

Re-Thinking Data Strategy and Integration for Artificial Intelligence: Concepts, Opportunities, and Challenges


Abstract
1. Introduction
2. Materials and Methods
2.1. Data for AI
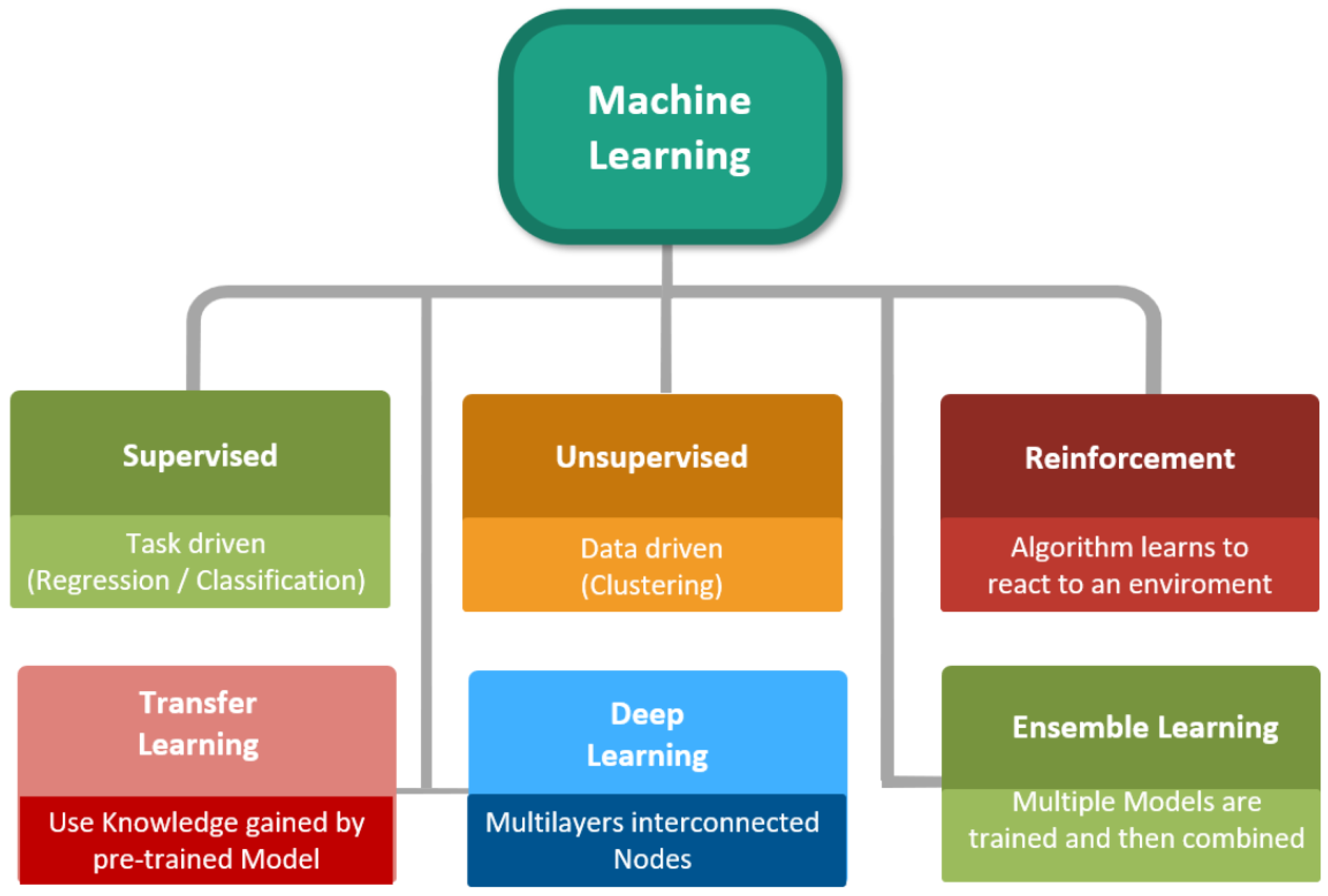
2.1.1. Data Learning Approaches
2.1.2. Data-Centric and Data-Driven AI
2.2. Dimensions of Data Challenges for AI
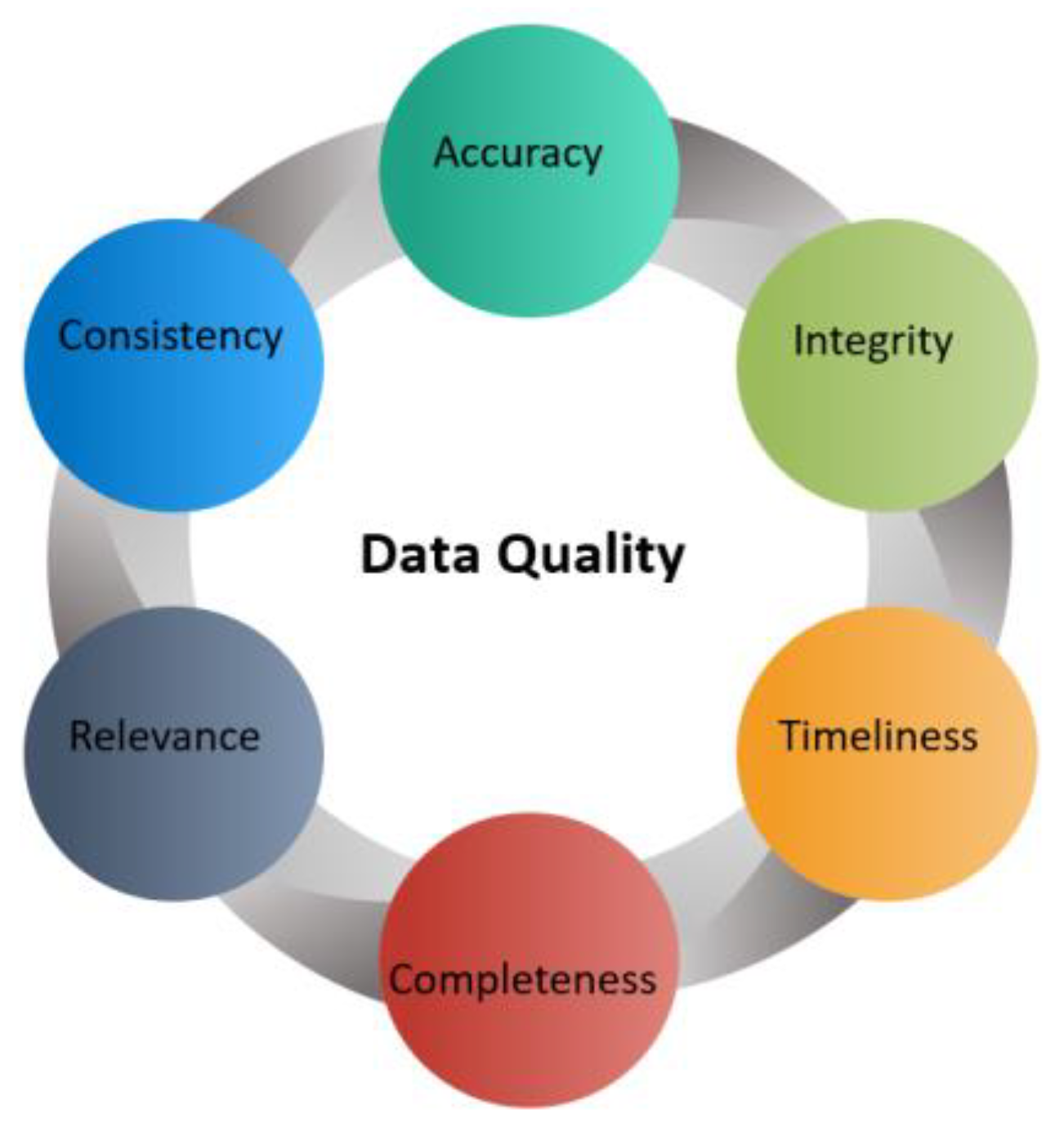
2.2.1. Dimension I: Data Quality
Challenging Measures of Data Quality and Implications on AI Systems
Challenges in Data Collection, Pre-Processing, and Management
The Role of Data Governance in Ensuring Data Quality
Addressing Data Quality Challenges: Techniques and Strategies
2.2.2. Dimension II: Data Volume
Challenging Elements of Data Volume
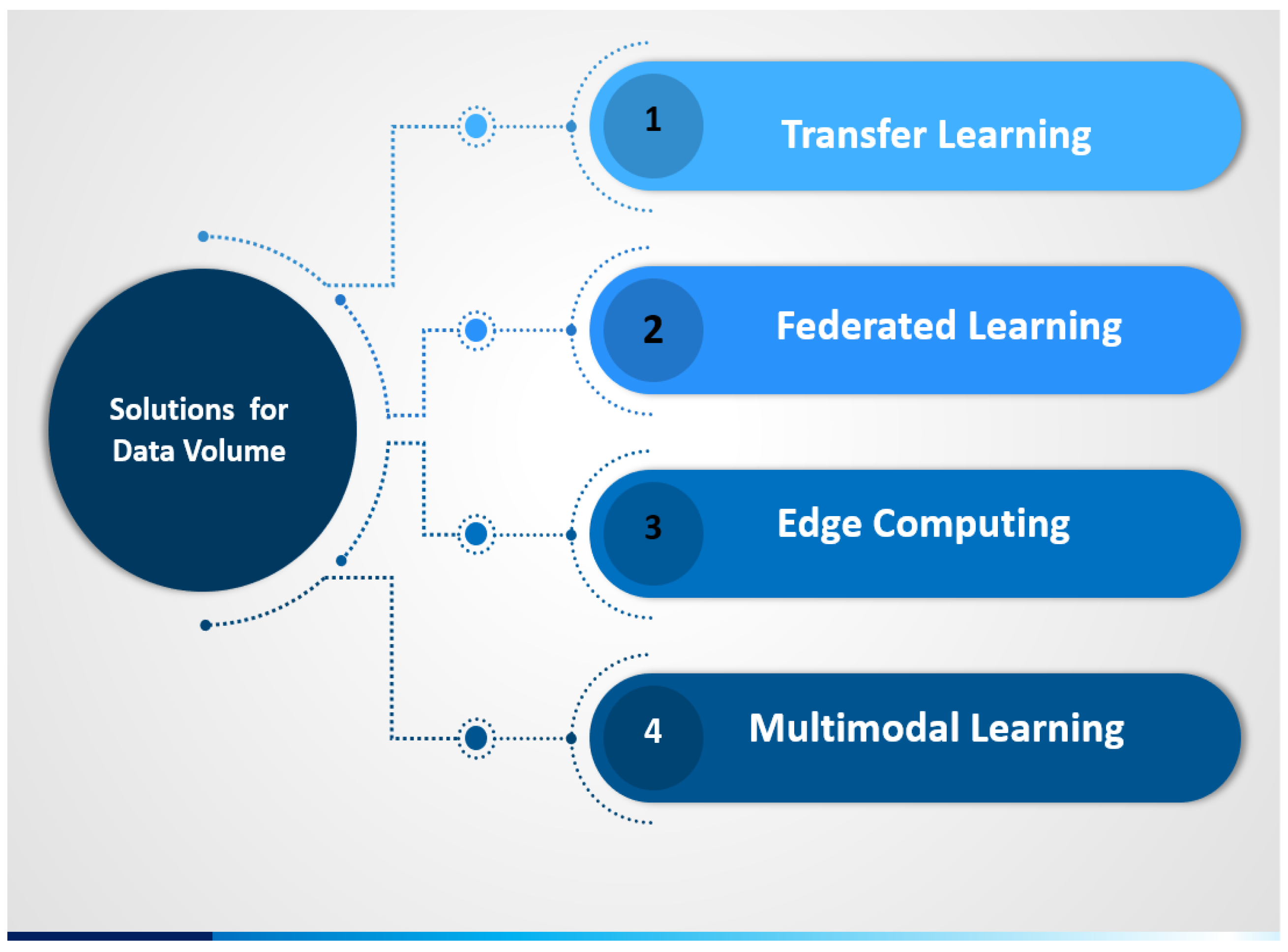
Mitigation Solutions for Challenges of Data Volume
- (a)
- Transfer Learning: Transfer learning involves leveraging pre-trained AI models to improve the performance of new models. Using pre-trained models, organizations can reduce the amount of training data required and improve the efficiency of the training process.
- (b)
- Federated Learning: This enables collaborative model training across multiple devices without sharing raw data [83].
- (c)
- Edge Computing: This brings data processing closer to the data source, thereby reducing the network latency and bandwidth usage [84].
- (d)
- Multimodal Learning: This leverages multiple data sources to improve the model performance and reduce reliance on large datasets [85].
- Federated Learning as a proposed solution:
- (a)
- Privacy: Because raw data remain on client devices, federated learning inherently provides a higher level of privacy compared to centralized approaches [83].
- (b)
- Reduced Data Transfer: By sharing only model updates rather than raw data, federated learning can significantly reduce the amount of data that needs to be transferred over the network, reducing bandwidth and latency issues [87].
- (c)
