
Intelligibility Improvement of Esophageal Speech Using Sequence-to-Sequence Voice Conversion with Auditory Attention

Abstract
1. Introduction
2. Methods
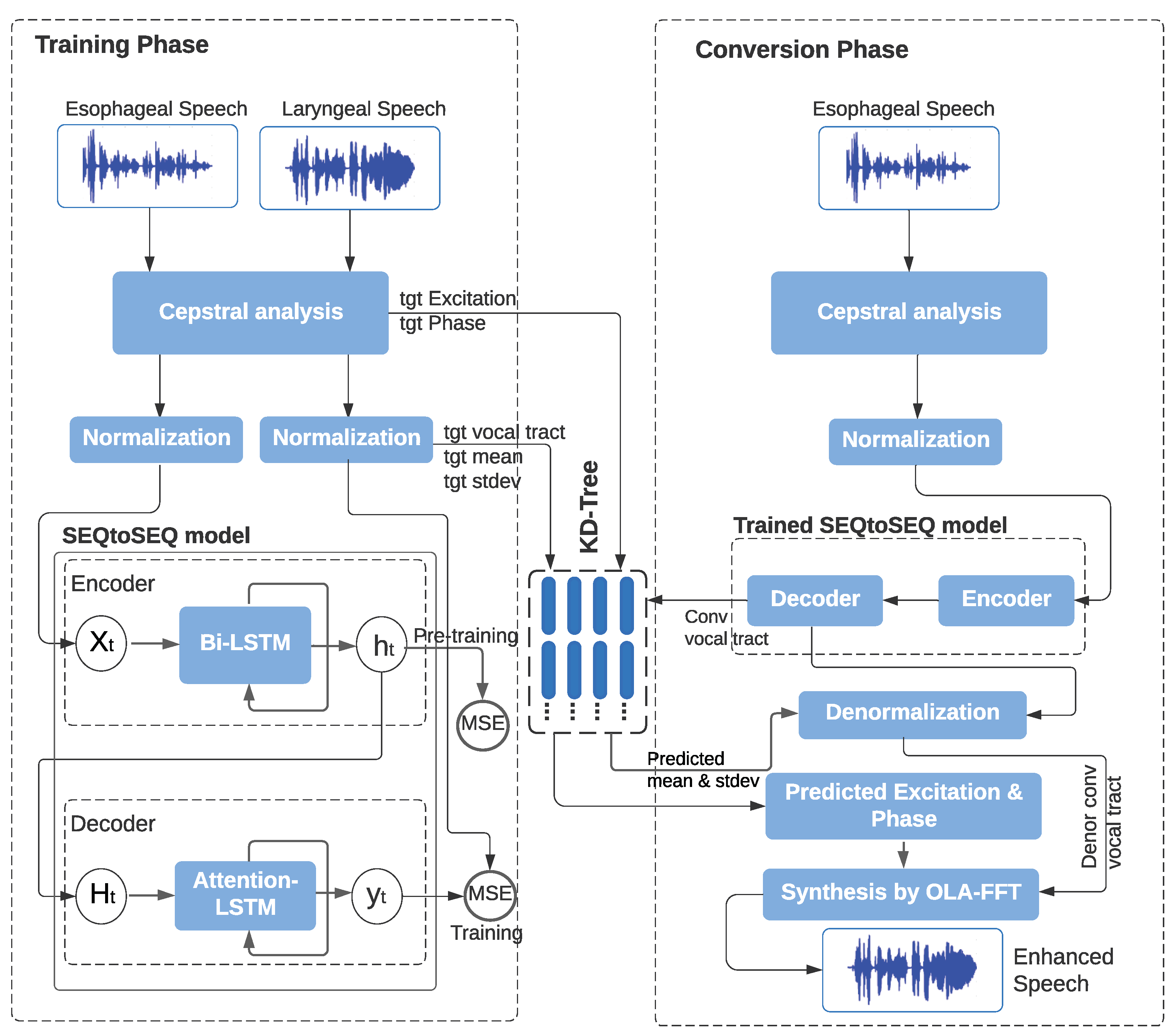
2.1. System Overview
2.2. Feature Extraction and Normalization
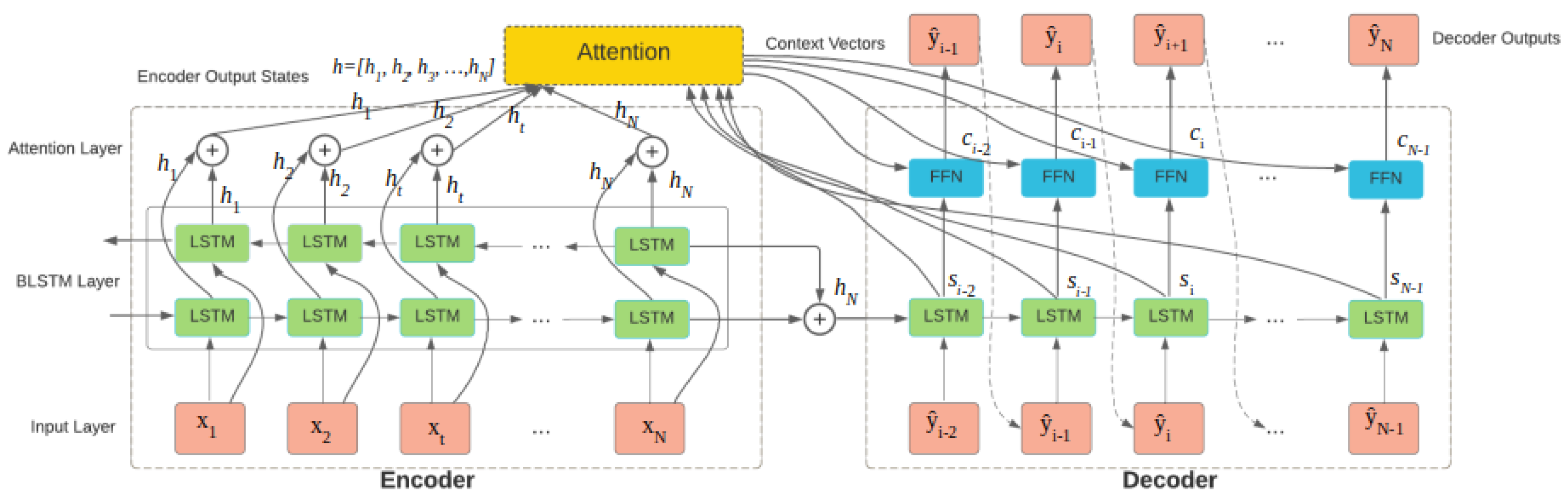
2.3. Network Model
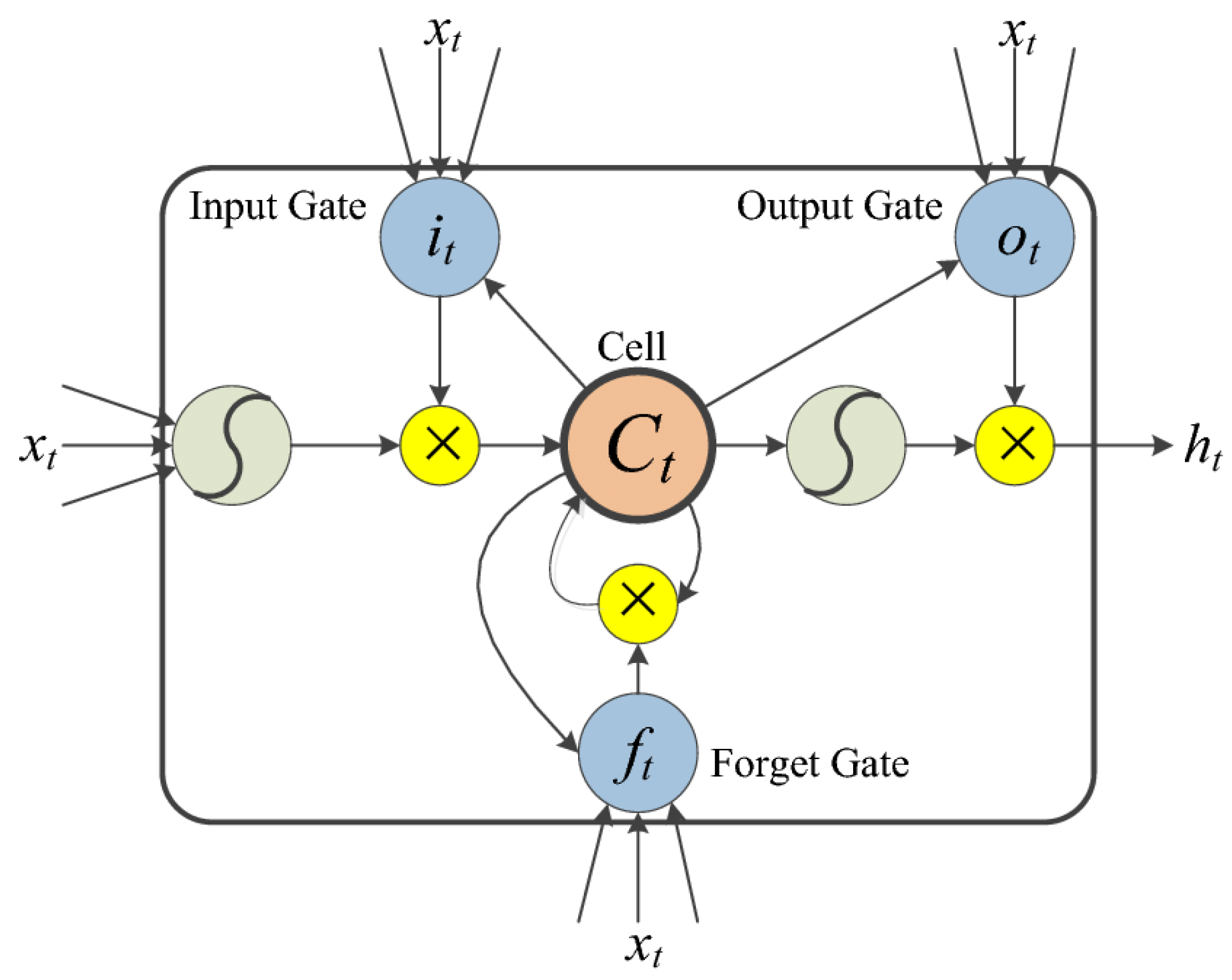
2.3.1. Bidirectional-LSTM-Based Encoder
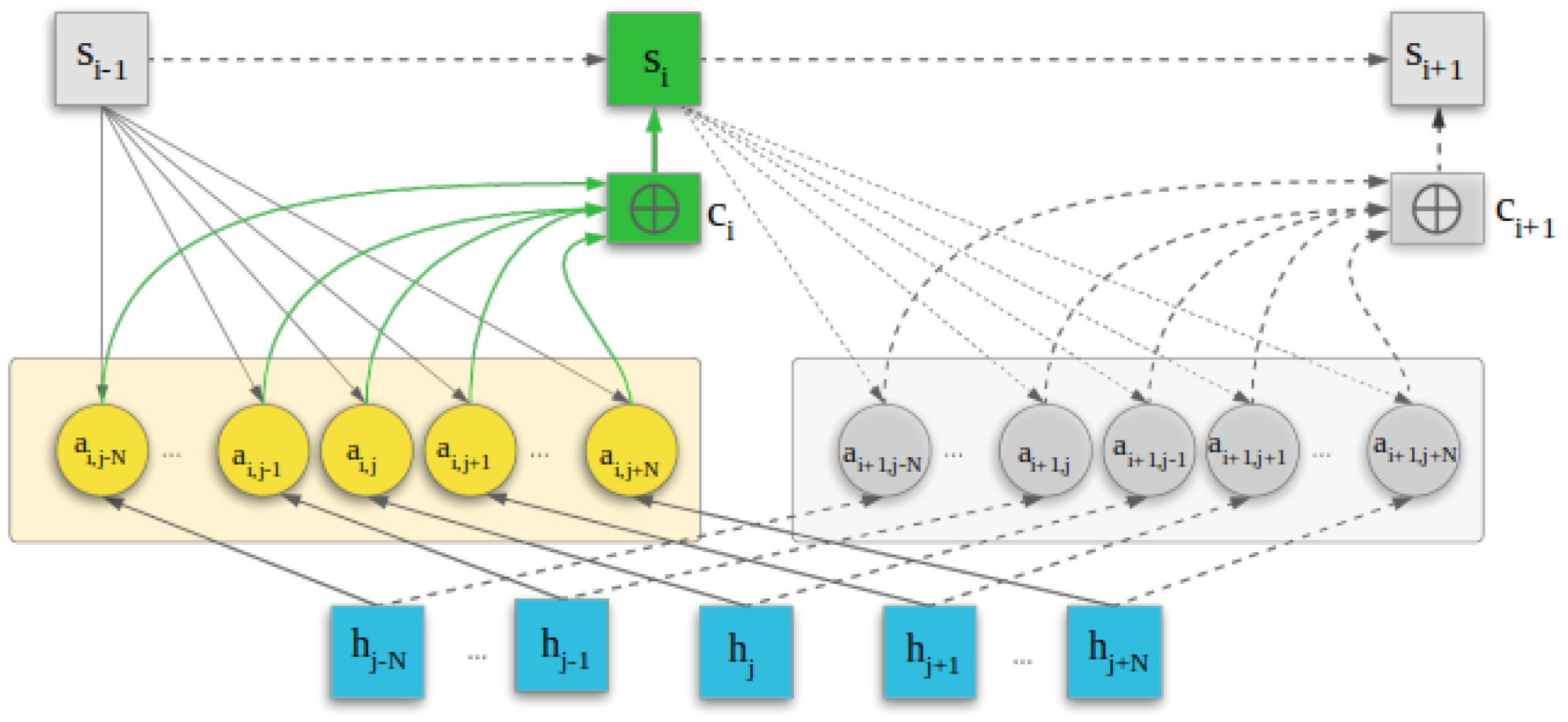
2.3.2. Attention Mechanism-Based Decoder
2.4. Loss Function
3. Experiments
3.1. Speech Datasets
- PC (ES male) and AL (NS male)
- MH (ES male) and AL (NS male)
3.2. Experimental Setups
- JD-GMM: the Joint Density GMM-based VC system was implemented based on the Sprocket toolkit introduced in VCC2018 [20] and considered as a baseline system. All the source and target parameters are directly estimated from the conversion function by the expectation-maximization (EM) algorithm. The source () and target () vectors