1. Introduction
Sarcasm is widely used in life. Irish playwright Oscar Wilde defined sarcasm as a low-level joke with high intelligence. In many cases, the sarcastic person is expressing their anger and disgust. Still, they try to use humor to weaken the unpleasantness caused to the other party and make it easier for the other party to accept it. Sarcasm is very common on today’s social platforms, and the progress of this research helps the review department to complete their tasks better. Moreover, the automatic detection of sarcasm has important practical significance in emotional analysis, harassment detection [
1], and various tasks that require knowledge of people’s honest thoughts.
The general problem of sarcasm detection is how to mine the inconsistent information of modal context and the conflicting information between different modalities. For example, there are two sarcasm cases in
Figure 1. The sarcasm in
Figure 1a is represented by inconsistencies between modalities, where both the text and tone indicate a downbeat, while the expression is surprised. Changes in human facial expressions manifest the sarcasm in
Figure 1b. Therefore, sarcasm detection needs to discover these inconsistencies.
Sarcasm is an essential way to express emotion and it is an important research direction of artificial intelligence sentiment analysis. Before the U.S. election, Facebook’s AI research team used language models to identify disinformation and hate speech on the web. In contrast, the subtlety of sarcasm makes it a challenging task. Identifying sarcasm is more complex than identifying false political discourse, so an efficient sarcasm detection model has significant practical significance.
Traditional sarcasm detection methods can be divided into three categories. The first category is based on text data. By capturing the inconsistency between texts, many sarcasm detection methods have been proposed [
2,
3,
4,
5]. However, these methods only detect sarcasm through textual data, ignoring the incongruity of information between different modalities. The second category includes methods based on images, text, and data seen from images (attributes, objects, text, descriptions, etc.) Cai et al. [
6] constructed a multimodal dataset and proposed a new hierarchical fusion model to fully utilize the information of three modalities of image, text, and image attributes to solve the problem of sarcasm detection. Yao et al. [
7] proposed a multi-modal, multi-interactive, multi-level neural network. This model takes images, texts in images, image descriptions, and Twitter text data as inputs and detects sarcasm by stimulating the brain’s first-order and second-order understanding of sarcasm. Pan et al. [
8] proposed an architecture based on the BERT model and found inconsistencies among multimodalities. However, such methods rely heavily on the clarity of the image and the data detected from the image. However, with the advent of the short video era, people are more willing to share short videos to record their lives on the social media platforms Twitter and TikTok. Therefore, only modeling text and image data are not enough to detect sarcasm. From this, the third category of sarcasm detection methods is derived—video, text, and speech-based methods. Castro et al. [
9] proposed the first sarcasm detection dataset based on text, speech, and video data. They extract text, speech, and video features separately and concatenate the features of the three modalities as the input of the SVM classifier. However, the SVM algorithm is difficult to implement for large-scale training samples, and the algorithm is also sensitive to missing data and parameters, as well as the choice of kernel functions. In addition, taking vision as a modality and simply concatenating the features of each modality is unfavorable for sarcasm detection. Wu et al. [
10] argue that previous work did not explicitly model the incongruity between modalities. Therefore, they propose an incongruity-aware attention network (IWAN) to detect sarcasm through a scoring mechanism for word-level incongruities between modalities. Chauhan et al. [
11] believe that contextual and multimodal information is sometimes unhelpful for sarcasm detection, so they extended the dataset proposed by Castro et al. [
9] using emojis and offered an emoji-aware multitask deep learning framework. However, such methods have a disadvantage in that the training speed is slow, and it ignores essential information, namely, that there is a large amount of data irrelevant to sarcasm detection in the video modality, such as the background information in the video.