- Scalability: Federated learning can accommodate a large number of client devices, allowing the use of different data sources without overloading the central server [75].
- (d)
- Real-time learning: By allowing clients to learn from local data, federated learning enables real-time adaptation and improves model performance [82].
- (a)
- Heterogeneity: The heterogeneity of client devices and data distribution may lead to an unbalanced contribution to the global model, which may affect convergence and model performance [75].
- (b)
- Communication Overhead: The iterative process of exchanging model updates incurs significant communication overhead and may negate the benefits of reduced data transfer [87].
- (c)
- Security: Federated learning is vulnerable to various security threats, including model poisoning, inference attacks, and Sybil attacks [88].
- -
- Edge Computing as a Proposed Solution: Edge computing is a distributed computing paradigm that aims to bring computation and data storage closer to the data source, or the “edge” of the network, where the data are generated [84]. By performing data processing on edge devices, such as smartphones, IoT devices, or edge servers, edge computing can reduce the amount of data that must be transmitted to the cloud or a centralized data center. This approach enables real-time data processing, reduces latency, and conserves the bandwidth.
- -
- Advantages of Edge Computing: Edge computing offers several benefits that can help address the data volume challenge in AI.
- (a)
- Reduced Latency: By processing data closer to the source, edge computing can significantly reduce latency and enable real-time AI applications [84].
- (b)
- Bandwidth Efficiency: Edge computing helps conserve bandwidth by reducing the amount of data transmitted over the network, which is particularly useful in situations where the network bandwidth is limited or expensive [76].
- (c)
- Enhanced privacy and security: Because data are processed and stored locally, edge computing can provide improved data privacy and security compared to centralized approaches [92].
