1. Introduction
In recent years, the exploration of the oceans has been significantly facilitated by the advancements in underwater robotics [
1]. Underwater robots are commonly equipped with visual sensing devices that capture information about the surrounding environment and record it using images as data carriers [
2]. Various underwater tasks, including submarine pipeline cleaning and mineral exploration [
3,
4], rely on the analysis of underwater images. However, the complexity of underwater environments introduces challenges such as color deviation and low contrast in underwater images due to wavelength- and distance-related attenuation and scattering. When light travels through water, it undergoes selective attenuation, leading to varying degrees of color deviation. Additionally, suspended particulate matter, such as phytoplankton and non-algal particles, scatters light, further reducing contrast. Based on recent research findings, we categorize the existing underwater image enhancement methods into three main categories: non-physical model-based, physical model-based, and deep learning-based approaches [
5].
Early non-physical model-based enhancement methods primarily focused on adjusting the pixel values of underwater images in order to enhance image presentation. These methods included techniques such as histogram equalization, white balance adjustment, and image fusion. While these non-physical model-based methods have the potential to improve visual quality to some extent, they overlook the underlying underwater imaging mechanism [
6]. As a result, these methods often produce over-enhanced results or introduce artificially created colors. For instance, Iqbal et al. [
7] propose a UCM algorithm that initially performs color equalization on underwater images in the RGB color space and then corrects the contrast in the HSV color space. However, these algorithms are characterized by their simplicity, which makes them susceptible to noise over-enhancement, as well as the introduction of artifacts and color distortion.
The predominant methods for enhancing underwater images are based on physical models [
6,
8]. These models involve specific mathematical representations of the imaging process, enabling the estimation of unknown parameters, and subsequently producing clear images by removing the influence of the water body. Among these methods, the Dark Channel Prior (DCP) algorithm [
9] is considered a classical approach. It establishes a relationship between land-based foggy images and the imaging model, enabling the estimation of light wave transmittance and atmospheric light, thus facilitating the restoration of foggy images. Given the similarity between the underwater imaging process and the fogging process, the DCP algorithm can also be applied to correct distorted underwater images. However, it is important to note that the application of this algorithm is limited, and the enhancement results are prone to introducing new distortion problems. Furthermore, P. Drews-Jr. et al. [
10] introduced the Underwater Dark Channel Priority (UDCP) algorithm, designed specifically for underwater scenarios. This algorithm considers the attenuation characteristics of light wave transmission in water, allowing for the estimation of a more accurate transmittance distribution. However, due to the complexity and variability of the underwater environment, constructing a precise and universally applicable imaging model becomes challenging. Moreover, parameter estimation is susceptible to bias, resulting in less satisfactory enhancement results. Peng et al. [
11] employed a modeling approach that considers image blurriness and light absorption (IBLA) to recover underwater images. Song et al. [
12] utilized the underwater light attenuation prior (ULAP) information to estimate the scene’s depth map, followed by the enhancement of the underwater images. However, it should be noted that these methods heavily rely on specific prior conditions and may not be effective for type-sensitive underwater image enhancement.
In recent years, considerable attention has been given to the field of deep learning, as deep learning neural networks demonstrate remarkable capabilities in solving complex nonlinear system modeling problems. This has led to significant advancements in the enhancement of underwater images. For instance, Li et al. [
13] proposed the UWCNN model, which utilizes distinct neural network models tailored to different types of underwater images. Wang et al. [
14] introduced the UIEC″2-Net, which incorporates RGB and HSV color spaces, as well as an attention module, to enhance underwater images. Additionally, Li et al. [
15] proposed the Ucolor network, which is based on a multi-color space approach. They introduced reverse medium transmission (RMT) images into the network as weight information to guide the enhancement of underwater RGB images. In a separate work, Li et al. [
16] presented the innovative WaterGAN model, a type of Generative Adversarial Network [
17] (GAN). This model generates underwater images by taking atmospheric RGB images, depth maps, and noise vectors as inputs. Subsequently, a convolutional neural network is trained using the synthesized images, atmospheric images, and depth maps to achieve the enhancement of target images. However, it should be noted that the WaterGAN model inherits the inherent drawback of GAN-based models, namely the production of unstable enhancement results. While these methods can enhance the visual quality of underwater images to a certain extent, they heavily rely on neural networks to learn parameters and achieve enhanced images through nonlinear mapping. However, this approach faces difficulties in effectively capturing the characteristics and laws of underwater optical imaging in complex underwater environments. Consequently, the reliability of the results is compromised, making it challenging to address the problem of deteriorating image quality in different underwater scenes.
The current deep learning-based models for underwater image enhancement exhibit limited robustness and generalization ability, which is unsatisfactory. This limitation stems from the fact that while deep learning-based methods circumvent the complex physical parameter estimation required by traditional approaches, they often overlook the domain knowledge specific to underwater imaging. To address this issue, we propose an underwater image enhancement method based on Adversarial Autoencoder (AAE), which combines the characteristics of underwater imaging. The method integrates features extracted from three color spaces of the image (RGB, HSV, and Lab) into a unified structure to enhance the diversity of feature representations. Additionally, the attention mechanism is employed to capture rich features. Secondly, the extracted features mentioned above are fused with the features obtained from the Reverse Medium Transmission (RMT) map using a feature fusion module. This fusion process enhances the network’s ability to respond to regions in the image that have experienced degradation in terms of image quality. Finally, the discriminator enhances the reconstructed image by accepting positive samples from the pre-trained model and negative samples generated by the encoder (generator). Through this process, the discriminator guides the hidden space of the autoencoder to approach the hidden space of the pre-trained model, contributing to the overall improvement of the image quality.
In this paper, the proposed method demonstrates excellent performance on an experimental dataset collected from the “Offshore Oil Platform HYSY-163” situated in the Beibu Gulf area of China.
