1. Introduction
Image processing in combination with artificial intelligence and deep learning techniques is a daily growing field of interest not only from the perspective of the IT industry but also of its fusion with different domains due to its numerous applications.
Image analysis is considered a powerful tool in medical diagnosis mainly because of the availability of different types of medical imaging devices, such as CT, PET, SPECT, and MRI (1.5T, 3T, 5T, 7T).
The most important benefit of imaging techniques is the diagnostic non-invasiveness that supports the recognition of diseases before they progress to a severe stage where treatment is much more complicated and can be less effective or come too late.
Automated systems based on artificial intelligence cannot be a substitute for expert diagnosis; they only provide a tool for better and quicker diagnosis. Medical staff should never fully rely on a solution provided by a machine. The findings from an automated system should always be subject to interpretation by a professional and weighed against other decisions based on medical experience.
In this article, we deal with MRI brain imaging and provide an automated system that segments parts of tumors in 3D MRI brain images.
Gliomas are the primary types of brain tumors. They come from the astrocytes of the central nervous system. Primary brain tumors are classified according to the WHO (World Health Organization) [
1] from grade I to grade IV. Grades I and II are considered low-grade tumors (LGG—low-grade glioma), while grades III and IV are highly malignant and called high-grade glioma (HGG). LGG are harder to detect in automated AI systems. LGG type I is generally benign and tends to remain unobservable and untreated in time. However, LGG type II presents the risk of recurring as a HGG [
2], which is a much more severe and advanced phase of the cancer. Rarely, especially if not discovered in time, they can form extracranial metastases. The prognosis of patients with HGG is very poor. Even after a surgery, they tend to reoccur. The overall survival time can be enlarged by one or even two gross-total or sub-total resection surgeries [
3].
The databases of MRI images used for brain tumor segmentation usually contain four modalities. The T1 image shows the longitudinal relaxation, while T1c does the same but with a contrast agent. In many cases, the most visible areas of the affected tissue show up on this image. T2 is the transverse relaxation time, and FLAIR fluid-attenuated inversion recovery suppresses the effects of cerebrospinal fluid on the MRI image.
Brain tumor segmentation means a frame-by-frame analysis of a 3D MRI image and the classification of every pixel in 2D or voxel in 3D into a class or tumor type category. The different classes to be distinguished are background and brain tissues (considered as non-tumor parts) and tumor tissues, such as edema, enhancing tumor, non-enhancing tumor core, or necrotic tumor.
Difficulties influencing stable and rigid segmentation via an automated system are the variety of MRI acquisition protocols and the unstandardized and unnormalized images that are not co-registered, the image intensities present inhomogeneity, and different variations of contrast and other lightning conditions. The resolution and quality of the images also have a great impact on the success of an AI system. In addition, the gliomas can vary in size, location, appearance, and structure; they can appear anywhere in the brain. LGG tumors are much blurrier and may contain only some incipient types of tumor tissue, not showing the most visible tumor core at all.
The limited number of collected and annotated MRI images also presents an issue, reducing generalization and limiting the convergence of the training process. Fortunately, the problem of a publicly available dataset is solved by several universities and research centers providing a very thoroughly annotated database collected and upgraded for the BRATS competitions from 2012 until today [
4,
5,
6]. The annotations of different tissues were conducted by 3–5 experts.
The contributions made by this paper refer to the experiments carried out on the Amazon Sagemaker via applying the implemented six deep learning convolutional neural network architectures. We assess the advantages and disadvantages of these architectures by applying them onto the BraTS 2020 Brain Tumor Segmentation Challenge Database. We compare our results to the best results obtained at this competition. In addition to the experimentally determined hyperparameter setup, we also apply the hyperparameter optimization framework offered by the Sagemaker system to determine the adequate values for the CNN hyperparameters.
The methods before the era of deep learning use several basic image processing techniques that apply supervised, semi-supervised, or unsupervised methods. The main methods include thresholding-based methods, region-based methods, and pixel classification methods [
7]. Thresholding methods include global and local thresholding. Region-based methods include region growing, watershed, fuzzy c-means clustering, active contour, and so on. Pixel segmentation methods are generally model-based methods such as level set, Markov random fields, self-organizing maps, model-based fuzzy classification, genetic algorithms, support vector machines, artificial neural networks, and one of the best including random forest [
8,
9,
10].
The research field of deep learning algorithms began in recent years, starting in 2012–2013. Deep neural networks require many input images and a high computational capacity executed on the most up-to-date GPU cards. Training consists of an optimization procedure that relies on a well-established deep neural network architecture, adequate weight initialization, well-chosen hyperparameters such as optimization algorithm, loss functions, learning rate, and so on. In the beginning, deep learning methods in the literature were developed for object detection and image segmentation. Since 2015–2016, the deep learning strategy has been applied in several medical applications: cell segmentation by UNet [
11], prostate segmentation by VNet [
12], and 3D UNet [
13] kidney segmentation in volumetric data. The most recent MRI brain tumor segmentation methods were published and summarized during the MICCAI BRATS Challenge [
14]. Since 2016, almost every paper published has been based on the deep learning strategy.
In the literature, deep learning methods are classified in the following three categories [
15]: convolutional neural networks, recurrent neural networks, and Generative Adversarial Networks, while a fourth category considers an ensemble or a combination of several architectures.
Convolutional neural networks are based on the convolution operation between layers followed by pooling for halving the input dimension activation, layer and finally the fully connected layer. These types of CNNs are divided into single-path and multi-path CNNs. Single-path CNNs build only a single path from the input to the output [
16,
17]. The most important disadvantage of single-path CNNs is the single scale, which is zoomed out from layer to layer. The multi-path CNNs can extract different features from different resolutions, considering multi-pathways of architecture. Multi-pathway CNNs consider a local and global pathway. The local pathways consider small-size kernels, and the global pathways take kernels of a larger size into account. Multi-pathway CNNs can also be implemented through multiple input path size resolution [
18,
19]. Here, they include the FCN—fully convolutional neural network—where the fully connected layers from the CNNs are replaced by deconvolution layers. These layers can up-sample the down-sampled innermost layer to a higher resolution by gradually doubling from layer to layer until the original size is reached. The most important bottleneck of these encoder-decoder networks is the lack of accurate boundary detection. In [
20], a boundary-aware fully connected CNN was proposed. The boundary is separately learned as a binary classification problem. The introduction of the so-called skip-connection detects the boundary more accurately [
21].
The recurrent neural network-based methods rely on LSTMs [
22] and an advanced form of Gated Recurrent Units. In [
23], a Multi-Dimensional Recurrent Unit was proposed for brain tumor segmentation. The RNN was combined with conditional random fields for post-processing [
24].
Generative adversarial networks run in the same manner as a min–max game. The generator network generates an artificial segmentation, while the discriminator network finds its differences compared to the ground truth. If the generator is able to generate segmentation very close to the ground truth, the network-pair is considered trained [
25]. Another network based on the GA technique is the SegAN [
26]. In this article, the segmentor network is an FCN network. The discriminator is trained with a multiscale L1 loss function by maximizing it, and the segmentor only uses the gradients of the critic.
The BraTS Challenge has been organized since 2012 and continues today [
4,
5,
6]. Many researchers in the field participated in different editions. In the first few years, i.e., 2012–2014, generative, discriminative, or their combinations were proposed. The best methods integrated a hierarchical random forest classifier [
27] or context-sensitive feature extraction with decision tree [
28]. Until 2016, different versions of the random forest [
9] classifier were in the top three methods [
29]. In the 2015 BraTS, the simple convolutional neural networks appeared. In [
30], a network similar to LeNet-5 for brain tumor segmentation was proposed. However, their Dice scores on the whole tumor (WT = 0.81) was slightly smaller than the leaders’ [
31] using random forest classification (WT = 0.84). The best results reported in 2016 were obtained by a 5-layered simple convnet reporting Dice scores of the Whole Tumor − WT = 0.87, Tumor Core − TC = 0.81, and Enhanced Tumor − ET = 0.72 [
32]. In 2017, Kamnitsas et al. [
25] proposed an ensemble of multiple architectures known from the literature and obtained the best results (WT = 0.90, TC = 0.82, ET = 0.79). The NVIDIA company was the winning team in 2018 using multiple Tesla V100 GPUs [
33] and applying an autoencoder-decoder CNN architecture (WT = 0.91, TC = 0.86, ET = 0.82). In 2019, a variant of cascaded versions of UNet obtained the best results combining 12 different CNNs into an ensemble model (WT = 0.89, TC = 0.83, ET = 0.83) [
34]. The most up-to-date and best brain tumor segmentation networks were presented recently at the 2020 edition of the BRATS Challenge. Last year’s third place research team presented an encoder-decoder architecture called SA-Net [
35]. Wang et al. [
36] and Jia et al. [
37] both occupied rank 2. In [
36], the authors used a modality pairing procedure instead of using all four modalities at the same time. The pairs of modalities fed into the two different branches are T1 with T1c and T2 with FLAIR, respectively. The architecture is the same 3D UNet presented in [
13]. In the other paper, which ranked second [
37], the authors propose a Hybrid-High-Resolution and Non-local Feature network.
Isensee proposed in [
38,
39] the so-called nnUNET architecture—an autonomous system that computes hyperparameters and ties three architectures (2D, 3D, 3Dcascade UNet) based on the vanilla UNet using k-fold cross-validation deep supervision learning and ensemble architecture. This application was put into practice and confirmed on several challenges in the medical field last year. It is based on a dataset fingerprint and a pipeline fingerprint. The dataset fingerprint determines the resampling, intensity normalization, standardization, image sizes, cropping, and class ratio. The pipeline fingerprint is separated into three groups: blueprint, inferred, and empirical. The inference is made via a sliding window approach using half overlapping adjacent patches. The empirical parameters refer to determining the best model out of the three models and the ensemble obtained in five-fold cross-validation, post-processing extracting the largest connected component. nnUNet is one of the best automatic approaches for medical image segmentation, but it needs lot of GPU resources and has a quite large computational complexity. Papers [
4,
5,
6] are summarizing the results of all competitions.
The aim of this paper is to develop an end-to-end system for multi-modal brain tumor segmentation that was implemented on AWS Amazon Sagemaker. The presented adapted CNNs are available in the Sagemaker framework and can be deployed for other medical image segmentation tasks in the same way as described for brain tumor segmentation. The training process is fast. With our experiments, we demonstrate that it achieves fine results even after a relatively small number of epochs. The adaptation of networks known in the literature makes preloading ImageNet weights into these networks possible. The presented results and performances can be fine-tuned or retrained even on low-cost hardware on AWS, permitting easy application in other tasks of medical image segmentation.
The paper is organized as follows: after the introduction and a short literature survey of the best-performing methods, we describe the six CNN architectures adapted and fine-tuned to our experiments.
Section 3 describes our system and the results obtained. In the last section, we draw some relevant conclusions and compare the results obtained.
3. Results
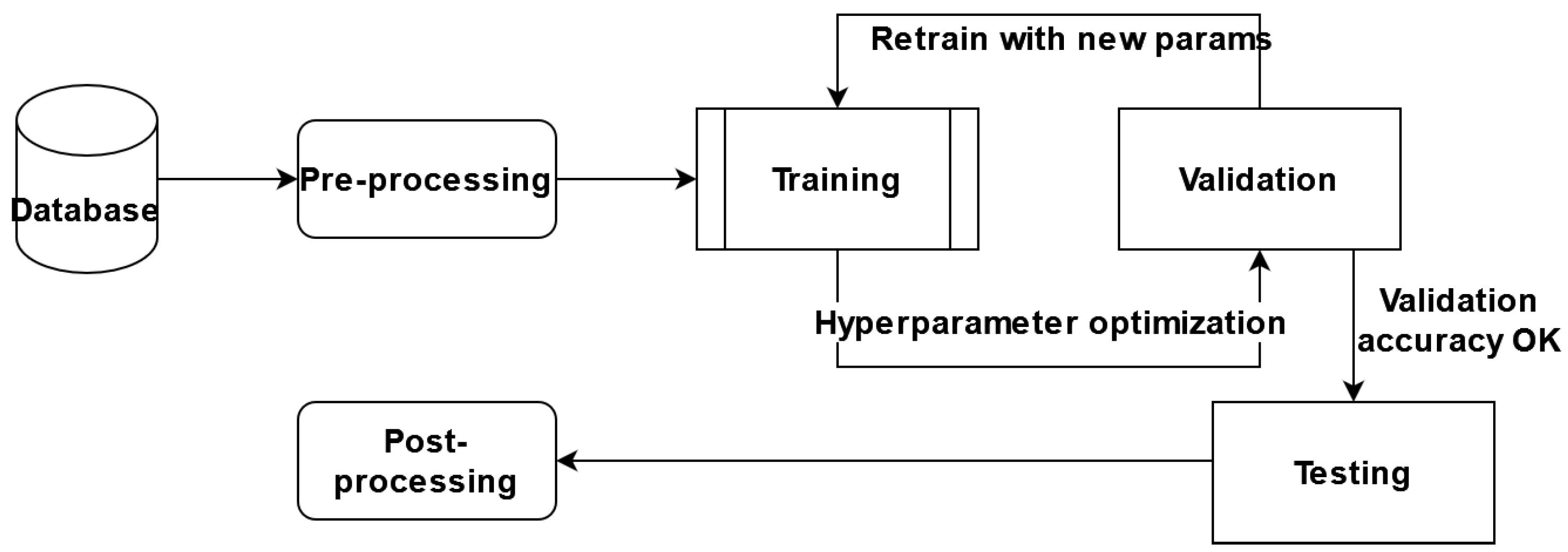
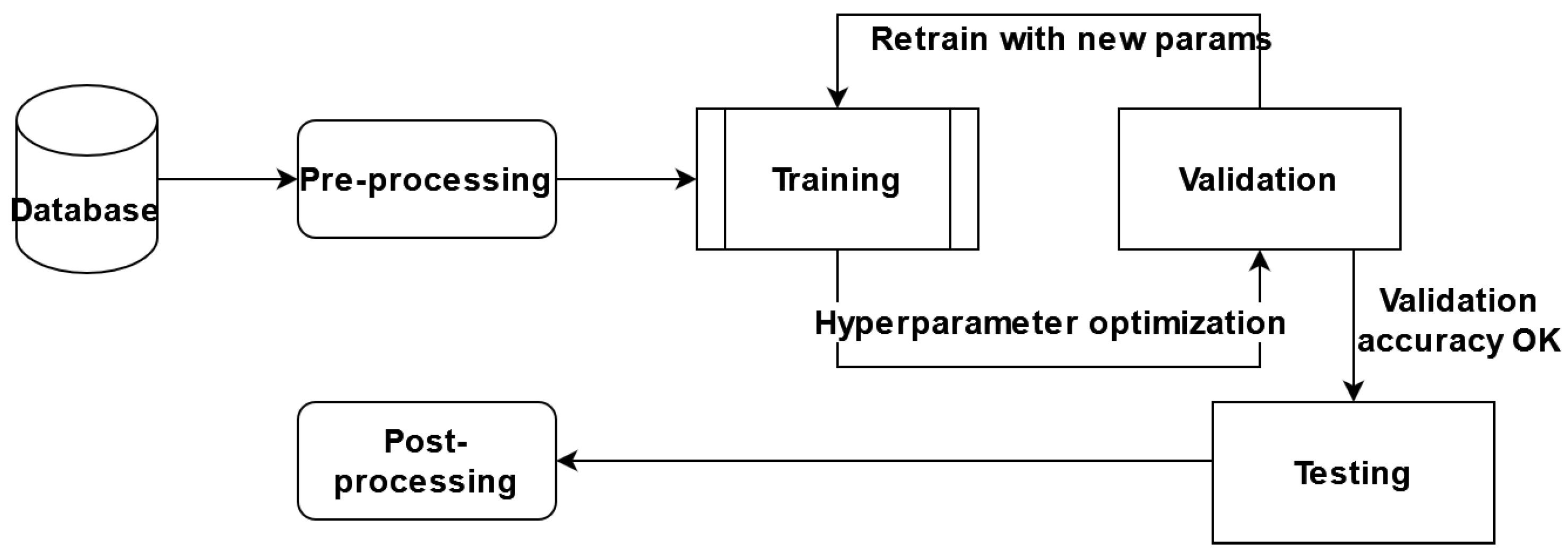
In this paper, we proposed performing certain experiments on the AWS Sagemaker platform and adapting the predefined architectures for segmentation, with brain tumor segmentation as our goal. We adapted and trained six different architectures, a variant of the hyperparameter optimized model, and an ensemble of the models obtained. The general component diagram of our system is shown in
Figure 6.
