
Semantic Similarity Based on Taxonomies





Abstract
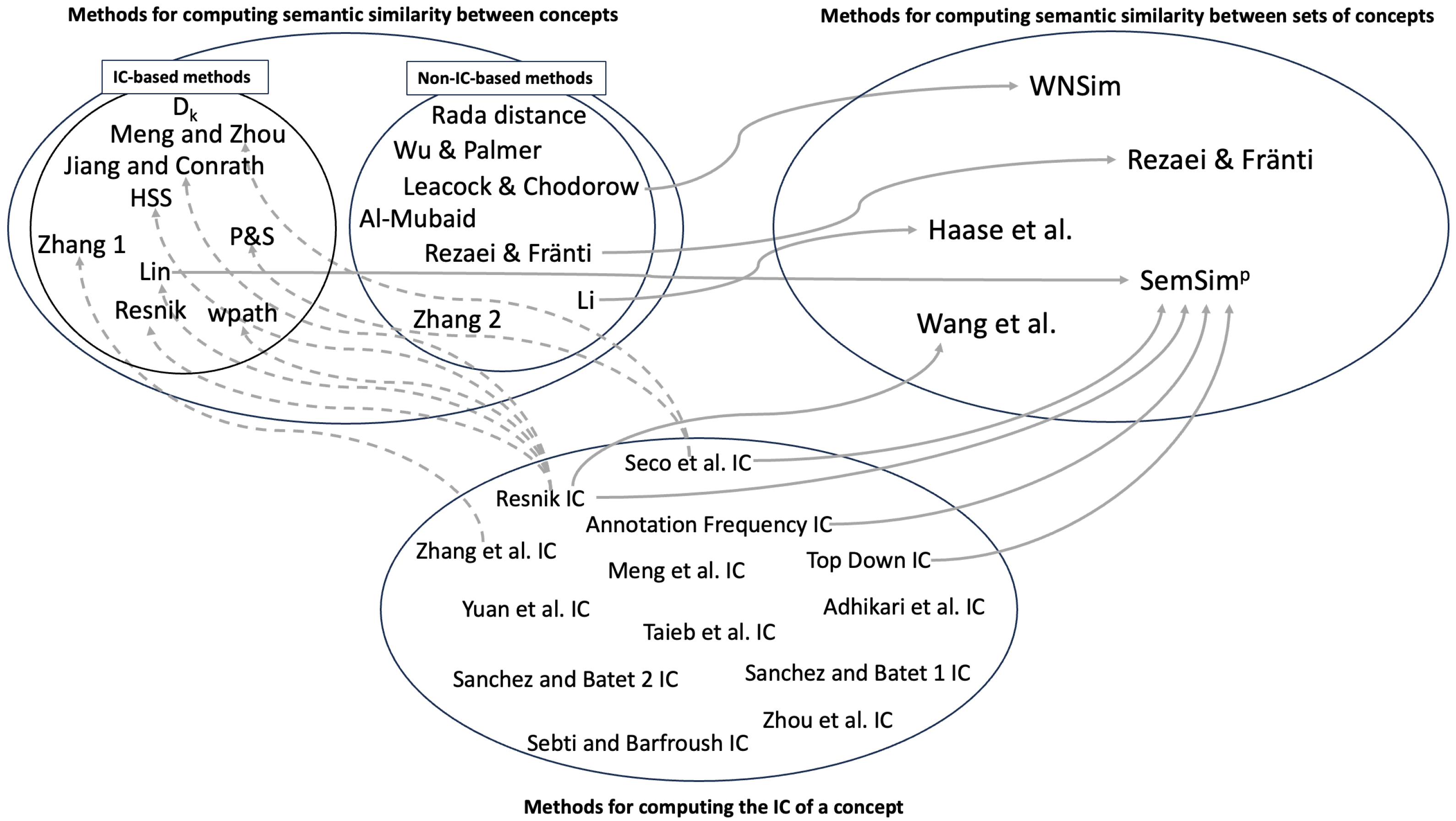
:1. Introduction
2. Methods for Computing the Information Content of a Concept in a Taxonomy
- The number of hyponyms of the concept, where the greater it is, the less the IC. This is due to the assumption that the more general a concept, the less its informativeness. This feature is used by Seco et al. IC [20], Zhou et al. IC [21], and Sanchez and Batet 2 IC [22]. Taieb et al. IC [23] considers the hyponyms of the hypernyms of the concept, but the basic assumption continues to be applied.
