
Spatial Audio Scene Characterization (SASC): Automatic Localization of Front-, Back-, Up-, and Down-Positioned Music Ensembles in Binaural Recordings




Abstract
:1. Introduction
2. State-of-the-Art Models for Binaural Localization
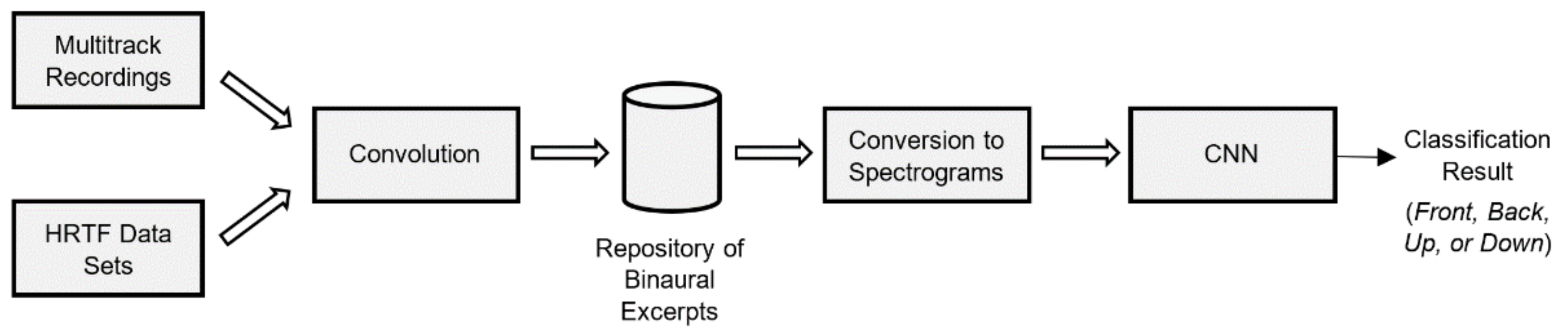
3. Methodology Overview
4. Synthesis of the Repository of Binaural Audio Recordings
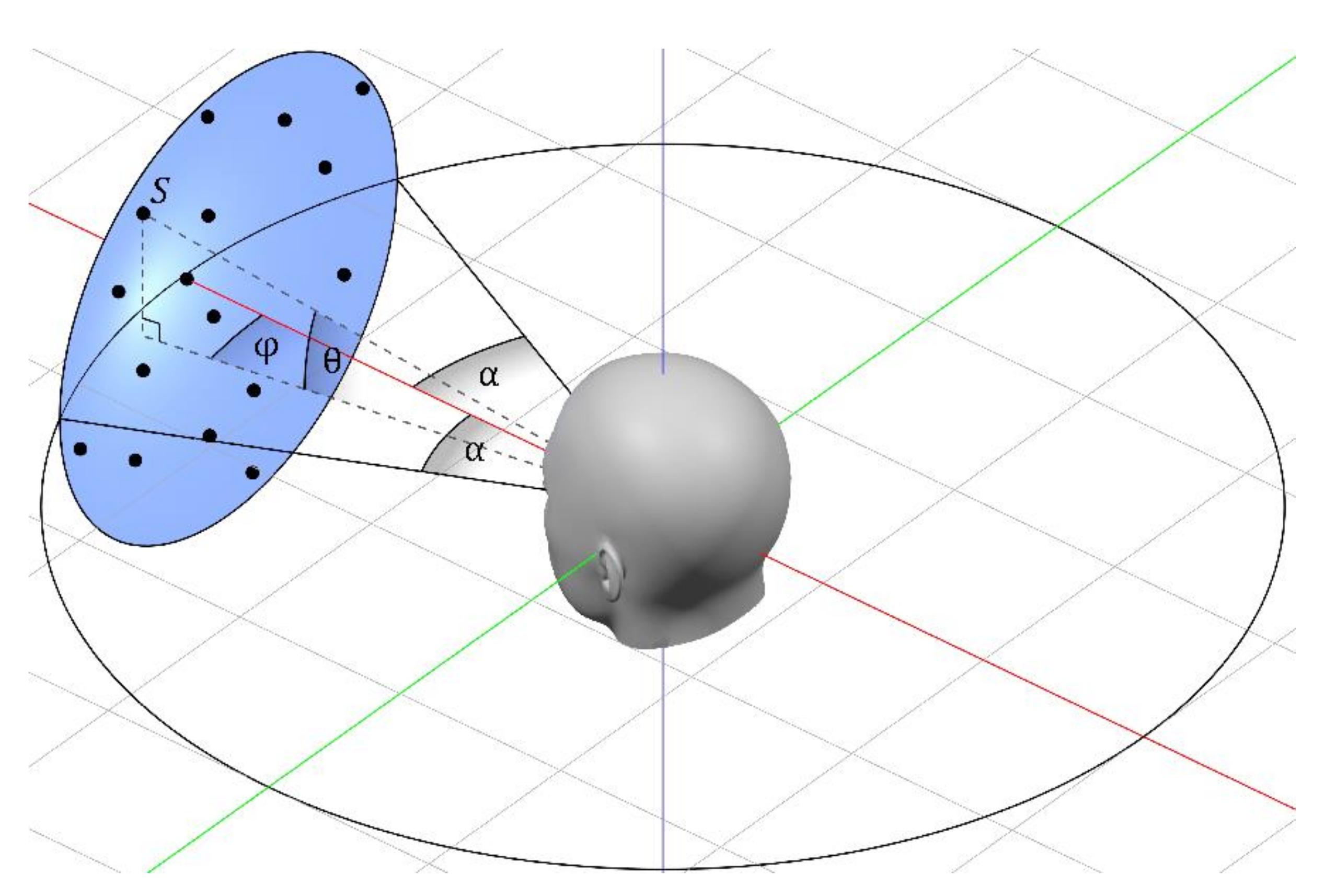
4.1. Composition of Spatial Audio Scenes
4.2. Multitrack Music Recordings
4.3. HRTF Sets
4.4. Convolution
4.5. Data Splits
4.6. Spectrograms Extraction
5. Convolutional Neural Network
5.1. Network Topology
5.2. Network Optimization
5.3. Network Testing
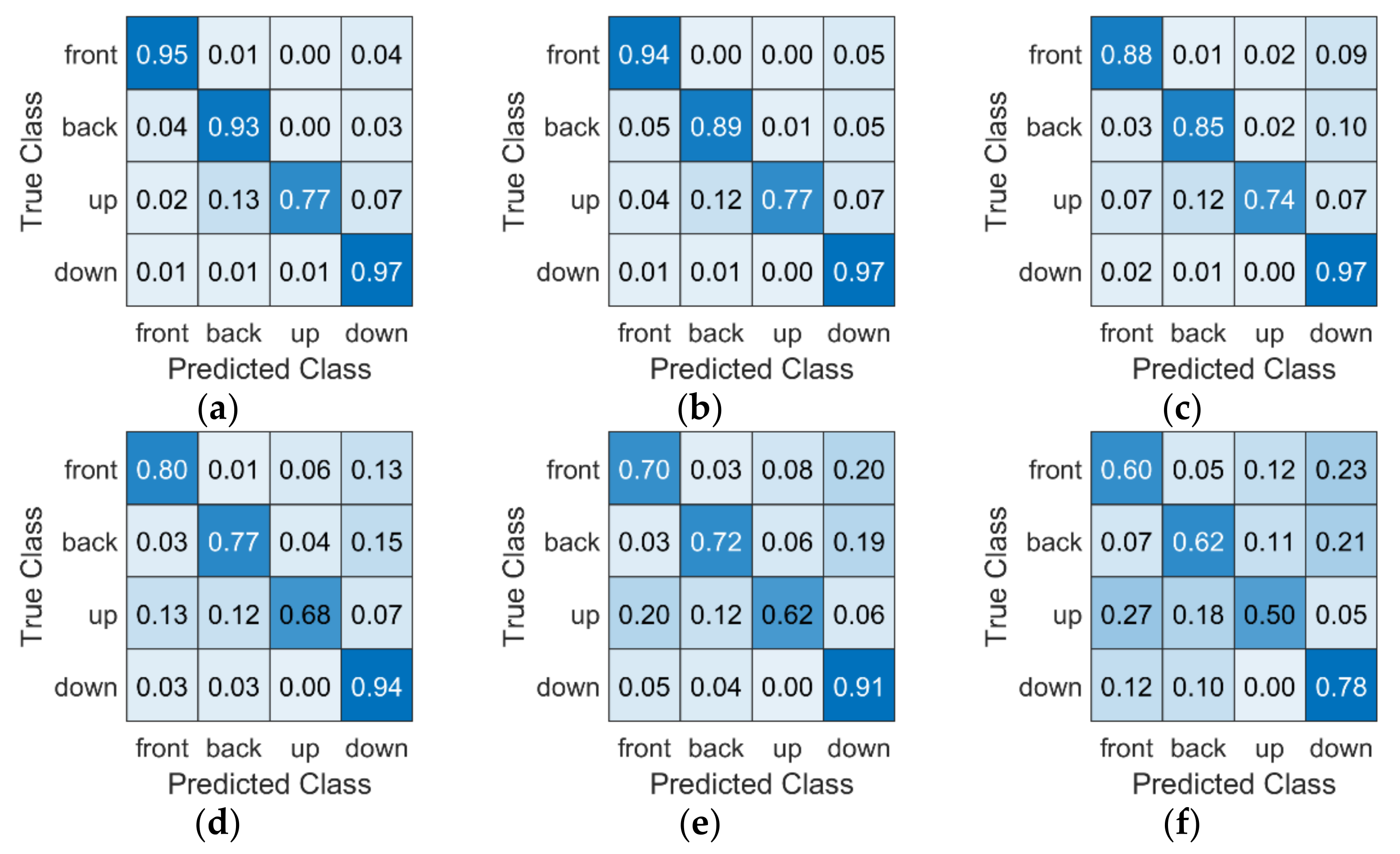
6. Results
6.1. HRTF-Dependent Tests
6.2. HRTF-Independent Tests
6.3. Individual vs. Generalized HRTF Tests
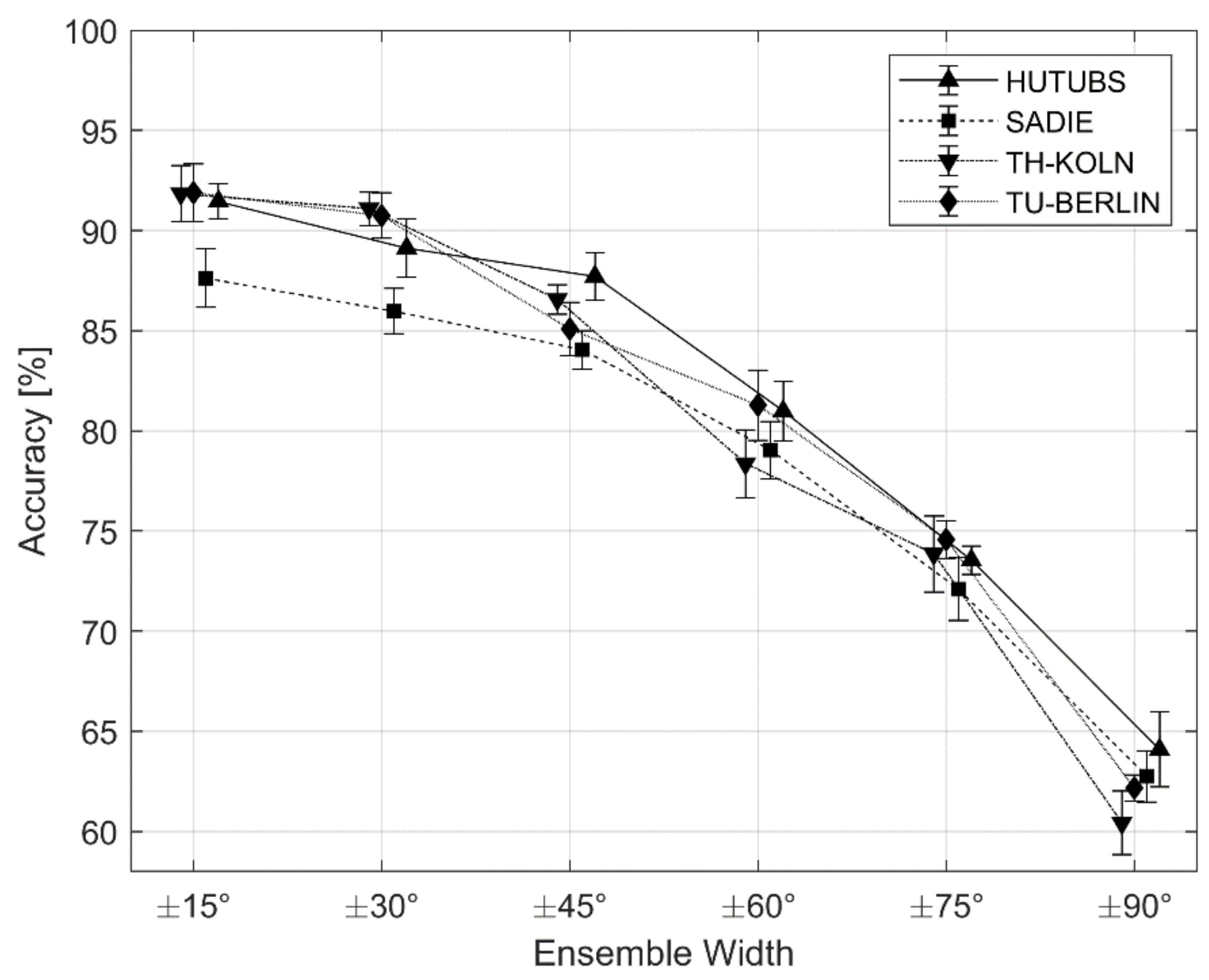
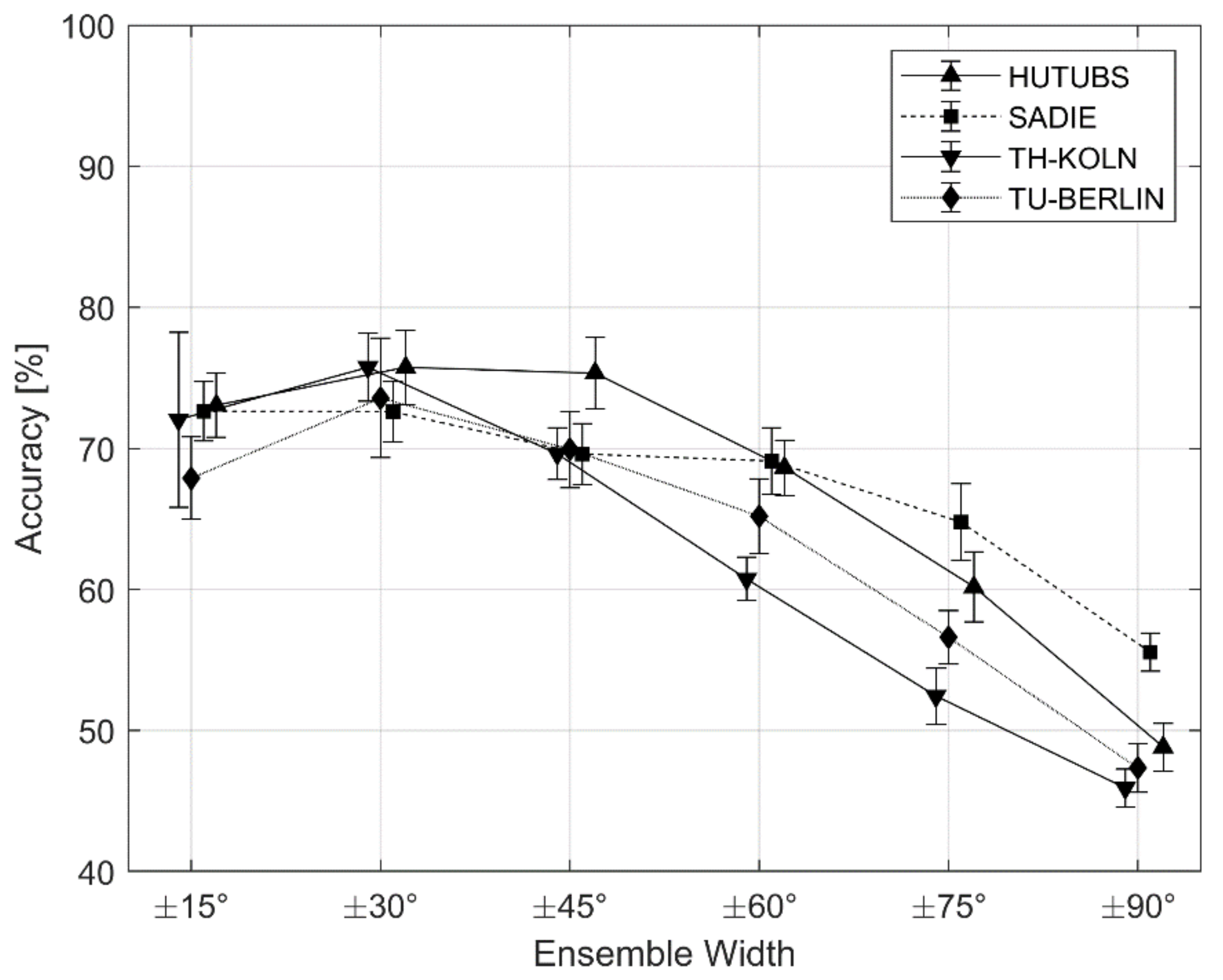
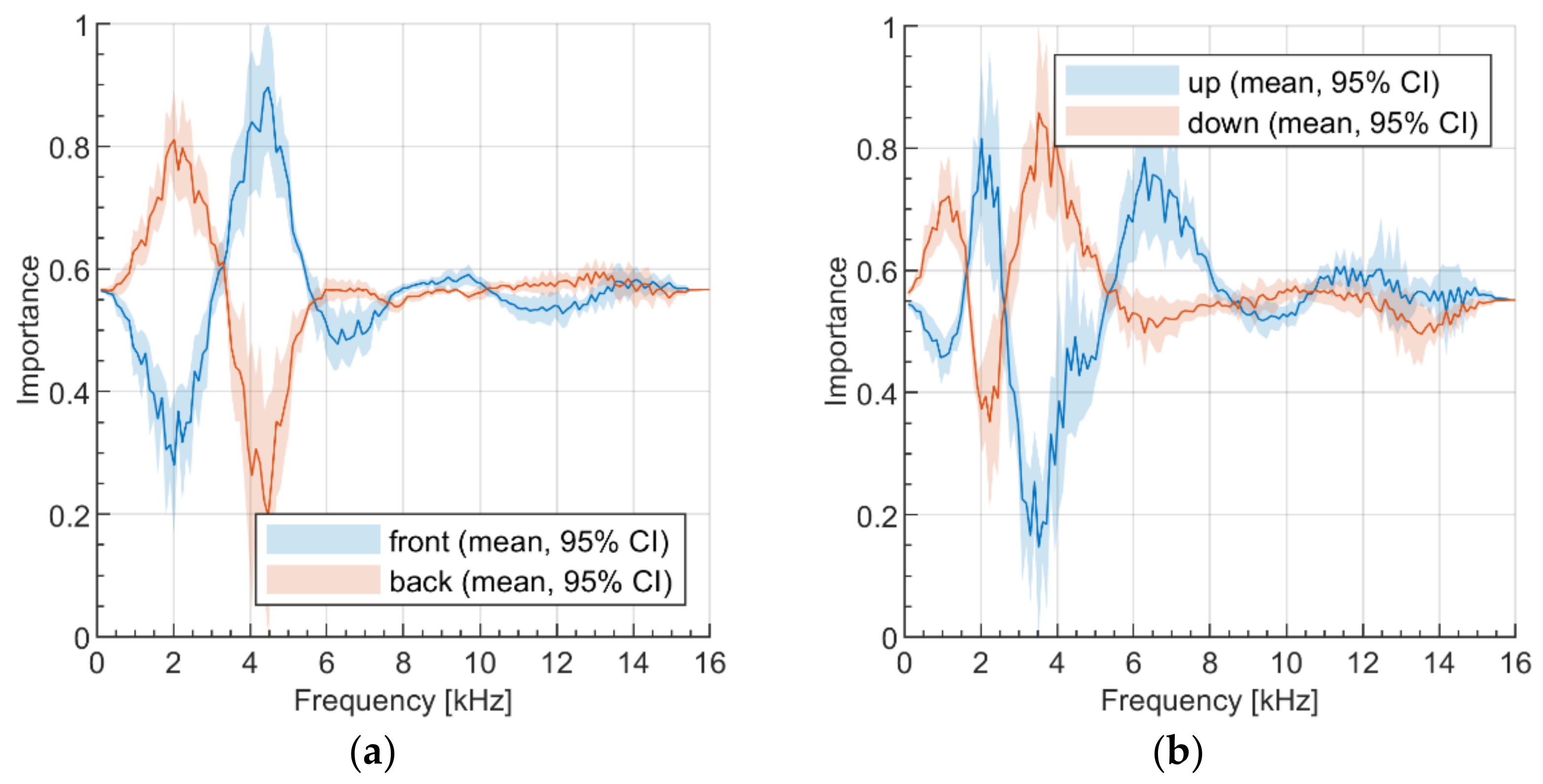
6.4. Follow-up Exploratory Study
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Begault, D.R. 3-D Sound for Virtual Reality and Multimedia; NASA Center for AeroSpace Information: Hanover, MD, USA, 2000. [Google Scholar]
- Kelion, L. YouTube Live-Streams in Virtual Reality and Adds 3D Sound, BBC News. Available online: http://www.bbc.com/news/technology-36073009 (accessed on 18 April 2016).