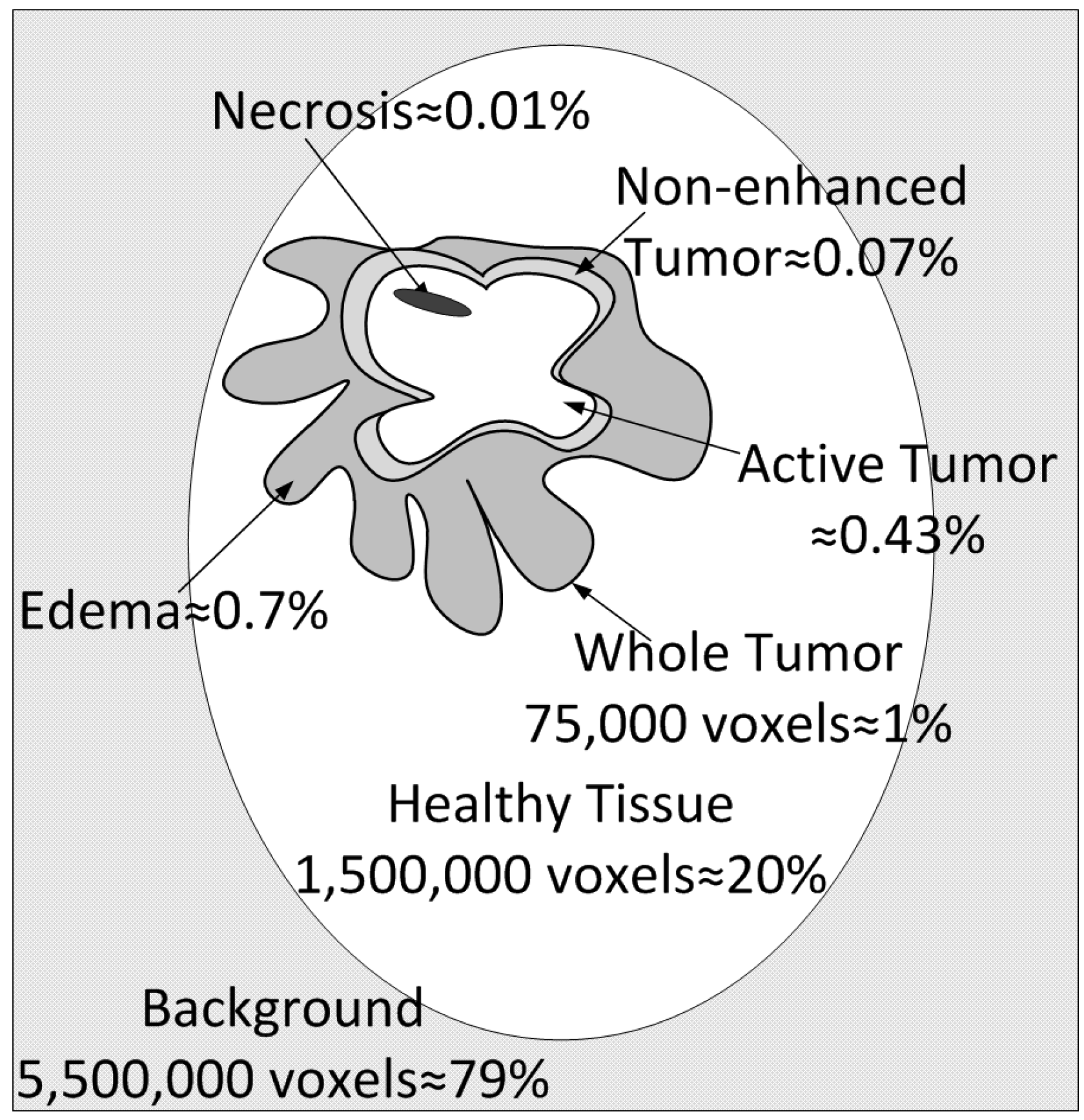
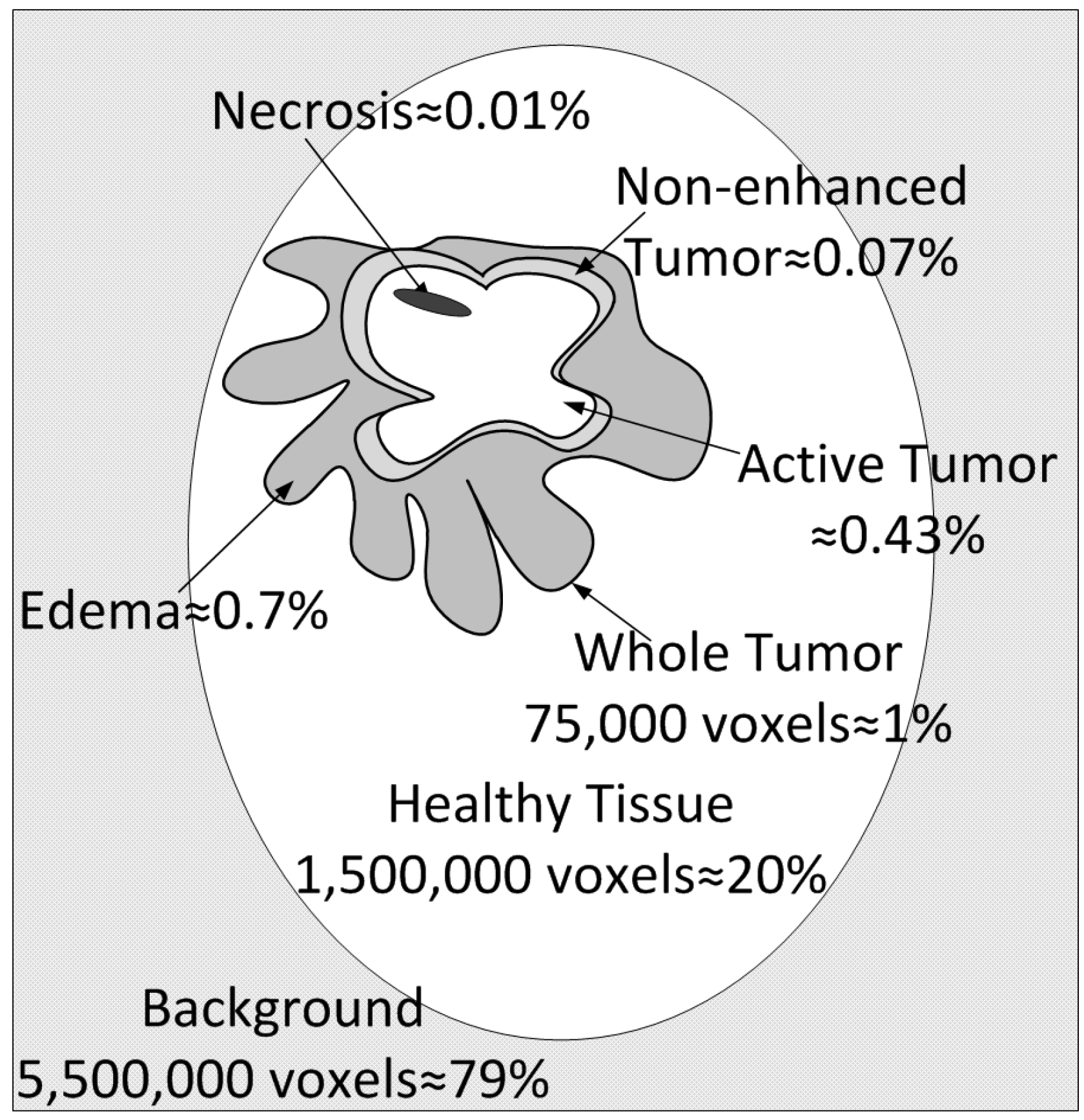
The database used for training is the publicly available BraTS 2017–2020 dataset. There are a total of 335 images, out of which 259 are glioblastoma (or high-grade tumor images) and 76 low-grade tumor MRI scans. Every image is 3D at a resolution of pixels, and there are four image modalities in total (T1, T1c, T2 and Flair), plus the ground truth image labeled by multiple experts and included in the public dataset. Before the training process, we randomly split this dataset into training, validation, and test sets in a proportion of 60% (201 images), 20% (67 images), and 20% (67 images). Class imbalance exerts a highly undesirable influence on the training process. The most frequent pixels are learned the best; these constitute the background (78–79% of the total image voxels) and the healthy brain (20–21%). The least frequent by far are the tumor voxels, which represent a total of about 1% of the whole image. The different tumor types are edema (ED) at around 0.7%, non-enhanced tumor (NET) at 0.07%, active tumor (AT) at 0.43%, and necrosis (NEC) at 0.01% of the total number of voxels.
The implementation of the described algorithms was conducted via the Amazon SageMaker. The definition of classes on the input images uses consecutive class numbering from 0 to n (n = 5) in our case. There are however five classes because classes 2 and 4 are conjoined. Detection differentiates background and healthy regions much better than between different tumor tissues, which is caused by the mentioned class imbalance.
