
Automated Detection of the Competency of Delivering Guided Self-Help for Anxiety via Speech and Language Processing


Abstract
:1. Introduction
2. GSHTS Dataset Description and Processing
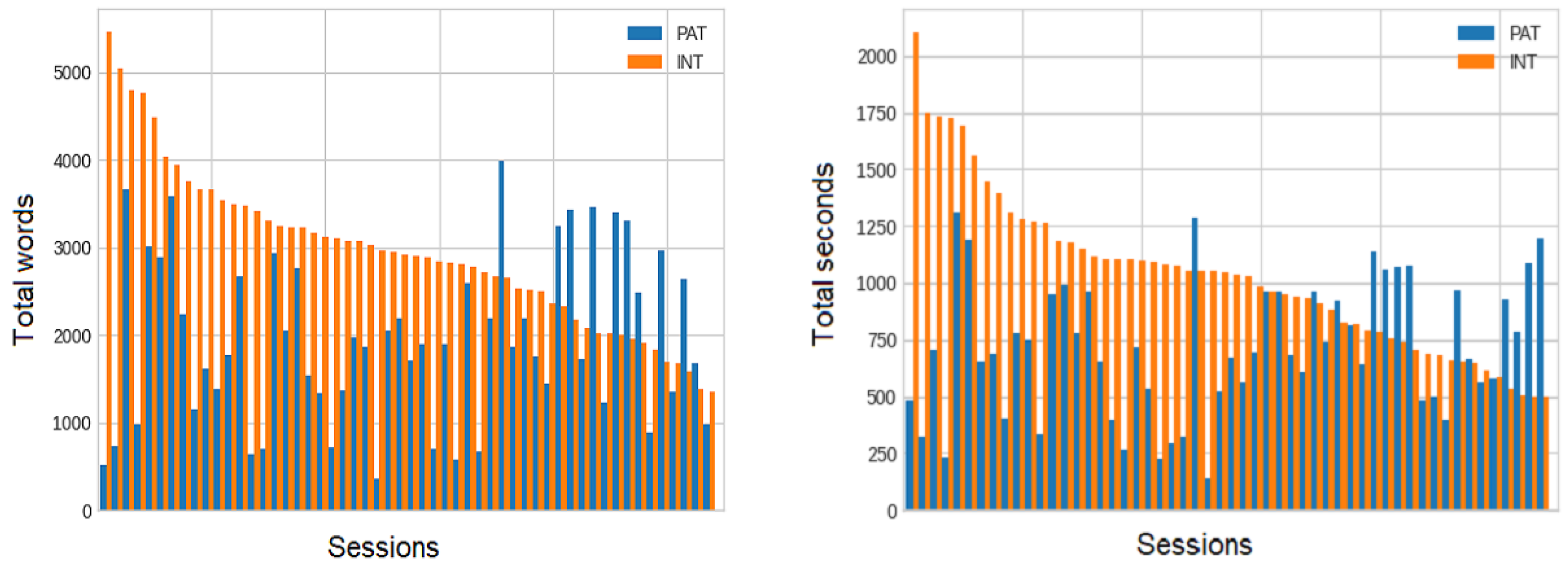
2.1. General Description
2.2. The LI-CBT Treatment Competency Scale
- focusing the session;
- continued engagement competencies;
- interpersonal competencies;
- information gathering: specific to change;
- within session self-help change method;
- planning and shared decision making competencies.