- Rumsey, F. Spatial quality evaluation for reproduced sound: Terminology, meaning, and a scene-based paradigm. J. Audio Eng. Soc. 2002, 50, 651–666. [Google Scholar]
- May, T.; Ma, N.; Brown, G.J. Robust localisation of multiple speakers exploiting head movements and multi-conditional training of binaural cues. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; Institute of Electrical and Electronics Engineers (IEEE): Brisbane, Australia, 2015; pp. 2679–2683. [Google Scholar]
- Ma, N.; Brown, G.J. Speech localisation in a multitalker mixture by humans and machines. In Proceedings of the INTERSPEECH 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3359–3363. [Google Scholar]
- Ma, N.; May, T.; Brown, G.J. Exploiting Deep Neural Networks and Head Movements for Robust Binaural Localization of Multiple Sources in Reverberant Environments. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2444–2453. [Google Scholar] [CrossRef] [Green Version]
- Ma, N.; Gonzalez, J.A.; Brown, G.J. Robust Binaural Localization of a Target Sound Source by Combining Spectral Source Models and Deep Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2122–2131. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Wang, J.; Qian, K.; Xie, X.; Kuang, J. Binaural sound localization based on deep neural network and affinity propagation clustering in mismatched HRTF condition. EURASIP J. Audio Speech Music Process. 2020, 2020, 4. [Google Scholar] [CrossRef] [Green Version]
