
Random Forests Machine Learning Applied to PEER Structural Performance Experimental Columns Database



Abstract
:1. Introduction
- According to the authors’ knowledge, the PEER structural performance database is employed for the first time in order to detect the failure mode of RC columns.
- The influence of the main design variables on the column ductility and failure mode is also thoroughly examined.
- Finally, all the performance metrics necessary for the evaluation of the ML methodology in detecting the failure mode of RC columns are provided too.
2. Materials and Methods
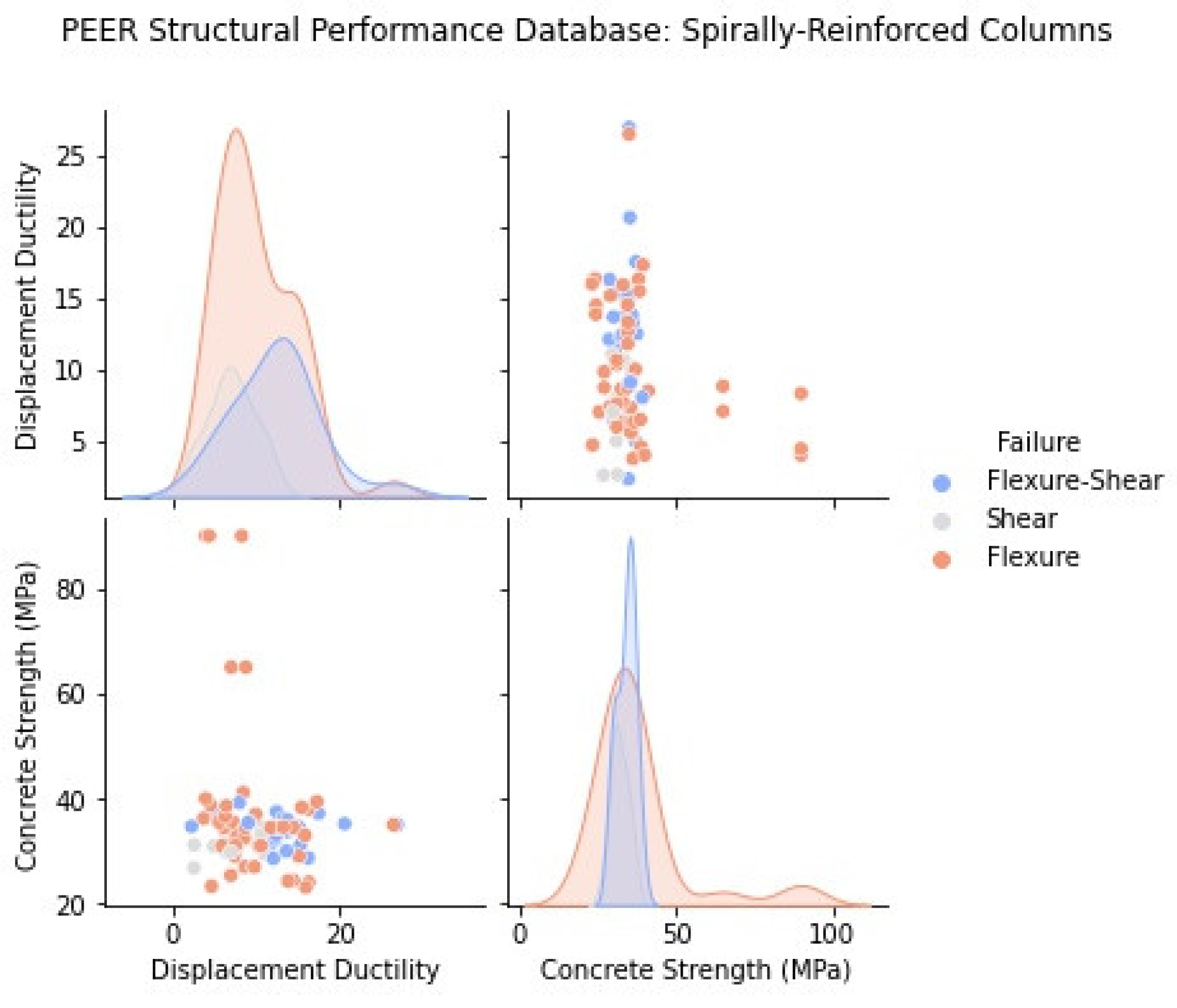
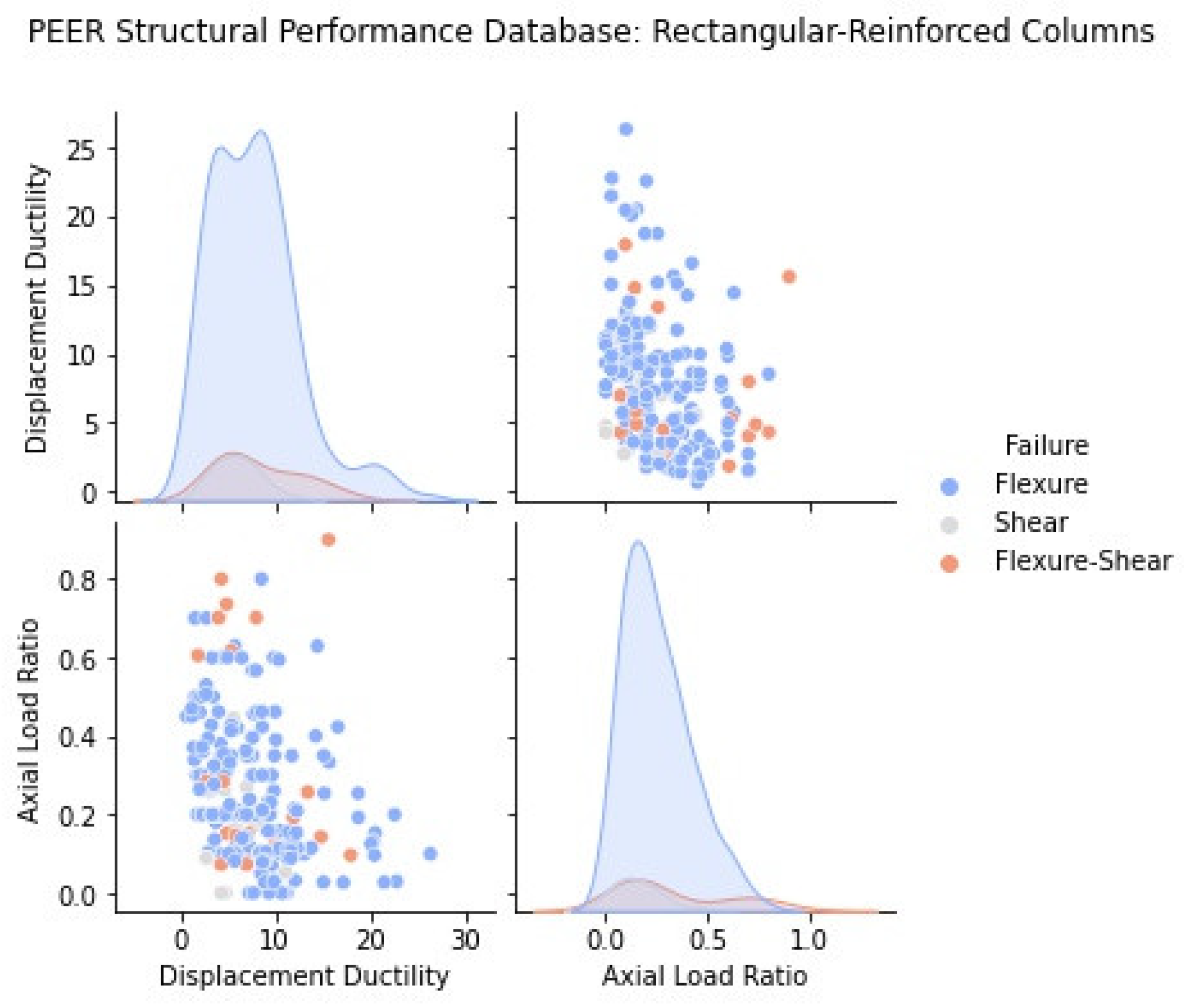
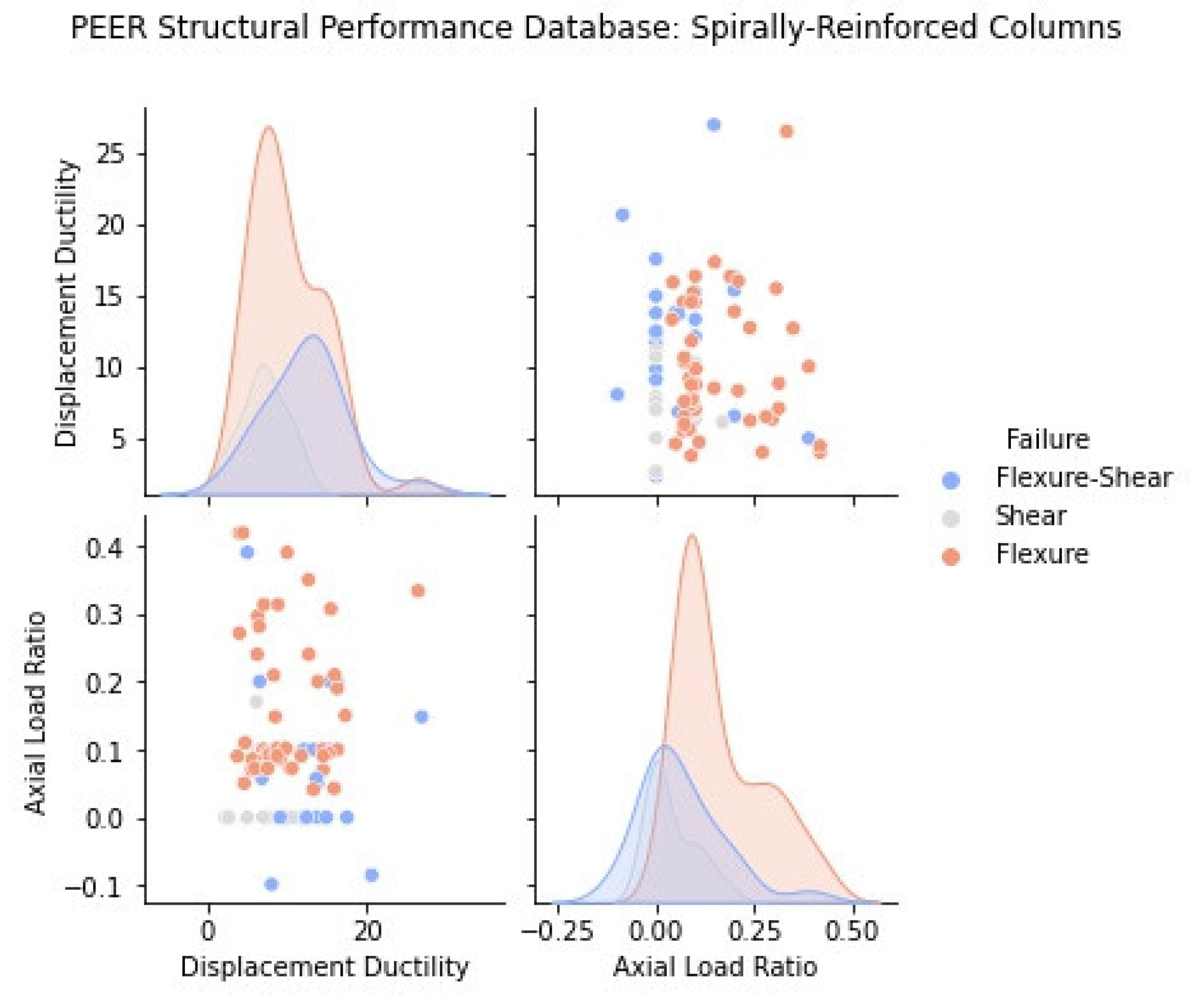
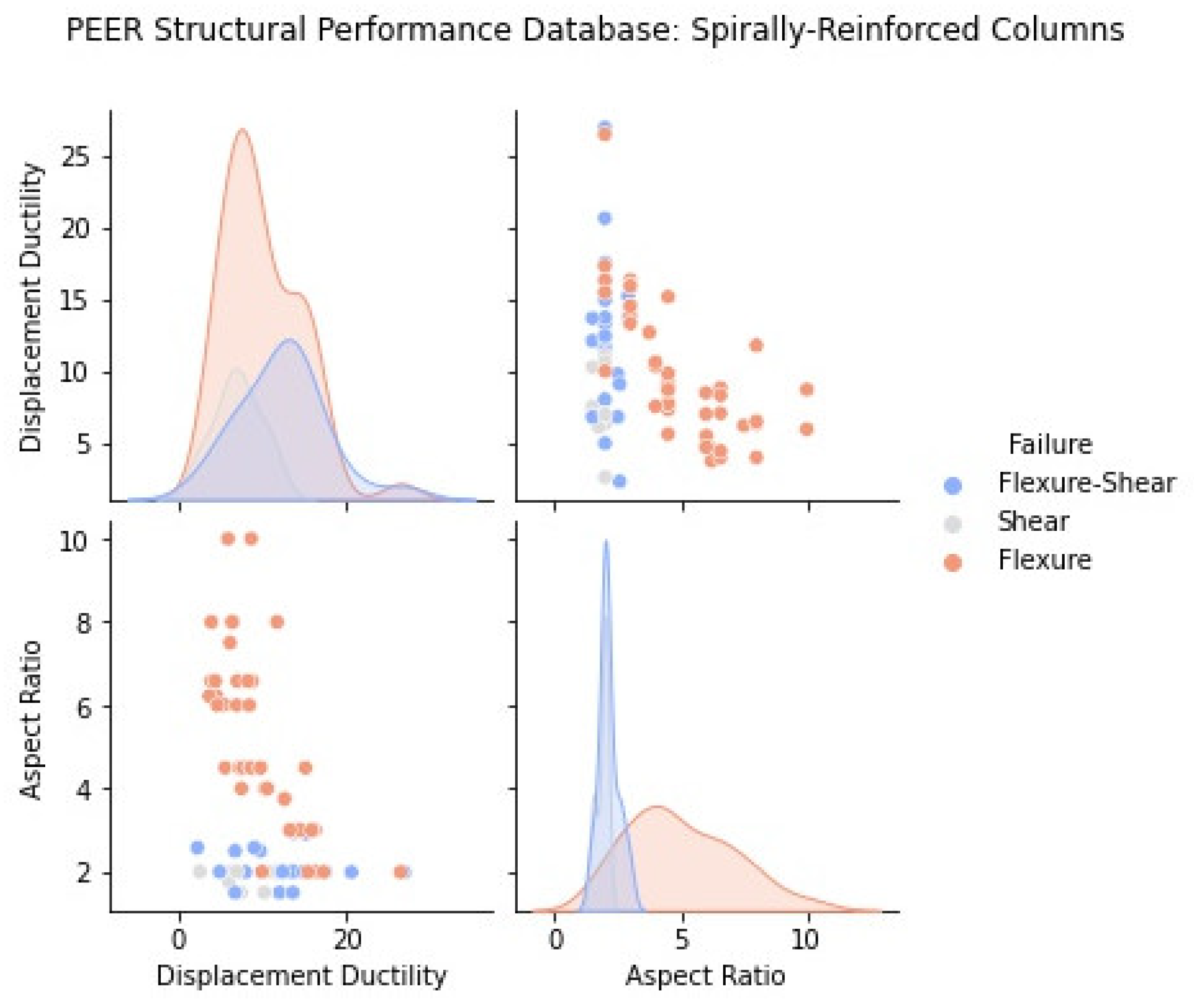
2.1. Statistical Representation of the PEER Structural Performance Database
2.2. Influence of Main Design Variables to Column Ductility and Failure Mode
- -
- If no shear damage was reported by the experimentalist, the column was classified as flexure critical.
- -
- If shear damage (diagonal cracks) was reported, the absolute maximum effective force (: absolute maximum measured force in the experimental column response) was compared with the calculated “ideal” force corresponding to a maximum axial compressive strain in the concrete cover set equal to 0.004, which corresponds to the spalling of unconfined concrete (). The failure displacement ductility at an effective force equal to 80% maximum was determined from the experimental envelope. If