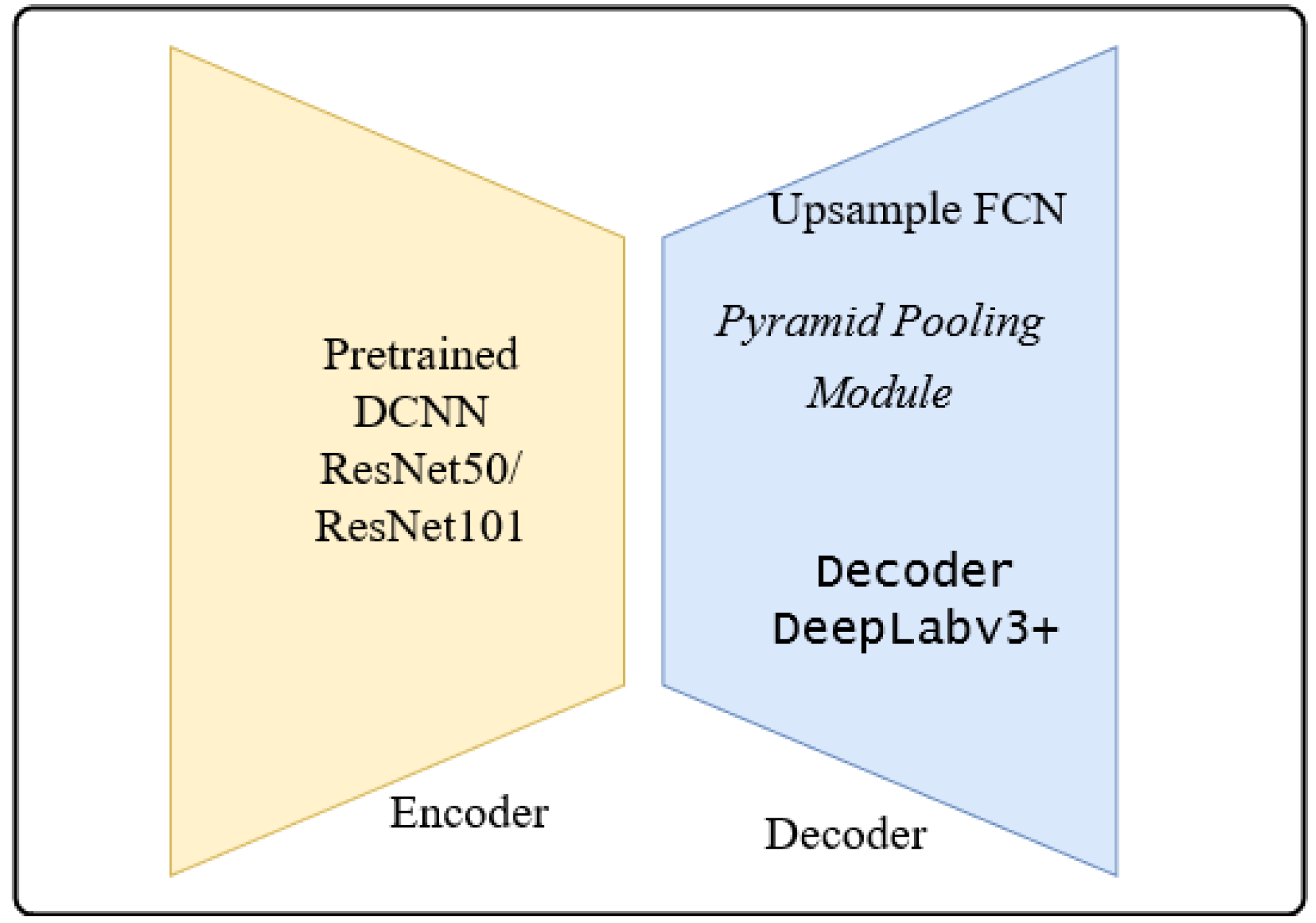
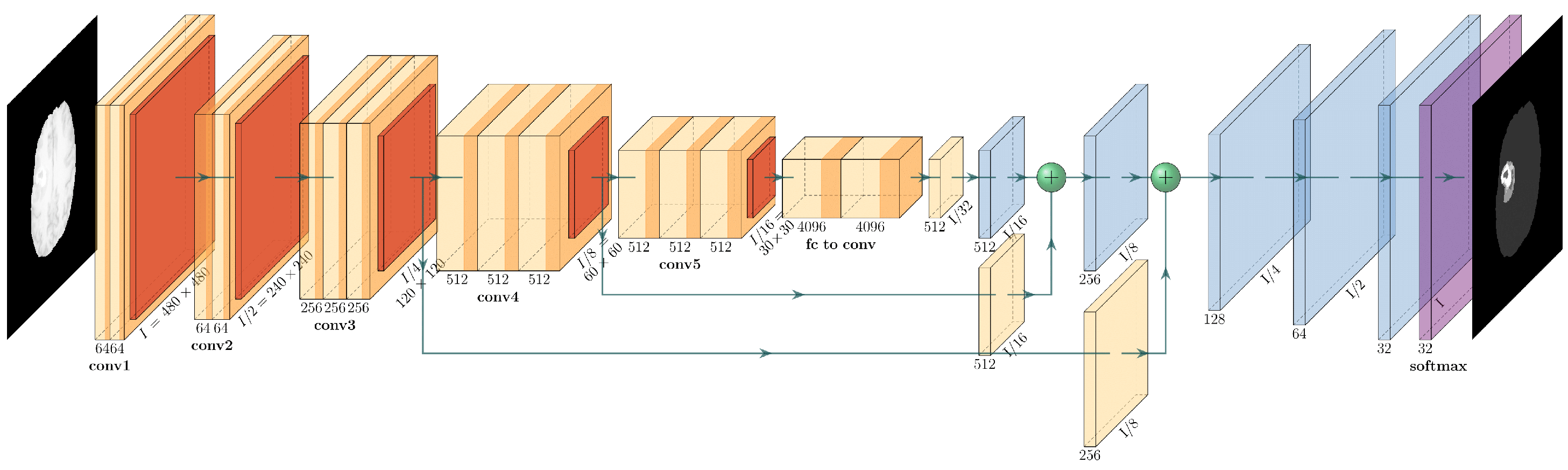
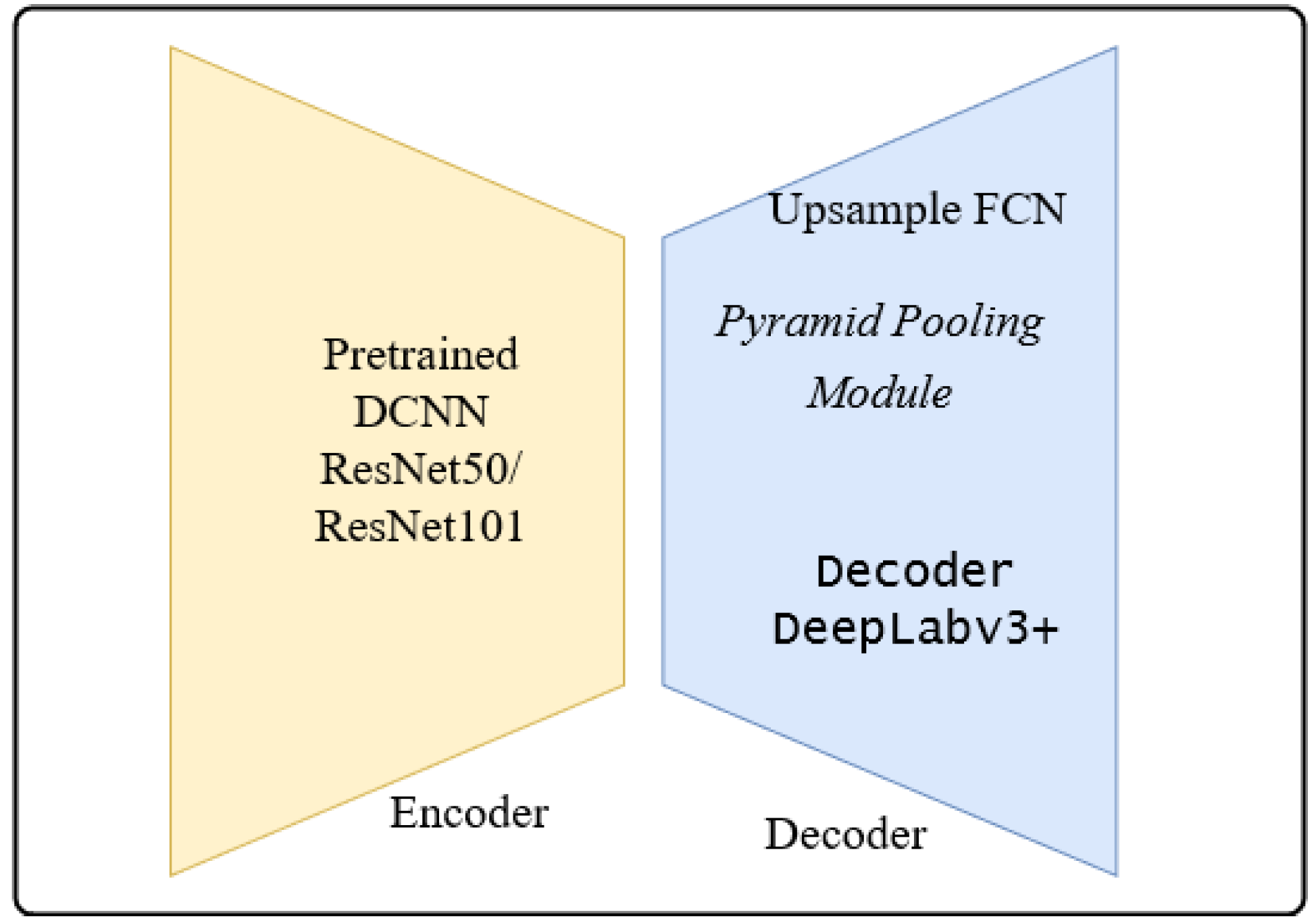
The architectures adapted to brain tumor segmentation follow the encoder-decoder architecture shown in
Figure 7.
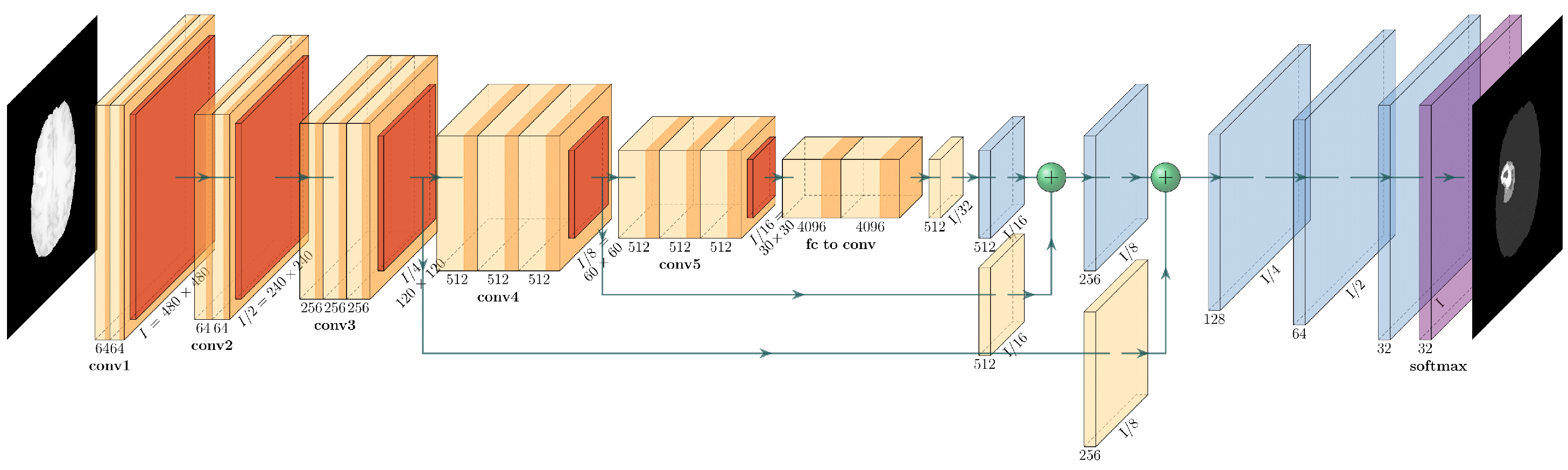
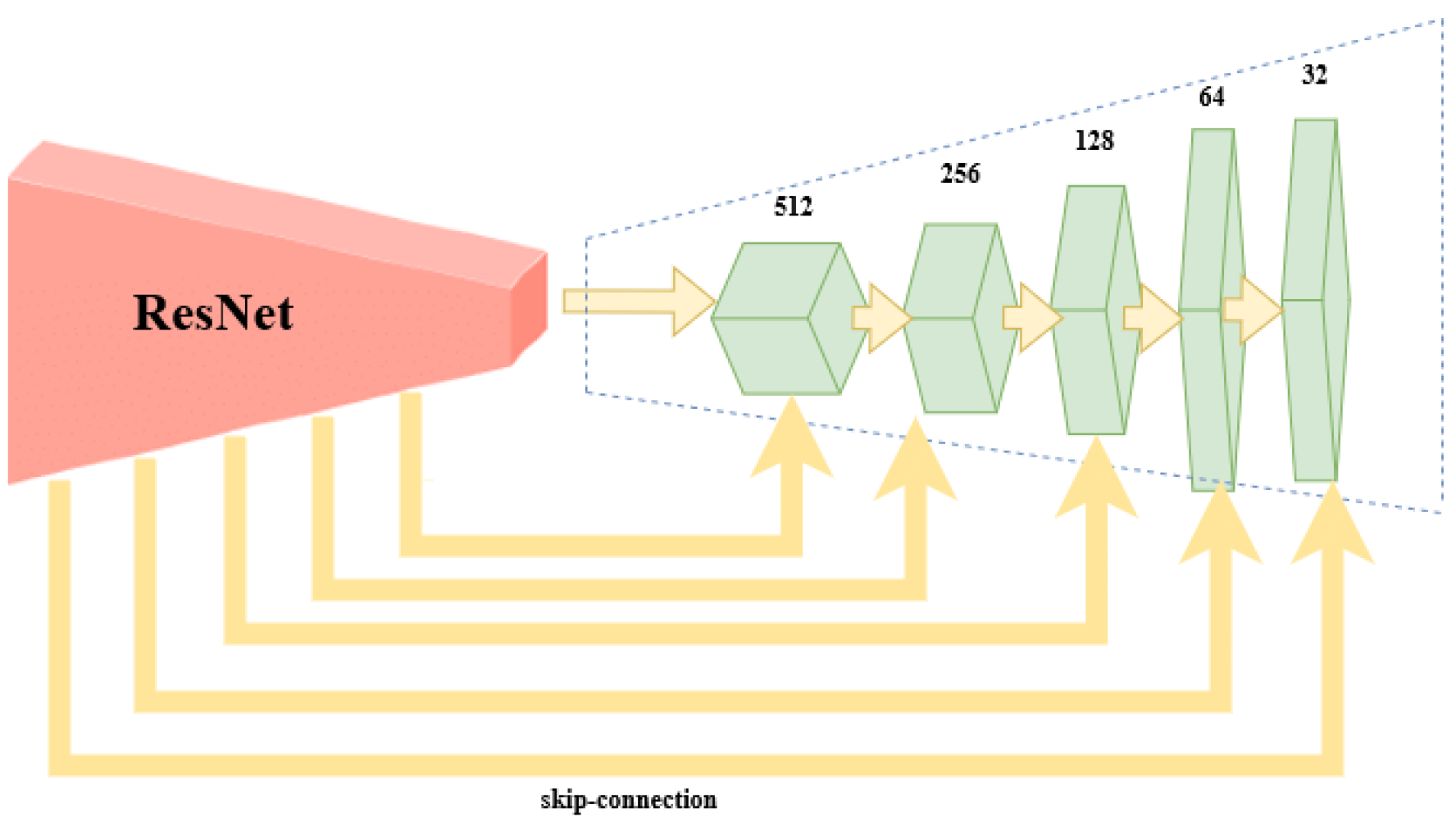
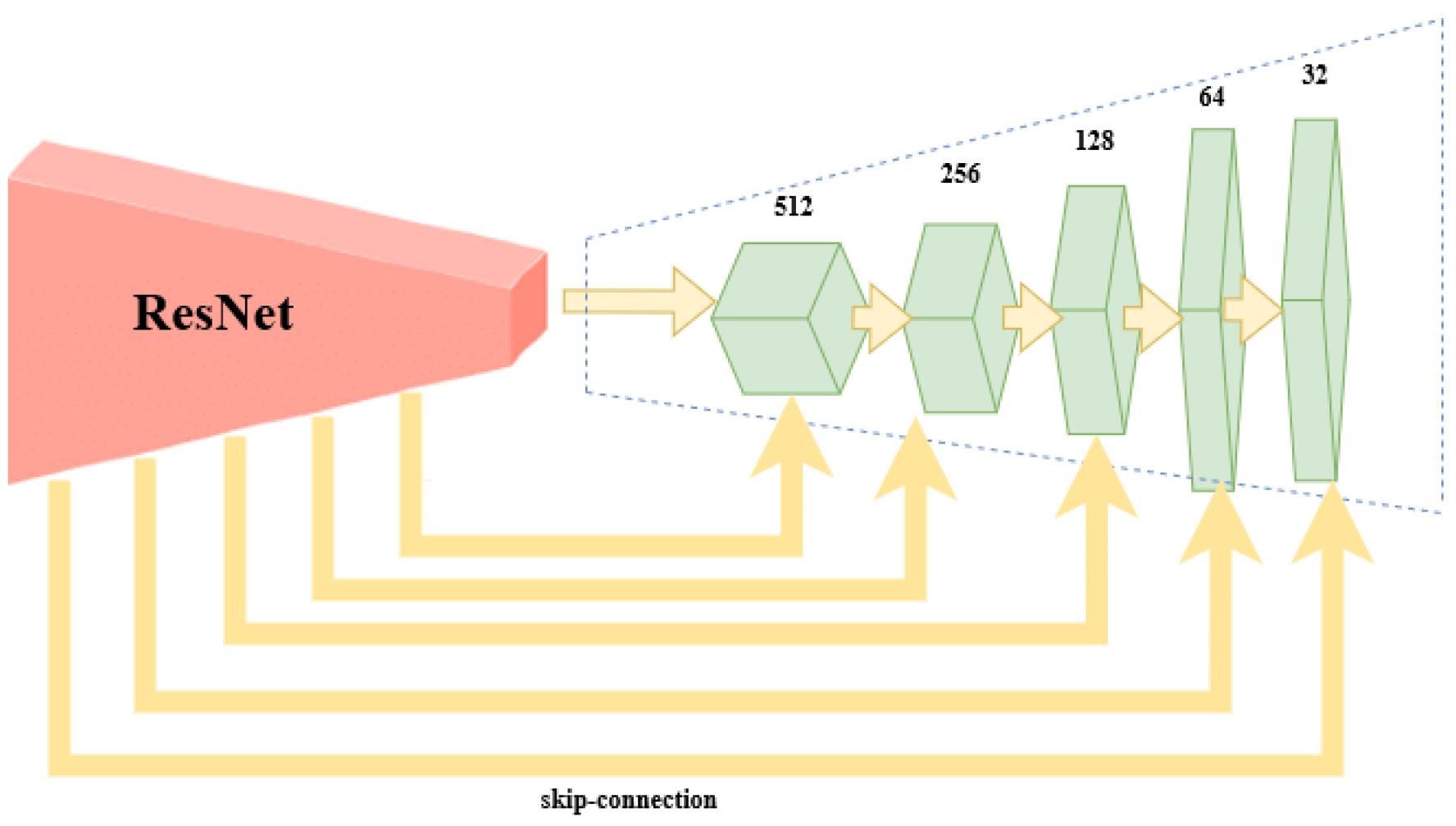
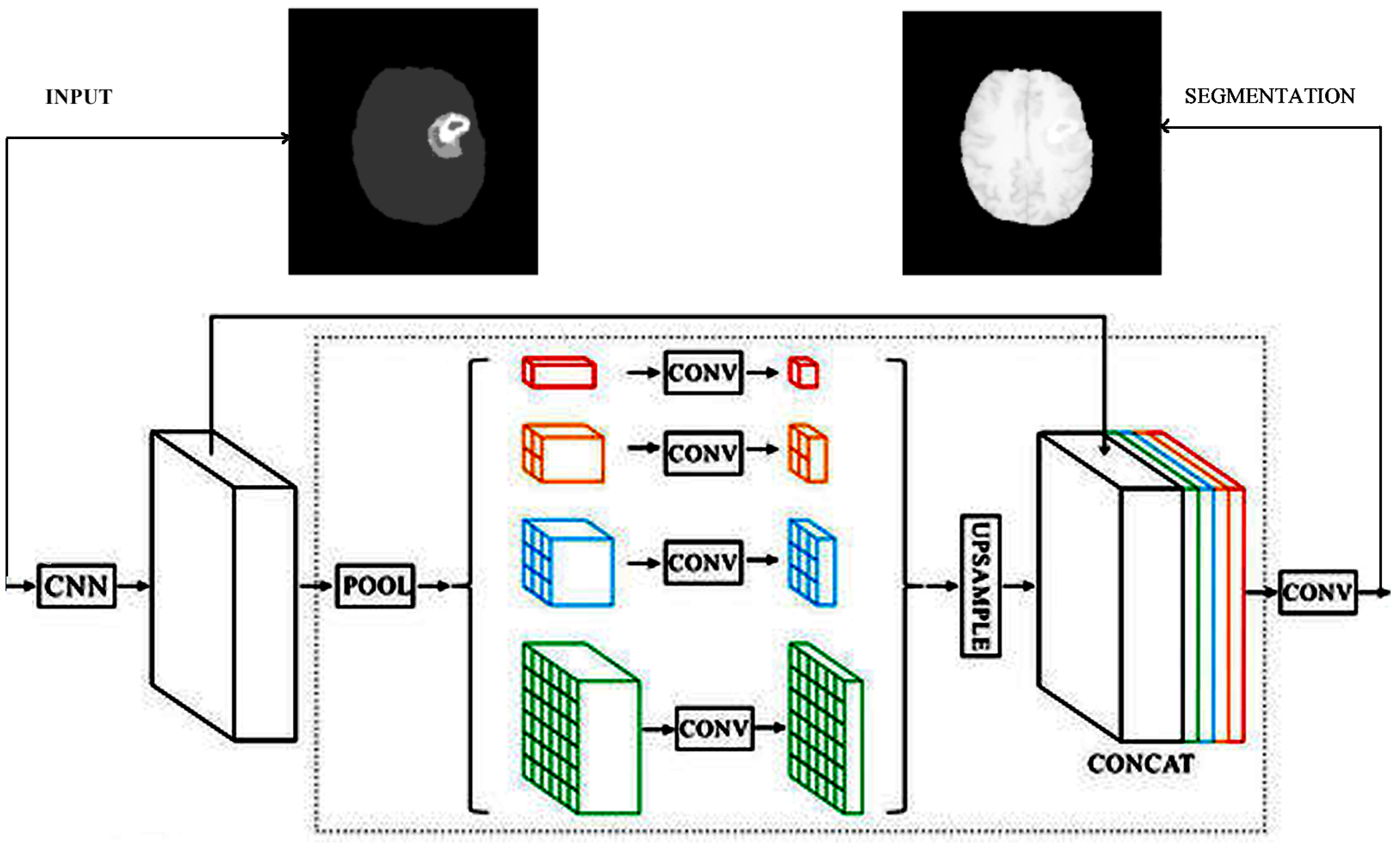
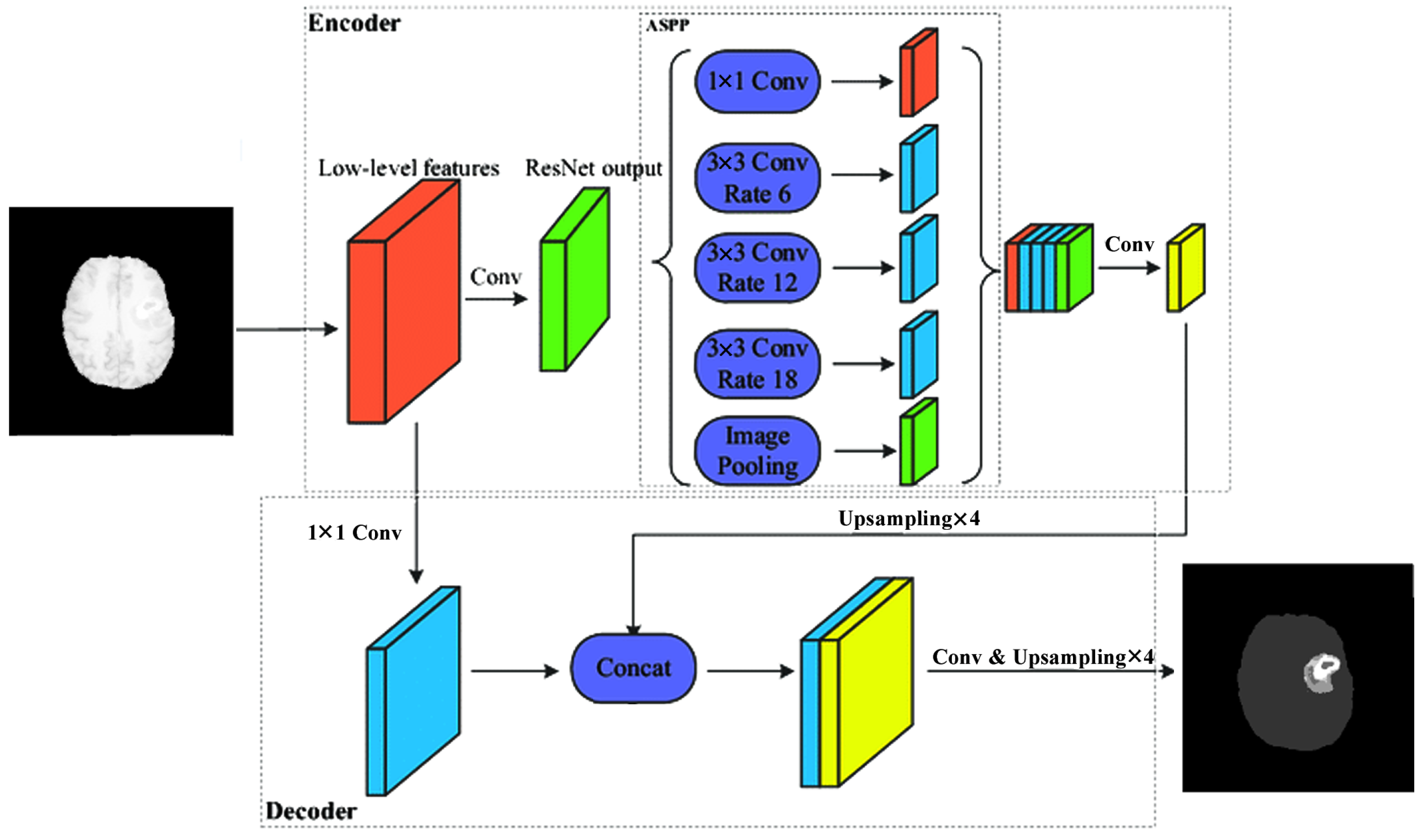
The encoder is the well-known ResNet50 or ResNet101 CNN initialized with pretrained weights of the ImageNet. The preloaded ImageNet weights can detect 1000 different objects from the ImageNet Challenge and are usually a good starting point for further training. The decoder is the up-sampling part of the smallest feature map obtained during encoding. The FCN up-sampling module is a three-layered upconvolution until the original dimension is reached again (
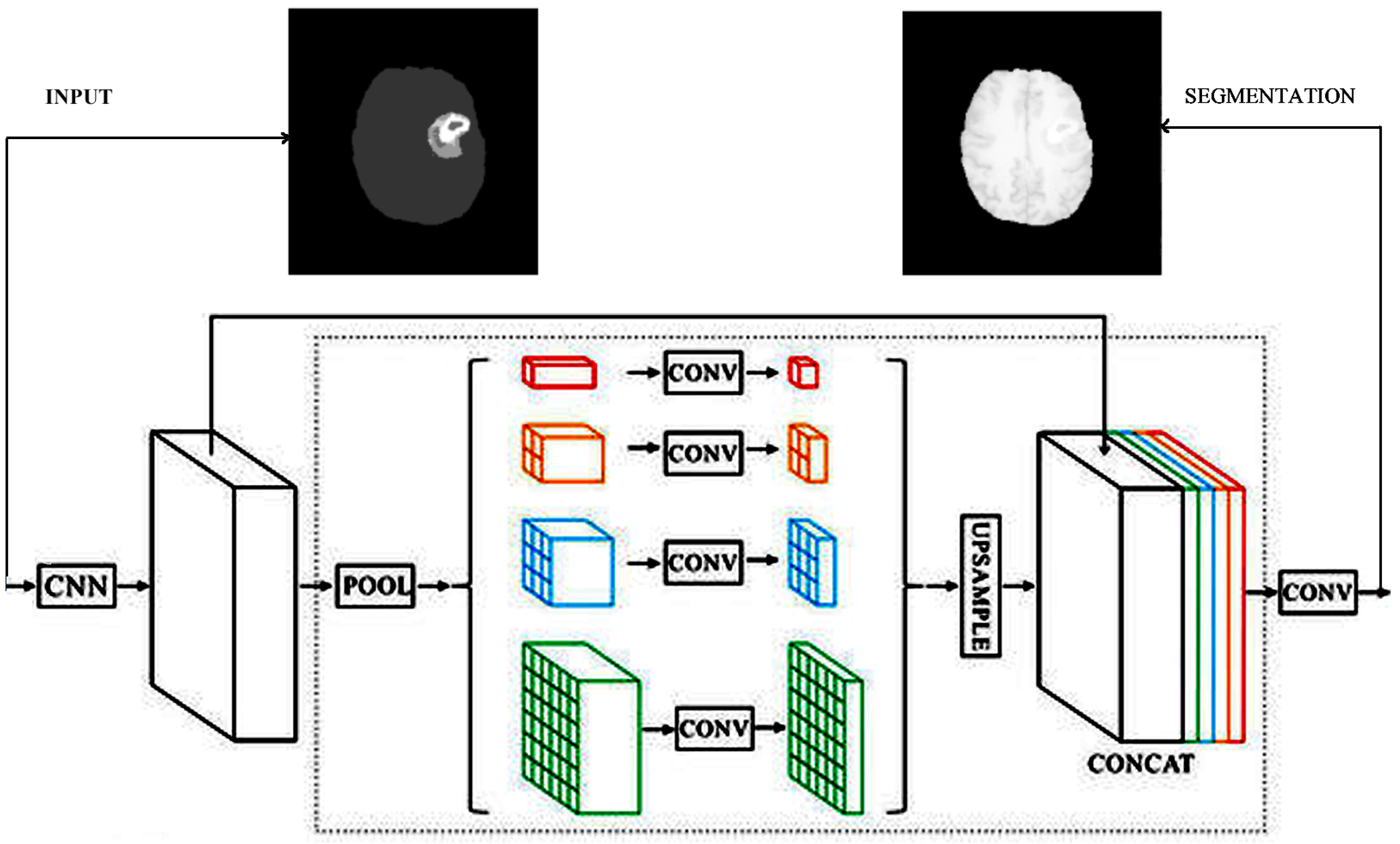
