5.2. Analysis of Results
This paper uses the constructed named entity recognition dataset in the field of power marketing for training evaluation, and uses precision, recall and value as the evaluation criteria to measure the performance of the model. Meanwhile, four sets of comparison experiments are set up to verify and analyze the effectiveness of the named entity recognition method proposed in this paper for the power marketing domain.
- (1)
Comparison of the performance of different masking strategies
In order to verify the effectiveness of the whole word masking strategy in improving named entity recognition capability in the field of power marketing, comparative experiments were carried out on the model DFENN-CRF with no masking strategy, the model BERT-DFENN-CRF using a word-level masking strategy, and the model RoBERTa-DFENN-CRF using a whole word masking strategy. The experimental results are shown in
Table 5.
As can be seen from
Table 5, the model that utilizes the whole word masking exhibits the best performance with a precision rate of 88.23%. In addition, when comparing whole word masking to word-level masking, the accuracy, recall and
values of the model improved by 2.51%, 2.93% and 2.73%, respectively. Moreover, compared to the no masking strategy, the accuracy, recall and
values of the model improved by 5.32%, 5.04% and 5.18%, respectively. Without using the masking strategy, the model outputs word vectors lack contextual semantic information, which makes it difficult to solve the problem of words with multiple meanings, leading to relatively poor recognition performance with a precision rate of 82.91%. By implementing the word-level masking strategy, the model randomly masks the characters during pre-training, and then allows the model to predict the masked characters, so that the encoder can retain the contextual semantic representation of each character, to some extent, which solves the problem of multiple word meanings by using the contextual information with the precision rate of 85.72%. Whole word masking is compared to word-level masking by first splitting the power marketing text and then randomly masking the words, and then allowing the model to predict the masked words, so that the model can learn the complete word-level semantic information and improve the inference and representation of Chinese semantics, thus the performance of the model is further improved with the precision rate of 88.23%.
- (2)
Comparison of the performance of different feature extraction methods in the middle layer of the model
In order to verify the effectiveness of different feature extraction approaches in the middle layer of the model for improving the recognition of named entities in the power marketing domain, comparative experiments were conducted on RoBERTa-CRF, RoBERTa-BiLSTM-CRF, RoBERTa-IDCNN-CRF, and RoBERTa-DFENN-CRF. The results of the experiments are shown in
Table 6.
From the experimental results in
Table 6, we can see that the intermediate layer has the highest
value of 87.39% using the DFENN model. This indicates that adding a dual feature extraction neural network in the middle layer can improve the effectiveness of named entities. Model 1 achieved the lowest
value because it did not add any intermediate layer network, and although the encoder was able to retain the contextual semantic representation of each character, the absence of an intermediate layer for global semantic information and local semantic information extraction led to the worst final results. Compared with model 3, model 2 has improved all indicators, but the difference is not significant, which is because the intermediate layers of these two models can further extract semantic information. The former is better at learning the features of the whole sentence and capturing the long-distance context dependence of the text, which is better for the recognition of entities with longer length; while the latter focuses more on the information and features around the entities, which can better distinguish the entity boundaries. For example, there are some obvious features around such entities as voltage level, such as the number in front of “KV”, and the entity type of station usually ends with “站”, so the obvious features can be captured for correct labeling. Model 4 adds a dual feature extraction neural network after the pre-trained model, which can make up for the deficiencies of BiLSTM and IDCNN, and thus achieves the best results with the precision rate of 87.39%.
