
HS-YOLO: Small Object Detection for Power Operation Scenarios


Abstract
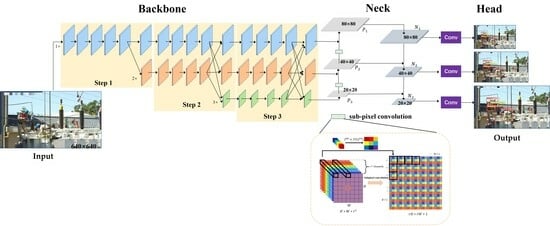
:
1. Introduction
- The information expressed by the features of small objects in power operation scenes is limited. The limited pixel count of small objects in power operation monitoring images makes it challenging to precisely determine their boundaries and positions. This necessitates the utilization of more intricate detection algorithms to capture discriminative feature information for small object detection [11].
- The object scale spans a large range. In power operation scenes, the scale of objects may vary significantly due to changes in camera angles. This variation hampers the localization accuracy and feature extraction capabilities of detection algorithms. Moreover, different scales of objects require the detector to adjust the search regions, impacting detection speed and reducing real-time performance [12].
- The background of small objects is complex. In the electric power operation scenes, the environment typically comprises various intricate structures and facilities, including different equipment, towers, power lines, and trees, among others. The visual appearance and textural features of these objects bear a resemblance to small objects, and mutual occlusions may also occur among them. As a result, the complex environment of power operation scenarios tends to perturb the feature information related to small objects, making it more challenging to extract precise details and characteristics [13].
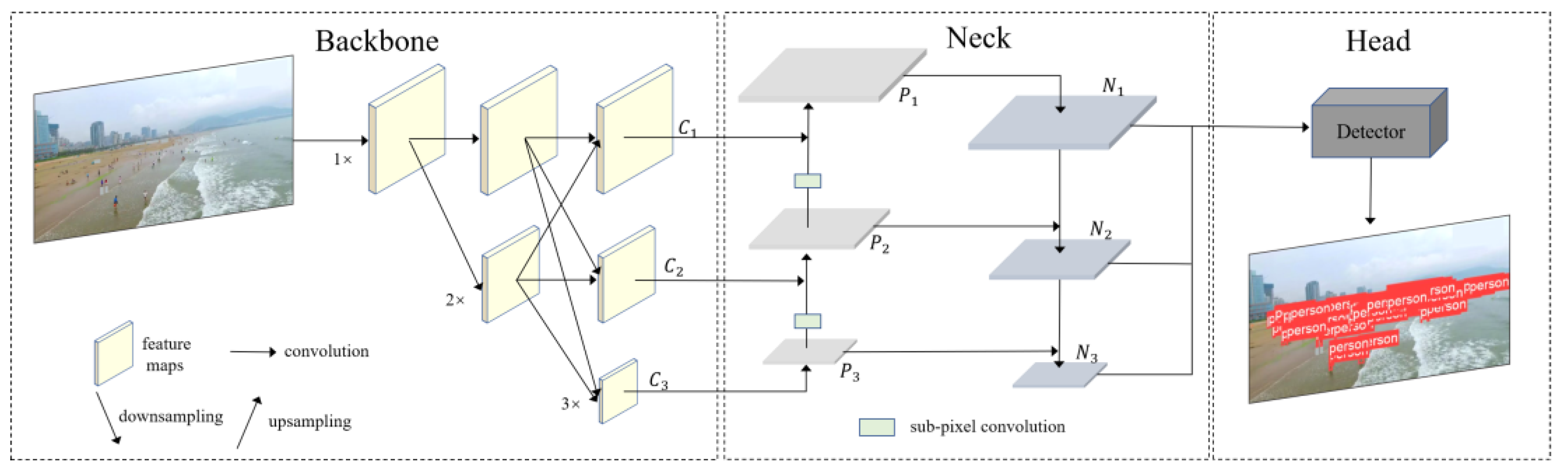
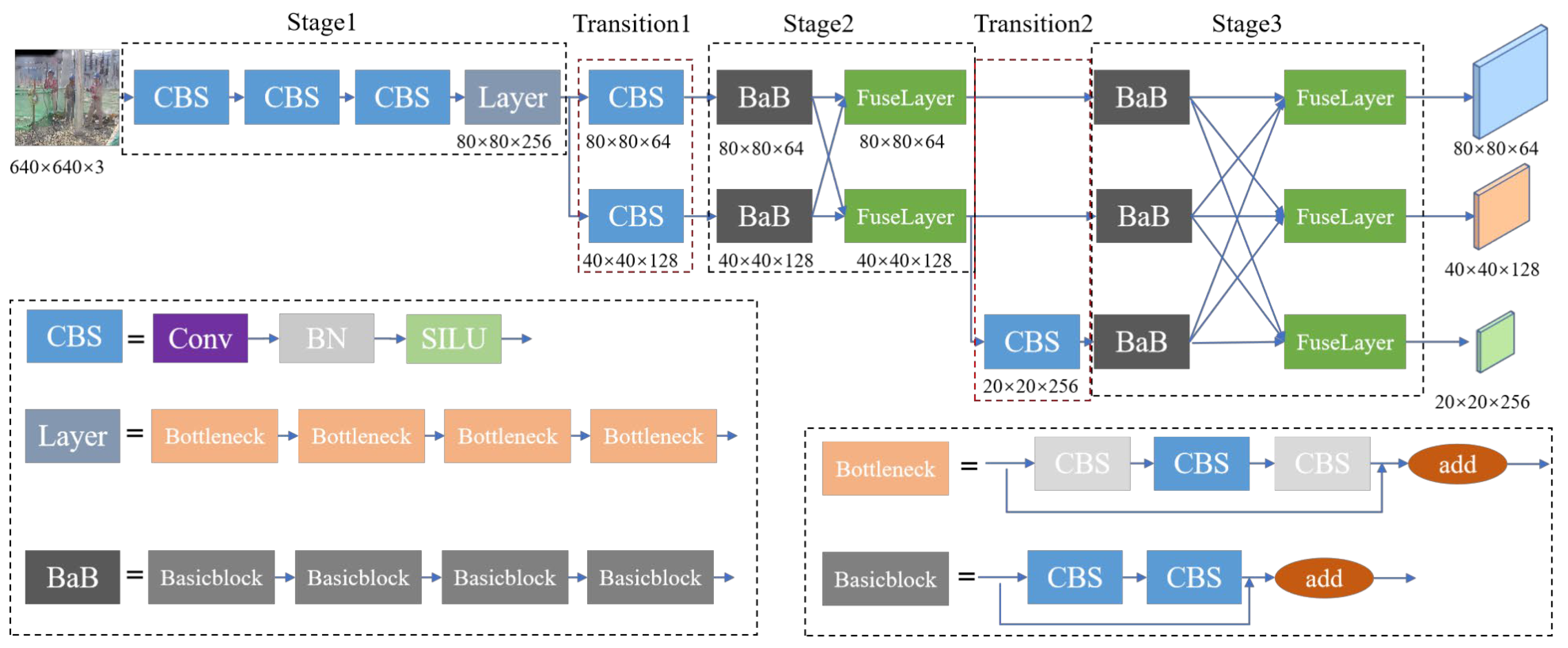
- To solve the problem of weak feature expression ability of small objects, we designed a feature extraction backbone network based on HRNet. The feature maps originating from diverse scales are processed through distinct branches to retain abundant high-resolution feature information for small objects. Simultaneously, the feature maps from different scales are fused to enhance the perception ability of the network to the objects of different scales. This approach enables the preservation of fine-grained details while enhancing the overall object detection capabilities across different scales.
