
An Architecture for a Tri-Programming Model-Based Parallel Hybrid Testing Tool

 ,
,  , ,
, ,  , and
, and 
Abstract
:1. Introduction
- Single-level, comprising a standalone model, such as OpenMP, MPI, or CUDA;
- Tri-level (MPI + X + Y) [14], comprising three distinct programming models to enhance parallelism.
2. Background
2.1. Programming Models
2.1.1. Message Passing Interface (MPI)
- Standardisation, as it is an exclusive message passing library that can, satisfactorily, be considered a standard. It works on almost any high-performance computing system and, in most cases, can replace any existing message passing library.
- Portability, as it requires minimal or no source code to port an application to a supported platform.
- Vendors, as they can to use its native capabilities to examine performance opportunities and achieve optimal performance, wherever possible. Optimal algorithms may also be developed for any implementation.
- Functionality, as it has over 430 functions, with MPI-2 and MPI-1 included in MPI-3. However, a dozen or so routines are required to create a typical MPI application.
- Availability, as it has a wide selection of vendor and open-source options available.
2.1.2. Open Multi-Processing (OpenMP)
2.1.3. Compute Unified Device Architecture (CUDA)
2.2. Tri-Level Programming Model (OPENMP + CUDA + MPI)
2.3. An Overview of Common Run-Time Errors
2.3.1. Deadlocks
2.3.2. Livelocks
2.3.3. Race Conditions
2.3.4. Data Races
2.3.5. Mismatches
2.4. Testing Techniques
3. Literature Review
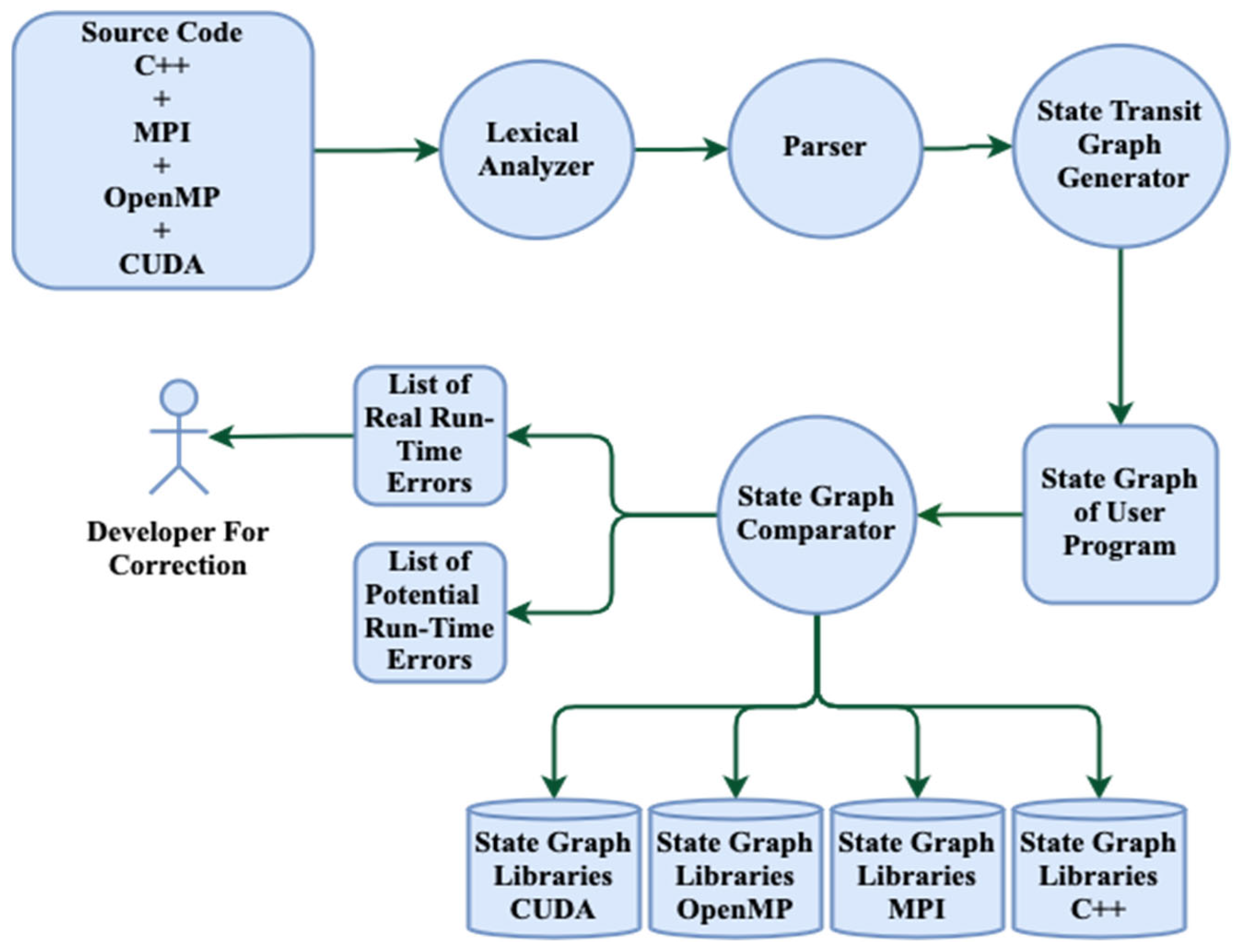
4. Architecture of the Proposed Tri-Level Programming Model
- A lexical analyser that reads the source code, which includes C++, MPI, OpenMP, and CUDA, line by line and then understands the source code before generating a token table containing at least two columns: the token name and token type.
