Abstract
With the advent of the digital age, traditional lifestyle activities, such as reading books, referencing recipes, and enjoying music, have progressively transitioned from offline to online. However, numerous issues plague the conventional approach to digital copyright protection. This is especially true in the realm of recipe protection, where the rights and interests of original creators are inadequately safeguarded due to the widespread dissemination of a large number of recipes on the Internet. This primarily stems from the high costs of gathering evidence, incomplete coverage of evidence collection, and the inability to identify and halt infringement activities in a timely manner during the process of traditional digital copyright protection. Therefore, this study designs and implements a blockchain-based digital recipe copyright protection scheme to address the issues of insufficient legal evidence and cumbersome processes in traditional digital copyright protection. First, we enhance standard short text similarity calculation method SimHash, boosting the accuracy of text similarity detection. We then utilize the decentralization, immutability, time-stamping, traceability, and smart contract features of blockchain technology for data privacy protection. We employ the Interplanetary File System (IPFS) to store raw data, thereby ensuring user privacy and security. Lastly, we improve the proxy voting node selection in the existing delegated proof of stake (DPOS) consensus mechanism. According thorough evaluation and empirical analysis, the scheme effectively improves the accuracy of text similarity detection. Simultaneously, the enhanced DPOS mechanism effectively rewards nodes with excellent performance and penalizes nodes exhibiting malicious behavior. In this study, we successfully designed and implemented an innovative digital recipe copyright protection scheme. This scheme effectively enhances the accuracy of text similarity detection; ensures the privacy and security of user data; and, through an enhanced DPOS mechanism, rewards well-performing nodes while penalizing those exhibiting malicious behavior.
1. Introduction
With the rapid development of technology and the popularity of digital products, all kinds of digital platforms have become a part of our daily life, for example, digital recipes [1]. In March 2011, a food software became popular among users, owing to its unique features; it has since become the premier family food app on the Chinese Internet. According to the latest data, this software is one of the most popular apps on the Chinese Internet regarding the number of downloads and the number of active users. In addition, it has a significant presence in the international market, especially in non-Chinese-speaking regions. The app provides users with a one-stop service, including functions such as ingredient purchase, kitchenware purchase, recipe search, and sharing.
With the success of leading digital recipe platforms, an increasing number of companies have begun to create their own digital recipe boards. Numerous food lovers share and upload their ideas and work on these platforms for other users to download and learn from. However, this convenience has also revealed some problems. For example, there is a large amount of repetitive and redundant recipes in the market, and plagiarism even occurs to a certain extent. These problems stem from the imperfection of the existing digital copyright protection system, which threatens the interests of original works and the market order and hinders the cultural market’s healthy development and innovation [2].
Currently, the challenges facing digital copyright protection [3] include the proliferation of copyright infringement, loopholes in copyright registration, difficulties in enforcing rights, and low public awareness of copyright protection. These problems are particularly evident in digital recipes, as numerous chefs and food enthusiasts share and upload their unique works on various apps, making the task of copyright protection increasingly arduous. Therefore, we need to find an innovative way to address these issues, protect the rights of creators, and promote the healthy development of the digital recipe field [4].
The application of blockchain technology in digital rights management has made significant progress. It has also been successfully applied in other fields, such as the management o medical records and music copyright, demonstrating its wide application potential. Some new technologies and strategies, such as SimHash and improved text similarity detection methods, are also improving the accuracy and efficiency of copyright protection. However, despite its many advantages, blockchain faces challenges such as widespread copyright infringement and weak copyright awareness in practical applications, which require further research and improvement.
This research aims to design and implement a blockchain-based digital recipe copyright protection scheme to address the many challenges faced in the digital recipe domain. Our method attempts to reshape the current digital copyright protection landscape by providing a secure, efficient, convenient, and traceable solution. The main contributions of this paper are outlined as follows:
- A novel blockchain-based copyright protection scheme for recipes is proposed to provide all participants with a fair, secure, and trustworthy digital environment.
- The traditional SimHash algorithm is improved for the problem of imperfect audit mechanisms. The method combines TF-IDF and PageRank to improve Simhash. Compared with the conventional model, this new approach introduces the consideration of semantic information and word importance while ensuring the word frequency, significantly improving accuracy and recall.
- To solve the centrality problem of the traditional DPOS consensus mechanism, a specific consensus mechanism based on the quality of recipes is proposed. The DPOS consensus mechanism is effectively improved by considering recipes’ completeness, logic, and detail to calculate the nodes’ rank.
Overall, with this study, we hope to change status quo of digital copyright protection by introducing blockchain technology to provide a fairer, safer, and more trustworthy digital environment for recipe authors and users. The remainder of this paper is organized as follows. Section 2 describes the current research status of blockchain digital copyright protection at home and abroad. Section 3 delves into the schematic design of this study, encompassing a thorough analysis of the problems at hand and a detailed exposition of the salient features of our proposed system. Section 4 elucidates our enhanced text similarity algorithm, showcasing its advantages and methodology. Section 5 provides an in-depth description of the improved delegated proof of stake (DPOS) algorithm, highlighting its modifications and relevance Section 6 presents a comprehensive experimental comparison, validating the effectiveness and efficiency of our proposed methods.
2. Literature Review
With the increasing digitization of content across various domains, the challenge of effectively managing and protecting intellectual property has taken center stage. One of the critical areas where these challenges are highly pronounced is in the digital recipe domain. As technology evolves, so does the need for robust mechanisms to ensure the integrity, authenticity, and security of digital content. In this literature review, we delve into the foundational works and recent advancements in blockchain technology, digital copyright protection, and text similarity detection that serve as the underpinning for our research.
In his 2008 paper, “Bitcoin: A Peer-to-Peer Electronic Cash System”, Satoshi Nakamoto proposed and practised the blockchain. This groundbreaking technology offers a unique solution to the problem of trust in a networked environment [5]. However, the great potential of blockchain technology does not stop there; in 2013, Vitalik Buterin led the way with Ethereum [6], a blockchain platform that not only supports digital currency [7] functionality but is also capable of running smart contracts, greatly broadening the application areas of blockchain.
For digital copyright issues, the smart contract function of Ethereum can realize the automated management and execution of copyright information, making the dissemination of works more standardized and legal. Copyright registration based on blockchain technology also greatly improves the security of copyright information due to its tamper-proof characteristics. These characteristics of Ethereum also provide strong technical support and judicial evidence for the subsequent rights defense activities of copyright holders, protecting the legitimate rights and interests of copyright owners more effectively. Therefore, Ethereum has great application value and development potential in the field of digital copyright [8].
The characteristics of blockchain make it show great potential for copyright protection. Once the information is written into the blockchain, neither the uploader nor the relevant registration organization can modify the registration information, which provides a trustworthy guarantee for copyright registration. In recent years, research on and applications of blockchain for digital copyright protection have also made remarkable progress, providing new ideas and solutions to solve current digital copyright problems.
