
Geographic Scene Understanding of High-Spatial-Resolution Remote Sensing Images: Methodological Trends and Current Challenges



Abstract
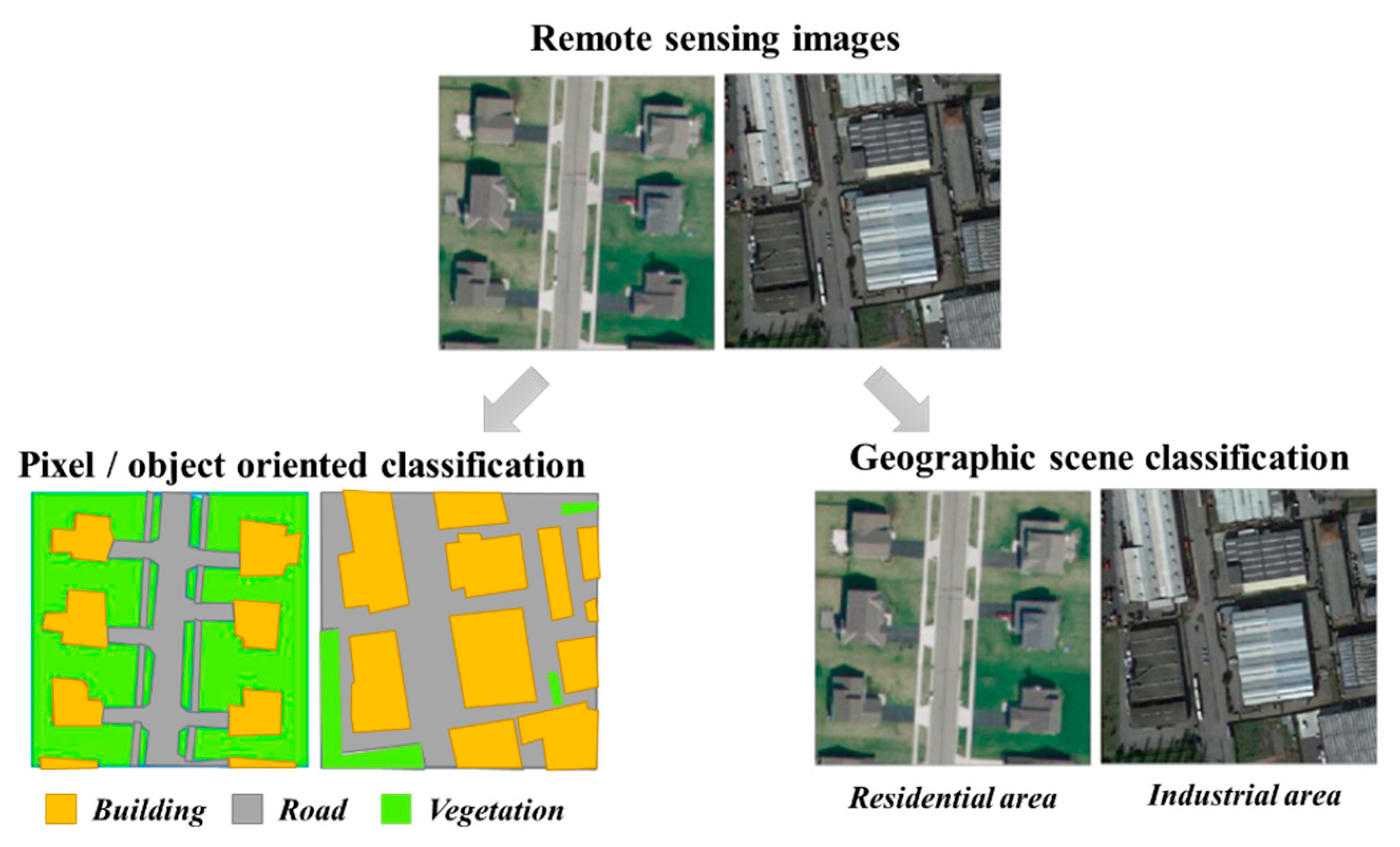
:1. Introduction
- (1)
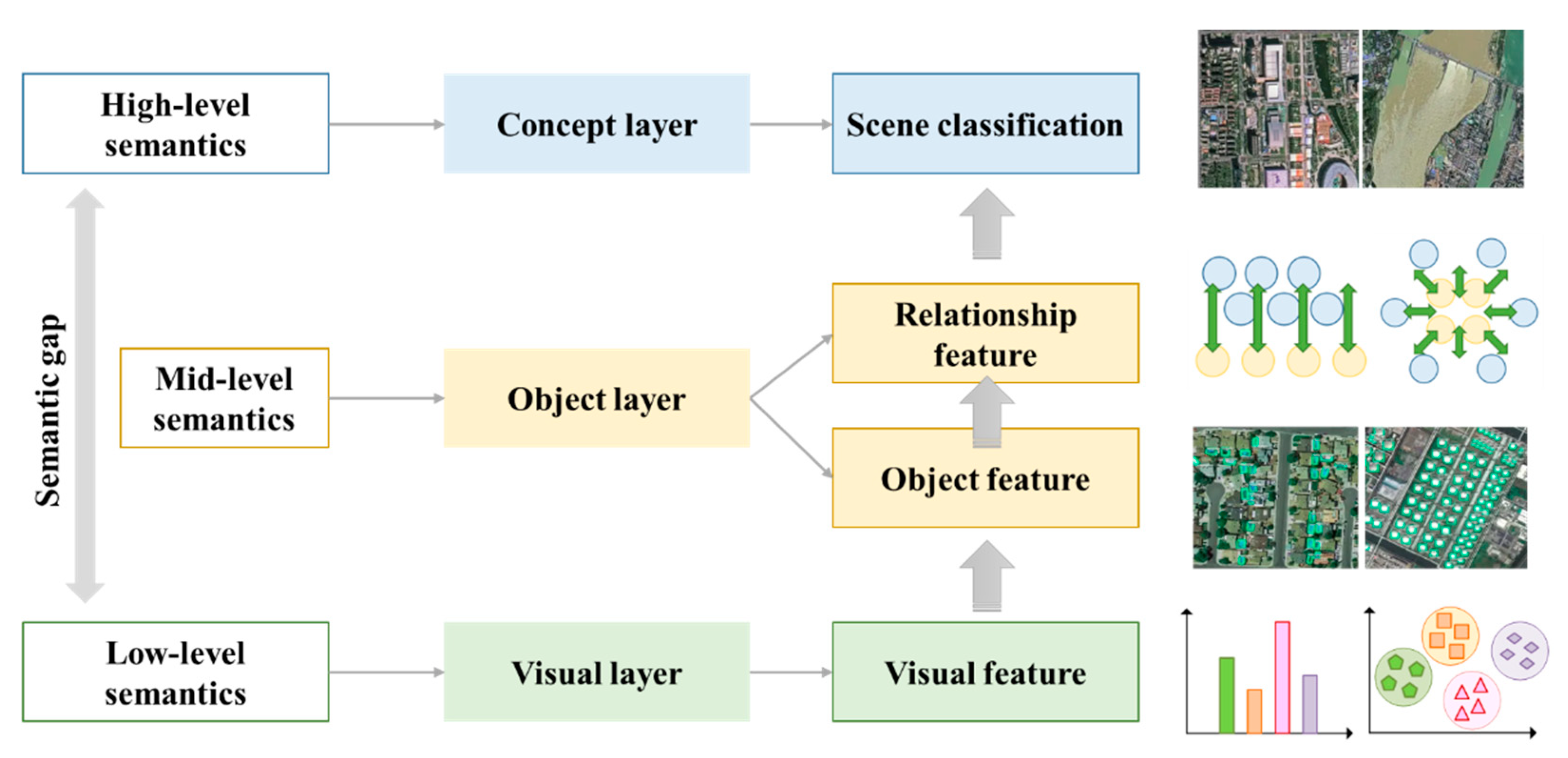
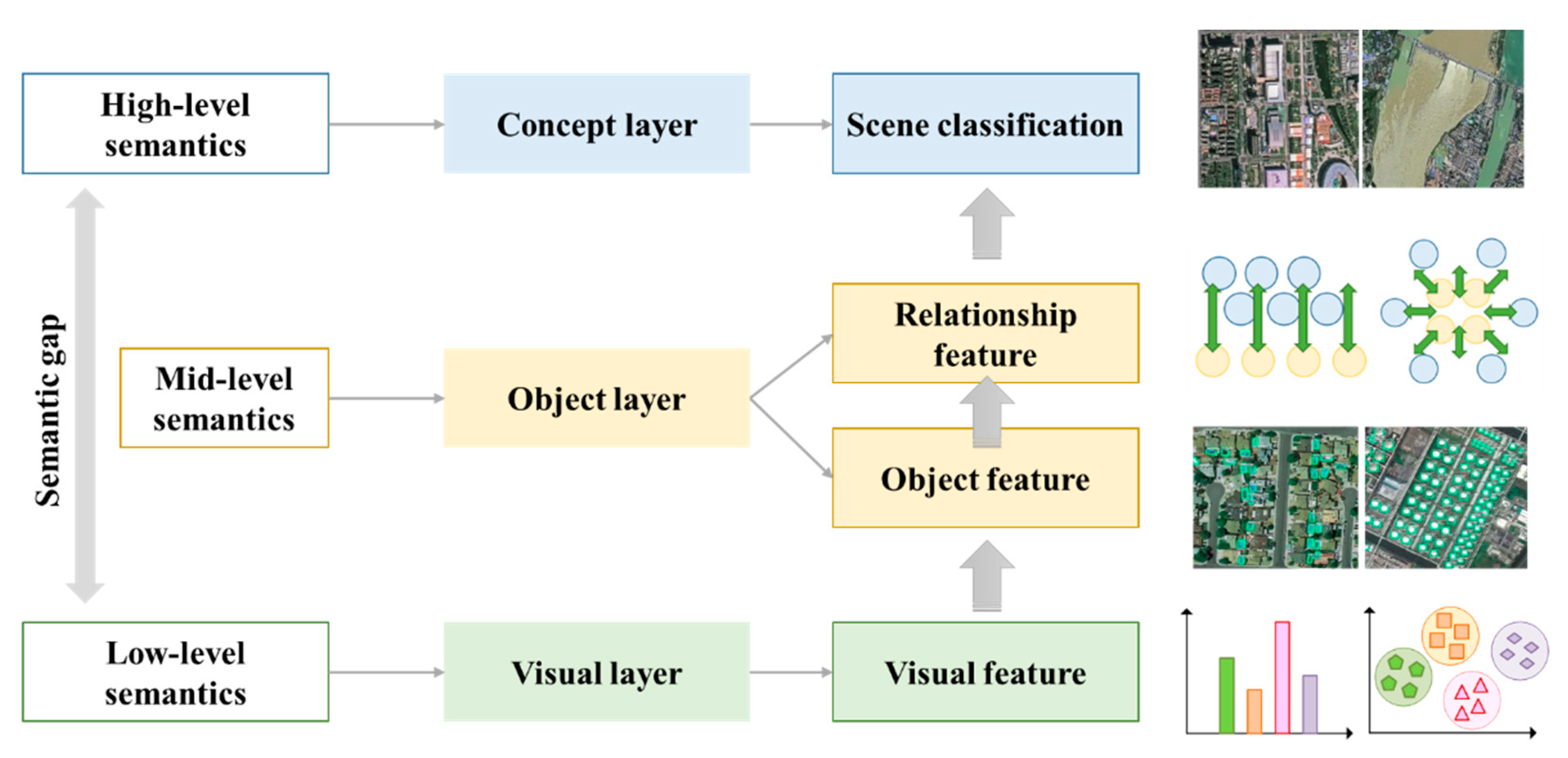
- In terms of the basic principles of geographic scene understanding, the machine will identify the objects or targets contained in the scene according to the similarity of image data. In contrast, humans analyze the semantic information of scene content through the category and spatial distribution of ground objects, and form high-level features through abstract concepts [7]. There is a semantic gap between the conceptual similarity of human understanding and the digital storage form similarity of machine identify. This makes it impossible to relate low-level visual features (such as color, shape, texture, etc.) to high-level semantic information directly.
- (2)
- In terms of the data characteristics of HSR remote sensing images, the improved spatial resolution makes the ground objects in the images have more fine texture features, more obvious geometric structure and clearer location layout. Correspondingly, it also aggravates the difficulty of data processing in intelligent image interpretation. In high resolution images, the spectral heterogeneity of similar objects is enhanced, and the spectral difference of different objects is reduced. This leads to a decrease in the statistical separability of different ground objects in the spectral domain [8]. A high resolution does not necessarily promote an improvement in interpretation accuracy.
- (3)
- In terms of the sophistication of geographic scenes, the structure and composition of the geographic scenes in the HSR remote sensing images are complex, highly variable and even messy. The types of geographic scenes with the same ground objects may be different. However, different types of ground objects also appear in similar geographic scenes [9]. Consequently, understanding the semantic information of the geographic scene and constructing the corresponding semantic feature description is crucial.
- (1)
- What are the objectives of geographic scene understanding?
- (2)
- How are remote sensing approaches being used for geographic scene understanding?
- (3)
- What are the current gaps in HSR remote-sensing-based geographic scene understanding?
