
A Comprehensive Review of Deep Learning-Based Crack Detection Approaches



Abstract
:1. Introduction
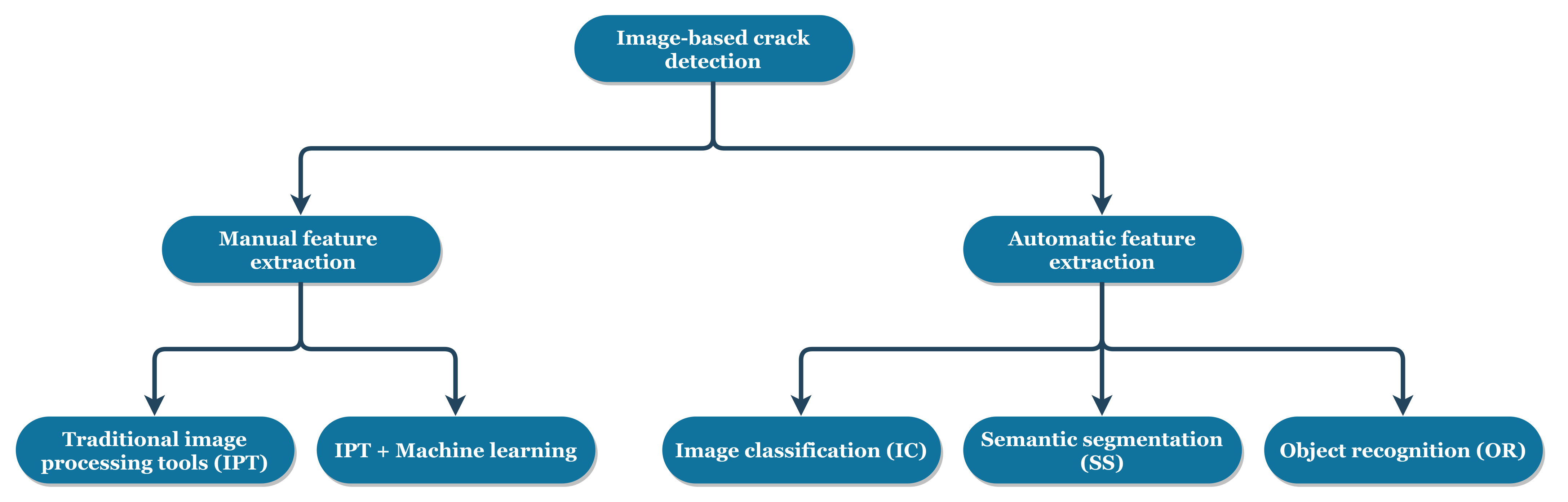
2. Automatic Feature Extraction
2.1. Image Classification
2.2. Object Recognition
2.2.1. R-CNN Family
2.2.2. SSD
2.2.3. YOLO Family
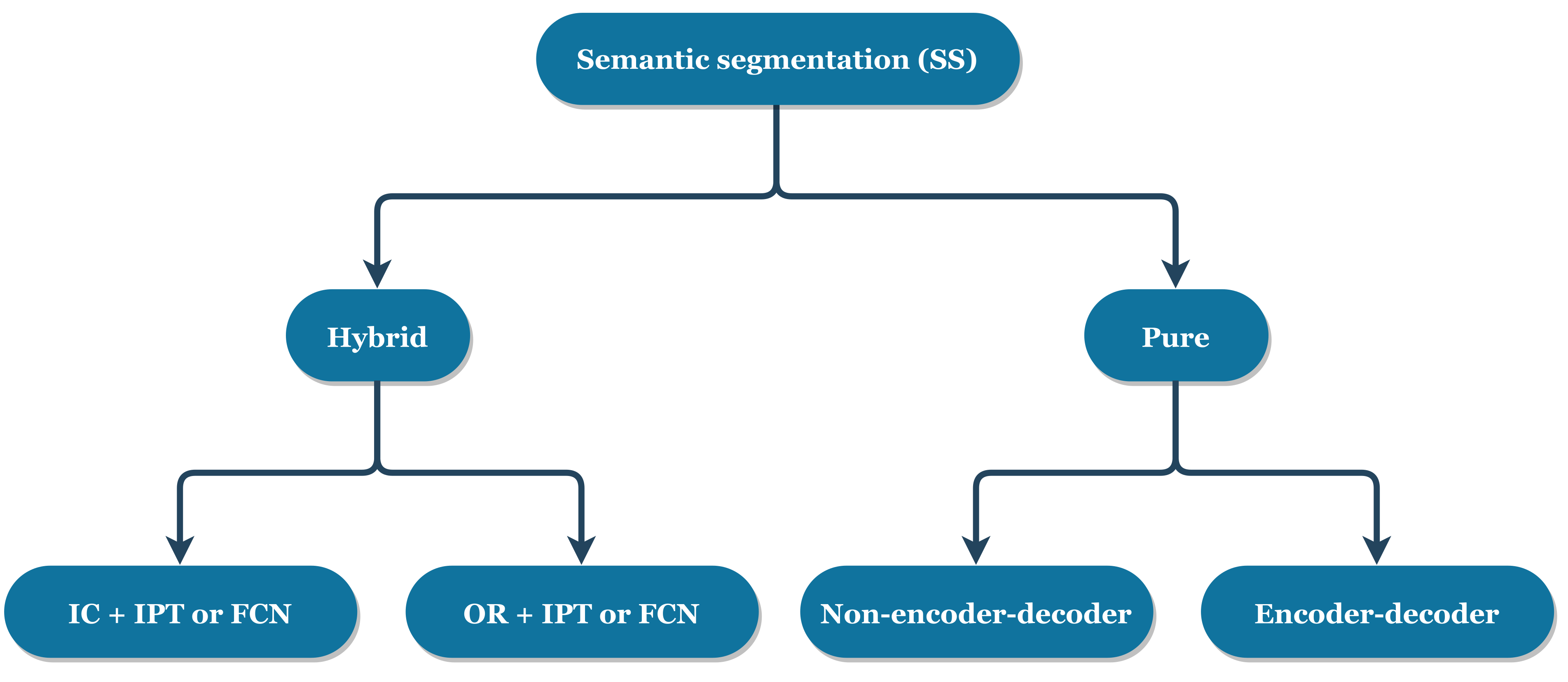
2.3. Semantic Segmentation
2.3.1. Hybrid Semantic Segmentation
2.3.2. Pure Semantic Segmentation
3. Public Data Sets
3.1. CFD Data Set
3.2. Aigle-RN Data Set
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cagle, R.F. Infrastructure Asset Management: An Emerging Direction; AACE International Transactions: Morgantown, WV, USA, 2003; pp. PM21–PM26. [Google Scholar]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef] [Green Version]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2017, 33, 731–747. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Gu, Y.; Zhu, H.; Lim, J.H. A novel hybrid approach for crack detection. Pattern Recognit. 2020, 107, 107474. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Kelly, J.S.; Masri, S.F.; Sukhatme, G.S. A survey and evaluation of promising approaches for automatic image-based defect detection of bridge structures. Struct. Infrastruct. Eng. 2009, 5, 455–486. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Cord, A.; Chambon, S. Automatic Road Defect Detection by Textural Pattern Recognition Based on AdaBoost. Comput.-Aided Civ. Infrastruct. Eng. 2011, 27, 244–259. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 2009 17th European Signal Processing Conference, Glasgow, UK, 24–28 August 2009; pp. 622–626. [Google Scholar]
- Prasanna, P.; Dana, K.J.; Gucunski, N.; Basily, B.B.; La, H.M.; Lim, R.S.; Parvardeh, H. Automated Crack Detection on Concrete Bridges. IEEE Trans. Autom. Sci. Eng. 2016, 13, 591–599. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Chen, J.H.; Su, M.C.; Cao, R.; Hsu, S.C.; Lu, J.C. A self organizing map optimization based image recognition and processing model for bridge crack inspection. Autom. Constr. 2017, 73, 58–66. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Hsieh, Y.A.; Tsai, Y.J. Machine Learning for Crack Detection: Review and Model Performance Comparison. J. Comput. Civ. Eng. 2020, 34, 04020038. [Google Scholar] [CrossRef]
- Gopalakrishnan, K. Deep Learning in Data-Driven Pavement Image Analysis and Automated Distress Detection: A Review. Data 2018, 3, 28. [Google Scholar] [CrossRef] [Green Version]
- Cao, W.; Liu, Q.; He, Z. Review of Pavement Defect Detection Methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Farrar, C.R.; Worden, K. Structural Health Monitoring: A Machine Learning Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Ramabhadran, B.; Khudanpur, S.; Arisoy, E. Proceedings of the NAACL-HLT 2012 Workshop: Will We Ever Really Replace the N-gram Model? On the Future of Language Modeling for HLT. IEEE Comput. Intell. Mag. 2012, 13, 55–75. [Google Scholar]
- Hinton, G.; Salakhutdinov, R. Discovering Binary Codes for Documents by Learning Deep Generative Models. Top. Cogn. Sci. 2010, 3, 74–91. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2013, 187, 27–48. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Sabokrou, M.; Fayyaz, M.; Fathy, M.; Moayed, Z.; Klette, R. Deep-anomaly: Fully convolutional neural network for fast anomaly detection in crowded scenes. Comput. Vis. Image Underst. 2018, 172, 88–97. [Google Scholar] [CrossRef] [Green Version]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Yokoyama, S.; Matsumoto, T. Development of an Automatic Detector of Cracks in Concrete Using Machine Learning. Procedia Eng. 2017, 171, 1250–1255. [Google Scholar] [CrossRef]
- Pauly, L.; Hogg, D.; Fuentes, R.; Peel, H. Deeper networks for pavement crack detection. In Proceedings of the 34th International Symposium in Automation and Robotics in Construction, Taipei, Taiwan, 28 June–1 July 2017; pp. 479–485. [Google Scholar]