- The depth of the concept, where the greater it is, the greater the IC. Again, this is in line with the general assumption regarding the specificity of a concept and its informativeness. This feature is used by Zhou et al. IC [21] and Meng et al. IC [24], who also consider the depth of the hyponyms, and Yuan et al. IC [25] and Taieb et al. IC [23], who also consider the depth of the hypernyms.
- The number of the hypernyms of the concept, which again take into consideration the assumption above. In fact, the greater the number of the hypernyms, the greater the IC. This feature is used by Yuan et al. IC [25] and Taieb et al. IC [23], who consider the hypernyms of the hypernyms, and Sanchez and Batet 1 IC [26].
- The number of siblings of the concept, where the greater it is, the greater the IC. Here, the underlying assumption is that the greater the number of siblings of a concept, the greater its peculiarity and its informativeness, too. This assumption is exploited in the top down IC found in [27] and by Sebti and Barfroush IC [28]. However, in the latter, the siblings of hypernyms are also considered.

{kind=link}
| Method | Year | Features |
|---|---|---|
| Resnik IC [17] | 1995 | Frequency of c in a corpus of documents |
| Seco et al. IC [20] | 2004 | Hyponyms of c |
| Zhou et al. IC [21] | 2008 | Hyponyms and depth of c, and height of T, and tuning parameter |
| Sebti and Barfroush IC [28] | 2008 | Siblings of c and of its hypernyms |
| Meng et al. IC [31] | 2012 | Depth of c and of its hyponyms, and height of T |
| Sanchez and Batet 1 IC [26] | 2012 | Hypernyms of c and of its leaves |
| Sanchez and Batet 2 IC [22] | 2013 | Hyponyms and leaves of c, and leaves of T |
| Top Down IC [27] | 2013 | Direct hypernyms and siblings of c |
| Yuan et al. IC [25] | 2013 | Hypernyms, depth, and leaves of c, and height and leaves of T |
| Taieb et al. IC [23] | 2014 | Hypernyms and depth of c, hyponyms, and depth of the hypernyms |
| Adhikari et al. IC [32] | 2015 | Depth, leaves and hypernyms of c, depth of hyponyms of c, height and leaves of T |
| Zhang et al. IC [33] | 2018 | Hypernyms and hyponyms of c, siblings of hypernyms of c |
| Annotation Frequency IC [18] | 2023 | of c in a corpus of documents |
3. Methods for Computing Semantic Similarity between Concepts
3.1. Information Content-Based Methods
- Resnik similarity () [17] (see Equation (1)), which assumes that the more information two concepts share, the more similar they are. Then, the information shared by two concepts is provided by the IC of the concepts that subsume them in the taxonomy:where the maximum value is obtained for is one of the .
- D similarity, proposed in [39] for IC-based similarity measures, which addresses the concept intended senses in a given context (or application domain). In particular, the semantic similarity of the concepts , indicated as , is defined by Equation (8):where , in the original proposal, is any similarity measure between concepts based on IC, is a weight, , defined by the domain expert according to , and is a function, referred to as the intended sense function, associating a concept with its meaning according to (which can be another concept or itself).
- Hierarchical semantic similarity () [40], which was originally conceived for computing the similarity between words. Due to polysemy, one word can refer to different concepts, each representing a sense of that word. Then, if we assume that a word can refer to only one concept in the taxonomy, the complexity of the method decreases. However, we present it according to its original formulation, in which and are the compared words (see Equation (9)):where is the number of pairs of senses of and , i.e., concepts in the taxonomy having as the lcs, and is the set of the lcs of pairs of concepts representing senses of and , respectively.