- (d)
- Scalability: Edge computing can support many devices and applications, making it suitable for the growing demands of AI and IoT [84].
- Challenges and Future Directions:
- (a)
- Resource Constraints: Edge devices typically have limited computational resources, which may hinder the performance of complex AI models [93].
- (b)
- Model Deployment and Management: Deploying and managing AI models across a large number of edge devices can be challenging because it requires efficient model distribution, updates, and monitoring [94].
- (c)
- Heterogeneity: The heterogeneity of edge devices in terms of hardware, software, and network connectivity can pose challenges for implementing consistent and efficient AI solutions [95].
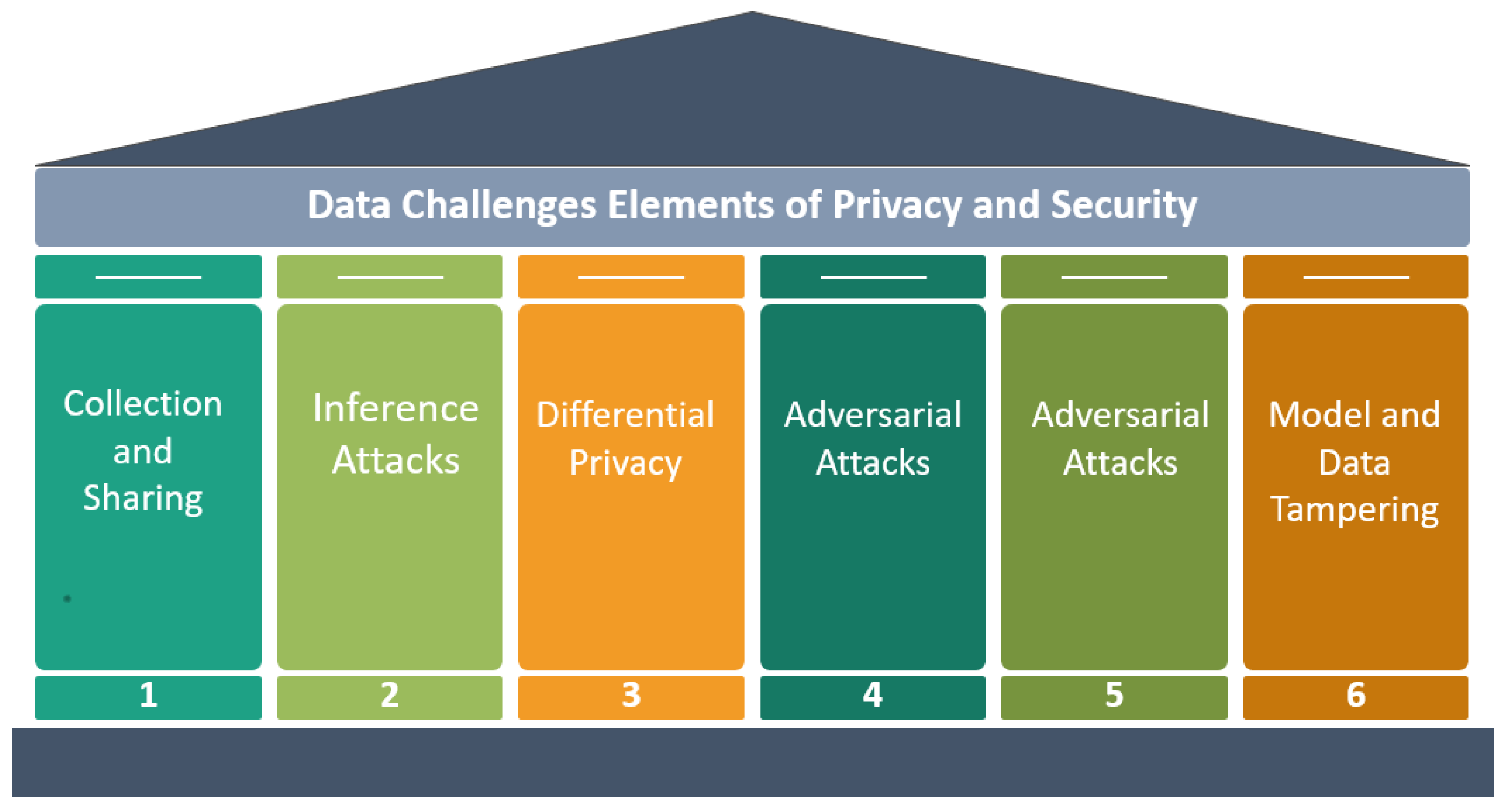
2.2.3. Dimension III: Data Privacy and Security
Data Privacy Challenges in AI
Data Security Challenges in AI
Mitigation Strategies for Data Privacy and Security Challenges
2.2.4. Dimension IV: Bias and Fairness
Types of Data Bias
Consequences of Data Bias and Unfairness in AI
Addressing Data Bias and Fairness in AI
2.2.5. Dimension V: Interpretability and Explainability
The Necessity of Interpretability and Explainability
Current Techniques for Interpretability and Explainability
Remaining Challenges and Future Directions
2.2.6. Dimension VI: Technical Expertise
Scarcity of Skilled Professionals
Ethical Concerns
The Growing Demand for AI-Related Expertise
Key Disciplines in High Demand for AI-Related Expertise
- (a)
- Computer Science and Computer Engineering: Professionals with skills in algorithm development, machine learning, deep learning, natural language processing, and computer vision are essential for designing, building, and maintaining AI systems [175].
- (b)
- Data Science and Analytics: AI systems often rely on large volumes of data. Experts in data science and analytics are required to preprocess, analyze, and interpret data to generate actionable insights and improve AI models [173].
- (c)
- Human–computer Interaction (HCI) and Cognitive Science: As AI technologies become more integrated into our daily lives, understanding how humans interact with these systems is becoming increasingly important. HCI and cognitive science experts can help design AI systems that are intuitive, user-friendly, and adaptable to human needs [176].
- (d)
- Ethics, Philosophy, and Policy: The growing influence of AI technology raises several ethical and philosophical questions. Experts in these fields are needed to address issues related to fairness, transparency, and accountability and to develop policies and frameworks that ensure responsible AI development and deployment [170].
- (e)
- Cybersecurity and Privacy: Protecting sensitive data and maintaining the security of AI systems is a critical concern. Professionals skilled in cryptography, secure multiparty computation, and privacy-preserving machine learning techniques are essential to ensure data privacy and security [177].
- (f)
- Robotics and Autonomous Systems: As AI-powered robotics and autonomous systems become more prevalent, expertise in areas such as control systems, sensor fusion, and robotics software engineering will become increasingly valuable [178].
Collaboration between Humans and AI
3. Results
3.1. Dimension of Data Quality and Implication for AI systems
3.2. The Role of Data Governance in Ensuring Data Quality
- (a)
- Quality standards and policies for data must be defined and put into action.
- (b)
- Throughout the lifecycle of the data, it is important to keep a close eye on their quality and maintain control.
- (c)
- Quality data and holding ourselves accountable should be part of a culture we strive to create.
- (d)
- The sharing, integration, and management of data can be enhanced through various means. The optimization of data management techniques should be prioritized. Improved data sharing is crucial for seamless exchanges between different systems. The integration of various data types can be achieved using appropriate methods.
- (e)
- Regulations and laws must be followed carefully to maintain compliance.
3.3. Best Practices to Ensure Data Quality for AI
- (a)
- Implementing an effective data management strategy that includes data curation and preprocessing before usage.
- (b)
- Fostering transparency and accountability in the data collection process, including defining data sources and conducting regular audits.
