
Application of Machine Learning to Assess the Quality of Food Products—Case Study: Coffee Bean

 ,
,  ,
,  ,
,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples
2.2. Color Analysis
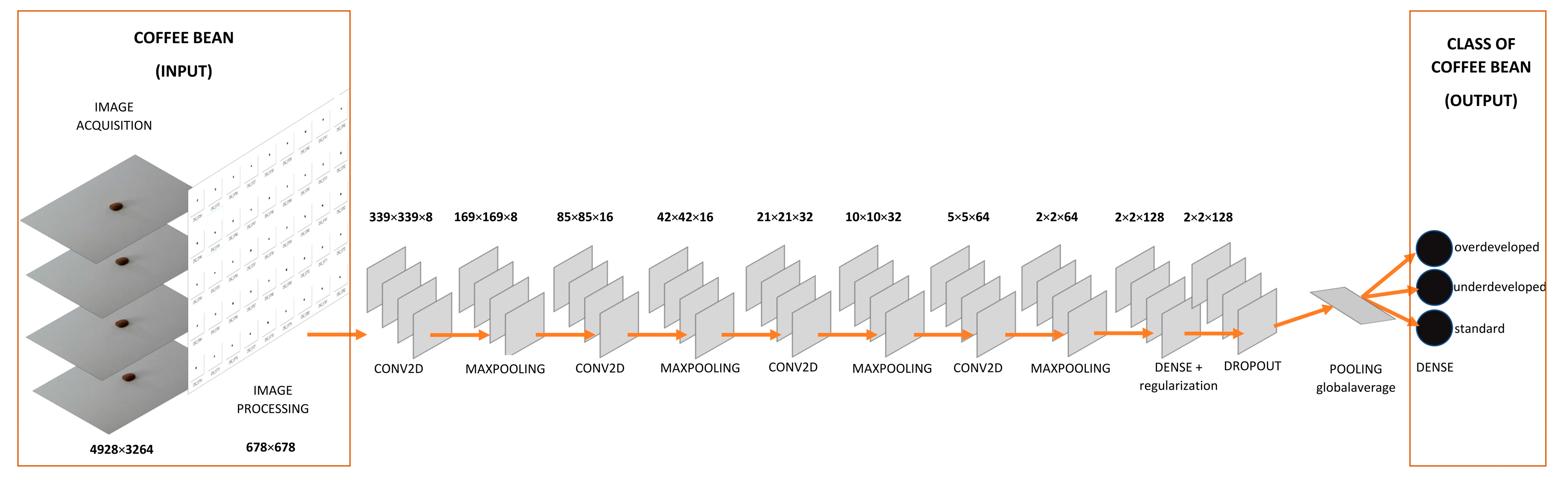
2.3. Image Collection by Camera
2.4. Preprocessing Data
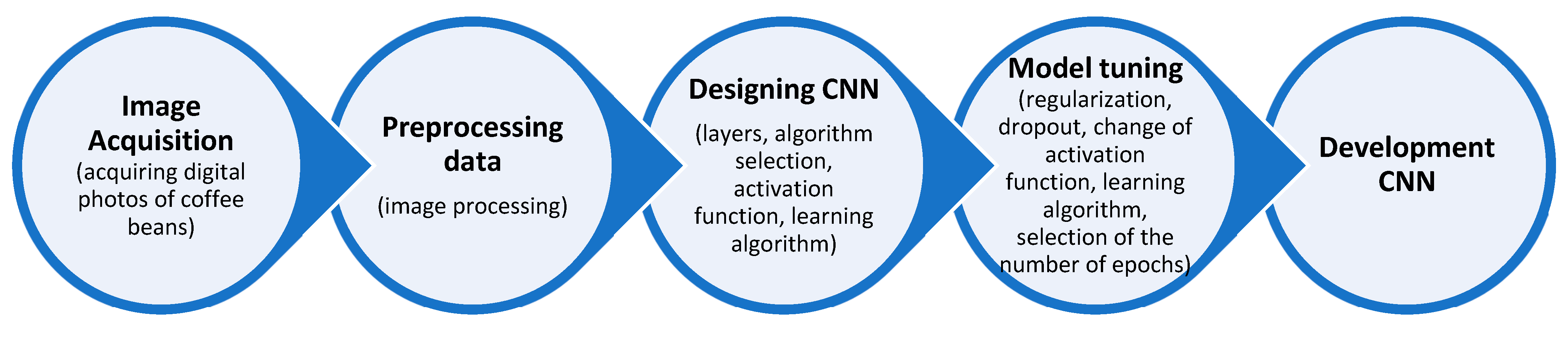
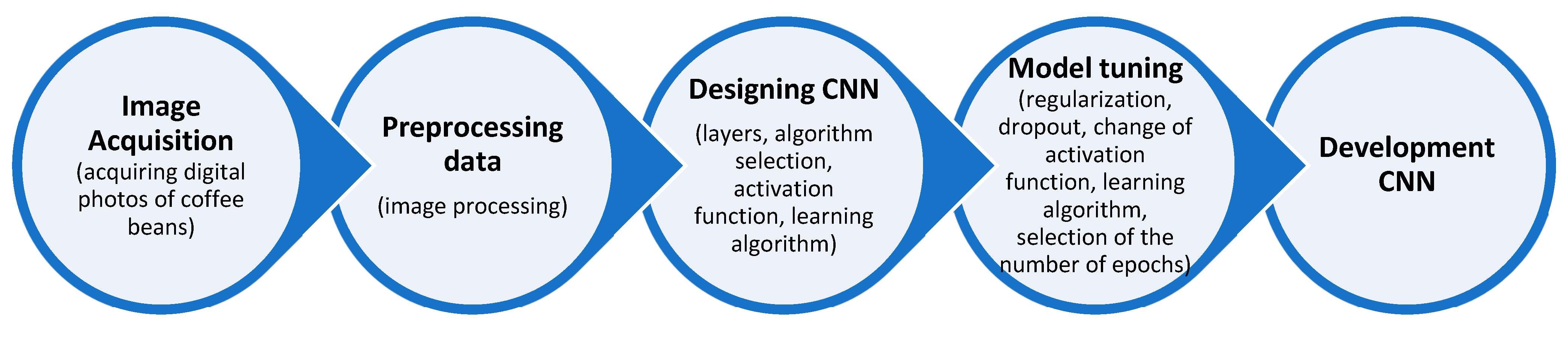
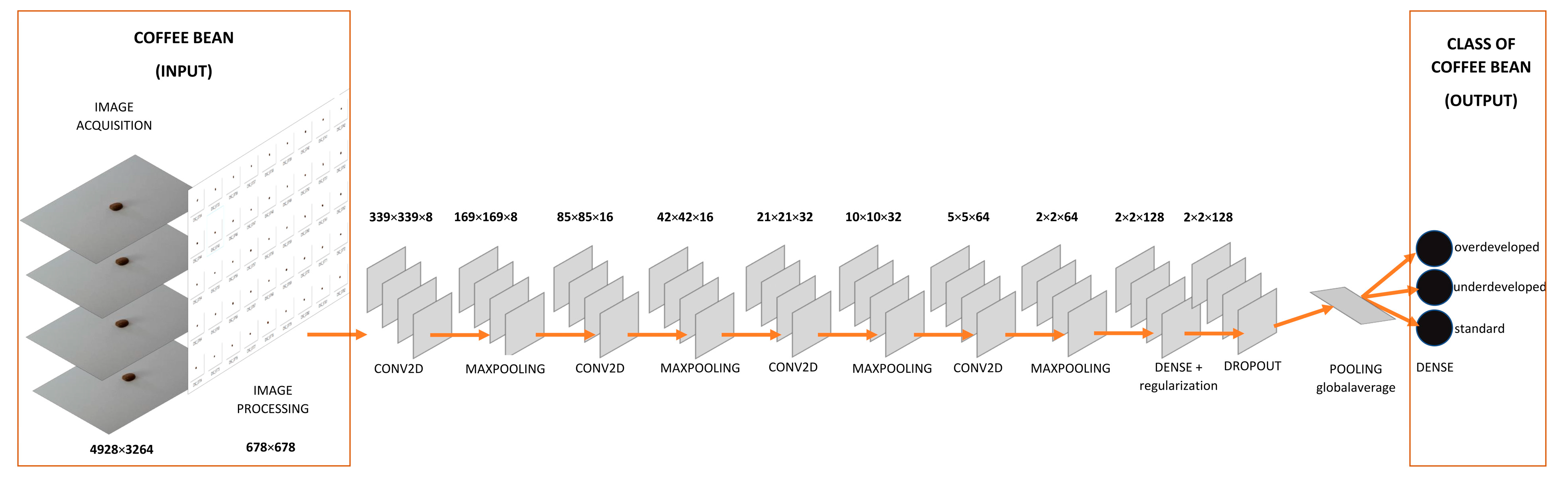
2.5. Building Neural Model by Python
2.6. Statistical Analysis
3. Results and Discussion
3.1. Color Analysis
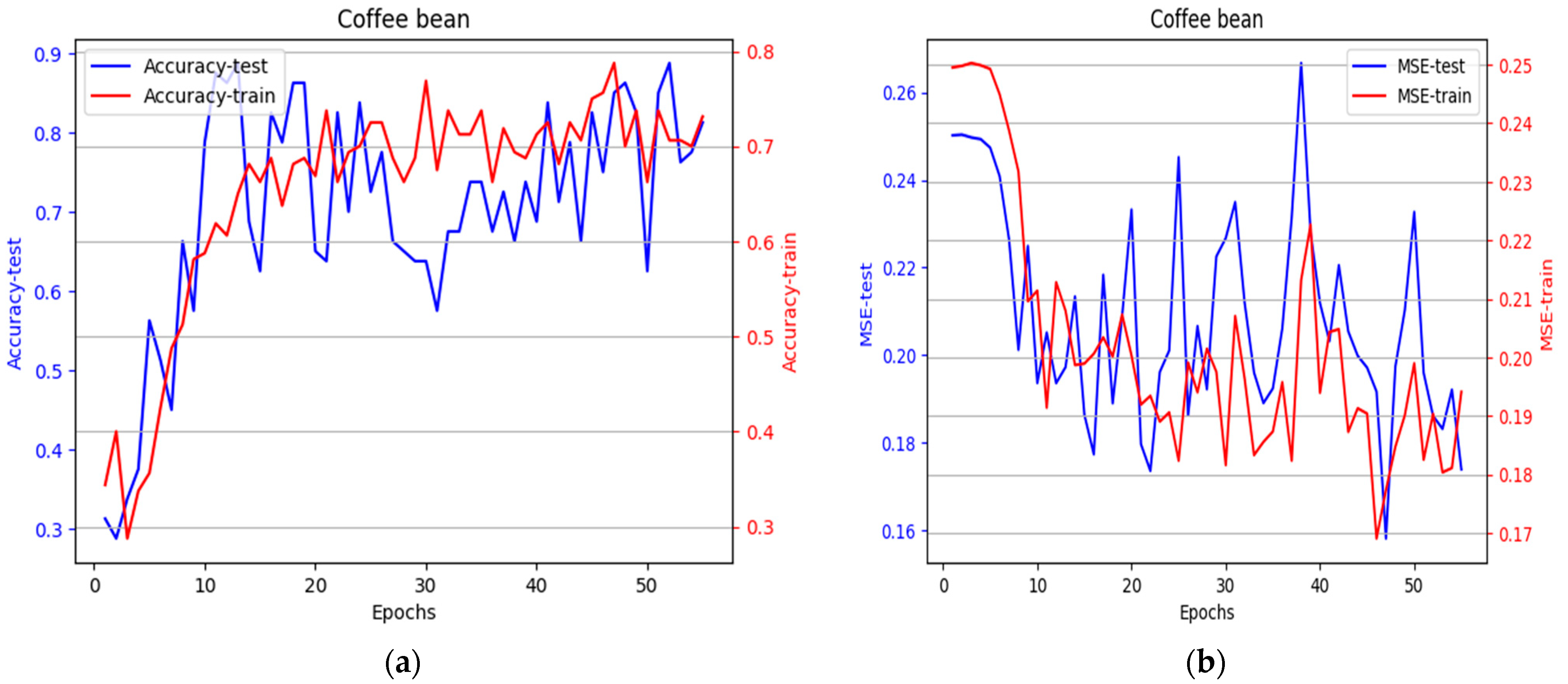
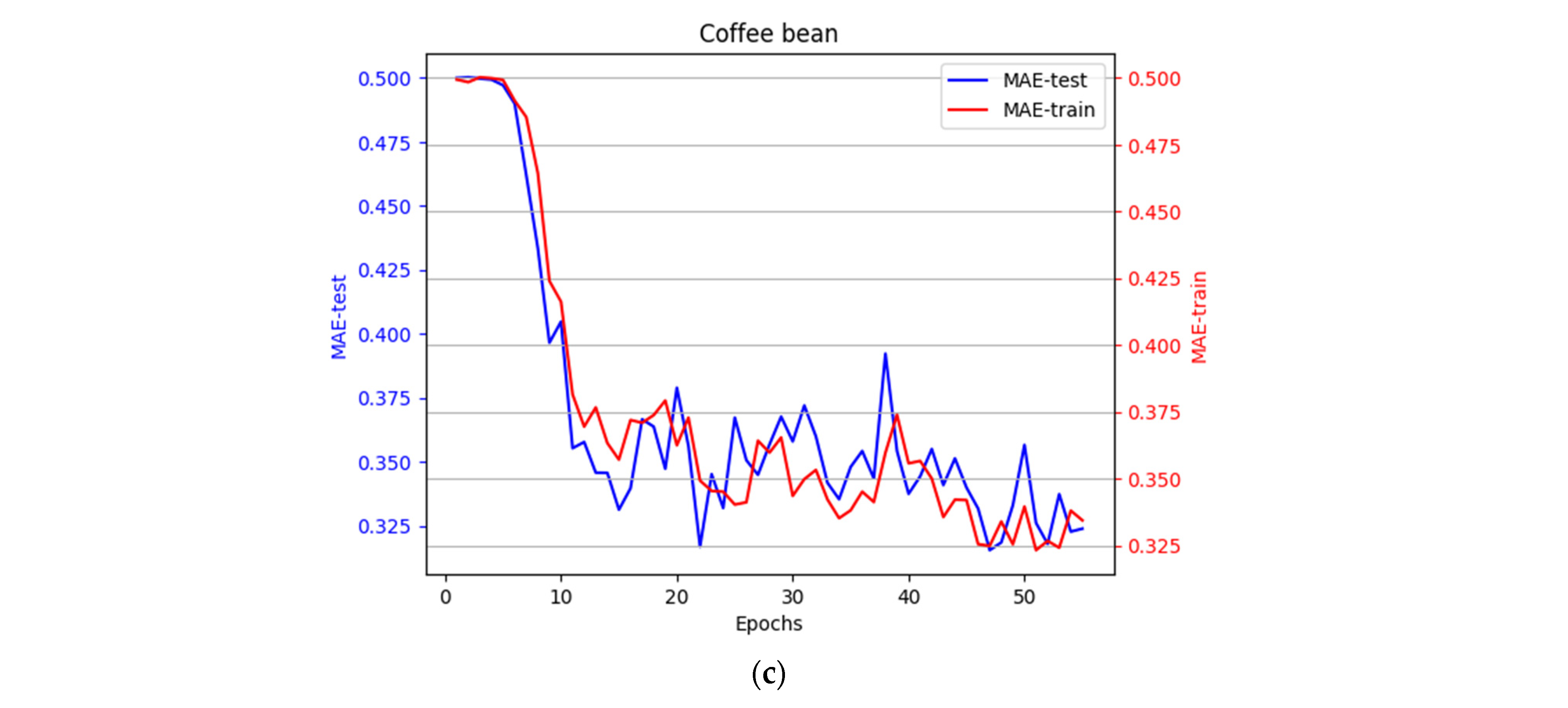
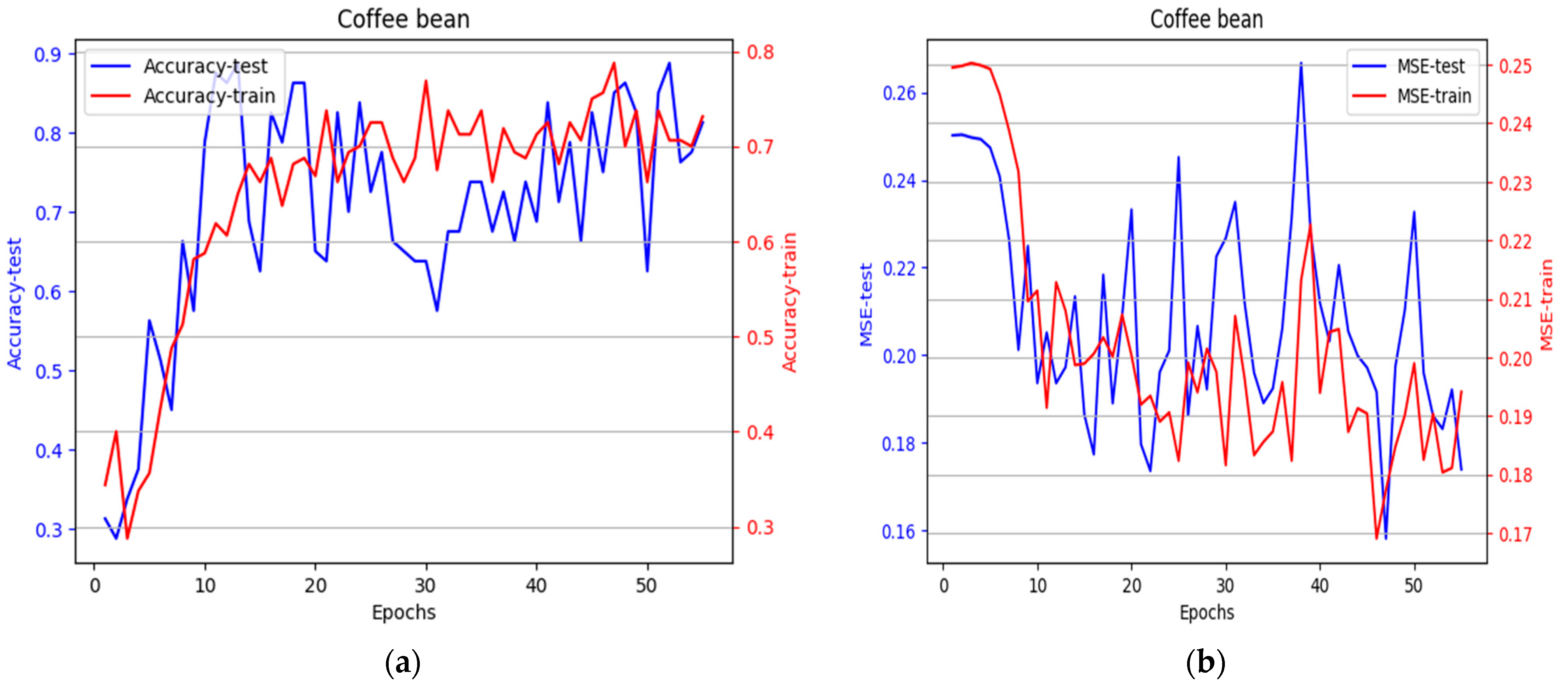
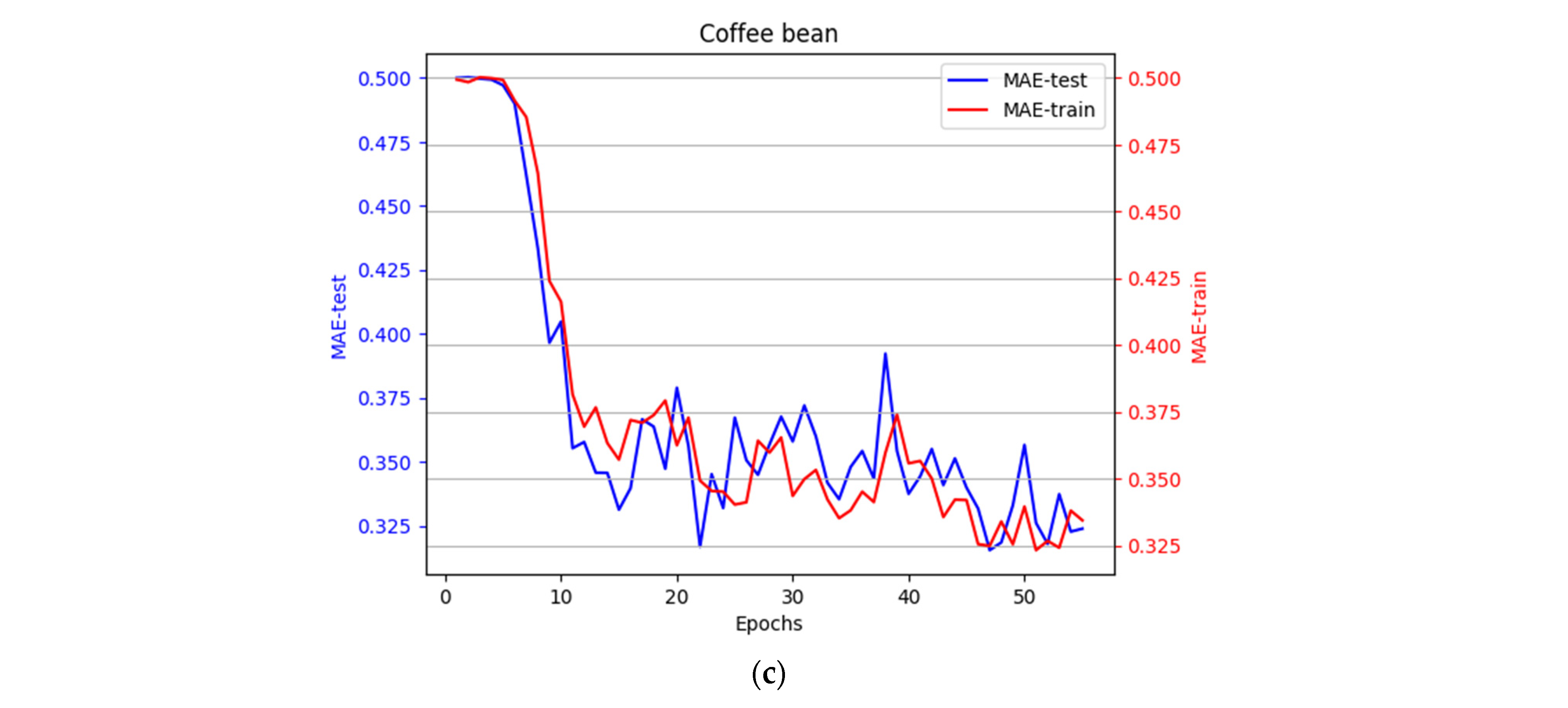
3.2. The Design and Learning Process of Convolutional Networks
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, Y.; Cao, Y.; Lai, Q.; Zhao, Q.; Sun, Z.; Zhou, S.; Song, D. Design and Operation Parameters of Vibrating Harvester for Coffea arabica L. Agriculture 2023, 13, 700. [Google Scholar] [CrossRef]
- Batista, L.R.; Chalfoun de Souza, S.M.; Silva e Batista, C.F.; Schwan, R.F. Coffee: Types and Production. In Encyclopedia of Food and Health; Elsevier Ltd.: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Bolka, M.; Emire, S. Effects of Coffee Roasting Technologies on Cup Quality and Bioactive Compounds of Specialty Coffee Beans. Food Sci. Nutr. 2020, 8, 6120–6130. [Google Scholar] [CrossRef] [PubMed]