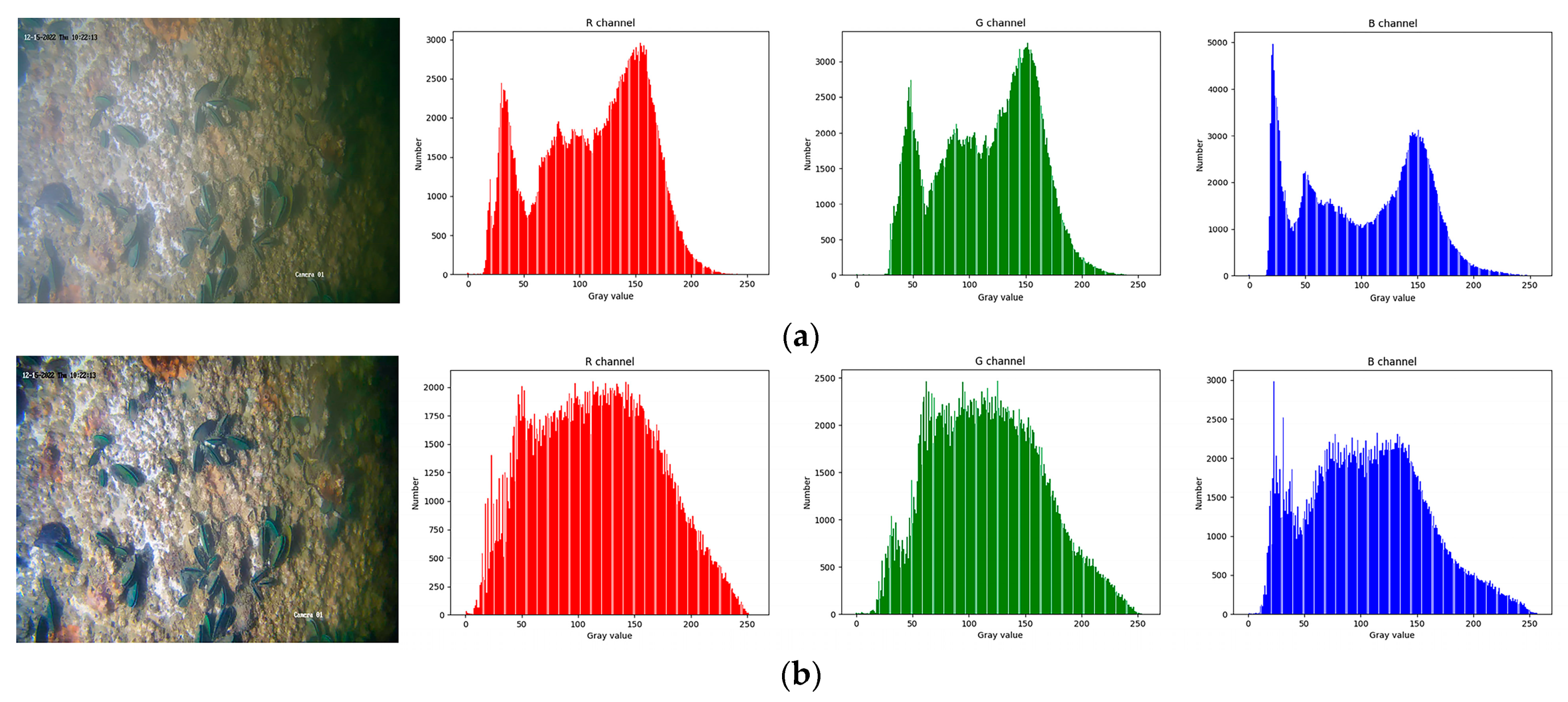
Figure 1 illustrates the results of the original image and the processed image using the three color channels (R, G, and B). The reconstructed image exhibits a more uniform distribution in the histogram and possesses enhanced clarity.
The remaining sections of the paper are organized as follows.
Section 2 presents the details of our proposed method for underwater image enhancement tasks. In
Section 3, we present the experimental results that demonstrate the effectiveness of our approach. Finally,
Section 4 provides the concluding remarks.
2. Materials and Methods
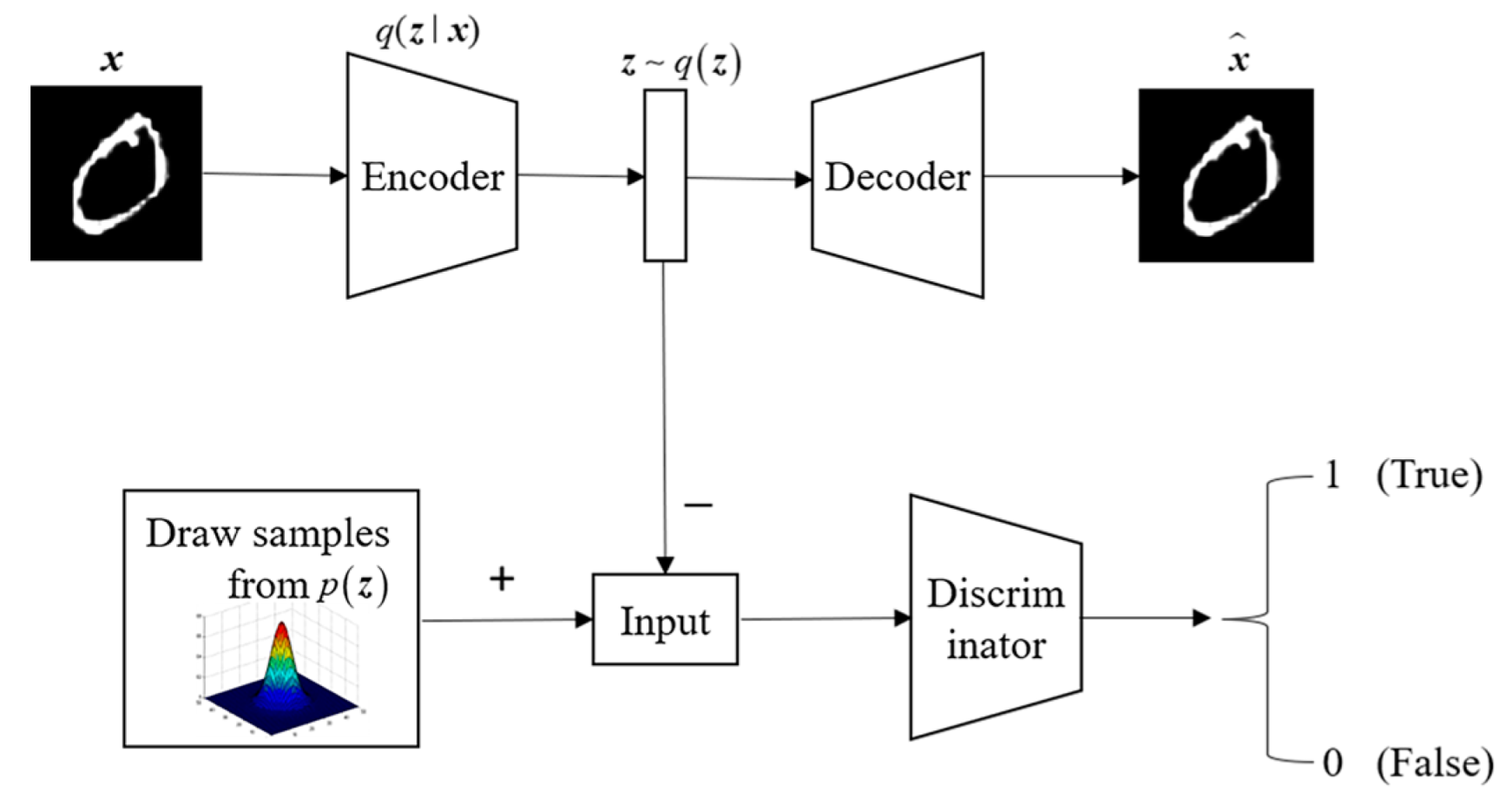
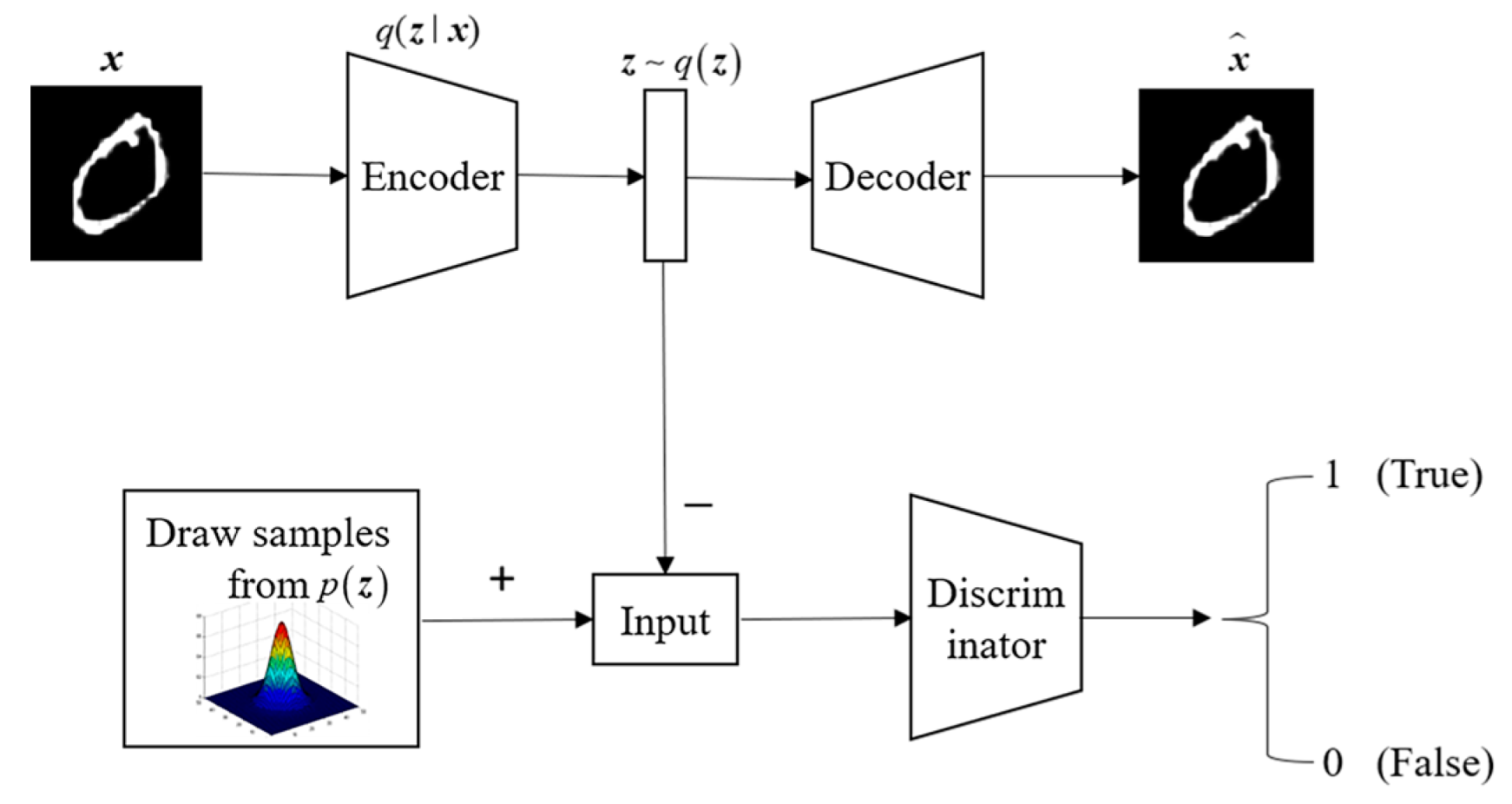
In 2015, Makhzani et al. [
18] introduced the concept of adversarial autoencoder, which combines the adversarial generative network with the autoencoder network. The specific architecture of the proposed model is depicted in
Figure 2. The adversarial autoencoder (AAE) model comprises two components: an autoencoder (AE) and a generative adversarial network (GAN). Adversarial training is incorporated into the autoencoder, enabling the dimensionally reduced data to adhere to a specific distribution. The training process of the adversarial autoencoder consists of two main parts. Firstly, it involves matching an aggregated posterior
with an arbitrary prior distribution
. To achieve this, an adversarial network is connected to the hidden code vector of the autoencoder. This adversarial network guides
to align with
, ensuring that the generated samples adhere to the desired prior distribution.
In the provided equation, represents the distribution of the target data from the training set.
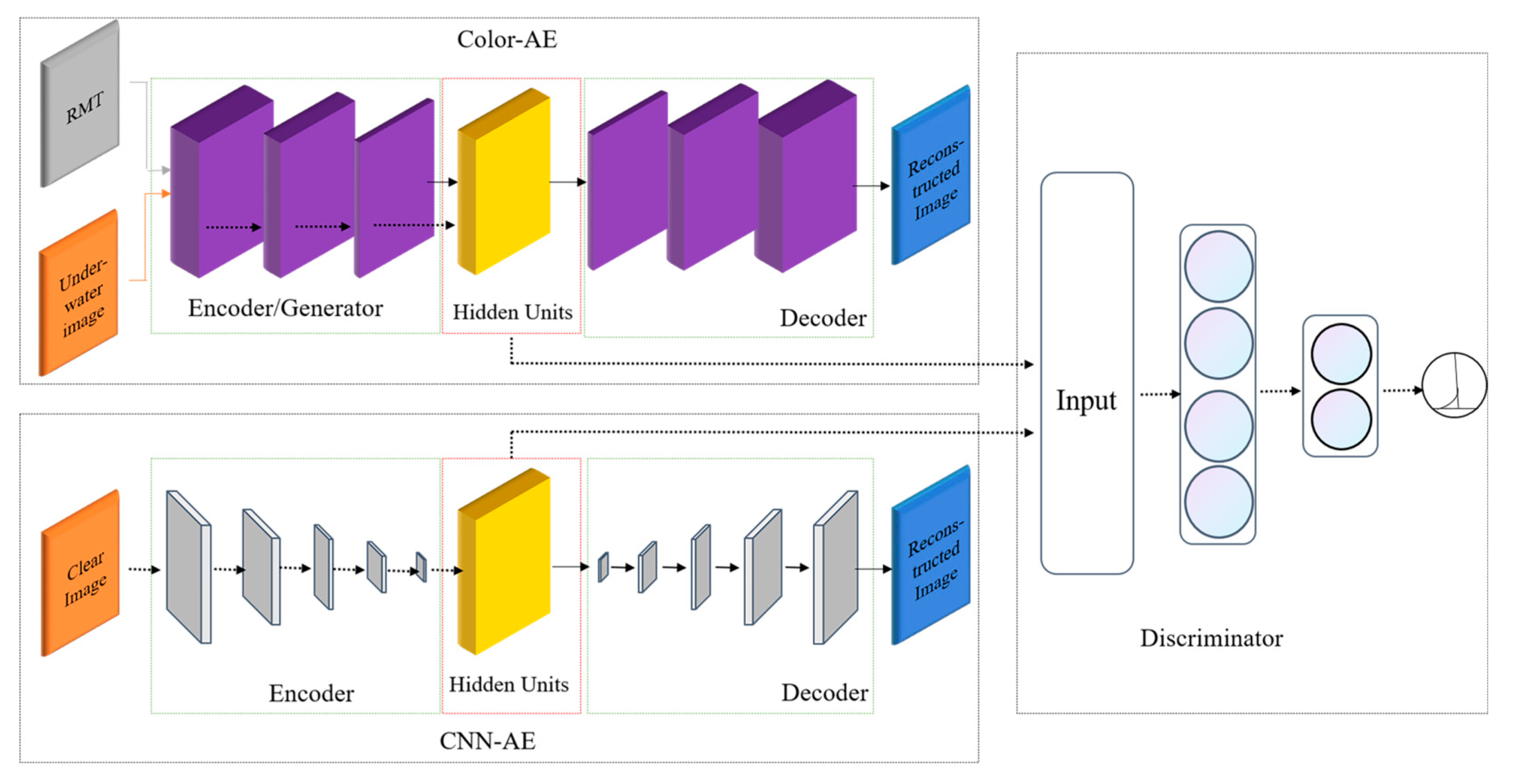
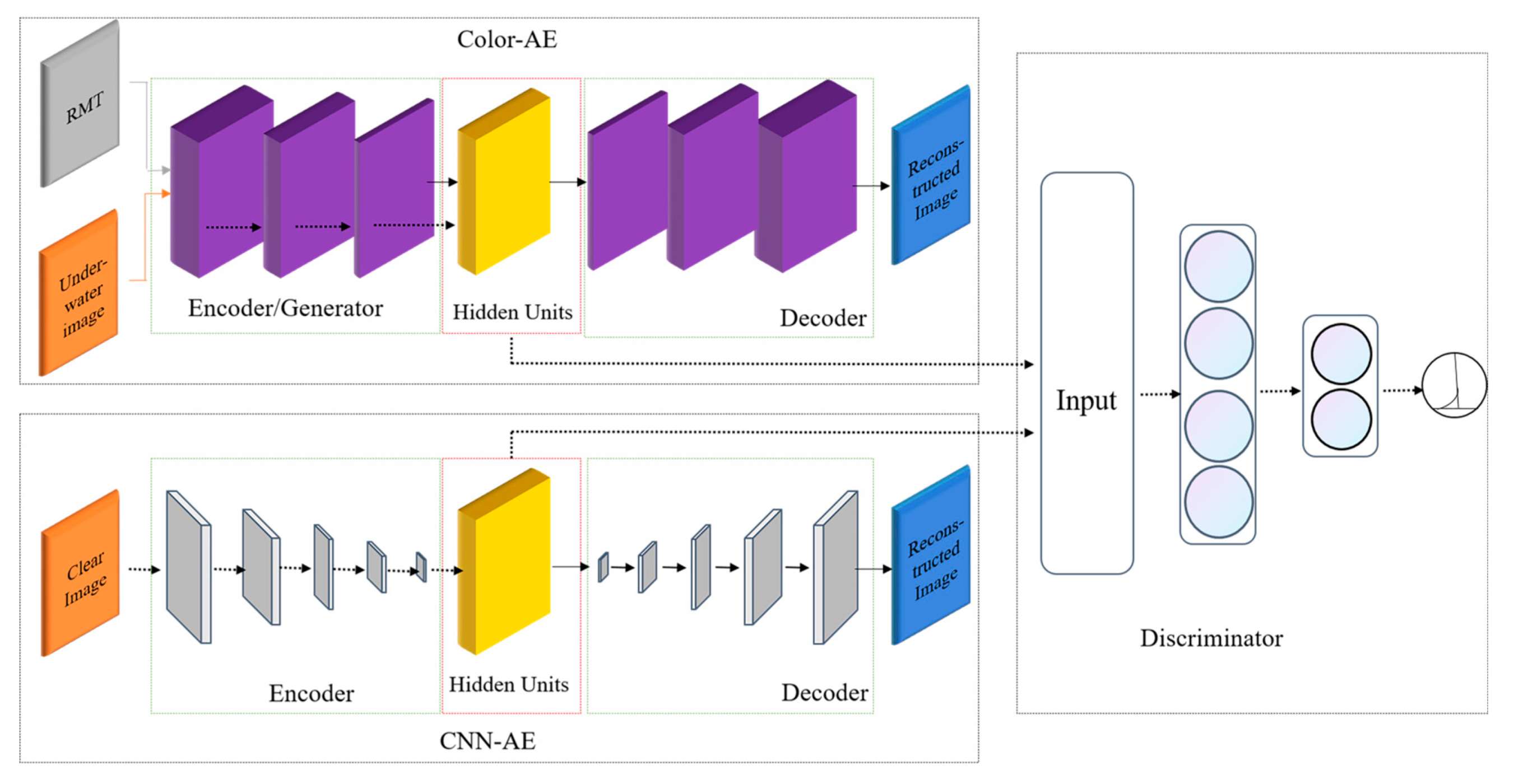
In this paper, we present an underwater image enhancement method named UW-AAE, which is based on the AAE model network. The overall framework diagram is illustrated in
Figure 3. The model comprises two main modules: the autoencoder and the adversarial network. The autoencoder consists of the Color-AAE network and the pre-training model [