2.3. Data Processing
2.4. Experimental Setup
3. Methods
3.1. ASR
3.2. Automatic Detection of the Treatment Competency
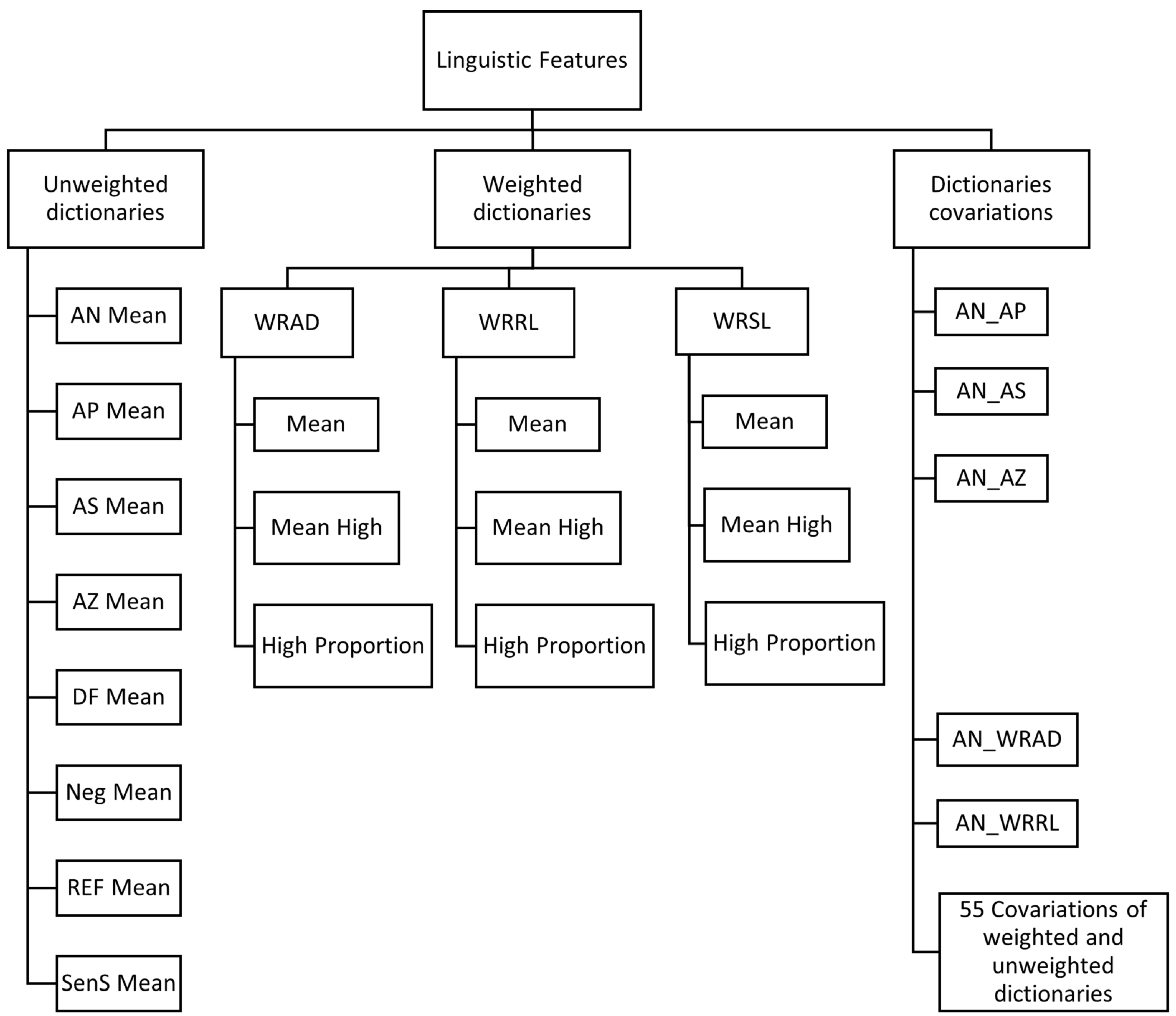
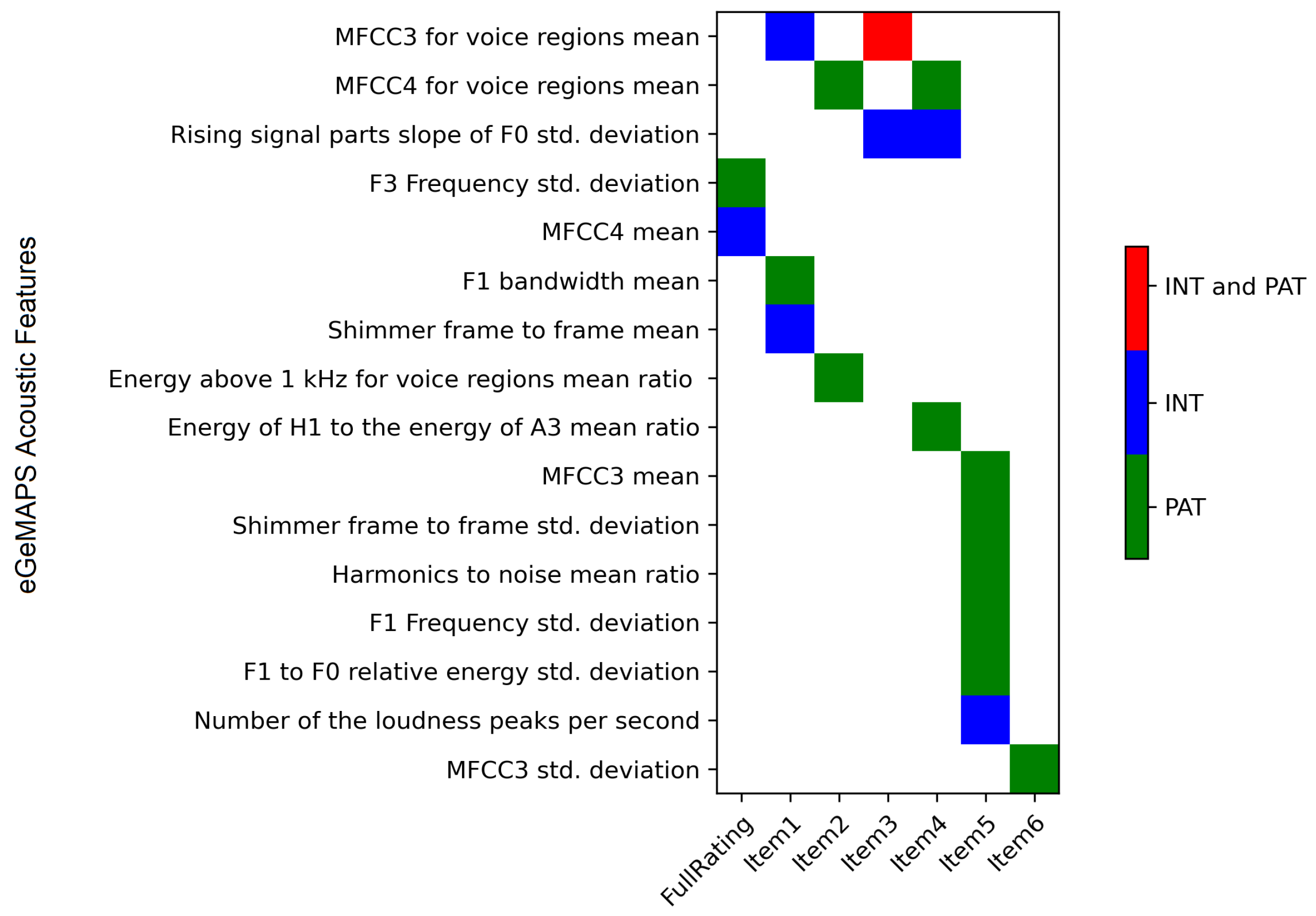
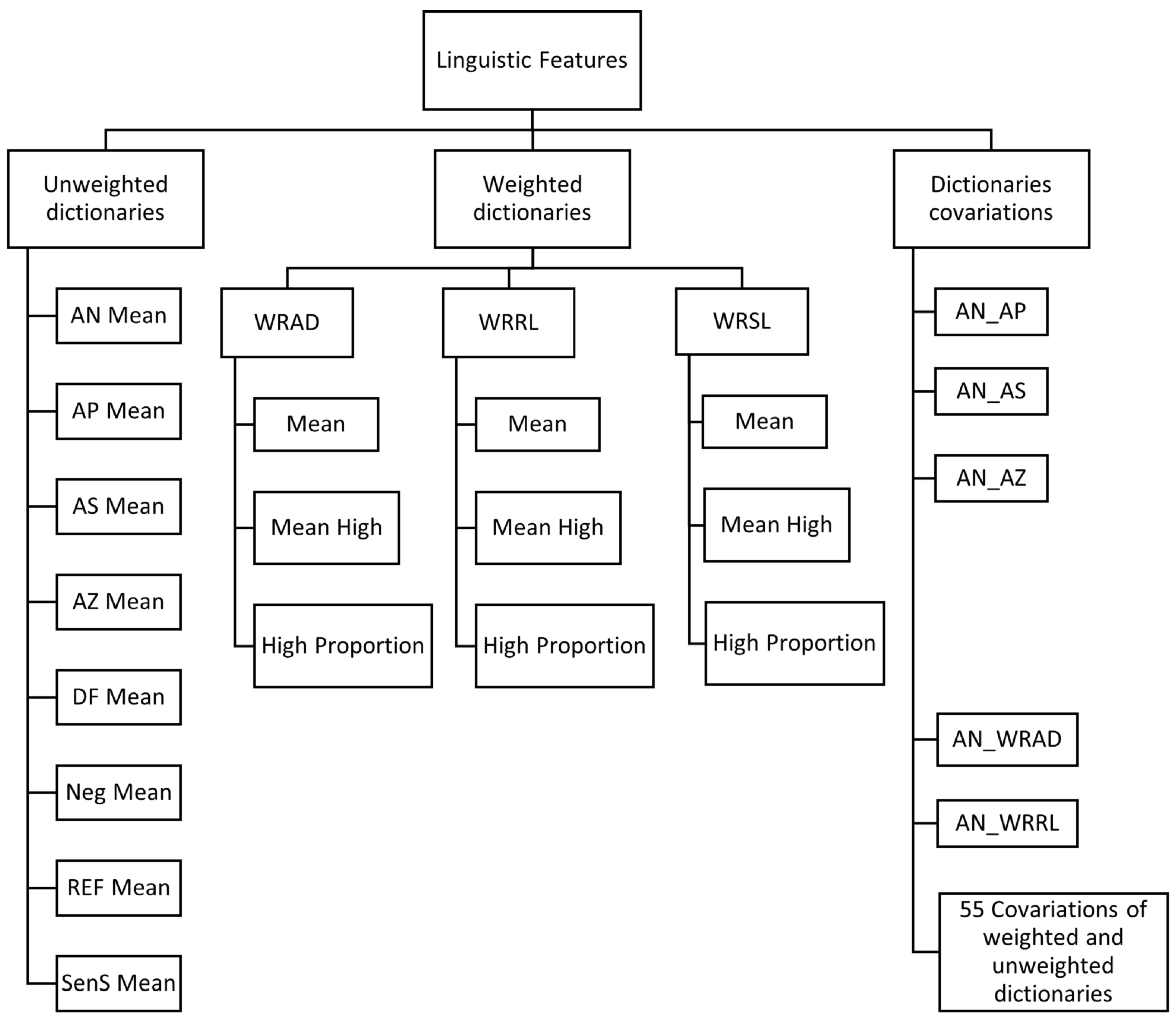
3.2.1. Feature Extraction
- The Weighted Referential Activity Dictionary (WRAD) is an RA measure that consists of words identifying moments in language when a speaker is immersed in the narrative such that high WRAD indicates the Symbolising phase in the RA process.
