1. Introduction
Visual object tracking has received widespread attention in the past few years due to its wide application in visual surveillance [
1], robotics [
2], human-computer interaction [
3], and augmented reality [
4]. With the state of an object in the initial frame as inference, tracking aims to predict the object’s state in each subsequent frame. With the development of deep learning, object tracking algorithms based on deep learning have become the research focus. The deep tracking methods can be roughly divided into two categories, i.e., Discriminative Correlation Filter (DCF) based methods and object Siamese networks based methods [
5,
6,
7].
The DCF-based algorithms [
8,
9,
10] train correlation filters by extracting depth features and filtering subsequent frame images to obtain the most relevant object. DCF-based approaches treat the tracking problem as a binary classification problem. The trained classifier distinguishes the object and the background. It selects the candidate sample with the highest confidence as the prediction result. Classifiers typically trained using neural networks have a relative advantage in discriminating targets and interferences. e.g., the ATOM [
8] (Accurate Tracking by Overlap Maximization) network introduces IOU-Net (Intersection Over Union Network) [
9] based on the Siamese network to accurately estimate the target frame and improve the accuracy. The DiMP (Discriminative Model Prediction) [
10] algorithm also improves the discriminative ability and design template update. While introducing the online learning model, the iterative process of the loss function is optimized by the extremely fast gradient algorithm. The speed of online iteration is very high. The overall algorithm has reached SOTA in terms of robustness and speed performance with a significant improvement. However, the discriminative algorithm essentially regards the tracking as a binary classification problem, separating the object’s relationship and background. When the background of adjacent frames