

Ball Tracking Based on Multiscale Feature Enhancement and Cooperative Trajectory Matching

Abstract
1. Introduction
- We propose a heuristic composite sampling strategy. In our method, local region sampling and global image sampling are used for data augmentation;
- We propose an anchor-free detection network with a classifier. Among them is the backbone network, a new multiscale feature enhancement and context information fusion network specially designed for balls;
- We propose a tracking algorithm for multilevel collaborative trajectory matching and correction. Automatically correcting the trajectory for different generated trajectory states can provide more stable tracking;
- We propose a ball-tracking data set specifically for sports match videos. The data set involves three sports, soccer, basketball, and volleyball, and the annotation information is all manually produced.
2. Related Work
2.1. Anchor-Free Detection
2.2. Ball Tracking by Detection
2.3. Kalman Filter
3. Methods
3.1. Method Overview
3.2. Heuristic Compound Sampling Strategy
3.2.1. Tiling
3.2.2. Heuristic Sampling
3.2.3. Hard Sample Mining
3.3. Detection Based on MNet
3.3.1. CenterNet
3.3.2. MNet
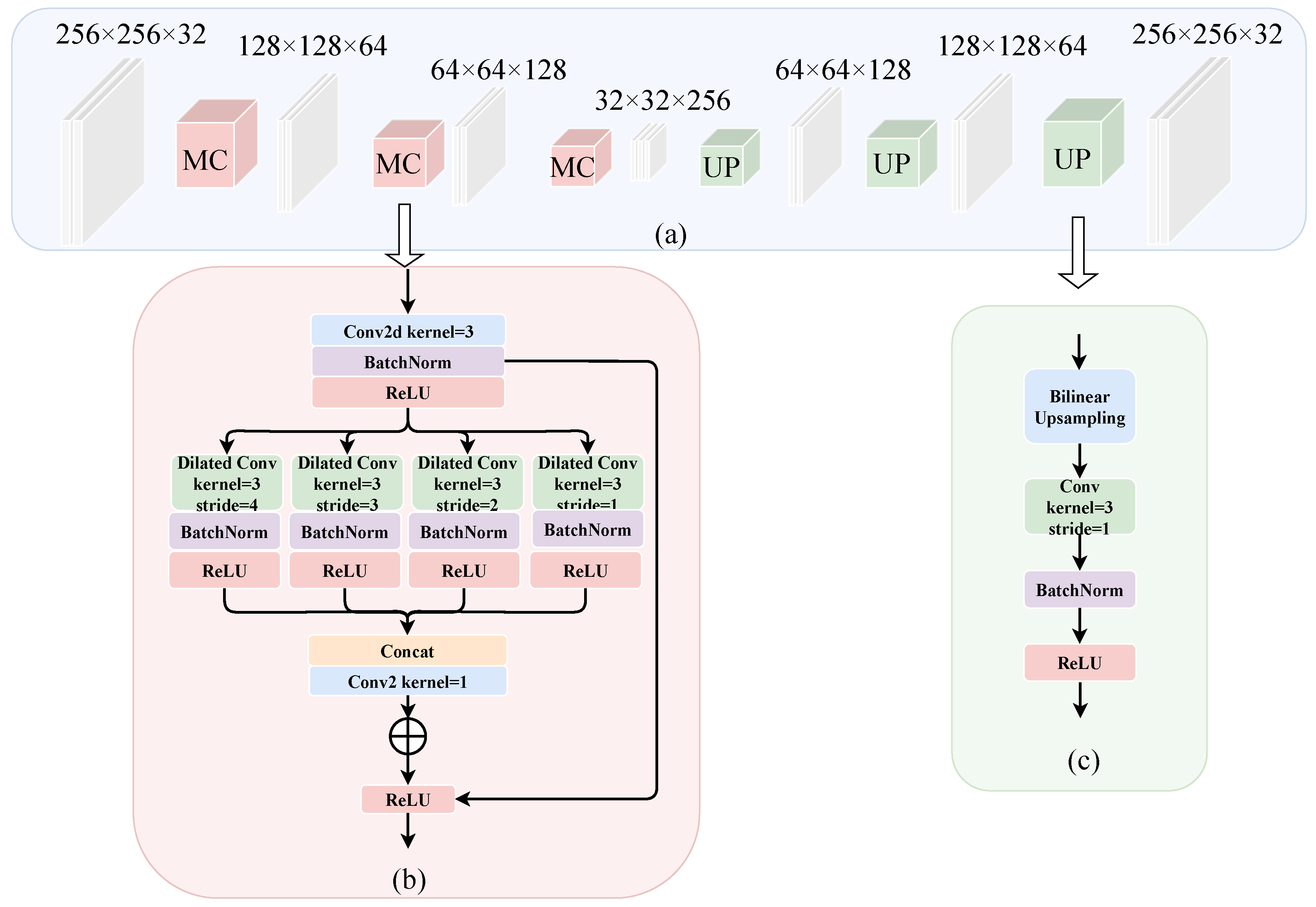
3.3.3. Detection Module
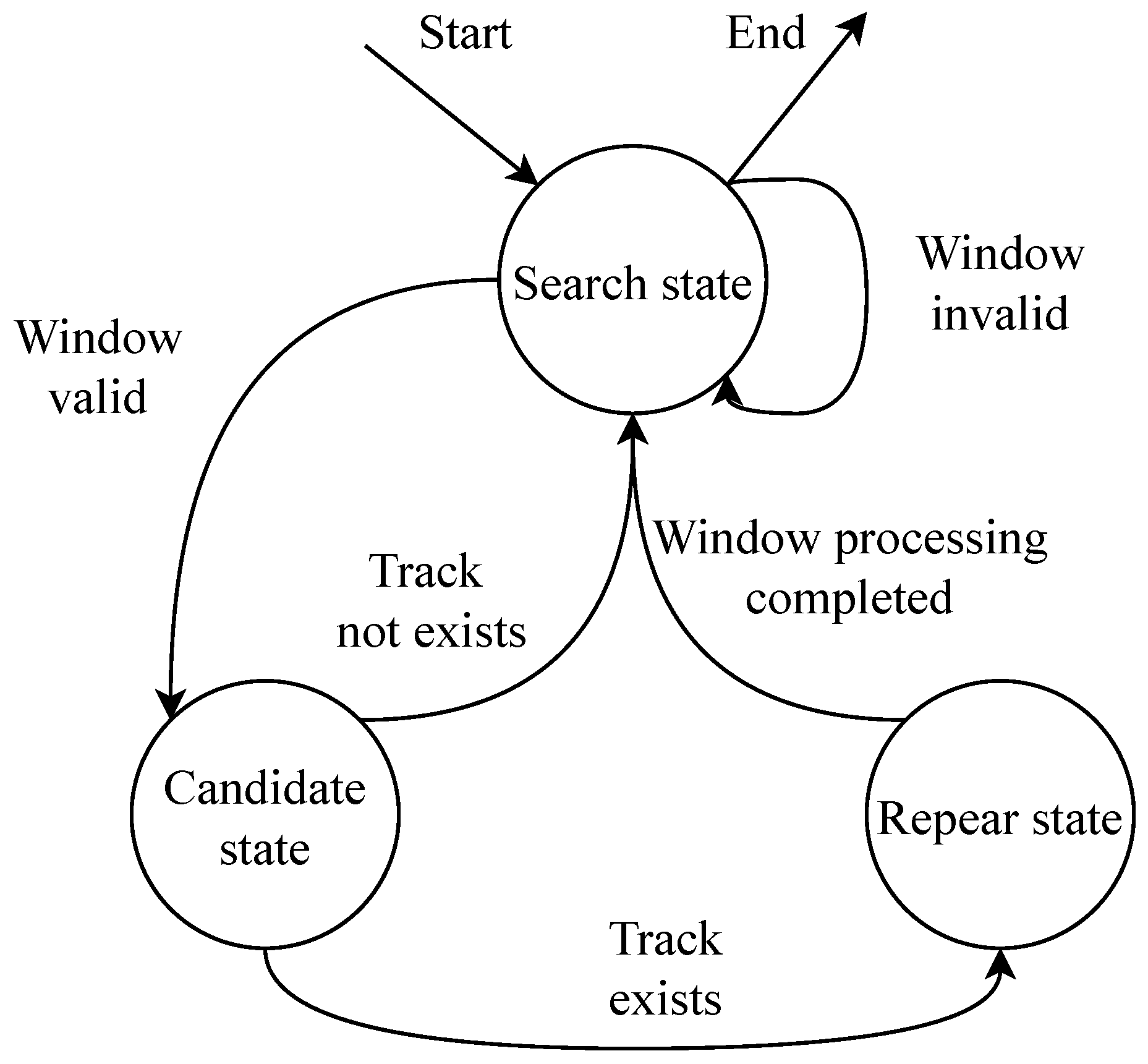
3.4. Ball Tracking
3.4.1. Multilevel Cooperative Matching
| Algorithm 1 Multilevel Cooperative Matching | |
| Require: Detection indices , Track indices | |
| Ensure: New track | |
| 1: | Initialization set of matches |
