
Fault-Prone Software Requirements Specification Detection Using Ensemble Learning for Edge/Cloud Applications

 , ,
, ,
Abstract
1. Introduction
- Development of a fault-prone software requirements specification detection model to ensure high accuracy in detecting the fault-prone SRS by utilizing the ambiguity classification model on ambiguous software requirements, title, description, and intended users of the SRS.
- Analysis of the fault-prone SRS of edge/cloud applications to reduce and identify potential issues early in the development process, allowing developers to make necessary changes and adjustments to ensure the application meets the needs of its users.
2. Research Background
2.1. Software Requirements Specification
2.2. Fault-Prone Software Requirements Specification
2.3. Ambiguity in Software Requirements Specification
2.4. Fault-Prone Severity Scale
3. Related Studies
4. Proposed Fault-Prone Software Requirements Specification Detection Model
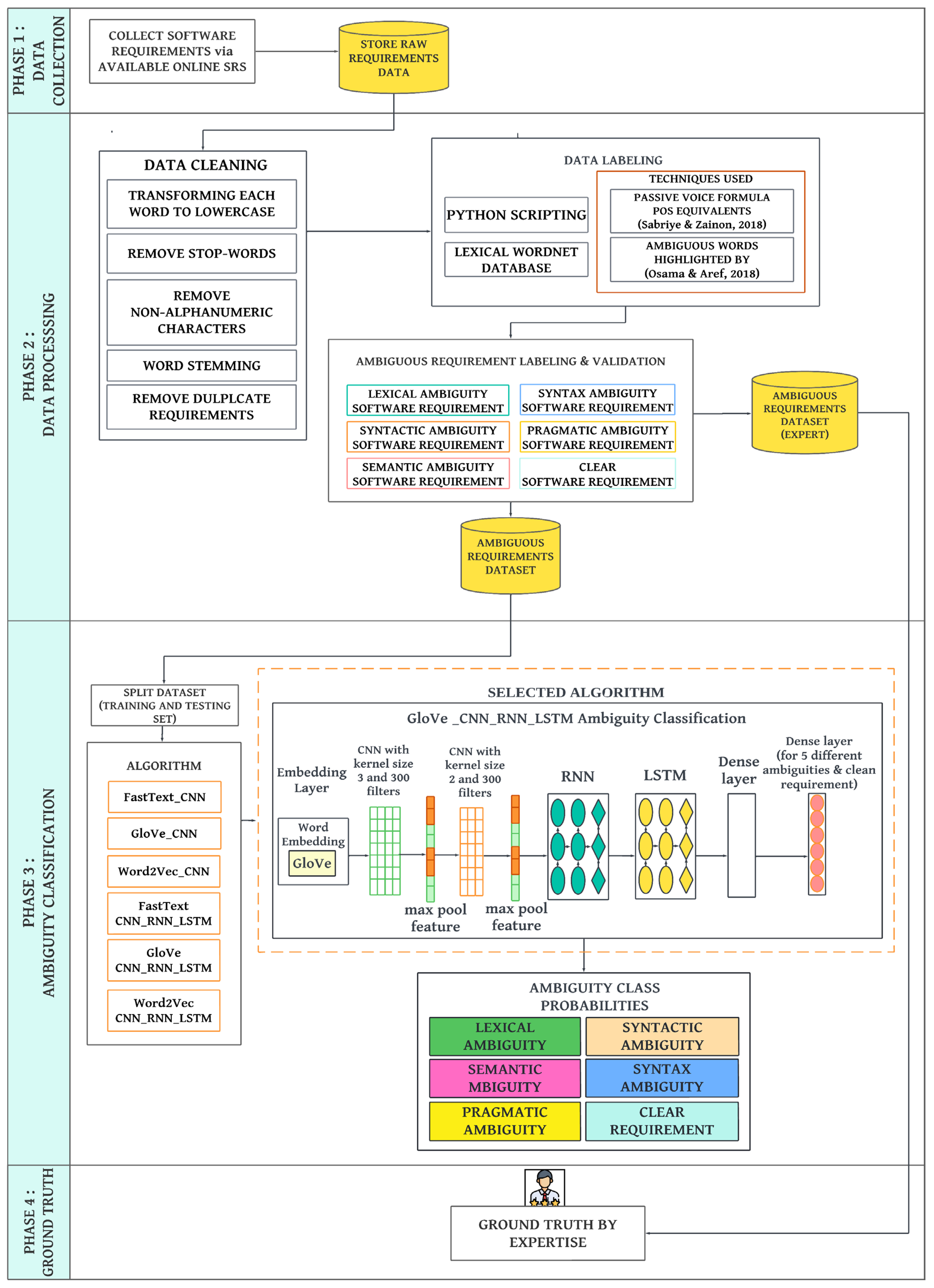
4.1. Ambiguous Classification Model
4.1.1. Phase 1: Data Collection
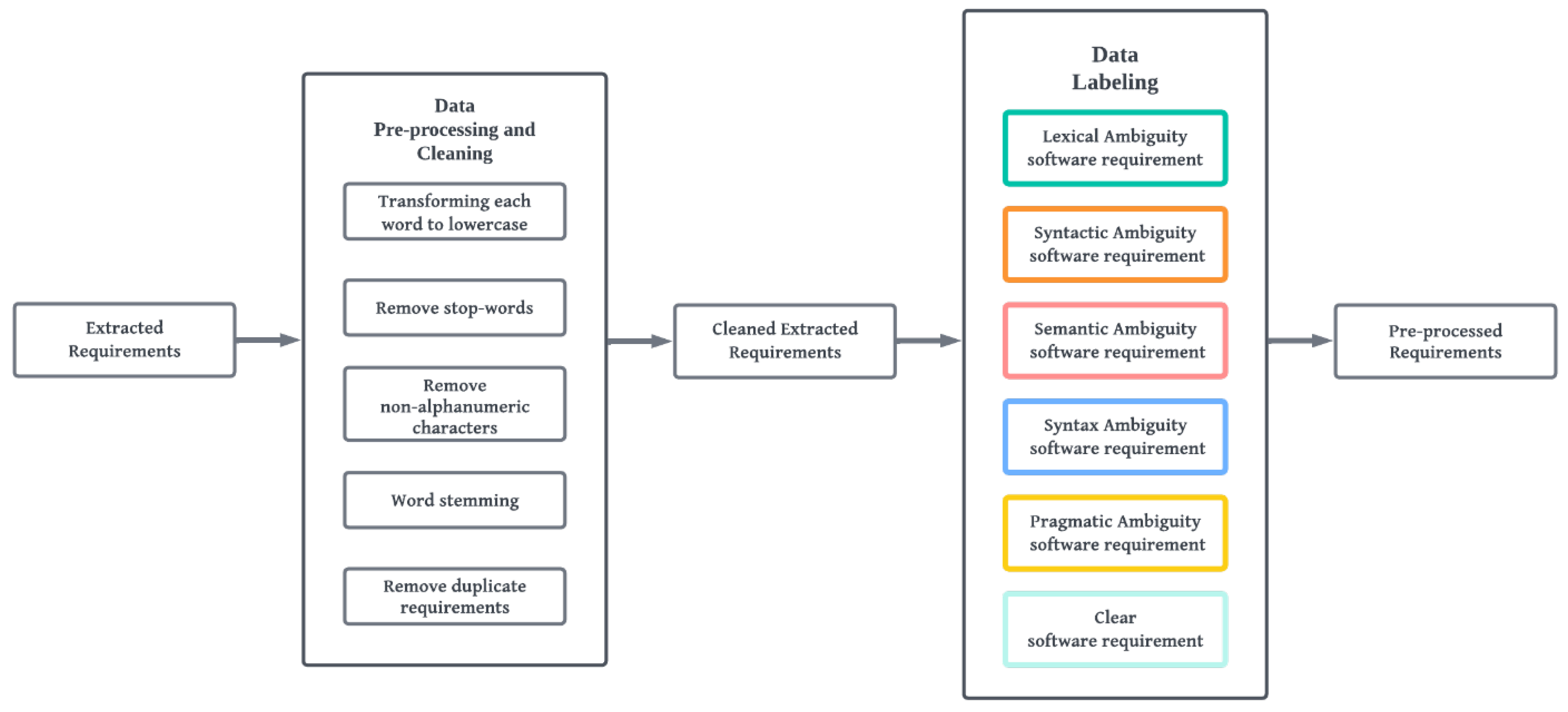
4.1.2. Phase 2: Data Processing
- Sentence splitter: The sentence splitter function isolates each sentence from the input text and turns the sentence into individual sentences.
- Tokenizer: The tokenizer function takes each sentence as input and breaks the sentence down into tokens, such as words, numbers, and punctuation.
- NLTK Part of speech Tagging (POS tagger): The parts of speech (POS) tagger function is the process of marking up words in text format for a specific segment of a speech depending on the definition and context.
- Syntactic parser: The syntactic parser function converts sequences of words into structures that reveal how the parts of a sentence are interconnected.
4.1.3. Data Labelling
4.1.4. Phase 3: Ambiguity Classification
4.1.5. Phase 4: Ground Truth
- One respondent provided the same result as the one generated by the ACM.
- Three respondents did not agree with 5 out of 50 software requirements that were detected as ambiguous, but the experts identified the software requirement as clear.
- One respondent did not agree with 6 out of 50 software requirements that were detected as ambiguous, but he identified the software requirement as clear.
- On average, across all five experts, only 8.27% of the responses concerning ambiguous and clean requirements did not match the results provided by ACM.