changes drastically, the discriminant algorithm cannot accurately track the object. Moreover, the discriminant algorithm relies on the appearance model’s construction. The discriminative algorithm relies on the construction of the appearance model, which requires the union of background and foreground information and the introduction of historical frame information.
The Siamese-based object tracking algorithm balances the tracking accuracy and speed, achieving real-time, high-precision target tracking. It is the mainstream algorithm in the current object tracking. Based on the pioneering SiamFC [
11] and SINT [
12], many methods try to improve the tracking performance of Siamese trackers. SiamFC is the earliest end-to-end Siamese network target tracking algorithm, which regards the tracking problem as a similarity matching problem. The same feature extraction network is used to extract features for the template and module search branches in the offline learning stage. Then the template feature is used as a window for sliding matching in the search area, and the highest response value is the object. However, SiamFC did not consider the scale problem when taking the bounding box and could not solve the problem of different scales of objects. Therefore, SiamRPN [
13] utilizes the Region Proposal Network [
14] (RPN) for joint high-quality foreground-background classification and bounding box regression learning. However, due to the imbalance of the negative sample categories in the training data, the Siamese network cannot distinguish objects similar to the target well.
Current algorithms usually solve this problem from two aspects: one type of algorithm expands positive samples by using translation, flipping, and other means, and at the same time increases various types of complex negative samples so that the network can discriminate. For example, in the training phase of DaSiamRPN [
15], the ImageNet [
16] and COCO detection datasets [
