

Using LSTM to Identify Help Needs in Primary School Scratch Students



Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Research Context and Technological Choices
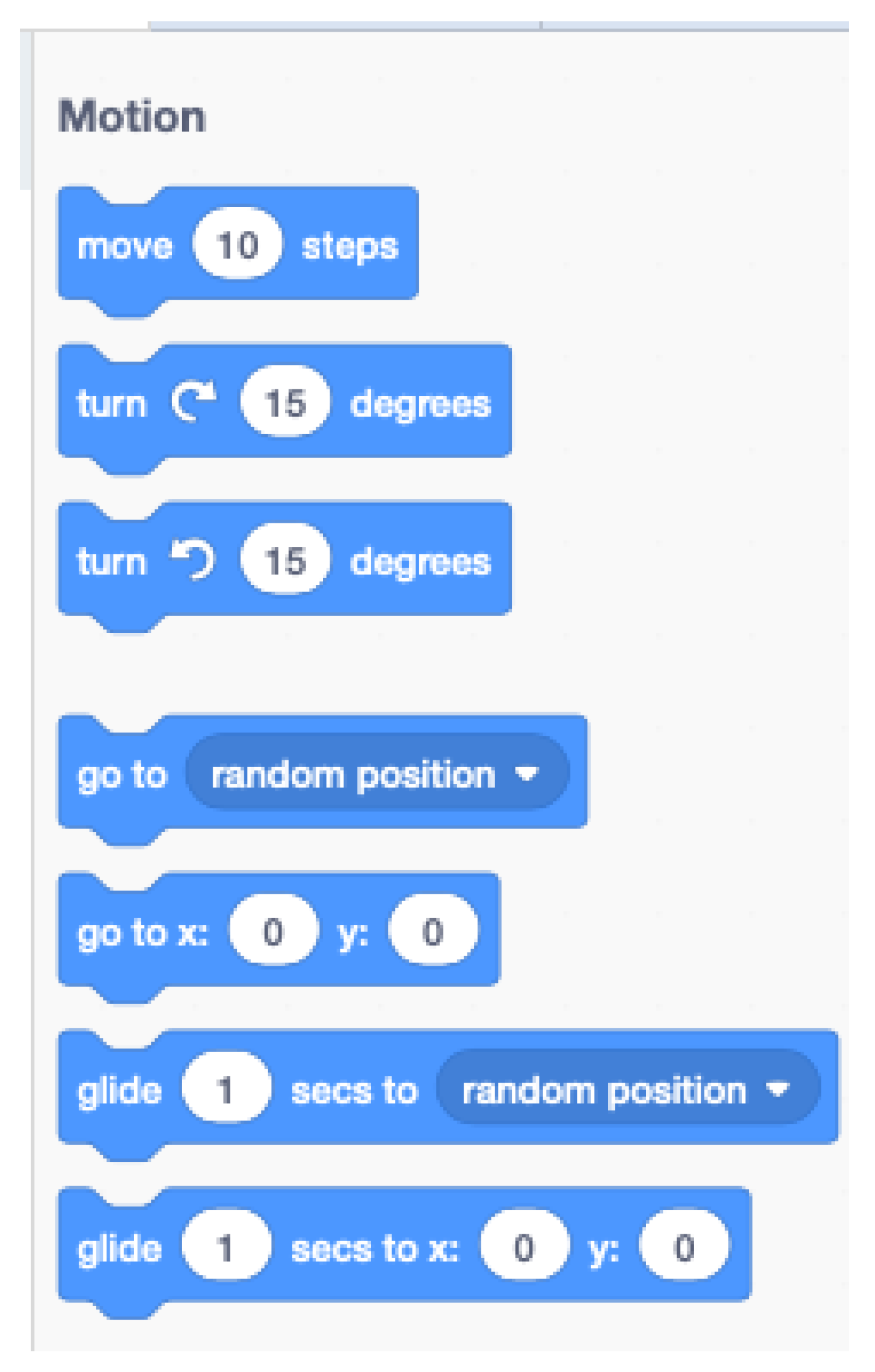
2.1.1. Block-Based Programming Interfaces in Primary School
2.1.2. Distance Calculation Methods in Block-Based Programming Languages
2.1.3. Time-Series Based Models
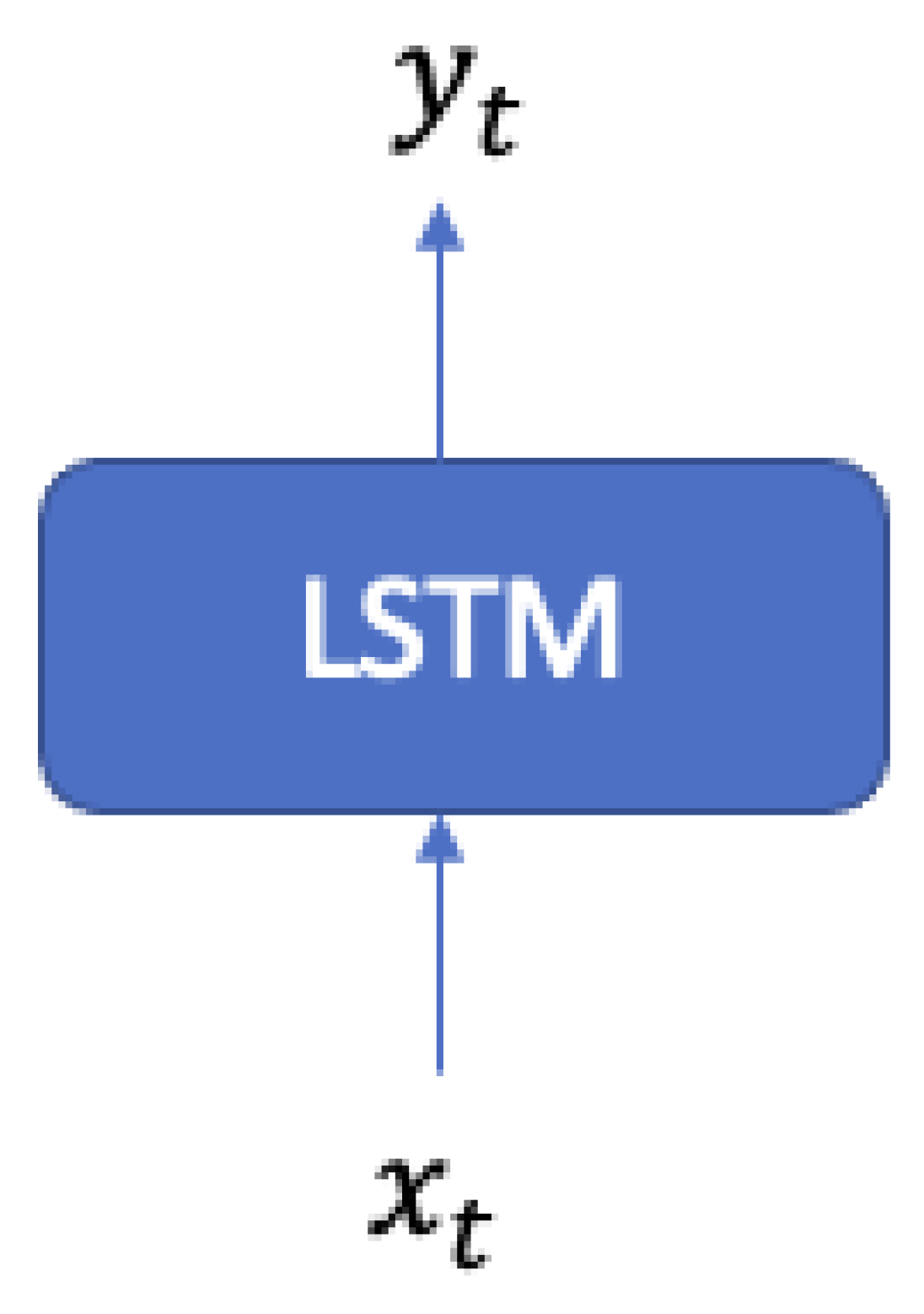
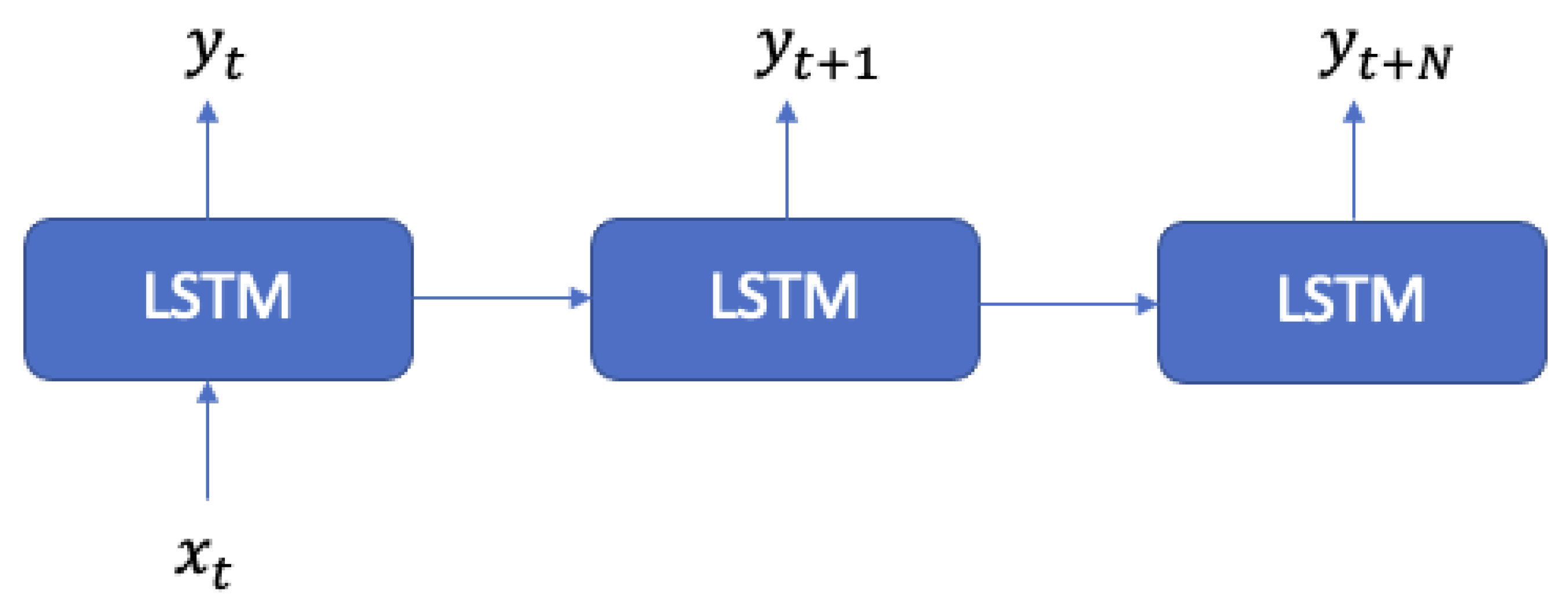
- One-to-one (Figure 1): One input and one output are suitable for classification tasks, but not for time series models;
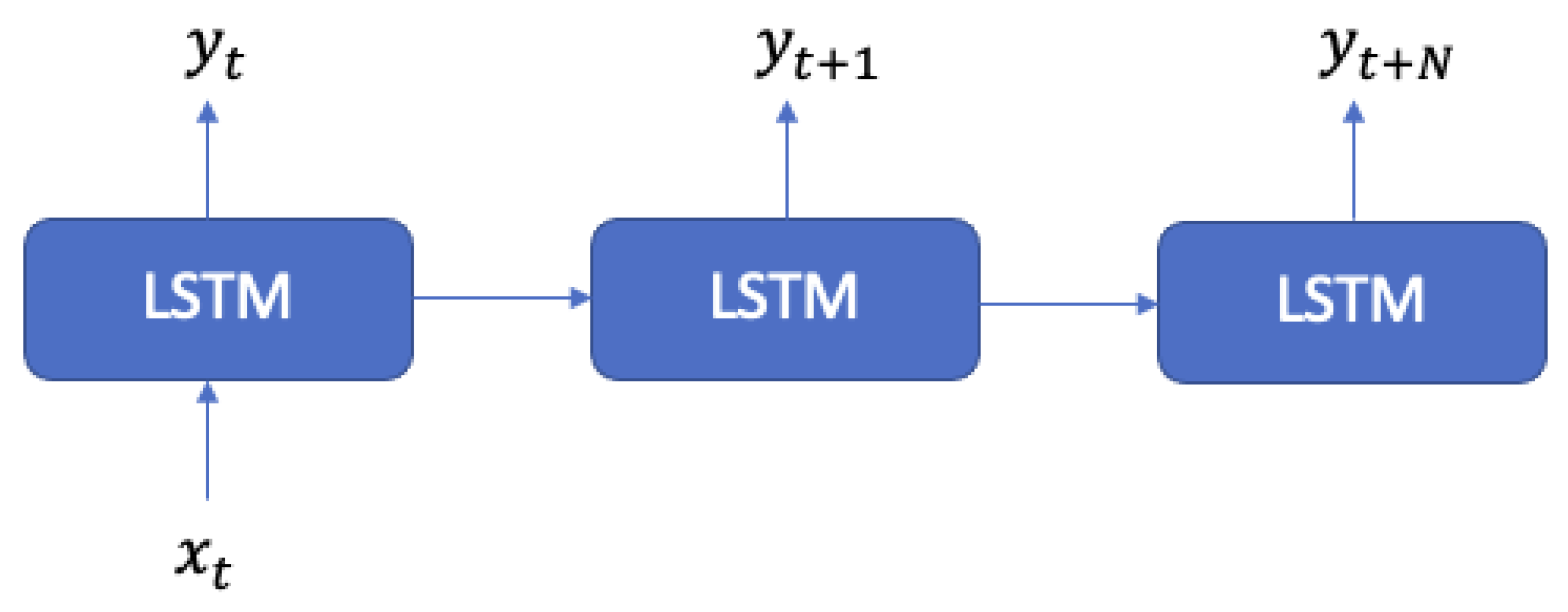
- One-to-many (Figure 2): This model converts an input into a sequence;
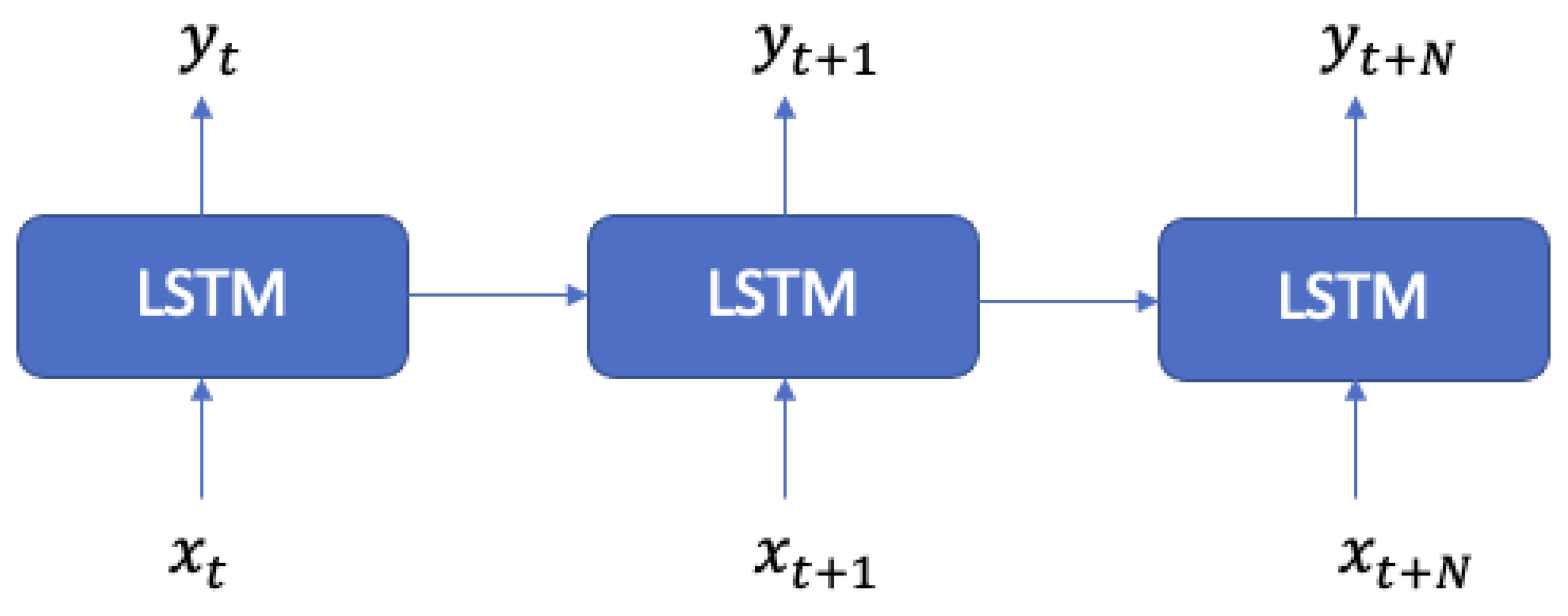
- Many-to-many (Figure 3): This model is a sequence to sequence generator;
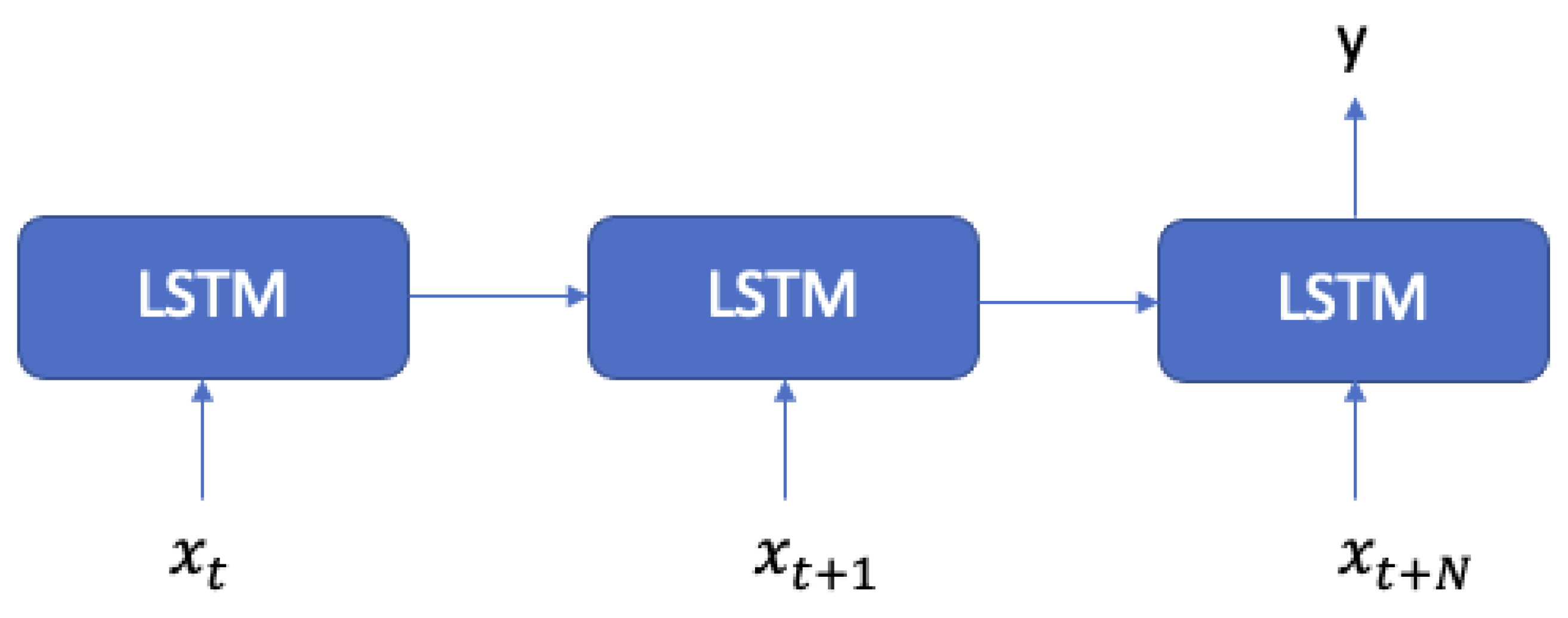
- Many-to-one (Figure 4): This model is suitable for a prediction or classification from a sequence.
2.1.4. Ethics in Education
