1. Introduction
Crime is a deed that is based on an offensive act, but to overcome such offensive acts it has always been necessary to utilize different means to minimize them in short time. Some of these crimes result in danger to both the environment and human life. Every country in the world seeks peace because it enables societies to flourish, and economies to grow and achieve new heights of success over time. Contrary to this, an unpeaceful environment full of illegal activities brings the downfall of societies, communities, and countries. For example, wars have the biggest impact on a society in which the whole country suffers from huge pain and loss. Peaceful people are forced to fight, which ends with the loss of life, property, and identity. Some people are forced to relocate and travel to other countries as refugees. Therefore, countries with good defense systems can protect their sovereignty and help others to live peaceful lives. Similarly, on a lower scale, people who are not educated or are mistreated by society try to take the law into their own hands and commit crimes such as robberies. In robberies, robbers use weapons to terrorize other humans to meet their end needs, which normally ends with a loss of life or money. In most of these events, handheld weapons like pistols are the commonly used firearms that are easy to carry and get away with. Likewise, weapons are used by terrorists against common citizens, which results in a massacre.
In the past few years, the incidents involving firearms have increased in public areas. A couple of years back were the attacks on mosques in New Zealand on 15 March 2019; at 1:40 pm, the attacker attacked the Christchurch AL-Noor Mosque during a Friday prayer, killing almost 44 innocent and unarmed worshippers, and with a break of just 15 min at 1:55 pm, another attack happened that killed seven more civilians [
1]. In the USA and then in Europe, incidents of active shooters have occurred, such as in Columbine High School (USA, 37 victims), Andreas Broeivik’s assault on Uotya Island (Norway, 179 victims), or the killing of 23 people in the Charlie Hebdo newspaper attack. UNODC statistics says that among 0.1 million people in a country, the crimes involving guns are very high, i.e., 1.6 in Belgium, 4.7 in the USA, and 21.5 in Mexico [
2].
The reason and motivation behind this work is to detect various weapons in real time, thus reducing the aforementioned incidents. These incidents can be controlled using an early alarm system by alerting the operators and concerned authorities so that action can be taken immediately.
For decades, law enforcement agencies have installed CCTV cameras for surveillance that have helped them in noticing illegal activities in streets, airports, etc., and utilize the video as a piece of evidence in a court of law. People install CCTV cameras in their shops or markets for protection from thieves and robbers [
3,
4]. One common issue that arises with CCTV cameras is that they are not intelligent, which means a person should be available round the clock for monitoring live videos to take timely action against illegal activity. This turns out to be a tiresome job when a person must monitor multiple video screens for a longer duration of time [
5].
Artificial intelligence (AI) and computer vision have enabled us to utilize video feeds in a way that we can detect and classify the objects of our interest in it. Therefore, it has been widely adopted and used in many applications such as autonomous vehicles, security feeds, etc. Many algorithms and architectural works have been done for the aforementioned tasks. In 2020, Murthy, Chinthakindi Balaram et al. [
6] provided a detailed and comprehensive discussion and analysis of state-of-the-art techniques and algorithms used in the field of computer vision using deep learning technology, especially for the GPU-based embedded system. They covered many state-of-the-art algorithms that were trained and tested on COCO, PASCAL VOC datasets. The algorithms included RCNN, SPPNet, FasterRCNN, MaskRCNN, FPN, YOLO, SSD, RetinaNet, Squeeze Det, and CornerNet; these algorithms were compared and analyzed based on accuracy, speed, and performance for important applications including pedestrian detection, crowd detection, medical imaging, and face detection. Moreover, we also previously implemented a real-time weapon detector model based on YOLOv4 trained with a custom dataset. The model has a decent accuracy but lacks performance [
7]. Therefore, we continued our research to further improve the model in terms of mAP and performance for both cloud and edge computing devices. In addition, the existing solutions are not highly accurate, lack real-time performance, and often utilize cloud computing in which resources are abundant. Cloud implementations have issues like performance bottlenecks caused by network bandwidth, latency and privacy breaches, etc. Hence, there is a need to improve the existing solutions by utilizing the state-of-the-art object detection algorithm deployed on edge computing devices to rectify the mentioned shortcomings of cloud computing. The notable limitations of the previous works are the usage of an older deep learning model that has lesser accuracy compared to the state-of-the-art models, very few and outdated preprocessing steps for dataset preparation, and no performance analysis on any embedded device. Furthermore, to the best of our knowledge, there is no previous work done to deploy and compare the performance of the weapon detection model on edge computing devices in real time.
The main contributions of this research work are as follows:
Improved the accuracy and performance of the existing weapon detection model by utilizing state-of-the-art algorithm and preprocessing techniques;
Improved number of frames per second FPS for real-time deployment;
Compared and analyzed the performance of the different deep learning models on different computing devices;
Utilized the TensorRT for network optimization that resulted in improved latency, throughput, power efficiency, and lower memory consumption.
The rest of the paper is organized as follows.
Section 2 contains the related work and the literature review of different approaches that were being used to achieve the desired outcomes.
Section 3 elaborates on the methodology of the research problem and what steps should be taken to successfully carry out this research.
Section 4 contains the results of the research and a discussion on it that provides the reader with deep insight into the research findings. Finally,
Section 5 concludes the paper and provides possible future directions in this area.
2. Related Work
The solution to overcome the problem of weapons in public places is to develop an automatic weapon detection system that works in real time with high accuracy and performance to quickly generate an alarm. Such detectors have many applications in security for the safety of human life that will enable the authorities to quickly act before a major incident can happen. Therefore, the weapon detector applications can be a valuable addition to society for developing a city to become much safer. The idea for real-time weapon detection using computer vision first came out in 2007 when scientists proposed a real-time firearm detector by utilizing a CCTV camera feed [
8]. A year later, an idea was implemented in 2008 in which the scientists developed a pistol detector for RGB images, but the detector failed to detect multiple pistols in a single image [
9]. Initially, researchers used machine learning-based algorithms, but with the development of deep learning algorithms, researchers shifted toward it.
Histogram of oriented gradients (HOG) and speeded-up robust features (SURF) as a feature extractor were utilized. For detecting the firearms in an image, SIFT- and SVM-based algorithms were used, but these algorithms were not highly accurate and had poor speed for real-time scenarios, taking more than 14 s per image for detection. Moreover, these algorithms do not learn features of their own; they use the handcrafted rules for feature extraction. The authors also pointed out that automatic feature representation provides better results than the manual approach [
10,
11]. Another publication, using HOG and neural networks, utilizes the possibility to only look for weapons in the vicinity of humans to save processing time [
12].