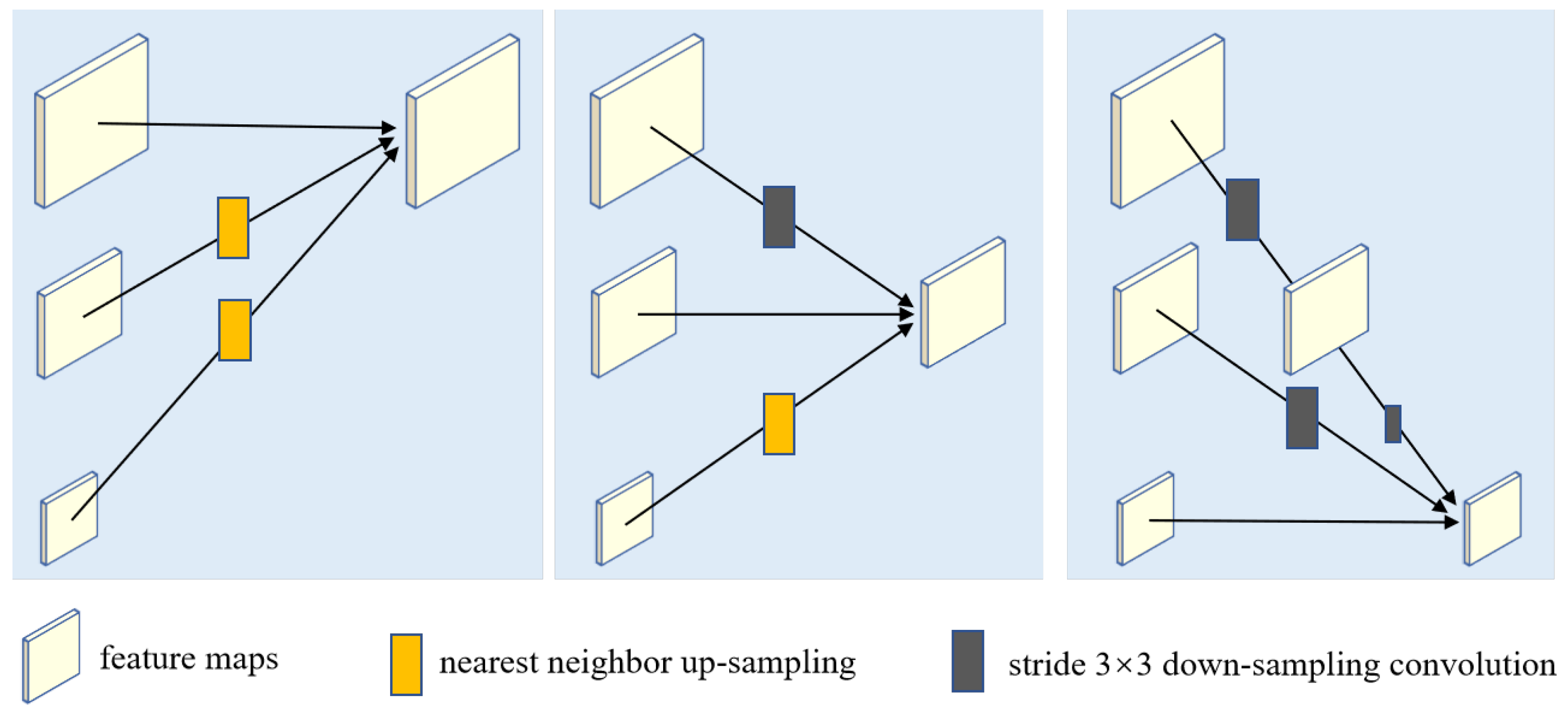
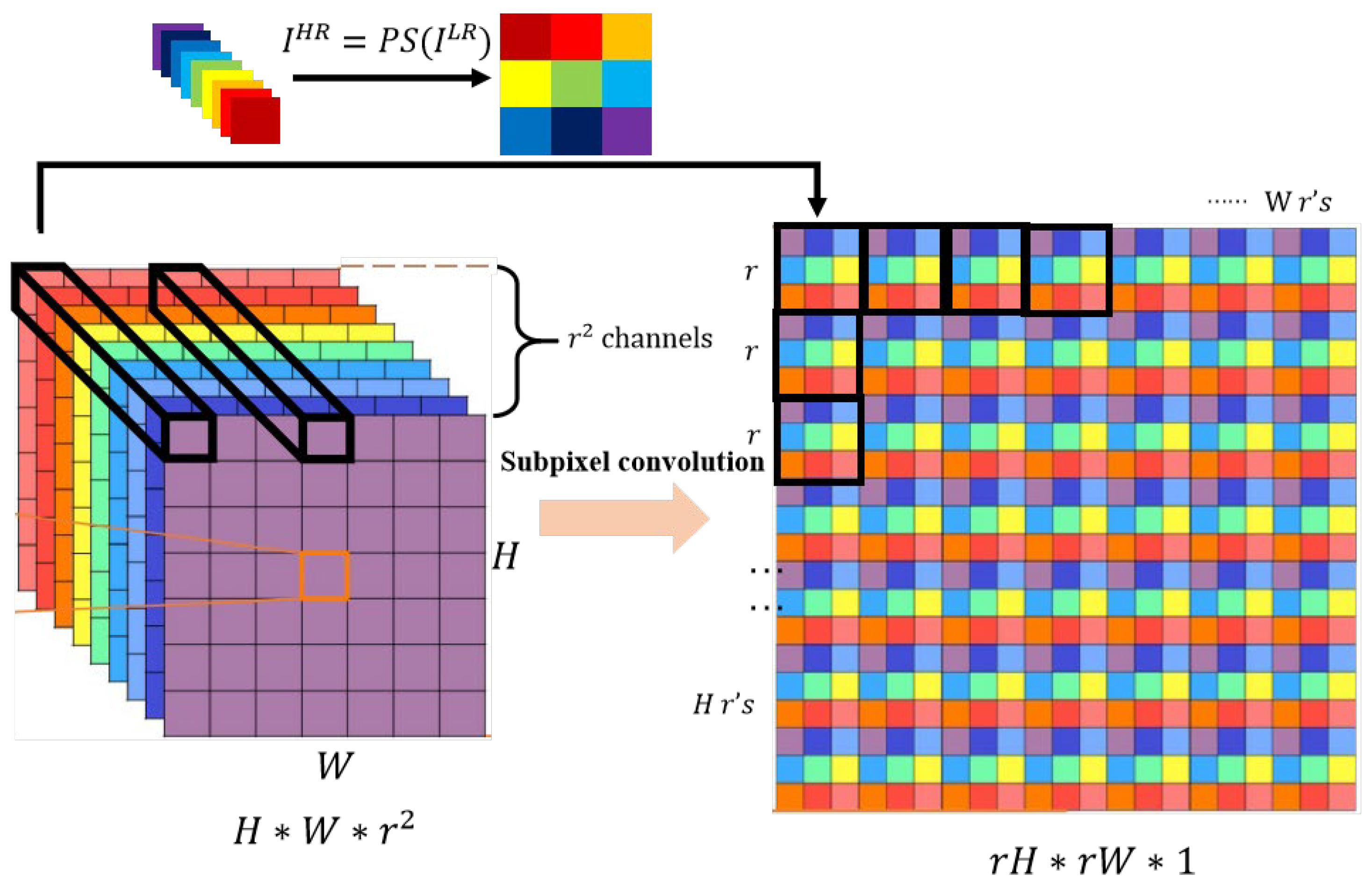
- To reduce the loss of detailed information in the process of small object feature fusion, we introduced sub-pixel convolution into multi-scale feature fusion. The upsampling process is realized by reorganizing pixel values and performing padding operations, which fully preserve the feature information of small objects. This approach also introduces more contextual information, facilitating the distinction between small objects and the background.