the maximum effective force or if the failure displacement ductility was less than or equal to 2 (), the column was classified as shear critical. Otherwise, the column was classified as flexure–shear critical. All columns in the database are divided into two sub-groups according to cross-sectional shape (rectangular and circular section columns).
2.3. Supervised ML-Based Prediction of Column Failure Mode with Random Forests
- The estimator number that defines the number of decision trees.
- The maximum feature number that defines the maximum feature number during the separation of nodes in each decision tree.
- The maximum depth: the maximum depth in each decision tree.
- Minimum sample points at each node separation: the minimum sample point number that should be taken into account at each node.
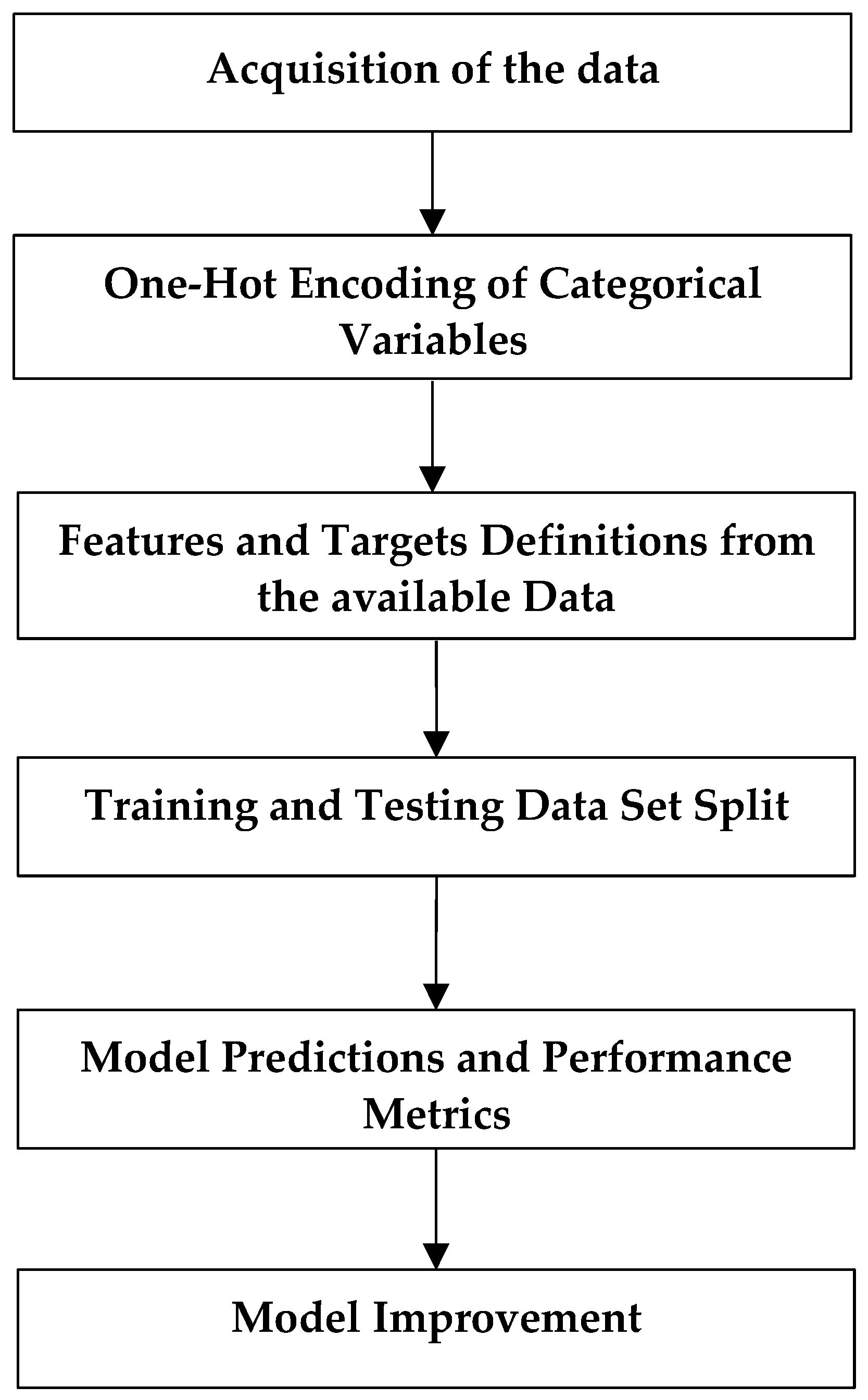
Random Forests with Python [22]
- The question is set and the demanded data are defined.
- The data are obtained in an accessible form.
- Any lack of data or uncertainty is defined and corrected accordingly.
- The data are prepared for the machine learning model.
- A baseline model is set that is intended to be overcome.
- The model is trained with the training data.
- Model predictions are made with the test data.
- The predictions are compared to the known test goals and the performance metrics are computed.
- If the performance is not satisfactory, we adjust the model and obtain more data or another modeling technique is tested too.
