
Malware Detection Using Memory Analysis Data in Big Data Environment


Abstract
:1. Introduction
- (1)
- It has been shown through the study that malware detection can be performed using memory data.
- (2)
- This study provides a basis for future studies on the analysis and classification of memory data with the big data approach.
- (3)
- Another contribution of the study is that various deep learning and machine learning approaches, which are frequently used in many intrusion detection systems in the literature and are very popular, have been confirmed to achieve successful results in memory data malware detection.
- (4)
- The memory data and malware detection performance of nine different machine learning and deep learning algorithms were compared. The results will guide researchers about the techniques to be preferred in future studies.
2. Related Works
3. Malware Families
- Zeus: It is also known as Zbot. It first appeared in 2007. It is a type of banking Trojan that is used to steal banking credentials via keylogging. Another important function is to create a botnet by communicating with the C&C server. In the years after its emergence, open-source code was shared and new versions such as Citadel, GameoverZeus, Ice IX, and KINS were created [41].
- Emonet: It is a Trojan horse that first appeared in 2014. It is a banking malware designed to snatch sensitive information by sniffing the network. In the years after its emergence, it has been transformed into a platform that allows other malware to be installed. It has capabilities such as creating and organizing botnets. It also has some worm properties to propagate [41].
- Refroso: It is a Trojan horse with a backdoor function that first appeared in 2009. It can change the settings of the firewall by deleting the registry entries. It can start and hide memory processes. It can perform some activities such as redirecting to malicious websites and hiding unwanted activities in the browser. It can assist access attacks by providing a configuration that allows outside access.
- Scar: It is a Trojan horse that allows different malware to be installed on the device it infects. It downloads a list of URLs that link to files with the exe extension to allow malware to download more. It can also perform operations such as collecting confidential information on the device and changing operating system settings.
- Reconyc: It is a Trojan horse that does the downloading different malware on the device it infects. Like most malware, it is distributed from untrusted websites or as an attachment to another file. It also can limit access to some important tools in the operating system such as Command Prompt, Task Manager, and Registry Editor.
- 180Solutions: It is spyware, also known as Zango. It monitors some activities on the Internet such as user movements, URLs visited, and cookies. It serves pop-ups and targeted advertisements using the information it collects.
- CoolWebSearch (CWS): It is a browser hijacker first seen in 2003. It transfers sensitive data collected through the browser to networks associated with CoolWebSearch. It has several versions with different techniques such as DataNoter, BootConf, PnP, Winres, SvcHost, and MSInfo. These versions perform different functions such as monitoring access to certain websites, ensuring that CoolWebSearch does not appear on the whitelist, and downloading adware.
- Gator: It is adware, also known as Gain AdServer. It can replicate itself by pretending to be a virus. It can also download other spyware programs and perform updates. Like other adware, it tracks user movements and delivers targeted ads and pop-ups. Gator can cause memory wear by taking up a lot of hard disk space.
- Transponder: It is spyware. It installs as a Browser Helper Object (BHO) distributed with third-party software. At its initial setup, it collects information about the device and user ID. Then, it monitors some activities such as user movements, URLs visited, cookies, etc., and transfers them to the server. It is also software that creates pop-up banners.
- TIBS: It is a malware known as TIBS dialer. It is spread through email attachments and unreliable websites. It makes paid calls to adult websites using the modem. It runs in the background of the device it has infected and does not affect its performance. It is manifested by abnormal situations such as uncontrollable connections, unwanted downloads, and hidden internet connections.
- Conti: A ransomware that emerged in 2020 that infiltrates local or networked drives via phishing email. When clicked, it downloads Bazar backdoor and IcedID Trojan horse to target machines. Encrypts SMB-type files with AES-256 using up to 32 logical threads. It ignores files with dll, exe, lnk, and sys extensions during encryption. It deletes shadow copies of encrypted files and prevents them from being uploaded again.
- Maze: It appeared in 2019. Maze is distributed via phishing emails that distribute malicious macros with docx extension attachments, or by vulnerable networks such as RDP servers, and Citrix/VPN servers. It is also distributed as a PE binary (dll, exe). It uses ChaCha20 stream ciphers and RSA-2048 public encryption keys to encrypt files. For this reason, it is also known as ChaCha ransomware. The creators of Maze publish some of their encrypted documents on their websites.
- Pysa: It is a type of ransomware that appeared in 2018 and cannot spread on its own. It is also known as Mespinoza. Phishing emails infiltrate machines by performing Brute Force attacks against RDP servers and Active Directory. It uses a hybrid encryption method created with AES-CBC and RSA algorithms. It stores the encrypted files with the Pysa extension. It deletes shadow copies of encrypted files and prevents them from being uploaded again.
- Ako: It is ransomware that infiltrates the machine with a phishing email that emerged in 2020. It is also known as MedusaReborn. It is distributed with an encrypted zip file. It is propagated by the src file in the folder. It encrypts files other than exe, dll, sys, ini, lnk, key, and rdp files using MD5, SHA-1, and SHA-256. It drops a text containing the ransom note and a folder named “id.key” containing the encryption key on the target desktop.
- Shade: It is ransomware that was first seen in 2019 and infiltrated the machine via phishing email. Also known as Troldesh. Shade is distributed in a zip file written in Javascript. It uses two separate keys generated with AES-256 in CBC mode to encrypt the content and filename of each file. It is also known for leaving notes with a large number of different extensions on the computer is infected.
