1. Introduction
The Internet of Things (IoT) is a growing trend with large varieties of consumer and industrial products being connected via the Internet. To operate with these devices, the implementation of a smart human–machine interface (HMI) becomes an important issue. Some HMI systems are based on hand gesture recognition. Although vision-based recognition (VBR) algorithms [
1] have been found to be effective, the information of hand gestures is extracted from video sequences captured by cameras. Because VBR systems may record users’ life continuously, there are risks of personal information disclosure, which lead to privacy issues [
2,
3]. In addition, high computational complexities may be required [
4] for carrying out the gesture information extraction from video sequences for real-time applications.
Alternatives to VBR algorithms are the sensor-based recognition (SBR) algorithms, which are based on the sensory data produced by devices different from cameras. Privacy-preserved activity recognition can then be achieved. Commonly used sensors include accelerometers [
5,
6], gyroscopes [
4,
7], photoplethysmography (PPG) [
8], flex sensors [
9], electromyography (EMG) [
10], and the fusion of these sensors. Although an SBR algorithm may have lower computational complexities, it is usually difficult to extract gestures from sensory data for the subsequent classification in the algorithm. In fact, for some sensory data, a precise gesture extraction can be challenging even by direct visual inspection of the samples because gesture movements may not be easily inferred from their corresponding sensor readings.
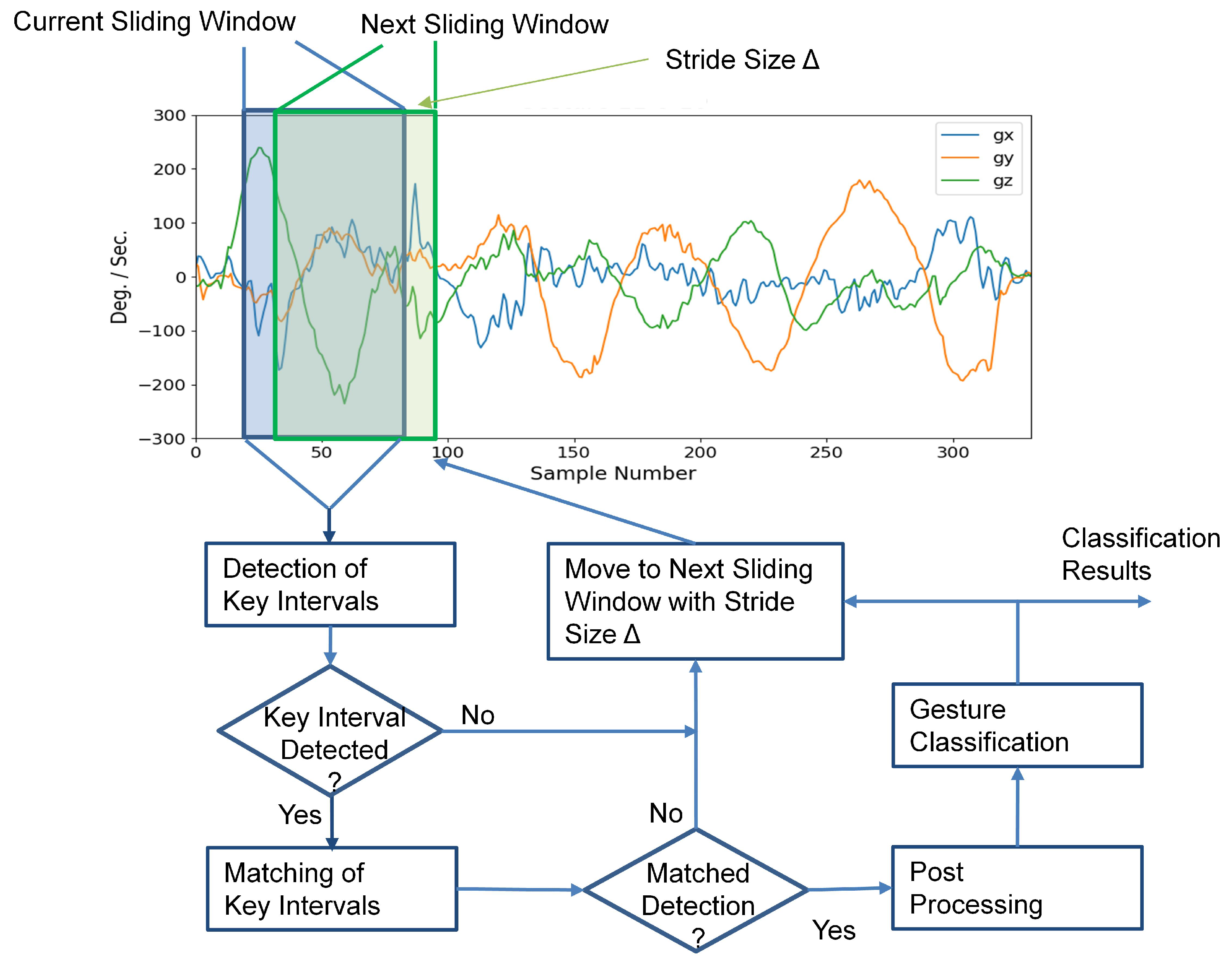
The extraction of gestures from sensory data is equivalent to the identification of the start and end points of the gestures. Dedicated sensors, explicit user actions, or special gesture markers are required for the studies in [
10,
11,
12,
13] for determining the start and end locations. These methods introduce extra overhead for the gesture detection. The SBR approaches in [
14,
15] carry out the gesture extraction automatically based on the variances of sensory data. However, because hand movements generally produce large variances, false alarms may be triggered as the unintended gestures are performed. In addition, accurate detection of a sequence of gestures could also be difficult. Deep learning techniques [
16] such as long short-term memory (LSTM) and/or convolution neural network (CNN) have been found to be effective for the detection and classification of a sequence of gestures [
7,
17,
18,
19]. However, the techniques operate under the assumptions that the start and end locations of the gesture sequences are available before each individual gesture can be identified.
