1. Introduction
Concrete dams are the most common types of dams for flood control, irrigation, and water supply. A dam in a safe state can significantly boost the national economy. The operation of dams is required not only to withstand various static and dynamic loads but also to avoid different impacts of harsh environmental conditions. Their service behavior is a nonlinear dynamic process [
1]. Once a dam fails, it can cause unpredictable economic damage downstream. In order to ensure the safe operation of dams, it is essential to implement effective monitoring and analysis methods. Among these, dam deformation serves as a crucial indicator for monitoring the safe operation of the dam and can effectively reflect the working condition of a concrete gravity dam under complex environmental conditions. Therefore, scientific research on the deformation data can help to better understand and monitor the health of dams [
2].
In the past few decades, researchers have proposed several effective mathematical models, including statistical, deterministic, and hybrid models, to forecast the deformation behavior of dams [
3]. These models can describe and evaluate the deformation behavior of concrete dams by considering the effects of hydrostatic pressure, ambient temperature, and time on the deformation behavior [
4,
5]. Among them, both deterministic and hybrid models require the solution of differential equations, for which closed-form solutions are difficult to obtain [
6]. In comparison, the statistical model has a more straightforward formula and is faster to execute. However, the relationships between the structural response of a concrete dam and its influencing factors are nonlinear, while most of the existing statistical models are constructed using linear assumptions as their foundation, which limits the accuracy of the model fitting and thus cannot accurately capture the structural behavior of concrete dams [
7].
In recent years, a variety of machine learning architectures have been used in the field of dam safety monitoring, such as the autoregressive integrated moving average (ARIMA) algorithm [
8], the support vector machine (SVM) algorithm [
9], the artificial neural network (ANN) algorithm [
10,
11,
12], and the random forest (RF) algorithm [
13,
14], etc. These algorithms can predict dam displacement with reasonable accuracy; among them, the ANN algorithm illustrates superior performance in dealing with nonlinear problems [
15,
16]. Liu et al. [
17] used the long short-term memory (LSTM) model to predict the displacement of the arch dam. The results showed that the LSTM model can predict dam displacement well. However, the LSTM model has the problem of difficult hyperparameter selection. In order to alleviate this problem, Zhang et al. [
18] proposed using an improved LSTM model to predict dam deformation and achieved good results. However, the relevant parameters need to be corrected within the iteration procedure, which makes it very expensive in terms of calculation time [
19]. In comparison, dam displacement prediction models developed based on the SVM algorithm can avoid the shortcomings of ANN algorithms and remarkably improve computational efficiency. Kang et al. [
20] proposed using the SVM algorithm to predict dam deformation and achieved certain results. Regarding the SVM-based models, prediction accuracy and generalization ability are affected by the determination of model parameters, which narrows their application.
The extreme learning machine (ELM) algorithm as a single hidden layer neural network is different from the traditional single hidden layer feedforward neural network. The ELM algorithm can randomly initialize the hidden layer bias and input layer weight; the whole learning is completed through a mathematical change without any iteration; there is only a need to set the number of hidden layer nodes, and in the process of algorithm implementation, there is no need to adjust the network input weight and hidden layer bias to generate the only optimal solution. The conventional ELM algorithm performs well in most cases; however, inappropriate parameter selection can lead to relatively poor prediction results [
21,
22]. In this regard, Huang et al. [
23] proposed the incremental extreme learning machine (IELM) algorithm by adding new hidden layer nodes to assist in reducing errors. While the IELM algorithm contains many useless neurons in hidden layers, and these redundant neurons increase the number of iterations and reduce the algorithm’s efficiency. To encounter the drawbacks of the IELM algorithm, the error minimized extreme learning machine (EMELM) algorithm is proposed. The hidden nodes in the EM-ELM algorithm can be added individually or in batches, which vigorously promote the efficiency of those models [
24].
