

Image Deblurring Based on an Improved CNN-Transformer Combination Network

Abstract
:1. Introduction
2. Related Work
2.1. Deep Learning Deblurring
2.2. Vision Transformer
3. Proposed Approach
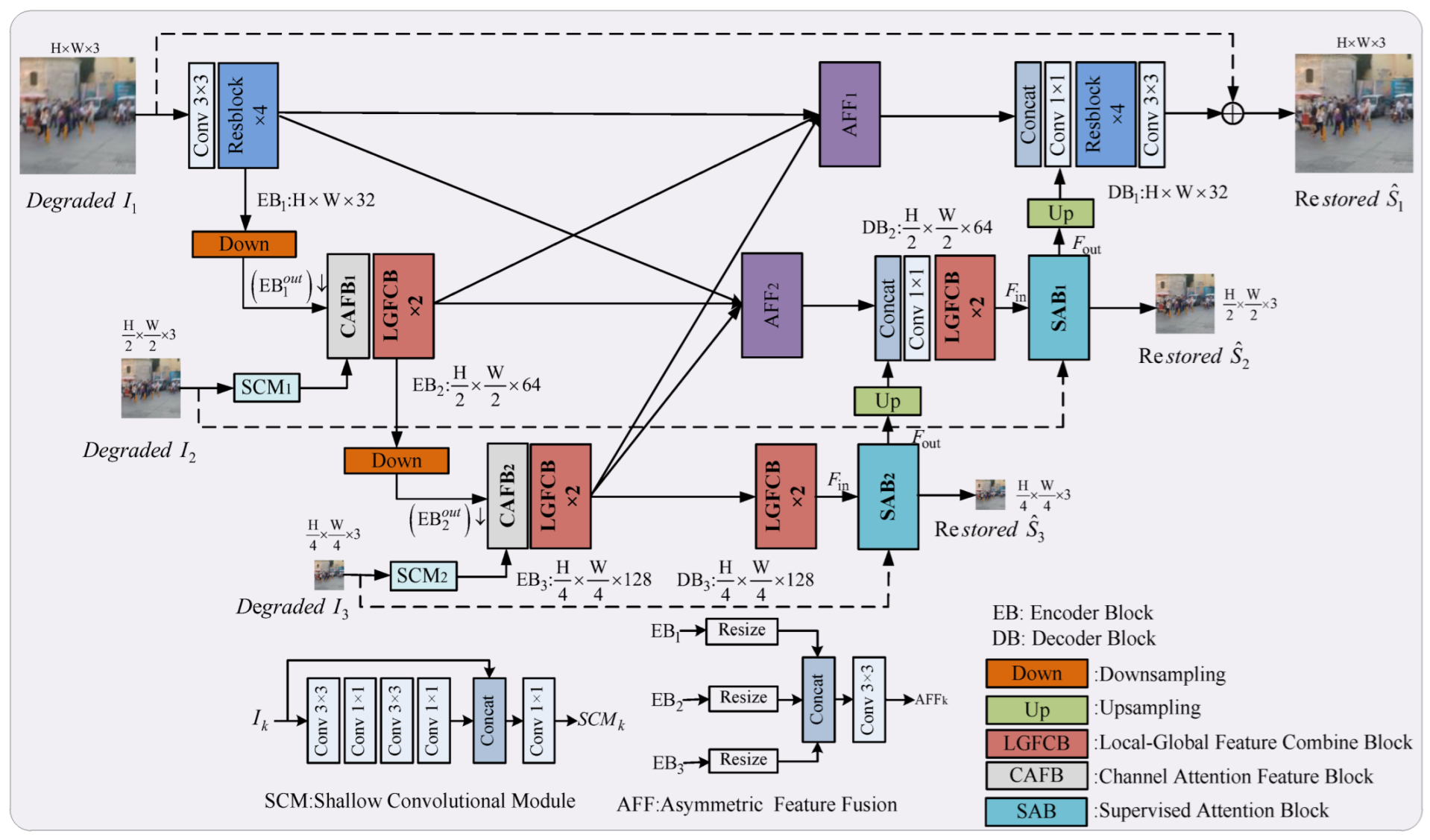
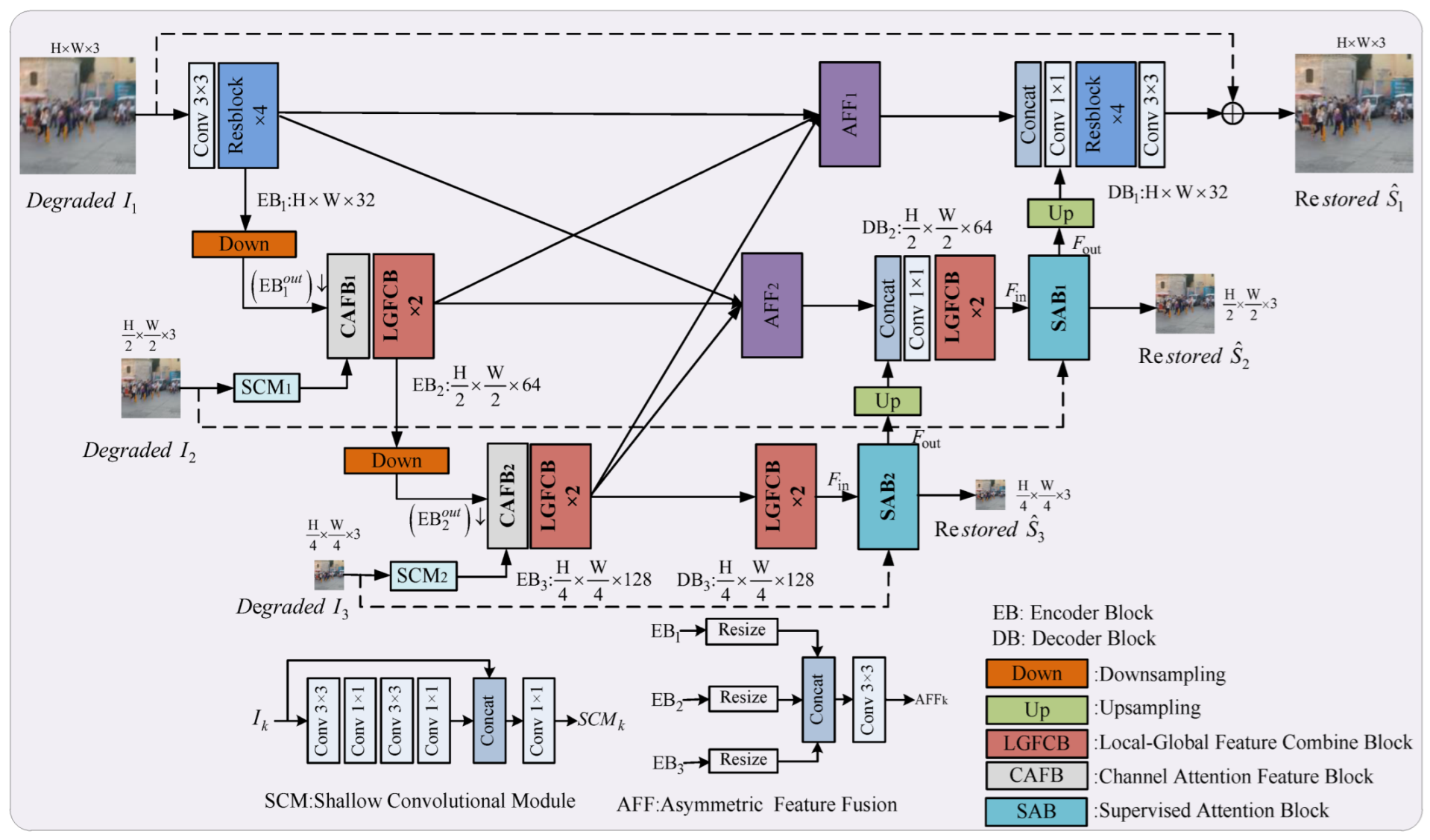
3.1. Framework
- (a)
- Encoder Path
- (b)
- Skip Connection
- (c)
- Decoder Path
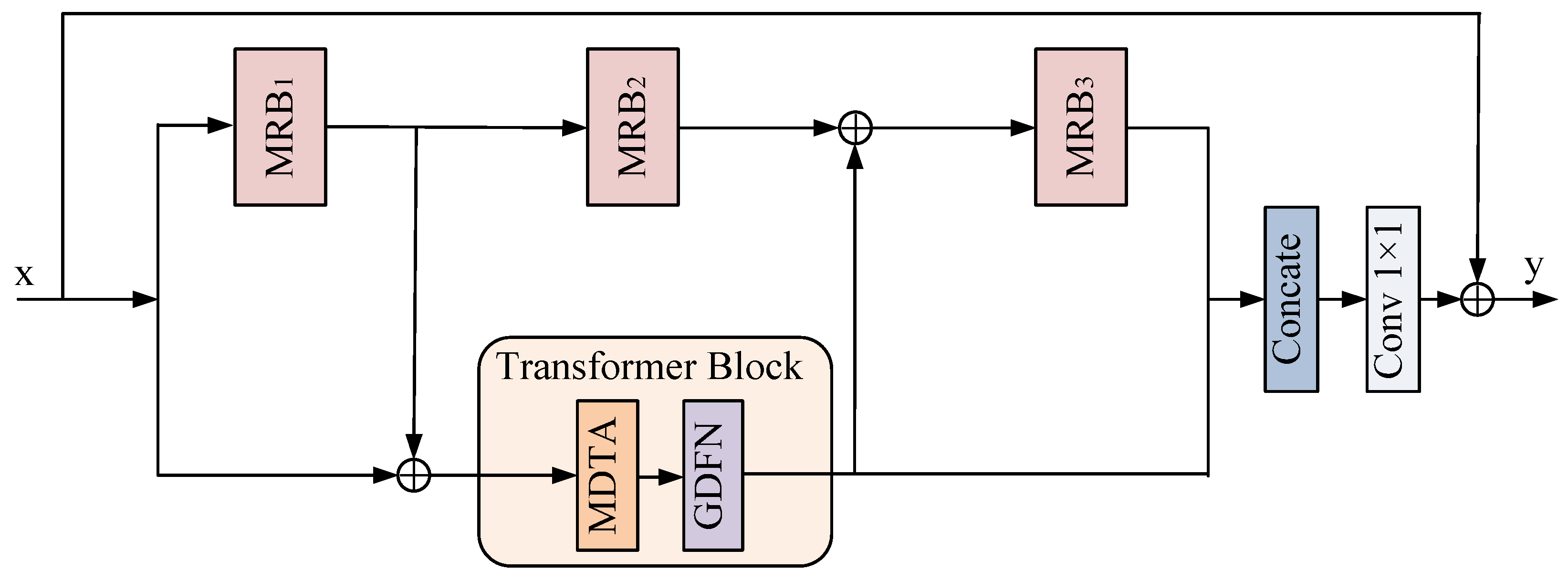
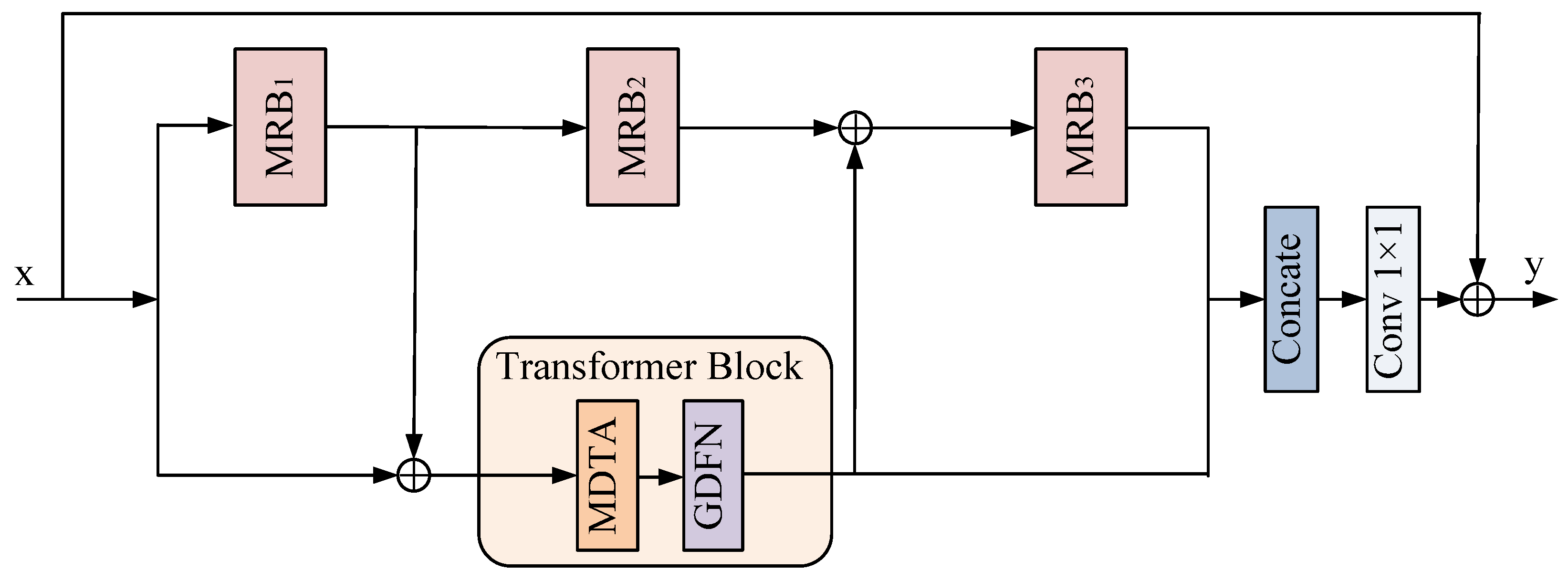
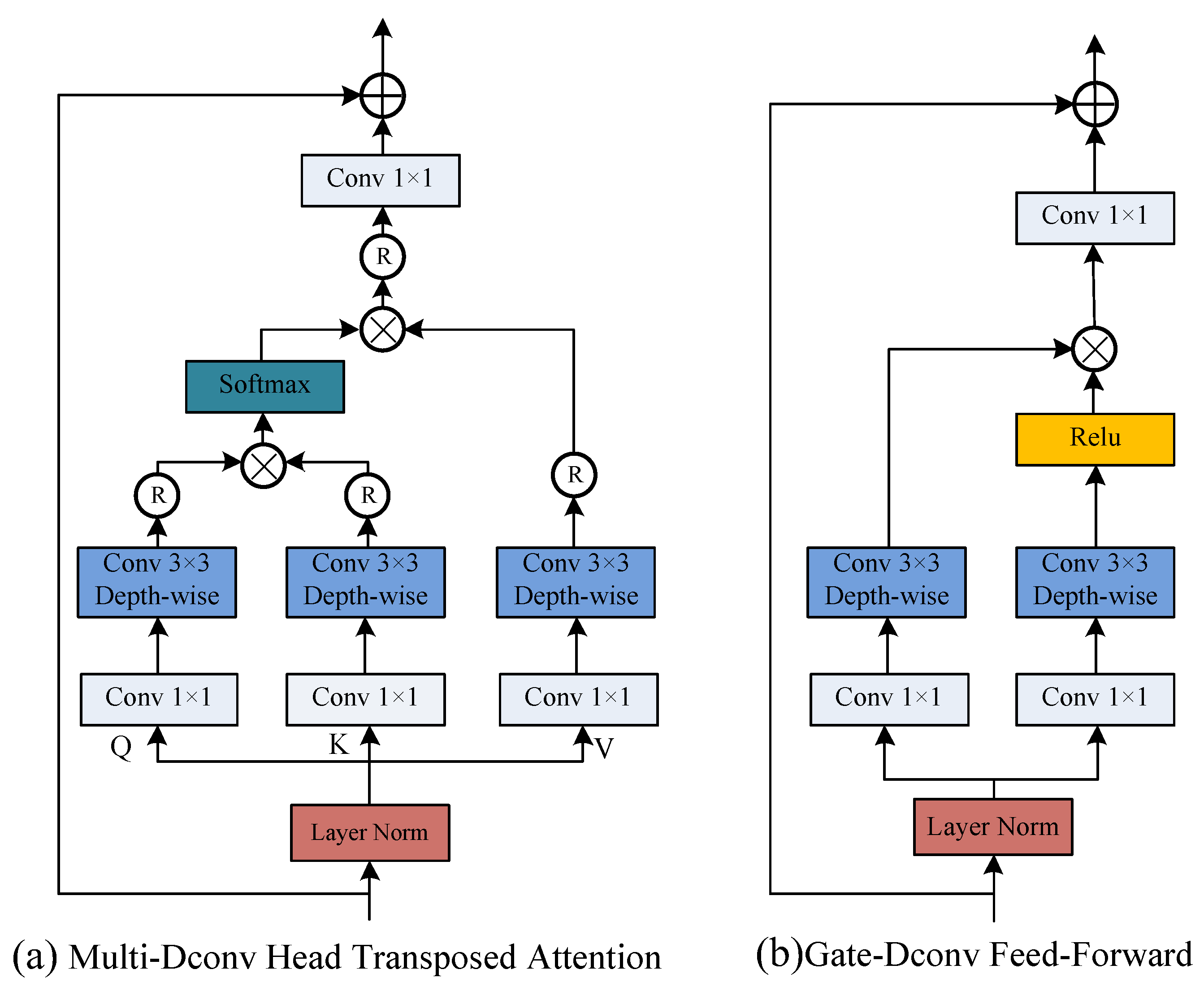
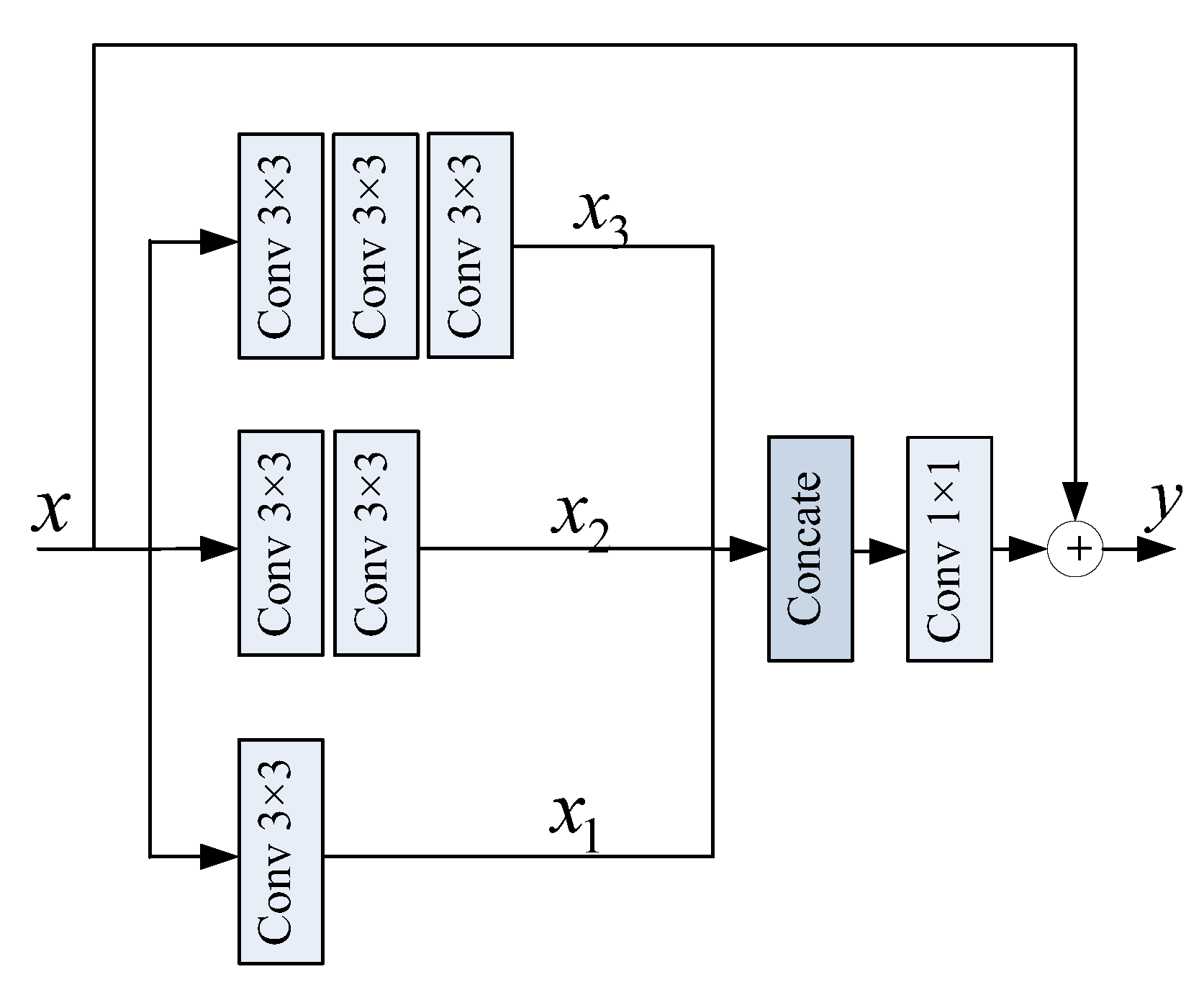
3.2. Local Global Feature Combination Block
- (a)
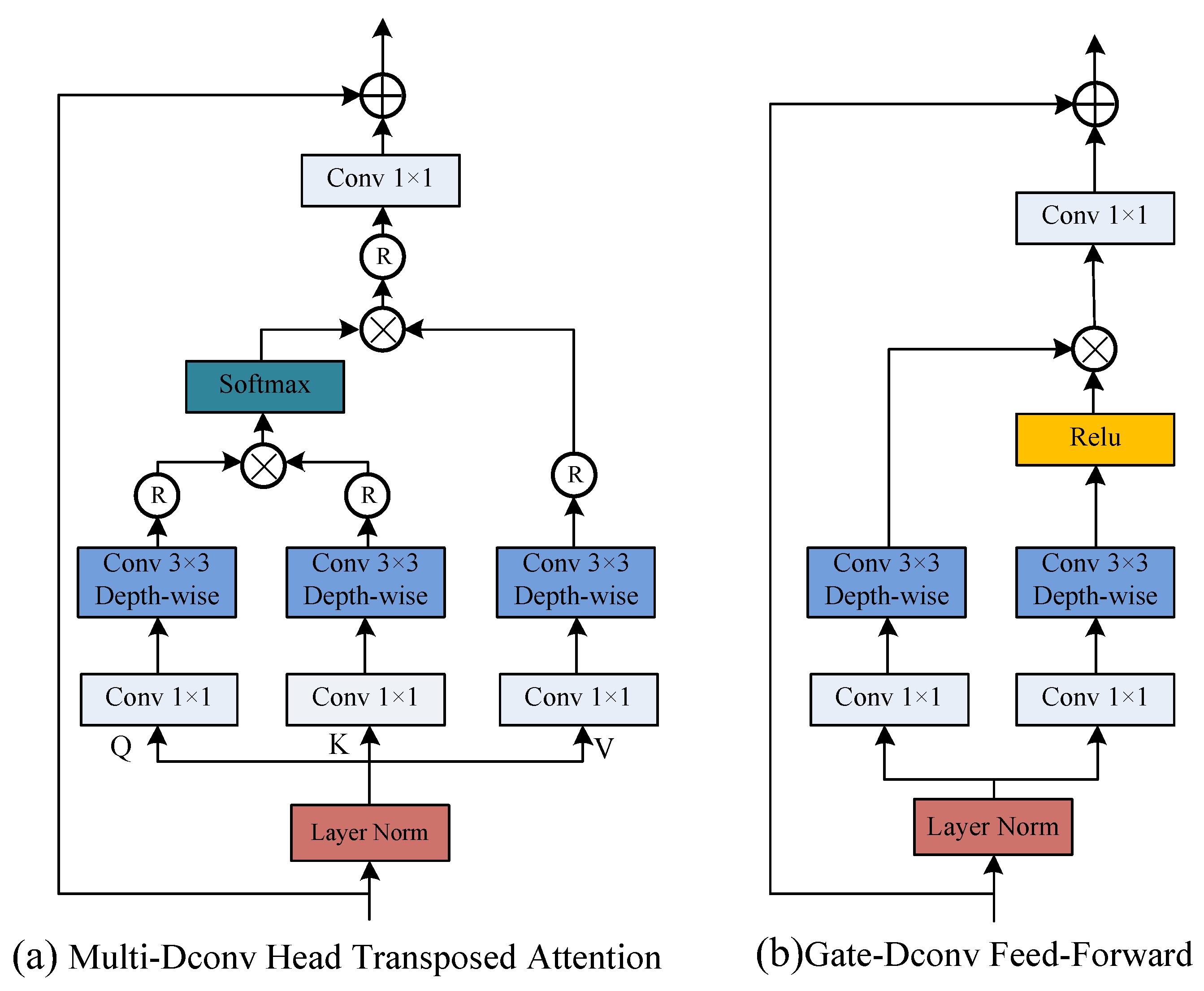
- Transformer Block
- (b)
- Multi-Scale Residual block
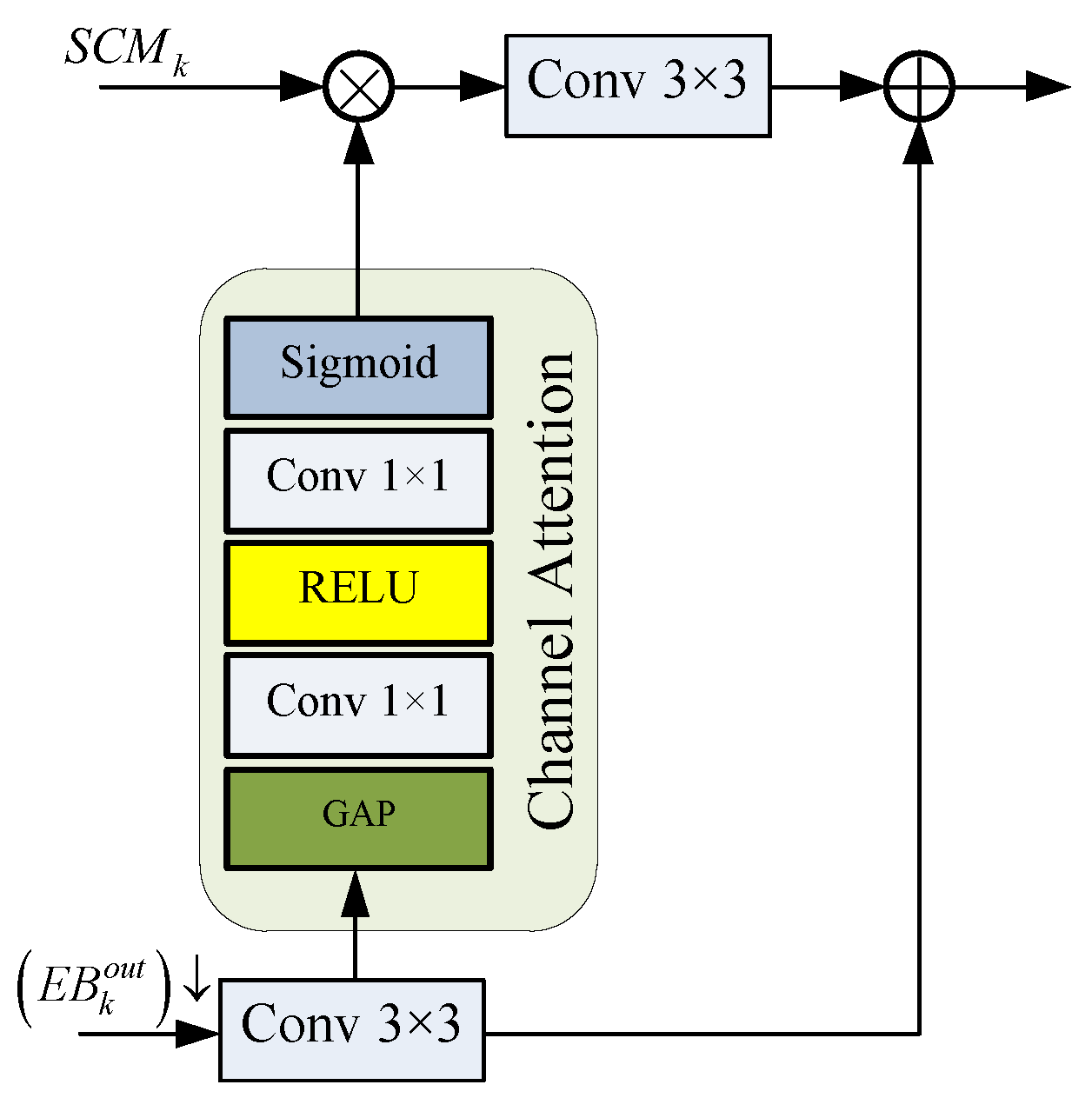
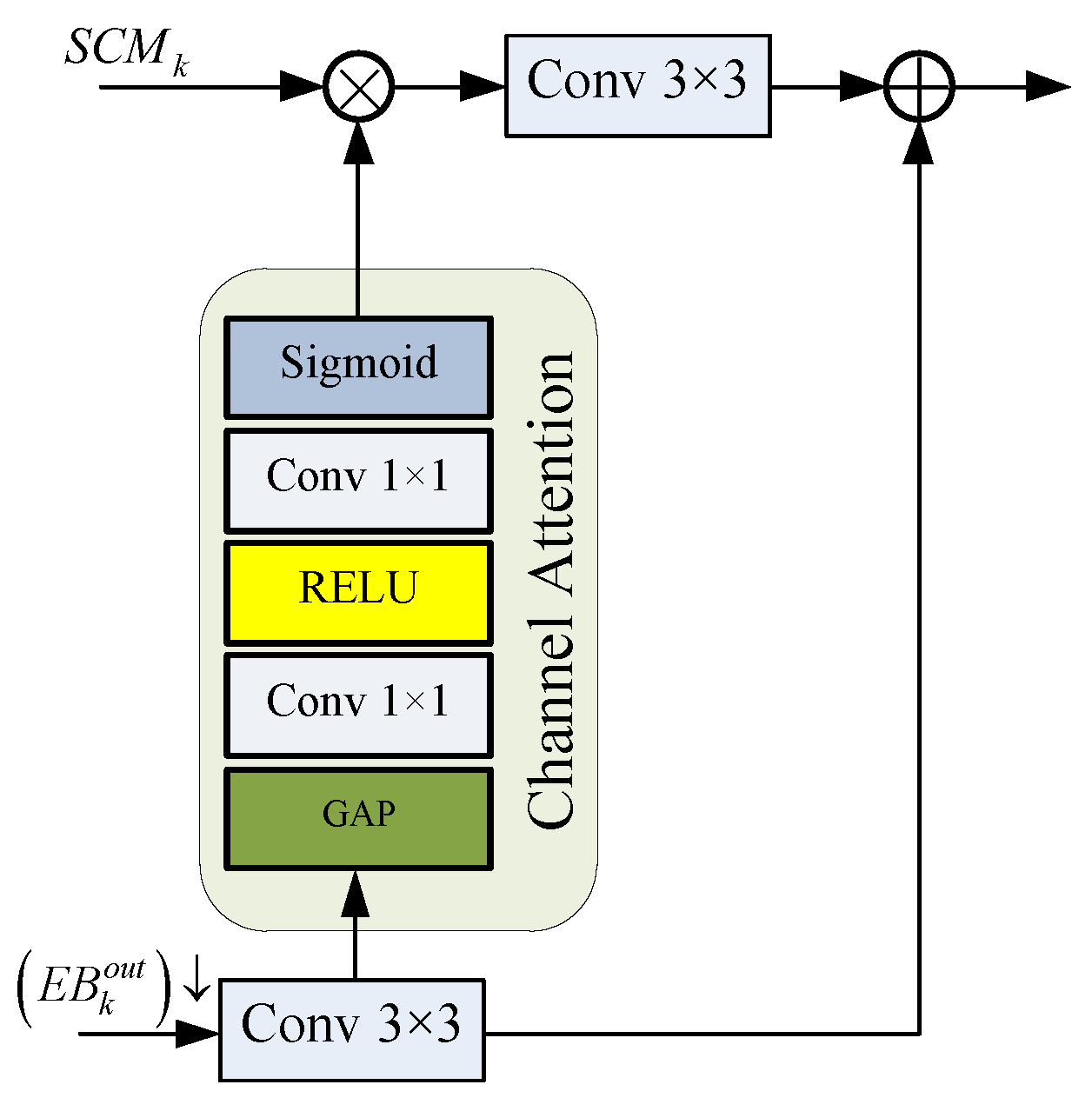
3.3. Channel Attention Fusion Block
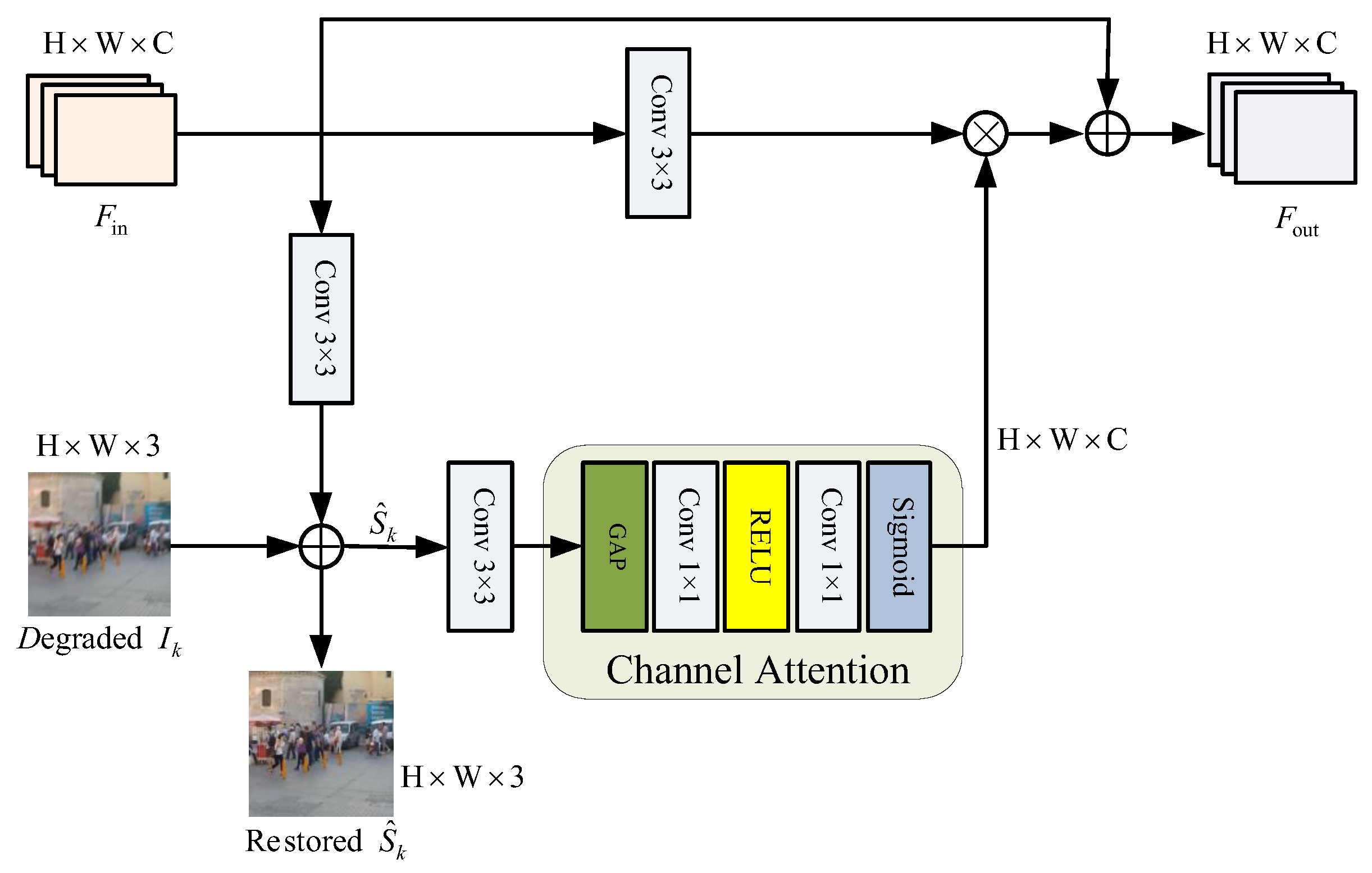
3.4. Supervised Attention Block
3.5. Loss Function
4. Experiments and Analysis
