
Induced Emotion-Based Music Recommendation through Reinforcement Learning





Abstract
1. Introduction
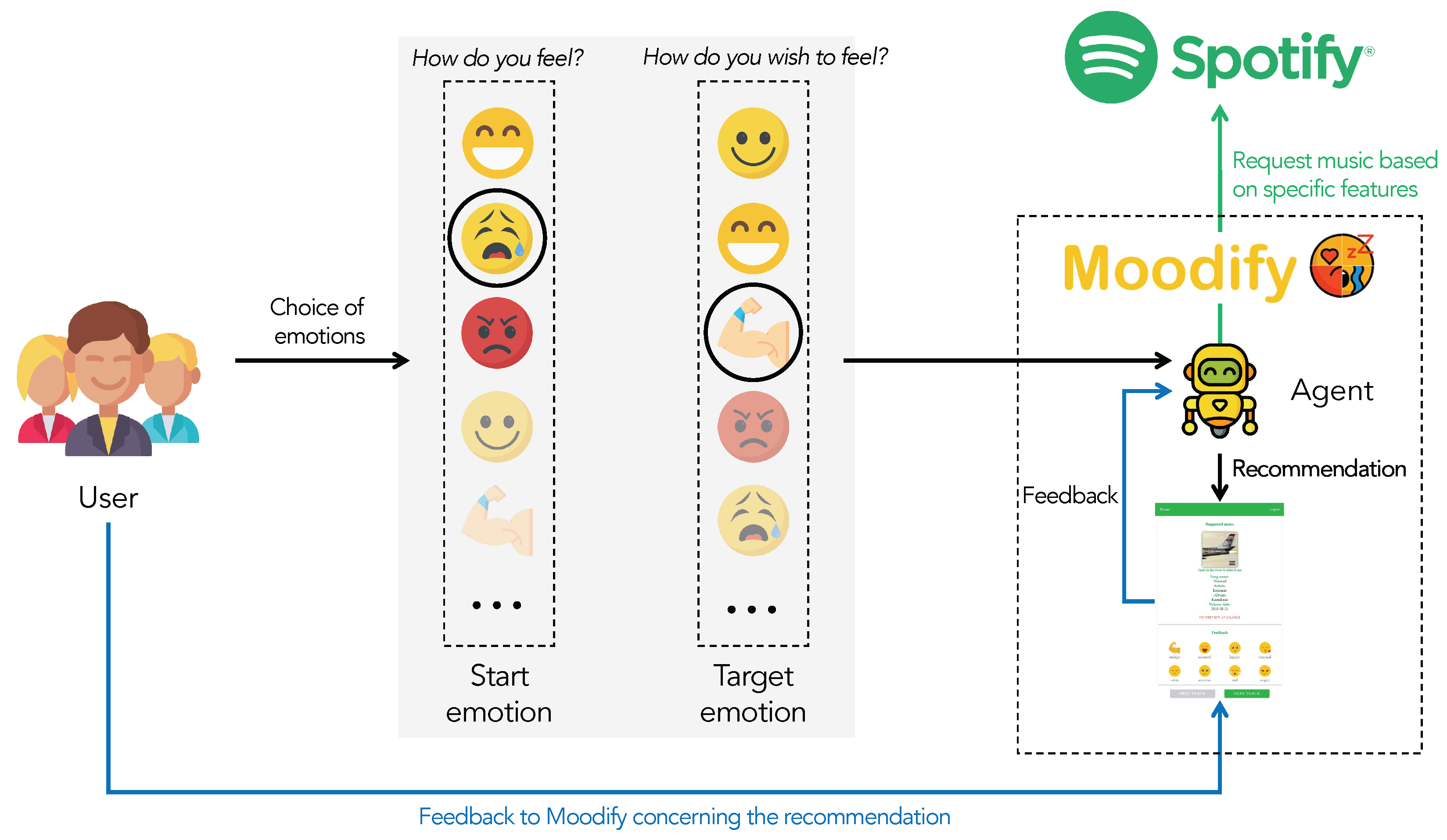
- We propose Moodify, a novel music recommendation system based on Go-Explore, which takes into account the listener’s emotional state for inducing a future target emotion; the main novelty is that it adopts a “look-forward-recommendation”, i.e., it recommends music intended to induce (in the future) a specific target emotion. Previous works in the literature have proposed methods that, based on the current user’s mood, recommend music or artists to listen to, for example, by computing similarities between artists’ and users’ moods.