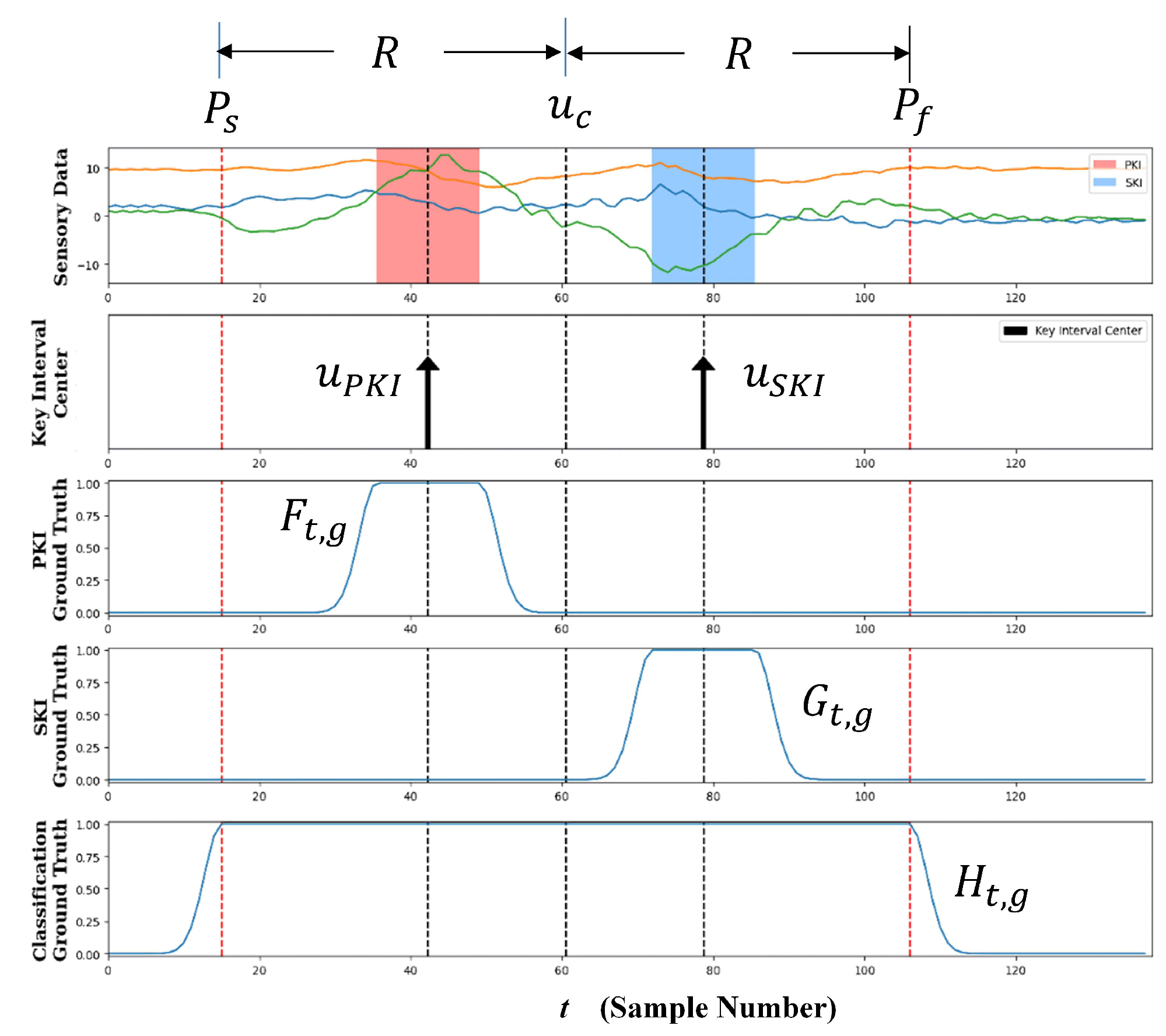
The goal of this study is to present a novel SBR detection and classification technique for a sequence of hand gestures. The sensors considered in this study are accelerometer and gyroscope. The proposed detection algorithm is automatic so that no dedicated sensors, explicit user actions, or special gesture markers are required. Furthermore, no prior knowledge on the start and end locations of the whole sequence of hand gestures is needed. In the proposed algorithm, each hand gesture in the sequence is regarded as an object. The detection of the object is based on a pair of key intervals. One interval, termed primary key interval (PKI), is located in the first half of the gesture. The other interval, termed secondary key interval (SKI), is in the second half. A gesture is detected when the paired key intervals are identified. The requirement for the detection of the paired key intervals is beneficial for lowering the false alarm rates triggered by unintended gestures.
Furthermore, a simple automatic labelling scheme for the identification of the key intervals is proposed in this study. No manual visual inspection is required. After locating the PKI and SKI, a Gaussian-like function is then adopted for spreading the label values outside the intervals. The label values associated with each sample are the scores indicating the likelihood that the corresponding sample belongs to the key intervals. During the inference process, the scores associated with each sample are then computed for gesture detection. A multitask learning technique [
20] is employed for the gesture detection and classification. Because the detection and classification are related tasks, the simultaneous learning of the tasks provides the advantages of a superior generalization and regularization through shared representation, and improved data efficiency as well as fast learning by leveraging auxiliary information offered by the other tasks.
The major contributions of this work are threefold:
We present a novel gesture detection and classification algorithm for sensory data based on objects as paired intervals. The algorithm is able to carry out semantic detection with a high detection accuracy and low false positive rate even in the presence of unintended gestures.
We propose a simple automatic soft-labelling scheme for the identification of key intervals. The simple labelling scheme is able to facilitate the collection and annotation of training data.
We propose a multitask learning algorithm for the simultaneous training for gesture detection and classification. The multitask learning is beneficial for providing superior generalization and regularization for SBR-based training.
The remaining parts of this paper are organized as follows.