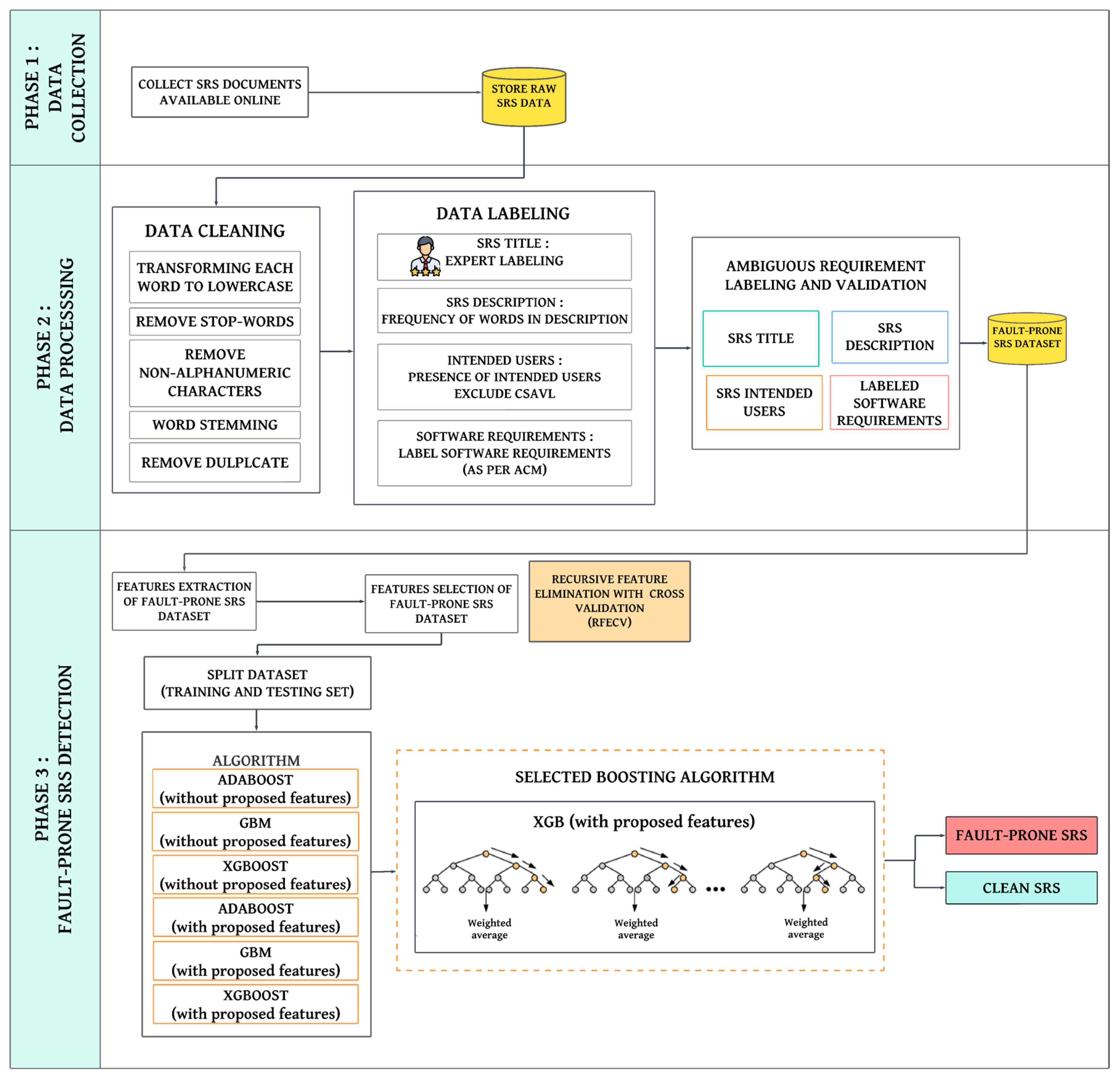
4.2. Fault-Prone Software Requirements Specification Detection Model
4.2.1. Phase 1: Data Collection
4.2.2. Phase 2: Data Processing
- SRS Title: The SRS title was evaluated to ensure that the title provides a clear idea of the system that will be implemented.
- SRS Description: The frequency of words present in the SRS description was analyzed by counting each word from the SRS title in the SRS description. To ensure consistency, the titles were converted into root word before calculating the frequency of words. The Computer Science Academic Vocabulary List (CSAVL) was excluded to ensure that the SRS description is related to the SRS title and is clear. A clear SRS description must contain more than three words related to the SRS title. For example, if the SRS title is Hotel Reservation System, the words “hotel” and “reserve” are checked, and the word “system” is excluded as “system” is part of the CSAVL.
- SRS intended users: We checked the presence of intended users of the system in the SRS.
- SRS requirements: Using custom Python scripting, we classified the requirements in each SRS based on the five types of ambiguity generated by the ACM.
4.2.3. Phase 3: Fault-Prone Software Requirements Specification Detection
5. Case Study: Detecting Fault-Prone Software Requirements Specification for Edge/Cloud Application
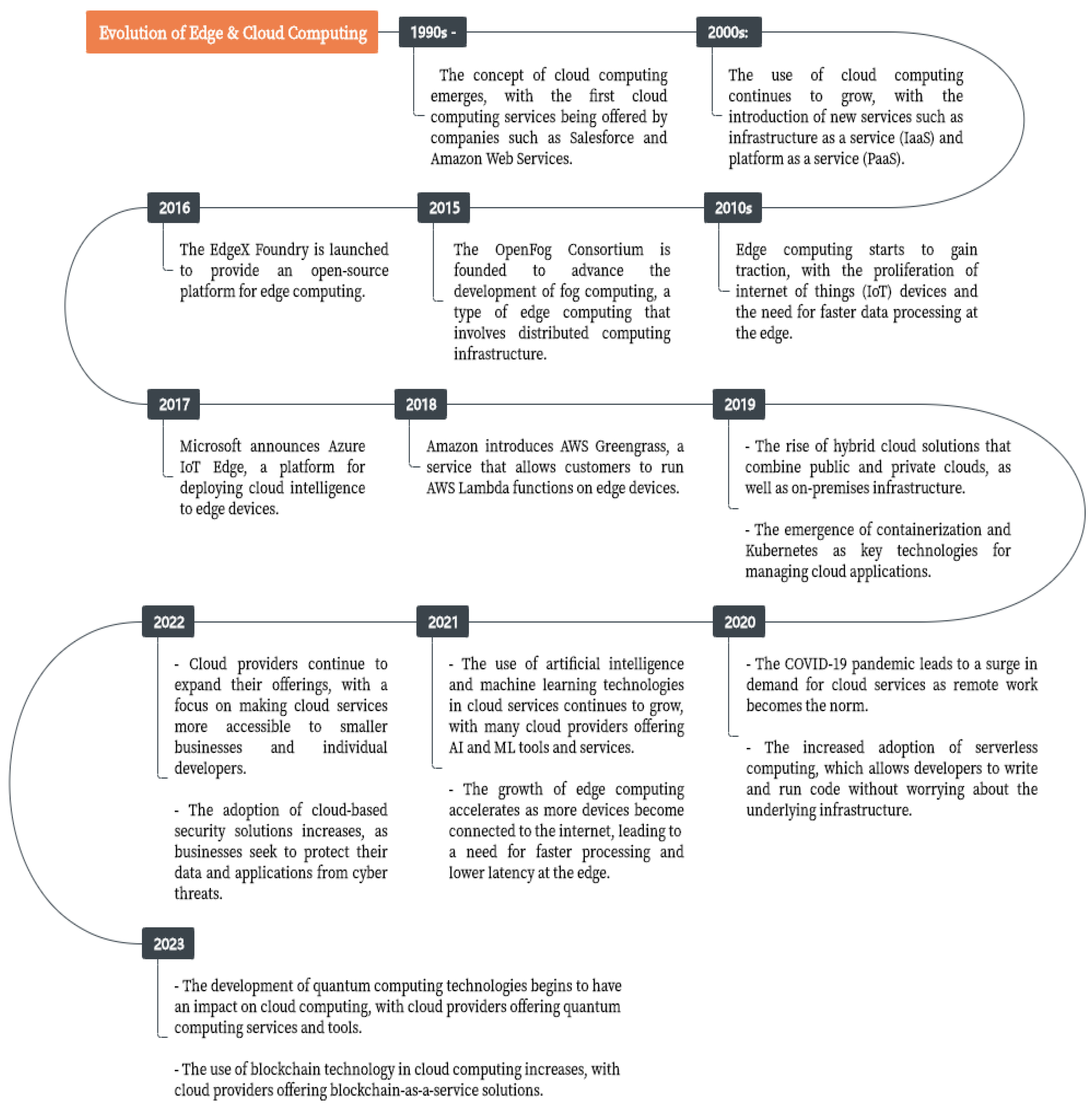
5.1. The Evolution of Edge/Cloud Computing
5.2. Edge/Cloud Application Software Requirements Specification
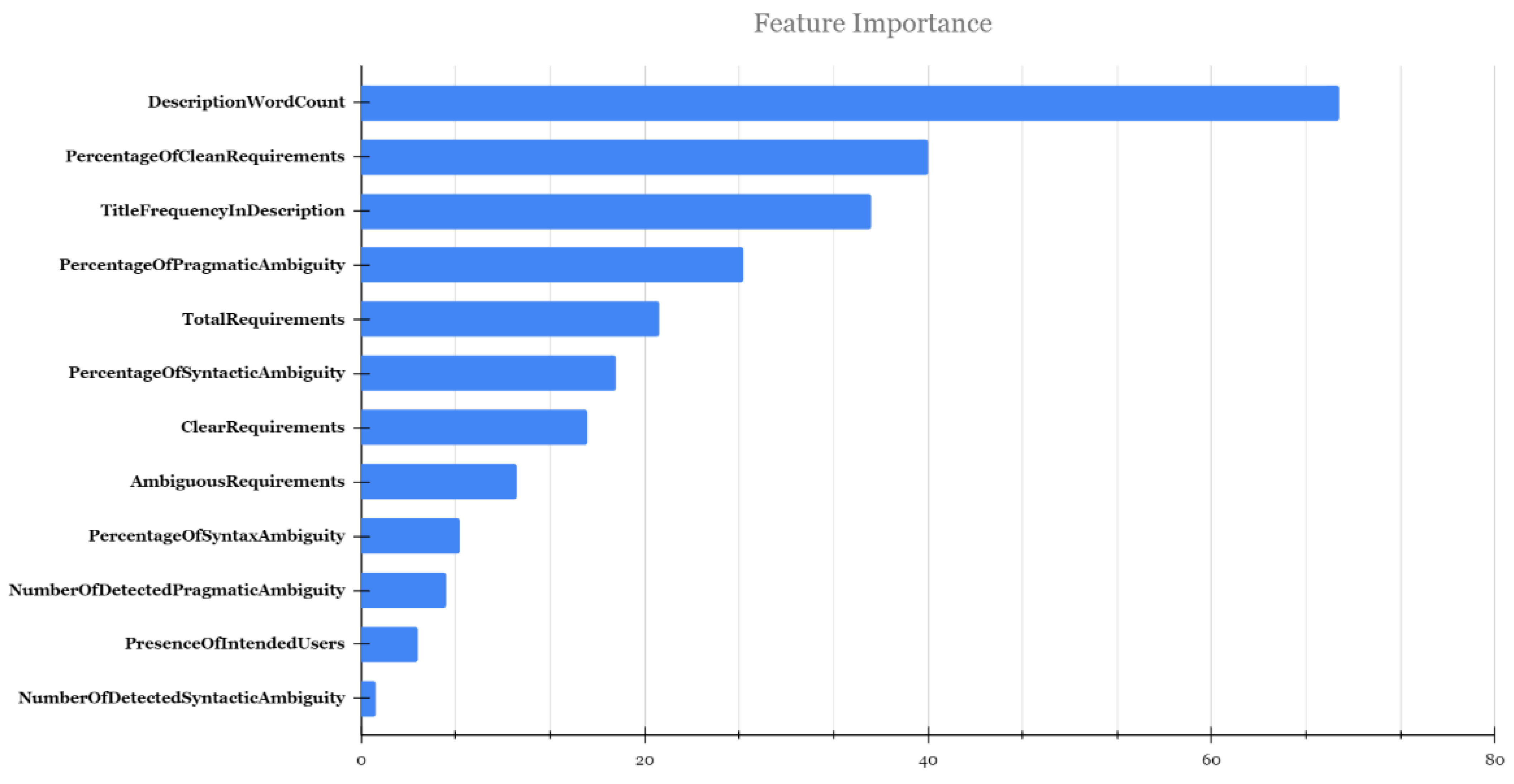
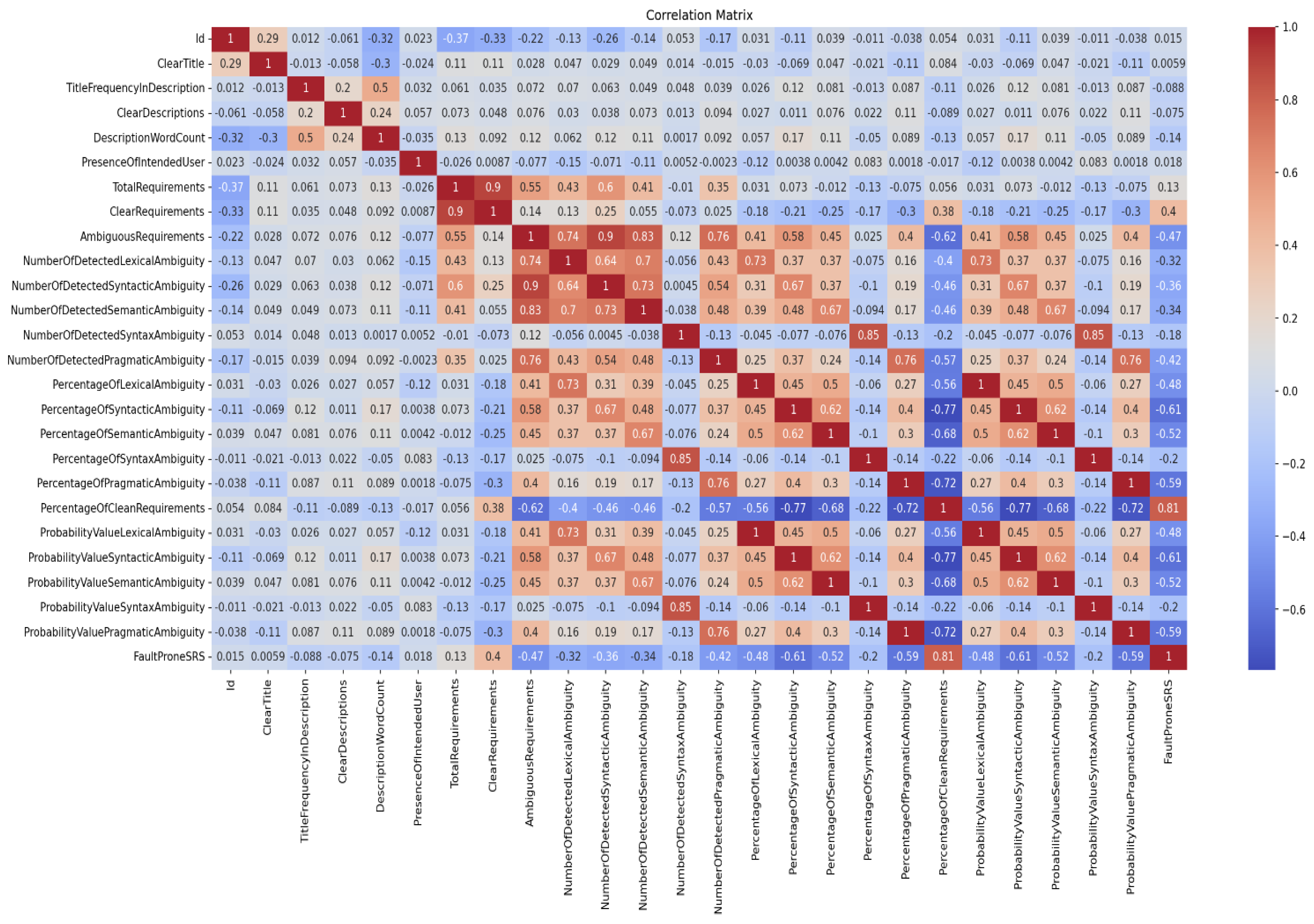
5.3. Analysis of Fault-Prone Edge/Cloud Application Software Requirements Specification
- Linear Mapping Function for Software Requirements: A mathematical formula used to calculate a score based on a given ratio of clear requirements to ambiguous requirements. The formula uses the concept of exponential decay, where the score decreases as the ratio of clear to ambiguous requirements decreases. The score ranges from 0 to 10, with 10 being the highest score and indicating a high ratio of clear requirements to ambiguous requirements. If the score is high, it means that there are more clear requirements compared to ambiguous requirements. A higher score indicates more clarity and less ambiguity in the requirements.
- Ambiguity Density Index (ADI): ADI formula quantifies the level of ambiguity in the SRS by measuring the ratio of the number of occurrences of ambiguous words in each SRS to the total number of words in the SRS. A lower ADI value indicates a lower level of ambiguity in the SRS, meaning that the specification is clearer and easier to understand. However, a high ADI value indicates a high level of ambiguity, and areas of the SRS may require further clarification or refinement to ensure a clear and unambiguous specification.
- Fault-prone SRS Score: The fault-prone SRS Score considers various factors such as the clarity of the title and description, the presence of intended users, the ratio of clear requirements to ambiguous requirements and the usage of ambiguous words to assign a score that reflects the overall fault-proneness of the SRS. These factors are assigned a weight based on the perceived importance in the development of a high-quality SRS.
- Low level: For the low severity level, which is defined as scores between 0.1 and 4.9, a ratio of 5 indicates that this level is expected to be the most common and indicates that there is relatively low ambiguity present. This means that most of the requirements and other SRS key components are clear and unambiguous, and no further action is necessary.