3. Results
3.1. Rectangular RC Columns
3.2. Circular RC Columns
3.3. Parametric Sensitivity of Random Forest Algorithm
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Values | True Label Values (1 = Flexure, 2 = Flexure–Shear, 3 = Shear) | ||||
|---|---|---|---|---|---|
| Aspect Ratio | Axial Load Ratio | ρs (%) | fc (MPa) | vmax/√fc | Failure |
| 2.00 | 0.00 | 0.51 | 37.5 | 0.42 | 2 |
| 2.00 | 0.00 | 0.51 | 37.2 | 0.29 | 2 |
| 2.50 | 0.00 | 0.51 | 36 | 0.37 | 2 |
| 2.00 | 0.00 | 0.51 | 30.6 | 0.42 | 3 |
| 2.00 | 0.00 | 0.76 | 31.1 | 0.47 | 2 |
| 1.50 | 0.00 | 0.51 | 30.1 | 0.57 | 3 |
| 2.00 | 0.00 | 0.38 | 29.5 | 0.41 | 3 |
| 2.00 | 0.20 | 1.02 | 28.7 | 0.69 | 2 |
| 2.00 | 0.20 | 1.02 | 31.2 | 0.64 | 2 |
| 2.00 | 0.20 | 0.51 | 29.9 | 0.59 | 2 |
| 1.50 | 0.10 | 1.02 | 28.6 | 0.78 | 2 |
| 2.00 | 0.10 | 1.02 | 36.2 | 0.58 | 2 |
| 2.00 | 0.00 | 0.51 | 33.7 | 0.43 | 2 |
| 2.00 | 0.00 | 0.51 | 34.8 | 0.31 | 2 |
| 2.00 | 0.10 | 0.51 | 33.4 | 0.51 | 3 |
| 2.50 | 0.10 | 0.51 | 34.3 | 0.44 | 2 |
| 1.50 | 0.10 | 0.51 | 35 | 0.68 | 3 |
| 1.50 | 0.10 | 0.38 | 34.4 | 0.59 | 3 |
| 1.75 | 0.17 | 0.38 | 36.7 | 0.64 | 3 |
| 2.00 | 0.00 | 0.38 | 33.2 | 0.37 | 3 |
| 2.00 | 0.00 | 0.39 | 30.9 | 0.41 | 3 |
| 2.00 | 0.00 | 0.76 | 32.3 | 0.47 | 2 |
| 2.00 | 0.00 | 0.77 | 33.1 | 0.47 | 2 |
| 2.00 | 0.19 | 1.42 | 38 | 0.60 | 1 |
| 2.00 | 0.39 | 0.47 | 37 | 0.64 | 2 |
| 2.00 | 0.39 | 1.42 | 37 | 0.76 | 1 |
| 6.22 | 0.05 | 0.63 | 38.8 | 0.07 | 1 |
| 6.22 | 0.09 | 0.63 | 36.2 | 0.08 | 1 |
| 2.93 | 0.05 | 0.63 | 35.9 | 0.19 | 2 |
| 2.92 | 0.10 | 0.63 | 34.4 | 0.21 | 2 |
| 7.50 | 0.24 | 1.45 | 34.5 | 0.18 | 1 |
| 3.75 | 0.24 | 1.45 | 34.5 | 0.39 | 1 |
| 3.75 | 0.35 | 1.45 | 34.5 | 0.40 | 1 |
| 6.01 | 0.07 | 0.63 | 35.8 | 0.12 | 1 |
| 3.01 | 0.07 | 1.49 | 34.3 | 0.31 | 1 |
| 3.00 | 0.10 | 1.41 | 24.1 | 0.27 | 1 |
| 3.00 | 0.21 | 1.41 | 23.1 | 0.31 | 1 |
| 6.00 | 0.10 | 0.68 | 25.4 | 0.13 | 1 |
| 3.00 | 0.10 | 1.41 | 24.4 | 0.26 | 1 |
| 3.00 | 0.20 | 1.41 | 24.3 | 0.32 | 1 |
| 6.00 | 0.11 | 0.68 | 23.3 | 0.13 | 1 |
| 4.50 | 0.09 | 0.94 | 29 | 0.19 | 1 |
| 4.50 | 0.09 | 0.94 | 29 | 0.19 | 1 |
| 4.50 | 0.09 | 0.94 | 35.5 | 0.17 | 1 |
| 4.50 | 0.09 | 0.94 | 35.5 | 0.21 | 1 |
| 4.50 | 0.09 | 0.94 | 35.5 | 0.18 | 1 |
| 4.50 | 0.09 | 0.94 | 32.8 | 0.19 | 1 |
| 4.50 | 0.09 | 0.94 | 32.8 | 0.17 | 1 |
| 4.50 | 0.09 | 0.94 | 32.5 | 0.18 | 1 |
| 4.50 | 0.10 | 0.94 | 27 | 0.20 | 1 |
| 4.50 | 0.10 | 0.94 | 27 | 0.19 | 1 |
| 4.50 | 0.10 | 0.94 | 27 | 0.19 | 1 |
| 1.50 | 0.06 | 0.28 | 30 | 0.26 | 2 |
| 1.50 | 0.06 | 0.17 | 30 | 0.37 | 2 |
| 6.00 | 0.15 | 0.89 | 41.1 | 0.19 | 1 |
| 1.99 | 0.31 | 1.14 | 38.3 | 0.61 | 1 |
| 1.99 | -0.10 | 1.14 | 39.2 | 0.28 | 2 |
| 1.99 | 0.15 | 1.14 | 39.4 | 0.54 | 1 |
| 1.99 | 0.15 | 2.70 | 35 | 1.02 | 2 |
| 1.99 | -0.08 | 0.85 | 35.2 | 0.41 | 2 |
| 1.99 | 0.33 | 3.04 | 35 | 1.14 | 1 |
| 8.00 | 0.30 | 0.92 | 36.6 | 0.19 | 1 |
| 8.00 | 0.27 | 1.38 | 40 | 0.17 | 1 |
| 8.00 | 0.28 | 0.92 | 38.6 | 0.19 | 1 |
| 4.00 | 0.07 | 0.70 | 31 | 0.18 | 1 |
| 8.00 | 0.07 | 0.70 | 31 | 0.09 | 1 |
| 10.00 | 0.07 | 0.70 | 31 | 0.06 | 1 |
| 4.00 | 0.07 | 0.70 | 31 | 0.11 | 1 |
| 4.00 | 0.07 | 0.70 | 31 | 0.30 | 1 |
| 3.00 | 0.09 | 0.89 | 34.5 | 0.32 | 1 |
| 8.00 | 0.09 | 0.89 | 34.5 | 0.12 | 1 |
| 10.00 | 0.09 | 0.89 | 34.5 | 0.11 | 1 |
| 3.00 | 0.04 | 0.54 | 34.6 | 0.26 | 1 |
| 3.00 | 0.04 | 0.81 | 33 | 0.28 | 1 |
| 6.58 | 0.31 | 1.54 | 65 | 0.18 | 1 |
| 6.58 | 0.31 | 3.49 | 65 | 0.17 | 1 |
| 6.58 | 0.42 | 1.74 | 90 | 0.17 | 1 |
| 6.58 | 0.21 | 1.54 | 90 | 0.16 | 1 |
| 6.58 | 0.42 | 1.54 | 90 | 0.17 | 1 |
| 2.58 | 0.00 | 0.10 | 34.7 | 0.19 | 2 |
| 2.58 | 0.00 | 0.26 | 35.4 | 0.23 | 2 |
| 2.00 | 0.00 | 0.13 | 29.8 | 0.25 | 3 |
| 2.00 | 0.00 | 0.13 | 26.8 | 0.22 | 3 |
| 2.00 | 0.00 | 0.13 | 31.2 | 0.20 | 3 |
| Feature Values | True Label Values (1 = Flexure, 2 = Flexure–Shear, 3 = Shear) | ||||
|---|---|---|---|---|---|
| Aspect Ratio | Axial Load Ratio | ρs (%) | fc (MPa) | vmax/√fc | Failure |
| 2.18 | 0.26 | 1.50 | 23.1 | 0.48 | 1 |
| 2.18 | 0.21 | 2.30 | 41.4 | 0.42 | 1 |
| 2.18 | 0.42 | 2.00 | 21.4 | 0.48 | 1 |
| 2.18 | 0.60 | 3.50 | 23.5 | 0.47 | 1 |
| 4.00 | 0.38 | 2.83 | 23.6 | 0.25 | 1 |
| 4.00 | 0.21 | 2.22 | 25 | 0.21 | 1 |
| 4.00 | 0.10 | 0.86 | 46.5 | 0.18 | 1 |
| 4.00 | 0.30 | 1.22 | 44 | 0.26 | 1 |
| 4.00 | 0.30 | 0.80 | 44 | 0.26 | 1 |
| 4.00 | 0.30 | 0.57 | 40 | 0.26 | 1 |
| 4.00 | 0.22 | 1.56 | 28.3 | 0.25 | 1 |
| 4.00 | 0.39 | 1.99 | 40.1 | 0.27 | 1 |
| 4.00 | 0.50 | 0.66 | 41 | 0.29 | 1 |
| 4.00 | 0.50 | 0.32 | 40 | 0.29 | 1 |
| 4.00 | 0.70 | 1.26 | 42 | 0.29 | 1 |
| 4.00 | 0.70 | 0.70 | 39 | 0.30 | 1 |
| 4.00 | 0.70 | 2.33 | 40 | 0.31 | 1 |
| 4.00 | 0.20 | 2.55 | 25.6 | 0.21 | 1 |
| 4.00 | 0.20 | 2.55 | 25.6 | 0.21 | 1 |
| 4.00 | 0.20 | 2.55 | 25.6 | 0.22 | 1 |
| 4.00 | 0.20 | 2.55 | 25.6 | 0.21 | 1 |
| 3.00 | 0.10 | 1.70 | 32 | 0.23 | 1 |
| 3.00 | 0.10 | 1.70 | 32 | 0.24 | 1 |
| 3.00 | 0.30 | 2.08 | 32.1 | 0.36 | 1 |
| 3.00 | 0.30 | 2.08 | 32.1 | 0.36 | 1 |
| 2.97 | 0.10 | 2.17 | 26.9 | 0.32 | 1 |
| 1.50 | 0.33 | 1.18 | 20.6 | 0.57 | 1 |
| 1.50 | 0.17 | 0.81 | 21.6 | 0.47 | 3 |
| 1.50 | 0.35 | 1.39 | 21 | 0.61 | 2 |
| 4.00 | 0.03 | 0.32 | 24.8 | 0.15 | 1 |
| 4.00 | 0.03 | 0.32 | 24.8 | 0.14 | 1 |
| 4.00 | 0.03 | 0.32 | 24.8 | 0.14 | 1 |
| 2.00 | 0.14 | 0.57 | 32 | 0.45 | 2 |
| 2.00 | 0.15 | 0.57 | 29.9 | 0.51 | 2 |
| 1.65 | 0.05 | 0.36 | 27.1 | 0.45 | 3 |
| 2.00 | 0.80 | 0.73 | 21.1 | 0.58 | 2 |
| 2.00 | 0.80 | 0.73 | 21.1 | 0.61 | 1 |
| 2.00 | 0.90 | 1.75 | 21.1 | 0.57 | 2 |
| 3.00 | 0.70 | 0.73 | 28.8 | 0.41 | 2 |
| 3.00 | 0.70 | 0.73 | 28.8 | 0.40 | 2 |
| 3.00 | 0.70 | 1.75 | 28.8 | 0.38 | 2 |
| 3.00 | 0.11 | 0.38 | 27.9 | 0.25 | 1 |
| 3.00 | 0.11 | 0.38 | 27.9 | 0.24 | 1 |
| 3.00 | 0.11 | 0.38 | 27.9 | 0.25 | 1 |
| 3.00 | 0.12 | 0.38 | 24.8 | 0.27 | 1 |
| 3.00 | 0.11 | 0.38 | 27.9 | 0.25 | 1 |
| 3.00 | 0.11 | 0.38 | 27.9 | 0.23 | 1 |
| 1.25 | 0.18 | 0.21 | 31.8 | 0.71 | 3 |
| 1.25 | 0.45 | 0.21 | 33 | 0.72 | 3 |
| 2.50 | 0.40 | 1.61 | 85.7 | 0.66 | 1 |
| 2.50 | 0.63 | 1.61 | 85.7 | 0.65 | 1 |
| 2.50 | 0.63 | 1.61 | 85.7 | 0.67 | 1 |
| 2.50 | 0.25 | 1.61 | 115.8 | 0.59 | 1 |
| 2.50 | 0.25 | 1.61 | 115.8 | 0.59 | 1 |