- According to the requirements of violation behavior detection, we created a data set of power operation scenarios. This power operation scenarios dataset is used to test the HS-YOLO model.
2. Related Works and Methods
2.1. Related Works
2.1.1. Small Object Detection
2.1.2. Multi-scale Feature Fusion
2.1.3. High Resolution Representation
2.2. Methods
2.2.1. HS-YOLO Algorithm
2.2.2. HRNet Feature Extraction Backbone Network
2.2.3. Feature Fusion Network
2.2.4. Object Detection Head
3. Results and Discussion
3.1. Dataset
3.2. Training Details
3.3. Evaluation Metrics
3.4. Experiments on the Power Operation Dataset
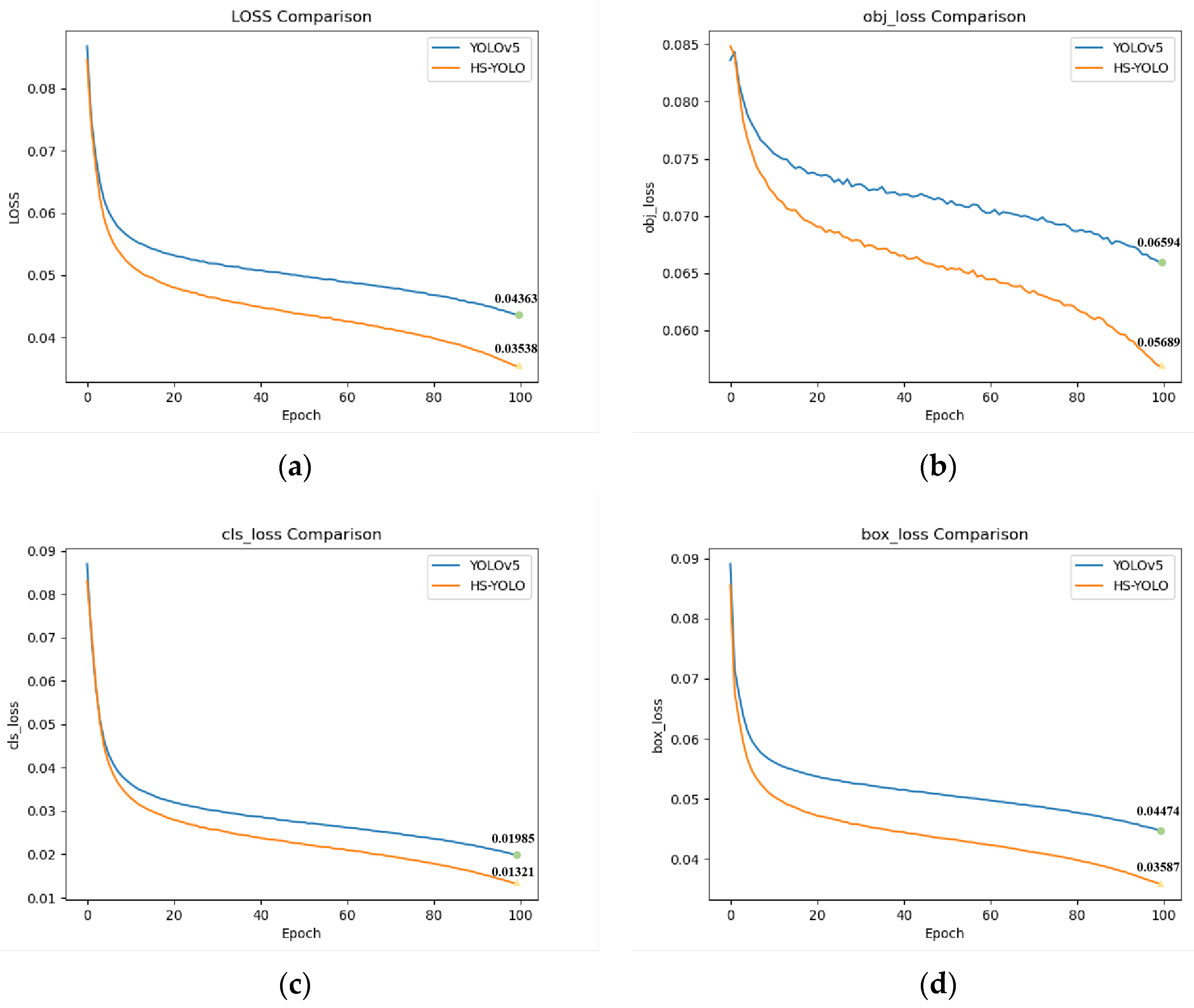
3.4.1. Model Training
3.4.2. Ablation Experiment
3.4.3. Comparative Experiments
3.4.4. Visualize the Results
3.5. Experiments on the COCO Dataset
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xiao, Y.; Chang, A.; Wang, Y.; Huang, Y.; Yu, J.; Huo, L. Real-time Object Detection for Substation Security Early-warning with Deep Neural Network based on YOLO-V5. In Proceedings of the IEEE IAS Global Conference on Emerging Technologies (GlobConET), Arad, Romania, 20–22 May 2022; pp. 45–50. [Google Scholar]
- Yan, X.; Jia, L.; Cao, H.; Yu, Y.; Wang, T.; Zhang, F.; Guan, Q. Multitargets joint training lightweight model for object detection of substation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 2022, 3190139. [Google Scholar] [CrossRef] [PubMed]
- Xiang, X.; Zhao, F.; Peng, B.; Qiu, H.; Tan, Z.; Shuai, Z. A YOLO-v4-Based Risk Detection Method for Power High Voltage Operation Scene. In Proceedings of the IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xi’an, China, 17–19 August 2021; pp. 1–5. [Google Scholar]
- Hu, Q.; Bai, Y.; He, L.; Huang, J.; Wang, H.; Cheng, G. Workers’ Unsafe Actions When Working at Heights: Detecting from Images. Sustainability 2022, 14, 6126. [Google Scholar] [CrossRef]
- Oliveira, B.A.S.; Neto, A.P.D.F.; Fernandino, R.M.A.; Carvalho, R.F.; Fernandes, A.L.; Guimaraes, F.G. Automated Monitoring of Construction Sites of Electric Power Substations Using Deep Learning. IEEE Access 2021, 9, 19195–19207. [Google Scholar] [CrossRef]
- Chen, X.; Chen, W.; Su, L.; Li, T. Slender Flexible Object Segmentation Based on Object Correlation Module and Loss Function Optimization. IEEE Access 2023, 11, 29684–29697. [Google Scholar] [CrossRef]