| 2: | Initialization set of unmatched detections |
| 3: | for in do |
| 4: | Compute KF matching distance |
| 5: | Compute LM matching distance |
| 6: | if and then |
| 7: | |
| 8: | end if |
| 9: | end for |
| 10: | for in do |
| 11: | Compute the minimize AF matching distance |
| 12: | |
| 13: | |
| 14: | end for |
| 15: | return |
3.4.2. Automatic Trajectory Correction
4. Experiments
4.1. Data Set and Evaluation
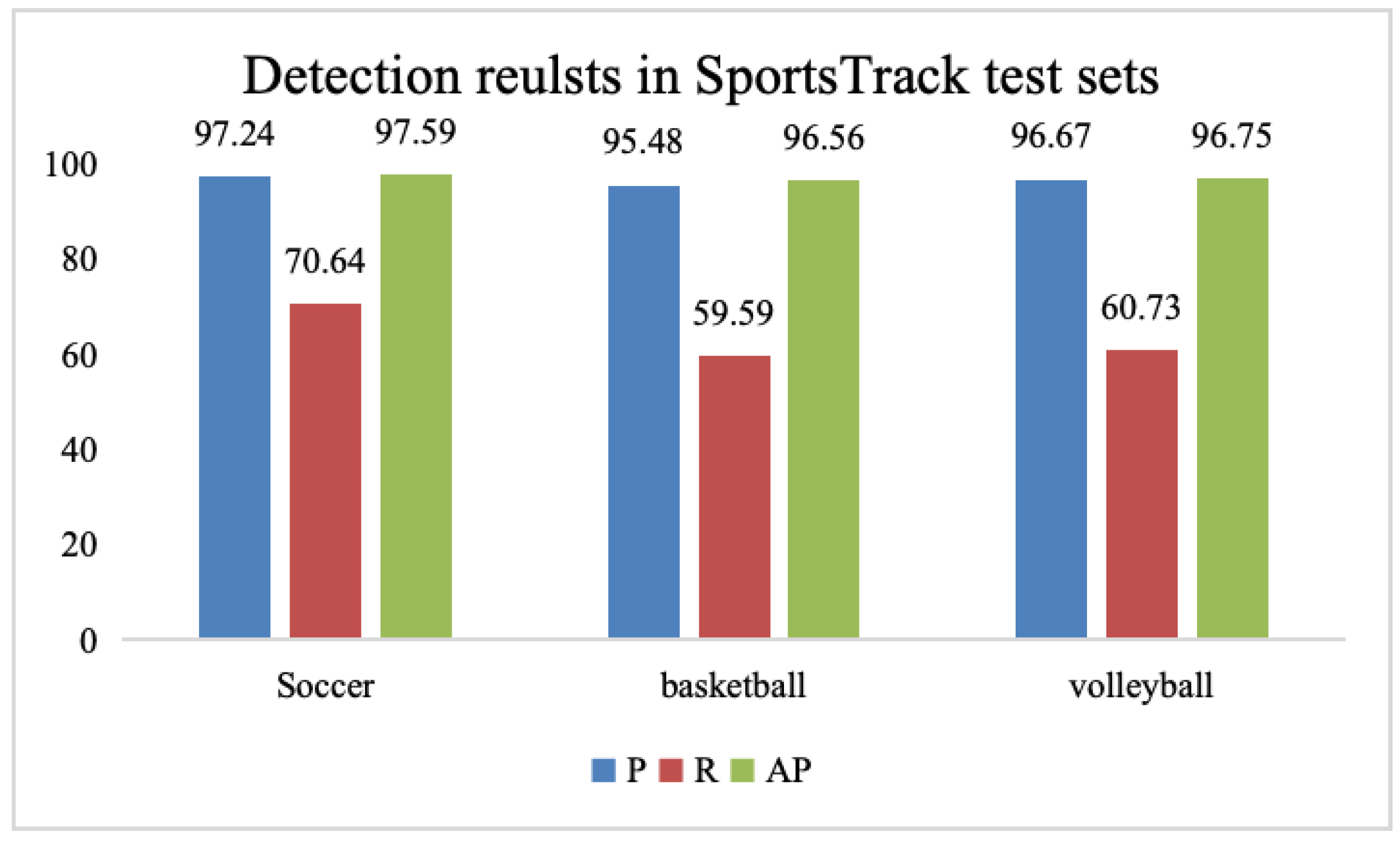
4.1.1. SportsTrack
- Contains multiple types of resolutions and higher resolutions. Soccer videos have larger stadiums, farther objects from the shooting camera, and smaller objects. The resolution of the collected competition broadcast videos reaches 4K, which can provide richer detailed information;
- Covers multiple complex sports scenes. Our data set contains three important team ball sports: soccer, basketball, and volleyball. Compared with other previous object tracking data set scenarios, the movement form and background information of the object in the video are more complex;
- The annotation information comes from manual annotation and has undergone secondary manual quality inspection, so the annotation accuracy is high.
4.1.2. Data Partition
4.1.3. Evaluation
4.2. Performance Comparison with Other Ball-Tracking Methods
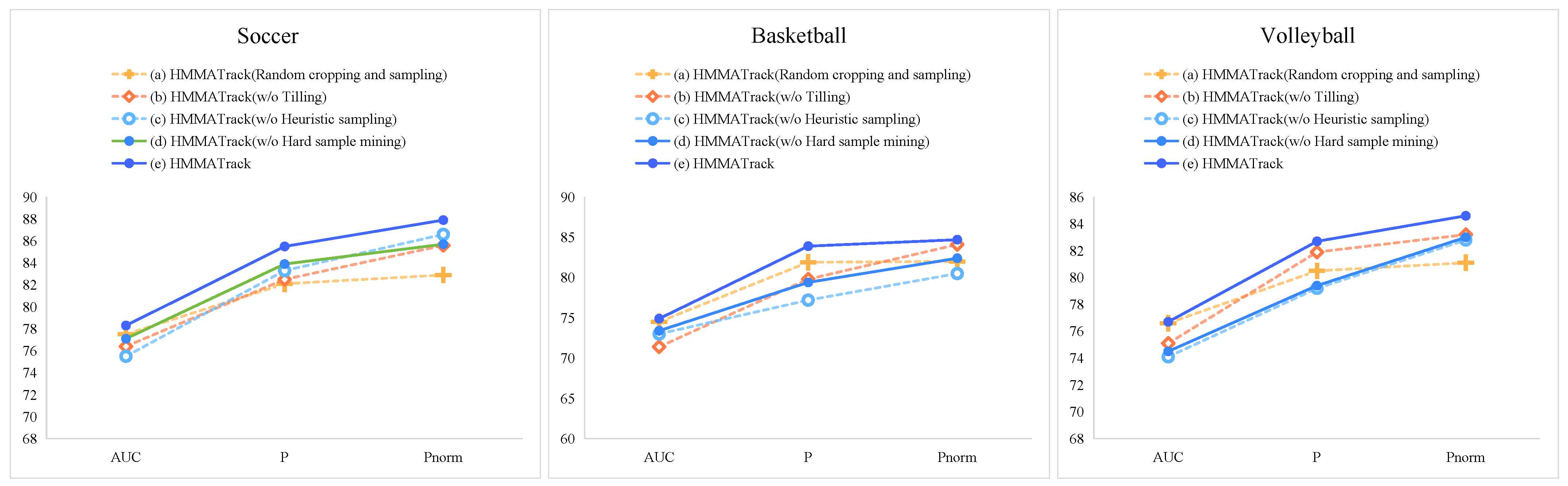
4.3. Ablation Experiments
4.3.1. Analysis of the Effectiveness of the Heuristic Composite Sampling Strategy
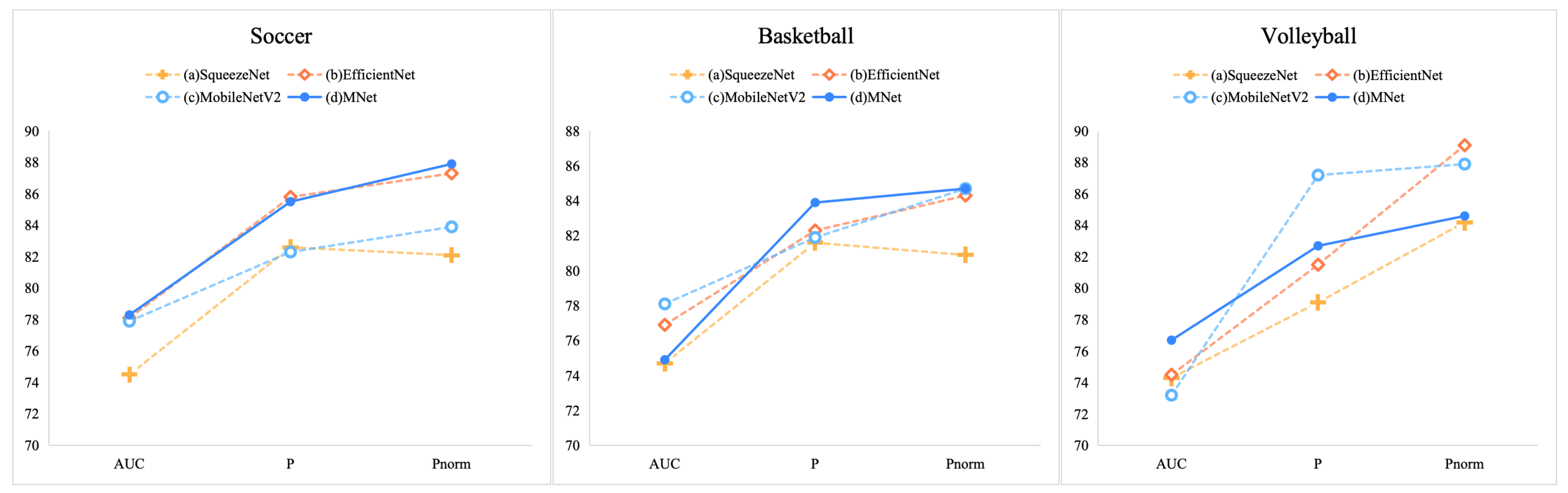
4.3.2. Analysis of the Effectiveness of MNet Backbone Network
