



Self-Supervised Video Representation and Temporally Adaptive Attention for Audio-Visual Event Localization


Abstract
1. Introduction
- We propose a self-supervised audio-visual representation method that encodes features in the same latent space and matches the semantic information contained in the audio and visual modalities. Such a design can narrow the heterogeneity gap between different modal features and benefit subsequent modeling of cross-modal relationships;
- We propose a weighting-based cross-modal attention module that dynamically weakens the connections between different modal features that are unrelated to events or temporally asynchronous;
- The proposed methods are combined in a framework to perform the event localization task on the public audio-visual event dataset. When directly classifying features learned by our self-supervised method for event localization, significant improvements are achieved in both unimodal and multimodal cases. When further combining these features with the proposed cross-modal attention, our overall approach achieves state-of-the-art localization accuracy.
2. Related Works
2.1. Self-Supervised Audio-Visual Representation Learning
2.2. Multimodal Fusion
2.3. AVE Localization
3. The Proposed Framework
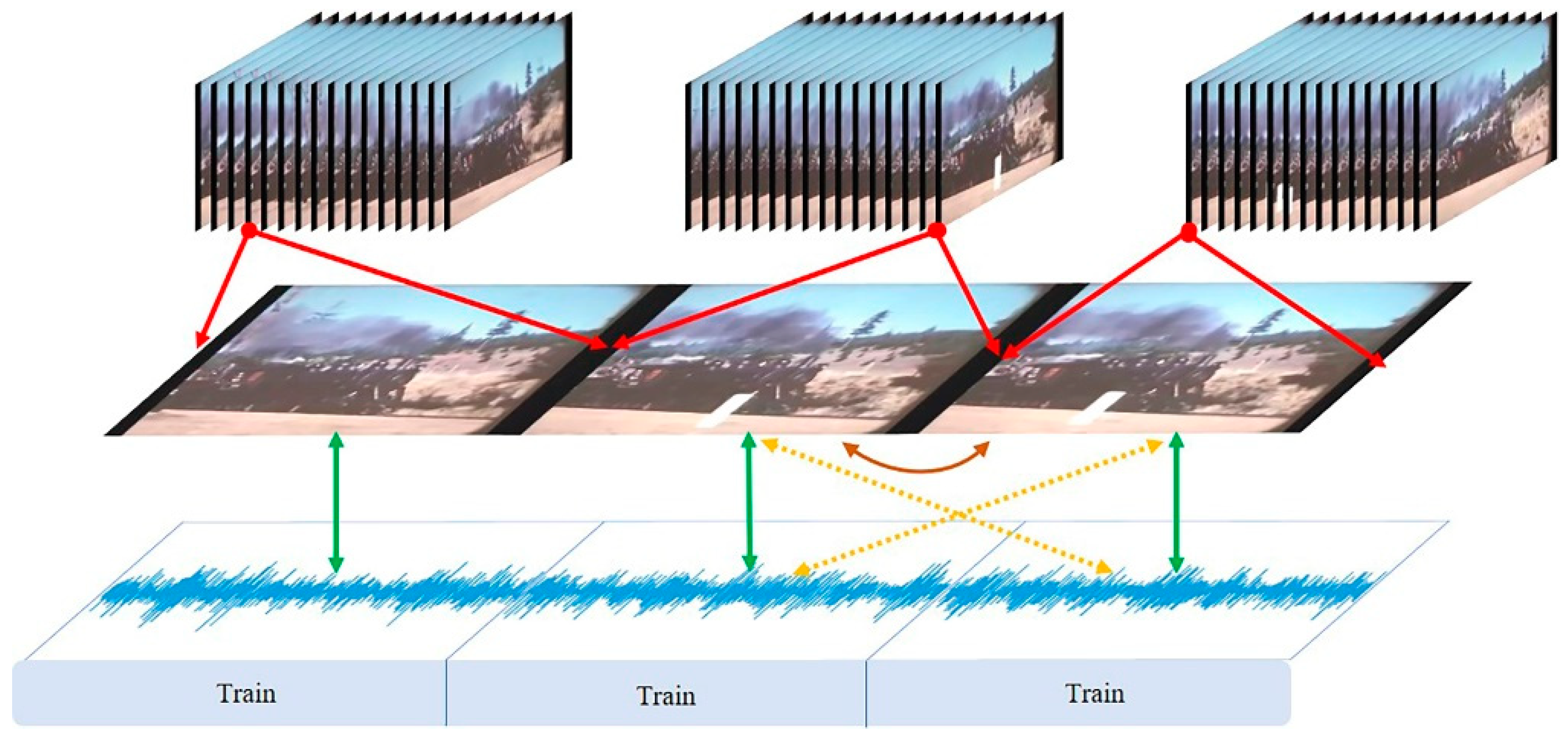
3.1. Task Statement
3.2. Self-Supervised Audio-Visual Representation
3.2.1. Audio-Visual Barlow Twins
| Algorithm 1 PyTorch-style pseudocode for Audio-Visual Barlow Twins. | |
| # # # # # # # # # | f: two-stream audio-visual encoder and projectors p: preprocess the video lambda: weight on the off-diagonal term N: batch size D: dimensionality of projected embeddings transpose: transpose the last two dimensions of a tensor bmm: matrix-matrix multiplication with batch dimension at first off_dia: off-diagonal elements of a matrix eye: identity matrix |
| for video in loader: # load a batch with N videos # extract frames randomly and converts raw audio spectrograms, frames = p (video) # encode feature and project z_a, z_v = f (spectrograms, frames) # [N, T, D] # normalize along the time dimension z_a_norm = (z_a – − z_a.mean (1) )/z_a.std (1) # [N, T, D] z_v_norm = (z_v – − z_v.mean (1) )/z_v.std (1) # [N, T, D] # compute cross-correlation matrix c = bmm (transpose (z_a_norm), z_v_norm) # [N, D, D] c = c.sum (0)/N # [D, D] # loss diff = (c − eye (D) ).pow (2) # [D, D] off_dia (diff) .mul_(lambda) loss = diff.sum () # optimize loss.backward () optimizer.step () | |
3.2.2. Discussion on Audio-Visual Barlow Twins
3.3. Temporally Adaptive Cross-Modal Attention
3.4. Classification and Optimization
4. Experiments
4.1. Experiment Setup
4.2. Results