- Tools focused on student assistance: they help students to understand the subject being studied and increase their motivation. An incorrect categorization of students by groups can lead to presenting students with tasks of inappropriate difficulty;
- Tools focused on teacher assistance: they help teachers to focus their time and effort on identifying which students need more help. An incorrect diagnosis about which students need more help can lead the teacher to focus on those who, in fact, require less attention;
- Tools focused on educational administration: they relate to problems found in the classroom with the didactic material. In these tools, errors usually come from an incorrect identification of the student profile or from an incorrect evaluation of the didactic material.
- Beneficence: technology must be beneficial to humanity;
- No maleficence: technology must be prevented from causing harm, particularly focused on privacy violations;
- Autonomy: technology should empower people’s autonomy, allowing them to choose what they delegate to technology and what not;
- Justice: technology must be fair, avoiding any kind of discrimination;
- Explicability: technology must be transparent, understandable, and interpretable by people, so that they understand the logic that the AI has followed, and are thus able to identify and correct errors.
- Use an ethical approach to the user experiences conducted to collect data for our research, taking into account the standards of the Universidad Nacional de Educación a Distancia (UNED) Research Ethics Committee and the Guide for research ethics committee members of the Council of Europe (https://www.coe.int/en/web/bioethics/guide-for-research-ethics-committees-members, accessed on 27 November 2023).
- Respect the five standard fundamental ethical principles to guide the development of AI applications, with a focus on developing affective robot tutors that support autonomous learning in a transparent way by acting as a support and not as a substitute for the human teacher (avoiding dehumanisation of teaching), and that do not act in a discriminatory way and take into account the idiosyncrasies of each student.
