
Test–Retest Reliability in Automated Emotional Facial Expression Analysis: Exploring FaceReader 8.0 on Data from Typically Developing Children and Children with Autism

 ,
,
Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Aims
- What level and pattern of test–retest reliability does a specific version of AEFEA technology, FR8, provide in a group of typically developing children of kindergarten age, and in a matched group of children with autism spectrum disorder (ASD)?
- Does test–retest reliability, if found imperfect, influence the overall pattern of results, especially between-group and between-emotion differences in detected EFE intensities? If so, how?
2.2. Participants
2.3. Stimuli
2.4. Setting and Equipment
2.5. Procedure
2.6. Data Processing and Analysis
3. Results
3.1. Test–Retest Reliability
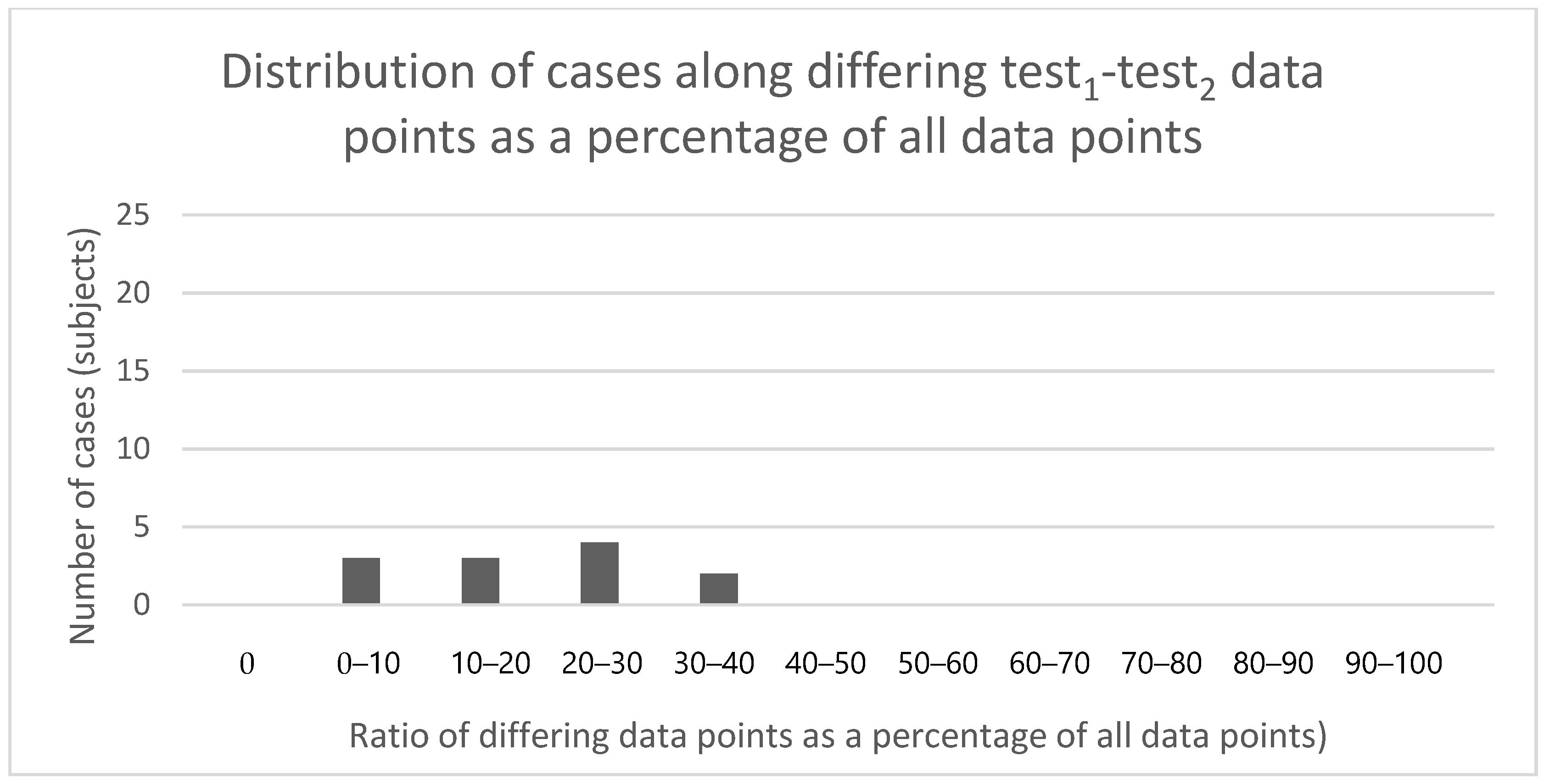
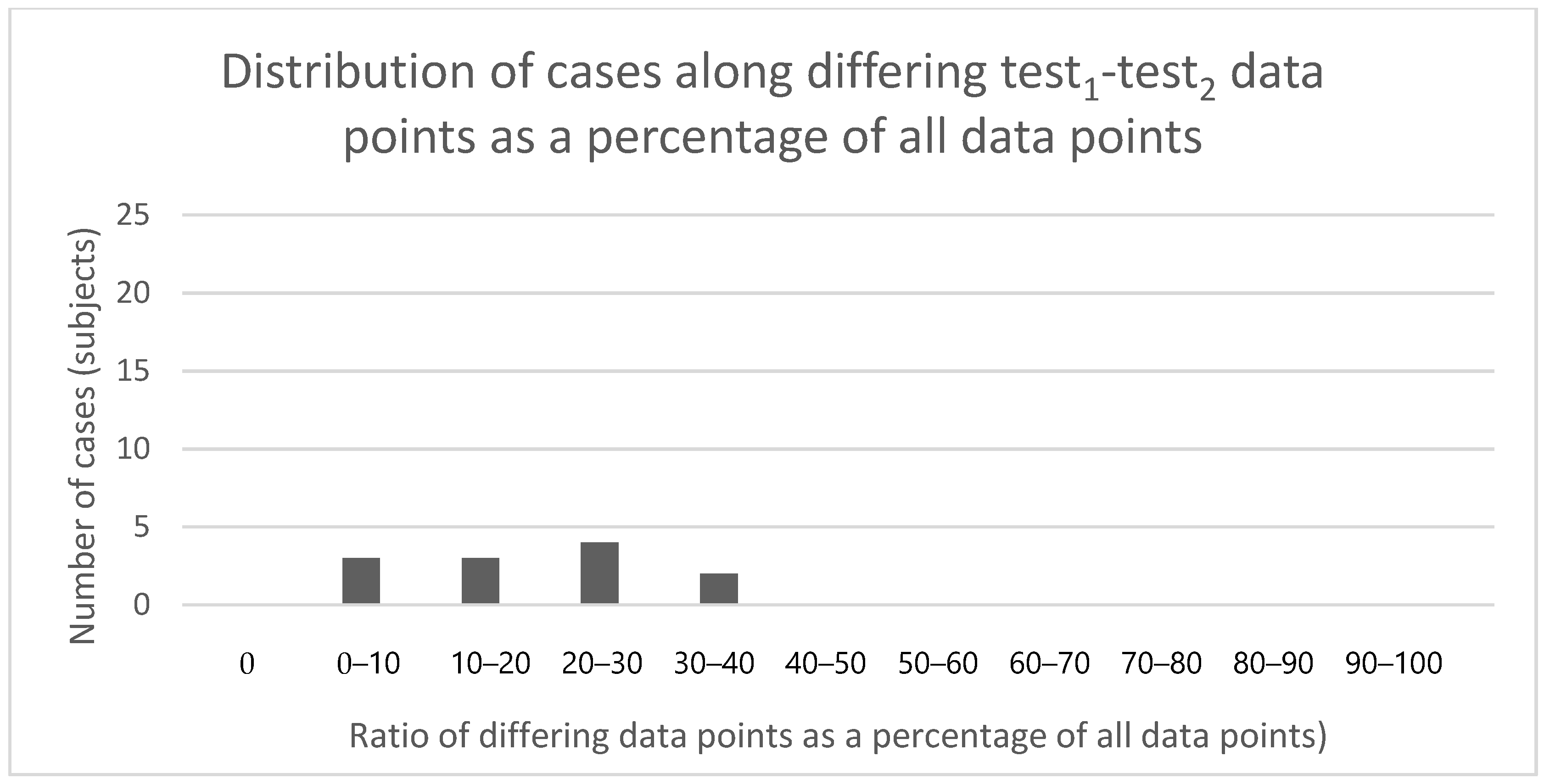
3.1.1. Test–Retest Differences between First and Second Test Data Series
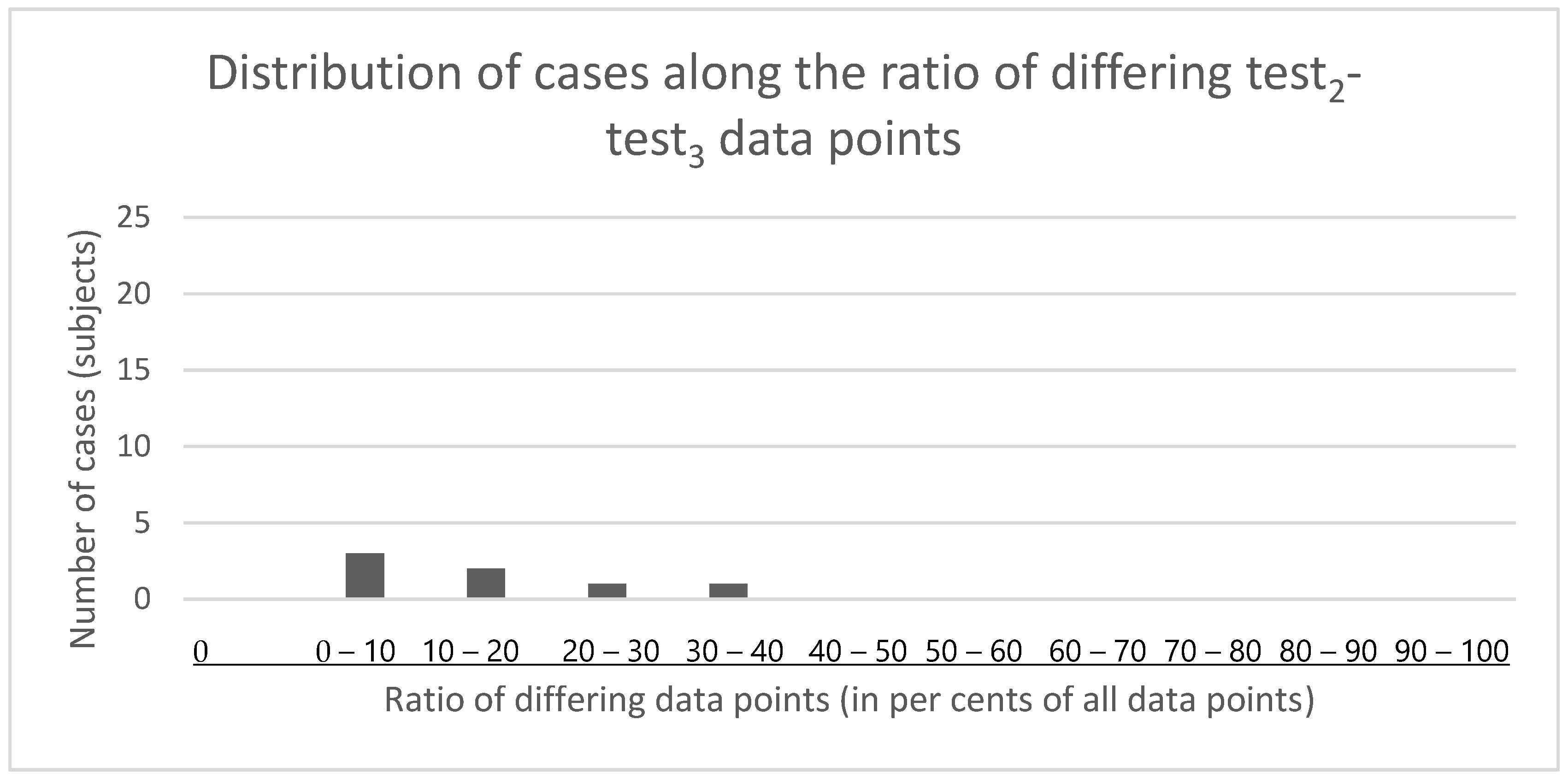
3.1.2. Test–Retest Differences between Second and Third Test Data Series
3.2. Data Robustness (Completeness)
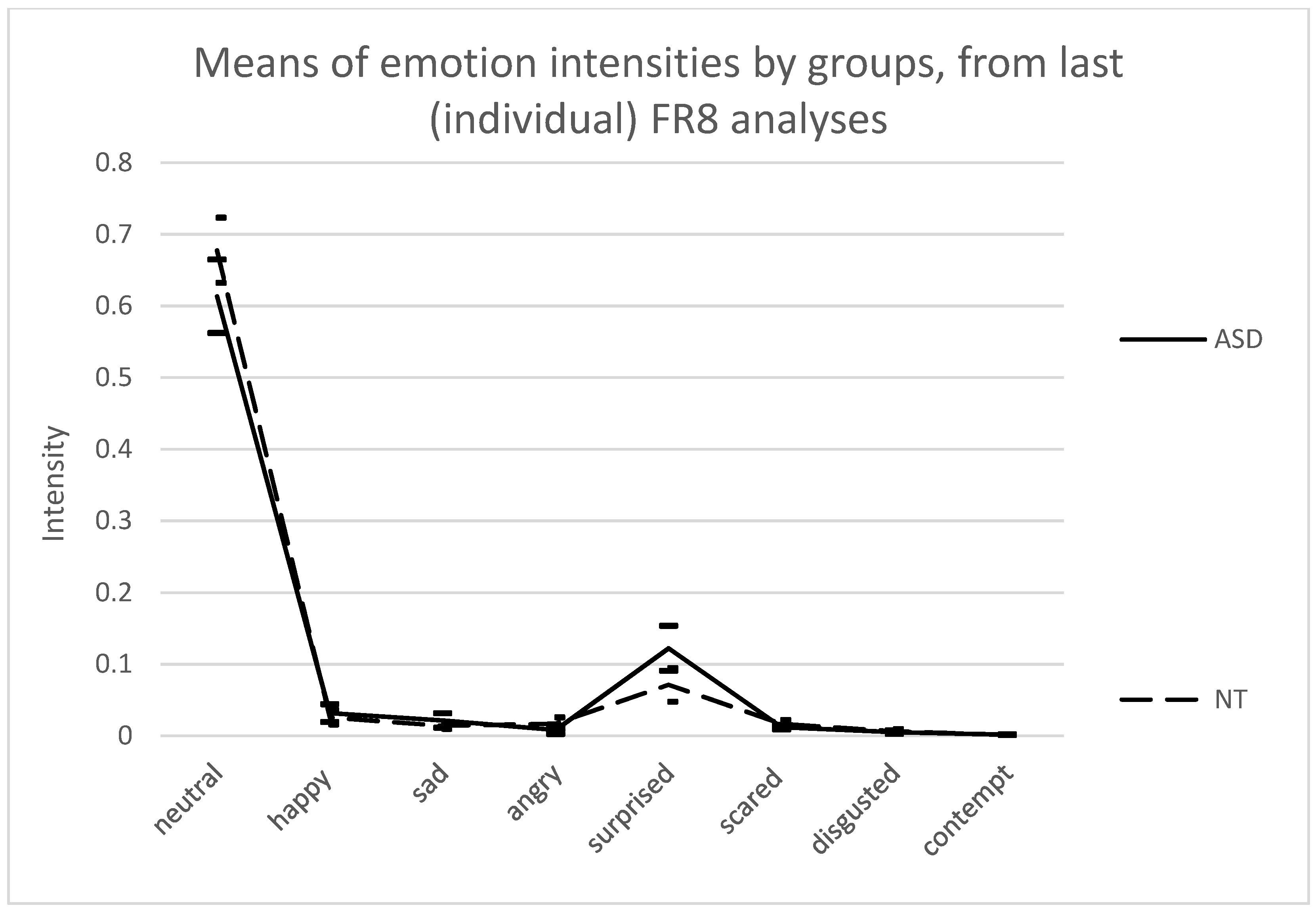
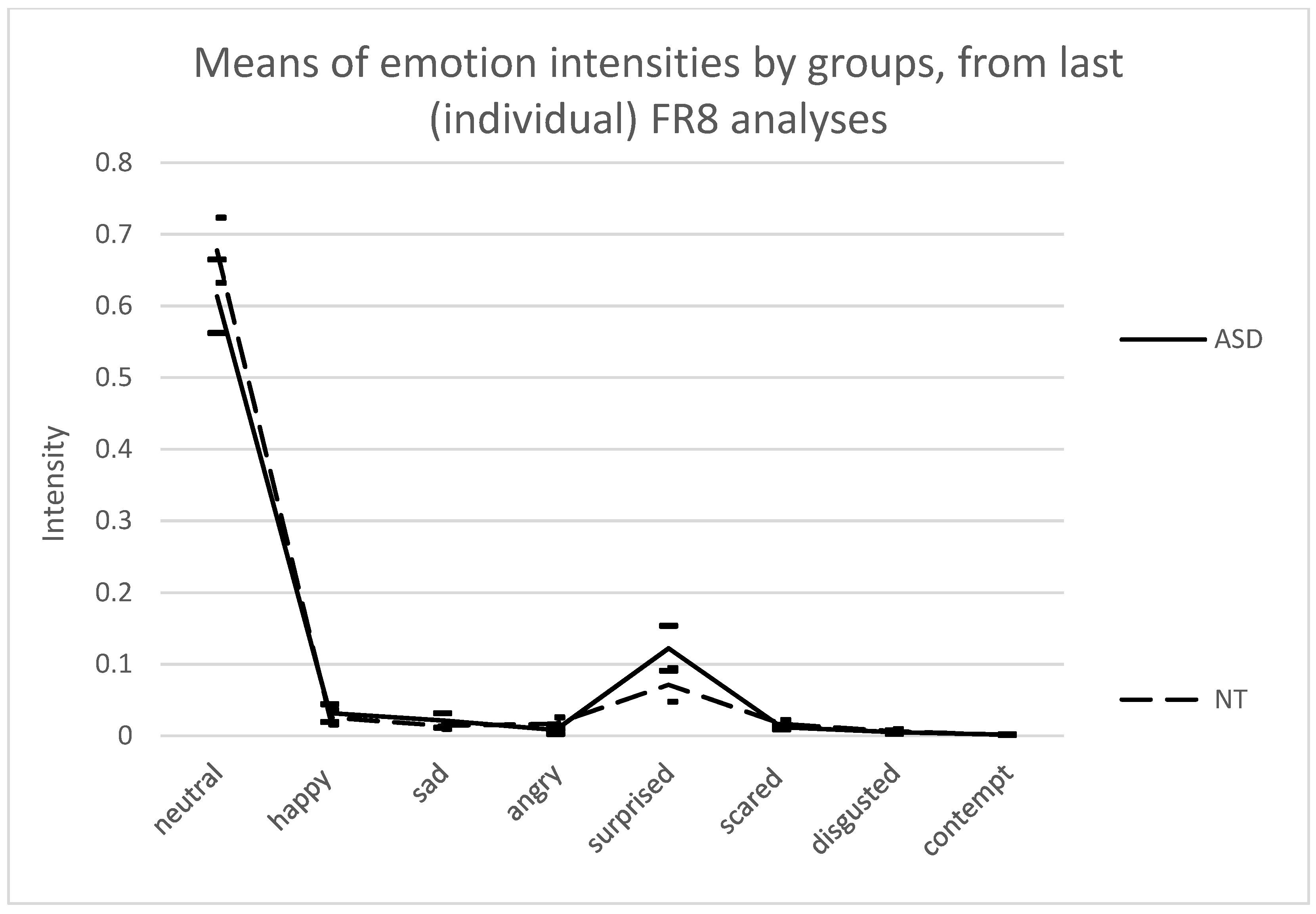
3.3. Between-Emotion and Between-Group Differences in Emotion Intensities
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Analysis Parameter | Applied Setting | Rationale |
|---|---|---|
| Face model | Children | In accordance with subjects’ age |
| Calibration | Continuous calibration | Aims to correct for person-specific biases in facial expressions, thus not requiring an initial input of a neutral face of each subject |
| Classification | Smoothen classification | Raw classification data are smoothened in relation to between-frame time gap (default setting) |
| Image rotation | No | All faces were recorded in upright position |
| Video sample rate | Every frame | No recorded frame to be skipped |
| Contempt | Treat contempt as an emotional state | To gain intensity values for “contempt” |
| Preset for face-finding function | Find all faces (slow) | The most robust setting in terms of size of potential target face on the frame (minimum face fraction = 0.08) |
| Preset for face-modeling function | Maximum accuracy (slow) | Robust setting in terms of the maximum number of iterations per frame to find face (12) |
| Engine | Use deep face engine | Slower but more accurate analysis which attempts to model the face even from partial information |
| Maximum face model error | 0.6 | Measure of error for estimating if face model is valid |
| Size of interest, maximum face fraction | 1 | Maximum value, allows the face surface to be the same as the entire image |
| Size of interest, face size scaling factor | 1.1 | The default factor value for increasing face size within minimum and maximum, for the analysis |
| Group | Emotion | Individual Test1–Test2 Emotion Intensity Differences | ||||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Median | Minimum | Maximum | Skewness | Kurtosis | ||
| ASD (n = 6) | Neutral | 0.00123 | 0.003744 | −0.0001 | −0.0009 | 0.0088 | 2.387 * | 5.767 ** |
| Happy | −0.00089 | 0.001878 | 0 | −0.0047 | 0.0002 | −2.286 * | 5.303 ** | |
| Sad | 0.000103 | 0.000201 | 0 | 0 | 0.0005 | 2.328 * | 5.535 ** | |
| Angry | −7.3 × 10−5 | 0.000197 | 0 | −0.0005 | 0.0001 | −2.280 * | 5.347 ** | |
| Surprised | −0.00322 | 0.007911 | 0 | −0.0194 | 0.0001 | −2.449 * | 6.000 ** | |
| Scared | 0.001027 | 0.002513 | 0 | 0 | 0.0062 | 2.449 * | 5.998 ** | |
| Disgusted | −0.00022 | 0.000389 | −0.0001 | −0.001 | 0.0001 | −2.139 * | 4.839 * | |
