
Calibrated Convolution with Gaussian of Difference

Abstract
:1. Introduction
- A novel convolution operator, called Calibrated Convolution with Gaussian of Difference (CCGD), which introduces scale-invariant information into the attention mechanism and has a heterogeneously grouped structure. CCGD is especially well-suited to feature transformation because of its remarkable capacity for self-calibration and multi-scale representation.
- The capacity to replace traditional convolution and plug-and-play methods in modern CNNs to form CCGDNet without introducing any extra parameters. This enables them to have a more robust representation learning capability.
2. Related Works
2.1. Architecture Design
2.2. Attention Mechanisms
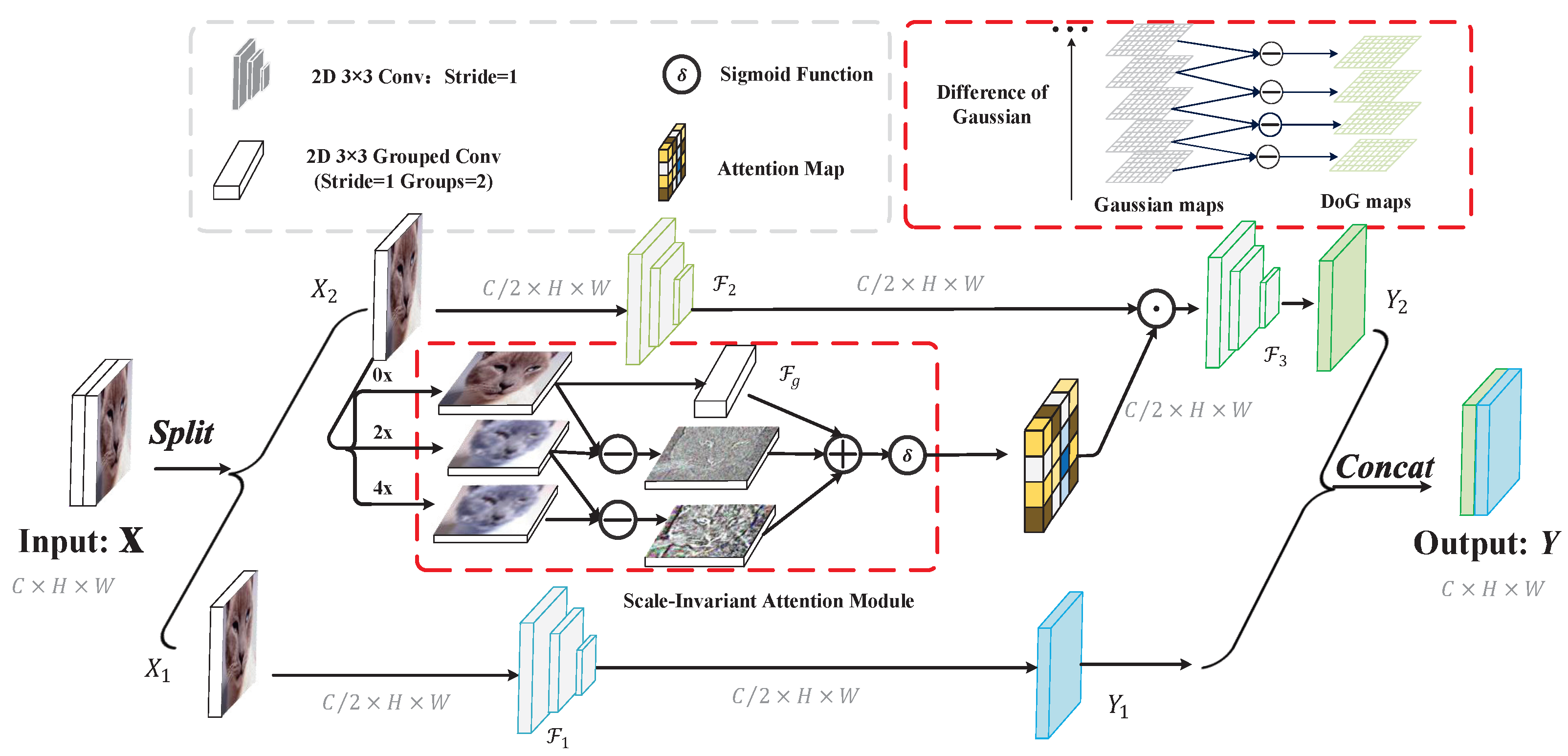
3. Methods
3.1. Motivation
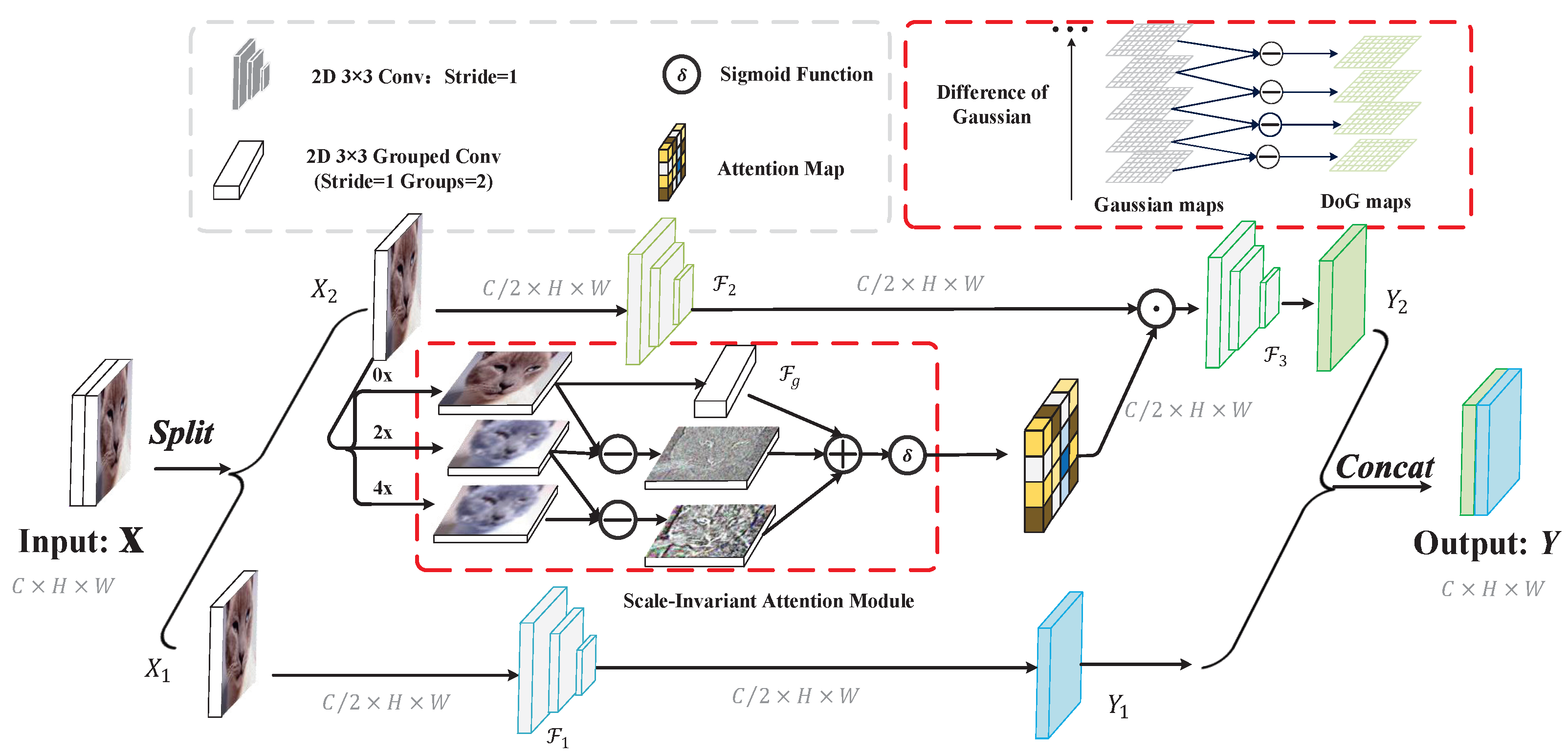
3.2. Scale-Invariant Calibrated Convolution
3.3. Instantiations
4. Experiments
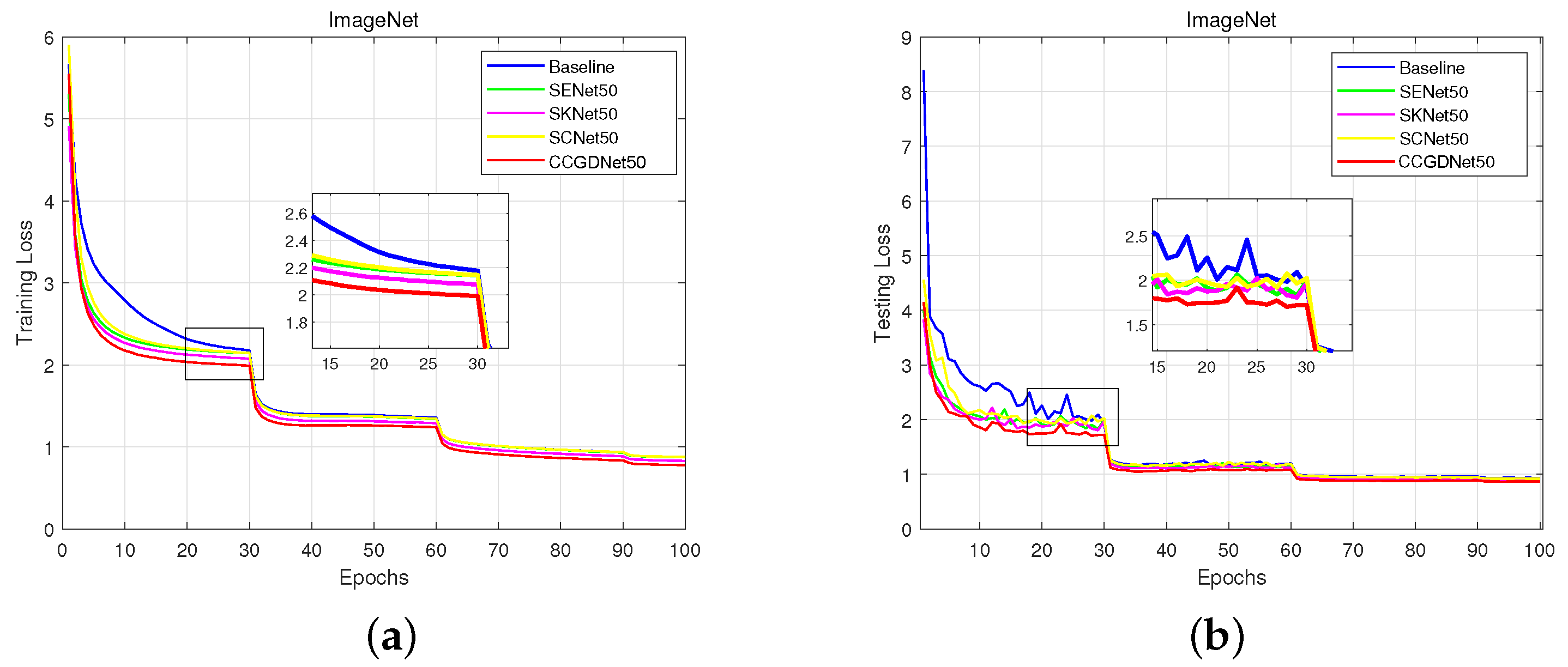
4.1. Implementations
4.2. Results for the Cifar100 Datasets
