved Model Fitting. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7890–7907. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhao, D.; Cheng, D.; Zhang, J.; Tian, D. A Fast and Precise Plane Segmentation Framework for Indoor Point Clouds. Remote Sens. 2022, 14, 3519. [Google Scholar] [CrossRef]
- Fotsing, C.; Hahn, P.; Cunningham, D.; Bobda, C. Volumetric wall detection in unorganized indoor point clouds using continuous segments in 2D grids. Autom. Constr. 2022, 141, 104462. [Google Scholar] [CrossRef]
- Hsieh, C.-S.; Ruan, X.-J. Automated Semantic Segmentation of Indoor Point Clouds from Close-Range Images with Three-Dimensional Deep Learning. Buildings 2023, 13, 468. [Google Scholar] [CrossRef]
- Li, Y.; Xu, W.; Chen, H.; Jiang, J.; Li, X. A Novel Framework Based on Mask R-CNN and Histogram Thresholding for Scalable Segmentation of New and Old Rural Buildings. Remote Sens. 2021, 13, 1070. [Google Scholar] [CrossRef]
- Xu, Z.; Baojie, X.; Guoxin, W. Canny edge detection based on Open CV. In Proceedings of the 2017 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 20–22 October 2017; pp. 53–56. [Google Scholar] [CrossRef]
- Macher, H.; Landes, T.; Grussenmeyer, P. Point clouds segmentation as base for as-built BIM creation. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II-5/W3, 191–197. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Liang, Z.; Li, Z.; Xu, S.; Tan, M.; Jia, K. Instance segmentation in 3D scenes using semantic superpoint tree networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2783–2792. [Google Scholar] [CrossRef]
- Liu, Z.; Qi, X.; Fu, C.-W. One thing one click: A self-training approach for weakly supervised 3d semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1726–1736. [Google Scholar] [CrossRef]
- Shen, T.; Gao, J.; Kar, A.; Fidler, S. Interactive annotation of 3D object geometry using 2D scribbles. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVII 16, 2020. pp. 751–767. [Google Scholar] [CrossRef]
- Kontogianni, T.; Celikkan, E.; Tang, S.; Schindler, K. Interactive Object Segmentation in 3D Point Clouds. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2891–2897. [Google Scholar] [CrossRef]
- Vo, A.-V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Cui, M.; Long, J.; Feng, M.; Li, B.; Kai, H. OctFormer: Efficient octree-based transformer for point cloud compression with local enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 470–478. [Google Scholar] [CrossRef]
- Yuan, G.; Fu, Q.; Mi, Z.; Luo, Y.; Tao, W. SSRNet: Scalable 3D Surface Reconstruction Network. IEEE Trans. Visual Comput. Graph. 2022, 29, 4906–4919. [Google Scholar] [CrossRef] [PubMed]
- López, F.; Lerones, P.; Llamas, J.; Gómez-García-Bermejo, J.; Zalama, E. A Review of Heritage Building Information Modeling (H-BIM). Multimodal Technol. Interact. 2018, 2, 21. [Google Scholar] [CrossRef]
- Zhao, Y.; Deng, X.; Lai, H. Reconstructing BIM from 2D structural drawings for existing buildings. Autom. Constr. 2021, 128, 103750. [Google Scholar] [CrossRef]
- Domínguez, B.; García, Á.L.; Feito, F.R. Semiautomatic detection of floor topology from CAD architectural drawings. Comput.-Aided Des. 2012, 44, 367–378. [Google Scholar] [CrossRef]
- Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Improved Automatic Analysis of Architectural Floor Plans. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 864–869. [Google Scholar] [CrossRef]
- Ma, J.W.; Czerniawski, T.; Leite, F. Semantic segmentation of point clouds of building interiors with deep learning: Augmenting training datasets with synthetic BIM-based point clouds. Autom. Constr. 2020, 113, 103144. [Google Scholar] [CrossRef]
- Lu, G.; Yan, Y.; Sebe, N.; Kambhamettu, C. Indoor localization via multi-view images and videos. Comput. Vis. Image Underst. 2017, 161, 145–160. [Google Scholar] [CrossRef]
- Hamledari, H.; McCabe, B.; Davari, S. Automated computer vision-based detection of components of under-construction indoor partitions. Autom. Constr. 2017, 74, 78–94. [Google Scholar] [CrossRef]
- Zhao, Y.; Deng, X.; Lai, H. A Deep Learning-Based Method to Detect Components from Scanned Structural Drawings for Reconstructing 3D Models. Appl. Sci. 2020, 10, 2066. [Google Scholar] [CrossRef]
- Xue, F.; Lu, W.; Chen, K. Automatic Generation of Semantically Rich As-Built Building Information Models Using 2D Images: A Derivative-Free Optimization Approach. Comput. Aided Civil Infrastruct. Eng. 2018, 33, 926–942. [Google Scholar] [CrossRef]
- Ma, Z.; Liu, S. A review of 3D reconstruction techniques in civil engineering and their applications. Adv. Eng. Inf. 2018, 37, 163–174. [Google Scholar] [CrossRef]