| 2.50 | 0.42 | 1.61 | 115.8 | 0.67 | 1 |
| 2.50 | 0.42 | 1.61 | 115.8 | 0.67 | 1 |
| 1.50 | 0.26 | 0.91 | 25.8 | 0.64 | 2 |
| 1.50 | 0.62 | 0.91 | 25.8 | 0.67 | 2 |
| 2.00 | 0.35 | 0.50 | 99.5 | 0.66 | 1 |
| 2.00 | 0.35 | 0.75 | 99.5 | 0.66 | 1 |
| 2.00 | 0.35 | 0.61 | 99.5 | 0.69 | 1 |
| 2.00 | 0.35 | 0.50 | 99.5 | 0.65 | 1 |
| 2.00 | 0.35 | 0.50 | 99.5 | 0.65 | 1 |
| 2.00 | 0.35 | 0.50 | 99.5 | 0.67 | 1 |
| 2.00 | 0.35 | 0.50 | 99.5 | 0.65 | 1 |
| 1.16 | 0.74 | 0.89 | 46.3 | 0.98 | 2 |
| 2.88 | 0.12 | 0.33 | 34.7 | 0.36 | 2 |
| 2.88 | 0.12 | 0.33 | 34.7 | 0.37 | 1 |
| 2.88 | 0.15 | 0.48 | 26.1 | 0.44 | 2 |
| 2.88 | 0.15 | 0.48 | 26.1 | 0.41 | 1 |
| 2.88 | 0.11 | 0.33 | 33.6 | 0.35 | 2 |
| 2.88 | 0.11 | 0.33 | 33.6 | 0.39 | 1 |
| 2.88 | 0.07 | 0.33 | 33.6 | 0.33 | 3 |
| 2.88 | 0.07 | 0.33 | 33.6 | 0.35 | 1 |
| 2.88 | 0.11 | 0.67 | 33.4 | 0.38 | 2 |
| 2.88 | 0.11 | 0.67 | 33.4 | 0.37 | 1 |
| 2.88 | 0.11 | 1.47 | 33.5 | 0.45 | 2 |
| 2.88 | 0.11 | 1.47 | 33.5 | 0.45 | 1 |
| 2.88 | 0.11 | 0.92 | 33.5 | 0.45 | 2 |
| 2.88 | 0.11 | 0.92 | 33.5 | 0.45 | 1 |
| 5.50 | 0.10 | 1.54 | 29.1 | 0.12 | 1 |
| 5.50 | 0.09 | 0.93 | 30.7 | 0.12 | 1 |
| 5.50 | 0.10 | 1.54 | 29.2 | 0.12 | 1 |
| 5.50 | 0.10 | 0.93 | 27.6 | 0.15 | 1 |
| 5.50 | 0.20 | 1.54 | 29.4 | 0.15 | 1 |
| 5.50 | 0.18 | 0.93 | 31.8 | 0.14 | 1 |
| 5.50 | 0.26 | 1.54 | 33.3 | 0.15 | 1 |
| 5.50 | 0.27 | 0.93 | 32.4 | 0.15 | 1 |
| 5.50 | 0.28 | 1.54 | 31 | 0.16 | 1 |
| 5.50 | 0.27 | 0.93 | 31.8 | 0.15 | 1 |
| 1.11 | 0.16 | 0.28 | 34.9 | 0.58 | 3 |
| 1.98 | 0.16 | 0.31 | 34.9 | 0.47 | 3 |
| 1.11 | 0.27 | 0.28 | 42 | 0.67 | 3 |
| 1.50 | 0.10 | 0.26 | 29.9 | 0.42 | 3 |
| 3.00 | 0.21 | 2.19 | 39.3 | 0.36 | 1 |
| 3.00 | 0.31 | 1.26 | 39.8 | 0.37 | 1 |
| 2.86 | 0.00 | 0.85 | 43.6 | 0.34 | 1 |
| 2.86 | 0.14 | 1.69 | 34.8 | 0.38 | 1 |
| 2.86 | 0.15 | 2.54 | 32 | 0.47 | 1 |
| 2.86 | 0.13 | 1.95 | 37.3 | 0.46 | 1 |
| 2.86 | 0.13 | 1.95 | 39 | 0.45 | 1 |
| 4.56 | 0.30 | 1.22 | 80 | 0.23 | 1 |
| 4.56 | 0.30 | 1.22 | 80 | 0.22 | 1 |
| 4.56 | 0.20 | 1.22 | 80 | 0.18 | 1 |
| 4.56 | 0.20 | 1.22 | 80 | 0.25 | 1 |
| 4.56 | 0.20 | 1.83 | 80 | 0.25 | 1 |
| 4.56 | 0.30 | 1.83 | 80 | 0.23 | 1 |
| 4.56 | 0.30 | 1.83 | 80 | 0.23 | 1 |
| 4.56 | 0.20 | 1.83 | 80 | 0.20 | 1 |
| 4.56 | 0.20 | 3.66 | 80 | 0.18 | 1 |
| 4.56 | 0.30 | 3.66 | 80 | 0.23 | 1 |
| 4.56 | 0.20 | 3.66 | 80 | 0.24 | 1 |
| 4.56 | 0.30 | 3.66 | 80 | 0.24 | 1 |
| 4.56 | 0.20 | 1.22 | 80 | 0.31 | 1 |
| 4.56 | 0.30 | 1.22 | 80 | 0.30 | 1 |
| 4.56 | 0.30 | 1.22 | 80 | 0.31 | 1 |
| 4.56 | 0.20 | 1.22 | 80 | 0.37 | 1 |
| 4.56 | 0.20 | 1.83 | 80 | 0.29 | 1 |
| 4.56 | 0.20 | 1.83 | 80 | 0.35 | 1 |
| 4.56 | 0.30 | 1.83 | 80 | 0.31 | 1 |
| 4.56 | 0.30 | 1.83 | 80 | 0.31 | 1 |
| 4.56 | 0.20 | 3.66 | 80 | 0.31 | 1 |
| 4.56 | 0.20 | 3.66 | 80 | 0.31 | 1 |
| 4.56 | 0.30 | 3.66 | 80 | 0.30 | 1 |
| 4.56 | 0.30 | 3.66 | 80 | 0.32 | 1 |
| 3.83 | 0.10 | 0.37 | 27.2 | 0.30 | 1 |
| 3.83 | 0.24 | 0.37 | 27.2 | 0.33 | 1 |
| 3.83 | 0.09 | 0.48 | 28.1 | 0.31 | 1 |
| 3.83 | 0.23 | 0.48 | 28.1 | 0.35 | 1 |
| 3.22 | 0.09 | 0.08 | 26.9 | 0.26 | 3 |
| 3.22 | 0.07 | 0.08 | 33.1 | 0.20 | 2 |
| 3.22 | 0.28 | 0.08 | 25.5 | 0.29 | 2 |
| 3.22 | 0.26 | 0.08 | 27.6 | 0.30 | 3 |
| 3.22 | 0.26 | 0.25 | 27.6 | 0.32 | 3 |
| 3.22 | 0.09 | 0.08 | 26.9 | 0.25 | 3 |
| 3.22 | 0.07 | 0.08 | 33.1 | 0.19 | 2 |
| 3.22 | 0.28 | 0.25 | 25.5 | 0.35 | 2 |
| 2.00 | 0.10 | 3.67 | 76 | 0.58 | 1 |
| 2.00 | 0.20 | 3.67 | 76 | 0.67 | 1 |
| 2.00 | 0.10 | 3.67 | 86 | 0.46 | 1 |
| 2.00 | 0.19 | 3.67 | 86 | 0.53 | 1 |
| 2.00 | 0.10 | 1.63 | 86 | 0.45 | 2 |
| 2.00 | 0.19 | 1.63 | 86 | 0.54 | 2 |
| 2.00 | 0.60 | 0.90 | 118 | 0.61 | 1 |
| 2.00 | 0.60 | 1.41 | 118 | 0.66 | 1 |
| 2.00 | 0.60 | 1.82 | 118 | 0.74 | 1 |
| 2.00 | 0.35 | 1.41 | 118 | 0.67 | 1 |
| 2.00 | 0.35 | 1.82 | 118 | 0.67 | 1 |
| 7.64 | 0.34 | 0.12 | 40.6 | 0.13 | 1 |
| 6.04 | 0.50 | 3.15 | 72.1 | 0.19 | 1 |
| 6.04 | 0.36 | 2.84 | 71.7 | 0.19 | 1 |
| 6.04 | 0.50 | 2.84 | 71.8 | 0.19 | 1 |
| 6.04 | 0.50 | 5.12 | 71.9 | 0.19 | 1 |
| 6.04 | 0.45 | 4.02 | 101.8 | 0.21 | 1 |
| 6.04 | 0.46 | 6.74 | 101.9 | 0.21 | 1 |
| 6.04 | 0.45 | 2.72 | 102 | 0.18 | 1 |
| 6.04 | 0.47 | 4.29 | 102.2 | 0.19 | 1 |
| 4.70 | 0.43 | 1.00 | 34 | 0.27 | 1 |
| 4.70 | 0.43 | 2.00 | 34 | 0.27 | 1 |
| 4.70 | 0.20 | 2.00 | 34 | 0.23 | 1 |
| 4.70 | 0.46 | 1.33 | 34 | 0.29 | 1 |
| 4.70 | 0.46 | 2.66 | 34 | 0.33 | 1 |
| 4.70 | 0.46 | 2.66 | 34 | 0.31 | 1 |
| 4.70 | 0.46 | 1.26 | 34 | 0.30 | 1 |
| 4.70 | 0.23 | 1.26 | 34 | 0.28 | 1 |
| 4.70 | 0.46 | 1.26 | 34 | 0.31 | 1 |
| 4.70 | 0.46 | 2.66 | 34 | 0.33 | 1 |
| 3.00 | 0.05 | 1.00 | 69.6 | 0.20 | 1 |
| 3.00 | 0.05 | 1.00 | 69.6 | 0.20 | 1 |
| 3.00 | 0.10 | 1.00 | 67.8 | 0.28 | 1 |
| 3.00 | 0.10 | 1.00 | 67.8 | 0.28 | 1 |
| 3.00 | 0.21 | 1.00 | 65.5 | 0.32 | 1 |
| 3.00 | 0.21 | 1.00 | 65.5 | 0.31 | 1 |
| 3.00 | 0.00 | 1.00 | 37.9 | 0.23 | 1 |
| 3.00 | 0.00 | 1.00 | 37.9 | 0.23 | 1 |
| 3.00 | 0.14 | 1.00 | 48.3 | 0.25 | 1 |
| 3.00 | 0.14 | 1.00 | 48.3 | 0.25 | 1 |
| 3.00 | 0.36 | 1.00 | 38.1 | 0.33 | 1 |
| 3.00 | 0.36 | 1.00 | 38.1 | 0.33 | 1 |
| 3.50 | 0.11 | 0.76 | 24.9 | 0.31 | 1 |
| 3.50 | 0.16 | 0.76 | 26.7 | 0.32 | 1 |
| 3.50 | 0.22 | 0.76 | 26.1 | 0.37 | 1 |
| 3.50 | 0.11 | 0.73 | 25.3 | 0.31 | 1 |
| 3.50 | 0.16 | 0.73 | 27.1 | 0.34 | 1 |
| 3.50 | 0.21 | 0.73 | 26.8 | 0.37 | 1 |
| 3.50 | 0.11 | 0.71 | 26.38 | 0.31 | 1 |
| 3.50 | 0.15 | 0.71 | 27.48 | 0.34 | 1 |
| 3.50 | 0.21 | 0.71 | 26.9 | 0.36 | 1 |
| 2.67 | 0.00 | 0.04 | 21.9 | 0.23 | 3 |
| 1.33 | 0.00 | 0.09 | 16 | 0.38 | 3 |
| 3.92 | 0.00 | 0.96 | 102.7 | 0.20 | 1 |
| 3.92 | 0.20 | 0.96 | 86.3 | 0.34 | 1 |
| 3.92 | 0.00 | 0.96 | 87.5 | 0.19 | 1 |
| 3.92 | 0.10 | 0.96 | 83.4 | 0.26 | 1 |
| 3.92 | 0.20 | 0.96 | 90 | 0.30 | 1 |
| 3.92 | 0.00 | 0.96 | 67.5 | 0.21 | 1 |
| 3.92 | 0.10 | 0.96 | 74.6 | 0.26 | 1 |
| 3.92 | 0.20 | 0.96 | 81.8 | 0.27 | 1 |
| 3.92 | 0.20 | 0.77 | 75.8 | 0.28 | 1 |
| 3.92 | 0.20 | 0.64 | 87 | 0.29 | 1 |
| 3.92 | 0.20 | 0.54 | 71.2 | 0.27 | 1 |
| 3.22 | 0.15 | 0.25 | 21.1 | 0.33 | 2 |
| 3.22 | 0.61 | 0.25 | 21.1 | 0.37 | 2 |
| 3.22 | 0.15 | 0.25 | 21.8 | 0.30 | 2 |
| 6.56 | 0.14 | 2.50 | 92.4 | 0.14 | 1 |
| 6.56 | 0.28 | 2.50 | 93.3 | 0.18 | 1 |
| 6.56 | 0.39 | 2.50 | 98.2 | 0.21 | 1 |
