
A Fusion Framework for Confusion Analysis in Learning Based on EEG Signals



Abstract
:1. Introduction
- We present a fusion framework that integrates the strengths of traditional feature extraction and deep learning to analyze confusion during the learning process. This framework enables targeted guidance by assessing the cognitive level of students.
- By harnessing the robust capabilities of the multi-head self-attention mechanism, we capture global contextual representations of long EEG segments, which proves beneficial for predicting confusion emotions.
- In both subject-dependent and subject-independent experiments, we compare our framework with traditional machine learning classifiers and end-to-end methods. The experimental results demonstrate the superiority of our framework.
2. Related Work
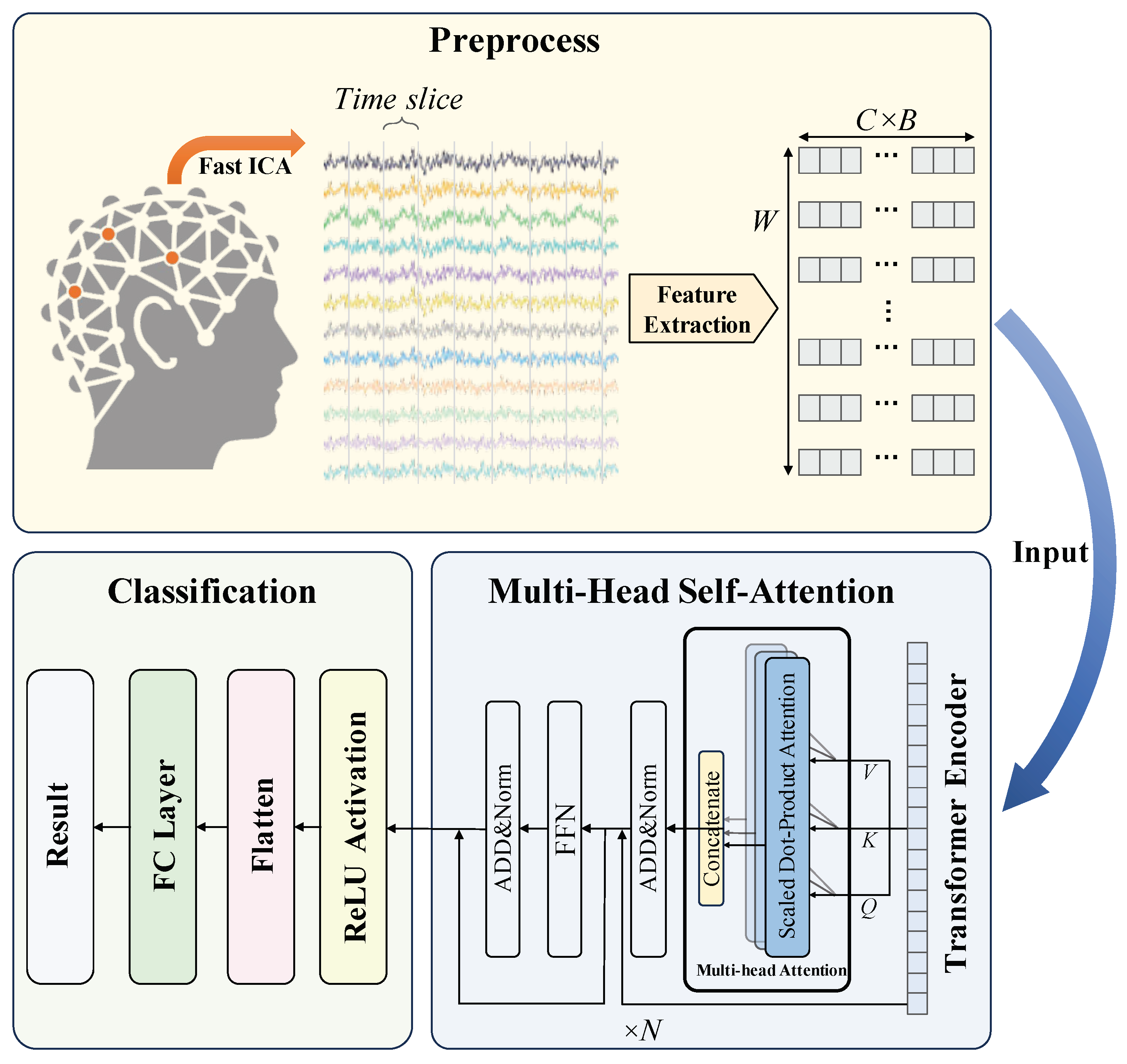