| Contempt | −5.9 × 10−5 | 0.000147 | 0 | −0.0004 | 0 | −2.448 * | 5.996 ** | |
| NT (n = 6) | Neutral | 2.85 × 10−6 | 0.000327 | 0 | −0.0004 | 0.0006 | 0.889 | 2.828 |
| Happy | −0.00017 | 0.000315 | 0 | −0.0008 | 0 | −2.211 * | 4.956 * | |
| Sad | 2.02 × 10−5 | 5.2 × 10−5 | 0 | 0 | 0.0001 | 0 | 0 | |
| Angry | 0.000255 | 0.000641 | 0 | 0 | 0.0016 | 2.447 * | 5.991 ** | |
| Surprised | −3.2 × 10−6 | 6.15 × 10−5 | 0 | −0.0001 | 0.0001 | 0 | 0 | |
| Scared | 0.000264 | 0.000681 | 0 | 0 | 0.0017 | 2.446 * | 5.987 ** | |
| Disgusted | −2.3 × 10−5 | 0.000252 | 0 | −0.0004 | 0.0004 | −0.065 | 2.171 | |
| Contempt | −5.8 × 10−7 | 1.39 × 10−6 | 0 | 0 | 0 | 0 | 0 | |
| Magnitude Range | Neutral | Happy | Sad | Angry | Surprised | Scared | Disgusted | Contempt |
|---|---|---|---|---|---|---|---|---|
| diff = −1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −1 < diff ≤ −0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.9 <diff ≤ −0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.8 < diff ≤ −0.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.7 < diff ≤ −0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.6 < diff ≤ −0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.5 < diff ≤ −0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.4 < diff ≤ −0.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.3 < diff ≤ −0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.2 < diff ≤ −0.1 | 0 | 0 | 0 | 0 | 168 | 0 | 0 | 0 |
| −0.1 < diff ≤ 0 | 5638 | 7493 | 5920 | 10,405 | 9736 | 397 | 9593 | 9680 |
| 0 < diff ≤ 0.1 | 11,661 | 511 | 9113 | 15 | 5661 | 11,322 | 1676 | 1 |
| 0.1 < diff ≤ 0.2 | 0 | 0 | 0 | 0 | 242 | 0 | 0 | 0 |
| 0.2 < diff ≤ 0.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.3 < diff ≤ 0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.4 < diff ≤ 0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.5 < diff ≤ 0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.6 < diff ≤ 0.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.7 < diff ≤ 0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.8 < diff ≤ 0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.9 < diff ≤ 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mean | 0.008829 | −0.00466 | 0.000509 | −0.00047 | −0.01937 | 0.006156 | −0.0002 | −0.00036 |
| Nonzero percent | 0.395333 | 0.182915 | 0.343549 | 0.238128 | 0.361237 | 0.267814 | 0.25753 | 0.22124 |
| Total frames | 43,758 |
| Magnitude Range | Neutral | Happy | Sad | Angry | Surprised | Scared | Disgusted | Contempt |
|---|---|---|---|---|---|---|---|---|
| diff = −1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −1 < diff ≤ −0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.9 < diff ≤ −0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.8 < diff ≤ −0.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.7 < diff ≤ −0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.6 < diff ≤ −0.5 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.5 < diff ≤ −0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.4 < diff ≤ −0.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.3 < diff ≤ −0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| −0.2 < diff ≤ −0.1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.1 < diff ≤ 0 | 205 | 1 | 635 | 312 | 479 | 44 | 83 | 516 |
| 0 < diff ≤ 0.1 | 535 | 262 | 0 | 72 | 0 | 281 | 268 | 0 |