- Vecchiotti, P.; Ma, N.; Squartini, S.; Brown, G.J. End-to-end binaural sound localisation from the raw waveform. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 451–455. [Google Scholar]
- May, T.; van de Par, S.; Kohlrausch, A. Binaural Localization and Detection of Speakers in Complex Acoustic Scenes. In The Technology of Binaural Listening, 1st ed.; Blauert, J., Ed.; Springer: London, UK, 2013; pp. 397–425. [Google Scholar]
- Wu, X.; Wu, Z.; Ju, L.; Wang, S. Binaural Audio-Visual Localization. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Virtual Conference, 2–9 February 2021. [Google Scholar]
- Örnolfsson, I.; Dau, T.; Ma, N.; May, T. Exploiting Non-Negative Matrix Factorization for Binaural Sound Localization in the Presence of Directional Interference. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; Institute of Electrical and Electronics Engineers (IEEE): Toronto, Canada, 2021; pp. 221–225. [Google Scholar]
- Nowak, J. Perception and prediction of apparent source width and listener envelopment in binaural spherical microphone array auralizations. J. Acoust. Soc. Am. 2017, 142, 1634. [Google Scholar] [CrossRef] [PubMed]
- Hammond, B.R.; Jackson, P.J. Robust Full-sphere Binaural Sound Source Localization Using Interaural and Spectral Cues. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 421–425. [Google Scholar]
- Yang, Y.; Xi, J.; Zhang, W.; Zhang, L. Full-Sphere Binaural Sound Source Localization Using Multi-task Neural Network. Proceedings of 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020; pp. 432–436. [Google Scholar]
- Wenzel, E.M.; Arruda, M.; Kistler, D.J.; Wightman, F.L. Localization using nonindividualized head-related transfer functions. J. Acoust. Soc. Am. 1993, 94, 111–123. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.; Xie, B.; Mai, H.; Liu, L.; Yi, K.; Zhang, C. The role of dynamic cue in auditory vertical localisation. Appl. Acoust. 2019, 146, 398–408. [Google Scholar] [CrossRef]
- Zieliński, S.; Rumsey, F.; Kassier, R. Development and Initial Validation of a Multichannel Audio Quality Expert System. J. Audio Eng. Soc. 2005, 53, 4–21. [Google Scholar]
- Usagawa, T.; Saho, A.; Imamura, K.; Chisaki, Y. A solution of front-back confusion within binaural processing by an estimation method of sound source direction on sagittal coordinate. In Proceedings of the IEEE Region 10 Conference TENCON, Bali, Indonesia, 21–24 November 2011; pp. 1–4. [Google Scholar]