19] CNN-AE. The discriminator plays a crucial role in guiding the hidden space of the Color-AAE network to progressively approach the hidden space of the pre-training model CNN-AE. It achieves this by accepting positive samples from the pre-training model and negative samples generated by the Color-AAE network.
2.1. Autoencoder Module
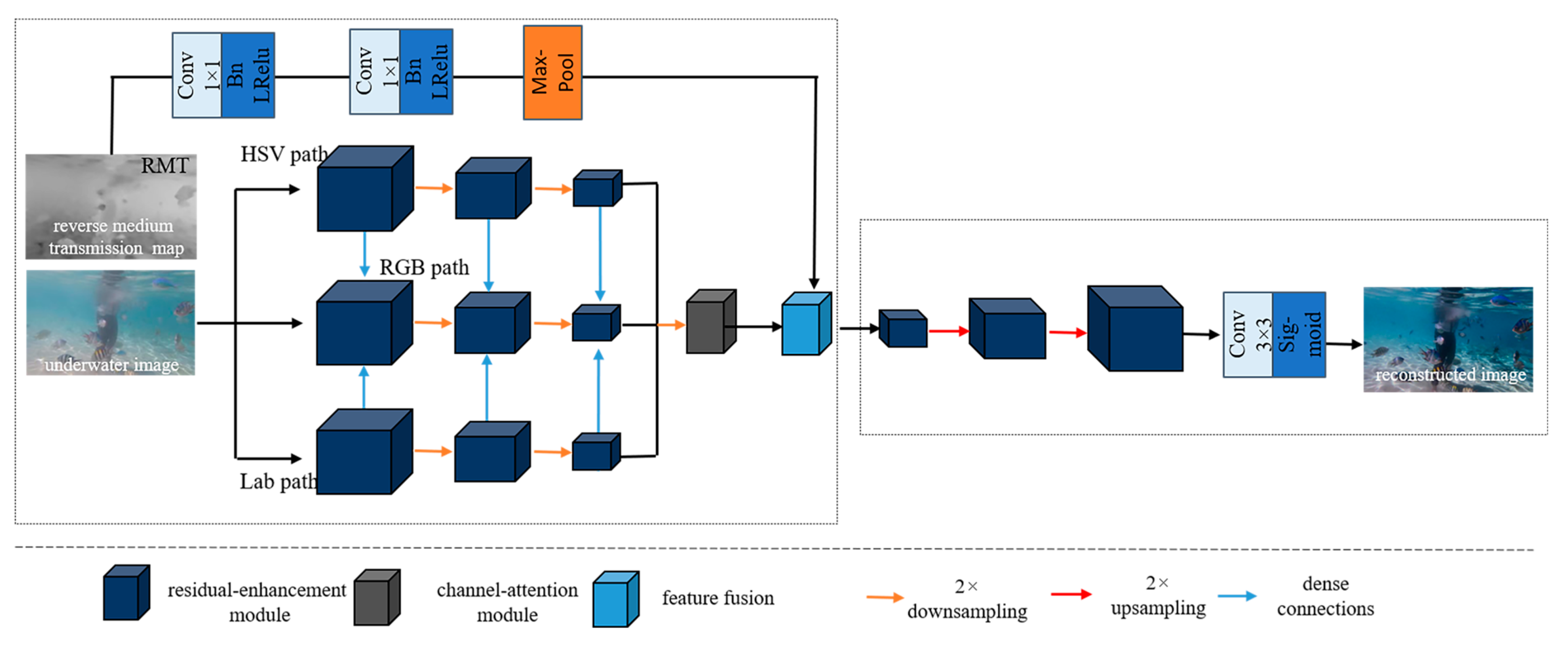
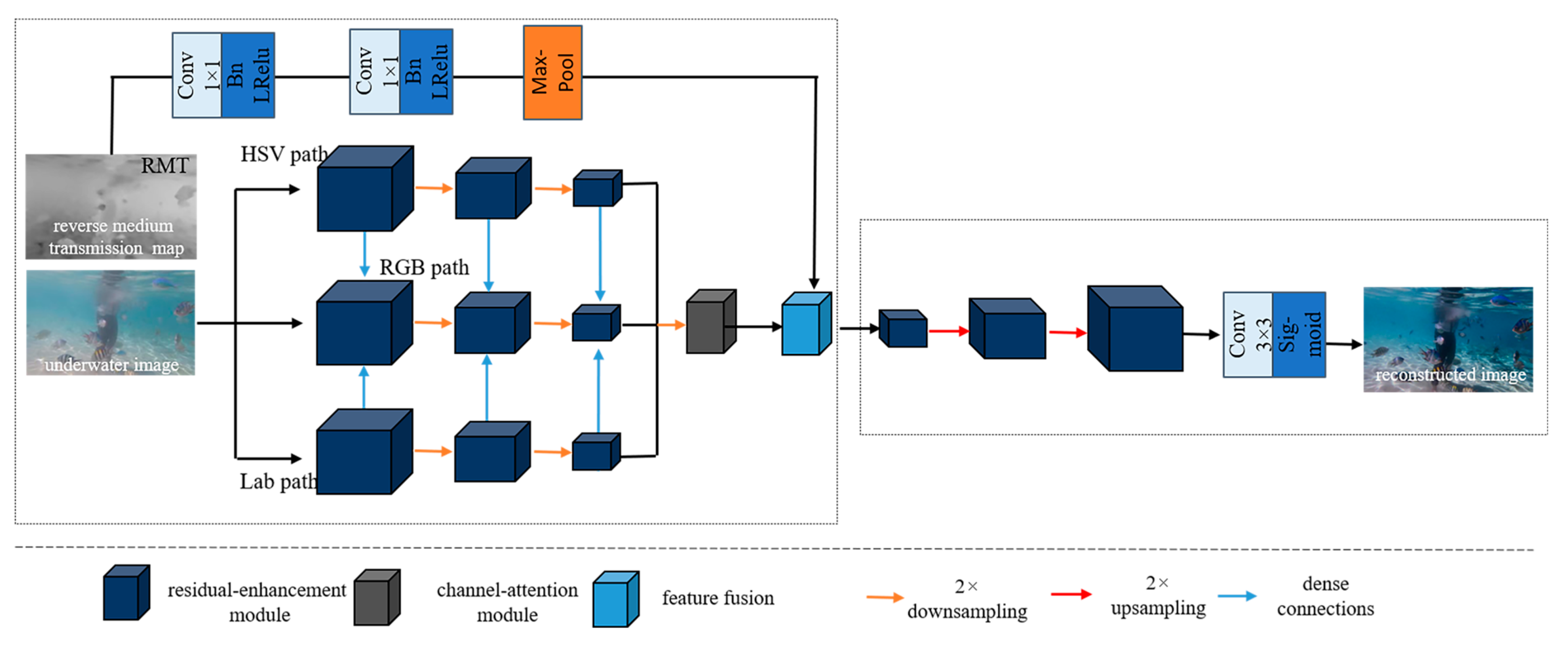
The structure of Color-AE is depicted in
Figure 4, comprising two modules: the multi-color encoder and decoder. The multi-color encoder extracts features from both the underwater image and its reverse medium transmittance map. These features are then fused through the feature fusion module. The fused features are directed to the decoder network, which generates the reconstructed output. The underwater image undergoes a color space transformation, leading to the formation of three encoding paths: the HSV path, the RGB path, and the Lab path. In each path, the color space features undergo enhancement through three consecutive residual enhancement modules, resulting in three levels of feature representations. Additionally, a 2× downsampling operation is employed during this process. Furthermore, the features of the RGB path are combined with the corresponding features of the HSV path and the Lab path through dense connections to enhance the RGB path. Subsequently, the same level features of these three parallel paths are combined to form three sets of multicolor space encoder features. These three sets of features are then provided to their respective attention mechanism modules, which effectively capture rich and discriminative image features from multiple color spaces.
As the Reverse Medium Transmission (RMT) map can partially reflect the physical principles of underwater imaging [
20], regions with higher pixel values in the RMT map correspond to more severe degradation in the corresponding underwater image regions. Consequently, the network assigns a larger weight response to the degraded regions of the image, acknowledging their significance in the enhancement process. The refinement of the RMT map is achieved through 1 × 1 convolutional layers with a step