3. Methods
3.1. Preprocessing
3.2. Multi-Head Self-Attention
4. Experiments and Discussions
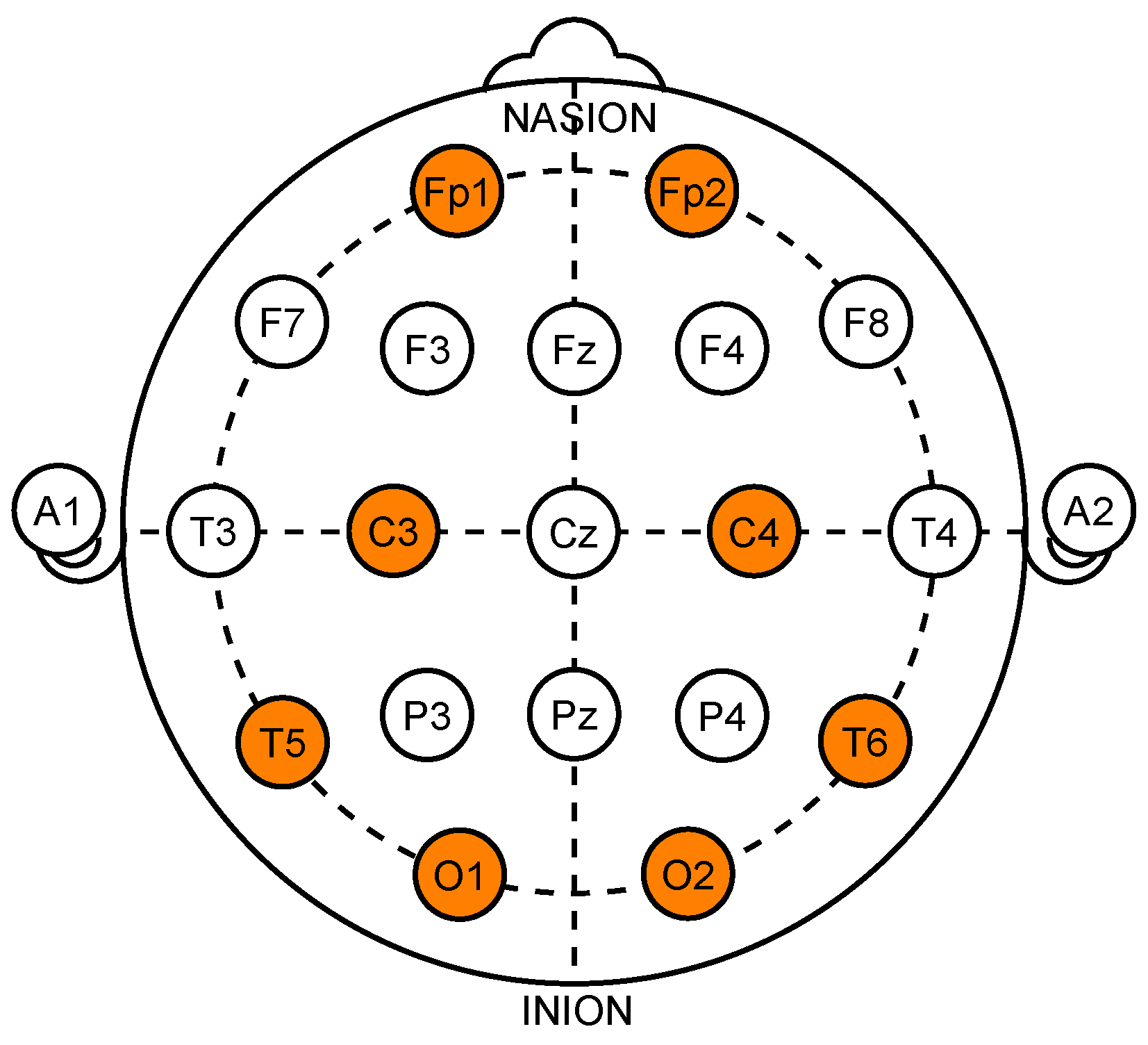
4.1. Dataset
4.2. Experiment Settings
- (1)
- subject-dependent: the data are trained across multiple subjects in the subject-dependent experiments. Specifically, 70% of the EEG data from all experiments for each participant are allocated as the training set, while the remaining 30% serve as the testing set.
- (2)
- subject-independent: In the subject-independent model, the experiment emphasizes the differences between different subjects to test the method’s generalization ability. Specifically, EEG data are divided into a cross-subject validation set with a split of 70%/30%, where the data from 16 subjects is used for training, and the data from the remaining seven subjects is used for testing.