3.2. Non-Information Content-Based Methods
- Rada distance. In the literature, many proposals compute semantic similarity by using the notion of conceptual distance between concepts in a taxonomy as defined by Rada [41], as reported in Equation (10)i.e., the minimum number of edges separating and in the taxonomy. In particular, the smaller the distance between concepts, the more similar the concepts are (conceptual distance is a decreasing function of similarity). In the mentioned paper, the authors show that conceptual distance satisfies the properties of a metric:- = 0 (zero property);- = (symmetric property);- ≥ 0 (positive property);- + ≥ (triangular inequality).However, in general, symmetry and triangular inequality are not satisfied by semantic similarity.
- Li similarity () [44] is based on the shortest path distance between the compared concepts and the depth of their , according to Equation (13)where e is Euler’s number, and , are parameters that contribute to the path length and depth, respectively. According to the experiment in [44], the empirical optimal parameters are and .
4. Methods for Computing Semantic Similarity between Sets of Concepts
- Haase et al. similarity [54] computes the similarity of pairs of concepts belonging to different sets by using the method proposed by Li et al. recalled above, which combines the shortest path length between the concepts and the depths of their subsumers in the taxonomy non-linearly (see Equation (19)):where is the cardinality of the set , and
- SemSim similarity [18] is derived from the SemSim method [27], which has been conceived for evaluating the semantic similarity of resources (i.e., real-world entities) annotated by sets of concepts taken from a taxonomy. It is a parametric measure depending on a weight associated with the concepts of the taxonomy, and a normalization factor is used when the two compared annotation vectors have different cardinalities.
5. The Parametric Semantic Similarity Method SemSim
6. Discussion
7. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Formulas of Methods for Computing the IC of Concepts in a Taxonomy
- and.
- and.
References
- Chandrasekaran, D.; Mago, V. Evolution of Semantic Similarity—A Survey. ACM Comput. Surv. 2021, 54, 41:1–41:37. [Google Scholar] [CrossRef]
- Berrhail, F.; Belhadef, H. Genetic Algorithm-based Feature Selection Approach for Enhancing the Effectiveness of Similarity Searching in Ligand-based Virtual Screening. Curr. Bioinform. 2020, 15, 431–444. [Google Scholar] [CrossRef]
- Sharma, S.; Sharma, S.; Pathak, V.; Kaur, P.; Singh, K.R. Drug Repurposing Using Similarity-based Target Prediction, Docking Studies and Scaffold Hopping of Lefamulin. Lett. Drug Des. Discov. 2021, 18, 733–743. [Google Scholar] [CrossRef]
- Kamath, S.; Ananthanarayana, V.S. Semantic Similarity Based Context-Aware Web Service Discovery Using NLP Techniques. J. Web Eng. 2016, 15, 110–139. [Google Scholar]
- Zhou, Y.; Li, C.; Huang, G.; Guo, Q.; Li, H.; Wei, X. A Short-Text Similarity Model Combining Semantic and Syntactic Information. Electronics 2023, 12, 3126. [Google Scholar] [CrossRef]
- Bollegala, D.; Matsuo, Y.; Ishizuka, M. A Web Search Engine-Based Approach to Measure Semantic Similarity between Words. IEEE Trans. Knowl. Data Eng. 2011, 23, 977–990. [Google Scholar] [CrossRef]
- Formica, A.; Missikoff, M.; Pourabbas, E.; Taglino, F. Semantic Search for Enterprises Competencies Management. In Proceedings of the KEOD 2010—International Conference on Knowledge Engineering and Ontology Development, Valencia, Spain, 25–28 October 2010; pp. 183–192. [Google Scholar]
