
Drivable Area Detection in Unstructured Environments based on Lightweight Convolutional Neural Network for Autonomous Driving Car



Abstract
:1. Introduction
- (1)
- The boundary between the drivable area and the non-drivable area of the unstructured road may be blurred. The road edge is irregular and discontinuous, and there is no clear lane line. Its complexity has a great influence on the accurate extraction of the edge points, which poses a challenge to the traditional edge fitting method.
- (2)
- The structured road has fewer obstacles, while the unstructured road environment has more complex road conditions and often has various kinds of interference, which may appear at random locations, vehicles, people or animals, and non-motorized vehicles suddenly appear behind buildings, with higher environmental variability, requiring real-time detection of interference information and differentiation from the feasible driving area.
2. Background
3. Method
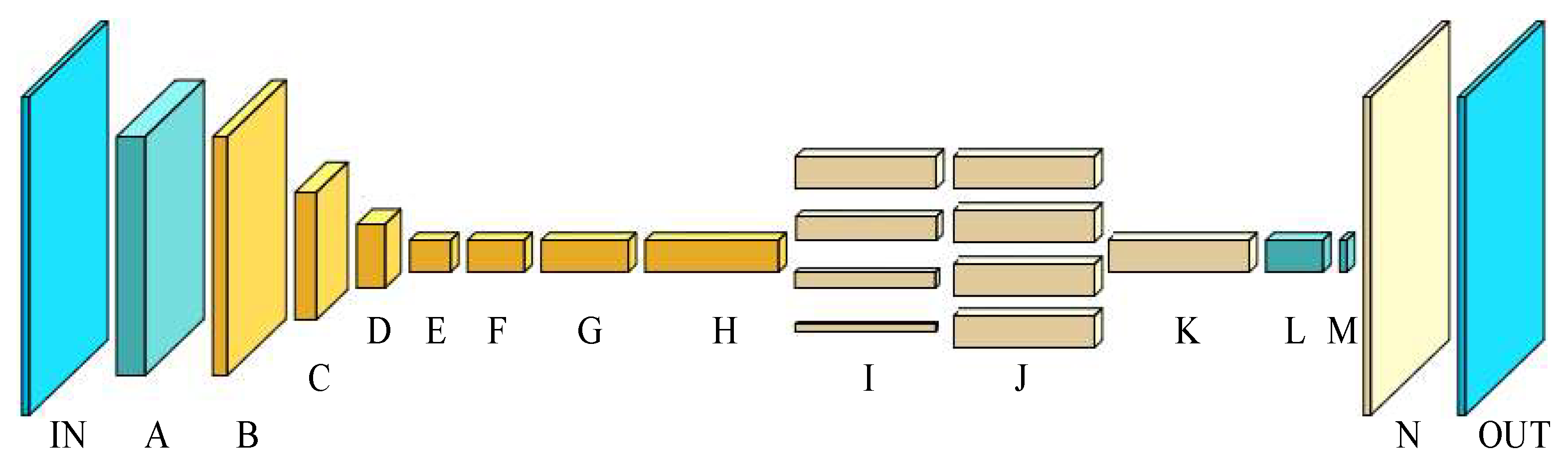
3.1. Structural Model
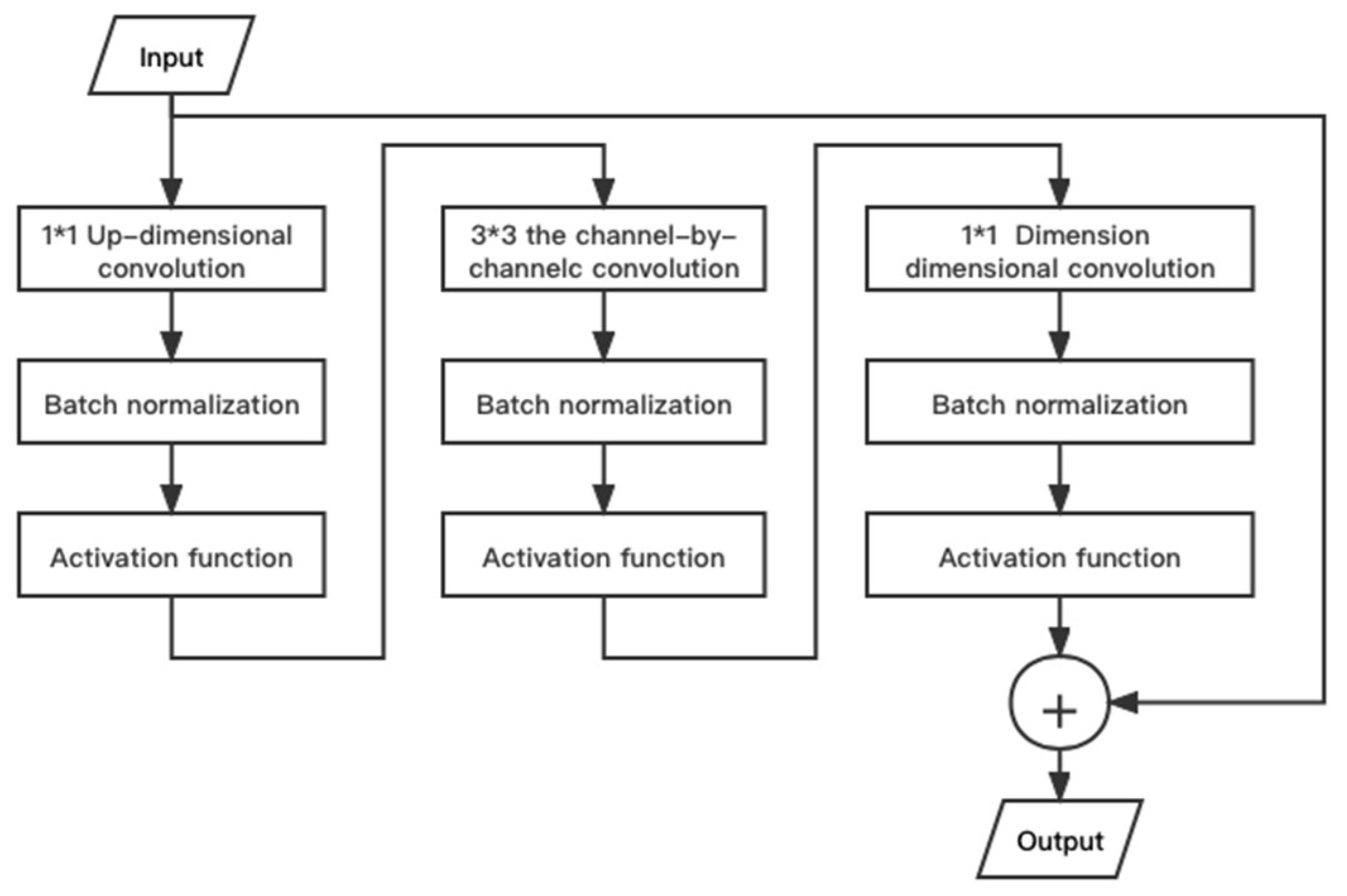
3.2. Convolution Module
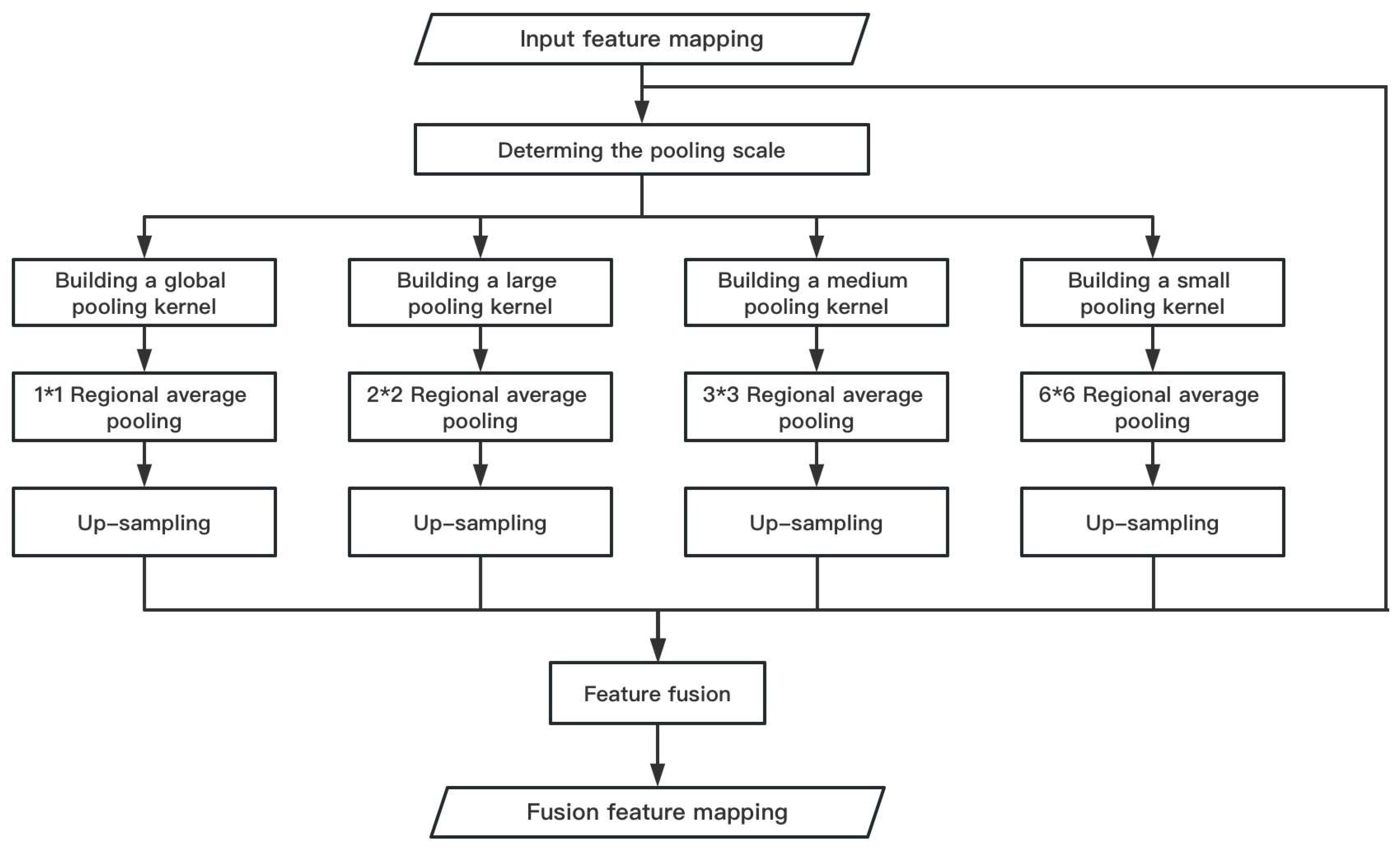
3.3. Parallel Pooling Module
3.4. Activation Function and Loss Function
4. Dataset
- (1)
- The global drivable area dataset includes 8000 instances of the BDD100k [46] dataset and 16,063 instances of the IDD dataset [47]. The road, parking, and ground annotations in the BDD100k dataset and the road, parking, and drivable fallback annotations in the IDD dataset are used as the target drivable areas, and the corresponding conversion masks are generated. The scene includes scenes of multiple pedestrians, vehicles, and obstacles in cities and villages, as well as lane-less roads, paved roads, and unpaved roads.
- (2)
- The road drivable area dataset contains 80,000 copies of BDD100k dataset data and corresponding conversion masks. This dataset mask file is mainly generated based on the area/drivable kinds and area/alternative kinds in the annotation of the BDD100k dataset, which can be used as a control group of unstructured environments to verify the applicability of the model structure of this paper in a variety of road situations.
