
An Abstract Summarization Method Combining Global Topics


Abstract
Featured Application
Abstract
1. Introduction
- We propose a summary generation method incorporating global topic information, model the topic of the document, and update the document representation by fusing the topic information of the text with word embeddings through the information fusion module.
- We propose the nTmG (n-TOPIC-m-GRAM) method to extract the key topic information in the original text. The essential method is used to avoid the noise caused by the introduction of the topic.
- Empirical studies show that the proposed method demonstrates a more advanced performance than baseline methods. It also shows that the number of incorporated topics is tightly correlated with the performance of generating summaries, which provides empirical evidence for subsequent automatic summary studies combining topics.
2. Related Works
3. Motivation
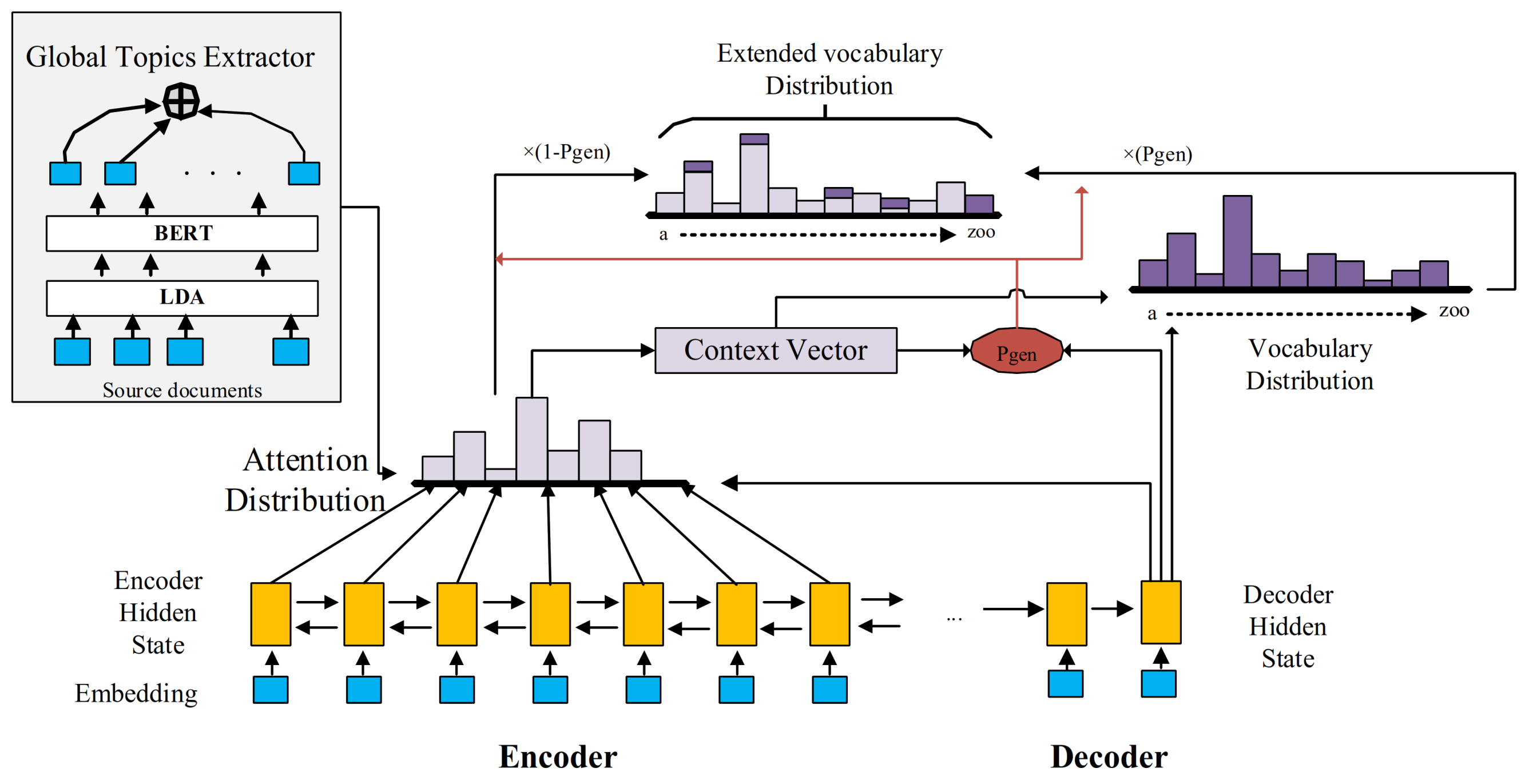
4. Approach
4.1. Global Topics Extractor
4.2. Global Topics with Combined Attention Module
4.3. Pointer Network and Coverage Mechanism
4.3.1. Pointer Network
4.3.2. Coverage Mechanism
4.4. Loss Function
5. Experiments
5.1. Dataset
5.2. Evaluation Metrics
5.3. Experimental Setup
5.4. Experimental Results
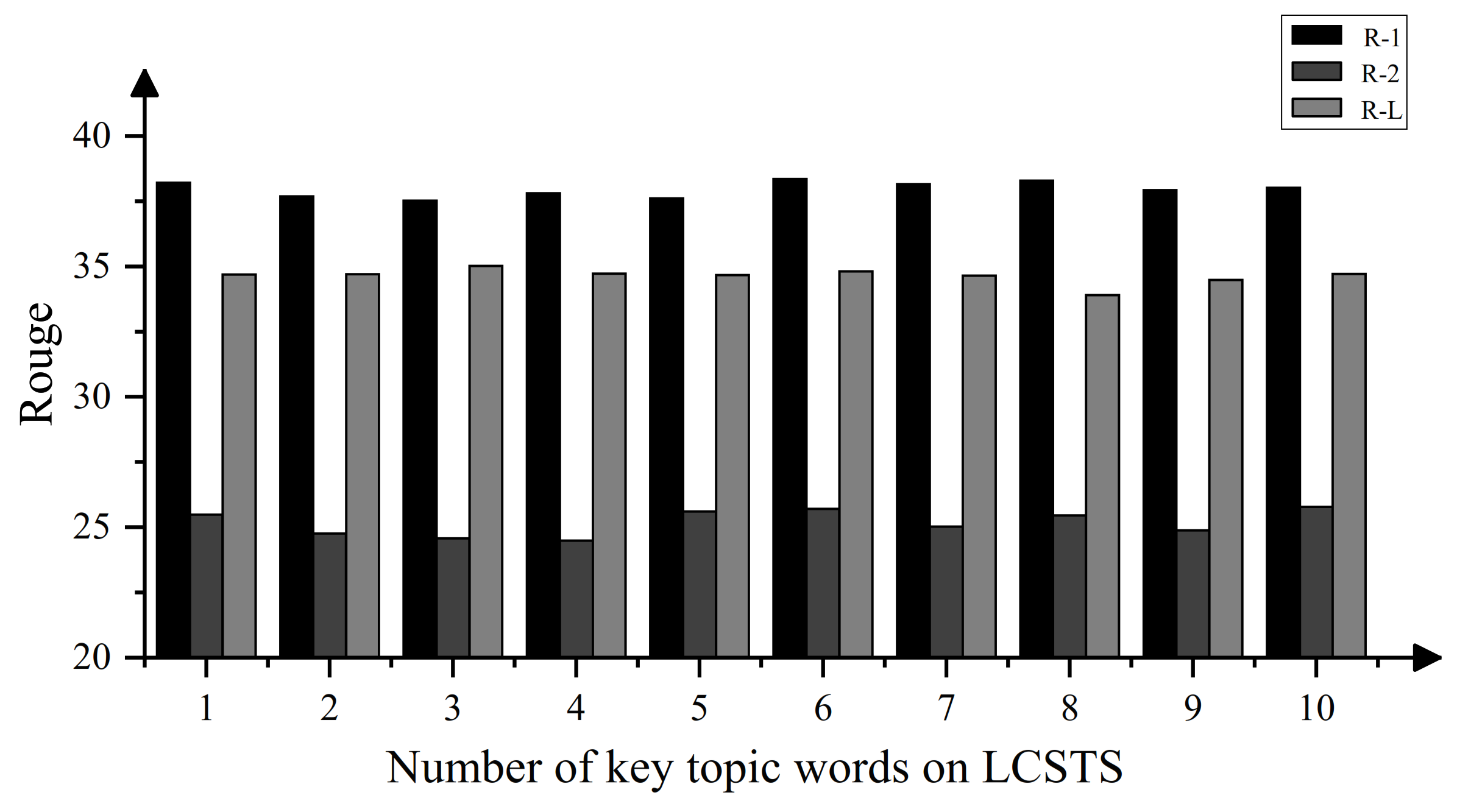
5.5. Ablation Experiment
6. Analysis and Discussion
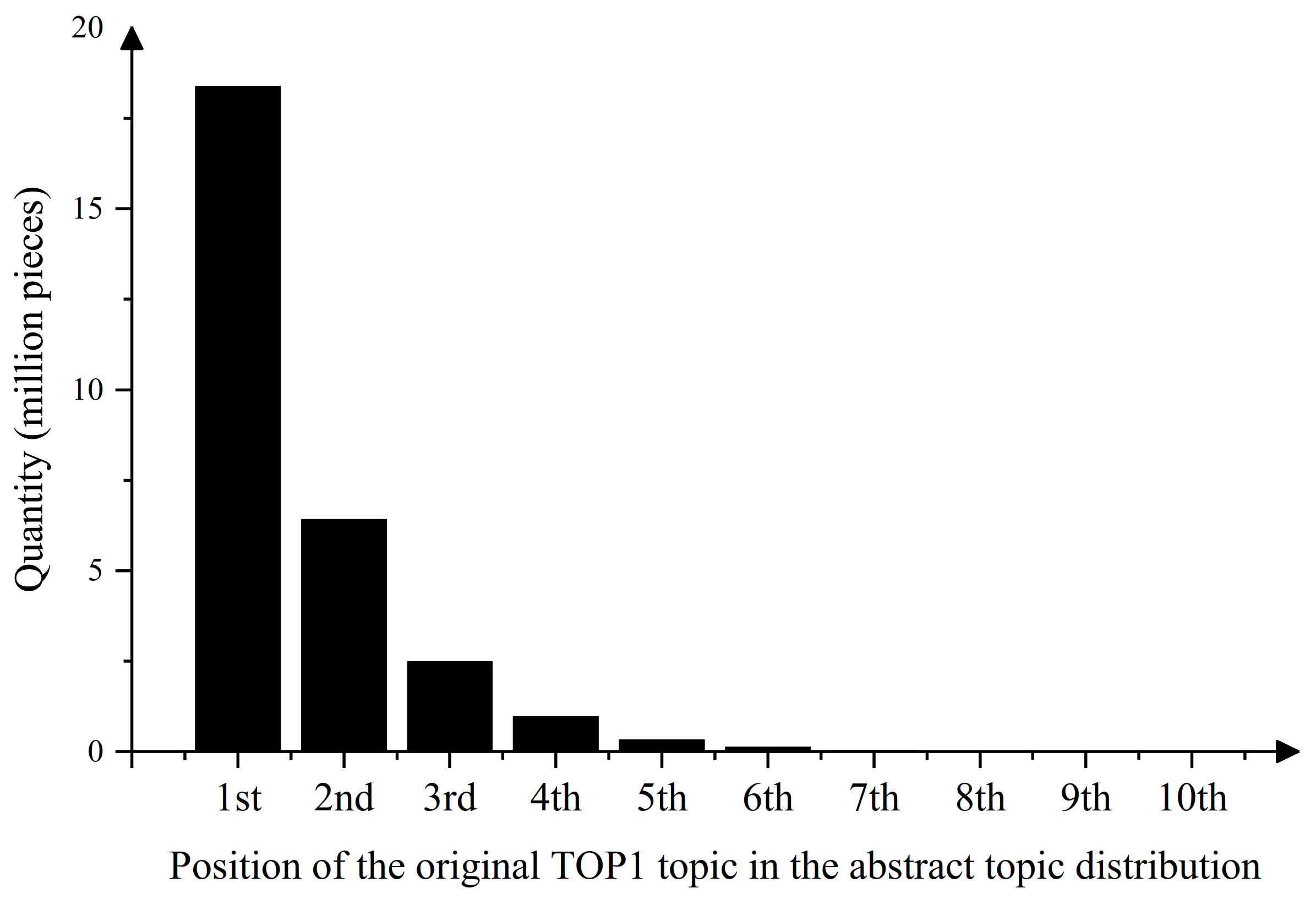
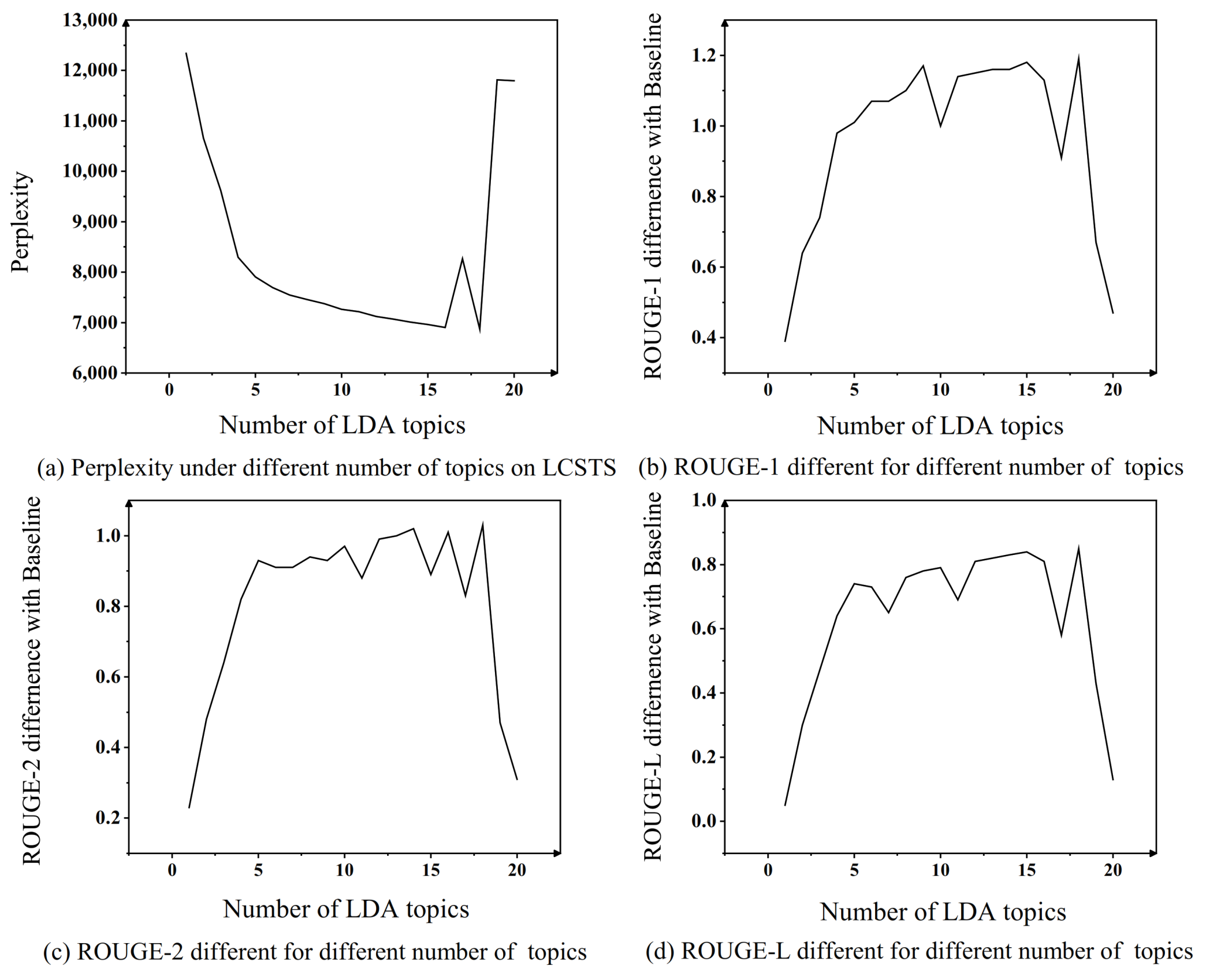
6.1. Effect of Number of Topics
6.2. Case Studies
