
A Feasibility Study for the Prediction of Concrete Pavement Condition Index (CPCI) Based on Machine Learning


Abstract
:1. Introduction
2. Literature Review
2.1. Research on Predictive Model Development Using Pavement Performance Database
2.2. Infrastructure Management Related Database Based on Machine/Deep Learning Research
3. Methodology
4. Prediction of Concrete Pavement Performance Based on Particle Filtering
4.1. Data Preparation
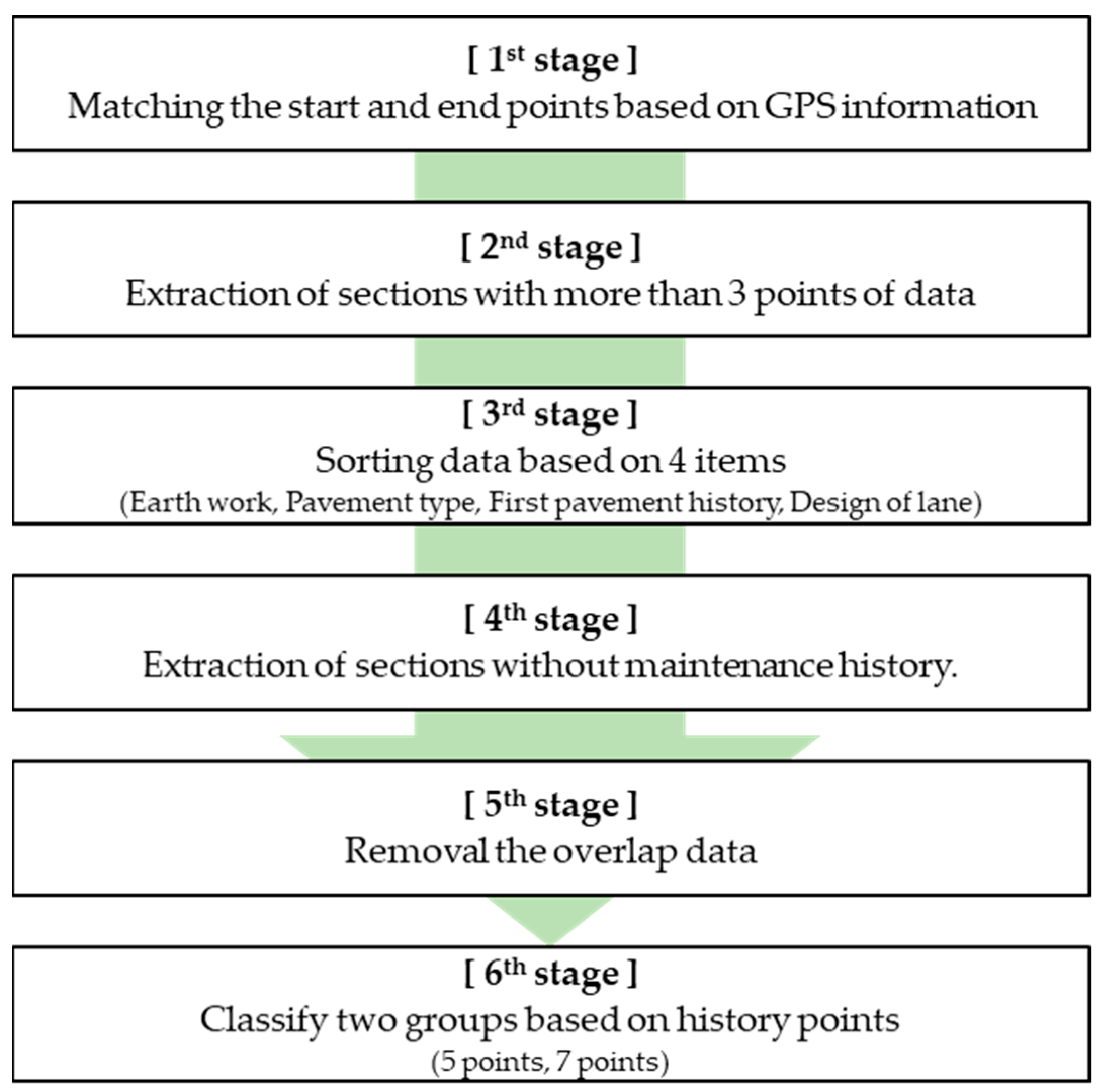
4.2. Data Pre-Processing
- The start and end points were matched using the GPS values for each age of concrete pavement and each 10 m section.
- Time-series sections collected over three consecutive points simultaneously and the endpoint section in the PMS DB are extracted.
- Data were sorted and filtered based on four items: earthworks, pavement type, first pavement history, and design lane (38,208 sections = 38.208 km).
- Data clusters that do not have a maintenance history after initial packaging were extracted (576 sections = 5.76 km).
- Redundantly written historical data were removed to improve data reliability (prediction accuracy) (469 sections = 4.69 km)
- Data sets were classified into two clusters based on consecutively collected time-series data points within the same time and endpoint interval (7 points = 208 sections; 5 points = 261 sections; a total of 469 intervals).