- (c)
- Conducting diversity checks on the collected dataset to avoid bias, and making sure that it is representative of the target population.
- (d)
- Ensuring the security and privacy of the data by implementing the necessary security protocols and obtaining consent from the data subjects.
- (e)
- Proactively monitoring and updating the dataset to maintain accuracy and relevance, especially when it comes to dynamic or constantly changing environments.
4. Discussion
4.1. Broader Implications
4.2. Limitations
4.3. Real-Time Time Environment Challenges
- (a)
- Real-Time Data Volume and Velocity: Real-time data often come in high volumes and at high velocities, requiring efficient processing and analysis techniques. AI systems must handle incoming data streams and make timely decisions or predictions based on these data.
- (b)
- Latency and Response Times: Real-time applications demand low latency and fast response times. AI models must be designed and optimized to provide quick insights and actions in real-time scenarios. High computational requirements and complex algorithms can hinder real-time performance.
- (c)
- Real-Time Data Quality and Noise: Real-time data can be noisy, incomplete, or contain outliers. Ensuring data quality becomes challenging as there is limited time for data validation and cleaning. AI models must be robust in order to handle such noisy data and make accurate predictions or decisions.
- (d)
- Scalability and Resource Constraints: Real-time AI applications often require scalability to handle large volumes of incoming data. Scaling AI models and infrastructure to handle the increased workload can be challenging considering resource constraints such as computing power, memory, and network bandwidth.
- (e)
- Data Synchronization: Real-time data may come from multiple sources and must be synchronized for accurate analysis and decision-making. Aligning and integrating data streams from various sources in real time can be complex, particularly when dealing with data in different formats or time zones.
- (f)
- Real-Time Model Training and Adaptation: Updating or retraining AI models in real-time can be challenging. Continuous learning and model adaptation may be required to incorporate new data and adjust model parameters to changing conditions. Balancing the model stability with the need for real-time updates is crucial.
- (g)
- Real-Time Analytics and Visualization: Effectively analyzing and visualizing real-time data to extract meaningful insights and support decision making is a challenge. Real-time analytics techniques and interactive visualization tools are required to process and present data in a timely and actionable manner.
4.4. Future Research Directions
- (a)
- Investigate the role of organizational culture, leadership, and technical infrastructure in ensuring data quality for AI systems.
- (b)
- Conduct empirical research to assess the effectiveness of different data governance practices and data quality management strategies in real-world AI applications.
- (c)
- Examine the relationship between specific dimensions of data quality and AI performance across different industries and use cases.
- (d)
- Develop novel AI and machine learning techniques to automatically detect, diagnose, and resolve data quality issues.
- (e)
- Explore the ethical and legal implications of data quality challenges in AI, particularly in relation to privacy, transparency, and fairness.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: London, UK, 2016. [Google Scholar]
- Sharma, L.; Garg, P.K. Artificial Intelligence: Technologies, Applications, and Challenges; Taylor & Francis: New York, NY, USA, 2021. [Google Scholar]
- Aguiar-Pérez, J.M.; Pérez-Juárez, M.A.; Alonso-Felipe, M.; Del-Pozo-Velázquez, J.; Rozada-Raneros, S.; Barrio-Conde, M. Understanding Machine Learning Concepts. In Encyclopedia of Data Science and Machine Learning; IGI Global: Hershey, PA, USA, 2023; pp. 1007–1022. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA; 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Gumbs, A.A.; Grasso, V.; Bourdel, N.; Croner, R.; Spolverato, G.; Frigerio, I.; Illanes, A.; Abu Hilal, M.; Park, A.; Elyan, E. The advances in computer vision that are enabling more autonomous actions in surgery: A systematic review of the literature. Sensors 2022, 22, 4918. [Google Scholar] [CrossRef] [PubMed]
- Enholm, I.M.; Papagiannidis, E.; Mikalef, P.; Krogstie, J. Artificial intelligence and business value: A literature review. Inf. Syst. Front. 2022, 24, 1709–1734. [Google Scholar] [CrossRef]
- Wang, Z.; Li, M.; Lu, J.; Cheng, X. Business Innovation based on artificial intelligence and Blockchain technology. Inf. Process. Manag. 2022, 59, 102759. [Google Scholar] [CrossRef]
- Dahiya, N.; Sheifali, G.; Sartajvir, S. A Review Paper on Machine Learning Applications, Advantages, and Techniques. ECS Trans. 2022, 107, 6137. [Google Scholar] [CrossRef]
- Marr, B. Artificial Intelligence in Practice: How 50 Successful Companies Used AI and Machine Learning to Solve Problems; John Wiley & Sons: New York, NY, USA, 2018. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Liu, X.; Yoo, C.; Xing, F.; Oh, H.; El Fakhri, G.; Kang, J.-W.; Woo, J. Deep unsupervised domain adaptation: A review of recent advances and perspectives. APSIPA Trans. Signal Inf. Process. 2022, 11, e25. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S.S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Sun, X.; Liu, Y.; Liu, J. Ensemble learning for multi-source remote sensing data classification based on different feature extraction methods. IEEE Access 2018, 6, 50861–50869. [Google Scholar]
- Zha, D.; Bhat, Z.P.; Lai, K.H.; Yang, F.; Jiang, Z.; Zhong, S.; Hu, X. Data-centric artificial intelligence: A survey. arXiv 2023, arXiv:2303.10158. [Google Scholar]
- Ntoutsi, E.; Fafalios, P.; Gadiraju, U.; Iosifidis, V.; Nejdl, W.; Vidal, M.E.; Ruggieri, S.; Turini, F.; Papadopoulos, S.; Krasanakis, E.; et al. Bias in data-driven artificial intelligence systems—An introductory survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1356. [Google Scholar] [CrossRef]
- Jarrahi, M.H.; Ali, M.; Shion, G. The Principles of Data-Centric AI (DCAI). arXiv 2022, arXiv:2211.14611. [Google Scholar]
- Zha, D.; Bhat, Z.P.; Lai, K.-H.; Yang, F.; Hu, X. Data-centric AI: Perspectives and Challenges. arXiv 2023, arXiv:2301.04819. [Google Scholar]
- Mazumder, M.; Banbury, C.; Yao, X.; Karlaš, B.; Rojas, W.G.; Diamos, S.; Diamos, G.; He, L.; Kiela, D.; Jurado, D.; et al. Dataperf: Benchmarks for data-centric ai development. arXiv 2022, arXiv:2207.10062. [Google Scholar]
- Miranda, L.J. Towards Data-Centric Machine Learning: A Short Review. Available online: https://ljvmiranda921.github.io/notebook/2021/07/30/data-centric-ml/ (accessed on 15 April 2023).