With the advent of deep learning-based algorithms, researchers shifted toward it and utilized the algorithms that learn features automatically from an image, improving the performance and reducing a lot of manual work to save time. Researchers used CNN-based techniques to learn the features automatically and a ReLu-based activation function to introduce the nonlinearity that resulted in higher accuracy than machine learning-based algorithms but, still, performance in real time remained an issue because these algorithms are based on a sliding window approach that results in slow speed [
13]. With the Faster RCNN algorithm and IMFDB database, researchers developed a weapon detection model that has 93.1% accuracy, but this database is not good for real-time cases and they did not consider the precision and recall in their design; therefore, it was prone to higher false alarms [
14]. Region proposal methods in the algorithms helped in reducing the inference speed in Faster RCNN, which achieved 140 ms with 7 FPS on a powerful GPU [
15]. Another researcher developed a weapon detection system by training the Faster RCNN using a feature pyramid network with Resnet50, but the performance of this was slow [
16]. The researchers of [
17] trained a weapon detection model on YOLOv3 and compared its performance with the YOLOv2 model. They used a customized dataset for their model but the dataset and model are not great because many state-of-the-art models are available that can perform much better in terms of mAP and real-time speed.
The authors of [
18] utilized a combination YOLOv3 model and human pose to perform handgun detection. They highlighted that only detecting weapons is not enough because if a model has lower average precision (AP) it will be generating too many false alarms; therefore, to mitigate this problem they added human pose to improve the detection results, which showed them an improvement of 17.5% in AP. Likewise, in reference [
19], the authors used the same YOLOv3 model to train a rifle detection classifier for their custom dataset of rifles that gave adequate AP; however, both systems are not good for real-time implementation and embedded devices as the base model have too many parameters that become overwhelming for a device with limited resources. The work presented in [
20] utilized three different CNN-based models for weapon detection, namely Faster R-CNN, Retina Net, and YOLOv3; along with it they added pose estimation to further enhance the model. The authors compared these models in terms of different performance metrics such as precision, recall, and F1 score, in which YOLOv3 showed good results but the rate of false positives was high. This approach lacks real-time capabilities and has poor performance issues on embedded devices. Furthermore, a model that was trained on only 1220 images does not cover all the real-time scenarios, such as, for example, images in different backgrounds and orientations for the generalized solution.
The study of [
21] shows the use of the transfer learning approach on AlexNet, VGG16, and VGG19 models to train gun and knife detection from images. The results show good accuracy, but accuracy is not a good metric to stand out the results in object detection models where mean average precision is preferred. Likewise, the model lacks the capabilities to be deployed in a real-time environment. In reference [
22], the authors trained a model on a public dataset that used the open pose methodology for pose estimation that aids in weapon detection and improves the weapon detectors’ detection capability. The authors of [
23] identified that there is a lack of datasets in weapon detection problems; therefore, they proposed a way to generate synthetic datasets using a graphics engine. They have added an anomaly detector as well to ensure a reduction in the false-positive rate; however, the created dataset does not help much in the reduction in false positives but the anomaly detector helps in reducing it. In reference [
24], the authors developed a weapon detector based on two models and compared them. They utilized a multi-contrast convolutional neural networks (MC-CNN) model and faster region-based convolutional neural networks (Faster R-CNN) model for concealed weapon detection. They have found that MC-CNN has a more complex architecture than the Faster R-CNN model; therefore, it performs much better than it. However, they developed a small, customized dataset for it that does not cover the real-time scenarios; moreover, the model is heavier for real-time scenarios and therefore not recommended for utilization in the real world. In work [
25], the authors proposed a novel method for improving hand-held firearms detection. They have extracted the human hand and combined it with the human pose by using the open pose method to train the classifier that detects whether the person is holding a weapon or not. If both pose and hand suggest that the person is holding a weapon, the model classifies it as a weapon detected. Their work is only a recommendation that can assist in a better weapon detection model; therefore, it is not good for any real-time system and is prone to false positives. In reference [
26], the authors utilized the YOLOv4 algorithm for weapon detection trained on the Google and Kaggle datasets. They used the internet of things (IoT) approach to collect video and fed it to their model. The method they have used is good but the dataset is not great because it does not cater to all real-time scenarios with different image qualities and backgrounds that affect the mAP of the model. The study of [
27] shows the comparison of two different weapon detection models, YOLOv3 and YOLOv4, trained on images collected from Google. They have shown that YOLOv4 outperforms the YOLOv3 model in terms of processing time and sensitivity of detection because the YOLOv4 algorithm is a superior model to YOLOv3. The researcher of [
28] used Alex-net in combination with some other techniques such as spatial pyramid pooling (spp) to train a weapon detection model. However, this approach is quite old and poor since many state-of-the-art algorithms outperform Alex-net now; therefore, it is not suitable for real-time systems. The work presented in [
29] used YOLOv4 as the main weapon detection model on their custom dataset, providing them with adequate results; however, the dataset is not good for real-time scenarios. Moreover, they are getting 35 FPS on 2080 TI GPU, which is quite low compared to recent models such as in Scaled-YOLOv4.
In 2021, Jesus Salido et al. [
30] proposed the detection of a handgun in deep learning surveillance images by training three convolutional neural network-based models (RetinaNet, FasterRCNN, and YOLOv3) and have done multiple experiments and claimed to have reduced the number of false positives, thus gaining best recall and average precision of 97.23 and 96.36%, respectively, using RetinaNet fine-tuned with unfrozen ResNet 50 as a backbone and, later adding the pose estimation training samples in the dataset, they have achieved 96.23% and 93.36% of precision and F1 score, respectively. The problem with this work was the use of high-definition images for training and also the 1220 data images might not cover the real-time case of having a lot of diverse incoming data [
20]. Volkan Kaya et al. [
30] proposed a weapon detection and classification technique by introducing a new model based on the VGGNet architecture trained on a dataset having seven different classes that include assault rifles, bazookas, grenades, hunting rifles, knives, pistols, and revolvers. They compared their model results to VGG-16, ResNet-101, and ResNet-50, examining the best classification results. Their proposed model achieved the highest accuracy of 98.4% among all, beating ResNet-50, VGG-16, and ResNet-101 with accuracies of 93.7, 89.75, and 83.33%, respectively. The problem with the work was the use of dataset images that are mostly animated or from a movie scene, hence making the model generalize less when implemented in real time [
30]. In [
31], the authors have proposed an object detection technique for abnormal situations such as guns and knives. They have introduced a new lightweight multiclass-subclass detection CNN (MSDCNN) model to extract and detect abnormal features in a real-time scenario. They have made a custom dataset and introduced a new evaluation method named detection time per interval (DTpI). Their proposed MSD-CNN has achieved the highest precision of 97.5% on imageNet and IMFDB datasets [
31].