- Janowicz, K.; Raubal, M.; Kuhn, W. The semantics of similarity in geographic information retrieval. J. Spat. Inf. Sci. 2011, 2, 29–57. [Google Scholar] [CrossRef]
- Formica, A.; Pourabbas, E. Content based similarity of geographic classes organized as partition hierarchies. Knowl. Inf. Syst. 2009, 20, 221–241. [Google Scholar] [CrossRef]
- Uriona Maldonado, M.; Leusin, M.E.; Bernardes, T.C.d.A.; Vaz, C.R. Similarities and differences between business process management and lean management. Bus. Process. Manag. J. 2020, 26, 1807–1831. [Google Scholar] [CrossRef]
- De Nicola, A.; Villani, M.L.; Sujan, M.; Watt, J.; Costantino, F.; Falegnami, A.; Patriarca, R. Development and measurement of a resilience indicator for cyber-socio-technical systems: The allostatic load. J. Ind. Inf. Integr. 2023, 35, 100489. [Google Scholar] [CrossRef]
- Jiang, X.; Tian, B.; Tian, X. Retrieval and Ranking of Combining Ontology and Content Attributes for Scientific Document. Entropy 2022, 24, 810. [Google Scholar] [CrossRef]
- Formica, A.; Taglino, F. Semantic relatedness in DBpedia: A comparative and experimental assessment. Inf. Sci. 2023, 621, 474–505. [Google Scholar] [CrossRef]
- Mohamed, M.A.; Oussalah, M. A hybrid approach for paraphrase identification based on knowledge-enriched semantic heuristics. Lang. Resour. Eval. 2020, 54, 457–485. [Google Scholar] [CrossRef]
- Zhou, T.; Law, K.M.Y. Semantic Relatedness Enhanced Graph Network for aspect category sentiment analysis. Expert Syst. Appl. 2022, 195, 116560. [Google Scholar] [CrossRef]
- Beeri, C.; Formica, A.; Missikoff, M. Inheritance Hierarchy Design in Object-Oriented Databases. Data Knowl. Eng. 1999, 30, 191–216. [Google Scholar] [CrossRef]
- Resnik, P. Using Information Content to Evaluate Semantic Similarity in a Taxonomy. In Proceedings of the 14th International Joint Conference on Artificial Intelligence—Volume 1, IJCAI’95, Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1995; pp. 448–453. [Google Scholar]
- De Nicola, A.; Formica, A.; Missikoff, M.; Pourabbas, E.; Taglino, F. A parametric similarity method: Comparative experiments based on semantically annotated large datasets. J. Web Semant. 2023, 76, 100773. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schutze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Seco, N.; Veale, T.; Hayes, J. An Intrinsic Information Content Metric for Semantic Similarity in WordNet. In Proceedings of the 16th European Conference on Artificial Intelligence, ECAI’04, Valencia, Spain, 22–27 August 2004; IOS Press: Amsterdam, The Netherlands, 2004; pp. 1089–1090. [Google Scholar]
- Zhou, Z.; Wang, Y.; Gu, J. A New Model of Information Content for Semantic Similarity in WordNet. In Proceedings of the 2008 Second International Conference on Future Generation Communication and Networking Symposia, Hinan Island, China, 13–15 December 2008; Volume 3, pp. 85–89. [Google Scholar]
- Sánchez, D.; Batet, M. A semantic similarity method based on information content exploiting multiple ontologies. Expert Syst. Appl. 2013, 40, 1393–1399. [Google Scholar] [CrossRef]
- Taieb, M.A.H.; Aouicha, M.B.; Hamadou, A.B. A new semantic relatedness measurement using WordNet features. Knowl. Inf. Syst. 2014, 41, 467–497. [Google Scholar] [CrossRef]