2. Basic Ideas
- (1)
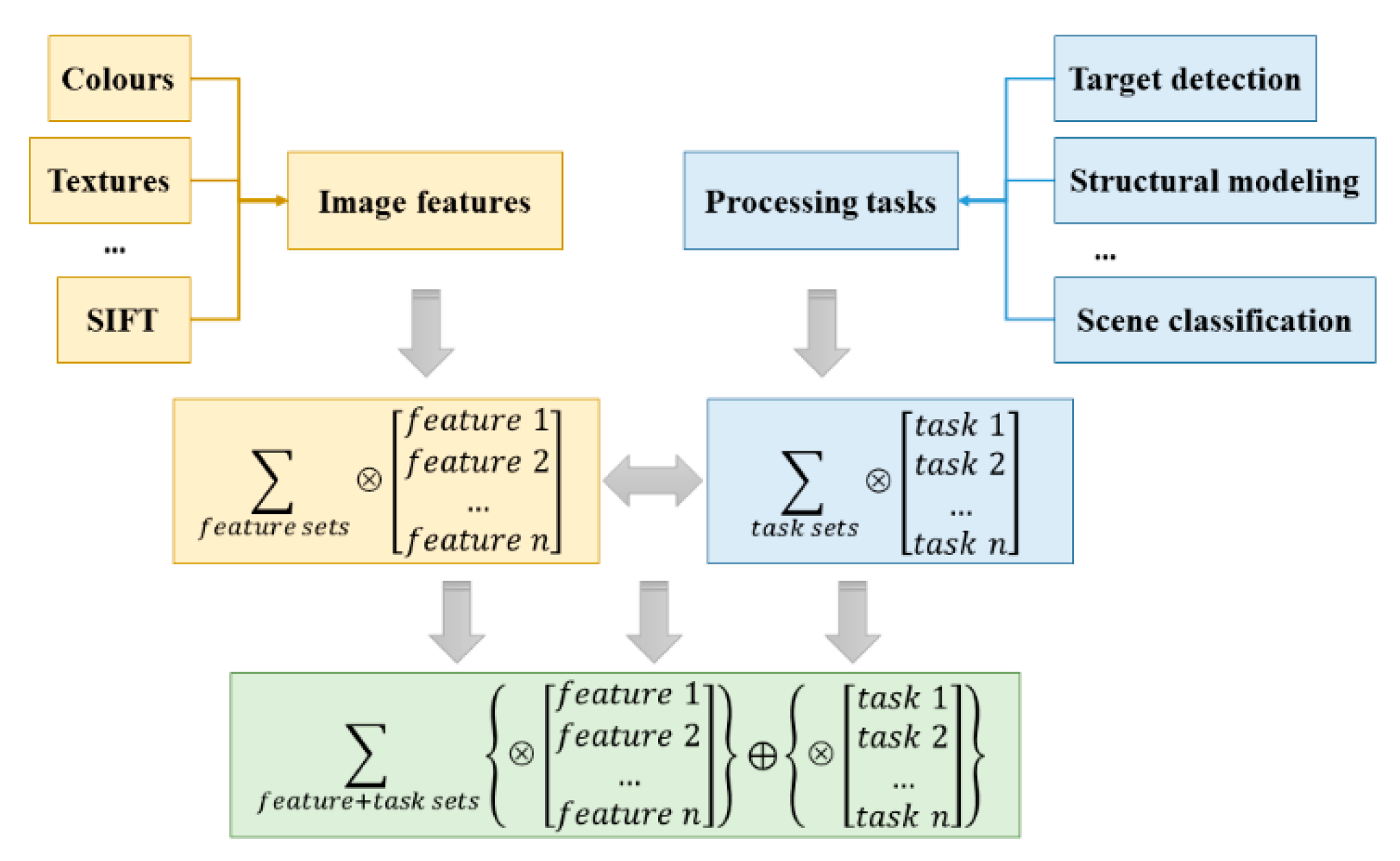
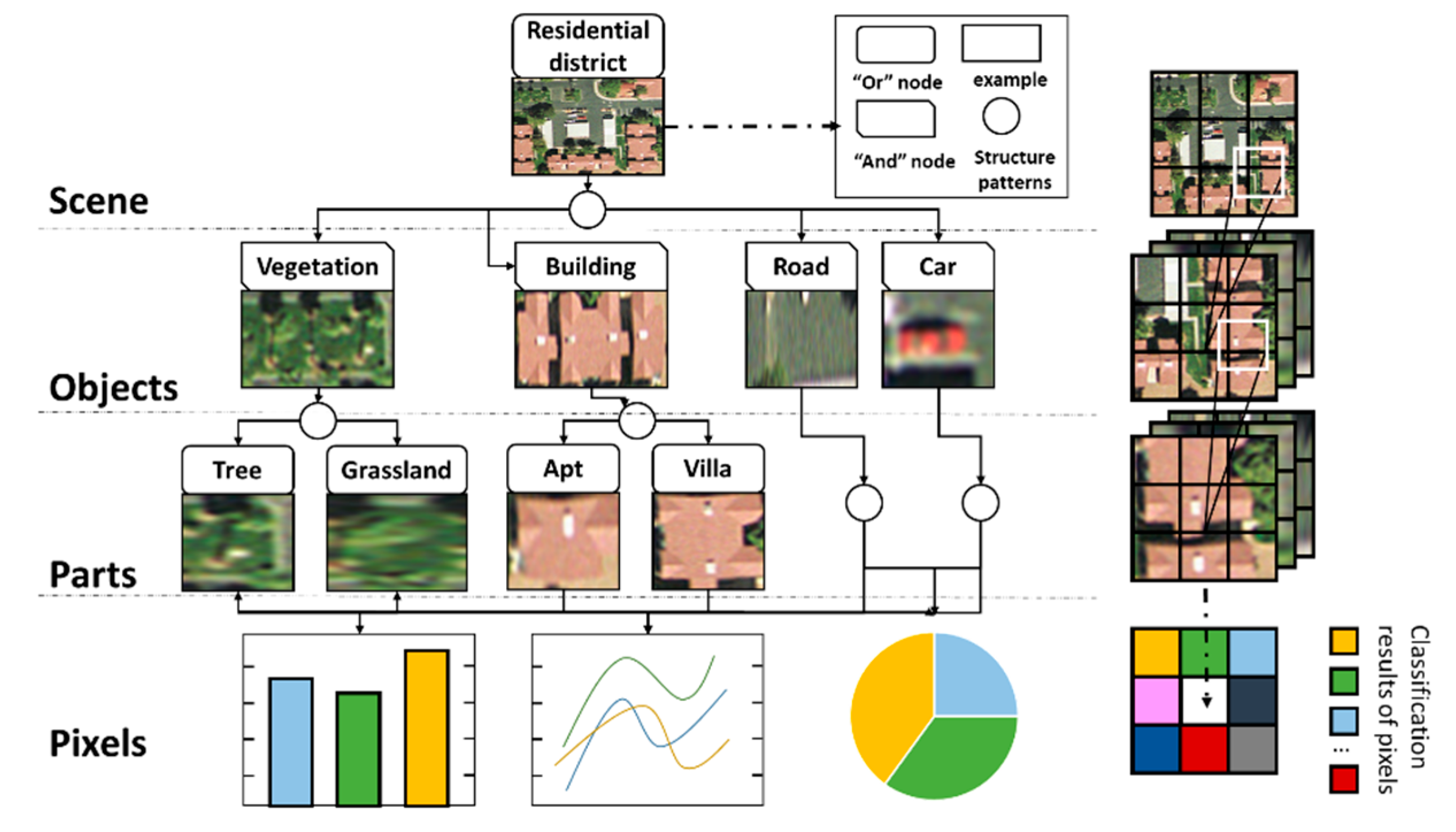
- The categories of ground objects in the geographic scene are diverse. The same category of geographic scene can contain different ground objects, and different geographic scenes