4. Material and Methods
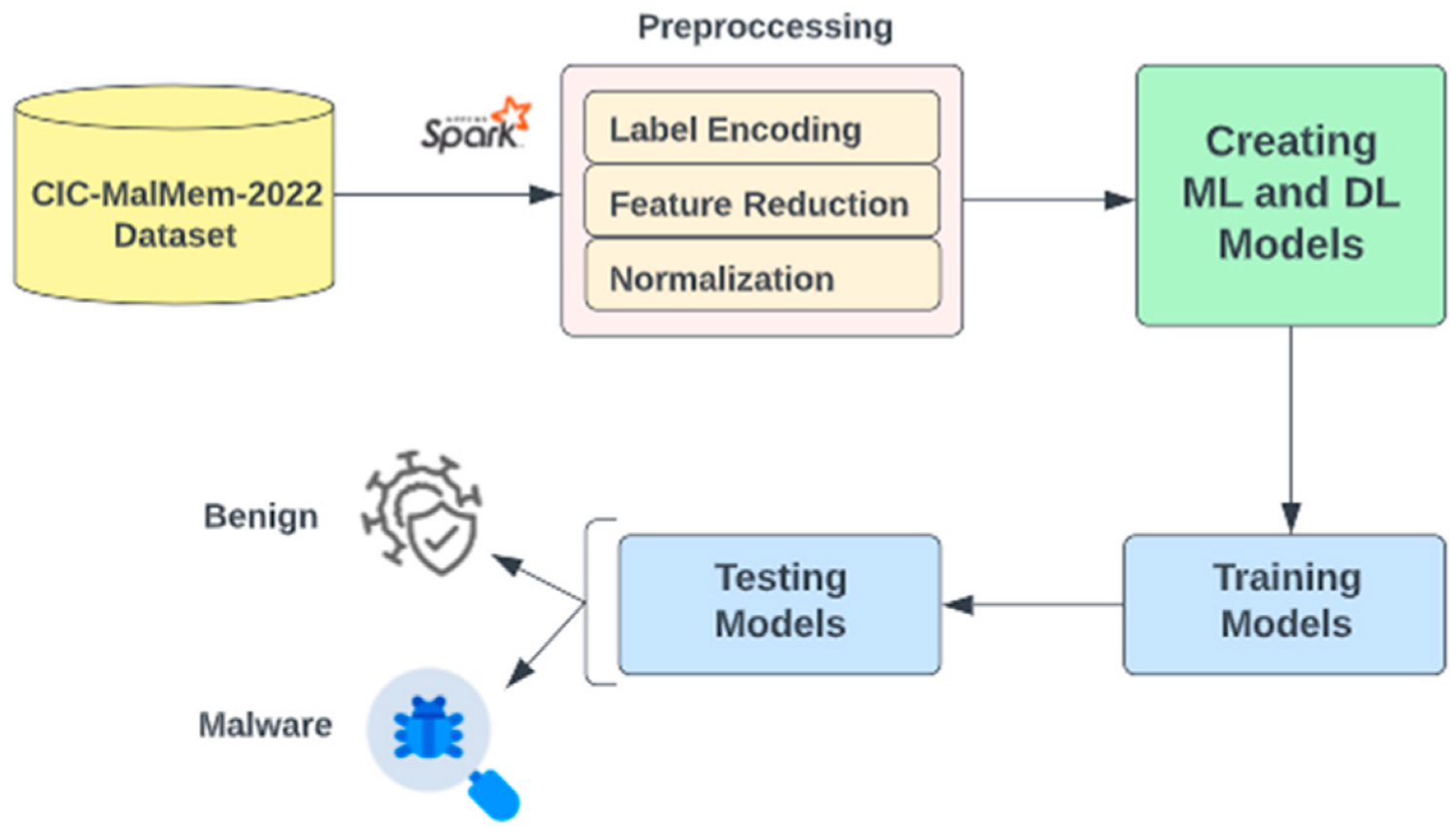
4.1. Dataset
4.2. Data Preprocessing
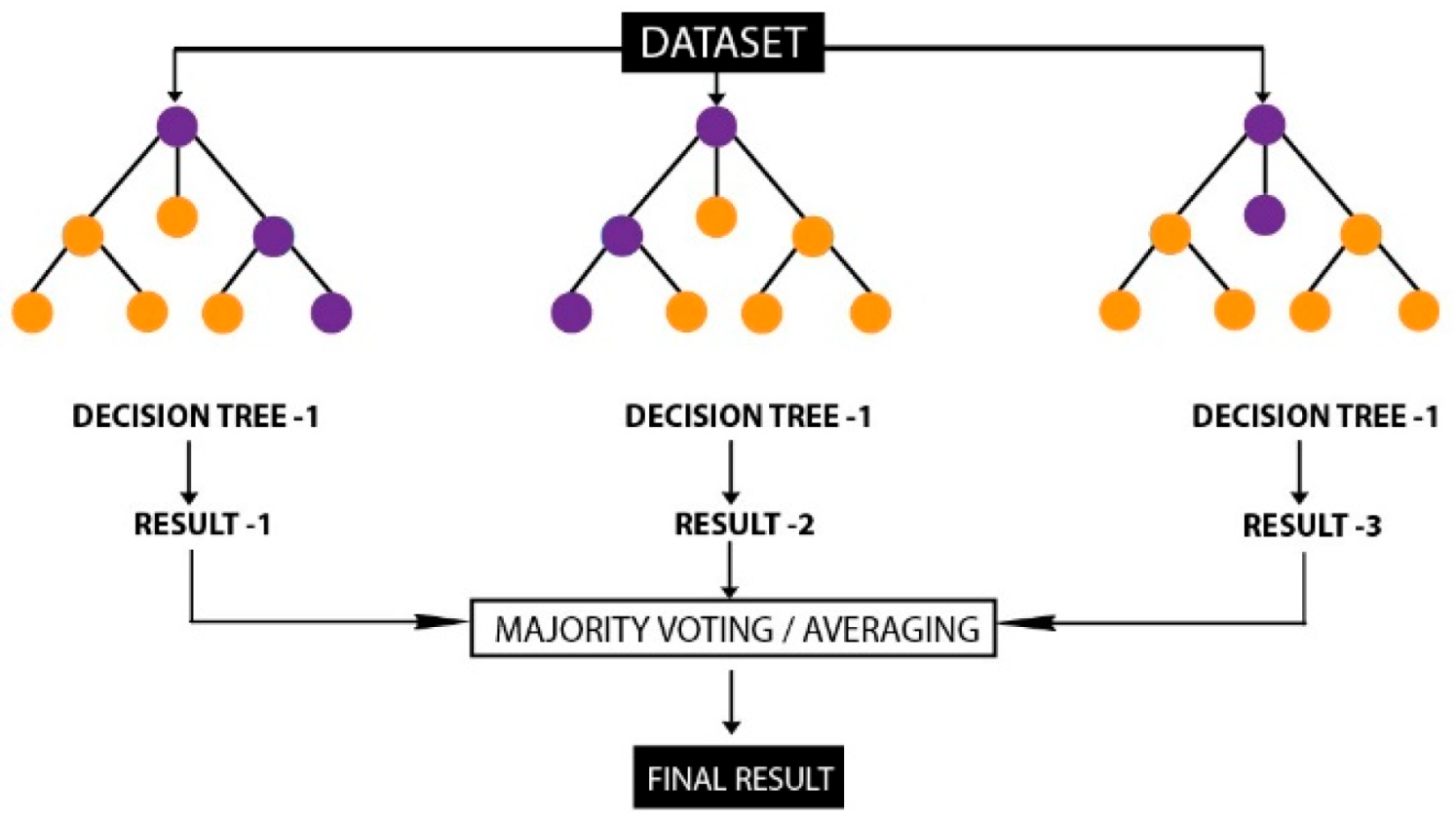
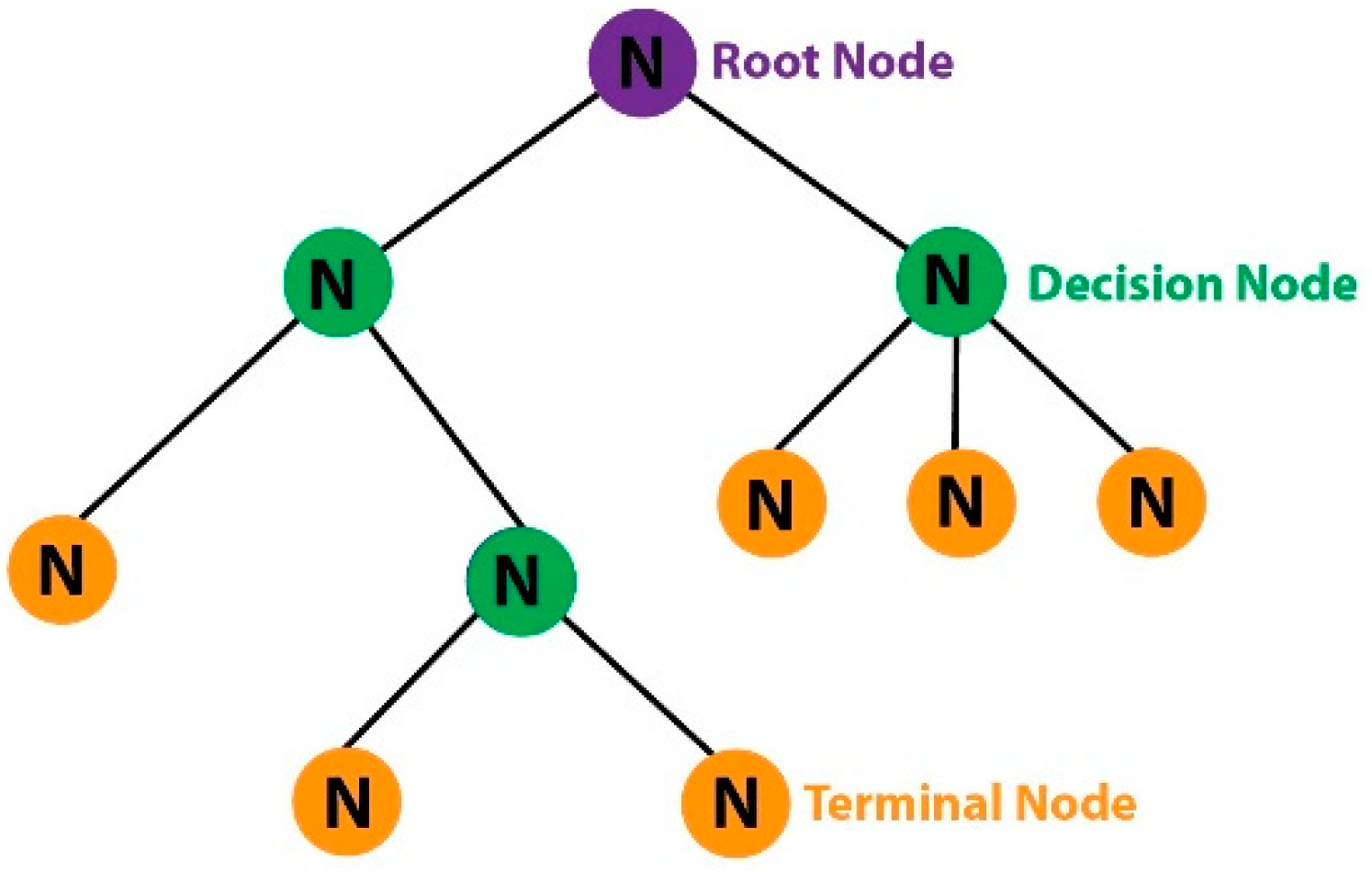
