
Rough Set Based Classification and Feature Selection Using Improved Harmony Search for Peptide Analysis and Prediction of Anti-HIV-1 Activities

 ,
,  ,
,
Abstract
:1. Introduction
Research Motivation and Contribution
2. Related Work
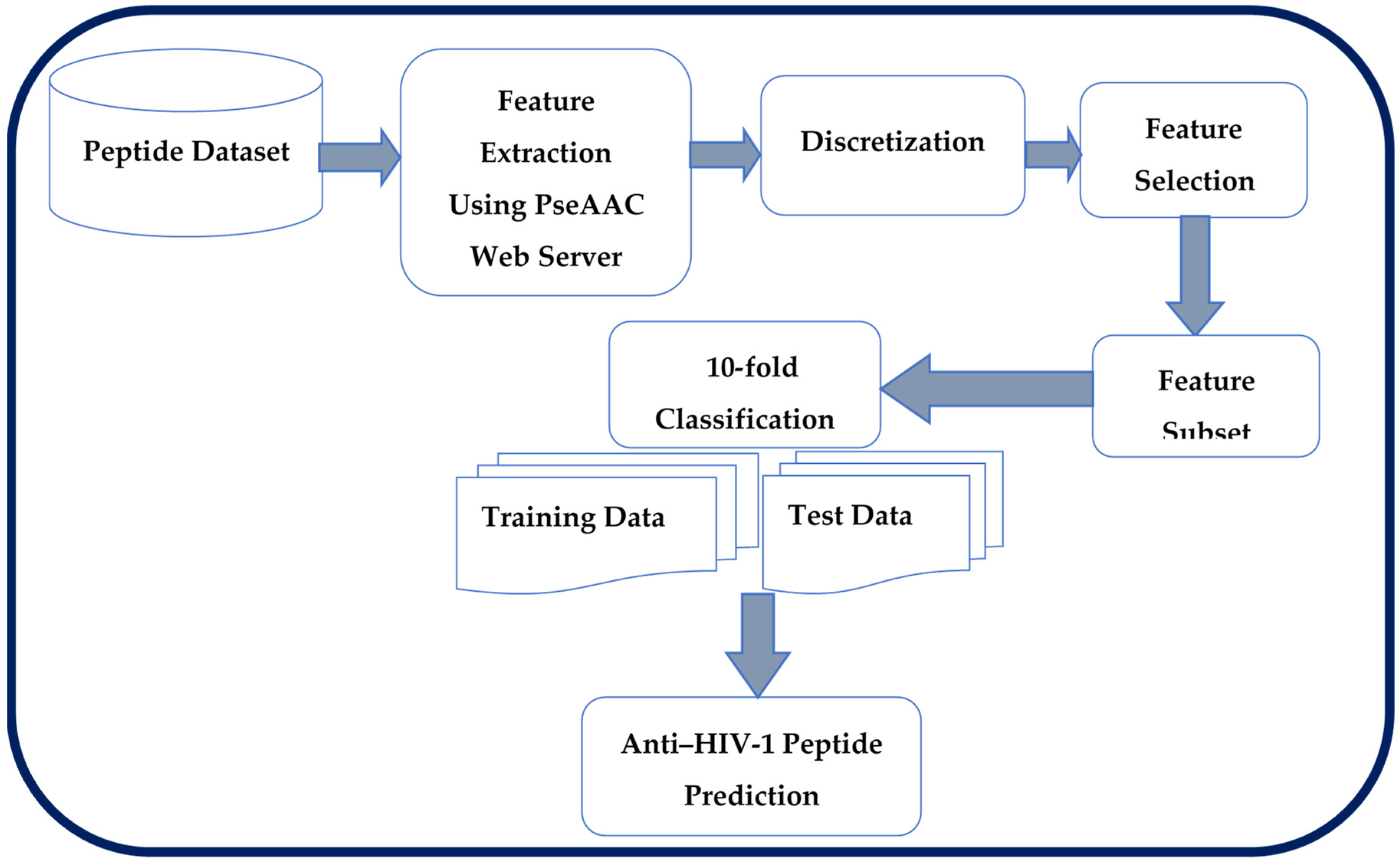
3. Proposed Method for Peptide Classification
3.1. Feature Extraction
3.2. Discretization of Peptide Features
3.3. Rough Set Based Feature Selection
| Algorithm 1. RSIHSQR FS algorithm |
| Algorithm: RSIHSQR(C,De) |
| Input: C, the conditional attributes; |
| De, the class attribute; |
| Output: Optimal feature subset |
| Step I: The fitness function, f(X) to be defined. |
| Initialize the parameters HMS = 30 |
| HMCR = 0.9 // HM constraint |
| MaxIt = 100 // iteration count |
| PVB//feasible value limit |
| PARmin,PARmax, bwmin, bwmax, // Pitch Adjusting Rate & bandwidth ∈ (0 to 1) |
| fit = 0; |
| Xold = X1; bestfit = X1; bestreduct = {}; |
| Step II: The Harmony Memory to be set as, HM = (X1, X2, …, XHMS) |
| For i = 1:HMS |
| ∀: Xi // Xi is the ith harmony of HM |
| R ← Xi (1’s of Xi) |
| ∀x ∈ (C − R) |
| R∪{x}(De) = |
| f(Xi) = R∪{x}(De) for all X ⊂ R, X(De) ≠ C(De) |
| if f(Xi) > fit |
| fit ← f(Xi) |
| Xold ← Xi |
| End if |
| End for |
| Step III: The new HM to be improvised. |
| While itr ≤ MaxIt | fit == 1 |
| for j = 1:NVAR |
| ∀:Xold (j) |
| Update PAR(); |
| Update bw(); |
| if random ( ) ≤ HMCR //random numberbetween 0 and 1 |
| Xnew ← Xold; |
| if random ( ) ≤ PAR |
| Xnew(j) = Xnew(j) ± random() * bw |
| end if |
| else |
| // select Xnew |
| Xnew(j) = PVBlower + random( ) * (PVBupper – PVBlower) |
| end if |
| end for |
| Step IV: The new HM to be updated |
| Calculate fitness for Xnew---(Step II) |
| if f(Xnew) f(Xold) |
| // Substitute the older harmony with new harmony, if it is best |
| Xold ← Xnew; |
| if f(Xnew) > fit |
| fit ← f(Xnew); |
| bestfit ← Xnew; |
| End if |
| Exit |
| end if |
| end while |
| bestreduct ← selected attributes of bestfit |
| Algorithm 2. RSIHSRR FS algorithm |
| Algorithm: RSIHSRR(C,De) |
| Input: C, the conditional attribute set; |
| De, the decision attribute |
| Output: Optimal feature subset |
| Step I: The fitness function, f(X) to be defined. |
| Initialize the parameters HMS = 30 |
| HMCR = 0.9 // HM constraint |
| MaxIt = 100 // iteration count |
| PVB//feasible value limit |
| PARmin, PARmax, bwmin, bwmax,// Pitch Adjusting Rate & bandwidth ∈ (0 to 1) |
| fit = 0; |
| Xold = X1; bestfit = X1; bestreduct = {}; |
| Step II: The Harmony Memory to be set as, HM = (X1,X2,….XHMS) |
| For i = 1:HMS |
| ∀: Xi // Xi is the ith harmony of HM |
| R ← Xi (1′s of Xi) |
| ∀x ∈ R |
| ƘR-{x}(De) = |
| f(Xi) = ƘR-{x}(De) for all X⊂R, ƘX(De) ≠ ƘC(De) |
| if f(Xi) > fit |
| fit ← f(Xi) |
| Xold ← Xi |
| End if |
| End for |
| if fit == 1 |
| bestfit = fit; |
| Return R; |
| Endif |