Figure 1). The next deconvolution architecture adapted for our task of brain tumor segmentation was the PSP architecture via the combination of feature maps of sub-blocks (
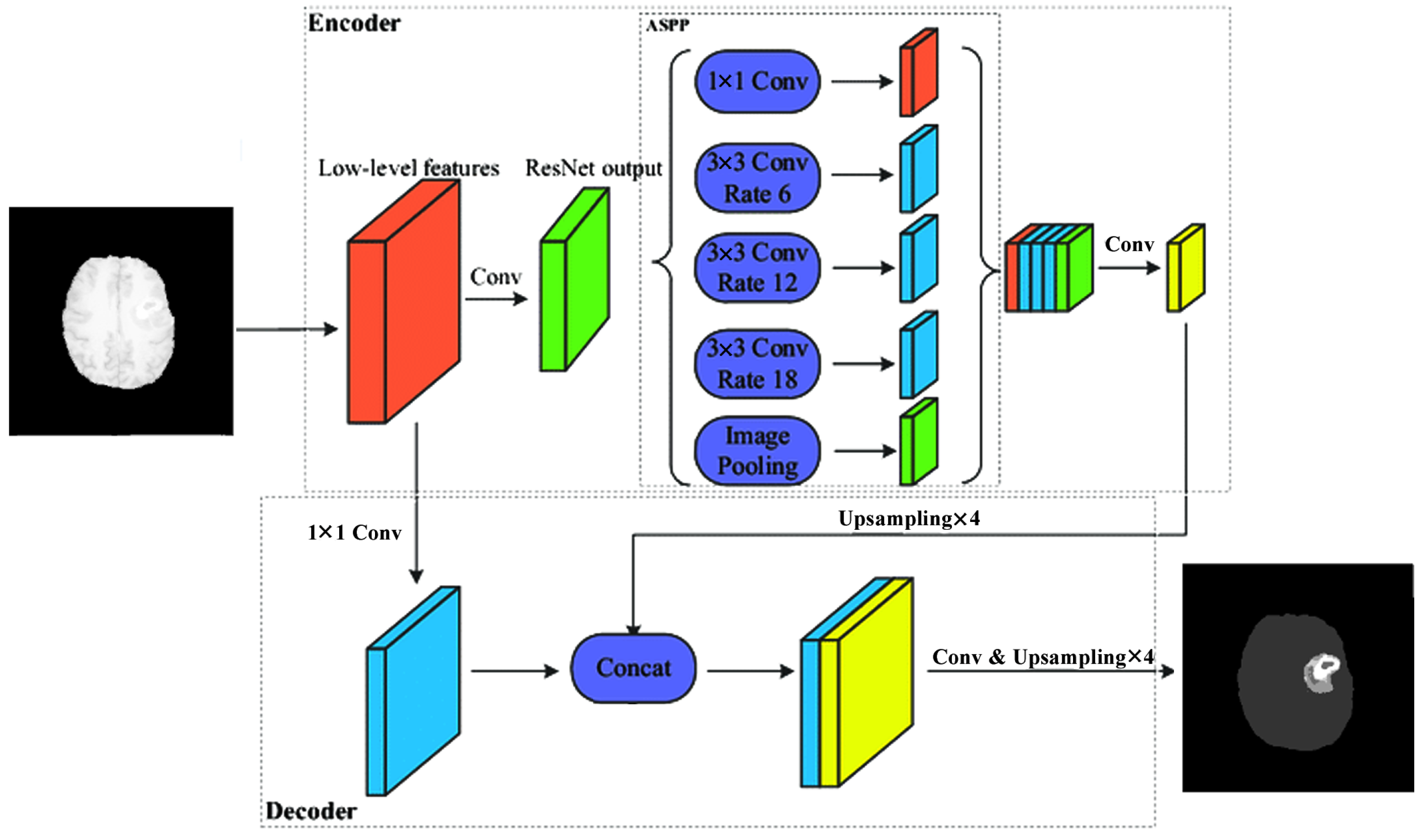
Figure 3). The third version of upconvolution is the DeepLab3+ decoder variant combining multi-scale feature maps by applying atrous convolution.
Using this method, six different CNN architectures were implemented and adapted for brain tumor segmentation. For all 6 architectures, the number of classes was 5, crop size was
pixels, the number of maximal epochs was 100, and the learning rate was 0.001. We used a polynomial learning rate scheduler with a scheduler factor of 0.1. The optimization method was SGD using a momentum value of 0.9 and an early stopping patience of four epochs. During the training process, we used the advantages of transfer learning. Transfer learning is a technique in machine learning that relies on knowledge obtained from one task applied to another task. Transfer