- Li, B.; Wang, K.C.P.; Zhang, A.; Yang, E.; Wang, G. Automatic classification of pavement crack using deep convolutional neural network. Int. J. Pavement Eng. 2020, 21, 457–463. [Google Scholar] [CrossRef]
- Nhat-Duc, H.; Nguyen, Q.L.; Tran, V.D. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Autom. Constr. 2018, 94, 203–213. [Google Scholar] [CrossRef]
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045. [Google Scholar] [CrossRef]
- Kim, H.; Ahn, E.; Shin, M.; Sim, S.H. Crack and Noncrack Classification from Concrete Surface Images Using Machine Learning. Struct. Health Monit. 2019, 18, 725–738. [Google Scholar] [CrossRef]
- Feng, C.; Liu, M.Y.; Kao, C.C.; Lee, T.Y. Deep Active Learning for Civil Infrastructure Defect Detection and Classification. Comput. Civ. Eng. 2017, 2017, 298–306. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Hu, Z. Grid-based pavement crack analysis using deep learning. In Proceedings of the 2017 4th International Conference on Transportation Information and Safety (ICTIS), Banff, AB, Canada, 8–10 August 2017. [Google Scholar] [CrossRef]
- Park, S.; Bang, S.; Kim, H.; Kim, H. Patch-Based Crack Detection in Black Box Images Using Convolutional Neural Networks. J. Comput. Civ. Eng. 2019, 33, 04019017. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Shin, H.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- da Silva, W.R.L.; de Lucena, D.S. Concrete Cracks Detection Based on Deep Learning Image Classification. Proceedings 2018, 2, 489. [Google Scholar] [CrossRef] [Green Version]
- Kim, B.; Cho, S. Automated Vision-Based Detection of Cracks on Concrete Surfaces Using a Deep Learning Technique. Sensors 2018, 18, 3452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dorafshan, S.; Thomas, R.J.; Coopmans, C.; Maguire, M. Deep Learning Neural Networks for sUAS-Assisted Structural Inspections: Feasibility and Application. In Proceedings of the 2018 International Conference on Unmanned Aircraft Systems (ICUAS), Dallas, TX, USA, 12–15 June 2018. [Google Scholar] [CrossRef]
- Vedaldi, A.; Lenc, K. MatConvNet. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015. [Google Scholar] [CrossRef]
- Kang, D.; Cha, Y.J. Autonomous UAVs for Structural Health Monitoring Using Deep Learning and an Ultrasonic Beacon System with Geo-Tagging. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 885–902. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, A.; Li, J.Q.; Fei, Y.; Chen, C.; Li, B. Deep learning for asphalt pavement cracking recognition using convolutional neural network. In Proceedings of the 2017 International Conference on Highway Pavements and Airfield Technology, Philadelphia, PA, USA, 27–30 August 2017. [Google Scholar]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Kim, I.H.; Jeon, H.; Baek, S.C.; Hong, W.H.; Jung, H.J. Application of Crack Identification Techniques for an Aging Concrete Bridge Inspection Using an Unmanned Aerial Vehicle. Sensors 2018, 18, 1881. [Google Scholar] [CrossRef] [Green Version]
- Li, R.; Yuan, Y.; Zhang, W.; Yuan, Y. Unified Vision-Based Methodology for Simultaneous Concrete Defect Detection and Geolocalization. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 527–544. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Zhai, J.; Xu, Z.; Chen, Y. Detection of sealed and unsealed cracks with complex backgrounds using deep convolutional neural network. Autom. Constr. 2019, 107, 102946. [Google Scholar] [CrossRef]
- Deng, J.; Lu, Y.; Lee, V.C.S. Concrete crack detection with handwriting script interferences using faster region-based convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 373–388. [Google Scholar] [CrossRef]