- To analyze its effectiveness and overall user satisfaction, we have involved 40 people in testing Moodify, with one million music playlists from the Spotify platform; results obtained show that the proposed system can bring both significant overall user satisfaction and high performance. To the best of our knowledge, this is one of the few proposals of a system which undergone an evaluation phase of this kind.
- The proposed method has been developed as a Web application, namely MoodifyWeb, which exploits Spotify API for developers and JavaScript. To the best of our knowledge, this is one of the first proposals deployed in software for end-users.
2. Related Work
2.1. Collaborative Filtering
2.2. Content-Based Filtering
- tags can either be assigned automatically or manually;
- the tags must be generated or assigned such that both the user’s profile and the items can be easily matched and compared to derive a similarity measure;
- a learning algorithm must be chosen that learns and classifies the user’s profile based on played songs (i.e., seen items) and offers recommendations based on it.
2.3. Context-Based Filtering
2.4. Emotion-Based Filtering
2.5. Summarizing Literature’s Proposals
3. Background
3.1. Models of Emotional States
3.2. Spotify
3.3. Reinforcement Learning Notes
3.3.1. The Learning Model
3.3.2. Markov Decision Processes
3.4. Go-Explore
4. Music Recommendation Based on Go-Explore
4.1. Preliminaries and Definitions
4.2. Problem Description
4.3. The Methodology
4.3.1. Induced Emotion-Based Music Recommendation as MDP
- state: one state corresponds to one specific emotion defined in the circumplex model (Section 3.1), represented as the pair where x and y are the coordinates in the two-dimensional plane; at each request of recommendation, the user starts with a start state, chooses a target state, and after listening each song reaches a new state.
- action: the action space is the set of possible musical songs; given a current state and it’s coordinate in the circumplex model x and y, our model recommends a song and stores which are the acousticness, danceability, energy, instrumentalness, loudness, speechness, tempo, and valence (see the Spotify audio features in Table 2); therefore, a recommendation is a tuple .
- reward: as also detailed in the following, in our approach, we adopt a “feedback-based reward”, i.e., after each listening, the user assigns a score (integer in ) which represents the perception of the user on “how much the emotion perceived after the listening is similar to the chosen target emotion”.
4.3.2. Step 1: Listen until Solved
Cell and State Representation
Selecting and Returning to Cells
Exploration from Cells
How to Update the Archive
4.3.3. Step 2: Emotion Robustification
4.3.4. Limitations of the method
5. MoodifyWeb: The Web Application
6. Moodify’s Assessment by Users
6.1. Method
6.2. Results
7. Conclusions
Limitations and Future Works of the Project
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RL | Reinforcement Learning |
| AI | Artificial Intelligence |
| IoT | Internet of Things |
Appendix A. MoodifyWeb’s Architecture

References
- Grand View Research. Music Streaming Market Size, Share & Trends Analysis Report By Service (On-demand Streaming, Live Streaming), By Platform (Apps, Browsers), By Content Type, By End-use, By Region, And Segment Forecasts, 2022–2030. 2022. Available online: https://www.grandviewresearch.com/industry-analysis/music-streaming-market (accessed on 18 October 2022).