- Rusinek, R.; Dobrzański, B.; Oniszczuk, A.; Gawrysiak-Witulska, M.; Siger, A.; Karami, H.; Ptaszyńska, A.A.; Żytek, A.; Kapela, K.; Gancarz, M. How to Identify Roast Defects in Coffee Beans Based on the Volatile Compound Profile. Molecules 2022, 27, 8530. [Google Scholar] [CrossRef] [PubMed]
- Liczbiński, P.; Bukowska, B. Tea and Coffee Polyphenols and Their Biological Properties Based on the Latest in Vitro Investigations. Ind. Crops Prod. 2022, 175, 114265. [Google Scholar] [CrossRef]
- Yesil, A.; Yilmaz, Y. Review Article: Coffee Consumption, the Metabolic Syndrome and Non-Alcoholic Fatty Liver Disease. Aliment. Pharmacol. Ther. 2013, 38, 1038–1044. [Google Scholar] [CrossRef]
- Tsai, C.F.; Jioe, I.P.J. The Analysis of Chlorogenic Acid and Caffeine Content and Its Correlation with Coffee Bean Color under Different Roasting Degree and Sources of Coffee (Coffea arabica Typica). Processes 2021, 9, 2040. [Google Scholar] [CrossRef]
- Mitiku, H.; Kim, T.Y.; Kang, H.; Apostolidis, E.; Lee, J.Y.; Kwon, Y.I. Selected Coffee (Coffea arabica L.) Extracts Inhibit Intestinal α-Glucosidases Activities in-Vitro and Postprandial Hyperglycemia in SD Rats. BMC Complement. Med. Ther. 2022, 22, 249. [Google Scholar] [CrossRef]