- Ciaparrone, G.; Serra, A.; Covito, V.; Finelli, P.; Scarpato, C.A.; Tagliaferri, R. A Deep Learning Approach for Road Damage Classification. In Lecture Notes in Electrical Engineering; Springer: Singapore, 2018; pp. 655–661. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated Road Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar]
- Pohlen, T.; Hermans, A.; Mathias, M.; Leibe, B. Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhang, Z.; Fidler, S.; Urtasun, R. Instance-Level Segmentation for Autonomous Driving With Deep Densely Connected MRFs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lee, D.C.; Hebert, M.; Kanade, T. Geometric reasoning for single image structure recovery. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2136–2143. [Google Scholar] [CrossRef] [Green Version]
- Kundu, A.; Li, Y.; Dellaert, F.; Li, F.; Rehg, J.M. Joint Semantic Segmentation and 3D Reconstruction from Monocular Video. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 703–718. [Google Scholar] [CrossRef] [Green Version]
- Pham, Q.; Hua, B.; Nguyen, T.; Yeung, S. Real-Time Progressive 3D Semantic Segmentation for Indoor Scenes. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 1089–1098. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Lee, D.; Kim, J.; Lee, D. Robust Concrete Crack Detection Using Deep Learning-Based Semantic Segmentation. Int. J. Aeronaut. Space Sci. 2019, 20, 287–299. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M.; Azim, M.R. Densely connected deep neural network considering connectivity of pixels for automatic crack detection. Autom. Constr. 2020, 110, 103018. [Google Scholar] [CrossRef]
- Kalfarisi, R.; Wu, Z.Y.; Soh, K. Crack Detection and Segmentation Using Deep Learning with 3D Reality Mesh Model for Quantitative Assessment and Integrated Visualization. J. Comput. Civ. Eng. 2020, 34, 04020010. [Google Scholar] [CrossRef]
- Kang, D.; Benipal, S.S.; Gopal, D.L.; Cha, Y.J. Hybrid pixel-level concrete crack segmentation and quantification across complex backgrounds using deep learning. Autom. Constr. 2020, 118, 103291. [Google Scholar] [CrossRef]
- Ni, F.; Zhang, J.; Chen, Z. Zernike-moment measurement of thin-crack width in images enabled by dual-scale deep learning. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 367–384. [Google Scholar] [CrossRef]
- Zhang, K.; Cheng, H.D.; Zhang, B. Unified Approach to Pavement Crack and Sealed Crack Detection Using Preclassification Based on Transfer Learning. J. Comput. Civ. Eng. 2018, 32, 04018001. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wei, F.; Yao, G.; Yang, Y.; Sun, Y. Instance-level recognition and quantification for concrete surface bughole based on deep learning. Autom. Constr. 2019, 107, 102920. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Image-based concrete crack assessment using mask and region-based convolutional neural network. Struct. Control Health Monit. 2019, 26, e2381. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Fang, F.; Li, L.; Rice, M.; Lim, J. Towards Real-Time Crack Detection Using a Deep Neural Network With a Bayesian Fusion Algorithm. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2976–2980. [Google Scholar] [CrossRef]
- Tan, C.; Uddin, N.; Mohammed, Y.M. Deep Learning-Based Crack Detection Using Mask R-CNN Technique. In Proceedings of the 9th International Conference on Structural Health Monitoring of Intelligent Infrastructure, St. Louis, MI, USA, 4–7 August 2019. [Google Scholar]