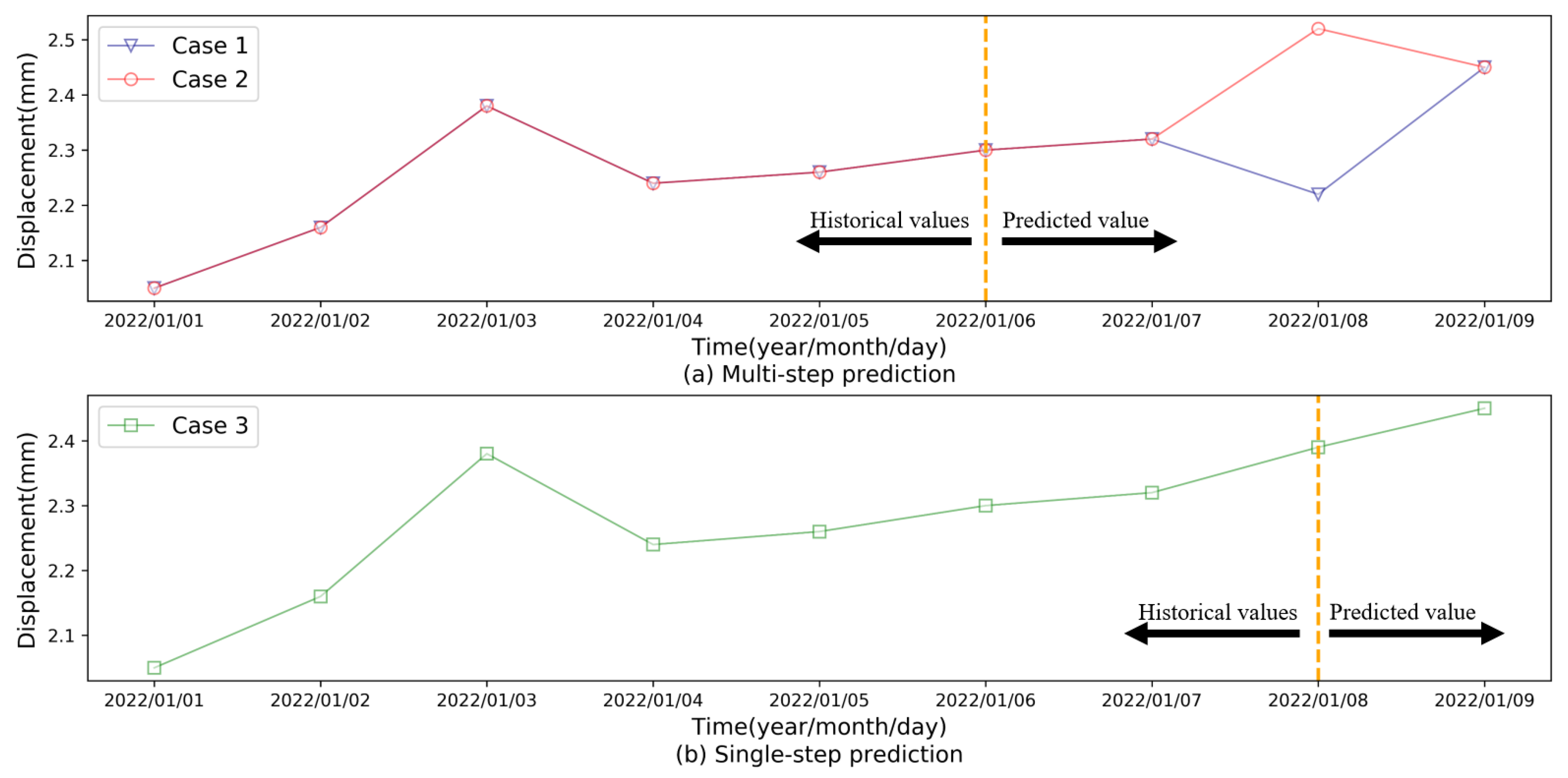
Although the models mentioned above have achieved good prediction results in single value dam displacement monitoring, considering the deformation tendency rather than a given predicted value can better depict the dam’s structural health status, it is of great importance to forecast the evolution of dam displacement in the short term. The multi-step prediction methods provide a means for tendency prediction as they can output multiple results to elaborate on the deformation evolution of dams. To further demonstrate the meaning of multi-step dam displacement predictions,
Figure 1 shows a comparison of multi-step and single-step predictions. As we can see in
Figure 1, although the multi-step and single-step prediction have the same displacement on 9 January 2022, the single-step result is unable to reflect the variation trend of the deformation among the predicted period. Diverse deformation processes can reflect different structural health statuses even at the same level of displacement. For instance, the last predicted values of Case 1, Case 2, and Case 3 are consistent, while their variation trends are remarkably distinct. Compared to Case 2 and Case 3, Case 1 presents a sharp uptrend, revealing the probable existence of more security risk in Case 1 than in other cases. In this context, capturing the variation trend in the dam displacement in advance can benefit in capturing the behaviors of the dam displacement so as to better ensure dam safety.
Bearing this in mind as motivation, this paper attempts to construct a multi-step prediction model of dam displacement and provide a suitable modeling strategy. Recursive and direct strategies are currently the most common modeling strategies for multi-step prediction. Regarding the recursive strategy, a prediction model is constructed by means of minimizing the squares of the sample one-step-ahead residuals, and the predicted value is used as input for the next prediction [
25]. Since the predicted values are used instead of the actual values, the recursive strategy suffers from the error accumulation problem [
26,
27]. By contrast, researchers proposed the direct strategy method, in which separated models using past observations are constructed for each time step [
28,
29]. Although the direct strategy can mitigate the cumulative error problem, it is a time-consuming process. To better address these issues, researchers introduced a multiple-input multiple-output (MIMO) strategy. In this multi-target output process, the prediction is performed through a set of vectors, and the size of the vector is equal to the number of forecasting days, which can effectively alleviate the consumption problem of the direct strategy and the error accumulation problem of the recursive strategy. Hence, this paper adopts the MIMO strategy to construct a hybrid model based on the EM-ELM algorithm, namely the CSSKEE model. The model can better predict the short-term dam displacement evolution with excellent predictive accuracy and good generalization performance, thus making dam monitoring more precise and effective.