Section 2 presents the related work to this study. The proposed SBR algorithm is discussed in detail in
Section 3. Experimental results of the proposed SBR algorithm are then presented in
Section 4. Finally,
Section 5 includes some concluding remarks of this work.
4. Experimental Results
This section presents some experimental results of the proposed algorithm. In the experiments, all the gesture sequences for training and testing were acquired by a smartphone equipped with an accelerometer and a gyroscope. The sensors were capable of measuring acceleration and angular velocity in three orthogonal axes, respectively. Therefore, the dimension of each sample was . The size of windows was . The sampling rate was 50 samples/s. For the inference operations, the stride size was . The smart phones adopted for the experiments were a Samsung Galaxy S8 and an HTC ONE M9. A Java-based app was built on the smartphones for gesture capturing and delivery.
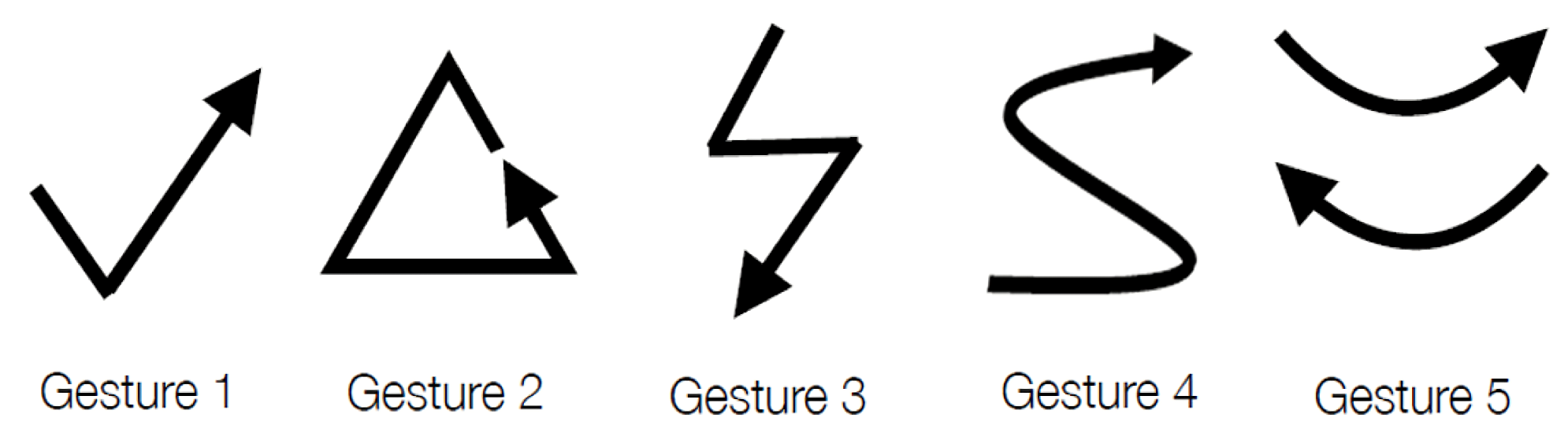
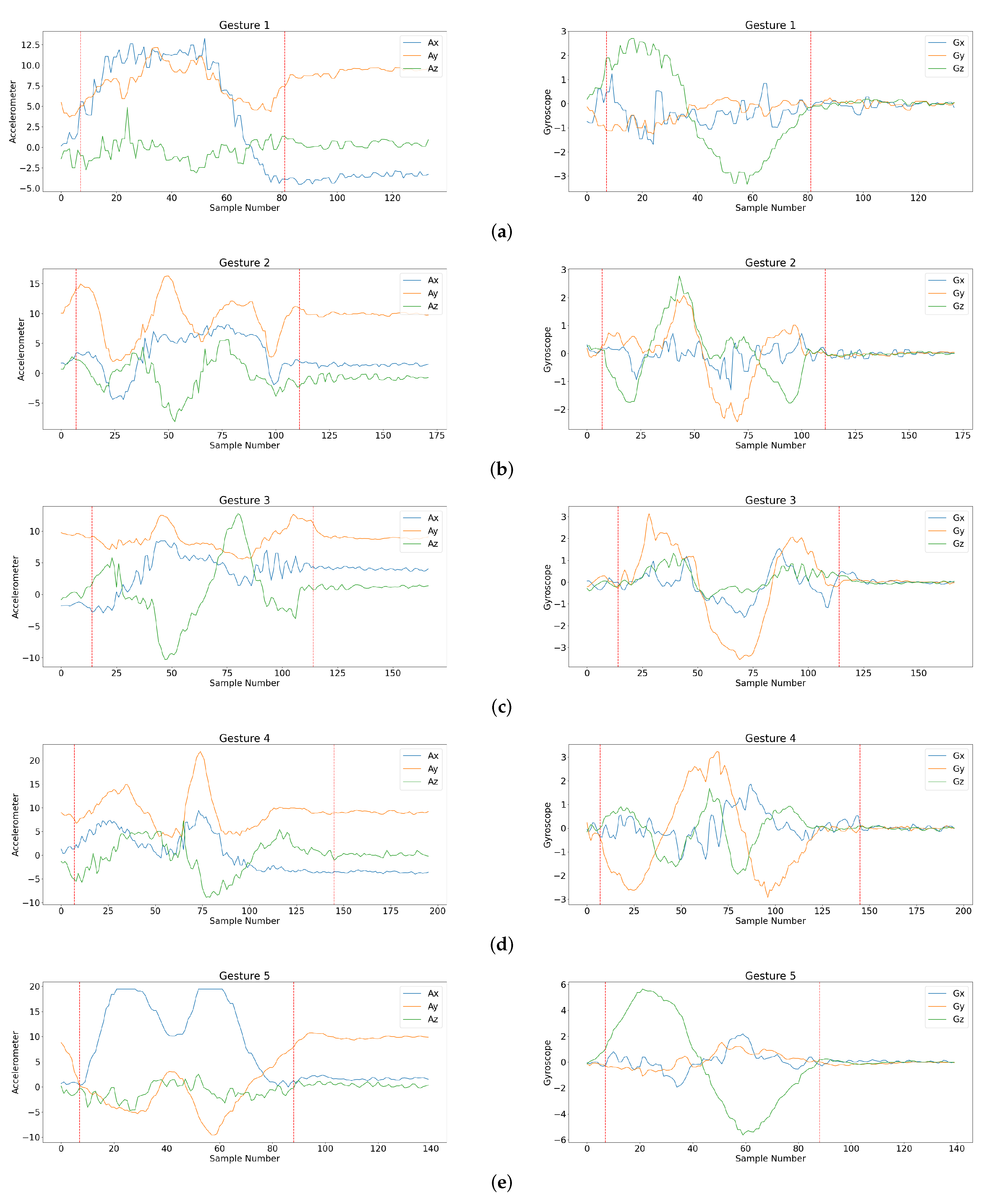
As shown in
Figure 5, there were five foreground gesture classes (i.e.,
) for the detection and classification. Samples of foreground gestures were recorded as training data for the training of the proposed network model. Let
be the number of the gestures in the training set. In the experiments, training sets with
gestures were considered. In this way, the impact on the performance of the proposed algorithm for different sizes of training sets could be evaluated. Samples of gestures for each foreground class in the training set are shown in
Figure 6. The training operations are implemented by Keras [
33].