Bodó, B. and others explored the application of blockchain and smart contracts in copyright licensing. They proposed that authors can create records of ownership for their works through blockchain and encode smart contracts to license the use of their works. This provides new possibilities for copyright management. However, the article also points out that this method may not fully comply with some fundamental components of copyright law, such as exceptions and limitations, the principle of exhaustion, formal restrictions, the public domain, and fair remuneration [9]. Jing Sun et al. counted and illustrated the infringement status of medical journal copyrights from the perspective of the current infringement status of medical journals, compared the differences between traditional digital copyright protection technology and blockchain technology, and analyzed the advantages of blockchain technology and the feasibility and prospects of blockchain technology applied to digital copyright protection of medical journals [10]. Asaph Azaria et al. proposed a MedRec system that uses blockchain technology for electronic medical records to provide a comprehensive, immutable log that enables patients to easily access their medical information across providers and treatment sites. The system utilizes blockchain features to manage authentication, confidentiality, accountability, and data sharing. In addition, MedRec enables a data economy by incentivizing medical researchers to participate in network mining and providing them with access to aggregated, anonymized data [11]. Natgunanathan et al. discussed a digital audio watermarking algorithm that utilizes blockchain technology to protect the copyright of musical works. The authors proposed a method that combines the benefits of blockchain technology (e.g., decentralization and tamper proofing) with the robustness of digital watermarking. The proposed method can effectively protect the copyright of digital music and verify the authenticity of musical works [12]. Based on the characteristics of blockchain, Zhao Feng and Zhou Wei illustrated that the technology brings opportunities for digital copyright, such as reducing costs, solving registration and proof challenges, and responding to transaction needs [13]. Jie Zhang and others proposed a strategy to improve existing text similarity detection methods. This strategy integrates the term frequency–inverse document frequency index (TF-IDF), linguistic attributes, word length, and word position to form a comprehensive weighted text similarity detection approach. Through this approach, the accuracy of copyright clearance algorithms has been significantly enhanced. Moreover, they analyzed the challenges faced by traditional digital copyright protection systems, such as the erosion of the value basis of works, rampant infringement, obvious shortcomings in copyright registration, difficulties in rights protection, the public’s insufficient awareness of copyright, etc. [14]. The theoretical foundations and algorithmic implementations of SimHash were described in detail by Charikar Moses et al. SimHash is a locally sensitive hashing algorithm that quickly detects similar data in high-dimensional space. In the article, the authors detailed the theoretical foundations of SimHash, including the design of its hash function, the similarity calculation method, and how to use SimHash for fast similarity detection [15]. Uddin, M.S. and Roy, C.K. proposed a novel method utilizing SimHash to detect near-miss clones in large-scale software systems. Their significant contribution lies in the development of a new clone detection approach that uses SimHash to gauge code similarity, further employing indexing strategies and data clustering algorithms to accelerate clone search. This approach has demonstrated high efficiency and accuracy when managing large-scale codebases [16].
In summary, the literature underscores the potential of blockchain technology as a transformative tool for digital rights management. While the initial focus of blockchain was primarily in the realm of cryptocurrencies, its application has since expanded to various sectors, including the protection of digital recipes. Additionally, the advancements in text similarity detection algorithms have paved the way for more accurate copyright infringement detection. Our study draws inspiration from these foundational works, aiming to address the existing gaps and contribute to the ongoing discourse in this domain.
3. Schematic Design
3.1. Problem Analysis
In the current ecosystem, piracy and plagiarism of digital recipes cannot be avoided. Therefore, our main task is to prevent piracy and enable rights holders to quickly trace their copyrights after a piracy incident. To this end, there are three main issues we need to address:
- When nodes transmit recipe data, we need to use a copyright review algorithm to conduct text similarity detection on the node’s data to prevent the occurrence of inappropriate content events;
- Solve the problem that the DPOS consensus mechanism is generally questioned as too centralized and the human operation space in the proxy bookkeeping nodes’ election process;
- When an incident of unauthorized use occurs, we need to ensure that rights holders can quickly trace their copyrights to protect the legitimate rights and interests of creators.
To address the above issues, we designed a system that uses an improved text similarity algorithm and image feature computation to compare users’ data, utilizing the Interplanetary File System (IPFS) for data storage and a blockchain-based dual-chain structure to store copyright information and transaction information, respectively. We also introduce an information reward mechanism to encourage users to upload recipes and participate in consensus. This design scheme not only realizes the digital copyright protection of recipes but also provides a strong guarantee for the fair governance of the system.
3.2. System Design
3.2.1. System Composition and User Interaction Flow
Our proposed digital copyright protection system is a multilayer, multirole network system initially designed to fulfill the needs of digital recipe copyright protection in a distributed network environment. The system, as a whole, is divided into a user layer, application service layer, node layer, contract layer, consensus layer, and data layer, as shown in Figure 1.
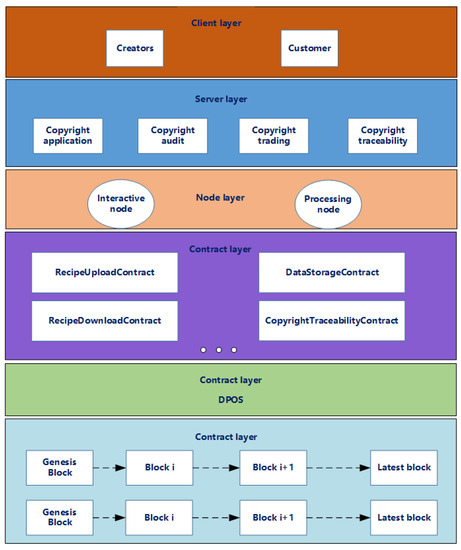
Figure 1.
Blockchain architecture diagram.
The user layer is mainly composed of creators and customers, which interact with the system through the client. Users can switch roles according to their needs to complete the uploading and downloading of recipes.
The service layer contains four main modules: copyright application, audit, transaction, and traceability. It is primarily responsible for accomplishing the overall functional requirements.
The node layer is divided into interaction nodes and processing nodes. Interaction nodes represent user interaction nodes, which are primarily involved in user interaction, including creating, uploading, downloading, and decryption of recipes. Processing nodes are responsible for data processing, validation, and storage.
The contract layer mainly realizes the modules used by the server side. It contains four primary smart contracts: RecipeUploadContract, DataStorageContract, RecipeDownloadContract, and CopyrightTraceabilityContract.
The consensus layer comprises an improved DPOS consensus mechanism. Transactions are quickly agreed upon between nodes in a distributed system. To ensure the security and integrity of transactions, we introduce an authentication system. Each node that participates in the consensus needs to go through an authentication process that ensures that it is a registered and trusted node. In addition, we design a credential management system to store, update, and revoke the credentials of nodes. This ensures that only nodes with valid credentials can participate in the consensus process, enhancing the security of the system.
The data layer is divided into the main chain and side chain. The main chain stores the hash address of the user’s data. It ensures that the creator’s work is public and cannot be tampered with. The side chain holds the user’s copyright transaction information, which is convenient for later rights holders to trace the copyright.
3.2.2. Blockchain Data Upload and Download
The user interaction of a digital copyright protection system consists of two main aspects: uploading and downloading data. The design and realization of these two key processes are described in detail below, as shown in Figure 2.
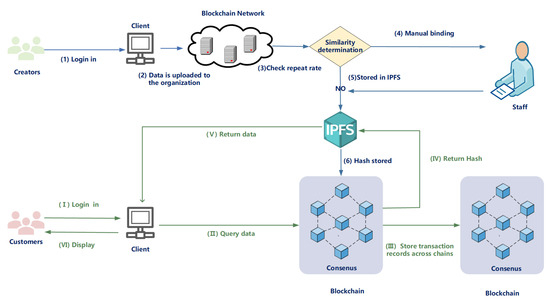
Figure 2.
System network architecture diagram.
In our Ethereum-based digital copyright protection system for blockchain recipes, first, a user registers, and the system automatically generates a public/private key pair. The public key is used for external data encryption, while the private key, known only to the user, is employed to decrypt received data. Furthermore, the private key’s storage on the server is encrypted, offering dual-layer protection. The system also allows users to easily update or revoke their keys if they suspect their key’s security is compromised. Through this method, we ensure the integrity and security of user credentials.A creator (e.g., Alice) uploads their recipe by invoking a smart contract [17], i.e., “RecipeUploadContract” (as described in Algorithm 1). Alice creates a new recipe, such as “Delicious Pasta”, and uses her private key () [18] to sign the content, then encrypts the recipe using her public key () [19]. In this way, the integrity and authenticity of the recipe are guaranteed. This process is called a transaction in the Ethereum blockchain, and Alice’s signature ensures the non-repudiation of the transaction. Next, the encrypted recipe and signature are sent to the main chain node responsible for duplicate recipe detection. This smart contract determines if there is a duplicate by comparing the newly uploaded recipe to the existing recipes on the blockchain. If a copy exists, then the recipe will not be accepted. If the recipe passes duplicate detection, it is sent to an IPFS [20] node, which stores the recipe in a distributed file system and generates a hash address based on its contents. This hash address is then sent to the master chain node. The master chain node runs a smart contract called “DataStorageContract” that stores the hash address, Alice’s public key, the recipe’s signature, a timestamp, and other metadata () (e.g., the title of the recipe, Alice’s name, the type of recipe, etc.) on the blockchain. This way, recipes are assigned unique data credentials, and copyrights are protected. When a user (e.g., Bob) wants to download a recipe, he calls the “RecipeDownloadContract” smart contract (as described in Algorithm 2) and provides his public key and the ID of the recipe () he wants to download; then, the smart contract validates Bob’s request. First, it checks if Bob has permission to download the recipe. If Bob has the license (), the smart contract obtains the hash address of the recipe from the blockchain and sends it to a specialized intermediate node. The intermediate node uses this hash address to download the recipes encrypted with Alice’s public key from the IPFS node. The intermediate node contacts Alice and asks her to generate a re-encryption key for Bob [21]. The intermediate node uses this key to transform the recipes encrypted with Alice’s public key into one with Bob’s public key. The intermediate node sends the recipes encrypted with Bob’s public key () back to Bob’s node. After Bob’s node receives this ciphertext, he can decrypt it using his private key to obtain the recipe’s contents. When Bob successfully downloads the recipe, this transaction needs to be recorded. The smart contract encapsulates the details of this download transaction, including the ID of the recipe, Bob’s public key, Alice’s public key, and the time when the transaction occurred, into a transaction record. This transaction record is then sent to the side chain for storage.