- (3)
- The off-road environment drivable dataset, containing 7436 data from the RUGD dataset [48], and the corresponding transformation masks validate the generalizability of the model in this paper in the face of somewhat challenging data situations.
- (4)
- Self-built small datasets are used to simply evaluate the applicability of this paper’s model in the Chinese environment and also participate in the training and testing of this paper’s network model together with the validation and test sets in the above (1) and (2) datasets.
5. Results
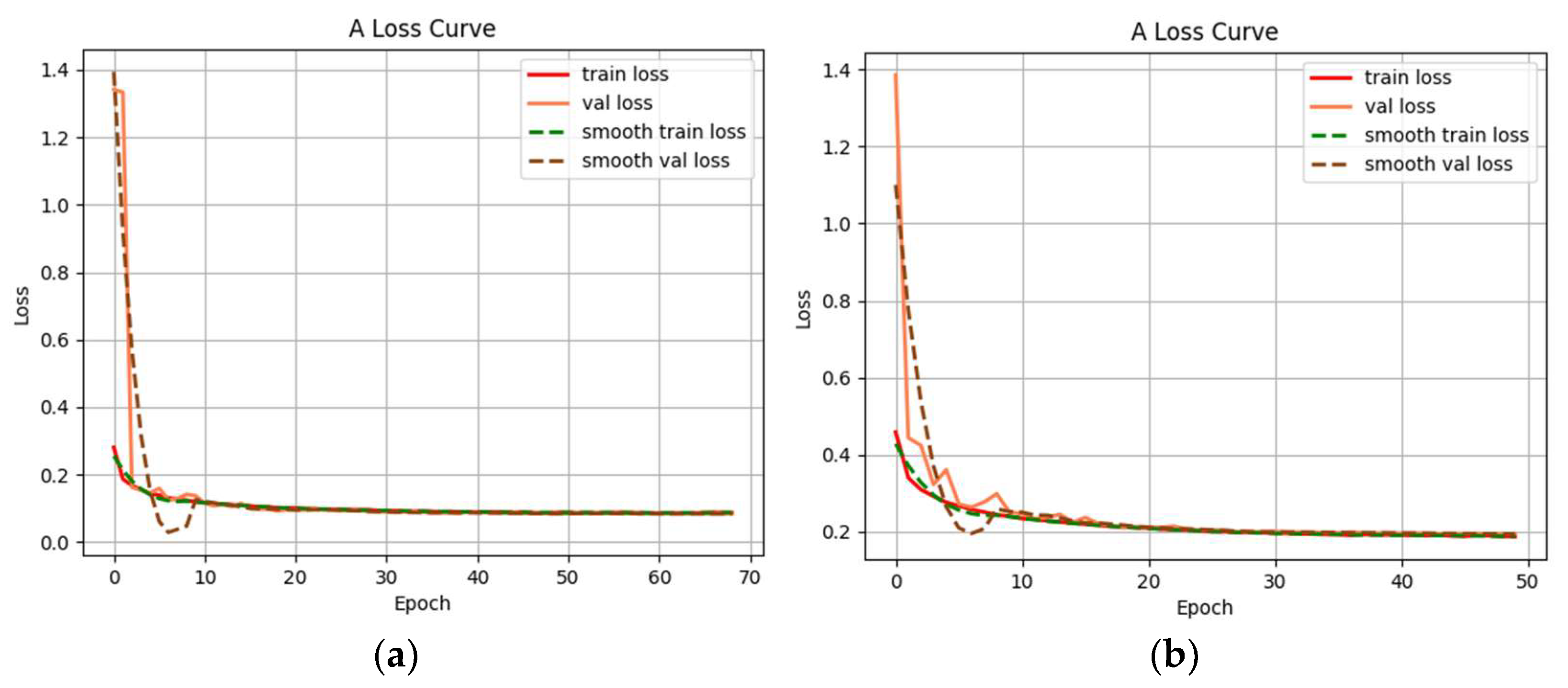
5.1. Experiment of Drivable Area Detection Algorithm based on Lightweight Neural Network
5.2. Network Model Test and Real Vehicle Experiments





5.3. Network Model Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoderdecoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Jung, C.R.; Kelber, C.R. Lane following and lane departure using a linear-parabolic model. Image Vis. Comput. 2005, 23, 1192–1202. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, B.; Wang, H.; Xu, L.; Li, Y.; Liu, Z. Detection of the drivable area on high-speed road via YOLACT. Signal Image Video Process. 2022, 16, 1623–1630. [Google Scholar] [CrossRef]
- Acun, O.; Küçükmanisa, A.; Genç, Y.; Urhan, O. D3NET (divide and detect drivable area net): Deep learning based drivable area detection and its embedded application. J. Real-Time Image Process. 2023, 20, 16. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Alvarez, J.M.; Gevers, T.; LeCun, Y.; Lopez, A.M. Road Scene Segmentation from a Single Image. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 376–389. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Mendes, C.C.T.; Fremont, V.; Wolf, D.F. Exploiting fully convolutional neural networks for fast road detection. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3174–3179. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Bilinski, P.; Prisacariu, V. Dense decoder shortcut connections for single-pass semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6596–6605. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Dense ASPP for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3684–3692. [Google Scholar]
- Li, X.; Zhao, H.; Han, L.; Tong, Y.; Tan, S.; Yang, K. Gated Fully Fusion for Semantic Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11418–11425. [Google Scholar]
- Chen, J.; Wei, D.; Long, T.; Luo, T.; Wang, H. All-weather road drivable area segmentation method based on CycleGAN. Vis. Comput. 2022. [Google Scholar] [CrossRef]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object Context Network for Scene Parsing. Int. J. Comput. Vis. (IJCV) 2021. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Jin, Y.; Han, D.; Ko, H. Trseg: Transformer for semantic segmentation. Pattern Recognit. Lett. 2021, 148, 29–35. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 16514–16524. [Google Scholar]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking Spatial Dimensions of Vision Transformers. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 11916–11925. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision 2020, Glasgow, UK, 23–28 August 2020; Volume 12346, pp. 213–229. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 10347–10357. [Google Scholar]
- Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.H.; Tay, F.E.; Feng, J.; Yan, S. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 19–25 June 2021; pp. 558–567. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early Convolutions Help Transformers See Better. In Proceedings of the Annual Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Rao, Y.; Zhao, W.; Liu, B.; Lu, J.; Zhou, J.; Hsieh, C.J. DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021. [Google Scholar]