- Zieliński, S.K.; Lee, H. Automatic Spatial Audio Scene Classification in Binaural Recordings of Music. Appl. Sci. 2019, 9, 1724. [Google Scholar] [CrossRef] [Green Version]
- Zieliński, S.K.; Lee, H.; Antoniuk, P.; Dadan, P. A Comparison of Human against Machine-Classification of Spatial Audio Scenes in Binaural Recordings of Music. Appl. Sci. 2020, 10, 5956. [Google Scholar] [CrossRef]
- Zieliński, S.K.; Antoniuk, P.; Lee, H.; Johnson, D. Automatic discrimination between front and back ensemble locations in HRTF-convolved binaural recordings of music. EURASIP J. Audio Speech Music Process. 2022, 2022, 3. [Google Scholar] [CrossRef]
- Szabó, B.T.; Denham, S.L.; Winkler, I. Computational models of auditory scene analysis: A review. Front. Neurosci. 2016, 10, 1–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barchiesi, D.; Giannoulis, D.; Stowell, D.; Plumbley, M.D. Acoustic scene classification: Classifying environments from the sounds they produce. IEEE Signal. Process. Mag. 2015, 32, 16–34. [Google Scholar] [CrossRef]
- Zieliński, S.K. Spatial Audio Scene Characterization (SASC). Automatic Classification of Five-Channel Surround Sound Recordings According to the Foreground and Background Content. In Multimedia and Network Information Systems, Proceedings of the MISSI 2018, Wrocław, Poland, 12–14 September 2018; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Blauert, J. Spatial Hearing. The Psychology of Human Sound Localization; The MIT Press: London, UK, 1974. [Google Scholar]