When an unauthorized use event occurs, Alice can quickly retrieve all transaction records related to her in the side chain through the smart contract “TransactionQueryContract” using the recipe ID and her public key as input. This has important implications for copyright protection because the information on the side chain can be used as legally valid evidence to prove her ownership if there is any dispute. All transactions are timestamped with the involved parties’ public keys, confirming that at a particular point in time, Alice’s recipes were downloaded by a specific user. In addition, because these records are on the blockchain, they are immutable, which provides strong evidence for resolution of copyright disputes.
The proposed solution ensures the integrity, authenticity, security, and availability of recipes while protecting the copyright of the creators. Data flow from one node to another in the network, each with specific tasks and functions. Through the collaborative work of these smart contracts and nodes, the blockchain network effectively protects the creators’ copyrights and provides users with a convenient recipe download service.
| Algorithm 1 RecipeUploadContract |
|
| Algorithm 2 RecipeDownloadContract |
|
4. Text Similarity Detection
Text similarity detection [22] plays a crucial role in our blockchain recipe copyright protection system. First, by analyzing the similarity of newly submitted recipes, highly similar or even duplicated recipes can be detected, preventing the uploading of duplicate content and ensuring the diversity and originality of recipe content in the system. Similarity detection can also help us make preliminary judgments on the issue of suspected copyright conflicts. For cases with a large number of similar passages or even a simple rewrite of existing recipes, we can detect and deal with these problems as early as possible through high similarity judgment to protect the rights and interests of the original creators.
4.1. SimHash Algorithm
The SimHash [23] algorithm is an efficient method of processing high-dimensional data by converting high-dimensional feature data into low-dimensional hash codes that maintain the approximate similarity of the original spatial data. The key idea of the SimHash algorithm is to reduce the dimensions of large-scale and high-dimensional feature vectors to a fixed-length bit string (usually 64 bits), while keeping the Hamming distance between the bit strings corresponding to similar feature vectors small. In this way, the Hamming distance between two bit strings can be calculated to approximately represent the similarity of the original feature vectors, as shown in Figure 3.
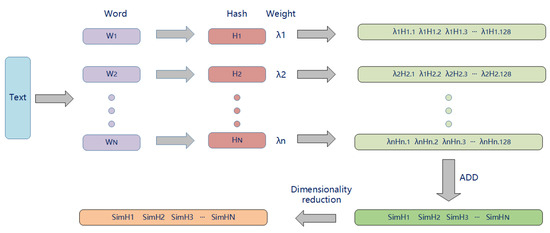
Figure 3.
SimHash algorithm diagram.
When performing the SimHash operation, features are first extracted from the text. Features are usually in the form of words or phrases, and the extraction process includes preprocessing, word segmentation, stop word removal, stemming, and other steps. A hash function maps each feature to a fixed-length binary string. This mapping should be homogeneous, i.e., any input has an equal probability of being mapped to any position in the hash space.
The next step is feature weighting. In this process, the algorithm considers the weight of each feature, which can be derived in several ways; for example, the widely used TF-IDF (term frequency–inverse document frequency) algorithm [24] is often employed to calculate weights. TF-IDF is a common algorithm in text mining that quantifies the importance of a word in a document relative to its frequency in a larger corpus. The ‘TF’ part measures the frequency of a word in a document, and ‘IDF’ reduces the weight of words that appear frequently across many documents, thereby ensuring that common words like ‘and’, ‘the’, etc., do not unduly influence the analysis. The weight reflects the importance of the feature in the text. The higher the weight, the greater the influence of the feature when generating the SimHash value.
The algorithm then weighs and aggregates the hash values based on the feature weights. Specifically, the algorithm assigns a weight to each bit of the hash value of each feature, then adds up the weighted hash values of all the features and finally decides whether each bit of the final SimHash value is a 0 or a 1 by comparing the size of the weighted sum of each bit with zero.
Finally, the SimHash algorithm estimates the similarity of the original data by calculating the Hamming distance (i.e., the number of corresponding bits of the binary string that are different) between the two hash values. Since SimHash retains the structure and content information of the original data, and the Hamming distance can better reflect the similarity between the original data.
4.2. PageRank Algorithm
PageRank [25] is an algorithm developed by the founders of Google, Larry Page and Sergey Brin, in 1996 that is used to measure the importance of web pages. The main idea of PageRank is that the extent of a web page depends not only on the number of other web pages linking to it but also on the importance of those pages themselves. The algorithm is based on hyperlinks between web pages, where each web page is considered a node, and each link as an edge pointing from one node to another.
In this formula [26], is the PageRank value of web page A that we want to calculate; to are the PageRank values of all web pages linking to web page A; to is the number of outgoing links of all web pages linking to web page A; and d is the damping factor, which is usually set to 0.85 and represents the probability that a web page will be accessed randomly.
When deployed for text similarity detection, the traditional SimHash algorithm exhibits a significant limitation. Primarily, this algorithm calculates the hash value of the text based on the frequency of words within the text. However, this method falls short in accurately reflecting the importance of individual words within the text.For instance, high-frequency words such as “de”, “shi”, and “in” appear frequently across various texts but contribute minimally to the semantic understanding of the content. Although one can minimize this effect by eliminating generic or “stop words”, some semantically insignificant words might still persist due to their high frequency.On the contrary, certain low-frequency words, despite their infrequent appearance, may serve as crucial keywords and contribute significantly to the semantics of the text. Hence, if the text’s hash value computation relies solely on word frequency, it may overlook these important low-frequency words, leading to imprecise results in text similarity calculation. In the context of blockchain algorithm engineering, these discrepancies can have notable impacts, possibly leading to erroneous conclusions or ineffective solutions. Therefore, refining the approach for better consideration of the semantic importance of words, regardless of their frequency, is a critical aspect of improving the effectiveness and precision of the SimHash algorithm.
To more accurately quantify the importance of each word within a text, this study proposes a text hashing calculation method based on the PageRank algorithm. In this approach, we conceptualize the text as a network where each word represents a node and syntactic dependencies between words act as the edges connecting these nodes [27]. Syntactic dependencies delineate the relationships between words within sentences. For example, in the sentence “the cat is sitting on the mat”, the term “sitting” depends on “cat” to denote the actor of the action, whereas “mat” relies on “sitting” to denote the target of the action.
We incorporate the concept of the PageRank algorithm into this language dependency network (Figure 4). Within this network, each word is viewed as a node, with the syntactic dependencies serving as the edges connecting these nodes. The damping factor from the PageRank algorithm, typically set at 0.85, is also employed, representing a user’s propensity to randomly click on links while browsing web pages. However, given the unique characteristics of natural language text as opposed to web page links, adjustments to the PageRank formula are necessary to suit the demands of natural language processing. We focus on the words that contribute significantly to the sentence’s semantics. Therefore, take specific dependencies into consideration, such as ROOT, adj, attr, obj, dobj, iobj, pobj, subj, nsubj, and csubj. These dependencies reflect the crucial roles that words play within sentences, such as subjects, objects, adjectives, and verbs. By using this method, we can calculate the PageRank score for each word in the vocabulary, which reflects its importance within the text. This method effectively filters out noise words that make minimal semantic contributions, accurately capturing the semantic information of the text. During the iterative process, we first calculate an initial PageRank score for each word, then iteratively update based on the PageRank formula and the damping factor. After each iteration, the updated PageRank score for each word represents the change in the importance of that word within the sentence, better reflecting the semantic information of the text. Taking the sentence “the cat is sitting on the mat” as an example, through several iterations, we continually update the PageRank scores for each word, ultimately obtaining a more precise representation of the sentence’s semantics through the weighted words. This text hashing calculation method based on the PageRank algorithm offers a novel and more precise approach for text similarity detection. The computation results are shown in Table 1.