- Chen, C.F.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 19–25 June 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Virtual, 19–25 June 2021. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Xiao, T.; Fidler, S.; Barriuso, A.; Torralba, A. Semantic Understanding of Scenes Through the ADE20K Dataset. Int. J. Comput. Vis. 2019, 127, 302–321. [Google Scholar] [CrossRef]
- Meng, L.; Xu, L.; Guo, J.Y. A MobileNetV2 Network Semantic Segmentation Algorithm Based on Improvement. Chin. J. Electron. 2020, 48, 1769. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016. [Google Scholar] [CrossRef]
- Zhang, X.; Du, B.; Wu, Z.; Wan, T. LAANet: Lightweight attention-guided asymmetric network for real-time semantic segmentation. Neural Comput. Appl. 2022, 34, 3573–3587. [Google Scholar] [CrossRef]
- Park, H.; Yoo, Y.; Seo, G.; Han, D.; Yun, S.; Kwak, N. Concentrated-comprehensive convolutions for lightweight semantic segmentation. arXiv 2018. [Google Scholar] [CrossRef]
- Ma, S.; An, J.B.; Yu, B. Real time image semantic segmentation algorithm based on improved DeepLabv2. Comput. Eng. Appl. 2020, 56, 157–164. [Google Scholar]
- Wang, M.; Liu, B.; Foroosh, H. Factorized Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 545–553. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 30. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2633–2642. [Google Scholar]
- Varma, G.; Subramanian, A.; Namboodiri, A.; Chandraker, M.; Jawahar, C.V. IDD: A Dataset for Exploring Problems of Autonomous Navigation in Unconstrained Environments. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1743–1751. [Google Scholar]
- Wigness, M.; Eum, S.; Rogers, J.G.; Han, D.; Kwon, H. A RUGD Dataset for Autonomous Navigation and Visual Perception in Unstructured Outdoor Environments. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5000–5007. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Layer | Input Data | Kernel Parameters | Step |
|---|---|---|---|
| Input layer IN | nil | nil | |
| Convolution layer A | 2 | ||
| Inverted residual layer B | 1 | ||