| Step III: The new HM to be improvised. |
| While itr ≤ MaxIt | fit != 1 |
| for j = 1:NVAR |
| ∀:Xold (j) |
| Update PAR(); |
| Update bw(); |
| if random ( ) ≤ HMCR |
| Xnew ← Xold; |
| if random ( ) ≤ PAR |
| Xnew(j) = Xnew(j) ± random() * bw |
| end if |
| else |
| //selectXnew |
| Xnew(j)=PVBlower + random( ) * (PVBupper—PVBlower) |
| end if |
| end for |
| Step IV: The new HM to be updated |
| Calculate fitness for Xnew ---(Step II). |
| if f(Xnew) == 1 |
| bestfit = Xnew; |
| Return R; |
| End if |
| if f(Xnew) f(Xold) |
| // Substitute the older harmony, if new harmony is acceptable. |
| Xold ← Xnew; |
| if f(Xnew) > fit |
| fit ← f(Xnew); |
| bestfit ← Xnew; |
| End if |
| Exit |
| end if |
| end while |
| bestreduct ← selected attributes of bestfit |
4. Rough Set Classification (RSC)
| Algorithm 3. Rough Set Classification Algorithm |
| Algorithm: RSC (C,D) |
| Input: Conditional attributes 1, 2, …, n − 1 and the Decision attribute D. |
| Output: Generated Decision Rules |
| Step 1: Generate training data set and test data in 10:1 ratio, respectively. |
| Step 2: The equivalence relation for the conditional attributes is to be constructed in the training set. |
| Step 3: The equivalence relation for the decision attribute is constructed in the training set. |
| Step 4: The rough set lower approximation for indiscernibility relation for conditional attributes and decision attribute to be built. |
| Step 5: The rough set upper approximation for indiscernibility relation for conditional attributes and the decision attribute to be constructed. |
| Step 6: Generate the specific rules from the lower approximation of the rough set. |
| Step 7: Generate the possible rules from rough set upper approximation. |
| Step 8: Remove the redundant rules from the rough approximation space. |
5. Experimental Analysis
5.1. Results
5.1.1. Performance Evaluation of Proposed FS Algorithms
5.1.2. Assessment of FS with a Classification Algorithm
5.1.3. Assessment of RSC with Other Classification Algorithms
6. Discussion
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Niinomi, M. Titanium Alloys. In Encyclopedia of Biomedical Engineering; Elsevier: Amsterdam, The Netherlands, 2019; Volume 5, pp. 213–224. ISBN 9780128012383. [Google Scholar]
- Tinguely, C.; Schild-Spycher, T.; Bahador, Z.; Gowland, P.; Stolz, M.; Niederhauser, C. Comparison of a conventional HIV 1/2 line immunoassay with a rapid confirmatory HIV 1/2 assay. J. Virol. Methods 2014, 206, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Mehellou, Y.; Clercq, E.D. Twenty-six years of anti-HIV drug discovery: Where do we stand and where do we go? J. Med. Chem. 2021, 53, 521–538. [Google Scholar] [CrossRef]
- Xiao, Y.F.; Jie, M.M.; Li, B.S.; Hu, C.J.; Xie, R.; Tang, B.; Yang, S.M. Peptide-Based Treatment: A Promising Cancer Therapy. J. Immunol. Res. 2015, 2015, 761820. [Google Scholar] [CrossRef] [Green Version]