- Ni, F.; Zhang, J.; Chen, Z. Pixel-level crack delineation in images with convolutional feature fusion. Struct. Control Health Monit. 2019, 26, e2286. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Rajan, D.; Story, B. Concrete crack detection using context-aware deep semantic segmentation network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 951–971. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Zhang, K.; Cheng, H.; Gai, S. Efficient Dense-Dilation Network for Pavement Cracks Detection with Large Input Image Size. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 884–889. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, Y.; Lu, J.; Li, W. Automatic Pavement Crack Detection Based on Structured Prediction with the Convolutional Neural Network. arXiv 2018, arXiv:1802.02208. [Google Scholar]
- Fan, Z.; Li, C.; Chen, Y.; Mascio, P.D.; Chen, X.; Zhu, G.; Loprencipe, G. Ensemble of Deep Convolutional Neural Networks for Automatic Pavement Crack Detection and Measurement. Coatings 2020, 10, 152. [Google Scholar] [CrossRef] [Green Version]
- Zhang, A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Tao, S.; Chen, C.; Li, J.Q.; Li, B. Deep Learning–Based Fully Automated Pavement Crack Detection on 3D Asphalt Surfaces with an Improved CrackNet. J. Comput. Civ. Eng. 2018, 32, 04018041. [Google Scholar] [CrossRef] [Green Version]
- Fei, Y.; Wang, K.C.P.; Zhang, A.; Chen, C.; Li, J.Q.; Liu, Y.; Yang, G.; Li, B. Pixel-Level Cracking Detection on 3D Asphalt Pavement Images Through Deep-Learning- Based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2020, 21, 273–284. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Fei, Y.; Liu, Y.; Chen, C.; Yang, G.; Li, J.Q.; Yang, E.; Qiu, S. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces with a Recurrent Neural Network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 213–229. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- David Jenkins, M.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A Deep Convolutional Neural Network for Semantic Pixel-Wise Segmentation of Road and Pavement Surface Cracks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.; Xiong, W.; Chen, W.; Gu, Y.; Li, Y. Pixel-level Crack Detection using U-Net. In Proceedings of the TENCON 2018—2018 IEEE Region 10 Conference, Jeju, Korea, 28–31 October 2018. [Google Scholar] [CrossRef]
- Konig, J.; Jenkins, M.D.; Barrie, P.; Mannion, M.; Morison, G. A Convolutional Neural Network for Pavement Surface Crack Segmentation Using Residual Connections and Attention Gating. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar] [CrossRef] [Green Version]
- Escalona, U.; Arce, F.; Zamora, E.; Sossa Azuela, J.H. Fully convolutional networks for automatic pavement crack segmentation. Comput. Sist. 2019, 23, 451–460. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Wei, J.; Loprencipe, G.; Chen, X.; Di Mascio, P. Automatic Crack Detection on Road Pavements Using Encoder-Decoder Architecture. Materials 2020, 13, 2960. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Y.; Cheng, H. CrackGAN: Pavement Crack Detection Using Partially Accurate Ground Truths Based on Generative Adversarial Learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1306–1319. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Chen, T.; Cai, Z.; Zhao, X.; Chen, C.; Liang, X.; Zou, T.; Wang, P. Pavement crack detection and recognition using the architecture of segNet. J. Ind. Inf. Integr. 2020, 18, 100144. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–decoder network for pixel-level road crack detection in black-box images. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Li, S.; Zhao, X.; Zhou, G. Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M. Multi-level feature fusion in densely connected deep-learning architecture and depth-first search for crack segmentation on images collected with smartphones. Struct. Health Monit. 2020, 19, 1726–1744. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M. A cost effective solution for pavement crack inspection using cameras and deep neural networks. Constr. Build. Mater. 2020, 256, 119397. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Wang, J.; Wang, L.; Yue, X.G. Concrete Cracks Detection Based on FCN with Dilated Convolution. Appl. Sci. 2019, 9, 2686. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic Crack Detection on Two-Dimensional Pavement Images: An Algorithm Based on Minimal Path Selection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer Convolutional Features for Edge Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