| 0.1 < diff ≤ 0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.2 < diff ≤ 0.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.3 < diff ≤ 0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.4 < diff ≤ 0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.5 < diff ≤ 0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.6 < diff ≤ 0.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.7 < diff ≤ 0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.8 < diff ≤ 0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.9 < diff ≤ 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mean | −0.00092 | −4.1 × 10−5 | −8.8 × 10−6 | 2.23 × 10−5 | −2.5 × 10−6 | −3.2 × 10−5 | −0.00099 | −6.19 × 10−8 |
| Nonzero percent | 0.031993 | 0.011355 | 0.027417 | 0.01658 | 0.020681 | 0.014032 | 0.015198 | 0.022279 |
| Total frames | 23,161 |
| Magnitude Range | Neutral | Happy | Sad | Angry | Surprised | Scared | Disgusted | Contempt |
|---|---|---|---|---|---|---|---|---|
| diff = −1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −1 < diff ≤ −0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.9 < diff ≤ −0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.8 < diff ≤ −0.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.7 < diff ≤ −0.6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.6 < diff ≤ −0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.5 < diff ≤ −0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.4 < diff ≤ −0.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.3 < diff ≤ −0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.2 < diff ≤ −0.1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| −0.1 < diff ≤ 0 | 2506 | 561 | 6427 | 139 | 46 | 4813 | 780 | 4570 |
| 0 < diff ≤ 0.1 | 5588 | 1 | 600 | 3043 | 4132 | 85 | 83 | 506 |
| 0.1 < diff ≤ 0.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.2 < diff ≤ 0.3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 0.3 < diff ≤ 0.4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.4 < diff ≤ 0.5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.5 < diff ≤ 0.6 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.6 < diff ≤ 0.7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.7 < diff < = 0.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.8 < diff ≤ 0.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0.9 < diff ≤ 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Mean | 9 × 10−5 | 2 × 10−5 | 4 × 10−5 | −3 × 10−6 | −5.7 × 10−5 | 3 × 10−6 | 0.000403 | −2.29 × 10−8 |
| Nonzero percent | 0.3495 | 0.0243 | 0.3034 | 0.1374 | 0.180389 | 0.2115 | 0.037304 | 0.2191615 |
| Total frames: | 23,161 |
| Emotion Means, Maxima, and Relative Frequencies of Differing Data Points | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Subject | Neutral | Happy | Sad | Angry | Surprised | Scared | Disgusted | Contempt | |
| #27 | Mean | −2.3 × 10−6 | 3.37 × 10−6 | 1.2 × 10−6 | 7.29 × 10−7 | −2.4 × 10−5 | 1.13 × 10−6 | 4.27 × 10−5 | 4.46 × 10−8 |
| maximum | 0.001467 | 0.001972 | 3.79 × 10−6 | 0.000158 | 0.011318 | 2.54 × 10−6 | 0.007265 | 1.49 × 10−7 | |
| rel. freq. in all data | 0.084117 | 0.027527 | 0.056829 | 0.026808 | 0.08287 | 0.045943 | 0.025993 | 0.032611 | |
| rel. freq. in valid data | 0.10206 | 0.033399 | 0.068951 | 0.032526 | 0.100547 | 0.055743 | 0.031537 | 0.039567 | |
| #43 | Mean | −6.7 × 10−6 | 9.14 × 10−8 | 8.03 × 10−6 | −6.7 × 10−7 | −1.1 × 10−6 | −4.1 × 10−7 | −4.6 × 10−8 | −2.4 × 10−8 |
| maximum | 0.005283 | 5.29 × 10−5 | 0.002069 | 1.79 × 10−6 | 1.39 × 10−5 | 9.04 × 10−7 | 1.1 × 10−7 | 1 × 10−7 | |
| rel. freq. in all data | 0.216552 | 0.101549 | 0.109482 | 0.105168 | 0.159352 | 0.175821 | 0.040314 | 0.166868 | |
| rel. freq. in valid data | 0.263016 | 0.123338 | 0.132973 | 0.127733 | 0.193543 | 0.213545 | 0.048963 | 0.202671 | |
| #46 | Mean | 3.72 × 10−6 | −9 × 10−6 | −1.6 × 10−7 | −2.8 × 10−8 | −1.3 × 10−5 | 1.31 × 10−7 | −2.2 × 10−8 | 1.32 × 10−7 |