- A parser or syntax analyser that checks the syntax of each statement and detects syntax errors. More specifically, it analyses the syntactical structure of the inputs and determines whether they are in the correct syntax for the programming language used.
- A generator that produces a dependable state transit graph for a code that comprises MPI, C++, OpenMP, and CUDA. An appropriate data structure is employed to build a suitable state graph.
- A state graph comparator that compares the user programme graph with the state graphs of all the programming languages and models. The grammar of each programming language is included in the state graph library, which is available via this comparator. As the static architecture may identify both potential and actual run-time errors, the outcomes of the comparisons are presented in a list. The actual run-time faults are sent to the developer to correct them as these errors will definitely occur if they are not corrected. In the second dynamic testing phase of the proposed architecture, assertions are injected into the sources and then instrumented to examine potential run-time errors.
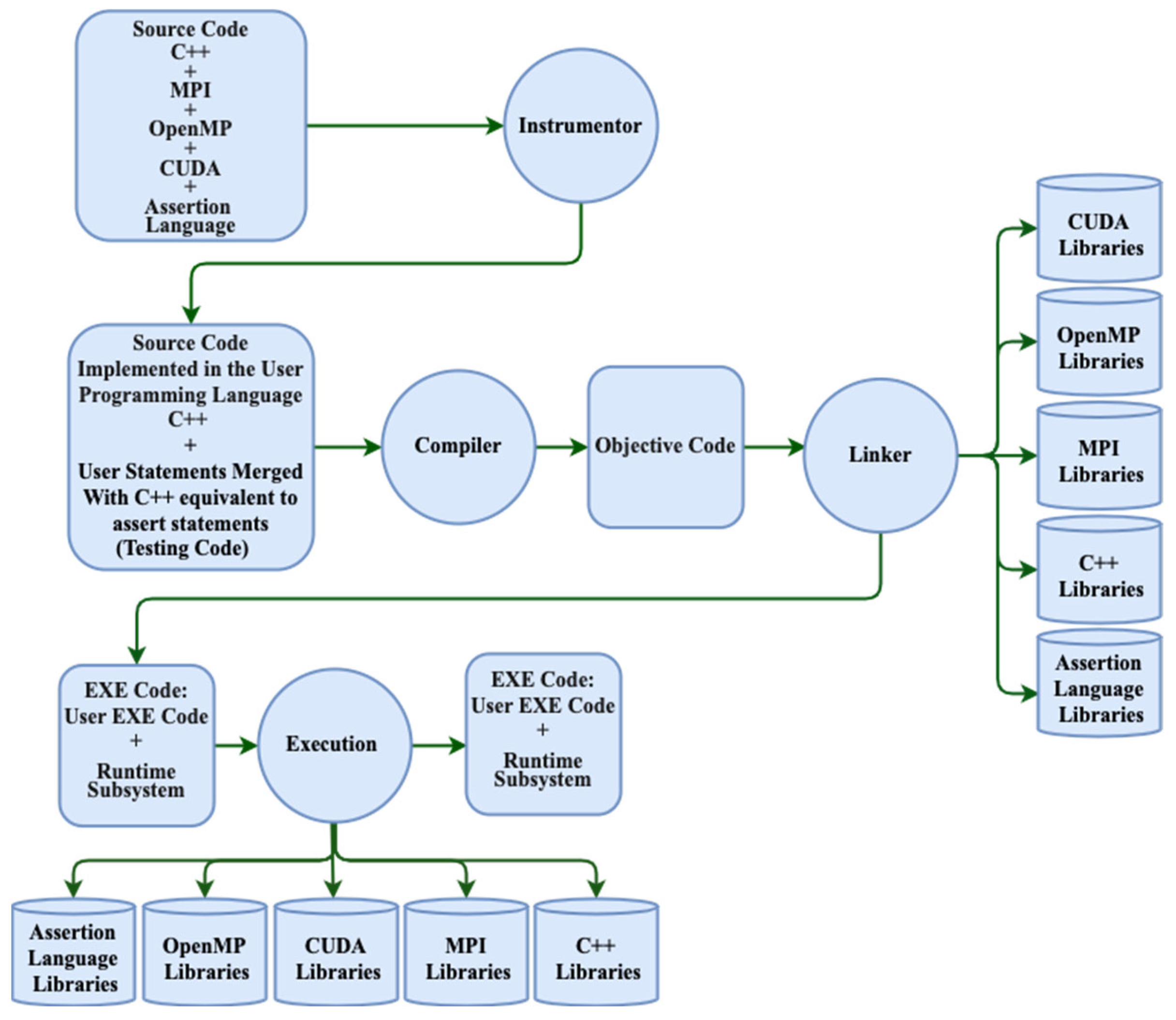
- Assertion language: the testing language that helps to detect and monitor the variables and behaviour of a system during run-time. It is combined with the user code to create a new code as part of the dynamic test.
- Instrumentor: this is responsible for converting the assertion statement into its equivalent C++ code.
- Run-time analyser subsystem: this includes a detecting and debugging module.
| Algorithm 1 Static Testing Phase |
| 1: Inputting the source code source_code = input (“Enter the source code containing the (C++) + tri-level programming (MPI + OpenMP + CUDA):”) 2: Lexical analysis tokens = perform_lexical_analysis(source_code) 3: Parsing parsed_output = perform_parsing(tokens) 4: Generating the state transition graph for the user code user_stg = generate_state_transition_graph(parsed_output) 5: Generating the state transition graphs for the MPI, OpenMP, CUDA, and C++ libraries mpi_stg = generate_mpi_state_transition_graph () openmp_stg = generate_openmp_state_transition_graph () cuda_stg = generate_cuda_state_transition_graph () cpp_stg = generate_cpp_state_transition_graph () 6: Comparing the state transition graphs Actual_errors = [] if not compare_state_transition_graphs (user_stg, mpi_stg): Actual _errors. append (“MPI run-time error”) if not compare_state_transition_graphs (user_stg, openmp_stg): Actual _errors. append (“OpenMP run-time error”) if not compare_state_transition_graphs (user_stg, cuda_stg): Actual _errors. append (“CUDA run-time error”) if not compare_state_transition_graphs (user_stg, cpp_stg): Actual _errors. append (“C++ run-time error”) 7: Listing the actual run-time errors if (Actual _errors) > 0: print (“Actual run-time errors found: “) if else: print (“No Actual run-time errors found.”) else: print (“Potential run-time errors found: “) |
