
You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection




Abstract
:1. Introduction
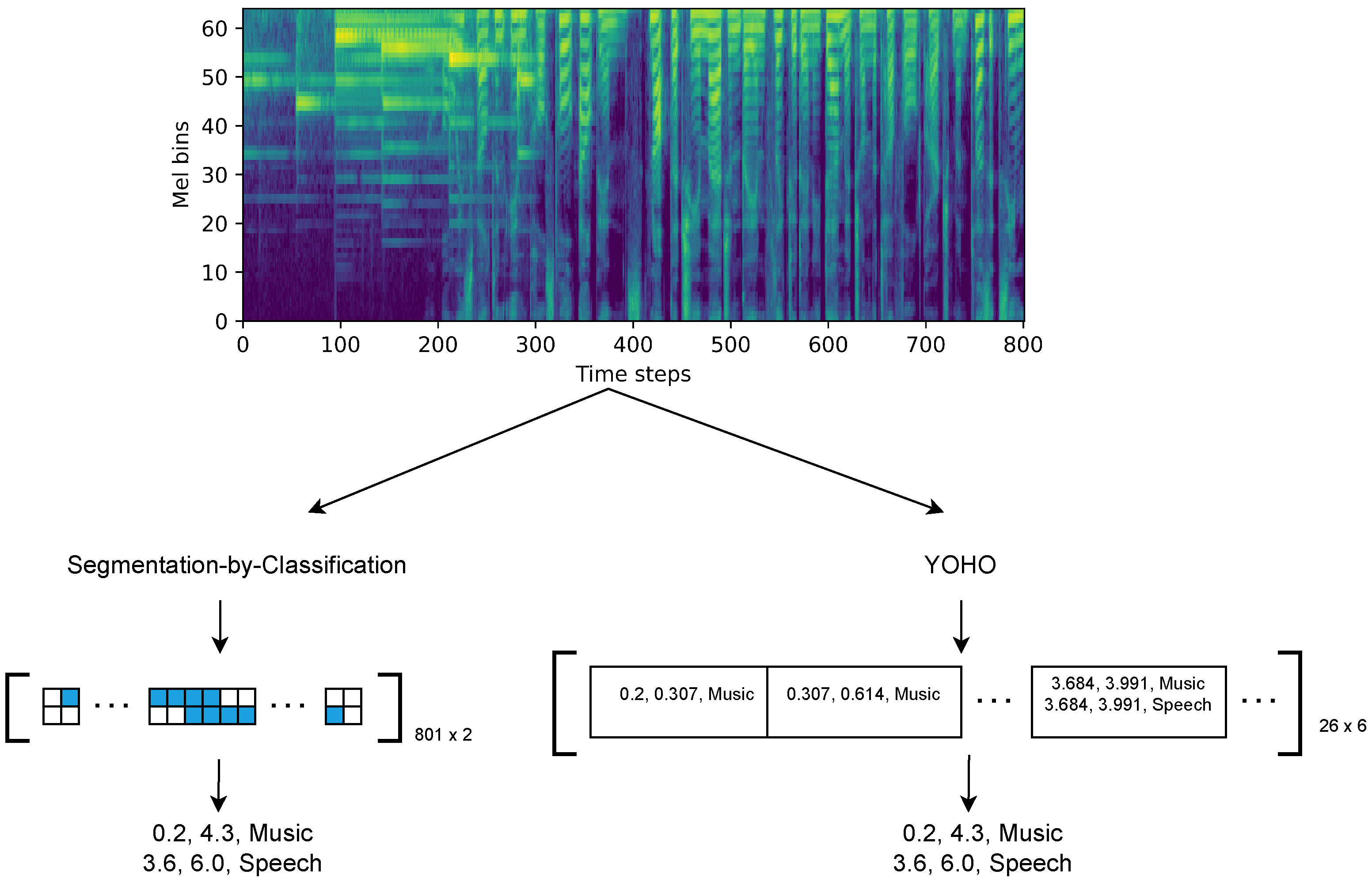
2. You Only Hear Once (YOHO)
2.1. Motivation
2.2. Network Architecture
2.3. Loss Function
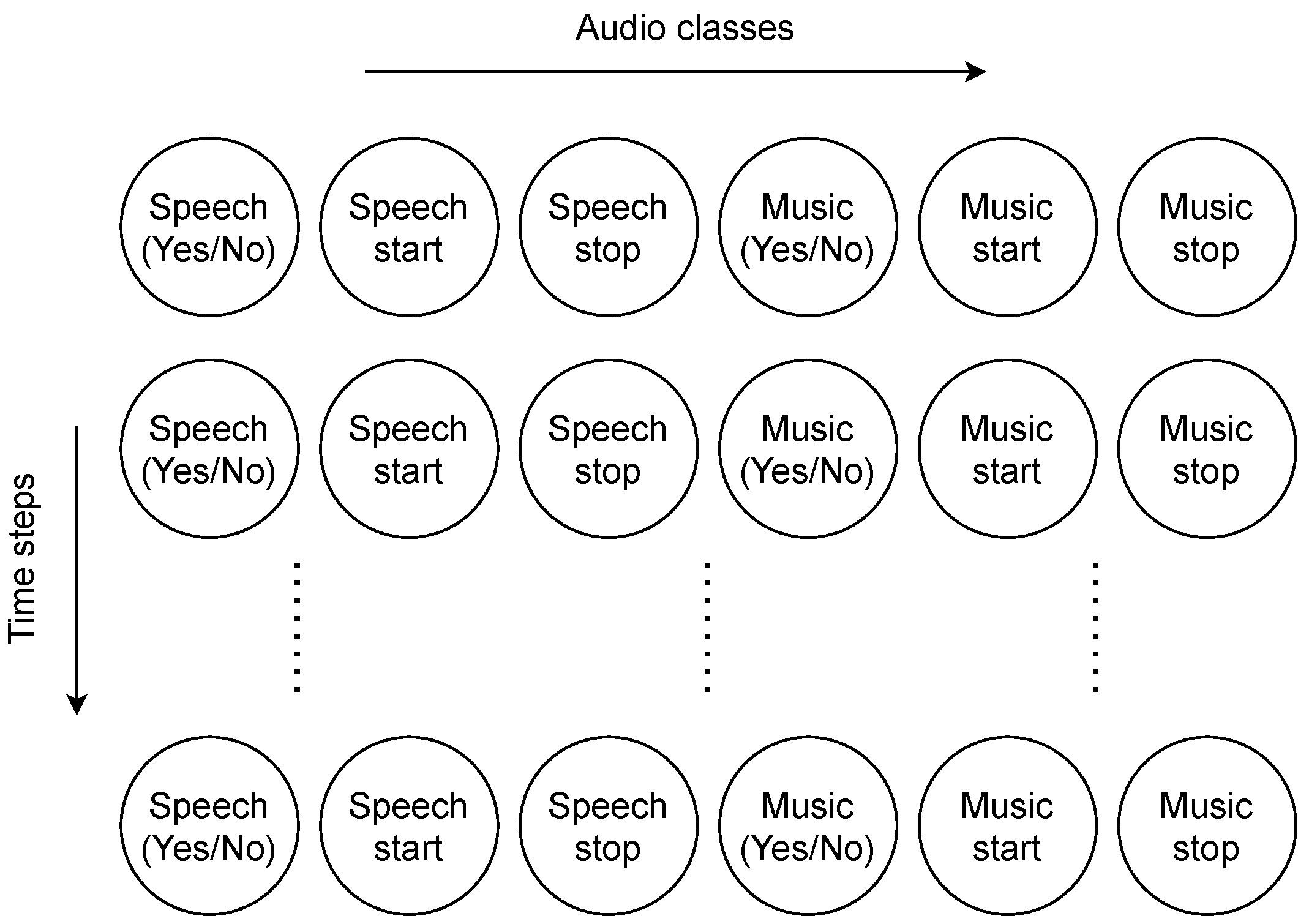
2.4. Example of Labels
2.5. Other Details
2.6. Post-Processing
2.7. Models for Comparison
3. Datasets
3.1. Music-Speech Detection
3.2. TUT Sound Event Detection
3.3. Urban-SED
4. Results
4.1. Music-Speech Detection
4.1.1. In-House Test Set
4.1.2. MIREX Music-Speech Detection
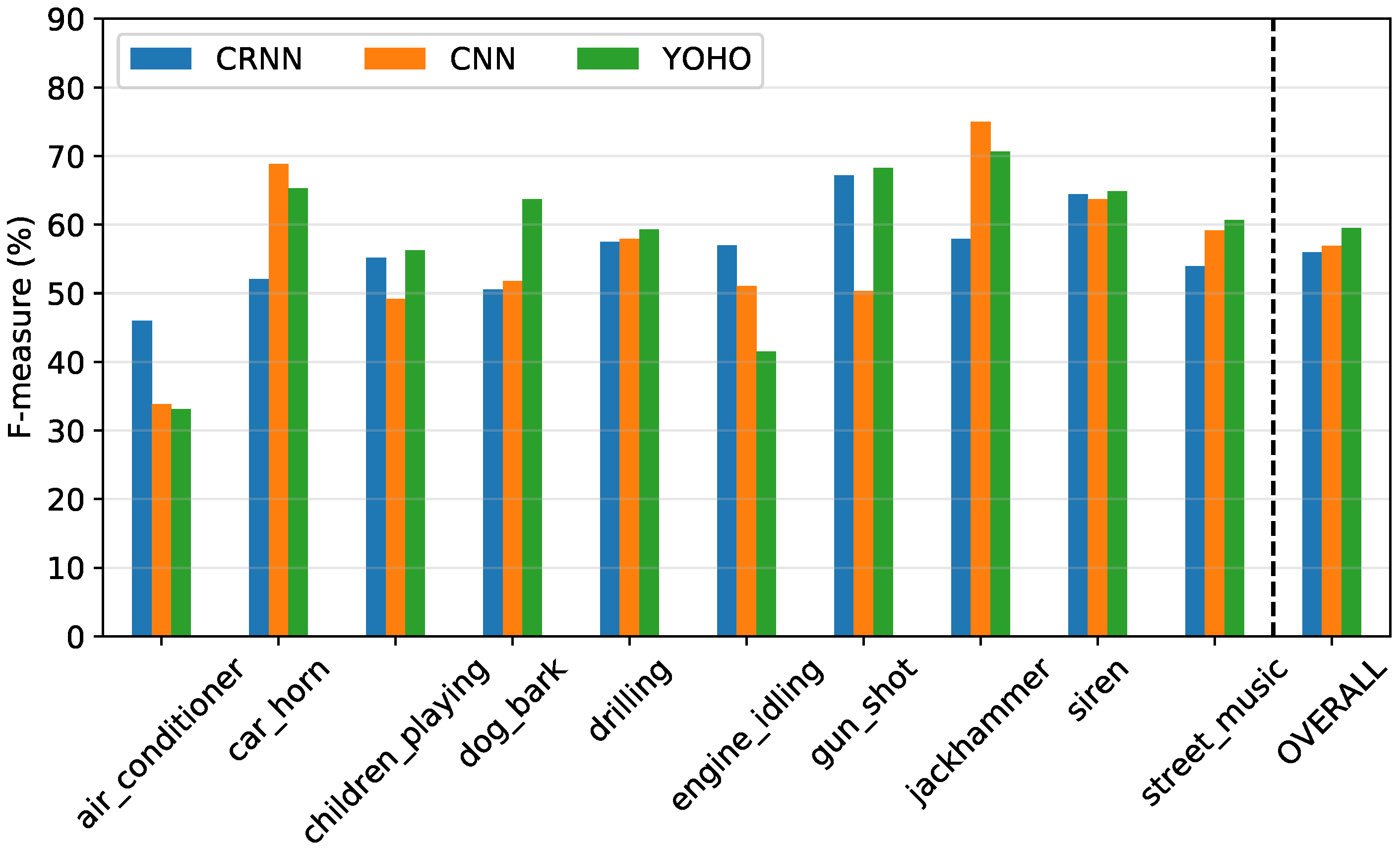
4.2. TUT Sound Event Detection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.3. Urban-SED