| maximum | 0.004441 | 0.003993 | 6 × 10−7 | 1.32 × 10−7 | 0.003331 | 3.86 × 10−5 | 1.67 × 10−6 | 5.37 × 10−7 | |
| rel. freq. in all data | 0.297395 | 0.215251 | 0.133531 | 0.218219 | 0.261457 | 0.24436 | 0.104281 | 0.203288 | |
| rel. freq. in valid data | 0.310698 | 0.224879 | 0.139504 | 0.22798 | 0.273152 | 0.25529 | 0.108946 | 0.212381 | |
| #55 | Mean | −1.5 × 10−5 | 4.36 × 10−7 | −1.6 × 10−6 | −0.0014 | −9.3 × 10−6 | −0.00147 | −0.00033 | −1.6 × 10−8 |
| maximum | 0.007317 | 5.29 × 10−5 | 4.08 × 10−6 | 0.114174 | 1.99 × 10−5 | 0.143154 | 0.026798 | 4 × 10−8 | |
| rel. freq. in all data | 0.059224 | 0.033343 | 0.031944 | 0.033762 | 0.052043 | 0.035208 | 0.029565 | 0.036794 | |
| rel. freq. in valid data | 0.063602 | 0.035807 | 0.034305 | 0.036258 | 0.055889 | 0.03781 | 0.031751 | 0.039513 | |
| #65 | Mean | 2.13 × 10−5 | −1.5 × 10−5 | 3.97 × 10−5 | −3.5 × 10−6 | −5.7 × 10−5 | 1.49 × 10−6 | 0.000171 | −2.3 × 10−8 |
| maximum | 0.012913 | 0.001319 | 0.030275 | 0.003676 | 0.024688 | 0.001189 | 0.02302 | 2 × 10−7 | |
| rel. freq. in all data | 0.34951 | 0.024265 | 0.303398 | 0.137343 | 0.180346 | 0.211476 | 0.037304 | 0.219118 | |
| rel. freq. in valid data | 0.500309 | 0.034734 | 0.434302 | 0.196601 | 0.258158 | 0.302719 | 0.053399 | 0.313659 | |
| #70 | Mean | −3.8 × 10−6 | −1 × 10−6 | 8.16 × 10−6 | −1.2 × 10−7 | −7.7 × 10−7 | −1.7 × 10−8 | −6.7 × 10−8 | −9.5 × 10−8 |
| maximum | 0.003799 | 3.25 × 10−6 | 0.007671 | 7.72 × 10−5 | 3.09 × 10−6 | 1 × 10−7 | 2 × 10−7 | 3.53 × 10−7 | |
| rel. freq. in all data | 0.08696 | 0.020023 | 0.088946 | 0.073142 | 0.038888 | 0.016465 | 0.030159 | 0.067433 | |
| rel. freq. in valid data | 0.125643 | 0.02893 | 0.128512 | 0.105678 | 0.056186 | 0.02379 | 0.043574 | 0.09743 | |
| #94 | Mean | −2.2 × 10−5 | 2.63 × 10−5 | 9.85 × 10−7 | 2.78 × 10−6 | −5.8 × 10−6 | −5.3 × 10−7 | −4 × 10−6 | −4.9 × 10−7 |
| maximum | 0.020348 | 0.069351 | 0.02824 | 0.005737 | 3.15 × 10−5 | 1.81 × 10−6 | 0.050832 | 0.000802 | |
| rel. freq. in all data | 0.514396 | 0.25565 | 0.28763 | 0.33138 | 0.331426 | 0.278346 | 0.264607 | 0.322986 | |
| rel. freq. in valid data | 0.801959 | 0.398567 | 0.448425 | 0.516631 | 0.516704 | 0.43395 | 0.41253 | 0.503546 | |
References
- Cohn, J.F.; Kanade, T. Use of automated facial image analysis for measurement of emotion expression. In Handbook of Emotion Elicitation and Assessment; Coan, J.A., Allen, J.J.B., Eds.; Oxford University Press: New York, NY, USA, 2007; pp. 222–228. [Google Scholar]
- Martinez, A.M. The Promises and Perils of Automated Facial Action Coding in Studying Children’s Emotions. Dev. Psychol. 2019, 55, 1965–1981. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stöckli, S.; Schulte-Mecklenbeck, M.; Borer, S.; Samson, A.C. Facial Expression Analysis with AFFDEX and FACET: A Validation Study. Behav. Res. 2018, 50, 1446–1460. [Google Scholar] [CrossRef] [PubMed]
- Valstar, M. Automatic Facial Expression Analysis. In Understanding Facial Expressions in Communication; Mandal, M.K., Awasthi, A., Eds.; Springer: New Delhi, India, 2015; pp. 143–172. ISBN 978-81-322-1933-0. [Google Scholar]
- Lewinski, P.; den Uyl, T.M.; Butler, C. Automated Facial Coding: Validation of Basic Emotions and FACS AUs in FaceReader. J. Neurosci. Psychol. Econ. 2014, 7, 227–236. [Google Scholar] [CrossRef] [Green Version]
- Flynn, M.; Effraimidis, D.; Angelopoulou, A.; Kapetanios, E.; Williams, D.; Hemanth, J.; Towell, T. Assessing the Effectiveness of Automated Emotion Recognition in Adults and Children for Clinical Investigation. Front. Hum. Neurosci. 2020, 14, 70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mortillaro, M.; Meuleman, B.; Scherer, K.R. Automated Recognition of Emotion appraisals. In Handbook of Research on Synthesizing Human Emotion in Intelligent Systems and Robotics; Vallverdú, J., Ed.; Advances in Computational Intelligence and Robotics; IGI Global: Hershey, PA, USA, 2015; ISBN 978-1-4666-7278-9. [Google Scholar]