can also contain the same ground objects. Different objects also have different characteristics in terms of spectrum, texture and structure [11].
- (2)
- The categories of ground objects in the geographic scene have variability. The change in the categories of some ground objects in geographic scenes does not necessarily lead to a change in the whole semantic information of geographic scenes [12].
- (3)
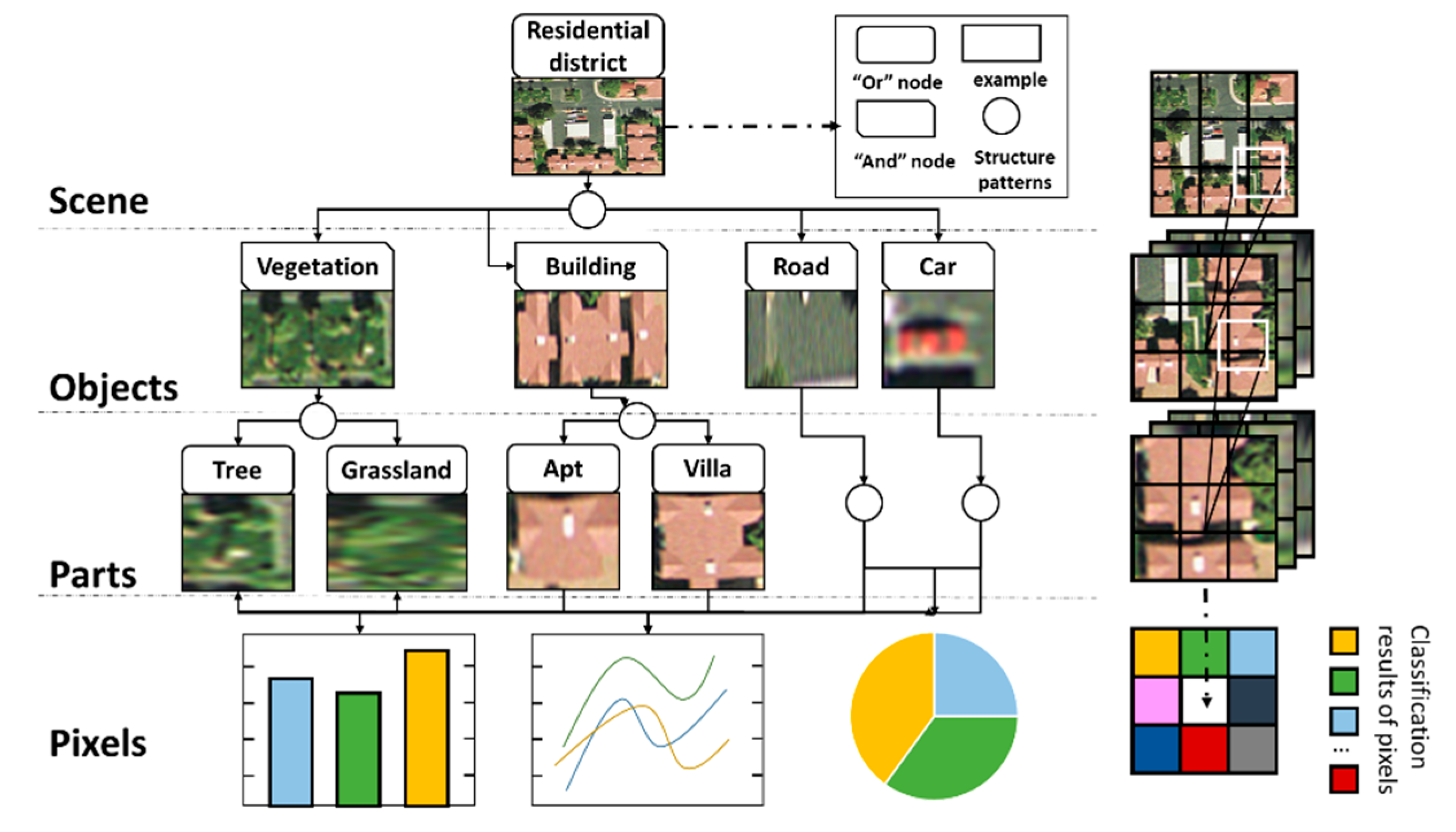
- The spatial relationship between ground objects in geographic scenes is complex. Different distribution