- Han, Y.; Park, J.; Lee, K. Convolutional neural networks with binaural representations and background subtraction for acoustic scene classification. In Proceedings of the Conference on Detection and Classification of Acoustic Scenes and Events, Munich, Germany, 16 November 2017; pp. 1–5. [Google Scholar]
- McLachlan, G.; Majdak, P.; Reijniers, J.; Peremans, H. Towards modelling active sound localisation based on Bayesian inference in a static environment. Acta Acust. 2021, 5, 45. [Google Scholar] [CrossRef]
- Raake, A. A Computational Framework for Modelling Active Exploratory Listening that Assigns Meaning to Auditory Scenes—Reading the World with Two Ears. Available online: http://twoears.eu (accessed on 19 November 2021).
- Pätynen, J.; Pulkki, V.; Lokki, T. Anechoic Recording System for Symphony Orchestra. Acta Acust. United Acust. 2008, 94, 856–865. [Google Scholar] [CrossRef]
- D’Orazio, D.; De Cesaris, S.; Garai, M. Recordings of Italian opera orchestra and soloists in a silent room. Proc. Mtgs. Acoust. 2016, 28, 015014. [Google Scholar]
- Mixing Secrets for The Small Studio. Available online: http://www.cambridge-mt.com/ms-mtk.htm (accessed on 19 November 2021).