- Clark, E.A.; Kessinger, J.; Duncan, S.E.; Bell, M.A.; Lahne, J.; Gallagher, D.L.; O’Keefe, S.F. The Facial Action Coding System for Characterization of Human Affective Response to Consumer Product-Based Stimuli: A Systematic Review. Front. Psychol. 2020, 11, 920. [Google Scholar] [CrossRef] [PubMed]
- Davies, H.; Wolz, I.; Leppanen, J.; Fernandez-Aranda, F.; Schmidt, U.; Tchanturia, K. Facial Expression to Emotional Stimuli in Non-Psychotic Disorders: A Systematic Review and Meta-Analysis. Neurosci. Biobehav. Rev. 2016, 64, 252–271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girard, J.M.; Cohn, J.F.; Mahoor, M.H.; Mavadati, S.; Rosenwald, D.P. Social Risk and Depression: Evidence from Manual and Automatic Facial Expression Analysis. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Ekman, P.; Friesen, W.V. Measuring Facial Movement. J. Nonverbal Behav. 1976, 1, 56–75. [Google Scholar] [CrossRef]
- Samadiani, N.; Huang, G.; Cai, B.; Luo, W.; Chi, C.-H.; Xiang, Y.; He, J. A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data. Sensors 2019, 19, 1863. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ekman, P.; Rosenberg, E.L. What the Face Reveals Basic and Applied Studies of Spontaneous Expression Using the Facial Action Coding System (FACS); Oxford University Press: Oxford, UK, 2005; ISBN 978-0-19-517964-4. [Google Scholar]
- Sayette, M.A.; Cohn, J.F.; Wertz, J.M.; Perrott, M.A.; Parrott, D.J. A psychometric evaluation of the facial action coding system for assessing spontaneous expression. J. Nonverbal Behav. 2001, 25, 167–185. [Google Scholar] [CrossRef]
- Valstar, M.F.; Mehu, M.; Bihan, J.; Pantic, M.; Scherer, K. Meta-Analysis of the First Facial Expression Recognition Challenge. IEEE Trans. Syst. Man Cybern. B 2012, 42, 966–979. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- El Kaliouby, R.; Robinson, P. Real-Time Inference of Complex Mental States from Facial Expressions and Head Gestures. In Real-Time Vision for Human-Computer Interaction; Kisačanin, B., Pavlović, V., Huang, T.S., Eds.; Springer: Boston, MA, USA, 2005; pp. 181–200. ISBN 978-0-387-27697-7. [Google Scholar]
- McDuff, D.; Kaliouby, R.E.; Cohn, J.F.; Picard, R.W. Predicting Ad Liking and Purchase Intent: Large-Scale Analysis of Facial Responses to Ads. IEEE Trans. Affect. Comput. 2015, 6, 223–235. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A Survey of Affect Recognition Methods: Audio, Visual, and Spontaneous Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Littlewort, G.; Whitehill, J.; Wu, T.; Fasel, I.; Frank, M.; Movellan, J.; Bartlett, M. The Computer Expression Recognition Toolbox (CERT). In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–25 March 2011; pp. 298–305. [Google Scholar]
- Den Uyl, M.J.; van Kuilenburg, H. The FaceReader: Online facial expression recognition. In Proceedings of the Measuring Behavior, Wageningen, The Netherlands, 30 August–2 September 2005; pp. 589–590. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.116.5261&rep=rep1&type=pdf (accessed on 15 August 2019).
- Dupré, D.; Krumhuber, E.G.; Küster, D.; McKeown, G.J. A Performance Comparison of Eight Commercially Available Automatic Classifiers for Facial Affect Recognition. PLoS ONE 2020, 15, e0231968. [Google Scholar] [CrossRef] [PubMed]