The testing set for performance evaluation was different from the training sets. In addition, there were gestures in the test sequences which did not belong to the foreground gesture classes defined in
Figure 5. These gestures were termed background gestures in this study.
Figure 7 shows the background gesture classes considered in the experiments. These background classes contained only simple gestures which could be parts of the foreground gesture. In this way, the effectiveness of the proposed algorithm for ignoring background gestures and detecting foreground gestures could be evaluated. Let
be the number of gestures in the testing set.
In the experiments, there were 1503 sequences in the testing set. Each sequence may contain two or more hand gestures. The total number of gestures in the testing set was . Among these testing gestures, 1617 gestures were foreground gestures, and 1666 gestures were background gestures. The initial orientation of the smartphone for data acquisition of both training and testing sequences was the portrait orientation. All our experimental results were evaluated on the same testing set.
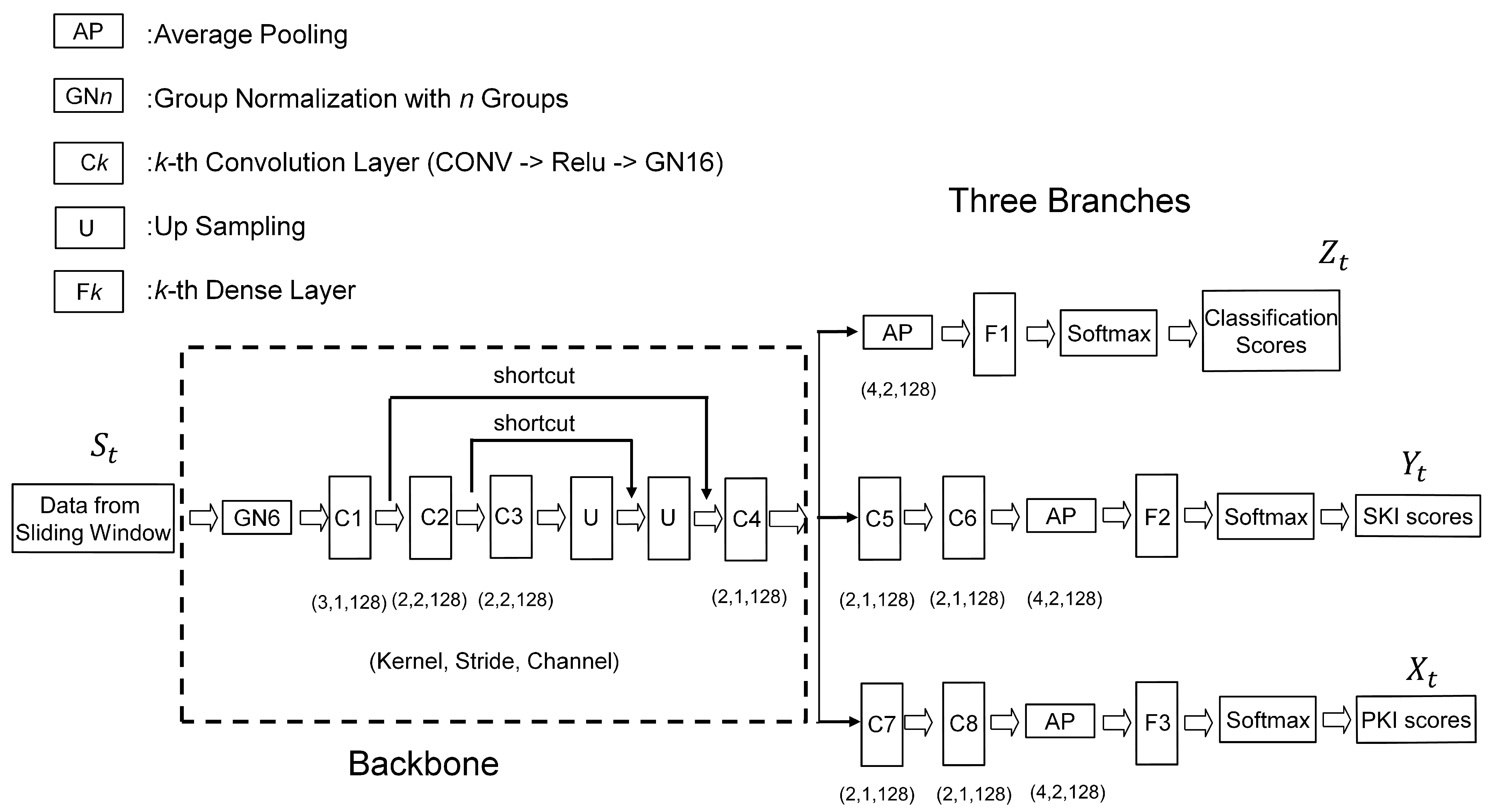
The network model adopted by the experiments is shown in
Figure 2. There were eight convolution layers and three dense layers in the model.