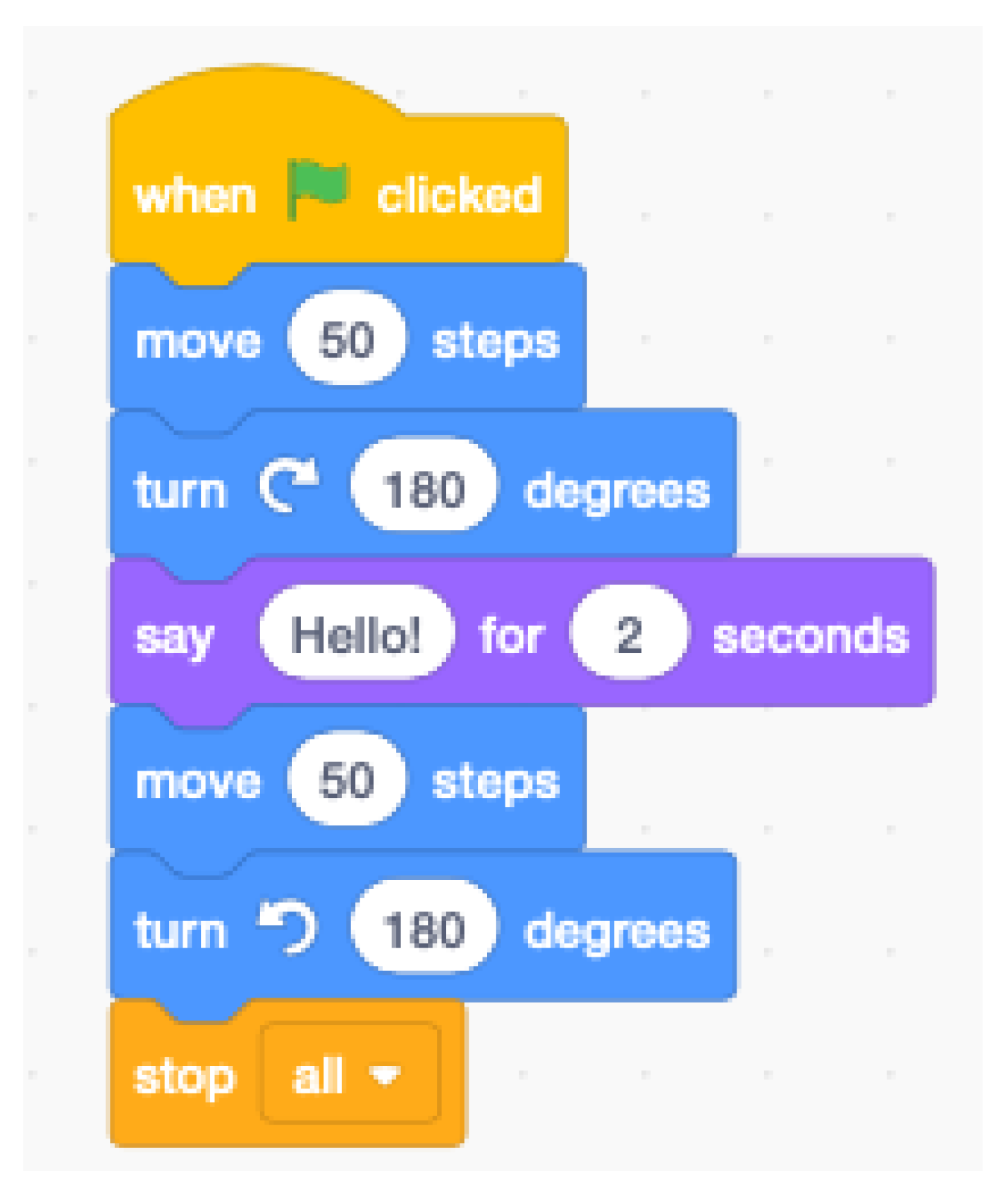
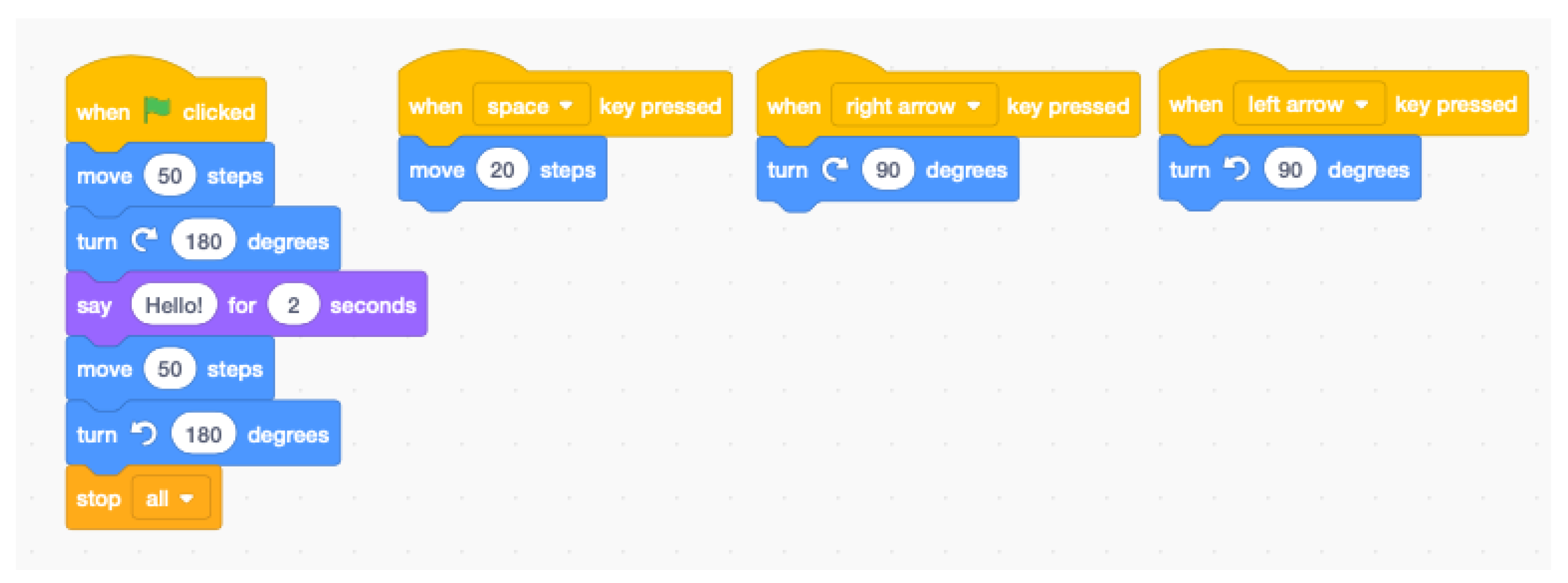
2.2. User Experience with Scratch
- We first sent the informed consent to the parents or legal guardians of the students. Before the students participated, both parents or legal guardians had enough time to consider participation;
- Then, the students whose parents had authorized their participation started by filling out a questionnaire.
- After that, they started the experience by carrying out the assessments. During them, they could not request any kind of help to evaluate the real prior knowledge of Scratch, but they could exit from the assessment at any time. Once the students had completed or exited from all the assessments, the knowledge level was set;
- Finally, the students could start performing the Scratch exercises in their preferred order. In those exercises they could ask for help and also switch to another exercise at any time.
- Student data:
- -
- Student number: the student number was randomly assigned to the student;
- -
- Gender: provided by the student in the opening questionnaire and stored in numerical format (1 for boy and 2 for girl);
- -
- Mother tongue: provided by the student in the opening questionnaire. It is a boolean field that indicates if the student’s mother tongue is Spanish or not. Given that the exercises and the user experiences were carried out in Spanish, we think that the variable “language” may affect whether a student understands the statements of the exercises and the teacher’s explanations. Therefore, this variable could influence the number of help requests made by the students;
- -
- Age: provided by the student in the opening questionnaire;
- -
- Competence: set by the aforementioned starting assessments.
- Exercise data:
- -
- Name: exercise name;
- -
- Description: exercise description;
- -
- Skills: each exercise may help to improve students’ CT skills to different degrees. These skills and their degrees (which are numerical values from 0 to 10) were set by experts;
- -
- Evaluation: indicates if the exercise is an evaluation level exercise or not.
- Solution distance data: family distance, element distance, position distance, input distance, total distance (explained in Section 2.3).
- Interaction data:
- -
- Date time: date and time of the interaction;
- -
- Request help: indicates if the student requested help or not;
- -
- Seconds help open: when a student requested help, this parameter indicates how many seconds the help popup was open before the student closed it;
- -
- Last login: date and time of the student’s last login.
- Workspace data:
- -
- Elements: block elements that the student currently has in their workspace. This information is then used to calculate the distance between the student workspace and the solution.
2.3. Distance Calculation for Block-Based Programming Languages
- Block family;
- Block;
- Block position;
- Block inputs values.
2.3.1. Block Family Distance Calculation
2.3.2. Block Distance Calculation
- , the set of blocks in the student’s workspace.
- , the set of blocks in the solution.
- , the incorrect block set.