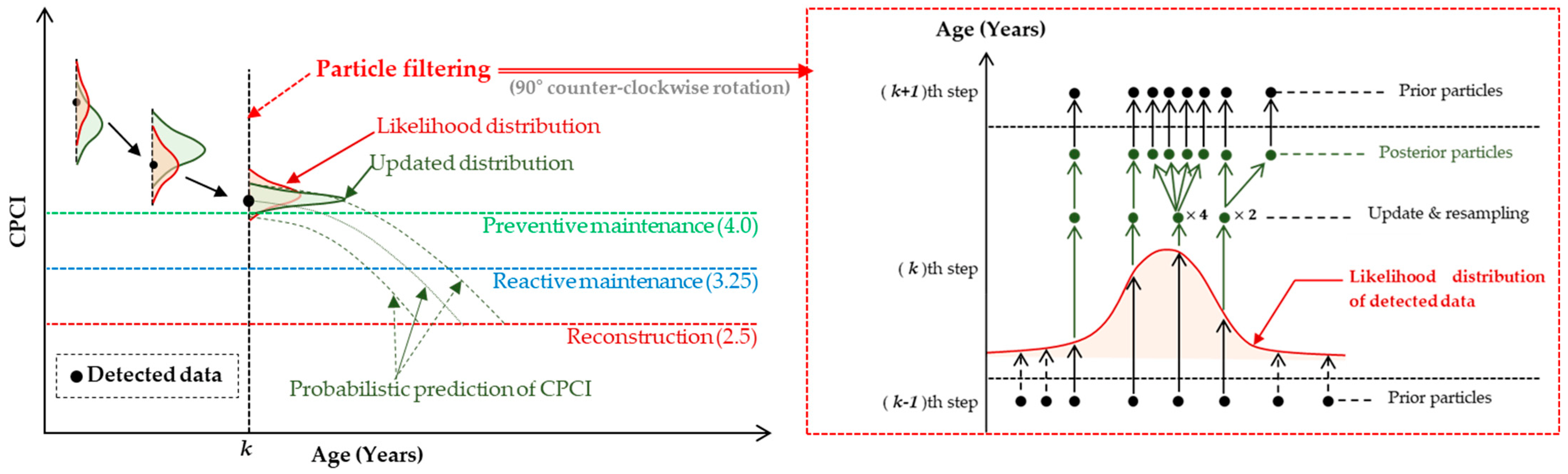
4.3. Particle Filter Model for CPCI Prediction
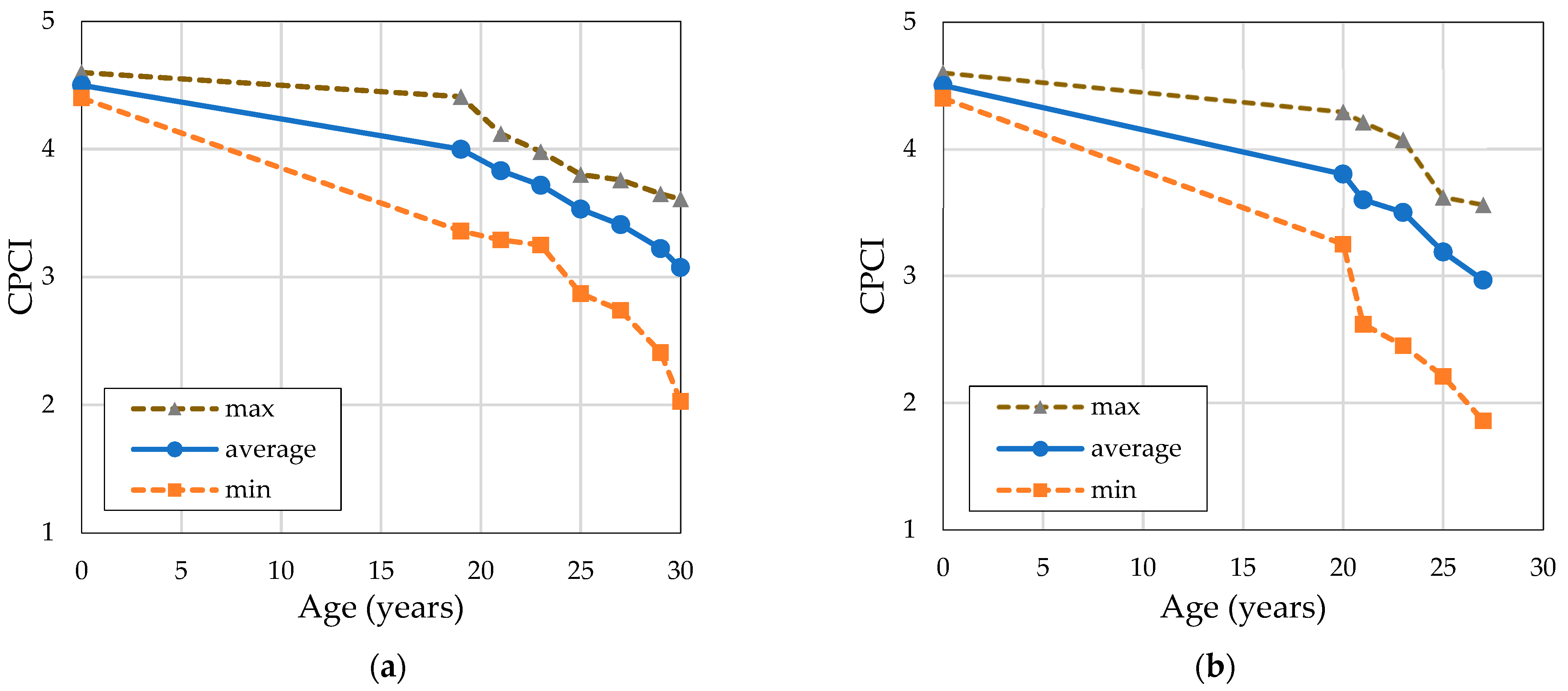
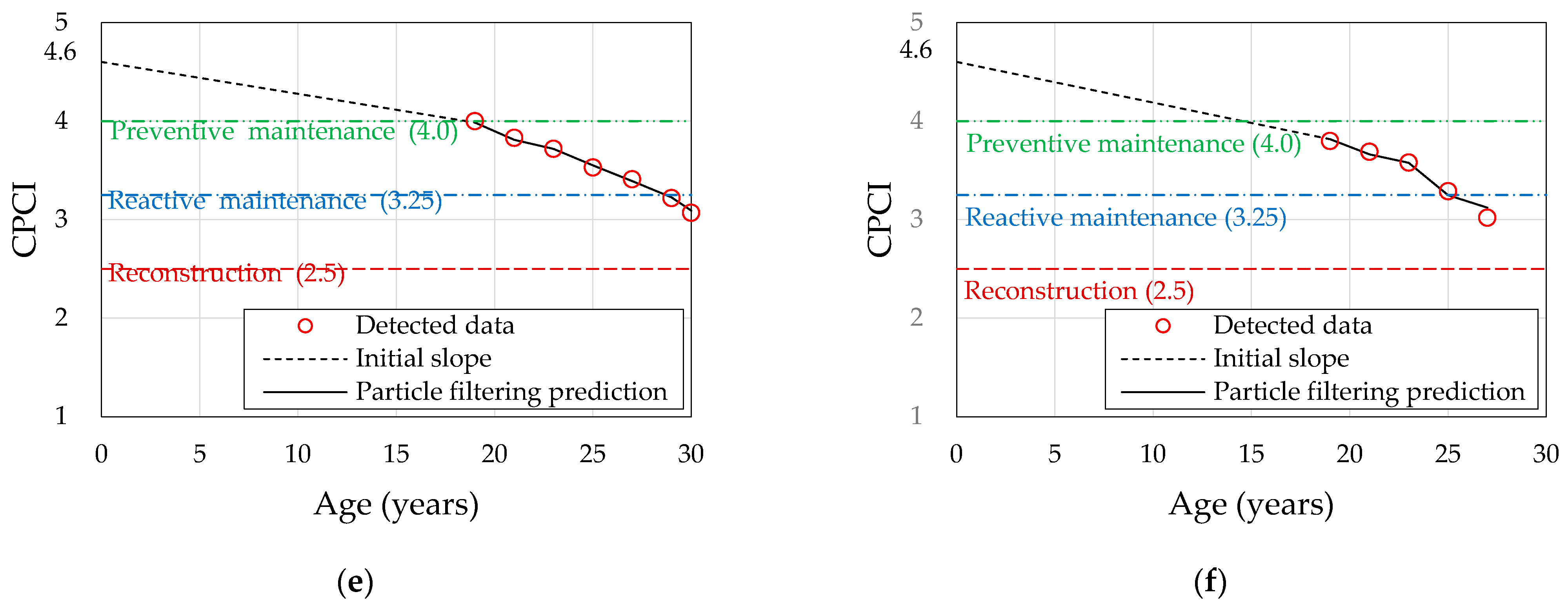
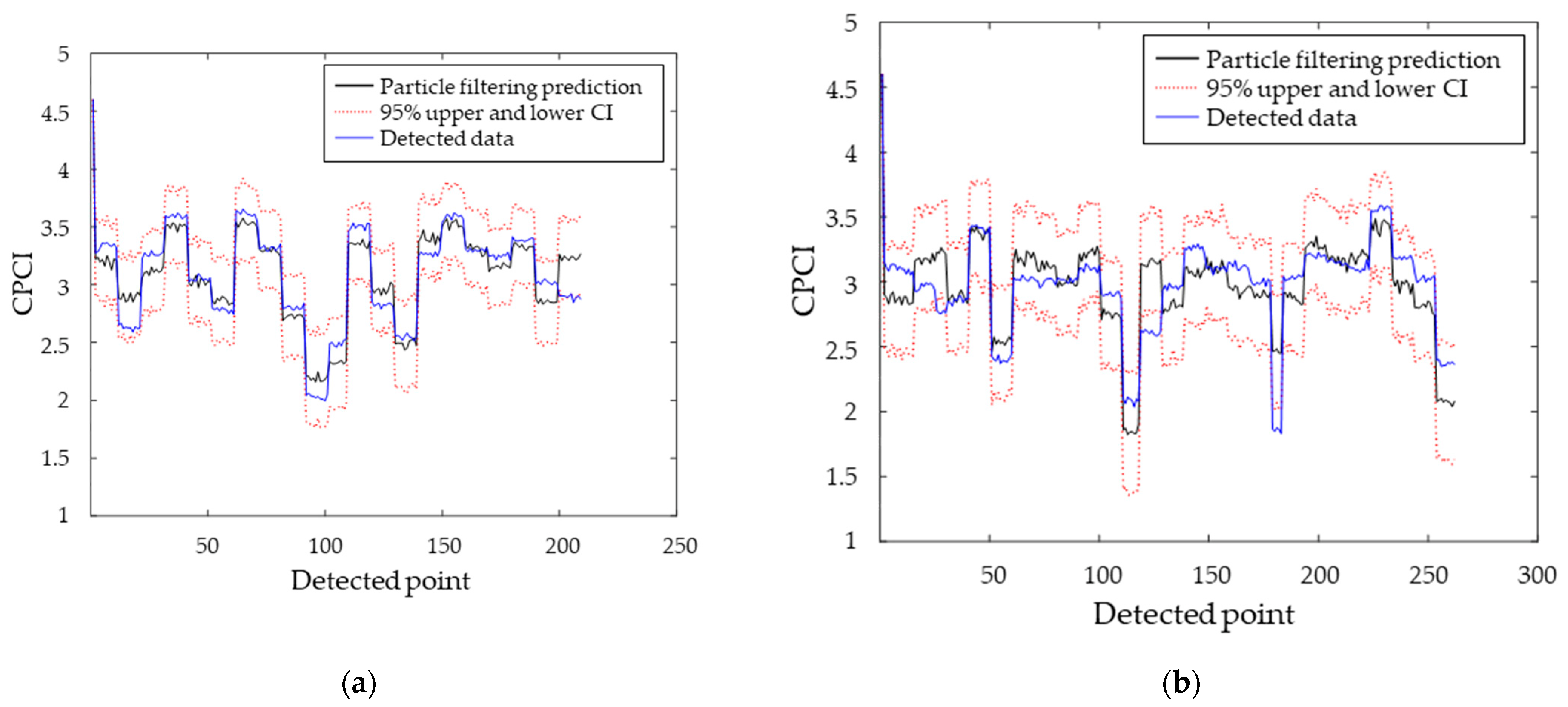
5. Results
5.1. Application of Particle Filtering
5.2. Verification of the CPCI Prediction Model
6. Conclusions
- This study applied particle filtering on time-series data of the concrete pavement condition of a specific section, which were collected for research, to predict pavement conditions. As a result of reviewing 22 different cases, the particle filtering technique showed a prediction accuracy between 86.09 and 99.33%, indicating its applicability in predicting the road pavement condition index. As national investigations are conducted for both express highways and national highways every year, unlike in the past, the utilization of PMS can be further increased for project level management, where it was difficult to use in the past, through more accurate predictions.
- The results of this study can be more easily utilized by the road pavement maintenance management team for making decisions in the future by presenting the deterioration model in the form of a category according to the performance index obtained at the time of the actual completion of the new section. In particular, modeling through future research is expected to allow practitioners to easily use it without further concerns by presenting the y-intercept value, CPCI at the time of completion, in a graph format for a more subdivided performance index, in addition to 4.2, 4.4, and 4.6.
- The function of the particle filtering technique itself increases the prediction accuracy for the analysis target section as the number of particles increases; however, the accuracy for other sections (routes) can be lowered by specifying the corresponding section. Therefore, as a result of analyzing the accuracy of cases using 1000, 5000, 10,000, 15,000, and 20,000 particles, the use of 15,000 particles was found to be the most efficient.