- The Weighted Reflection/Recognising List (WRRL) is a measure that assesses the Reflection/Recognising phase in RA. It measures the degree to which a speaker is attempting to recognise and understand the emotional implications of an event or set of events in their own or someone else’s life or in a dream or fantasy.
- The Weighted Arousal List (WRSL) is a preliminary measure for modelling the Arousal phase in the RA process. Based on a preliminary clinical validation of the WRSL dictionary, the results showed that the measure could distinguish between the step that can reflect moments going toward subsequent Symbolising and Reflection/Recognising phases as opposed to moments of avoiding, that do not lead to such an RA process [49].
- The Affect Dictionary (AFF) measures how a person feels and communicates using feelings. The dictionary contains many emotional words such as “sad”, “happy” and “angry”. Furthermore, the dictionary contains words related to the arousal affected by emotions, such as “cried” and “screams”. The words in the dictionary are classified as Affect Positive (AP), Affect Negative (AN), Neutral Affect (AZ) or Affect Sum (AS). AN words denote negative affect, AP words denote positive affect, AZ denote words without valence and AS is the union of AN, AP and AZ
- The Reflection Dictionary (REF) concerns how a person thinks and communicates through thinking. It includes words relating to logic, such as “if” and “but”. It also contains words referring to logical and cognitive activities, logical entities, failures in logical activities, difficult communicative actions and mental functioning.
- The Disfluency Dictionary (DF) includes items that people use in situations when they cannot describe their experiences in verbal form. The dictionary comprises exactly five items: “kind”, “like”, “know”, “mean” and filled pauses. The pauses are transcribed as “uhm” or “uh”.
- The Negation Dictionary (Neg) includes words denoting negating in communication, for example, “no”, “not” and “never”.
- The Sensory Somatic Dictionary (SenS) includes words denoting bodily and/or sensory experiences, for example, “dizzy”, “eye”, “face” and “listen”.
3.2.2. Feature Selection
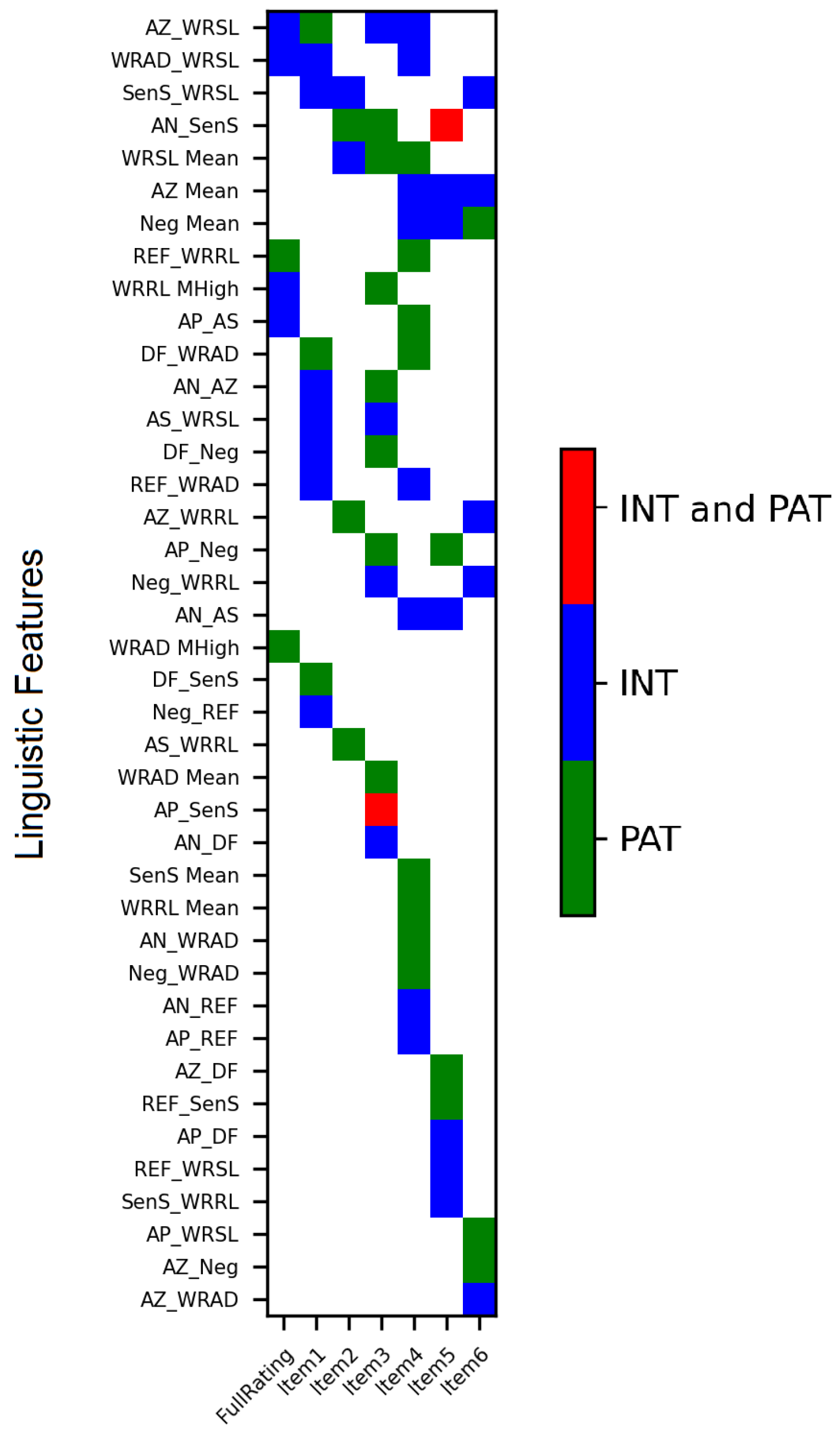
3.2.3. Estimating Treatment Competency; Classification and Prediction
4. Results and Discussion
4.1. ASR Results
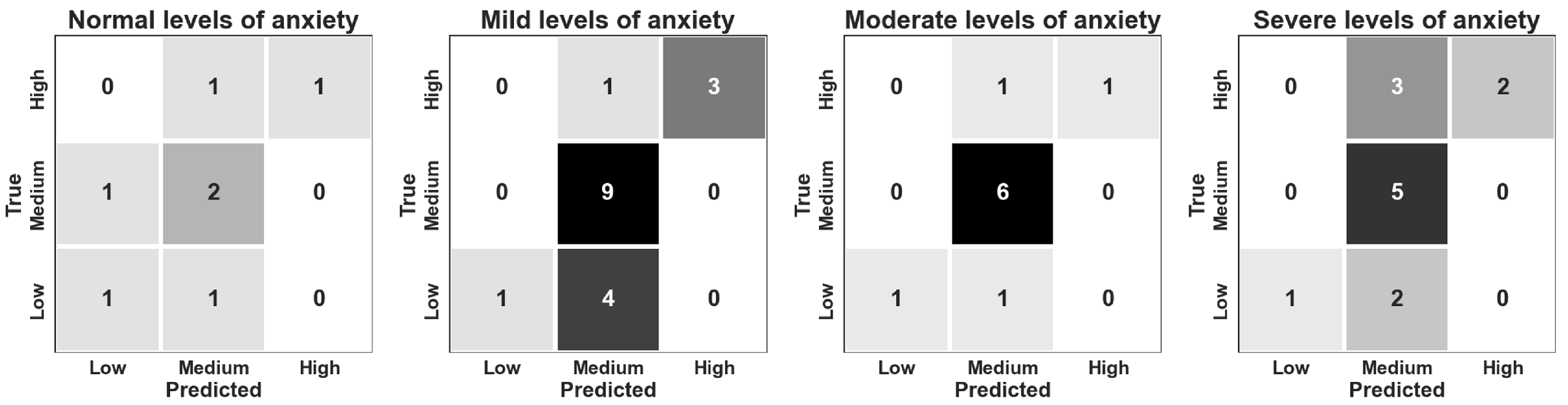
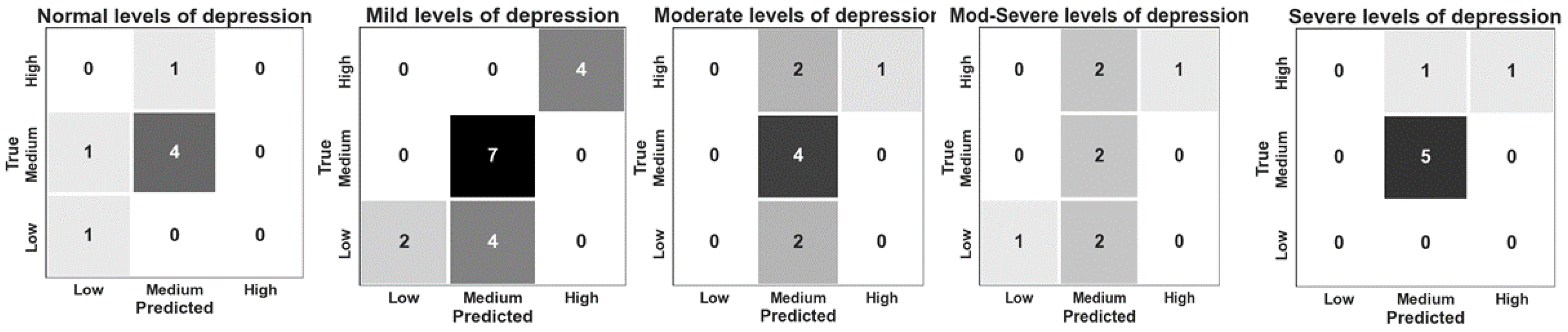
4.2. Treatment Competency: Classification and Prediction
4.2.1. Prediction Results
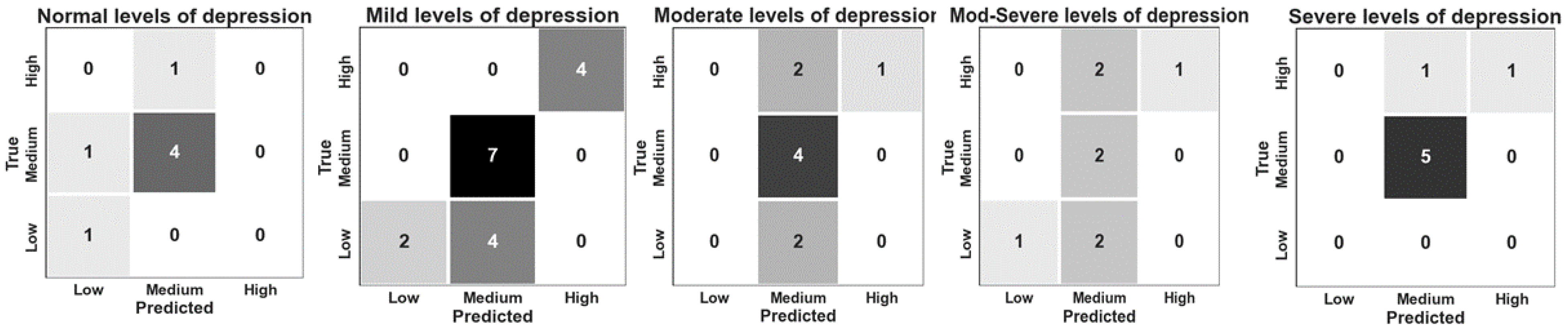
4.2.2. Classification Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wickramasinghe, N.; Geisler, E. Encyclopedia of Healthcare Information Systems; IGI Global: London, UK, 2008. [Google Scholar]
- Stegmann, G.; Hahn, S.; Liss, J.; Shefner, J.; Rutkove, S.; Kawabata, K.; Bhandari, S.; Shelton, K.; Duncan, C.; Berisha, V. Repeatability of commonly used speech and language features for clinical applications. Digit. Biomarkers 2020, 4, 109–122. [Google Scholar] [CrossRef] [PubMed]
- Waltz, J.; Addis, M.; Koerner, K.; Jacobson, N. Testing the integrity of a psychotherapy protocol: Assessment of adherence and competence. J. Consult. Clin. Psychol. 1993, 61, 620. [Google Scholar] [CrossRef] [PubMed]
- McLeod, B.D.; Southam-Gerow, M.A.; Jensen-Doss, A.; Hogue, A.; Kendall, P.C.; Weisz, J.R. Benchmarking treatment adherence and therapist competence in individual cognitive-behavioral treatment for youth anxiety disorders. J. Clin. Child Adolesc. Psychol. 2019, 48, S234–S246. [Google Scholar] [CrossRef] [PubMed]