- Ascherio, A.; Zhang, S.M.; Hernán, M.A.; Kawachi, I.; Colditz, G.A.; Speizer, F.E.; Willett, W.C. Prospective Study of Caffeine Consumption and Risk of Parkinson’s Disease in Men and Women. Ann. Neurol. 2001, 50, 56–63. [Google Scholar] [CrossRef]
- Camandola, S.; Plick, N.; Mattson, M.P. Impact of Coffee and Cacao Purine Metabolites on Neuroplasticity and Neurodegenerative Disease. Neurochem. Res. 2019, 44, 214–227. [Google Scholar] [CrossRef]
- Qi, H.; Li, S. Dose-Response Meta-Analysis on Coffee, Tea and Caffeine Consumption with Risk of Parkinson’s Disease. Geriatr. Gerontol. Int. 2014, 14, 430–439. [Google Scholar] [CrossRef]
- Hu, G.; Bidel, S.; Jousilahti, P.; Antikainen, R.; Tuomilehto, J. Coffee and Tea Consumption and the Risk of Parkinson’s Disease. Mov. Disord. 2007, 22, 2242–2248. [Google Scholar] [CrossRef] [PubMed]
- Król, K.; Gantner, M.; Tatarak, A.; Hallmann, E. The Content of Polyphenols in Coffee Beans as Roasting, Origin and Storage Effect. Eur. Food Res. Technol. 2020, 246, 33–39. [Google Scholar] [CrossRef]
- Tajik, N.; Tajik, M.; Mack, I.; Enck, P. The Potential Effects of Chlorogenic Acid, the Main Phenolic Components in Coffee, on Health: A Comprehensive Review of the Literature. Eur. J. Nutr. 2017, 56, 2215–2244. [Google Scholar] [CrossRef] [PubMed]