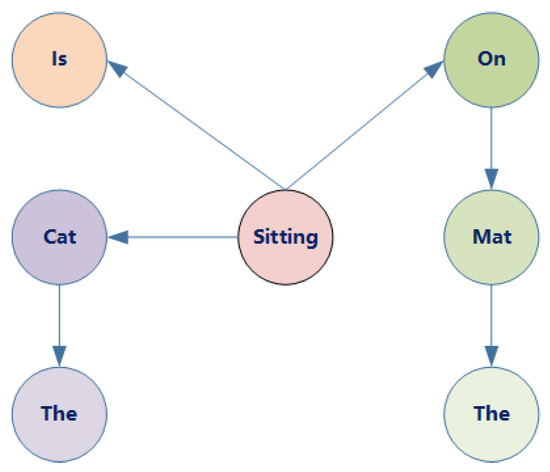
Figure 4.
“The cat is sitting on the mat” dependency network.

Table 1.
Iterative calculation of PageRank scores.
- Initialization of PageRank values:
- First iteration:
4.3. Improved SimHash Algorithm
The current SimHash has some limitations in terms of semantics and word importance when dealing with natural language processing problems, so we propose an improved P-SimHash algorithm (as shown in Figure 5), the goal of which is to more accurately capture semantic similarities between texts. This improved SimHash algorithm combines dependency parsing and the PageRank algorithm for weight computation based on the traditional SimHash algorithm. In the preprocessing stage, we perform lexical segmentation on the text and lexical lemmatization with WordNetLemmatizer [28] for English text in order to transform words with different morphologies into their original forms (The Chinese dataset does not need to use lemmatization). Then, we adopt the dependency parsing technique to construct a co-occurrence network based on the dependencies between words. In this network, nodes represent words and edges represent dependencies between words. Sentences are parsed using spaCy [29], and directed graphs are constructed based on word dependencies. Next, we score each node in the co-occurrence network using the PageRank algorithm. The PageRank score represents the importance of the word in the text, i.e., its centrality in the dependency network. We also use the TF-IDF method to calculate the weights of the words, and the TF-IDF values reflect the uniqueness of the words. Our improvement is to combine the PageRank score and TF-IDF weights to generate a composite weight. This composite weight considers both the importance and uniqueness of the word. We replace the frequency count in the traditional SimHash algorithm with the improved combined weight to calculate the SimHash value. Unlike the conventional SimHash algorithm, our SimHash value is a weighted hash code whose weights reflect the importance and uniqueness of words.
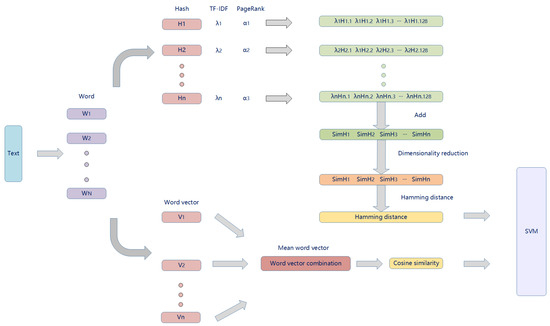
Figure 5.
P-SimHash algorithm diagram.
To solve the relationship between semantics, we introduce a pretrained word model [29] in natural processing that learns the contextual information of words in a large-scale corpus and maps each subword to a fixed-size vector space. The subword contains semantic and syntactic relations of common contexts, which enables us to compute text similarity much faster. Common pretrained models include Word2Vec [30], GloVe [31], BERT [32], etc. Each sentence is the average of the corresponding word vectors of all the words. Then, this representation is used to compute the cosine similarity of the two sentences. Both cosine similarity and Hamming distance are key measures of similarity between texts. Among them, cosine similarity [33] quantifies the angle between two text vectors in a multidimensional space, which captures the semantic similarity of the texts. Hamming distance [34] measures the structural differences of the texts by calculating the number of different characters in the corresponding positions between two equal-length strings. To fully utilize the respective advantages of these two metrics, we input them as features into a support vector machine (SVM) [35] model for binary classification tasks, as described in Algorithm 3.
| Algorithm 3 Sentence Similarity Calculation |
|
4.4. Results of the Experiment
4.4.1. Datasets
In the experiments, we choose two datasets (English and Chinese) for testing. Our selected dataset for English is STS [36], a widely accepted and used English dataset for evaluation of the performance of text similarity algorithms. The STS dataset contains a human marker with a score between 1 and 5, with higher scores indicating higher similarity of the human marker. Based on experiments and textual analysis, texts with scores greater than or equal to 2 are determined to be similar.
Because there is no authoritatively recognized Chinese dataset for the digital recipe text detection task, we crawled 600 related recipe data points from mainstream websites as experimental data. To evaluate whether the SimHash algorithm proposed in this paper improves the accuracy in a similar text detection task, we processed 300 of the original data as follows (as shown in the Figure 6):
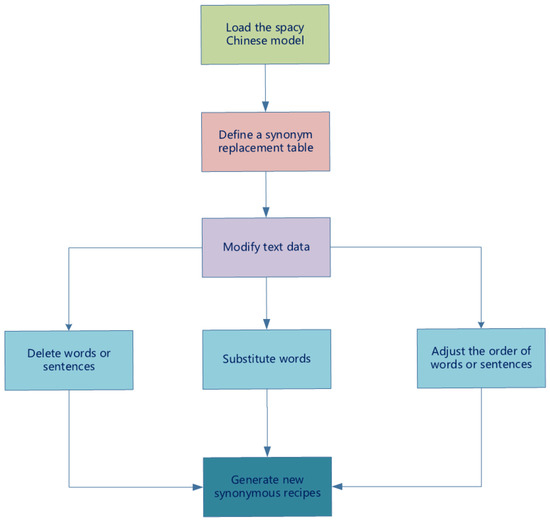
Figure 6.
Preprocessing of the Chinese dataset.
- Delete words or sentences: Delete parts of the ingredients or parts of the steps of the steps with a probability of 20%;
- Replace ingredients: Replace some ingredients or cooking methods in a recipe with a predefined list of ingredient synonyms, e.g., replace “red pepper” with [“red chili pepper”, “red bell pepper”] or replace “stir-fry” with [“boil”, “slow stir-fry”];
- Reordering words or statements: Swapping the order of some words and statements;
4.4.2. Experimental Environment and Comparison Algorithms
This experiment was developed and tested in a Python programming environment, and the hardware platform used was a Windows mainframe equipped with an 11th-generation Intel(R) Core(TM) i5-11400H processor (with a base frequency of 2.70 GHz), 16 GB of RAM, and a 1 TB hard disk.
In the experimental design, we systematically compared and evaluated three different text similarity calculation methods:
- SimHash algorithm [15]: SimHash is a technique that transforms high-dimensional feature vectors into low-dimensional feature fingerprints. It generates fingerprints by calculating the statistical characteristics of the input data and compares these fingerprints using the Hamming distance. Due to its dimensionality reduction properties, SimHash is capable of effectively handling large-scale or high-dimensional data, reducing the complexity of storage and computation. It is particularly suited for detecting near-duplicate contents, such as in web crawling or copyright detection scenarios.
- Method based on pretrained word models [37]: This method leverages word vector models that are pretrained on extensive corpora, like Word2Vec or GloVe. Through these models, each word can be translated into a vector of fixed size, capturing the semantic information and relationships between words. Averaging or weighted averaging of word vectors in a sentence or document can derive a vector representation of the sentence or document. The strength of this method lies in its ability to capture the deep semantic information of texts.