4.1. Dataset and Implementation Details
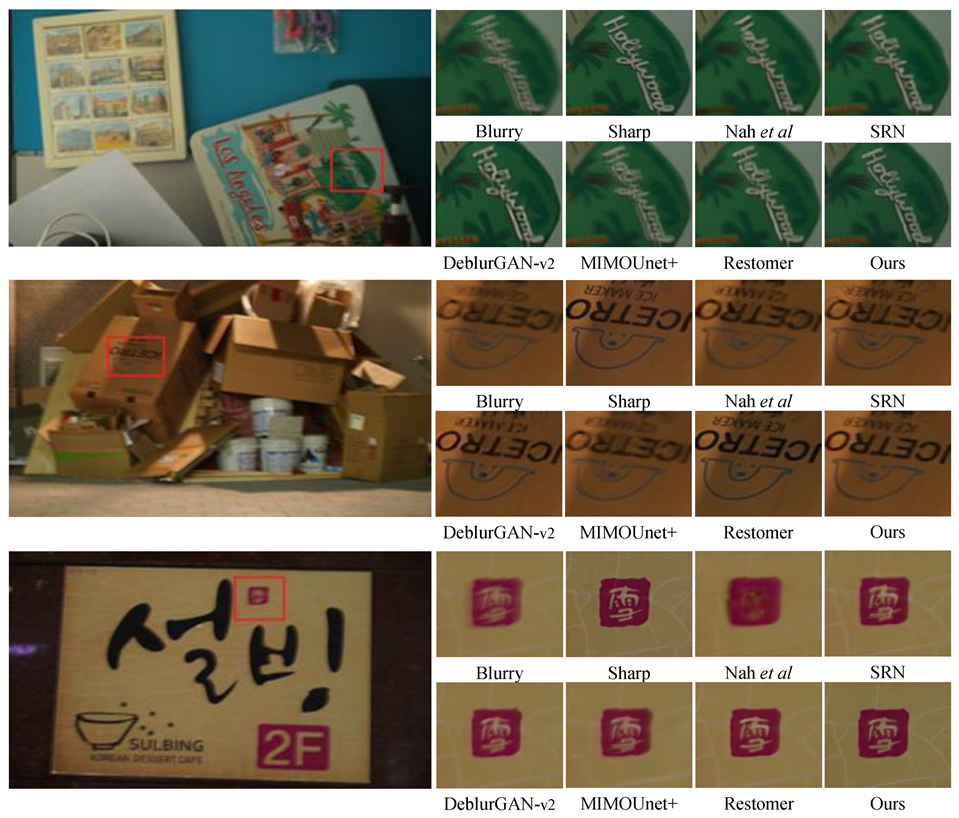
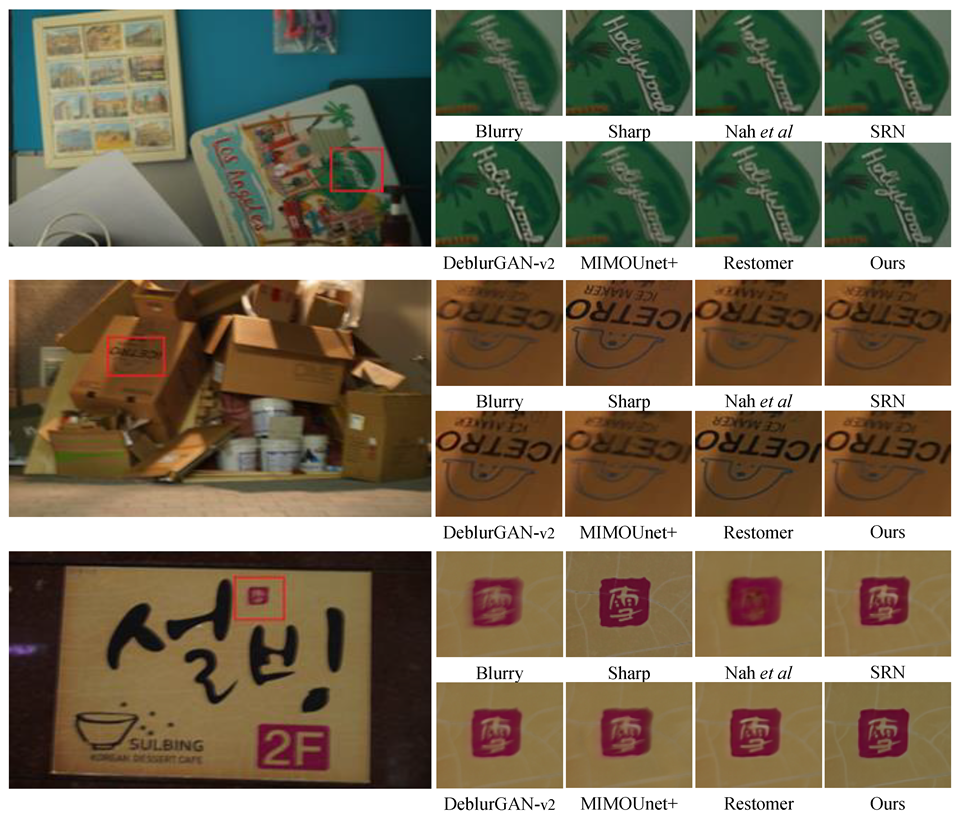
4.2. Experimental Results
4.3. Ablation Studies
4.4. Runtime Comparison
4.5. Object Detection Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake a single photograph. In Proceedings of the ACM SIGGRAPH 2006 Papers, Boston, MA, USA, 30 July–3 August 2006; pp. 787–794. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the CVPR, Online, 19–25 June 2021; pp. 14816–14826. [Google Scholar]
- Chakrabarti, A. A neural approach to blind motion deblurring. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 221–235. [Google Scholar]
- Hradiš, M.; Kotera, J.; Zemčík, P.; Šroubek, F. Convolutional neural networks for direct text deblurring. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; Volume 10, p. 2. [Google Scholar]