- Moderate Level: The moderate severity level, which is defined as scores between 5.0 and 6.9, has a ratio of 2. This level indicates that there is some ambiguity present in the software requirements and other SRS key components, which may require further investigation or clarification.
- High Level: A high severity level, which is defined as scores between 7.0 and 10.0, has a ratio of 3. This level indicates that there is a significant amount of ambiguity present, which is capable of leading to significant issues if not addressed. Therefore, more attention is needed to resolve the ambiguity at this level compared to the moderate level.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sivarajah, S.; Irani, M.A.; Weerakkody, C.; Akter, R.L.E. Critical analysis of Big Data challenges and analytical methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef]
- Mitchel. Leveraging Natural Language Processing in Requirements Analysis. QRA Corp. 16 February 2021. Available online: https://qracorp.com/nlp-requirements-analysis/ (accessed on 14 March 2022).
- Sabriye, A.O.J.; Zainon, W.M.N.W. A framework for detecting ambiguity in software requirement specification. In Proceedings of the 2017 8th International Conference on Information Technology (ICIT), Amman, Jordan, 17–18 May 2017. [Google Scholar] [CrossRef]
- Singh, M.; Walia, G.S. Automating Key Phrase Extraction from Fault Logs to Support Post-Inspection Repair of Software Requirements. In Proceedings of the India Software Engineering Conference, Bhubaneswar, India, 25–27 February 2021. [Google Scholar] [CrossRef]
- Nigam, A.; Arya, N.; Nigam, B.; Jain, D. Tool for Automatic Discovery of Ambiguity in Requirements. Int. J. Comput. Sci. Issues 2012, 9, 350. [Google Scholar]
- Sabriye, A.O.J.; Zainon, W.M.N.W. An approach for detecting syntax and syntactic ambiguity in software requirement specification. J. Theor. Appl. Inf. Technol. 2018, 96, 2275–2284. [Google Scholar]
- Rani, A.; Aggarwal, G. Algorithm for Automatic Detection of Ambiguities from Software Requirements. Int. J. Innov. Technol. Explor. Eng. (IJITEE) 2019, 8, 878–882. [Google Scholar] [CrossRef]
- IBajwa, S.; Lee, M.; Bordbar, B. Resolving Syntactic Ambiguities in Natural Language Specification of Constraints; Springer eBooks: Berlin/Heidelberg, Germany, 2012; pp. 178–187. [Google Scholar] [CrossRef]
- Ferrari, A.; Donati, B.; Gnesi, S. Detecting Domain-Specific Ambiguities: An NLP Approach Based on Wikipedia Crawling and Word Embeddings. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017. [Google Scholar] [CrossRef]
- Osman, M.H.; Zaharin, M.F. Ambi Detect: An Ambiguous Software Requirements Specification Detection Tool. Turk. J. Comput. Math. Educ. 2021, 12, 2023–2028. [Google Scholar] [CrossRef]
- Kurtanovic, Z.; Maalej, W. Automatically Classifying Functional and Non-functional Requirements Using Supervised Machine Learning. In Proceedings of the IEEE International Conference on Requirements Engineering, Lisbon, Portugal, 4–8 September 2017. [Google Scholar] [CrossRef]
- Alshazly, A.A.; Elfatatry, A.; Abougabal, M.S. Detecting defects in software requirements specification. Alex. Eng. J. 2014, 53, 513–527. [Google Scholar] [CrossRef]
- Singh, M. Automated Validation of Requirement Reviews: A Machine Learning Approach. In Proceedings of the IEEE International Conference on Requirements Engineering, Banff, AB, Canada, 20–24 August 2018. [Google Scholar] [CrossRef]
- IEEE Std 830-1998; IEEE Recommended Practice for Software Requirements Specifications. IEEE: New York, NY, USA, 1998.