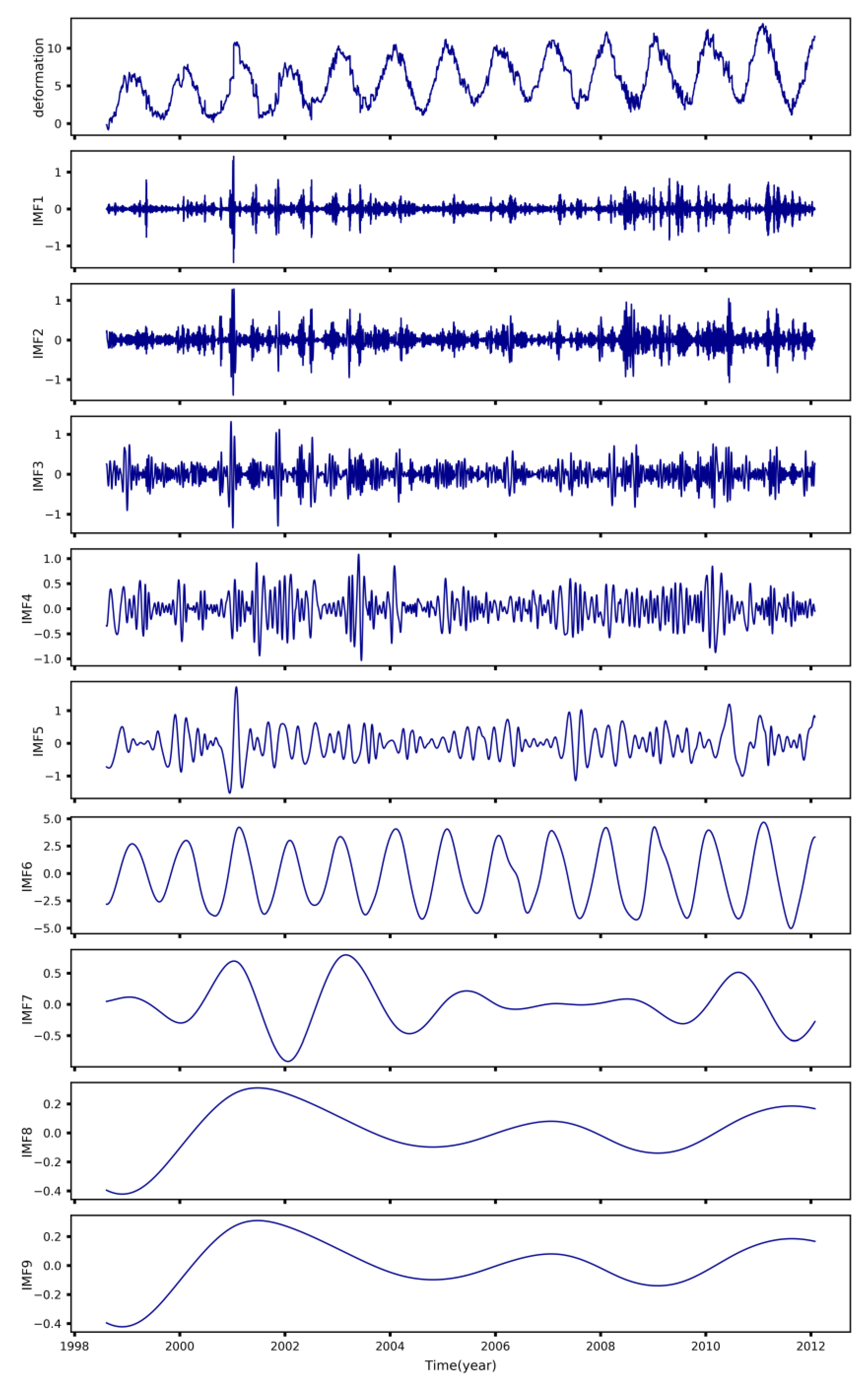
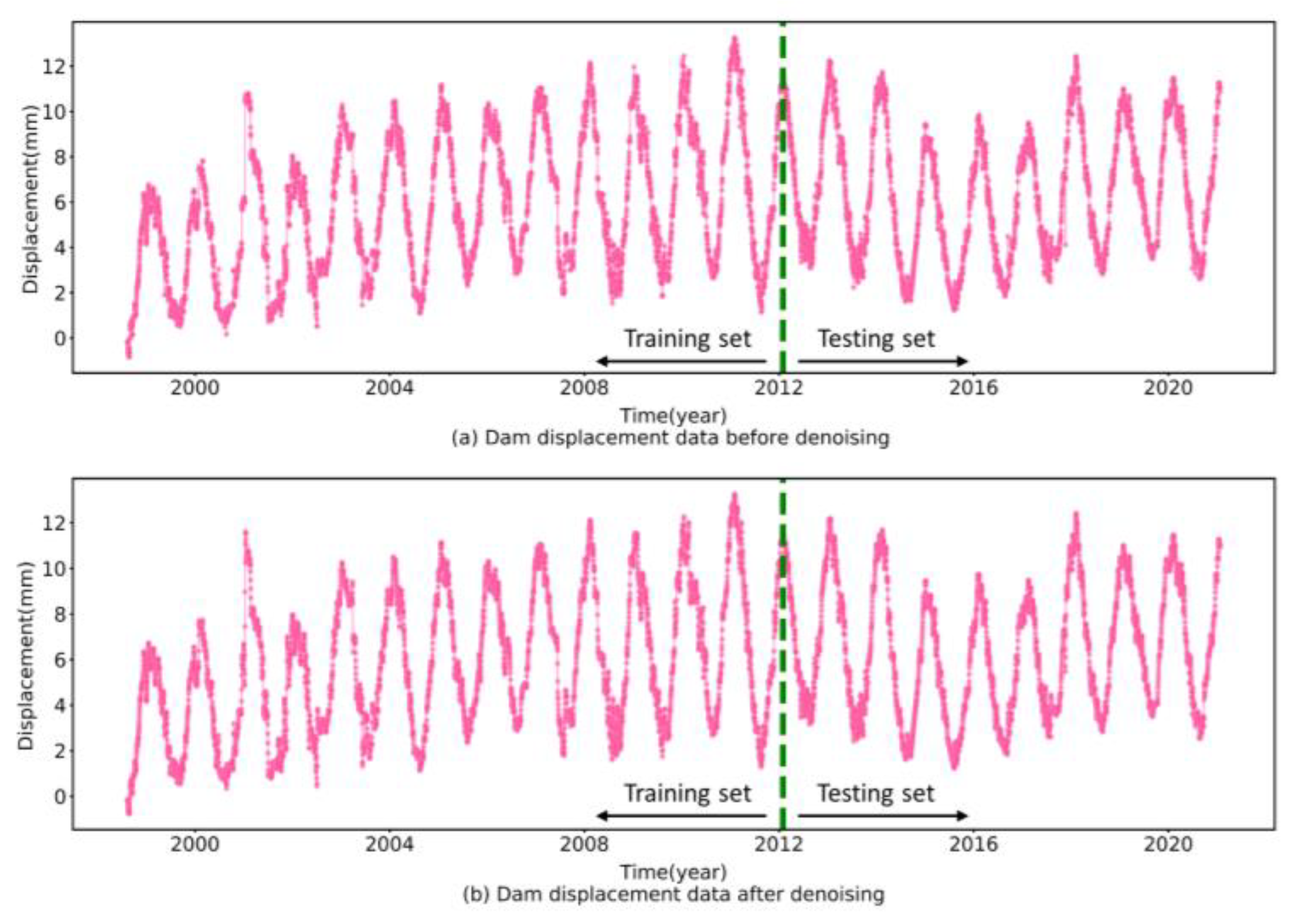
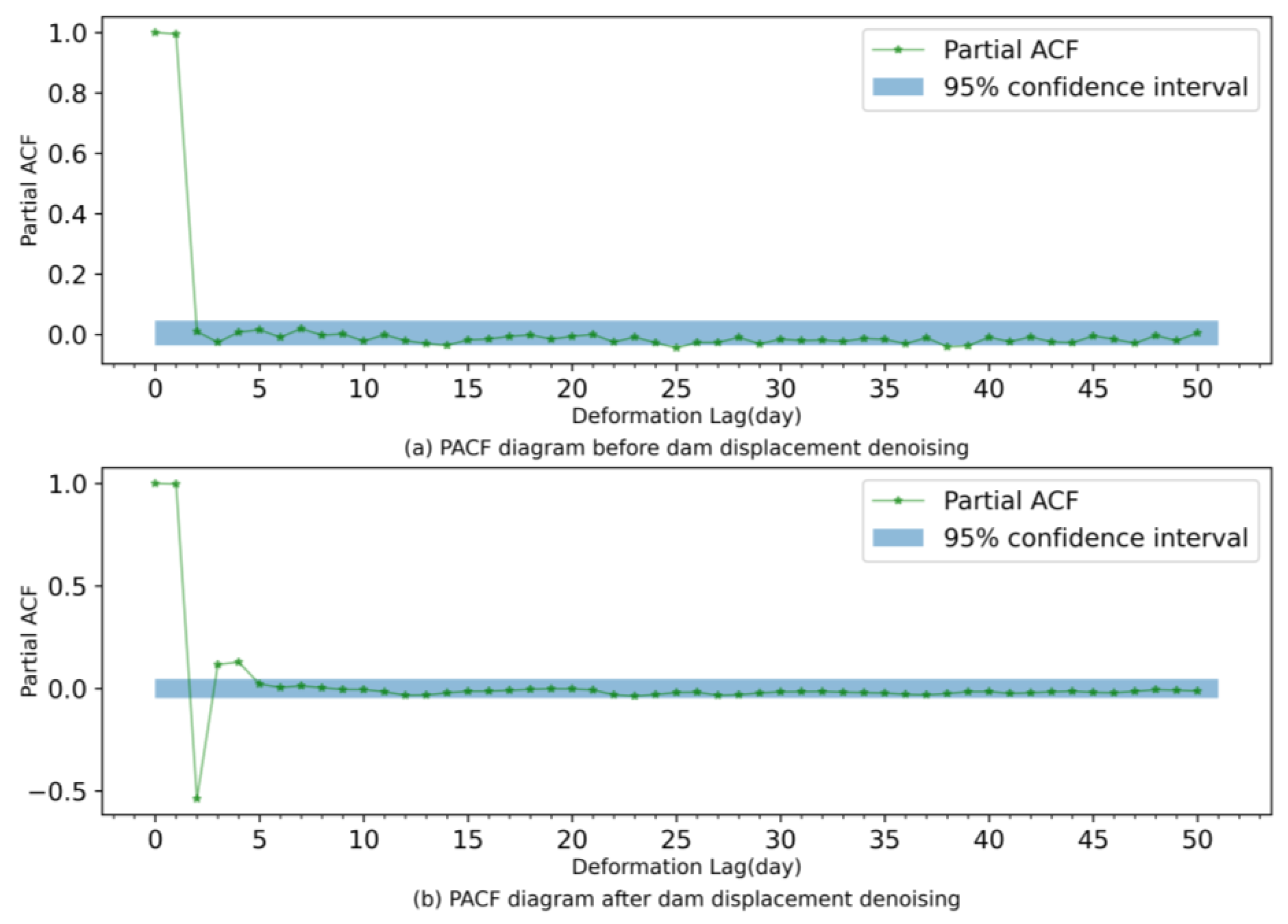
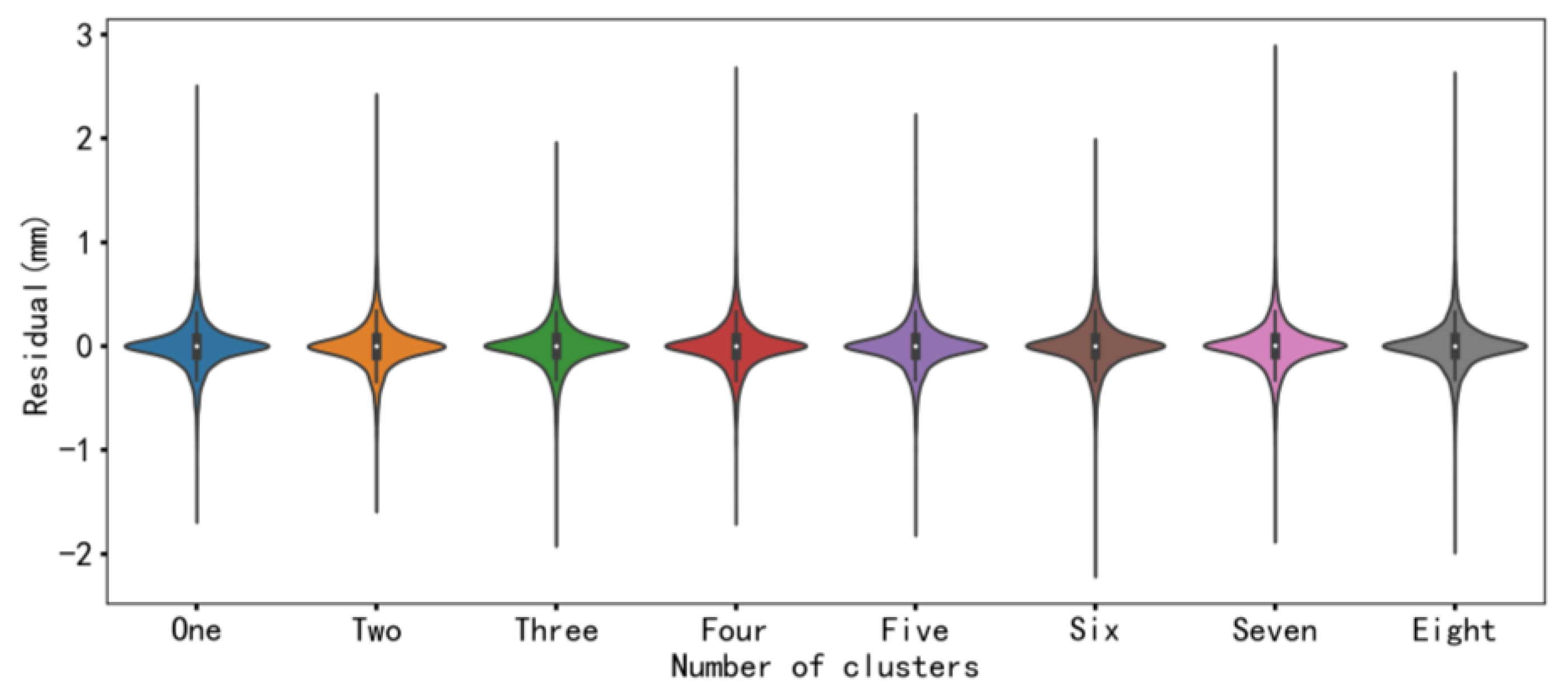
Since uncertainty errors and anomalous data contained in dam displacement data can directly affect the predictive accuracy of the models, signal decomposition techniques have found extensive application in enhancing the predictive accuracy of dam displacement models as they can extract the features of the original data and remove the noise in the original data [
30]. The EMD, EEMD, and CEEMD algorithms are three typical signal decomposition techniques [
31,
32,
33]. However, these decomposition techniques suffer from problems such as modal confounding, and energy leakage in the low-frequency region, and other phenomena [