- Meng, L.; Gu, J.; Zhou, Z. A New Hybrid Semantic Similarity Measure Based on WordNet. In Proceedings of the Network Computing and Information Security, Shanghai, China, 7–9 December 2012; Lei, J., Wang, F.L., Li, M., Luo, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 739–744. [Google Scholar]
- Yuan, Q.; Yu, Z.; Wang, K. A New Model of Information Content for Measuring the Semantic Similarity between Concepts. In Proceedings of the 2013 International Conference on Cloud Computing and Big Data, Fuzhou, China, 16–19 December 2013; pp. 141–146. [Google Scholar] [CrossRef]
- Sánchez, D.; Batet, M. A New Model to Compute the Information Content of Concepts from Taxonomic Knowledge. Inter J. Semant. Web Inf. Syst. 2012, 8, 34–50. [Google Scholar] [CrossRef]
- Formica, A.; Missikoff, M.; Pourabbas, E.; Taglino, F. Semantic search for matching user requests with profiled enterprises. Comput. Ind. 2013, 64, 191–202. [Google Scholar] [CrossRef]
- Sebti, A.; Barfroush, A.A. A new word sense similarity measure in wordnet. In Proceedings of the the International Multiconference on Computer Science and Information Technology, IMCSIT 2008, Wisla, Poland, 20–22 October 2008; pp. 369–373. [Google Scholar] [CrossRef]
- Batet, M.; Sánchez, D. Leveraging synonymy and polysemy to improve semantic similarity assessments based on intrinsic information content. Artif. Intell. Rev. 2020, 53, 2023–2041. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, Y.; Wang, X. A semantic similarity computation method for virtual resources in cloud manufacturing environment based on information content. J. Manuf. Syst. 2021, 59, 646–660. [Google Scholar] [CrossRef]
- Meng, L.; Gu, J.; Zhou, Z. A New Model of Information Content Based on Concept’s Topology for Measuring Semantic Similarity in WordNet. Int. J. Grid Distrib. Comput. 2012, 5, 81–93. [Google Scholar]
- Adhikari, A.; Singh, S.; Dutta, A.; Dutta, B. A novel information theoretic approach for finding semantic similarity in WordNet. In Proceedings of the TENCON 2015—2015 IEEE Region 10 Conference, Macao, China, 1–4 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, S.; Zhang, K. An information Content-Based Approach for Measuring Concept Semantic Similarity in WordNet. Wirel. Pers. Commun. 2018, 103, 117–132. [Google Scholar] [CrossRef]
- Jiang, J.J.; Conrath, D.W. Semantic similarity based on corpus statistics and lexical taxonomy. In Proceedings of the International Conference on Research in Computational Linguistics, Taipei, Taiwan, 14–20 August 1997; pp. 19–33. [Google Scholar]
- Lin, D. An Information-Theoretic Definition of Similarity. In Proceedings of the 15th International Conference on Machine Learning, ICML ’98, Madison, WD, USA, 24–27 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 296–304. [Google Scholar]
- Pirrò, G. A semantic similarity metric combining features and intrinsic information content. Data Knowl. Eng. 2009, 68, 1289–1308. [Google Scholar] [CrossRef]
- Tversky, A. Features of similarity. Psychol. Rev. 1977, 84, 327–352. [Google Scholar] [CrossRef]
- Zhu, G.; Iglesias, C.A. Computing Semantic Similarity of Concepts in Knowledge Graphs. IEEE Trans. Knowl. Data Eng. 2017, 29, 72–85. [Google Scholar] [CrossRef]
- Formica, A.; Taglino, F. An Enriched Information-Theoretic Definition of Semantic Similarity in a Taxonomy. IEEE Access 2021, 9, 100583–100593. [Google Scholar] [CrossRef]
- Giabelli, A.; Malandri, L.; Mercorio, F.; Mezzanzanica, M.; Nobani, N. Embeddings Evaluation Using a Novel Measure of Semantic Similarity. Cogn. Comput. 2022, 14, 749–763. [Google Scholar] [CrossRef]