- Martinez, B.; Valstar, M.F. Advances, Challenges, and Opportunities in Automatic Facial Expression Recognition. In Advances in Face Detection and Facial Image Analysis; Kawulok, M., Celebi, M.E., Smolka, B., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 63–100. ISBN 978-3-319-25956-7. [Google Scholar]
- Borges, N.; Lindblom, L.; Clarke, B.; Gander, A.; Lowe, R. Classifying Confusion: Autodetection of Communicative Misunderstandings Using Facial Action Units. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Cambridge, UK, 3–6 September 2019; pp. 401–406. [Google Scholar]
- Cohn, J.F.; De La Torre, F. Automated Face Analysis for Affective Computing. In The Oxford Handbook of Affective Computing; Calvo, R., D’Mello, S., Gratch, J., Kappas, A., Eds.; Oxford University Press: Oxford, UK, 2015; ISBN 978-0-19-994223-7. [Google Scholar]
- Kulke, L.; Feyerabend, D.; Schacht, A. A Comparison of the Affectiva IMotions Facial Expression Analysis Software with EMG for Identifying Facial Expressions of Emotion. Front. Psychol. 2020, 11, 329. [Google Scholar] [CrossRef] [PubMed]
- Beumer, G.M.; Tao, Q.; Bazen, A.M.; Veldhuis, R.N.J. A Landmark Paper in Face Recognition. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 73–78. [Google Scholar]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active Appearance Models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef] [Green Version]
- Dupré, D.; Andelic, N.; Morrison, G.; McKeown, G. Accuracy of Three Commercial Automatic Emotion Recognition Systems across Different Individuals and Their Facial Expressions. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; pp. 627–632. [Google Scholar]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. I-511–I-518. [Google Scholar]
- Van Kuilenburg, H.; Wiering, M.; den Uyl, M. A Model Based Method for Automatic Facial Expression Recognition. In Machine Learning: ECML 2005; Gama, J., Camacho, R., Brazdil, P.B., Jorge, A.M., Torgo, L., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3720, pp. 194–205. ISBN 978-3-540-29243-2. [Google Scholar]
- Lundqvist, D.; Flykt, A.; Öhman, A. The Karolinska Directed Emotional Faces—KDEF (CD ROM); Karolinska Institute, Department of Clinical Neuroscience, Psychology Section: Stockholm, Sweden, 1998. [Google Scholar]
- Olszanowski, M.; Pochwatko, G.; Kuklinski, K.; Scibor-Rylski, M.; Lewinski, P.; Ohme, R.K. Warsaw Set of Emotional Facial Expression Pictures: A Validation Study of Facial Display Photographs. Front. Psychol. 2015, 5, 1516. [Google Scholar] [CrossRef] [PubMed]
- Van der Schalk, J.; Hawk, S.T.; Fischer, A.H.; Doosje, B. Moving Faces, Looking Places: Validation of the Amsterdam Dynamic Facial Expression Set (ADFES). Emotion 2011, 11, 907–920. [Google Scholar] [CrossRef] [PubMed]
- Lewinski, P. Automated Facial Coding Software Outperforms People in Recognizing Neutral Faces as Neutral from Standardized Datasets. Front. Psychol. 2015, 6, 1386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Skiendziel, T.; Rösch, A.G.; Schultheiss, O.C. Assessing the Convergent Validity between the Automated Emotion Recognition Software Noldus FaceReader 7 and Facial Action Coding System Scoring. PLoS ONE 2019, 14, e0223905. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rösch, A.G. The Influence of Implicit Motives on the Expression and Perception of Facial Expressions of Emotion [Der Einfluss impliziter Motive auf den Ausdruck und die Wahrnehmung Emotionaler Gesichtsausdrücke]. Ph.D. Thesis, Friedrich-Alexander University, Erlangen, Germany, 2012. Available online: https://opus4.kobv.de/opus4-fau/frontdoor/index/index/docId/2304 (accessed on 20 December 2021).