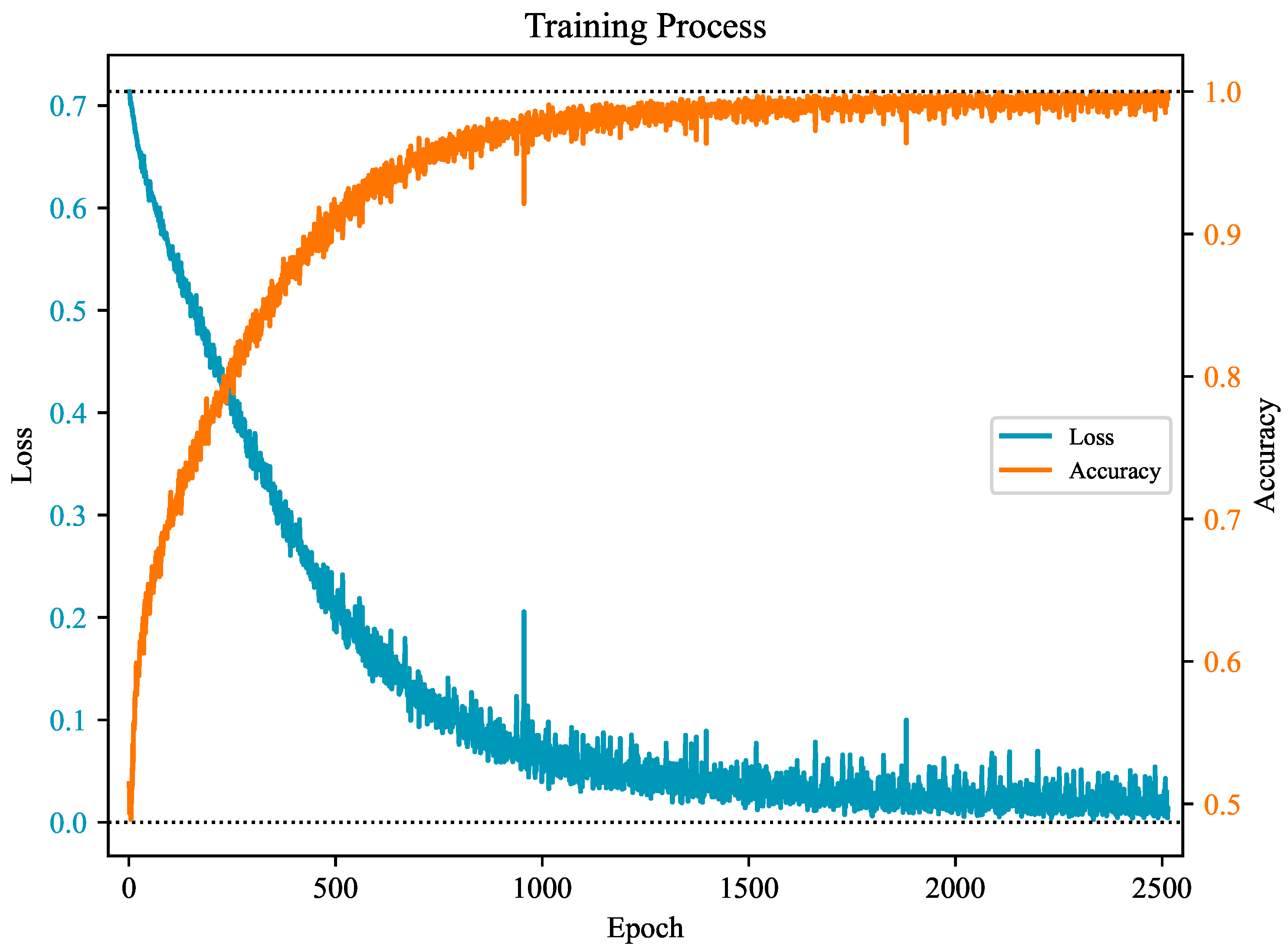
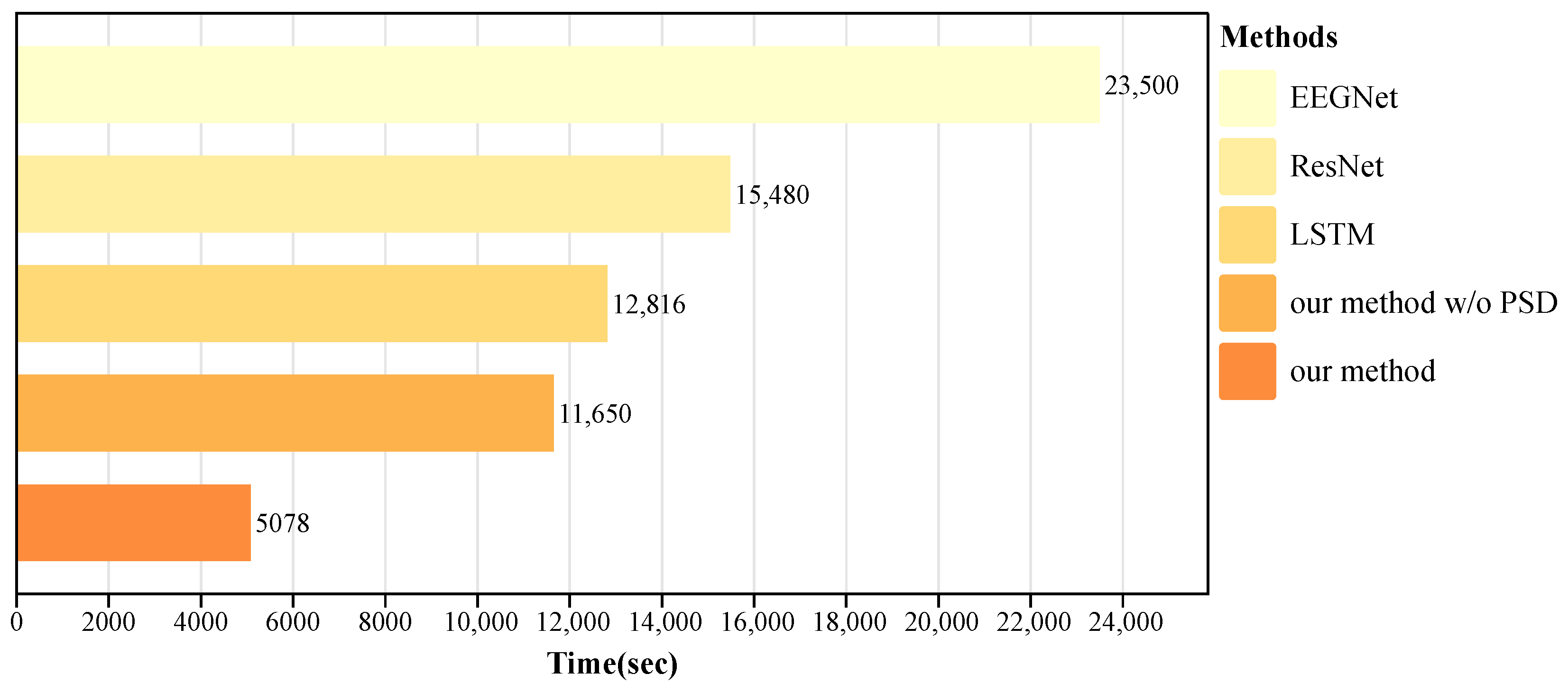
4.3. Analysis of Results
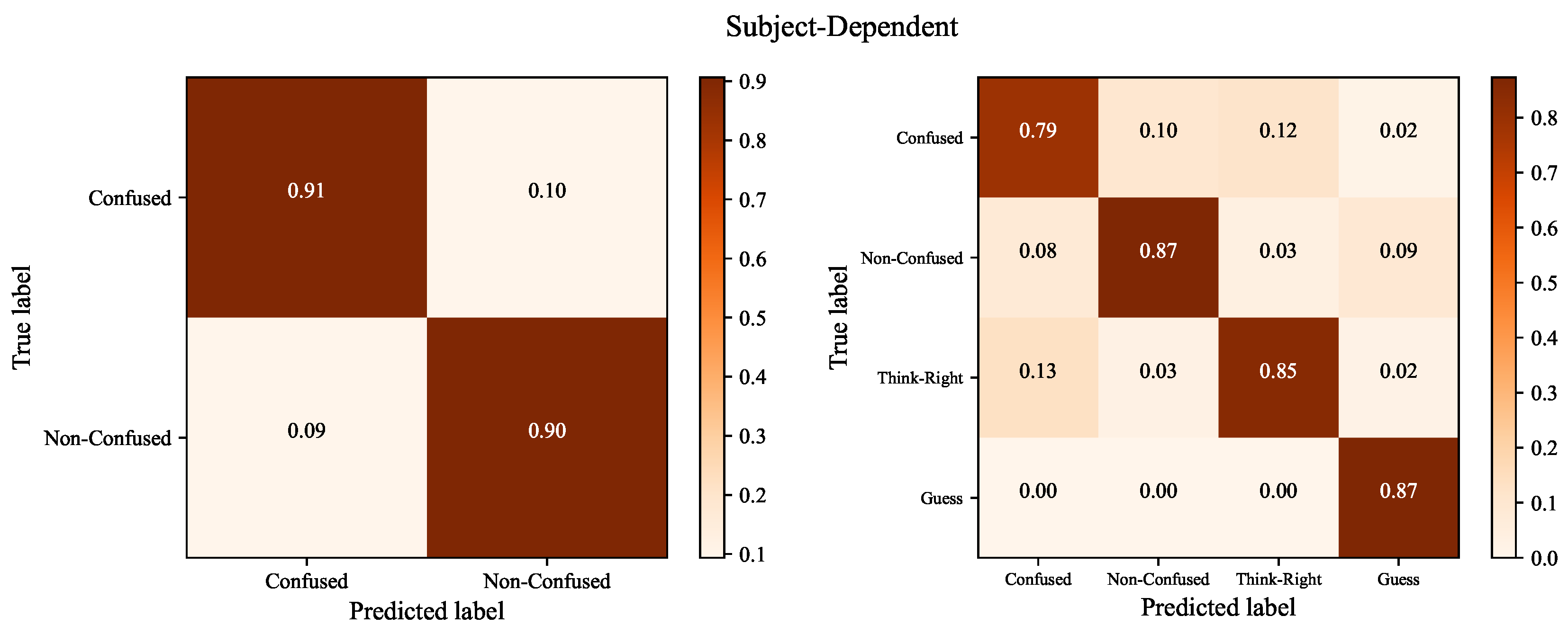
4.4. Analysis of Confusion Matrix
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, T.; Wang, J.; Zhang, G.; Zhang, L.; Zhou, Y. Confused or not: Decoding brain activity and recognizing confusion in reasoning learning using EEG. J. Neural Eng. 2023, 20, 026018. [Google Scholar] [CrossRef]
- Peng, T.; Liang, Y.; Wu, W.; Ren, J.; Pengrui, Z.; Pu, Y. CLGT: A graph transformer for student performance prediction in collaborative learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 15947–15954. [Google Scholar]
- Liang, Y.; Peng, T.; Pu, Y.; Wu, W. HELP-DKT: An interpretable cognitive model of how students learn programming based on deep knowledge tracing. Sci. Rep. 2022, 12, 4012. [Google Scholar] [CrossRef]
- Baker, R.S.; D’Mello, S.K.; Rodrigo, M.M.T.; Graesser, A.C. Better to be frustrated than bored: The incidence, persistence, and impact of learners’ cognitive–affective states during interactions with three different computer-based learning environments. Int. J. Hum.-Comput. Stud. 2010, 68, 223–241. [Google Scholar] [CrossRef]
- Han, Z.M.; Huang, C.Q.; Yu, J.H.; Tsai, C.C. Identifying patterns of epistemic emotions with respect to interactions in massive online open courses using deep learning and social network analysis. Comput. Hum. Behav. 2021, 122, 106843. [Google Scholar] [CrossRef]
- Lehman, B.; Matthews, M.; D’Mello, S.; Person, N. What are you feeling? Investigating student affective states during expert human tutoring sessions. In Proceedings of the International Conference on Intelligent Tutoring Systems, Montreal, QC, Canada, 23–27 June 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 50–59. [Google Scholar]