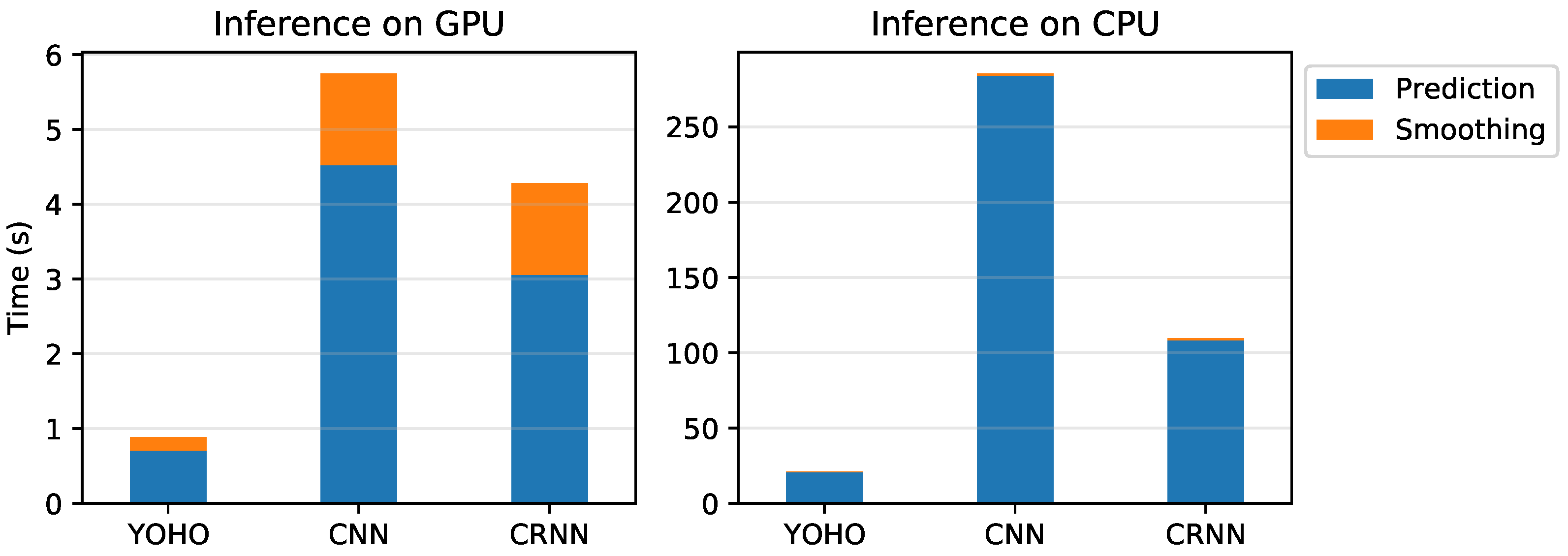
4.4. Speed of Prediction
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| B-GRU | Bidirectional Gated Recurrent Unit |
| B-LSTM | Bidirectional Long Short-Term Memory |
| BBC | British Broadcasting Corporation |
| CapsNet | Capsule Neural Network |
| CapsNet-RNN | Capsule Neural Network Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| CRNN | Convolutional Recurrent Neural Network |
| DCASE | Detection and Classification of Acoustic Scenes and Events |
| GPU | Graphical Processing Unit |
| MIREX | Music Information Retrieval Evaluation eXchange |
| MLP | Multi-Layer Perceptron |
| RAM | Random Access Memory |
| STFT | Short-Time Fourier Transform |
| Urban-SED | Urban Sound Event Detection |
| YOHO | You Only Hear Once |
| YOLO | You Only Look Once |
References
- Butko, T.; Nadeu, C. Audio segmentation of broadcast news in the Albayzin-2010 evaluation: Overview, results, and discussion. EURASIP J. Audio Speech Music Process. 2011, 2011, 1. [Google Scholar] [CrossRef] [Green Version]
- Elizalde, B.; Raja, B.; Vincent, E. Task 4: Large-Scale Weakly Supervised Sound Event Detection for Smart Cars. 2017. Available online: http://dcase.community/challenge2017/task-large-scale-sound-event-detection (accessed on 2 March 2022).