- Hanjalic, A.; Xu, L.Q. Affective video content representation and modeling. IEEE Trans. Multimed. 2005, 7, 143–154. [Google Scholar] [CrossRef]
- Lu, L.; Liu, D.; Zhang, H.J. Automatic mood detection and tracking of music audio signals. IEEE Trans. Audio Speech Lang. Process. 2005, 14, 5–18. [Google Scholar] [CrossRef]
- Yang, Y.H.; Chen, H.H. Ranking-based emotion recognition for music organization and retrieval. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 762–774. [Google Scholar] [CrossRef]
- Yang, Y.H.; Chen, H.H. Machine recognition of music emotion: A review. ACM Trans. Intell. Syst. Technol. (TIST) 2012, 3, 1–30. [Google Scholar] [CrossRef]
- Lara, C.A.; Mitre-Hernandez, H.; Flores, J.; Perez, H. Induction of emotional states in educational video games through a fuzzy control system. IEEE Trans. Affect. Comput. 2018, 12, 66–77. [Google Scholar] [CrossRef]
- Muszynski, M.; Tian, L.; Lai, C.; Moore, J.; Kostoulas, T.; Lombardo, P.; Pun, T.; Chanel, G. Recognizing induced emotions of movie audiences from multimodal information. IEEE Trans. Affect. Comput. 2019, 12, 36–52. [Google Scholar] [CrossRef]
- Juslin, P.N.; Sloboda, J.A. Music and Emotion: Theory and Research; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Zentner, M.; Grandjean, D.; Scherer, K.R. Emotions evoked by the sound of music: Characterization, classification, and measurement. Emotion 2008, 8, 494. [Google Scholar] [CrossRef]
- Gabrielsson, A. Emotion perceived and emotion felt: Same or different? Music. Sci. 2001, 5, 123–147. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Paul, D.; Kundu, S. A survey of music recommendation systems with a proposed music recommendation system. In Emerging Technology in Modelling and Graphics; Springer: Berlin/Heidelberg, Germany, 2020; pp. 279–285. [Google Scholar]
- Agrafioti, F.; Hatzinakos, D.; Anderson, A.K. ECG pattern analysis for emotion detection. IEEE Trans. Affect. Comput. 2011, 3, 102–115. [Google Scholar] [CrossRef]
- Lin, Y.P.; Wang, C.H.; Jung, T.P.; Wu, T.L.; Jeng, S.K.; Duann, J.R.; Chen, J.H. EEG-based emotion recognition in music listening. IEEE Trans. Biomed. Eng. 2010, 57, 1798–1806. [Google Scholar]
- Wijnalda, G.; Pauws, S.; Vignoli, F.; Stuckenschmidt, H. A personalized music system for motivation in sport performance. IEEE Pervasive Comput. 2005, 4, 26–32. [Google Scholar] [CrossRef]
- Yang, Y.H.; Lin, Y.C.; Su, Y.F.; Chen, H.H. A regression approach to music emotion recognition. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 448–457. [Google Scholar] [CrossRef]
- Deng, J.J.; Leung, C.H. Music retrieval in joint emotion space using audio features and emotional tags. In Proceedings of the International Conference on Multimedia Modeling, Huangshan, China, 7–9 January 2013; Springer: Heidelberg, Germany, 2013; pp. 524–534. [Google Scholar]
- Deng, J.J.; Leung, C.H.; Milani, A.; Chen, L. Emotional states associated with music: Classification, prediction of changes, and consideration in recommendation. ACM Trans. Interact. Intell. Syst. (TiiS) 2015, 5, 1–36. [Google Scholar] [CrossRef]
- Ecoffet, A.; Huizinga, J.; Lehman, J.; Stanley, K.O.; Clune, J. Go-Explore: A New Approach for Hard-Exploration Problems. arXiv 2019, arXiv:1901.10995. Available online: https://arxiv.org/abs/1901.10995 (accessed on 18 October 2022).