4.2.1. Evaluating AV-BT
4.2.2. Evaluating TACMA
4.3. Ablations
4.3.1. Architecture of AV-BT
4.3.2. Data Augmentations in AV-BT
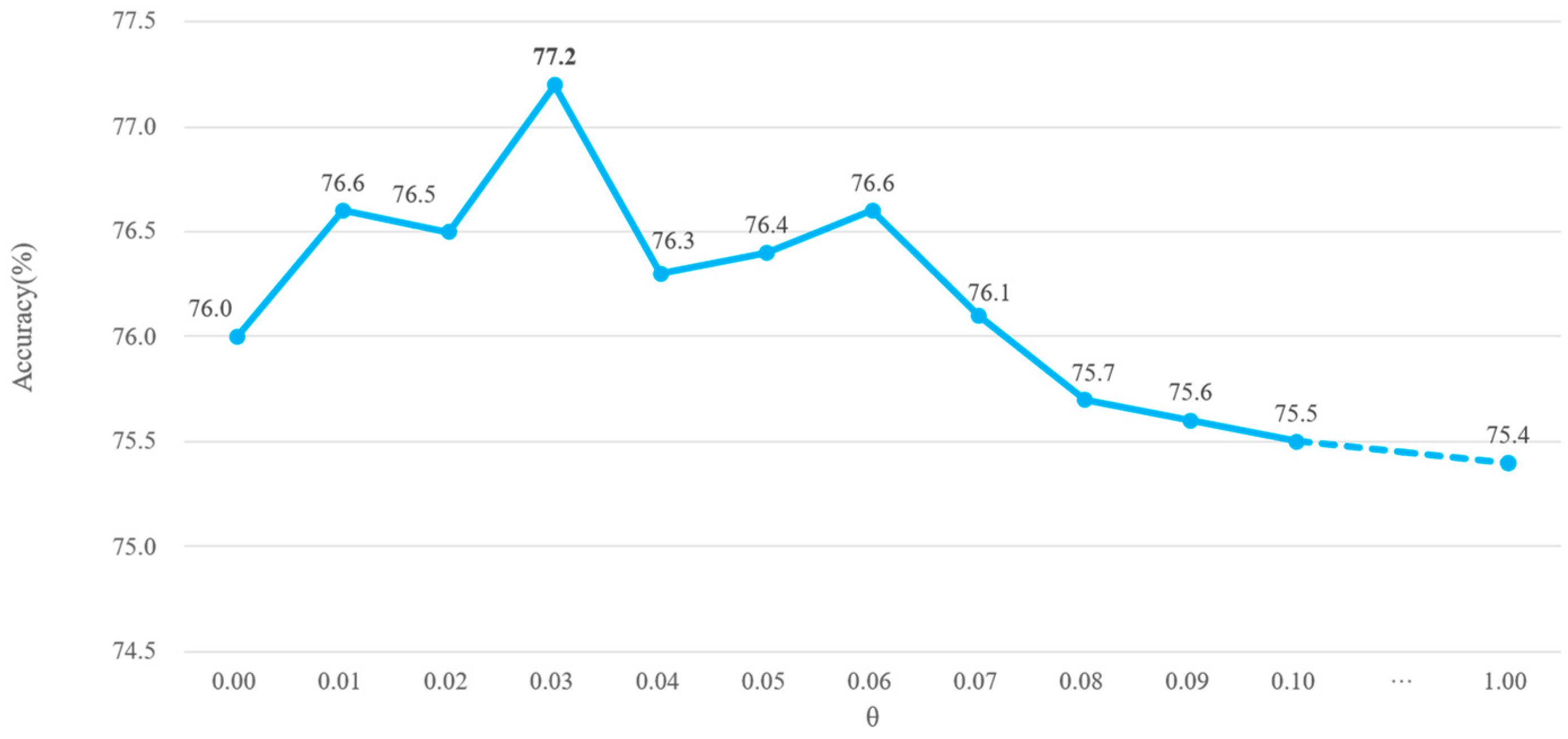
4.3.3. Ablation on in TACMA
4.4. Visualization
5. Conclusions
6. Future Direction
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, S.; Xu, K.; Jiang, X.; Sun, T. Pyramid Spatial-Temporal Graph Transformer for Skeleton-Based Action Recognition. Appl. Sci. 2022, 12, 9229. [Google Scholar] [CrossRef]
- Gowda, S.N.; Rohrbach, M.; Sevilla-Lara, L.; Assoc Advancement Artificial, I. SMART Frame Selection for Action Recognition. In Proceedings of the 35th AAAI Conference on Artificial Intelligence/33rd Conference on Innovative Applications of Artificial Intelligence/11th Symposium on Educational Advances in Artificial Intelligence, Electr Network, Virtually, 2–9 February 2021; pp. 1451–1459. [Google Scholar]
- Park, S.K.; Chung, J.H.; Pae, D.S.; Lim, M.T. Binary Dense SIFT Flow Based Position-Information Added Two-Stream CNN for Pedestrian Action Recognition. Appl. Sci. 2022, 12, 10445. [Google Scholar] [CrossRef]
- Piczak, K.J. Environmental sound classification with convolutional neural networks. In Proceedings of the 2015 IEEE 25th International Workshop on Machine Learning for Signal Processing (MLSP), Boston, MA, USA, 17–20 September 2015; pp. 1–6. [Google Scholar]
- Koutini, K.; Eghbal-zadeh, H.; Dorfer, M.; Widmer, G. The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification. In Proceedings of the 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019. [Google Scholar]
- Tian, Y.P.; Shi, J.; Li, B.C.; Duan, Z.Y.; Xu, C.L. Audio-Visual Event Localization in Unconstrained Videos. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Yu, W.; Linchao, Z.; Yan, Y.; Yi, Y. Dual Attention Matching for Audio-Visual Event Localization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6291–6299. [Google Scholar]
- Yu, J.; Cheng, Y.; Feng, R. Mpn: Multimodal parallel network for audio-visual event localization. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Lin, Y.B.; Li, Y.J.; Wang, Y.C.F. Dual-Modality Seq2seq Network for Audio-Visual Event Localization. In Proceedings of the 44th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2002–2006. [Google Scholar]
- Ramaswamy, J.; Das, S.; Soc, I.C. See the Sound, Hear the Pixels. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 2959–2968. [Google Scholar]
- Ramaswamy, J. What makes the sound?: A dual-modality interacting network for audio-visual event localization. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 4372–4376. [Google Scholar]