Recently, researchers utilized the YOLOv4 object detection algorithm in [
7] to design a real-time weapon detection system that managed to achieve the 91.73% mAP and F1 score of 91%. They have trained many algorithms and provided a very good overview of different algorithms in terms of speed and accuracy on a powerful GPU, but they have not utilized the optimization techniques to improve performance for any embedded devices. The authors suggested in their future work that there is a lot of improvement required in terms of reducing the false positives and negatives [
7].
Existing solutions can be improved by utilizing the latest model known as Scaled-YOLOv4, which has shown higher performance than its predecessors; better data augmentation techniques in the preprocessing step, such as mosaic augmentation, improve the accuracy of the model when the objects to detect are small. Likewise, adding TensorRT for network optimization for improved latency, throughput, power efficiency, and memory consumption can further enhance the model for an embedded device such as Jetson Nano. This approach will improve the accuracy of the existing solution by reducing the false positives and false negatives. It will enhance the performance of the existing solution for embedded devices by reducing the latency, increasing throughput, and privacy of an edge computing device. Edge computing will rectify the privacy and security issues as data will be stored locally and model deployment will be private. Moreover, minimal latency and power consumption on the edge computing device will further improve it. The bandwidth bottleneck issue will be resolved by deploying models on edge devices.
The Scaled-YOLOv4 algorithm with its higher accuracy enables the design of a highly accurate real-time weapon detector that will be deployable on an embedded device to achieve lower latency, higher throughput, better privacy, and security for humans. The comparison between the existing solution of YOLOv4 and Scaled-YOLOv4 in terms of accuracy and performance on an edge computing device will provide a thorough overview of different metrics along with a deeper insight into how current algorithms perform on an edge computing device.
4. Results and Discussion
4.1. Experimentation
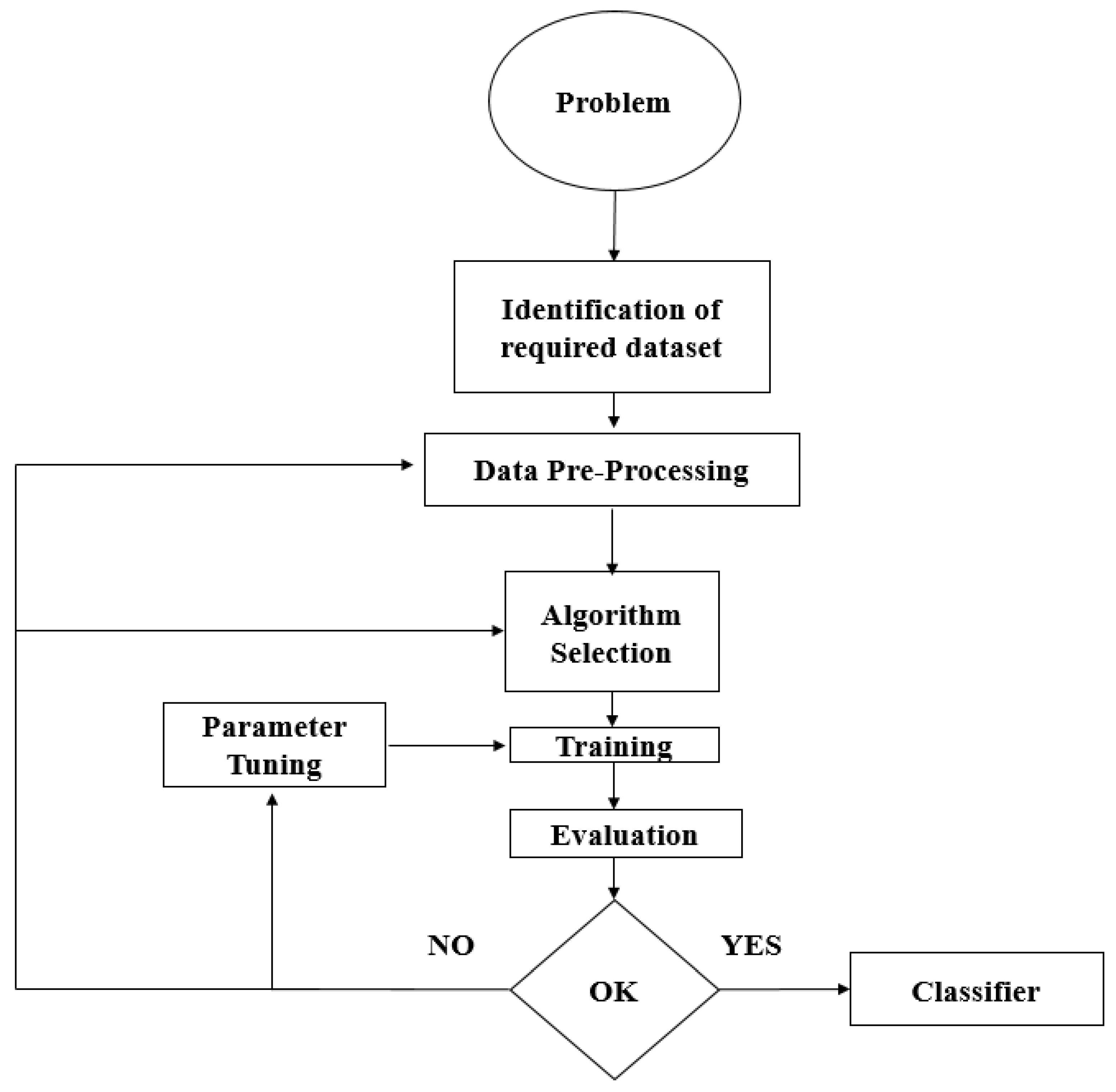
The objective was to train and fine-tune the model to improve the mAP and FPS of the weapon detector by following the training and optimization workflows as shown in
Figure 6 and
Figure 7. We have trained several models to evaluate and find the best possible model for inference purposes. The training of the models was performed on different computing devices, first on high-performance machines like RTX 2060, RTX 2080TI, and Tesla T4, and then they were trained and tested on edge computing devices like Jetson Nano and Raspberry pi. The hyperparameters are set at the default setting for all the models to have an unbiased result and are listed in
Table 2 below.
Different parameters play important roles in Scaled-YOLOv4 such as image resolution, subdivision, intersection over union (IOU), intersection over union normalization, new coordinates, object smoothness, scaling x y, and loss functions. The first step of model training is to provide the dataset to the model and quickly finish the model training to observe and understand the trend, whether the model is improving the mAP and reducing the loss or not.
We followed the aforementioned process and first trained the model with different settings mentioned in the previous table for RTX 2060-based Scaled-YOLOv4 optimization process. Default hyperparameter settings along with subdivision and image resolution of 64 and 512 × 512, respectively, gave us 85.5% mAP and an average loss of 14.42.