learning in the case of CNNs can be used if the network architecture of the original and current networks is the same until a given layer. The weights to that point can be loaded from the CNN, trained in other purposes, into the current network. Thus, the training process starts considering those initial weights. In our case, the ImageNet weights were the initial weights. The ImageNet Challenge [
51] differentiates 1000 usual objects, but has nothing to do with medical image segmentation. Due to applying the transfer learning technique, we were able to obtain better results with a smaller number of epochs than training the system without this technique.
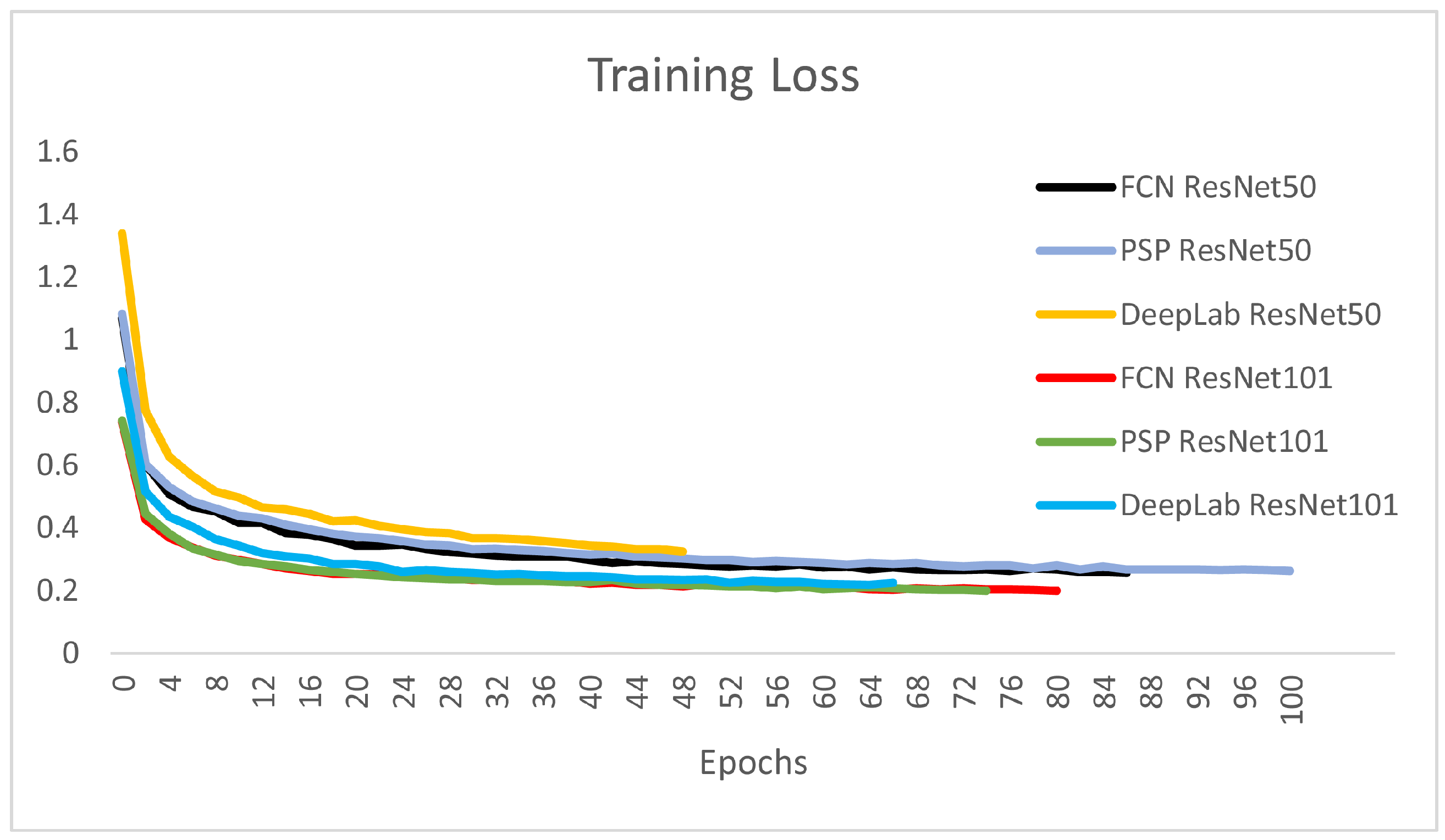
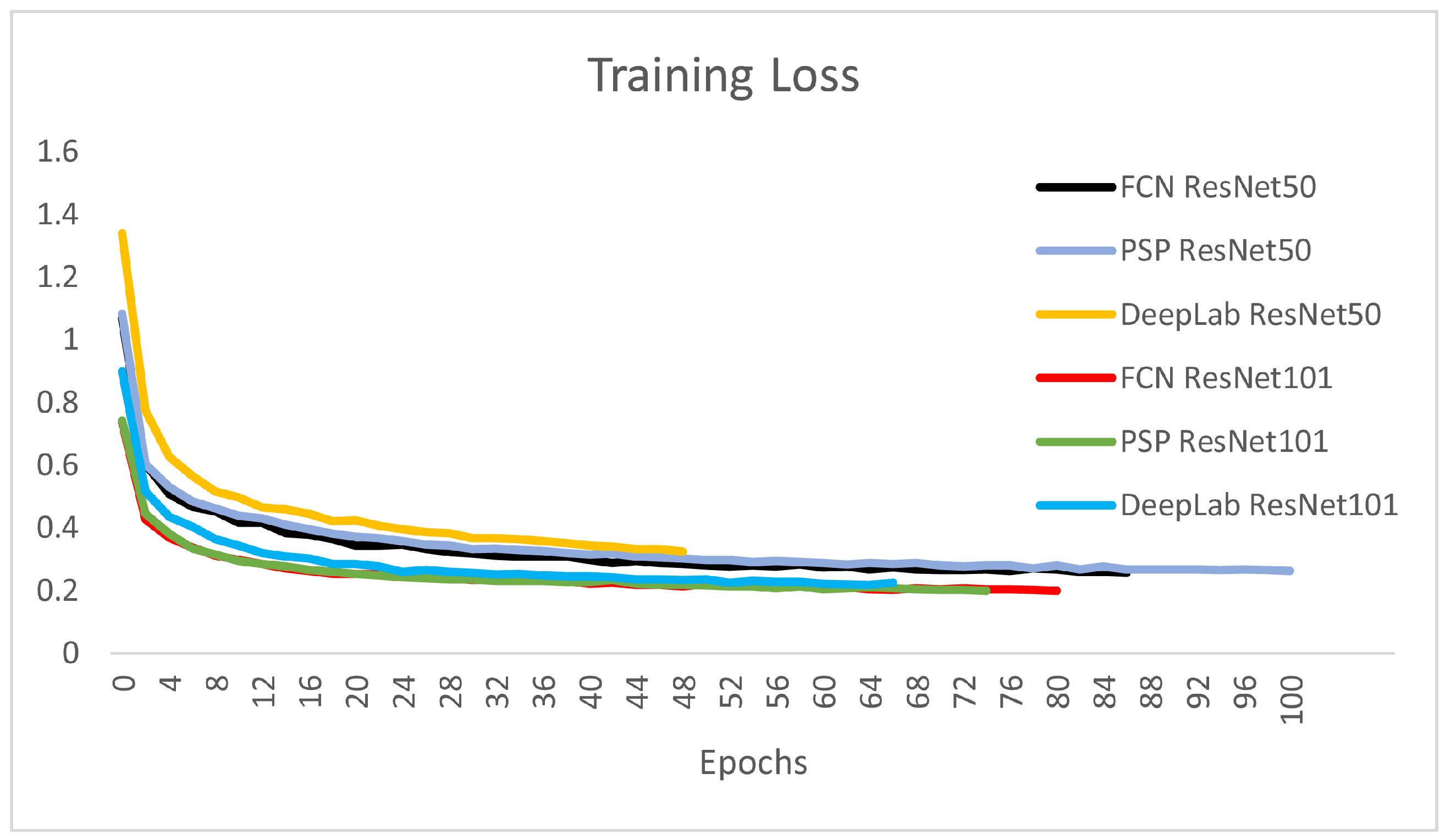
Figure 8 depicts the training loss over the progress of epochs for the six CNNs presented. It is obvious that the larger encoder architectures using ResNet101 are steeper and converge slightly faster in the training process.