- Xuan, H.Y.; Zhang, Z.Y.; Chen, S.; Yang, J.; Yan, Y.; Assoc Advancement Artificial, I. Cross-Modal Attention Network for Temporal Inconsistent Audio-Visual Event Localization. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 279–286. [Google Scholar]
- Duan, B.; Tang, H.; Wang, W.; Zong, Z.L.; Yang, G.W.; Yan, Y. Audio-Visual Event Localization via Recursive Fusion by Joint Co-Attention. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Electr Network, Virtual, 5–9 January 2021; pp. 4012–4021. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE-Computer-Society Conference on Computer Vision and Pattern Recognition Workshops, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An Ontology and Human-Labeled Dataset for Audio Events. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Smith, L.; Gasser, M. The development of embodied cognition: Six lessons from babies. Artif. Life 2005, 11, 13–29. [Google Scholar] [CrossRef] [PubMed]
- Schwartz, J.-L.; Berthommier, F.; Savariaux, C. Audio-visual scene analysis: Evidence for a” very-early” integration process in audio-visual speech perception. In Proceedings of the Seventh International Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- Omata, K.; Mogi, K. Fusion and combination in audio-visual integration. Proc. R. Soc. A Math. Phys. Eng. Sci. 2008, 464, 319–340. [Google Scholar] [CrossRef]
- Zhou, J.X.; Zheng, L.; Zhong, Y.R.; Hao, S.J.; Wang, M.; Ieee Comp, S.O.C. Positive Sample Propagation along the Audio-Visual Event Line. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Nashville, TN, USA, 19–25 June 2021; pp. 8432–8440. [Google Scholar]
- Sekuler, R. Sound alters visual motion perception. Nature 1997, 385, 308. [Google Scholar] [CrossRef]
- McGurk, H.; MacDonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746–748. [Google Scholar] [CrossRef]
- Owens, A.; Efros, A.A. Audio-Visual Scene Analysis with Self-Supervised Multisensory Features. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings: Lecture Notes in Computer Science (LNCS 11210); Springer: Cham, Swizerland, 2018; pp. 639–658. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. In Proceedings of the 38th International Conference on Machine Learning, Proceedings of Machine Learning Research, Online, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Kaiming, H.; Haoqi, F.; Yuxin, W.; Saining, X.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar]