- Ali, S.; Khan, N.A.; Alshayeb, M.; Alghamdi, A. An Empirical Study of the Impact of SRS Quality on the Fault Proneness of Software Systems. In Proceedings of the 9th International Conference on Software Engineering and Service Science, Beijing, China, 23–25 November 2018; pp. 279–283. [Google Scholar]
- Aggarwal, A.; Singh, S.; Kaur, N. A Study of Software Requirement Specification. Int. J. Comput. Appl. 2015, 126, 1–6. [Google Scholar]
- Bäumer, F.S.; Geierhos, M. Flexible Ambiguity Resolution and Incompleteness Detection in Requirements Descriptions via an Indicator-Based Configuration of Text Analysis Pipelines. In Proceedings of the Annual Hawaii International Conference on System Sciences, Hilton Waikoloa Village, HI, USA, 3–6 January 2018. [Google Scholar] [CrossRef]
- Osama, S.; Aref, M. Detecting and resolving ambiguity approach in requirement specification: Implementation, results and evaluation. Int. J. Intell. Comput. Inf. Sci. 2018, 18, 27–36. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Firdaus, A.; Anuar, N.B.; Razak, M.A.A.; Sangaiah, A.K. Bio-inspired computational paradigm for feature investigation and malware detection: Interactive analytics. Multimed. Tools Appl. 2018, 77, 17519–17555. [Google Scholar] [CrossRef]
- Virgolin, M.; Alderliesten, T.; Bosman, P.A.N. On explaining machine learning models by evolving crucial and compact features. Swarm Evol. Comput. 2019, 53, 100640. [Google Scholar] [CrossRef]
- Hazim, M.; Anuar, N.B.; Razak, M.F.A.; Abdullah, N.A. Detecting Opinion Spams through Supervised Boosting Approach. PLoS ONE 2018, 13, e0198884. [Google Scholar]
- Razak, C.S.A.; Hamid, S.H.A.; Meon, H.; Hema, A.; Subramaniam, P.; Anuar, N.B. Two-step model for emotion detection on twitter users: A Covid-19 case study in Malaysia. Malays. J. Comput. Sci. 2021, 34, 374–388. [Google Scholar] [CrossRef]
- Ranger, S. What Is Cloud Computing? Everything You Need to Know About the Cloud Explained. ZDNET. 25 February 2022. Available online: https://www.zdnet.com/article/what-is-cloud-computing-everything-you-need-to-know-about-the-cloud/ (accessed on 18 May 2023).
- Aggarwal, G. How The Pandemic Has Accelerated Cloud Adoption. Forbes. 15 January 2021. Available online: https://www.forbes.com/sites/forbestechcouncil/2021/01/15/how-the-pandemic-has-accelerated-cloud-adoption/?sh=3ca3ba626621 (accessed on 18 May 2023).
- Zalazar, A.S.; Ballejos, L.C.; Rodriguez, S. Analyzing Requirements Engineering for Cloud Computing. In Requirements Engineering for Service and Cloud Computing; Ramachandran, M., Mahmood, Z., Eds.; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Wongcharoen, S.; Senivongse, T. Twitter analysis of road traffic congestion severity estimation. In Proceedings of the 2016 13th International Joint Conference on Computer Science and Software Engineering (JCSSE), Khon Kaen, Thailand, 13–15 July 2016; pp. 1–6. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Title | Description | Intended Users | Explanation |
|---|---|---|---|---|
| Title | ProDash | ProDash is a software application that helps project managers track and manage projects. The system will provide a centralized platform for project managers to monitor project progress, assign tasks, and collaborate with team members. The dashboard will display real-time project data and analytics, allowing managers to make informed decisions about project timelines and resource allocation. |
Executives The system will be particularly useful for teams working on complex projects with multiple stakeholders and dependencies. | A vague or confusing title leads to miscommunication and misunderstandings among stakeholders. The title of a project is an essential component of its overall description and should be clear and concise. The project title should accurately reflect the purpose of the project and provide a clear indication of what the project aims to accomplish. Having a clear title helps people who are involved understand the project’s purpose and focus. |
| Description | Virtual Event Management System | A software application designed to help businesses and individuals plan, organize, and manage events of all types and sizes. The system provides a range of tools for creating and managing events, including event scheduling, budget management, vendor and attendee management, and task tracking. The system enables event planners to create and manage event calendars. The system is intended to streamline the event planning process and provide real-time analytics and reporting. |
The system is particularly useful for those who want to engage with a large audience remotely, such as in-person event organizers who want to transition to virtual events due to COVID-19. | The system serves different purposes and is designed for different types of events. Based on the title, we expect it to be specifically designed to help organizations host and manage virtual events, providing features such as online registration, virtual venue setup, and live streaming capabilities. Plus, there is an emphasis due to COVID-19. |
| Intended Users | Veritas Student Portal | Veritas Student Portal is a web-based platform that serves as the primary online resource for students, faculty, staff, and prospective students. The website provides a range of information and services, including course catalogs, event calendars, news and announcements, academic and financial aid resources, and access to online learning platforms. |
| Intended users for the Veritas Student Portal suddenly expanded to include alumni and the public, it would be important to update the SRS accordingly. This is because the needs and requirements of alumni and the public may differ significantly from those of students, faculty, and staff. The clear presence of users in the SRS is important because it helps software developers and stakeholders to understand the specific needs and requirements of each user group. |
| Ambiguous Software Requirement | Detected Ambiguity | Program Code/ User Interface | Explanation | Recommended Software Requirement |
|---|---|---|---|---|