- Vector space model (VSM) combined with TF-IDF [38]: The VSM is a method of representing text as vectors, where each dimension represents a specific word or term. TF-IDF is a statistical method used to evaluate the importance of a word in a collection of documents, with TF representing term frequency and IDF denoting inverse document frequency. Combining VSM with TF-IDF results in a weighted feature vector of the text. Subsequently, cosine similarity can be utilized to compute the similarity between these vectors. This method’s advantage is that it captures the term frequency and significance in the text, thereby enhancing the accuracy of similarity computation.
- WMF-LDA [39]: The WMF-LDA algorithm utilizes the semantic and part-of-speech information of words, as well as the domain differences between different types of texts, to improve the application of the traditional LDA model in the field of text similarity computation. This algorithm first maps domain words and synonyms to a unified word through the word2vec model, filters out irrelevant words based on their part-of-speech, and finally uses the LDA model to perform topic modeling on the text. The JS distance is then used to calculate the similarity between texts.
Each of these algorithms has its own strengths and characteristics, making them suitable for different types of text similarity calculation tasks and offering a comprehensive reference and comparison for the experiment.
4.4.3. Experimental Results and Analysis
We selected 1400 pairs of preprocessed English text data from the STS dataset and 600 pairs from the Chinese recipe dataset, to which we applied the traditional SimHash algorithm, the pretrained word-model-based approach, VSM, WMF-LDA, and our improved P-SimHash algorithm. The specific process is shown in Figure 7. We recorded and counted the number of similar texts and the number of misclassified texts found by each algorithm. Comparison results on the STS dataset are shown in Table 2, which demonstrates the average performance of each algorithm in terms of accuracy.
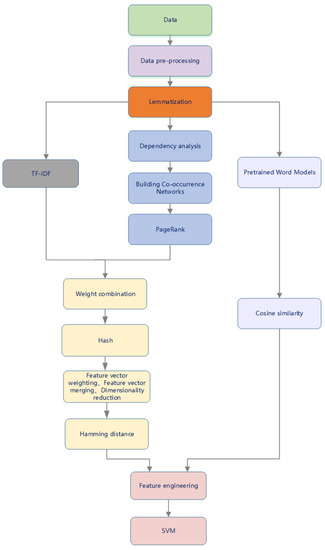
Figure 7.
P-SimHash algorithm diagram.
Table 2.
Experimental comparison results of the STS dataset.
There are many ways to evaluate a similar text detection task, and the common evaluation criteria are the detection rate and recall rate, through which the evaluation index can effectively reflect the effectiveness of the similar text detection algorithm. To better show the experimental results, the average detection rate and recall rate of similar text detection are shown as a cluster bar chart Figure 8.
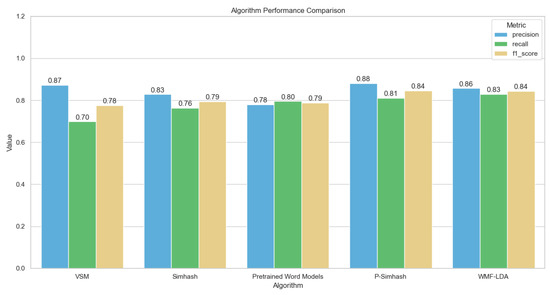
Figure 8.
Cluster diagram of comparative experiment on the STS.
For datasets in Chinese, it is necessary to omit the lemmatization step, which is specific to English data processing. This is because Chinese grammatical structure does not differentiate tenses such as past tense or present continuous as English does, and such differentiation might lead to polysemy in natural language processing. Therefore, the lemmatization step is not practically necessary in a Chinese context.
Furthermore, we need to replace the pretrained word embedding model for the Chinese corpus. The Glove model we previously used is trained on an English corpus and is not suitable for Chinese data processing. To this end, we employ the Chinese word and phrase embedding corpus released by Tencent AI Lab as the pretrained word embedding model.
Despite these adjustments, we continue with the comparative experiments as before. The results are shown in Table 3 and Figure 9.
Table 3.
Experimental comparison results of the Chinese dataset.
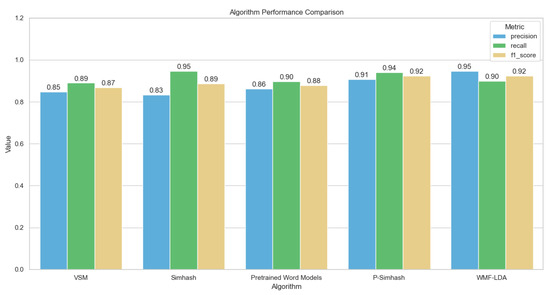
Figure 9.
Cluster diagram of comparative experiment on the Chinese dataset.
Experimental data confirm that our improved SimHash algorithm performed exceptionally well in text similarity detection tasks, regardless of whether the text was in Chinese or English. Compared to other algorithms, our method improved on all metrics. Although the improvements in precision and recall were only one percentage point over the original vector space model (VSM) and pretrained word models in the STS dataset, all other metrics improved in the Chinese recipe dataset, albeit with a slightly lower recall rate than the traditional SimHash algorithm. Overall, the effectiveness of the improved SimHash algorithm is still commendable.
4.5. Time Complexity Analysis
In traditional SimHash algorithms, the primary steps encompass feature extraction, feature weighting, and SimHash value construction. Notably, almost all of these steps exhibit linear time complexity. The overall time complexity of the SimHash algorithm is denoted by , which is determined by the hash length and the number of features, where m signifies the quantity of features in the input data, while b represents the bit length of the SimHash value. A salient distinction in time complexity between the improved model proposed in this paper and the conventional model is the inclusion of the SVM method in the former. The training time complexity of SVM, in its worst-case scenario, ranges between and . Hence, the disparity in time complexities of the two primarily stems from the SVM’s time complexity. With respect to the WMF_LDA text similarity algorithm, the main components of its time complexity are as follows: vocabulary merging and filtering at , WMF_LDA topic modeling at , and text similarity computation at , where N is the number of vocabularies, representing either the word count in individual documents or sentences or the unique word count across the entire dataset; M usually denotes the count of documents or sentences in the dataset; and K signifies the number of topics, typically indicating the number of topics to be extracted from the data in topic modeling.
From a macroscopic perspective, even though traditional SimHash boasts an approximate linear time complexity, granting it superior performance in large-scale text data retrieval, its accuracy is not always on par with other sophisticated models. The p-SimHash retains the efficiency of SimHash, but by integrating concepts from machine learning and graph networks, it significantly enhances its accuracy. Nevertheless, the introduction of a machine learning model implies an addition in time complexity for p-SimHash, specifically the time complexity of SVM. In contrast, while WMF-LDA offers profound insights into text similarity modeling, its computational overhead, especially with an increasing number of documents, is noticeably more demanding. In the context of large datasets, it might necessitate substantial computational resources and time.
Assuming we have features and a fixed-length SimHash value:
- Feature extraction: ;
- Feature weighting: ;
- Constructing SimHash value: , where b is the length of the SimHash value. Assuming a value of 64, then ;
- SVM training (in the worst case): . Assuming we have samples, then .
The overall time complexity of P-SimHash is approximately .
- Vocabulary amalgamation and filtering: ;
- WMF_LDA topic modeling: ;
- Text similarity computation: .
The overall time complexity is approximately . From this simplified mathematical analysis, it is evident that even in the worst case for SVM, the time complexity for p-SimHash (around ) is significantly higher than that of WMF_LDA (around ). This indicates that when processing large-scale datasets, WMF_LDA might necessitate more computational time.
5. Improvement of Consensus Mechanisms and Quality Testing of Recipes
5.1. DPOS (Delegated Proof of Stake)
The DPOS (proof of share authorization) [40] consensus mechanism is a bookkeeping method that borrows from real-life shareholder voting. In this network, the nodes are mainly categorized into verification nodes and ordinary nodes. The coin-holding nodes in the network elect 101 validation nodes through voting, and these validation nodes take turns exercising power with equal rights, including a series of operations in the network, such as transaction validation, packing to blocks, etc., which are completed by these validation nodes. When some nodes fail to complete their tasks on time or carry out malicious behaviors that may affect the whole blockchain network, the other ordinary nodes withdraw their votes for that node [41].
Compared to POS [42] and POW [43], DPOS no longer uses competition to elect bookkeeping nodes and reduces the network’s energy consumption by reducing the number of nodes. In addition, the DPOS mechanism improves the confirmation speed, with each block being generated in about 10 seconds. However, DPOS also poses some challenges:
- The enthusiasm of node voting is insufficient;
- Malicious behavior cannot be stopped in time;
- There is a lot of room for human manipulation in the voting process, so it is widely questioned as being too centralized.