2.3.3. Block Position Distance Calculation
2.3.4. Block Input Values Distance Calculation
2.3.5. Total Distance
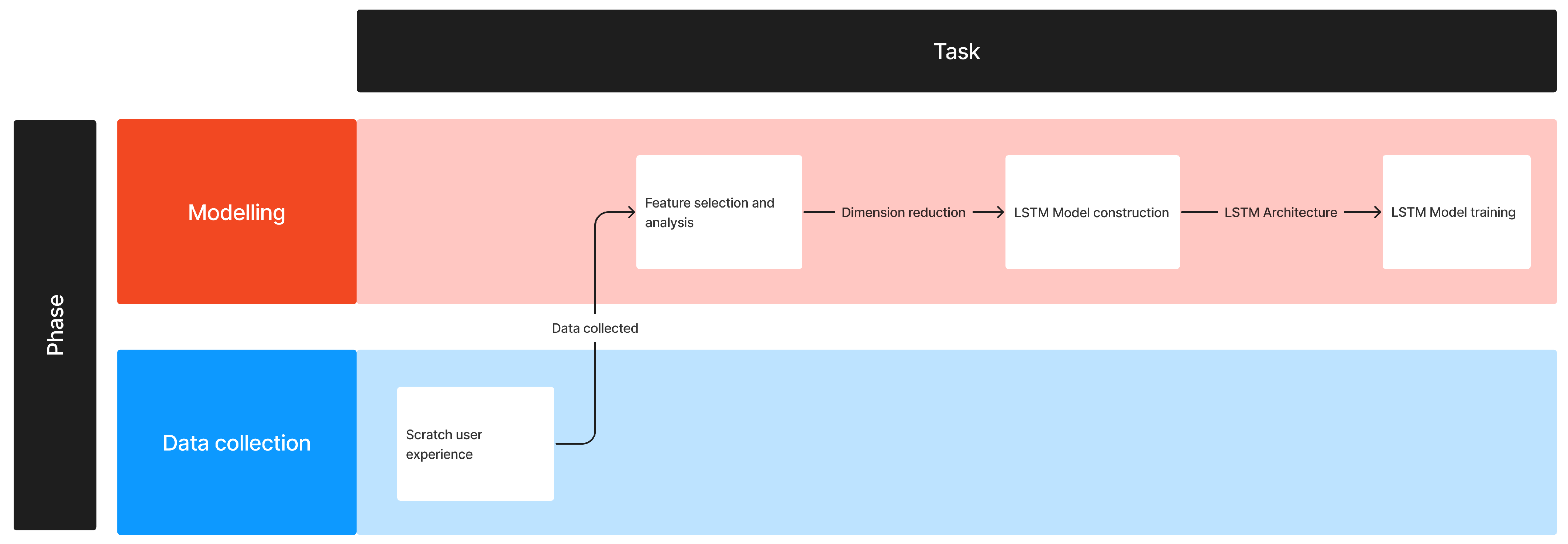
2.4. Help Identification Model Development
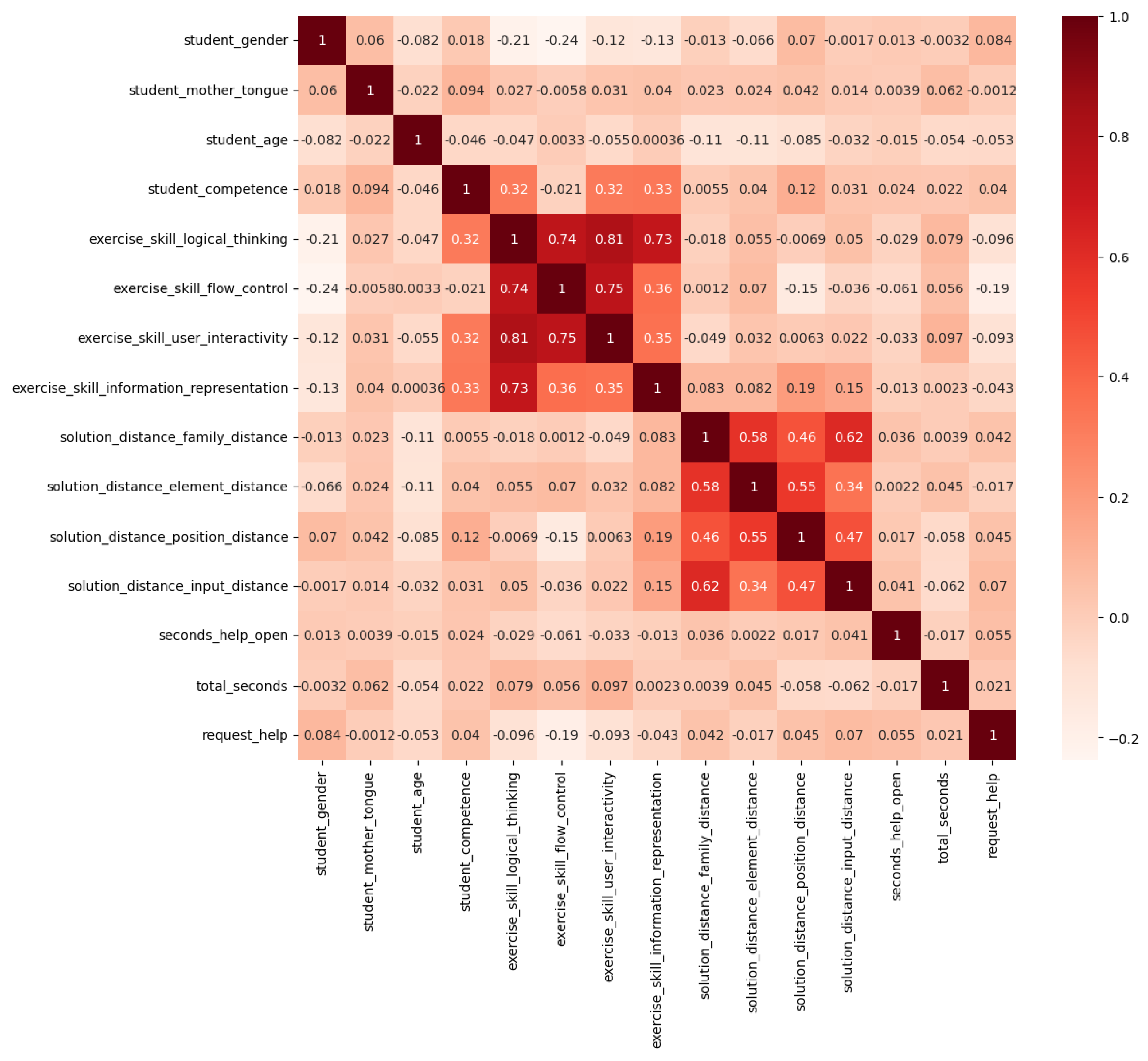
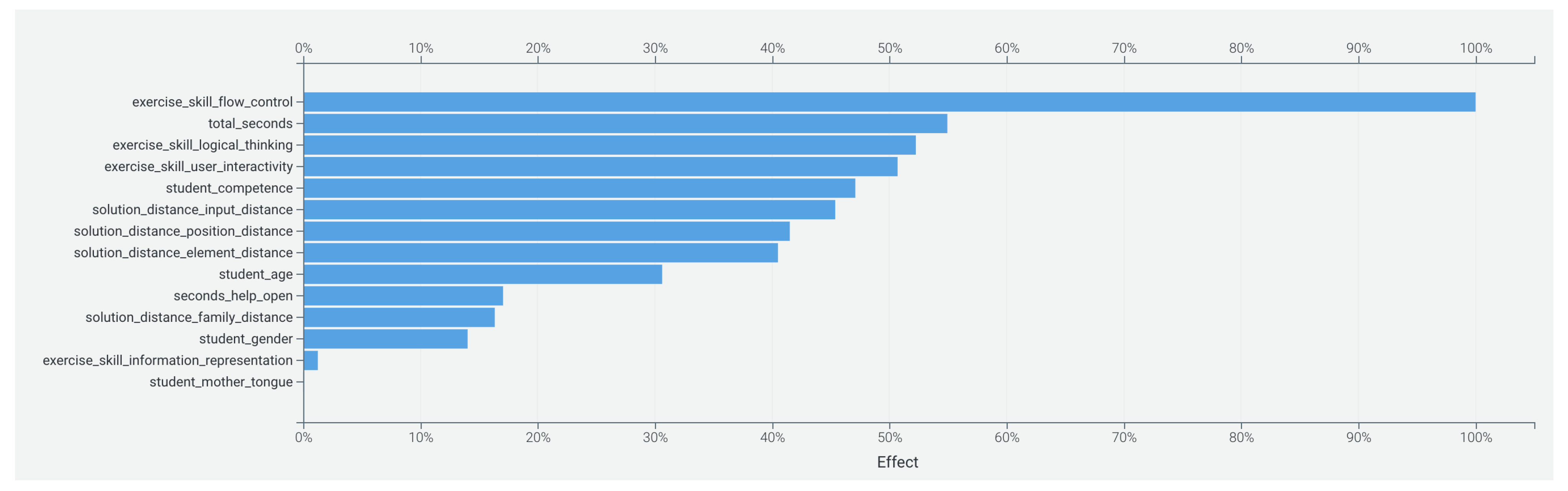
2.4.1. Feature Selection and Analysis
- Takes a sample of records from the training data;
- Computes SHAP values for each record in the sample, generating the local importance of each feature in each record;
- Computes global importance by taking the average of abs(SHAP values) for each feature in the sample;
- Normalizes the results.