| Algorithm 2 Dynamic Testing Phase |
| 1: Reading the source code containing the (C++) + tri-level programming MPI + OpenMP + CUDA and the assert statement as inputted, the potential run-time errors. 2: Applying instrumentation to the source code, the potential run-time errors, to insert run-time checks for the run-time errors. if (MPI is used in the code) insert MPI run-time checks if (OpenMP is used in the code) insert OpenMP run-time checks if (CUDA is used in the code) insert CUDA run-time checks if (assert statements are used in the code) insert assert statement checks Saving the instrumented source code. 3: Compiling the instrumented source code and linking it with the relevant libraries. if (MPI is used in the code) link with MPI library if (OpenMP is used in the code) link with OpenMP library if (CUDA is used in the code) link with CUDA library Compiling and linking the code. 4: Executing the instrumented executable code on the target system. if (MPI is used in the code) execute with MPI run-time if (OpenMP is used in the code) execute with OpenMP run-time if (CUDA is used in the code) execute with CUDA run-time 5: Monitoring the execution of the instrumented code for any run-time errors. while (the code is executing) if (a run-time error occurs) log the error) 6: Sending a list of the run-time errors to the developer for further analysis and correction. 7: Displaying a list of run-time errors. |
5. Discussion
6. Environment Required to Implement the Proposed Architecture
7. Conclusions and Recommendations for Future Studies
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahmadpour, S.-S.; Heidari, A.; Navimipour, N.; Asadi, M.-A.; Yalcin, S. An Efficient Design of Multiplier for Using in Nano-Scale IoT Systems Using Atomic Silicon. IEEE Internet Things J. 2023, 10, 14908–14909. [Google Scholar] [CrossRef]
- Ahmadpour, S.-S.; Navimipour, N.J.; Mosleh, M.; Bahar, A.N.; Yalcin, S. A Nano-Scale n-Bit Ripple Carry Adder Using an Optimized XOR Gate and Quantum-Dots Technology with Diminished Cells and Power Dissipation. Nano Commun. Netw. 2023, 36, 100442. [Google Scholar] [CrossRef]
- Pramanik, A.K.; Mahalat, M.H.; Pal, J.; Ahmadpour, S.-S.; Sen, B. Cost-Effective Synthesis of QCA Logic Circuit Using Genetic Algorithm. J. Supercomput. 2023, 79, 3850–3877. [Google Scholar] [CrossRef]
- Ahmadpour, S.-S.; Jafari Navimipour, N.; Bahar, A.N.; Mosleh, M.; Yalcin, S. An Energy-Aware Nanoscale Design of Reversible Atomic Silicon Based on Miller Algorithm. IEEE Des. Test 2023, 40, 62–69. [Google Scholar] [CrossRef]
- MPI Forum MPI Documents. Available online: https://www.mpi-forum.org/docs/ (accessed on 6 February 2023).