Therefore, according to the production environment, we need to make appropriate adjustments and optimizations to the DPOS consensus mechanism.
5.2. Improved DPOS Algorithm
In the current practical production environment for digital copyright protection, creators submit their own recipes to be stored inside the blockchain, generating a unique proof of copyright. However, the traditional DPOS has a lot of room for human manipulation in the voting process. Therefore, in response to this phenomenon, we dynamically change the rank of the node by obtaining the node’s score. A node’s score (S) depends on the current recipe’s quality. The quality of a recipes is determined by three factors, namely logic (L), detail (D), and completeness (C). and are parameter weights of 0 to 1. The formula is as follows:
In this way, the quality of user recipes can be improved, and human influence in the traditional DPOS voting process can be avoided. In the DPOS consensus mechanism, there are certain kinds of malicious behaviors, such as bribery, whereby certain nodes that want to become validators unite with other voting nodes to increase their probability of becoming validator nodes. In the improved DPOS consensus mechanism, nodes with high data quality are classified as validator nodes, and nodes with low data quality are classified as ordinary nodes, which avoids this phenomenon to a certain extent, and ordinary nodes can improve their rank by improving the quality of their recipes so that they can become validator nodes in the next round of selection. The validator nodes are mainly responsible for creating new blocks to add to the blockchain and validating the blocks created by other nodes. However, in the current environment, malicious nodes aiming to improve their scores inevitably become validator nodes, then carry out negative behaviors [44], including the following categories:
- Non-production of blocks: Some nodes refuse to generate blocks after they become verifier nodes, which is likely to cause delays in the network and reduce the system’s operational efficiency;
- Double signatures: Supporting two different types of blockchain at the same time can lead to the generation of double payments and other problems, seriously affecting the balance of the blockchain;
- Inactivity: Validator nodes must actively participate in the network to validate transactions and generate new blocks. If a validator node is inactive for a long period, then it may be considered a malicious node by the network;
- Denial of service attacks: Validator nodes may still attempt to block the network connectivity of other nodes by sending many invalid transactions or blocks;
- Transaction censorship: Validator nodes selectively pack transactions for some reason;
To avoid this situation, in this paper, we introduce a penalty mechanism. When different malicious behaviors occur in the validator node, we adopt the following strategy.
- Validator nodes that produce malicious behavior cancel their scores and are treated as normal nodes;
- For nodes that have had malicious behavior to transmit data again for scoring, an exponential decay factor (F) is introduced.
The value of F depends on the number of times the current node has acted maliciously. k represents a random coefficient. E represents the number of negative behaviors; the larger the value of E, the less likely the node is to become a validation node. The specific formula is as follows:
Even if the node’s L, D, and C scores are high, if the F score is also high (i.e., the node has exhibited multiple malicious behaviors), S is reduced. At the same time, we consider that if the node with negative behavior actively participates in the consensus and submits high-quality data later in the process, we should reduce the impact of maliciousness and ensure that the node can normally join the network after a period of positive behavior, so we add a time decay factor (T) for the node with malicious behavior.
where represents the decay rate, and is time since the last occurrence of malicious behavior. This function decreases over time. The penalty score is progressively smaller when there is no negative behavior for a long period. Therefore, the score for malicious nodes is expressed as:
5.3. Dynamic Update of Node Rank
In order to allow the system to respond more quickly to changes in node behavior, we introduce a mechanism to update node rankings each time a new block is generated. At the end of each block cycle, the system re-evaluates the behavior of all nodes, including the quality of submitted recipes, occurrences of malicious behavior, etc., and updates each node’s rank accordingly. In this way, nodes making significant contributions to the system are promoted to a higher rank, while those engaged in malicious behavior are downgraded. This process occurs every time a new block is generated, ensuring that our system always reflects the most recent node behaviors. However, frequent rank updates may bring some challenges, including increased computational load, complexity in network communication, and data consistency issues. To address these challenges, we employed efficient rank calculation algorithms, adopted a distributed [45] rank update protocol to ensure data consistency, and ensured system stability through appropriate system design. This allows our blockchain system to respond to changes in node behavior while also maintaining efficiency and stability, as shown in Figure 10.
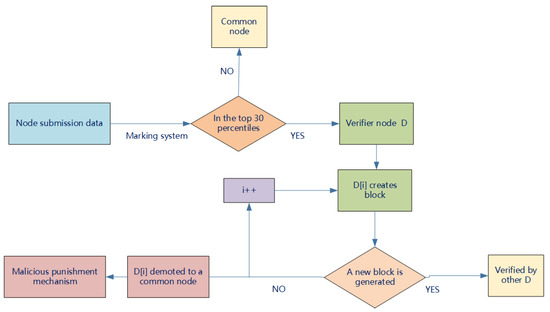
Figure 10.
Improved DPOS.
5.4. Recipe Evaluation Criteria
For the current production environment, the data transmitted by the nodes are digital recipes, and the improved consensus mechanism is to classify the nodes by evaluating the quality of the recipes, so we need to adopt an open, transparent, and reliable way to evaluate the quality of the recipes.
This thesis uses Logic (L), detail (D), and completeness (C) to rate the quality of recipes.
Completeness (C): The user must submit a recipe containing three types of data, i.e., recipe name, ingredients, and steps. These three parts are needed to build a complete recipe.
Logic (L) is determined according to whether each item in the list of ingredients appears in the corresponding step: l = (number of ingredients that appear in the cooking step/total number of ingredients) ∗ 100.
Degree of detail (D) measures the number of modifiers and verbs in the ingredients and steps of the recipe. Specifically, a recipe is considered more detailed if it contains a large number of modifiers for ingredients (such as “fresh” and “tender”) and specific quantities required for the ingredients (such as “grams”, “stalks”, and “spoons”), as well as a large number of verbs in the steps (such as “cut”, “sauté”, and “stir-fry”). The specific calculation formula is: ((number of ingredient modifiers + number of step verbs)/(number of types of ingredients + number of types of step verbs)) ∗ 100.
The total score is , where , , and represent the different weights of each score. After actual comparison, it is found that beginners usually pay more attention to the logic and the degree of detail, so to address this phenomenon, the values of and are increased, as well as the weight of logic and the degree of detail. The specific allocation is , , , as described in Algorithm 4.
| Algorithm 4 Recipe Scoring Algorithm |
|
5.5. Experimental Comparison
5.5.1. Dataset
The dataset used in this experiment comes from 200 unique recipes distributed across 200 nodes in a simulated blockchain network. We set evaluation criteria for each recipe and calculated a composite score. The evaluation criteria consist of multiple dimensions, including the completeness (C), logic (L), and detail (D) of the recipes. For example, one of the recipes (as shown in Figure 11) has a completeness score of 100, a logic score of , and a level of detail score of . Through the weighted average of these dimensions, we obtain a composite score of 84 for this recipe (S). As another example, another recipe (as shown in Figure 12) has a completeness score of 100, a logic score of , a detail score of , and a composite score (S) of 66. We assign a composite score to the recipes on each node accordingly.

Figure 11.
Recipe: garlic roasted chicken wings.

Figure 12.
Recipe: grilled eel.
5.5.2. Experimental Setting, Experimental Design, and Analysis of Results
The experiments are conducted on a Windows host configured with an 11th Gen Intel(R) Core(TM) i5-11400H @ 2.70 GHz 2.69 GHz with 16 GB of RAM and a 1 TB hard disk and simulated using Python language. In the simulated blockchain network, each node broadcasts in the network based on the score of its recipe.