| The system shall be able to easily navigate to the main features of the app. | Syntactic | Based on ambiguous software requirement: class ClickCounter: # Example usage: counter = ClickCounter() button1 = Button(text=“Feature 1”, command=lambda: counter.count_click()) Based on clear software requirement: class ClickCounter: def __init__(self): self.clicks = 0 def count_click(self): self.clicks += 1 if self.clicks > 3: raise ValueError(“Exceeded maximum number of clicks”) # Example usage: counter = ClickCounter() button1 = Button(text=“Feature 1”, command=lambda: counter.count_click()) | The ambiguous software requirement lacks specific details about how navigation should be achieved and does not provide any information about the number of taps or clicks required to reach the main features, or the specific navigation methods to be used. People may interpret this to mean that navigation should be achieved through gestures, voice commands, or other methods. Additionally, it does not provide any specific criteria for what constitutes “easy” navigation. This lack of clarity can result in different interpretations and expectations for the final product. | The system shall be able to easily navigate to the main features of the app using not more than three taps or clicks. |
| The system shall display the company crane logo on the home page. | Lexical |  | This ambiguous software requirement is not specific. This is because “Crane” refers to a bird with long legs and a long neck. Additionally, “Crane” also refers to a large machine used for lifting and moving heavy objects. | The system shall display the company crane (bird) logo on the home page. |
| Ambiguity | Possible Ambiguity Indicators |
|---|---|
| Lexical | Lexical ambiguity indicators: Access, address, application, archive, array, bandwidth, binary, cache, compiler, compression, configuration, console, data, directory, disk, domain, driver, encryption, file, firewall, folder, gateway, interface, kernel, library, link, load, logic, macro, malware, memory, metadata, migration, monitor, object, optimization, packet, path, pixel, protocol, query, registry, resource, router, script, security, server, etc. |
| Syntactic | Syntactic ambiguity indicators: And, or, but, so, yet, nor, for, if, although, because, since, unless, until, while, even though, then, as, whenever, wherever, whereas, as if, as long as, etc. |
| Semantic | Semantic ambiguity indicators: All, every, many, several, any, some, few, a lot of, much, little, enough, most, none, half, whole, both, either, neither each, more, less, plenty of, a number of, a great deal of, a bit of, a few, a majority of, etc. |
| Syntax | Checks the absence of a full stop at the end of a condemnation, indicated by the “./.” tag, or the use of passive voice for each software requirement. |
| Pragmatic | Pragmatic ambiguity indicators: I, me, you, he, him, she, her, it, we, us, they, them, mine, yours, his, hers, its, ours, theirs, myself, yourself, himself, herself, itself, ourselves, yourselves, themselves, this, that, these, those, somebody, someone, something, etc. |
| Software Requirements | Labelled Dataset |
|---|---|
| Lexical Ambiguity | 474 |
| Syntactic Ambiguity | 615 |
| Semantic Ambiguity | 614 |
| Syntax Ambiguity | 504 |
| Pragmatic Ambiguity | 834 |
| Clean | 4020 |
| Total | 7061 |
| Algorithm | Main Layer | Neural Network Layer | Output Size | Kernel Size | Max-Pool Size | Activation Function |
|---|---|---|---|---|---|---|
| Word2Vec_CNN | Input layer | Word2Vec Embedding | 300 | None | None | None |
| Layer | ||||||
| Hidden | CNN Layer 1 | 300 | 3 | 50 | ReLU | |
| layer | CNN Layer 2 | 300 | 2 | 10 | ReLU | |
| Fully | Dense Layer 1 | 300 | None | None | ReLU | |
| connected layer | Dense Layer 2 (output layer) | 6 | None | None | None | |
| GloVe_CNN | Input layer | GloVe Embedding layer | 300 | None | None | None |
| Hidden | CNN Layer 1 | 300 | 3 | 50 | ReLU | |
| layer | CNN Layer 2 | 300 | 2 | 10 | ReLU | |
| Fully | Dense Layer 1 | 300 | None | None | ReLu | |
| connected layer | Dense Layer 2 (output layer) | 6 | None | None | None | |
| FastText_CNN | Input layer | FastText Embedding | 300 | None | None | None |
| Layer | ||||||
| Hidden | CNN Layer 1 | 300 | 3 | 50 | ReLU | |
| layer | CNN Layer 2 | 300 | 2 | 10 | ReLU | |
| Fully | Dense Layer 1 | 300 | None | None | ReLU | |
| connected layer | Dense Layer 2 (output layer) | 6 | None | None | Softmax | |
| Word2Vec_CNN_ RNN_LSTM | Input layer | Word2Vec Embedding Layer | 300 | None | None | None |
| Hidden | CNN Layer 1 | 300 | 3 | 50 | ReLU | |
| layer | CNN Layer 2 | 300 | 2 | 10 | ReLU | |
| RNN Layer 1 | 300 | None | None | Sigmoid | ||
| LSTM Layer 1 | 256 | ReLU | ||||
| Fully | Dense Layer 1 | 300 | None | None | ReLU | |
| connected layer | Dense Layer 2 (output layer) | 6 | None | None | None | |
| GloVe_CNN_ RNN_LSTM | Input layer Hidden layer Fully connected layer | GloVe Embedding Layer CNN Layer 1 CNN Layer 2 RNN Layer 1 LSTM Layer 1 Dense Layer 1 Dense Layer 2 (output layer) | 300 300 300 300 128 300 6 | None 3 3 2 None None | None 50 10 None None None | None ReLu ReLu ReLu ReLu Softmax |
| FastText_CNN_ RNN_LSTM | Input layer Hidden layer Fully connected layer | FastText Embedding Layer CNN Layer 1 CNN Layer 2 RNN Layer 1 LSTM Layer 1 Dense Layer 1 Dense Layer 2 (output layer) | 300 300 300 300 128 300 6 | None 3 3 2 None None | None 50 10 None None None | None ReLu ReLu ReLu ReLu Softmax |
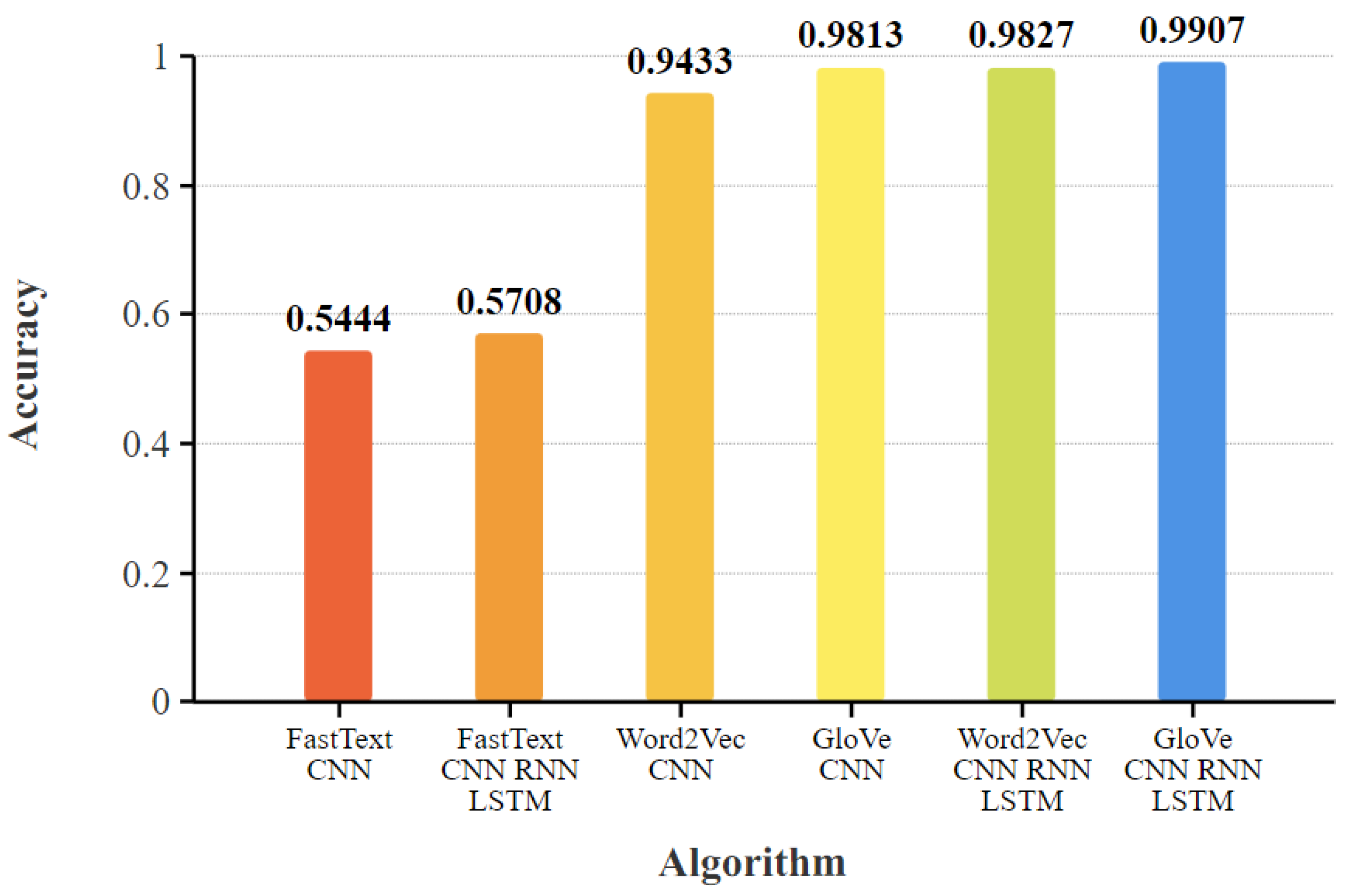
| Algorithm | Precision | Recall | F-Measure |
|---|---|---|---|
| FastText_CNN | 0.9366 | 0.7636 | 0.8413 |
| GloVe_CNN | 0.9641 | 0.9553 | 0.9597 |
| Word2Vec_CNN | 0.9561 | 0.9156 | 0.9356 |
| FastText_CNN_RNN_LSTM | 0.5712 | 0.5713 | 0.5712 |
| GloVe_CNN_RNN_LSTM | 0.9664 | 0.9533 | 0.9598 |
| Word2Vec_CNN_RNN_LSTM | 0.9594 | 0.9509 | 0.9551 |
| Algorithm | Ambiguity | Precision | Recall | F-Measure |
|---|---|---|---|---|
| GloVe_CNN_RNN_LSTM | Lexical | 0.9826 | 0.9811 | 0.9819 |
| Syntactic | 0.9739 | 0.9745 | 0.9742 | |
| Semantic | 0.9634 | 0.9621 | 0.9628 | |
| Syntax | 0.9674 | 0.9660 | 0.9667 | |
| Pragmatic | 0.9860 | 0.9848 | 0.9854 |
| Label | Features | Category | Ref. |
|---|---|---|---|
| F1 | Clear title for each SRS | Boolean | Proposed |
| F2 | Frequency of title word in description for each SRS | Numerical | Proposed |
| F3 | Clear description for each SRS | Boolean | Proposed |
| F4 | Description word count for each SRS | Numerical | Proposed |
| F5 | Presence of SRS intended users for each SRS | Boolean | Proposed |
| F6 | Total of software requirements for each SRS | Numerical | [10] |
| F7 | Number of clear software requirements for each SRS | Numerical | Proposed |
| F8 | Number of ambiguous software requirements for each SRS | Numerical | Proposed |
| F9 | Number of lexical ambiguity requirements for each SRS | Numerical | Proposed |
| F10 | Number of syntactic ambiguity requirements for each SRS | Numerical | Proposed |
| F11 | Number of semantic ambiguity requirements for each SRS | Numerical | Proposed |
| F12 | Number of syntax ambiguity requirements for each SRS | Numerical | Proposed |