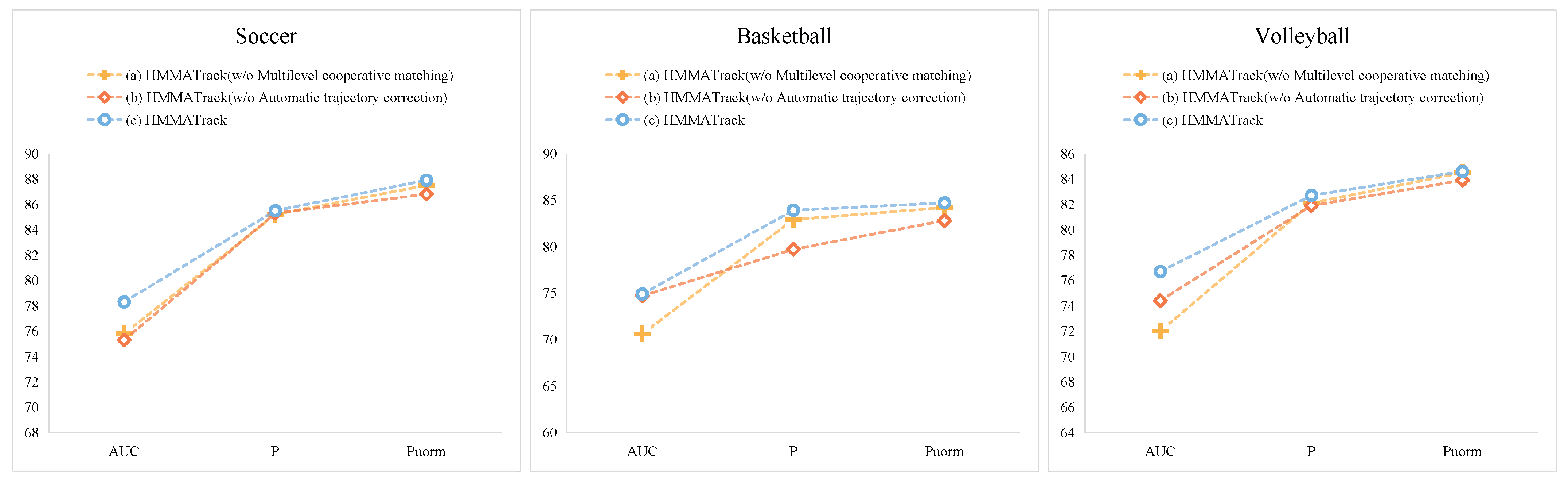
4.3.3. Tracking Module Effectiveness Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gobhinath, S.; Sophia, S.; Karthikeyan, S.; Janani, K. Dynamic Objects Detection and Tracking from Videos for Surveillance Applications. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; IEEE: New York, NY, USA, 2022; Volume 1, pp. 419–422. [Google Scholar]
- Rangesh, A.; Trivedi, M.M. No blind spots: Full-surround multi-object tracking for autonomous vehicles using cameras and lidars. IEEE Trans. Intell. Veh. 2019, 4, 588–599. [Google Scholar] [CrossRef]
- Yu, X.; Leong, H.W.; Xu, C.; Tian, Q. Trajectory-based ball detection and tracking in broadcast soccer video. IEEE Trans. Multimed. 2006, 8, 1164–1178. [Google Scholar] [CrossRef]
- Kamble, P.R.; Keskar, A.G.; Bhurchandi, K.M. A convolutional neural network based 3D ball tracking by detection in soccer videos. In Proceedings of the Eleventh International Conference on machine vision (ICMV 2018), Munich, Germany, 1–3 November 2018; SPIE: Bellingham, WA, USA, 2018; Volume 11041, pp. 730–737. [Google Scholar]
- Kamble, P.R.; Keskar, A.G.; Bhurchandi, K.M. A deep learning ball tracking system in soccer videos. Opto-Electron. Rev. 2019, 27, 58–69. [Google Scholar] [CrossRef]
- Kukleva, A.; Khan, M.A.; Farazi, H.; Behnke, S. Utilizing temporal information in deep convolutional network for efficient soccer ball detection and tracking. In Proceedings of the RoboCup 2019: Robot World Cup XXIII 23, Sydney, NSW, Australia, 23–23 July 2019; Springer: Berlin, Germany, 2019; pp. 112–125. [Google Scholar]