- De Prisco, R.; Guarino, A.; Lettieri, N.; Malandrino, D.; Zaccagnino, R. Providing music service in ambient intelligence: Experiments with gym users. Expert Syst. Appl. 2021, 177, 114951. [Google Scholar] [CrossRef]
- Wen, X. Using deep learning approach and IoT architecture to build the intelligent music recommendation system. Soft Comput. 2021, 25, 3087–3096. [Google Scholar] [CrossRef]
- De Prisco, R.; Zaccagnino, G.; Zaccagnino, R. A multi-objective differential evolution algorithm for 4-voice compositions. In Proceedings of the 2011 IEEE Symposium on Differential Evolution (SDE), Paris, France, 11–15 April 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–8. [Google Scholar]
- Prisco, R.D.; Zaccagnino, G.; Zaccagnino, R. A genetic algorithm for dodecaphonic compositions. In Proceedings of the European Conference on the Applications of Evolutionary Computation, Torino, Italy, 27–29 April; Springer: Berlin/Heidelberg, Germany, 2011; pp. 244–253. [Google Scholar]
- O’Bryant, J. A Survey of Music Recommendation and Possible Improvements. 2017. Available online: https://www.semanticscholar.org/paper/A-survey-of-music-recommendation-and-possible-O%E2%80%99Bryant/7442c1ebd6c9ceafa8979f683c5b1584d659b728 (accessed on 18 October 2022).
- Knees, P.; Schedl, M. A survey of music similarity and recommendation from music context data. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2013, 10, 1–21. [Google Scholar] [CrossRef]
- Wenzhen, W. Personalized music recommendation algorithm based on hybrid collaborative filtering technology. In Proceedings of the 2019 International Conference on Smart Grid and Electrical Automation (ICSGEA), Xiangtan, China, 10–11 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 280–283. [Google Scholar]
- Ferretti, S. Clustering of musical pieces through complex networks: An Assessment over Guitar Solos. IEEE Multimed. 2018, 25, 57–67. [Google Scholar] [CrossRef]
- Song, Y.; Dixon, S.; Pearce, M. A survey of music recommendation systems and future perspectives. In Proceedings of the 9th International Symposium on Computer Music Modeling and Retrieval, Citeseer, London, UK, 19–22 June 2012; Volume 4, pp. 395–410. [Google Scholar]
- Andjelkovic, I.; Parra, D.; O’Donovan, J. Moodplay: Interactive music recommendation based on artists’ mood similarity. Int. J. Hum.-Comput. Stud. 2019, 121, 142–159. [Google Scholar] [CrossRef]
- Skowronek, J.; McKinney, M.F.; Van De Par, S. Ground truth for automatic music mood classification. In Proceedings of the ISMIR, Citeseer, Victoria, BC, Canada, 8–12 October 2006; pp. 395–396. [Google Scholar]
- Kim, H.G.; Kim, G.Y.; Kim, J.Y. Music Recommendation System Using Human Activity Recognition from Accelerometer Data. IEEE Trans. Consum. Electron. 2019, 65, 349–358. [Google Scholar] [CrossRef]
- de Santana, M.A.; de Lima, C.L.; Torcate, A.S.; Fonseca, F.S.; dos Santos, W.P. Affective computing in the context of music therapy: A systematic review. Res. Soc. Dev. 2021, 10, e392101522844. [Google Scholar] [CrossRef]
- Savery, R.; Rose, R.; Weinberg, G. Establishing human-robot trust through music-driven robotic emotion prosody and gesture. In Proceedings of the 2019 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), New Delhi, India, 14–18 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Subramaniam, G.; Verma, J.; Chandrasekhar, N.; Narendra, K.; George, K. Generating playlists on the basis of emotion. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (Ssci), Bangalore, India, 18–21 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 366–373. [Google Scholar]
- Su, J.H.; Liao, Y.W.; Wu, H.Y.; Zhao, Y.W. Ubiquitous music retrieval by context-brain awareness techniques. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (smc), Toronto, ON, Canada, 11–14 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 4140–4145. [Google Scholar]