Experiment 1: Punishment and Recovery Experiment for Malicious Nodes
In this experiment, we initially set up 50 validator nodes for the first round. We randomly selected 25 nodes as malicious nodes, assigned different malicious behaviors, and conducted 1000 rounds of the consensus process. The main focus during this process was whether our penalty mechanism could effectively punish the malicious nodes and reduce their scores. As time progressed, as long as nodes actively participated in the network and consensus process, the penalty for malicious nodes could be mitigated through a time decay factor. We randomly selected the consensus processes of five nodes for evaluation. The experimental results are presented in Figure 13:
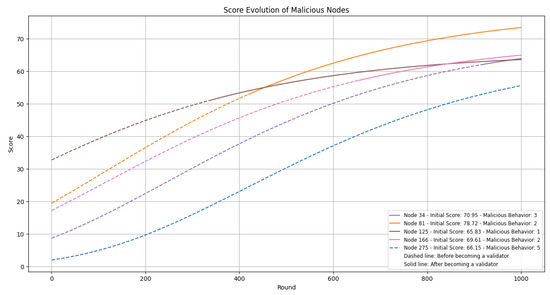
Figure 13.
Punishment and recovery experiment for malicious nodes.
The results of this experiment indicate that the punishment mechanism effectively penalizes the nodes, and with time, the punishment for malicious nodes gradually reduces. After 400 rounds, some nodes can become validator nodes while submitting high-quality data. The speed of this recovery is determined by two factors: the score of the node’s data and the number of malicious behaviors by the node. In the experimental results, we can observe that the 275th node, despite the quality of its submitted data not significantly differing from that of other nodes, has participated in various malicious behaviors. This has resulted in a recovery speed much slower than that of other malicious nodes. Even after undergoing 1000 consensus mechanisms, is not able to become a validator node.
Experiment 2: Average time required to eliminate the influence of malicious behavior
In this experiment, we focus on evaluating the time required for nodes with different numbers of malicious behaviors to eliminate their malicious impact; we calculate the average number of rounds required for nodes with different numbers of malicious behaviors to revert back to being a verified node for the first time after they actively participate in the network maintenance and do not produce any more malicious behaviors, since the impact of malicious behaviors on the blockchain network is crucial. Therefore, we have to ensure that the negative impact can be eliminated only after a certain period of time. In addition, we need to focus on the average number of rounds required for nodes with different numbers of malicious behaviors to eliminate the malicious impact, and the punishment for nodes with multiple malicious behaviors should be more severe. The experimental results are shown in Figure 14.
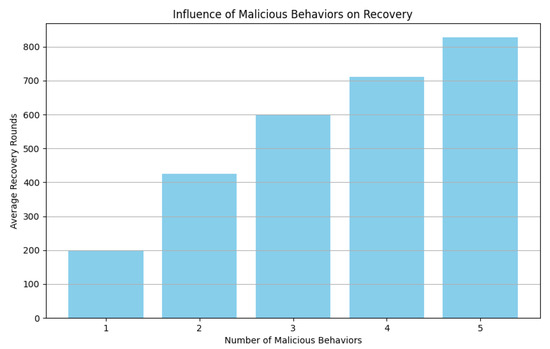
Figure 14.
Average time required to eliminate the influence of malicious behavior.
The experimental results show that the average number of recovery rounds required for different numbers of malicious behavior nodes to truly eliminate their negative impact varies. The more malicious behaviors there are, the more average recovery rounds are required, which also shows that our punitive measures for nodes with multiple negative behaviors are effective. The overall number of recovery rounds ranges from 200 to 800 rounds, which indicates that the malicious behavior nodes are unable to return to normal operation within a certain period of time, proving that our punishment mechanism achieves the guarantee of relative fairness in the network.
Experiments show that the improved DPOS consensus mechanism can effectively encourage all nodes to actively participate in the network. The behavior of a node directly affects its score and status. This is an effective positive feedback mechanism that can motivate all nodes in the network to actively participate and provide high-quality data. The model also has effective means to punish those nodes that exhibit malicious behaviors.
6. Performance Analysis
The experiment was conducted on a Ubuntu 18.04.5 LTS system in a hardware environment equipped with AMD Ryzen 54600H CPU@3.00 GHz and 16 GB memory. A private Ethereum network is constructed in the experiment, which consists of several Ethereum nodes running locally to process all transaction requests. Because the files uploaded by users in the current scheme are text data, differing from the traditional blockchain transaction mode, the experiment needs to perform on-chain operations on files of various sizes, and 20 experimental comparisons are carried out to evaluate the performance of the system in dealing with different workloads. The test data include different text file sizes, specifically 1 KB, 10 KB, 100 KB, 1000 KB, and 5000 KB.
According to the experimental results, the basic time consumption of 1100 KB files is about 0–10 ms, the average time consumption of approximately 1000 KB files is 35.25 ms, and the average time consumption approximately 5000 KB files is 57.4 ms, as shown in Figure 15 and Figure 16. Experiments show that the model achieves good results in terms of data storage and upload. However, in chain operations, the results show that as the data size increases, the chain operation time also increases, mainly due to the validation process required to process transactions on the Ethereum network; the time consumption of this process increases as the data size increases. In general, the experimental results prove the effectiveness of the design scheme proposed in this paper. The scheme can smoothly process data of different sizes and types and meet users’ normal needs in the current blockchain environment without affecting the normal network performance of the system.
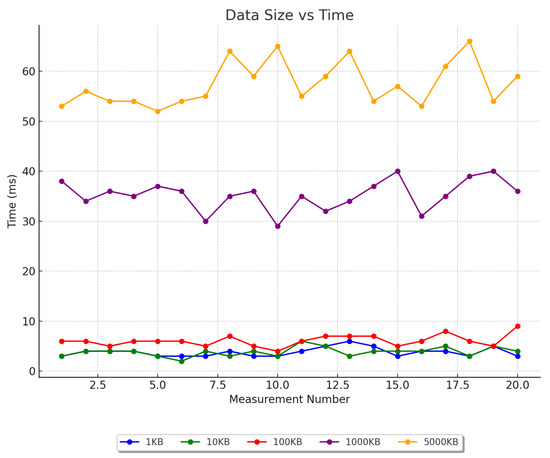
Figure 15.
Line comparison of uplink times for different file sizes.
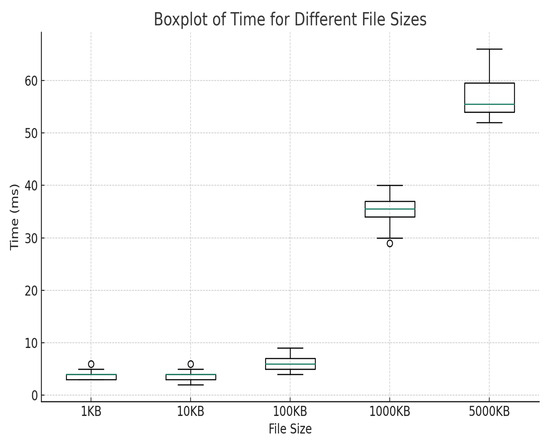
Figure 16.
Box plot of time to link for different file sizes.
7. Conclusions
We first conducted in-depth research on the market and found that text plagiarism is a frequent problem, especially in the recipe field. Therefore, we choose recipes as the main research object and hope to protect their copyright information. We propose a blockchain-based copyright protection system for recipes. The system deeply analyzes the defects of the existing digital copyright protection systems and offers a dual-chain mechanism to achieve fast traceability of copyright. We also introduce IPFS to ensure the efficiency of data storage and access while maintaining distributed storage. Our research results are not only limited to the construction of the system but also include the optimization of related algorithms. Our proposed P-SimHash algorithm excels in accuracy and recall, effectively improving the detection precision of similar texts. In response to the problem of overcentralization of the traditional DPOS consensus mechanism, we improve it by increasing the motivation of the nodes in the network through the recipe quality evaluation system and by effectively constraining and punishing malicious nodes by introducing a negative factor and a time decay factor.
While this study has achieved initial results in applying blockchain technology to copyright protection, we recognize that this is only the beginning. Future challenges include how to increase the processing power of the system to cope with large-scale demands, identify and discipline malicious nodes more accurately, and ensure fairness and security. We also look forward to potential applications of blockchain technology in more areas of copyright protection, such as music, movies, and artistic works, to more fully protect the rights of creators.