- Lehman, B.; D’Mello, S.; Graesser, A. Confusion and complex learning during interactions with computer learning environments. Internet High. Educ. 2012, 15, 184–194. [Google Scholar] [CrossRef]
- D’Mello, S.; Lehman, B.; Pekrun, R.; Graesser, A. Confusion can be beneficial for learning. Learn. Instr. 2014, 29, 153–170. [Google Scholar] [CrossRef]
- Vogl, E.; Pekrun, R.; Murayama, K.; Loderer, K.; Schubert, S. Surprise, curiosity, and confusion promote knowledge exploration: Evidence for robust effects of epistemic emotions. Front. Psychol. 2019, 10, 2474. [Google Scholar] [CrossRef] [PubMed]
- Gunes, H.; Piccardi, M. Bi-modal emotion recognition from expressive face and body gestures. J. Netw. Comput. Appl. 2007, 30, 1334–1345. [Google Scholar] [CrossRef]
- Kaneshiro, B.; Perreau Guimaraes, M.; Kim, H.S.; Norcia, A.M.; Suppes, P. A representational similarity analysis of the dynamics of object processing using single-trial EEG classification. PLoS ONE 2015, 10, e0135697. [Google Scholar] [CrossRef]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef] [PubMed]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Wu, Q.; Qiu, M.; Wang, Y.; Chen, X. Emotion recognition from multi-channel EEG through parallel convolutional recurrent neural network. In Proceedings of the IEEE 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Xu, T.; Zhou, Y.; Wang, Z.; Peng, Y. Learning emotions EEG-based recognition and brain activity: A survey study on BCI for intelligent tutoring system. Procedia Comput. Sci. 2018, 130, 376–382. [Google Scholar] [CrossRef]
- Huang, J.; Yu, C.; Wang, Y.; Zhao, Y.; Liu, S.; Mo, C.; Liu, J.; Zhang, L.; Shi, Y. FOCUS: Enhancing children’s engagement in reading by using contextual BCI training sessions. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; pp. 1905–1908. [Google Scholar]