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Yuan, D.; Wang, L.; Wu, Q.; Meng, F.; Ngan, N.; Xu, L. Language Bias-Driven Self-Knowledge Distillation with Generalization Uncertainty for Reducing Language Bias in Visual Question Answering. Appl. Sci. 2022, 12, 7588. [Google Scholar] [CrossRef]
- Jwa, H.; Oh, D.; Park, K.; Kang, J.; Lim, H. Exbake: Automatic fake news detection model based on bidirectional encoder representations from transformers (bert). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. arXiv 2015, arXiv:1509.00685. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the Point: Summarization with Pointer-Generator Networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Lin, C.Y.; Hovy, E. Automatic evaluation of summaries using n-gram co-occurrence statistics. In Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, Edmonton, AB, Canada, 27 May–1 June 2003; pp. 150–157. [Google Scholar]
- Abdel-Salam, S.; Rafea, A. Performance Study on Extractive Text Summarization Using BERT Models. Information 2022, 13, 67. [Google Scholar] [CrossRef]
- Lamsiyah, S.; El Mahdaouy, A.; Espinasse, B.; El Alaoui Ouatik, S. An unsupervised method for extractive multi-document summarization based on centroid approach and sentence embeddings. Expert Syst. Appl. 2021, 167, 114152. [Google Scholar] [CrossRef]
- Rani, R.; Lobiyal, D.K. Document vector embedding based extractive text summarization system for Hindi and English text. Appl. Intell. 2022, 52, 9353–9372. [Google Scholar] [CrossRef]
- Nallapati, R.; Zhou, B.; dos Santos, C.N.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond. arXiv 2022, arXiv:1602.06023. [Google Scholar]
- Gehrmann, S.; Deng, Y.; Rush, A.M. Bottom-up abstractive summarization. arXiv 2018, arXiv:1808.10792. [Google Scholar]
- Celikyilmaz, A.; Bosselut, A.; He, X.; Choi, Y. Deep communicating agents for abstractive summarization. arXiv 2018, arXiv:1803.10357. [Google Scholar]
- Gulcehre, C.; Ahn, S.; Nallapati, R.; Zhou, B.; Bengio, Y. Pointing the Unknown Words. arXiv 2022, arXiv:1603.08148. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O.K. Incorporating Copying Mechanism in Sequence-to-Sequence Learning. arXiv 2016, arXiv:1603.06393. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://proceedings.neurips.cc/paper/2015/file/29921001f2f04bd3baee84a12e98098f-Paper.pdf (accessed on 15 August 2022).