| 6.56 | 0.14 | 1.16 | 94.8 | 0.12 | 1 |
| 6.56 | 0.26 | 1.16 | 97.7 | 0.18 | 1 |
| 6.56 | 0.37 | 1.16 | 104.3 | 0.19 | 1 |
| 6.56 | 0.40 | 2.50 | 78.7 | 0.21 | 1 |
| 6.56 | 0.41 | 2.50 | 109.2 | 0.22 | 1 |
| 6.56 | 0.35 | 1.93 | 109.5 | 0.20 | 1 |
| 6.56 | 0.37 | 1.33 | 104.2 | 0.21 | 1 |
| 6.56 | 0.53 | 1.93 | 104.5 | 0.21 | 1 |
| 6.56 | 0.51 | 2.50 | 109.4 | 0.22 | 1 |
| 2.25 | 0.08 | 0.57 | 33.7 | 0.42 | 1 |
| 2.25 | 0.08 | 0.57 | 33.7 | 0.42 | 1 |
| 2.25 | 0.09 | 1.64 | 32.1 | 0.44 | 1 |
| 2.25 | 0.09 | 1.64 | 32.1 | 0.44 | 1 |
| 2.25 | 0.10 | 0.82 | 29.9 | 0.45 | 1 |
| 2.25 | 0.10 | 0.82 | 29.9 | 0.45 | 1 |
| 2.25 | 0.10 | 1.09 | 27.4 | 0.47 | 1 |
| 2.25 | 0.10 | 1.09 | 27.4 | 0.47 | 1 |
| 2.25 | 0.16 | 0.82 | 36.4 | 0.47 | 1 |
| 2.25 | 0.16 | 0.82 | 36.4 | 0.47 | 1 |
| 2.25 | 0.08 | 1.09 | 34.9 | 0.42 | 1 |
| 2.25 | 0.08 | 1.09 | 34.9 | 0.42 | 1 |
| 2.25 | 0.08 | 1.09 | 36.5 | 0.42 | 1 |
| 2.25 | 0.08 | 1.09 | 36.5 | 0.42 | 1 |
| 2.50 | 0.30 | 0.59 | 37.6 | 0.52 | 1 |
| 2.50 | 0.60 | 0.59 | 37.6 | 0.49 | 1 |
| 2.00 | 0.57 | 0.99 | 39.2 | 0.55 | 1 |
| 2.00 | 0.57 | 0.99 | 39.2 | 0.59 | 1 |
| 2.14 | 0.59 | 0.99 | 32.2 | 0.67 | 1 |
| 3.11 | 0.03 | 0.23 | 35.9 | 0.16 | 1 |
| 3.11 | 0.03 | 0.23 | 35.7 | 0.15 | 1 |
| 3.11 | 0.03 | 0.23 | 34.3 | 0.16 | 1 |
| 3.11 | 0.03 | 0.23 | 33.2 | 0.17 | 1 |
| 3.11 | 0.03 | 0.23 | 36.8 | 0.16 | 1 |
| 3.11 | 0.03 | 0.23 | 35.9 | 0.18 | 1 |
| 3.49 | 0.20 | 1.85 | 64.1 | 0.35 | 1 |
| 3.49 | 0.33 | 1.85 | 62.1 | 0.40 | 1 |
| 3.49 | 0.22 | 1.48 | 62.1 | 0.36 | 1 |
| 3.49 | 0.32 | 1.48 | 62.1 | 0.40 | 1 |
| 3.49 | 0.20 | 1.23 | 64.1 | 0.34 | 1 |
| 3.49 | 0.20 | 1.23 | 64.1 | 0.34 | 1 |
References
- Megalooikonomou, K.G. Modeling the Behavior of Shear-Critical Reinforced Concrete Columns under Lateral Loads. Ph.D. Thesis, Department of Civil and Environmental Engineering, Faculty of Engineering, University of Cyprus, Nicosia, Cyprus, December 2019. [Google Scholar] [CrossRef]
- Megalooikonomou, K.G. Seismic Assessment and Retrofit of Reinforced Concrete Columns, 1st ed.; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2019; p. 387. [Google Scholar]
- Mangalathu, S.; Jeon, J.-S. Machine Learning-Based Failure Mode Recognition of Circular Reinforced Concrete Bridge Columns: Comparative Study. ASCE J. Struct. Eng. 2019, 145, 04019104. [Google Scholar] [CrossRef]
- Xie, Y.; Sichani, M.E.; Padgett, J.E.; DesRoches, R. The promise of implementing machine learning in earthquake engineering: A state-of-the-art review. Earthq. Spectra 2020, 36, 1769–1801. [Google Scholar] [CrossRef]
- Ghosh, J.; Padgett, J.E.; Dueñas-Osorio, L. Surrogate modeling and failure surface visualization for efficient seismic vulnerability assessment of highway bridges. Probab. Eng. Mech. 2013, 34, 189–199. [Google Scholar] [CrossRef]
- Jeon, J.-S.; Shafieezadeh, A.; DesRoches, R. Statistical models for shear strength of RC beam-column joints using machine-learning techniques. Earthq. Eng. Struct. Dyn. 2014, 43, 2075–2095. [Google Scholar] [CrossRef]
- Krishnan, N.; Mangalathu, S.; Smedskjaer, M.M.; Tandia, A.; Burton, H.; Bauchy, M. Predicting the dissolution kinetics of silicate glasses using machine learning. J. Non-Cryst. Solids 2017, 487, 37–45. [Google Scholar] [CrossRef]
- Mangalathu, S.; Heo, G.; Jeon, J.-S. Artificial neural network based multi-dimensional fragility development of skewed concrete bridge classes. Eng. Struct. 2018, 162, 166–176. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.-S. Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Eng. Struct. 2018, 160, 85–94. [Google Scholar] [CrossRef]
- Wang, Z.; Pedroni, N.; Zentner, I.; Zio, E. Seismic fragility analysis with artificial neural networks: Application to nuclear power plant equipment. Eng. Struct. 2018, 162, 213–225. [Google Scholar] [CrossRef]
- Zhang, Y.; Burton, H.V.; Sun, H.; Shokrabadi, M. A machine learning framework for assessing post-earthquake structural safety. Struct. Saf. 2018, 72, 1–16. [Google Scholar] [CrossRef]
- Mitra, N.; Mitra, S.; Lowes, L.N. Probabilistic model for failure initiation of reinforced concrete interior beam-column connections subjected to seismic loading. Eng. Struct. 2011, 33, 154–162. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Afan, H.A.; Tran, M.T. Beam-column joint shear prediction using hybridized deep learning neural network with genetic algorithm. IOP Conf. Ser. Earth Environ. Sci. 2018, 143, 1–7. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, Y.; Wu, D.; Chen, M.; Pang, L.; Sun, J.; Feng, W.; Wang, X. Exploring temperature-resilient recycled aggregate concrete with waste rubber: An experimental and multi-objective optimization analysis. Rev. Adv. Mater. Sci. 2023, 62, 20230347. [Google Scholar] [CrossRef]
- Tang, Y.; Wang, Y.; Wu, D.; Liu, Z.; Zhang, H.; Zhu, M.; Chen, Z.; Sun, J.; Wang, X. An experimental investigation and machine learning-based prediction for seismic performance of steel tubular column filled with recycled aggregate concrete. Rev. Adv. Mater. Sci. 2022, 61, 849–872. [Google Scholar] [CrossRef]
- Berry, M.P.; Parrish, M.; Eberhard, M.O. PEER Structural Performance Database User’s Manual; Version 1.0, Pacific Earthquake Engineering Research Center (PEER) Report; University of California: Berkeley, CA, USA, 2004; Available online: http://nisee.berkeley.edu/spd/ (accessed on 10 October 2023).
- Phan, V.-T.; Tran, V.-L.; Nguyen, V.-Q.; Nguyen, D.-D. Machine Learning Models for Predicting Shear Strength and Identifying Failure Modes of Rectangular RC Columns. Buildings 2022, 12, 1493. [Google Scholar] [CrossRef]
- EN 1998-1; Eurocode 8: Design of Structures for Earthquake Resistance—Part 1: General Rules Seismic Actions and Rules for Buildings. European Committee for Standardization (CEN): Brussels, Belgium, 2004.
- AASHTO LRFD. Bridge Design Specifications and Commentary, 3rd ed.; American Association of State Highway Transportation Officials: Washington, DC, USA, 2013; p. 1264. [Google Scholar]
- The FEMA 440 Report. Improvement of Nonlinear Static Seismic Analysis Procedures; Federal Emergency Management Agency (FEMA): Washington, DC, USA, 2005; p. 392.