17] are made into positive sample pairs through data amplification to expand the types of training data sets and improve the generalization ability of the tracker. Moreover, it extracts pictures in different categories, and the same category as negative samples generates various kinds of complex negative samples and improves the discriminative ability of the tracker. The other is to improve the feature expression ability of the feature extraction module. For example, SiamRPN++ [
18] introduces deeper Resnet [
19] as the backbone network. The extracted features have a more vital expressive ability, which improves the anti-interference ability of the tracker. However, SiamRPN++ is still susceptible to interference from similar objects in a complex background. The Siamese network is essentially a template matching process that takes the first frame of target information as a template and cannot judge interferers in the background similar to the object. Moreover, they use the same classification network for feature extraction. It is impossible to obtain features with different directivity between the template and the search area. As shown in
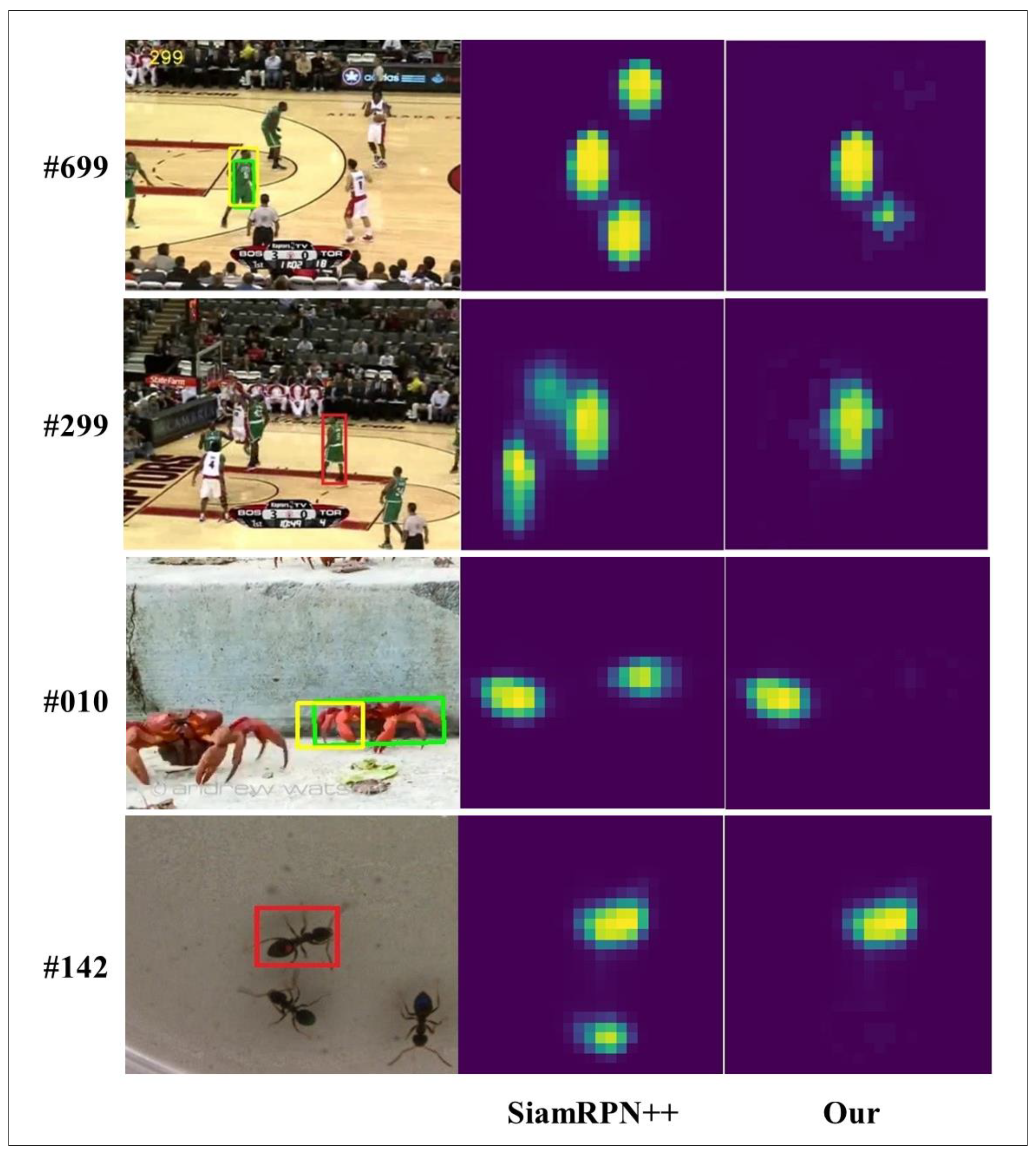
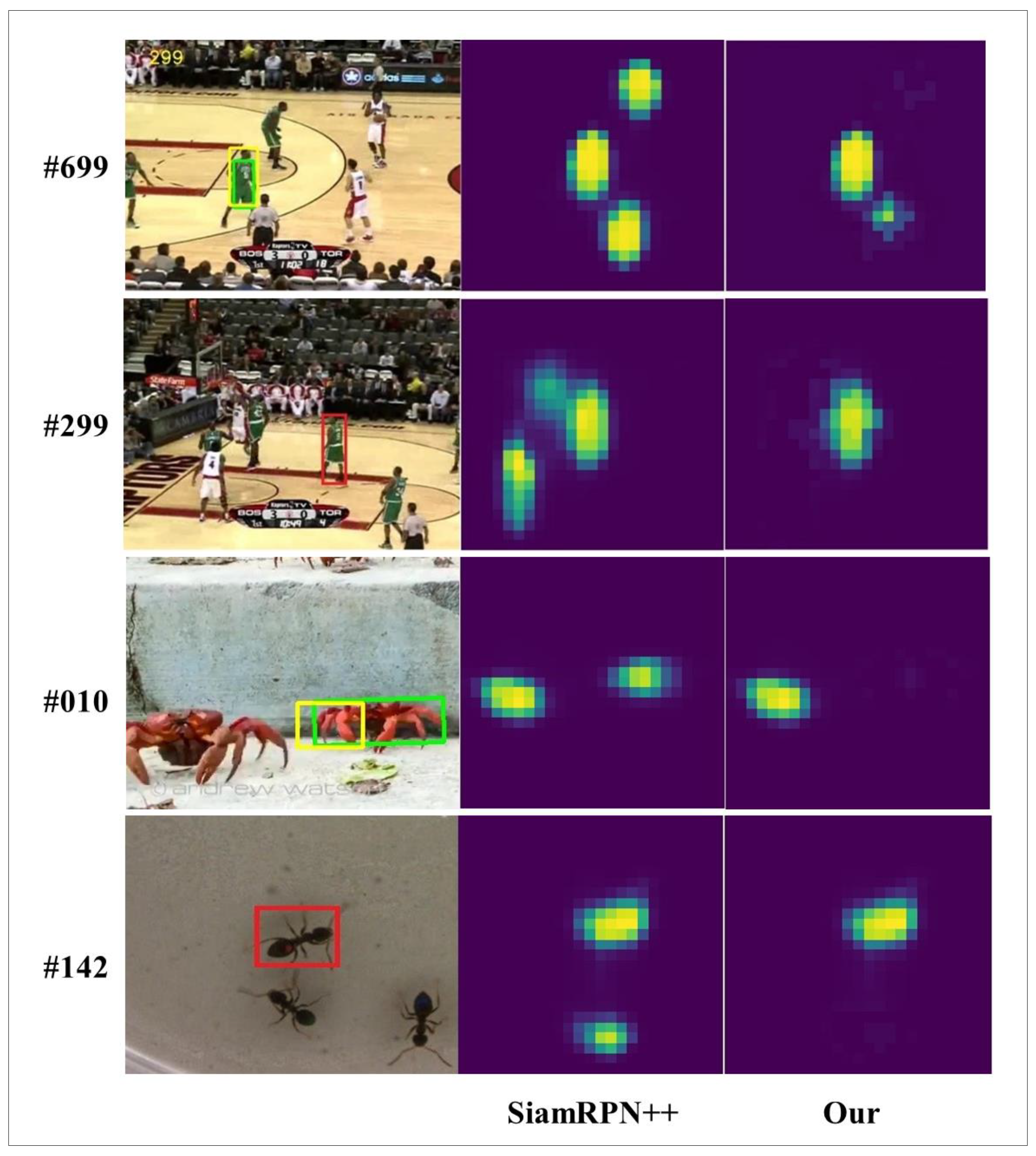
Figure 1, when other objects similar to the target appear in the current frame, the features extracted by the feature extraction network are very similar. As a result, double peaks appear in the response map, it is impossible to resolve the correct target. The Siamese-based algorithms do not have an online update mechanism, so the drifts are generated, and the tracking fails.
These methods enhance the ability to express features and improve the ability to distinguish similar objects to a certain extent. However, these algorithms will still lose track when similar objects of the same type have interfered in the scene. SiamRPN++ proves through experiments that the same category has a high response in some specific feature channels. In contrast, the response is shallow in other channels, indicating that the channel can reflect object category information to a certain extent.