- Cohn, J.F.; Ambadar, Z.; Ekman, P. Observer-based measurement of facial expression with the facial action coding system. In Handbook of Emotion Elicitation and Assessment; Coan, J.A., Allen, J.J.B., Eds.; Oxford University Press: New York, NY, USA, 2007; pp. 203–221. [Google Scholar]
- Beringer, M.; Spohn, F.; Hildebrandt, A.; Wacker, J.; Recio, G. Reliability and Validity of Machine Vision for the Assessment of Facial Expressions. Cogn. Syst. Res. 2019, 56, 119–132. [Google Scholar] [CrossRef]
- Terzis, V.; Moridis, C.N.; Economides, A.A. Measuring Instant Emotions during a Self-Assessment Test: The Use of FaceReader. In Proceedings of the 7th International Conference on Methods and Techniques in Behavioral Research—MB ’10, Eindhoven, The Netherlands, 24–27 August 2010; ACM Press: New York, NY, USA, 2010; pp. 1–4. [Google Scholar]
- D’Arcey, J.T. Assessing the Validity of FaceReader Using Facial EMG; California State University: Chico, CA, USA, 2013; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.916.6560&rep=rep1&type=pdf (accessed on 5 March 2020).
- Owada, K.; Kojima, M.; Yassin, W.; Kuroda, M.; Kawakubo, Y.; Kuwabara, H.; Kano, Y.; Yamasue, H. Computer-Analyzed Facial Expression as a Surrogate Marker for Autism Spectrum Social Core Symptoms. PLoS ONE 2018, 13, e0190442. [Google Scholar] [CrossRef] [Green Version]
- Carpenter, K.L.H.; Hahemi, J.; Campbell, K.; Lippmann, S.J.; Baker, J.P.; Egger, H.L.; Espinosa, S.; Vermeer, S.; Sapiro, G.; Dawson, G. Digital Behavioral Phenotyping Detects Atypical Pattern of Facial Expression in Toddlers with Autism. Autism Res. 2021, 14, 488–499. [Google Scholar] [CrossRef] [PubMed]
- Bersani, F.S.; Polli, E.; Valeriani, G.; Zullo, D.; Melcore, C.; Capra, E.; Quartini, A.; Marino, P.; Minichino, A.; Bernabei, L.; et al. Facial Expression in Patients with Bipolar Disorder and Schizophrenia in Response to Emotional Stimuli: A Partially Shared Cognitive and Social Deficit of the Two Disorders. NDT 2013, 9, 1137–1144. [Google Scholar] [CrossRef] [Green Version]
- Leppanen, J.; Dapelo, M.M.; Davies, H.; Lang, K.; Treasure, J.; Tchanturia, K. Computerised Analysis of Facial Emotion Expression in Eating Disorders. PLoS ONE 2017, 12, e0178972. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mass, E.; Belostoky, L. Craniofacial Morphology of Children with Williams Syndrome. Cleft Palate-Craniofacial J. 1993, 30, 343–349. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Okada, K.; Rosenbaum, K.; Kehoe, L.; Zand, D.J.; Sze, R.; Summar, M.; Linguraru, M.G. Digital Facial Dysmorphology for Genetic Screening: Hierarchical Constrained Local Model Using ICA. Med. Image Anal. 2014, 18, 699–710. [Google Scholar] [CrossRef] [PubMed]
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders: DSM-5, 5th ed.; American Psychiatric Association: Washington, DC, USA, 2013; ISBN 978-0-89042-554-1. [Google Scholar]
- Aldridge, K.; George, I.D.; Cole, K.K.; Austin, J.R.; Takahashi, T.N.; Duan, Y.; Miles, J.H. Facial Phenotypes in Subgroups of Prepubertal Boys with Autism Spectrum Disorders Are Correlated with Clinical Phenotypes. Mol. Autism 2011, 2, 15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bonnet-Brilhault, F.; Rajerison, T.A.; Paillet, C.; Guimard-Brunault, M.; Saby, A.; Ponson, L.; Tripi, G.; Malvy, J.; Roux, S. Autism Is a Prenatal Disorder: Evidence from Late Gestation Brain Overgrowth: Prenatal Brain Overgrowth in Autism. Autism Res. 2018, 11, 1635–1642. [Google Scholar] [CrossRef]
- Sacco, R.; Gabriele, S.; Persico, A.M. Head Circumference and Brain Size in Autism Spectrum Disorder: A Systematic Review and Meta-Analysis. Psychiatry Res. Neuroimaging 2015, 234, 239–251. [Google Scholar] [CrossRef]
- Tan, D.W.; Gilani, S.Z.; Maybery, M.T.; Mian, A.; Hunt, A.; Walters, M.; Whitehouse, A.J.O. Hypermasculinised Facial Morphology in Boys and Girls with Autism Spectrum Disorder and Its Association with Symptomatology. Sci. Rep. 2017, 7, 9348. [Google Scholar] [CrossRef] [Green Version]
- Tripi, G.; Roux, S.; Matranga, D.; Maniscalco, L.; Glorioso, P.; Bonnet-Brilhault, F.; Roccella, M. Cranio-Facial Characteristics in Children with Autism Spectrum Disorders (ASD). JCM 2019, 8, 641. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grossard, C.; Dapogny, A.; Cohen, D.; Bernheim, S.; Juillet, E.; Hamel, F.; Hun, S.; Bourgeois, J.; Pellerin, H.; Serret, S.; et al. Children with Autism Spectrum Disorder Produce More Ambiguous and Less Socially Meaningful Facial Expressions: An Experimental Study Using Random Forest Classifiers. Mol. Autism 2020, 11, 5. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grossman, R.B.; Edelson, L.R.; Tager-Flusberg, H. Emotional Facial and Vocal Expressions During Story Retelling by Children and Adolescents with High-Functioning Autism. J. Speech Lang. Hear. Res. 2013, 56, 1035–1044. [Google Scholar] [CrossRef] [Green Version]
- Reddy, V.; Williams, E.; Vaughan, A. Sharing Humour and Laughter in Autism and Down’s Syndrome. Br. J. Psychol. 2002, 93, 219–242. [Google Scholar] [CrossRef] [PubMed]
- Trevisan, D.A.; Hoskyn, M.; Birmingham, E. Facial Expression Production in Autism: A Meta-Analysis: Facial Expression Production in Autism. Autism Res. 2018, 11, 1586–1601. [Google Scholar] [CrossRef]
- Hull, L.; Petrides, K.V.; Allison, C.; Smith, P.; Baron-Cohen, S.; Lai, M.-C.; Mandy, W. “Putting on My Best Normal”: Social Camouflaging in Adults with Autism Spectrum Conditions. J. Autism Dev. Disord. 2017, 47, 2519–2534. [Google Scholar] [CrossRef]
- Borsos, Z.; Gyori, M. Can Automated Facial Expression Analysis Show Differences Between Autism and Typical Functioning? Stud. Health Technol. Inform. 2017, 242, 797–804. [Google Scholar]
- Gyori, M.; Borsos, Z.; Stefanik, K. Evidence-Based Development and First Usability Testing of a Social Serious Game Based Multi-Modal System for Early Screening for Atypical Socio-Cognitive Development. Stud. Health Technol. Inform. 2015, 217, 48–54. [Google Scholar]
- Gyori, M.; Borsos, Z.; Stefanik, K.; Csákvári, J. Data Quality as a Bottleneck in Developing a Social-Serious-Game-Based Multi-Modal System for Early Screening for ‘High Functioning’ Cases of Autism Spectrum Condition. In Computers Helping People with Special Needs; Miesenberger, K., Bühler, C., Penaz, P., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9759, pp. 358–366. ISBN 978-3-319-41266-5. [Google Scholar]
- Gyori, M.; Borsos, Z.; Stefanik, K.; Jakab, Z.; Varga, F.; Csákvári, J. Automated vs Human Recognition of Emotional Facial Expressions of High-Functioning Children with Autism in a Diagnostic-Technological Context: Explorations via a Bottom-Up Approach. In Computers Helping People with Special Needs; Miesenberger, K., Kouroupetroglou, G., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 10896, pp. 466–473. ISBN 978-3-319-94276-6. [Google Scholar]
- Rutter, M.; Bailey, A.; Lord, C. The Social Communication Questionnaire: Manual; Western Psychological Services: Los Angeles, CA, USA, 2003. [Google Scholar]
- Lord, C.; Rutter, M.; DiLavore, P.C.; Risi, S. Autism Diagnostic Observation Schedule; Western Psychological Services: Los Angeles, CA, USA, 1999. [Google Scholar]
- Le Couteur, A.; Lord, C.; Rutter, M. The Autism Diagnostic Interview-Revised; Western Psychological Services: Los Angeles, CA, USA, 2003. [Google Scholar]
- Roid, G.; Miller, L. Leiter international performance scale-revised: Examiner’s manual. In Leiter International Performance Scale—Revised; Roid, G.H., Miller, L.J., Eds.; Wood Dale: Stoelting, IL, USA, 1997. [Google Scholar]
- Bishop, D. The Test for Reception of Grammar; Medical Research Council, Applied Psychology Unit: London, UK; Cambridge, UK, 1983. [Google Scholar]
- Lukács, Á.; Győri, M.; Rózsa, S. TROG-H: Új sztenderdizált módszer a nyelvtani megértés fejlődésének vizsgálatára. Gyógypedagógiai Szle. 2013, 1, 1–22. Available online: https://epa.oszk.hu/03000/03047/00059/pdf/EPA03047_gyosze_2013_1_001-022.pdf (accessed on 10 November 2019).