- Reis, C.E.G.; Dórea, J.G.; da Costa, T.H.M. Effects of Coffee Consumption on Glucose Metabolism: A Systematic Review of Clinical Trials. J. Tradit. Complement. Med. 2019, 9, 184–191. [Google Scholar] [CrossRef]
- Wang, P.; Tseng, H.W.; Chen, T.C.; Hsia, C.H. Deep Convolutional Neural Network for Coffee Bean Inspection. Sens. Mater. 2021, 33, 2299–2310. [Google Scholar] [CrossRef]
- Wesołowski, P.; Gawałek, J. Effect of the Conditions of Cereal Instant Coffee Granulation on the Product Yield and Quality. Przem. Chem. 2008, 87, 311–314. [Google Scholar]
- Huang, N.F.; Chou, D.L.; Lee, C.A.; Wu, F.P.; Chuang, A.C.; Chen, Y.H.; Tsai, Y.C. Smart Agriculture: Real-Time Classification of Green Coffee Beans by Using a Convolutional Neural Network. IET Smart Cities 2020, 2, 167–172. [Google Scholar] [CrossRef]
- Przybył, K.; Samborska, K.; Koszela, K.; Masewicz, L.; Pawlak, T. Artificial Neural Networks in the Evaluation of the Influence of the Type and Content of Carrier on Selected Quality Parameters of Spray Dried Raspberry Powders. Measurement 2021, 186, 110014. [Google Scholar] [CrossRef]