size of 2. Each convolutional layer is linked to the batch normalization layer and the Leaky ReLU activation function. Subsequently, a maximum pooling downsampling layer is employed to eliminate redundant repetitive information. The output of the feature fusion module is then transmitted to the corresponding residual enhancement module. Following three consecutive serial residual enhancement modules and two 2× upsampling operations, the decoder features are forwarded to the convolutional layers, leading to the reconstruction of the final result.
2.2. Residual Enhancement Module
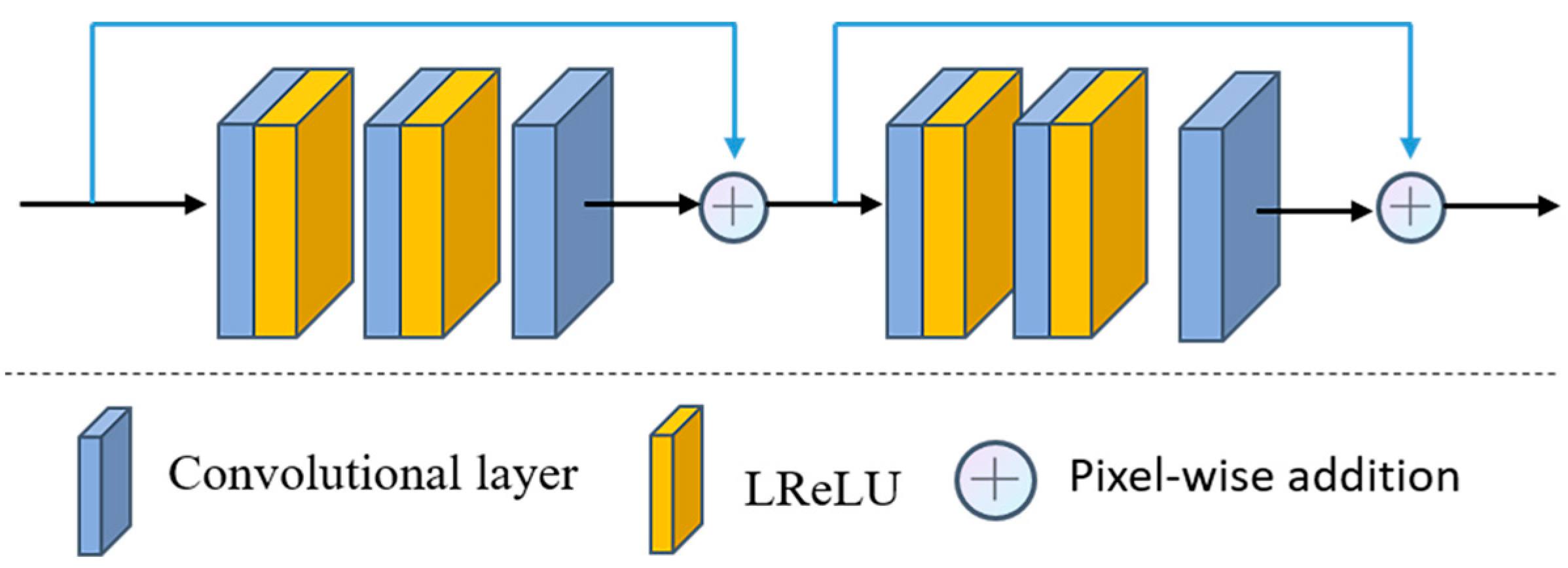
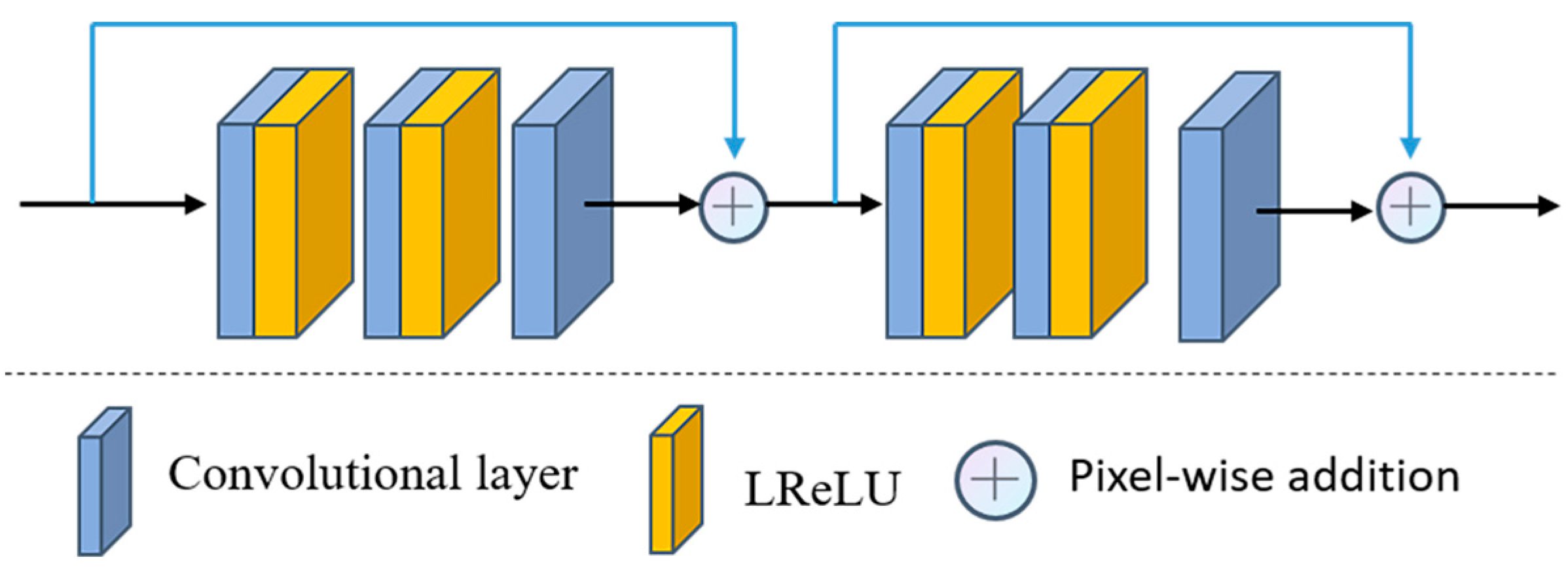
As depicted in
Figure 5, each residual enhancement module comprises two residual blocks, each composed of three convolutions and two Leaky ReLU activation functions, with a 3 × 3 convolution kernel size and a step size of 1. Following each residual block, pixel-by-pixel addition is employed as a constant connection, with the purpose of enhancing the detailed features of the image and addressing the issue of gradient vanishing [
21]. In each residual enhancement module, the convolutional layer maintains a consistent number of filters. Notably, the number of filters progressively increases from 128 to 512 in the encoder network, and conversely, it decreases from 512 to 128 in the decoder network.
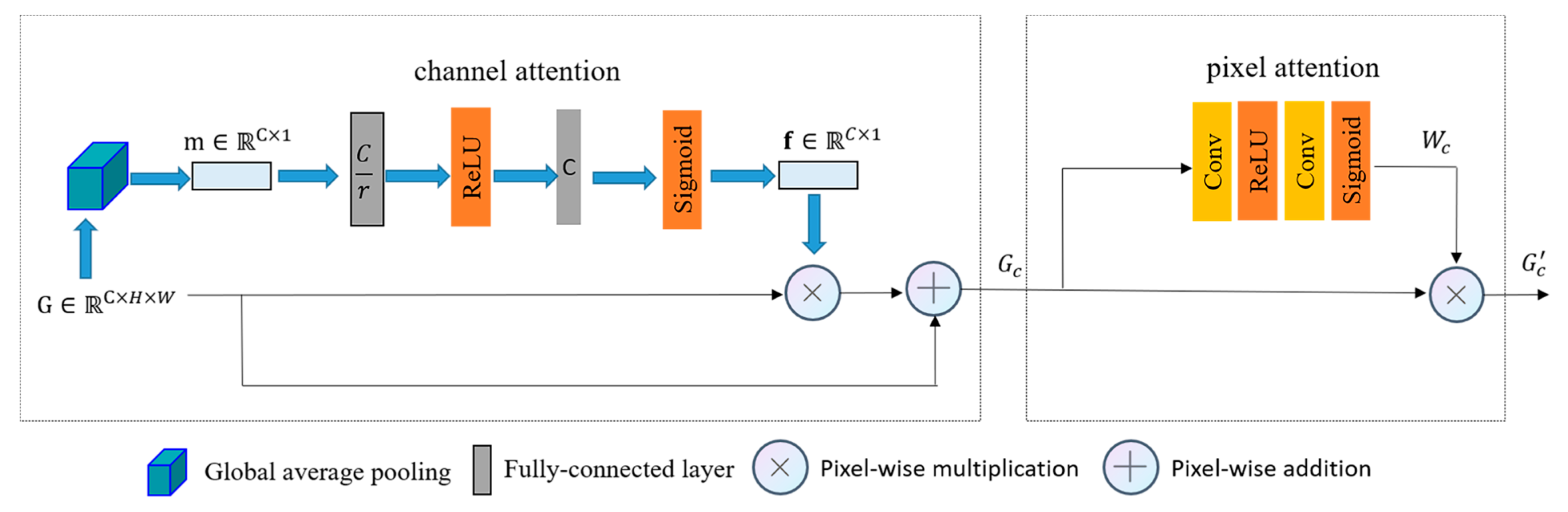
2.3. Feature Attention Module
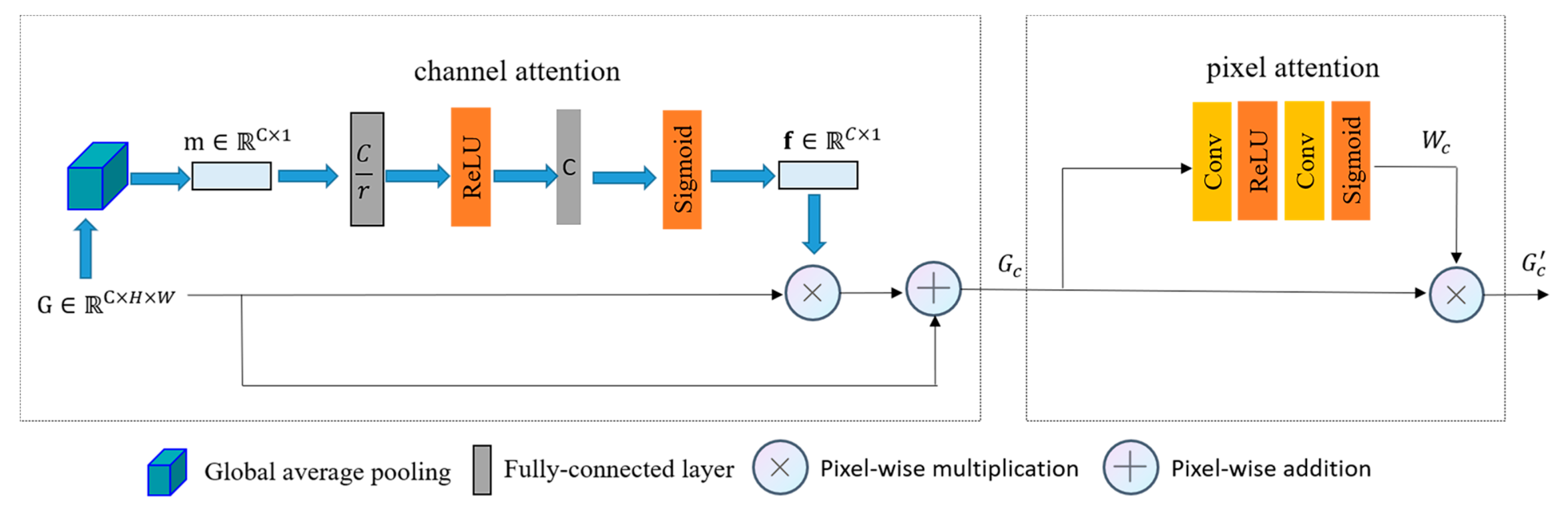
Considering the distinct characteristics of the three color space models—RGB, HSV, and Lab—these features, extracted from the three distinct color spaces, are expected to contribute differently. This study employs the channel attention mechanism and the pixel attention mechanism [
22] to effectively handle the color variations in underwater images and account for the impact of different water qualities on the images. The specifics of the attention mechanism module are illustrated in
Figure 6. Let
represent the input feature, where
denotes the nominal mapping of a certain path,
is the number of channels of the feature mapping,
denotes the feature concatenation, and