| F13 | Number of pragmatic ambiguity requirements for each SRS | Numerical | Proposed |
| F14 | Percentage of lexical ambiguity requirements for each SRS | Numerical | [5,7,18] |
| F15 | Percentage of syntactic ambiguity requirements for each SRS | Numerical | [5,6,7,18] |
| F16 | Percentage of semantic ambiguity requirements for each SRS | Numerical | [7] |
| F17 | Percentage of syntax ambiguity requirements for each SRS | Numerical | [5,6,18] |
| F18 | Percentage of pragmatic ambiguity requirements for each SRS | Numerical | [7,18] |
| F19 | Percentage of clear software requirements for each SRS | Numerical | Proposed |
| F20 | Probability value of lexical ambiguity software requirements for each SRS | Numerical | Proposed |
| F21 | Probability value of syntactic ambiguity software requirements for each SRS | Numerical | Proposed |
| F22 | Probability value of semantic ambiguity software requirements for each SRS | Numerical | Proposed |
| F23 | Probability value of syntax ambiguity software requirements for each SRS | Numerical | Proposed |
| F24 | Probability value of pragmatic ambiguity software requirements for each SRS | Numerical | Proposed |
| F25 | Probability value of clear software requirements for each SRS | Numerical | Proposed |
| Algorithm | Precision | Recall | F-Measure |
|---|---|---|---|
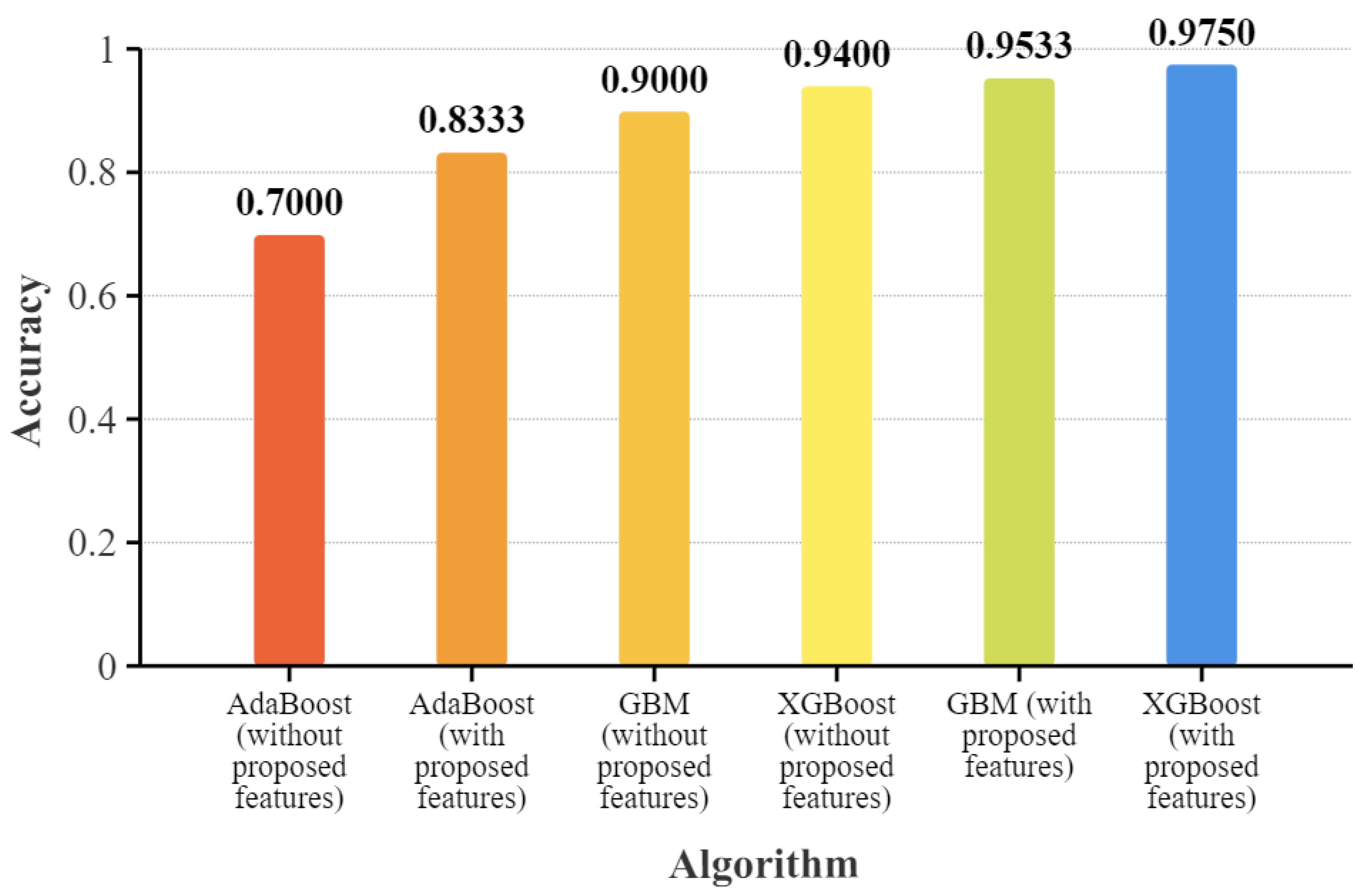
| AdaBoost (without proposed features) | 0.7000 | 1.000 | 0.8235 |
| GBM (without proposed features) | 0.8700 | 0.8900 | 0.8300 |
| XGBoost (without proposed features) | 0.9300 | 0.9100 | 0.9200 |
| AdaBoost (with proposed features) | 0.6667 | 1.000 | 0.8000 |
| GBM (with proposed features) | 0.9693 | 0.9752 | 0.9714 |
| XGBoost (with proposed features) | 0.9706 | 1.000 | 0.9851 |
| Algorithm | SRS | Precision | Recall | F-Measure |
|---|---|---|---|---|
| AdaBoost (without proposed features) | Fault-prone | 0.9200 | 0.9700 | 0.9400 |
| Clean | 0.9200 | 0.8000 | 0.8600 | |
| GBM (without proposed features) | Fault-prone | 0.8000 | 0.8600 | 0.8300 |
| Clean | 0.9400 | 0.9200 | 0.9300 | |
| XGBoost (without proposed features) | Fault-prone | 0.9500 | 0.9700 | 0.9600 |
| Clean | 0.9200 | 0.8500 | 0.8800 | |
| AdaBoost (with proposed features) | Fault-prone | 0.9100 | 0.8300 | 0.8700 |
| Clean | 0.9500 | 0.9700 | 0.9600 | |
| GBM (with proposed features) | Fault-prone | 1.0000 | 0.7500 | 0.8600 |
| Clean | 0.8900 | 1.0000 | 0.9400 | |
| XGBoost (with proposed features) | Fault-prone | 0.9800 | 1.0000 | 0.9500 |
| Clean | 1.000 | 0.9700 | 0.9900 |
| Established Year | SRS Project Title | Project Introduction |
|---|---|---|
| 2017 | Istio—Connect Secure Control and Observe Services | Connect Secure Control and Observe Services: Istio is an open-source service mesh platform that provides a way to connect, secure, control, and observe microservices. It provides a powerful set of tools for managing traffic, enforcing policies, and monitoring performance, with built-in support for service-level agreements (SLAs) and other features. |
| 2016 | OpenFaaS—Serverless Functions Made Simple | Serverless Functions Made Simple: OpenFaaS is an open-source serverless framework that allows developers to deploy their code as functions to the cloud or on-premises infrastructure. It provides a simple and scalable way to run functions in any language or runtime, with built-in support for Docker containers. |
| 2016 | CareKit | CareKit is an open-source framework for developing health and wellness applications for iOS. |
| 2015 | MedStack | MedStack is a cloud-based platform for developing and deploying healthcare applications. It provides a secure and compliant environment for developers to build and test their applications, with built-in support for HIPAA and other regulatory requirements. |
| 2015 | User Profiling in social media | User profiling in social media refers to the process of analyzing user data from social media platforms to gain insights into user behavior, preferences, and interests. It can be used for targeted advertising, personalized recommendations, and other applications. |
| 2014 | Terraform—Infrastructure as Code | Terraform is an open-source tool for building, changing, and versioning infrastructure safely and efficiently. It uses a declarative configuration language to describe infrastructure as code, allowing users to automate the provisioning and management of cloud resources. |
| 2014 | CloudMedX | CloudMedX is a cloud-based platform for healthcare data analytics. It uses machine learning and natural language processing to analyze clinical data and generate insights for healthcare providers and payers. |
| 2014 | Kubernetes—Automated Container Management | Kubernetes is an open-source platform for automated container management. It provides a powerful set of tools for deploying, scaling, and managing containerized applications, with built-in support for load balancing, service discovery, and other features. |
| 2013 | Docker | Docker is an open-source platform for developing, shipping, and running applications in containers. It provides a lightweight and portable way to package and deploy applications, allowing developers to build once and run anywhere. |
| 2013 | Roomzilla | Roomzilla is a cloud-based platform for managing conference rooms and other shared spaces. It provides a user-friendly interface for scheduling and availability management. |
| 2013 | Appointlet | Appointlet is a cloud-based platform for scheduling appointments and meetings. It provides a customizable booking page and integrations with popular calendar tools. |
| 2012 | Prometheus—Monitoring and Alerting | Prometheus is an open-source monitoring and alerting system that collects metrics from different sources, stores them in a time-series database, and provides a powerful query language for analyzing and visualizing them. It also has built-in support for alerting and notifications. |
| 2012 | Reservio | Reservio is a cloud-based platform for managing appointments and bookings for businesses of all sizes. It provides a user-friendly interface for scheduling, payment processing, and customer management. |
| 2012 | RoomKey | A cloud-based hotel property management system (PMS) that allows hoteliers to manage their properties and reservations from a centralized platform. The system includes features such as reservation management, online booking, housekeeping, front desk management, payment processing, and reporting. |
| 2011 | Cloud Foundry | Cloud Foundry is an open-source platform for building, deploying, and managing cloud-native applications. It provides a scalable and resilient environment for running applications, with built-in support for continuous integration and delivery (CI/CD) pipelines. |