- Przybył, K.; Walkowiak, K.; Jedlińska, A.; Samborska, K.; Masewicz, Ł.; Biegalski, J.; Pawlak, T.; Koszela, K. Fruit Powder Analysis Using Machine Learning Based on Color and FTIR-ATR Spectroscopy—Case Study: Blackcurrant Powders. Appl. Sci. 2023, 13, 9098. [Google Scholar] [CrossRef]
- Dwiecki, K.; Przybył, K.; Dezor, D.; Bąkowska, E.; Rocha, S.M. Interactions of Oleanolic Acid, Apigenin, Rutin, Resveratrol and Ferulic Acid with Phosphatidylcholine Lipid Membranes—A Spectroscopic and Machine Learning Study. Appl. Sci. 2023, 13, 9362. [Google Scholar] [CrossRef]
- Pandey, V.K.; Srivastava, S.; Dash, K.K.; Singh, R.; Mukarram, S.A.; Kovács, B.; Harsányi, E. Machine Learning Algorithms and Fundamentals as Emerging Safety Tools in Preservation of Fruits and Vegetables: A Review. Processes 2023, 11, 1720. [Google Scholar] [CrossRef]
- Przybył, K.; Wawrzyniak, J.; Koszela, K.; Adamski, F.; Gawrysiak-Witulska, M. Application of Deep and Machine Learning Using Image Analysis to Detect Fungal Contamination of Rapeseed. Sensors 2020, 20, 7305. [Google Scholar] [CrossRef] [PubMed]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 420. [Google Scholar] [CrossRef] [PubMed]
- Das, S. CNN Architectures: LeNet, AlexNet, VGG, GoogLeNet, ResNet and More. Medium, 16 November 2017. [Google Scholar]