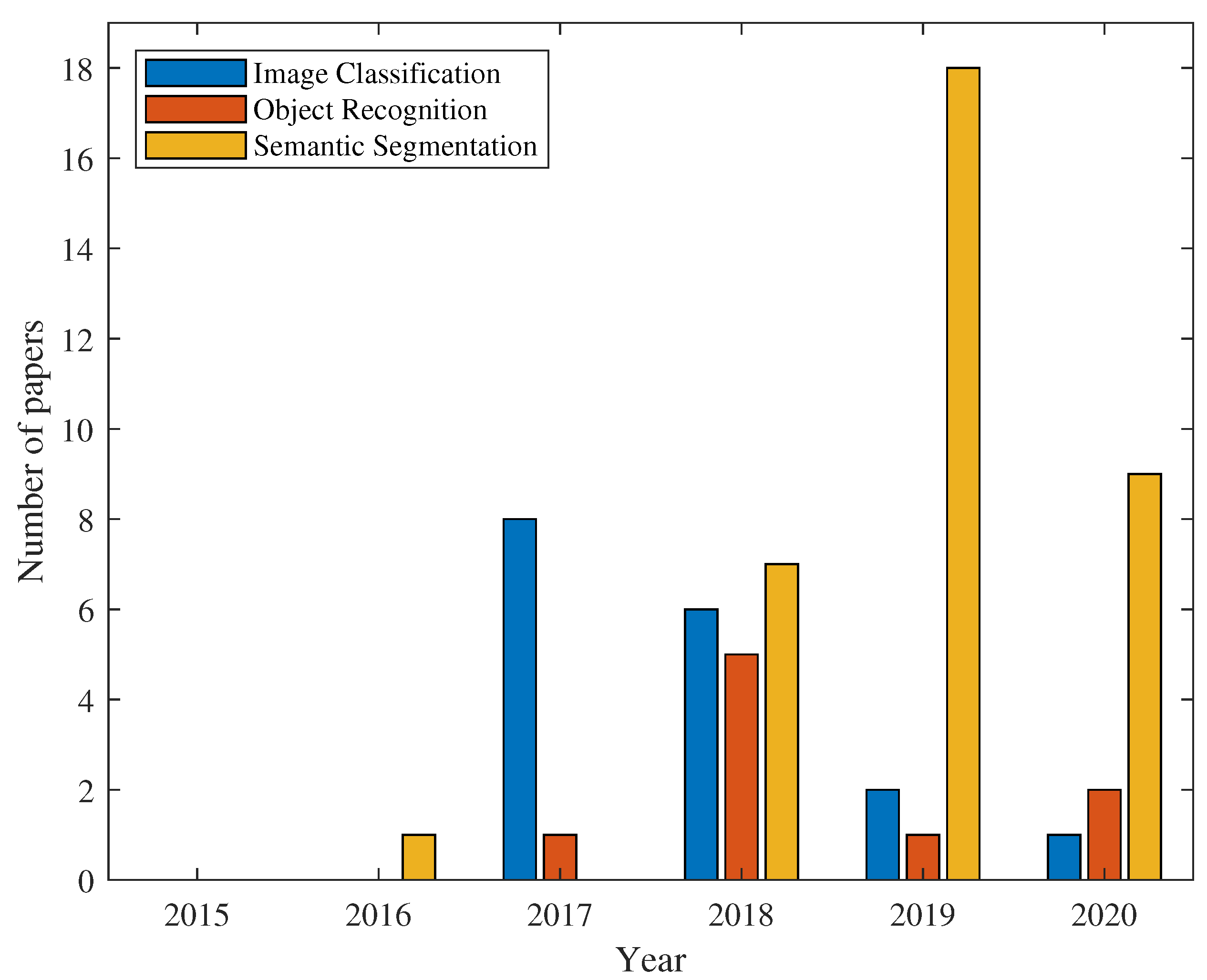
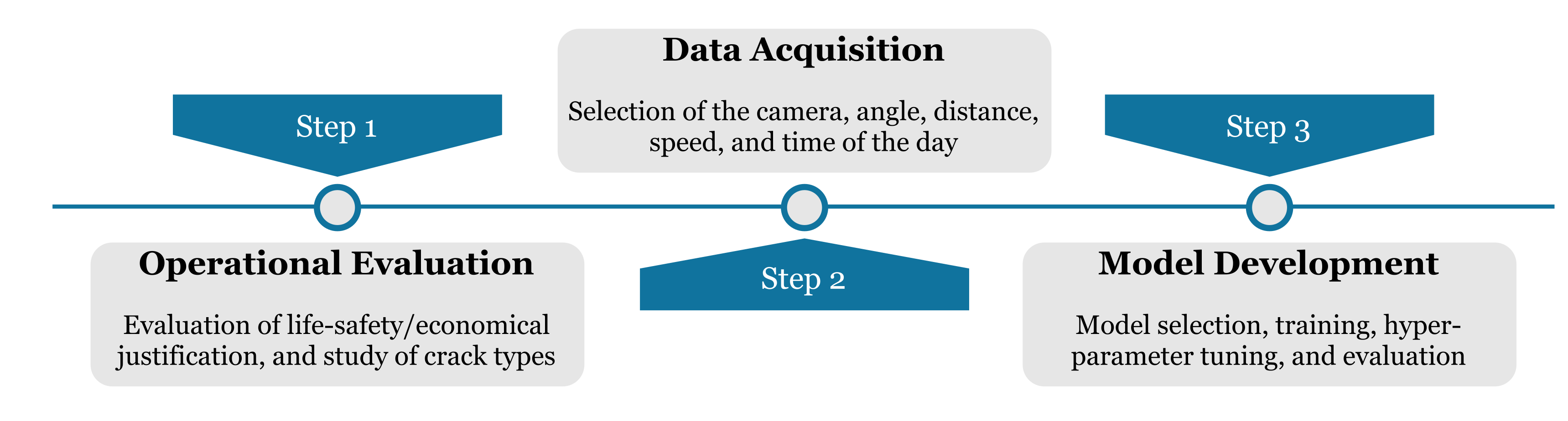




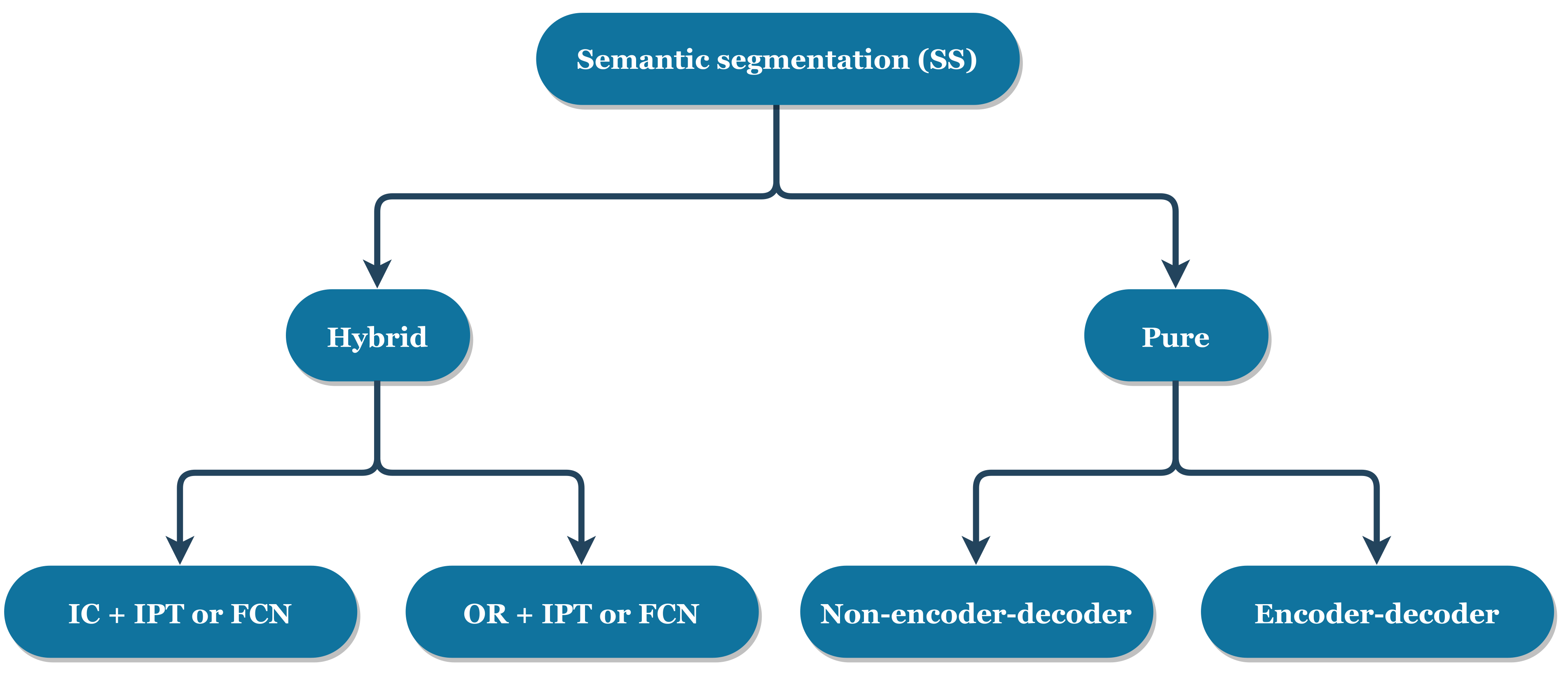

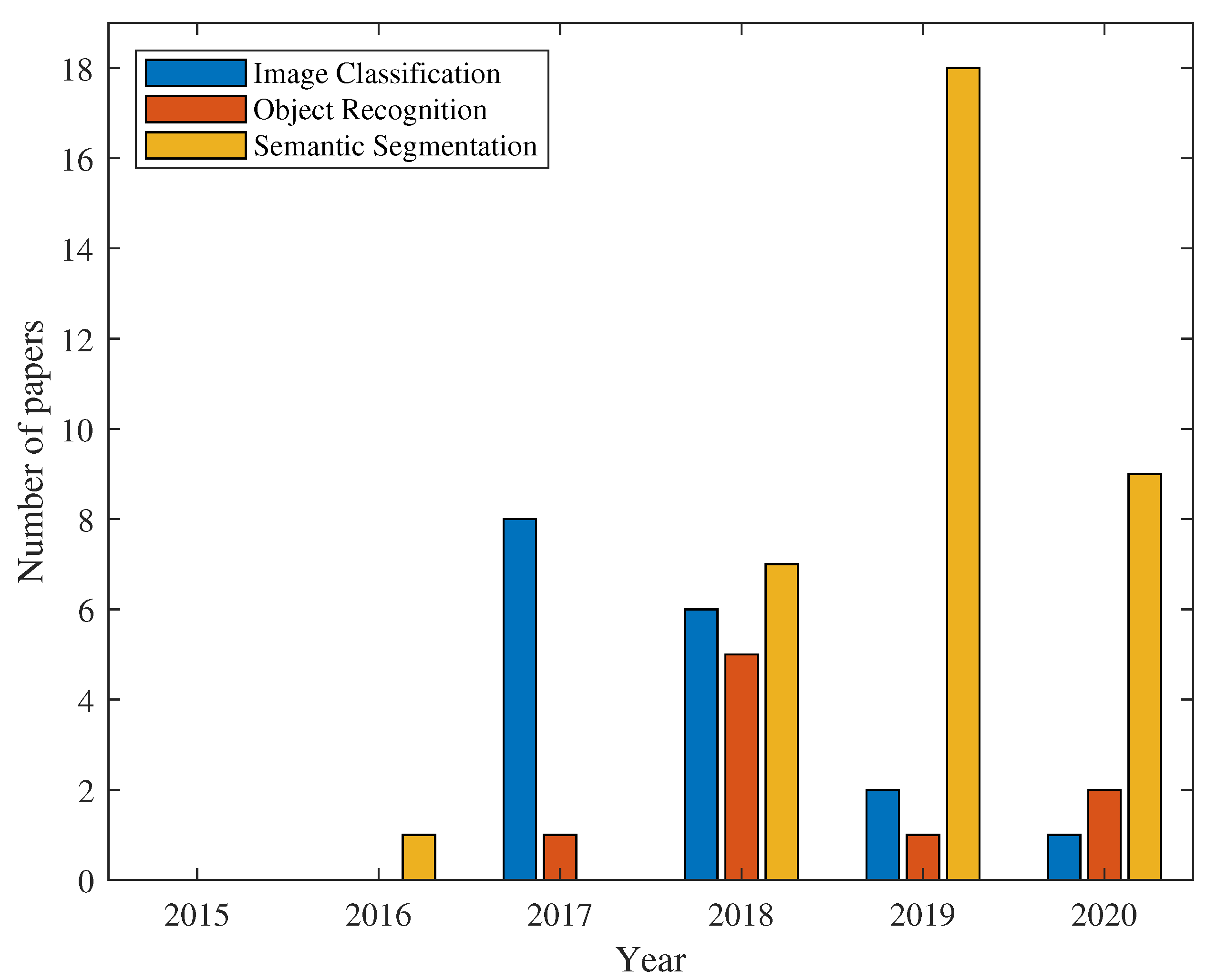{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Novelty/Novelties | Core Architecture |
|---|---|---|
| [24] | The first application of deep learning for crack classification using an IC setting. | - |
| [23] | Application of a sliding window technique resulting in scanning images with any resolution at the testing phase. | MatConvNet |
| [25] | Investigation of the effect of the number of layers on the performance. | - |
| [31] | 1. Investigation of the effect of patch size on the performance. 2. Crack type classification using PCA. | - |
| [30] | 1. Crack type classification. 2. Applying active learning in the training phase. | ResNet |
| [37] | 1. Application of the pre-trained VGG-16 on ImageNet data for feature extraction. 2. Application of classical machine learning algorithms to classify the extracted features. | VGG-16 |
| [44] | Utilization of a larger data set with complex and diverse pavement surfaces (3D images). | - |
| [45] | 1. Application of a shallow network (inspired by LeNet) and ANIVOS architecture (inspired by VGG and AlexNet) to perform deep crack detection. 2. Collecting and making GAPs data set publicly available. | LeNet, AlexNet, VGG-models |
| [27] | IC of road images into crack and non-crack images using deep learning and comparing the performance with handcrafted features-based approaches. | - |
| [41] | Performing a comparison between the application of AlexNet for crack detection in two settings of (i) training from scratch and (ii) transfer learning. | AlexNet |
| [28] | Performing a comparative study between the application of deep architectures relying on transfer learning and different edge detectors to perform crack detection. | AlexNet |
| [43] | In addition to crack detection, performing crack geo-localization using ultrasonic beacon system to cope with the limitations of GPS. | MatConvNet |
| [39] | Performing crack detection in an IC setting using CNN and relying on transfer learning. | VGG-16 |
| [40] | 1. Application of pre-trained AlexNet on ImageNet data to perform crack detection. 2. Considering a richer data set where non-crack objects are included. | AlexNet |
| [29] | Performing a comparison between two frameworks of crack detection using (i) fully connected CNN and (ii) based on speeded-up robust features method. | AlexNet |
| [32] | Focusing on crack detection in black-box images and classifying images into the crack, road marking, and intact areas. | - |
| [26] | 1. Investigation of the effect of receptive field size on the performance. 2. Multi-class classification of different types of cracks. | Inspired by AlexNet and LeNet |
| Ref | Novelty/Novelties | Core Architecture |
|---|---|---|
| [3] | 1. First application of the OR setting for the task of defect detection. 2. Considering a richer data set, including five types of defects in comparison to the previous study. | Faster R-CNN |
| [57] | 1. Collecting and making publicly available a new data set including eight types of road damage. 2. Applying the SSD framework with two different backbone architectures for the sake of comparison. | SSD |
| [53] | 1. Proposing a new RPN dealing with different scales and improving accuracy. 2. Considering defect localization in the map using the NetVLAD module. | Faster R-CNN |