- OpenMP ARB About Us—OpenMP. Available online: https://www.openmp.org/about/about-us/ (accessed on 6 February 2023).
- About OpenACC|OpenACC. Available online: https://www.openacc.org/about (accessed on 6 February 2023).
- The Khronos Group Inc OpenCL Overview—The Khronos Group Inc. Available online: https://www.khronos.org/opencl/ (accessed on 6 February 2023).
- NVIDIA about CUDA|NVIDIA Developer 2021. Available online: https://developer.nvidia.com/about-cuda (accessed on 5 September 2023).
- Thiffault, C.; Voss, M.; Healey, S.T.; Kim, S.W. Dynamic Instrumentation of Large-Scale MPI and OpenMP Applications. In Proceedings of the International Parallel and Distributed Processing Symposium, Nice, France, 22–26 April 2003. [Google Scholar] [CrossRef]
- Vargas-Perez, S.; Saeed, F. A Hybrid MPI-OpenMP Strategy to Speedup the Compression of Big Next-Generation Sequencing Datasets. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 2760–2769. [Google Scholar] [CrossRef]
- Wu, X.; Taylor, V. Performance Characteristics of Hybrid MPI/OpenMP Scientific Applications on a Large-Scale Multithreaded BlueGene/Q Supercomputer. In Proceedings of the 14th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Honolulu, HI, USA, 1–3 July 2013; Volume 5, pp. 303–309. [Google Scholar] [CrossRef]
- Guan, J.; Yan, S.; Jin, J.M. An OpenMP-CUDA Implementation of Multilevel Fast Multipole Algorithm for Electromagnetic Simulation on Multi-GPU Computing Systems. IEEE Trans. Antennas Propag. 2013, 61, 3607–3616. [Google Scholar] [CrossRef]
- Jacobsen, D.A.; Senocak, I. Multi-Level Parallelism for Incompressible Flow Computations on GPU Clusters. Parallel Comput. 2013, 39, 1–20. [Google Scholar] [CrossRef]
- Agueny, H. Porting OpenACC to OpenMP on Heterogeneous Systems. arXiv 2022, arXiv:2201.11811. [Google Scholar]
- Herdman, J.A.; Gaudin, W.P.; Perks, O.; Beckingsale, D.A.; Mallinson, A.C.; Jarvis, S.A. Achieving Portability and Performance through OpenACC. In Proceedings of the 2014 First Workshop on Accelerator Programming Using Directives, New Orleans, LA, USA, 17 November 2015; pp. 19–26. [Google Scholar] [CrossRef]
- OpenMPI Open MPI: Open Source High Performance Computing. Available online: https://www.open-mpi.org/ (accessed on 6 February 2023).
- MPICH Overview|MPICH. Available online: https://www.mpich.org/about/overview/ (accessed on 6 February 2023).
- IBM Spectrum MPI—Overview|IBM. Available online: https://www.ibm.com/products/spectrum-mpi (accessed on 6 February 2023).
- Introducing Intel® MPI Library. Available online: https://www.intel.com/content/www/us/en/develop/documentation/mpi-developer-reference-linux/top/introduction/introducing-intel-mpi-library.html (accessed on 6 February 2023).