- Wael, A. Data Science from Scratch with Python; AI Publishing LLC: Oxford, UK; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019; ISBN -13: 978-1-7330426-3-5. [Google Scholar]
- Thompson, M.J. Python: 3 Manuscripts in 1 Book: Python Programming for Beginners—Python Programming for Intermediates-Python Programming for Advanced; White Flower Publishing: Torrington, CT, USA, 2018. [Google Scholar]
- Elwood, K.J.; Moehle, J.P. Drift Capacity of Reinforced Concrete Columns with Light Transverse Reinforcement. Earthq. Spectra 2005, 21, 71–89. [Google Scholar] [CrossRef]
- Elwood, K.J.; Moehle, J.P. Axial Capacity Model for Shear-Damaged Columns. ACI Struct. J. 2005, 102, 578–587. [Google Scholar]
- Panagiotakos, T.B.; Fardis, M.N. Deformations of reinforced concrete members at yielding and ultimate. ACI Struct. J. 2001, 98, 135–148. [Google Scholar]
- Priestley, M.J.N.; Seible, F.; Calvi, M. Seismic Design and Retrofit of Bridges; John Wiley & Sons Inc.: New York, NY, USA, 1996. [Google Scholar]
- Pujol, S.; Ramirez, J.A.; Sozen, M.A. Drift Capacity of Reinforced Concrete Columns Subjected to Cyclic Shear Reversals, Seismic Response of Concrete Bridges; SP-187; American Concrete Institute: Farmington Hills, MI, USA, 1999; pp. 255–274. [Google Scholar]
- Sezen, H.; Moehle, J.P. Seismic Tests of Concrete Columns with Light Transverse Reinforcement. ACI Struct. J. 2006, 103, 842–849. [Google Scholar]
- Vecchio, F.J.; Collins, M.P. Predicting the Response of Reinforced Concrete Beams Subjected to Shear Using Modified Compression Field Theory. ACI Struct. J. 1988, 85, 258–268. [Google Scholar]
- Megalooikonomou, K.G.; Tastani, S.P.; Pantazopoulou, S.J. Effect of Yield Penetration on Column Plastic Hinge Length. Eng. Struct. 2018, 156, 161–174. [Google Scholar] [CrossRef]