forms between ground objects lead to different semantic information of geographic scenes. Other relevant characteristics are shown in Figure 1.
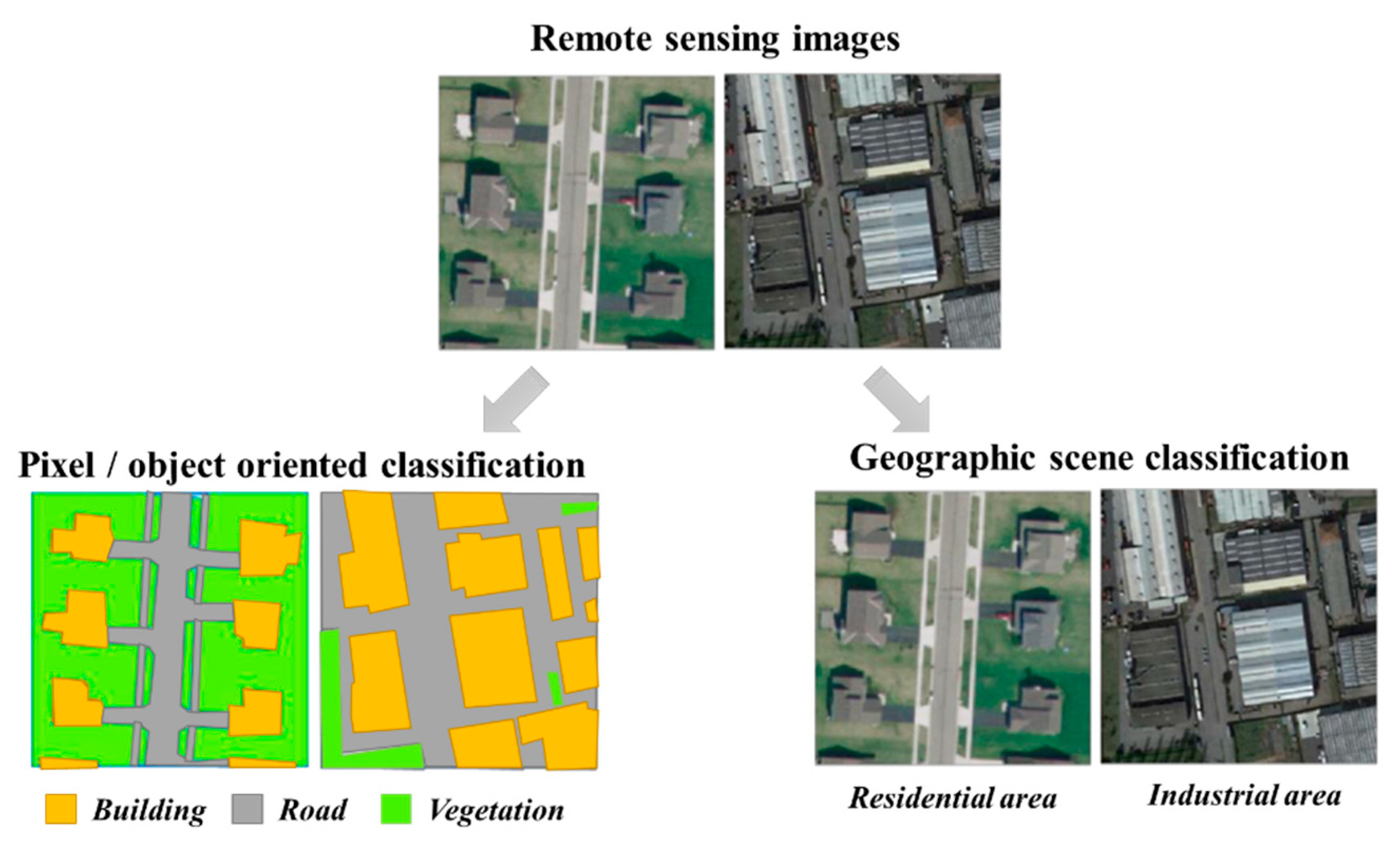
3. Semantic Understanding of Visual Layer
4. Semantic Understanding of Object Layer