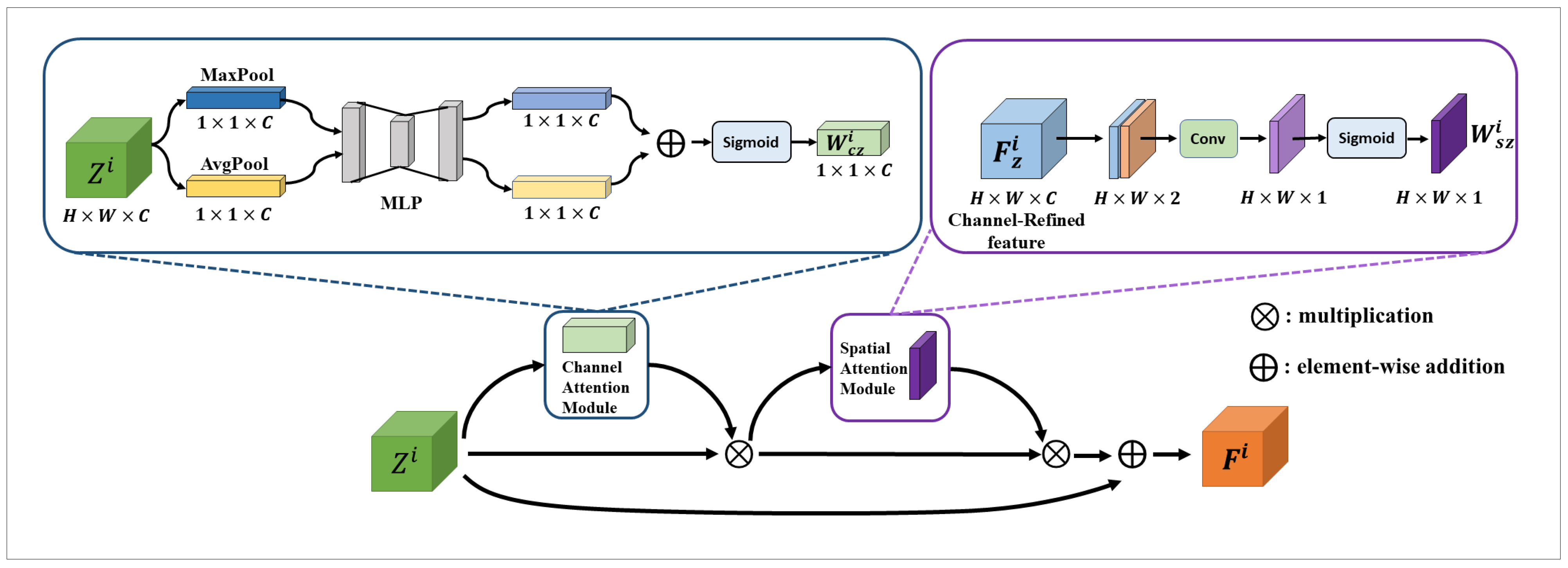
We propose a robust tracking algorithm based on compensating attention to solve the above problems. The channel-spatial attention mechanism is introduced into the double branches of the Siamese network to strengthen the high-response channel characteristics of specific target categories and at the same time, strengthen the dominant characteristics of a specific area of the object. Then we add a compensation attention model based on the dual-branch attention, introduce the attention of template branch selection into the search branch, and merge the attention of the search area and the template branch selection. It improves the feature discrimination ability of the search branch to the target. It solves the problem that the channel-space attention introduced by the search branch enhances the target characteristics while also enhancing the characteristics of similar objects near the target.