| [56] | 1. Considering 14 defect types in the data set. 2. Performing a comparative study between OR and SS settings. | Faster R-CNN |
| [62] | Application of YOLO9000 architecture for crack detection of roads in an OR setting. | YOLO v2 |
| [52] | 1. Application of R-CNN framework to perform crack detection in an OR setting. 2. Employing a pre-trained CNN on ImageNet and Cifar-10 data sets to perform crack classification and bounding box regression. | R-CNN |
| [54] | 1. Proposing CrackDN consisting of Faster R-CNN, a sensitivity detection network, and a region proposal refinement network. 2. Considering a richer data set where different backgrounds of normal, unbalanced illuminations, with markings and shadings, are included. | Faster R-CNN |
| [55] | Considering complex backgrounds in the images including handwritten scripts and applying Faster R-CNN to identify cracks in the images. | Faster R-CNN |
| [4] | Combining Faster R-CNN with a new Bayesian integration algorithm to suppress false detection and address challenging vision problems where a simple end-to-end learning strategy might not be effective. | Faster R-CNN |
| Ref | Novelty/Novelties | Method | Core Architecture |
|---|---|---|---|
| [78] | 1. Application of transfer learning to identify crack and sealed crack patches. 2. Applying fast block-wise segmentation based on linear regression to segment the identified patches. 3. Application of tensor voting curve detection to extract the detected crack curves. | IC + IP | - |
| [88] | 1. Application of pre-trained AlexNet on ImageNet data set to classify road images into the crack, sealed crack, and background patches. 2. Application of an FCN combined with dilated convolution to segment the detected crack patches. | IC + FCN | AlexNet |
| [85] | Proposing a crack delineation network including a generic pre-trained CNN model (GoogLeNet) combined with a feature pyramid network to achieve feature-map fusion. | IC + FCN | GoogLeNet |
| [77] | 1. Proposing a dual-scale CNN to perform crack patch classification and segmentation. 2. Application of Zernike moment operator for quantitative crack width estimation. | IC + IP | GoogLeNet |
| [80] | Application of mask R-CNN for bughole segmentation in concrete surface images and quantification of the segmented bugholes. | OR + FCN | Mask R-CNN |
| [84] | Application of mask R-CNN to detect cracks in pavement image data sets | OR + FCN | Mask R-CNN |
| [83] | Application of faster R-CNN combined with a Bayesian probability algorithm to suppress false detection and a set of IPTs to perform crack segmentation. | OR + IP | Faster R-CNN |
| [81] | 1. Application of mask R-CNN to output crack masks. 2. Applying IPTs to quantify the detected masks. | OR + FCN | Mask R-CNN |
| [86] | Proposing a new hybrid crack segmentation approach based on the global non-overlapping sliding windows and Sobel-edge detector to identify crack patches combined with a deep encoder–decoder architecture (SegNet) to perform crack segmentation. | IC + FCN | SegNet |
| [75] | Performing a comparative study between two crack segmentation frameworks of (i) Faster R-CNN combined with structured Random Forest edge detection and (ii) Mask R-CNN. | OR + IP and OR + FCN | Faster R-CNN, Mask R-CNN |
| [76] | 1. Performing crack segmentation using Faster R-CNN combined with a modified tabularity flow field. 2. Performing crack quantification using a modified distance transform method. | OR + IP | Faster R-CNN |
| Ref | Novelty/Novelties | Method |
|---|---|---|
| [91] | The first application of deep learning for the task of crack segmentation, where using ConvNet, the feature extraction is done on raw images. | Centre crack pixels in the patches |