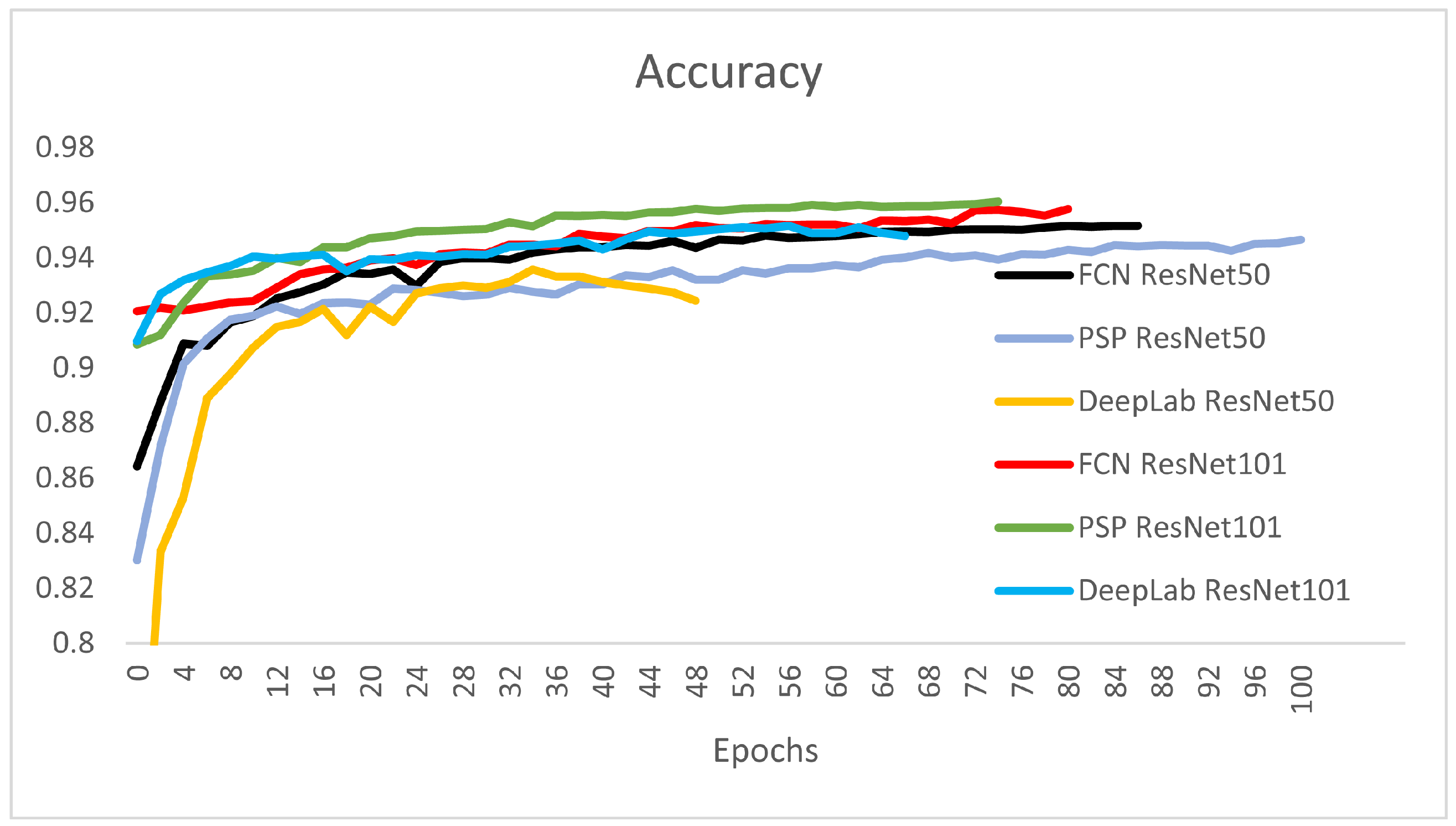
Figure 9 and
Table 1 show the overall validation accuracy for the networks presented. From the perspective of the validation accuracy for all classes, the PSP-ResNet101 is the best, followed by FCN-ResNet101 and DeepLab-ResNet101. The overall validation accuracy is measured on the validation set and is obtained as the mean accuracy (Equation (
2)) over all four classes.
It can be observed that the DeepLab-ResNet50 was stopped at epoch 49 because it had the highest training loss and lowest validation accuracy from all the six architectures.The best architecture from the perspective of overall accuracy are the DeepLab-ResNet101, PSP-ResNet101, FCN-ResNet101, and FCN-ResNet50. The stopping condition of the final epoch was set by considering the stopping patience of four epochs with non-decreasing training loss, and the stopping tolerance was set to 0.001. This was the reason for different stopping epochs of the networks (
Table 1).
The quantitative evaluation of different architectures was conducted by computing the Dice score on the test set. The Sørensen–Dice score measures the similarity of two samples; in our case, the similarity between the ground truth (GT) and the segmentations obtained (predicted segmentations). It is twice the overlap area over the cardinality of both sets (Equation (
3)). In the case of binary segmentation, it can be expressed by the 2 × TPR (true positive rate) over the total number of pixels: 2 × TPR + FPR (false positive rate) + FNR (false negative rate).
In the case of multi-class classification, the Dice score is computed considering class i and class for all other pixels.
In the training process of the six different networks, we used the mIOU (Equation (
9)) as the loss function of the optimization algorithm. The mean intersection over reunion is a region-based loss function, also called the Jaccard loss. The Jaccard loss and the Dice loss [
52] are very similar losses, and they can be alternatively used in segmentation tasks.
The Tversky Distance [
53] is a generalization of the Dice loss that considers the true positive pixels over a weighted sum of true positives and false positives and false negatives.
We have considered this type of loss too, but it can improve the training loss if it is considered on binary segmentation cases. In our case, the coefficients weighting the FP and FN in the nominator have to be setup separately form one class to the other. This can be completed if the five-class segmentation is divided into four times applied binary segmentation (Background-Healthy; Healthy-Whole Tumor; Edema-Tumor Core; Enhanced Tumor-Necrosis/Non-Enhanced Tumor). This multiple binary classification pipeline will surely bring considerable improvement because the class imbalance is eliminated and, the loss is computed not based on a mean loss of all the classes, but considering the two relevant classes at each binary classification phase.
In
Table 2, we measured the Dice scores for background voxels, healthy voxels, and the Whole Tumor (classes 2/4 + 3 + 5). The detection of background and healthy voxels is as expected. Background Dice is between 99.29 and 99.7%, and for healthy voxels, the Dice is between 95.99 and 97.46%. The detection of tumor voxels is about 90% (88.89–90.66%), which is a good result compared to the BraTS Challenge WT (Whole Tumor) average of 82.74%. The average WT Dice score of the BraTS Challenge is based on the validation table results, namely, the Validation Leaderboard [
14]. The best result on the leaderboard had a Dice coefficient of 92.45%, and 80 participants out of a total of 291 are above 90%.
Table 3 shows the results of the six different architectures on the three types of tumor tissue: edema (ED), active tumor (AT), and necrotic and non-enhanced tumor (NEC/NET). Both the edema and active tumor were about 70%. The worst results of 38–47% were obtained on the NEC/NET tissue type. In
Table 1 and
Table 2, ResNet101 is slightly better than the ResNet50 architecture. The best results were obtained by DeepLab-ResNet101 for AT (73.7%) and NEC/NET (47.63%) and PSP-ResNet101 for ED (75.21%).
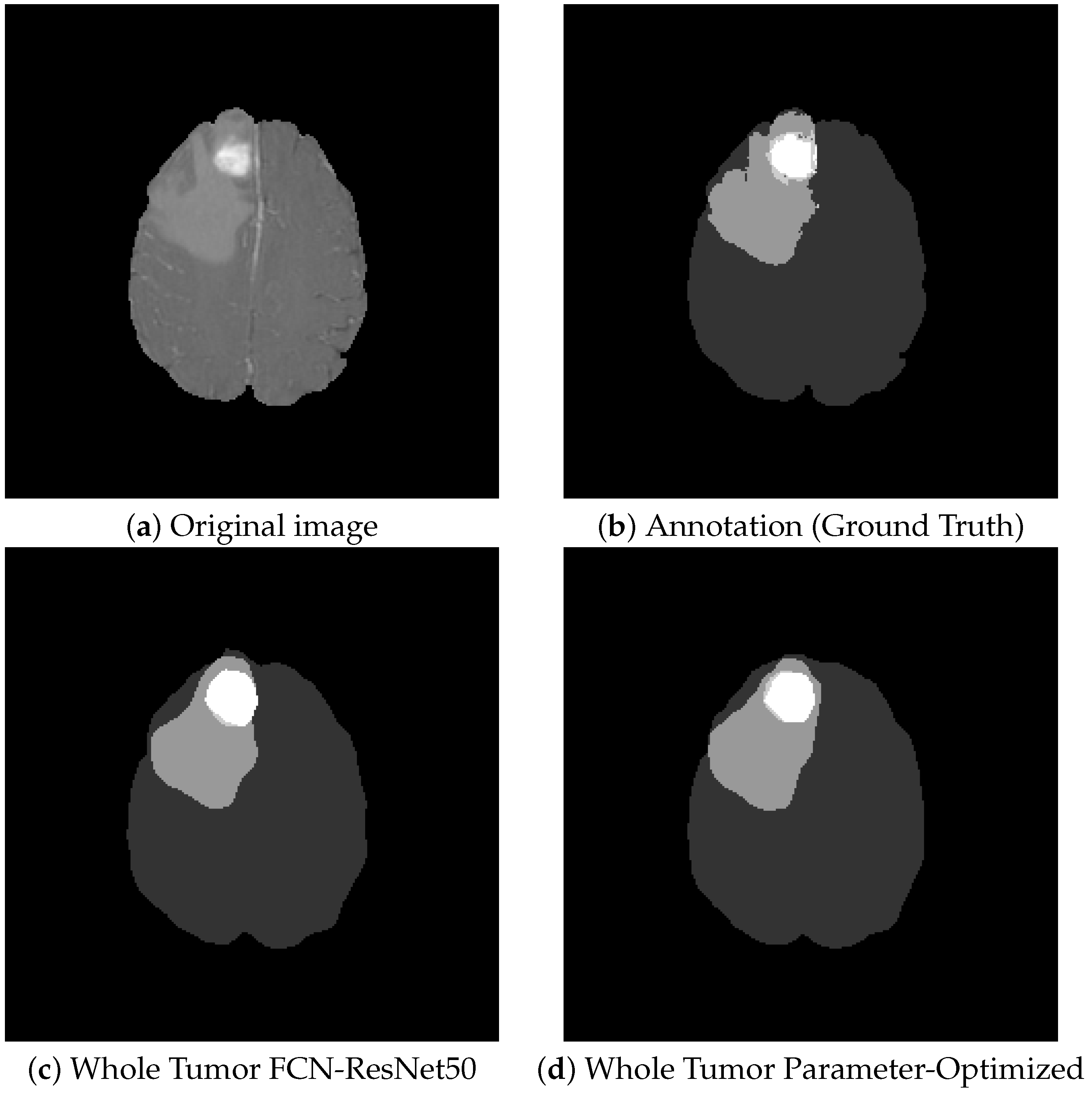
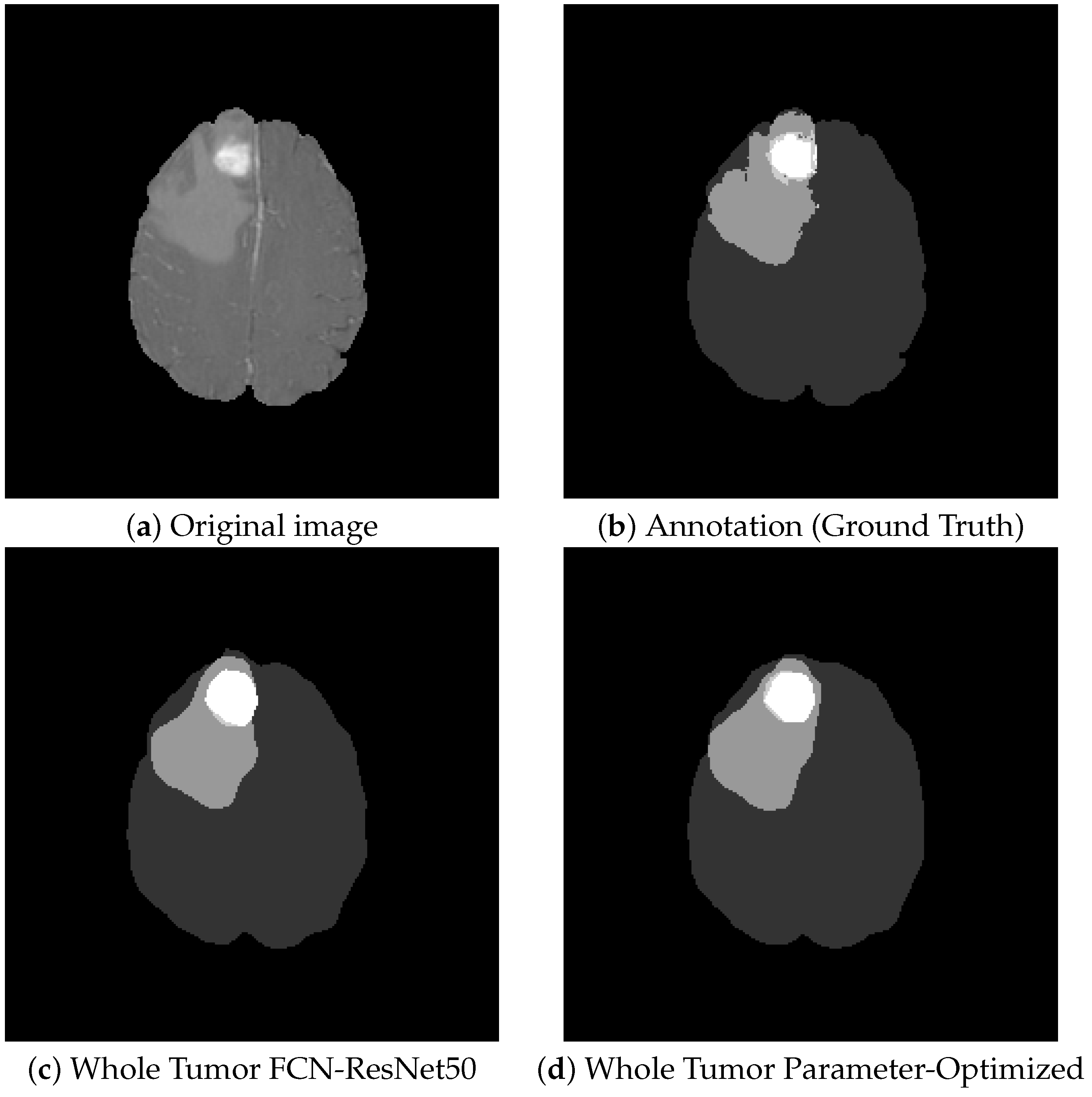
Figure 10 shows some segmentation results for the visual comparison of different tumor types and the six architectures studied. On average, this barely visible difference is around 1–2%. There is no quantitative evidence clearly showing that one architecture is better than all the others. In different images, the other architecture outstrips the rest. This led to the idea of combining them into an ensemble model.