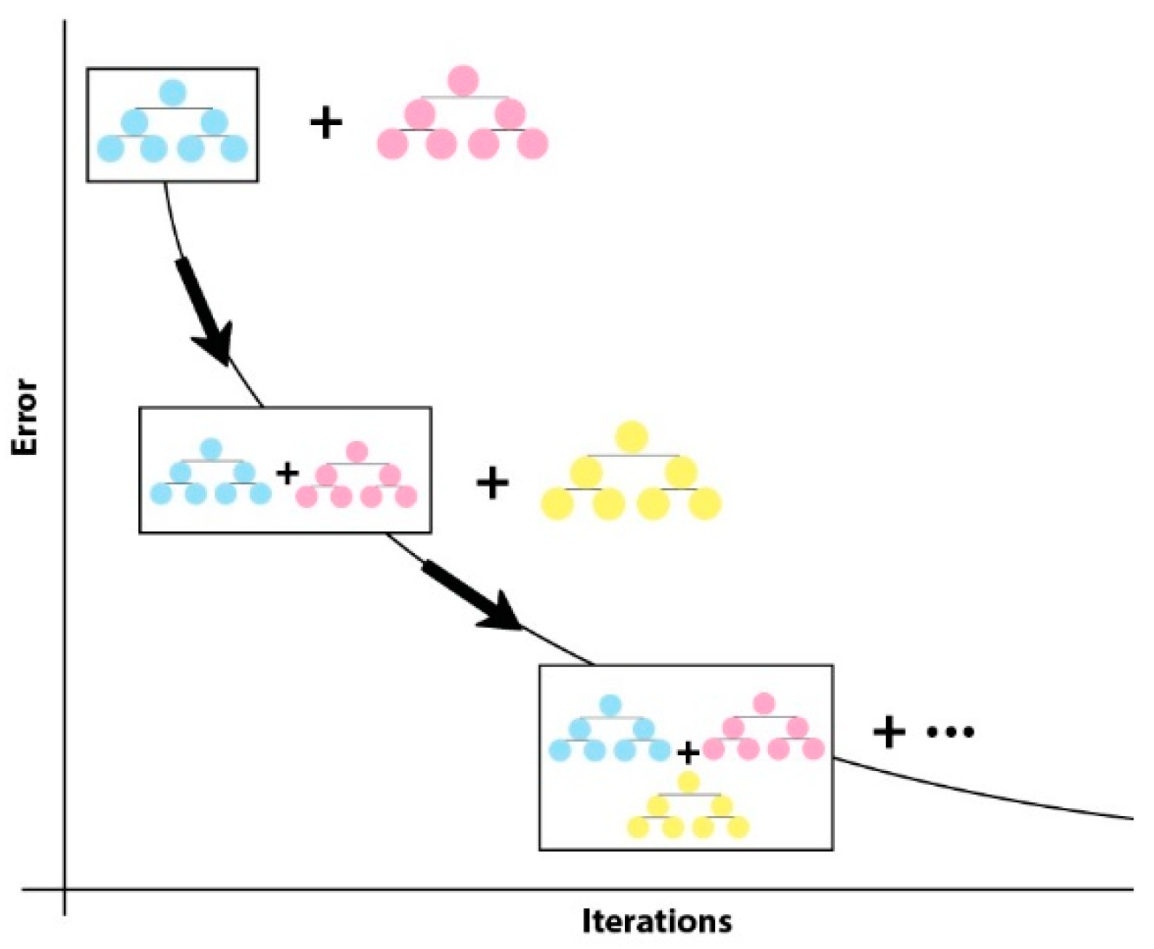
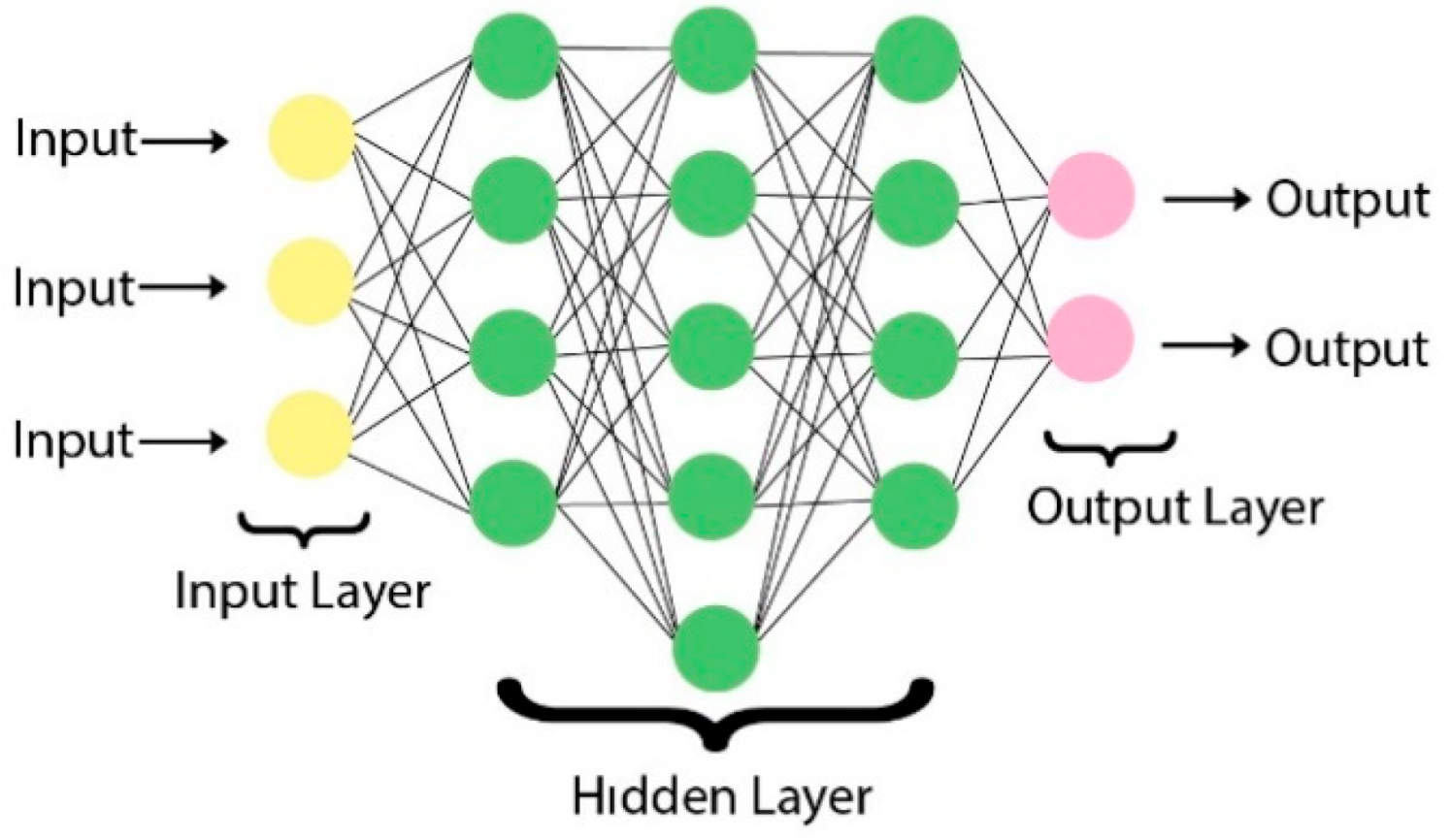
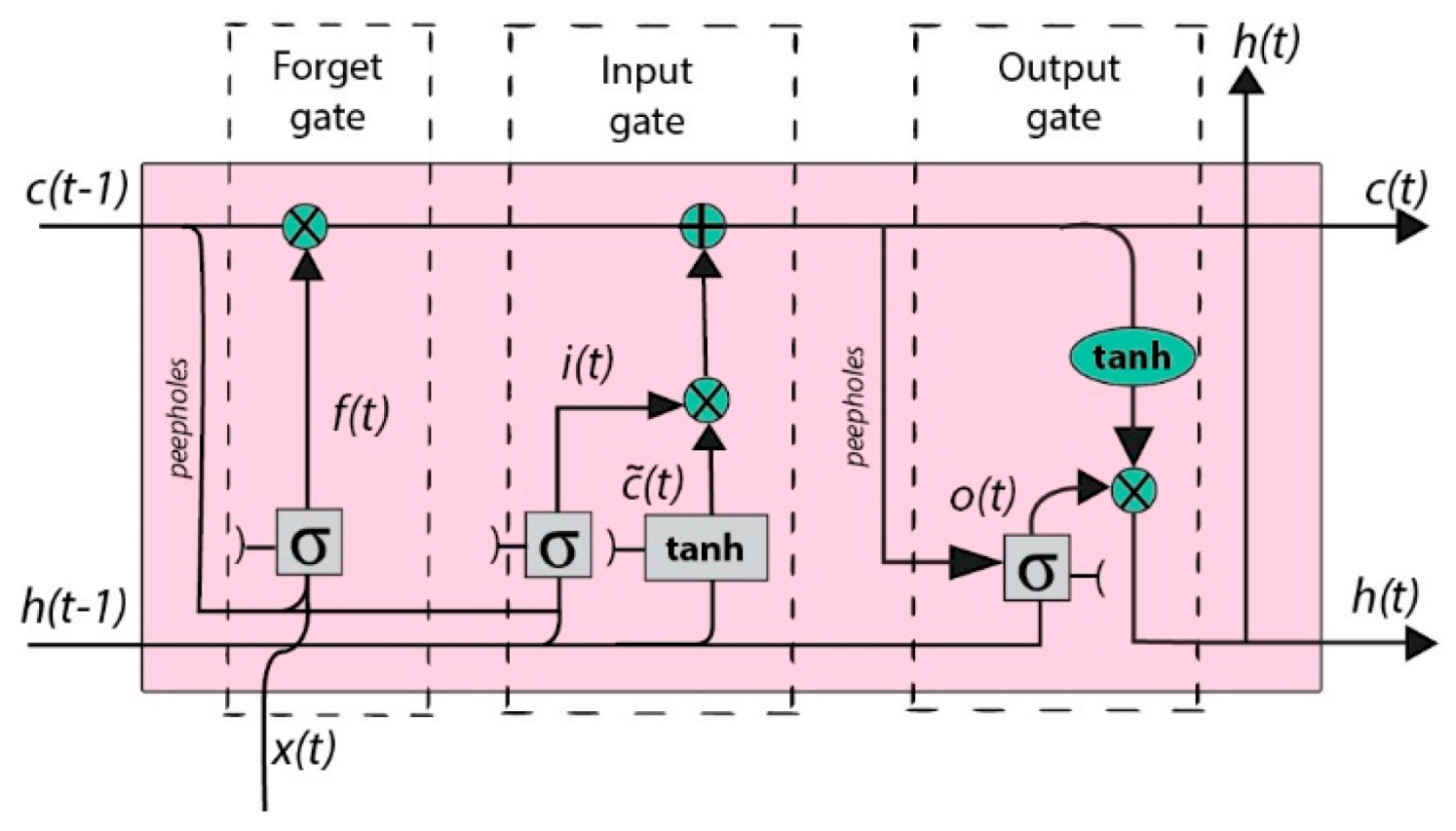
4.3. Machine Learning and Deep Learning Algorithms