- Van Zandycke, G.; De Vleeschouwer, C. Ball 3D Localization From A Single Calibrated Image. arXiv 2022, arXiv:2204.00003. [Google Scholar]
- Najeeb, H.D.; Ghani, R.F. Tracking ball in soccer game video using extended Kalman filter. In Proceedings of the 2020 International Conference on Computer Science and Software Engineering (CSASE), Duhok, Iraq, 16–18 April 2020; IEEE: New York, NY, USA, 2020; pp. 78–82. [Google Scholar]
- Cheng, X.; Liang, L.; Ikenaga, T. Automatic data volley: Game data acquisition with temporal-spatial filters. Complex Intell. Syst. 2022, 8, 4993–5010. [Google Scholar] [CrossRef]
- Dong, J.; Cheng, X.; Ikenaga, T. Multi-physical and temporal feature based self-correcting approximation model for monocular 3D volleyball trajectory analysis. In Proceedings of the 2021 17th International Conference on Machine Vision and Applications (MVA), Virtual, 25–27 July 2021; IEEE: New York, NY, USA, 2021; pp. 1–4. [Google Scholar]
- Guan, S.; Li, X. WITHDRAWN: Moving target tracking algorithm and trajectory generation based on Kalman filter in sports video. J. Vis. Commun. Image Represent. 2019, in press. [CrossRef]
- Zhao, K.; Jiang, W.; Jin, X.; Xiao, X. Artificial intelligence system based on the layout effect of both sides in volleyball matches. J. Intell. Fuzzy Syst. 2021, 40, 3075–3084. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Alshawi, B.; Alturki, R. Basketball flight trajectory tracking using video signal filtering. Mob. Netw. Appl. 2023, 1–13. [Google Scholar] [CrossRef]