Table 1 shows the number of weights in each layer, the number of weights for the backbone, and the branches in the model. We can see from
Table 1 that the backbone had the largest number of weights compared with the branches in the model. This was because the backbone contained four convolution layers for effective feature extraction. A fewer number of convolution layers were needed in the branches. The total number of weights in the model was only 282,142, which is the sum of the number of weights for the backbone and branches.
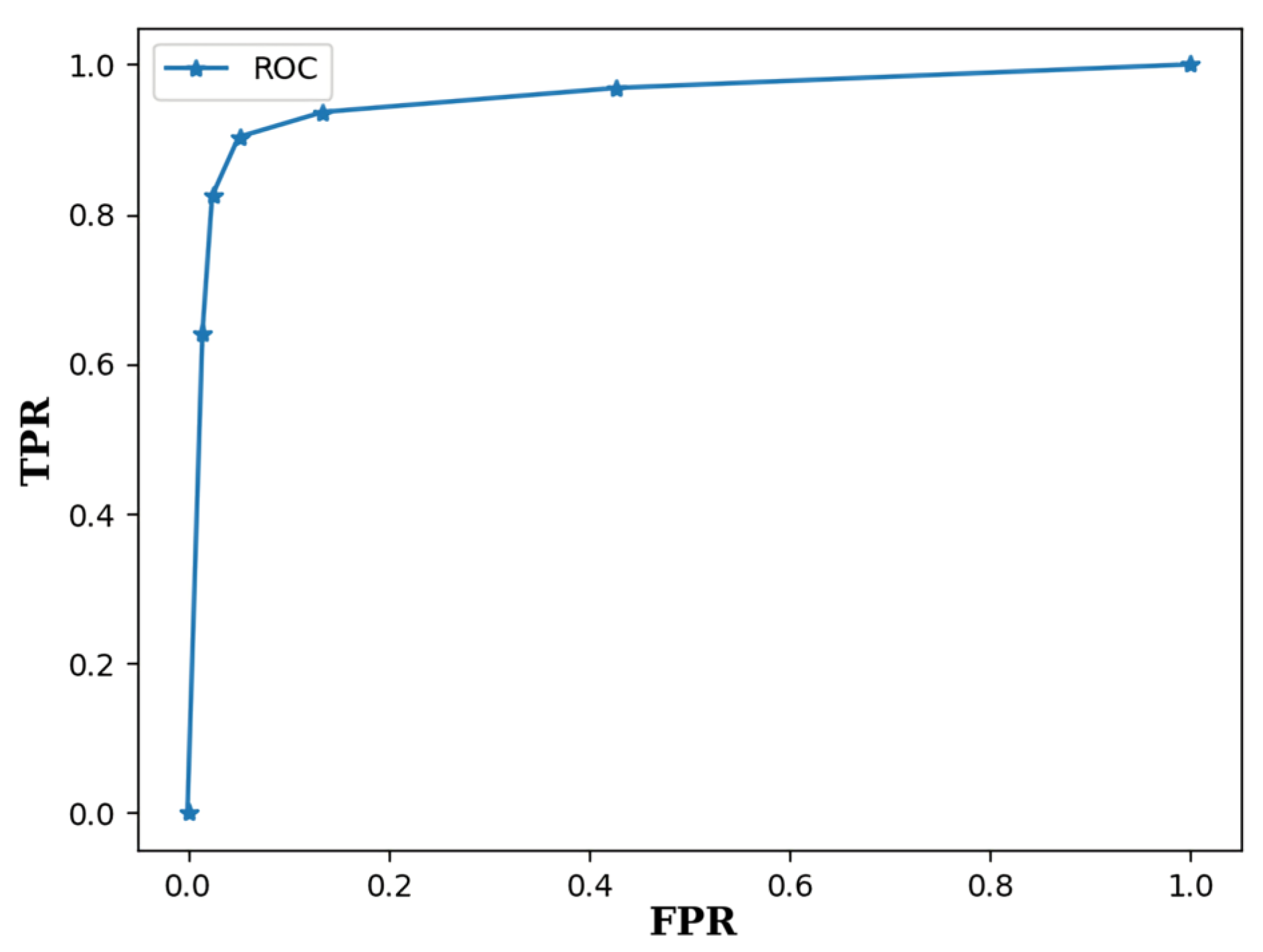
The separate evaluations of gesture detection and classification are first presented. The detection performance was evaluated by the receiver operating characteristic (ROC) curve [
34], which is a curve formed by pairs of true positive rate (TPR) and false positive rate (FPR) for various threshold values
T for gesture detection. The TPR is defined as the number of correctly detected foreground gestures divided by the total number of foreground gestures in the testing set. The FPR is defined as the number of falsely detected background gestures divided by the total number of background gestures in the testing set. The neural network for the experiment was trained by a set with
gestures. The ITR ratio
r in Equation (
5) was set to 0.3. That is, the key interval length
I was only 30% of the gesture radius
R.
Figure 8 shows the corresponding ROC curve, where the corresponding area under the ROC (AUROC) is 0.954. Therefore, with a low FPR, a high TPR can be achieved by the proposed algorithm.
To further evaluate the detection performance of the proposed algorithm, we compared the AUROC of the proposed algorithm with that of the CornerNet [
26] for various sizes
of training sets. For the proposed algorithm, we set the ITR ratio
. The CornerNet is based on keypoints for object detection. The corresponding results are revealed in
Table 2. All the training set contained the same number of classes
. We can see from
Table 2 that the proposed algorithm has a high AUROC even when the size of the training set is small. Furthermore, the AUROC becomes higher as the size of the training set increases. Based on the same training set, the proposed algorithm outperforms the CornerNet in AUROC for detection. These results justify the employment of key intervals for the detection of hand gestures.