5. Experiments and Evaluation
5.1. Model Parameters
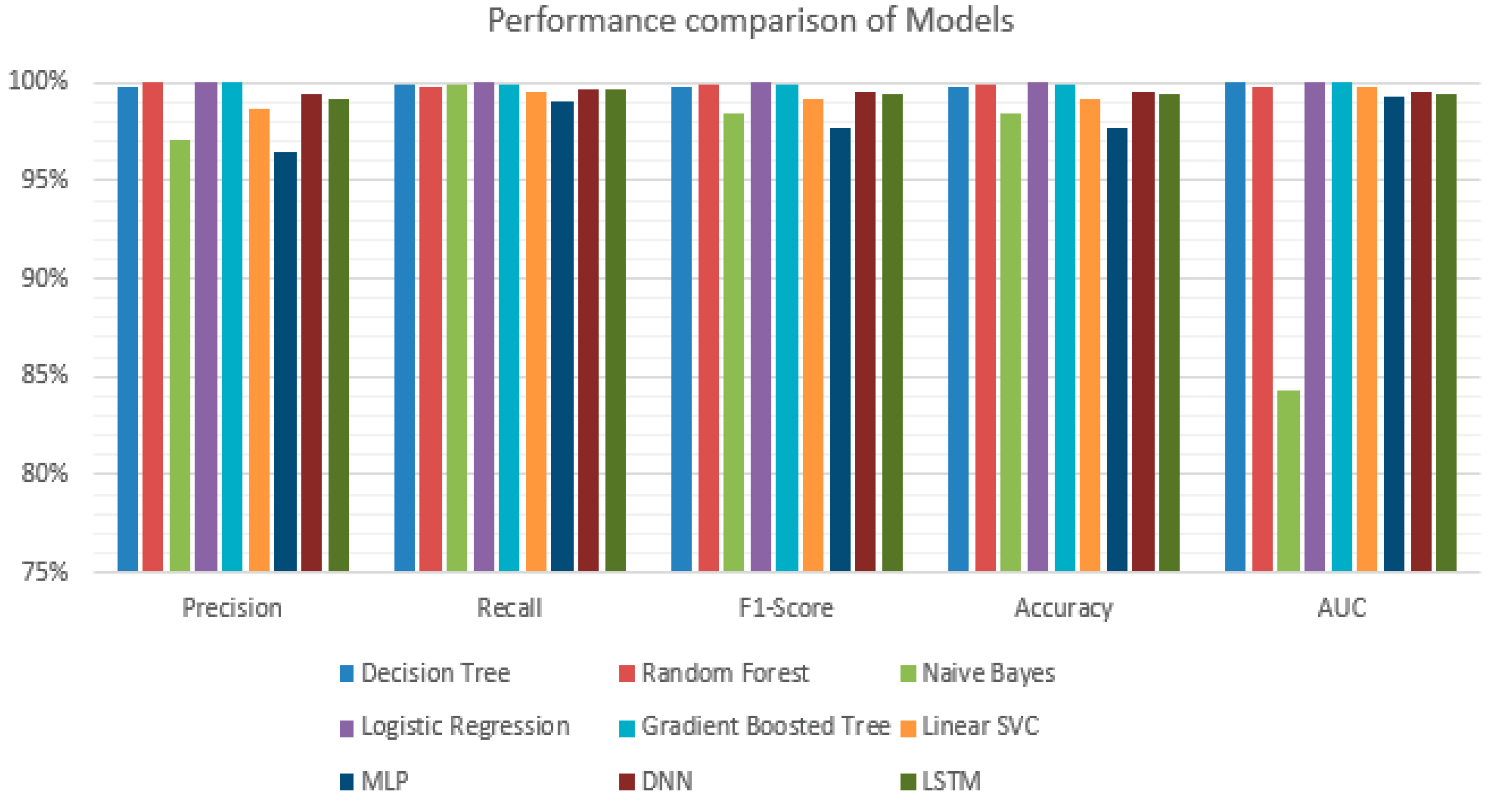
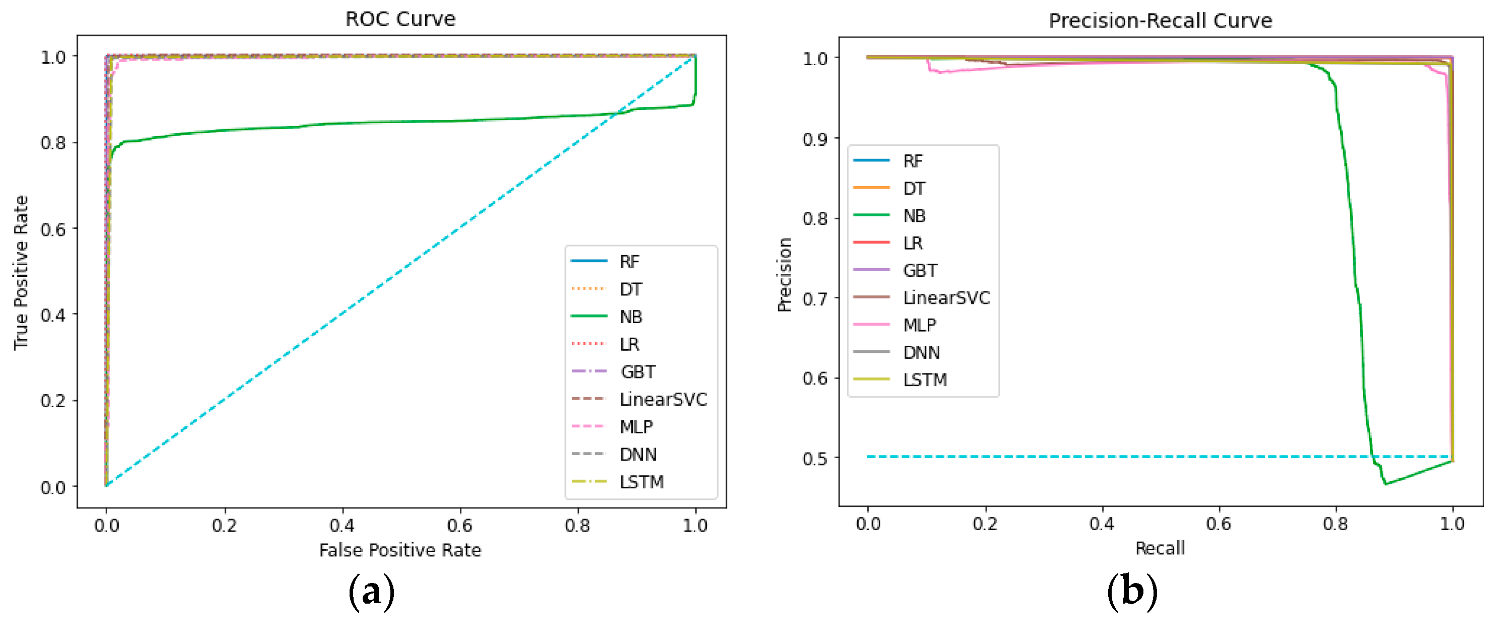
5.2. Results and Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- AV-Test Institute. Available online: https://www.av-test.org/en/statistics/malware/ (accessed on 17 May 2022).