- Roman-Rivera, L.R.; Pedraza-Ortega, J.C.; Aceves-Fernandez, M.A.; Ramos-Arreguín, J.M.; Gorrostieta-Hurtado, E.; Tovar-Arriaga, S. A Robust Sphere Detection in a Realsense Point Cloud by USING Z-Score and RANSAC. Mathematics 2023, 11, 1023. [Google Scholar] [CrossRef]
- Huang, G. An Effective Volleyball Trajectory Estimation and Analysis Method With Embedded Graph Convolution. Int. J. Distrib. Syst. Technol. (IJDST) 2023, 14, 1–13. [Google Scholar] [CrossRef]
- Naik, B.T.; Hashmi, M.F. YOLOv3-SORT: Detection and tracking player/ball in soccer sport. J. Electron. Imaging 2023, 32, 011003. [Google Scholar] [CrossRef]
- Vicente-Martínez, J.A.; Márquez-Olivera, M.; García-Aliaga, A.; Hernández-Herrera, V. Adaptation of YOLOv7 and YOLOv7_tiny for soccer-ball multi-detection with DeepSORT for tracking by semi-supervised system. Sensors 2023, 23, 8693. [Google Scholar] [CrossRef]
- Keča, D.; Kunović, I.; Matić, J.; Sovic Krzic, A. Ball Detection Using Deep Learning Implemented on an Educational Robot Based on Raspberry Pi. Sensors 2023, 23, 4071. [Google Scholar] [CrossRef]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 850–859. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhou, H.; Guo, W.; Zhao, Q. An Anchor-Free Network for Increasing Attention to Small Objects in High Resolution Remote Sensing Images. Appl. Sci. 2023, 13, 2073. [Google Scholar] [CrossRef]