After the first training and testing results, we conceived the idea to set the right number of iterations, which came out to be 4800 and 5400 according to our two classes. For the next training, we changed the subdivision to 32 and kept the resolution size the same as in the previous training along with the default hyperparameter setting and found that the mAP changed to 91.2 and the average loss of the model also dropped down to 16.2.
Since the last training session gave good mAP, we kept the subdivision to 32 and changed different parameter settings that could help in further improving the mAP and reducing the loss. Some of the parameters recommended by the authors are:
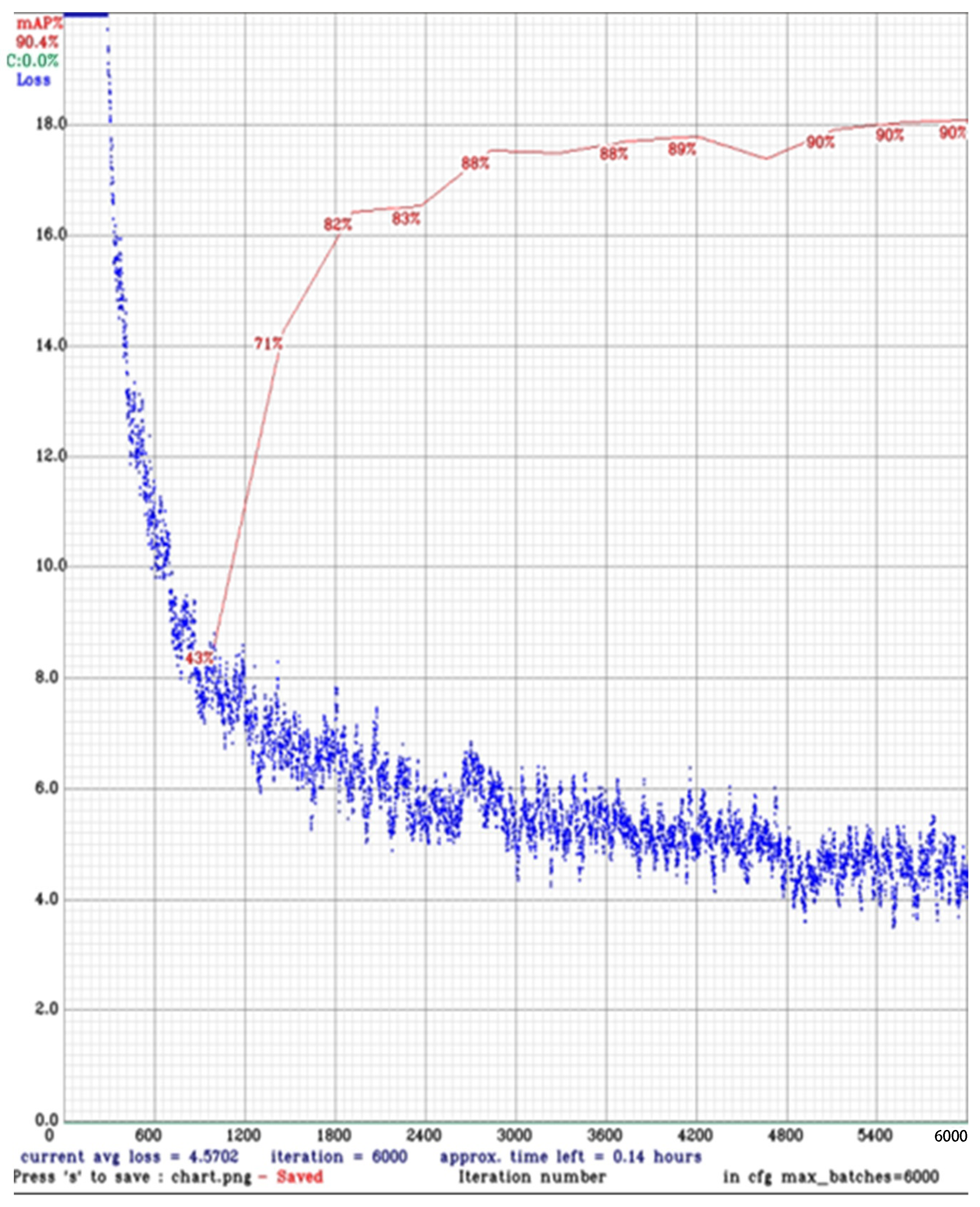
We observed that the mAP reduced to 90.4 while the average loss improved and dropped to near 4. There is a positive change, however, as mAP plays the main role and therefore we moved toward different parameter settings. Now we reset all the settings and only change the resolution of the input image 608 × 608 with subdivision 32 and retrain the model. We observed that changing only the resolution improved the mAP to 91.2; however, there is no effect on average loss, which is still high at around 14.
In the next step, we increased the number of iterations to 10,000 with the subdivision and resolution the same as the previous of 32 and 606 × 608 to check if increasing the iteration can help the model in learning new features; however, mAP reduced to 91.2 but loss slightly reduced so it did not show any major impact on the results.
To observe the effect of changing the resolution, we changed the input resolution to 640 × 640 with a subdivision of 64 and retrained the model; however, it negatively impacted the model, reducing mAP to 83.3. It helped us understand that image resolution can be increased to a certain limit; after that it can impact poorly on the model mAP and average loss. All the results described above and graphs for the best performing models on RTX 2060 machine are listed and shown in
Table 3 and
Figure 8.
It can be observed from the above that the model performed best on RTX 2060 when having a subdivision of 32 and an image resolution of 608 × 608.