- Chertov, O.; Zhang, N.; Chen, X.; Oppenheim, J.J.; Lubkowski, J.; McGrath, C.; Ii, R.C.S.; Crise, B.J.; Malyguine, A.; Kutzler, M.A.; et al. Novel Peptides Based on HIV-1 gp120 Sequence with Homology to Chemokines Inhibit HIV Infection in Cell Culture. PLoS ONE 2011, 6, e14474. [Google Scholar] [CrossRef] [PubMed]
- Poorinmohammad, N.; Mohabatkar, H. A Comparison of Different Machine Learning Algorithms for the Prediction of Anti-HIV-1 Peptides Based on Their Sequence-Related Properties. Int. J. Pept. Res. Ther. 2015, 21, 57–62. [Google Scholar] [CrossRef]
- Iqbal, M.J.; Faye, I.; Samir, B.B.; Said, A.M. Efficient Feature Selection and Classification of Protein Sequence Data in Bioinformatics. Sci. World J. 2014, 2014, 173869. [Google Scholar] [CrossRef] [Green Version]
- Al-Betar, M.; Khader, A.; Liao, I. A harmony search with multi-pitch adjusting rate for the university course timetabling. In Recent Advances in Harmony Search Algorithm; Geem, Z.W., Ed.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 147–161. [Google Scholar]
- Alia, O.M.; Mandava, R. The variants of the harmony search algorithm: An Overview. Artif. Intell. Rev. 2011, 36, 49–68. [Google Scholar] [CrossRef]
- Zhu, Q.; Tang, X.; Elahi, A. Application of the novel harmony search optimization algorithm for DBSCAN clustering. Expert Syst. Appl. 2021, 178, 115054. [Google Scholar] [CrossRef]
- Manjarres, D.; Landa-Torres, I.; Gil-Lopez, S.; Del Ser, J.; Bilbao, M.; Salcedo-Sanz, S.; Geem, Z.W. A survey on applications of the harmony search algorithm. Eng. Appl. Artif. Intell. 2013, 26, 1818–1831. [Google Scholar] [CrossRef]
- Hasan, B.H.F.; Abu Doush, I.; Al Maghayreh, E.; Alkhateeb, F.; Hamdan, M. Hybridizing Harmony Search algorithm with different mutation operators for continuous problems. Appl. Math. Comput. 2014, 232, 1166–1182. [Google Scholar] [CrossRef]
- Poursalehi, N.; Zolfaghari, A.; Minuchehr, A. Differential harmony search algorithm to optimize PWRs loading pattern. Nucl. Eng. Des. 2013, 257, 161–174. [Google Scholar] [CrossRef]
- Yao, N.; Miao, D.; Pedrycz, W.; Zhang, H.; Zhang, Z. Causality measures and analysis: A rough set framework. Expert Syst. Appl. 2019, 136, 187–200. [Google Scholar] [CrossRef]
- Inbarani, H.H.; Bagyamathi, M.; Azar, A.T. A Novel Hybrid Feature Selection Method Based on Rough Set and Improved Harmony Search. Neural Computing and Applications; Springer: Berlin/Heidelberg, Germany, 2015; Volume 26, pp. 1–22. [Google Scholar]
- Mac Parthalain, N.; Jensen, R. Unsupervised fuzzy-rough set-based dimensionality reduction. Inf. Sci. 2013, 229, 106–121. [Google Scholar] [CrossRef]
- Bagyamathi, M.; Inbarani, H.H. A Novel Hybridized Rough Set and Improved Harmony Search Based Feature Selection for Protein Sequence Classification. Big Data in Complex Systems: Challenges and Opportunities, Studies in Big Data; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9, pp. 173–204. [Google Scholar]