previously aligned by the DTW algorithm are concatenated together into an extended vector and then the GMM parameters that model the joint probability density are estimated.
- DNN: the DNN-based VC system was implemented based on the approach of [10]. The number of units at each layer is chosen in order to ensure the best network performance. The ReLU (Rectified Linear Unit) activation function was used for its good performance [34], the dropout was set to 0.5, the learning rate was 0.001, the batch size was 32, and the training epoch was set to 500. For synthesis, an overlap-add method was adopted to reconstruct the waveform of the estimated enhanced speech.
- LSTM and BiLSTM: the LSTM and BiLSTM-based esophageal-to-laryngeal speech conversion models were implemented without an attention mechanism. For LSTM, the network architecture contained two hidden stacked LSTM layers and a fully connected output layer. For BiLSTM, we used 128 hidden units for each forward and backward encoder layer, and a single LSTM layer with 256 hidden units for the decoder. This architecture aims to progressively create a higher-dimensional feature space from one layer to another, to attempt to more easily represent the speaker’s information. For training the BiLSTM model, the back-propagation through time (BPTT) algorithm was adopted. Both models have been trained for around 500 epochs, with a lot size of 32 and a dropout of 0.3, until the early stop condition was reached.
3.3. Objective Performance Measures
- Cepstral distance (CD): This is used to evaluate the cepstral distance between the converted and target frames. We evaluated the source (ES-SRC) and the different types of converted stimuli, which is calculated as:where and represent the ith component of the aligned converted and target cepstral vectors, respectively. D is the dimension of the cepstral vectors and M is the number of couples.