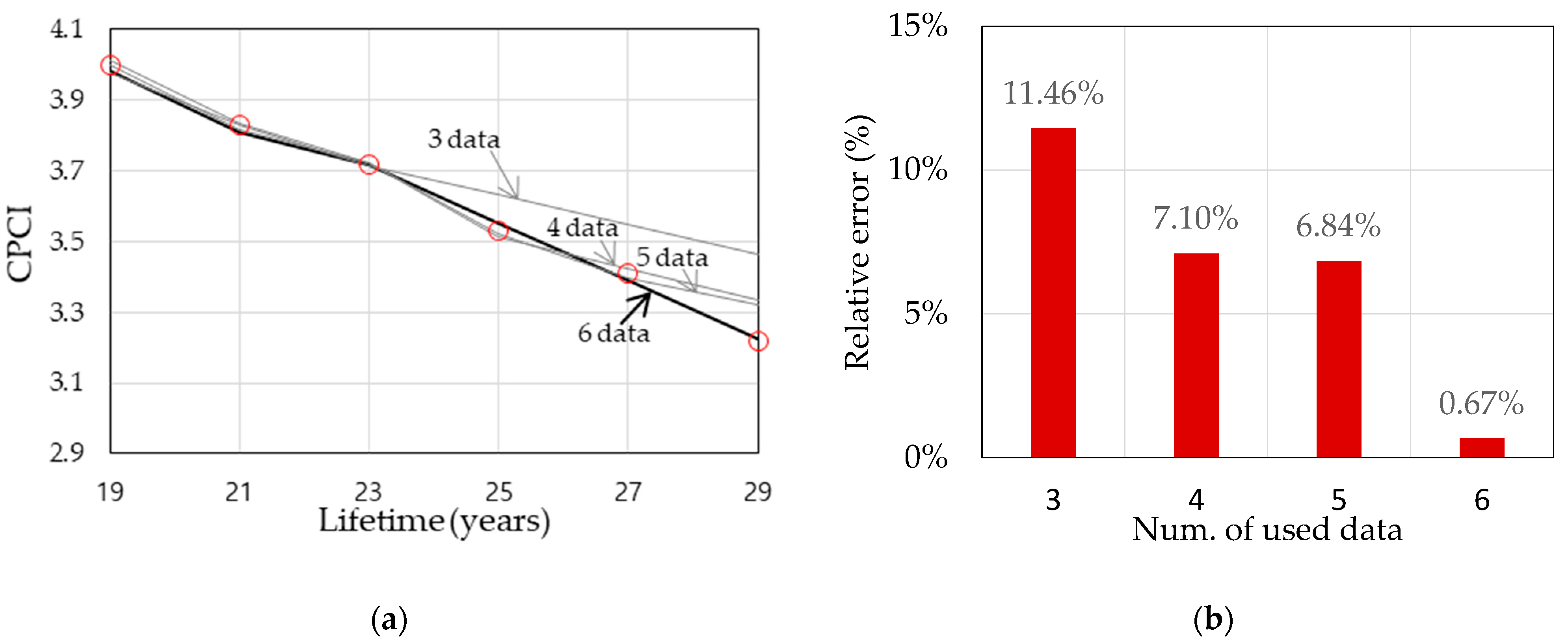
- We found that the number of time series points in one section had a higher impact on the improvement of prediction accuracy than the number of sections analyzed. The prediction accuracy was 92.3% when using the section with 5 points (261), whereas it was 98.1% when using the section with 7 points (208) (when 15,000 particles were used).
- As a result of analyzing the prediction accuracy by increasing the number of points to 3, 4, 5, and 6 in the section with 7 points, the prediction accuracy was 88.5%, 92.9%, 93.2%, and 99.3%, respectively. Accordingly, we determined that a section with at least six consecutive data points should be selected to secure a prediction accuracy of 95% or more in a study related to the prediction of the road pavement condition index, thereby obtaining the reliability of data and results.
- The relative error by each predicted age for the same section decreased as the number of time series points increased. Meanwhile, prediction accuracy decreased when farther future was predicted in the section. Accordingly, the particle filtering technique is deemed to be effective to predict up to two years of future road pavement conditions.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- MoLIT. 2013~2021 Status of Road Repair by Road Infrastructure (only Pavement Section); MoLIT: Seoul, Korea, 2021. [Google Scholar]
- MoLIT. Roadway Status Survey; MoLIT: Seoul, Korea, 2020. [Google Scholar]
- Jung, D.H.; Suh, Y.C.; Nam, J.H. Life of Asphalt Overlay over Old Concrete Pavements according to Time of Overlay. Int. J. Highw. Eng. 2019, 21, 69–76. [Google Scholar] [CrossRef]
- George, K.P.; Rajagopal, L.S.; Lim, L.K. Models for Predicting Pavement Deterioration. Trans. Res. Rec. 1989, 1215, 1–7. [Google Scholar]
- Johnson, K.D.; Cation, K.A. Performance Prediction Development Using Three Indexes for North Dakota Pavement Management System. Trans. Res. Rec. 1992, 1344, 22–30. [Google Scholar]
- Abaza, K.; Ashur, S.A.; Al-Khatib, I.A. Integrated Pavement Management System with a Markovian Prediction Model. J. Transp. Eng. 2004, 130, 24–33. [Google Scholar] [CrossRef]
- Kulkarni, R.B.; Miler, R.W. Pavement Management System: Past, present, and future. Trans. Res. Rec. 2003, 1853, 65–71. [Google Scholar] [CrossRef]
- Suh, Y.C.; Kwon, S.H.; Jung, D.H.; Jeon, J.H.; Kang, M.S. Development of HPCI Prediction Model for Concrete Pavement Using Expressway PMS Database. Int. J. Highw. Eng. 2017, 19, 83–95. [Google Scholar] [CrossRef]
- Shah, Y.U.; Jain, S.S.; Tiwari, D.; Jain, M.K. Development of Overall Pavement Condition Index for Urban Road Network. Procedia Soc. Behav. Sc. 2013, 104, 332–341. [Google Scholar] [CrossRef]
