
Medical Named Entity Recognition Fusing Part-of-Speech and Stroke Features


Abstract
1. Introduction
2. Related Work
2.1. NER Approaches
2.2. NER Approaches Based on Deep Learning
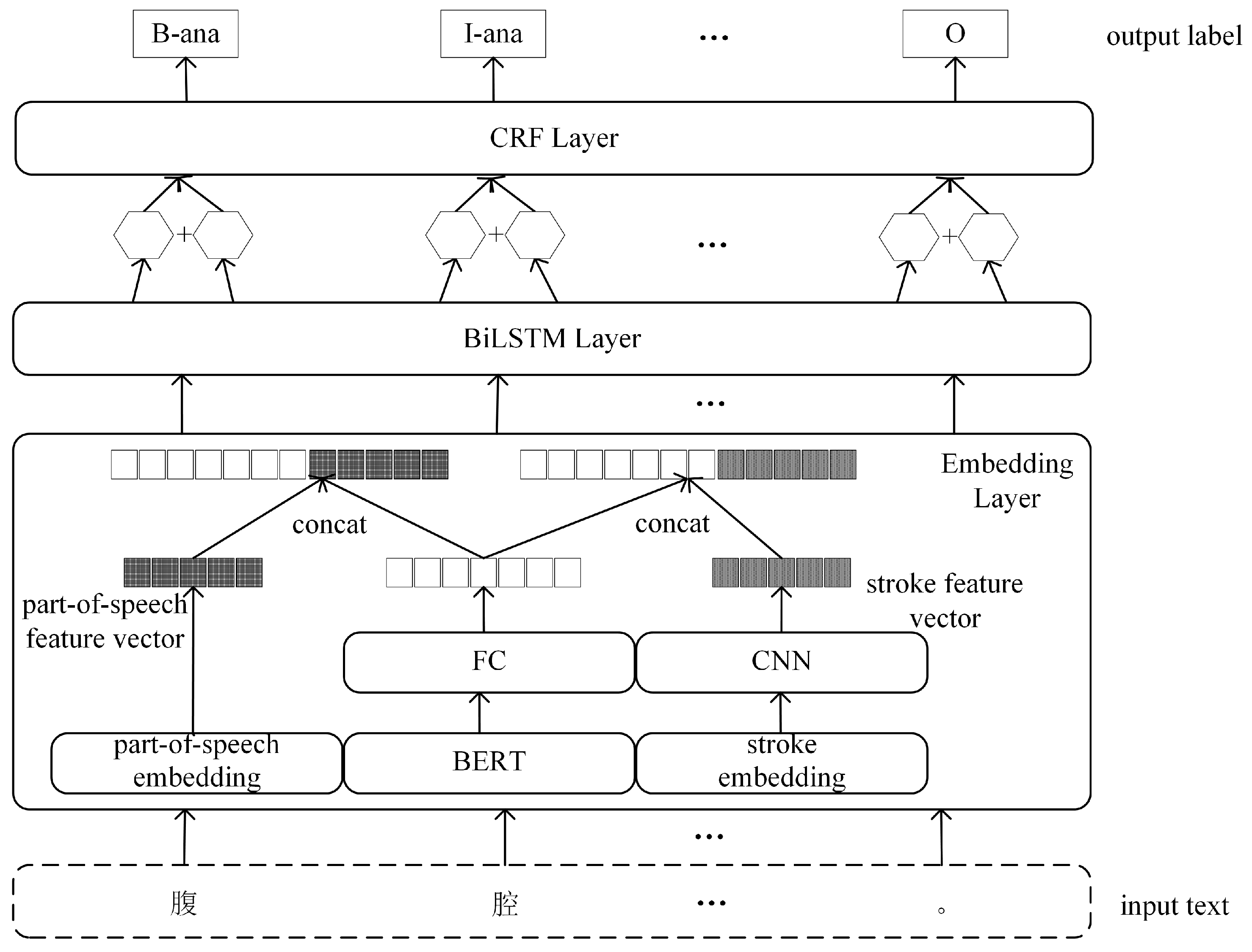
3. Methods
3.1. Embedding Layer
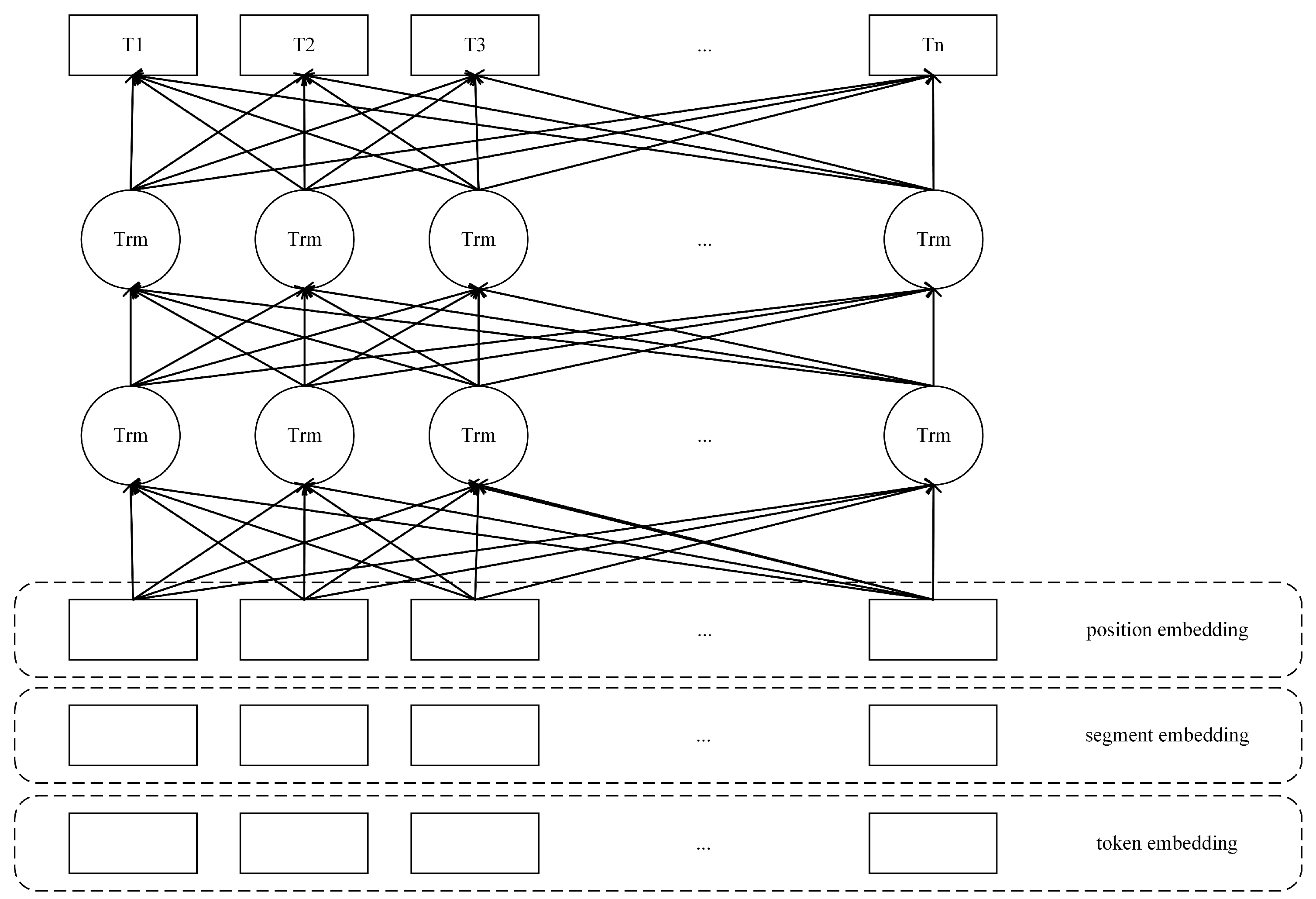
3.1.1. BERT Model
3.1.2. Part-of-Speech Embedding
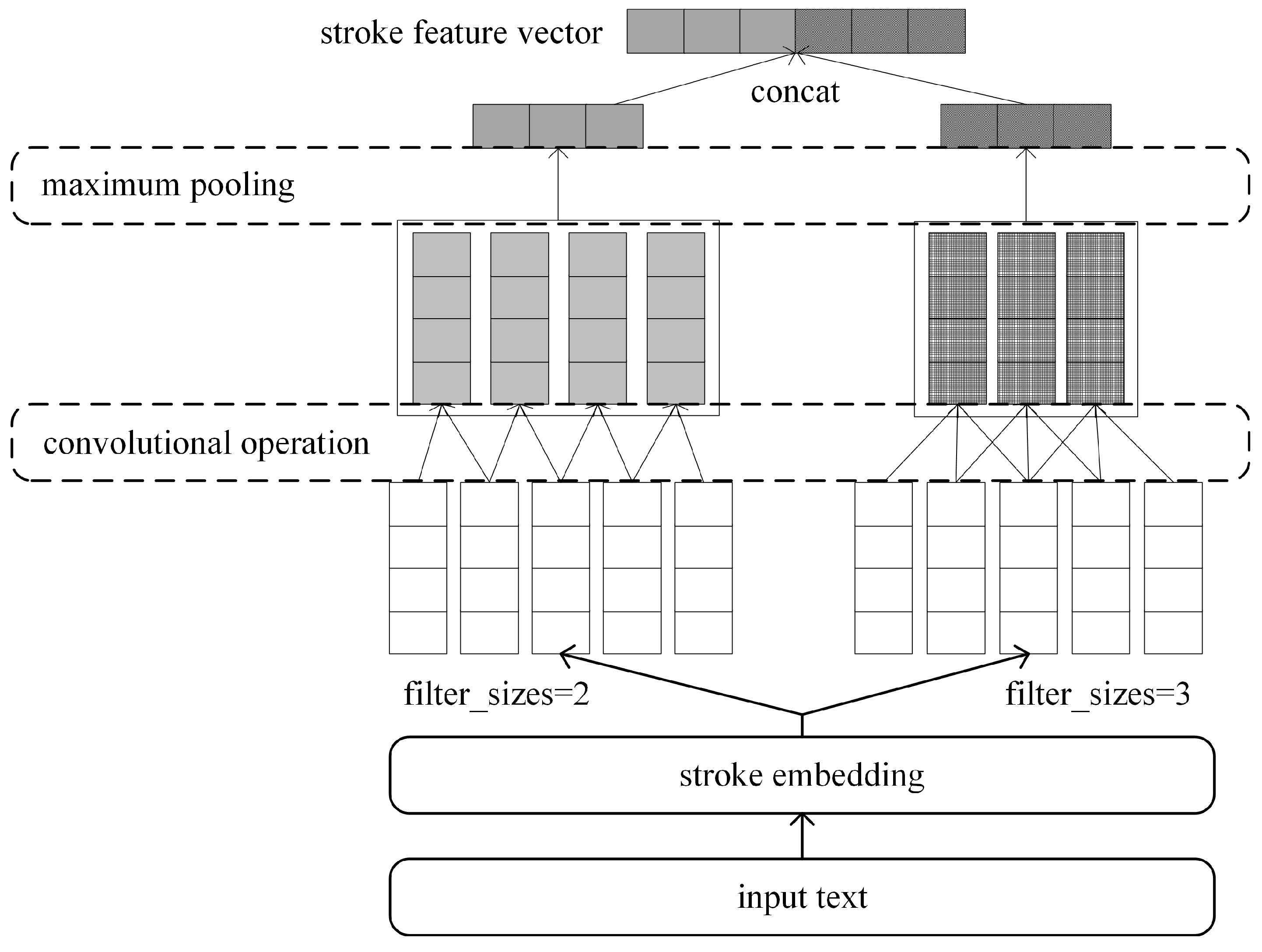
3.1.3. Stroke Embedding
3.2. BiLSTM Layer
3.3. CRF Layer
4. Analysis and Results from Experiments
4.1. Experimental Dataset
4.2. Improvement of Loss Function
4.3. Experimental Setup
4.4. Results
- IDCNN-CRF, the encoding layer uses the expansion convolution network. Unlike the traditional convolution network, the expansion convolution expands the receptive field of the model by adding holes in the convolution kernel and obtains more context by using fewer convolution layers.
- BiLSTM-CRF, a popular model for handling NER tasks, takes the word vector representing the input text from the embedding layer, feeds it into BiLSTM to obtain characteristics, and then outputs the expected tag results following CRF.
- BERT-CRF, the encoding layer using the BERT model.
- BERT + BC, acquiring word vectors by pre-training the BERT model, followed by BiLSTM-CRF for the NER task.
- BERT-WWM + BC obtains word vectors by pre-training the BERT-WWM model. Unlike BERT, in the initial pre-training phase, BERT-WWM modifies the training sample generation approach and increases the whole word mask.