- Perceptual Evaluation of Speech Quality (PESQ): referred to by the ITU-T recommendation in the P.862 standard [35]. PESQ is a suitable means to evaluate the subjective voice quality of codecs (waveform and CELP-like encoders) and end-to-end measurements [36]. The range for the PESQ score is between −0.5 and 4.5.
- Short-Time Objective Intelligibility (STOI): this is a function that compares the temporal envelopes of normal and converted speech in segments of short duration using a correlation coefficient. A greater STOI value indicates better intelligibility of enhanced speech.
- Segmental Signal to Noise Ratio (segSNR): it defines the average of SNRs computed from aligned converted and target cepstra and was determined by Equation (20).where and are, respectively, the ith component of the aligned converted and target cepstral vectors. N (512) is the cepstrum length.
4. Results and Discussion
4.1. Objective Evaluations
- Comparison between baseline and proposed methods: objective evaluations were first performed to compare the performance of CD, PESQ, STOI, and segSNR of the proposed and reference methods introduced above.Table 1 and Table 2 summarize the objective assessment results of source esophageal speech ES-SRC, and enhanced speech obtained by JD-GMM, DNN, LSTM, BiLSTM, and Seq2Seq-based methods. First, we can see that the cepstral vectors of ES-SRC are very different from those of laryngeal speech (target). Then, since the JD-GMM is a linear model and has a poor ability to model nonlinear relationships, its performance in converting ES to laryngeal voice is poorer than all other methods. Compared to the DNN model, the LSTM and BiLSTM models have better inter-frame characterization capability because the LSTM networks can take advantage of the relationship between long-distance frames.As indicated in Table 1, the BiLSTM model achieved better conversion performance than the GMM, DNN, and LSTM methods. This is because we adopt the BiLSTM model in our proposed Seq2Seq since it is adequate to characterize the difference between ES and its laryngeal speech counterpart. Note that the Seq2Seq-based method has a similar inter-frame characterization ability to the BiLSTM. However, our proposed method adopts the principle of the attention mechanism to accomplish an adaptive mapping between parallel sequences of esophageal and laryngeal speech. Compared to the BiLSTM model, our proposed method has improvements in CD, PESQ, STOI, and segSNR.