34]. In this regard, the complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) algorithm is proposed by introducing particular noises and computing unique residues which could provide better frequency separation of the extracted sequences. Therefore, this paper uses the CEEMDAN method to decompose the original data and combines other methods, such as the sample entropy method, to eliminate the noise sequence.
Clustering is a search process to excavate possible hidden patterns in data. The clustering method divides the data into several disjoint groups, each of which is similar but different from the other groups [
35]. The clustering techniques are applied in fields such as data mining and natural language [
36,
37,
38]. In this paper, clustering analysis is conducted to help identify the features of the short-term variation trend in the dam displacement and to merge similar features. The k-means (KM) algorithm is widely used due to its speed, simple structure, and suitability for regular datasets. However, the clustering results are sensitive to the initial state of the cluster center, making this algorithm prone to falling into local optimal solutions [
39,
40]. The k-harmonic means (KHM) algorithm is proposed, using the distance of the harmonic mean as a component of the objective to mitigate local optimal issues. To further address this problem, some optimization algorithms have been introduced to enhance the ability of KHM models to obtain the optimal solution. As a novel swarm optimization method, the sparrow search algorithm (SSA) has the superiority of high stability and robustness [
41]. Therefore, it is promising to combine the SSA algorithm with the KHM model, and the integrated approach could overcome the shortcoming of falling into the local optimum of the KM algorithm, thus improving the clustering effect as well as the prediction accuracy.