In this paper, we propose an efficient feature adaptive fusion network with a facial feature for multimodal sarcasm detection (EFAFN). We utilize three types of components, namely, text, speech, and face image features, and use an adaptive feature fusion strategy to fuse the three types of features into a single vector for prediction. Our model is divided into three stages: multimodal feature extraction, adaptive feature fusion, and feature classification. First, use BERT [
12] and Librosa [
13] to extract the features of text and speech modalities, and then use the face detection tool provided by DLIB to cut out all the face images in each frame for horizontal stitching operation. The obtained stitched image is used as the input of ResNet-152 [
14] to obtain the face image features of each video. Second, three types of parts are fused using an adaptive fusion strategy, which is different from other fusion strategies because it uses a fusion weight parameter to control the incongruity of information between different modalities. Furthermore, high performance is another manifestation of the fusion strategy. Finally, the fused vector is sent to the fully connected layer for prediction. Our results show that image features from face regions are more helpful for model performance. Furthermore, our fusion strategy is more effective than simply concatenating the three types of components.
To sum up, the adaptive fusion network with facial features is effective for sarcasm detection and it has the advantages of fast fusion speed and high performance. In addition, the model proposed in this paper solves the existence of information irrelevant to sarcasm detection in video modalities, improves the efficiency of multimodal fusion strategies, and promotes the practical implementation requirements of multimodal sarcasm detection. It has significant reference significance for other tasks in multimodal fields.
The rest of this paper is organized as follows:
Section 2 mainly introduces the related research work.
Section 3 presents the architecture of our proposed efficient adaptive fusion network with facial features and the feature fusion strategy.
Section 4 offers our proposed data augmentation method, baseline model, experimental setup, and evaluation metrics.
Section 5 presents extensive experimental results and demonstrates the effectiveness of our network.
Section 6 presents the conclusions of this paper and ideas for future research work.
Our main contributions are summarized as follows:
We propose a new multimodal deep learning sarcasm detection model, which aims to solve the problem that the existing multimodal sarcasm detection models based on three modalities of text, speech, and image only take the whole image as input, which will bring the model a sea of redundant image data, thus affecting the classification accuracy of the model. At the same time, because facial information contains emotional information related to sarcasm, we believe that we should pay attention to the image features of the facial region. Therefore, the face recognition operation is performed on the image first, and then the detected face regions are stitched horizontally to obtain the image data of the final input model;
Traditional feature fusion methods connect each modality’s features or add each modality’s characteristics. Since the parts of the speech modality are numerically different from those of the other two modalities, they are easily filtered out as noise in the network, so we propose an adaptive feature fusion strategy. The characteristic feature of this fusion strategy is that the fusion weights between the three modalities can be adjusted adaptively to simulate the inconsistency between multiple modalities;
We use a data augmentation method based on the MUStARD dataset to address the overfitting problem during deep learning training. Additionally, a series of experiments are conducted to demonstrate the effectiveness of our model; our model achieves a 6.5% improvement in F1-score over the method using a baseline for sarcasm detection.
3. The Proposed EFAFN Model
In this section, we first formulate our problem, then introduce multimodal feature extraction, and finally detail our proposed model structure. As shown in
Figure 2, our network architecture can be divided into three parts: (a) multimodal feature extraction, (b) adaptive feature fusion, and (c) feature classification.
3.1. Problem Formulation
Multimodal sarcasm detection aims to identify whether a speech and text associated with a video are sarcastic. Formally, given a set of multimodal dataset D, for each sample , it contains a video V with n frames , a sentence T with m words , and an associated speech A. Our model’s target is to classify unseen samples as sarcastic or non-sarcastic precisely.
3.2. Multi-Modal Feature Extraction
Text Features: we use BERT [
12] to process the text data in the dataset into a unique feature vector. First, we remove the data with empty text in the dataset, then input the text into the
model and average the outputs of the last
transformer layers in the
model as the feature vector of each text. Finally, each piece of text will be represented by a
dimensional feature vector
.
where
represents the output of the last i-th transformer layer in the BERT-base model, and
T represents a piece of text.