- (3)
Comparative analysis of the performance of different models
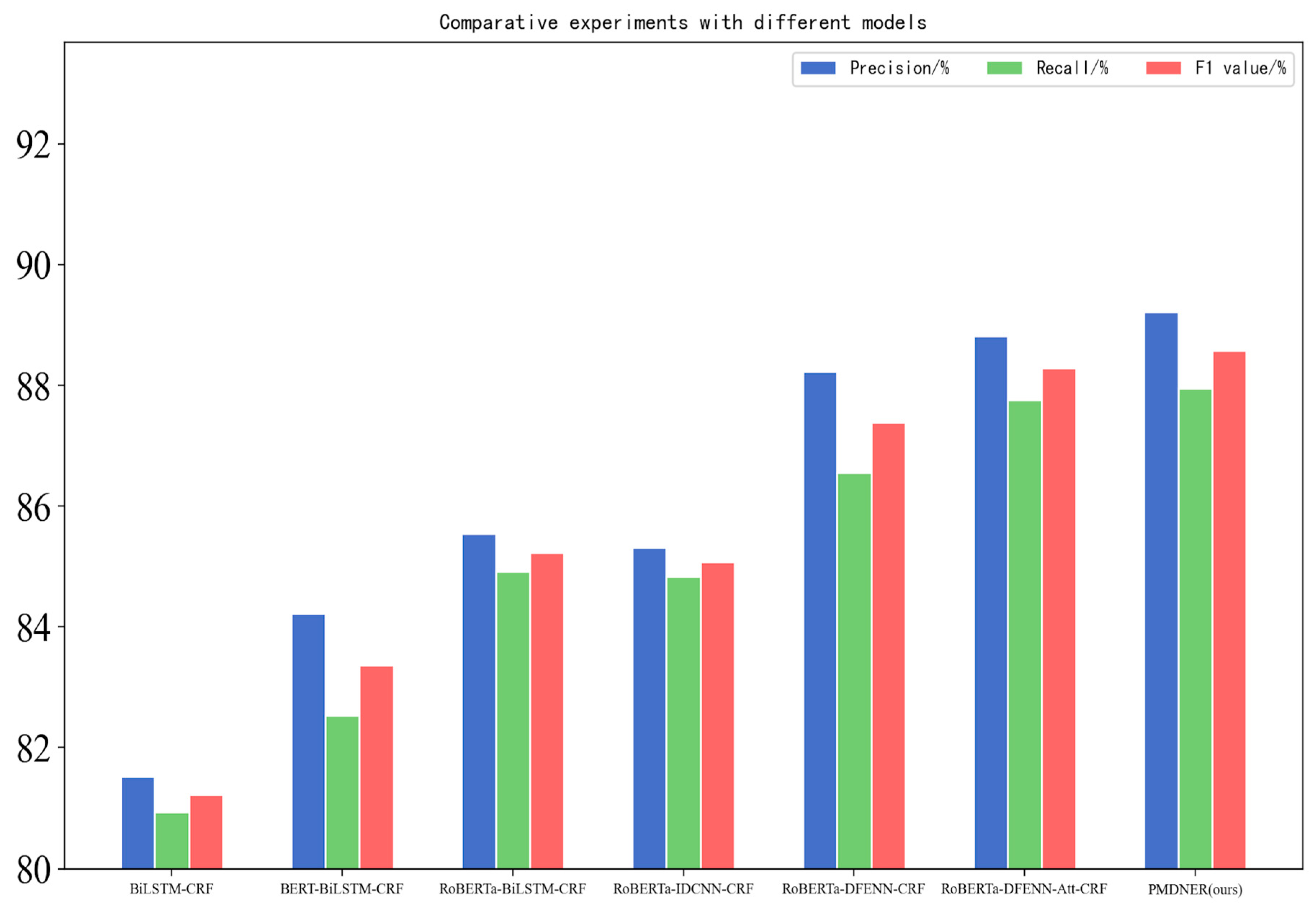
To verify the performance of the PMDNER model in the recognition of named entities in the field of power marketing, comparative experiments were conducted with BiLSTM-CRF, BERT-BiLSTM-CRF, RoBERTa-BiLSTM-CRF, RoBERTa-IDCNN-CRF, RoBERTa-DFENN-CRF and RoBERTa-DFENN-Att-CRF models. The results of named entity recognition in the field of power marketing are shown in
Table 7 and
Figure 7. From the experimental results, it can be seen that the proposed model 7 has better recognition performance than other models, with an
value of 88.58%. When compared to the BiLSTM-CRF benchmark model without the use of pre-trained models, the
value has an improvement of 7.36%.
After using the BERT pre-trained model, model 2 can more fully consider the location information and contextual semantic information of the characters, and improves in recognition with a 2.15% improvement in the value compared to model 1.
Regarding the selection of pre-trained models, model 3, which utilizes RoBERTa, demonstrates further improvement with a 1.86% increase in the value compared to model 2. This could be attributed to the whole word masking strategy employed by RoBERTa pre-trained model, which can better characterize the Chinese semantics and is more applicable to Chinese named entities.
The value of model 5 after using the DFENN proposed in this paper is also improved by 2.16% compared with model 3 and 2.32% compared with model 4. This is because the dual feature extraction neural network proposed in this paper can obtain the global feature information and local feature information of the input text in parallel, which makes up for the BiLSTM that only focuses on the extraction of full-text information but not local information, and also makes up for the shortcomings of IDCNN, which can only obtain local features but not long-range global features, and finally achieves good results in the named entity task in the field of power marketing.
Model 6 is improved from model 5 by using the output of the RoBERTa layer as the auxiliary classification layer and the output of the DFENN layer as the master classification layer with weighted fusion using the attention mechanism function. Finally, model 6 proposed in this paper improves 0.9% compared with model 5. It is because the word vector output of the RoBERTa layer incorporates rich contextual semantic information, which can learn the global features of text and the local feature information of text after feeding it into the DFENN neural network model. Finally, the output vectors of both are used to calculate the weights by the attention mechanism function, and then after the weighted fusion can be better for the sequence annotation of power marketing data.
Model 7 is based on model 6, which introduces a focal loss function to alleviate the problem of unbalanced sample distribution. By increasing the weight of the types with a small number of entities in the loss function, the model focuses more on the hard-to-identify samples during the training process and improves the recognition ability of the model for hard-to-identify samples, and the recognition effect of the model is better than all the above models, with an value of 88.58%, which is the most ideal recognition effect.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}