- Grill, J.-B.; Strub, F.; Altche, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent a new approach to self-supervised learning. In Proceedings of the 34th Conference on Neural Information Processing Systems, NeurIPS 2020, Virtual Online, 6–12 December 2020. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 15750–15758. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning (ICML), Electr Network, Vienna, Austria, 13–18 July 2020. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised learning of visual features by contrasting cluster assignments. Adv. Condens. Matter Phys. 2020, 33, 9912–9924. [Google Scholar]
- Ying, C.; Ruize, W.; Zhihao, P.; Rui, F.; Yuejie, Z. Look, Listen, and Attend: Co-Attention Network for Self-Supervised Audio-Visual Representation Learning. In Proceedings of the MM ‘20: Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 3884–3892. [Google Scholar]
- Sarkar, P.; Etemad, A. Self-Supervised Audio-Visual Representation Learning with Relaxed Cross-Modal Temporal Synchronicity. arXiv 2021, arXiv:2111.05329. [Google Scholar]
- Patrick, M.; Asano, Y.M.; Kuznetsova, P.; Fong, R.; Henriques, J.F.; Zweig, G.; Vedaldi, A. On compositions of transformations in contrastive self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9577–9587. [Google Scholar]
- Yang, K.; Russell, B.; Salamon, J. Telling Left From Right: Learning Spatial Correspondence of Sight and Sound. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9929–9938. [Google Scholar]
- Terbouche, H.; Schoneveld, L.; Benson, O.; Othmani, A. Comparing Learning Methodologies for Self-Supervised Audio-Visual Representation Learning. IEEE Access 2022, 10, 41622–41638. [Google Scholar] [CrossRef]
- Feng, Z.S.; Tu, M.; Xia, R.; Wang, Y.X.; Krishnamurthy, A. Self-Supervised Audio-Visual Representation Learning for in-the-wild Videos. In Proceedings of the 8th IEEE International Conference on Big Data (Big Data), Electr Network, Atlanta, GA, USA, 10–13 December 2020; pp. 5671–5672. [Google Scholar]
- Arandjelovic, R.; Zisserman, A. Look, listen and learn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 609–617. [Google Scholar]
- Parekh, S.; Essid, S.; Ozerov, A.; Duong, N.Q.; Pérez, P.; Richard, G. Weakly supervised representation learning for unsynchronized audio-visual events. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2518–2519. [Google Scholar]
- Nojavanasghari, B.; Gopinath, D.; Koushik, J.; Baltrušaitis, T.; Morency, L.-P. Deep multimodal fusion for persuasiveness prediction. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 284–288. [Google Scholar]
- Wang, H.; Meghawat, A.; Morency, L.-P.; Xing, E.P. Select-additive learning: Improving generalization in multimodal sentiment analysis. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 949–954. [Google Scholar]