- Comparison between different variants: in this experiment, we compared our proposed model based on a BiLSTM encoder–decoder network with three variants of this model:
- (V1) Keeping the BiLSTM encoder but excluding the attention mechanism;
- (V2) Replacing the BiLSTM encoder by an LSTM of 256 hidden units and keeping attention;
- (V3) Using the LSTM network but excluding attention.
Table 3 lists the evaluation results. The proposed method outperforms the three other variants, with a larger PESQ score and lower CD value. In addition, adding the attention mechanism seems to have little effect on encoder–decoder networks based on LSTM. This explains that the hidden state generated by an LSTM network only considers the information in ; consequently, the attention mechanism will be inefficient due to insufficient information in the source hidden states. Moreover, the proposed method exceeds its variant without attention in terms of PESQ and STOI, which indicates that the incorporation of the attention mechanism would improve the performance of the VC system.
4.2. Subjective Evaluations
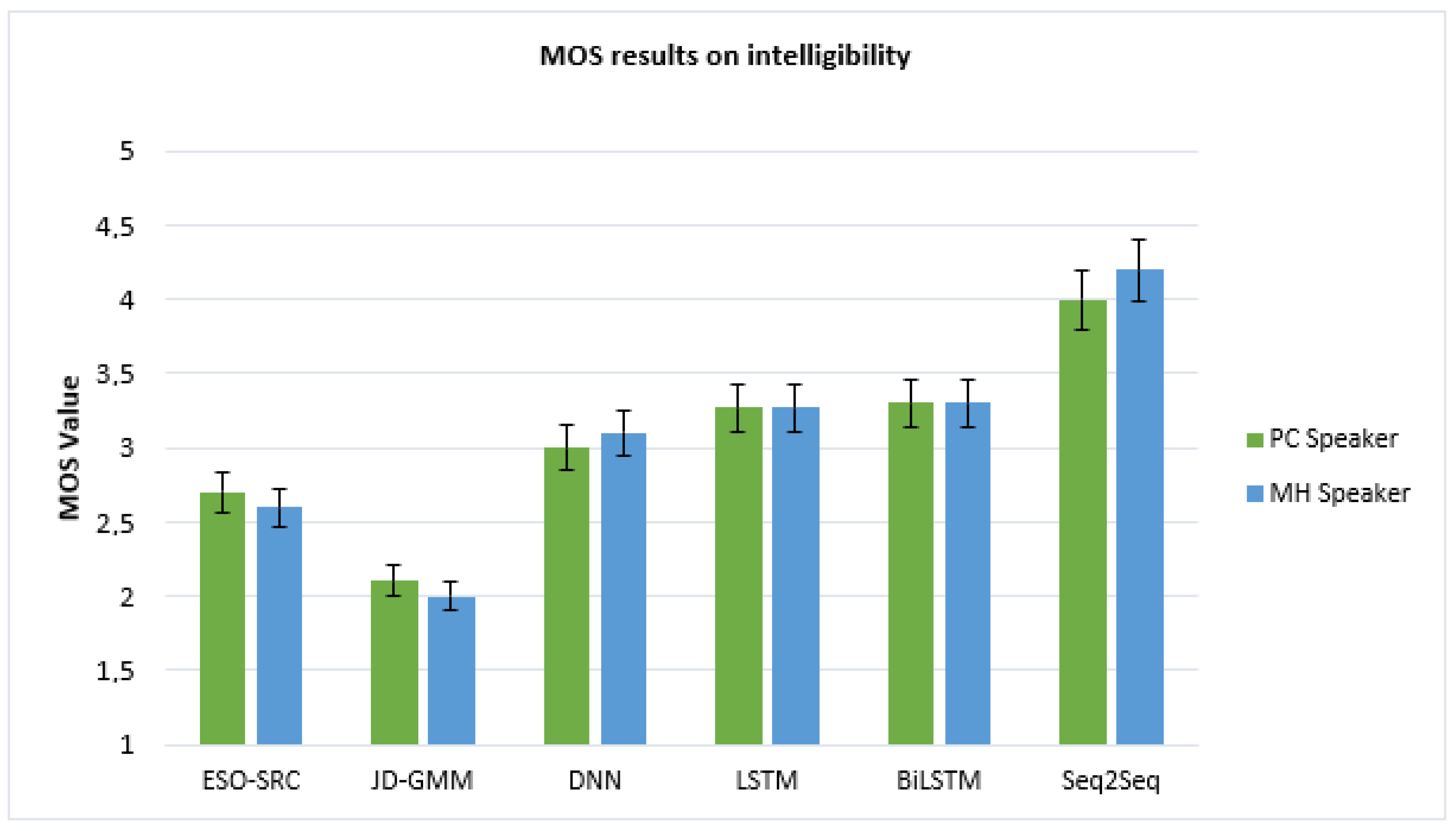
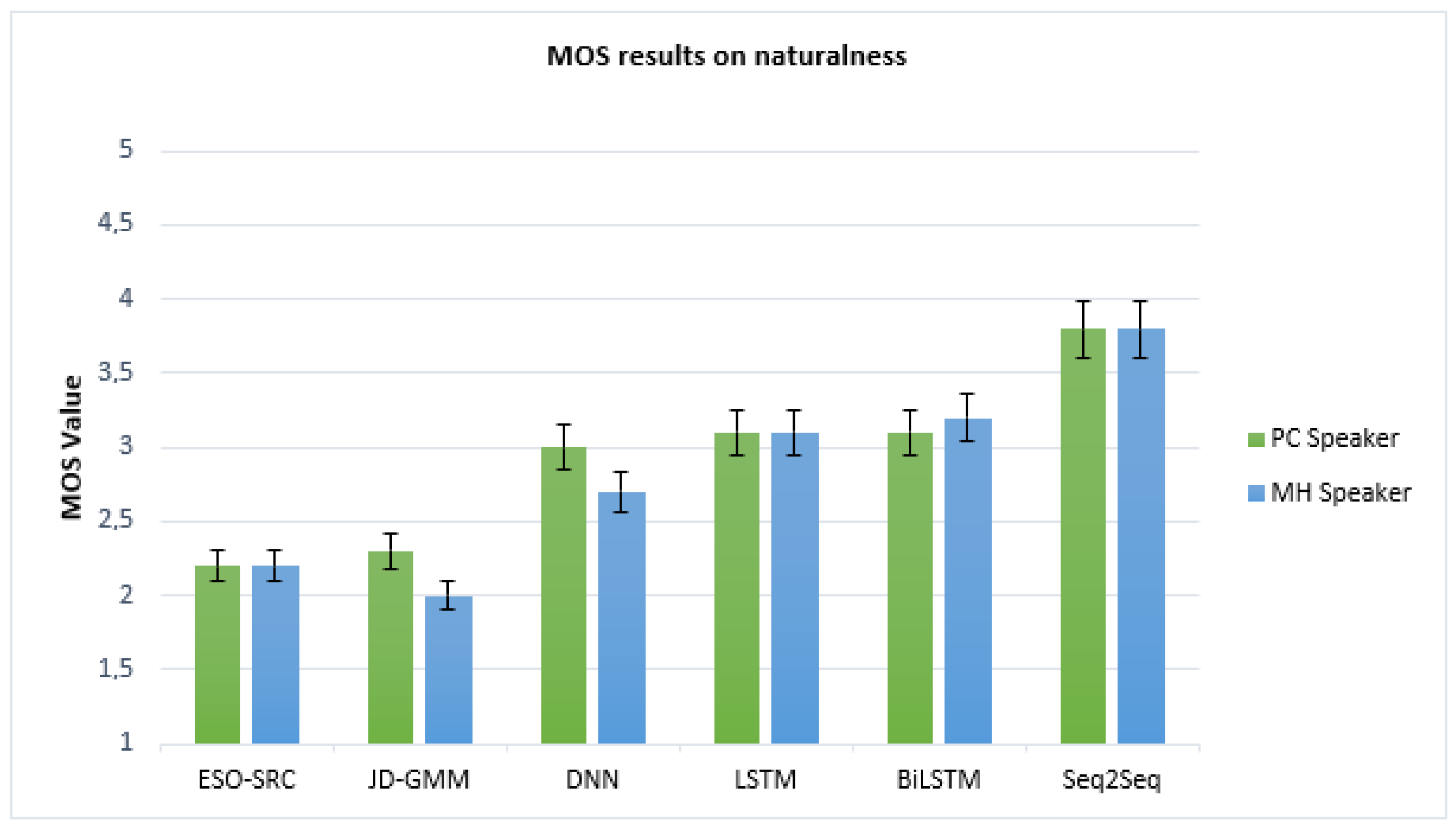
- MOS test (Mean Opinion Score): used to evaluate the speech quality and intelligibility of the resynthesized voice. In this experiment, a group of fifteen auditors (five males and ten females) listened to a set of sample utterances and judged them independently, one by one, according to a rating scale of perceived quality. This scale ranged from (1) for the poorest quality to (5) for excellent quality, ((2) poor, (3) average, and (4) good quality)). The average score awarded, therefore, constituted the MOS, which indicated the intelligibility and the quality of the enhanced speech.For these tests, we conducted an opinion test for intelligibility and another opinion test for naturalness. Five sets of comparative experiments were evaluated by fifteen auditors.