- Yucel, C.; Koltuksuz, A. Imaging and evaluating the memory access for malware. Forens. Sci. Int. Digit. Investig. 2020, 32, 200903. [Google Scholar] [CrossRef]
- Banin, S.; Dyrkolbotn, G.O. Detection of Previously Unseen Malware Using Memory Access Patterns Recorded before the Entry Point. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 2242–2253. [Google Scholar]
- Sihwail, R.; Omar, K.; Zainol Ariffin, K.A. A Survey on Malware Analysis Techniques: Static, Dynamic, Hybrid and Memory Analysis. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1662–1671. [Google Scholar] [CrossRef]
- Mosli, R.N.; Li, R.; Yuan, B.; Pan, Y. Automated malware detection using artifacts in forensic memory images. In Proceedings of the 2016 IEEE Symposium on Technologies for Homeland Security (HST), Waltham, MA, USA, 10–11 May 2016. [Google Scholar]
- Rathnayaka, C.; Jamdagni, A. An Efficient Approach for Advanced Malware Analysis Using Memory Forensic Technique. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, NSW, Australia, 1–4 August 2017; pp. 1145–1150. [Google Scholar]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z. An Effective Memory Analysis for Malware Detection and Classification. CMC Comput. Mater. Contin. 2021, 67, 2301–2320. [Google Scholar] [CrossRef]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z.; Al Afghani, S. Malware Detection Approach Based on Artifacts in Memory Image and Dynamic Analysis. Appl. Sci. 2019, 9, 3680. [Google Scholar] [CrossRef]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Aghaeikheirabady, M.; Farshchi, S.M.R.; Shirazi, H. A New Approach to Malware Detection by Comparative Analysis of Data Structures in a Memory Image. In Proceedings of the 2014 International Congress on Technology, Communication and Knowledge (ICTCK), Mashhad, Iran, 26–27 November 2014. [Google Scholar]
- Mohaisen, A.; Alrawi, O.; Mohaisen, M. AMAL: High-fidelity, behavior-based automated malware analysis and classification. Comput. Secur. 2015, 52, 251–266. [Google Scholar] [CrossRef]
- Ahmadi, M.; Ulyanov, D.; Semenov, S.; Trofimov, M.; Giacinto, G. Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification. In Proceedings of the Codaspy’16: Proceedings of the Sixth Acm Conference on Data and Application Security and Privacy, New Orleans, LA, USA, 9–11 March 2016; pp. 183–194. [Google Scholar]
- Kumara, M.A.A.; Jaidhar, C.D. Leveraging virtual machine introspection with memory forensics to detect and characterize unknown malware using machine learning techniques at hypervisor. Digit. Investig. 2017, 23, 99–123. [Google Scholar] [CrossRef]
- Mosli, R.; Li, R.; Yuan, B.; Pan, Y. A Behavior-Based Approach for Malware Detection. IFIP Adv. Inf. Commun. Technol. 2017, 511, 187–201. [Google Scholar]
- Petrik, R.; Arik, B.; Smith, J.M. Towards Architecture and OS-Independent Malware Detection via Memory Forensics. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (Ccs’18), Toronto, ON, Canada, 15–19 October 2018; pp. 2267–2269. [Google Scholar]
- Nissim, N.; Lahav, O.; Cohen, A.; Elovici, Y.; Rokach, L. Volatile memory analysis using the MinHash method for efficient and secured detection of malware in private cloud. Comput. Secur. 2019, 87, 101590. [Google Scholar] [CrossRef]
- Lashkari, A.H.; Li, B.; Carrier, T.L.; Kaur, G. VolMemLyzer: Volatile Memory Analyzer for Malware Classification Using Feature Engineering. In Proceedings of the 2021 Reconciling Data Analytics, Automation, Privacy, and Security: A Big Data Challenge (RDAAPS), Hamilton, ON, Canada, 18–19 May 2021; pp. 1–8. [Google Scholar]
- Severi, G.; Leek, T.; Dolan-Gavitt, B. MALREC: Compact Full-Trace Malware Recording for Retrospective Deep Analysis. In Detection of Intrusions and Malware, and Vulnerability Assessment; Springer: Cham, Switzerland, 2018; Volume 10885, pp. 3–23. [Google Scholar]
- Kang, J.; Jang, S.; Li, S.; Jeong, Y.S.; Sung, Y. Long short-term memory-based Malware classification method for information security. Comput. Electr. Eng. 2019, 77, 366–375. [Google Scholar] [CrossRef]
- Safa, H.; Nassar, M.; Al Orabi, W.A. Benchmarking Convolutional and Recurrent Neural Networks for Malware Classification. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 561–566. [Google Scholar]
- Lu, X.F.; Jiang, F.S.; Zhou, X.; Yi, S.W.; Sha, J.; Lio, P. ASSCA: API sequence and statistics features combined architecture for malware detection. Comput. Netw. 2019, 157, 99–111. [Google Scholar]
- Sung, Y.; Jang, S.; Jeong, Y.S.; Park, J.H. Malware classification algorithm using advanced Word2vec-based Bi-LSTM for ground control stations. Comput. Commun. 2020, 153, 342–348. [Google Scholar] [CrossRef]
- Panker, T.; Nissim, N. Leveraging malicious behavior traces from volatile memory using machine learning methods for trusted unknown malware detection in Linux cloud environments. Knowl. Based Syst. 2021, 226, 107095. [Google Scholar] [CrossRef]
- Diaz, J.A.; Bandala, A. Portable Executable Malware Classifier Using Long Short Term Memory and Sophos-ReversingLabs 20 Million Dataset. In Proceedings of the TENCON 2021—2021 IEEE Region 10 Conference (TENCON), Auckland, New Zealand, 7–10 December 2021; pp. 881–884. [Google Scholar]
- Wang, Q.H.; Qian, Q. Malicious code classification based on opcode sequences and textCNN network. J. Inf. Secur. Appl. 2022, 67, 103151. [Google Scholar] [CrossRef]
- Arfeen, A.; Khan, M.A.; Zafar, O.; Ahsan, U. Process based volatile memory forensics for ransomware detection. Concurr. Comput. Pract. Exp. 2022, 34, e6672. [Google Scholar] [CrossRef]
- Rezende, E.; Ruppert, G.; Carvalho, T.; Ramos, F.; de Geus, P. Malicious Software Classification using Transfer Learning of ResNet-50 Deep Neural Network. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 1011–1014. [Google Scholar]
- Ni, S.; Qian, Q.; Zhang, R. Malware identification using visualization images and deep learning. Comput. Secur. 2018, 77, 871–885. [Google Scholar] [CrossRef]
- Dai, Y.S.; Li, H.; Qian, Y.K.; Lu, X.D. A malware classification method based on memory dump grayscale image. Digit. Investig. 2018, 27, 30–37. [Google Scholar] [CrossRef]
- Li, H.H.; Zhan, D.Y.; Liu, T.R.; Ye, L. Using Deep-Learning-Based Memory Analysis for Malware Detection in Cloud. In Proceedings of the 2019 IEEE 16th International Conference on Mobile Ad Hoc and Sensor Systems Workshops (MASSW), Monterey, CA, USA, 4–7 November 2019; pp. 1–6. [Google Scholar]
- Dai, Y.S.; Li, H.; Qian, Y.K.; Yang, R.P.; Zheng, M. SMASH: A Malware Detection Method Based on Multi-Feature Ensemble Learning. IEEE Access 2019, 7, 112588–112597. [Google Scholar] [CrossRef]
- Wong, W.K.; Juwono, F.H.; Apriono, C. Vision-Based Malware Detection: A Transfer Learning Approach Using Optimal ECOC-SVM Configuration. IEEE Access 2021, 9, 159262–159270. [Google Scholar] [CrossRef]
- Bozkir, A.S.; Tahillioglu, E.; Aydos, M.; Kara, I. Catch them alive: A malware detection approach through memory forensics, manifold learning and computer vision. Comput. Secur. 2021, 103, 102166. [Google Scholar] [CrossRef]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damasevicius, R. An Efficient DenseNet-Based Deep Learning Model for Malware Detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef] [PubMed]
- Tekerek, A.; Yapici, M.M. A novel malware classification and augmentation model based on convolutional neural network. Comput. Secur. 2022, 112, 102515. [Google Scholar] [CrossRef]
- Awan, M.J.; Masood, O.A.; Mohammed, M.A.; Yasin, A.; Zain, A.M.; Damaševičius, R.; Abdulkareem, K.H. Image-Based Malware Classification Using VGG19 Network and Spatial Convolutional Attention. Electronics 2021, 10, 2444. [Google Scholar] [CrossRef]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T.D. EfficientNet convolutional neural networks-based Android malware detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Damaševičius, R.; Venčkauskas, A.; Toldinas, J.; Grigaliūnas, Š. Ensemble-Based Classification Using Neural Networks and Machine Learning Models for Windows PE Malware Detection. Electronics 2021, 10, 485. [Google Scholar] [CrossRef]
- Azeez, N.A.; Odufuwa, O.E.; Misra, S.; Oluranti, J.; Damaševičius, R. Windows PE Malware Detection Using Ensemble Learning. Informatics. 2021, 8, 10. [Google Scholar] [CrossRef]
- Kim, D.; Solomon, M.G. Fundamentals of Information Systems Security; Jones & Bartlett Learning: Burlington, MA, USA, 2016. [Google Scholar]
- Grammatikakis, K.P.; Koufos, I.; Kolokotronis, N.; Vassilakis, C.; Shiaeles, S. Understanding and Mitigating Banking Trojans: From Zeus to Emotet. In Proceedings of the 2021 IEEE International Conference on Cyber Security and Resilience (CSR), Rhodes, Greece, 26–28 July 2021; pp. 121–128. [Google Scholar]
- Apache Spark. Available online: https://spark.apache.org/ (accessed on 17 May 2022).