| 2011 | BookingSync | BookingSync is a cloud-based platform for managing vacation rentals, holiday homes, and other short-term rentals. |
| 2011 | ClassDojo | ClassDojo is a cloud-based platform for communication and collaboration between teachers, students, and parents. It provides a suite of tools for managing classroom activities, sharing assignments, and providing feedback |
| 2010 | OpenStack | OpenStack is an open-source cloud computing platform that provides a set of tools for building and managing private and public clouds. It provides a scalable and flexible infrastructure for running virtual machines, containers, and other cloud-native applications. |
| 2010 | HotelTonight | HotelTonight is a cloud-based platform for last-minute hotel bookings. It provides a user-friendly interface for searching and booking hotels, with discounts and special offers. |
| 2009 | BookingsPlus | BookingsPlus is a cloud-based platform for managing bookings and reservations for events, facilities, and other resources. It provides a user-friendly interface for booking and payment processing, with built-in support for scheduling and availability management. |
| 2009 | Schoology | Schoology is a cloud-based platform for K-12 and higher education institutions. It provides a suite of tools for course management, student engagement, and assessment. |
| 2008 | Bookeo | Bookeo is a cloud-based platform for managing bookings and reservations for tours, classes, and other activities. It provides a user-friendly interface for scheduling, payment processing, and customer management. |
| 2008 | Cloud Based Hotel Management System | A cloud-based hotel management system is a software platform for managing hotel operations, such as reservations, bookings, payments, and customer service. It provides real-time visibility into hotel activities, with built-in analytics and reporting. It can be used by hotels of all sizes and types. |
| 2007 | Cloud based File Sharing System | A cloud-based file sharing system is a software platform for storing and sharing files in the cloud. It provides secure and convenient access to files from any device, with built-in collaboration and version control features. It can be used by individuals, teams, and organizations of all sizes. |
| 2006 | Amazon EC2 | Amazon Elastic Compute Cloud (EC2) is a web service that provides scalable computing capacity in the cloud. It allows users to launch and manage virtual machines, called instances, on Amazon’s infrastructure, providing flexibility and cost savings for a variety of use cases. |
| 2006 | Appointy | Appointy is a cloud-based platform for managing appointments and bookings for businesses of all sizes. It provides a user-friendly interface for scheduling, payment processing, and customer management. |
| 2004 | OpenMRS | OpenMRS is an open-source electronic medical record system that provides a way to manage patient data in healthcare settings. It is designed to be flexible and customizable, allowing healthcare providers to adapt it to their specific needs. |
| 2002 | Cloud based Inventory Management System | A cloud-based inventory management system is a software platform for managing inventory and supply chain operations. It provides real-time visibility into inventory levels, orders, and shipments, with built-in analytics and reporting. It can be used by businesses of all sizes and industries. |
| 1999 | Cloud Based Library Management System | A cloud-based library management system is a software platform for managing library operations, such as cataloging, circulation, and patron management. It provides a user-friendly interface for searching and checking out books, with built-in analytics and reporting. It can be used by libraries of all sizes and types. |
| 1997 | Athena Health | Athena Health is a cloud-based platform for electronic health records, revenue cycle management, and practice management. |
| Title | SRS Classification | Equal | |
|---|---|---|---|
| Expert Evaluation | Fault-Prone SRS Detection Model | ||
| OpenFaaS—Serverless Functions Made Simple | Clean | Clean | Yes |
| Terraform—Infrastructure as Code | Clean | Clean | Yes |
| Prometheus—Monitoring and Alerting | Clean | Clean | Yes |
| Docker | Clean | Clean | Yes |
| Amazon EC2 | Clean | Clean | Yes |
| MedStack | Clean | Clean | Yes |
| User Profiling in social media | Clean | Clean | Yes |
| CloudMedX | Clean | Clean | Yes |
| BookingsPlus | Clean | Clean | Yes |
| Kubernetes—Automated Container Management | Fault-prone | Fault-prone | Yes |
| Istio—Connect Secure Control and Observe Services | Fault-prone | Fault-prone | Yes |
| Cloud Foundry | Fault-prone | Fault-prone | Yes |
| OpenStack | Fault-prone | Fault-prone | Yes |
| OpenMRS | Fault-prone | Fault-prone | Yes |
| CareKit | Fault-prone | Fault-prone | Yes |
| Athena Health | Fault-prone | Fault-prone | Yes |
| BookingSync | Fault-prone | Fault-prone | Yes |
| Roomzilla | Fault-prone | Fault-prone | Yes |
| Appointy | Fault-prone | Fault-prone | Yes |
| Appointlet | Fault-prone | Fault-prone | Yes |
| Bookeo | Fault-prone | Fault-prone | Yes |
| Schoology | Fault-prone | Fault-prone | Yes |
| ClassDojo | Fault-prone | Fault-prone | Yes |
| HotelTonight | Fault-prone | Fault-prone | Yes |
| Cloud based Inventory Management System | Fault-prone | Fault-prone | Yes |
| Cloud based File Sharing System | Fault-prone | Fault-prone | Yes |
| Cloud Based Hotel Management System | Fault-prone | Fault-prone | Yes |
| Cloud Based Library Management System | Fault-prone | Fault-prone | Yes |
| Reservio | Clean | Fault-prone | No |
| RoomKey | Fault-prone | Clean | No |
| Factor | Weightage Distribution |
|---|---|
| Software Requirements | 0.5 |
| ADI | 0.2 |
| Clear SRS Title | 0.1 |
| Clear SRS Description | 0.1 |
| Presence of Intended Users | 0.1 |
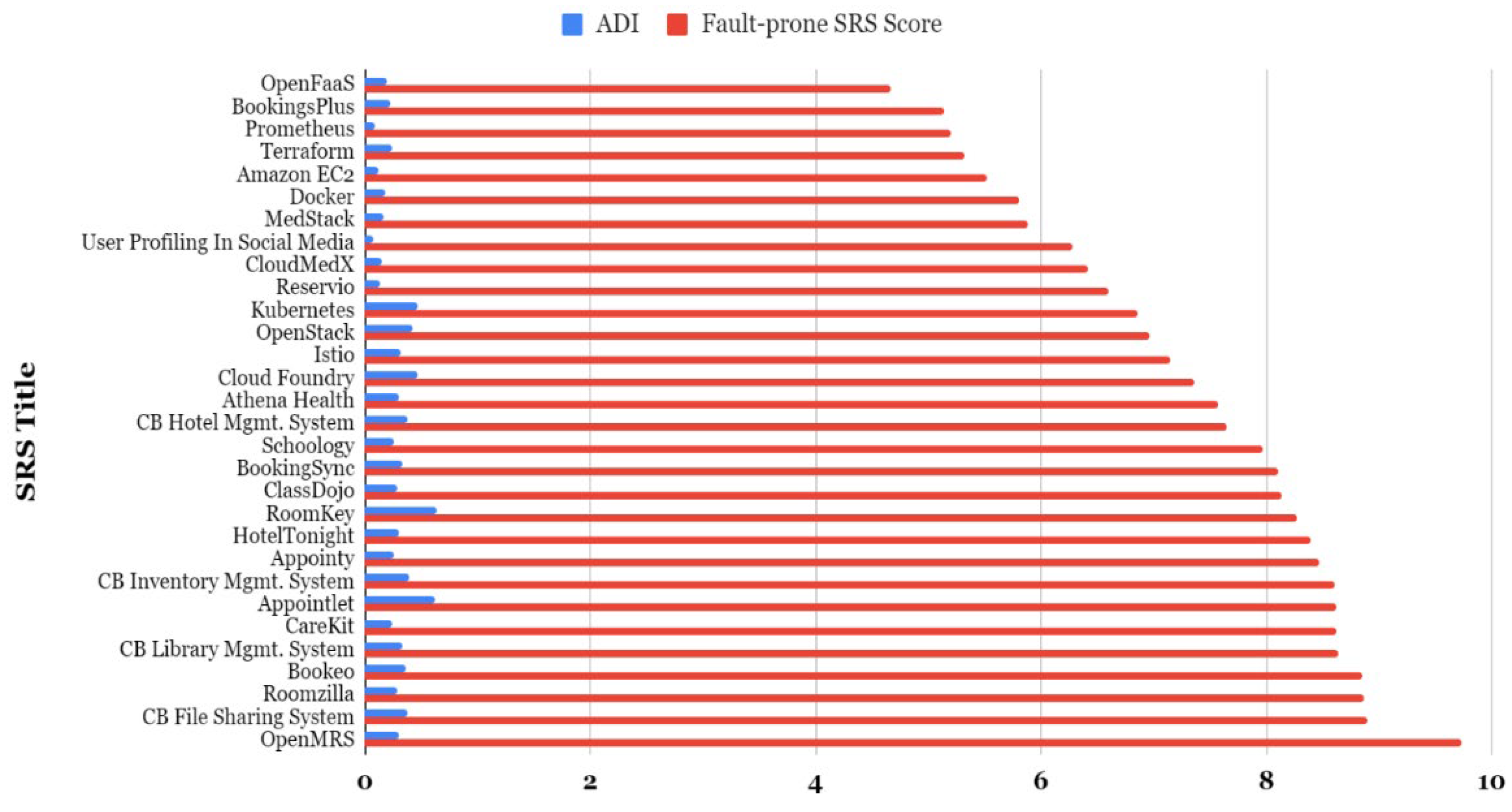
| Title | Ratio Clear to Ambiguous | Software Requirements (LMF) | w1 | Total Words | Count Ambiguous Words | ADI | w2 | Title | w3 | Desc | w4 | User | w5 | Fault-Prone SRS Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenFaaS—Serverless Functions Made Simple | 20:3 | 9.987316012 | 0.5 | 419 | 85 | 0.2028639618 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 4.665769201 |
| BookingsPlus | 21:9 | 9.027042529 | 0.5 | 339 | 77 | 0.2271386431 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 5.141051007 |
| Prometheus—Monitoring and Alerting | 15:6 | 9.179150014 | 0.5 | 298 | 25 | 0.08389261745 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 5.19364647 |