- Xu, T.; Wang, X.; Wang, J.; Zhou, Y. From textbook to teacher: An adaptive intelligent tutoring system based on BCI. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Guadalajara, Mexico, 1–5 November 2021; pp. 7621–7624. [Google Scholar]
- Xu, J.; Zhong, B. Review on portable EEG technology in educational research. Comput. Hum. Behav. 2018, 81, 340–349. [Google Scholar] [CrossRef]
- Ramoser, H.; Muller-Gerking, J.; Pfurtscheller, G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 2000, 8, 441–446. [Google Scholar] [CrossRef] [PubMed]
- Ang, K.K.; Chin, Z.Y.; Wang, C.; Guan, C.; Zhang, H. Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front. Neurosci. 2012, 6, 39. [Google Scholar] [CrossRef] [PubMed]
- Karimi-Rouzbahani, H.; Shahmohammadi, M.; Vahab, E.; Setayeshi, S.; Carlson, T. Temporal codes provide additional category-related information in object category decoding: A systematic comparison of informative EEG features. bioRxiv 2020. [Google Scholar] [CrossRef]
- Zheng, W.L.; Lu, B.L. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Auton. Ment. Dev. 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Jensen, O.; Tesche, C.D. Frontal theta activity in humans increases with memory load in a working memory task. Eur. J. Neurosci. 2002, 15, 1395–1399. [Google Scholar] [CrossRef]
- Bashivan, P.; Bidelman, G.M.; Yeasin, M. Spectrotemporal dynamics of the EEG during working memory encoding and maintenance predicts individual behavioral capacity. Eur. J. Neurosci. 2014, 40, 3774–3784. [Google Scholar] [CrossRef]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- Tian, T.; Wang, L.; Luo, M.; Sun, Y.; Liu, X. ResNet-50 based technique for EEG image characterization due to varying environmental stimuli. Comput. Methods Programs Biomed. 2022, 225, 107092. [Google Scholar] [CrossRef]