We further moved toward changing the image resolution, subdivision, and other parameters and found that RTX 2060 GPU was not able to load the model if we changed the network to do more complex work; therefore, we switched to RTX 2080TI GPU to further change the settings to get better results. We changed some hyperparameters as follows:
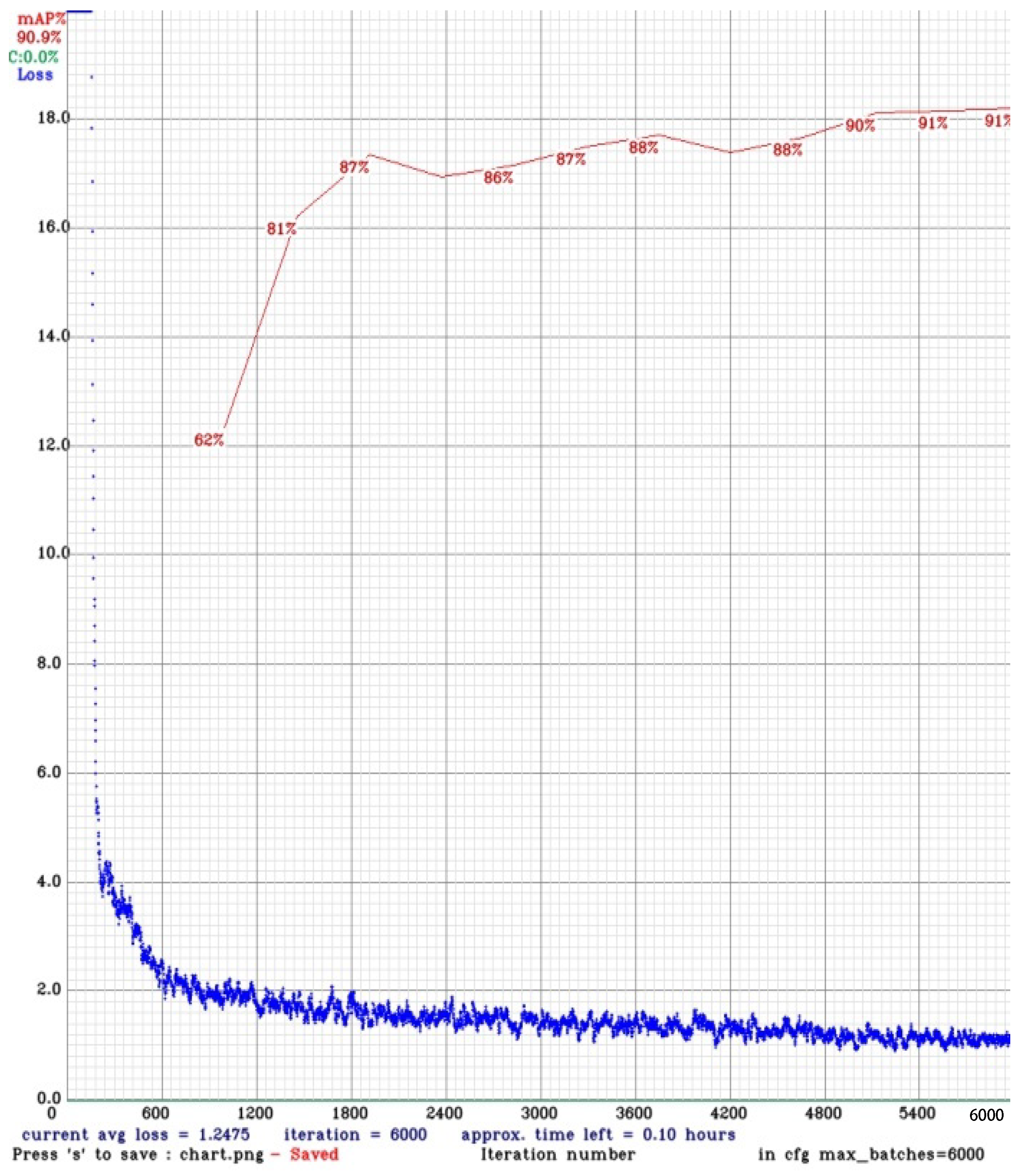
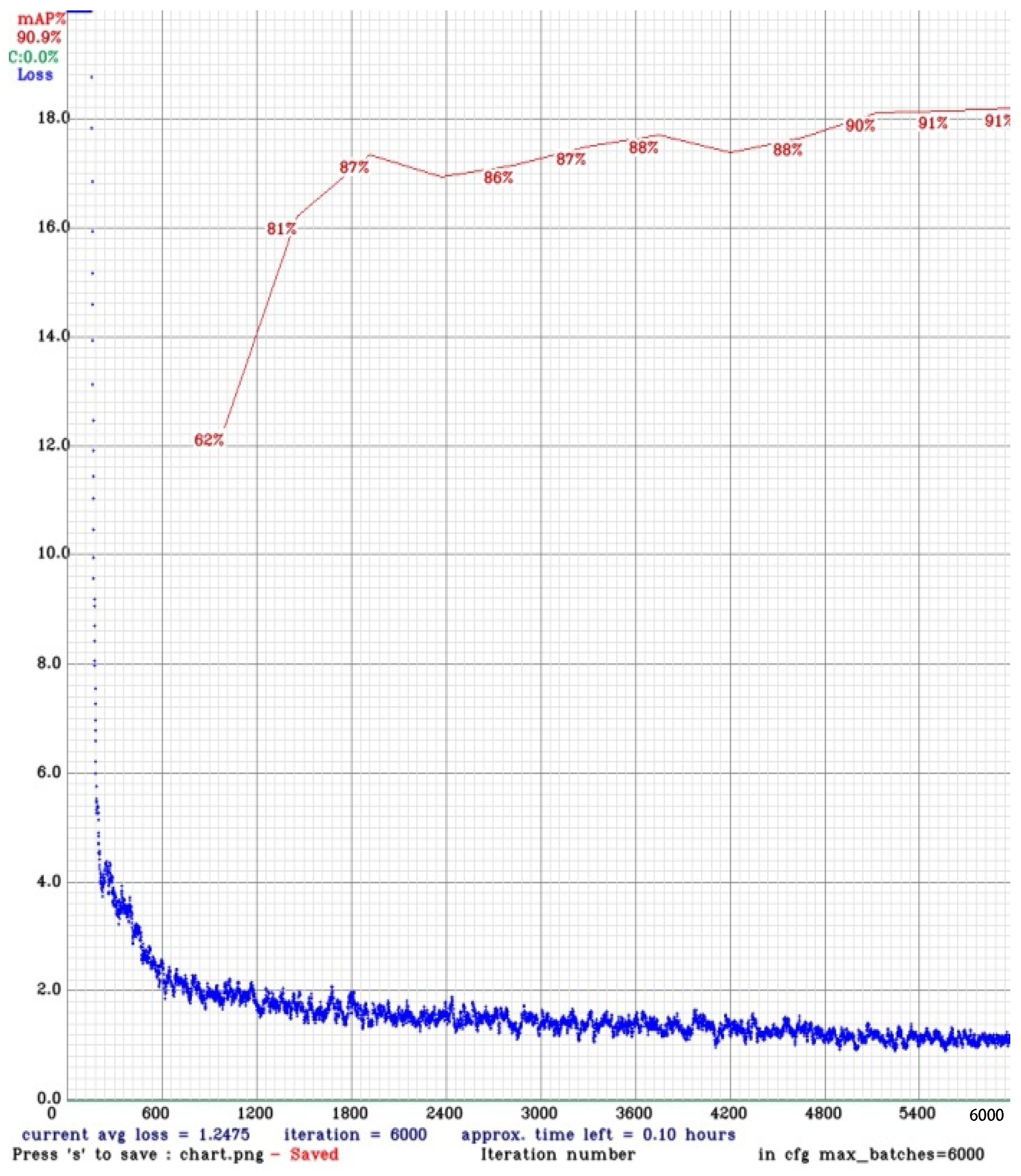
In the first run, it gave us adequate results with mAP increasing to 90.4 and loss reducing to 4.57. We further tuned the parameters to get better results with mAP becoming 90.9 and loss hitting the lowest of 1.24 utilizing the following settings, i.e.,
All the results described above and graphs for the best performing models on RTX 2080TI machine are listed and shown in
Table 4 and
Figure 9 and
Figure 10.