- Barney, B. OpenMP|LLNL HPC Tutorials. Available online: https://hpc-tutorials.llnl.gov/openmp/ (accessed on 6 February 2023).
- Oracle Developer Studio 12.5: OpenMP API®. Available online: https://www.oracle.com/application-development/technologies/developerstudio-documentation.html (accessed on 6 February 2023).
- Harakal, M. Compute Unified Device Architecture (CUDA) GPU Programming Model and Possible Integration to the Parallel Environment. Sci. Mil. J. 2008, 3, 64–68. [Google Scholar]
- Cai, Y.; Lu, Q. Dynamic Testing for Deadlocks via Constraints. IEEE Trans. Softw. Eng. 2016, 42, 825–842. [Google Scholar] [CrossRef]
- Ganai, M.K. Dynamic Livelock Analysis of Multi-Threaded Programs. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2013; Volume 7687, pp. 3–18. ISBN 9783642356315. [Google Scholar]
- Lin, Y.; Kulkarni, S.S. Automatic Repair for Multi-Threaded Programs with Deadlock/Livelock Using Maximum Satisfiability. In Proceedings of the International Symposium on Software Testing and Analysis, San Jose, CA, USA, 21–25 July 2014; pp. 237–247. [Google Scholar]
- Münchhalfen, J.F.; Hilbrich, T.; Protze, J.; Terboven, C.; Müller, M.S. Classification of Common Errors in OpenMP Applications. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Salvador, Brazil, 28–30 September 2014; DeRose, L., de Supinski, B.R., Olivier, S.L., Chapman, B.M., Müller, M.S., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8766, pp. 58–72. [Google Scholar]
- Cao, M. Efficient, Practical Dynamic Program Analyses for Concurrency Correctness. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2017. [Google Scholar]
- Huchant, P. Static Analysis and Dynamic Adaptation of Parallelism. Ph.D. Thesis, Université de Bordeaux, Bordeaux, France, 2019. [Google Scholar]
- Sawant, A.A.; Bari, P.H.; Chawan, P. Software Testing Techniques and Strategies. J. Eng. Res. Appl. 2012, 2, 980–986. [Google Scholar]
- Saillard, E. Static/Dynamic Analyses for Validation and Improvements of Multi-Model HPC Applications. Ph.D. Thesis, Universit’e de Bordeaux, Bordeaux, France, 2015. [Google Scholar]
- Saillard, E.; Carribault, P.; Barthou, D. Static/Dynamic Validation of MPI Collective Communications in Multi-Threaded Context. In Proceedings of the ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPOPP, Chicago, IL, USA, 15–17 June 2015; ACM: New York, NY, USA, 2015; Volume 2015, pp. 279–280. [Google Scholar]
- Correctness Checking of MPI Applications. Available online: https://www.intel.com/content/www/us/en/docs/trace-analyzer-collector/user-guide-reference/2023-1/correctness-checking-of-mpi-applications.html (accessed on 18 June 2023).
- Droste, A.; Kuhn, M.; Ludwig, T. MPI-Checker. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, Austin, TX, USA, 15 November 2015; ACM: New York, NY, USA, 2015; pp. 1–10. [Google Scholar]
- Keller, R.; Fan, S.; Resch, M. Memory Debugging of MPI-Parallel Applications in Open MPI. Adv. Parallel Comput. 2008, 15, 517–523. [Google Scholar]
- Vetter, J.S.; de Supinski, B.R. Dynamic Software Testing of MPI Applications with Umpire. In Proceedings of the ACM/IEEE SC 2000 Conference (SC ‘00): Proceedings of the 2000 ACM/IEEE Conference on Supercomputing), Dallas, TX, USA, 4–10 November 2000; p. 51. [Google Scholar]
- Hilbrich, T.; Schulz, M.; de Supinski, B.R.; Müller, M.S. A Scalable Approach to Runtime Error Detection in MPI Programs. In Tools for High Performance Computing 2009; Springer: Berlin/Heidelberg, Germany, 2010; pp. 53–66. ISBN 978-3-64211-260-7. [Google Scholar]