The impact of the ITR ratio
r on the performance of the proposed algorithm is revealed in
Table 3 for various training set sizes
. As
r increases, it can be observed from
Table 3 that the performance of the proposed algorithm can be improved. In fact, when ITR ratio
r is above 0.2, the proposed algorithm is able to achieve an AUROC above 0.91 for all the training set sizes considered in the experiments. On the contrary, when
, the AUROC may be below 0.9 when
. Therefore, larger values of ITR ratio
r are beneficial for improving the accuracy and robustness of the proposed algorithm.
We next considered the classification performance for the correctly detected foreground gestures.
Table 4 shows the corresponding confusion matrix of the proposed algorithm with
. The corresponding neural network was trained by a set with size
. Each cell in the confusion matrix represents the percentage of the gesture in the corresponding row classified as the gesture in the corresponding column. Let
be the classification accuracy of gesture class
i, which is defined as the number of gestures in class
i that are correctly classified divided by the total number of gestures in class
i. Therefore,
is the value of the cell in the
ith column and
ith row of the confusion matrix. As revealed in
Table 4, the proposed algorithm attains a high classification accuracy
for all the gesture classes.
The proposed algorithm is also able to operate in conjunction with other classification algorithms. In these cases, the proposed algorithm serves only as the gesture detector. Existing gesture classification techniques such as support vector machine (SVM) [
6], LSTM [
7], bidirectional LSTM (Bi-LSTM) [
17], CNN [
18], and Residual PairNet [
19] can then be adopted to classify the detected gestures.
Table 5 shows the classification accuracies of these classification algorithms. For comparison purpose, the proposed algorithm for both detection and classification was also considered in
Table 5. We can see from the table that the proposed algorithm outperforms the other algorithms for classification. This is because the joint training of both detection and classification in the proposed algorithm is beneficial for simultaneous detection and classification. That is, when PKI and SKI are matched, the corresponding class is the gesture class of the detected gesture. No other additional efforts are needed for the classification.