- ES-SRC: source esophageal speech;
- JD-GMM: conversion system based on a joint density Gaussian mixture model;
- DNN: conversion system based on feed-forward DNN model;
- BiLSTM: conversion system based on Bidirectional LSTM model;
- Seq2Seq: conversion system based on sequence to sequence with attention mechanism model.
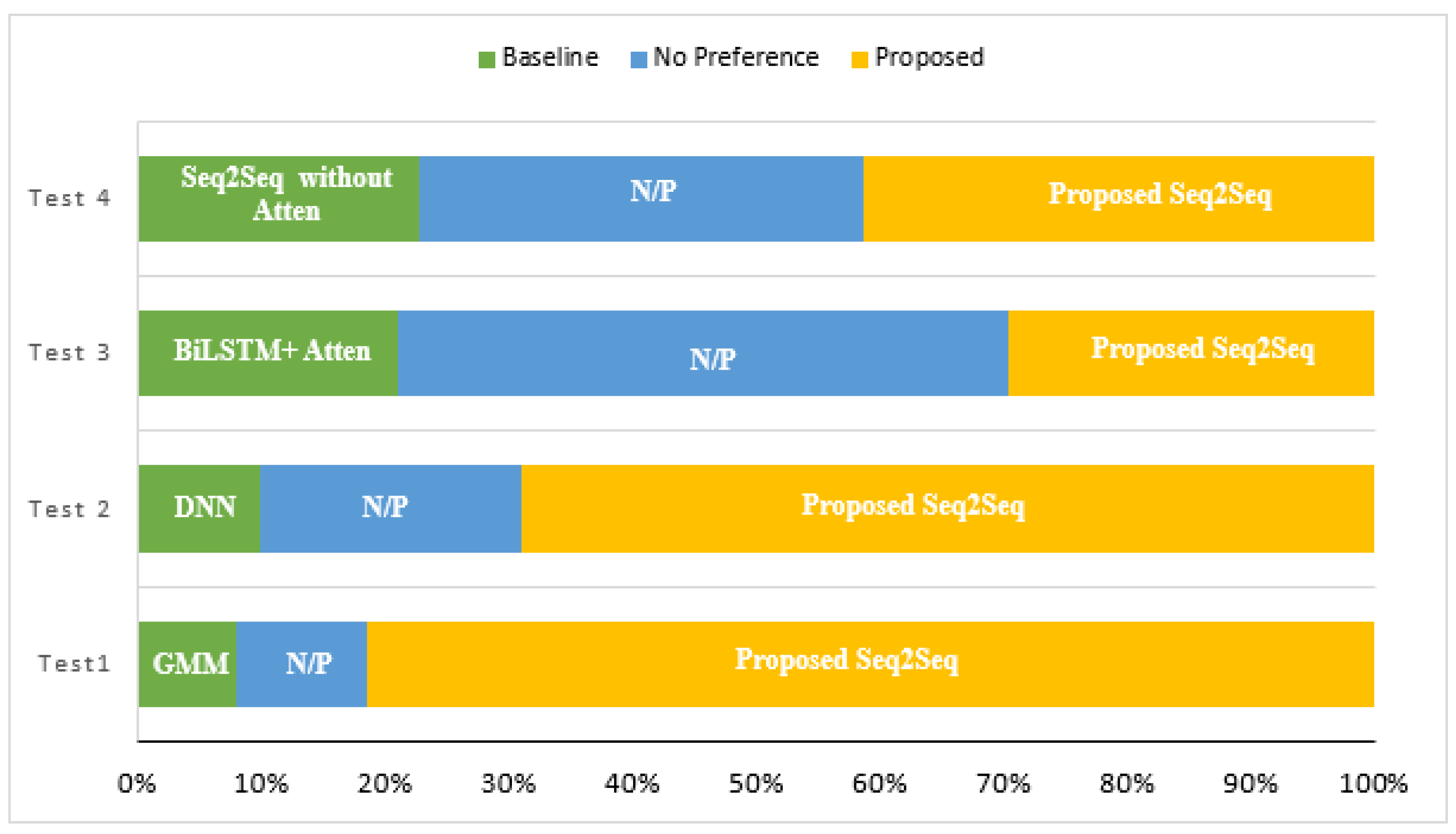
Figure 5 and Figure 6 show the MOS values on intelligibility and speech quality using different conversion methods.From both figures, we can see that the method based on GMM has the lower performance when compared with all the other methods, and this method has a high refusal rate by the laryngectomees. The LSTM method achieved almost similar intelligibility and naturalness when compared with the BiLSTM method, which in turn outperformed the DNN-based method, with a slight improvement. On the other hand, we can clearly notice that the converted speech using our method achieves the highest MOS in both tests. Thus, considering the average MOS of each approach, it is obvious that listeners prefer the samples obtained by our proposed method due to its effectiveness in improving the intelligibility and naturalness of ES. - ABX preference test: this is a test to identify the similarity between enhanced and target sequences. In this evaluation, we presented to fifteen listeners a series of three speech samples: A, B, and X, respectively, as the source, target, and enhanced speech sample. We asked each listener to judge by a score the degree of closeness of enhanced sample X to the two other samples A and B. No preference (NP) could be selected in the event that the listener could not distinguish between two types of voice. Thus, we carried out four series of experiments: GMM with our method (Seq2Seq+Attention mechanism), DNN with our method, BiLSTM+Attention with our method, and Seq2Seq without attention with our method.Figure 7 summarizes the results of the ABX test. The first two bars indicate that our model behaves much better than GMM and DNN. The third bar shows that our model works at similar levels with a BiLSTM+Attention. From the fourth bar, we can see that our method performs much better when attention is applied and the speech generated by our approach is of better quality than that obtained by the other three methods. It is therefore clear that the inclusion of the attention mechanism increases the robustness of the model.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Chalstrey, S.E.; Bleach, N.R.; Cheung, D.; Van Hasselt, C.A. A pneumatic artificial larynx popularized in Hong Kong. J. Laryngol. Otol. 1994, 108, 852–854. [Google Scholar] [CrossRef] [PubMed]
- Diamond, L. Laryngectomy: The silent unknowns and challenges of surgical treatment. J. Am. Acad. PAs 2011, 24, 38–42. [Google Scholar] [CrossRef] [PubMed]
- Guerrier, Y.; Jazouli, N. Vertical partial laryngectomy—Results. In Functional Partial Laryngectomy; Springer: Berlin/Heidelberg, Germany, 1984; pp. 145–149. [Google Scholar]
- Matsui, K.; Hara, N.; Kobayashi, N.; Hirose, H. Enhancement of esophageal speech using formant synthesis. Acoust. Sci. Technol. 2002, 23, 69–76. [Google Scholar] [CrossRef][Green Version]
- Hisada, A.; Sawada, H. Real-time clarification of esophageal speech using a comb filter. In Proceedings of the International Conference on Disability, Virtual Reality and Associated Technologies, Veszprém, Hungary, 18–20 September 2002; pp. 39–46. [Google Scholar]
- Desai, S.; Black, A.W.; Yegnanarayana, B.; Prahallad, K. Spectral mapping using artificial neural networks for voice conversion. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 954–964. [Google Scholar] [CrossRef]