- Cao, Y.; Liu, S.; Zhang, L.; Qin, J.; Wang, J.; Tang, K. Prediction of protein structural class with Rough Sets. BMC Bioinform. 2006, 7, 20. [Google Scholar] [CrossRef] [Green Version]
- Anand, A.; Pugalenthi, G.; Suganthan, P. Predicting protein structural class by SVM with class-wise optimized features and decision probabilities. J. Theor. Biol. 2008, 253, 375–380. [Google Scholar] [CrossRef]
- Velayutham, C.; Thangavel, K. Unsupervised quick reduct algorithm using rough set theory. J. Electron. Sci. Technol. 2011, 9, 193–201. [Google Scholar]
- Bagyamathi, M.; Azar, A.T.; Inbarani, H.H. Hybrid Rough Set with Black Hole Optimization Based Feature Selection Algorithm for Protein Structure Prediction. Int. J. Adv. Intell. Paradig. 2018, 10, 1. [Google Scholar] [CrossRef] [Green Version]
- Bagyamathi, M.; Inbarani, H.H. Prediction of Protein Structural Classes by Pseudo Amino Acid Composition Using Improved Harmony Search Relative Reduct Feature Selection and Rough Set Classification Algorithms. Int. J. Invent. Comput. Sci. Eng. 2017, 4, 55–65. [Google Scholar]
- Meher, P.K.; Sahu, T.K.; Saini V and Roa, A.R. Predicting anti-microbial peptides with improved accuracy by incorporating the compositional, physico-chemical and structural features into Chou’s general PseAAC. Sci. Rep. 2017, 7, 42362. [Google Scholar] [CrossRef]
- Azar, A.T.; Kumar, S.S.; Inbarani, H.H.; Hassanien, A.E. Pessimistic multi-granulation rough set-based classification for heart valve disease diagnosis. Int. J. Modeling Identif. Control. 2016, 26, 42–51. [Google Scholar] [CrossRef]
- Zare, M.; Mohabatkar, H.; Faramarzi, F.K.; Beigi, M.M.; Behbahani, M. Using Chou’s Pseudo Amino Acid Composition and Machine Learning Method to predict the Antiviral Peptides. Open Bioinform. J. 2015, 9, 13–19. [Google Scholar] [CrossRef]
- Bagyamathi, M.; Inbarani, H.H. Feature Selection using Improved Harmony Search Hybridized with Relative Reduct for Medical Data Classification. Int. J. Appl. Eng. Res. (IJAER) 2015, 10, 19476–19480. [Google Scholar]
- Bagyamathi, M.; Inbarani, H.H. Feature Selection using Relative Reduct hybridized with Improved Harmony Search for Protein Sequence Classification. Int. J. Trend Res. Dev. 2015. Available online: http://www.ijtrd.com/papers/IJTRD1328.pdf (accessed on 10 January 2022).
- Barrett, R.; Jiang, S.; White, A.D. Classifying antimicrobial and multifunctional peptides with Bayesian network models. Pept. Sci. 2018, 110, e24079. [Google Scholar] [CrossRef] [Green Version]
- Tantisatirapong, S.; Davies, N.P.; Rodriguez, D.; Abernethy, L.; Auer, D.P.; Clark, C.A.; Arvanitis, T.N. Magnetic Resonance Texture Analysis: Optimal Feature Selection in Classifying Child Brain Tumors. In Proceedings of the XIII Mediterranean Conference on Medical and Biological Engineering and Computing, Seville, Spain, 25–28 September 2013; pp. 309–312. [Google Scholar]