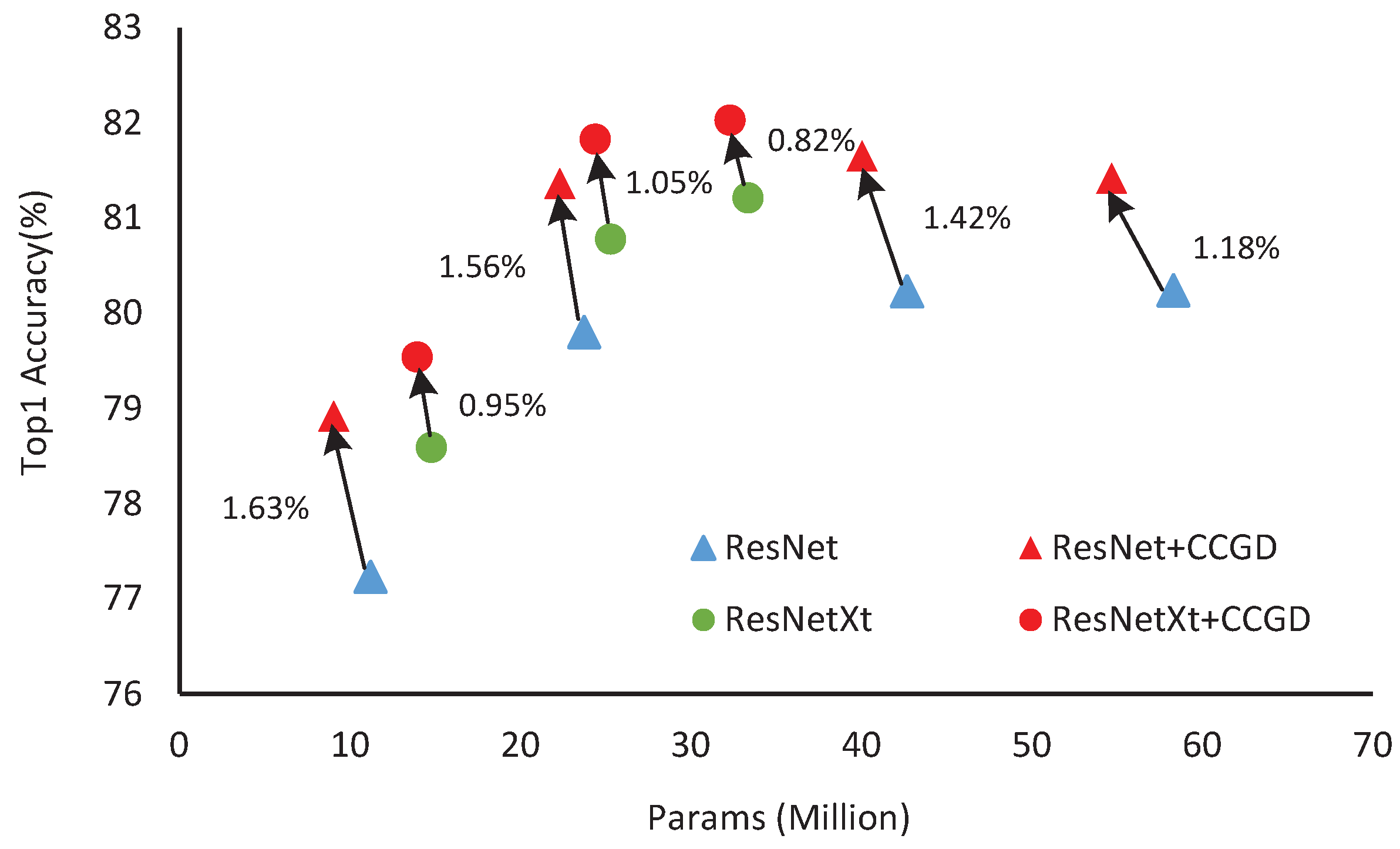
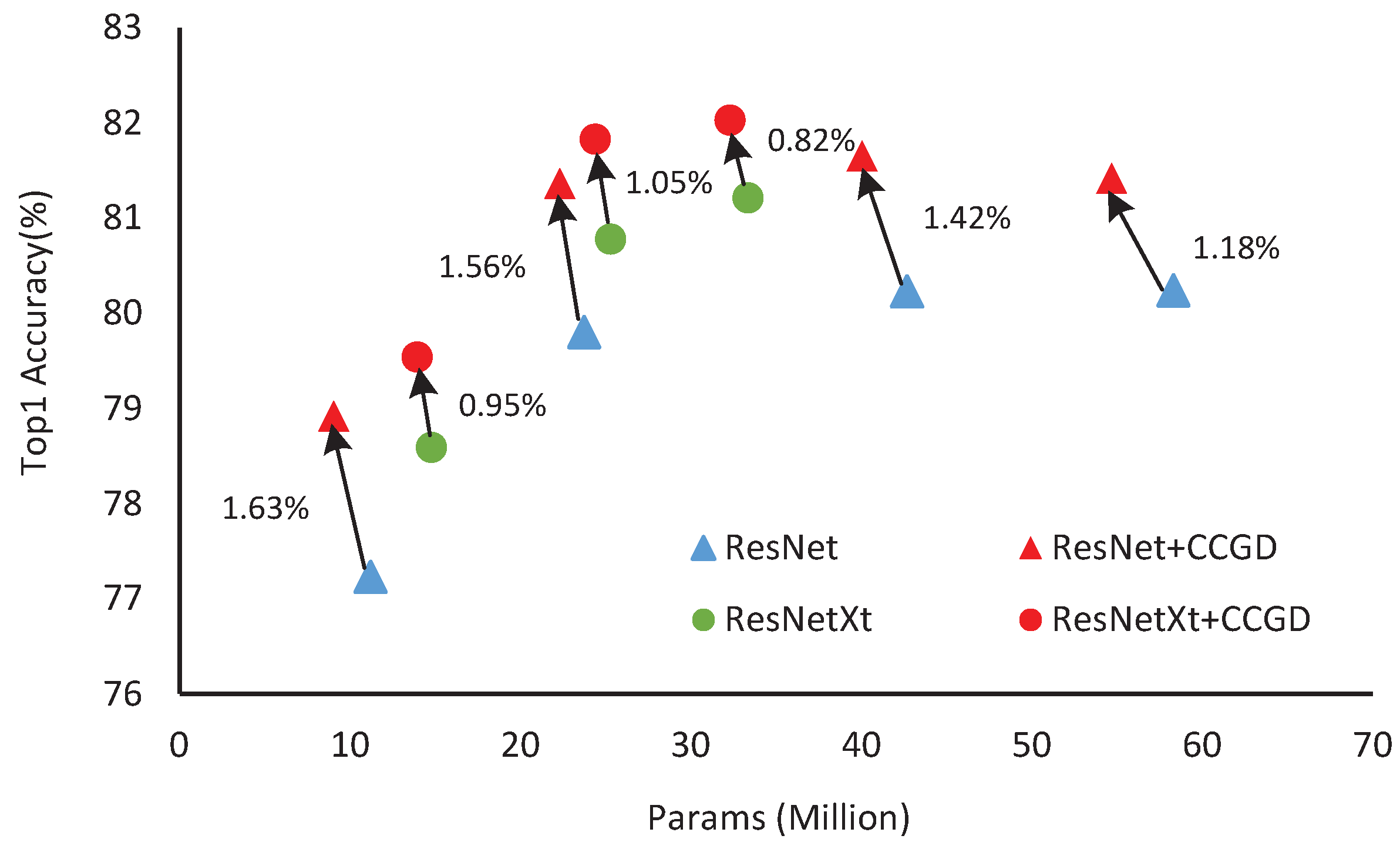
4.3. Results for the ImageNet Datasets
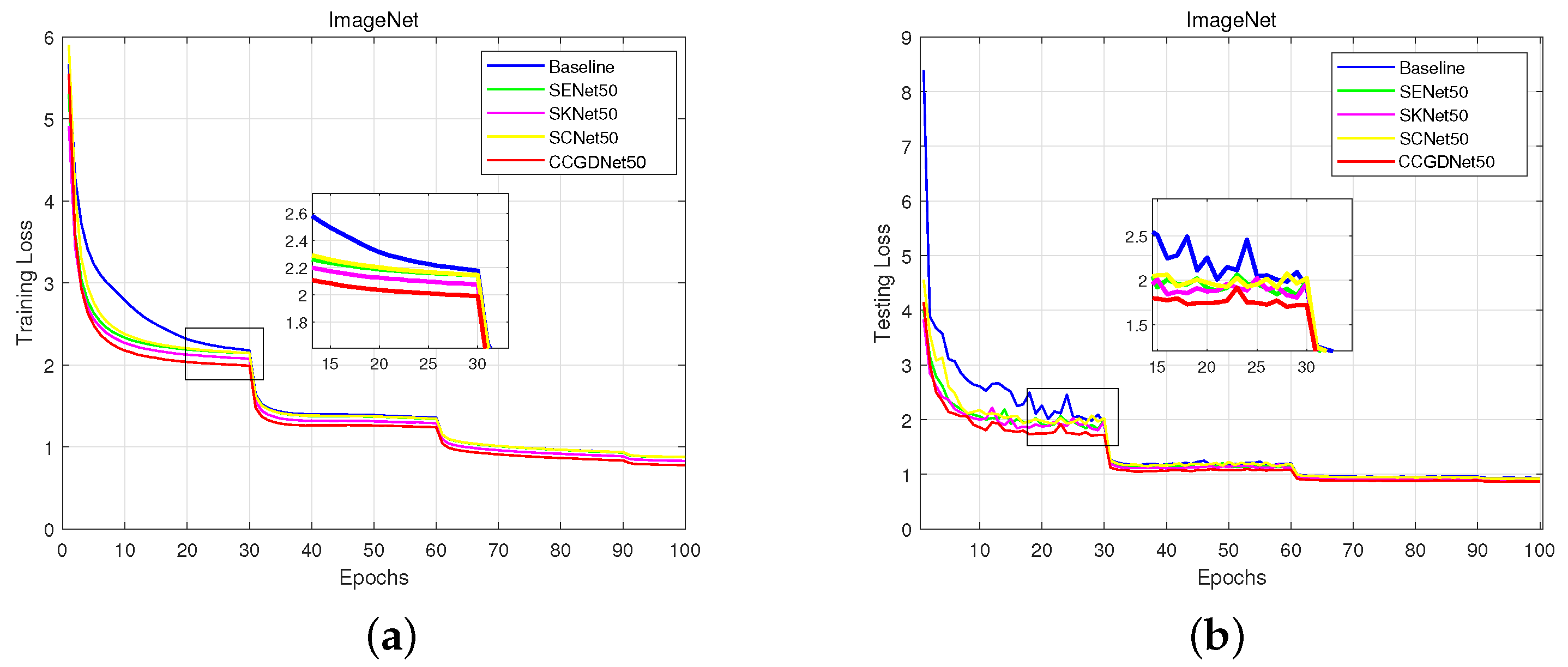
4.4. Ablation Analysis
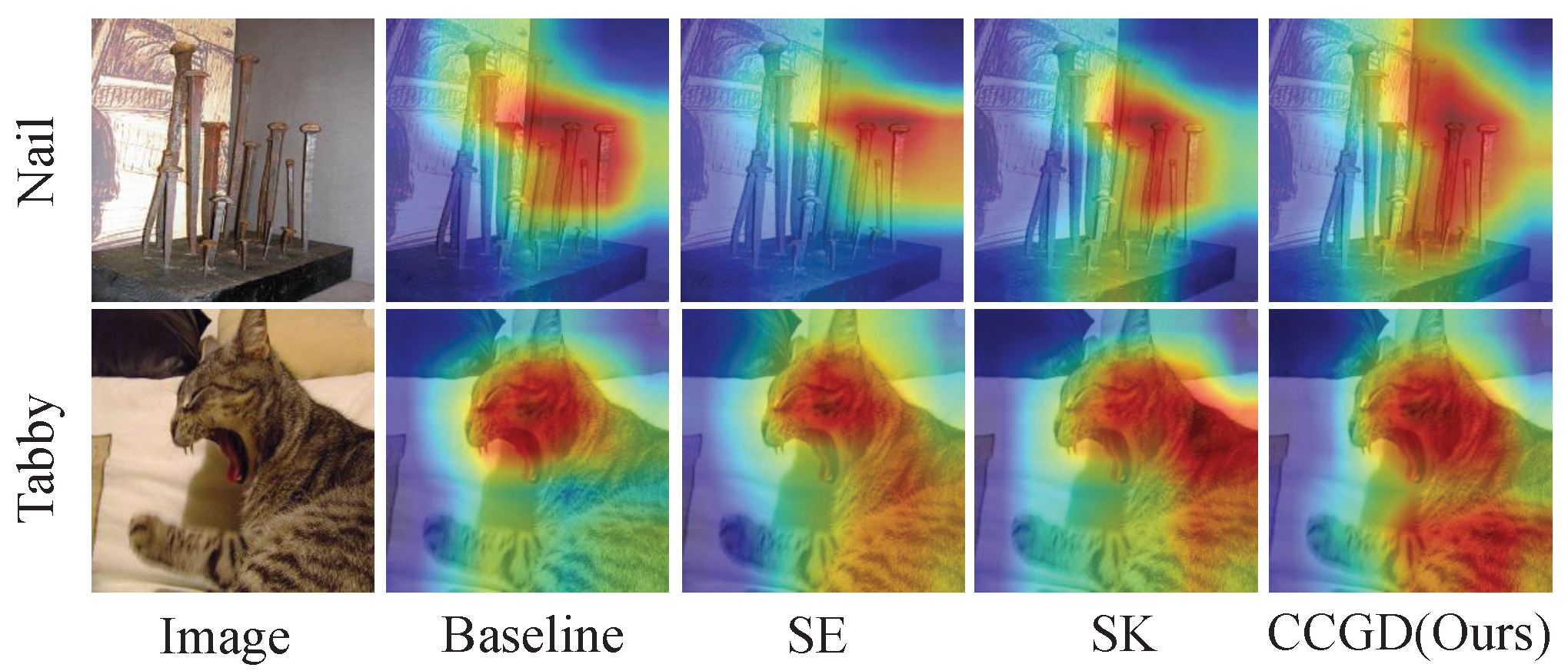
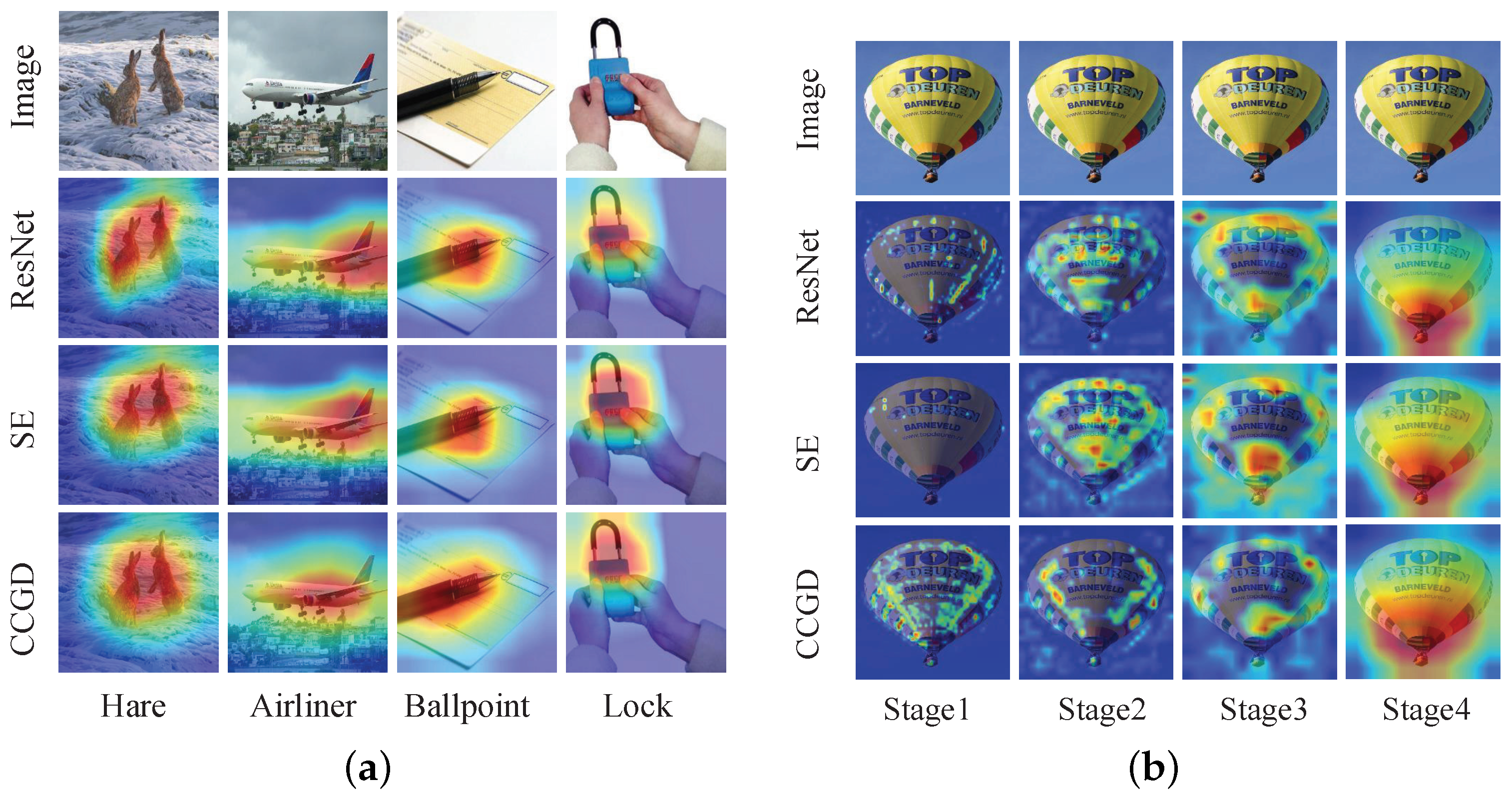
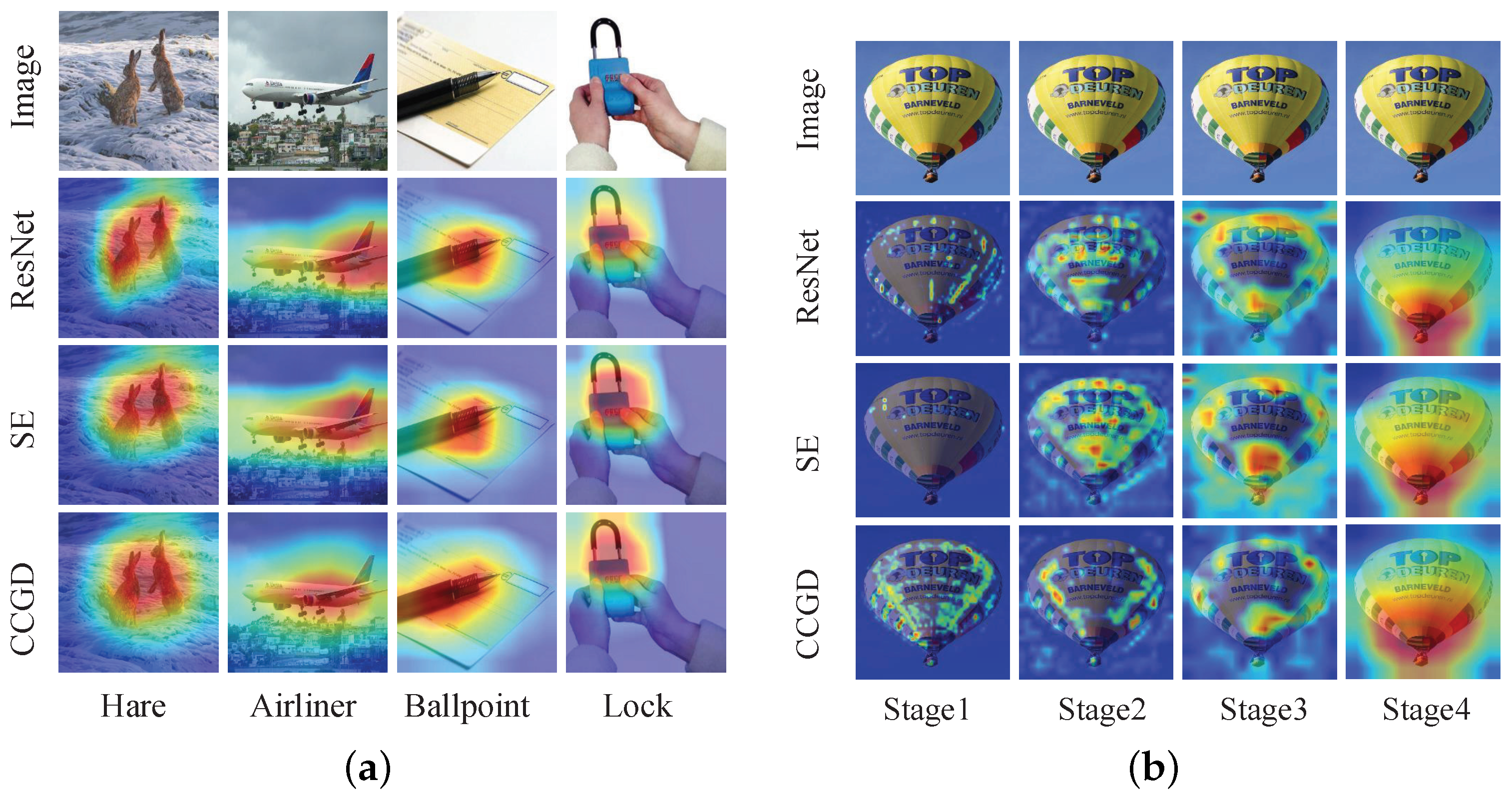
4.5. Visualization with Grad-CAM
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zhang, Y.; Wallaceand, B. A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv 2015, arXiv:1510.03820. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y. Bam: Bottleneck attention module. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 67–86. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lee, H.; Kim, H.E.; Nam, H. Srm: A style-based recalibration module for convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1854–1862. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3286–3295. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshops (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.L.; Yang, J. Selective kernel networks. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Guo, J.; Ma, X.; Sansom, A.; McGuire, M. Spanet: Spatial Pyramid Attention Network for Enhanced Image Recognition. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Beijing, China, 13–16 October 2020; pp. 1–6. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving Convolutional Networks with Self-Calibrated Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10096–10105. [Google Scholar]
- Russakovsky, O.; Deng, J.; Satheesh, S. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017; pp. 618–626. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Satheesh, S. Learning multiple layers of features from tiny images. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images (Technical Report). University of Toronto, Canada. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 23 June 2022).
- Karen, S.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2828. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, V.D.; Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zagoruyko, S.; Nikos, K. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, A.P. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Gao, S.; Cheng, M.M.; Zhao, K.Z. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, P.; Lin, S.; Cui, C. Hierarchical-Split Block on Convolutional Neural Network. arXiv 2020, arXiv:2010.07621. [Google Scholar]
- Huang, G.; Liu, S.; Maaten, L.; Weinberger, K.Q. An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2752–2761. [Google Scholar]
- Barret, Z.; Vijay, V.; Jonathon, S.; Quoc, V.L.E. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Tao, A.; Sapra, K.; Catanzaro, B. Hierarchical multi-scale attention for semantic segmentation. arXiv 2020, arXiv:2005.10821. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Misra, D.; Nalamada, T.; Ajay, U.; Hou, Q.B. Rotate to Attend: Convolutional Triplet Attention Module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3139–3148. [Google Scholar]