and
are the height and width of the input image, respectively. In the channel attention mechanism, the spatial dimension of the input feature
is initially compressed. The feature maps of each channel are then downscaled through a global average pooling operation. This operation transforms the comprehensive spatial information along the channel dimension into a channel descriptor denoted as
, effectively minimizing the network’s parameter complexity. The central function of the channel descriptor is to produce an embedded global distribution of channel features, symbolizing the holistic significance of features within the channel. The mathematical expression for the
th term of
is as follows:
where
.
represents the compressed “squeeze” representation of the channel, encapsulating the overarching perceptual information embedded within each channel. Moreover,
denotes the weighting coefficients employed in the attention mechanism of the channel’s “excitation” representation, enabling the targeted amplification of distinct spatial positions within a particular channel. To fully capture individual channel dependencies, a self-gating mechanism [
23] is employed to generate a set of modulation weights
.
In the equation,
and
represent the weights of the two fully connected layers.
denotes the Sigmoid activation function,
represents the ReLU activation function, and
denotes the convolution operation. The number of output channels for
and
is equal to
and
, respectively. The hyper-parameter
defines the dimensionality relationship between the two fully connected layers, allowing control over the proportion of dimensionality reduction for the channel weights, thus influencing the model’s performance and computational efficiency. For computational purposes,
is set to 16; comprehensive details can be accessed in [
23]. These weights are subsequently applied to the input features
to produce the output channel features
. Moreover, to mitigate the issue of vanishing gradients and retain valuable information about the original features, we handle the channel attention weights in a similar mapping manner:
where
represents pixel-by-pixel addition, and