- Adam, A.; Chatzilari, E.; Nikolopoulos, S.; Kompatsiaris, I. H-Ransac: A Hybrid Point Cloud Segmentation Combining 2d and 3d Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, IV-2, 1–8. [Google Scholar] [CrossRef]
- Bassier, M.; Van Genechten, B.; Vergauwen, M. Classification of sensor independent point cloud data of building objects using random forests. J. Build. Eng. 2019, 21, 468–477. [Google Scholar] [CrossRef]
- Abeywickrama, T.; Cheema, M.A.; Taniar, D. k-nearest neighbors on road networks: A journey in experimentation and in-memory implementation. Proc. VLDB Endow. 2016, 9, 492–503. [Google Scholar] [CrossRef]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2107–2115. [Google Scholar] [CrossRef]
- Lu, B.; Wang, Q.; Li, A.N. Massive Point Cloud Space Management Method Based on Octree-Like Encoding. Arab. J. Sci. Eng. 2019, 44, 9397–9411. [Google Scholar] [CrossRef]
- Wang, P.-S.; Liu, Y.; Guo, Y.-X.; Sun, C.-Y.; Tong, X. O-CNN: Octree-based convolutional neural networks for 3d shape analysis. ACM Trans. Graph. 2017, 36, 1–11. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1534–1543. [Google Scholar] [CrossRef]
- Divin, N.V. BIM by using Revit API and Dynamo. A review. AlfaBuild 2020, 14, 1404. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction Model | mIoU (%) | OA (%) |
|---|---|---|
| Point Net | 42.70 | 79.1 |
| Point Net++ | 49.39 | 81.1 |
| Point Transformer (k = 16) | 70.3 | 90.8 |
| Point Transformer (k = 64) | 70.8 | 91.2 |
| Feature-Enhanced Point Transformer (r = 0.1) | 70.6 | 91.1 |
| Feature-Enhanced Point Transformer (r = 0.2) | 71.3 | 91.9 |
| Class | Point Transformer (k = 64) (%) | Feature-Enhanced Point Transformer (%) |
|---|---|---|
| mIoU | 70.8 | 71.3 |
| Ceiling | 95 | 95.3 |
| Floor | 98.5 | 98.6 |
| Wall | 88.3 | 89.1 |
| Beam | 0 | 0.1 |
| Column | 38 | 37.8 |
| Window | 64.4 | 63.5 |
| Door | 74.3 | 74.1 |
| Table | 89.1 | 89.3 |
| Chair | 84.4 | 85.6 |
| Sofa | 74.3 | 76.1 |
| Bookcase | 80.2 | 81.3 |
| Board | 76 | 77.1 |
| Clutter | 58.3 | 58.9 |
| Label | ||||||
|---|---|---|---|---|---|---|
| Desk | 3.042 | 3.291 | 0.560 | 0.802 | −0.479 | 0.999 |
| Chair #1 | 2.467 | 5.118 | 0.619 | −0.032 | −0.013 | 0.999 |
| Chair #2 | 0.227 | 0.213 | 0.048 | −0.038 | 0.015 | 0.999 |
| Chair #3 | 3.382 | 1.741 | 0.449 | 0.057 | 0.010 | 0.998 |
| Chair #4 | 2.802 | 1.834 | 0.467 | 0.038 | 0.018 | 0.999 |
| Chair #5 | 1.547 | 1.967 | 0.451 | 0.064 | 0.007 | 0.998 |
| Chair #6 | 1.016 | 4.706 | 0.454 | 0.036 | 0.003 | 0.999 |
| Chair #7 | 1.206 | 4.764 | 0.537 | 0.036 | 0.003 | 0.999 |
| Chair #8 | 1.275 | 7.329 | 0.505 | 0.042 | 0.003 | 0.999 |
| Chair #9 | 2.485 | 4.611 | 0.508 | 0.050 | 0.031 | 0.998 |
| NO. | BIM Distances | Design Distances | Errors |
|---|---|---|---|
| Point #0–Point #1 | 779.516 mm | 780 mm | −0.484 mm |
| Point #1–Point #2 | 801.626 mm | 800 mm | −1.570 mm |
| Point #2–Point #3 | 80.962 mm | 80 mm | −0.962 mm |
| Point #3–Point #4 | 517.951 mm | 520 mm | 2.049 mm |
| Point #4–Point #5 | 80.144 mm | 80 mm | −0.144 mm |
| Point #5–Point #6 | 80.114 mm | 80 mm | −0.114 mm |
| Point #6–Point #7 | 613.223 mm | 620 mm | 6.777 mm |
| Point #7–Point #8 | 80.144 mm | 80 mm | −0.144 mm |
| Point #8–Point #9 | 80.114 mm | 80 mm | −0.114 mm |
| Point #9–Point #10 | 517.951 mm | 520 mm | 2.049 mm |
| Point #10–Point #11 | 80.962 mm | 80 mm | −0.962 mm |
| Point #11–Point #12 | 260.061 mm | 260 mm | −0.061 mm |
| Average error | ±1.276 mm | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Liang, Y.; Xie, Z.; Wang, S.; Xu, Z. Automated Reconstruction of Existing Building Interior Scene BIMs Using a Feature-Enhanced Point Transformer and an Octree. Appl. Sci. 2023, 13, 13239. https://doi.org/10.3390/app132413239
Chen J, Liang Y, Xie Z, Wang S, Xu Z. Automated Reconstruction of Existing Building Interior Scene BIMs Using a Feature-Enhanced Point Transformer and an Octree. Applied Sciences. 2023; 13(24):13239. https://doi.org/10.3390/app132413239
Chicago/Turabian StyleChen, Junwei, Yangze Liang, Zheng Xie, Shaofeng Wang, and Zhao Xu. 2023. "Automated Reconstruction of Existing Building Interior Scene BIMs Using a Feature-Enhanced Point Transformer and an Octree" Applied Sciences 13, no. 24: 13239. https://doi.org/10.3390/app132413239
APA StyleChen, J., Liang, Y., Xie, Z., Wang, S., & Xu, Z. (2023). Automated Reconstruction of Existing Building Interior Scene BIMs Using a Feature-Enhanced Point Transformer and an Octree. Applied Sciences, 13(24), 13239. https://doi.org/10.3390/app132413239