The second group of experiments was related to hyperparameter optimization to possibly extract the best architecture from it.
The training jobs and hyperparameter optimization setup that had to be defined in the Amazon SageMaker framework were related to the six types of CNN networks, their hyperparameters, and the input database type. The data were provided in pipe mode stored in an S3-bucket. These data were accessed via an AugmentedManifestFile containing the path to every image and to every corresponding annotation file along with the training job name and other metadata. The validation and test data were provided in the same way. The hyperparameter tuning job was run on an ml.p3.2xlarge system on three instances. Every instance was set to run a maximum of five parallel training jobs. The maximum duration per training job was set to 48 h.
SageMaker hyperparameter tuning uses Grid Search and Bayesian Search [
54] to obtain the best set of parameters. The tuning algorithm for SageMaker performs guesses as to which sets of hyperparameters are likely to achieve better results and runs the training jobs with those parameters.
The training job is abandoned before the preset number of epochs if another training job had better results regarding the objective metric in the same iteration. The objective metric was the mIOU (mean intersection over reunion). IOU computes the intersection over reunion between the predicted segmentation and the ground truth for every image (Equation (
7)). The meanIOU computes the average value of IOU for every image (Equation (
8)) over each class
Equation (
9).
This metric is the same as the Jaccard index (Equation (
10)).The Jaccard index can be expressed not only by the IOU but also as a fraction of TPR over TPR + FPR + FNR.
The optimization parameters [
55] that had to be set up to give reasonable and quite restricted intervals for them were the optimization function, learning rate, weight decay, momentum, and minibatch-size.
Firstly, we set the mini-batch size between 16 and 64. The optimization functions added in the optimization process were MB-SGD, SGD with momentum, AdaDelta, and Adagrad. SGD for mini-batches takes the gradient step for a mini-batch with a regularization term called weight decay (=0.0001) multiplied by the weight and added to the gradient. SGD with momentum reduces the fluctuation towards the optimal value by adding the momentum term. AdaGrad (Adapted Gradient Descent) modifies the learning rate in each iteration biased towards the past gradient of that parameter. Instead of the past gradient in AdaGrad, AdaDelta modifies the learning rate by the average over the past squared gradients of a weight.
The learning rate scheduler controls the decrease in the initial learning rate over time over the progress of the epochs. The learning rate is multiplied by a factor of 0.1 after a given number of epochs (=10). The early stopping algorithm stops a training job if certain stopping conditions are met. The minimum number of epochs was set to 5, early stopping patience was 4, and early stopping tolerance was 0.001.
Hyperparameter optimization was conducted for only one architecture of the six studied, namely, FCN-ResNet50. The best parameters obtained via hyperparameter optimization were minibatch-size = 18, learning rate = 0.0009, weight decay = 0.0114, momentum = 0.803, and the AdaGrad optimization method. Several training jobs with different parameter setups stopped before the end of the job, recognizing at a very early epoch that their process involving the optimization metric is smaller than the best thus far. The validation mIOU for the best hyperparameter setup was 0.7732. This mIOU is a value similar to the one obtained for the first variant of FCN-ResNet50 without hyperparameter optimization (mIOU = 0.7649).
We note that the hyperparameter optimization procedure provided by the SageMaker framework did not lead to considerably better results for the following reasons: 42 different parameter sets were tried, and out of these, only about 10 ran until the end, namely, 100 epochs, for about 48 h per training job of the 10 runs (200 h in total). In these 42 jobs, the batch size, learning rate, weight-decay, and momentum parameters were selected according to a random grid search. Out of the optimization functions, only AdaGrad and SGD were selected. The Sagemaker hyperparameter optimization process slightly modified the numerical parameters for each run of a different training job. The only parameter that was modified considerably on a logarithmic scale was the learning rate. The enormous resource requirements coupled with the small improvement achieved made us decide against running the hyperparameter optimization on the five other architectures studied.
From
Table 4 and
Table 5, we can see that the FCN with parameter optimization led to a barely observable Dice score improvement of 0.8% on average for all classes.
Figure 11 shows a visual comparison of tumor tissue segmentation with and without hyperparameter optimization on the FCN-ResNet50 architecture. On average, there is an improvement of only about 1% to the detriment of the enormous computational complexity.
The last group of experiments that were carried out was related to the combination of all six segmentation models in an attempt to obtain a so-called ensemble model from them. We obtained weighted segmentation maps from all six individual classifiers presented above.
Comparing
Table 2,
Table 4, and
Table 6, we can draw the following conclusions: The Dice score for the Whole Tumor is reduced by approximately 2–3% compared to the best method out of the six. On the other hand, the Dice scores for different tumor tissues of the ensemble model are better by about 4–10% (
Table 3,
Table 5 and
Table 7). This is a considerable improvement.
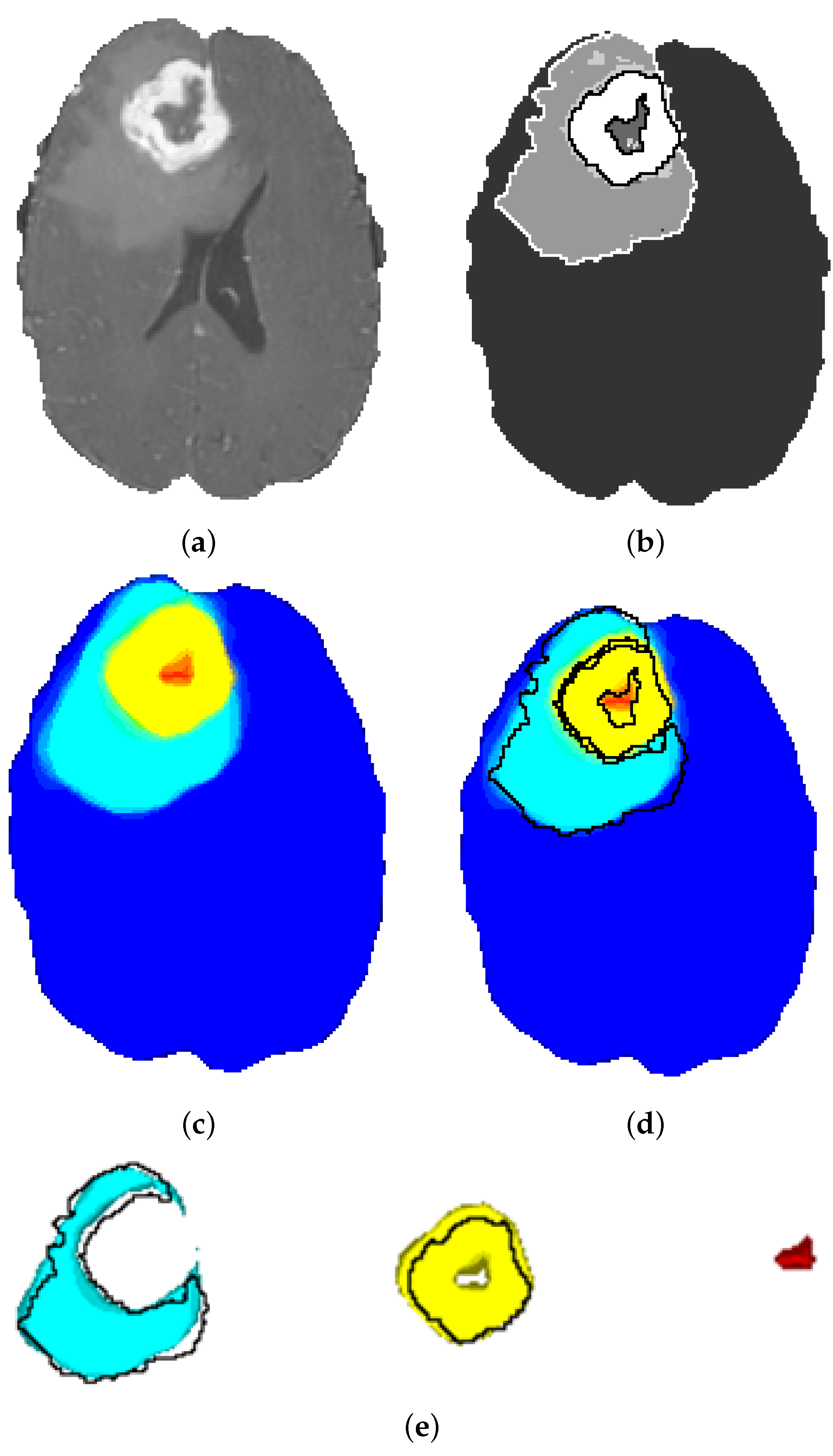
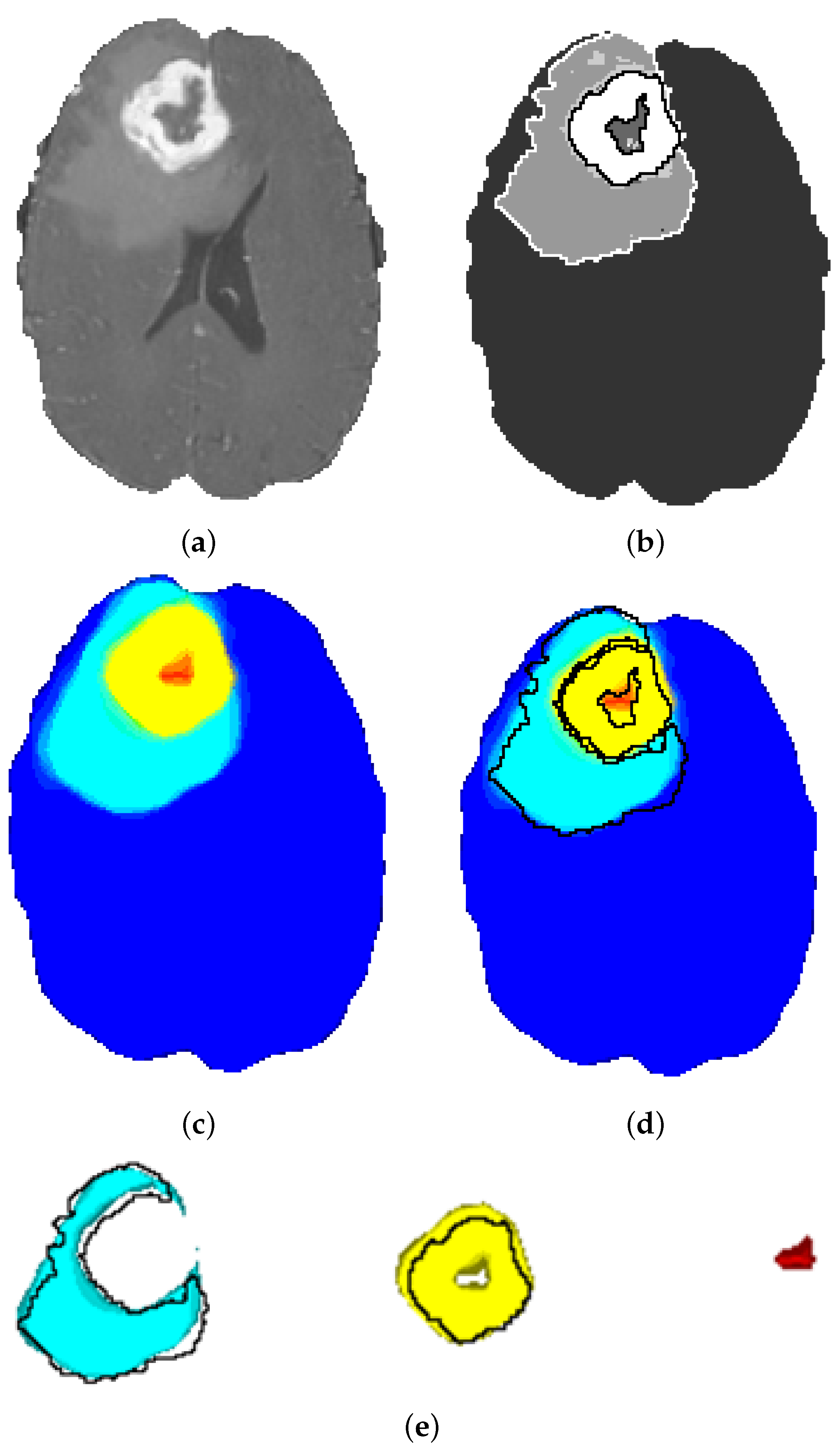
The segmentation maps obtained by the ensemble model are depicted in
Figure 12. It is obvious that the tissue contours and transitions from one tissue to the other are gradually colored from turquoise to yellow, and there is a slight green ring at the transition. This shows that the ensemble model obtains a probability map and does not make a final decision favoring any class for uncertain tissue voxels on the contour. These voxels are, in fact, the hard examples and are not clearly classifiable. The probabilistic heatmap of the ensemble model solves this problem through probabilistic voting.