- Linsley, D.; Shiebler, D.; Eberhardt, S.; Serre, T. Learning what and where to attend. arXiv 2018, arXiv:1805.08819. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | Params | Flops | Top-1 (%) |
|---|---|---|---|---|
| ResNet (Baseline) | ResNet18 | 11.22 M | 0.56 G | 77.56 |
| SE [3] | 11.31 M | 0.57 G | 78.11 | |
| BAM [4] | 11.25 M | 0.57 G | 77.77 | |
| CBAM [5] | 11.31 M | 0.57 G | 77.94 | |
| SKNet [9] | 11.55 M | 0.57 G | 78.76 | |
| GC [8] | 11.32 M | 0.57 G | 77.92 | |
| SRM [6] | 11.23 M | 0.57 G | 78.05 | |
| SC [11] | 9.83 M | 0.60 G | 78.50 | |
| CCGD(Ours) | 9.04 M | 0.66 G | 79.19 (↑ 1.63) | |
| ResNet (Baseline) | ResNet50 | 23.76 M | 1.31 G | 79.80 |
| SE [3] | 26.24 M | 1.31 G | 80.18 | |
| BAM [4] | 26.28 M | 1.31 G | 80.24 | |
| CBAM [5] | 26.28 M | 1.31 G | 80.45 | |
| SK [9] | 24.03 M | 1.33 G | 80.84 | |
| GC [8] | 26.28 M | 1.32 G | 79.97 | |
| SRM [6] | 23.76 M | 1.31 G | 80.34 | |
| SC [11] | 23.71 M | 1.25 G | 80.47 | |
| CCGD(Ours) | 22.30M | 1.36 G | 81.36 (↑ 1.56) |
| Methods | Backbone | ||
|---|---|---|---|
| ResNetXt | DenseNet | DLANet | |
| Baseline | 80.78 | 80.24 | 80.43 |