- Schuler, C.J.; Hirsch, M.; Harmeling, S.; Schölkopf, B. Learning to deblur. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1439–1451. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Cho, S.-J.; Ji, S.-W.; Hong, J.-P.; Jung, S.-W.; Ko, S.-J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the ICCV, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 January 2018. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the ICCV, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, J.; Pan, J.; Jimmy; Ren, S.J.; Song, Y.; Bao, L.; Rynson; Lau, W.H.; Yang, M.-H. Dynamic scene deblurring using spatially variant recurrent neural networks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 January 2018. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 January 2018. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 January 2019. [Google Scholar]
- Park, D.; Kang, D.U.; Kim, J.; Chun, S.Y. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020; pp. 327–343. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the CVPR, Online, 14–19 January 2020. [Google Scholar]
- Zou, W.; Jiang, M.; Zhang, Y.; Chen, L.; Lu, Z.; Wu, Y. SDWNet: A straight dilated network with wavelet transformation for image deblurring. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1895–1904. [Google Scholar]
- Tsai, F.-J.; Peng, Y.-T.; Tsai, C.-C.; Lin, Y.-Y.; Lin, C.-W. BANet: A blur-aware attention network for dynamic scene deblurring. IEEE Trans. Image Process. 2022, 31, 6789–6799. [Google Scholar] [CrossRef] [PubMed]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the CVPR, New Orleans, USA, 19–24 June 2022; pp. 5718–5729. [Google Scholar]
- Kumar, J.; Mastan, I.D.; Raman, S. FMD-cGAN: Fast motion deblurring using conditional generative adversarial networks. In Communications in Computer and Information Science; CVIP; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Gao, G.; Xu, Z.; Li, J.; Yang, J.; Zeng, T.; Qi, G.