- Ringeval, F.; Schuller, B.; Valstar, M.; Cowie, R.; Kaya, H.; Schmitt, M.; Amiriparian, S.; Cummins, N.; Lalanne, D.; Michaud, A.; et al. AVEC 2018 workshop and challenge: Bipolar disorder and cross-cultural affect recognition. In Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, Seoul, Korea, 22 October 2018; ACM: New York, NY, USA, 2018; pp. 3–13. [Google Scholar]
- Schuller, B.; Batliner, A.; Steidl, S.; Seppi, D. Recognising realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Commun. 2011, 53, 1062–1087. [Google Scholar] [CrossRef]
- Liang, Y.; Zheng, X.; Zeng, D. A survey on big data-driven digital phenotyping of mental health. Inf. Fusion 2019, 52, 290–307. [Google Scholar] [CrossRef]
- Kohrt, B.; Jordans, M.; Rai, S.; Shrestha, P.; Luitel, N.; Ramaiya, M.; Singla, D.; Patel, V. Therapist competence in global mental health: Development of the ENhancing Assessment of Common Therapeutic factors (ENACT) rating scale. Behav. Res. Ther. 2015, 69, 11–21. [Google Scholar] [CrossRef]
- Kellett, S.; Simmonds-Buckley, M.; Limon, E.; Hague, J.; Hughes, L.; Stride, C.; Millings, A. Defining the Assessment and Treatment Competencies to Deliver Low-Intensity Cognitive Behavior Therapy: A Multi-Center Validation Study. Behav. Ther. 2021, 52, 15–27. [Google Scholar] [CrossRef]
- Kellett, S.; Simmonds-Buckley, M.; Limon, E.; Hague, J.; Hughes, L.; Stride, C.; Millings, A. Low Intensity Cognitive Behavioural Competency Scale Manual. 2021; Unpublished document. [Google Scholar]
- Fairburn, C.; Cooper, Z. Therapist competence, therapy quality, and therapist training. Behav. Res. Ther. 2011, 49, 373–378. [Google Scholar] [CrossRef]
- Watkins, C.E., Jr. Educating psychotherapy supervisors. Am. J. Psychother. 2012, 66, 279–307. [Google Scholar] [CrossRef]
- Ackerman, S.; Hilsenroth, M. A review of therapist characteristics and techniques positively impacting the therapeutic alliance. Clin. Psychol. Rev. 2003, 23, 1–33. [Google Scholar] [CrossRef]
- Weck, F.; Richtberg, S.; Jakob, M.; Neng, J.M.; Höfling, V. Therapist competence and therapeutic alliance are important in the treatment of health anxiety (hypochondriasis). Psychiatry Res. 2015, 228, 53–58. [Google Scholar] [CrossRef] [PubMed]
- Attas, D.; Kellett, S.; Blackmore, C.; Christensen, H. Automatic Time-Continuous Prediction of Emotional Dimensions during Guided Self Help for Anxiety Disorders. In Proceedings of the FRIAS Junior Researcher Conference: Human Perspectives on Spoken Human-Machine Interaction (SpoHuMa21), Online, 15–17 November 2021. [Google Scholar]
- Bucci, W.; Maskit, B. Beneath the surface of the therapeutic interaction: The psychoanalytic method in modern dress. J. Am. Psychoanal. Assoc. 2007, 55, 1355–1397. [Google Scholar] [CrossRef]
- Mergenthaler, E.; Bucci, W. Linking verbal and non-verbal representations: Computer analysis of referential activity. Br. J. Med Psychol. 1999, 72, 339–354. [Google Scholar] [CrossRef] [PubMed]
- Nasir, M.; Baucom, B.; Georgiou, P.; Narayanan, S. Predicting couple therapy outcomes based on speech acoustic features. PLoS ONE 2017, 12, e0185123. [Google Scholar] [CrossRef] [PubMed]
- Amir, N.; Mixdorff, H.; Amir, O.; Rochman, D.; Diamond, G.; Pfitzinger, H.; Levi-Isserlish, T.; Abramson, S. Unresolved anger: Prosodic analysis and classification of speech from a therapeutic setting. In Proceedings of the Speech Prosody 2010-Fifth International Conference, Chicago, IL, USA, 10–14 May 2010. [Google Scholar]
- Sümer, Ö.; Beyan, C.; Ruth, F.; Kramer, O.; Trautwein, U.; Kasneci, E. Estimating Presentation Competence using Multimodal Nonverbal Behavioral Cues. arXiv 2021, arXiv:2105.02636. [Google Scholar]