| SE | 81.40 | 80.66 | - |
| BAM | 81.15 | 80.48 | - |
| SK | - | 80.24 | 80.79 |
| SGE | 81.35 | 80.08 | 80.74 |
| CCGD(Ours) | 81.83 | 80.53 | 81.10 |
| Methods | Backbone | Years | Parameters | FLOPS | Top-1 (%) | Top-5 (%) |
|---|---|---|---|---|---|---|
| ResNet (baseline) | ResNet-18 | CVPR-16 | 11.69 M | 1.82 G | 69.83 | 89.10 |
| SE [3] | CVPR-18 | 11.78 M | 1.82 G | 70.86 | 89.78 | |
| BAM [4] | BMVC-18 | 11.71 M | 1.83 G | 71.12 | 89.99 | |
| CBAM [5] | ECCV-18 | 11.78 M | 1.82 G | 70.73 | 89.91 | |
| TA [27] | WACV-21 | 11.69 M | 1.83 G | 71.19 | 89.99 | |
| CCGD (Ours) | 9.16 M | 2.05 G | 71.22 (↑ 1.39) | 90.03 (↑ 0.93) | ||
| ResNet (baseline) | ResNet-50 | CVPR-16 | 25.56 M | 4.12 G | 76.40 | 92.94 |
| SENet [3] | CVPR-18 | 28.08 M | 4.13 G | 77.11 | 93.40 | |
| BAM [4] | BMCV-18 | 25.92 M | 4.21 G | 76.90 | 93.66 | |
| CBAM [5] | ECCV-18 | 28.09 M | 4.13 G | 77.34 | 93.69 | |
| GALA [28] | ICLR-19 | 29.40 M | - | 77.27 | 93.66 | |
| GC [8] | CVPR-19 | 28.10 M | 4.13 G | 77.70 | 93.76 | |