denotes pixel-by-pixel multiplication.
The channel attention mechanism primarily concentrates on the allocation of weights across distinct channels. As a complementary technique to the channel attention mechanism, the pixel attention mechanism is centered on weight distribution across various pixel locations within a singular feature map, enabling the network to focus on regions with varying turbidity levels underwater. Illustrated in
Figure 6, the pixel attention layer consists of two convolutional layers, each incorporating a ReLU activation function and a Sigmoid activation function:
represents the convolution operation,
denotes the Sigmoid activation function, and
denotes the ReLU activation function. A pixel-by-pixel multiplication of the input feature
with the weights
obtained from Equation (5) is performed:
2.4. Feature Fusion Module
Considering the need to perform underwater image enhancement with a focus on regions containing severe image degradation areas [
24], we have designed a feature fusion module capable of adaptively selecting image features. This module processes both RGB image features and RMT image features by employing convolutional layers with different receptive fields. The selective utilization of these diverse features enhances the network’s ability to identify and address regions with significant image degradation, contributing to more effective underwater image enhancement. The RMT image serves as a representation of the physical laws governing underwater optical imaging. Higher pixel values within the RMT image indicate more severe degradation in the corresponding positions of the RGB image, necessitating a greater emphasis on the enhancement process. Leveraging the RMT image to guide the RGB image enhancement enables differentiation in the significance of various regions, thereby facilitating adaptive enhancement with varying degrees of emphasis. Training deep neural networks for RMT map estimation poses a challenge due to the unavailability of practical ground truth RMT maps for the input underwater images. To address this issue, we adopt the commonly used underwater image restoration algorithms’ image imaging model [