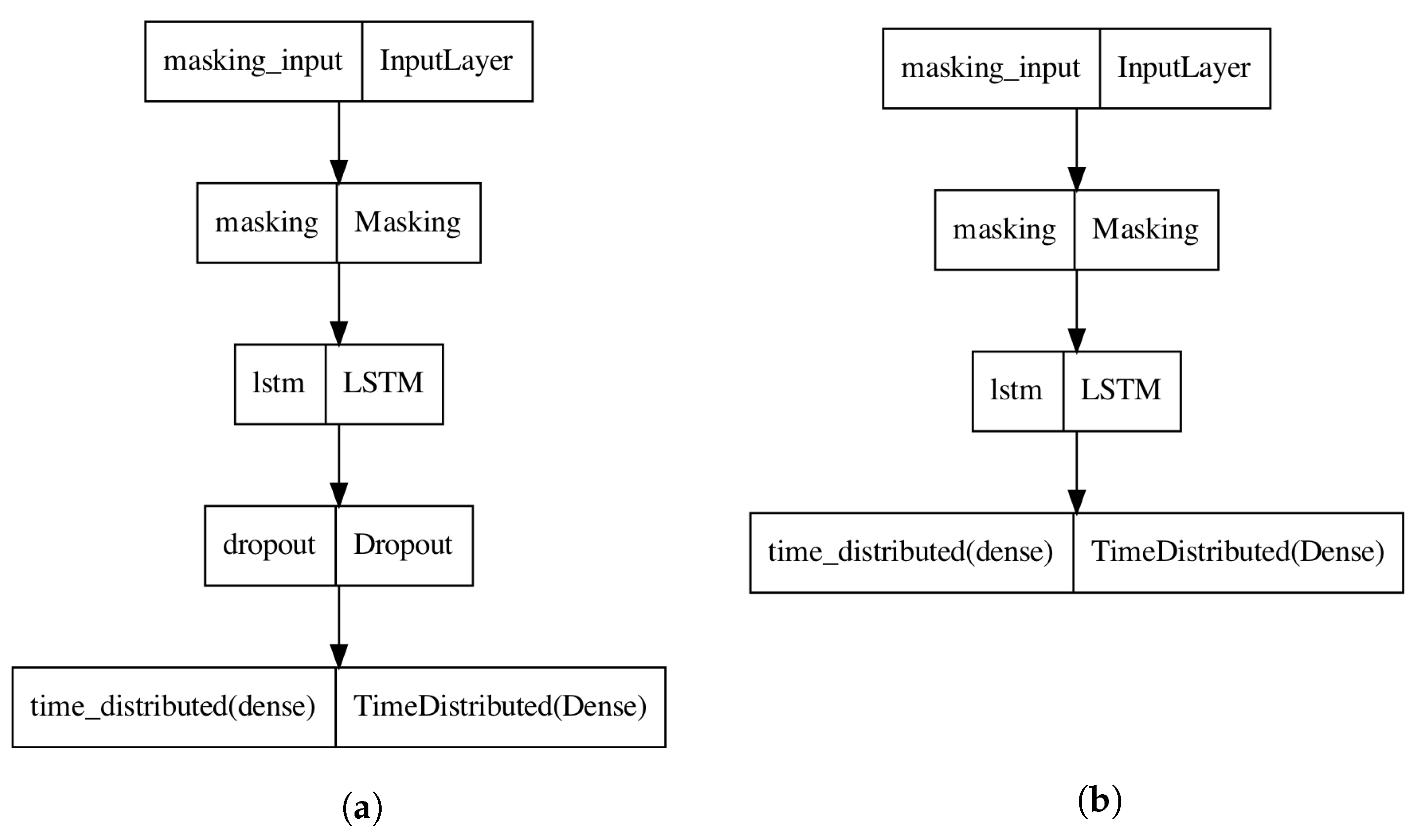
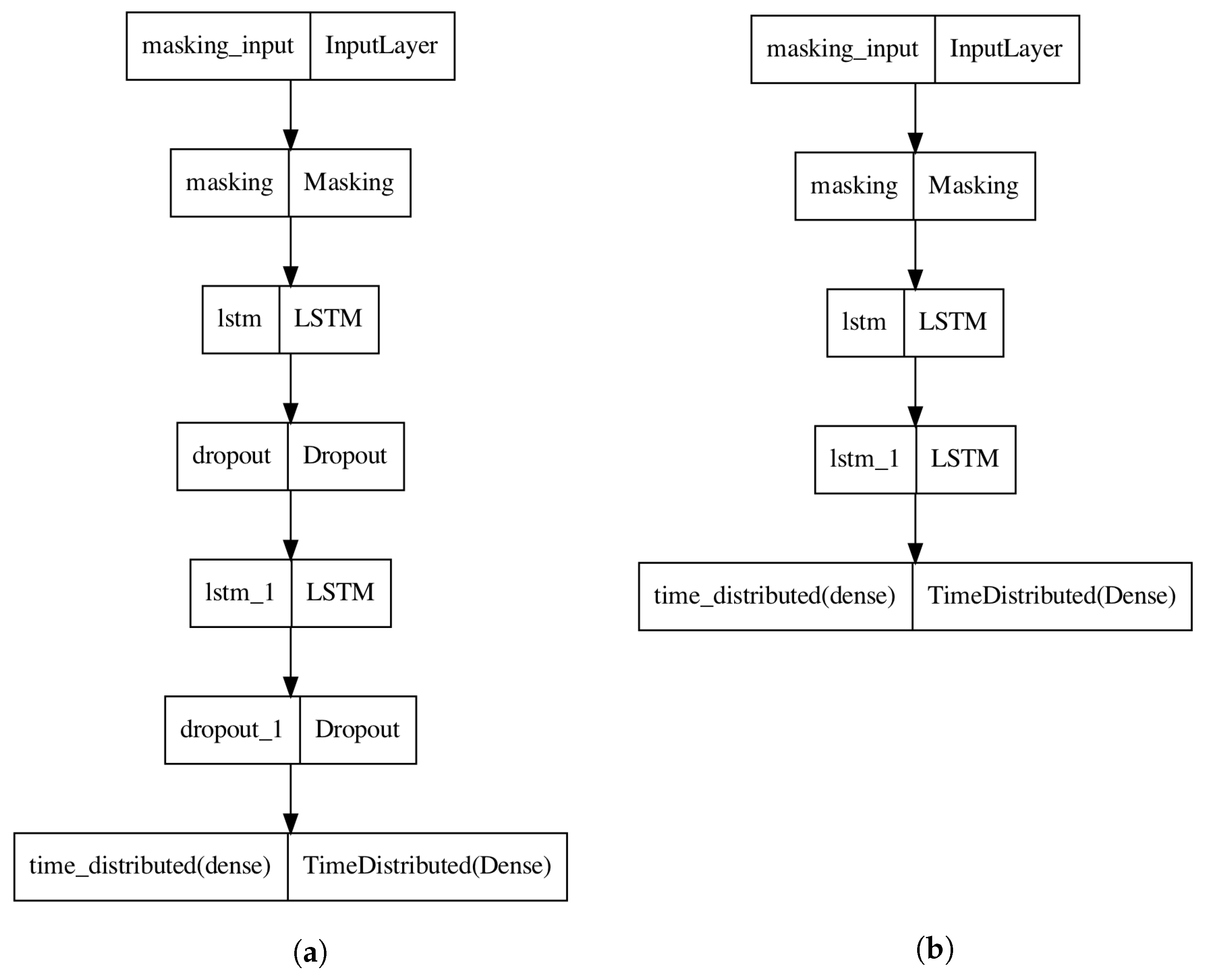
2.4.2. Model Construction
- LSTM units (in each LSTM layer): 256;
- Activation function of the LSTM layers: sigmoid;
- Return sequences: true;
- Dropout layer value (in each dropout layer if applicable): 0.5;
- Dense layer units: 1;
- Dense layer activation function: sigmoid;
- Dense layer dropout function: binary_crossentropy;
- Dense layer optimizer: adam;
- Dense layer metrics: binary_accuracy;
- Training batch size: 1;
- Number of training epochs: 50;
- Percentage of training data: 70%;
- Percentage of validation data: 30%.