| SK [9] | CVPR-19 | 26.15 M | 4.19 G | 77.54 | 93.62 | |
| SRM [6] | CVPR-19 | 25.62 M | 4.12 G | 77.13 | 93.70 | |
| SC [11] | CVPR-20 | 25.60 M | 3.95 G | 77.52 | 93.78 | |
| TA [27] | WACV-21 | 25.56 M | 4.17 G | 77.48 | 93.68 | |
| CCGD (Ours) | 24.15 M | 4.27 G | 77.87 (↑ 1.47) | 93.95 (↑ 1.01) | ||
| ResNet (baseline) | ResNet-101 | CVPR-16 | 44.46 M | 7.84 G | 78.20 | 93.91 |
| SE [3] | CVPR-18 | 49.32 M | 7.86 G | 78.46 | 94.10 | |
| BAM [4] | BMVC-18 | 44.91 M | 7.93 G | 78.46 | 94.02 | |
| CBAM [5] | ECCV-18 | 49.33 M | 7.86 G | 78.49 | 94.31 | |
| SK [9] | CVPR-19 | 45.68 M | 7.98 G | 78.79 | 94.26 | |
| SRM [6] | CVPR-19 | 44.68 M | 7.85 G | 78.47 | 93.75 | |
| SC [11] | CVPR-20 | 44.56 M | 7.20 G | 78.60 | 93.98 | |
| TA [27] | WACV-21 | 44.56 M | 7.95 G | 78.03 | 93.77 | |
| CCGD (Ours) | 41.89 M | - | 78.84 (↑ 0.64) | 94.32 (↑ 0.41) |
| Methods | Design Choice | Top1-Acc | ||
|---|---|---|---|---|
| SIC Operation | FR | Square Function | ||
| ResNet | - | - | - | 76.40 |
| CCGD | - | - | - | 77.07 |
| ✓ | - | - | 77.56 | |