- RWTH Aachen University. MUST: MPI Runtime Error Detection Tool; RWTH Aachen University: Aachen, Germany, 2018. [Google Scholar]
- Hilbrich, T.; Protze, J.; Schulz, M.; de Supinski, B.R.; Muller, M.S. MPI Runtime Error Detection with MUST: Advances in Deadlock Detection. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 1–10. [Google Scholar]
- Kranzlmueller, D.; Schaubschlaeger, C. A Brief Overview of the MUST MAD Debugging Activities. arXiv 2000, arXiv:cs/0012012. [Google Scholar]
- Forejt, V.; Joshi, S.; Kroening, D.; Narayanaswamy, G.; Sharma, S. Precise Predictive Analysis for Discovering Communication Deadlocks in MPI Programs. ACM Trans. Program. Lang. Syst. 2017, 39, 1–27. [Google Scholar] [CrossRef]
- Luecke, G.R.; Coyle, J.; Hoekstra, J.; Kraeva, M.; Xu, Y.; Park, M.-Y.; Kleiman, E.; Weiss, O.; Wehe, A.; Yahya, M. The Importance of Run-Time Error Detection. In Tools for High Performance Computing 2009; Müller, M.S., Resch, M.M., Schulz, A., Nagel, W.E., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 145–155. ISBN 978-3-642-11261-4. [Google Scholar]
- Saillard, E.; Carribault, P.; Barthou, D. Combining Static and Dynamic Validation of MPI Collective Communications. In Proceedings of the 20th European MPI Users’ Group Meeting, Madrid, Spain, 15–18 September 2013; ACM: New York, NY, USA, 2013; pp. 117–122. [Google Scholar]
- Alghamdi, A.S.A.; Alghamdi, A.M.; Eassa, F.E.; Khemakhem, M.A. ACC_TEST: Hybrid Testing Techniques for MPI-Based Programs. IEEE Access 2020, 8, 91488–91500. [Google Scholar] [CrossRef]
- Betts, A.; Chong, N.; Donaldson, A.F.; Qadeer, S.; Thomson, P. GPU Verify: A Verifier for GPU Kernels. In Proceedings of the Conference on Object-Oriented Programming Systems, Languages, and Applications, OOPSLA, New York, NY, USA, 19–26 October 2012; pp. 113–131. [Google Scholar]
- Basupalli, V.; Yuki, T.; Rajopadhye, S.; Morvan, A.; Derrien, S.; Quinton, P.; Wonnacott, D. OmpVerify: Polyhedral Analysis for the OpenMP Programmer. In OpenMP in the Petascale Era: 7th International Workshop on OpenMP, IWOMP 2011, Chicago, IL, USA, 13–15 June 2011; Proceedings 7; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6665, pp. 37–53. [Google Scholar] [CrossRef]
- Ye, F.; Schordan, M.; Liao, C.; Lin, P.-H.; Karlin, I.; Sarkar, V. Using Polyhedral Analysis to Verify OpenMP Applications Are Data Race Free. In Proceedings of the IEEE/ACM 2nd International Workshop on Software Correctness for HPC Applications (Correctness), Dallas, TX, USA, 12 November 2018; pp. 42–50. [Google Scholar]
- Jannesari, A.; Kaibin, B.; Pankratius, V.; Tichy, W.F. Helgrind+: An Efficient Dynamic Race Detector. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–13. [Google Scholar]
- Nethercote, N.; Seward, J. Valgrind: A Framework for Heavyweight Dynamic Binary Instrumentation. ACM SIGPLAN Not. 2007, 42, 89–100. [Google Scholar] [CrossRef]
- Gu, Y.; Mellor-Crummey, J. Dynamic Data Race Detection for OpenMP Programs. In Proceedings of the SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 11–16 November 2018; pp. 767–778. [Google Scholar] [CrossRef]
- Terboven, C. Comparing Intel Thread Checker and Sun Thread Analyzer. In Advances in Parallel Computing; IOS Press: Amsterdam, The Netherlands, 2008; Volume 15, pp. 669–676. [Google Scholar]
- Intel(R) Thread Checker 3.1 Release Notes. Available online: https://registrationcenter-download.intel.com/akdlm/irc_nas/1366/ReleaseNotes.htm (accessed on 8 March 2023).
- Sun Microsystems. Sun Studio 12: Thread Analyzer User’ s Guide. Available online: https://docs.oracle.com/cd/E19205-01/820-0619/820-0619.pdf (accessed on 8 March 2023).