Finally, after many different parameters tweaking, we changed the following hyperparameters to get the highest mAP of 92.1, beating the previous model mAP. Some of the settings are as follow:
To go to an even lower subdivision made us move to a high-end GPU because RTX 2060 and RTX 2080TI GPUs were not capable of running the complex calculation. We ran the final training on Tesla T4, which gave us the expected results with parameter setting and model inference outcome as listed and shown in
Table 5 and
Figure 11.
It has been noted from the results that subdivision plays an important role in improving the mAP of a model. However, if subdivision is a lower number, then more GPU memory will be used; therefore, a powerful GPU should be selected to support it.
4.2. Comparison of Mean Average Precision
The mAP of the weapon detector trained on Scaled-YOLOv4 is compared with its predecessor YOLOv4 as reported in
Table 6.
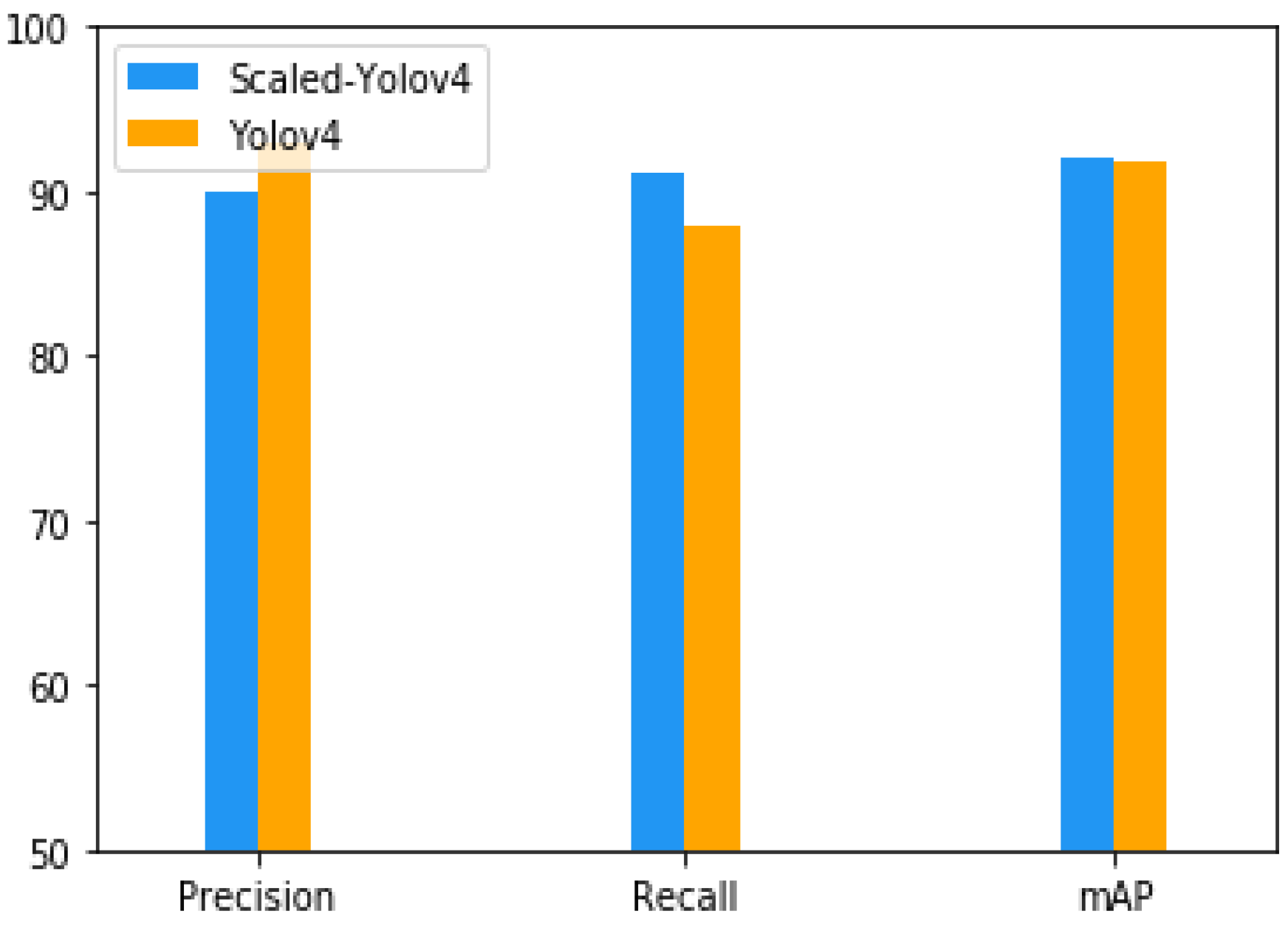
It can be noted from the results that the mAP is improved but it is closer to its predecessor [
4]. In terms of precision, the previous model achieved 93% while ours reduced it to 90. However, in terms of recall, previous model achieved only 88% while our model gave 91%. Finally, the F1 score of our model is 91% while the previous model has 91. The result’s comparison of the best performing Scaled-YOLOv4 vs. its predecessor YOLOv4 in terms is shown in
Figure 12.