4. Experiment
Our proposed tracking algorithm is evaluated on the generic tracking datasets VOT2018 [
43], OTB2015 [
44], and LaSOT [
45]. At the same time, ablation experiments are performed on different components. Some of the state-of-the-art tracking algorithms, such as the Siamese family of algorithms, DiMP, ATOM, and the algorithms in this paper, are selected for comparison. Then, the effectiveness of different domain attention is evaluated at different layers of the network and in different combinations. Our method is trained with stochastic gradient descent (SGD). The experimental environment is 128G of running memory and 4 GTX 1080ti. We use synchronized SGD over 4 GPUs with 128 pairs per minibatch (32 pairs per GPU), which takes 12 h to converge. We use a warmup learning rate of 0.001 for the first 5 epochs to train the RPN braches. The Siamese network framework used is the PySOT [
46] framework based on PyTorch 0.4.1 [
47]. For the last 10 epochs, the whole network is end-to-end trained with a learning rate exponentially decayed from 0.005 to 0.0005. The parameters of the whole network are released for training later. One iteration processes 64 images with a CPU work thread of 1. The whole training is supported by the YouTubeBB [
48], GOT10k [
49], VOT2018, and DET [
50] datasets.
4.1. Analysis
We evaluate the algorithms in this paper using two small datasets, OTB2015, VOT2018, and one large dataset LaSOT. OTB2015 and VOT2018 have been developed for a long time, have a well-developed assessment system, and have more authoritative assessment data in small datasets. The LaSOT is a large target tracking dataset containing 1400 video sequences, 70 categories, and over 3.52 million precise bounding boxes. Visualizing bounding box annotations makes the LaSOT dataset a large and finely annotated dataset.
Table 1 illustrates the experimental results of the OTB dataset. As can be seen from
Table 1, the algorithm in this paper is the highest in both accuracy and precision on the OTB dataset, surpassing the mainstream depth correlation filtering algorithms. It is nearly 0.01 higher than the baseline algorithm SiamRPN++ and more than 0.02 than other mainstream algorithms. The algorithm’s performance reaches 0.703 and 0.920 after appropriate tuning of the baseline network parameters. a comparison of the algorithm’s performance with the mainstream algorithm after fine-tuning is shown in
Figure 7.
Table 2 shows the comparison results on the VOT2018 dataset. Compared to the baseline network SiamRPN++, the algorithm in this paper improves by nearly 0.02. Due to the difference in experimental equipment and parameter settings, there is an inevitable error in reproducing SiamRPN++ and the original paper. The algorithm for comparison with this paper is the result of our reproduction. However, there is still a gap compared with the mainstream depth correlation filtering algorithms DiMP and ATOM, which have better performance. Compared to OTB2015, the OTB2018 dataset scene is more complex. The related filter series algorithm will perform online fine-tuning during tracking. Its ability to update the image based on its contextualization information during tracking is suitable for objects with similar interference.
In addition, the average frame speed of different algorithms on VOT2018 is evaluated in this paper, and the results are shown in
Table 3. The algorithm in this paper is better in robustness and other data than the Siamese series papers. The speed is not reduced too much, indicating that this paper can improve the accuracy without sacrificing speed. The comparison between the Siamese family of algorithms and other algorithms also reflects the apparent advantage of Siamese networks in terms of speed, although not accuracy.
Table 4 illustrates the comparison between the algorithm in this paper and the mainstream algorithm on the LaSOT dataset. From the table, it can be observed that the algorithm of this paper performs well in long sequence videos, and compared with the Siamese network series of algorithms, our algorithm improves the ability of the Siamese network to track targets with severe deformation in videos with a long time and many frames, which further confirms the substantial improvement of the algorithm of this paper in feature discrimination ability.
4.2. Visualization
Our algorithm can still accurately identify targets and calculate target frames in many complex scenes.
