3.1. Entity Description
In tasks related to graph topology, only two constituent elements—nodes and edges—are usually considered. The attributes are often considered as nodes and thus the fact that attributes are intrinsic properties of nodes is ignored; this blurs the definition of basic constituent elements of a knowledge graph. In the knowledge graph, entity nodes should be independent and distinguishable; if the scene does not change, the entity node itself should remain unchanged when it interacts with other entities.
Figure 2 can more conveniently help us understand the importance of entity node independence. As shown in
Figure 2a, in a scene with three entities—a table, a chair, and a cup—placing the cup on the table or chair will generate different relations cup-on-table and cup-on-chair, but the cup in this scene is the same cup regardless of the relation with which object. When we represent this cup using the knowledge representation represented by GCN, the high-dimensional vector representation of the cup is affected by the entities it interacts with, resulting in multiple representations of a concrete, physically existing object in a semantic space, causing the model’s ability to express knowledge to shrink and the cost of parsing it to increase.
The distinguishability of entity nodes is equally important. In the scene shown in
Figure 2b, when there are many objects that can generate relations with the table, the distance-based approach in the spatial domain represented by TransE reveals the drawback that it is difficult to handle complex one-to-many and many-to-many relations, because at this time a large number of entities generates the same interaction with the central entity, such as the table, which means that the high-dimensional representations of a large number of mutually-independent entities are concentrated in a same hyperplane, the distinguishability between entities is greatly reduced, and then the relationships between these entities, and other kinds of relationships involved in the central node, are also difficult to express.
Combining the above reasons, we want to take full advantage of the knowledge graph. As shown in
Figure 2c, the representation of entity nodes focuses on describing the information of the entities themselves. Suppose entity nodes in the knowledge graph have the set of attributes
A. For its attributes of different modalities, it uses different static feature extraction networks to represent them as a tensor with the same dimension, while attributes of the same modality are extracted using the same extraction network to ensure that a class of attributes is embedded in the same feature space. In order to avoid the attributes of different modalities from influencing each other, the processes of attribute acquisition features are all independent of each other, and finally they are stitched together to distinguish different attributes at different locations. Then, its Entity Descriptor
can be expressed as:
where
is the weight matrix of features,
is the attribute embedding matrix. Aggregate means aggregate function.
means activation function. In different scenarios, the aggregation function can choose many methods, such as weighted sum, splicing, and mapping. Splicing means to connect the obtained attribute tensors back and forth, and the result is a one-dimensional tensor. Mapping involves converting high-dimensional attribute tensors into low-dimensional representation tensors through mapping functions or convolutional layers.
Suppose the set of nodes is
; every node has its attributes set
, then all attributes could be expressed as
, in which
means that the value of the
ith entity’s
jth attribute is
. According to Entity Descriptor, the representation of entity
should be:
While the aggregation function chooses weighted sum, splicing and mapping methods, for
, we have:
where
is the representation matrix of attributes and each column vector is the embedded representation of the corresponding attribute value.
means the weight transformation matrix, the form of which is trainable hidden layers.
aims to adjust all types of attribute vectors to the same dimension. The aggregation of weighted sum is the most direct, but this method requires manually setting the weight of each attribute and the entity representation obtained in this way is prone to confusion; splicing retains all attributes of the entity but usually causes the dimension of the entity representation to be too long to train. Using the direct mapping method, although solving the disadvantages of the first two methods, usually requires the appropriate weight transformation hidden layer in the long-term and a large number of trainings.
In order to reduce the training time and support the dynamic of new entities, based on the GCN for graph structure information aggregation, using the triangle matrix
U as an attribute node and the entity link matrix, we can obtain a new aggregation function which is small and easy to train:
To sum up, when there are few attributes, the aggregation function can choose the way of weighted sum. When the attribute is short and easy to splice, we can choose splicing as the aggregation function. When there are many, or complex, attributes, attribute features should be extracted first and then the aggregation function in Equation (
4) should be selected to aggregate the attribute information.
Entity Descriptor uses each entity’s own attributes to generate the corresponding representation results, which makes it possible to obtain the same entity representation for the same entity in different scenes, always maintaining the independent distinguishability of entity nodes in the process of generating the representation. The generated entity representations are also distinguishable between different entities of the same class due to the differences in attributes.