25], which represents the quality-degraded image as follows:
Let represent the coordinate of any pixel in the color image, where refers to the three color channels R, G, and B, respectively. corresponds to the image captured directly underwater, while denotes the ideally clear image. represents the ambient background light intensity in the R, G, and B channels. represents the medium transmittance of each pixel point, which signifies the percentage of radiation that arrives at the camera after reflection in the medium, relative to the scene radiation. This value indicates the degree of quality degradation in different regions.
Drawing inspiration from the dark channel prior [
9], the DCP (Dark Channel Prior) method seeks the minimum value in the RGB channel for each pixel
within the local region
centered at
. In other words, we have
. For an unfogged image of an outdoor ground surface,
typically approaches zero because, in the local facets (represented by units of
), at least one of the three color channels generally contains a low-intensity pixel. In the context of Equation (7), the term involving
is rounded off due to its proximity to zero, and this enables the estimation of the medium transmittance, denoted as follows:
Additionally, it can be expressed as follows:
According to the Beer–Lambert law of light attenuation, the transmittance is commonly expressed as an exponential decay term.
where
is the distance from the camera to the radiating object, and
is the spectral volume attenuation coefficient, ensuring that
. In cases where Equation (10) results in a negative number (i.e.,
), the value of
becomes negative, making the use of Equation (8) inaccurate. To address this issue, an estimation algorithm [
26] based on prior information is employed to obtain the influence of the medium transmittance map. In this paper, the medium transmittance is estimated as follows:
The estimated medium transmittance map, denoted as , represents a local region of size 15 × 15 centered on . Here, denotes the color channel, and the medium transmittance estimate is related to the uniform background light .