- Cliff, N. Dominance Statistics: Ordinal Analyses to Answer Ordinal Questions. Psychol. Bull. 1993, 114, 494–509. [Google Scholar] [CrossRef]
- Sodian, B.; Frith, U. Deception and Sabotage in Autistic, Retarded and Normal Children. J. Child Psychol. Psychiatry 1992, 33, 591–605. [Google Scholar] [CrossRef] [PubMed]
- Keating, C.T.; Cook, J.L. Facial expression production and recognition in autism spectrum disorders: A shifting landscape. Child Adolesc. Psychiatry Clin. 2020, 29, 557–571. [Google Scholar] [CrossRef] [PubMed]
- Egger, H.L.; Dawson, G.; Hashemi, J.; Carpenter, K.L.H.; Espinosa, S.; Campbell, K.; Brotkin, S.; Schaich-Borg, J.; Qiu, Q.; Tepper, M.; et al. Automatic Emotion and Attention Analysis of Young Children at Home: A ResearchKit Autism Feasibility Study. NPJ Digit. Med. 2018, 1, 20. [Google Scholar] [CrossRef] [PubMed]

| NT Group n = 31 18 Male/13 Female | ASD Group n = 29 21 Male/8 Female | Statistical Difference between Groups | |||
|---|---|---|---|---|---|
| Mean (SD) | Range | Mean (SD) | Range | ||
| Age (months) | 53.2 (8.65) | 38–68 | 57.8 (8.65) | 41–70 | t(58) = −2.042; p = 0.046; Cohen’s d = 0.26 |
| IQ by Leiter-R Brief | 120.5 (14.04) | 98–147 | 116.3 (13.9) | 91–139 | t(58) = 1.156; p = 0.252 (ns) |
| TROG-H score (receptive grammar) | 118.2 (14.40) | 83–147 | 111.3 (14.93) | 82–153 | t(58) = 1.156; p = 0.074 (ns); Cohen’s d = 0.23 |
| Median | Range | Median | Range | ||
| SCQ score (ASD symptom severity estimate) | 1 | 0–3 | 21 | 8–29 | Mann–Whitney’s U < 0.0001; z = −6.732; p < 0.001 (Mann–Whitney); effect size (stochastic difference; [68]): 1 (large) |
| Game total score (number of correct mouse responses out of the total 24) | 24 | 19–24 | 23 | 2–24 | Mann–Whitney’s U = 342; z = −1.660; p = 0.097 (ns); effect size (stochastic difference [68]: 0.239 (large) |
| Scene Theme | Scene Function | Stimuli Presented (Visually) |
|---|---|---|
| “Perceptual preferences” | To evoke spontaneous emotional and gaze responses | Pinwheel, two birds, human agent (narrator) |
| Introduction and instructions—1 | To familiarize with characters, task, controls | Human-like characters (narrator, competitor, cooperator), chest, candy, bowl, controls |
| Sabotage in cooperative context | To evoke spontaneous emotional and gaze responses, intentional behavioral (mouse) responses | |
| Sabotage in competitive context | ||
| Sabotage in cooperative context | ||
| Sabotage in competitive context | ||
| Introduction and instructions—2 | To familiarize with task and controls | |
| Deception in cooperative context | To evoke spontaneous emotional and gaze responses, intentional behavioral (mouse) responses | |
| Deception in competitive context | ||
| Deception in cooperative context | ||
| Deception in competitive context | ||
| Closing | To close the session | Human agent (narrator) |
| ASD Group | NT Group | Total | |
|---|---|---|---|
| Number of input cases for test1 and test2/number of identical test1–test2 data series | 29/23 | 31/25 | 60/48 |
| Number of input cases for test3/number of identical test2–test3 data series | 6/3 | 6/2 | 12/5 |
| Remaining “non-stabilized” data series after test3 | 3 | 4 | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borsos, Z.; Jakab, Z.; Stefanik, K.; Bogdán, B.; Gyori, M. Test–Retest Reliability in Automated Emotional Facial Expression Analysis: Exploring FaceReader 8.0 on Data from Typically Developing Children and Children with Autism. Appl. Sci. 2022, 12, 7759. https://doi.org/10.3390/app12157759
Borsos Z, Jakab Z, Stefanik K, Bogdán B, Gyori M. Test–Retest Reliability in Automated Emotional Facial Expression Analysis: Exploring FaceReader 8.0 on Data from Typically Developing Children and Children with Autism. Applied Sciences. 2022; 12(15):7759. https://doi.org/10.3390/app12157759
Chicago/Turabian StyleBorsos, Zsófia, Zoltán Jakab, Krisztina Stefanik, Bianka Bogdán, and Miklos Gyori. 2022. "Test–Retest Reliability in Automated Emotional Facial Expression Analysis: Exploring FaceReader 8.0 on Data from Typically Developing Children and Children with Autism" Applied Sciences 12, no. 15: 7759. https://doi.org/10.3390/app12157759
APA StyleBorsos, Z., Jakab, Z., Stefanik, K., Bogdán, B., & Gyori, M. (2022). Test–Retest Reliability in Automated Emotional Facial Expression Analysis: Exploring FaceReader 8.0 on Data from Typically Developing Children and Children with Autism. Applied Sciences, 12(15), 7759. https://doi.org/10.3390/app12157759