| [94] | Proposing an improved version of CrackNet called CrackNet II resulting in higher performance in terms of accuracy and speed. | Consecutive conv layers with an invariant spatial size |
| [118] | 1. Application of an encoder–decoder structure to perform crack segmentation without employing the sliding windows technique. 2. Extracting the geometric characteristic of cracks via the application of morphological operations. | Encoder–decoder (feature fusion) |
| [102] | The first application of U-Net architecture in the crack detection area to cope with several limitations of applying CNN for the task of crack detection. | Encoder–decoder (U-Net) |
| [103] | Application of U-Net architecture equipped with a new proposed loss function based on distance transform to perform the task of crack segmentation. | Encoder–decoder (U-Net) |
| [92] | 1. Predicting the crack structure using CNN. 2. Proposing a strategy to deal with the class imbalance challenge. | Centre crack pixels in the patches |
| [97] | Proposing an improved version of CrackNet called CrackNet-R based on RNN, including a new recurrent unit. | RNN |
| [122] | Investigation of the performance of FCN architectures in the crack detection area for the task of crack segmentation. | Encoder–decoder |
| [104] | Proposing an encoder–decoder structure based on U-Net architecture combined with attention gating and residual connections to improve the performance. | Encoder–decoder (U-Net) |
| [105] | Investigating the effect of the depth of the U-Net architecture on the crack segmentation performance. | Encoder–decoder (U-Net) |
| [111] | Designing a new end-to-end trainable neural network based on SegNet architecture for robust crack detection. | Encoder–decoder (SegNet) |
| [115] | Proposing a deeper and more comprehensive FCN architecture to detect four concrete damages where it requires no sliding window technique. | Encoder–decoder (FC-DenseNet) |
| [112] | Performing a successful application of deep learning methods for detecting road cracks in black-box images. | Encoder–decoder (ResNet + SegNet, FCN, ZFNet) |
| [73] | 1. Proving the superiority of the SS over OR setting. 2. Proposing a method based on Gaussian kernel and Brownian motion process to generate arbitrary simulated crack images. | Encoder–decoder |
| [119] | Application of an FCN architecture based on dilated convolution to perform SS of crack images. | Encoder–decoder (dilated convolution) |
| [121] | 1. Proposing an FCN combined with condition random field and guided filtering methods. 2. Designing a new loss function to deal with the class imbalance challenge. 3. Making the employed data set publicly available. | Encoder–decoder (feature fusion) |
| [106] | Application of U-Net architecture for crack segmentation where Adam algorithm and focal loss function are used as the optimizer and evaluation function, respectively. | Encoder–decoder (U-Net) |
| [2] | Proposing a feature pyramid and hierarchical boosting network to achieve more robust feature representation and deal with the class imbalance challenge. | Encoder–decoder (feature fusion) |
| [74] | 1. Proposing a novel deep architecture based on dense blocks. 2. Proposing a novel loss function based on the connectivity of crack pixels in the crack areas. | Encoder–decoder (FC-DenseNet) |
| [108] | Proposing a CrackGAN framework based on the application of GAN architecture where the proposed approach is capable of working with partially annotated ground truths. | Encoder–decoder (U-Net as generator) |
| [117] | Proposing a crack segmentation approach based on conditional Wasserstein GAN combined with connectivity map to refine the results. | Encoder–decoder (FC-DenseNet as generator) |
| [116] | 1. Application of skip connections in the deep architecture for feature fusion. 2. Application of a depth-first search algorithm for post-processing and improving the accuracy. | Encoder–decoder (FC-DenseNet) |