- RoBERTa-WWM-ext + BC, using the RoBERTa-WWM-ext model in the embedding layer, RoBERTa has enhanced the training tasks and data generation methods over BERT.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Luo, L.; Yang, Z.; Yang, P.; Zhang, Y.; Wang, L.; Lin, H.; Wang, J. An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition. Bioinformatics 2018, 34, 1381–1388. [Google Scholar] [CrossRef] [PubMed]
- Tarasova, O.A.; Rudik, A.V.; Biziukova, N.Y.; Filimonov, D.A.; Poroikov, V.V. Chemical named entity recognition in the texts of scientific publications using the naive Bayes classifier approach. J. Cheminform. 2022, 14, 55. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Ye, L.; Zhang, H.; Guo, X. Named entity recognition of legal judgment based on small-scale labeled data. In Proceedings of the 2020 International Conference on Cyberspace Innovation of Advanced Technologies, Guangzhou, China, 4–6 December 2020; pp. 549–555. [Google Scholar] [CrossRef]
- Donnelly, J.; Roegiest, A. The Utility of Context When Extracting Entities from Legal Documents. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, New York, NY, USA, 19–23 October 2020; pp. 2397–2404. [Google Scholar] [CrossRef]
- Aguilar, G.; Maharjan, S.; López-Monroy, A.P.; Solorio, T. A multi-task approach for named entity recognition in social media data. arXiv 2019, arXiv:1906.04135. [Google Scholar] [CrossRef]
- Ruokolainen, T.; Kauppinen, P.; Silfverberg, M.; Lindén, K. A Finnish news corpus for named entity recognition. J. Lang. Resour. Eval. 2020, 54, 247–272. [Google Scholar] [CrossRef]
- Gaio, M.; Moncla, L. Extended named entity recognition using finite-state transducers: An application to place names. In Proceedings of the Ninth International Conference on Advanced Geographic Information Systems, Applications, and Services (GEOProcessing 2017), Nice, France, 19–23 March 2017; pp. 15–20. [Google Scholar]
- Zhu, Q.; Li, X.; Conesa, A.; Pereira, C. GRAM-CNN: A Deep Learning Approach with Local Context for Named Entity Recognition in Biomedical Text. Bioinformatics 2018, 34, 1547–1554. [Google Scholar] [CrossRef]
- Yoon, W.; So, C.H.; Lee, J.; Kang, J. CollaboNet: Collaboration of Deep Neural Networks for Biomedical Named Entity Recognition. Bioinformatics 2019, 20 (Suppl. S10), 249. [Google Scholar] [CrossRef]
- Popovski, G.; Kochev, S.; Seljak, B.; Eftimov, T. FoodIE: A Rule-Based Named-Entity Recognition Method for Food Information Extraction. In Proceedings of the 8th International Conference on Pattern Recognition Applications and Methods, Prague, Czech Republic, 19–21 February 2019; pp. 915–922. [Google Scholar] [CrossRef]
- Gabbard, R.; DeYoung, J.; Lignos, C.; Freedman, M.; Weischedel, R. Combining Rule-Based and Statistical Mechanisms for Low-Resource Named Entity Recognition. Mach. Transl. 2017, 32, 31–43. [Google Scholar] [CrossRef]
- Gorinski, P.J.; Wu, H.; Grover, C.; Tobin, R.; Talbot, C.; Whalley, H.; Sudlow, C.; Whiteley, W.; Alex, B. Named Entity Recognition for Electronic Health Records: A Comparison of Rule-Based and Machine Learning Approaches. arXiv 2017, arXiv:1903.03985. [Google Scholar] [CrossRef]
- Patil, N.; Patil, A.; Pawar, B.V. Named Entity Recognition Using Conditional Random Fields. Procedia Comput. Sci. 2020, 167, 1181–1188. [Google Scholar] [CrossRef]
- Suthaharan, S. Support Vector Machine. Mach. Learn. Model. Algorithms Big Data Classif. 2016, 36, 207–235. [Google Scholar] [CrossRef]
- Morwal, S.; Jahan, N.; Chopra, D. Named Entity Recognition Using Hidden Markov Model (HMM). Int. J. Nat. Lang. Comput. 2012, 1, 15–23. [Google Scholar] [CrossRef]
- Setiyoaji, A.; Muflikhah, L.; Fauzi, M. Named entity recognition menggunakan hidden markov model dan algoritma viterbi pada teks tanaman obat. J. Pengemb. Teknol. Inf. Dan Ilmu Komput. e-ISSN 2017, 2548, 964X. [Google Scholar]