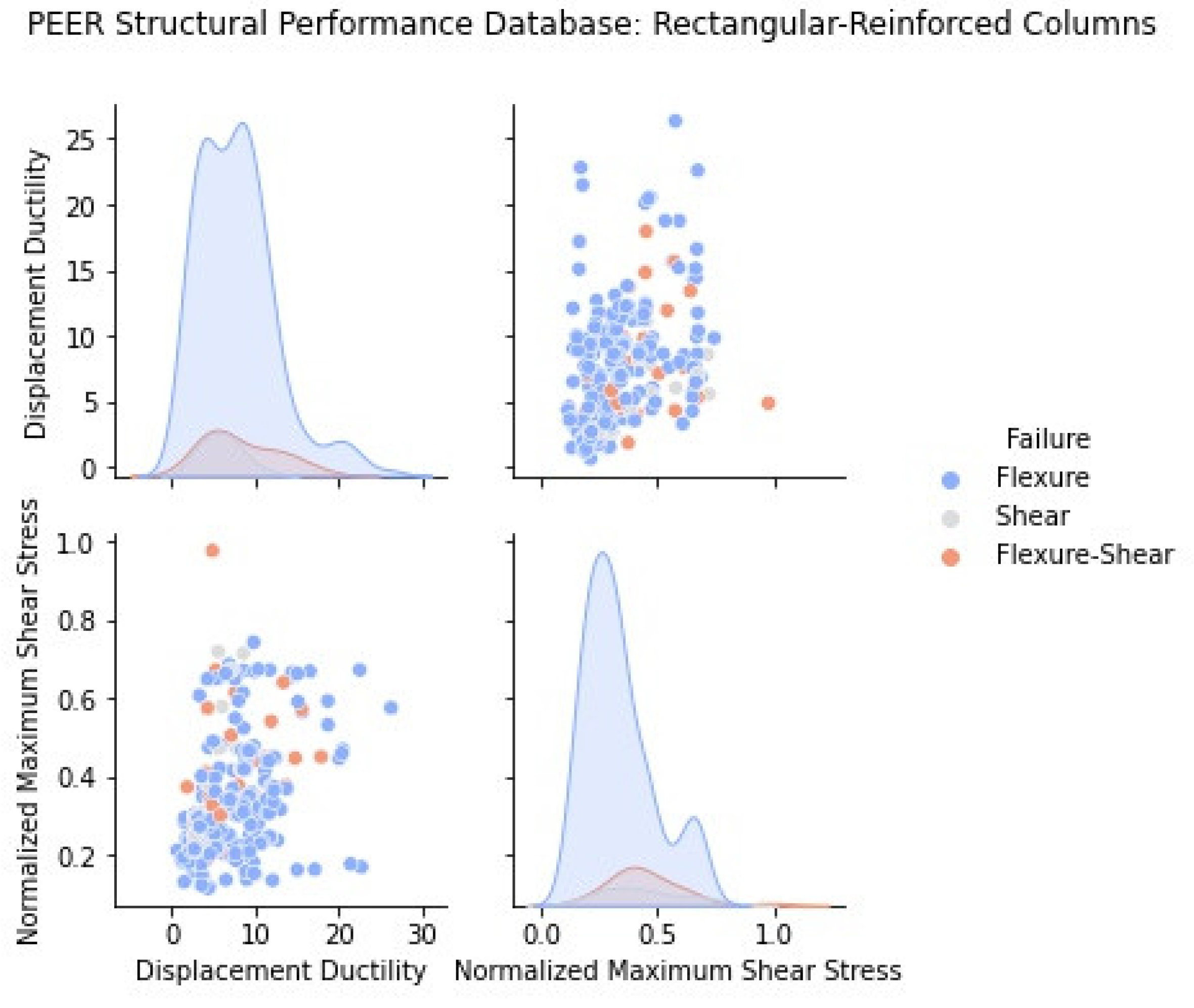
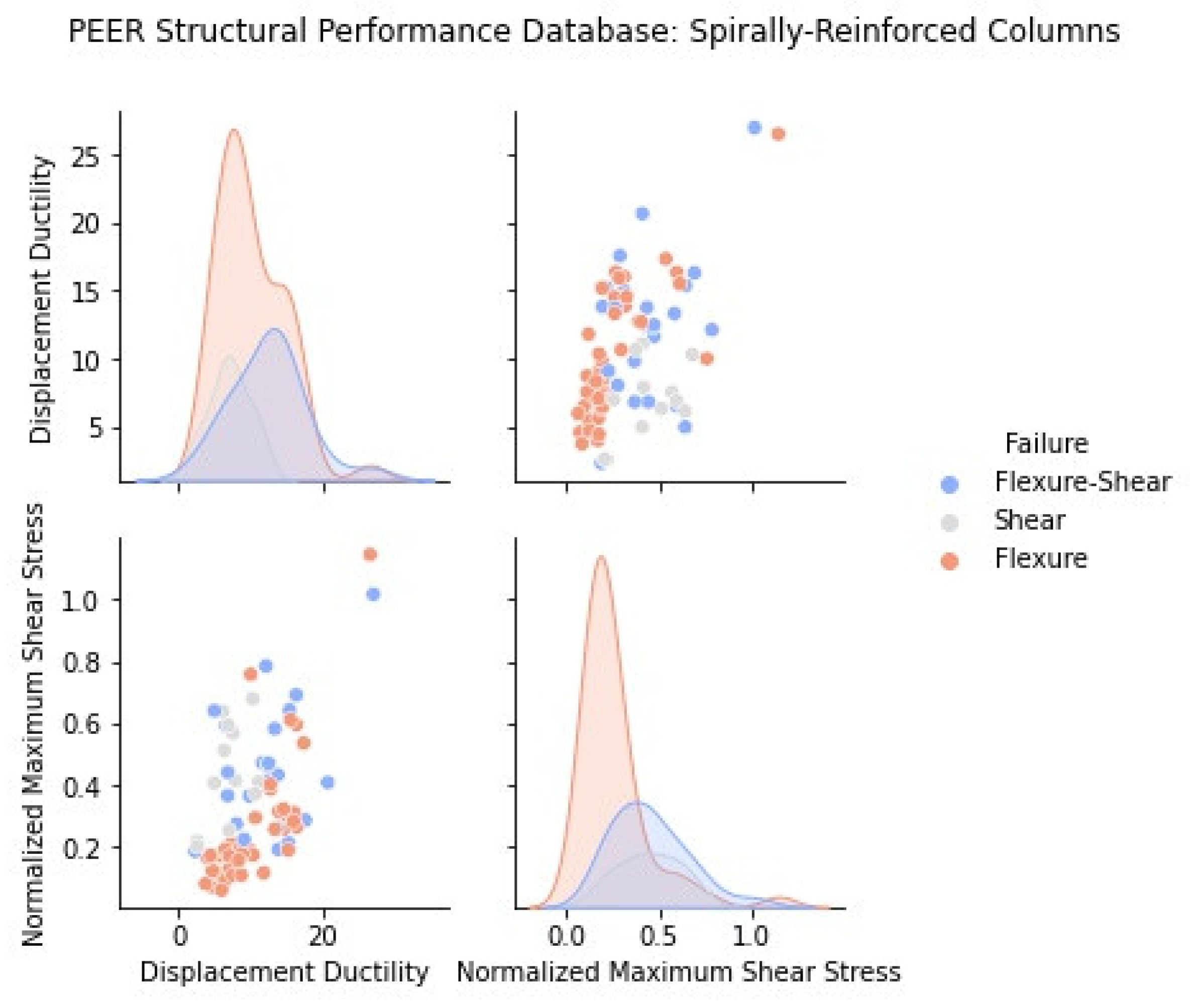
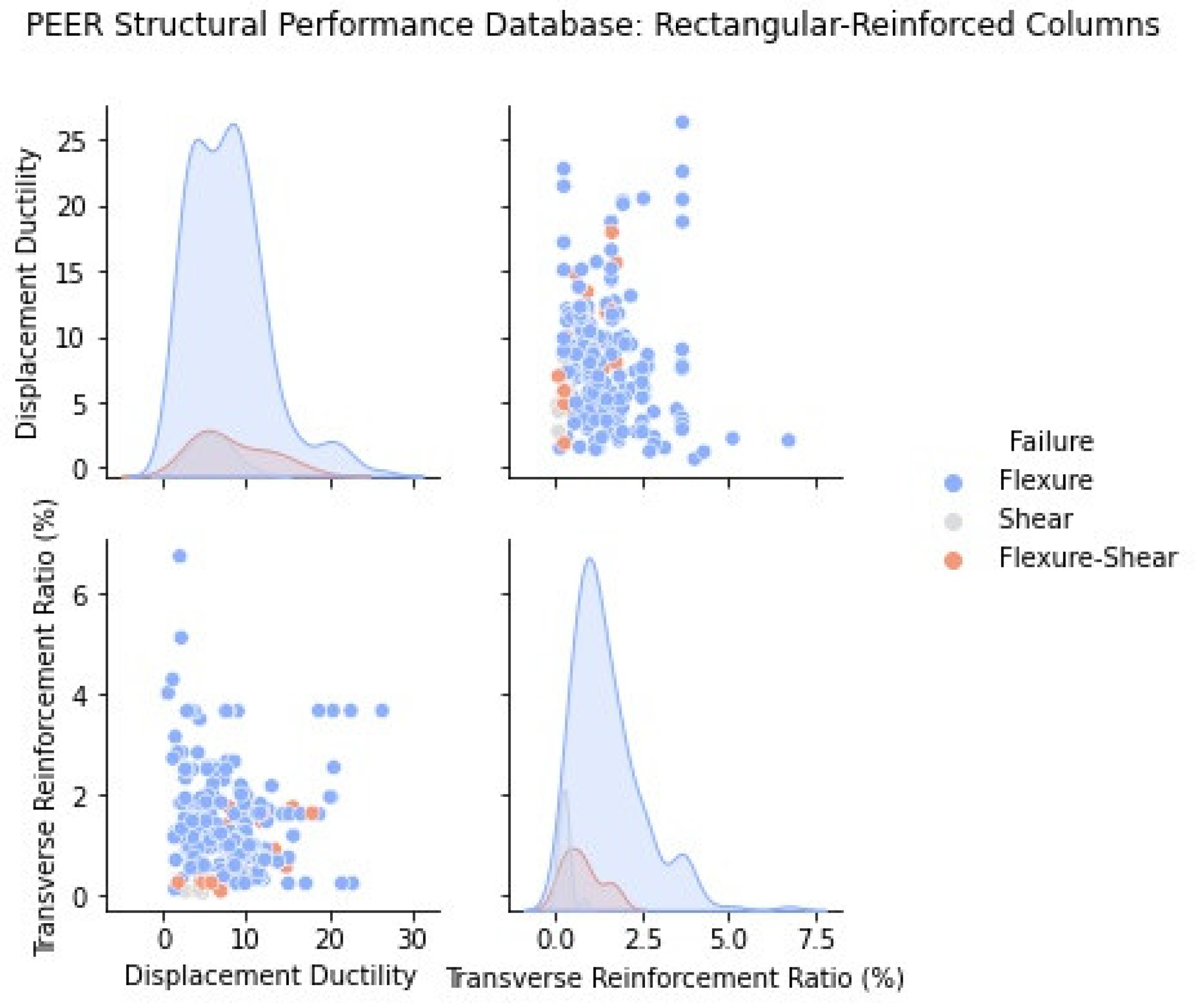
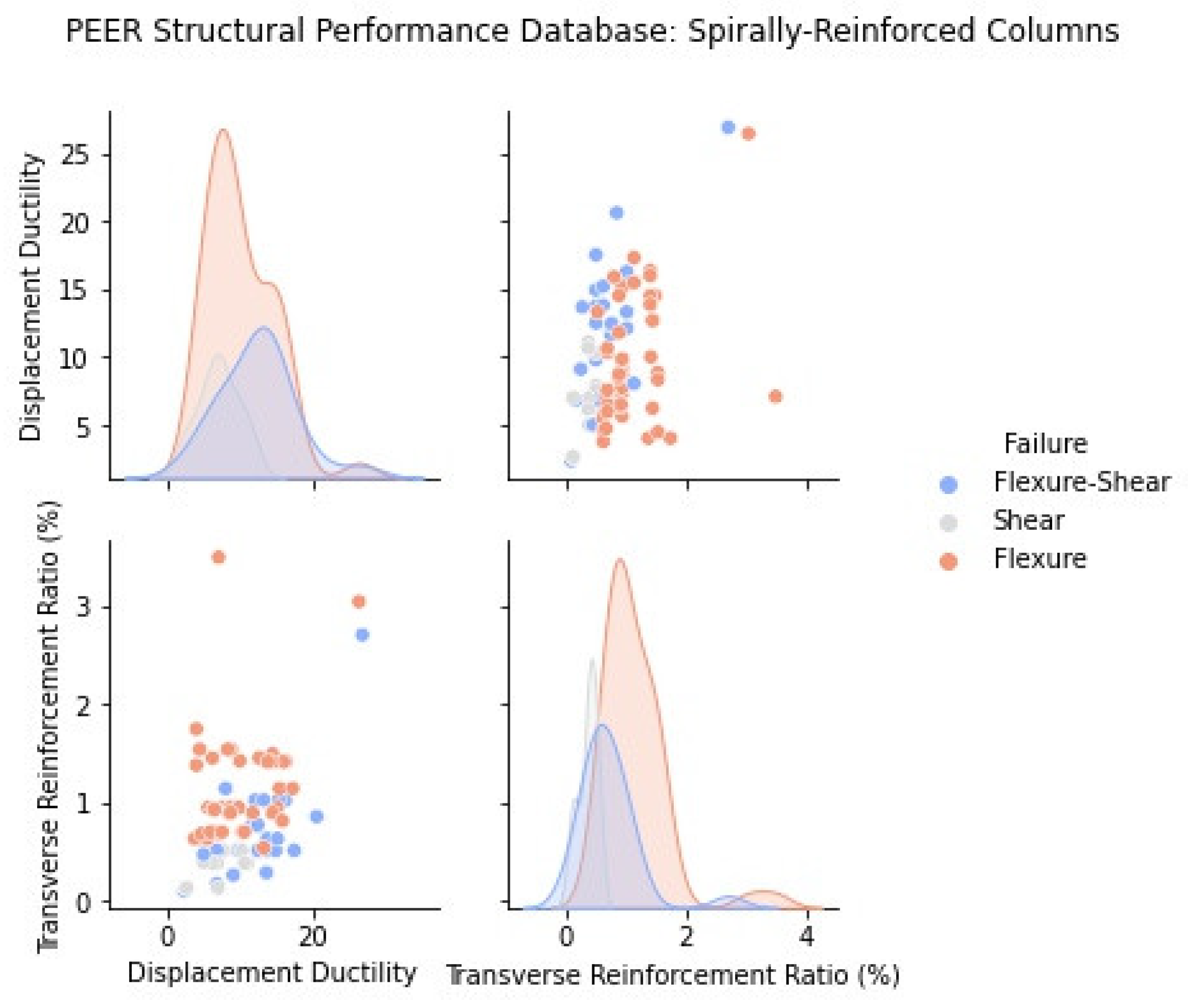

| Rectangular Reinforced (306 Tests) | Spiral Reinforced (177 Tests) | |||||
|---|---|---|---|---|---|---|
| Column Property | Mean | Std | CoV | Mean | Std | CoV |
| Depth (mm) | 323.43 | 116.5 | 0.36 | 420.97 | 202.11 | 0.48 |
| Aspect Ratio | 3.44 | 1.44 | 0.42 | 3.31 | 1.96 | 0.59 |
| Axial-Load Ratio | 0.27 | 0.19 | 0.73 | 0.14 | 0.14 | 1.04 |
| ρl (%) | 2.45 | 1.00 | 0.41 | 2.62 | 1.02 | 0.39 |
| ρs (%) | 1.34 | 1.07 | 0.80 | 0.93 | 0.74 | 0.80 |
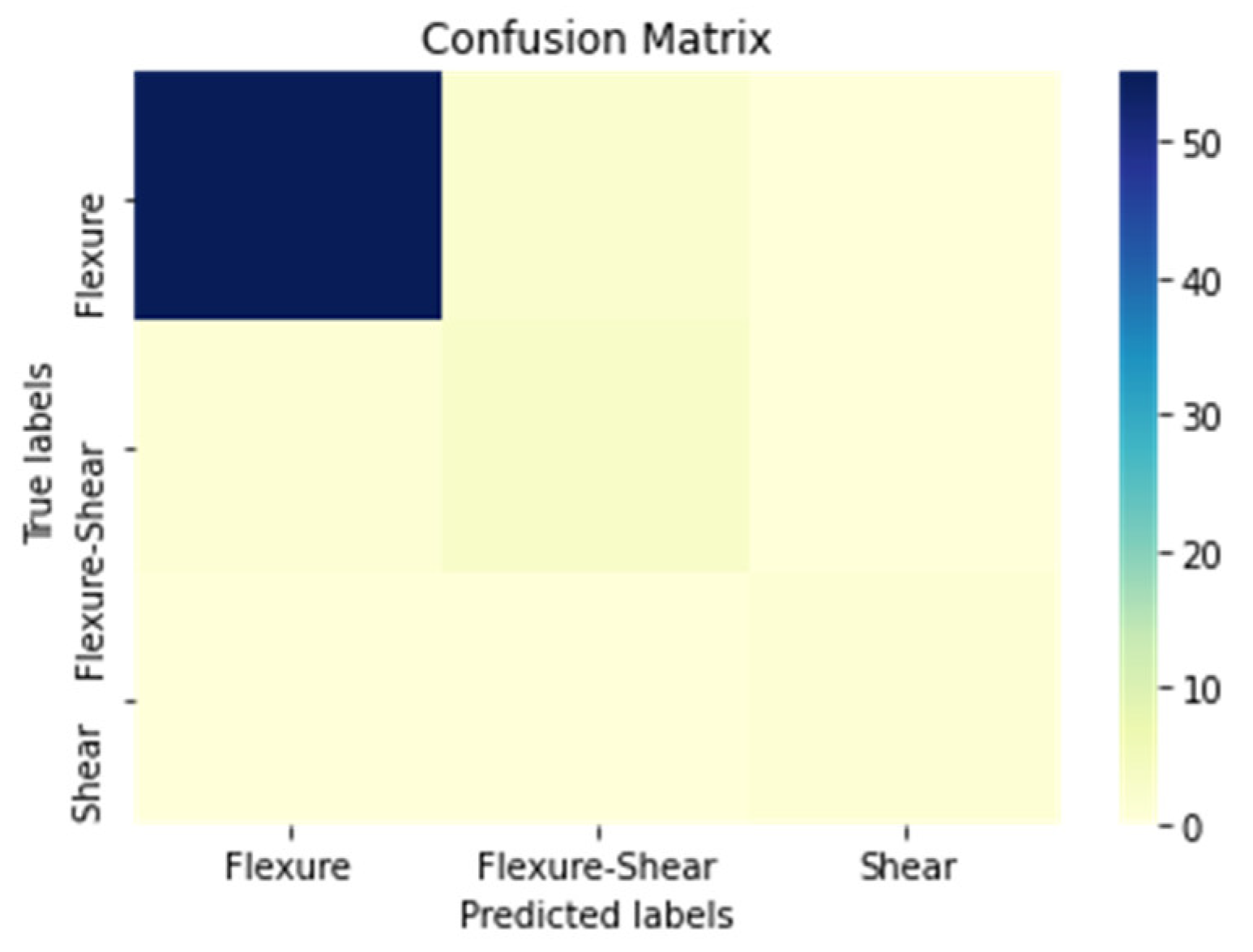
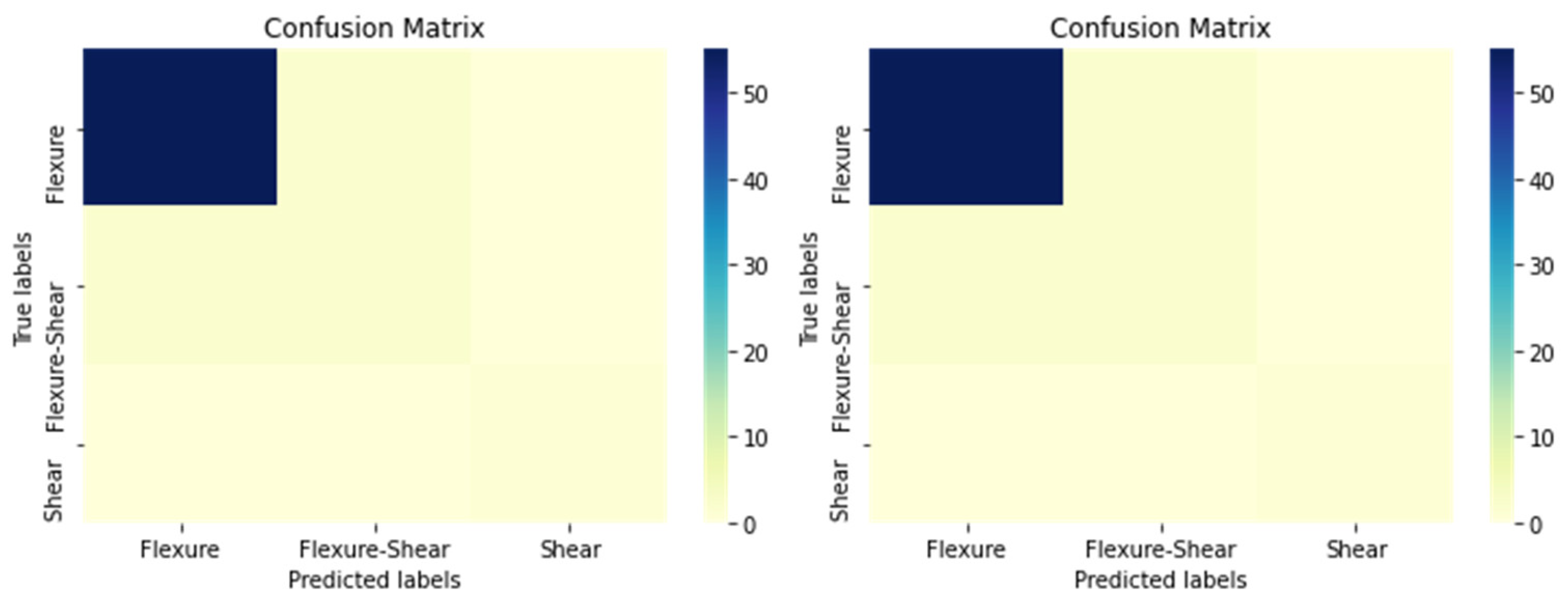
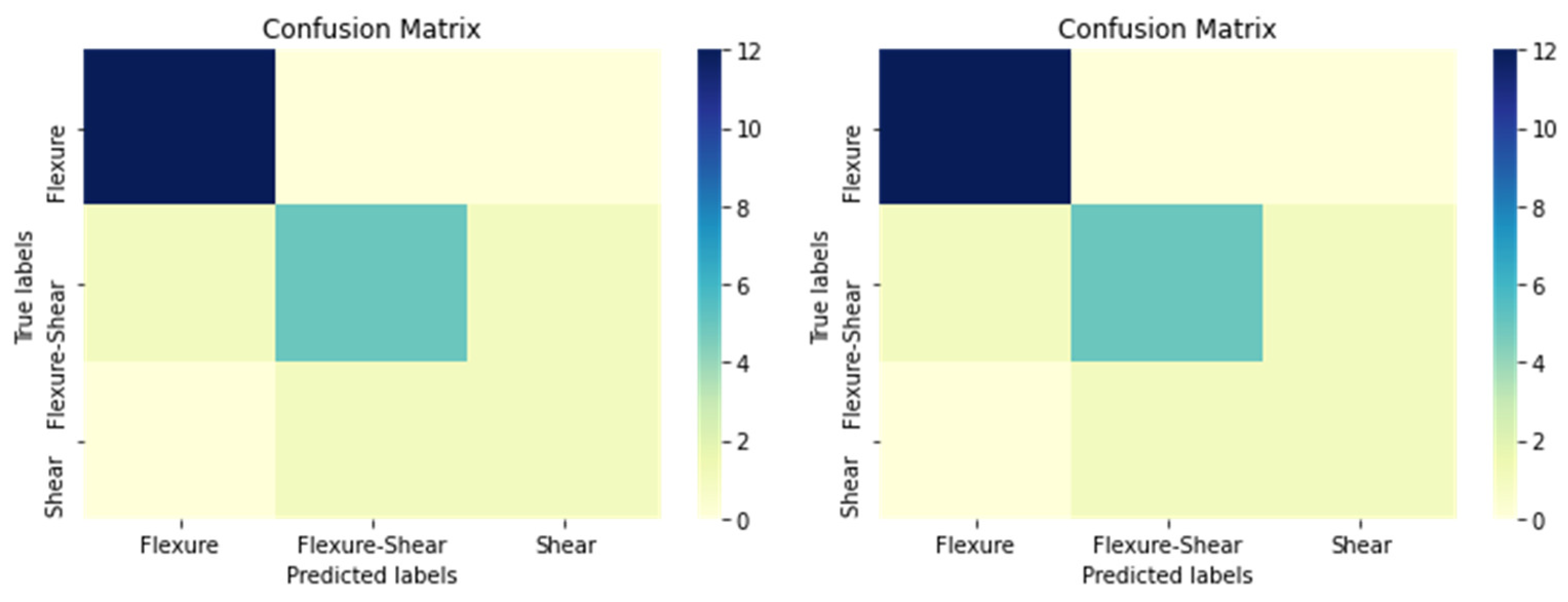
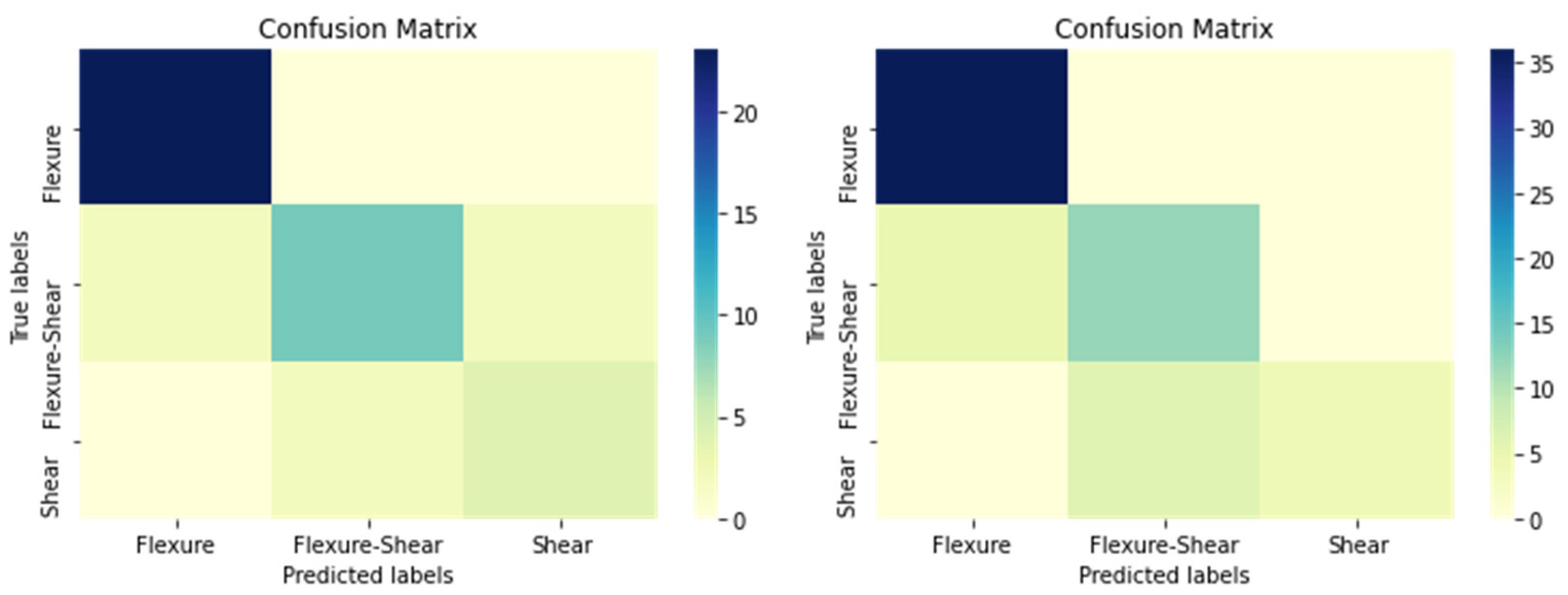
| Confusion Matrix in Numbers * | ||||
|---|---|---|---|---|
| True Values | Flexure | 55 | 2 | 0 |
| Flexure–Shear | 2 | 2 | 0 | |
| Shear | 0 | 0 | 1 | |
| Flexure | Flexure–Shear | Shear | ||
| Predicted Values | ||||
| Performance Metrics * | |||||||
|---|---|---|---|---|---|---|---|
| True Positive | True Negative | False Positive | False Negative | Accuracy | Precision | Recall | |
| Flexure | 55 | 2 + 1 + 0 + 0 = 3 | 2 + 0 = 2 | 2 + 0 = 2 | (55 + 3)/(55 + 3 + 2 + 2) = 58/62 = 94% | (55)/(55 + 2) = 55/57 = 97% | (55)/(55 + 2) = 55/57 = 97% |
| Flexure–Shear | 2 | 55 + 0 + 0 + 1= 56 | 2 + 0 = 2 | 2 + 0 = 2 | (2 + 56)/(2 + 56 + 2 + 2) = 58/62 = 94% | (2)/(2 + 2) = 2/4 = 50% | (2)/(2 + 2) = 2/4 = 50% |
| Shear | 1 | 55 + 2 + 2 + 2 = 61 | 0 + 0 = 0 | 0 + 0 = 0 | (1 + 61)/(1 + 61 + 0 + 0) = 62/62 = 100% | (1)/(1 + 0) = 1/1 = 100% | (1)/(1 + 0) = 1/1 = 100% |
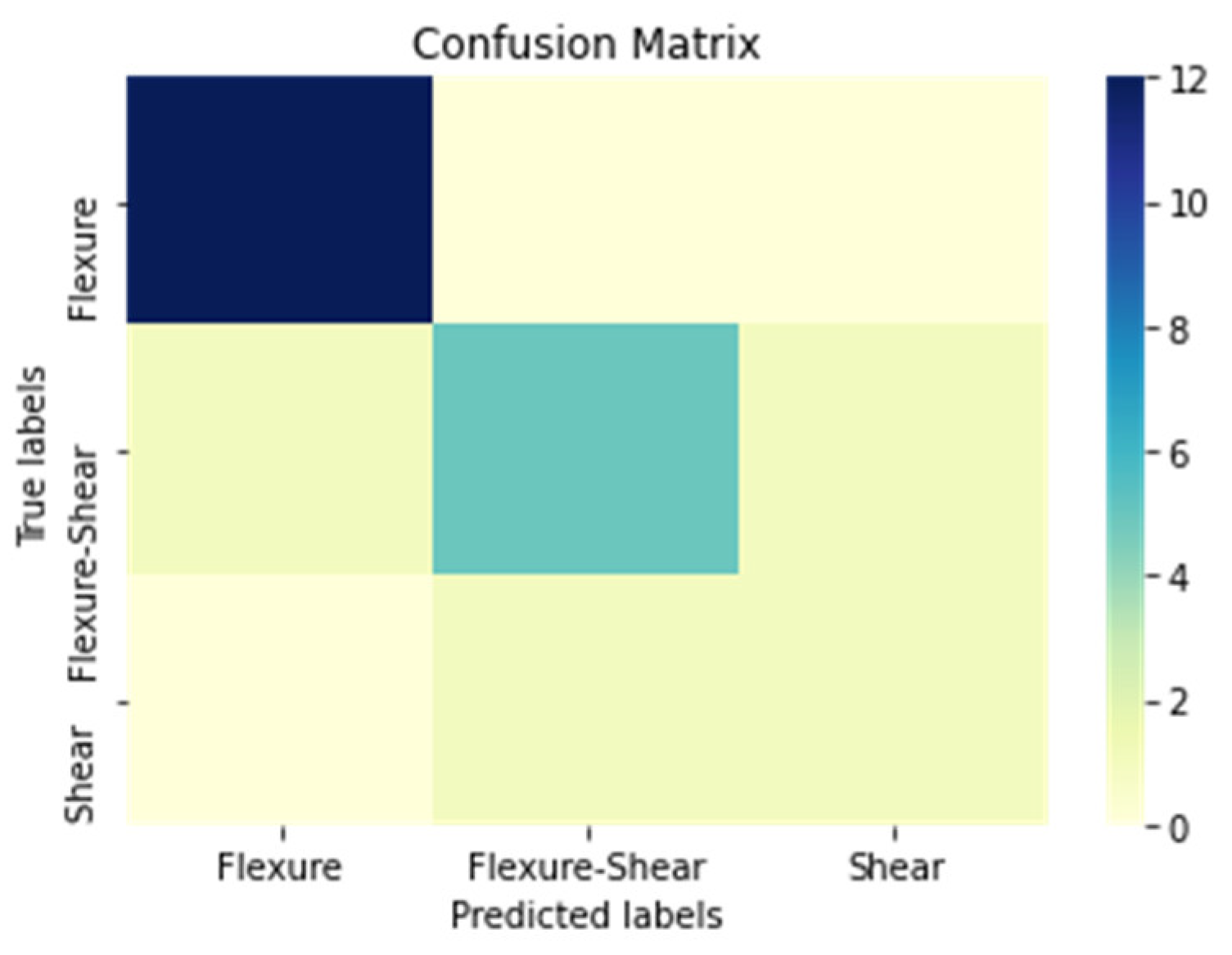
| Confusion Matrix in Numbers * | ||||
|---|---|---|---|---|