| Inverted residual layer C | |||
| Inverted residual layer D | |||
| Inverted residual layer E | |||
| Inverted residual layer F | |||
| Inverted residual layer G | |||
| Inverted residual layer H | |||
| Parallel pooling layer I + J | |||
| Feature fusion layer K | nil | nil | |
| Convolution layer L | 1 | ||
| Convolution layer M | 1 | ||
| Up-sampling layer N | nil | nil | |
| Output layer OUT | nil | nil |
| Vehicle Model | Body Size | Curb Weight | Power Type |
|---|---|---|---|
| Qichen R50 | 4280 × 1695 × 1535 | 1113 | Gasoline engine |
| MINIEV | 2920 × 1493 × 1621 | 700 | Pure electric |
| Network Model | Single Batch Time | Single Iteration Time | Accuracy | Average Cross-Merger Ratio |
|---|---|---|---|---|
| MobileNetV2 + PSPNet | 350 ms | 307s | 0.937 | 89.06 |
| ResNet50 + PSPNet | 418 ms | 731s | 0.965 | 90.15 |
| Network model of this paper | 340 ms | 298s | 0.967 | 90.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; Lu, Y.; Wang, P.; Han, Y.; Xu, T.; Li, J. Drivable Area Detection in Unstructured Environments based on Lightweight Convolutional Neural Network for Autonomous Driving Car. Appl. Sci. 2023, 13, 9801. https://doi.org/10.3390/app13179801
Yu Y, Lu Y, Wang P, Han Y, Xu T, Li J. Drivable Area Detection in Unstructured Environments based on Lightweight Convolutional Neural Network for Autonomous Driving Car. Applied Sciences. 2023; 13(17):9801. https://doi.org/10.3390/app13179801
Chicago/Turabian StyleYu, Yue, Yanhui Lu, Pengyu Wang, Yifei Han, Tao Xu, and Jianhua Li. 2023. "Drivable Area Detection in Unstructured Environments based on Lightweight Convolutional Neural Network for Autonomous Driving Car" Applied Sciences 13, no. 17: 9801. https://doi.org/10.3390/app13179801
APA StyleYu, Y., Lu, Y., Wang, P., Han, Y., Xu, T., & Li, J. (2023). Drivable Area Detection in Unstructured Environments based on Lightweight Convolutional Neural Network for Autonomous Driving Car. Applied Sciences, 13(17), 9801. https://doi.org/10.3390/app13179801