- Bittner, R.; Salamon, J.; Tierney, M.; Mauch, M.; Cannam, C.; Bello, J.P. MedleyDB: A Multitrack Dataset for Annotation-Intensive MIR Research. In Proceedings of the 15th International Society for Music Information Retrieval Conference, Taipei, Taiwan, 27 October 2014. [Google Scholar]
- Studio Sessions. Telefunken Elektroakustik. Available online: https://telefunken-elektroakustik.com/multitracks (accessed on 19 November 2021).
- Brinkmann, F.; Dinakaran, M.; Pelzer, R.; Grosche, P.; Voss, D.; Weinzierl, S. A Cross-Evaluated Database of Measured and Simulated HRTFs Including 3D Head Meshes, Anthropometric Features, and Headphone Impulse Responses. J. Audio Eng. Soc. 2019, 67, 705–718. [Google Scholar] [CrossRef]
- Armstrong, C.; Thresh, L.; Murphy, D.; Kearney, G. A Perceptual Evaluation of Individual and Non-Individual HRTFs: A Case Study of the SADIE II Database. Appl. Sci. 2018, 8, 2029. [Google Scholar] [CrossRef] [Green Version]
- Pörschmann, C.; Arend, J.M.; Neidhardt, A. A Spherical Near-Field HRTF Set for Auralization and Psychoacoustic Research. In Proceedings of the 142nd Audio Engineering Convention, Berlin, Germany, 20–23 May 2017. [Google Scholar]
- Brinkmann, F.; Lindau, A.; Weinzierl, S.; van de Par, S.; Müller-Trapet, M.; Opdam, R.; Vorländer, M. A High Resolution and Full-Spherical Head-Related Transfer Function Database for Different Head-Above-Torso Orientations. J. Audio Eng. Soc. 2017, 65, 841–848. [Google Scholar] [CrossRef]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. arXiv 2018, arXiv:abs/1811.12808. [Google Scholar]
- Brookes, M. VOICEBOX: Speech Processing Toolbox for MATLAB. Available online: http://www.ee.ic.ac.uk/hp/staff/dmb/voicebox/voicebox.html (accessed on 25 November 2021).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Available online: https://arxiv.org/abs/1412.6980 (accessed on 25 November 2021).
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- So, R.H.Y.; Ngan, B.; Horner, A.; Braasch, J.; Blauert, J.; Leung, K.L. Toward orthogonal non-individualised head-related transfer functions for forward and backward directional sound: Cluster analysis and an experimental study. Ergonomics 2010, 53, 767–778. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Blauert, J. Sound localization in the median plane. Acustica 1969, 22, 205–213. [Google Scholar]
- Cheng, C.I.; Wakefield, G.H. Introduction to Head-Related Transfer Functions (HRTFs): Representations of HRTFs in Time, Frequency, and Space. J. Audio Eng. Soc. 2001, 49, 231–249. [Google Scholar]
- Zonooz, B.; Arani, E.; Körding, K.P.; Aalbers, P.A.T.R.; Celikel, T.; van Opstal, A.J. Spectral Weighting Underlies Perceived Sound Elevation. Sci. Rep. 2019, 9, 1642. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HRTF Set | Acronym | Head | Type | Radius | Source |
|---|---|---|---|---|---|
| 1 | HUTUBS | Subject pp2 | Human | 1.47 m | Huawei Technologies, TU Berlin, Munich Research Centre, Sennheiser Electronic [35] |
| 2 | Subject pp3 | ||||
| 3 | Subject pp4 | ||||
| 4 | Subject H3 | Human | |||
| 5 | SADIE | Subject H4 | 1.2 m | University of York [36] | |
| 6 | Subject H5 | ||||
| 7 | Neumann KU 100 | Artificial | 0.75 m | TH Köln, TU Berlin, TU Ilmenau [37] | |
| 8 | TH KÖLN | 1 m | |||
| 9 | 1.5 m | ||||
| 10 | FABIAN HATO 0° | Artificial | 1.7 m | TU Berlin, Carl von Ossietzky University, RWTH Aachen University [38] | |
| 11 | TU BERLIN | FABIAN HATO 10° | |||
| 12 | FABIAN HATO 350° |
| Development | Test | ||
|---|---|---|---|
| Train | Validation | ||
| Number of Excerpts | 25,632 | 6624 | 11,520 |
| Data Proportion | 59% | 15% | 26% |