- Chen, J.; Pan, F.; Zhong, P.; He, T.; Qi, L.; Lu, J.; He, P.; Zheng, Y. An automatic method to develop music with music segment and long short term memory for tinnitus music therapy. IEEE Access 2020, 8, 141860–141871. [Google Scholar] [CrossRef]
- González, E.J.S.; McMullen, K. The design of an algorithmic modal music platform for eliciting and detecting emotion. In Proceedings of the 2020 8th International Winter Conference on Brain-Computer Interface (bci), Gangwon, Korea, 26–28 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–3. [Google Scholar]
- Sawata, R.; Ogawa, T.; Haseyama, M. Novel audio feature projection using KDLPCCA-based correlation with EEG features for favorite music classification. IEEE Trans. Affect. Comput. 2017, 10, 430–444. [Google Scholar] [CrossRef]
- Amali, D.N.; Barakbah, A.R.; Besari, A.R.A.; Agata, D. Semantic video recommendation system based on video viewers impression from emotion detection. In Proceedings of the 2018 International Electronics Symposium on Knowledge Creation and Intelligent Computing (ies-kcic), East Java, Indonesia, 29–30 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 176–183. [Google Scholar]
- Fernandes, C.M.; Migotina, D.; Rosa, A.C. Brain’s Night Symphony (BraiNSy): A Methodology for EEG Sonification. IEEE Trans. Affect. Comput. 2018, 12, 103–112. [Google Scholar] [CrossRef]
- Hossan, A.; Chowdhury, A.M. Real time EEG based automatic brainwave regulation by music. In Proceedings of the 2016 5th International Conference on Informatics, Electronics and Vision (iciev), Dhaka, Bangladesh, 13–14 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 780–784. [Google Scholar]
- Chang, H.Y.; Huang, S.C.; Wu, J.H. A personalized music recommendation system based on electroencephalography feedback. Multimed. Tools Appl. 2017, 76, 19523–19542. [Google Scholar] [CrossRef]
- Ayata, D.; Yaslan, Y.; Kamasak, M.E. Emotion Based Music Recommendation System Using Wearable Physiological Sensors. IEEE Trans. Consum. Electron. 2018, 64, 196–203. [Google Scholar] [CrossRef]
- Lang, P.J. The emotion probe: Studies of motivation and attention. Am. Psychol. 1995, 50, 372. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I.; et al. Deep q-learning from demonstrations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Pohlen, T.; Piot, B.; Hester, T.; Azar, M.G.; Horgan, D.; Budden, D.; Barth-Maron, G.; Van Hasselt, H.; Quan, J.; Večerík, M.; et al. Observe and look further: Achieving consistent performance on atari. arXiv 2018, arXiv:1805.11593. [Google Scholar]
- Salimans, T.; Chen, R. Learning montezuma’s revenge from a single demonstration. arXiv 2018, arXiv:1812.03381. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. Adv. Neural Inf. Process. Syst. 2016, 29, 4572–4580. [Google Scholar]
- Malandrino, D.; Pirozzi, D.; Zaccagnino, R. Learning the harmonic analysis: Is visualization an effective approach? Multimed. Tools Appl. 2019, 78, 32967–32998. [Google Scholar] [CrossRef]
- De Prisco, R.; Esposito, A.; Lettieri, N.; Malandrino, D.; Pirozzi, D.; Zaccagnino, G.; Zaccagnino, R. Music Plagiarism at a Glance: Metrics of Similarity and Visualizations. In Proceedings of the 21st International Conference Information Visualisation, IV 2017, London, UK, 11–14 July 2017; IEEE Computer Society: Piscataway, NJ, USA, 2017; pp. 410–415. [Google Scholar]
- Erra, U.; Malandrino, D.; Pepe, L. A methodological evaluation of natural user interfaces for immersive 3D Graph explorations. J. Vis. Lang. Comput. 2018, 44, 13–27. [Google Scholar] [CrossRef]
- Oliver, R.L. A cognitive model of the antecedents and consequences of satisfaction decisions. J. Mark. Res. 1980, 17, 460–469. [Google Scholar] [CrossRef]