- Pérez-Rúa, J.-M.; Vielzeuf, V.; Pateux, S.; Baccouche, M.; Jurie, F. Mfas: Multimodal fusion architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6966–6975. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Tay, Y.; Dehghani, M.; Aribandi, V.; Gupta, J.; Pham, P.M.; Qin, Z.; Bahri, D.; Juan, D.-C.; Metzler, D. Omninet: Omnidirectional representations from transformers. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10193–10202. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical question-image co-attention for visual question answering. Adv. Condens. Matter Phys. 2016, 29, 289–297. [Google Scholar]
- Dou, Z.-Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Yuan, L.; Peng, N. An empirical study of training end-to-end vision-and-language transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 18166–18176. [Google Scholar]
- Sharma, S.; Mittal, R.; Goyal, N. An Assessment of Machine Learning and Deep Learning Techniques with Applications. ECS Trans. 2022, 107, 8979–8988. [Google Scholar] [CrossRef]
- Popli, R.; Sethi, M.; Kansal, I.; Garg, A.; Goyal, N. Machine learning based security solutions in MANETs: State of the art approaches. J. Phys. Conf. Ser. 2021, 1950, 012070. [Google Scholar] [CrossRef]
- Popli, R.; Kansal, I.; Garg, A.; Goyal, N.; Garg, K. Classification and recognition of online hand-written alphabets using Machine Learning Methods. IOP Conf. Ser. Mater. Sci. Eng. 2021, 2021, 012111–012119. [Google Scholar] [CrossRef]
- Gautam, V.; Trivedi, N.K.; Singh, A.; Mohamed, H.G.; Noya, I.D.; Kaur, P.; Goyal, N. A Transfer Learning-Based Artificial Intelligence Model for Leaf Disease Assessment. Sustainability 2022, 14, 19. [Google Scholar] [CrossRef]
- Verma, V.; Gupta, D.; Gupta, S.; Uppal, M.; Anand, D.; Ortega-Mansilla, A.; Alharithi, F.S.; Almotiri, J.; Goyal, N. A Deep Learning-Based Intelligent Garbage Detection System Using an Unmanned Aerial Vehicle. Symmetry 2022, 14, 15. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Yan-Bo, L.; Wang, Y.C.F. Audiovisual Transformer with Instance Attention for Audio-Visual Event Localization. In Computer Vision—ACCV 2020, Proceedings of the 15th Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020; Revised Selected Papers; Lecture Notes in Computer Science (LNCS 12647); Springer: Cham, Swizerland, 2021; pp. 274–290. [Google Scholar]
- Redlich, A.N. Redundancy Reduction as a Strategy for Unsupervised Learning. Neural Comput. 1993, 5, 289–304. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Condens. Matter Phys. 2017, 30, 6000–6010. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN Architectures for Large-Scale Audio Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- You, Y.; Gitman, I.; Ginsburg, B. Large batch training of convolutional networks. arXiv 2017, arXiv:1708.03888. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn Res. 2008, 9, 2579–2605. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Definition |