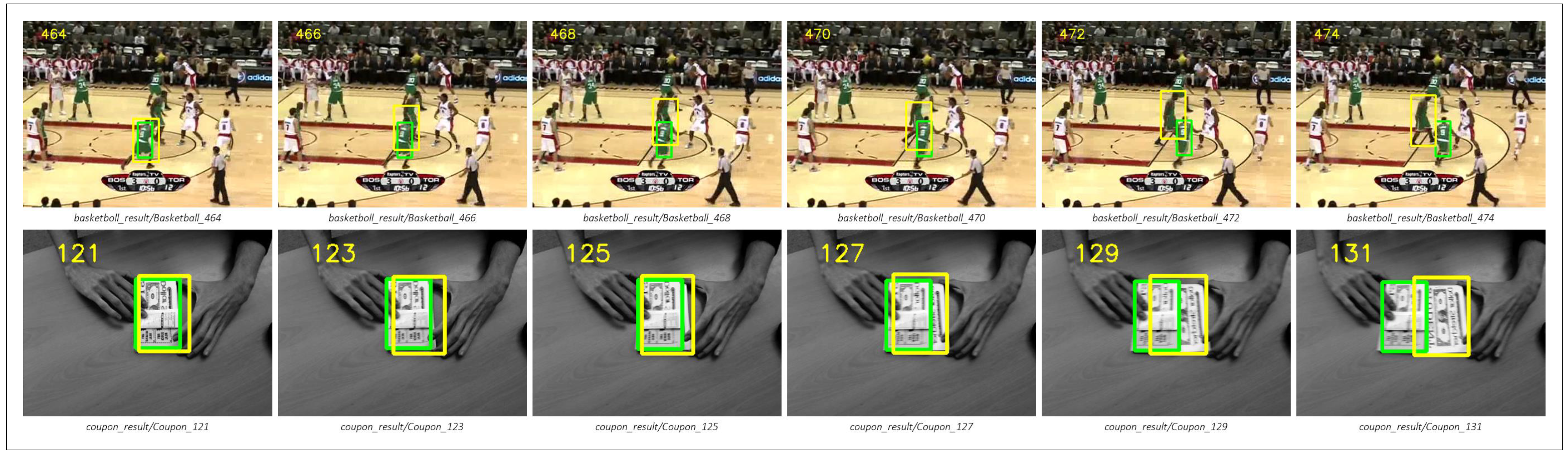
Figure 8 shows the tracking results of our algorithm compared with mainstream algorithms such as the SiamRPN++ algorithm on some video sequences. The figure below shows that our algorithm outperforms the SiamRPN++ algorithm on all these video frames. The first four video sequences are taken from the OTB dataset. The last two video sequences are taken from the VOT dataset.
4.3. Ablation Experiments
Ablation experiments were performed on the OTB2015 dataset for different components and combinations of approaches, and SiamRPN++ was chosen for the base network. To avoid different feature extraction networks being affected by different parameters and network layers, the ablation experiments of the attention mechanism were all performed on the same feature extraction network. ResNet is selected here.
Table 5 shows the ablation experiments of applying different types of attention to the feature extraction network and adding attention at different positions. The attention mechanism is combined in a default weighted approach.
The performance of the tracker is degraded by first using channel attention directly on Layer4 of ResNet. The different layers are tested, and the reasons for failure are analyzed. It is analyzed that SiamRPN++ already suppresses the category that is not the target when performing the deep inter-correlation operation. This operation plays a specific role in channel selection, so there is no corresponding effect of further enhancement of the channel of the target response.
Then our algorithm combines different types of attention mechanisms in the channel and spatial domains, and the enhancement of the target features is somewhat improved. The tracking effect is also improved, and the accuracy is increased from 89.7 to 89.9. However, the effect was slight. After experimenting with different network layers for analysis, the analysis concluded that ResNet has deep network layers. The features extracted from different layers are different types of image features. The lower layer features are more of some region, line, and color features. In comparison, the deeper layer features are more oriented to get the semantic information of the image, which is why the feature pyramid can achieve better results in combining different layers of features. We analyzed the effect of feature information noticed by different features layers on the experimental results and found that deeper semantic information was more effective than shallow feature attention. Therefore, we improved the performance of the tracker to 90.8 after fusing the information of different layers which combined the attentional enhancement of Layer1, Layer3, and Layer4. The experimental results are shown in
Table 5.
After we determined that the combined attention mechanism was effective for feature extraction, we conducted ablation experiments on the combined way of compensating attention, as shown in
Table 6.
Three combinations of template branch and search branch attention were selected for experimentation: weighted, dot product, and connected. The connection achieved the best effect, which improved the tracker performance by almost one percentage point to 91.6; the other two methods also improved the experimental results, 91.0 and 91.5, respectively. It shows that the feature attention of the template branch does have a compensating effect on the search branch.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}