- Hossain, M.A.; Quaddus, M. Expectation–Confirmation Theory in Information System Research: A Review and Analysis. In Information Systems Theory: Explaining and Predicting Our Digital Society; Dwivedi, Y.K., Wade, M.R., Schneberger, S.L., Eds.; Springer: New York, NY, USA, 2012; Volume 1, pp. 441–469. [Google Scholar]
- Linda, G.; Oliver, R.L. Multiple brand analysis of expectation and disconfirmation effects on satisfaction. In Proceedings of the 87th Annual Convention of the American Psychological Association, New York, NY, USA, 1–5 September 1979; pp. 102–111. [Google Scholar]
- Zaccagnino, R.; Capo, C.; Guarino, A.; Lettieri, N.; Malandrino, D. Techno-regulation and intelligent safeguards. Multimed. Tools Appl. 2021, 80, 15803–15824. [Google Scholar] [CrossRef]
- Guarino, A.; Lettieri, N.; Malandrino, D.; Zaccagnino, R.; Capo, C. Adam or Eve? Automatic users’ gender classification via gestures analysis on touch devices. Neural Comput. Appl. 2022, 34, 18473–18495. [Google Scholar] [CrossRef]
- Gao, Y.; Bianchi-Berthouze, N.; Meng, H. What does touch tell us about emotions in touchscreen-based gameplay? ACM Trans.-Comput.-Hum. Interact. (TOCHI) 2012, 19, 1–30. [Google Scholar] [CrossRef]
- Lum, H.C.; Greatbatch, R.; Waldfogle, G.; Benedict, J. How immersion, presence, emotion, & workload differ in virtual reality and traditional game mediums. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Philadelphia, PA, USA, 1–5 October 2018; SAGE Publications Sage CA: Los Angeles, CA, USA, 2018; Volume 62, pp. 1474–1478. [Google Scholar]
- Hashemian, M.; Prada, R.; Santos, P.A.; Dias, J.; Mascarenhas, S. Inferring Emotions from Touching Patterns. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Pallavicini, F.; Pepe, A. Virtual reality games and the role of body involvement in enhancing positive emotions and decreasing anxiety: Within-subjects pilot study. JMIR Serious Games 2020, 8, e15635. [Google Scholar] [CrossRef] [PubMed]
- Du, G.; Zhou, W.; Li, C.; Li, D.; Liu, P.X. An emotion recognition method for game evaluation based on electroencephalogram. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Approach | Idea | Method | Software | User Evaluation |
|---|---|---|---|---|---|
| [26] | Collaborative | Suggesting music based on similarities between users’ preferences and music features | ✓ | ✓ † | ✓ † |
| [29] | Content + Emotion | Suggesting music artists suitable to a specific mood based on similarities between artists’ and users’ moods | ✓ | ✓ | ✓ |
| [31] | Context | Capturing human activities via smartphones’ accelerometer and suggesting suitable music | ✓ | ✗ | ✗ |
| [21] | Context | Capturing human activities via IoT devices and suggesting suitable music | ✓ * | ✗ | ✗ |
| [43] | Emotion | Capturing emotions through wearable sensors suggesting music suitable to those emotions | ✓ | ✗ | ✗ |
| This work | Emotion | Induce emotion creating a trajectory of music songs to listen so to get an indicated target emotion given a starting emotion | ✓ | ✓ | ✓ |
| Feature | Description | Range |
|---|---|---|
| Acousticness (a) | “A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic.” | [0, 1] |
| Danceability (d) | “Danceability describes how suitable a track is for dancing based on a combination of musical elements, including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is the least danceable, and 1.0 is the most danceable.” | [0, 1] |
| Energy (e) | “Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy.” | [0, 1] |
| Instrumentalness (in) | “Predicts whether a track contains no vocals. "Ooh" and "aah" sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly ’vocal.’ The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0.” | [0, 1] |