- Radhakrishnan, R.; Divakaran, A.; Smaragdis, A. Audio analysis for surveillance applications. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 16–19 October 2005; pp. 158–161. [Google Scholar]
- Salamon, J.; Bello, J.P.; Farnsworth, A.; Robbins, M.; Keen, S.; Klinck, H.; Kelling, S. Towards the automatic classification of avian flight calls for bioacoustic monitoring. PLoS ONE 2016, 11, e0166866. [Google Scholar]
- Ramirez, M.M.; Stoller, D.; Moffat, D. A Deep Learning Approach to Intelligent Drum Mixing with the Wave-U-Net. J. Audio Eng. Soc. 2021, 69, 142–151. [Google Scholar] [CrossRef]
- Theodorou, T.; Mporas, I.; Fakotakis, N. An overview of automatic audio segmentation. Int. J. Inf. Technol. Comput. Sci. (IJITCS) 2014, 6, 1. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Hansen, J.H. Advances in unsupervised audio classification and segmentation for the broadcast news and NGSW corpora. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 907–919. [Google Scholar] [CrossRef]
- Venkatesh, S.; Moffat, D.; Kirke, A.; Shakeri, G.; Brewster, S.; Fachner, J.; Odell-Miller, H.; Street, A.; Farina, N.; Banerjee, S.; et al. Artificially Synthesising Data for Audio Classification and Segmentation to Improve Speech and Music Detection in Radio Broadcast. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 636–640. [Google Scholar]
- Salamon, J.; MacConnell, D.; Cartwright, M.; Li, P.; Bello, J.P. Scaper: A library for soundscape synthesis and augmentation. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017; pp. 344–348. [Google Scholar]
- Turpault, N.; Serizel, R.; Shah, A.; Salamon, J. Sound Event Detection in Domestic Environments with Weakly Labeled Data and Soundscape Synthesis. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE), New York, NY, USA, 25–26 October 2019; p. 253. [Google Scholar]
- Miyazaki, K.; Komatsu, T.; Hayashi, T.; Watanabe, S.; Toda, T.; Takeda, K. Weakly-supervised sound event detection with self-attention. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 66–70. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Hershey, S.; Ellis, D.P.; Fonseca, E.; Jansen, A.; Liu, C.; Moore, R.C.; Plakal, M. The benefit of temporally-strong labels in audio event classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 366–370. [Google Scholar]
- Gimeno, P.; Viñals, I.; Ortega, A.; Miguel, A.; Lleida, E. Multiclass audio segmentation based on recurrent neural networks for broadcast domain data. EURASIP J. Audio Speech Music Process. 2020, 2020, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Lemaire, Q.; Holzapfel, A. Temporal Convolutional Networks for Speech and Music Detection in Radio Broadcast. In Proceedings of the 20th International Society for Music Information Retrieval Conference (ISMIR), Delft, The Netherlands, 4–8 November 2019. [Google Scholar]
- Cakır, E.; Parascandolo, G.; Heittola, T.; Huttunen, H.; Virtanen, T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1291–1303. [Google Scholar] [CrossRef] [Green Version]
- Venkatesh, S.; Moffat, D.; Miranda, E.R. Investigating the Effects of Training Set Synthesis for Audio Segmentation of Radio Broadcast. Electronics 2021, 10, 827. [Google Scholar] [CrossRef]
- Dieleman, S.; Schrauwen, B. End-to-end learning for music audio. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6964–6968. [Google Scholar]
- Lee, J.; Park, J.; Kim, T.; Nam, J. Raw Waveform-based Audio Classification Using Sample-level CNN Architectures. In Proceedings of the Machine Learning for Audio Signal Processing Workshop, Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Phan, H.; Maaß, M.; Mazur, R.; Mertins, A. Random regression forests for acoustic event detection and classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 20–31. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Du, J.; Dai, L.R.; Lee, C.H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 7–19. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Zsebok, S.; Nagy-Egri, M.F.; Barnaföldi, G.G.; Laczi, M.; Nagy, G.; Vaskuti, É.; Garamszegi, L.Z. Automatic bird song and syllable segmentation with an open-source deep-learning object detection method–a case study in the Collared Flycatcher. Ornis Hung. 2019, 27, 59–66. [Google Scholar] [CrossRef] [Green Version]
- Segal, Y.; Fuchs, T.S.; Keshet, J. SpeechYOLO: Detection and Localization of Speech Objects. arXiv 2019, arXiv:1904.07704. [Google Scholar]
- Algabri, M.; Mathkour, H.; Bencherif, M.A.; Alsulaiman, M.; Mekhtiche, M.A. Towards deep object detection techniques for phoneme recognition. IEEE Access 2020, 8, 54663–54680. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Schlüter, J.; Doukhan, D.; Meléndez-Catalán, B. MIREX Challenge: Music and/or Speech Detection. 2018. Available online: https://www.music-ir.org/mirex/wiki/2018:Music_and/or_Speech_Detection (accessed on 2 March 2022).
- Mesaros, A.; Heittola, T.; Diment, A.; Elizalde, B.; Shah, A.; Vincent, E.; Raj, B.; Virtanen, T. DCASE 2017 challenge setup: Tasks, datasets and baseline system. In Proceedings of the Workshop on Detection and Classification of Acoustic Scenes and Events, Munich, Germany, 16 November 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Plakal, M.; Ellis, D. YAMNet. 2020. Available online: https://github.com/tensorflow/models/tree/master/research/audioset/yamnet/ (accessed on 2 March 2022).
- Sifre, L. Rigid-Motion Scattering for Image Classification. Ph.D. Thesis, Ecole Normale Superieure, Paris, France, 2014. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 448–456. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. In Proceedings of the 2nd International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. Metrics for polyphonic sound event detection. Appl. Sci. 2016, 6, 162. [Google Scholar] [CrossRef]
- MuSpeak Team. MIREX MuSpeak Sample Dataset. 2015. Available online: http://mirg.city.ac.uk/datasets/muspeak/ (accessed on 2 March 2022).
- Snyder, D.; Chen, G.; Povey, D. Musan: A music, speech, and noise corpus. arXiv 2015, arXiv:1510.08484. [Google Scholar]
- Tzanetakis, G.; Cook, P. Marsyas: A framework for audio analysis. Organised Sound 2000, 4, 169–175. [Google Scholar] [CrossRef] [Green Version]
- Tzanetakis, G.; Cook, P. Musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Scheirer, E.; Slaney, M. Construction and evaluation of a robust multifeature speech/music discriminator. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Munich, Germany, 21–24 April 1997; Volume 2, pp. 1331–1334. [Google Scholar]
- Bosch, J.J.; Janer, J.; Fuhrmann, F.; Herrera, P. A Comparison of Sound Segregation Techniques for Predominant Instrument Recognition in Musical Audio Signals. In Proceedings of the 13th International Society for Music Information Retrieval Conference (ISMIR), Porto, Portugal, 8–12 October 2012; pp. 559–564. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Marolt, M. Music/Speech Classification and Detection Submission for MIREX 2018. Music Inf. Retr. Eval. eXchange MIREX. 2018. Available online: https://www.music-ir.org/mirex/abstracts/2018/MM2.pdf (accessed on 2 March 2022).