- Ringeval, F.; Marchi, E.; Grossard, C.; Xavier, J.; Chetouani, M.; Cohen, D.; Schuller, B. Automatic analysis of typical and atypical encoding of spontaneous emotion in the voice of children. In Proceedings of the INTERSPEECH 2016, 17th Annual Conference of the International Speech Communication Association (ISCA), San Francisco, CA, USA, 8–12 September 2016; pp. 1210–1214. [Google Scholar]
- Mencattini, A.; Mosciano, F.; Comes, M.; Di Gregorio, T.; Raguso, G.; Daprati, E.; Ringeval, F.; Schuller, B.; Di Natale, C.; Martinelli, E. An emotional modulation model as signature for the identification of children developmental disorders. Sci. Rep. 2018, 8, 14487. [Google Scholar] [CrossRef]
- Gideon, J.; Schatten, H.; McInnis, M.; Provost, E. Emotion recognition from natural phone conversations in individuals with and without recent suicidal ideation. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Zhang, Z.; Lin, W.; Liu, M.; Mahmoud, M. Multimodal deep learning framework for mental disorder recognition. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 344–350. [Google Scholar]
- Atta, N.; Christopher, C.; Mariani, R.; Belotti, L.; Andreoli, G.; Danskin, K. Linguistic features of the therapeutic alliance in the first session: A psychotherapy process study. Res. Psychother. Psychopathol. Process. Outcome 2019, 22, 374. [Google Scholar]
- Christian, C.; Barzilai, E.; Nyman, J.; Negri, A. Assessing key linguistic dimensions of ruptures in the therapeutic alliance. J. Psycholinguist. Res. 2021, 50, 143–153. [Google Scholar] [CrossRef]
- Sitaula, C.; Basnet, A.; Mainali, A.; Shahi, T.B. Deep learning-based methods for sentiment analysis on Nepali COVID-19-related tweets. Comput. Intell. Neurosci. 2021, 2021, 2158184. [Google Scholar] [CrossRef]
- Wiegersma, S.; Nijdam, M.; van Hessen, A.; Truong, K.; Veldkamp, B.; Olff, M. Recognizing hotspots in Brief Eclectic Psychotherapy for PTSD by text and audio mining. Eur. J. Psychotraumatol. 2020, 11, 1726672. [Google Scholar] [CrossRef]
- Tavabi, L.; Stefanov, K.; Zhang, L.; Borsari, B.; Woolley, J.; Scherer, S.; Soleymani, M. Multimodal Automatic Coding of Client Behavior in Motivational Interviewing. In Proceedings of the 2020 International Conference on Multimodal Interaction, Virtual, 25–29 October 2020; pp. 406–413. [Google Scholar]
- Bhardwaj, V.; Ben Othman, M.T.; Kukreja, V.; Belkhier, Y.; Bajaj, M.; Goud, B.S.; Rehman, A.U.; Shafiq, M.; Hamam, H. Automatic Speech Recognition (ASR) Systems for Children: A Systematic Literature Review. Appl. Sci. 2022, 12, 4419. [Google Scholar] [CrossRef]
- Kodish-Wachs, J.; Agassi, E.; Kenny, P., III; Overhage, J.M. A systematic comparison of contemporary automatic speech recognition engines for conversational clinical speech. Amia Annu. Symp. Proc. 2018, 2018, 683. [Google Scholar] [PubMed]
- Xiao, B.; Imel, Z.; Georgiou, P.; Atkins, D.; Narayanan, S. “Rate my therapist”: Automated detection of empathy in drug and alcohol counseling via speech and language processing. PLoS ONE 2015, 10, e0143055. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Flemotomos, N.; Ardulov, V.; Creed, T.; Imel, Z.; Atkins, D.; Narayanan, S. Feature fusion strategies for end-to-end evaluation of cognitive behavior therapy sessions. In Proceedings of the 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Virtual Conference, 1–5 November 2021; pp. 1836–1839. [Google Scholar]