Speech Features: we adopt the method of extracting features from speech data proposed by Castro et al. [
9], and use the speech processing library Librosa, which extracts basic features from audio data. First, we load audio samples into a time series signal with a sampling rate of 22,050 Hz; we use a heuristic sound extraction method to remove background noise. Finally, we divide the audio signal into
non-overlapping windows to extract local features, including MFCC, Mel-spectogram, spectral centroid, and their associated temporary derivatives (delta). All the elements are connected to form a joint feature vector
with
dimensions for each window. Finally, the joint feature
of each piece of audio is obtained by calculating the average value of all windows.
where ⊕ is the concatenation operator,
,
,
,
, and
represent MFCC features, MFCC associated temporary derivatives, Mel-spectogram features, Mel-spectogram associated temporary derivatives, and spectral centroid of each window, respectively.
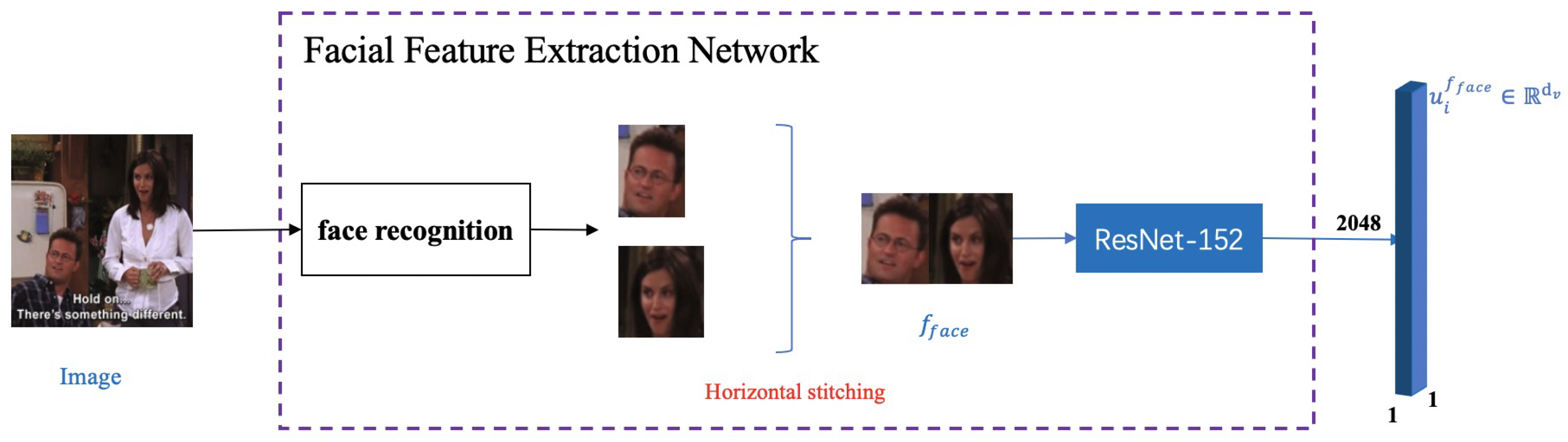
Face Image Features: as facial information contains emotional information related to sarcasm detection, we believe that the video modality should focus on the person’s news rather than the image’s background information. The network architecture of facial feature extraction is shown in
Figure 3. First, we use the face detection model provided by DLIB (
http://dlib.net/face_detection_ex.cpp.html, accessed on 13 August 2021.) to detect the face
of each frame in the video conversation. Let
denote the maximum height of the face image seen from each image frame. Since the size of each face detected in the face detection process is inconsistent, the black block
is used to fill the vacant part in the splicing process. After the filling operation, the heights of all face images are uniform. Then, a horizontal stitching operation is performed on all faces to obtain the final image input to the network. The formulation is as follows.
where
represents the width of the image,
represents the height of the image,
represents the dimension of the black block that the face needs to be supplemented with, ⊕ represents the vertical stitching operation, and
represents the padding operation,
represents a horizontal stitching operation.