- Alvarez-Coello, D.; Wilms, D.; Bekan, A.; Gómez, J.M. Towards a data-centric architecture in the automotive industry. Procedia Comput. Sci. 2021, 181, 658–663. [Google Scholar] [CrossRef]
- Uddin, M.F.; Navarun, G. Seven V’s of Big Data understanding Big Data to extract value. In Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014. [Google Scholar]
- O’Leary, D.E. Artificial intelligence and big data. IEEE Intell. Syst. 2013, 28, 96–99. [Google Scholar] [CrossRef]
- Broo, D.G.; Jennifer, S. Towards data-centric decision making for smart infrastructure: Data and its challenges. IFAC-Pap. 2020, 53, 90–94. [Google Scholar] [CrossRef]
- Jakubik, J.; Vössing, M.; Kühl, N.; Walk, J.; Satzger, G. Data-centric Artificial Intelligence. arXiv 2022, arXiv:2212.11854. [Google Scholar]
- Li, X.-H.; Cao, C.C.; Shi, Y.; Bai, W.; Gao, H.; Qiu, L.; Wang, C.; Gao, Y.; Zhang, S.; Xue, X.; et al. A survey of data-driven and knowledge-aware explainable ai. IEEE Trans. Knowl. Data Eng. 2020, 34, 29–49. [Google Scholar] [CrossRef]
- Hajian, S.; Bonchi, F.; Castillo, C. Algorithmic bias: From discrimination discovery to fairness-aware data mining. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 2125–2126. [Google Scholar]
- Kanter, J.M.; Benjamin, S.; Kalyan, V. Machine Learning 2.0: Engineering Data Driven AI Products. arXiv 2018, arXiv:1807.00401. [Google Scholar]
- Xu, K.; Li, Y.; Liu, C.; Liu, X.; Hao, X.; Gao, J.; Maropoulos, P.G. Maropoulos. Advanced data collection and analysis in data-driven manufacturing process. Chin. J. Mech. Eng. 2020, 33, 1–21. [Google Scholar] [CrossRef]
- Maranghi, M.; Anagnostopoulos, A.; Cannistraci, I.; Chatzigiannakis, I.; Croce, F.; Di Teodoro, G.; Gentile, M.; Grani, G.; Lenzerini, M.; Leonardi, S.; et al. AI-based Data Preparation and Data Analytics in Healthcare: The Case of Diabetes. arXiv 2022, arXiv:2206.06182. [Google Scholar]
- Bergen, K.J.; Johnson, P.A.; de Hoop, M.V.; Beroza, G.C. Machine learning for data-driven discovery in solid Earth geoscience. Science 2019, 363, eaau0323. [Google Scholar] [CrossRef] [PubMed]
- Jöckel, L.; Michael, K. Increasing Trust in Data-Driven Model Validation: A Framework for Probabilistic Augmentation of Images and Meta-data Generation Using Application Scope Characteristics. In Computer Safety, Reliability, and Security, Proceeding of the 38th International Conference, SAFECOMP 2019, Turku, Finland, 11–13 September 2019; Springer International Publishing: New York, NY, USA, 2019. [Google Scholar]
- Burr, C.; Leslie, D. Ethical assurance: A practical approach to the responsible design, development, and deployment of data-driven technologies. AI Ethics 2023, 3, 73–98. [Google Scholar] [CrossRef]
- Lomas, J.; Nirmal, P.; Jodi, F. Continuous improvement: How systems design can benefit the data-driven design community. In Proceedings of the RSD7, Relating Systems Thinking and Design 7, Turin, Italy, 23–26 October 2018. [Google Scholar]
- Yablonsky, S. Multidimensional data-driven artificial intelligence innovation. Technol. Innov. Manag. Rev. 2019, 9, 16–28. [Google Scholar] [CrossRef]
- Batista, G.E.; Monard, M.C. Data quality in machine learning: A study in the context of imbalanced data. Neurocomputing 2018, 275, 1665–1679. [Google Scholar]
- Pipino, L.L.; Lee, Y.W.; Wang, R.Y. Data quality assessment. In Data and Information Quality; Springer: Cham, Switzerland, 2018; pp. 219–253. [Google Scholar]
- Halevy, A.; Korn, F.; Noy, N.; Olston, C.; Polyzotis, N.; Roy, S.; Whang, S. Goods: Organizing Google’s datasets. Commun. ACM 2020, 63, 50–57. [Google Scholar]
- Redman, T.C. Data Quality for the Information Age; Artech House, Inc.: Norwood, MA, USA, 1996. [Google Scholar]
- Juran, J.M.; Godfrey, A.B. Juran’s Quality Handbook: The Complete Guide to Performance Excellence; McGraw-Hill Education: New York, NY, USA, 2018. [Google Scholar]
- Yang, Y.; Zheng, L.; Zhang, J.; Cui, Q.; Li, Z.; Yu, P.S. TI-CNN: Convolutional neural networks for fake news detection. arXiv 2018, arXiv:1806.00749. [Google Scholar]
- Barocas, S.; Hardt, M.; Narayanan, A. Fairness and machine learning. Limit. Oppor. 2021, 1, 1–269. [Google Scholar]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: New York, NY, USA, 2019. [Google Scholar]
- Hassan, N.U.; Asghar, M.Z.; Ahmed, S.; Zafar, H. A survey on data quality issues in big data. ACM Comput. Surv. (CSUR) 2021, 54, 1–37. [Google Scholar]
- Chen, H.; Chiang, R.H.; Storey, V.C. Business intelligence and analytics: From big data to big impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar] [CrossRef]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Karkouch, A.; Mousannif, H.; Al Moatassime, H.; Noel, T. Data quality in the Internet of Things: A state-of-the-art survey. J. Netw. Comput. Appl. 2018, 124, 289–310. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Petersen, S. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Daries, J.P.; Reich, J.; Waldo, J.; Young, E.M.; Whittinghill, J.; Ho, A.D.; Chuang, I. Privacy, anonymity, and big data in the social sciences. Commun. ACM 2014, 57, 56–63. [Google Scholar] [CrossRef]
- García, S.; Luengo, J.; Herrera, F. Data Preprocessing in Data Mining; Springer: New York, NY, USA, 2016. [Google Scholar]
- Kelleher, J.D.; Mac Namee, B.; D’Arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; MIT Press: Boston, MA, USA, 2018. [Google Scholar]
- Guyon, I.; Gunn, S.; Ben-Hur, A. Result analysis of the NIPS 2003 feature selection challenge. Adv. Neural Inf. Process. Syst. 2004, 17, 545–552. [Google Scholar]
- Khatri, V.; Brown, C.V. Designing data governance. Commun. ACM 2010, 53, 148–152. [Google Scholar] [CrossRef]
- Otto, B. Organizing data quality management in enterprises. In Proceedings of the 17th Americas Conference on Information Systems (AMCIS), Detroit, MI, USA, 4–8 August 2011; pp. 1–9. [Google Scholar]
- Weill, P.; Ross, J.W. IT Governance: How Top Performers Manage IT Decision Rights for Superior Results; Harvard Business Press: Boston, MA, USA, 2004. [Google Scholar]
- Tallon, P.P. Corporate governance of big data: Perspectives on value, risk, and cost. IEEE Comput. 2013, 46, 32–38. [Google Scholar] [CrossRef]
- Panian, Z. Some practical experiences in data governance. World Acad. Sci. Eng. Technol. 2010, 66, 1248–1253. [Google Scholar]
- Laney, D.B. Infonomics: How to Monetize, Manage, and Measure Information as an Asset for Competitive Advantage; Routledge: Oxfordshire, UK, 2017. [Google Scholar]
- Thomas, G.; Griffin, R. Data governance: A taxonomy of data quality interventions. Int. J. Inf. Qual. 2015, 4, 4–17. [Google Scholar]