- Choi, M.; Lee, J.; Nam, J. Hybrid Features for Music and Speech Detection. Music Inf. Retr. Eval. eXchange (MIREX). 2018. Available online: https://www.music-ir.org/mirex/abstracts/2018/LN1.pdf (accessed on 2 March 2022).
- Adavanne, S.; Virtanen, T. A Report on Sound Event Detection with Different Binaural Features. In Proceedings of the Detection and Classification of Acoustic Scenes and Events (DCASE), Munich, Germany, 16 November 2017. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Jeong, I.Y.; Lee, S.; Han, Y.; Lee, K. Audio Event Detection Using Multiple-Input Convolutional Neural Network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events (DCASE), Munich, Germany, 16 November 2017. [Google Scholar]
- Lu, R.; Duan, Z. Bidirectional GRU for Sound Event Detection. In Proceedings of the Detection and Classification of Acoustic Scenes and Events (DCASE), Munich, Germany, 16 November 2017. [Google Scholar]
- Vesperini, F.; Gabrielli, L.; Principi, E.; Squartini, S. Polyphonic sound event detection by using capsule neural networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 310–322. [Google Scholar] [CrossRef] [Green Version]
- Luo, L.; Zhang, L.; Wang, M.; Liu, Z.; Liu, X.; He, R.; Jin, Y. A System for the Detection of Polyphonic Sound on a University Campus Based on CapsNet-RNN. IEEE Access 2021, 9, 147900–147913. [Google Scholar] [CrossRef]
- Martín-Morató, I.; Mesaros, A.; Heittola, T.; Virtanen, T.; Cobos, M.; Ferri, F.J. Sound event envelope estimation in polyphonic mixtures. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 935–939. [Google Scholar]