- Zhu, J.; Li, D.; Han, T.; Tian, L.; Shan, Y. Progressface: Scale-aware progressive learning for face detection. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16. Springer: Berlin, Germany, 2020; pp. 344–360. [Google Scholar]
- Wolpert, A.; Teutsch, M.; Sarfraz, M.S.; Stiefelhagen, R. Anchor-free small-scale multispectral pedestrian detection. arXiv 2020, arXiv:2008.08418. [Google Scholar]
- Tian, B.; Zhang, D.; Zhang, C. High-speed tiny tennis ball detection based on deep convolutional neural networks. In Proceedings of the 2020 IEEE 14th International Conference on Anti-Counterfeiting, Security, and Identification (ASID), Xiamen, China, 30 October–1 November 2020; IEEE: New York, NY, USA, 2020; pp. 30–33. [Google Scholar]
- Tao, R.; Gavves, E.; Smeulders, A.W. Siamese instance search for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware siamese networks for visual object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 101–117. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. Mar. 1960, 82, 35–45. [Google Scholar] [CrossRef]
- Ozge Unel, F.; Ozkalayci, B.O.; Cigla, C. The power of tiling for small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated residual networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 472–480. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Liu, C.; Huynh, D.Q.; Reynolds, M. Toward occlusion handling in visual tracking via probabilistic finite state machines. IEEE Trans. Cybern. 2018, 50, 1726–1738. [Google Scholar] [CrossRef]