| Terraform—Infrastructure as Code | 16:8 | 8.646647168 | 0.5 | 395 | 94 | 0.2379746835 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 5.329081479 |
| Amazon Elastic Compute Cloud | 16:9 | 8.313618527 | 0.5 | 389 | 45 | 0.1156812339 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 5.52005449 |
| Docker | 11:7 | 7.919548176 | 0.5 | 243 | 44 | 0.1810699588 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 5.80401192 |
| MedStack | 27:18 | 7.768698399 | 0.5 | 670 | 116 | 0.1731343284 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 5.881023935 |
| User Profiling In Social Media | 8:7 | 6.801809782 | 0.5 | 397 | 32 | 0.08060453401 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 6.282974202 |
| CloudMedX | 21:19 | 6.704410389 | 0.5 | 373 | 58 | 0.1554959786 | 0.2 | 0 | 0.1 | 1 | 0.1 | 1 | 0.1 | 6.41669561 |
| Reservio: Appointment Scheduling Software | 19:20 | 6.132589765 | 0.5 | 604 | 81 | 0.1341059603 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 6.606883925 |
| Kubernetes—Automated Container Management | 8:10 | 5.506710359 | 0.5 | 298 | 138 | 0.4630872483 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 6.854027371 |
| OpenStack | 8:10 | 5.506710359 | 0.5 | 438 | 183 | 0.4178082192 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 6.963083177 |
| Istio—Connect, Secure, Control, and Observe Services | 11:16 | 4.97419775 | 0.5 | 454 | 146 | 0.3215859031 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 7.148583945 |
| Cloud Foundry | 7:11 | 4.705941823 | 0.5 | 324 | 150 | 0.462962963 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 7.354436496 |
| Athena Health | 8:15 | 4.131581992 | 0.5 | 337 | 100 | 0.296735905 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 7.574861823 |
| Cloud-based Hotel Management System | 8:16 | 3.934693403 | 0.5 | 556 | 215 | 0.3866906475 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 7.655315169 |
| Schoology | 11:25 | 3.559635789 | 0.5 | 739 | 187 | 0.2530446549 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 7.969573174 |
| BookingSync: Vacation Rental Software | 8:22 | 3.051088053 | 0.5 | 410 | 136 | 0.3317073171 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.10811451 |
| ClassDojo | 5:14 | 3.002275023 | 0.5 | 413 | 118 | 0.2857142857 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.141719632 |
| RoomKey | 3:10 | 2.591817793 | 0.5 | 393 | 251 | 0.6386768448 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.276355734 |
| HotelTonight | 6:21 | 2.487373841 | 0.5 | 315 | 96 | 0.3047619048 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.395360699 |
| Appointy | 4:15 | 2.343269285 | 0.5 | 390 | 101 | 0.258974359 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.476570486 |
| Cloud-based Inventory Management System | 5:22 | 2.030792177 | 0.5 | 642 | 257 | 0.4003115265 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.604541606 |
| Appointlet | 5:21 | 2.117973089 | 0.5 | 508 | 313 | 0.6161417323 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 8.617785109 |
| CareKit | 6:26 | 2.06260534 | 0.5 | 545 | 130 | 0.2385321101 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.620990908 |
| Cloud-based Library Management System | 4:18 | 1.990846357 | 0.5 | 470 | 160 | 0.3404255319 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.636491715 |
| Bookeo | 4:24 | 1.538003887 | 0.5 | 480 | 176 | 0.3666666667 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.857664723 |
| Roomzilla: Smart Workplace Management System | 4:24 | 1.538003887 | 0.5 | 572 | 167 | 0.291958042 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.872606448 |
| Cloud-based File Sharing System | 3:19 | 1.46150218 | 0.5 | 544 | 207 | 0.3805147059 | 0.2 | 1 | 0.1 | 1 | 0.1 | 1 | 0.1 | 8.893145969 |
| OpenMRS | 0:19 | 0 | 0.5 | 531 | 159 | 0.2994350282 | 0.2 | 1 | 0.1 | 0 | 0.1 | 1 | 0.1 | 9.740112994 |
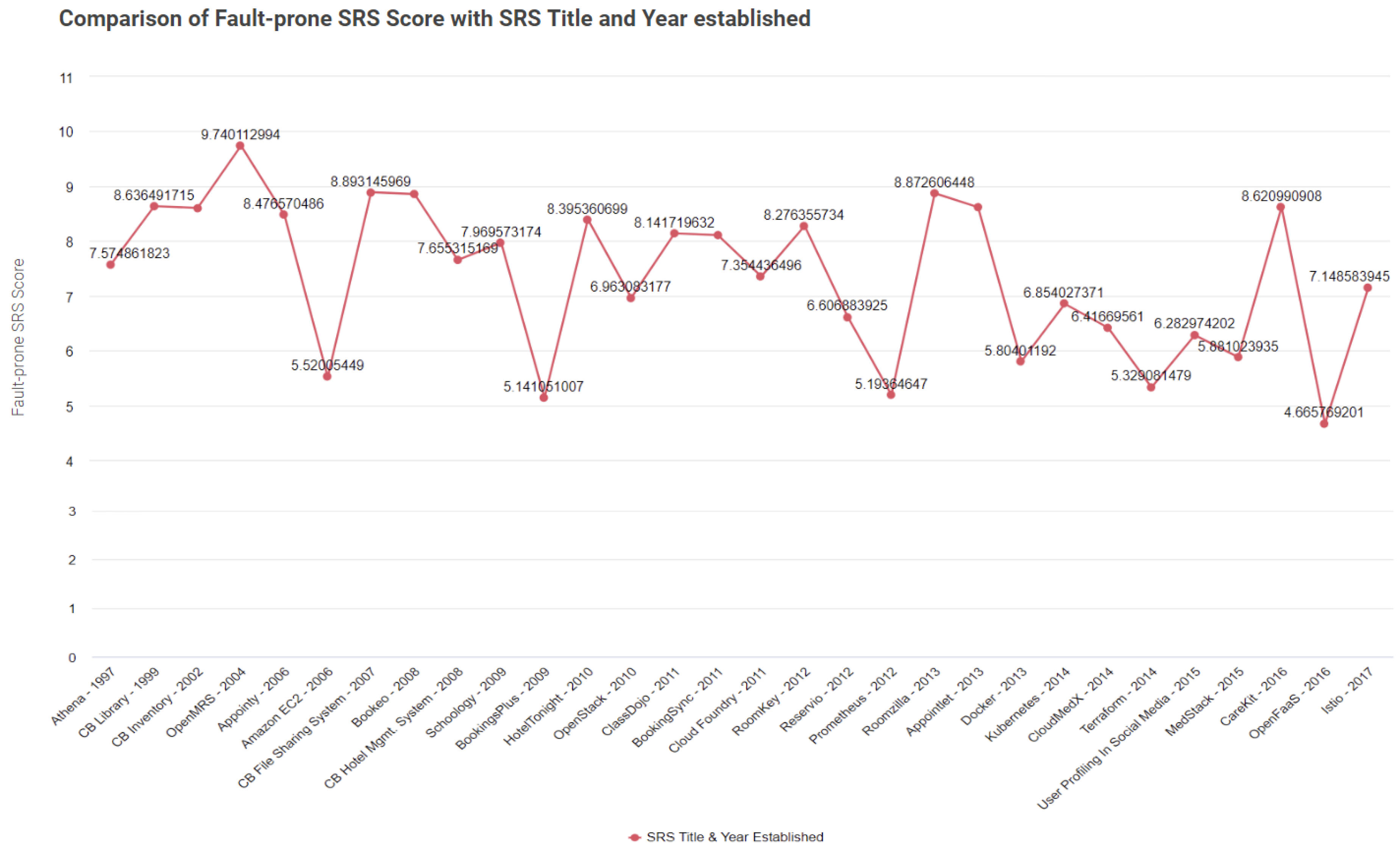
| Title | Fault-Prone SRS Score | Fault-Prone Severity Scale |
|---|---|---|
| OpenFaaS—Serverless Functions Made Simple | 4.665769201 | Low |
| BookingsPlus | 5.141051007 | Moderate |
| Prometheus—Monitoring and Alerting | 5.19364647 | Moderate |
| Terraform—Infrastructure as Code | 5.329081479 | Moderate |
| Amazon Elastic Compute Cloud | 5.52005449 | Moderate |
| Docker | 5.80401192 | Moderate |
| MedStack | 5.881023935 | Moderate |
| User Profiling In Social Media | 6.282974202 | Moderate |
| CloudMedX | 6.41669561 | Moderate |
| Reservio: Appointment Scheduling Software | 6.606883925 | Moderate |
| Kubernetes—Automated Container Management | 6.854027371 | Moderate |
| OpenStack | 6.963083177 | Moderate |
| Istio—Connect, Secure, Control, and Observe Services | 7.148583945 | High |
| Cloud Foundry | 7.354436496 | High |
| Athena Health | 7.574861823 | High |
| Cloud-based Hotel Management System | 7.655315169 | High |
| Schoology | 7.969573174 | High |
| BookingSync: Vacation Rental Software | 8.10811451 | High |
| ClassDojo | 8.141719632 | High |
| RoomKey | 8.276355734 | High |
| HotelTonight | 8.395360699 | High |
| Appointy | 8.476570486 | High |
| Cloud-based Inventory Management System | 8.604541606 | High |
| Appointlet | 8.617785109 | High |
| CareKit | 8.620990908 | High |
| Cloud-based Library Management System | 8.636491715 | High |
| Bookeo | 8.857664723 | High |
| Roomzilla: Smart Workplace Management System | 8.872606448 | High |
| Cloud-based File Sharing System | 8.893145969 | High |
| OpenMRS | 9.740112994 | High |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhamad, F.N.J.; Ab Hamid, S.H.; Subramaniam, H.; Abdul Rashid, R.; Fahmi, F. Fault-Prone Software Requirements Specification Detection Using Ensemble Learning for Edge/Cloud Applications. Appl. Sci. 2023, 13, 8368. https://doi.org/10.3390/app13148368
Muhamad FNJ, Ab Hamid SH, Subramaniam H, Abdul Rashid R, Fahmi F. Fault-Prone Software Requirements Specification Detection Using Ensemble Learning for Edge/Cloud Applications. Applied Sciences. 2023; 13(14):8368. https://doi.org/10.3390/app13148368
Chicago/Turabian StyleMuhamad, Fatin Nur Jannah, Siti Hafizah Ab Hamid, Hema Subramaniam, Razailin Abdul Rashid, and Faisal Fahmi. 2023. "Fault-Prone Software Requirements Specification Detection Using Ensemble Learning for Edge/Cloud Applications" Applied Sciences 13, no. 14: 8368. https://doi.org/10.3390/app13148368
APA StyleMuhamad, F. N. J., Ab Hamid, S. H., Subramaniam, H., Abdul Rashid, R., & Fahmi, F. (2023). Fault-Prone Software Requirements Specification Detection Using Ensemble Learning for Edge/Cloud Applications. Applied Sciences, 13(14), 8368. https://doi.org/10.3390/app13148368