- Doi, H.; Nakamura, K.; Toda, T.; Saruwatari, H.; Shikano, K. Esophageal speech enhancement based on statistical voice conversion with Gaussian mixture models. IEICE Trans. Inf. Syst. 2010, 93, 2472–2482. [Google Scholar] [CrossRef]
- Doi, H.; Nakamura, K.; Toda, T.; Saruwatari, H.; Shikano, K. Statistical approach to enhancing esophageal speech based on Gaussian mixture models. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4250–4253. [Google Scholar]
- Al-Radhi, M.S.; Csapó, T.G.; Németh, G. Time-Domain Envelope Modulating the Noise Component of Excitation in a Continuous Residual-Based Vocoder for Statistical Parametric Speech Synthesis. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 434–438. [Google Scholar] [CrossRef]
- Ben Othmane, I.; Di Martino, J.; Ouni, K. Enhancement of esophageal speech obtained by a voice conversion technique using time dilated fourier cepstra. Int. J. Speech Technol. 2019, 22, 99–110. [Google Scholar] [CrossRef]
- Ezzine, K.; Frikha, M. A comparative study of voice conversion techniques: A review. In Proceedings of the International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Fez, Morocco, 22–24 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Doi, H.; Toda, T.; Nakamura, K.; Saruwatari, H.; Shikano, K. Alaryngeal speech enhancement based on one-to-many eigenvoice conversion. IEEE/ACM Trans. Audio Speech Lang. Process. 2013, 22, 172–183. [Google Scholar] [CrossRef]
- Zhao, Y.; Huang, W.C.; Tian, X.; Yamagishi, J.; Das, R.K.; Kinnunen, T.; Ling, Z.; Toda, T. Voice conversion challenge 2020: Intra-lingual semi-parallel and cross-lingual voice conversion. arXiv 2020, arXiv:2008.12527. [Google Scholar]
- Lachhab, O.; Di Martino, J.; Elhaj, E.I.; Hammouch, A. A preliminary study on improving the recognition of esophageal speech using a hybrid system based on statistical voice conversion. SpringerPlus 2015, 4, 1–14. [Google Scholar] [CrossRef]
- Raman, S.; Sarasola, X.; Navas, E.; Hernaez, I. Enrichment of oesophageal speech: Voice conversion with duration–matched synthetic speech as target. Appl. Sci. 2021, 11, 5940. [Google Scholar] [CrossRef]
- Alers, T.J.; Fennema, B.A.; van Breukelen, J.J. Tracheo-Esophageal Speech Enhancement: Real-Time Pitch Shift and Output. Bachelor’s Thesis, Delft University of Technology, Delft, The Netherlands, 2020. [Google Scholar]
- Mohammadi, S.H.; Kain, A. An overview of voice conversion systems. Speech Commun. 2017, 88, 65–82. [Google Scholar] [CrossRef]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef]
- Keogh, E.J.; Pazzani, M.J. Derivative dynamic time warping. In Proceedings of the 2001 SIAM International Conference on Data Mining, Chicago, IL, USA, 5–7 April 2001; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2001; pp. 1–11. [Google Scholar]
- Lorenzo-Trueba, J.; Yamagishi, J.; Toda, T.; Saito, D.; Villavicencio, F.; Kinnunen, T.; Ling, Z. The voice conversion challenge 2018: Promoting development of parallel and nonparallel methods. arXiv 2018, arXiv:1804.04262. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Miyoshi, H.; Saito, Y.; Takamichi, S.; Saruwatari, H. Voice conversion using sequence-to-sequence learning of context posterior probabilities. arXiv 2017, arXiv:1704.02360. [Google Scholar]
- Tachibana, H.; Uenoyama, K.; Aihara, S. Efficiently trainable text-to-speech system based on deep convolutional networks with guided attention. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4784–4788. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Ramos, M.V.; Black, A.W.; Astudillo, R.F.; Trancoso, I.; Fonseca, N. Segment Level Voice Conversion with Recurrent Neural Networks. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 3414–3418. [Google Scholar]