- Canadian Institute for Cybersecurity. Available online: https://www.unb.ca/cic/datasets/malmem-2022.html (accessed on 17 May 2022).
- Carrier, T.; Victor, P.; Tekeoglu, A.; Lashkari, A. Detecting Obfuscated Malware using Memory Feature Engineering. In Proceedings of the 8th International Conference on Information Systems Security and Privacy, Online Streaming, 9–11 February 2022; pp. 177–188. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Gupta, D.; Rani, R. Improving malware detection using big data and ensemble learning. Comput. Electr. Eng. 2020, 86, 106729. [Google Scholar] [CrossRef]
- Gandotra, E.; Bansal, D.; Sofat, S. Tools & Techniques for Malware Analysis and Classification. Int. J. Next-Gener. Com. 2016, 7, 176–197. [Google Scholar]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. 2017, 18, 851–869. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Model | Dataset/Repository | Samples | Accuracy (%) | |
|---|---|---|---|---|---|
| 2014 | Aghaeikheirabady et al. [10] | NB | Virussign VxHeaven | 350 m 200 b | 98.90 |
| 2015 | Mohaisen et al. [11] | SVM | AutoMal | 115,157 | 99.22 |
| 2016 | Mosli et al. [5] | SGD | VirusShare VXHeaven | 400 m 100 b | 96.00 |
| 2016 | Ahmadi et al. [12] | XGBoost | BIG 2015 | 21,741 | 99.80 |
| 2017 | Kumara and Jaidhar [13] | RF | VXHeaven SourceForge | 3750 m 4500 b | 99.55 |
| 2017 | Mosli et al. [14] | RF | VirusShare | 3130 m 1157 b | 91.40 |
| 2017 | Rezende et al. [27] | DCNN | Malimg | 9339 | 98.62 |
| 2018 | Dai et al. [29] | MLP | OpenMalware | 1984 m | 95.20 |
| 2018 | Severi et al. [18] | DNN | MalRec | 66,301 m | F-Score: 94.20 |
| 2018 | Petrik et al. [15] | RF CNN | MalRec | 9000 m 3000 m | 99.65 98.00+ |
| 2018 | Ni et al. [28] | Hashing + CNN | BIG 2015 | 10,805 m | 99.26 |
| 2019 | Li et al. [30] | CNN | VirusTotal | 10,000+ | 90.50 |
| 2019 | Dai et al. [31] | RF+ MLP | OpenMalware | 27,000 | 96.90 |
| 2019 | Sihwail et al. [8] | SVM | VirusTotal Das Malwerk | 1200 m 400 b | 98.50 |
| 2019 | Safa et al. [20] | CNN + LSTM | BIG 2015 | 10,868 m | 99.31 |
| 2019 | Kang et al. [19] | Word2Vec + LSTM | BIG 2015 | 10,868 m | 97.59 |
| 2019 | Lu et al. [21] | LSTM | VirusShare VirusTotal | 1430 m 1352 b | 96.70 |
| 2021 | Hemalatha et al. [34] | DenseNet | Malimg BIG 2015 MaleVis Malicia | 9339 m 10,868 m 13,183 9670 m 1043 b | 98.23 98.46 98.21 89.48 |
| 2020 | Sung et al. [22] | fastText + LSTM | BIG 2015 | 10,868 m | 96.76 |
| 2021 | Bozkir et al. [33] | SMO | Dumpware10 | 3686 m 608 b | 96.39 |
| 2021 | Panker and Nissim [23] | RF,KNN | ViruShare VirusTotal | 21,800 | 98.70–99.90 |
| 2021 | Wong et al. [32] | DenseNet201 + ShuffleNet + ECOC-SVM | Malimg MaleVis Virüs-MNIST Dumpware10 | 9339 13,760 51,880 4294 | 99.14 95.01 86.36 96.62 |
| 2021 | Diaz and Bandala [24] | LSTM + LightGBM | SoReL-20M | 91.73 | |
| 2022 | Tekerek and Yapici [35] | CNN | BIG 2015 Dumpware 10 | 10,868 m 3686 m 608 b | 99.86 99.60 |
| 2022 | Arfeen et al. [26] | XGBoost | 29,273 | 88.70 | |
| 2022 | Wang and Qian [25] | TextCNN | SoReL-20M BIG 2015 | 10,260 m 3759 m | 98.18 93.46 |
| 2022 | This Study | LR | CIC-MalMem-2022 | 29,298 m 29,298 b | 99.97 |
| ID | Modul.Feature_Name | Description |
|---|---|---|
| 1 | Category | Category |
| 2 | pslist.nproc | Total number of processes |
| 3 | pslist.nppid | Total number of parent processes |
| 4 | pslist.avg_threads | Average number of threads for the processes |
| 5 | pslist.nprocs64bit | Total number of 64 bit processes |
| 6 | pslist.avg_handlers | Average number of handlers |
| 7 | dllist.ndlls | Total number of loaded libraries for every process |
| 8 | dllist.avg_dlls_per_proc | Average number of loaded libraries per process |
| 9 | handles.nhandles | Total number of opened handles |
| 10 | handles.avg_handles_per_proc | Average number of handles per process |
| 11 | handles.nport | Total number of port handles |
| 12 | handles.nfile | Total number of file handles |
| 13 | handles.nevent | Total number of event handles |
| 14 | handles.ndesktop | Total number of desktop handles |
| 15 | handles.nkey | Total number of key handles |
| 16 | handles.nthread | Total number of thread handles |
| 17 | handles.ndirectory | Total number of directory handles |
| 18 | handles.nsemaphore | Total number of semaphore handles |
| 19 | handles.ntimer | Total number of timer handles |
| 20 | handles.nsection | Total number of section handles |
| 21 | handles.nmutant | Total number of mutant handles |
| 22 | ldrmodules.not_in_load | Total number of modules missing from the load list |
| 23 | ldrmodules.not_in_init | Total number of modules missing from the init list |