- Dinkel, H.; Wu, M.; Yu, K. Towards duration robust weakly supervised sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 887–900. [Google Scholar] [CrossRef]
- Kong, Q.; Xu, Y.; Wang, W.; Plumbley, M.D. Sound event detection of weakly labelled data with CNN-transformer and automatic threshold optimization. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2450–2460. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Turpault, N.; Serizel, R.; Wisdom, S.; Erdogan, H.; Hershey, J.R.; Fonseca, E.; Seetharaman, P.; Salamon, J. Sound Event Detection and Separation: A Benchmark on Desed Synthetic Soundscapes. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 840–844. [Google Scholar]
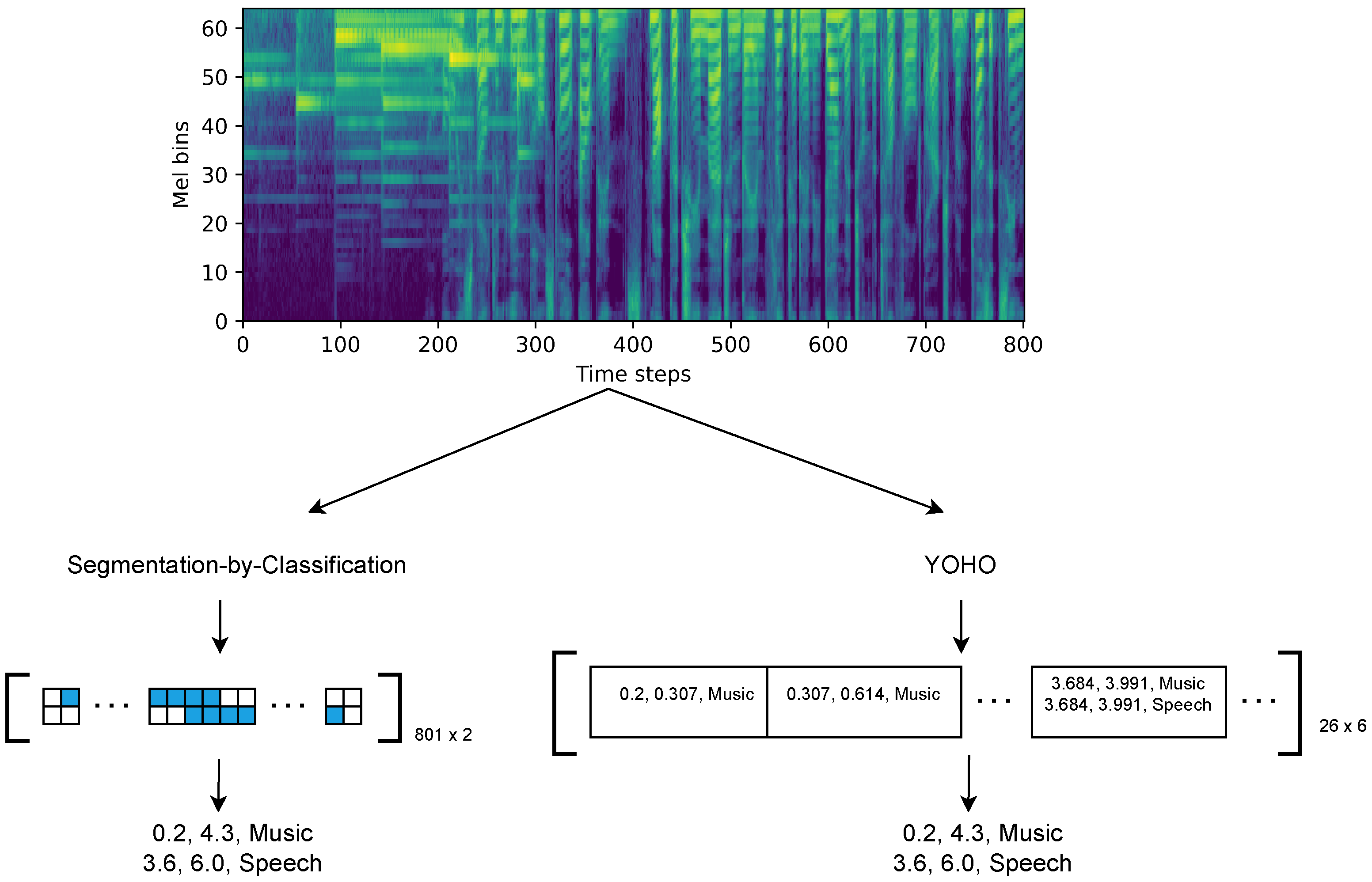
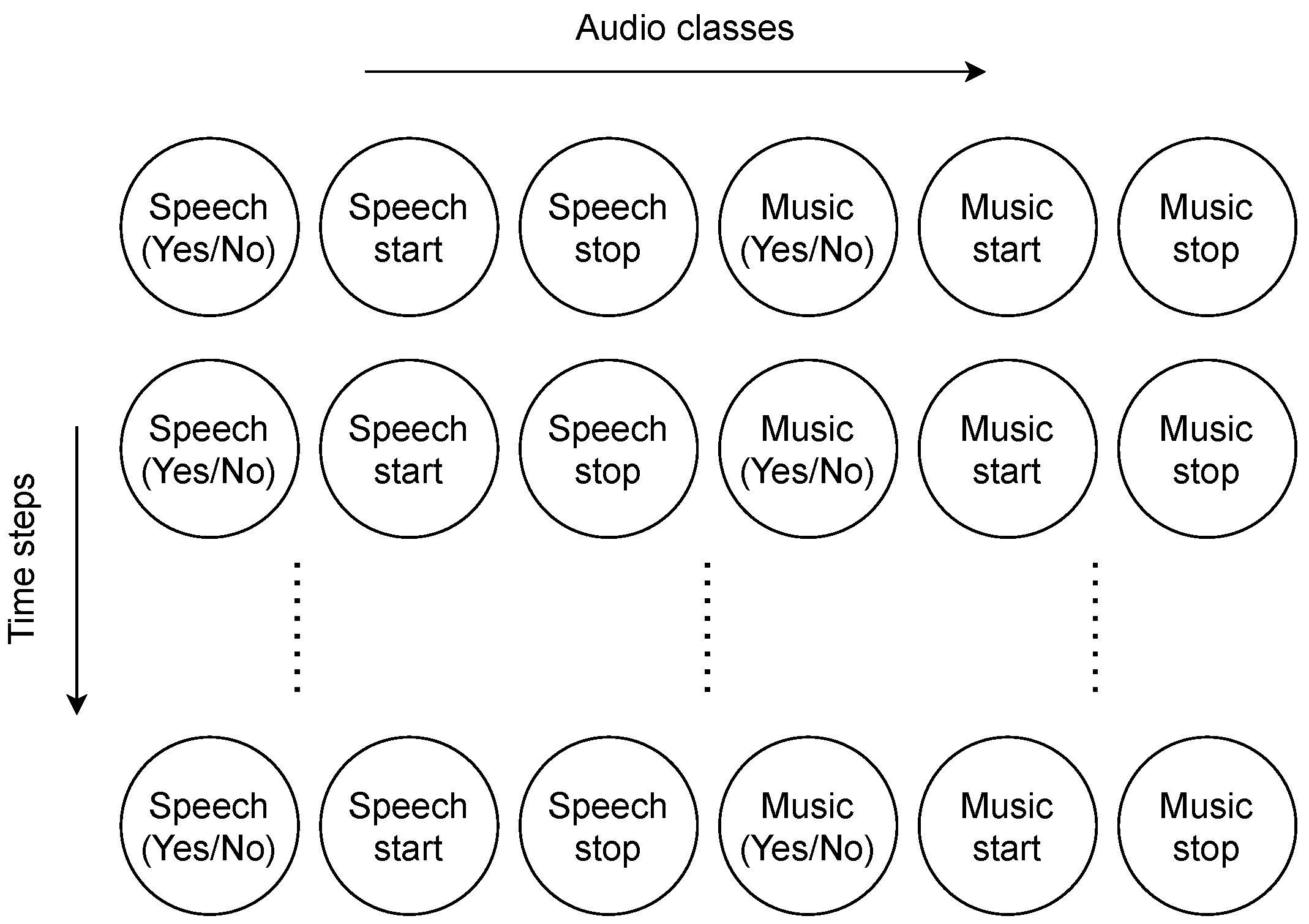
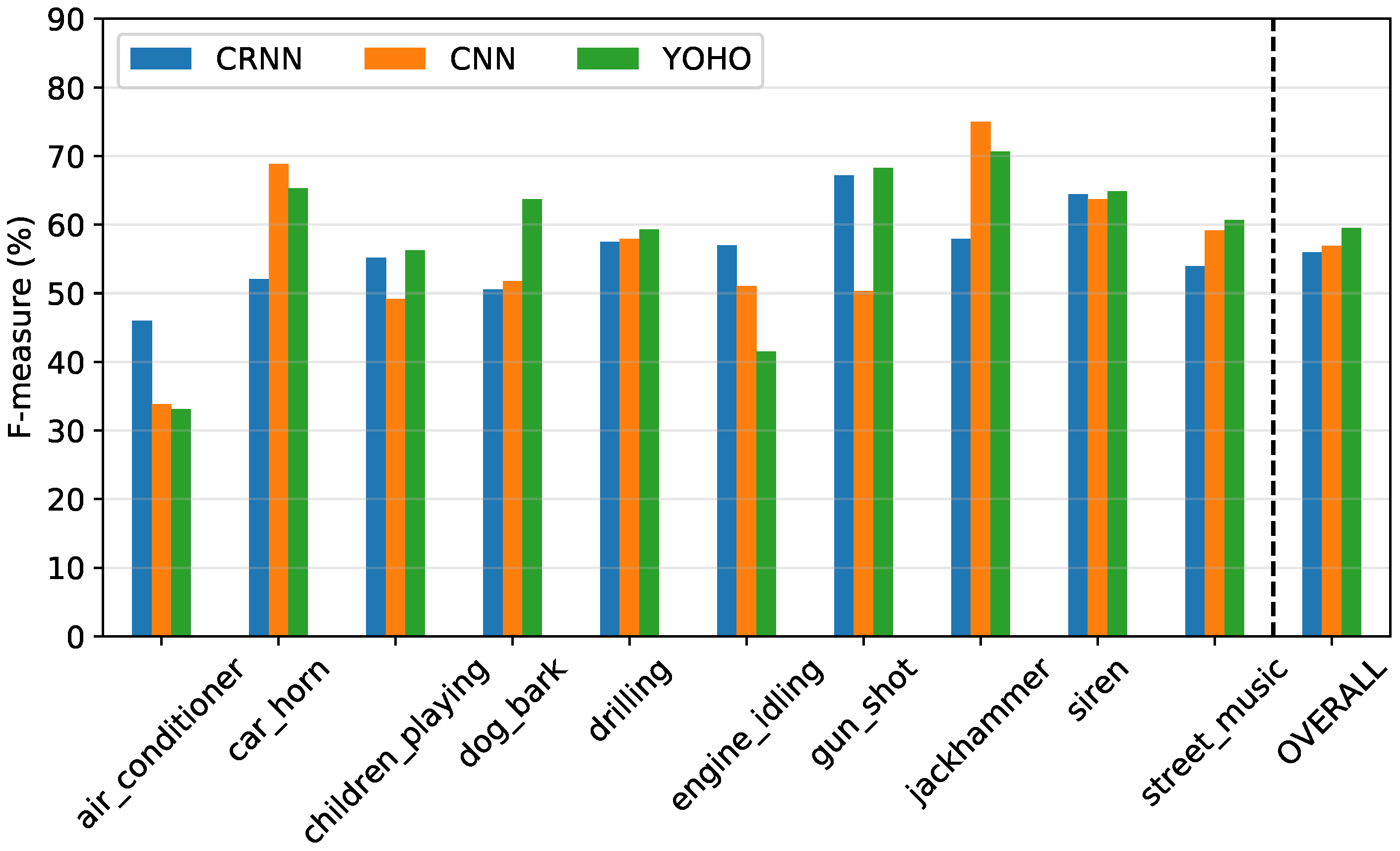
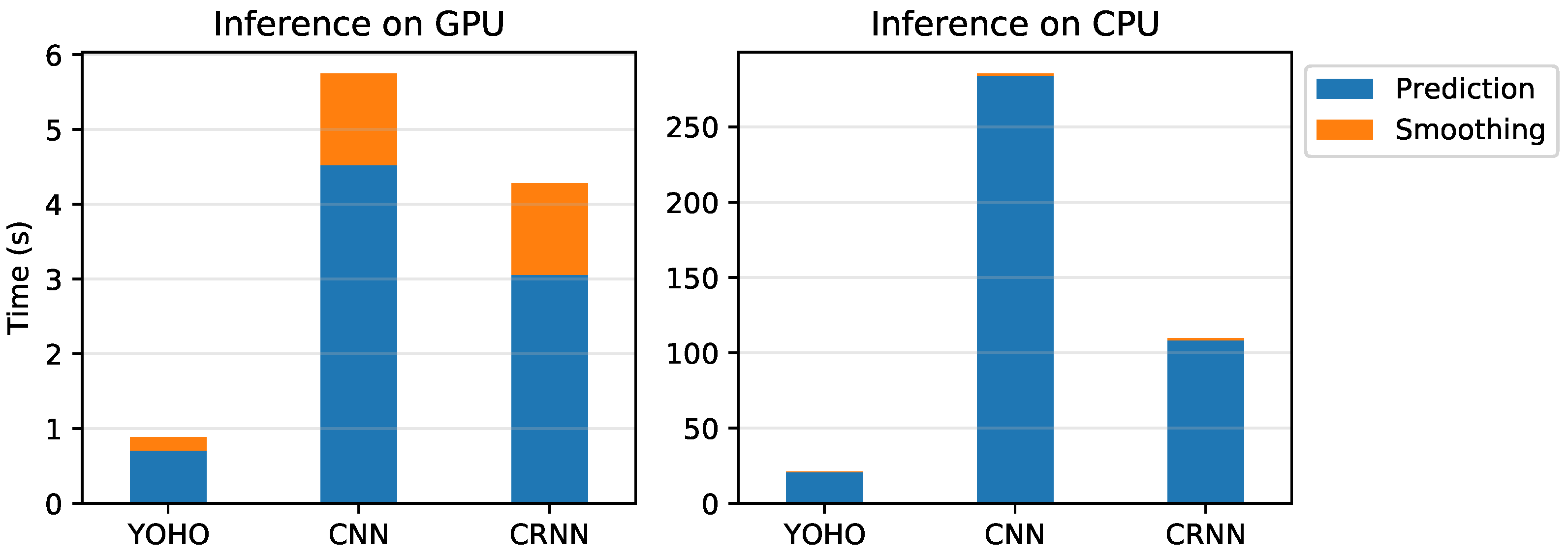
| Layer Type | Filters | Shape/Stride | Output Shape | |
|---|---|---|---|---|
| Reshape | - | - | 801 × 64 × 1 | |
| Conv2D | 32 | 3 × 3/2 | 401 × 32 × 32 | |
| Conv2D-dw | - | 3 × 3 | 401 × 32 × 32 | |
| Conv2D | 64 | 1 × 1 | 401 × 32 × 64 | |
| Conv2D-dw | - | 3 × 3/2 | 201 × 16 × 64 | |
| Conv2D | 128 | 1 × 1 | 201 × 16 × 128 | |
| Conv2D-dw | - | 3 × 3 | 201 × 16 × 128 | |
| Conv2D | 128 | 1 × 1 | 201 × 16 × 128 | |
| Conv2D-dw | - | 3 × 3/2 | 101 × 8 × 128 | |
| Conv2D | 256 | 1 × 1 | 101 × 8 × 256 | |
| Conv2D-dw | - | 3 × 3 | 101 × 8 × 256 | |
| Conv2D | 256 | 1 × 1 | 101 × 8 × 256 | |
| Conv2D-dw | - | 3 × 3/2 | 51 × 4 × 256 | |
| Conv2D | 512 | 1 × 1 | 51 × 4 × 256 | |
| 5× | Conv2D-dw Conv2D | - 512 | 3 × 3 1 × 1 | 51 × 4 × 256 51 × 4 × 256 |