| [110] | Application of SegNet architecture to perform the crack segmentation where the “Adadelta” optimizer and cross-entropy loss function are used | Encoder–decoder (SegNet) |
| [95] | 1. Proposing an improved version of CrackNet called CrackNet-V resulting in higher performance in terms of accuracy and speed. 2. Proposing a new activation function to improve the accuracy of crack segmentation for shallow cracks. | Consecutive conv layers with an invariant spatial size |
| [107] | Proposing U-hierarchical dilated network, a modified encoder–decoder architecture based on U-Net, where two modules of multi-dilation and hierarchical feature learning are added to improve the performance of crack segmentation. | Encoder–decoder (U-Net) |
| Ref. | Comparison with | Data Set | #Training-Validation-Testing Data | Data Augmentation | #Training Patches | Precision % | Recall % | F1-Score % | Time/ Image (s) |
|---|---|---|---|---|---|---|---|---|---|
| [102] | None | CFD | 80-20-18 | Patch extraction with a stride of 1 | 160,000 | 92.46 | 82.82 | 87.38 | ≈3 |
| [103] | None | CFD | 78-0-40 | Rotation, width and height shifting, horizontal flipping, and zooming | 2415 | 92.12 | 95.7 | 93.88 | - |
| Aigle-RN | 25-0-13 | 773 | 92.02 | 93.21 | 92.61 | - | |||
| [92] | None | CFD | 72-0-46 | Patch extraction | 741,932 | 91.19 | 94.81 | 92.44 | - |
| Aigle-RN | 24-0-14 | 156,832 | 91.78 | 88.12 | 89.54 | - | |||
| [104] | U-Net [102], CNN [92] | CFD | 71-0-46 | Patch extraction | 142,000 | 96.37 | 93.55 | 94.94 | - |
| Aigle-RN | 24-0-14 | 84,000 | 86.9 | 93.04 | 89.86 | - | |||
| [105] | CNN [92], VGG-16 | CFD | 100-0-18 | - | - | 97.31 | 94.28 | 95.75 | - |
| Aigle-RN | 0-0-38 | - | - | 93.51 | 82.9 | 87.33 | - | ||
| [2] | HED [125], RCF [126], FCN [89] | Crack500 | 250-50-200 | Patch extraction | 1896 | AIU = 0.489 | ODS = 0.604 | OIS = 0.635 | 0.197 |
| CFD | 0-0-118 | - | - | AIU = 0.173 | ODS = 0.683 | OIS = 0.705 | 0.133 | ||
| AEL | 0-0-58 | - | - | AIU = 0.079 | ODS = 0.492 | OIS = 0.507 | 0.259 | ||
| [86] | Original-Segnet [87] | CFD | 70-24-24 | Patch extraction | - | 82.03 | 82.83 | 82.34 | 2.4 |
| TRIMMED | 31-11-11 | Patch extraction | - | 79.99 | 85.38 | 82.52 | 5.8 | ||
| [116] | CrackNet-V [95] | CFD | 70-0-48 | Horizontal and vertical flipping, patch extraction with a stride of 16 | 62,790 | 92.02 | 91.13 | 91.58 | 1.66 |
| [74] | ResNet152-FCN [112], VGG19-FCN [118], CrackNet-V [95], U-Net [106], and FPHBN [2] | CFD | 70-0-48 | Horizontal and vertical flipping, patch extraction with a stride of 16 | 62,790 | 91 | 93.22 | 91.99 | ≈3.5 |
| [117] | ResNet152-FCN [112], VGG119-FCN [118], U-Net [106], CrackNet-V [95] | CFD | 70-0-48 | Patch extraction | - | 96.79 | 87.75 | 91.96 | ≈1.5 |
| [107] | HED [125], RCF [126], FCN [89], FPHBN [2], U-Net [99] | CFD | 70-0-48 | - | - | 94.50 | 93.60 | 93.90 | - |
| Aigle-RN | 24-0-14 | - | - | 92.10 | 93.10 | 92.40 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hamishebahar, Y.; Guan, H.; So, S.; Jo, J. A Comprehensive Review of Deep Learning-Based Crack Detection Approaches. Appl. Sci. 2022, 12, 1374. https://doi.org/10.3390/app12031374
Hamishebahar Y, Guan H, So S, Jo J. A Comprehensive Review of Deep Learning-Based Crack Detection Approaches. Applied Sciences. 2022; 12(3):1374. https://doi.org/10.3390/app12031374
Chicago/Turabian StyleHamishebahar, Younes, Hong Guan, Stephen So, and Jun Jo. 2022. "A Comprehensive Review of Deep Learning-Based Crack Detection Approaches" Applied Sciences 12, no. 3: 1374. https://doi.org/10.3390/app12031374
APA StyleHamishebahar, Y., Guan, H., So, S., & Jo, J. (2022). A Comprehensive Review of Deep Learning-Based Crack Detection Approaches. Applied Sciences, 12(3), 1374. https://doi.org/10.3390/app12031374