- Flemotomos, N.; Martinez, V.R.; Chen, Z.; Singla, K.; Ardulov, V.; Peri, R.; Caperton, D.D.; Gibson, J.; Tanana, M.J.; Georgiou, P.; et al. Automated evaluation of psychotherapy skills using speech and language technologies. Behav. Res. Methods 2021, 54, 690–711. [Google Scholar] [CrossRef]
- Kellett, S.; Bee, C.; Aadahl, V.; Headley, E.; Delgadillo, J. A pragmatic patient preference trial of cognitive behavioural versus cognitive analytic guided self-help for anxiety disorders. Behav. Cogn. Psychother. 2020, 49, 1–8. [Google Scholar] [CrossRef]
- Firth, N.; Barkham, M.; Kellett, S.; Saxon, D. Therapist effects and moderators of effectiveness and efficiency in psychological wellbeing practitioners: A multilevel modelling analysis. Behav. Res. Ther. 2015, 69, 54–62. [Google Scholar] [CrossRef]
- Barras, C.; Geoffrois, E.; Wu, Z.; Liberman, M. Transcriber: Development and use of a tool for assisting speech corpora production. Speech Commun. 2001, 33, 5–22. [Google Scholar] [CrossRef]
- Renals, S.; Swietojanski, P. Distant speech recognition experiments using the AMI Corpus. In New Era for Robust Speech Recognition; Springer: Cham, Switzerland, 2017; pp. 355–368. [Google Scholar]
- Wang, Y. Automatic Speech Recognition Model for Swedish Using Kaldi; KTH School of Electrical Engineering and Computer Science: Stockholm, Sweden, 2020. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Mirheidari, B.; Blackburn, D.; O’Malley, R.; Venneri, A.; Walker, T.; Reuber, M.; Christensen, H. Improving Cognitive Impairment Classification by Generative Neural Network-Based Feature Augmentation. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 2527–2531. [Google Scholar]
- Mirheidari, B.; Pan, Y.; Blackburn, D.; O’Malley, R.; Christensen, H. Identifying Cognitive Impairment Using Sentence Representation Vectors. In Proceedings of the INTERSPEECH 2021, Brno, Czechia, 30 August–3 September 2021; pp. 2941–2945. [Google Scholar]
- Sitaula, C.; He, J.; Priyadarshi, A.; Tracy, M.; Kavehei, O.; Hinder, M.; Withana, A.; McEwan, A.; Marzbanrad, F. Neonatal bowel sound detection using convolutional neural network and Laplace hidden semi-Markov model. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1853–1864. [Google Scholar] [CrossRef]
- Eyben, F.; Scherer, K.; Schuller, B.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.; Epps, J.; Laukka, P.; Narayanan, S.; et al. The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2015, 7, 190–202. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Valstar, M.; Gratch, J.; Schuller, B.; Ringeval, F.; Lalanne, D.; Torres Torres, M.; Scherer, S.; Stratou, G.; Cowie, R.; Pantic, M. AVEC 2016: Depression, mood, and emotion recognition workshop and challenge. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 3–10. [Google Scholar]
- Schmitt, M.; Schuller, B. OpenXBOW: Introducing the passau open-source crossmodal Bag-of-Words Toolkit. J. Machine Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Maskit, B. Overview of computer measures of the referential process. J. Psycholinguist. Res. 2021, 50, 29–49. [Google Scholar] [CrossRef] [PubMed]
- Tocatly, K.; Bucci, W.; Maskit, B. Developing a Preliminary Measure of the Arousal Function of the Referential Process; [Poster presentation]; Research Day Colloquium at the City College of New York’s Clinical Psychology Doctoral Program; City University of New York: New York, NY, USA, 2019. [Google Scholar]
- Maskit, B. The Discourse Attributes Analysis Program (DAAP) (Series 8) [Computer Software]. 2012. Available online: http://www.thereferentialprocess.org/dictionary-measures-and-computer-programs (accessed on 22 September 2021).