- Kalafatovich, J.; Lee, M.; Lee, S.W. Decoding visual recognition of objects from eeg signals based on attention-driven convolutional neural network. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 2985–2990. [Google Scholar]
- Chowdary, M.K.; Anitha, J.; Hemanth, D.J. Emotion recognition from EEG signals using recurrent neural networks. Electronics 2022, 11, 2387. [Google Scholar] [CrossRef]
- Lu, P. Human emotion recognition based on multi-channel EEG signals using LSTM neural network. In Proceedings of the IEEE 2022 Prognostics and Health Management Conference (PHM-2022 London), London, UK, 27–29 May 2022; pp. 303–308. [Google Scholar]
- Fraiwan, L.; Lweesy, K.; Khasawneh, N.; Wenz, H.; Dickhaus, H. Automated sleep stage identification system based on time–frequency analysis of a single EEG channel and random forest classifier. Comput. Methods Programs Biomed. 2012, 108, 10–19. [Google Scholar] [CrossRef] [PubMed]
- Deivanayagi, S.; Manivannan, M.; Fernandez, P. Spectral analysis of EEG signals during hypnosis. Int. J. Syst. Cybern. Informatics 2007, 4, 75–80. [Google Scholar]
- Brodu, N.; Lotte, F.; Lécuyer, A. Exploring two novel features for EEG-based brain–computer interfaces: Multifractal cumulants and predictive complexity. Neurocomputing 2012, 79, 87–94. [Google Scholar] [CrossRef]
- Duan, L.; Zhong, H.; Miao, J.; Yang, Z.; Ma, W.; Zhang, X. A voting optimized strategy based on ELM for improving classification of motor imagery BCI data. Cogn. Comput. 2014, 6, 477–483. [Google Scholar] [CrossRef]