We use
to represent the stitched image. Then, we preprocess each frame of
by normalization, and then redefine the last layer of the ResNet-152 [
14] image classification model pre-trained by ImageNet to 2048 dimensions, using this model to extract features for
representation. To obtain the visual representation of each sentence of text, we calculate the average value of the feature vector
with
dimensions obtained in each frame.
where
F represents the number of video frames.
3.3. Adaptive Feature Fusion
Typical feature fusion methods are divided into early fusion and late fusion. Early fusion refers to the fusion of features and input into a model for training. For example, the most common method is to perform a simple concatenation operation on the parts. Early fusion methods learn to exploit the correlations and interactions between low-level features of each modality. The late fusion method trains a model for each modality separately and then uses a fusion mechanism to integrate the results of all single-modality models. Commonly used fusion mechanisms include averaging, voting, and training fusion models. Since late fusion methods train different models for different modalities, each modality can be better modeled, allowing for better flexibility. It is worth noting, however, that the late fusion approach ignores low-level interactions between modalities. In theory, early fusion should achieve better results for the sarcasm detection task than late fusion because the corresponding features have a specific index relationship and less feature abstraction in reality. Beyond that, sarcasm detection is all about finding interactions between modalities.
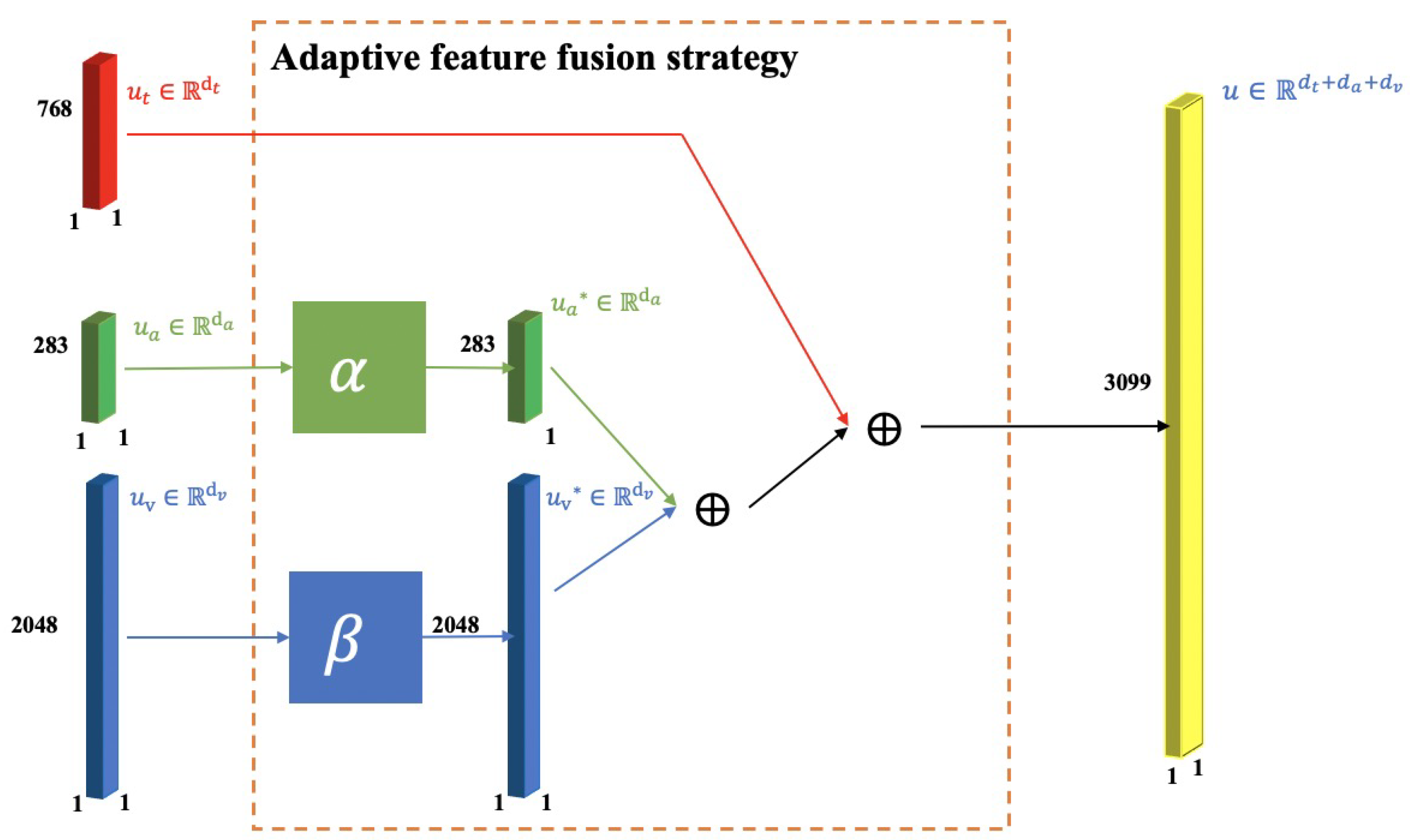
After the above analysis, to better fuse the features of the three modalities together, we propose an adaptive feature fusion strategy with an early fusion method, as shown in
Figure 4. Given the initial text feature
, speech feature
, and face image feature
, the final prediction vector
u is obtained according to the strategy
. We approximate the policy by a deep policy network
:
where
,
, and
are the parameters of the network, which can be updated according to gradients. Since text features, speech features, and face image features come from three different modalities, we design two sub-network branches
and
to combine speech features and face image features are mapped into a feature vector that combines text features.
3.4. Feature Classification
Inspired by the VGG16 [
32] network structure, we designed a Multilayer Perceptron (MLP) and Softmax layers for feature classification, as shown in