- Begg, C.; Caira, T. Data governance: More than just keeping data clean. J. Enterp. Inf. Manag. 2013, 26, 595–610. [Google Scholar]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; John Wiley & Sons: New York, NY, USA, 2004. [Google Scholar]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2018, 66, 31–47. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical Learning with Sparsity: The Lasso and Generalizations; Chapman and Hall/CRC: New York, NY, USA, 2019. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the 2018 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation policies from data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Yang, Y.; Loog, M.; Hospedales, T.M. Active Learning by Querying Informative and Representative Examples. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2436–2450. [Google Scholar] [CrossRef]
- Li, Y.; Guo, Y. Adaptive Active Learning for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 7663–7671. [Google Scholar] [CrossRef]
- Siddiquie, B.; Gupta, A. Human Effort Estimation for Visual Tasks. Int. J. Comput. Vis. 2019, 127, 1161–1179. [Google Scholar]
- Zhang, Y.; Chen, T.; Zhang, Y. Challenges and countermeasures of big data in artificial intelligence. J. Phys. Conf. Ser. 2019, 1237, 032023. [Google Scholar] [CrossRef]
- Zhu, Y.; Lapata, M. Learning to attend, copy, and generate for session-based query suggestion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Halevy, A.; Norvig, P.; Pereira, F. The unreasonable effectiveness of data. IEEE Intell. Syst. 2020, 24, 8–12. [Google Scholar] [CrossRef]
- Li, Q.; Dong, S.; Ye, S. Storage challenges and solutions in the AI era. Front. Inf. Technol. Electron. Eng. 2021, 22, 743–767. [Google Scholar]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, J.; He, H.; Chen, H.; Chen, J. Data storage technology in artificial intelligence. IEEE Access 2021, 9, 37864–37881. [Google Scholar]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. (Eds.) Automated Machine Learning: Methods, Systems, Challenges; Springer Nature: New York, NY, USA, 2019. [Google Scholar]
- Sharma, H.; Park, J.; Mahajan, D.; Amaro, E.; Kaeli, D.; Kim, Y. From high-level deep neural models to FPGAs. In Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020. [Google Scholar]
- Chen, Y.; Wang, T.; Yang, Y.; Zhang, B. Deep model compression: Distilling knowledge from noisy teachers. arXiv 2020, arXiv:1610.09650. [Google Scholar]
- Ratner, A.; Bach, S.; Ehrenberg, H.; Fries, J.; Wu, S.; Ré, C. Snorkel: Rapid training data creation with weak supervision. Proc. VLDB Endow. 2019, 11, 269–282. [Google Scholar] [CrossRef] [PubMed]
- Maheshwari, A.; Killamsetty, K.; Ramakrishnan, G.; Iyer, R.; Danilevsky, M.; Popa, L. Learning to Robustly Aggregate Labeling Functions for Semi-supervised Data Programming. arXiv 2021, arXiv:2109.11410. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Zhang, Y. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2020, 3, 637–646. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-IID data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the 2020 International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Yurochkin, M.; Agarwal, N.; Ghosh, S.; Greenewald, K.; Hoang, L.; Khazaeni, Y. Bayesian nonparametric federated learning of neural networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security (AISec), Virtual Event, 13 November 2020. [Google Scholar]
- Roman, R.; Lopez, J.; Mambo, M. Mobile edge computing, Fog et al.: A survey and analysis of security threats and challenges. Future Gener. Comput. Syst. 2018, 78, 680–698. [Google Scholar] [CrossRef]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive deep learning model selection on embedded systems. In Proceedings of the 3rd ACM/IEEE Symposium on Edge Computing (SEC), Arlington, VA, USA, 7–9 November 2019. [Google Scholar]
- Kumar, A.; Goyal, S.; Varma, M.; Jain, P. Resource-constrained distributed machine learning: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–34. [Google Scholar]
- Zhang, Z.; Mao, Y.; Letaief, K.B. Energy-efficient user association and resource allocation in heterogeneous cloud radio access networks. IEEE J. Sel. Areas Commun. 2019, 37, 1107–1121. [Google Scholar]
- Zhang, H.; Wu, J.; Zhang, Z.; Yang, Q. Collaborative learning for data privacy and data utility. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar]
- Liang, X.; Zhao, J.; Shetty, S.; Liu, J.; Li, D. Integrating blockchain for data sharing and collaboration in mobile healthcare applications. In Proceedings of the IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), London, UK, 31 August–3 September 2020. [Google Scholar]
- Chen, X.; Zhang, W.; Wang, X.; Li, T. Privacy-Preserving Federated Learning for IoT Applications: A Review. IEEE Internet Things J. 2021, 8, 6078–6093. [Google Scholar]
- Zhao, Y.; Fan, L. A secure data sharing scheme for cross-border cooperation in the artificial intelligence era. Secur. Commun. Netw. 2021, 2021, 1–12. [Google Scholar]
- Carlini, N.; Liu, C.; Erlingsson, U.; Kos, J.; Song, D.; Wicker, M. The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019; pp. 267–284. Available online: https://www.usenix.org/system/files/sec19-carlini.pdf (accessed on 20 March 2023).
- Jayaraman, B.; Evans, D. Evaluating Membership Inference Attacks in Machine Learning: An Information Theoretic Framework. IEEE Trans. Inf. Secur. 2020, 15, 1875–1890. [Google Scholar]
- Dwork, C.; Roth, A.; Naor, M. Differential Privacy: A Survey of Results. In Theory and Applications of Models of Computation; Springer: New York, NY, USA, 2018; pp. 1–19. [Google Scholar]
- Truex, S.; Xu, C.; Calandrino, J.; Boneh, D. The Limitations of Differential Privacy in Practice. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019; pp. 1045–1062. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. Commun. ACM 2022, 65, 56–65. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified Defenses against Adversarial Examples. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhu, M.; Yin, H.; Yang, X. A Comprehensive Survey of Poisoning Attacks in Federated Learning. IEEE Access 2021, 9, 57427–57447. [Google Scholar]
- Sun, Y.; Zhang, T.; Wang, J.; Wang, X. A Survey of Deep Neural Network Backdoor Attacks and Defenses. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4150–4169. [Google Scholar]
- Gu, T.; Dolan-Gavitt, B.; Garg, S. BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain. In Proceedings of the 28th USENIX Security Symposium, Santa Clara, CA, USA, 14–16 August 2019; pp. 1965–1980. [Google Scholar]
- Liu, Y.; Ma, X.; Ateniese, G.; Hsu, W.L. Trojaning Attack on Neural Networks. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 27–41. [Google Scholar] [CrossRef]
- Gao, Y.; Sun, X.; Zhang, Y.; Liu, J. Trojan Attacks on Federated Learning Systems: An Overview. IEEE Netw. 2021, 35, 144–150. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing Machine Learning Models via Prediction APIs. In USENIX Security Symposium. 2016, 16, pp. 601–618. Available online: https://www.usenix.org/system/files/conference/usenixsecurity16/sec16_paper_tramer.pdf (accessed on 25 March 2023).