Overall, we propose the sequential application of the best DeepLabv3 model or the parameter-optimized FCN ResNet50 for obtaining the tumoral region, and after that, finetuning the results by obtaining the different tumor tissues through the use of the ensemble model. Finally, to highlight our results, we compare them to the best results from the BraTS Challenge 2020, published in 2021.
All our experiments were conducted on the p3.2xlarge AWS EC2 instance. That is a Tesla V100 GPU with 16 GB memory. By running only on Spot instances instead of on-demand usage, we could carry out our experiments on a very low cost of USD 200–300.
The most important advantage of our model is the relatively low number of epochs (80–100) each CNN is trained for. Overall, the training process lasted under 12 h for each of the presented models (
Table 8). The more complex networks that achieve better results have to be trained much more, even 4–5 days on multiple GPUs with larger computational capacity and memory [
39].
As can be seen, our results are comparable with the competition performances between 2017 and 2020. Our goal with this article was to create simple models available in the AWS Sagemaker that can be easily combined into an ensemble model with good performances. The Dice score of the tumor core is 0.8599 for our ensemble model, which is comparable to the best results. The goal in our research was not to obtain the best results but to create a rapidly trainable system that can be applied for other types of medical image segmentation in a similar way. The performances of such a system can be considered quite competitive. The Dice score differences of 1–5% out of the tumor tissue volume of every type comes from the slightly inaccurate contour detection. A contour delimitation displaced with a single voxel considerably influences the Dice score results, especially on small tumors of a few voxels. The exact contours are always re-evaluated by the neurosurgeons during preoperative planning before a gross-total resection.
4. Discussion
In the BraTS Challenge, the tumor tissue types are grouped into different tumor regions. The NEC/NET results are not considered separately. The Leaderboard results show the Enhancing Tumor (ET = class 5), the Whole Tumor (WT = classes 2/4 + 3 + 5), and Tumor Core (2/4 + 5 = NEC/NET + AT). The Leaderboard of the BraTS competition shows the results of the various participating teams, measuring the Dice scores on the so-called validation dataset. At the BraTS 2020 competition, there were 292 teams present on the Leaderboard.
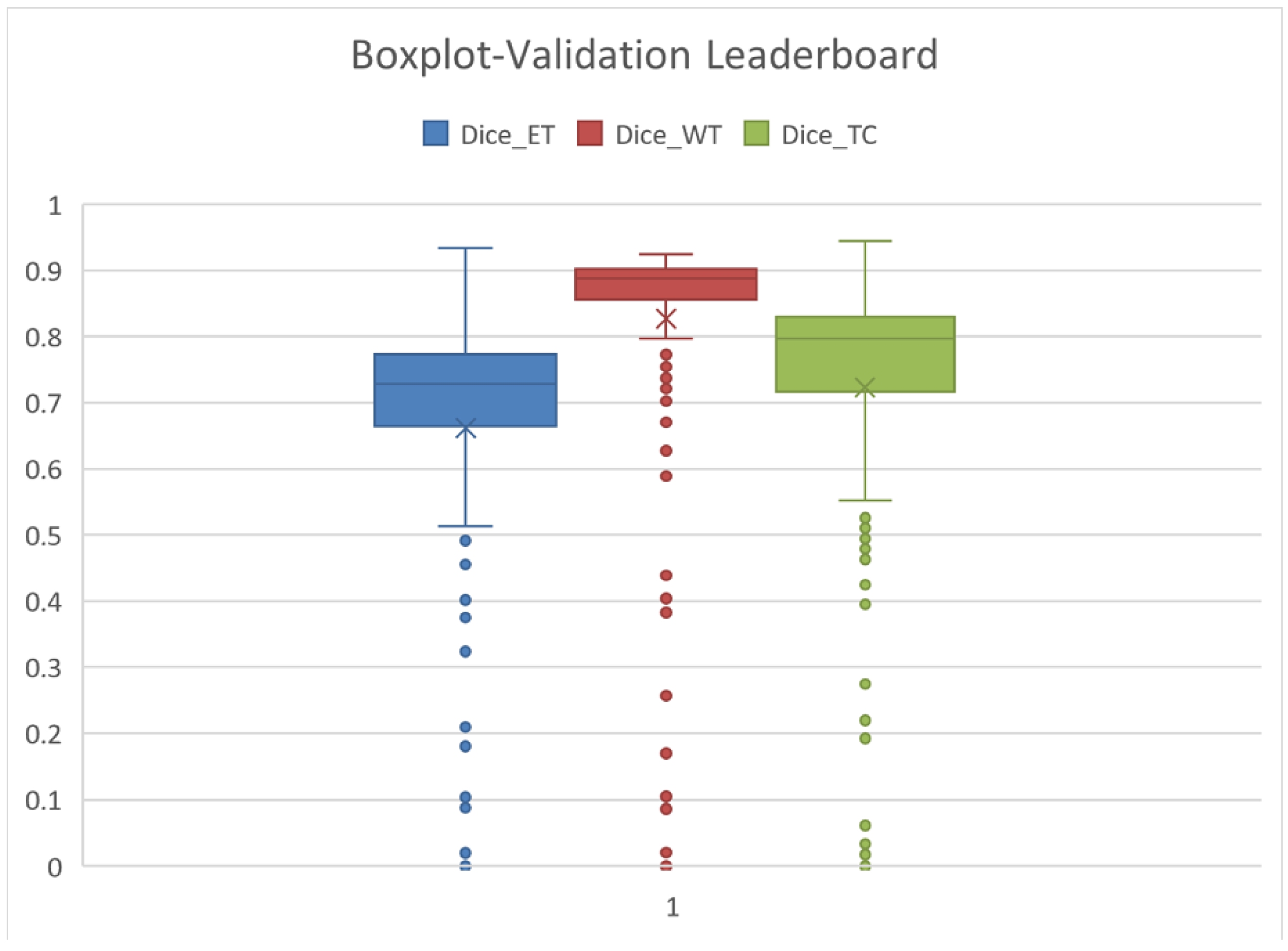
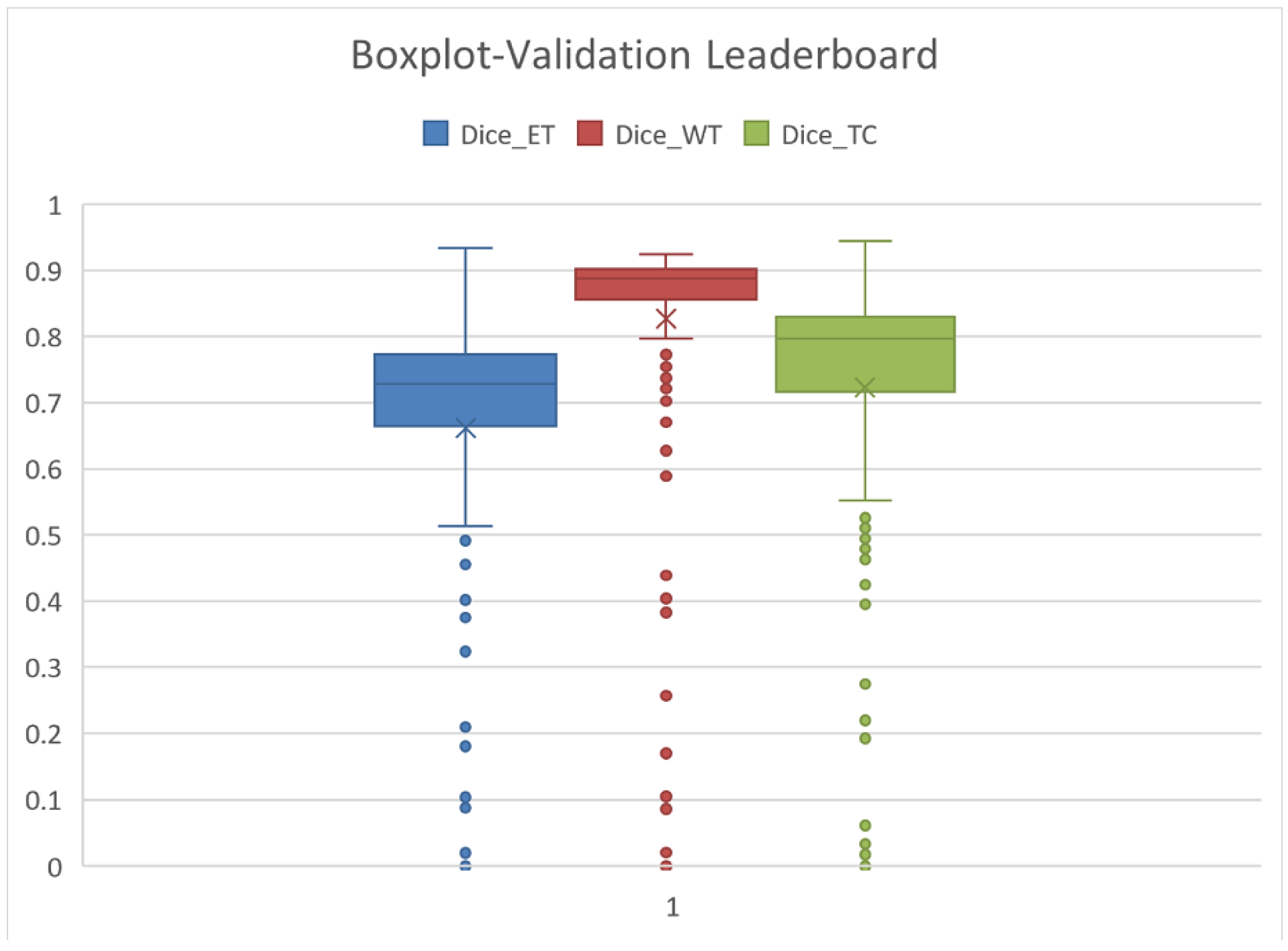
The statistics related to the average results are detailed in
Table 9 and
Figure 13. The average is marked by X, the median is the center-line, and the Q1 and Q3 values are the lower and upper margins of the box.
The mean and Q3–75% quartiles are relevant from our perspective. Our results regarding ET, WT, and TC, as presented in
Table 10, are far better than the average of the Leaderboard and are comparable to the Q3 quartile results. This means that our results are among the first 25% of the Leaderboard.
We compare our results obtained on the test set, which is 20% taken separately from the BraTS dataset. The Leaderboard results are measured on a validation dataset not publicly available. If we consider both datasets being sufficiently general, the results are comparable.
Table 10 presents our results from the six different architectures and the BraTS tumor regions. The three tumor regions are ET (Enhanced Tumor), Whole Tumor (WT), and TC (Tumor Core). The best Dice scores we obtained are about 90% for WT, 84% for TC, and 78% for ET.
The best results obtained in the BraTS competition are presented in
Table 11. These are slightly worse than the Leaderboard maximums. The competition score is a result of a one-time experiment, making the progressive architecture adjustments impossible, whereas the leaderboard score is the best score achieved by a team. Therefore, the best results at competitions are 7–8% worse than the best results on the leaderboard.
Comparing the six different architectures (
Table 9) with the ensemble model, we can see a 2% decrease in the Dice score for WT but a 2% increase for ET and TC (
Table 12).
Overall, we obtained fairly good results that are comparable to the BraTS Leaderboard results. We suggest applying the best model for WT (DeepLab-ResNet101), and after that, finetuning the contour regions between different tumor tissues with the ensemble model.
However, our results are quite competitive, and they will be improved in several ways. We propose some aspects for future improvement and further development.
The quality and resolution of the images is not standardized. In the image augmentation stage, we normalize the images to a mean of 0 and a standard deviation of 1, but the inhomogeneity correction should also be applied before the training process.
Better results could be obtained if the five-class classification process were divided into four binary classification steps. First, the tumor should be delimited from the background (including healthy tissue). Next, the tumor types should be discovered according to the anatomical structure depicted in
Figure 5. Accordingly, the edema can be delimited next, followed by the tumor core, and the very last should be the delimitation of the necrotic tumor. This type of structure may be also discovered by wearing AR-based neuronavigators that have a crucial importance in preoperative planning and a simulation of surgical scenario [
56,
57]. Considering multiple binary classification steps and not a single five-class classification, the tumor types with a considerably smaller number of representative voxels in the database would be much better delimited. This issue can be eliminated through the random sampling of the initial images at a smaller given patch size, with the goal of including the same number of healthy and tumoral tissue pixels in the database. The most important bottleneck of the models obtained is the slightly inaccurate contour detection. The cause of these less-precise boundary detections is the multi-class classification and the class imbalance. This can be further corrected by introducing different architectures specifically trained for boundary detection.
As a post-processing step, we propose the verification of tumor structure connectedness. The tumor is a connected region without any holes or gaps. In addition, the anatomical structure of the tumor can be a posterior condition, knowing that some tissues should be inside others: necrotic tumor ⊆ tumor core ⊆ edema. The improvements suggested should furthermore improve the results obtained thus far.
The ensemble model based on the combined response of the six CNNs has similar results for the tumor core as the results presented in the BraTS Challenge (
Table 11 and
Table 12).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}