- Szarvas, G.; Farkas, R.; Kocsor, A. A multilingual named entity recognition system using boosting and c4. 5 decision tree learning algorithms. In Proceedings of the Discovery Science, Berlin/Heidelberg, Germany, 7–10 October 2006; pp. 267–278. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural Language Processing (Almost) from Scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar] [CrossRef]
- Strubell, E.; Verga, P.; Belanger, D.; McCallum, A. Fast and Accurate Entity Recognition with Iterated Dilated Convolutions. arXiv 2017, arXiv:1702.02098. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-Training with Whole Word Masking for Chinese BERT. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Ren, X.; Zhang, Y.; Zitnik, M.; Shang, J.; Langlotz, C.; Han, J. Cross-Type Biomedical Named Entity Recognition with Deep Multi-Task Learning. Bioinformatics 2019, 35, 1745–1752. [Google Scholar] [CrossRef] [PubMed]
- Cho, M.; Ha, J.; Park, C.; Park, S. Combinatorial feature embedding based on CNN and LSTM for biomedical named entity recognition. J. Biomed. Inform. 2020, 103, 103381. [Google Scholar] [CrossRef] [PubMed]
- Chang, Y.; Kong, L.; Jia, K.; Meng, Q. Chinese Named Entity Recognition Method Based on BERT. In Proceedings of the 2021 IEEE International Conference on Data Science and Computer Application (ICDSCA), Dalian, China, 29–31 October 2021; pp. 294–299. [Google Scholar] [CrossRef]
- Yao, L.; Liu, H.; Liu, Y.; Li, X.; Anwar, M.W. Biomedical Named Entity Recognition Based on Deep Neutral Network. Int. J. Hybrid Inf. Technol. 2015, 8, 279–288. [Google Scholar] [CrossRef]
- Lin, B.Y.; Xu, F.; Luo, Z.; Zhu, K. Multi-Channel BiLSTM-CRF Model for Emerging Named Entity Recognition in Social Media. In Proceedings of the 3rd Workshop on Noisy User-Generated Text, Copenhagen, Denmark, 7 September 2017; pp. 160–165. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, J.; Yang, L.; Xia, R. Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3342–3352. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Type | Train | Dev |
|---|---|---|
| disease and diagnosis | 2924 | 1288 |
| laboratory test | 799 | 396 |
| image examination | 661 | 308 |
| drug | 1250 | 572 |
| operation | 709 | 320 |
| anatomical site | 5804 | 2622 |
| total | 12,147 | 5506 |
| Hyperparameter | Value |
|---|---|
| BiLSTM hidden size | 128 |
| Embedding size | 768 |
| Learning rate | 3 |
| Max sequence length | 150 |
| Dropout | 0.5 |
| Batch size | 16 |
| Epoch | 30 |
| Model | P/% | R/% | F1/% |
|---|---|---|---|
| IDCNN-CRF | 72.62 | 73.88 | 73.24 |
| BiLSTM-CRF | 73.43 | 74.32 | 73.87 |
| BERT-CRF | 73.90 | 80.43 | 77.03 |
| BERT + BC | 75.58 | 79.01 | 77.26 |
| BERT-WWM + BC | 76.46 | 79.89 | 78.14 |
| RoBERTa-WWM-ext + BC | 75.16 | 79.89 | 77.45 |
| Our Model | 77.49 | 79.84 | 78.65 |
| Model | P/% | R/% | F1/% |
|---|---|---|---|
| Baseline | 75.58 | 79.01 | 77.26 |
| Baseline + Loss | 75.95 | 79.84 | 77.85 |
| Baseline + Part-of-speech embedding | 76.37 | 79.55 | 77.93 |
| Baseline + Stroke embedding(BiLSTM) | 75.03 | 79.94 | 77.41 |
| Baseline + Stroke embedding(CNN) | 75.83 | 79.80 | 77.76 |
| Baseline + all | 77.49 | 79.84 | 78.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, F.; Liu, H.; Wang, Y.; Wu, S.; Sun, C.; Feng, P.; Zhang, J. Medical Named Entity Recognition Fusing Part-of-Speech and Stroke Features. Appl. Sci. 2023, 13, 8913. https://doi.org/10.3390/app13158913
Yi F, Liu H, Wang Y, Wu S, Sun C, Feng P, Zhang J. Medical Named Entity Recognition Fusing Part-of-Speech and Stroke Features. Applied Sciences. 2023; 13(15):8913. https://doi.org/10.3390/app13158913
Chicago/Turabian StyleYi, Fen, Hong Liu, You Wang, Sheng Wu, Cheng Sun, Peng Feng, and Jin Zhang. 2023. "Medical Named Entity Recognition Fusing Part-of-Speech and Stroke Features" Applied Sciences 13, no. 15: 8913. https://doi.org/10.3390/app13158913
APA StyleYi, F., Liu, H., Wang, Y., Wu, S., Sun, C., Feng, P., & Zhang, J. (2023). Medical Named Entity Recognition Fusing Part-of-Speech and Stroke Features. Applied Sciences, 13(15), 8913. https://doi.org/10.3390/app13158913