- Jagielski, M.; Severi, G.; Pousette Harger, N.; Oprea, A. Subpopulation Data Poisoning Attacks. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 15–19 November 2021; pp. 31–3122. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, J.; Liu, T.; Yang, Y. Trojan Detection via Fine-Pruning. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 9–13 November 2020; pp. 1151–1168. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar] [CrossRef]
- Shneiderman, B. Bridging the Gap Between Ethics and Practice: Guidelines for Reliable, Safe, and Trustworthy Human-centered AI Systems. ACM Trans. Interact. Intell. Syst. 2020, 10, 1–31. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. In Proceedings of the 2nd Workshop on Systems for ML at Scale; 2019; pp. 1–6. [Google Scholar]
- Liu, P.; Wang, L.; Ranjan, R.; He, G.; Zhao, L. A Survey on Active Deep Learning: From Model Driven to Data Driven. ACM Comput. Surv. 2022, 54, 1–34. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 35th International Conference on Machine Learning, Vienna, Austria, 25–31 July 2018; pp. 297–306. [Google Scholar]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed]
- Onwuzurike, L.; Mariconti, E.; Andriotis, P.; Cristofaro, E.D.; Ross, G.; Stringhini, G. Mamadroid: Detecting android malware by building markov chains of behavioral models (extended version). ACM Trans. Priv. Secur. (TOPS) 2019, 22, 1–34. [Google Scholar] [CrossRef]
- Ramirez, M.A.; Kim, S.K.; Hamadi, H.A.; Damiani, E.; Byon, Y.J.; Kim, T.Y.; Cho, C.S.; Yeun, C.Y. Poisoning attacks and defenses on artificial intelligence: A survey. arXiv 2022, arXiv:2202.10276. [Google Scholar]
- Polonetsky, J.; Tene, O. GDPR and AI: Friends or Foes? IEEE Secur. Priv. 2018, 16, 26–33. [Google Scholar]
- Barocas, S.; Hardt, M.; Narayanan, A. Fairness and Machine Learning. 2019. Available online: FairMLBook.org (accessed on 20 May 2023).
- Dastin, J. Amazon Scraps Secret AI Recruiting Tool That Showed Bias against Women; Reuters: London, UK, 2018. [Google Scholar]
- Simonite, T. When It Comes to Gorillas, Google Photos Remains Blind; Wired: San Francisco, CA, USA, 2018. [Google Scholar]
- Vincent, J. Twitter Taught Microsoft’s AI Chatbot to Be a Racist in Less Than a Day; The Verge: Sant Monica, CA, USA, 2016. [Google Scholar]
- Harding, S. Apple’s Credit Card Gender Bias Draws Regulatory Scrutiny; Forbes: New York, NY, USA, 2019. [Google Scholar]
- Angwin, J.; Larson, J.; Mattu, S.; Kirchner, L. Machine Bias: There’s Software Used Across the Country to Predict Future Criminals. And It’s Biased against Blacks; ProPublica: New York, NY, USA, 2016. [Google Scholar]
- Olteanu, A.; Castillo, C.; Diaz, F.; Kıcıman, E. Social data: Biases, methodological pitfalls, and ethical boundaries. Front. Big Data Sci. 2019, 2, 13. [Google Scholar] [CrossRef] [PubMed]
- Sun, T.; Gaut, A.; Tang, S.; Huang, Y.; ElSherief, M.; Zhao, J.; Wang, W.Y. Mitigating gender bias in natural language processing: Literature review. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1630–1640. [Google Scholar]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Springs, CO, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Zhao, Z.; Wallace, B.C.; Jang, E.; Choi, Y.; Lease, M. Combating human trafficking: A survey of AI techniques and opportunities for technology-enabled counter-trafficking. ACM Comput. Surv. 2021, 54, 1–35. [Google Scholar]
- Nickerson, R.S. Confirmation bias: A ubiquitous phenomenon in many guises. Rev. Gen. Psychol. 1998, 2, 175–220. [Google Scholar] [CrossRef]
- Krueger, J.I.; Funder, D.C. Towards a balanced social psychology: Causes, consequences, and cures for the problem-seeking approach to social behavior and cognition. Behav. Brain Sci. 2004, 27, 313–327. [Google Scholar] [CrossRef] [PubMed]
- Gupta, P.; Raghavan, H. Temporal bias in machine learning. arXiv 2021, arXiv:2104.12843. [Google Scholar]
- Gutierrez, M.; Serrano-Guerrero, J. Bias-aware feature selection in machine learning. arXiv 2020, arXiv:2007.07956. [Google Scholar]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus, and Giroux: New York, NY, USA, 2011. [Google Scholar]
- Lee, J.D.; See, K.A. Trust in automation: Designing for appropriate reliance. Hum. Factors 2004, 46, 50–80. [Google Scholar] [CrossRef] [PubMed]
- Buolamwini, J.; Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 77–91. [Google Scholar]
- Crawford, K. Atlas of AI: Power, Politics, and the Planetary Costs of Artificial Intelligence; Yale University Press: New Haven, CT, USA, 2021. [Google Scholar]
- Kriebitz, A.; Lütge, C. Artificial intelligence and human rights: A business ethical assessment. Bus. Hum. Rights J. 2020, 5, 84–104. [Google Scholar] [CrossRef]
- Pleiss, G.; Raghavan, M.; Wu, F.; Kleinberg, J.; Weinberger, K.Q. On fairness and calibration. Adv. Neural Inf. Process. Syst. 2020, 33, 2–4. [Google Scholar]
- Zhao, J.; Wang, T.; Yatskar, M.; Ordonez, V.; Chang, K.W. Gender bias in contextualized word embeddings. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 629–634. [Google Scholar]
- Bellamy, R.K.E.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Nagar, S. AI Fairness 360: An extensible toolkit for detecting, understanding, and mitigating unwanted algorithmic bias. IBM J. Res. Dev. 2018, 63, 4. [Google Scholar]
- Verma, S.; Rubin, J. Fairness definitions explained. In Proceedings of the International Workshop on Software Fairness, Gothenburg, Sweden, 29 May 2018; pp. 1–7. [Google Scholar]
- Dwork, C.; Hardt, M.; Pitassi, T.; Reingold, O.; Zemel, R. Fairness through awareness. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–10 January 2012; pp. 214–226. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Herrera, F. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Hao, K. This Is How AI Bias Really Happens—And Why It’s So Hard to Fix; MIT Technology Review; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Bhatt, U.; Xiang, A.; Sharma, S.; Weller, A.; Taly, A.; Jia, Y.; Eckersley, P. Explainable machine learning in deployment. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 648–657. [Google Scholar]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. J. Law Technol. 2017, 31, 841–887. [Google Scholar] [CrossRef]
- Jobin, A.; Ienca, M.; Vayena, E. The global landscape of AI ethics guidelines. Nat. Mach. Intell. 2019, 1, 389–399. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black-box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Carter, S.; Armstrong, Z.; Schönberger, L.; Olah, C. Activation atlases: Unsupervised exploration of high-dimensional model internals. Distill 2019, 4, e00020. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Holzinger, A.; Langs, G.; Denk, H.; Zatloukal, K.; Müller, H. Causability and explainability of artificial intelligence in medicine. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1312. [Google Scholar] [CrossRef]
- Mittelstadt, B.; Russell, C.; Wachter, S. Explaining explanations in AI. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 279–288. [Google Scholar]
- Vinuesa, R.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Langhans, S.D. The role of artificial intelligence in achieving the Sustainable Development Goals. Nat. Commun. 2020, 11, 233. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Agarwal, S. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Knight, W. The Future of AI Depends on a Huge Workforce of Human Teachers; Wired: San Francisco, CA, USA, 2021. [Google Scholar]
- Kaplan, A.; Haenlein, M. Siri, Siri, in my hand: Who’s the fairest in the land? On the interpretations, illustrations, and implications of artificial intelligence. Bus. Horiz. 2019, 62, 15–25. [Google Scholar] [CrossRef]
- Wang, S.; Fisch, A.; Oh, J.; Liang, P. Data Programming for Learning with Noisy Labels. Adv. Neural Inf. Process. Syst. 2020, 33, 14883–14894. [Google Scholar]
- Crawford, K.; Calo, R. There is a blind spot in AI research. Nature 2021, 538, 311–313. [Google Scholar] [CrossRef]
- McDermid, J.A.; Jia, Y.; Porter, Z.; Habli, I. Artificial intelligence explainability: The technical and ethical dimensions. Philos. Trans. R. Soc. A 2021, 379, 20200363. [Google Scholar] [CrossRef] [PubMed]
- Whittlestone, J.; Nyrup, R.; Alexandrova, A.; Dihal, K.; Cave, S. Ethical and Societal Implications of Algorithms, Data, and Artificial Intelligence: A Roadmap for Research; Nuffield Foundation: London, UK, 2019. [Google Scholar]
- Bughin, J.; Hazan, E.; Ramaswamy, S.; Chui, M.; Allas, T.; Dahlström, P.; Trench, M. Skill Shift: Automation and the Future of the Workforce; McKinsey Global Institute: Washington, DC, USA, 2018. [Google Scholar]
- World Economic Forum. Jobs of Tomorrow: Mapping Opportunity in the New Economy. 2021. Available online: http://www3.weforum.org/docs/WEF_Jobs_of_Tomorrow_2020.pdf (accessed on 12 February 2023).