| ✓ | ✓ | - | 77.68 | |
| ✓ | - | ✓ | 77.53 | |
| ✓ | ✓ | ✓ | 77.87 | |
| Methods | Number | Top1-Acc (%) | Top5-Acc (%) |
|---|---|---|---|
| CCGD | 0 | 77.10 | 93.22 |
| 1 | 77.43 | 93.25 | |
| 2 | 77.87 | 93.95 | |
| 3 | 77.84 | 93.84 | |
| 4 | 77.63 | 93.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Li, C.; Liang, Y.; Liu, W.; Meng, F. Calibrated Convolution with Gaussian of Difference. Appl. Sci. 2022, 12, 6570. https://doi.org/10.3390/app12136570
Yang H, Li C, Liang Y, Liu W, Meng F. Calibrated Convolution with Gaussian of Difference. Applied Sciences. 2022; 12(13):6570. https://doi.org/10.3390/app12136570
Chicago/Turabian StyleYang, Huoxiang, Chao Li, Yongsheng Liang, Wei Liu, and Fanyang Meng. 2022. "Calibrated Convolution with Gaussian of Difference" Applied Sciences 12, no. 13: 6570. https://doi.org/10.3390/app12136570
APA StyleYang, H., Li, C., Liang, Y., Liu, W., & Meng, F. (2022). Calibrated Convolution with Gaussian of Difference. Applied Sciences, 12(13), 6570. https://doi.org/10.3390/app12136570