-J. CTCNet: A CNN-transformer cooperation network for face image super-resolution. arXiv 2022, arXiv:2204.08696. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, P.; Han, S.; Zhao, J.; Liu, D.; Wang, H.; Yu, E.; Kot, A.C. Refinements in motion and appearance for online multi-object tracking. arXiv 2020, arXiv:2003.07177. [Google Scholar]
- Charbonnier, P.; Blanc-Feraud, L.; Aubert, G.; Barlaud, M. Two deterministic half-quadratic regularization algorithms for computed imaging. In Proceedings of the ICIP, Austin, TX, USA, 13–16 November 1994; p. 3. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Rim, J.; Lee, H.; Won, J.; Cho, S. Real-world blur dataset for learning and benchmarking deblurring algorithms. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 184–201. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Method | GoPro | RealBlur | Params (M) | ||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | |||
| CNN-based models | Nah et al. [7] | 29.08 | 0.914 | 27.87 | 0.827 | 11.7 |
| Zhang et al. [11] | 29.19 | 0.931 | 27.80 | 0.847 | 9.2 | |
| DeblurGAN-V2 [10] | 29.55 | 0.934 | 28.70 | 0.866 | 60.9 | |
| SRN [12] | 30.26 | 0.934 | 28.56 | 0.867 | 6.8 | |
| DBGAN [15] | 31.10 | 0.942 | 24.93 | 0.745 | 11.6 | |
| MT-RNN [14] | 31.15 | 0.945 | 28.44 | 0.862 | 2.6 | |
| DMPHN [13] | 31.20 | 0.940 | 28.42 | 0.860 | 21.7 | |
| BANet [17] | 32.44 | 0.957 | - | - | 85.65 | |
| SDWNet [16] | 31.26 | 0.966 | 28.61 | 0.867 | 7.2 | |
| FMD-cGAN [19] | 28.33 | 0.962 | - | - | 1.98 | |
| MIMO-UNet+ [8] | 32.45 | 0.957 | 27.63 | 0.837 | 16.1 | |
| MPRNet [2] | 32.66 | 0.959 | 28.70 | 0.873 | 20.1 | |
| Transformer-based model | Restomer [18] | 32.92 | 0.961 | 28.96 | 0.879 | 26.12 |
| CNN-Transformer | Our model | 32.68 | 0.962 | 28.73 | 0.881 | 15.6 |