| 24 | ldrmodules.not_in_mem | Total number of modules missing from the memory list |
| 25 | ldrmodules.not_in_load_avg | The average amount of modules missing from the load list |
| 26 | ldrmodules.not_in_init_avg | The average amount of modules missing from the init list |
| 27 | ldrmodules.not_in_mem_avg | The average amount of modules missing from the memory |
| 28 | malfind.ninjections | Total number of hidden code injections |
| 29 | malfind.commitCharge | Total number of Commit Charges |
| 30 | malfind.protection | Total number of protection |
| 31 | malfind.uniqueInjections | Total number of unique injections |
| 32 | psxview.not_in_pslist | Total number of processes not found in the pslist |
| 33 | psxview.not_in_eprocess_pool | Total number of processes not found in the psscan |
| 34 | psxview.not_in_ethread_pool | Total number of processes not found in the thrdproc |
| 35 | psxview.not_in_pspcid_list | Total number of processes not found in the pspcid |
| 36 | psxview.not_in_csrss_handles | Total number of processes not found in the csrss |
| 37 | psxview. not_in_session | Total number of processes not found in the session |
| 38 | psxview. not_in_deskthrd | Total number of processes not found in the desktrd |
| 39 | psxview.not_in_pslist_false_avg | Average false ratio of the process list |
| 40 | psxview.not_in_eprocess_pool_false_avg | Average false ratio of the process scan |
| 41 | psxview.not_in_ethread_pool_false_avg | Average false ratio of the third process |
| 42 | psxview.not_in_pspcid_list_false_avg | Average false ratio of the process id |
| 43 | psxview.not_in_csrss_handles_false_avg | Average false ratio of the csrss |
| 44 | psxview.not_in_session_false_avg | Average false ratio of the session |
| 45 | psxview.not_in_deskthrd_false_avg | Average false ratio of the deskthrd |
| 46 | modules.nmodules | Total number of modules |
| 47 | svcscan.nservices | Total number of services |
| 48 | svcscan.kernel_drivers | Total number of kernel drivers |
| 49 | svcscan.fs_drivers | Total number of file system drivers |
| 50 | svcscan.process_services | Total number of Windows 32 owned processes |
| 51 | svcscan.shared_process_services | Total number of Windows 32 shared processes |
| 52 | svcscan.interactive_process_services | Total number of interactive service processes |
| 53 | svcscan.nactive | Total number of actively running service processes |
| 54 | callbacks.ncallbacks | Total number of callbacks |
| 55 | callbacks.nanonymous | Total number of unknown processes |
| 56 | callbacks.ngeneric | Total number of generic processes |
| 57 | Class | Benign or Malware |
| Malware Category | Malware Families | Count |
|---|---|---|
| Trojan Horse | Zeus | 1950 |
| Emotet | 1967 | |
| Refroso | 2000 | |
| Scar | 2000 | |
| Reconyc | 1570 | |
| Spyware | 180Solutions | 2000 |
| Coolwebsearch | 2000 | |
| Gator | 2200 | |
| Transponder | 2410 | |
| TIBS | 1410 | |
| Ransomware | Conti | 1988 |
| Maze | 1958 | |
| Pysa | 1717 | |
| Ako | 2000 | |
| Shade | 2128 | |
| Total | 29,298 | |
| Label | Class Name |
|---|---|
| 0 | Benign |
| 1 | Malware |
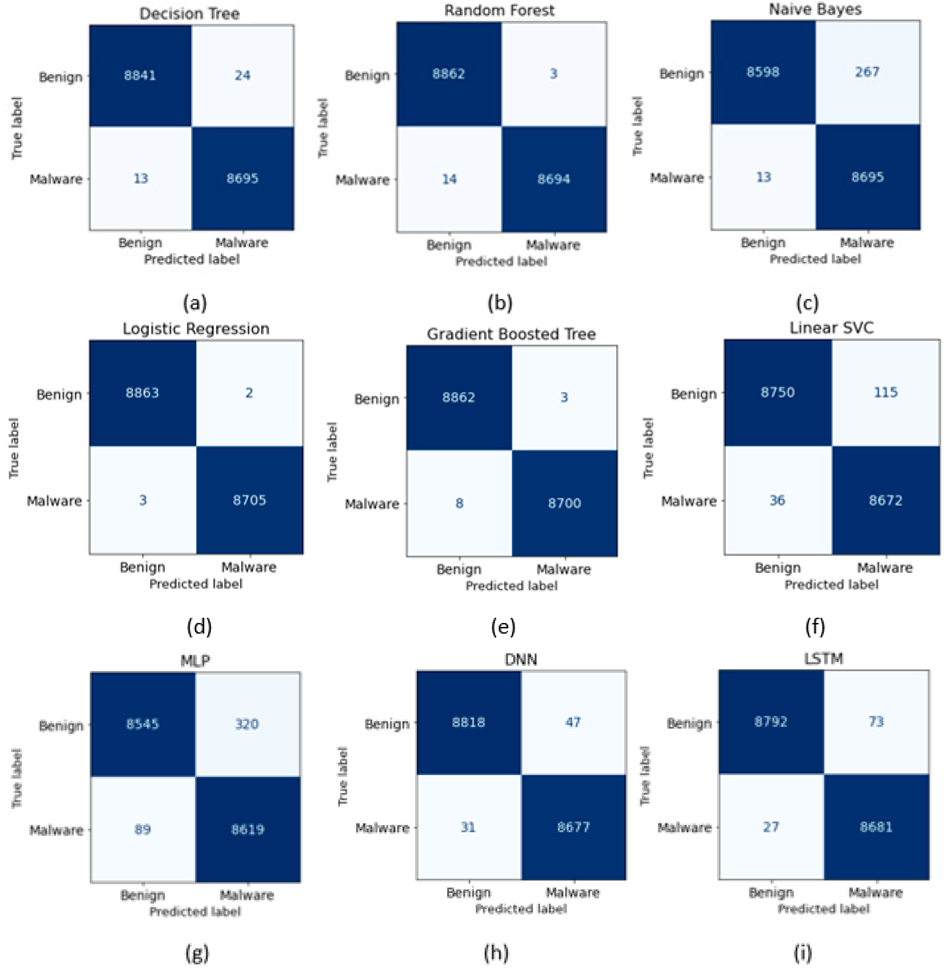
| Base Classifier | Precision | Recall | F1-Score | Accuracy | ROC-AUC |
|---|---|---|---|---|---|
| Decision Tree | 99.73% | 99.85% | 99.79% | 99.79% | 99.98% |
| Random Forest | 99.97% | 99.84% | 99.90% | 99.90% | 99.76% |
| Naive Bayes | 97.02% | 99.85% | 98.42% | 98.41% | 84.25% |
| Logistic Regression | 99.98% | 99.97% | 99.97% | 99.97% | 100.00% |
| Gradient Boosted Tree | 99.97% | 99.91% | 99.94% | 99.94% | 99.98% |
| Linear SVC | 98.69% | 99.57% | 99.14% | 99.14% | 99.76% |
| MLP | 96.42% | 98.98% | 97.68% | 97.67% | 99.23% |
| DNN | 99.46% | 99.64% | 99.55% | 99.56% | 99.56% |
| LSTM | 99.17% | 99.69% | 99.43% | 99.43% | 99.43% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dener, M.; Ok, G.; Orman, A. Malware Detection Using Memory Analysis Data in Big Data Environment. Appl. Sci. 2022, 12, 8604. https://doi.org/10.3390/app12178604
Dener M, Ok G, Orman A. Malware Detection Using Memory Analysis Data in Big Data Environment. Applied Sciences. 2022; 12(17):8604. https://doi.org/10.3390/app12178604
Chicago/Turabian StyleDener, Murat, Gökçe Ok, and Abdullah Orman. 2022. "Malware Detection Using Memory Analysis Data in Big Data Environment" Applied Sciences 12, no. 17: 8604. https://doi.org/10.3390/app12178604
APA StyleDener, M., Ok, G., & Orman, A. (2022). Malware Detection Using Memory Analysis Data in Big Data Environment. Applied Sciences, 12(17), 8604. https://doi.org/10.3390/app12178604