- Serebryany, K.; Bruening, D.; Potapenko, A.; Vyukov, D. AddressSanitizer: A Fast Address Sanity Checker. In Proceedings of the USENIX Annual Technical Conference (USENIX ATC 12), Boston, MA, USA, 13–15 June 2012; pp. 309–318. [Google Scholar]
- Serebryany, K.; Potapenko, A.; Iskhodzhanov, T.; Vyukov, D. Dynamic Race Detection with LLVM Compiler: Compile-Time Instrumentation for ThreadSanitizer. In International Conference on Runtime Verification; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7186, pp. 110–114. [Google Scholar] [CrossRef]
- Atzeni, S.; Gopalakrishnan, G.; Rakamaric, Z.; Ahn, D.H.; Laguna, I.; Schulz, M.; Lee, G.L.; Protze, J.; Muller, M.S. ARCHER: Effectively Spotting Data Races in Large OpenMP Applications. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS), Chicago, IL, USA, 23–27 May 2016; pp. 53–62. [Google Scholar] [CrossRef]
- Hilbrich, T.; Müller, M.S.; Krammer, B. Detection of Violations to the MPI Standard in Hybrid OpenMP/MPI Applications. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2008; Volume 3744, pp. 26–35. ISBN 3540294104. [Google Scholar]
- Krammer, B.; Bidmon, K.; Müller, M.S.; Resch, M.M. MARMOT: An MPI Analysis and Checking Tool. Adv. Parallel Comput. 2004, 13, 493–500. [Google Scholar] [CrossRef]
- Chatarasi, P.; Shirako, J.; Kong, M.; Sarkar, V. An Extended Polyhedral Model for SPMD Programs and Its Use in Static Data Race Detection. In Languages and Compilers for Parallel Computing: 29th International Workshop, LCPC 2016, Rochester, NY, USA, 28–30 September 2016; Revised Papers 29; Springer International Publishing: Cham, Switzerland, 2017; Volume 10136, pp. 106–120. [Google Scholar] [CrossRef]
- Mekkat, V.; Holey, A.; Zhai, A. Accelerating Data Race Detection Utilizing On-Chip Data-Parallel Cores. In Runtime Verification: 4th International Conference, RV 2013, Rennes, France, 24–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8174, pp. 201–218. [Google Scholar] [CrossRef]
- Gupta, S.; Sultan, F.; Cadambi, S.; Ivančić, F.; Rötteler, M. Using Hardware Transactional Memory for Data Race Detection. In Proceedings of the IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009. [Google Scholar] [CrossRef]
- Bekar, U.C.; Elmas, T.; Okur, S.; Tasiran, S. KUDA: GPU Accelerated Split Race Checker. In Workshop on Determinism and Correctness in Parallel Programming (WoDet); Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Zheng, M.; Ravi, V.T.; Qin, F.; Agrawal, G. GMRace: Detecting Data Races in GPU Programs via a Low-Overhead Scheme. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 104–115. [Google Scholar] [CrossRef]
- Zheng, M.; Ravi, V.T.; Qin, F.; Agrawal, G. GRace: A Low-Overhead Mechanism for Detecting Data Races in GPU Programs. ACM SIGPLAN Notices 2011, 46, 135–145. [Google Scholar] [CrossRef]
- Dai, Z.; Zhang, Z.; Wang, H.; Li, Y.; Zhang, W. Parallelized Race Detection Based on GPU Architecture. Commun. Comput. Inf. Sci. 2014, 451 CCIS, 113–127. [Google Scholar] [CrossRef]
- Boyer, M.; Skadron, K.; Weimer, W. Automated Dynamic Analysis of CUDA Programs. Available online: https://www.nvidia.com/docs/io/67190/stmcs08.pdf (accessed on 5 September 2023).
- Li, P.; Li, G.; Gopalakrishnan, G. Practical Symbolic Race Checking of GPU Programs. In Proceedings of the SC ‘14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, New Orleans, LA, USA, 16–21 November 2014; pp. 179–190. [Google Scholar] [CrossRef]
- Bronevetsky, G.; Laguna, I.; Bagchi, S.; De Supinski, B.R.; Ahn, D.H.; Schulz, M. AutomaDeD: Automata-Based Debugging for Dissimilar Parallel Tasks. In Proceedings of the International Conference on Dependable Systems and Networks, Chicago, IL, USA, 28 June–1 July 2010; pp. 231–240. [Google Scholar]
- Allinea Software Ltd. ALLINEA DDT. Available online: https://www.linaroforge.com/about (accessed on 5 September 2023).
- Allinea DDT|HPC @ LLNL. Available online: https://hpc.llnl.gov/software/development-environment-software/allinea-ddt (accessed on 31 October 2023).
- Totalview Technologies: Totalview—Parallel and Thread Debugger. Available online: http://www.Totalviewtech.Com/Products/Totalview.Html (accessed on 5 September 2023).
- TotalView Debugger|HPC @ LLNL. Available online: https://hpc.llnl.gov/software/development-environment-software/totalview-debugger (accessed on 5 September 2023).
