
Single Image Super-Resolution Method Based on an Improved Adversarial Generation Network



Abstract
:1. Introduction
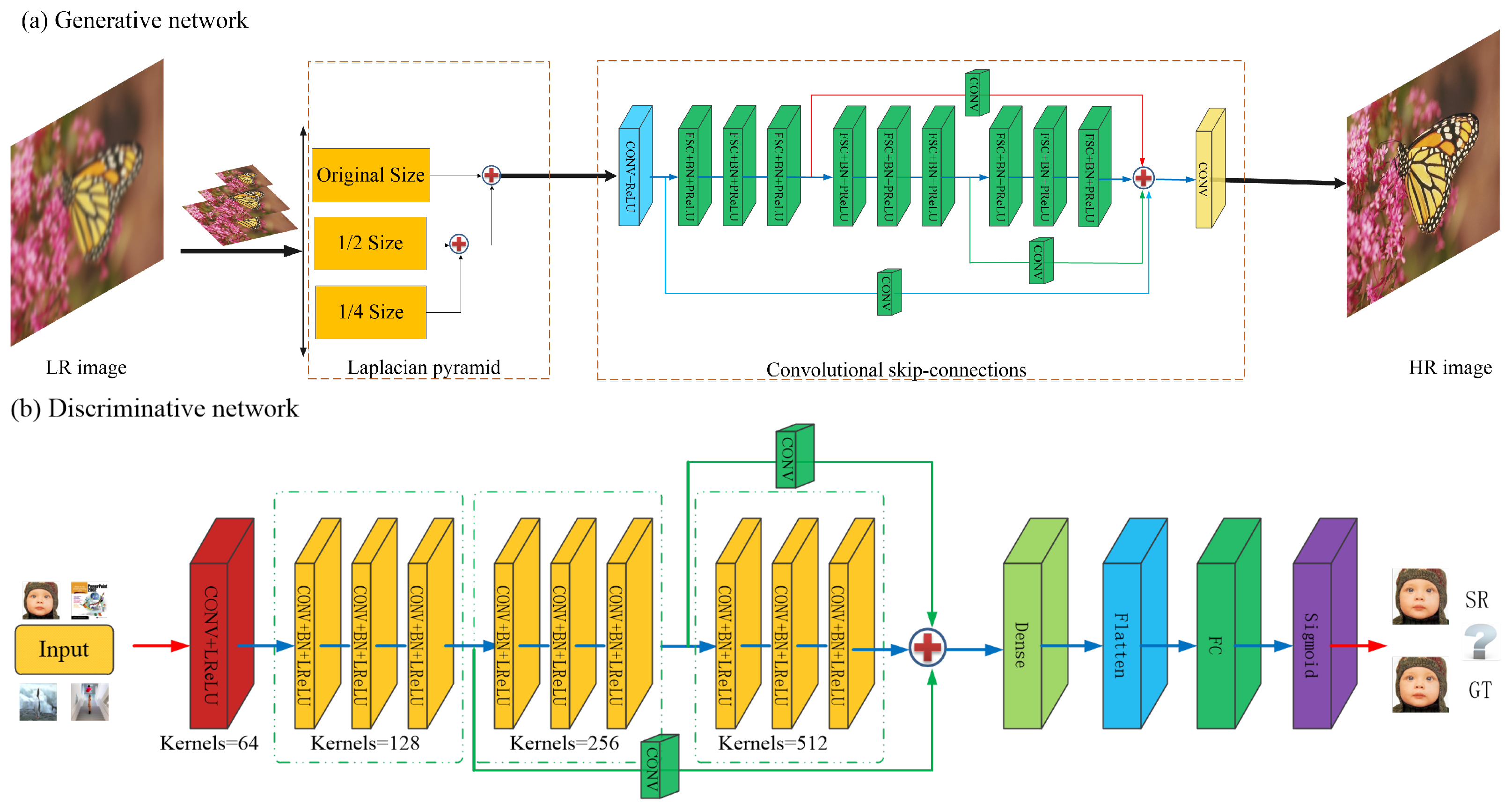
- Convolutional skip-connections: Some CNN algorithms show significant advantages for SR tasks. Different from cascade networks in typical methods, we design a convolutional skip-connections network based on an end-to-end manner. Note that feature maps from the intermediate layers may contain some latent information. It is crucial for the generative model to generate a plausible-looking image that relies on the convolutional skip-connections. Therefore, our generator can project some high-frequency details onto the synthesized images to fool the discriminator, D.
- Perceptual loss function: Normally, several GAN methods are limited by instability learning during training. We propose a perceptual loss function to penalize the samples in our adversarial network. Considering that the edge details usually play a significant role in image generation, the generator produces synthesized images that are closer to the real images via our loss function. Moreover, our loss function corrects the errors between the real images and the generated images, which improves the accuracy of the discriminator.