- Hajisharifi, Z.; Piryaiee, M.; Beigi, M.M.; Behbahani, M.; Mohabatkar, H. Predicting anticancer peptides with Chou’s pseudo amino acid composition and investigating their mutagenicity via Ames test. J. Theor. Biol. 2014, 341, 34–40. [Google Scholar] [CrossRef]
- Inbarani, H.H.; Azar, A.T.; Jothi, G. Supervised hybrid feature selection based on PSO and rough sets for medical diagnosis. Comput. Methods Programs Biomed. 2014, 113, 175–185. [Google Scholar] [CrossRef]
- Azar, A.T. Neuro-fuzzy feature selection approach based on linguistic hedges for medical diagnosis. Int. J. Model. Identif Control. (IJMIC) 2014, 22, 195–206. [Google Scholar] [CrossRef]
- Jothi, G.; Inbarani, H.H.; Azar, A.T. Hybrid tolerance-PSO based supervised feature selection for digital mammogram images. Int. J. Fuzzy Syst Appl (IJFSA) 2013, 3, 15–30. [Google Scholar]
- Qureshi, A.; Thakur, N.; Kumar, M. HIPdb: A database of experimentally validated HIV inhibiting peptides. PLoS ONE 2013, 8, e54908. [Google Scholar] [CrossRef] [Green Version]
- Du, P.; Wang, X.; Xu, C.; Gao, Y. PseAAC-Builder: A Cross-Platform Stand-Alone Program for Generating Various Special Chou’s Pseudo-Amino Acid Compositions. Anal. Biochem. 2012, 425, 117–119. [Google Scholar] [CrossRef]
- Khosravian, M.; Faramarzi, F.K.; Beigi, M.M.; Behbahani, M.; Mohabatkar, H. Predicting Antibacterial Peptides by the Concept of Chou’s Pseudo-Amino Acid Composition and Machine Learning Methods. Protein Pept. Lett. 2013, 20, 180–186. [Google Scholar] [CrossRef]
- Beniwal, S.; Arora, J. Classification and feature selection techniques in data Mining. Int. J. Eng. Research Technol. 2012, 1, 2278–2284. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D. Discretization Techniques: A recent survey. GESTS Int. Trans. Comput. Sci. Eng. 2006, 32, 47–58. [Google Scholar]
- Ali, R.; Siddiqi, M.H.; Lee, S. Rough set-based approaches for discretization: A compact review. Artif. Intell. Rev. 2015, 44, 235–263. [Google Scholar] [CrossRef]
- Tsoukalas, A.; Parpas, P.; Rustem, B. A smoothing algorithm for finite min–max–min problems. Optim. Lett. 2008, 3, 49–62. [Google Scholar] [CrossRef]
- Sathishkumar, E.N.; Thangavel, K.; Nishama, A. Comparative analysis of discretization methods for gene selection of breast cancer gene expression data. In Computational Intelligence, Cyber Security and Computational Models; Springer: Coimbatore, India, 2014; pp. 373–378. [Google Scholar]
- Anaraki, J.R.; Eftekhari, M. Rough set based feature selection: A Review Fifth conference on information and knowledge technology (IKT). IEEE 2013, 2013, 301–306. [Google Scholar] [CrossRef]