Author Contributions
Conceptualization, L.Z. and S.L.; methodology, L.Z.; software, L.Z.; validation, L.Z., T.S. and C.M.; formal analysis, L.Z.; investigation, L.Z.; resources, L.Z.; data curation, L.Z.; writing—original draft preparation, L.Z.; writing—review and editing, L.Z.; visualization, L.Z.; supervision, L.Z.; project administration, S.L.; funding acquisition, S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (61762085), And the Natural Science Foundation of Xinjiang Uygur Autonomous Region Project (2019D01C081).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mizrahi, M.; Golan, A.; Mizrahi, A.B.; Gruber, R.; Lachnise, A.Z.; Zoran, A. Digital gastronomy: Methods & recipes for hybrid cooking. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 541–552. [Google Scholar]
- Subramanya, S.; Yi, B.K. Digital rights management. IEEE Potentials 2006, 25, 31–34. [Google Scholar] [CrossRef]
- Ma, Z.; Jiang, M.; Gao, H.; Wang, Z. Blockchain for digital rights management. Future Gener. Comput. Syst. 2018, 89, 746–764. [Google Scholar] [CrossRef]
- Holland, M.; Nigischer, C.; Stjepandić, J. Copyright protection in additive manufacturing with blockchain approach. In Transdisciplinary Engineering: A Paradigm Shift; IOS Press: Amsterdam, The Netherlands, 2017; pp. 914–921. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Decentralized Bus. Rev. 2008. Available online: https://assets.pubpub.org/d8wct41f/31611263538139.pdf (accessed on 28 August 2023).
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Taherdoost, H. The Role of Blockchain in Medical Data Sharing. Cryptography 2023, 7, 36. [Google Scholar] [CrossRef]
- Garba, A.; Dwivedi, A.D.; Kamal, M.; Srivastava, G.; Tariq, M.; Hasan, M.A.; Chen, Z. A digital rights management system based on a scalable blockchain. Peer-Netw. Appl. 2021, 14, 2665–2680. [Google Scholar] [CrossRef]
- Bodó, B.; Gervais, D.; Quintais, J.P. Blockchain and smart contracts: The missing link in copyright licensing? Int. J. Law Inf. Technol. 2018, 26, 311–336. [Google Scholar] [CrossRef]
- Sun, J. Current Status of Digital Infringement and Copyright Protection in Scientific Journals—A Preliminary Exploration of the Feasibility of Blockchain Technology (科技期刊数字侵权现状与版权保护——区块链技术可行性初探). Chin. J. Sci. Tech. Period. (中国科技期刊研究) 2018, 29, 1000–1005. [Google Scholar]
- Azaria, A.; Ekblaw, A.; Vieira, T.; Lippman, A. Medrec: Using blockchain for medical data access and permission management. In Proceedings of the 2016 2nd International Conference on Open and Big Data (OBD), Vienna, Austria, 22–24 August 2016; pp. 25–30. [Google Scholar]
- Natgunanathan, I.; Praitheeshan, P.; Gao, L.; Xiang, Y.; Pan, L. Blockchain-based audio watermarking technique for multimedia copyright protection in distribution networks. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–23. [Google Scholar] [CrossRef]
- Zhao, F.; Zhou, W. Analysis of Digital Copyright Protection Based on Blockchain Technology (基于区块链技术保护数字版权问题探析). Sci. Technol. Law Rev. (科技与法律) 2017, 125, 59–70. [Google Scholar]
- Zhang, J. Research and Implementation of Digital Copyright System Based on Blockchain Technology (基于区块链技术的数字版权系统研究与实现). Ph.D. Thesis, Jiangsu University, Zhenjiang, China, 2022. [Google Scholar] [CrossRef]
- Charikar, M.S. Similarity estimation techniques from rounding algorithms. In Proceedings of the Thiry-Fourth Annual ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 380–388. [Google Scholar]
- Uddin, M.S.; Roy, C.K.; Schneider, K.A.; Hindle, A. On the effectiveness of simhash for detecting near-miss clones in large scale software systems. In Proceedings of the 2011 18th Working Conference on Reverse Engineering, Limerick, Ireland, 17–20 October 2011; pp. 13–22. [Google Scholar]
- Zou, W.; Lo, D.; Kochhar, P.S.; Le, X.B.D.; Xia, X.; Feng, Y.; Chen, Z.; Xu, B. Smart contract development: Challenges and opportunities. IEEE Trans. Softw. Eng. 2019, 47, 2084–2106. [Google Scholar] [CrossRef]
- Bellare, M.; Yee, B. Forward-security in private-key cryptography. In Proceedings of the Topics in Cryptology—CT-RSA 2003: The Cryptographers’ Track at the RSA Conference 2003, San Francisco, CA, USA, 13–17 April 2003; pp. 1–18. [Google Scholar]
- Salomaa, A. Public-Key Cryptography; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Benet, J. Ipfs-content addressed, versioned, p2p file system. arXiv 2014, arXiv:1407.3561. [Google Scholar]
- Ateniese, G.; Fu, K.; Green, M.; Hohenberger, S. Improved proxy re-encryption schemes with applications to secure distributed storage. ACM Trans. Inf. Syst. Secur. (TISSEC) 2006, 9, 1–30. [Google Scholar] [CrossRef]
- Kent, C.K.; Salim, N. Features based text similarity detection. arXiv 2010, arXiv:1001.3487. [Google Scholar]
- Buyrukbilen, S.; Bakiras, S. Secure similar document detection with simhash. In Proceedings of the Secure Data Management: 10th VLDB Workshop, SDM 2013, Trento, Italy, 30 August 2013; Springer: Cham, Switzerland, 2014; pp. 61–75. [Google Scholar]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The Pagerank Citation Ranking: Bring Order to the Web; Technical Report; Stanford University: Stanford, CA, USA, 1998. [Google Scholar]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Toutanova, K.; Klein, D.; Manning, C.D.; Singer, Y. Feature-rich part-of-speech tagging with a cyclic dependency network. In Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, Edmonton, AB, Canada, 27 May–1 June 2003; pp. 252–259. [Google Scholar]
- Schofield, A.; Mimno, D. Comparing apples to apple: The effects of stemmers on topic models. Trans. Assoc. Comput. Linguist. 2016, 4, 287–300. [Google Scholar] [CrossRef]
- Vasiliev, Y. Natural Language Processing with Python and spaCy: A Practical Introduction; No Starch Press: San Francisco, CA, USA, 2020. [Google Scholar]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, B.; Han, L. Distance weighted cosine similarity measure for text classification. In Proceedings of the Intelligent Data Engineering and Automated Learning–IDEAL 2013: 14th International Conference, IDEAL 2013, Hefei, China, 20–23 October 2013; pp. 611–618. [Google Scholar]
- Norouzi, M.; Fleet, D.J.; Salakhutdinov, R.R. Hamming distance metric learning. Adv. Neural Inf. Process. Syst. 2012, 25. Available online: https://proceedings.neurips.cc/paper_files/paper/2012/file/59b90e1005a220e2ebc542eb9d950b1e-Paper.pdf (accessed on 28 August 2023).
- Cherkassky, V.; Ma, Y. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W.; Mihalcea, R.; Rigau, G.; Uria, L. SemEval-2016 task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 497–511. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Zhai, C.; Lafferty, J. A study of smoothing methods for language models applied to ad hoc information retrieval. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001; pp. 334–342. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic modeling: Models, applications, a survey. arXiv 2018, arXiv:1711.04305. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, Y.; Chen, Q.; Liang, Q. A new election algorithm for DPos consensus mechanism in blockchain. In Proceedings of the 2018 7th International Conference on Digital Home (ICDH), Guilin, China, 30 November–1 December 2018; pp. 116–120. [Google Scholar]
- Saad, S.M.S.; Radzi, R.Z.R.M. Comparative review of the blockchain consensus algorithm between proof of stake (pos) and delegated proof of stake (dpos). Int. J. Innov. Comput. 2020, 10. [Google Scholar] [CrossRef]
- Cao, B.; Zhang, Z.; Feng, D.; Zhang, S.; Zhang, L.; Peng, M.; Li, Y. Performance analysis and comparison of PoW, PoS and DAG based blockchains. Digit. Commun. Networks 2020, 6, 480–485. [Google Scholar] [CrossRef]
- Baliga, A. Understanding blockchain consensus models. Persistent 2017, 4, 14. [Google Scholar]
- Yaga, D.; Mell, P.; Roby, N.; Scarfone, K. Blockchain technology overview. arXiv 2019, arXiv:1906.11078. [Google Scholar]
- Segall, A. Distributed network protocols. IEEE Trans. Inf. Theory 1983, 29, 23–35. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).