3. Results
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ARTIE | Affective Robot Tutor Integrated Environment |
| ASTs | Abstract Syntax Trees |
| AI | Artificial Intelligence |
| CS | Computer Science |
| CT | Computational Thinking |
| CNN | Convolutional Neural Network |
| DAILy | Developing AI Literacy |
| DKT | Deep Knowledge Tracing |
| GRU | Gated Recurrent Unit |
| LSTM | Long Short-Term Memory |
| MLP | Multilayer Perceptron |
| RNN | Recurrent Neural Network |
| SHAP | SHapley Additive exPlanations |
| TED | Tree Edit Distance |
| TID | Tree Inherited Distance |
| TSC | Time Series Classification |
| UNED | Universidad Nacional de Educación a Distancia |
References
- Uddin, I.; Imran, A.S.; Muhammad, K.; Fayyaz, N.; Sajjad, M. A Systematic Mapping Review on MOOC Recommender Systems. IEEE Access 2021, 9, 118379–118405. [Google Scholar] [CrossRef]
- Jiang, B.; Li, Z. Effect of Scratch on computational thinking skills of Chinese primary school students. J. Comput. Educ. 2021, 8, 505–525. [Google Scholar] [CrossRef]
- Fagerlund, J.; Häkkinen, P.; Vesisenaho, M.; Viiri, J. Computational thinking in programming with Scratch in primary schools: A systematic review. Comput. Appl. Eng. Educ. 2021, 29, 12–28. [Google Scholar] [CrossRef]
- Howard, N.R. How Did I Do?: Giving learners effective and affective feedback. Educ. Technol. Res. Dev. 2021, 69, 123–126. [Google Scholar] [CrossRef]
- Cavalcanti, A.P.; Barbosa, A.; Carvalho, R.; Freitas, F.; Tsai, Y.-S.; Gašević, D.; Mello, R.F. Supporting Teachers Through Social and Emotional Learning. Comput. Educ. Artif. Intell. 2021, 2, 100027. [Google Scholar] [CrossRef]
- Cuadrado, L.-E.I.; Riesco, A.M.; de la Paz López, F. A first-in-class block-based programming language distance calculation. In Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2019; Volume 13259, pp. 423–432. [Google Scholar] [CrossRef]
- Kamil, K.; Sevimli, M.; Aydin, E. An investigation of primary school students’ self regulatory learning skills. In Proceedings of the 7th International Conference on Education and Education on Social Sciences, Taipei, Taiwan, 15–17 June 2020. [Google Scholar] [CrossRef]
- Wiggins, J.B.; Fahid, F.M.; Emerson, A.; Hinckle, M.; Smith, A.; Boyer, K.E.; Mott, B.; Wiebe, E.; Lester, J. Exploring Novice Programmers’ Hint Requests in an Intelligent Block-Based Coding Environment. In Proceedings of the 52nd ACM Technical Symposium on Computer Science Education (SIGCSE 2021), Virtual Conference, 13–20 March 2021; pp. 52–58. [Google Scholar] [CrossRef]
- Alsharef, A.; Aggarwal, K.; Kumar, M.; Mishra, A. Review of ML and AutoML Solutions to Forecast Time-Series Data. Arch. Comput. Methods Eng. 2022, 29, 5297–5311. [Google Scholar] [CrossRef]
- He, K.; Gao, K. Analysis of Concentration in English Education Learning Based on CNN Model. Sci. Program. 2022, 2022, 1489832. [Google Scholar] [CrossRef]
- Jarbou, M.; Won, D.; Gillis-Mattson, J.; Romanczyk, R. Deep learning-based school attendance prediction for autistic students. Sci. Rep. 2022, 12, 1431. [Google Scholar] [CrossRef]
- Holmes, W.; Porayska-Pomsta, K.; Holstein, K.; Sutherland, E.; Baker, T.; Buckingham, S.; Santos, S.O.C.; Rodrigo, M.T.; Cukurova, M.; Bittencourt, I.I.; et al. Ethics of AI in Education: Towards a Community-Wide Framework. Int. J. Artif. Intell. Educ. 2022, 32, 504–526. [Google Scholar] [CrossRef]
- Cuadrado, L.-E.I.; Riesco, A.M.; de la Paz López, F. ARTIE: An Integrated Environment for the Development of Affective Robot Tutors. Front. Comput. Neurosci. 2016, 10, 77. [Google Scholar] [CrossRef]
- Cuadrado, L.-E.I.; Riesco, A.M.; de la Paz López, F. FER in primary school children for affective robot tutors. In From Bioinspired Systems and Biomedical Applications to Machine Learning; Springer: Berlin/Heidelberg, Germany, 2019; pp. 461–471. [Google Scholar] [CrossRef]
- Ng, O.L.; Cui, Z. Examining primary students’ mathematical problem-solving in a programming context: Towards computationally enhanced mathematics education. Zdm Math. Educ. 2021, 53, 847–860. [Google Scholar] [CrossRef]
- López, J.M.S.; Otero, R.B.; García-Cervigón, S.D.L. Introducing robotics and block programming in elementary education. Rev. Iberoam. Educ. Distancia 2020, 24, 95. [Google Scholar] [CrossRef]
- Jen-I, C.; Mengping, T. Meta-analysis of children’s learning outcomes in block-based programming courses. In HCI International 2020—Late Breaking Posters; Springer: Berlin/Heidelberg, Germany, 2020; pp. 259–266. [Google Scholar] [CrossRef]
- Demirkiran, M.C.; Hocanin, F.T. An investigation on primary school students’ dispositions towards programming with game-based learning. Educ. Inf. Technol. 2021, 26, 3871–3892. [Google Scholar] [CrossRef]
- Wang, J. Use Hopscotch to Develop Positive Attitudes Toward Programming For Elementary School Students. Int. J. Comput. Sci. Educ. Sch. 2021, 5, 48–58. [Google Scholar] [CrossRef]
- Jo, Y.; Chun, S.J.; Ryoo, J. Tactile scratch electronic block system: Expanding opportunities for younger children to learn programming. Int. J. Inf. Educ. Technol. 2021, 11, 319–323. [Google Scholar] [CrossRef]
- Obermüller, F.; Heuer, U.; Fraser, G. Guiding Next-Step Hint Generation Using Automated Tests. Annu. Conf. Innov. Technol. Comput. Sci. Educ. 2021, 1293, 220–226. [Google Scholar] [CrossRef]
- Fahid, M.F.; Tian, X.; Emerson, A.; Wiggins, J.B.; Bounajim, D.; Smith, A.; Wiebe, E.; Mott, B.; Boyer, K.E.; Lester, J. Progression trajectory-based student modeling for novice block-based programming. In Proceedings of the 29th ACM Conference on User Modeling, Adaptation and Personalization (UMAP 2021), Utrecht, Netherlands, 21–25 June 2021; pp. 189–200. [Google Scholar] [CrossRef]
- Mlinaric, D.; Milasinovic, B.; Mornar, V. Tree Inheritance Distance. IEEE Access 2020, 8, 52489–52504. [Google Scholar] [CrossRef]
- Yu, W.; Yong, I.; Mechefske, K.C. Analysis of Different RNN Autoencoder Variants for Time Series Classification and Machine Prognostics; Academic Press: Cambridge, MA, USA, 2021; Volume 149. [Google Scholar] [CrossRef]