| Number of Music Recordings | 89 | 23 | 40 |
| Ensemble Location | Precision [%] | Recall [%] | F1-Score [%] |
|---|---|---|---|
| front | 93.5 (1.6) | 95.4 (1.2) | 94.4 (1.0) |
| back | 85.6 (2.5) | 93.1 (1.4) | 89.2 (1.5) |
| up | 98.9 (0.8) | 77.5 (3.7) | 86.8 (2.1) |
| down | 87.5 (0.9) | 96.9 (1.1) | 92.0 (0.6) |
| Ensemble Location | Precision [%] | Recall [%] | F1-Score [%] |
|---|---|---|---|
| front | 57.3 (1.8) | 60.1 (1.9) | 58.6 (1.5) |
| back | 64.5 (2.5) | 61.6 (1.9) | 63.0 (1.1) |
| up | 69.1 (1.9) | 50.2 (3.0) | 58.1 (1.6) |
| down | 61.3 (1.1) | 77.6 (1.8) | 68.5 (1.1) |
| Fold No. | HRTF Corpora Used for Development | HRTF Corpus Used for Testing |
|---|---|---|
| 1 | SADIE, TH-Köln, TU-Berlin | HUTUBS |
| 2 | HUTUBS, TH-Köln, TU-Berlin | SADIE |
| 3 | SADIE, HUTUBS, TU-Berlin | TH-Köln |
| 4 | SADIE, HUTUBS, TH-Köln | TU-Berlin |
| Ensemble Location | Precision | Recall | F1-Score |
|---|---|---|---|
| front | 86.6 (4.5) | 59.4 (7.2) | 70.3 (5.8) |
| back | 60.3 (3.3) | 79.3 (2.8) | 68.4 (1.7) |
| up | 80.0 (2.6) | 50.0 (2.8) | 61.5 (3.3) |
| down | 64.1 (2.2) | 87.7 (2.5) | 74.0 (1.4) |
| Ensemble Location | Precision | Recall | F1-Score |
|---|---|---|---|
| front | 85.8 (3.4) | 52.6 (5.4) | 65.0 (4.0) |
| back | 54.2 (2.7) | 72.1 (4.5) | 61.8 (2.1) |
| up | 81.7 (3.1) | 22.9 (5.1) | 35.5 (6.1) |
| down | 54.1 (3.5) | 95.3 (2.2) | 68.8 (2.5) |
| Fold No. | HRTF Corpora Used for Development | HRTF Corpora Used for Testing |
|---|---|---|
| 1 | TH-Köln, TU-Berlin (Artificial Heads) | HUTUBS, SADIE (Human Heads) |
| 2 | HUTUBS, SADIE (Human Heads) | TH-Köln, TU-Berlin (Artificial Heads) |
| Study | Impulse Response Type | Rendering Type | Ensemble Locations | Ensemble Width | Classification Method | Test Accuracy | |
|---|---|---|---|---|---|---|---|
| Room Dependent | Room Independent | ||||||
| Zieliński and Lee (2019) [20] | Reverberant (13 BRIRs) | 2D | 1. Front 2. Back 3. Front & Back | Fixed (±30°) | LASSO | 76.9% | 56.8% |
| Zieliński et al. (2020) [21] | Reverberant (13 BRIRs) | 2D | 1. Front 2. Back 3. Front & Back | Fixed (±30°) | Logit SVM XGBoost CNN | 83.9% (SVM) | 56.7% (Logit) |
| Zieliński et al. (2022) [22] | Anechoic (74 HRIRs) | 2D | 1. Front 2. Back | Fixed (±30°) | Logit SVM XGBoost CNN | 99.4% (CNN) | 94.5% (XGBoost) |
| This study | Anechoic (12 HRIRs) | 3D | 1. Front 2. Back 3. Up 4. Down | Varied (±15°, ±30°, ±45°, ±60°, ±75°, ±90°) | CNN | 89.2% * | 74.4% * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zieliński, S.K.; Antoniuk, P.; Lee, H. Spatial Audio Scene Characterization (SASC): Automatic Localization of Front-, Back-, Up-, and Down-Positioned Music Ensembles in Binaural Recordings. Appl. Sci. 2022, 12, 1569. https://doi.org/10.3390/app12031569
Zieliński SK, Antoniuk P, Lee H. Spatial Audio Scene Characterization (SASC): Automatic Localization of Front-, Back-, Up-, and Down-Positioned Music Ensembles in Binaural Recordings. Applied Sciences. 2022; 12(3):1569. https://doi.org/10.3390/app12031569
Chicago/Turabian StyleZieliński, Sławomir K., Paweł Antoniuk, and Hyunkook Lee. 2022. "Spatial Audio Scene Characterization (SASC): Automatic Localization of Front-, Back-, Up-, and Down-Positioned Music Ensembles in Binaural Recordings" Applied Sciences 12, no. 3: 1569. https://doi.org/10.3390/app12031569
APA StyleZieliński, S. K., Antoniuk, P., & Lee, H. (2022). Spatial Audio Scene Characterization (SASC): Automatic Localization of Front-, Back-, Up-, and Down-Positioned Music Ensembles in Binaural Recordings. Applied Sciences, 12(3), 1569. https://doi.org/10.3390/app12031569