- Raschka, S.; Mirjalili, V. Python. Machine Learning. 2nd edition. book, e-book. Helion IT Bookstore. Available online: https://helion.pl/ksiazki/python-uczenie-maszynowe-wydanie-ii-sebastian-raschka-vahid-mirjalili,pythu2.htm#format/e (accessed on 11 July 2021).
- Nelli, F. Deep Learning with TensorFlow. In Python Data Analytics; Apress: Berkeley, CA, USA, 2018; pp. 349–407. [Google Scholar]
- Patterson, J.; Gibson, A. Deep Learning A Practitioner’s Approach; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Chollet, F. Deep Learning with Python, 2nd ed.; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Chollet, F. Deep Learning with Python. Manning Publications Co.: Shelter Island, NY, USA, 2018. [Google Scholar]
- Chollet, F. Keras: The Python Deep Learning Library. 2015. Available online: https://keras.io/ (accessed on 24 August 2023).
- Pinto, C.; Furukawa, J.; Fukai, H.; Tamura, S. Classification of Green Coffee Bean Images Basec on Defect Types Using Convolutional Neural Network (CNN). In Proceedings of the 2017 International Conference on Advanced Informatics, Concepts, Theory, and Applications (ICAICTA), Denpasar, Indonesia, 16–17 August 2017; pp. 1–5. [Google Scholar]
- World Coffee Research. This Catalog Aims to Present Information for Varieties. Available online: https://varieties.worldcoffeeresearch.org/arabica/varieties (accessed on 21 September 2023).