3.2. Attribute Selection Conditions
In the process of scene parsing mentioned above, it is necessary to transform the data in the scene into a knowledge graph; this part of the work is not annotated in the current scene parsing dataset. While in a fixed scene, the choice of entity nodes is often uncontroversial—using the minimum level entity that is involved in the task—what needs to be discussed is how to choose attributes among the massive data. So, we summarized three attribute selection conditions to guide the construction of the knowledge graph.
3.2.1. Common Condition: The Characteristics That Entity Nodes of the Same Class Have Can Be Used as Attributes
In a knowledge graph, entities are the smallest unit involved in the problem. Entity nodes of the same class should maintain homogeneity, that is, when discussing entity nodes, the characteristics they all possess can be seen as attributes. When the characteristics of an entity node are unique and cannot be expressed by other nodes, these characteristics cannot be treated as attributes and they cannot be merged for similar nodes. The purpose of this condition is to classify the entity nodes in a knowledge graph, and the processing methods of similar nodes are unified, which not only conforms to the understanding of things in the real world but also saves computing resources.
3.2.2. Unique Interaction Condition: An Attribute Cannot Have Multiple Kind of Relationship Links to Entities of the Same Class
The idea of the unique interaction condition comes from the concept of the lattice representation method of Formal Concept Analysis. This method expresses things with their own connotation, and there is only a unique partial order set in the binary relationship between things and descriptors, that is, under a fixed background and attributes, the representation of things in that attribute is unique. This condition is to ensure that, in a class of attributes, there is one and only one kind of relationship between attributes and entity nodes. In the case of a fixed relationship, a single entity cannot be connected to multiple homogeneous attributes, while a single attribute can be connected to multiple homogeneous entity nodes.
3.2.3. Limited Scope Conditions: Entity Nodes and Attribute Nodes Only Exist in Their Respective Scopes