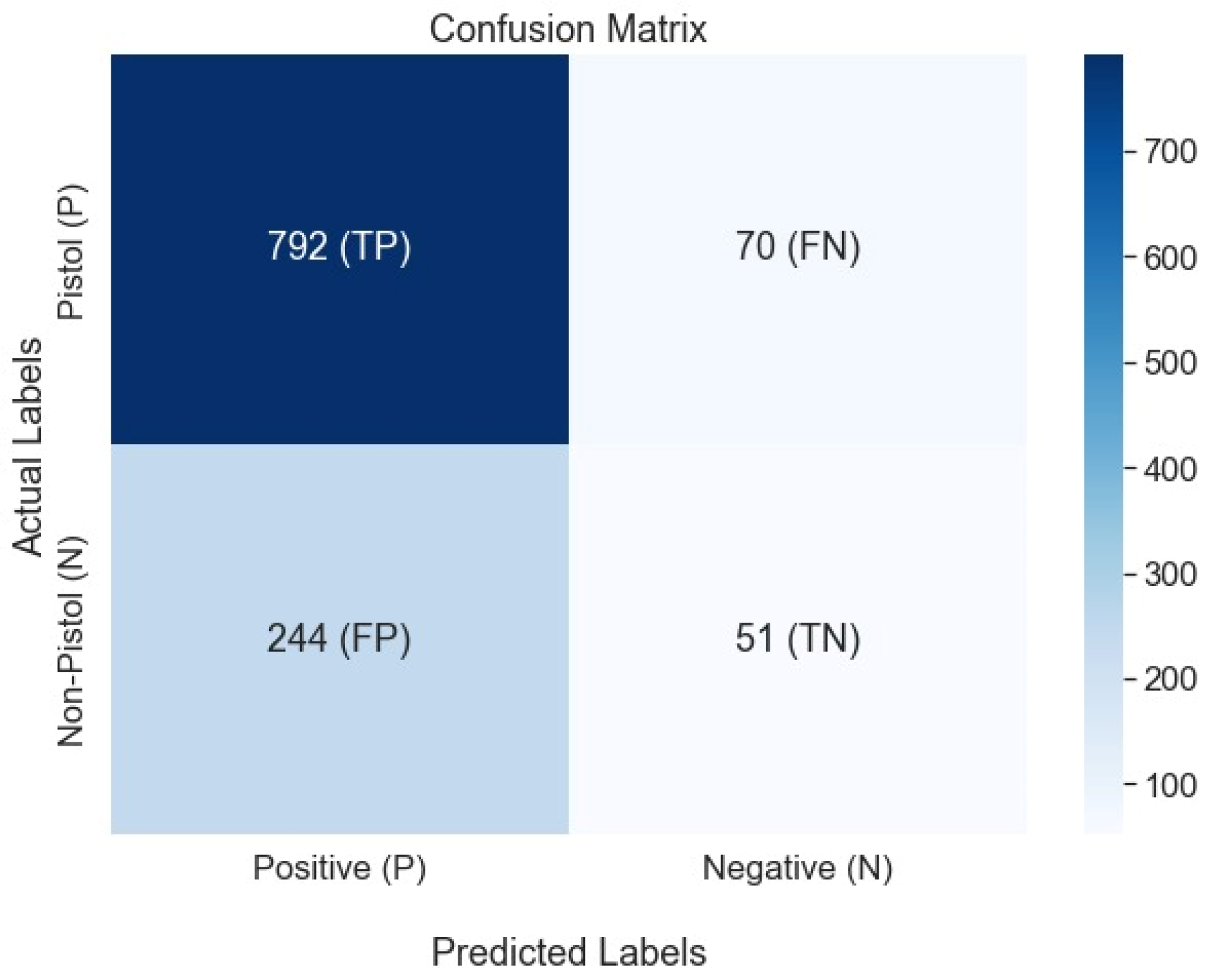
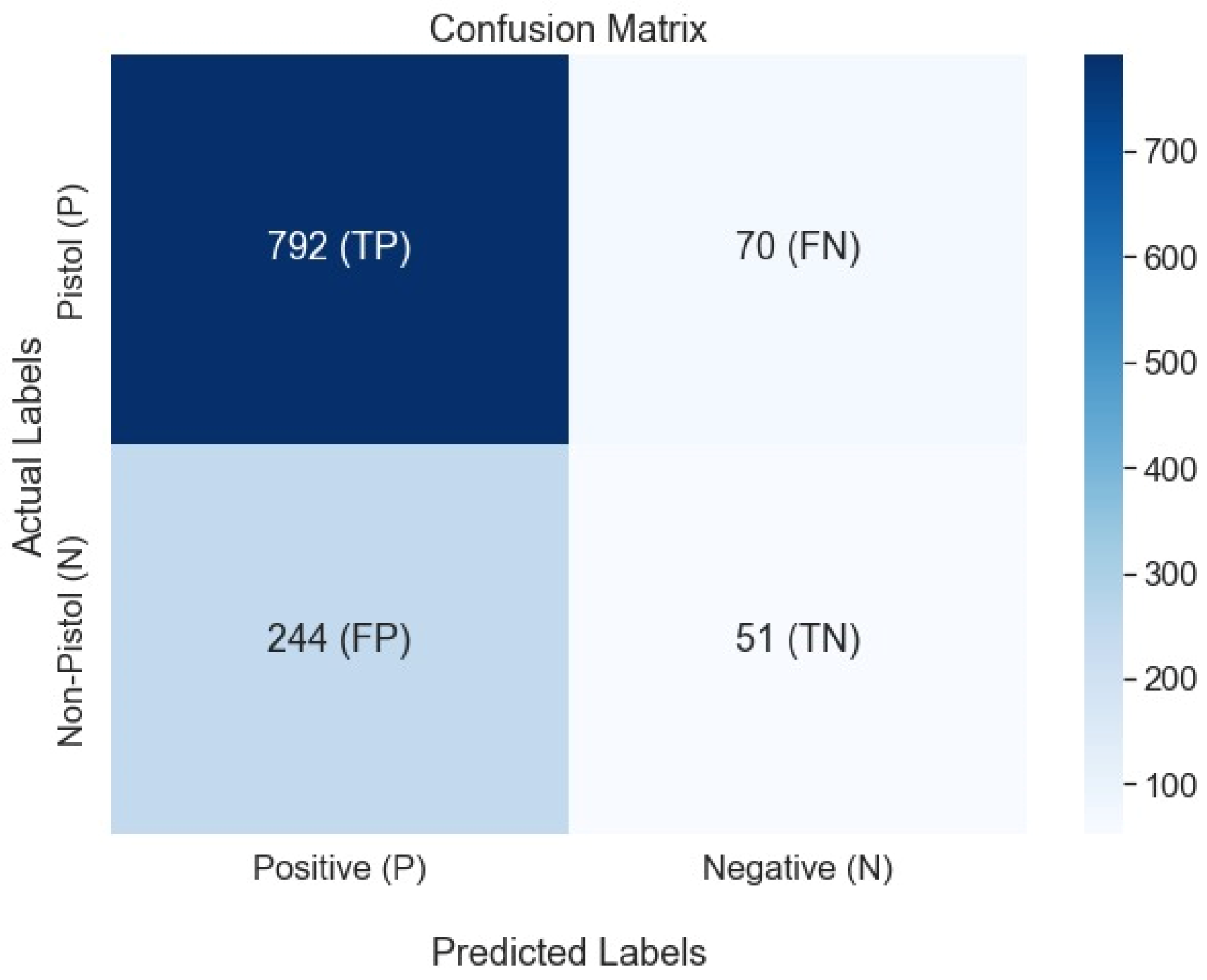
The confusion matrix of the weapon detection shows that the true positive rate is considerably higher than the false positives rates as shown in
Figure 13.