- Jiang, Y.; Cui, K.; Chen, L.; Wang, C.; Xu, C. Soccerdb: A large-scale database for comprehensive video understanding. In Proceedings of the 3rd International Workshop on Multimedia Content Analysis in Sports, Seattle, WA, USA, 16 October 2020; pp. 1–8. [Google Scholar]
- Kumar, K.; De Vleeschouwer, C. Discriminative label propagation for multi-object tracking with sporadic appearance features. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2000–2007. [Google Scholar]
- Kaczmarek, K. Volleyball Tracking Dataset. 2023. Available online: https://universe.roboflow.com/kamil-kaczmarek-txftt/volleyball-tracking-bdtqj (accessed on 5 October 2023).
- Yan, B.; Jiang, Y.; Wu, J.; Wang, D.; Luo, P.; Yuan, Z.; Lu, H. Universal instance perception as object discovery and retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15325–15336. [Google Scholar]
- Ye, B.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Joint feature learning and relation modeling for tracking: A one-stream framework. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin, Germany, 2022; pp. 341–357. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning spatio-temporal transformer for visual tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10448–10457. [Google Scholar]
- Van Zandycke, G.; De Vleeschouwer, C. 3d ball localization from a single calibrated image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–22 June 2022; pp. 3472–3480. [Google Scholar]
- VolleyVision. 2023. Available online: https://github.com/shukkkur/VolleyVision (accessed on 5 October 2023).