2. Related Work
2.1. Typical Image SR Algorithms
2.2. SR Based on Deep-Learning Algorithms
3. An Enhanced Generative Adversarial Network for SR
3.1. Generative Network Structure
3.1.1. Laplacian Pyramid
- We construct a Gaussian pyramid G(I) = [, , …, ]; here, = I and is N recursive applications of down(•) to I. The can be viewed as the Nth number of levels in the pyramid. In addition, the top level has to retain a certain size because the image has too few pixels to recover (we usually set N = 3 in the pre-trained module). We initialize the down-top levels with the Gaussian kernel w, and then remove the even lines:
- The image (I) denotes the Nth levels of the Laplacian pyramid, which is made up of two adjacent levels in the Gaussian pyramid. Then, we up-sample the smaller image with the up(•) operator, so that the image (I) sizes can be expressed as:
3.1.2. Convolutional Skip-Connections
3.2. Discriminative Network Structure
3.3. Perceptual Loss Function
4. Experiments
4.1. Experimental Dataset and Setting
4.2. Implementation Details
4.2.1. Laplacian Pyramid Performance
4.2.2. Convolutional Skip-Connections Performance
4.2.3. Perceptual Loss Function Performance
4.3. Comparisons with the State-of-the-Art Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SR | Super-Resolution |
| GANs | Generative Adversarial Networks |
| EGAN | Enhanced Generative Adversarial Networks |
| CNNs | Convolutional Neural Networks |
| HR | High-resolution |
| LR | Low-resolution |
| SRCNN | Super-Resolution Convolutional Neural Network |
| LapSRN | Deep Laplacian Pyramid Network |
| DRRN | Deep Recursive Residual Network |
| VAE | Variational AutoEncoders |
| FSRCNN | Fast Super Resolution Convolutional Neural Networks |
| VDSR | Very Deep Convolutional Network |
| DRCN | Deeply Recursive Convolutional Network |
| DRRN | Deep Recursive Residual Network |
| LapGAN | Laplacian Pyramid of Generative Adversarial Network |
| DCGAN | Deep Convolutional Generative Adversarial Network |
| SRGAN | Super-Resolution using a Generative Adversarial Network |
| MSE | Mean squared error |
| FSC | Fractional-strided convolutions |
| BN | Batch normalization |
| PSNR | Signal-to-noise ratio |
| SSIM | Structural similarity index |
| IFC | Information fidelity criterion |
| CSC | Convolutional skip-connections |
References
- Dong, J.; Hong, Z.; Yuan, D.; Chen, H.; You, Y. Fast video super-resolution via sparse coding. In Proceedings of the International Conference on Graphic & Image Processing, Singapore, 23–25 October 2015. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chao, D.; Chen, C.L.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar]
- Ying, T.; Jian, Y.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hong, Y.; Hwang, U.; Yoo, J.; Yoon, S. How Generative Adversarial Nets and its variants Work: An Overview of GAN. ACM Comput. Surv. 2017, 52, 10. [Google Scholar]
- Doersch, C. Tutorial on Variational Autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are GANs Created Equal? A Large-Scale Study. arXiv 2017, arXiv:1711.10337. [Google Scholar]
- Blu, T.; Thévenaz, P.; Unser, M. Linear interpolation revitalized. IEEE Trans. Image Process. 2004, 13, 710. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Timofte, R.; Desmet, V.; Vangool, L. A+: Adjusted Anchored Neighborhood Regression for Fast Super-Resolution. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014. [Google Scholar]
- Wang, Z.; Liu, D.; Yang, J.; Han, W.; Huang, T. Deep Networks for Image Super-Resolution with Sparse Prior. In Proceedings of the IEEE International Conference on Computer Vision, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, G.; Shen, C.; Anton, V.; Reid, I. Exploring Context with Deep Structured models for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 1352–1366. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-Recursive Convolutional Network for Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Denton, E.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models Using a Laplacian Pyramid of Adversarial Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Sanur, Bali, Indonesia, 8–12 December 2015; Volume 1, pp. 1486–1494. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, K.; Gao, X.; Tao, D.; Li, X. Multi-scale dictionary for single image super-resolution. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1114–1121. [Google Scholar]