| Liveness (liv) | “Detects the presence of an audience in the recording. Higher liveness values represent an increased probability that the track was performed live. A value above 0.8 provides a strong likelihood that the track is live.” | [0, 1] |
| Loudness (lou) | “The overall loudness of a track in decibels (dB). Loudness values are averaged across the entire track and are useful for comparing the relative loudness of tracks. Loudness is the quality of a sound that is the primary psychological correlate of physical strength (amplitude).” | [−60, 0] |
| Speechiness (s) | “Speechiness detects the presence of spoken words in a track. The more exclusively speech-like the recording (e.g., talk show, audiobook, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks.” | [0, 1] |
| Tempo (t) | “The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, the tempo is the speed or pace of a given piece and derives directly from the average beat duration.” | [30, 240] |
| Valence (v) | “A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g., happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g., sad, depressed, angry).” | [0, 1] |
| Go-Explore | Moodify |
|---|---|
| The states correspond to the game’s cells (e.g., pixels) | The states correspond to the emotions |
| The agent begins by exploring the environment without any prior knowledge about it | The agent learns during the training phase based on user feedback without having to make any decisions |
| When the agent reaches a new state rewarding him with points, the algorithm stores such a state | When the agent reaches a new state rewarding him with points, the algorithm memorizes the musical features corresponding to that state |
| The agent continues to explore from a stored state, thus, being able to progress to new states over time | The agent continues to listen to memorized music, thus, being able to progress towards new emotions over time |
| Each time the game character dies, a negative reward is assigned to that cell | Whenever the user gives feedback that does not correspond to the desired emotion, the agent receives a negative reward |
| Number | Percentage | |
|---|---|---|
| Participants | 40 | |
| Gender | ||
| Male | 24 | 60.0% |
| Female | 16 | 40.0% |
| Age | ||
| 15–20 years old | 8 | 31.0% |
| 20–30 years old | 28 | 62.0% |
| 30+ years old | 4 | 7.0% |
| Time spent on listening music per week | ||
| <1 h | 4 | 10.0% |
| 1–3 h | 12 | 30.0% |
| 3+ h | 24 | 60.0% |
| Recommendation | Appropriateness of the Recommendations | User Satisfaction | System Responsiveness |
|---|---|---|---|
| #1 | 4.15 | 4.25 | 4.45 |
| #2 | 4.20 | 4.15 | 4.05 |
| #3 | 3.85 | 4.15 | 3.90 |
| #4 | 4.20 | 4.00 | 3.95 |
| #5 | 4.75 | 4.15 | 4.10 |
| #6 | 4.15 | 4.05 | 4.25 |
| #7 | 3.95 | 3.90 | 4.15 |
| #8 | 4.75 | 4.15 | 4.05 |
| #9 | 4.10 | 4.15 | 3.90 |
| #10 | 4.75 | 4.30 | 4.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Prisco, R.; Guarino, A.; Malandrino, D.; Zaccagnino, R. Induced Emotion-Based Music Recommendation through Reinforcement Learning. Appl. Sci. 2022, 12, 11209. https://doi.org/10.3390/app122111209
De Prisco R, Guarino A, Malandrino D, Zaccagnino R. Induced Emotion-Based Music Recommendation through Reinforcement Learning. Applied Sciences. 2022; 12(21):11209. https://doi.org/10.3390/app122111209
Chicago/Turabian StyleDe Prisco, Roberto, Alfonso Guarino, Delfina Malandrino, and Rocco Zaccagnino. 2022. "Induced Emotion-Based Music Recommendation through Reinforcement Learning" Applied Sciences 12, no. 21: 11209. https://doi.org/10.3390/app122111209
APA StyleDe Prisco, R., Guarino, A., Malandrino, D., & Zaccagnino, R. (2022). Induced Emotion-Based Music Recommendation through Reinforcement Learning. Applied Sciences, 12(21), 11209. https://doi.org/10.3390/app122111209