- Ramos, M.V. Voice Conversion with Deep Learning. Masters’s Thesis, Tecnico Lisboa, Lisbon, Portugal, 2016. [Google Scholar]
- Kaneko, T.; Kameoka, H.; Hiramatsu, K.; Kashino, K. Sequence-to-Sequence Voice Conversion with Similarity Metric Learned Using Generative Adversarial Networks. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Tanaka, K.; Kameoka, H.; Kaneko, T.; Hojo, N. AttS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6805–6809. [Google Scholar]
- Lian, H.; Hu, Y.; Yu, W.; Zhou, J.; Zheng, W. Whisper to normal speech conversion using sequence-to-sequence mapping model with auditory attention. IEEE Access 2019, 7, 130495–130504. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. Acm 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Griffin, D.; Lim, J. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Wei, H.; Zhou, A.; Zhang, Y.; Chen, F.; Qu, W.; Lu, M. Biomedical event trigger extraction based on multi-layer residual BiLSTM and contextualized word representations. Int. J. Mach. Learn. Cybern. 2021, 13, 721–733. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 January 2010. [Google Scholar]
- Recommendation, I.T. Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs; International Telecommunication Union: Geneva, Switzerland, 2001; p. 862. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Proceedings (Cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MODELS | CD Value | PESQ Score | STOI Score | segSNR Value |
|---|---|---|---|---|
| ES-SRC | 9.408 | 2.407 | 0.606 | 2.981 |
| JD-GMM | 8.795 | 2.102 | 0.518 | 9.706 |
| DNN | 8.257 | 2.570 | 0.544 | 10.099 |
| LSTM | 8.009 | 2.808 | 0.624 | 10.915 |
| BiLSTM | 7.311 | 2.914 | 0.641 | 11.943 |
| Seq2Seq | 6.836 | 2.994 | 0.733 | 12.854 |
| MODELS | CD Value | PESQ Score | STOI Score | segSNR Value |
|---|---|---|---|---|
| ES-SRC | 9.153 | 2.381 | 0.597 | 2.999 |
| JD-GMM | 8.861 | 2.179 | 0.513 | 9.741 |
| DNN | 8.405 | 2.619 | 0.581 | 10.305 |
| LSTM | 7.910 | 2.805 | 0.624 | 11.083 |
| BiLSTM | 7.127 | 2.903 | 0.633 | 11.977 |
| Seq2Seq | 6.605 | 3.002 | 0.775 | 12.901 |
| VARIANTS | CD Value | PESQ Score | STOI Score | segSNR Value |
|---|---|---|---|---|
| BiLSTM+Attention | 6.994 | 2.933 | 0.718 | 12.407 |
| BiLSTM | 7.311 | 2.914 | 0.641 | 11.943 |
| LSTM+Attention | 7.826 | 2.871 | 0.639 | 11.866 |
| LSTM | 8.009 | 2.808 | 0.624 | 10.915 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ezzine, K.; Di Martino, J.; Frikha, M. Intelligibility Improvement of Esophageal Speech Using Sequence-to-Sequence Voice Conversion with Auditory Attention. Appl. Sci. 2022, 12, 7062. https://doi.org/10.3390/app12147062
Ezzine K, Di Martino J, Frikha M. Intelligibility Improvement of Esophageal Speech Using Sequence-to-Sequence Voice Conversion with Auditory Attention. Applied Sciences. 2022; 12(14):7062. https://doi.org/10.3390/app12147062
Chicago/Turabian StyleEzzine, Kadria, Joseph Di Martino, and Mondher Frikha. 2022. "Intelligibility Improvement of Esophageal Speech Using Sequence-to-Sequence Voice Conversion with Auditory Attention" Applied Sciences 12, no. 14: 7062. https://doi.org/10.3390/app12147062
APA StyleEzzine, K., Di Martino, J., & Frikha, M. (2022). Intelligibility Improvement of Esophageal Speech Using Sequence-to-Sequence Voice Conversion with Auditory Attention. Applied Sciences, 12(14), 7062. https://doi.org/10.3390/app12147062