|---|---|
| / | Audio/visual portion of the video |
| Annotation of the -th video segment | |
| / | Preprocessed audio/visual data |
| / | Encoded audio/visual feature |
| / | Projected audio/visual embedding |
| Cross-correlation matrix of / | |
| / | Parameters for computing audio/visual query and key |
| / | Cross-modal attention matrix |
| / | Weight matrix for / |
| / | Weighted attention matrix |
| / | Parameters for computing audio/visual value |
| / | Attended audio/visual feature |
| / | Parameters for / |
| / | Fused audio/visual feature |
| Prediction of the input video |
| Method | Accuracy (%) |
|---|---|
| Audio only [6] | 59.5 |
| Visual only [6] | 55.3 |
| AVEL [6] | 71.3 |
| Ours (Audio only) Ours (Visual only) Ours (Audio-Visual) | 63.5 61.0 75.6 |
| Method | Accuracy (%) |
|---|---|
| CMAN [12] | 73.3 |
| AVRB [10] AVIN [11] MPN [8] JCAN [13] PSP [19] AVT [50] AV-BT+TACMA (Ours) | 74.8 75.2 75.2 76.2 76.6 * 76.8 77.2 |
| Modification | Audio-Visual | Audio Only | Visual Only |
|---|---|---|---|
| Baseline w/AGVA w/o sharing projector | 75.6 71.5 72.5 | 63.5 - 63.0 | 61.0 - 60.4 |
| Crop | Flip | Solarize | Grayscale | Jitter | Blur | Accuracy (%) |
|---|---|---|---|---|---|---|
| ✓ * | ✓ | ✓ | ✓ | ✓ | ✓ | 74.0 |
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 74.5 |
| ✓ | ✕ | ✓ | ✓ | ✓ | ✓ | 74.2 |
| ✓ | ✕ | ✕ | ✓ | ✓ | ✓ | 74.3 |
| ✓ | ✕ | ✕ | ✕ | ✓ | ✓ | 74.4 |
| ✓ | ✕ | ✕ | ✕ | ✕ | ✓ | 75.6 |
| ✓ | ✕ | ✕ | ✕ | ✕ | ✕ | 74.3 |
| ✓ | ✓ | ✕ | ✕ | ✕ | ✓ | 74.7 |
| ✓ | ✓ | ✓ | ✓ | ✕ | ✓ | 74.5 |
| ✕ | ✕ | ✕ | ✕ | ✕ | ✕ | 74.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ran, Y.; Tang, H.; Li, B.; Wang, G. Self-Supervised Video Representation and Temporally Adaptive Attention for Audio-Visual Event Localization. Appl. Sci. 2022, 12, 12622. https://doi.org/10.3390/app122412622
Ran Y, Tang H, Li B, Wang G. Self-Supervised Video Representation and Temporally Adaptive Attention for Audio-Visual Event Localization. Applied Sciences. 2022; 12(24):12622. https://doi.org/10.3390/app122412622
Chicago/Turabian StyleRan, Yue, Hongying Tang, Baoqing Li, and Guohui Wang. 2022. "Self-Supervised Video Representation and Temporally Adaptive Attention for Audio-Visual Event Localization" Applied Sciences 12, no. 24: 12622. https://doi.org/10.3390/app122412622
APA StyleRan, Y., Tang, H., Li, B., & Wang, G. (2022). Self-Supervised Video Representation and Temporally Adaptive Attention for Audio-Visual Event Localization. Applied Sciences, 12(24), 12622. https://doi.org/10.3390/app122412622