- Kim, J.R.; Park, D.G.; Suh, Y.C.; Jung, D.H. Development of Sidewalk Block Pavement Condition Index (SBPCI) using Analytical Hierarchy Process. Sustainability 2019, 11, 7086. [Google Scholar] [CrossRef]
- Choi, S.H.; Do, M.S.; You, S.H.; Cho, C.S. Determination of Visual Based Asphalt Pavement Crack Condition Using Deep Learning. Int. J. Highw. Eng. 2018, 20, 75–83. [Google Scholar] [CrossRef]
- Lee, Y.J.; Jeon, S.I.; Kim, R.E. A Computer-Vision-Based Classification of Road Surface Roughness Grade Using Machine Learning Techniques. Int. J. Highw. Eng. 2021, 23, 75–81. [Google Scholar] [CrossRef]
- Lee, J.S.; Kim, J.H.; Kim, J.R. Use of Deep Learning Image Classification Models and Vehicle Mounted Cameras for Automatic Pavement Pothole Detection. Int. J. Highw. Eng. 2021, 23, 25–34. [Google Scholar] [CrossRef]
- Wang, W.; Wang, M.; Li, H.; Zhao, H.; Wang, K.; He, C.; Wang, J.; Zheng, S.; Chen, J. Pavement Crack Image Acquisition Methods and Crack Extraction Algorithms. J. Traffic Transp. Eng. 2021, 6, 535–556. [Google Scholar]
- Abdellatif, M.; Peel, H.; Vohn, A.G.; Fuentes, R. Combining Block-Based and Pixel-Based Approaches to Improve Crack Detection and Localization. Autom. Constr. 2021, 122, 103492. [Google Scholar] [CrossRef]
- Practico, F.G.; Fedele, R.; Naumov, V.; Sauer, T. Detection and Monitoring of Bottom-up Cracks in Road Pavement Using a Machine-Learning Approach. Algorithms 2020, 13, 81. [Google Scholar] [CrossRef]
- Riid, A.; Louk, R.; Pihlak, R.; Tepljakov, A.; Vassiljeva, K. Pavement Distress Detection with Deep Learning Using the Orthofracmes Acquired by a Mobile Mapping System. Appl. Sci. 2019, 9, 4829. [Google Scholar] [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Mascio, P.D.; Chen, X.; Zhu, G.; Loprencipe, C. Ensemble of Deep Convolutional Neural Networks for Automatic Pavement Crack Detection and Measurement. Coatings 2020, 10, 152. [Google Scholar] [CrossRef]
- Choi, S.H.; Do, M.S. Development of the Road Pavement Deterioration Model Based on the Deep Learning Method. Electronics 2020, 9, 3. [Google Scholar] [CrossRef]
- Chun, C.J.; Ryu, S.K. Road Surface Damage Detection Using Fully Convolutional Neural Networks and Semi-Supervised Learning. Sensors 2019, 19, 5501. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack Detection and Comparison Study Based on Faster R-CNN and Mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef]
- Chen, G.H.; Chen, Z.; Huang, H.; Sun, Y.L.; Ip, W.H.; Yung, K.L. Detection of Highway Pavement Damage Based on a CNN Using Grayscale and HOG Features. Sensors 2022, 22, 2455. [Google Scholar] [CrossRef]
- Bektas, B.A.; Carriquiry, A.; Smadi, O. Using Classification Trees for Predicting National Bridge Inventory Condition Ratings. J. Infrastruct. Syst. 2013, 19, 425–433. [Google Scholar] [CrossRef]