4.3. TensorRT Network Optimization
To deploy the deep learning model on the edge computing device, especially on Jetson Nano, we utilized the TensorRT framework that enabled us to perform the network optimization. This optimization enables edge devices to perform high-speed inference by utilizing fewer resources efficiently. For this purpose, we applied FP16 optimization on our weapon detection model because Jetson Nano only supports FP16, and this was getting reasonable FPS on Jetson Nano.
4.4. FPS Evaluation on Different Machines
We evaluated the FPS of our weapon detection model on various machines. We got the highest FPS of 85.7 on RTX 2080TI, 59.3 FPS on RTX 2060, 0.69 FPS on Raspberry Pi 4, 4.26 FPS on Jetson Nano, and 22.5 FPS on Intel CoreI5 10th Generation. It can be noted that the powerful machines gave very high FPS while on resource-constrained edge devices FPS is quite low. However, if we compare Jetson Nano with Raspberry Pi 4 it can be noted that the Jetson Nano TensorRT network optimization keeps it ahead of the game. The graph showing FPS comparison of Scaled-YOLO v4 on different machines can be seen in
Figure 14.
4.5. Comparison of Scaled-YOLOv4 and YOLOv4 FPS
The previous researchers were only focused on generating results on RTX 2080TI, so if we compare our results with theirs, it can be noted that the Scaled-YOLOv4-based model is ahead of it with 7 FPS. We reproduced the results and measured the FPS of the older YOLOv4 weapon detection model, which gave us 78.9 on an offline video.
4.6. Real-Time Weapon Detection and FPS Evaluation of Scaled-YOLOv4 on Jetson Nano
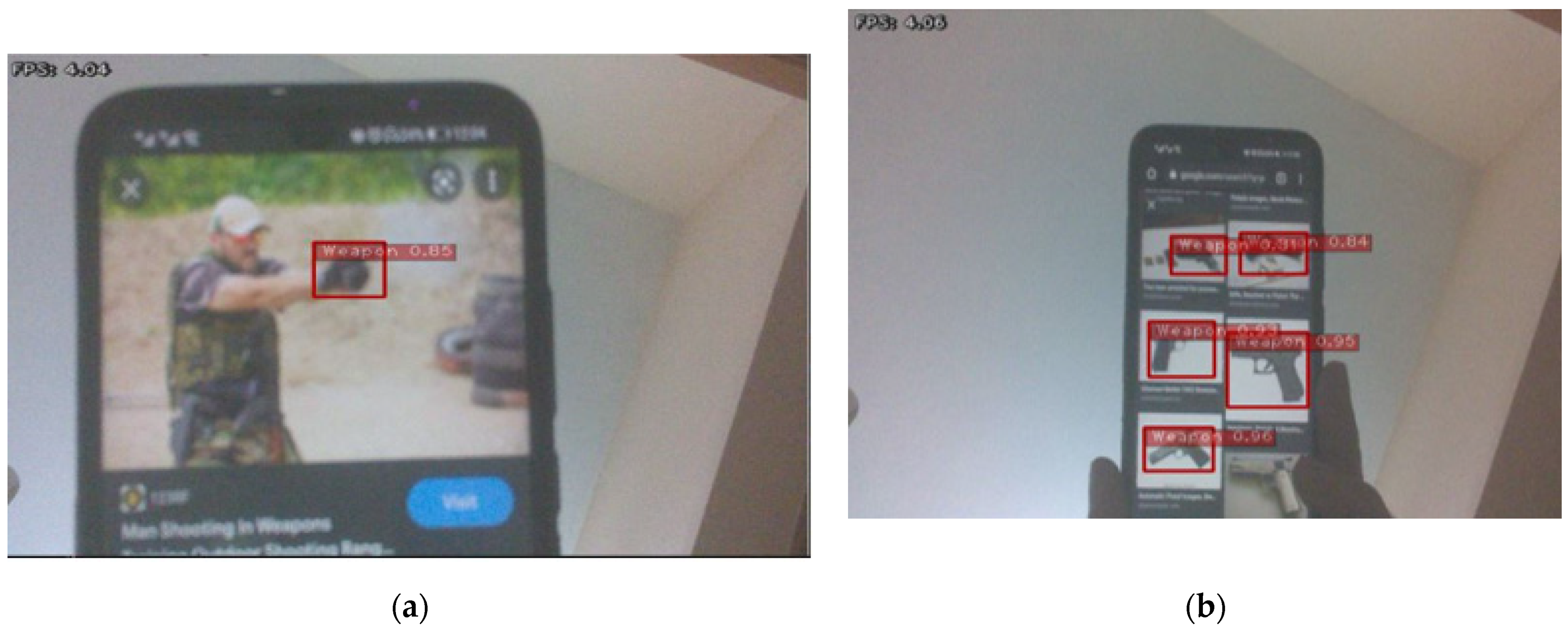
The weapon detection model’s FPS is evaluated on Jetson Nano in real time by interfacing Raspberry Pi camera module version 2. Models are converted into ONNX format to use further on Jetson Nano. A different set of images was shown to the camera to detect the respected class of weapon and the frame per second, which can be seen in
Figure 15.
We can see that the FPS is closer to the one measured in the videos and the model was able to detect many images of weapons in real time. It can be also observed from the real-time video that converting the model into the TensorRT format for weapon detection has reduced the mAP. Jetson Nano is observed to be confusing non-weaponry objects with the actual weapon class. After reproducing the work of previous researchers, we performed the TensorRT network optimization on the YOLOv4 model and deployed it on Jetson Nano. It can be noted the YOLOv4 gave 3.59 average FPS, which is lower than the Scaled-YOLOv4-based model.
4.7. Weapon Detection of TeslaT4 Trained Scaled-YOLOv4 on RTX 2080TI on Images
Weapon images of different categories having different angles, resolutions, and backgrounds were tested. Some of the results with a weapon as pistol class label with no background and with the background are shown in
Figure 16 and
Figure 17.
4.8. Weapon Detection of TeslaT4 Trained Scaled-YOLOv4 on RTX 2080TI in Real-Time CCTV
The ultimate goal of the work was to make it work successfully in real-time CCTV streams and we have successfully achieved that by testing it. The face of the security person holding the weapon is made blurred for privacy purposes. The results obtained after testing it in real time with pistol as label on the targeted object can be seen in
Figure 18 below.
4.9. Misdetections
Even though it provides excellent detection results on the weapon in various categories including pistols, revolvers, and rifles, the system had very few false positives that can be improved in the future. An example of a false positive is depicted in
Figure 19, which shows a smartphone detected as a pistol with a very low confidence of 25% that can be overcome by model improvement, as well as by setting the threshold.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}