- Bagyamathi, M.; Inbarani, H.H. Prediction of Protein Structural Classes using Rough Set based Feature Selection and Classification Framework. J. Recent Res. Eng. Technol. 2017, 4, 1–9. [Google Scholar]
- Geem, Z.W. Particle-Swarm Harmony Search for Water Network Design. Eng. Optim. 2009, 41, 297–311. [Google Scholar] [CrossRef]
- Inbarani, H.H.; Banu, P.K.N.; Azar, A.T. Feature selection using swarm based relative reduct technique for fetal heart rate. Neural Comput. Appl. 2014, 25, 793–806. [Google Scholar] [CrossRef]
- Kumar, S.U.; Inbarani, H.H.; Kumar, S.S. Improved Bijective-Soft-Set-Based Classification for Gene Expression Data. Computational Intelligence, Cyber Security and Computational Models. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2014; Volume 246, pp. 127–132. [Google Scholar]
- Kumar, S.U.; Inbarani, H.H. PSO-based feature selection and neighborhood rough set-based classification for BCI multiclass motor imagery task. Neural Comput. Appl. 2016, 28, 3239–3258. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, G.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann Publishers: Amsterdam, The Netherlands, 2016; ISBN 978-0-12-804291-5. [Google Scholar]
- Thakur, N.; Qureshi, A.; Kumar, M. AVPpred: Collection and prediction of highly effective antiviral peptides. Nucleic Acids Res. 2012, 40, W199–W204. [Google Scholar] [CrossRef] [Green Version]
- Salam, M.A.; Azar, A.T.; Elgendy, M.S.; Fouad, K.M. The Effect of Different Dimensionality Reduction Techniques on Machine Learning Overfitting Problem. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 641–655. [Google Scholar] [CrossRef]
- Azar, A.T.; Anter, A.M.; Fouad, K.M. Intelligent system for feature selection based on rough set and chaotic binary grey wolf optimization. Int. J. Comput. Appl. Technol. 2020, 63, 4–24. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Author | Purpose and Methodology |
|---|---|
| Poorinmohammad et al. [6] | Anti-HIV-1 peptides are predicted using the InfoGainAttributeEval feature selection algorithm and MLP, K-Star, J48, Random Forest, and LMT classification algorithms on the Weka framework. |
| Bagyamathi and Inbarani [7] | The protein sequences are classified into four structural classes using benchmark classifiers. The RSIHSQR feature selection algorithm gradually improves the precision of the classification algorithm. |
| Inbarani et al. [21] | The primary protein sequences are classified with the PseAAC feature subset selected by Rough Set Black Hole Quick Reduct (RSBHQR) and Rough Set Black Hole Relative Reduct (RSBHRR) benchmark classification algorithms. |
| Bagyamathi and Inbarani [22] | In this study, the structural protein classes are predicted by RSC algorithm using the selected features by the RSIHSQR algorithm. |
| Meher eta l. [23] | In this study, anti-microbial peptides are predicted with a support vector machine (SVM) using physicochemical and structural features extracted from peptides and developed an aiAMPpred online tool for the prediction of the anti-microbial peptide. |