- Faust, O.; Acharya, R.; Allen, A.R.; Lin, C. Analysis of EEG signals during epileptic and alcoholic states using AR modeling techniques. Irbm 2008, 29, 44–52. [Google Scholar] [CrossRef]
- Raven, J. The Raven’s progressive matrices: Change and stability over culture and time. Cogn. Psychol. 2000, 41, 1–48. [Google Scholar] [CrossRef]
- Wang, P.; Guo, C.; Xie, S.; Qiao, X.; Mao, L.; Fu, X. EEG emotion recognition based on knowledge distillation optimized residual networks. In Proceedings of the 2022 IEEE 6th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Beijing, China, 3–5 October 2022; pp. 574–581. [Google Scholar]
- Zheng, W.L.; Liu, W.; Lu, Y.; Lu, B.L.; Cichocki, A. Emotionmeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 2018, 49, 1110–1122. [Google Scholar] [CrossRef]
- Liu, W.; Qiu, J.L.; Zheng, W.L.; Lu, B.L. Comparing recognition performance and robustness of multimodal deep learning models for multimodal emotion recognition. IEEE Trans. Cogn. Dev. Syst. 2021, 14, 715–729. [Google Scholar] [CrossRef]
- Gramfort, A.; Luessi, M.; Larson, E.; Engemann, D.A.; Strohmeier, D.; Brodbeck, C.; Goj, R.; Jas, M.; Brooks, T.; Parkkonen, L.; et al. MEG and EEG data analysis with MNE-Python. Front. Neurosci. 2013, 7, 267. [Google Scholar] [CrossRef] [PubMed]
- Powers, D. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bands | Frequencies | States | Examples |
|---|---|---|---|
| delta | 1–4 Hz | Sleep and dreaming |  |
| theta | 4–8 Hz | Deep relaxation or meditative states | |
| alpha | 8–14 Hz | Resting or relaxed | |
| beta | 14–31 Hz | Alert, active mind | |
| gamma | 31–50 Hz | Intense focus, problem solving |
| Emotion Categories | Emotion Stimuli | #Subjects | #Channels | Sampling Rate |
|---|---|---|---|---|
| confused, non-confused, think-right, guess | tests | 23 male/female: 12/11 | 8 | 250 Hz |