- Pudikov, A.; Brovko, A. Comparison of LSTM and GRU Recurrent Neural Network Architectures. In Recent Research in Control Engineering and Decision Making; Springer: Cham, Switzerland, 2021; Volume 337, pp. 114–124. [Google Scholar] [CrossRef]
- Affonso, F.; Rodrigues, T.M.; Pinto, D.A.L. Financial Times Series Forecasting of Clustered Stocks. Mob. Netw. Appl. 2021, 26, 256–265. [Google Scholar] [CrossRef]
- Bandara, K.; Hewamalage, H.; Hao, Y.; Kang, L.Y.; Bergmeir, C. Improving the accuracy of global forecasting models using time series data augmentation. Pattern Recognit. 2021, 120, 108148. [Google Scholar] [CrossRef]
- Yongjun, M.; Wei, L. Design and Implementation of Learning System Based on T-LSTM. In Proceedings of the Advances in Web-Based Learning—ICWL 2021, Macau, China, 13–14 November 2021; pp. 148–153. [Google Scholar] [CrossRef]
- Terada, K.; Watanobe, Y. Code completion for programming education based on deep learning. Int. J. Comput. Intell. Stud. 2021, 10, 78–98. [Google Scholar] [CrossRef]
- Smagulova, K.; James, A.P. A survey on LSTM memristive neural network architectures and applications. Eur. Phys. J. Spec. Top. 2019, 228, 2313–2324. [Google Scholar] [CrossRef]
- Zhang, H.; Lee, I.; Ali, S.; DiPaola, D.; Cheng, Y.; Breazeal, C. Integrating Ethics and Career Futures with Technical Learning to Promote AI Literacy for Middle School Students: An Exploratory Study. Int. J. Artif. Intell. Educ. 2022, 33, 290–324. [Google Scholar] [CrossRef]
- Kazi, K.; Solutions, K.K.; Solapur, M.; Devi, S.; Sreedhar, B.; Arulprakash, P.; Kazi, K. A Path Towards Child-Centric Artificial Intelligence based Education. Int. J. Early Child. Spec. Educ. (INT-JECS) 2022, 14, 9915–9922. [Google Scholar] [CrossRef]
- Santos, J.; Bittencourt, I.; Reis, M.; Chalco, G.; Isotani, S. Two billion registered students affected by stereotyped educational environments: An analysis of gender-based color bias. Humanit. Soc. Sci. Commun. 2022, 9, 249. [Google Scholar] [CrossRef]
- Du Boulay, B. Artificial intelligence in education and ethics. In Handbook of Open, Distance and Digital Education; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–16. [Google Scholar] [CrossRef]
- Floridi, L.; Cowls, J. A Unified Framework of Five Principles for AI in Society. Harv. Data Sci. Rev. 2019, 1, 1. [Google Scholar] [CrossRef]
- Schiff, D. Education for AI, not AI for Education: The Role of Education and Ethics in National AI Policy Strategies. Int. J. Artif. Intell. Educ. 2022, 32, 527–563. [Google Scholar] [CrossRef]
- Samuel, Y.; George, J.; Samuel, J. Beyond Stem, How Can Women Engage Big Data, Analytics, Robotics and Artificial Intelligence?—An Exploratory Analysis of Confidence and Educational Factors in the Emerging Technology Waves Influencing the Role of, and Impact Upon, Women; Leibniz Center for Informatics: Wadern, Germany, 2018. [Google Scholar]
- Hajibabaei, A.; Schiffauerova, A.; Ebadi, A. Women, artificial intelligence, and key positions in collaboration networks: Towards a more equal scientific ecosystem. arXiv 2022, arXiv:2205.12339. [Google Scholar]
- West, M.; Kraut, R.; Ei Chew, H. I’d Blush if I Could: Closing Gender Divides in Digital Skills through Education. 2019. Available online: https://en.unesco.org/Id-blush-if-I-could (accessed on 27 November 2023).
- UNESCO. AI and Gender Equality: Key Findings of UNESCO’S Global Dialogue. Available online: https://unesdoc.unesco.org/ark:/48223/pf0000387610.locale=es (accessed on 27 November 2023).
- ONTSI. Brecha Digital de Género. Available online: https://www.ontsi.es/es/publicaciones/brecha-digital-de-genero-2022 (accessed on 27 November 2023).
- UGT. Informe Agosto 2022. Available online: https://www.fesmcugt.org/wp-content/uploads/2022/09/Resumen-Estadistico-242-AGO22.pdf (accessed on 27 November 2023).
- WEF. Global Gender Gap Report 2021. Available online: https://www.weforum.org/publications/global-gender-gap-report-2021/ (accessed on 27 November 2023).
- Lundberg, S.M.; Allen, P.G.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. 2017. Available online: https://github.com/slundberg/shap (accessed on 27 November 2023).
- Kordaki, M.; Berdousis, I. Identifying Barriers for Women Participation in Computer Science. Int. J. Educ. Sci. 2020, 2, 5–20. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interactions | Help Requests | Students | Average Age | Girls | Boys |
|---|---|---|---|---|---|
| 11,790 | 695 | 82 | 13.3 | 30 | 52 |
| Phase | Time Series | Help Requests | Students | Average Age | Girls | Boys |
|---|---|---|---|---|---|---|
| Training | 221 | 450 | 52 | 13.5 | 16 | 36 |
| Validation | 95 | 245 | 30 | 13 | 14 | 16 |
| LSTM Layers | Dropout Layers | Loss | Binary Accuracy | Val Loss | Val Binary Accuracy |
|---|---|---|---|---|---|
| 1 | False | 0.017185 | 0.94459 | 0.0071762 | 0.99144 |
| 1 | True | 0.019589 | 0.94277 | 0.0077519 | 0.99249 |
| 2 | False | 0.017146 | 0.94621 | 0.0078189 | 0.98975 |
| 2 | True | 0.020001 | 0.94273 | 0.0085079 | 0.99266 |
| LSTM Layers | Dropout Layers | Loss | Binary Accuracy | Val Loss | Val Binary Accuracy |
|---|---|---|---|---|---|
| 1 | False | 0.015799 | 0.9574 | 0.04275 | 0.91122 |
| 1 | True | 0.013381 | 0.95972 | 0.047054 | 0.91095 |
| 2 | False | 0.015337 | 0.95727 | 0.045792 | 0.91122 |
| 2 | True | 0.013264 | 0.94273 | 0.045034 | 0.91116 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imbernón Cuadrado, L.E.; Manjarrés Riesco, Á.; de la Paz López, F. Using LSTM to Identify Help Needs in Primary School Scratch Students. Appl. Sci. 2023, 13, 12869. https://doi.org/10.3390/app132312869
Imbernón Cuadrado LE, Manjarrés Riesco Á, de la Paz López F. Using LSTM to Identify Help Needs in Primary School Scratch Students. Applied Sciences. 2023; 13(23):12869. https://doi.org/10.3390/app132312869
Chicago/Turabian StyleImbernón Cuadrado, Luis Eduardo, Ángeles Manjarrés Riesco, and Félix de la Paz López. 2023. "Using LSTM to Identify Help Needs in Primary School Scratch Students" Applied Sciences 13, no. 23: 12869. https://doi.org/10.3390/app132312869
APA StyleImbernón Cuadrado, L. E., Manjarrés Riesco, Á., & de la Paz López, F. (2023). Using LSTM to Identify Help Needs in Primary School Scratch Students. Applied Sciences, 13(23), 12869. https://doi.org/10.3390/app132312869