Figure 5. The activation function of the hidden layer and output layer is LeakyReLU, and the loss function uses cross entropy.
where
J is the cost function.
is the prediction result of our model for sample
i, and
is the true label for sample
i.
N is the size of the training data.
R is the standard L2 regularization, and
is the weight of
R.
6. Conclusions
We studied the redundant information problem of video modalities in multimodal sarcasm detection. We constructed an EFAFN multimodal sarcasm detection model that used the open-source sarcasm detection dataset MUStARD for experiments and proposed a data augmentation method to solve the overfitting problem during model training. In addition, a ViViT-VAT model was also constructed for comparative experiments. The final experimental results show that the EFAFN multimodal sarcasm detection model outperforms the ViViT-VAT model, proving the effectiveness of our model. The model based on facial features outperforms the model based on whole image features, demonstrating the importance of facial information in sarcasm detection. Ablation experiment results show that not using data augmentation methods and adaptive fusion strategies will cause model performance degradation, illustrating the necessity of our proposed two components. The use of global speech features and unaveraged local speech features also degrades the model performance, indicating that the operation of averaging features will highlight the sarcasm features of speech modalities.
Although the model’s effectiveness in this paper, the usefulness of the three modalities, and the necessity of the adaptive fusion strategy are proved by experiments, there is still room for further optimization. First, this paper only removes information irrelevant to sarcasm detection for video modalities, and then we can discuss redundant information removal algorithms for speech and text modalities. Second, some multimodal information may not be helpful for sarcasm detection. We will consider designing better processing methods for text and speech modalities in the future. For example, the speech data in the dataset are augmented with additional data, such as emojis [
11], to add valuable information for sarcasm detection. Third, the dataset used in this paper only contains three modalities, and the influence of other modalities’ data, such as text in images, on sarcasm detection is not considered. Other existing public datasets can be used in the future.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}