| Baseline | CAFB | SAB | LGFCB | PSNR | SSIM | |
|---|---|---|---|---|---|---|
| MRB | TB | |||||
| √ | 31.44 | 0.943 | ||||
| √ | √ | √ | √ | 32.37 | 0.957 | |
| √ | √ | √ | √ | 32.42 | 0.959 | |
| √ | √ | √ | √ | 32.11 | 0.952 | |
| √ | √ | √ | √ | 32.07 | 0.951 | |
| √ | √ | √ | √ | √ | 32.68 | 0.962 |
| DeblurGAN-V2 [10] | MIMO-Unet+ [8] | MPRNet [2] | SDWNet [16] | Ours | |
|---|---|---|---|---|---|
| Params (M) | 60.9 | 16.1 | 20.1 | 7.2 | 15.6 |
| Runtime (s) | 0.21 | 0.017 | 0.18 | 0.14 | 0.012 |
| PSNR (dB) | 29.55 | 32.45 | 32.66 | 31.26 | 32.68 |
| SSIM | 0.934 | 0.957 | 0.959 | 0.966 | 0.962 |
| Blur | SRN [12] | MIMO-Unet+ [8] | MPRNet [2] | Restomer [18] | Ours | |
|---|---|---|---|---|---|---|
| car(left) | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| plant | ☓ | 0.78 | 0.56 | 0.74 | 0.75 | 0.66 |
| person | 0.88 | 0.76 | 0.86 | 0.77 | 0.86 | 0.89 |
| chair | ☓ | ☓ | 0.65 | ☓ | 0.72 | 0.64 |
| umbrella | ☓ | 0.54 | 0.51 | 0.58 | 0.59 | 0.54 |
| car(right) | ☓ | ☓ | ☓ | ☓ | 0.60 | 0.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Wan, Y.; Wang, D.; Wang, Y. Image Deblurring Based on an Improved CNN-Transformer Combination Network. Appl. Sci. 2023, 13, 311. https://doi.org/10.3390/app13010311
Chen X, Wan Y, Wang D, Wang Y. Image Deblurring Based on an Improved CNN-Transformer Combination Network. Applied Sciences. 2023; 13(1):311. https://doi.org/10.3390/app13010311
Chicago/Turabian StyleChen, Xiaolin, Yuanyuan Wan, Donghe Wang, and Yuqing Wang. 2023. "Image Deblurring Based on an Improved CNN-Transformer Combination Network" Applied Sciences 13, no. 1: 311. https://doi.org/10.3390/app13010311
APA StyleChen, X., Wan, Y., Wang, D., & Wang, Y. (2023). Image Deblurring Based on an Improved CNN-Transformer Combination Network. Applied Sciences, 13(1), 311. https://doi.org/10.3390/app13010311