In addition to the separate evaluation of detection and classification, the combined evaluation was also considered in this study. To carry out the evaluation, we considered a sequence of gestures as a string of characters, where each character corresponds to a gesture. The alphabet of the characters was the set of all the foreground gesture classes. The evaluation of the classification results of a gesture sequence was then based on the edit distance [
35] between two strings, where one string corresponds to the ground truth of the sequence, and the other is the classification results of the sequence.
In the edit distance between two strings, the displacements, deletions, and insertions of characters from one string to the other are taken into consideration [
35]. A displacement corresponds to the misclassification of one foreground gesture to another foreground gesture. A deletion implies a misdetection of one foreground gesture. An insertion would be the results of the false detection of a background gesture as a foreground one, or the multiple detections of a single foreground gesture. Let
E be the edit distance between two gesture sequences: one is the ground truth sequence, and the other is its prediction by the proposed algorithm. Furthermore, let
U be the length of the ground truth of the gesture sequence (in number of gestures). We then defined the edit distance accuracy (EDA) as
Based on the definition, the EDA with highest accuracy is EDA = 1.0. As an example, consider a gesture sequence
S = {Gesture 2, Gesture 4, Gesture 1}. After the gesture detection and classification, suppose the outcome is
Gesture 2, Gesture 3, Gesture 5, Gesture 1}. Because
S actually contains three gestures, the length of the ground truth is
. There exists one displacement and one insertion between
S and
. The edit distance is
. From Equation (
23), the EDA is 1/3.
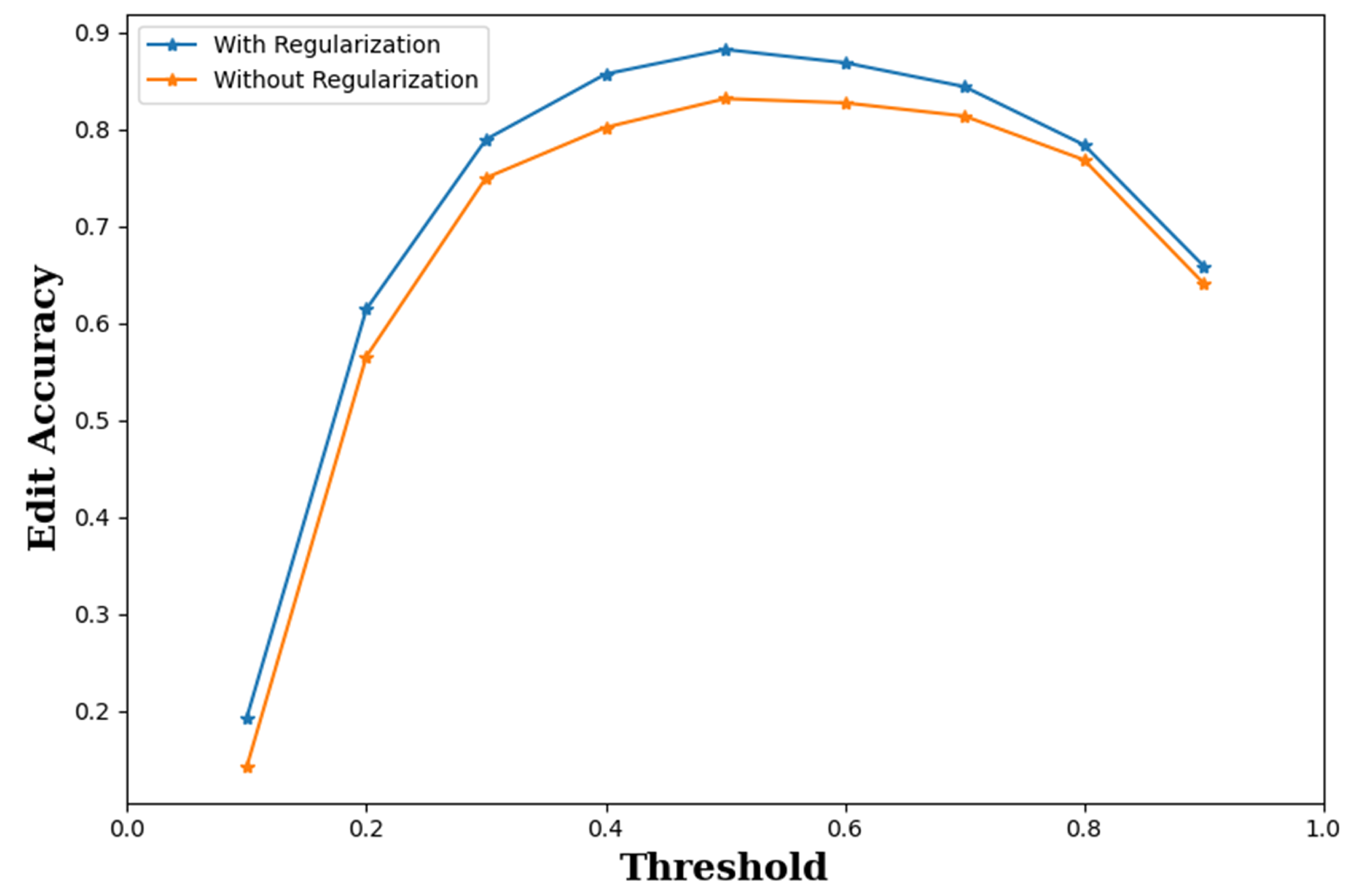
Figure 9 shows the average EDA of the proposed algorithm for various threshold values for detection
T. The average EDA was measured on the gesture sequences in the testing set. For comparison purpose, the average EDA of the proposed algorithm trained without regularization was also considered in
Figure 9. Recall that the regularization was imposed by including the network branch for classification scores in the training process. Nevertheless, the branch and the scores were not used for inference. Therefore, it would be possible to remove from the training the network branch used for producing classification scores. However, it can be observed from
Figure 9 that regularization was beneficial for improving the network performance. In fact, it outperformed its counterpart without regularization for all the thresholds considered in this experiment. In particular, when