- Yang, J.; Wright, J.; Huang, T.S.; Yi, M. Image super-resolution as sparse representation of raw image patches. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008), Anchorage, AK, USA, 24–26 June 2008. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On Single Image Scale-Up Using Sparse-Representations; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Identity Mappings in Deep Residual Networks; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Gross, S.; Wilber, M. Training and Investigating Residual Nets. Torch. 2016. Available online: http://torch.ch/blog/2016/02/04/resnets.html (accessed on 9 June 2022).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5769–5779. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Morel, A. Low-Complexity Single Image Super-Resolution Based on Nonnegative Neighbor Embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar] [CrossRef] [Green Version]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | BSD100 | Urban100 | ||
|---|---|---|---|---|
| PSNR(dB) | ||||
| Inputs | ||||
| Original size | 32.30 | 30.79 | ||
| Original size + 1/2 size | 32.38 | 30.88 | ||
| Original size + 1/2 size +1/4 size | 32.41 | 30.93 | ||
| CSC | 1st CSC (Red) | 2nd CSC (Blue) | 3rd CSC (Green) | |
|---|---|---|---|---|
| Inputs | ||||
| (a) | √ | |||
| (b) | √ | √ | ||
| (c) | √ | √ | √ | |
| Algorithms | SRCNN [3] | VDSR [4] | DRRN [6] | SRGAN [22] | EGAN | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Datasets | P(dB) | T(s) | P(dB) | T(s) | P(dB) | T(s) | P(dB) | T(s) | P(dB) | T(s) |
| Set5 | 30.48 | 0.25 | 31.35 | 0.15 | 31.54 | 2.30 | 30.91 | 1.82 | 31.53 | 1.12 |
| Set14 | 27.50 | 0.46 | 28.01 | 0.28 | 28.19 | 4.88 | 27.40 | 3.56 | 28.15 | 2.46 |
| BSD100 | 26.90 | 0.22 | 27.29 | 0.17 | 27.32 | 2.69 | 26.84 | 2.02 | 27.41 | 1.42 |
| Urban100 | 24.52 | 3.56 | 25.18 | 3.02 | 25.21 | 10.52 | 24.79 | 6.87 | 25.28 | 4.98 |
| Datasets | Scale | SRCNN [3] | VDSR [4] | DRRN [6] | SRGAN [22] | EGAN |
|---|---|---|---|---|---|---|
| Set5 | × 2 | 36.66/0.9542/8.04 | 37.53/0.9587/8.19 | 37.74/0.9571/8.67 | 35.63/0.9418/8.23 | 36.96/0.9553/8.43 |
| × 3 | 32.75/0.9090/4.66 | 33.66/0.9213/5.22 | 34.03/0.9244/5.40 | 31.82/0.8826/4.69 | 33.92/0.9234/5.47 | |
| × 4 | 30.48/0.8628/3.00 | 31.35/0.8838 /3.50 | 31.68/0.8888/3.70 | 29.53/0.8304/3.12 | 31.64/0.8798/3.76 | |
| Set14 | × 2 | 32.45/0.9067/7.79 | 33.03/0.9124/7.88 | 33.23/0.9136/8.32 | 31.04/0.9018/7.83 | 33.17/0.9123/8.25 |
| × 3 | 29.30/0.8215/4.34 | 29.77/0.8314/4.73 | 29.96/0.8349/4.88 | 28.76/0.8171/4.82 | 29.25/0.8324/4.99 | |
| × 4 | 27.50/0.7513/2.75 | 28.01/0.7674/3.07 | 28.21/0.7720/3.25 | 26.52/0.7470/3.17 | 28.13/0.7602/3.29 | |
| BSD100 | × 2 | 31.36/0.8879/7.24 | 31.90/0.8960/7.17 | 32.05/0.8973/7.70 | 30.85/0.8342/7.32 | 31.98/0.8921/7.74 |
| × 3 | 28.41/0.7863/3.37 | 28.82/0.7976/3.94 | 28.95/0.8004/4.21 | 27.80/0.7363/4.04 | 28.89/0.8005/4.35 | |
| × 4 | 26.90/0.7101/2.41 | 27.29/0.7251/2.63 | 27.36/0.7284/2.77 | 25.43/0.6633/2.59 | 27.11/0.7186/2.82 | |
| Urban100 | × 2 | 29.50/0.8946/8.00 | 30.76/0.9140/8.27 | 31.23/0.9188/8.92 | 29.75/0.9033/8.33 | 31.39/0.9202/9.01 |
| × 3 | 26.24/0.7989/4.58 | 27.14/0.8279/5.19 | 27.53/0.8076/5.32 | 27.15/0.7076/5.32 | 27.61/0.8441/5.54 | |
| × 4 | 24.52/7.221/2.96 | 25.18/0.7524/3.41 | 25.44/0.7310/3.68 | 25.34/0.7310/3.51 | 25.40/0.7639/3.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Zhou, H.; Li, G.; Guo, J. Single Image Super-Resolution Method Based on an Improved Adversarial Generation Network. Appl. Sci. 2022, 12, 6067. https://doi.org/10.3390/app12126067
Wang Q, Zhou H, Li G, Guo J. Single Image Super-Resolution Method Based on an Improved Adversarial Generation Network. Applied Sciences. 2022; 12(12):6067. https://doi.org/10.3390/app12126067
Chicago/Turabian StyleWang, Qiang, Hongbin Zhou, Guangyuan Li, and Jiansheng Guo. 2022. "Single Image Super-Resolution Method Based on an Improved Adversarial Generation Network" Applied Sciences 12, no. 12: 6067. https://doi.org/10.3390/app12126067
APA StyleWang, Q., Zhou, H., Li, G., & Guo, J. (2022). Single Image Super-Resolution Method Based on an Improved Adversarial Generation Network. Applied Sciences, 12(12), 6067. https://doi.org/10.3390/app12126067