- Claudio, A.P.; Cunha, J.D.; Carmo, M.B. Monitoring and Debugging Message Passing Applications with MPVisualizer. In Proceedings of the 8th Euromicro Workshop on Parallel and Distributed Processing, Rhodes, Greece, 19–21 January 2000; pp. 376–382. [Google Scholar]
- Intel Inspector|HPC @ LLNL. Available online: https://hpc.llnl.gov/software/development-environment-software/intel-inspector (accessed on 8 March 2023).
- Clemencon, C.; Fritscher, J.; Rühl, R. Visualization, Execution Control and Replay of Massively Parallel Programs within Annai’s Debugging Tool. In Proceedings of the High Performance Computing Symposium, HPCS ‘95, Montreal, QC, Canada, 10–12 July 1995; pp. 393–404. [Google Scholar]
- Arm Forge (Formerly Allinea DDT)|NVIDIA Developer. Available online: https://developer.nvidia.com/allinea-ddt (accessed on 5 September 2023).
- Documentation—Arm Developer. Available online: https://developer.arm.com/documentation/101136/22-1-3/DDT (accessed on 5 September 2023).

{kind=link}
{kind=link}
| References | Technique | Error(s) Detected | Programme Model | Limitation(s) |
|---|---|---|---|---|
| [34] | Static | Mismatches | MPI | Works with single-level programming models. Only identifies mismatches in MPI. |
| [45] | Static | Data Races | CUDA, and OpenCL™ | Works with single-level programming models. |
| [59] | Static | Data Races | OpenMP | Works with single-level programming models. |
| [36] | Dynamic | Deadlocks Mismatched Collective Operations Resource Exhaustion | MPI | Works with single-level programming models. |
| [37,38,39] | Dynamic | Deadlocks Data Races Mismatches | MPI | Works with single-level programming models and MPI only. |
| [66] | Dynamic | Deadlocks, Data Races | CUDA | Works with single-level programming models. |
| [43] | Hybrid | Deadlocks | MPI | Works with single-level programming models. Only identifies deadlocks. |
| [44] | Hybrid | Deadlocks Mismatches Livelocks Data Races/Race Conditions | MPI | Work with single-level programming models. |
| [57] | Hybrid | Data Races | OpenMP | Work with single-level programming models. |
| Programming Model | Tool Name | Run-Time Errors | Error Type |
|---|---|---|---|
| CUDA only | GPUVerify [45] | Data Races | Real |
| MPI only | MPI-Checker [34] | Mismatches | Potential |
| MPI only | MUST [37,38,39] | Deadlocks, Data Races, and Mismatches | Real |
| OpenMP only | Deadlocks and Data Races | Real | |
| CUDA only | GUARD [60] | Data Races | Real |
| Dual: MPI + OpenMP | Marmot [57,58] | Deadlocks, Race Conditions, and Mismatches | Real |
| Tri: MPI + OpenMP + CUDA | Proposed Tool | Deadlocks, Race Conditions, Data Races, Mismatches, and Livelocks | Both |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Altalhi, S.M.; Eassa, F.E.; Al-Ghamdi, A.S.A.-M.; Sharaf, S.A.; Alghamdi, A.M.; Almarhabi, K.A.; Khemakhem, M.A. An Architecture for a Tri-Programming Model-Based Parallel Hybrid Testing Tool. Appl. Sci. 2023, 13, 11960. https://doi.org/10.3390/app132111960
Altalhi SM, Eassa FE, Al-Ghamdi ASA-M, Sharaf SA, Alghamdi AM, Almarhabi KA, Khemakhem MA. An Architecture for a Tri-Programming Model-Based Parallel Hybrid Testing Tool. Applied Sciences. 2023; 13(21):11960. https://doi.org/10.3390/app132111960
Chicago/Turabian StyleAltalhi, Saeed Musaad, Fathy Elbouraey Eassa, Abdullah Saad Al-Malaise Al-Ghamdi, Sanaa Abdullah Sharaf, Ahmed Mohammed Alghamdi, Khalid Ali Almarhabi, and Maher Ali Khemakhem. 2023. "An Architecture for a Tri-Programming Model-Based Parallel Hybrid Testing Tool" Applied Sciences 13, no. 21: 11960. https://doi.org/10.3390/app132111960
APA StyleAltalhi, S. M., Eassa, F. E., Al-Ghamdi, A. S. A.-M., Sharaf, S. A., Alghamdi, A. M., Almarhabi, K. A., & Khemakhem, M. A. (2023). An Architecture for a Tri-Programming Model-Based Parallel Hybrid Testing Tool. Applied Sciences, 13(21), 11960. https://doi.org/10.3390/app132111960