- Kulapichitr, F.; Borompichaichartkul, C.; Fang, M.; Suppavorasatit, I.; Cadwallader, K.R. Effect of Post-Harvest Drying Process on Chlorogenic Acids, Antioxidant Activities and CIE-Lab Color of Thai Arabica Green Coffee Beans. Food Chem. 2022, 366, 130504. [Google Scholar] [CrossRef]
- Brühl, L.; Unbehend, G. Precise Color Communication by Determination of the Color of Vegetable Oils and Fats in the CIELAB 1976 (L*a*b*) Color Space. Eur. J. Lipid Sci. Technol. 2021, 123, 2000329. [Google Scholar] [CrossRef]
- Price, T.D. Sensory Drive, Color, and Color Vision. Am. Nat. 2017, 190, 157–170. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Mao, Y.; Feng, K.; Wei, D.; Song, L. Decoding of the Neural Representation of the Visual RGB Color Model. PeerJ Comput. Sci. 2023, 9, e1376. [Google Scholar] [CrossRef]
- Kamiyama, M.; Taguchi, A. Color Conversion Formula with Saturation Correction from HSI Color Space to RGB Color Space. IEICE Trans. Fundam.Electron. Commun. Comput. Sci. 2021, 104, 1000–1005. [Google Scholar] [CrossRef]
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-Image: Image Processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef]
- Przybył, K.; Gawałek, J.; Koszela, K. Application of Artificial Neural Network for the Quality-Based Classification of Spray-Dried Rhubarb Juice Powders. J. Food Sci. Technol. 2023, 60, 809–819. [Google Scholar] [CrossRef]
- Al-Sammarraie, M.A.J.; Gierz, Ł.; Przybył, K.; Koszela, K.; Szychta, M.; Brzykcy, J.; Baranowska, H.M. Predicting Fruit’s Sweetness Using Artificial Intelligence—Case Study: Orange. Appl. Sci. 2022, 12, 8233. [Google Scholar] [CrossRef]
- Przybył, K.; Ryniecki, A.; Niedbała, G.; Mueller, W.; Boniecki, P.; Zaborowicz, M.; Koszela, K.; Kujawa, S.; Kozłowski, R.J. Software Supporting Definition and Extraction of the Quality Parameters of Potatoes by Using Image Analysis. In Proceedings of the Eighth International Conference on Digital Image Processing (ICDIP 2016), Chengdu, China, 20–22 May 2016; Falco, C.M., Jiang, X., Eds.; 2016; Volume 10033, p. 100332L. [Google Scholar] [CrossRef]
- Vithu, P.; Moses, J.A. Machine Vision System for Food Grain Quality Evaluation: A Review. Trends Food Sci. Technol. 2016, 56, 13–20. [Google Scholar] [CrossRef]
- Carracedo-Reboredo, P.; Liñares-Blanco, J.; Rodríguez-Fernández, N.; Cedrón, F.; Novoa, F.J.; Carballal, A.; Maojo, V.; Pazos, A.; Fernandez-Lozano, C. A Review on Machine Learning Approaches and Trends in Drug Discovery. Comput. Struct. Biotechnol. J. 2021, 19, 4538–4558. [Google Scholar] [CrossRef] [PubMed]
- Dara, S.; Dhamercherla, S.; Jadav, S.S.; Babu, C.M.; Ahsan, M.J. Machine Learning in Drug Discovery: A Review. Artif. Intell. Rev. 2022, 55, 1947–1999. [Google Scholar] [CrossRef]
- Bland, J.M.; Altman, D.G. Statistics Notes: Multiple Significance Tests: The Bonferroni Method. BMJ 1995, 310, 170. [Google Scholar] [CrossRef]
- De Lasarte, M.; Vilaseca, M.; Pujol, J.; Arjona, M. Color Measurements with Colorimetric and Multispectral Imaging Systems; Rosen, M.R., Imai, F.H., Tominaga, S., Eds.; SPIE: Bellingham, WA, USA, 2006; p. 60620F. [Google Scholar]
- Przybył, K.; Masewicz, Ł.; Koszela, K.; Duda, A.; Szychta, M.; Gierz, Ł. An MLP Artificial Neural Network for Detection of the Degree of Saccharification of Arabic Gum Used as a Carrier Agent of Raspberry Powders. In Proceedings of the Thirteenth International Conference on Digital Image Processing (ICDIP 2021); Jiang, X., Fujita, H., Eds.; SPIE: Bellingham, WA, USA, 2021; Volume 11878, p. 93. [Google Scholar]
- Spence, C. Background Colour & Its Impact on Food Perception & Behaviour. Food Qual. Prefer. 2018, 68, 156–166. [Google Scholar]
- Spence, C. On the Changing Colour of Food & Drink. Int. J. Gastron. Food Sci. 2019, 17, 100161. [Google Scholar]
- Dooley, D.M.; Griffiths, E.J.; Gosal, G.S.; Buttigieg, P.L.; Hoehndorf, R.; Lange, M.C.; Schriml, L.M.; Brinkman, F.S.L.; Hsiao, W.W.L. Food on: A Harmonized Food Ontology to Increase Global Food Traceability, Quality Control and Data Integration. Npj Sci Food 2018, 2, 23. [Google Scholar] [CrossRef]
- Xu, X.; Zhu, L.; Zhuang, W.; Lu, L.; Yuan, P. A Convolution Neural Network Implemented by Three 3 × 3 Photonic Integrated Reconfigurable Linear Processors. Photonics 2022, 9, 80. [Google Scholar] [CrossRef]