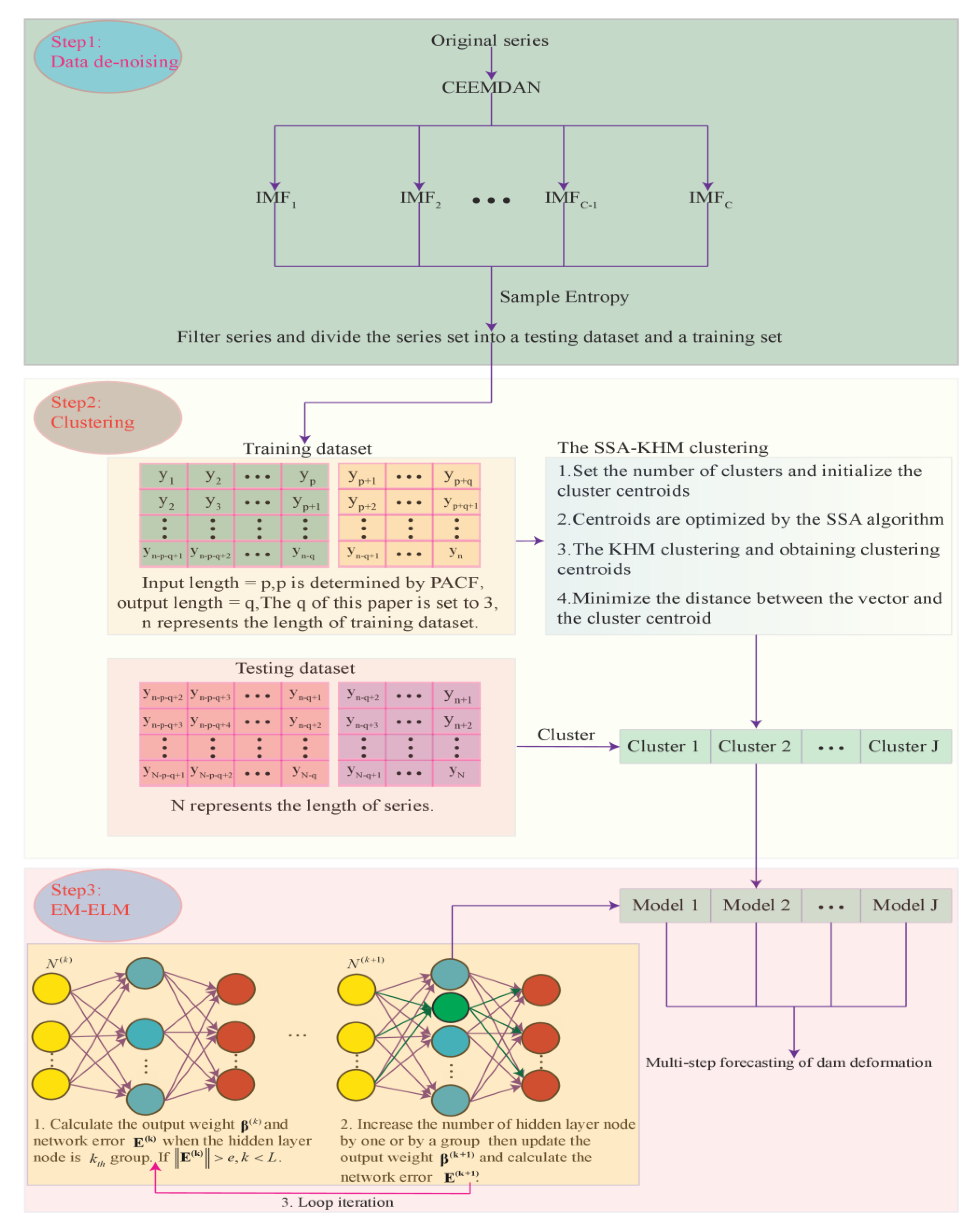
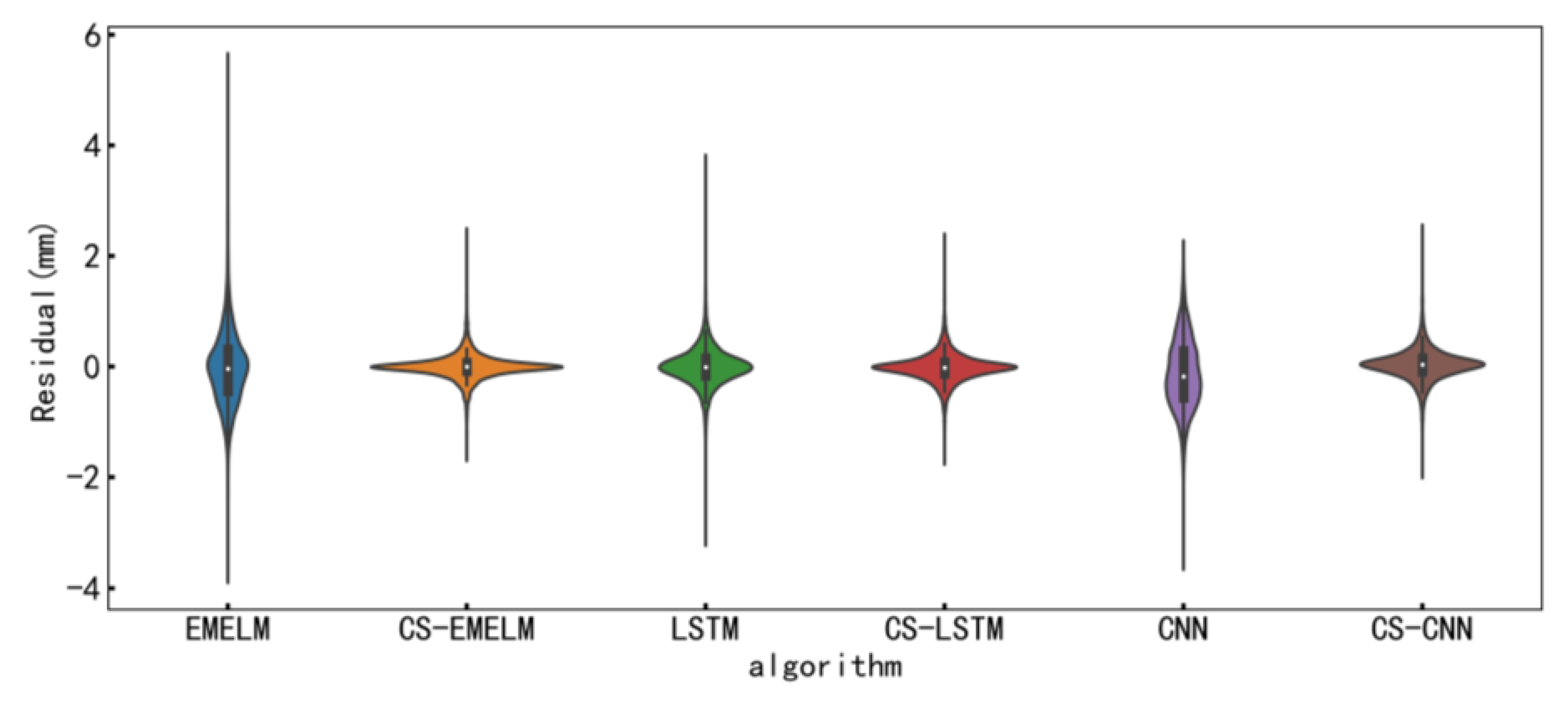
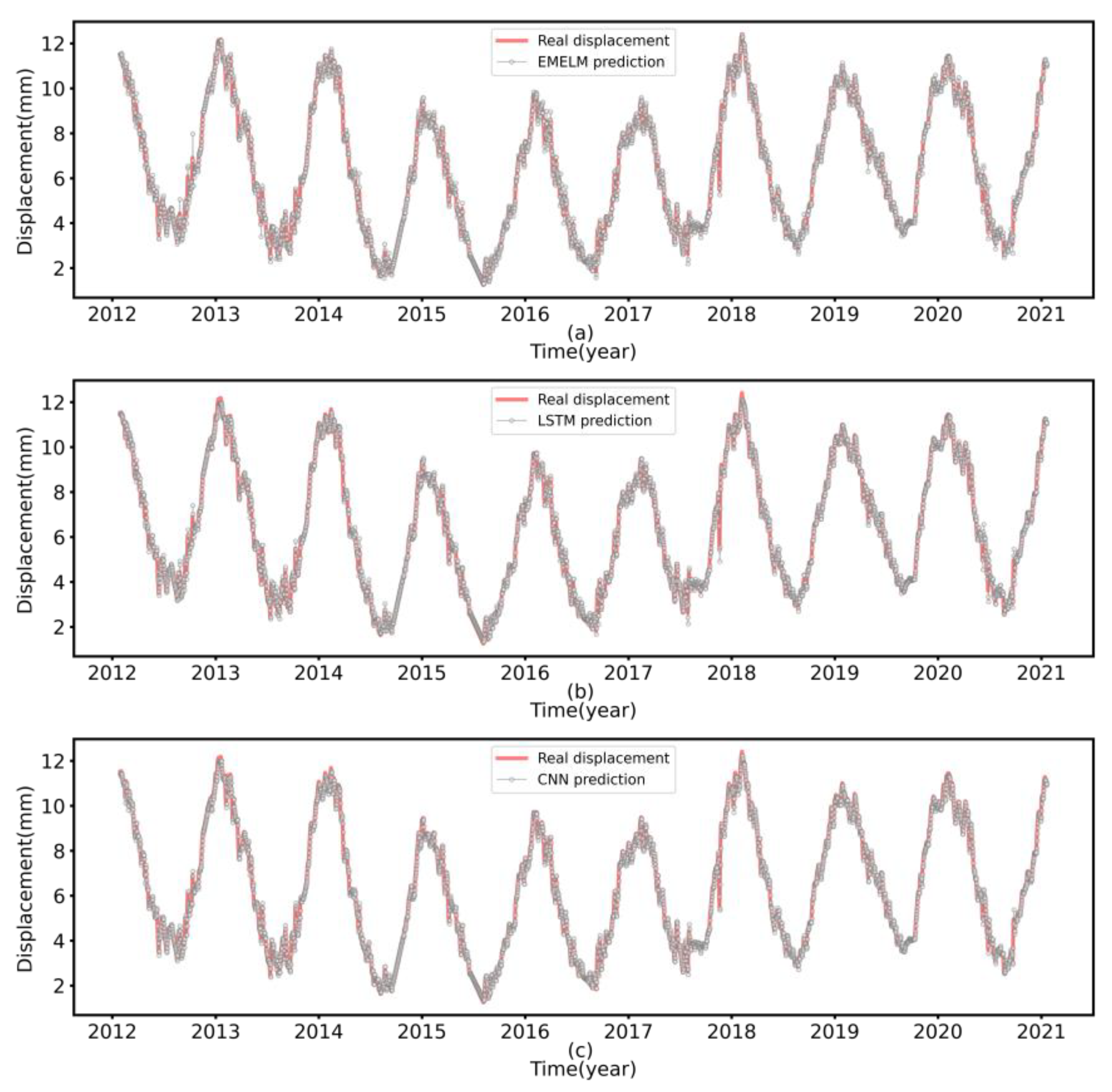
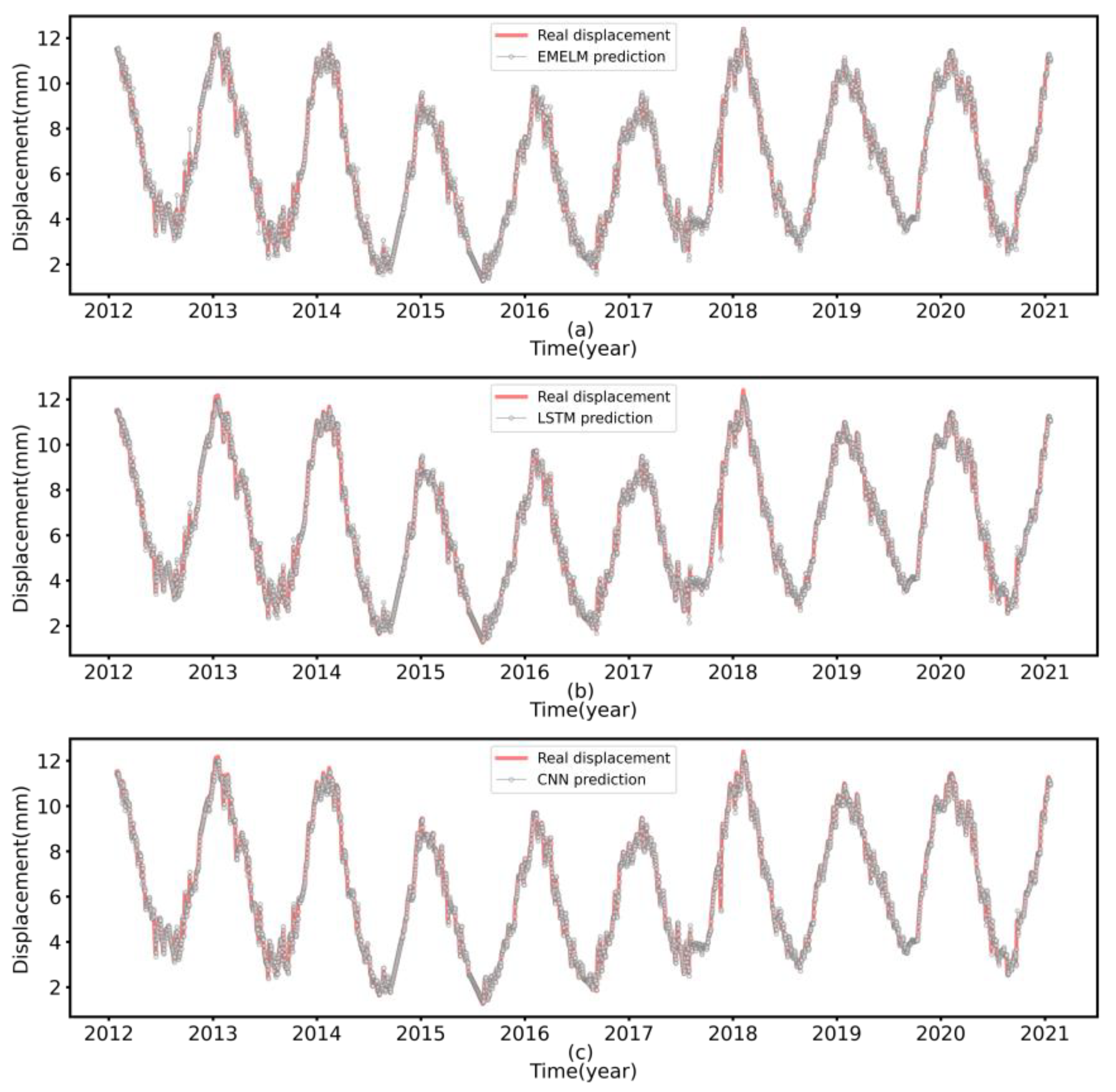
The main contribution of this paper is the proposal of a short-term multi-step prediction method for dam displacement, termed the CSSKEE model. Generally, the model is implemented based on the signal processing method, the computational intelligence algorithm, and multiple machine learning techniques. Firstly, the original data is decomposed by the CEEMDAN model, and the noise is eliminated through counting the sample entropy of decomposed sequences. Secondly, the SSA-KHM algorithm is utilized to cluster the denoised data. Thirdly, the clustered data is finally predicted by the EM-ELM algorithm.
Figure 2 shows the specific details of the model. The simulation results confirm that the proposed method can better predict the multi-step dam displacement in the short term.
The remainder of this paper is structured in the following manner.
Section 2 introduces the methodology. Then, the effectiveness of the proposed model is elaborated by the case study in
Section 3. Finally, the conclusions and future perspectives are outlined in
Section 4.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}