, the EDA values of the proposed algorithm with and without regularization were 0.879 and 0.821, respectively. An improvement in EDA by 0.058 was observed. These results justify the employment of regularization for the proposed algorithm.
Another advantage is that the proposed algorithm may not be sensitive to the selection of thresholds. It can be observed from
Figure 9 that the average EDA of the proposed algorithm is higher than 0.8 for
T in the range of 0.4 to 0.8. The robustness of the proposed algorithm would be beneficial for providing a reliable performance for gesture detection and classification without the requirement for an elaborate search on the threshold.
Although the experiments considered above were based on an inference procedure with stride size
, larger stride sizes can also be considered at the expense of a lower EDA performance.
Table 6 shows the average EDA of the proposed algorithm for various stride sizes for inference. Two thresholds
and
were considered for the detection of PKI and SKI. It can be observed from
Table 6 that it is possible to maintain an average EDA above 0.8 even for stride size
. Furthermore, inference operations based on stride sizes
and
attained the same average EDA performance. In particular, when
, the average EDA was 0.879 for both
and 2. This implies the number of sliding windows computed for the gesture detection and classification can be reduced by half without sacrificing the performance.
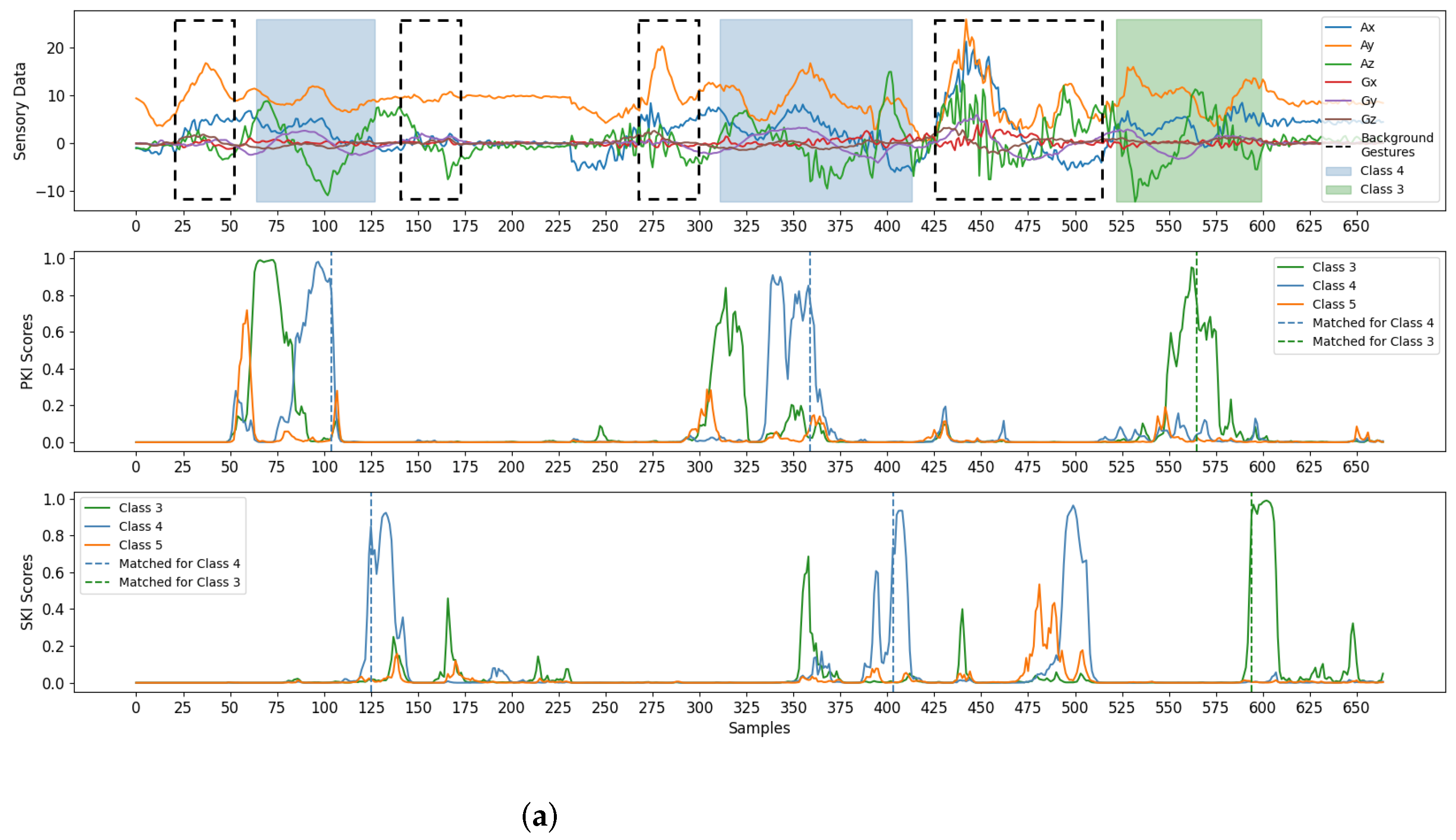
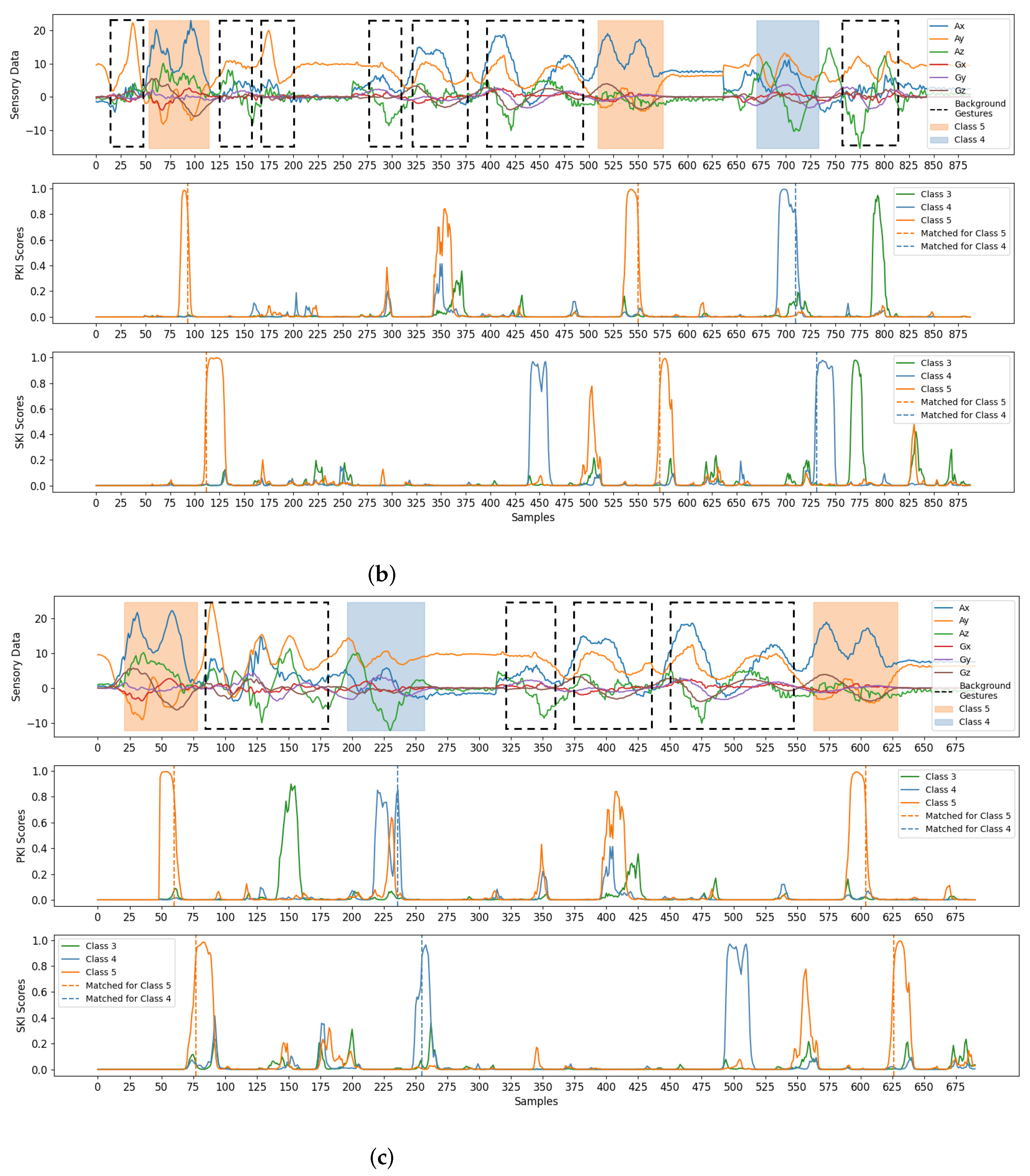
Finally, some examples for gesture detection and classification are revealed in
Figure 10. There were three test sequences considered in the experiments. Each sequence was a mixture of foreground gestures and background samples/gestures. To visualize the effectiveness of the proposed algorithm, the test sequences shown in
Figure 10 were randomly selected from the testing set adopted in this study. From
Figure 10, we see that the foreground gestures can still be effectively identified even with the presence of background gestures. Please note that the background gestures defined in
Figure 7 were the simple gestures constituting other unintended gestures in real-life applications. Therefore, the avoidance of unexpected triggering of these background gestures is beneficial for an accurate gesture detection and classification. All these results show the effectiveness of the algorithm.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}