- Murphy, S.; Maskit, B.; Bucci, W. Putting feelings into words: Cross-linguistic markers of the referential process. In Proceedings of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, Denver, CO, USA, 5 June 2015; pp. 80–88. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Mirheidari, B.; Blackburn, D.; O’Malley, R.; Walker, T.; Venneri, A.; Reuber, M.; Christensen, H. Computational Cognitive Assessment: Investigating the Use of an Intelligent Virtual Agent for the Detection of Early Signs of Dementia. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- De Boer, J.; Voppel, A.; Brederoo, S.; Schnack, H.; Truong, K.; Wijnen, F.; Sommer, I. Acoustic speech markers for schizophrenia-spectrum disorders: A diagnostic and symptom-recognition tool. Psychol. Med. 2021, 51, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Corrales-Astorgano, M.; Martínez-Castilla, P.; Escudero-Mancebo, D.; Aguilar, L.; González-Ferreras, C.; Carde noso-Payo, V. Automatic assessment of prosodic quality in down syndrome: Analysis of the impact of speaker heterogeneity. Appl. Sci. 2019, 9, 1440. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
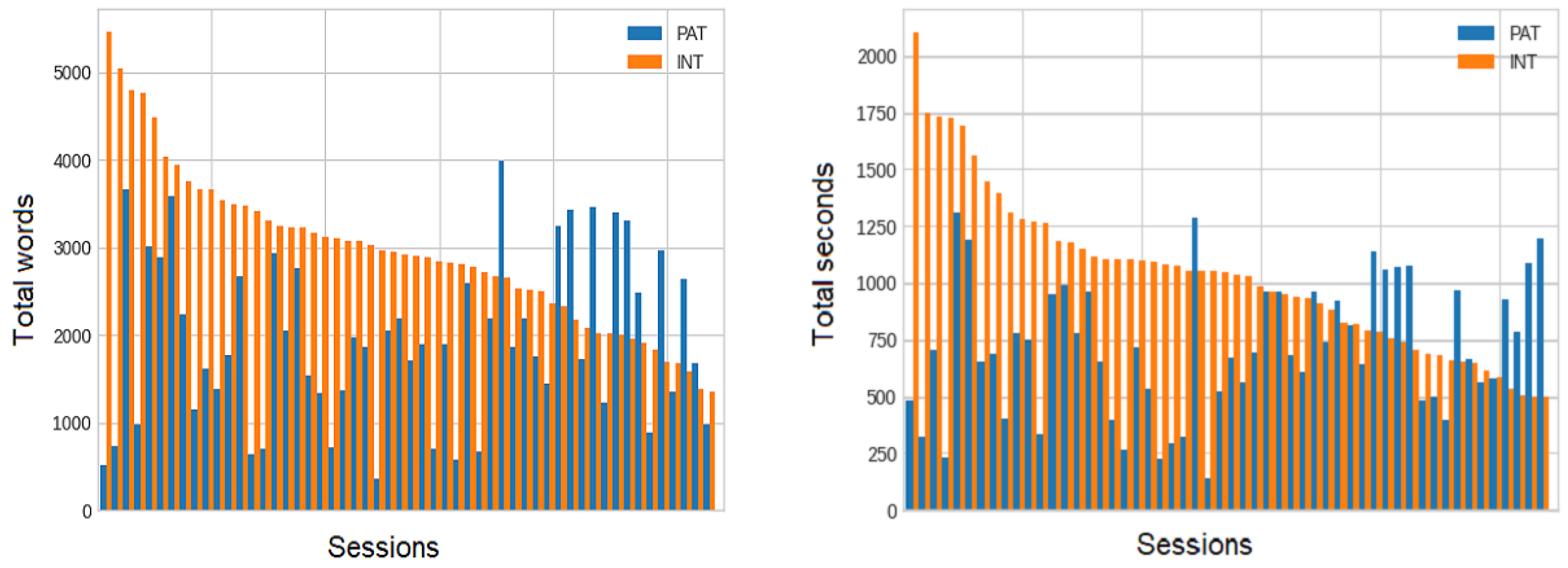
| Patient Demographics | Total (All Sessions) | Average | Min | Max |
|---|---|---|---|---|
| Number of patients | 54 | - | - | - |
| Female | 39% | - | - | - |
| Age | - | 37 | 16 | 74 |
| In-person sessions | 34% | - | - | - |
| Session information | ||||
| Length (mins) | 1634 | 30 | 20 | 52 |
| Number of words | 264,069 | 4890 | 354 | 5462 |
| Number of segments | 9271 | 172 | 35 | 194 |
| Time talking per session (mins) | ||||
| Patient | 644 | 12 | 3 | 22 |
| Practitioner | 927 | 18 | 8 | 28 |
| Words spoken per session | ||||
| Patient | 104,981 | 1944 | 354 | 3997 |
| Practitioner | 159,088 | 2946 | 1351 | 5462 |
| Number of segments per session (N) | ||||
| Patient | 4526 | 84 | 35 | 193 |
| Practitioner | 4745 | 88 | 36 | 194 |
| System | Number of Sessions | Train | Test | Cross-Validation | Adapt/Transfer | %WER |
|---|---|---|---|---|---|---|
| HMM-GMM | 54 | GSHTS | GSHTS | 67.18 | ||
| TDNN | 54 | GSHTS | GSHTS | 47.18 | ||
| TDNN | 54 | LibriSpeech | GSHTS | 70.30 | ||
| TDNN | 54 | GSHTS | GSHTS | LibriSpeech model + GSHTS dataset | 35.86 | |
| HMM-GMM | 54 | GSHTS | GSHTS | 6 folds | 65.49 | |
| TDNN | 54 | GSHTS | GSHTS | 6 folds | 45.29 | |
| TDNN | 54 | GSHTS | GSHTS | 6 folds | LibriSpeech model + GSHTS dataset | 33.88 |
| Regressor | Automatic Transcripts | Manual Transcripts | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | R | MAE | RMSE | R | |
| Lasso | 1.91 (3.76%) | 2.64 (5.72%) | 0.88 | 1.66 (3.25%) | 2.25 (4.42%) | 0.92 |
| SVR | 2.91 (5.72%) | 3.67 (7.19%) | 0.84 | 2.65 (5.20%) | 3.12 (6.11%) | 0.91 |
| Elastic Net | 3.51 (6.88%) | 4.30 (8.43%) | 0.76 | 3.39 (6.64%) | 4.24 (8.31%) | 0.77 |