When an attribute has the same name as an entity, or both are the same object in reality, the attribute node and entity node of the object cannot be represented as the same vector. Although entities and attributes are often represented as nodes in the process of building or designing knowledge graphs, they are actually completely different. This condition exists to distinguish attributes and entities. In a knowledge graph, as the size of entity nodes increases, the links between entity nodes and attributes will become more complex and some entities may exist as attributes of other entities. Using limited scope conditions to divide nodes and draw the boundary between entities and attributes can not only represent entities more clearly but can also more conveniently model entities and attributes separately to avoid confusion.
3.3. Entity Descriptors in Multi-Modal Tasks
For aggregate functions in Equation (
3), the weighted sum and direct splicing ways are only applicable to the knowledge graph with only a class of entities and simple attributes while, in most cases, the knowledge graph is complex and with diverse attributes. When choosing mapping, it not only faces the situation in which the dimension of the obtained representation is higher than that of the transformer architecture needed, but also faces the problem that different categories of entity nodes have different vector dimensions and do not meet the requirements of equal length sequence.
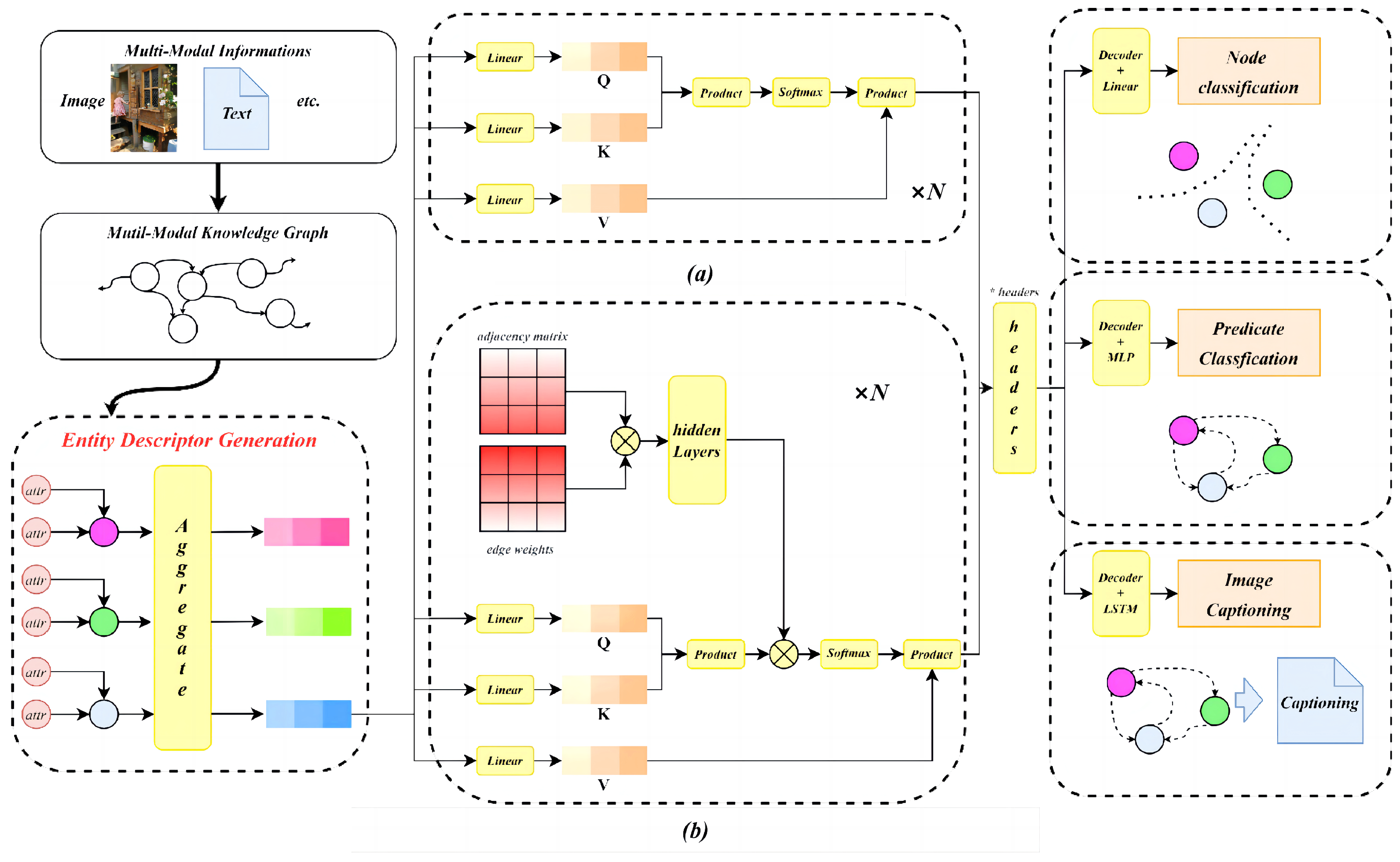
For the problems existing in the aggregation function of mapping, we can imitate the processing method of high-dimensional patches in CV and set a separate convolution channel or linear channel for each type of entity. The node representation of the same entity uses the same channel and different types of entities are processed separately. This is due to the large difference in attributes between different categories of entities, and the data of heterogeneous entity representation vectors in the same column may come from completely irrelevant information. However, using different channels to extract features of different types of heterogeneous attributes not only compresses the entity representation to two dimensions, which is easy for the model to learn, but also converts them to the same dimension while retaining the differences between different types of entity for parallel processing. This paper uniformly names the models containing Entity Descriptor as EDET (Entity Descriptor Encoder of Transformer).
In the existing multi-modal graphs, there is no corresponding processing task to verify the effectiveness of its specific application. Therefore, tasks can be converted into the form of multi-modal knowledge graphs and then Entity Descriptor can be used to solve the task.