- Hasan, S.; Elwakil, E. Stochastic Regression Deterioration Models for Superstructure of Prestressed Concrete Bridges in California. J. Struct. Integr. Maint. 2019, 4, 97–108. [Google Scholar] [CrossRef]
- Huang, Y.H. Artificial Neural Network Model of Bridge Deterioration. J. Perform. Constr. Facil. 2010, 24, 597–602. [Google Scholar] [CrossRef]
- Fathalla, E.; Tanaka, Y.; Maekawa, K. Remaining Fatigue Life Assessment of In-Service Road Bridge Decks Based Upon Artificial Neural Networks. Eng. Struct. 2018, 171, 602–616. [Google Scholar] [CrossRef]
- Ali, G.; Elsayegh, A.; Assaad, R.; El-adaway, I.H.; Abotaleb, I.S. Artificial Neural Network Model for Bridge Deterioration and Assessment. In Proceedings of the Canadian Society for Civil Engineering Conference 2019, Montreal, QC, Canada, 12–15 June 2019. [Google Scholar]
- Choi, Y.J.; Lee, J.H.; Kong, J.S. Performance Degradation Model for Concrete Deck of Bridge Using Pseudo-LSTM. Sustainability 2020, 12, 3848. [Google Scholar] [CrossRef]
- Lee, J.H.; Choi, Y.; Ann, H.; Jin, S.Y.; Lee, S.J.; Kong, J.S. Maintenance Cost Estimation in PSCI Girder Bridges Using Updating Probabilistic Deterioration Model. Sustainability 2019, 11, 6593. [Google Scholar]
- Jeong, M.C.; Lee, S.J.; Cha, K.; Zi, G.; Kong, J.S. Probabilistic Model Forecasting for Rail Wear in Seoul Metro Based on Bayesian Theory. Eng. Fail. Anal. 2019, 96, 202–210. [Google Scholar] [CrossRef]
- Lee, S.J.; Zi, G.; Mun, S.; Kong, J.S.; Choi, J.H. Probabilistic Prognosis of Fatigue Crack Growth for Asphalt Concretes. Eng. Fract. Mech. 2015, 141, 212–229. [Google Scholar] [CrossRef]
- Dowd, M.; Joy, R. Estimating Behavioral Parameters in Animal Movement Models Using a State-Augmented Particle Filter. Ecology 2011, 92, 568–575. [Google Scholar] [CrossRef] [Green Version]
- Simon, D. Optimal State Estimation: Kalman, H-Infinity, and Nonlinear Approaches; John Willey & Sons: Hoboken, NJ, USA, 2006; pp. 461–483. [Google Scholar]
- Ristic, B.; Arulampalam, S.; Gordon, N. Beyond the Kalman Filter: Particle Filters for Tracking Applications; Artech House Publishers: Boston, MA, USA; London, UK, 2004. [Google Scholar]
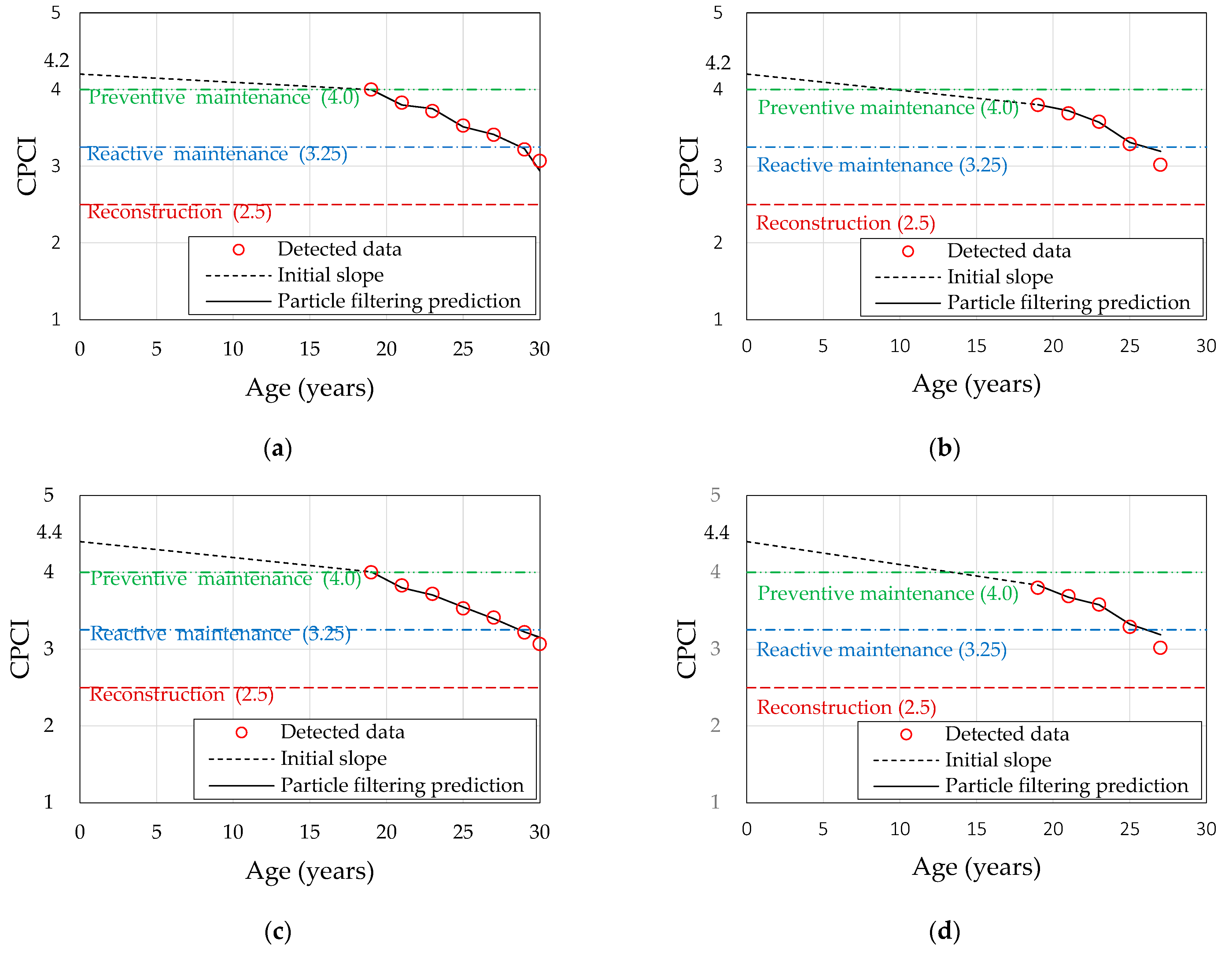

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Latitude | Longitude | Route | Start | End | Bound | Lane | Type | Age 25 | Age 27 | … | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IRI | SD | CPCI | IRI | SD | CPCI | … | ||||||||
| 37.2084 | 127.4418 | A | 0 | 0.01 | South bound | 1 | JPCP | 0.81 | 0 | 4.31 | 0.73 | 0.51 | 3.39 | … |
| 37.2088 | 127.4415 | A | 0.01 | 0.02 | South bound | 1 | JPCP | 0.71 | 0 | 4.37 | 1.29 | 0.24 | 3.33 | … |