- Rada, R.; Mili, H.; Bicknell, E.; Blettner, M. Development and application of a metric on semantic nets. IEEE Trans. Syst. Man Cybern. 1989, 19, 17–30. [Google Scholar] [CrossRef]
- Wu, Z.; Palmer, M. Verb semantics and lexical selection. In Proceedings of the 32nd Annual meeting of the Associations for Computational Linguistics, ACL ’94, Las Cruces, NM, USA, 27–30 June 1994; Association for Computational Linguistics: Kerrville, TX, USA; pp. 133–138. [Google Scholar]
- Leacock, C.; Chodorow, M. Combining local context and WordNet similarity for word sense identification. In WordNet: An Electronic Lexical Database; MIT Press: Cambridge, MA, USA, 1998; Volume 49, pp. 265–283. [Google Scholar] [CrossRef]
- Li, Y.; Bandar, Z.; Mclean, D. An approach for measuring semantic similarity between words using multiple information sources. IEEE Trans. Knowl. Data Eng. 2003, 15, 871–882. [Google Scholar] [CrossRef]
- Al-Mubaid, H.; Nguyen, H.A. A Cluster-Based Approach for Semantic Similarity in the Biomedical Domain. In Proceedings of the 28th International Conference of the IEEE Engineering in Medicine and Biology Society, EMBC 2006, New York City, NY, USA, 30 August–3 September 2006; pp. 2713–2717. [Google Scholar] [CrossRef]
- Rezaei, M.; Fränti, P. Matching Similarity for Keyword-Based Clustering. In Proceedings of the Structural, Syntactic, and Statistical Pattern Recognition. S+SSPR 2014. Lecture Notes in Computer Science, Joensuu, Finland, 20–22 August 2014; Fränti, P., Brown, G., Loog, M., Escolano, F., Pelillo, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8621, pp. 193–202. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, S.; Zhang, K. A New Hybrid Improved Method for Measuring Concept Semantic Similarity in WordNet. Int. Arab. J. Inf. Technol. (IAJIT) 2018, 17, 1–7. [Google Scholar] [CrossRef]
- Hussain, M.J.; Wasti, S.H.; Huang, G.; Wei, L.; Jiang, Y.; Tang, Y. An approach for measuring semantic similarity between Wikipedia concepts using multiple inheritances. Inf. Process. Manag. 2020, 57, 102188. [Google Scholar] [CrossRef]
- Li, Y.; McLean, D.; Bandar, Z.A.; O’Shea, J.D.; Crockett, K. Sentence similarity based on semantic nets and corpus statistics. IEEE Trans. Knowl. Data Eng. 2006, 18, 1138–1150. [Google Scholar] [CrossRef]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Jaccard, P. The Distribution of the flora in the alpine zone. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Likavec, S.; Lombardi, I.; Cena, F. Sigmoid similarity—A new feature-based similarity measure. Inf. Sci. 2019, 481, 203–218. [Google Scholar] [CrossRef]
- Shajalal, M.; Aono, M. Semantic textual similarity between sentences using bilingual word semantics. Prog. Artif. Intell. 2019, 8, 263–272. [Google Scholar] [CrossRef]
- Haase, P.; Siebes, R.; van Harmelen, F. Peer Selection in Peer-to-Peer Networks with Semantic Topologies. In Lecture Notes in Computer Science, Proceedings of the Semantics of a Networked World, Semantics for Grid Databases, ICSNW 2004, Paris, France, 17–19 June 2004; Bouzeghoub, M., Goble, C., Kashyap, V., Spaccapietra, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3226, pp. 108–125. [Google Scholar] [CrossRef]
- Wang, N.; Huang, Y.; Liu, H.; Zhang, Z.; Wei, L.; Fei, X.; Chen, H. Study on the semi-supervised learning-based patient similarity from heterogeneous electronic medical records. BMC Med. Inform. Decis. Mak. 2021, 21, 58. [Google Scholar] [CrossRef]