| Conv2D-dw | - | 3 × 3/2 | 26 × 2 × 512 | |
| Conv2D | 1024 | 1 × 1 | 26 × 2 × 1024 | |
| Conv2D-dw | - | 3 × 3 | 26 × 2 × 1024 | |
| Conv2D | 1024 | 1 × 1 | 26 × 2 × 1024 | |
| | | | | |
| Conv2D-dw | - | 3 × 3 | 26 × 2 × 1024 | |
| Conv2D | 512 | 1 × 1 | 26 × 2 × 512 | |
| Conv2D-dw | - | 3 × 3 | 26 × 2 × 512 | |
| Conv2D | 256 | 1 × 1 | 26 × 2 × 256 | |
| Conv2D-dw | - | 3 × 3 | 26 × 2 × 256 | |
| Conv2D | 128 | 1 × 1 | 26 × 2 × 128 | |
| Reshape | - | - | 26 × 256 | |
| Conv1D | 6 | 1 | 26 × 6 | |
| Speech (Yes/No) | Speech Start | Speech Stop | Music (Yes/No) | Music Start | Music Stop |
|---|---|---|---|---|---|
| 0 | - | - | 1 | 0.65 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 0 | - | - | 1 | 0.0 | 1.0 |
| 1 | 0.7 | 1.0 | 1 | 0.0 | 1.0 |
| 1 | 0.0 | 1.0 | 1 | 0.0 | 1.0 |
| 1 | 0.0 | 1.0 | 1 | 0.0 | 0.975 |
| 1 | 0.0 | 1.0 | 0 | - | - |
| 1 | 0.0 | 1.0 | 0 | - | - |
| 1 | 0.0 | 1.0 | 0 | - | - |
| 1 | 0.0 | 1.0 | 0 | - | - |
| 1 | 0.0 | 1.0 | 0 | - | - |
| 1 | 0.0 | 0.5 | 0 | - | - |
| 0 | - | - | 0 | - | - |
| 0 | - | - | 0 | - | - |
| 0 | - | - | 0 | - | - |
| 0 | - | - | 0 | - | - |
| 0 | - | - | 0 | - | - |
| 0 | - | - | 0 | - | - |
| Model | Remarks |
|---|---|
| YOHO | The architecture is explained in Section 2.2. |
| CNN | [2, 2] strides in convolutions are replaced by [1, 1] strides, followed by max-pooling of [1, 2] to maintain the time resolution. |
| CRNN | Only Conv2D and Conv2D-dw layers until 256 filters are included from Table 1. After this, two B-GRU layers with 80 units each are added. |
| Dataset Division | Contents |
|---|---|