- Ruan, Q.; Ostendorff, M.; Rehm, G. Histruct+: Improving extractive text summarization with hierarchical structure information. arXiv 2022, arXiv:2203.09629. [Google Scholar]
- Mao, Z.; Wu, C.H.; Ni, A.; Zhang, Y.; Zhang, R.; Yu, T.; Deb, B.; Zhu, C.; Awadallah, A.H.; Radev, D. Dyle: Dynamic latent extraction for abstractive long-input summarization. arXiv 2021, arXiv:2110.08168. [Google Scholar]
- Li, J.; Shang, J.; McAuley, J. UCTopic: Unsupervised Contrastive Learning for Phrase Representations and Topic Mining. arXiv 2022, arXiv:2202.13469. [Google Scholar]
- Bahrainian, S.A.; Feucht, S.; Eickhoff, C. NEWTS: A Corpus for News Topic-Focused Summarization. arXiv 2022, arXiv:2205.15661. [Google Scholar]
- Li, M.; Lin, X.X.; Chen, X.; Chang, J.; Zhang, Q.; Wang, F.; Wang, T.; Liu, Z.; Chu, W.; Zhao, D.; et al. Keywords and Instances: A Hierarchical Contrastive Learning Framework Unifying Hybrid Granularities for Text Generation. arXiv 2022, arXiv:2205.13346. [Google Scholar]
- Lei, D.M.B.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Wu, D.; Yuan, Z.; Li, X. Automatic Summarization Algorithm Based on the Combined Features of LDA. Computer Sci. Appl. 2013, 3, 145–148. [Google Scholar]
- Liu, N.; Lu, Y.; Tang, X.-J.; Li, M.-X. Multi-document automatic summarization algorithm based on important topics of LDA. J. Front. Comput. Sci. Technol. 2015, 9, 242–248. [Google Scholar]
- Yang, T.; Xie, Q.; Liu, Y.-J.; Liu, P.-F. Topic-aware long text automatic summarization algorithm. Comput. Eng. Appl. 2022, 34(Part A), 2651–2665. [Google Scholar]
- Guo, J.-F.; Fei, Y.-X.; Sun, W.-B.; Xie, P.-P.; Zhang, J. A PGN-GAN Text Summarization Model Fusion Topic. J. Chin. Comput. Syst. 2022, 1–7. [Google Scholar]
- Chou, Y.C.; Kuo, C.J.; Chen, T.T.; Horng, G.J.; Pai, M.Y.; Wu, M.E.; Lin, Y.C.; Huang, M.H.; Su, M.Y.; Chen, Y.C.; et al. Deep-learning-based defective bean inspection with GAN-structured automated labeled data augmentation in coffee industry. Appl. Sci. 2019, 9, 4166. [Google Scholar] [CrossRef]
- Onah, D.F.O.; Pang, E.L.L.; El-Haj, M. A Data-driven Latent Semantic Analysis for Automatic Text Summarization using LDA Topic Modelling. arXiv 2022, arXiv:2207.14687. [Google Scholar]
- Rani, R.; Lobiyal, D.K. An extractive text summarization approach using tagged-LDA based topic modeling. Multimed. Tools Appl. 2021, 80, 3275–3305. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Hu, B.; Chen, Q.; Zhu, F. Lcsts: A large scale chinese short text summarization dataset. arXiv 2015, arXiv:1506.05865. [Google Scholar]
- Lin, C.Y. Rouge: A Package for Automatic Evaluation of Summaries. Proceedings of the Workshop on Text Summarization of ACL, Barcelona, Spain, 25–26 July 2004; pp. 74–81. Available online: https://aclanthology.org/W04-1013.pdf (accessed on 15 August 2022).
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Wasson, M. Using Leading Text for News Summaries: Evaluation Results and Implications for Commercial Summarization Applications[C]//COLING 1998 Volume 2: The 17th International Conference on Computational Linguistics. 1998. Available online: https://aclanthology.org/C98-2217.pdf (accessed on 15 August 2022).