- Wu, J.; Su, L.; Lin, Z.; Chen, Y.; Ji, J.; Li, T. Object Detection of Flexible Objects with Arbitrary Orientation Based on Rotation-Adaptive YOLOv5. Sensors 2023, 23, 4925. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Zhang, Y.; Xin, M.; Liao, J.; Xie, Q. A Light-Weight Network for Small Insulator and Defect Detection Using UAV Imaging Based on Improved YOLOv5. Sensors 2023, 23, 5249. [Google Scholar] [CrossRef] [PubMed]
- Gu, J.; Hu, J.; Jiang, L.; Wang, Z.; Zhang, X.; Xu, Y.; Zhu, J.; Fang, L. Research on object detection of overhead transmission lines based on optimized YOLOv5s. Energies 2023, 16, 2706. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small object detection using context and attention. In Proceedings of the IEEE International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 181–186. [Google Scholar]
- Arulprakash, E.; Aruldoss, M. A study on generic object detection with emphasis on future research directions. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 7347–7365. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, H.; Lu, X. Adaptive Feature Fusion for Small Object Detection. Appl. Sci. 2022, 12, 11854. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; Meng, P. Attention-YOLOV4: A real-time and high-accurate traffic sign detection algorithm. Multimed. Tools Appl. 2023, 82, 7567–7582. [Google Scholar] [CrossRef]
- Wang, Y.; Bashir, S.M.A.; Khan, M.; Ullah, Q.; Wang, R.; Song, Y.; Guo, Z.; Niu, Y. Remote sensing image super-resolution and object detection: Benchmark and state of the art. Expert Syst. Appl. 2022, 197, 116793. [Google Scholar] [CrossRef]
- Yang, R.; Yu, Y. Artificial convolutional neural network in object detection and semantic segmentation for medical imaging analysis. Front. Oncol. 2021, 11, 638182. [Google Scholar] [CrossRef] [PubMed]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y. Rethinking PASCAL-VOC and MS-COCO dataset for small object detection. J. Vis. Commun. Image Represent. 2023, 93, 103830. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017; pp. 2117–2125. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An improved SSD object detection algorithm based on DenseNet and feature fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Zeng, N.; Wu, P.; Wang, Z.; Li, H.; Liu, W.; Liu, X. A small-sized object detection oriented multi-scale feature fusion approach with application to defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual generative adversarial networks for small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017; pp. 1222–1230. [Google Scholar]
- Xing, C.; Liang, X.; Bao, Z. A small object detection solution by using super-resolution recovery. In Proceedings of the IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 313–316. [Google Scholar]
- Liu, Z.; Gao, G.; Sun, L.; Fang, Z. HRDNet: High-resolution detection network for small objects. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Wang, Z.Z.; Xie, K.; Zhang, X.Y.; Chen, H.Q.; Wen, C.; He, J.B. Small-object detection based on yolo and dense block via image super-resolution. IEEE Access 2021, 9, 56416–56429. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 5693–5703. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Huang, X.; Zhang, Y.J. 300-FPS salient object detection via minimum directional contrast. IEEE Trans. Image Process. 2017, 26, 4243–4254. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sum | Training Set | Validation Set | Testing Set |
|---|---|---|---|---|
| Number of images | 4950 | 3465 | 990 | 495 |
| Number of annotations for ‘Human’ | 3351 | 2384 | 676 | 291 |
| Number of annotations for ‘Hat’ | 2786 | 2005 | 541 | 240 |
| Number of annotations for ‘Safetybelt’ | 1478 | 1044 | 238 | 196 |
| Number of annotations for ‘Seine’ | 2618 | 1820 | 512 | 286 |
| Number of annotations for ‘Fence’ | 1663 | 1184 | 312 | 167 |
| Number of annotations for ‘Noneckline’ | 1358 | 997 | 229 | 132 |
| Number of annotations for ‘Nocuff’ | 1245 | 895 | 213 | 137 |
| Order | A | B | Recall (%) | Precision (%) | mAP (%) | FPS (t/n) |
|---|---|---|---|---|---|---|
| ① | 90.0 | 93.8 | 83.7 | 47.8 | ||
| ② | √ | 89.0 | 97.9 | 86.4 | 41.7 | |
| ③ | √ | 92.0 | 96.9 | 84.7 | 48.3 | |
| ④ | √ | √ | 91.0 | 98.7 | 87.2 | 42.1 |
| Order | A | B | Human (%) | Hat (%) | Safetybelt (%) | Seine (%) | Fence (%) | Noneckline (%) | Nocuff (%) |
|---|---|---|---|---|---|---|---|---|---|
| ① | 94.3 | 96.5 | 86.8 | 68.0 | 94.1 | 85.1 | 60.9 | ||
| ② | √ | 95.0 | 97.8 | 89.1 | 70.3 | 90.7 | 89.4 | 72.7 | |