- Yang, J.; Yang, G. Modified Convolutional Neural Network Based on Dropout and the Stochastic Gradient Descent Optimizer. Algorithms 2018, 11, 28. [Google Scholar] [CrossRef]
- Krohn, J. Deep Learning Illustrated: A Visual, Interactive Guide to Artificial Intelligence; Persion: London, UK, 2020. [Google Scholar]
- Pan, S.Y.; Liu, M.X.; Forero-Romero, J.; Sabiu, C.G.; Li, Z.G.; Miao, H.T.; Li, X.D. Cosmological Parameter Estimation from Large-Scale Structure Deep Learning. Sci. China Phys. Mech. Astron. 2020, 63, 110412. [Google Scholar] [CrossRef]
- Yang, G.; Yang, J.; Li, S.; Hu, J. Modified CNN Algorithm Based on Dropout and ADAM Optimizer. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2018, 46, 122–127. [Google Scholar] [CrossRef]
- Ogundokun, R.O.; Maskeliunas, R.; Misra, S.; Damaševičius, R. Improved CNN Based on Batch Normalization and Adam Optimizer. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Cham, Switzerland, 2022; Volume 13381, pp. 593–604. [Google Scholar]
- Liu, J.; Xu, D.; Zhang, H.; Mandic, D. On Hyper-Parameter Selection for Guaranteed Convergence of RMSProp. Cogn. Neurodynamics 2022. [Google Scholar] [CrossRef]
- Zou, F.; Shen, L.; Jie, Z.; Zhang, W.; Liu, W. A Sufficient Condition for Convergences of Adam and RMSProp. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; Volume 2019, pp. 11119–11127. [Google Scholar]
- Irfan, D.; Rosnelly, R.; Wahyuni, M.; Samudra, J.T.; Rangga, A. Perbandingan Optimasi Sgd, Adadelta, Dan Adam Dalam Klasifikasi Hydrangea Menggunakan Cnn. J. Sci. Soc. Res. 2022, 5, 244. [Google Scholar] [CrossRef]
- Yang, J.; Bagavathiannan, M.; Wang, Y.; Chen, Y.; Yu, J. A Comparative Evaluation of Convolutional Neural Networks, Training Image Sizes, and Deep Learning Optimizers for Weed Detection in Alfalfa. Weed Technol. 2022, 36, 512–522. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings 2014, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- An Overview of Regularization Techniques in Deep Learning (with Python Code). Available online: https://www.analyticsvidhya.com/blog/2018/04/fundamentals-deep-learning-regularization-techniques/ (accessed on 23 September 2023).
- Michelucci, U. Applied Deep Learning: A Case-Based Approach to Understanding Deep Neural Networks; Apress Media, LLC: New York, NY, USA, 2018. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class of Coffee | L* | a* | b* |
|---|---|---|---|
| underdeveloped | 18.07 ± 2.03 b | 7.86 ± 0.51 b | 10.83 ± 0.84 b |
| overdeveloped | 15.38 ± 2.31 a | 5.86 ± 0.58 a | 6.44 ± 1.16 a |
| standard | 20.13 ± 3.69 b | 8.13 ± 0.75 b | 11.81 ± 1.61 b |
| Class of Coffee | R | G | B |
|---|---|---|---|
| underdeveloped | 0.33 ± 0.06 a | 0.24 ± 0.05 a | 0.16 ± 0.03 c |
| overdeveloped | 0.42 ± 0.09 c | 0.27 ± 0.05 c | 0.18 ± 0.04 b |
| standard | 0.46 ± 0.08 b | 0.30 ± 0.05 b | 0.19 ± 0.03 a |
| Type | Testing Set | Training Set | ||||||
|---|---|---|---|---|---|---|---|---|
| MSE | MAE | R2 | MSE | MAE | R2 | Activation Hidden | Training Algorithm | |
| CNN | 0.1739 | 0.3238 | 0.8125 | 0.1941 | 0.3344 | 0.7312 | ReLU | Adam |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Przybył, K.; Gawrysiak-Witulska, M.; Bielska, P.; Rusinek, R.; Gancarz, M.; Dobrzański, B., Jr.; Siger, A. Application of Machine Learning to Assess the Quality of Food Products—Case Study: Coffee Bean. Appl. Sci. 2023, 13, 10786. https://doi.org/10.3390/app131910786
Przybył K, Gawrysiak-Witulska M, Bielska P, Rusinek R, Gancarz M, Dobrzański B Jr., Siger A. Application of Machine Learning to Assess the Quality of Food Products—Case Study: Coffee Bean. Applied Sciences. 2023; 13(19):10786. https://doi.org/10.3390/app131910786
Chicago/Turabian StylePrzybył, Krzysztof, Marzena Gawrysiak-Witulska, Paulina Bielska, Robert Rusinek, Marek Gancarz, Bohdan Dobrzański, Jr., and Aleksander Siger. 2023. "Application of Machine Learning to Assess the Quality of Food Products—Case Study: Coffee Bean" Applied Sciences 13, no. 19: 10786. https://doi.org/10.3390/app131910786
APA StylePrzybył, K., Gawrysiak-Witulska, M., Bielska, P., Rusinek, R., Gancarz, M., Dobrzański, B., Jr., & Siger, A. (2023). Application of Machine Learning to Assess the Quality of Food Products—Case Study: Coffee Bean. Applied Sciences, 13(19), 10786. https://doi.org/10.3390/app131910786