| Linear Regression | 3.98 (7.80%) | 4.91 (9.62%) | 0.60 | 3.80 (7.45%) | 4.59 (9.00%) | 0.69 |
| Decision Tree | 3.86 (7.56%) | 6.24 (12.23%) | 0.45 | 3.61 (7.07%) | 5.39 (10.56%) | 0.51 |
| Ada-Boost | 3.54 (6.94%) | 5.53 (10.84%) | 0.45 | 3.50 (6.86%) | 5.25 (10.29%) | 0.47 |
| Gradient Boosting | 4.31 (8.45%) | 5.77 (11.31%) | 0.44 | 3.51 (6.88%) | 4.80 (9.41%) | 0.50 |
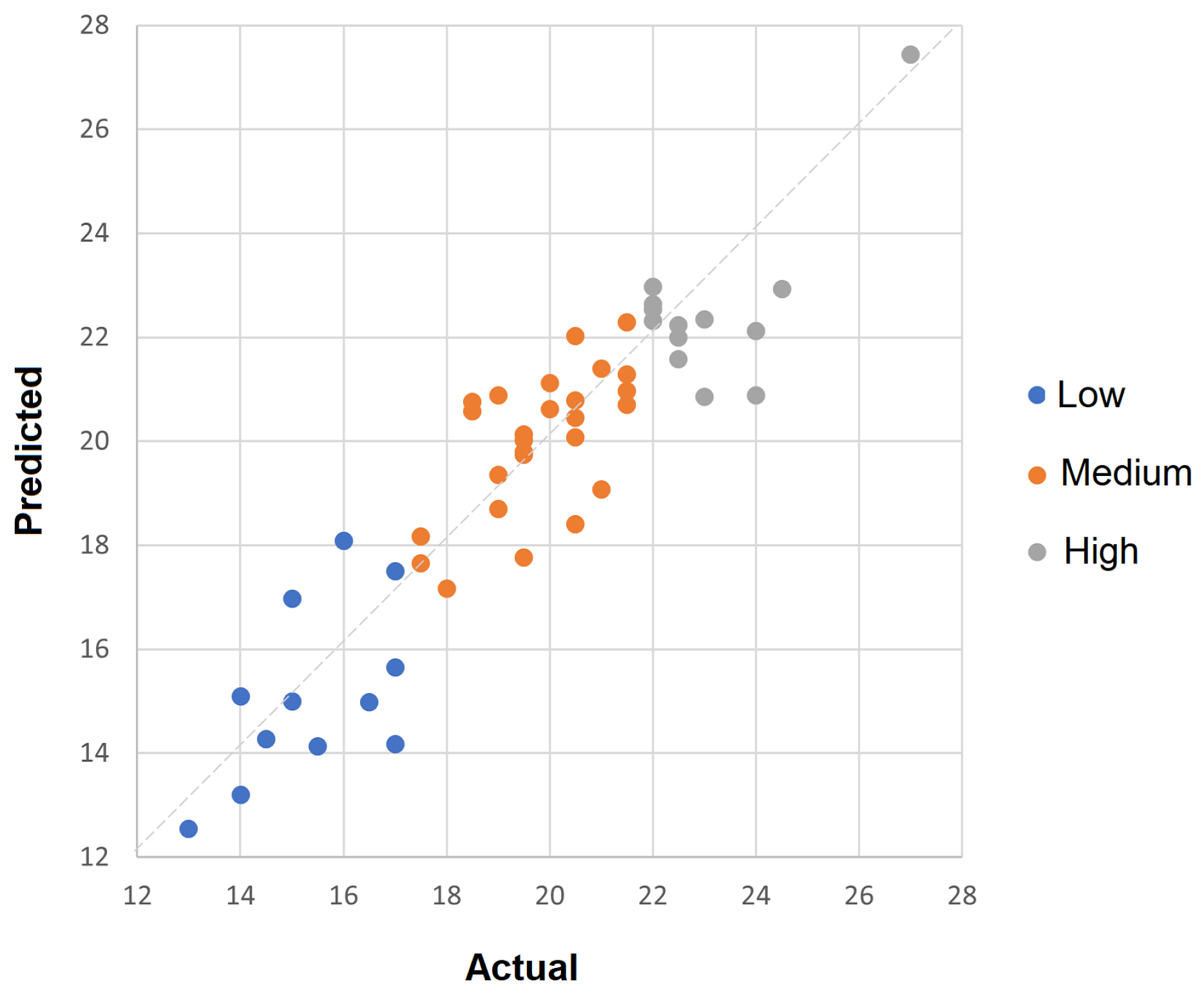
| Competency Items | Num. Feat. | MAE | RMSE | R |
|---|---|---|---|---|
| 1—Focusing the session | 27/520 | 0.35 (6.86%) | 0.44 (8.75%) | 0.89 |
| 2—Continued engagement competencies | 11/250 | 0.30 (6.02%) | 0.38 (7.55%) | 0.82 |
| 3—Interpersonal competencies | 23/250 | 0.34 (6.76%) | 0.42 (8.39%) | 0.87 |
| 4—Information gathering: specific to change | 33/250 | 0.51 (10.17%) | 0.62 (12.31%) | 0.75 |
| 5—Within session self-help change method | 27/250 | 0.33 (6.64%) | 0.41 (8.16%) | 0.81 |
| 6—Planning and shared decision-making competencies | 24/250 | 0.34 (6.70%) | 0.45 (8.98%) | 0.73 |
| Classifier | Automatic Transcripts | Manual Transcripts | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | Accuracy | Precision | Recall | Accuracy | |
| SVM | 0.61 (0.11) | 0.53 (0.21) | 56.86% | 0.92 (0.03) | 0.91 (0.02) | 90.20% |
| Decision Tree | 0.54 (0.09) | 0.51 (0.13) | 53.92% | 0.63 (0.08) | 0.65 (0.07) | 66.66% |
| Random Forest | 0.51 (0.08) | 0.49 (0.16) | 52.94% | 0.62 (0.07) | 0.59 (0.11) | 62.09% |
| Ada-Boost | 0.53 (0.07) | 0.49 (0.16) | 52.94% | 0.57 (0.06) | 0.55 (0.12) | 58.33% |
| Gradient Boosting | 0.52 (0.07) | 0.50 (0.17) | 53.33% | 0.61 (0.06) | 0.57 (0.10) | 59.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Attas, D.; Power, N.; Smithies, J.; Bee, C.; Aadahl, V.; Kellett, S.; Blackmore, C.; Christensen, H. Automated Detection of the Competency of Delivering Guided Self-Help for Anxiety via Speech and Language Processing. Appl. Sci. 2022, 12, 8608. https://doi.org/10.3390/app12178608
Attas D, Power N, Smithies J, Bee C, Aadahl V, Kellett S, Blackmore C, Christensen H. Automated Detection of the Competency of Delivering Guided Self-Help for Anxiety via Speech and Language Processing. Applied Sciences. 2022; 12(17):8608. https://doi.org/10.3390/app12178608
Chicago/Turabian StyleAttas, Dalia, Niall Power, Jessica Smithies, Charlotte Bee, Vikki Aadahl, Stephen Kellett, Chris Blackmore, and Heidi Christensen. 2022. "Automated Detection of the Competency of Delivering Guided Self-Help for Anxiety via Speech and Language Processing" Applied Sciences 12, no. 17: 8608. https://doi.org/10.3390/app12178608
APA StyleAttas, D., Power, N., Smithies, J., Bee, C., Aadahl, V., Kellett, S., Blackmore, C., & Christensen, H. (2022). Automated Detection of the Competency of Delivering Guided Self-Help for Anxiety via Speech and Language Processing. Applied Sciences, 12(17), 8608. https://doi.org/10.3390/app12178608