| ③ | √ | 93.3 | 97.2 | 86.9 | 72.4 | 94.3 | 86.1 | 62.5 | |
| ④ | √ | √ | 94.9 | 97.6 | 91.2 | 69.4 | 94.5 | 90.9 | 71.6 |
| 100 Epoch | 200 Epoch | 300 Epoch | |||||
|---|---|---|---|---|---|---|---|
| YOLOv5 | HS-YOLO | YOLOv5 | HS-YOLO | YOLOv5 | HS-YOLO | ||
| AP (%) | Human | 93.3 | 93.5 | 93.9 | 94.0 | 94.3 | 94.4 |
| Hat | 96.3 | 96.7 | 96.7 | 97.2 | 96.7 | 97.6 | |
| Safetybelt | 79.0 | 79.1 | 80.4 | 85.6 | 86.0 | 89.8 | |
| Seine | 63.0 | 64.6 | 66.7 | 67.0 | 68.3 | 68.8 | |
| Fence | 91.8 | 91.8 | 91.4 | 92.6 | 93.7 | 94.7 | |
| Noneckline | 67.9 | 78.2 | 73.5 | 84.1 | 85.8 | 89.5 | |
| Nocuff | 18.6 | 42.6 | 43.8 | 63.6 | 62.2 | 71.6 | |
| mAP (%) | 72.9 | 78.1 | 78.1 | 83.4 | 83.8 | 86.6 | |
| Model | Human (%) | Hat (%) | Safetybelt (%) | Seine (%) | Fence (%) | Noneckline (%) | Nocuff (%) | mAP (%) |
|---|---|---|---|---|---|---|---|---|
| Faster-RCNN | 86.7 | 82.4 | 64.7 | 63.6 | 87.5 | 78.3 | 56.9 | 74.3 |
| SSD | 85.9 | 80.6 | 65.8 | 60.8 | 88.4 | 79.5 | 54.8 | 73.7 |
| YOLOv3 | 91.2 | 83.4 | 72.9 | 66.3 | 92.7 | 82.1 | 60.1 | 78.4 |
| YOLOv4 | 91.8 | 85.5 | 77.4 | 65.1 | 93.6 | 83.9 | 59.8 | 79.6 |
| YOLOv5 | 94.3 | 96.5 | 86.8 | 68.0 | 94.1 | 85.1 | 60.9 | 83.7 |
| YOLOv8 | 95.3 | 97.4 | 89.5 | 70.5 | 94.9 | 88.4 | 67.3 | 86.2 |
| HS-YOLO | 94.9 | 97.6 | 91.2 | 69.4 | 94.5 | 90.9 | 71.6 | 87.2 |
| Model | (%) | (%) | mAP (%) | |
|---|---|---|---|---|
| YOLOv5 | 18.5 | 39.3 | 44.8 | 53.6 |
| HS-YOLO | 27.1 | 48.6 | 56.2 | 63.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Z.; Chen, W.; Su, L.; Chen, Y.; Li, T. HS-YOLO: Small Object Detection for Power Operation Scenarios. Appl. Sci. 2023, 13, 11114. https://doi.org/10.3390/app131911114
Lin Z, Chen W, Su L, Chen Y, Li T. HS-YOLO: Small Object Detection for Power Operation Scenarios. Applied Sciences. 2023; 13(19):11114. https://doi.org/10.3390/app131911114
Chicago/Turabian StyleLin, Zhiwei, Weihao Chen, Lumei Su, Yuhan Chen, and Tianyou Li. 2023. "HS-YOLO: Small Object Detection for Power Operation Scenarios" Applied Sciences 13, no. 19: 11114. https://doi.org/10.3390/app131911114
APA StyleLin, Z., Chen, W., Su, L., Chen, Y., & Li, T. (2023). HS-YOLO: Small Object Detection for Power Operation Scenarios. Applied Sciences, 13(19), 11114. https://doi.org/10.3390/app131911114