- Bessen, J.E.; Impink, S.M.; Reichensperger, L.; Seamans, R. The Business of AI Startups; NBER Working Paper No. 24255; Boston University School of Law: Boston, MA, USA, 2019. [Google Scholar]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Xu, H.; Gu, L.; Choi, E.; Zhang, Y. Secure and privacy-preserving machine learning: A survey. Front. Comput. Sci. 2021, 15, 1–38. [Google Scholar]
- Yang, G.Z.; Bellingham, J.; Dupont, P.E.; Fischer, P.; Floridi, L.; Full, R.; Wood, R. The grand challenges of Science Robotics. Sci. Robot. 2020, 3, 7650. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A.; Keiblinger, K.; Holub, P.; Zatloukal, K.; Müller, H. AI for life: Trends in artificial intelligence for biotechnology. New Biotechnol. 2023, 74, 16–24. [Google Scholar] [CrossRef]
- Jawad, K.; Mahto, R.; Das, A.; Ahmed, S.U.; Aziz, R.M.; Kumar, P. Novel Cuckoo Search-Based Metaheuristic Approach for Deep Learning Prediction of Depression. Appl. Sci. 2023, 13, 5322. [Google Scholar] [CrossRef]
- Yaqoob, A.; Aziz, R.M.; Verma, N.K.; Lalwani, P.; Makrariya, A.; Kumar, P. A review on nature-inspired algorithms for cancer disease prediction and classification. Mathematics 2023, 11, 1081. [Google Scholar] [CrossRef]
- Aziz, R.M.; Mahto, R.; Goel, K.; Das, A.; Kumar, P.; Saxena, A. Modified Genetic Algorithm with Deep Learning for Fraud Transactions of Ethereum Smart Contract. Appl. Sci. 2023, 13, 697. [Google Scholar] [CrossRef]
- Aziz, R.M.; Desai, N.P.; Baluch, M.F. Computer vision model with novel cuckoo search based deep learning approach for classification of fish image. Multimed. Tools Appl. 2023, 82, 3677–3696. [Google Scholar] [CrossRef]
- Aziz, R.M.; Baluch, M.F.; Patel, S.; Kumar, P. A Machine Learning based Approach to Detect the Ethereum Fraud Transactions with Limited Attributes. Karbala Int. J. Mod. Sci. 2022, 8, 13. [Google Scholar] [CrossRef]
- Thayyib, P.V.; Mamilla, R.; Khan, M.; Fatima, H.; Asim, M.; Anwar, I.; Shamsudheen, M.K.; Khan, M.A. State-of-the-Art of Artificial Intelligence and Big Data Analytics Reviews in Five Different Domains: A Bibliometric Summary. Sustainability 2023, 15, 4026. [Google Scholar] [CrossRef]
- Saghiri, A.M.; Vahidipour, S.M.; Jabbarpour, M.R.; Sookhak, M.; Forestiero, A. A Survey of Artificial Intelligence Challenges: Analyzing the Definitions, Relationships, and Evolutions. Appl. Sci. 2022, 12, 4054. [Google Scholar] [CrossRef]
- Serey, J.; Quezada, L.; Alfaro, M.; Fuertes, G.; Vargas, M.; Ternero, R.; Sabattin, J.; Duran, C.; Gutierrez, S. Artificial Intelligence Methodologies for Data Management. Symmetry 2021, 13, 2040. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Challenge | Reference | |
|---|---|---|
| Data Quality | Introduction | [37,38,39] |
| Quality Measures | [37,38,39,40,41,42,43,44,45,46,47] | |
| Collection and Management | [41,46,49,50,51,52,53] | |
| Data Governance | [54,55,56,57,58,59,60,61,62,63] | |
| Proposed solutions | [54,55,64,65,66,67,68,69,70] | |
| Data Volume | Introduction | [71] |
| Data Deluge | [72,73] | |
| Storage Challenges | [74,75,76] | |
| Processing Challenges | [77,78,79] | |
| Data Management Challenges | [80,81] | |
| Data Privacy and Security | [82] | |
| Proposed Solutions | [75,76,79,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97] | |
| Data Privacy and Security | Data Privacy | [98,99,100,101,102,103] |
| Data Security | [104,105,106,107,108,109,110,111,112,113,114,115,116] | |
| Mitigation Strategies | [117,118,119,120,121,122,123] | |
| Bias and Fairness | Introduction | [124,125,126,127,128,129] |
| Types of Data Bias | [130,131,132,133,134,135,136,137,138,139] | |
| Consequences of Data Bias and Unfairness | [140,141,142] | |
| Proposed Solutions | [143,144,145,146,147,148,149] | |
| Interpretability and Explainability | Introduction | [150,151] |
| The Necessity | [152,153,154,155] | |
| Current Techniques | [156,157,158,159,160,161,162] | |
| Remaining Challenges and Future Directions | [150,157,162,163,164] | |
| Technical Expertise | Introduction | [165,166,167] |
| Scarcity of Skilled Professionals | [168,169] | |
| Ethical Concerns | [170,171,172] | |
| The Growing Demand for AI-Related Expertise | [169,173,174,175] | |
| Key Disciplines in High Demand for AI-Related Expertise | [170,173,179,180,181,182,183] | |
| Collaboration between Humans and AI | [176,178,184,185,186,187] | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldoseri, A.; Al-Khalifa, K.N.; Hamouda, A.M. Re-Thinking Data Strategy and Integration for Artificial Intelligence: Concepts, Opportunities, and Challenges. Appl. Sci. 2023, 13, 7082. https://doi.org/10.3390/app13127082
Aldoseri A, Al-Khalifa KN, Hamouda AM. Re-Thinking Data Strategy and Integration for Artificial Intelligence: Concepts, Opportunities, and Challenges. Applied Sciences. 2023; 13(12):7082. https://doi.org/10.3390/app13127082
Chicago/Turabian StyleAldoseri, Abdulaziz, Khalifa N. Al-Khalifa, and Abdel Magid Hamouda. 2023. "Re-Thinking Data Strategy and Integration for Artificial Intelligence: Concepts, Opportunities, and Challenges" Applied Sciences 13, no. 12: 7082. https://doi.org/10.3390/app13127082
APA StyleAldoseri, A., Al-Khalifa, K. N., & Hamouda, A. M. (2023). Re-Thinking Data Strategy and Integration for Artificial Intelligence: Concepts, Opportunities, and Challenges. Applied Sciences, 13(12), 7082. https://doi.org/10.3390/app13127082