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Train | Test | Frame | GT | Pixel | FPS |
|---|---|---|---|---|---|---|
| Soccer | 2164 | 1196 | 3360 | 3282 | 1280 × 720 | 30 |
| Basketball | 2196 | 1464 | 3660 | 3498 | 1280 × 720 | 30 |
| Volleyball | 2160 | 1400 | 3600 | 3520 | 1280 × 720 | 30 |
| Data Set | Object | Train | Test |
|---|---|---|---|
| SoccerDB | Soccer | 40,615 | - |
| VolleyballVision | Volleyball | 20,218 | - |
| APIDIS | Basketball | 12,907 | - |
| SportsTrack | Soccer/Basketball/Volleyball | 6520 | 4060 |
| Method | Soccer | Basketball | Volleyball | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AUC | AUC | AUC | FPS | |||||||
| UNINEXT | 78.5 | 86.1 | 87.5 | 63.7 | 69.0 | 71.2 | 61.6 | 67.7 | 70.3 | 30.3 |
| OSTrack | 76.1 | 81.6 | 84.2 | 71.6 | 77.5 | 79.5 | 72.3 | 79.0 | 81.9 | 69.7 |
| STACK | 66.5 | 72.9 | 75.0 | 57.9 | 63.4 | 65.5 | 56.7 | 62.2 | 64.8 | 35.6 |
| Deepsport | 63.7 | 70.0 | 72.8 | 72.0 | 77.9 | 80.4 | 60.7 | 66.7 | 69.2 | 28.6 |
| VolleyVision | 67.0 | 73.0 | 75.1 | 59.8 | 65.1 | 67.2 | 70.4 | 76.2 | 78.9 | 57.3 |
| EKF | 64.4 | 70.1 | 72.3 | 66.8 | 72.6 | 75.2 | 57.3 | 64.0 | 66.3 | 16.4 |
| Ours | 78.3 | 85.5 | 87.9 | 74.9 | 83.9 | 84.7 | 76.7 | 82.7 | 84.6 | 28.2 |
| Modules | Network | AUC | P | |
|---|---|---|---|---|
| Sampling Module | (a) Random cropping and sampling | 76.2 | 81.5 | 83.0 |
| (b) w/o Tilling | 74.3 | 81.4 | 84.3 | |
| (c) w/o Heuristic sampling | 74.2 | 79.9 | 83.3 | |
| (d) w/o Hard sample mining | 75.0 | 80.9 | 83.7 | |
| MNet Backbone | (a) SqueezeNet | 74.5 | 81.1 | 82.4 |
| (b) EfficientNet | 76.5 | 83.2 | 86.9 | |
| (c) MobileNetV2 | 76.4 | 83.8 | 85.5 | |
| Track Module | (a) w/o Multilevel cooperative matching | 78.8 | 83.4 | 85.4 |
| (b) w/o Automatic trajectory correction | 74.8 | 82.3 | 84.5 | |
| HMMATrack | 76.6 | 84.0 | 85.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.; Wang, Q.; Wang, Y. Ball Tracking Based on Multiscale Feature Enhancement and Cooperative Trajectory Matching. Appl. Sci. 2024, 14, 1376. https://doi.org/10.3390/app14041376
Han X, Wang Q, Wang Y. Ball Tracking Based on Multiscale Feature Enhancement and Cooperative Trajectory Matching. Applied Sciences. 2024; 14(4):1376. https://doi.org/10.3390/app14041376
Chicago/Turabian StyleHan, Xiao, Qi Wang, and Yongbin Wang. 2024. "Ball Tracking Based on Multiscale Feature Enhancement and Cooperative Trajectory Matching" Applied Sciences 14, no. 4: 1376. https://doi.org/10.3390/app14041376
APA StyleHan, X., Wang, Q., & Wang, Y. (2024). Ball Tracking Based on Multiscale Feature Enhancement and Cooperative Trajectory Matching. Applied Sciences, 14(4), 1376. https://doi.org/10.3390/app14041376