| 37.2092 | 127.4413 | A | 0.02 | 0.03 | South bound | 1 | JPCP | 0.68 | 0 | 4.39 | 0.69 | 0.08 | 3.97 | … |
 | | | | | | | | | | | | | | |
| Division | 206 Sections (in 30 Years) | 261 Sections (in 27 Years) | ||||
|---|---|---|---|---|---|---|
| Detected CPCI | Predicted CPCI | Accuracy (%) | Detected CPCI | Predicted CPCI | Accuracy (%) | |
| 4.2 (a),(b) | 3.07 | 2.938 | 95.71 | 3.02 | 3.195 | 94.21 |
| 4.4 (c),(d) | 3.154 | 97.27 | 3.187 | 94.48 | ||
| 4.6 (e),(f) | 3.091 | 99.33 | 3.121 | 96.66 | ||
| No. of Particles | 206 Sections (in 30 Years) | 261 Sections (in 27 Years) | ||||
|---|---|---|---|---|---|---|
| 95% Confidential Interval | ||||||
| Included | Not Included | Validation Accuracy (%) | Included | Not Included | Validation Accuracy (%) | |
| 1000 | 200 | 8 | 96.15 | 236 | 25 | 90.42 |
| 5000 | 199 | 9 | 95.67 | 241 | 20 | 92.34 |
| 10,000 | 202 | 6 | 97.12 | 241 | 20 | 92.34 |
| 15,000 | 204 | 4 | 98.08 | 241 | 20 | 92.34 |
| 20,000 | 201 | 7 | 96.63 | 241 | 20 | 92.34 |
| Age (Year) | Actual CPCI | 3 Data | 4 Data | 5 Data | 6 Data | ||||
|---|---|---|---|---|---|---|---|---|---|
| PF * CPCI | Prediction Accuracy (%) | PF * CPCI | Prediction Accuracy (%) | PF * CPCI | Prediction Accuracy (%) | PF * CPCI | Prediction Accuracy (%) | ||
| 19 | 4.00 | 3.98 | 99.45 | 4.01 | 99.73 | 4.00 | 99.98 | 3.98 | 99.61 |
| 21 | 3.83 | 3.83 | 99.98 | 3.83 | 99.94 | 3.82 | 99.62 | 3.81 | 99.43 |
| 23 | 3.72 | 3.72 | 99.88 | 3.72 | 99.92 | 3.72 | 99.95 | 3.72 | 99.95 |
| 25 | 3.53 | 3.63 | 97.12 | 3.51 | 99.50 | 3.52 | 99.80 | 3.55 | 99.42 |
| 27 | 3.41 | 3.55 | 95.97 | 3.42 | 99.63 | 3.40 | 99.65 | 3.39 | 99.43 |
| 29 | 3.22 | 3.46 | 92.43 | 3.33 | 96.49 | 3.32 | 96.91 | 3.22 | 99.86 |
| 30 | 3.07 | 3.42 | 88.54 | 3.29 | 92.90 | 3.28 | 93.16 | 3.09 | 99.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.-H.; Jung, D.-H.; Lee, M.-S.; Jeon, S.-I. A Feasibility Study for the Prediction of Concrete Pavement Condition Index (CPCI) Based on Machine Learning. Appl. Sci. 2022, 12, 8731. https://doi.org/10.3390/app12178731
Lee J-H, Jung D-H, Lee M-S, Jeon S-I. A Feasibility Study for the Prediction of Concrete Pavement Condition Index (CPCI) Based on Machine Learning. Applied Sciences. 2022; 12(17):8731. https://doi.org/10.3390/app12178731
Chicago/Turabian StyleLee, Jin-Hyuk, Dong-Hyuk Jung, Moon-Sub Lee, and Sung-Il Jeon. 2022. "A Feasibility Study for the Prediction of Concrete Pavement Condition Index (CPCI) Based on Machine Learning" Applied Sciences 12, no. 17: 8731. https://doi.org/10.3390/app12178731
APA StyleLee, J.-H., Jung, D.-H., Lee, M.-S., & Jeon, S.-I. (2022). A Feasibility Study for the Prediction of Concrete Pavement Condition Index (CPCI) Based on Machine Learning. Applied Sciences, 12(17), 8731. https://doi.org/10.3390/app12178731