| Train | 46 h of synthetic radio data + 9 h from BBC Radio Devon + 1 h 30 min from MuSpeak |
| Validation | 5 h from BBC Radio Devon + 2 h from MuSpeak |
| Test | 4 h from BBC Radio Devon + 1 h 42 min from MuSpeak |
| Algorithm | Foverall | Fmusic | Fspeech |
|---|---|---|---|
| YOHO | 97.22 | 98.20 | 94.89 |
| CRNN | 96.79 | 97.84 | 94.26 |
| CNN | 93.89 | 97.96 | 85.13 |
| CRNN [17] | 96.37 | 97.37 | 94.00 |
| CRNN [8] | 96.24 | 97.30 | 93.80 |
| CNN [17] | 95.23 | 97.72 | 89.62 |
| Algorithm | Foverall | Fmusic | Fspeech |
|---|---|---|---|
| YOHO | 90.20 | 85.66 | 93.18 |
| CRNN [8] | 89.53 | 85.76 | 92.21 |
| CRNN [17] | 89.09 | 85.01 | 92.16 |
| CNN [45] | - | 54.78 | 90.9 |
| Logistic Regression [45] | - | 38.99 | 91.15 |
| ResNet [45] | - | 31.24 | 90.86 |
| MLP [46] | - | 49.36 | 77.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Venkatesh, S.; Moffat, D.; Miranda, E.R. You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection. Appl. Sci. 2022, 12, 3293. https://doi.org/10.3390/app12073293
Venkatesh S, Moffat D, Miranda ER. You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection. Applied Sciences. 2022; 12(7):3293. https://doi.org/10.3390/app12073293
Chicago/Turabian StyleVenkatesh, Satvik, David Moffat, and Eduardo Reck Miranda. 2022. "You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection" Applied Sciences 12, no. 7: 3293. https://doi.org/10.3390/app12073293
APA StyleVenkatesh, S., Moffat, D., & Miranda, E. R. (2022). You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection. Applied Sciences, 12(7), 3293. https://doi.org/10.3390/app12073293