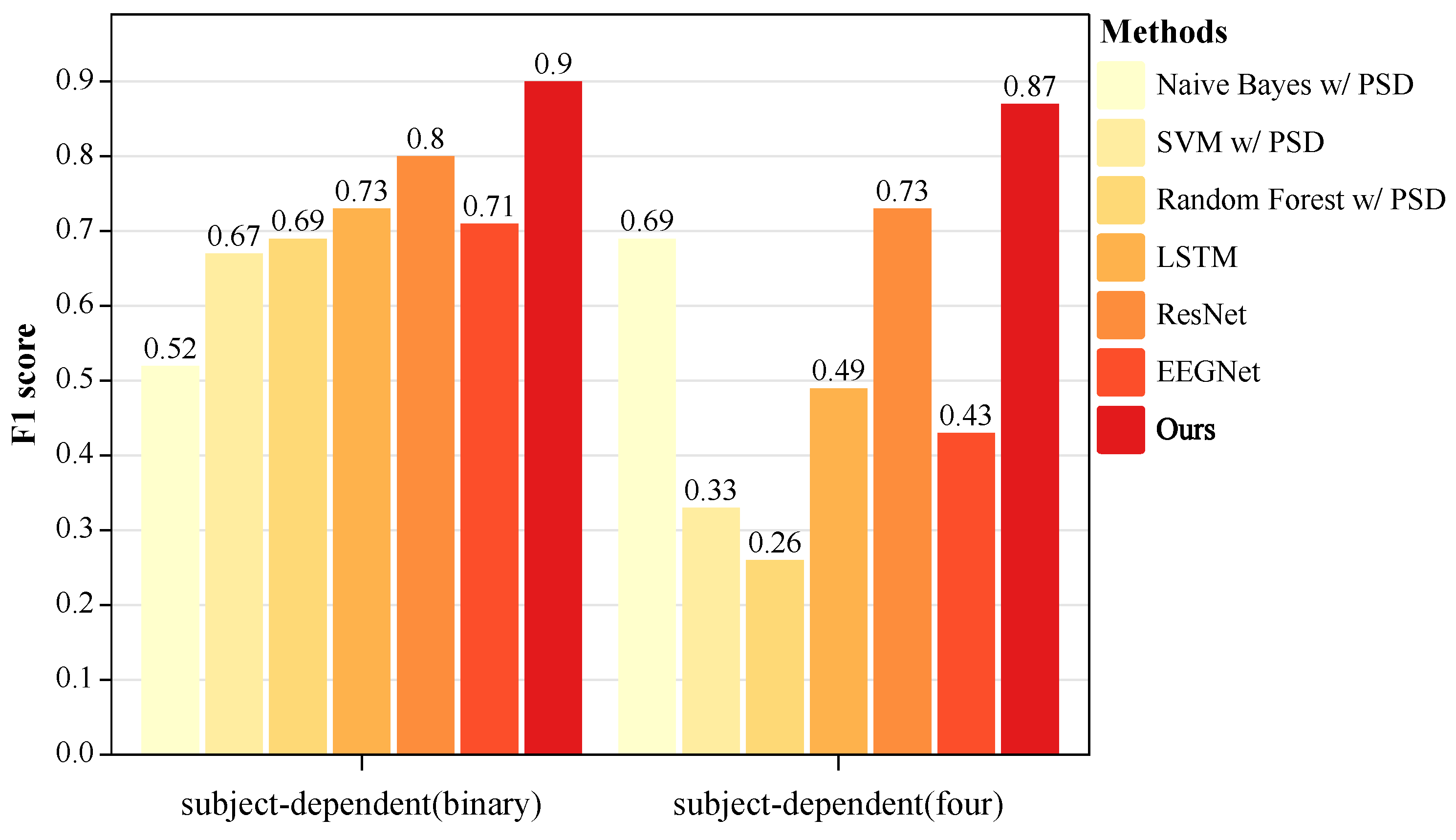
| Methods | Binary Classification | Four Classification |
|---|---|---|
| Naive Bayes w/ PSD | 57.30/0.52 | 69.72/0.69 |
| SVM w/ PSD | 67.43/0.67 | 48.10/0.33 |
| Random Forest w/ PSD | 69.72/0.69 | 37.72/0.26 |
| EEGNet | 72.02/0.71 | 49.81/0.43 |
| LSTM | 73.45/0.73 | 53.29/0.49 |
| ResNet | 80.61/0.80 | 73.10/0.73 |
| Our method w/o PSD | 85.53/0.85 | 85.99/0.86 |
| Our method | 90.49/0.90 | 87.59/0.87 |
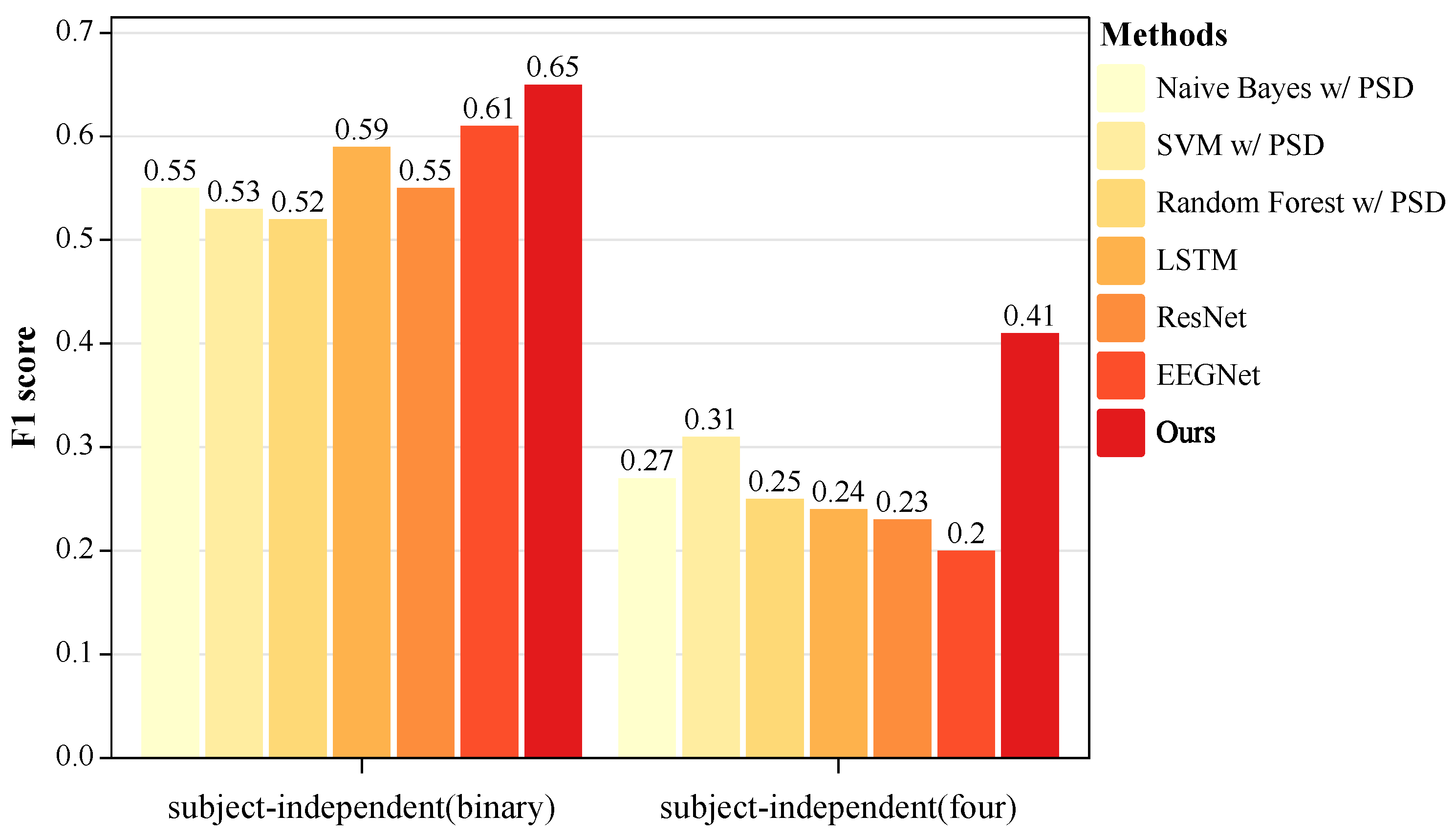
| Methods | Binary Classification | Four Classification |
|---|---|---|
| Naive Bayes w/ PSD | 60.59/0.55 | 40.83/0.27 |
| SVM w/ PSD | 55.71/0.53 | 38.05/0.31 |
| Random Forest w/ PSD | 55.98/0.52 | 35.94/0.25 |
| EEGNet | 64.46/0.61 | 39.14/0.20 |
| LSTM | 61.25/0.59 | 40.53/0.24 |
| ResNet | 57.95/0.55 | 40.05/0.23 |
| Our method w/o PSD | 65.85/0.63 | 40.88/0.39 |
| Our method | 66.08/0.65 | 41.28/0.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; He, J.; Liang, Y.; Wang, Z.; Xie, X. A Fusion Framework for Confusion Analysis in Learning Based on EEG Signals. Appl. Sci. 2023, 13, 12832. https://doi.org/10.3390/app132312832
Zhang C, He J, Liang Y, Wang Z, Xie X. A Fusion Framework for Confusion Analysis in Learning Based on EEG Signals. Applied Sciences. 2023; 13(23):12832. https://doi.org/10.3390/app132312832
Chicago/Turabian StyleZhang, Chenlong, Jian He, Yu Liang, Zaitian Wang, and Xiaoyang Xie. 2023. "A Fusion Framework for Confusion Analysis in Learning Based on EEG Signals" Applied Sciences 13, no. 23: 12832. https://doi.org/10.3390/app132312832
APA StyleZhang, C., He, J., Liang, Y., Wang, Z., & Xie, X. (2023). A Fusion Framework for Confusion Analysis in Learning Based on EEG Signals. Applied Sciences, 13(23), 12832. https://doi.org/10.3390/app132312832