| Azar et al. [24] | In this study, the Pessimistic Multi-Granulation Rough Sets (PMGRS) classification algorithm is implemented to diagnose heart valve disease. |
| Zare et al. [25] | In this study, the antiviral peptides are predicted by RBF, Naïve Bayes, J48, Decision Stump, and REPTree classification techniques. |
| Bagyamathi and Inbarani [26] | In this study, the imperative features are selected by RSIHSRR algorithm for the medical data classification. |
| Bagyamathi and Inbarani [27] | The structural classes of the protein are predicted using the subset of features selected by RSIHSRR algorithm, and classification algorithms evaluate the originality of the feature subset. |
| Barrett et al. [28] | In this work, the peptides are modeled by statistical methods by concurrently predicting amino acid sequence motifs. The motif-based method is used to elucidate the functional motifs in anti-microbial activity. |
| Tantisatirapong et al. [29] | This work investigates principal component analysis, max-relevance, and min-redundancy feed-forward selection for brain tumor classification. |
| Hajisharifi et al. [30] | This study uses a SVM classification algorithm on anti-cancer. Chou’s PseAAC based features are applied to the proposed classification algorithm. |
| Inbarani et al. [31] | This study analyzes the medical dataset with RSPSOQR and RSPSORR feature selection for disease identification. |
| Azar et al. [32] | This study proposes a linguistic hedges neuro-fuzzy classifier (LHNFCSF) for the medical diagnosis with the selected features. |
| Jothi et al. [33] | In this paper, the mammogram images are selected using STRSPSOQR and STRSPSO-RR algorithms to select the best features. |
| FS Algorithm | No. of Selected Features | Selected Features |
|---|---|---|
| RSIHSRR | 6 | pk1_pk2_pI Hydrophobicity_mass_pk2_pI Hydrophilicity_mass_pk2_pI Hydrophobicity_hydrophilicity_mass_pk1_pk2 Hydrophobicity_hydrophilicity_mass_pk2_pI Hydrophilicity_mass_pk1_pk2_pI |
| RSIHSQR | 7 | pk2_pI Mass_pk1_pI Hydrophobicity_hydrophilicity_ pI Hydrophobicity_hydrophilicity_ pk1_ pI Hydrophobicity_hydrophilicity_mass_pk2_pI Hydrophobicity_ mass_ pk2_pI Hydrophilicity_mass_pk2_pI |
| RSPSORR | 10 | Hydrophobicity Hydrophobicity_hydrophilicity Hydrophilicity_pk1 pk1_pI pk2_pI Hydrophobicity_hydrophilicity_pk1 Hydrophobicity_pk1_pk2 Hydrophobicity_pk1_pI Hydrophobicity_hydrophilicity_mass_pk1_pk2 Hydrophobicity_hydrophilicity_mass_pk1_ pk2_pI |
| RSPSOQR | 12 | Hydrophobicity pk2 Hydrophobicity_mass Hydrophobicity_pk1 Hydrophilicity_mass Mass_pI pk1_pk2 pk1_pI Hydrophobicity_hydrophilicity_pk1 Hydrophobicity_pk1_pk2 Hydrophobicity_hydrophilicity_mass_pk1 Hydrophobicity_hydrophilicity_mass_pk1_pk2 |