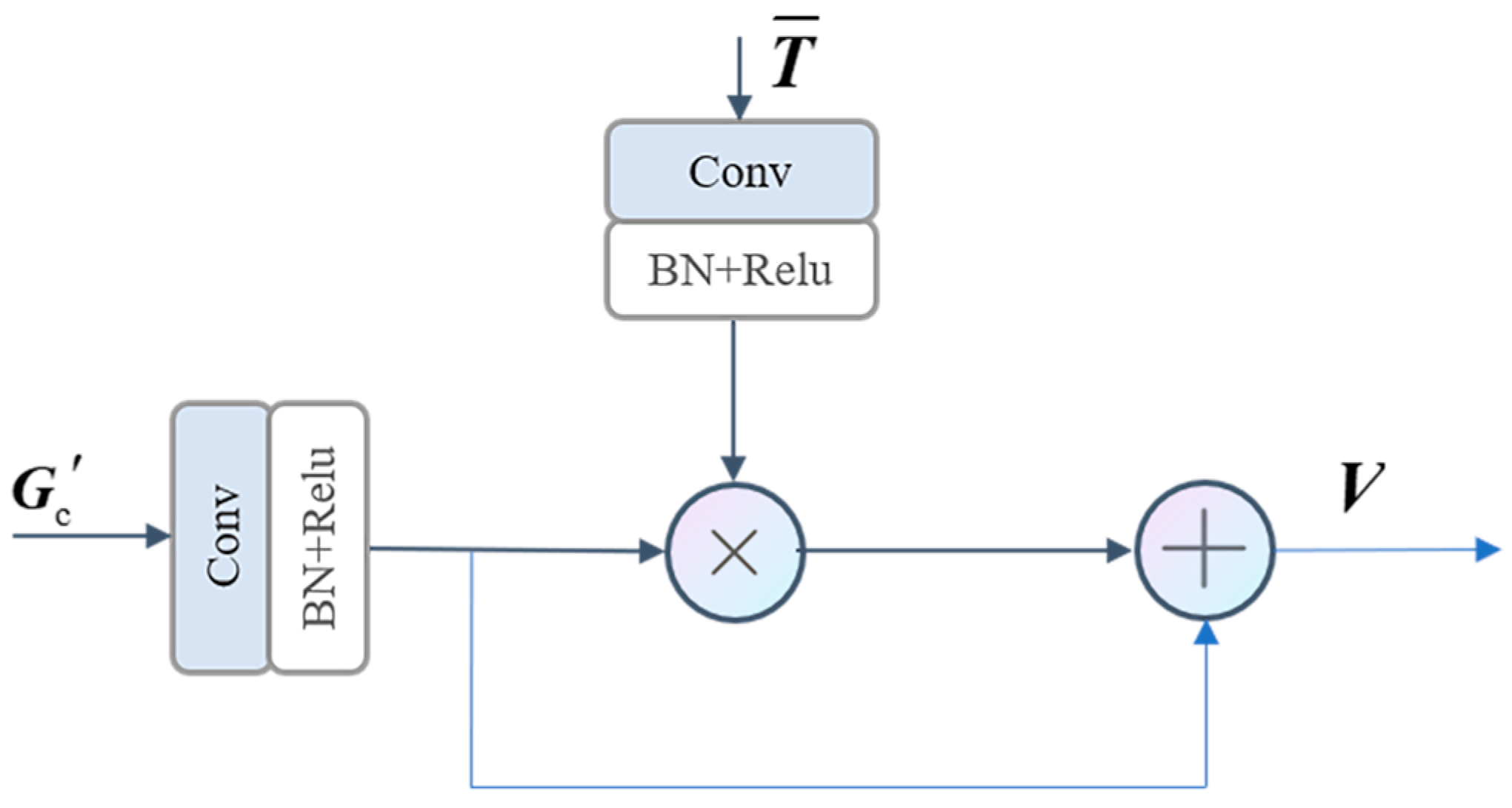
The schematic diagram of the proposed feature fusion module is illustrated in
Figure 7, where
and
represent the input features and output features in the feature fusion module, respectively. The RMT map
, with
, represents the reverse medium transmittance map in the range of [0, 1]. This map acts as a feature selector, assigning weights to different spatial locations of the features based on their respective importance. High-quality degraded pixels, represented by larger RMT values, are assigned higher weights. To extract RMT features and obtain rich local area features, a dilated convolution with a dilation rate of 2, a convolution kernel size of 3 × 3, and a convolution step of 1 are employed. Additionally, a convolution with a convolution kernel size of 3 × 3, a padding of 1, and a step size of 2 is used to extract RGB image features. The RMT features act as auxiliary information for feature selection of RGB image features, allowing the network to adaptively select regional features with severe image degradation.
2.5. Loss Function
The loss function of the proposed UW-AAE model in this study comprises two main components: the Color-AE module
and the adversarial network module
.
is a linearly optimized combination of the reconstruction loss function
and the perceptual loss function
, utilized to train the Color-AE module. The final loss
is expressed as follows:
The hyperparameter
is used as a trade-off factor to balance the weights of the loss functions
and
. In this study,
is set to 0.05.
represents the difference between the reconstructed result
and the corresponding true data
, and can be expressed as follows:
To enhance the visual quality of the image, the VGG19 pre-training model [
27] is incorporated into the framework. The perceptual loss, denoted as
, is computed based on the disparity between the reconstructed image response from the convolutional neural network and the feature mapping of the target image. Here,
represents the high-level feature extracted from the
th convolutional layer. The distance between the reconstructed result
and the feature representation of the ground truth image
is defined as follows:
This formula delineates the establishment of a perceptual loss at each pixel position through the computation of the absolute disparity between the feature representations of the reconstructed image and the truth image at feature layer . This perceptual loss is computed as the disparity between the reconstructed image and the truth image. This metric of disparity serves to gauge the semblance between the reconstructed image and the truth image within the feature space. This methodology offers the advantage of proficiently steering the optimization of the reconstructed image, circumventing the necessity for real data, which can be arduous to acquire.
The generator
in the adversarial network serves as the encoder of Color-AE, generating negative samples denoted as
. In other words,
. The discriminator receives both the positive samples
from the encoder of the pre-trained CNN-AE and the negative samples
. The loss function of the discriminator in the adversarial network is given as follows:
where
represents the hidden space distribution of the pre-trained model CNN-AE, and
is the training data distribution. Through adversarial training,
is enforced to approach the hidden space of Color-AEE.
4. Conclusions
In this paper, to address the challenges of color deviation and low contrast in underwater images, we present an underwater image enhancement method based on the attention mechanism and adversarial autoencoder. By incorporating positive samples from the pre-trained model and negative samples generated by the encoder, the discriminator guides the autoencoder’s hidden space to approximate that of the pre-trained model. Furthermore, the encoder features, extracted using the attention mechanism, are fused with the features from the reverse medium transmittance map in the feature fusion module. This enhances the network’s ability to respond to regions with degraded image quality. The comparison experiments demonstrate that the reconstructed images outperform the existing six algorithms. When compared with the unprocessed real underwater images, the average Natural Image Quality Evaluator value is reduced by 27.8%, the average Underwater Color Image Quality Evaluation value is improved by 28.8%, and the average Structural Similarity and Peak Signal-to-Noise Ratio values are enhanced by 35.7% and 42.8%, respectively. The method exhibits excellent visual effects, effectively restoring the real scene of underwater images and enhancing the visibility of underwater target objects. It holds the potential to be utilized by underwater robots in future applications such as exploring marine resources and cleaning the bottoms of large ships.
Our proposed method is not without limitations. Primarily, our approach emphasizes underwater image color correction and contrast enhancement, but it may fall short in addressing the enhancement challenges posed by extremely turbid underwater images. To address this limitation, future research endeavors could focus on expanding the dataset to enhance the accuracy of transmission map estimation and bolster the model’s overall robustness. In the future, we will continue to explore the combination of traditional methods with deep learning-based approaches to develop more innovative interaction designs. Moreover, we aim to generalize our algorithms to various other domains.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}