| True Values | Flexure | 12 | 0 | 0 |
| Flexure–Shear | 1 | 5 | 1 | |
| Shear | 0 | 1 | 1 | |
| Flexure | Flexure–Shear | Shear | ||
| Predicted Values | ||||
| Performance Metrics * | |||||||
|---|---|---|---|---|---|---|---|
| True Positive | True Negative | False Positive | False Negative | Accuracy | Precision | Recall | |
| Flexure | 12 | 5 + 1 + 1 + 1 = 8 | 1 + 0 = 1 | 0 + 0 = 0 | (12 + 8)/(12 + 8 + 1 + 0) = 20/21 = 95% | (12)/(12 + 1) = 12/13 = 92% | (12)/(12 + 0) = 12/12 = 100% |
| Flexure–Shear | 5 | 12 + 0 + 0 + 1 = 13 | 0 + 1 = 1 | 1 + 1 = 2 | (5 + 13)/(5 + 13 + 1 + 2) = 18/21 = 95% | (5)/(5 + 1) = 5/6 = 83% | (5)/(5 + 2) = 5/7 = 71% |
| Shear | 1 | 12 + 0 + 1 + 5 = 18 | 0 + 1 = 1 | 0 + 1 = 1 | (1 + 18)/(1 + 18 + 1 + 1) = 19/21 = 90% | (1)/(1 + 1) = 1/2 = 50% | (1)/(1 + 1) = 1/2 = 50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Megalooikonomou, K.G.; Beligiannis, G.N. Random Forests Machine Learning Applied to PEER Structural Performance Experimental Columns Database. Appl. Sci. 2023, 13, 12821. https://doi.org/10.3390/app132312821
Megalooikonomou KG, Beligiannis GN. Random Forests Machine Learning Applied to PEER Structural Performance Experimental Columns Database. Applied Sciences. 2023; 13(23):12821. https://doi.org/10.3390/app132312821
Chicago/Turabian StyleMegalooikonomou, Konstantinos G., and Grigorios N. Beligiannis. 2023. "Random Forests Machine Learning Applied to PEER Structural Performance Experimental Columns Database" Applied Sciences 13, no. 23: 12821. https://doi.org/10.3390/app132312821
APA StyleMegalooikonomou, K. G., & Beligiannis, G. N. (2023). Random Forests Machine Learning Applied to PEER Structural Performance Experimental Columns Database. Applied Sciences, 13(23), 12821. https://doi.org/10.3390/app132312821