| Classification Technique | FS Algorithm | Precision | Recall | F-Measure | Kulczynski Index | Fowlkes–Mallows Index |
|---|---|---|---|---|---|---|
| Naïve Bayes | RSIHSRR | 0.793 | 0.790 | 0.788 | 0.792 | 0.791 |
| RSIHSQR | 0.796 | 0.790 | 0.786 | 0.793 | 0.793 | |
| RSPSORR | 0.625 | 0.593 | 0.578 | 0.609 | 0.609 | |
| RSPSOQR | 0.620 | 0.593 | 0.581 | 0.607 | 0.606 | |
| IBK | RSIHSRR | 0.964 | 0.958 | 0.952 | 0.961 | 0.961 |
| RSIHSQR | 0.927 | 0.926 | 0.926 | 0.927 | 0.926 | |
| RSPSORR | 0.788 | 0.786 | 0.782 | 0.787 | 0.787 | |
| RSPSOQR | 0.742 | 0.741 | 0.741 | 0.742 | 0.741 | |
| J48 | RSIHSRR | 0.865 | 0.862 | 0.863 | 0.864 | 0.863 |
| RSIHSQR | 0.821 | 0.814 | 0.812 | 0.818 | 0.817 | |
| RSPSORR | 0.679 | 0.677 | 0.677 | 0.678 | 0.678 | |
| RSPSOQR | 0.783 | 0.783 | 0.783 | 0.783 | 0.783 | |
| Random Forest | RSIHSRR | 0.823 | 0.823 | 0.823 | 0.823 | 0.823 |
| RSIHSQR | 0.823 | 0.823 | 0.823 | 0.823 | 0.823 | |
| RSPSORR | 0.670 | 0.670 | 0.670 | 0.670 | 0.670 | |
| RSPSOQR | 0.790 | 0.790 | 0.790 | 0.790 | 0.790 | |
| JRip | RSIHSRR | 0.945 | 0.948 | 0.947 | 0.947 | 0.946 |
| RSIHSQR | 0.925 | 0.929 | 0.928 | 0.927 | 0.927 | |
| RSPSORR | 0.827 | 0.826 | 0.824 | 0.827 | 0.826 | |
| RSPSOQR | 0.838 | 0.832 | 0.830 | 0.835 | 0.835 | |
| Rough Set Classifier (RSC) | RSIHSRR | 0.956 | 0.942 | 0.941 | 0.948 | 0.940 |
| RSIHSQR | 0.915 | 0.924 | 0.938 | 0.968 | 0.962 | |
| RSPSORR | 0.825 | 0.936 | 0.854 | 0.917 | 0.966 | |
| RSPSOQR | 0.883 | 0.843 | 0.811 | 0.839 | 0.835 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mathiyazhagan, B.; Liyaskar, J.; Azar, A.T.; Inbarani, H.H.; Javed, Y.; Kamal, N.A.; Fouad, K.M. Rough Set Based Classification and Feature Selection Using Improved Harmony Search for Peptide Analysis and Prediction of Anti-HIV-1 Activities. Appl. Sci. 2022, 12, 2020. https://doi.org/10.3390/app12042020
Mathiyazhagan B, Liyaskar J, Azar AT, Inbarani HH, Javed Y, Kamal NA, Fouad KM. Rough Set Based Classification and Feature Selection Using Improved Harmony Search for Peptide Analysis and Prediction of Anti-HIV-1 Activities. Applied Sciences. 2022; 12(4):2020. https://doi.org/10.3390/app12042020
Chicago/Turabian StyleMathiyazhagan, Bagyamathi, Joseph Liyaskar, Ahmad Taher Azar, Hannah H. Inbarani, Yasir Javed, Nashwa Ahmad Kamal, and Khaled M. Fouad. 2022. "Rough Set Based Classification and Feature Selection Using Improved Harmony Search for Peptide Analysis and Prediction of Anti-HIV-1 Activities" Applied Sciences 12, no. 4: 2020. https://doi.org/10.3390/app12042020
APA StyleMathiyazhagan, B., Liyaskar, J., Azar, A. T., Inbarani, H. H., Javed, Y., Kamal, N. A., & Fouad, K. M. (2022). Rough Set Based Classification and Feature Selection Using Improved Harmony Search for Peptide Analysis and Prediction of Anti-HIV-1 Activities. Applied Sciences, 12(4), 2020. https://doi.org/10.3390/app12042020