- Dulmage, A.L.; Mendelsohn, N.S. Coverings of bipartite graphs. Can. J. Math. 1958, 10, 517–534. [Google Scholar] [CrossRef]
- Miller, G.A.; Charles, W.G. Contextual Correlates of Semantic Similarity. Lang. Cogn. Process. 1991, 6, 1–28. [Google Scholar] [CrossRef]
- Szumlanski, S.R.; Gomez, F.; Sims, V.K. A New Set of Norms for Semantic Relatedness Measures. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; pp. 890–895. [Google Scholar]
- Rubenstein, H.; Goodenough, J.B. Contextual Correlates of Synonymy. Commun. ACM 1965, 8, 627–633. [Google Scholar] [CrossRef]

| Notation | Description |
|---|---|
| Taxonomy T | , where C is a set of nodes or concepts, and E is a set of edges, |
| i.e., concept pairs, , such that , ∈ C, and is-a holds | |
| hyper(c) | The set of the hypernyms (or subsumers) of the concept c |
| hypo(c) | The set of the hyponyms (or subsumes) of the concept c |
| directHyper(c) | The set of hypernyms of c directly linked to it, i.e., the set of concepts |
| , such that | |
| directHypo(c) | The set of hyponyms of c directly linked to it, i.e., the set of concepts |
| such that | |
| lcs(c, c) | The least common subsumer, i.e., one of the most specific common hypernyms |
| of and (that, in a tree-shaped taxonomy, is unique) | |
| len(c, c) | The shortest path length between and , i.e, the length of the path |
| with the minimum number of edges connecting , | |
| depth(c) | The shortest path length between c and the root of the taxonomy |
| height(T) | The maximum depth that a concept can have in T |
| leaves(T) | The set of all the leaves in T, i.e., the concepts without hyponyms |
| leaves(c) | The set of leaves having c as an hypernym |
| siblings(c) | The set of concepts such that |
| Depth | Height | len | lcs | Hypo | Hyper | IC | Further Info | ||
|---|---|---|---|---|---|---|---|---|---|
| [41] | 1989 | X | distance | ||||||
| [42] | 1994 | X | X | X | |||||
| [17] | 1995 | X | X | Resnik [17] | |||||
| [34] | 1997 | X | Resnik [17] | ||||||
| [43] | 1998 | X | X | ||||||
| [35] | 1998 | X | Resnik [17] | ||||||
| [49] | 2006 | X | X | X | |||||
| [45] | 2006 | X | X | X | X | ||||
| [36] | 2009 | X | Seco et al. [20] | ||||||
| [24] | 2012 | X | X | Seco et al. [20] | tuning param. | ||||
| [46] | 2014 | X | X | ||||||
| [38] | 2017 | X | X | Resnik [17] | tuning param. | ||||
| [33] | 2018 | X | Zhang 1 et al. [33] | ||||||
| [47] | 2018 | X | X | ||||||
| [39] | 2021 | any | tuning param. words senses | ||||||
| [40] | 2022 | X | X | Resnik [17] | words senses |
| Correlation with HJ | Degree of Confidence | |
|---|---|---|
| WNSim similarity | 0.61 | 84.33% |
| Rezaei and Fränti similarity | 0.46 | 74.73% |
| Haase et al. similarity | 0.69 | 77.89% |
| Wang et al. similarity | 0.04 | 74.09% |
| SemSim similarity | 0.69 | 85.67% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Nicola, A.; Formica, A.; Mele, I.; Taglino, F. Semantic Similarity Based on Taxonomies. Appl. Sci. 2023, 13, 11959. https://doi.org/10.3390/app132111959
De Nicola A, Formica A, Mele I, Taglino F. Semantic Similarity Based on Taxonomies. Applied Sciences. 2023; 13(21):11959. https://doi.org/10.3390/app132111959
Chicago/Turabian StyleDe Nicola, Antonio, Anna Formica, Ida Mele, and Francesco Taglino. 2023. "Semantic Similarity Based on Taxonomies" Applied Sciences 13, no. 21: 11959. https://doi.org/10.3390/app132111959
APA StyleDe Nicola, A., Formica, A., Mele, I., & Taglino, F. (2023). Semantic Similarity Based on Taxonomies. Applied Sciences, 13(21), 11959. https://doi.org/10.3390/app132111959