3.3.1. Predicate Classification
While facing the predicate classification task, the attribute selection conditions above were used to build a knowledge graph of the source data. Then, the entity in scene graph was noted as
N and all
n entities set as
. Each entity node
has attributes including sub-image
, label
, and location
. Set the shape of the feature vector as 1 × 512. Among them, the sub-image uses a pre-trained feature extraction convolutional model such as VGG16, which could be marked as
CNN, and then obtains a 1 × 512-dimensional feature vector by flattening. The way to process label information is to establish a vocabulary and then use the word embedding method [
14] to obtain the corresponding vector representation. This methods is marked as
embed. The location information contains less information and its dimension can be expanded to 512 through a linear layer, which is marked as
Linear. The aggregation function chooses to use a 3 × 3 convolutional layer and fills it with padding to maintain the dimension of the final result. At this time, the Entity Descriptor
of the node
is expressed as:
In the predicate classification, the result that needs to be output is the relationships between entity nodes, so the representation of relational elements can be ignored when input and the model structure is shown in
Figure 3a. However, knowledge graphs usually have relationships, so in order to operate uniformly on the model, a set of relationship edges can be preset using the information they already have. Then, the model structure is as shown in
Figure 3b. For this task, the relative location between the entity nodes can be used as the preset information of the edges. Suppose two nodes in graph with their position
and
, their relative location
could be expressed as:
3.3.2. Image Captioning
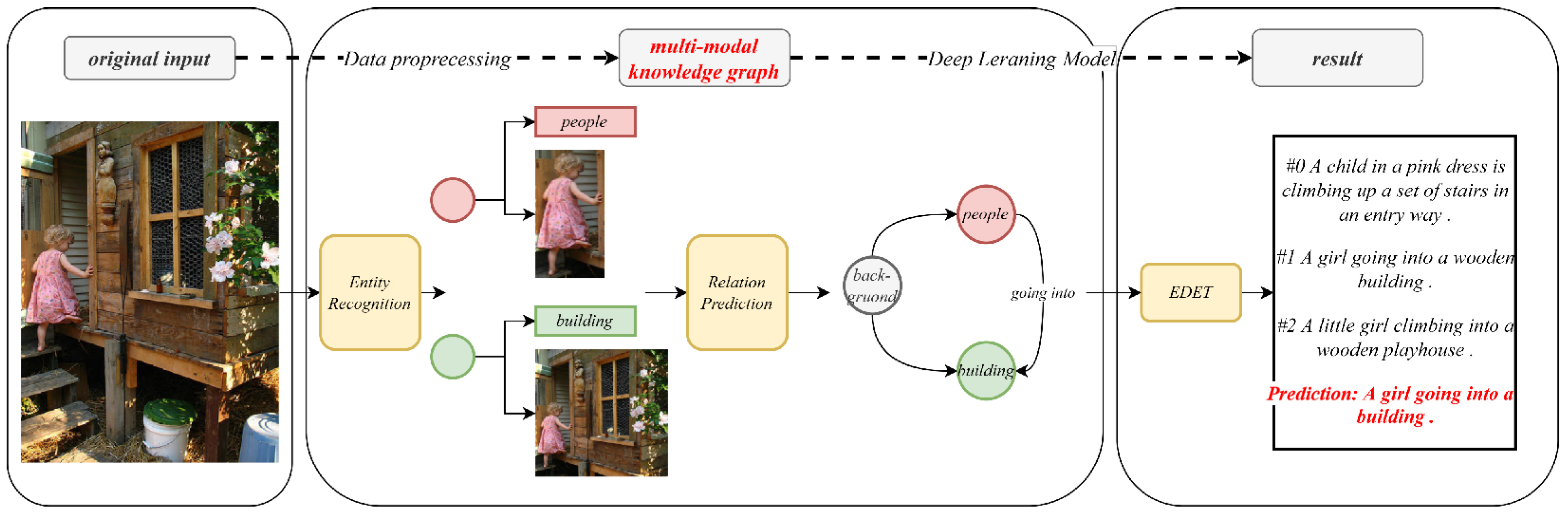
Image captioning is a task for generating the captioning of the current image. Unlike in the predicate classification task, the scene image in an image captioning dataset does not mark the target and its location at first. As shown in
Figure 4, for the image captioning task, the Mask R-CNN [
15] model is used to obtain the entity and its attribute information. It should be noted that the entity nodes and attributes obtained here have biases and errors compared with the entities involved in the annotation sentences of the image captioning. The bias mainly comes from three aspects: one is that the entity object obtained by the pre-trained model is not necessarily the entity in the sentence; the other is that the model can usually recognize the visual target by shape but it cannot recognize backgrounds such as the sky; third, the model can recognize limited objects, and the target objects involved in the sentence may not be within the scope of recognition. The source of the error is because the model cannot achieve 100% accuracy for the target objects within the recognition range.
The entity and its attributes in the image captioning task are treated in the same way as in predicate classification. Meanwhile, in image captioning, there is another method used to generate edges for the graph—using a predicate classification model that has been trained in the previous section. It should be noted that, with this method, the relationship between entity nodes is trained by external data and has bias which exists in the predicate classification task.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}