- Xu, W.; Li, C.; Lee, M.; Zhang, C. Multi-task learning for abstractive text summarization with key information guide network. EURASIP J. Adv. Signal Process. 2020, 2020, 16. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Avg Length | CNN | DM | ||||
|---|---|---|---|---|---|---|
| Train | Verify | Test | Train | Verify | Test | |
| Text | 762 | 763 | 716 | 813 | 774 | 780 |
| Sum. | 66 | 67 | 67 | 67 | 66 | 65 |
| Set | Text, Summary) Pairs | |
|---|---|---|
| part I | 2,400,591 | |
| part II | number of pairs | 10,666 |
| manual score 1 | 942 | |
| manual score 2 | 1039 | |
| manual score 3 | 2019 | |
| manual score 4 | 3128 | |
| manual score 5 | 3538 | |
| part III | number of pairs | 1106 |
| manual score 1 | 165 | |
| manual score 2 | 216 | |
| manual score 3 | 227 | |
| manual score 4 | 301 | |
| manual score 5 | 197 | |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Lead-3 | 35.10 | 14.51 | 34.38 |
| ABS | 31.33 | 11.81 | 28.83 |
| PGEN | 36.44 | 15.66 | 33.42 |
| PGEN + Cov | 39.53 | 17.28 | 36.38 |
| Key-inf-guide | 40.34 | 17.70 | 36.57 |
| ACGT(Ours) | 40.49 (std = 0.043) | 19.72 (std = 0.031) | 37.41(std = 0.027) |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Hu.RNN | 17.7 | 8.5 | 15.8 |
| Hu.RNN context | 26.8 | 16.1 | 24.1 |
| Copy Net | 35.0 | 22.3 | 32 |
| PGEN | 36.68 | 21.39 | 31.12 |
| PGEN + Cov | 37.16 | 24.67 | 33.96 |
| ACGT(Ours) | 38.35(std = 0.039) | 25.70(std = 0.018) | 34.81(std = 0.011) |
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Hu.RNN | 21.5 | 8.9 | 18.6 |
| Hu.RNN context | 29.9 | 17.4 | 27.2 |
| Copy Net | 34.4 | 21.6 | 31.3 |
| PGEN | 36.57 | 22.14 | 31.46 |
| PGEN + Cov | 37.15 | 24.00 | 34.05 |
| ACGT(Ours) | 38.72(std = 0.031) | 24.80(std = 0.025) | 34.92(std = 0.016) |
| Original text: A mammoth fire broke out Friday morning in a Kentucky industrial park, sending plumes of thick smoke over the area as authorities worked to contain the damage. |
| Reference summary: Fire breaks out in a Kentucky industrial park. City official states: no one is believed to be injured or trapped. |
| PGEN + Cov: A fire broke out Friday morning in an industrial park, and the authorities did not know what had caused the fire. |
| ACGT(ours): Fire breaks out at the general electric appliance park in Louisville, Kentucky. The authorities said: no one was injured or trapped, but the cause of the fire is unknown. |
| Original text: At around 15:00 this afternoon, the 2016 International Champions Cup China officially announced that the “2016 International Champions Cup China—Beijing Station—Manchester City vs. Manchester United” originally scheduled to be held at the “Bird’s Nest” at 19:30 on 25 July, Cancelled due to continuous heavy rain in recent days. The Manchester City club said in an official statement that the extreme weather in recent days has made the pitch conditions unsuitable for athletes to compete. Fans can go to the sponsor’s website for a full refund. However, according to Sky Sports UK, the real reason for the cancellation was the poor venue rather than the weather. Just last weekend, Manchester United manager Jose Mourinho called the pitch very bad. On Weibo, some netizens posted the situation of the “Bird’s Nest” lawn, let’s feel it. |
| Reference summary: Is the Manchester City vs. Manchester United Bird’s Nest match cancelled because of the weather or other reasons? |
| PGEN + Co: Champions League Manchester City vs. Manchester United reported that the weather caused the venue environment to be too bad? |
| ACGT(Ours): The real reason for the cancellation of the International Champions Cup China match between Manchester City and Manchester United is that the venue is too bad and the weather is bad? |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, Z.; Lu, L.; Yang, W.; Wang, J.; Wang, Y. An Abstract Summarization Method Combining Global Topics. Appl. Sci. 2022, 12, 10378. https://doi.org/10.3390/app122010378
Duan Z, Lu L, Yang W, Wang J, Wang Y. An Abstract Summarization Method Combining Global Topics. Applied Sciences. 2022; 12(20):10378. https://doi.org/10.3390/app122010378
Chicago/Turabian StyleDuan, Zhili, Ling Lu, Wu Yang, Jinghui Wang, and Yuke Wang. 2022. "An Abstract Summarization Method Combining Global Topics" Applied Sciences 12, no. 20: 10378. https://doi.org/10.3390/app122010378
APA StyleDuan, Z., Lu, L., Yang, W., Wang, J., & Wang, Y. (2022). An Abstract Summarization Method Combining Global Topics. Applied Sciences, 12(20), 10378. https://doi.org/10.3390/app122010378