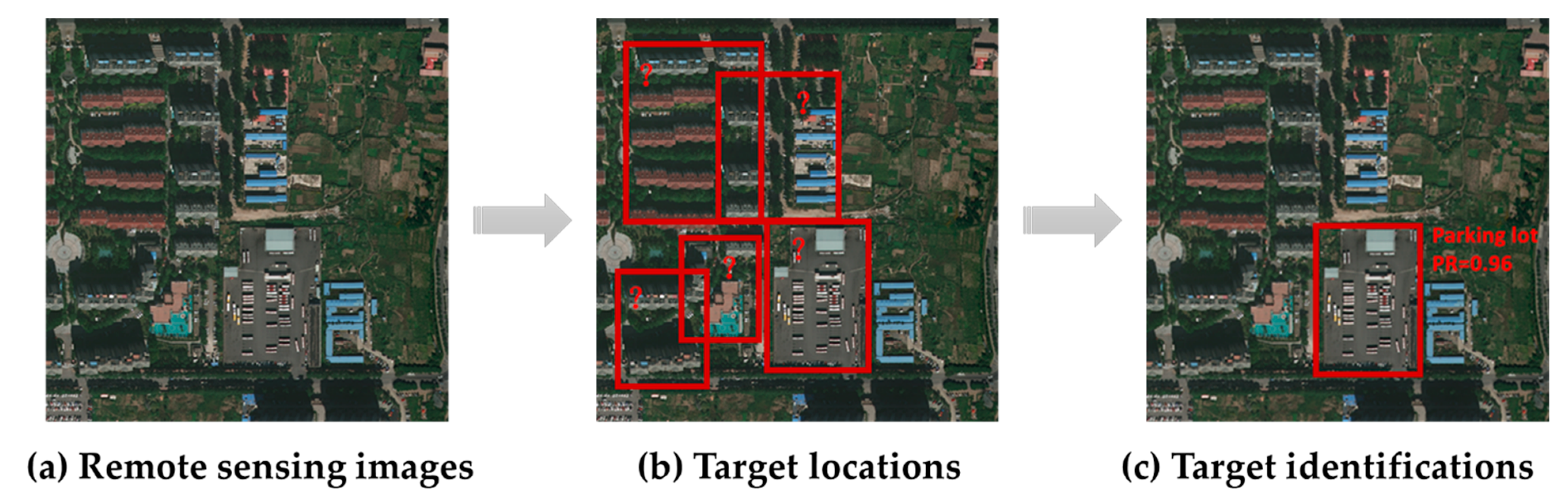
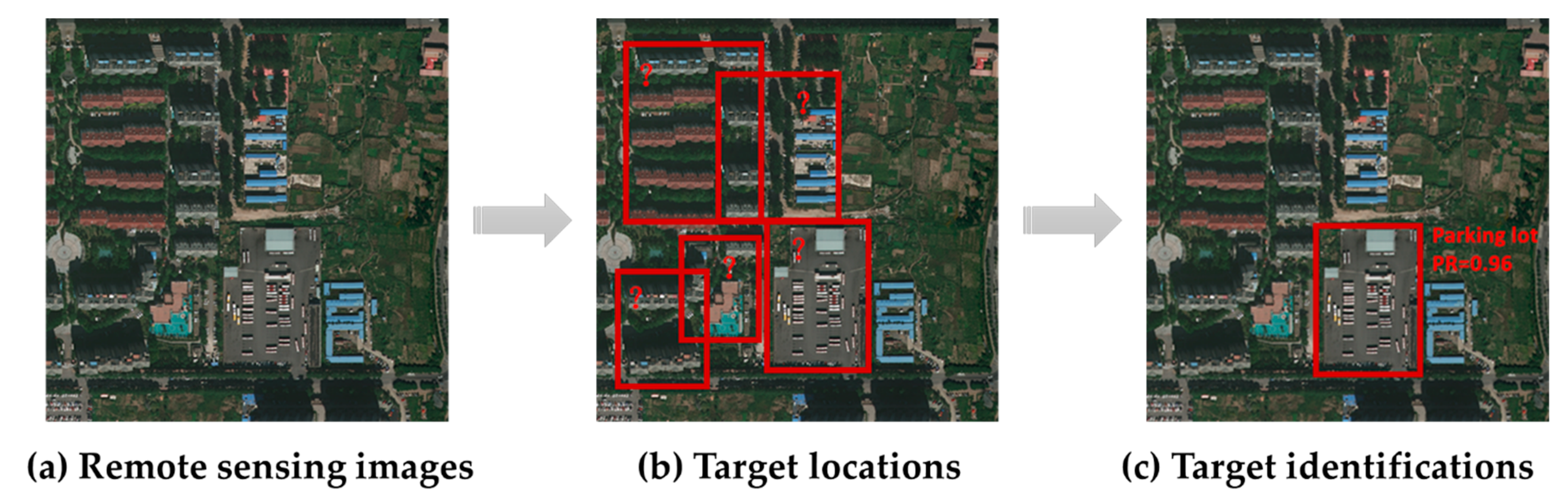
4.1. Target Object Semantics
4.2. Local Area Semantics
4.2.1. Visual Dictionary
4.2.2. Feature Mapping
4.2.3. Probabilistic Topic Model
4.3. Spatial Structure Semantics
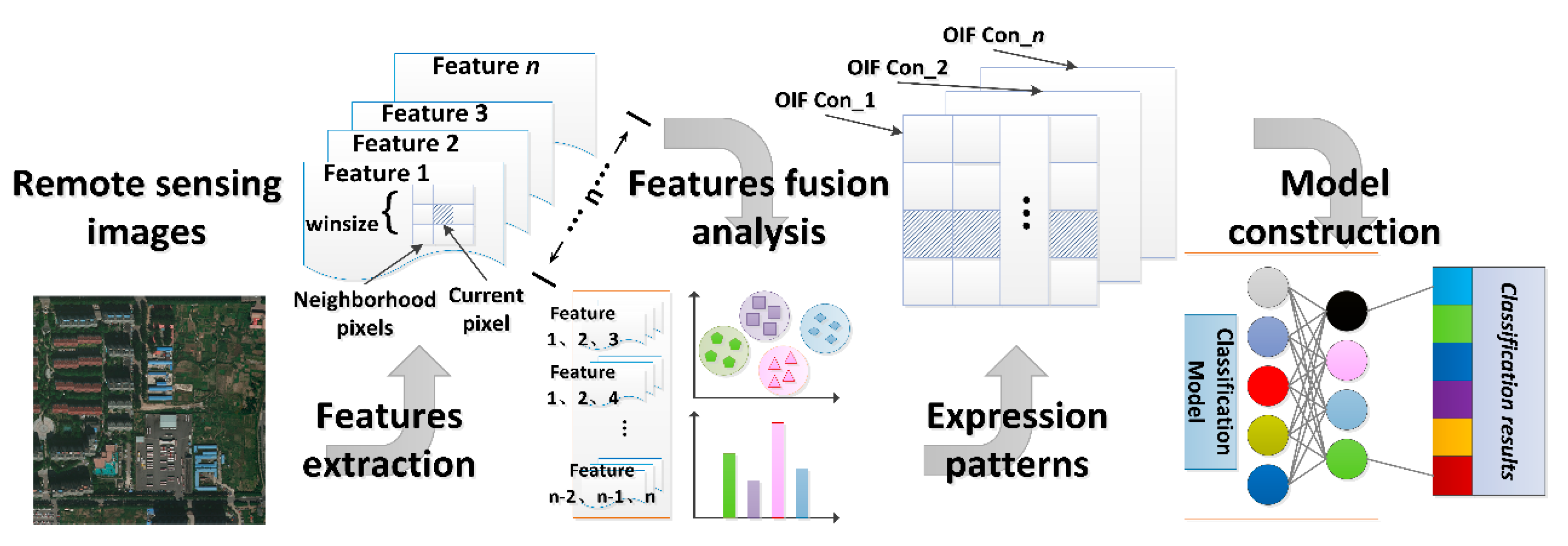
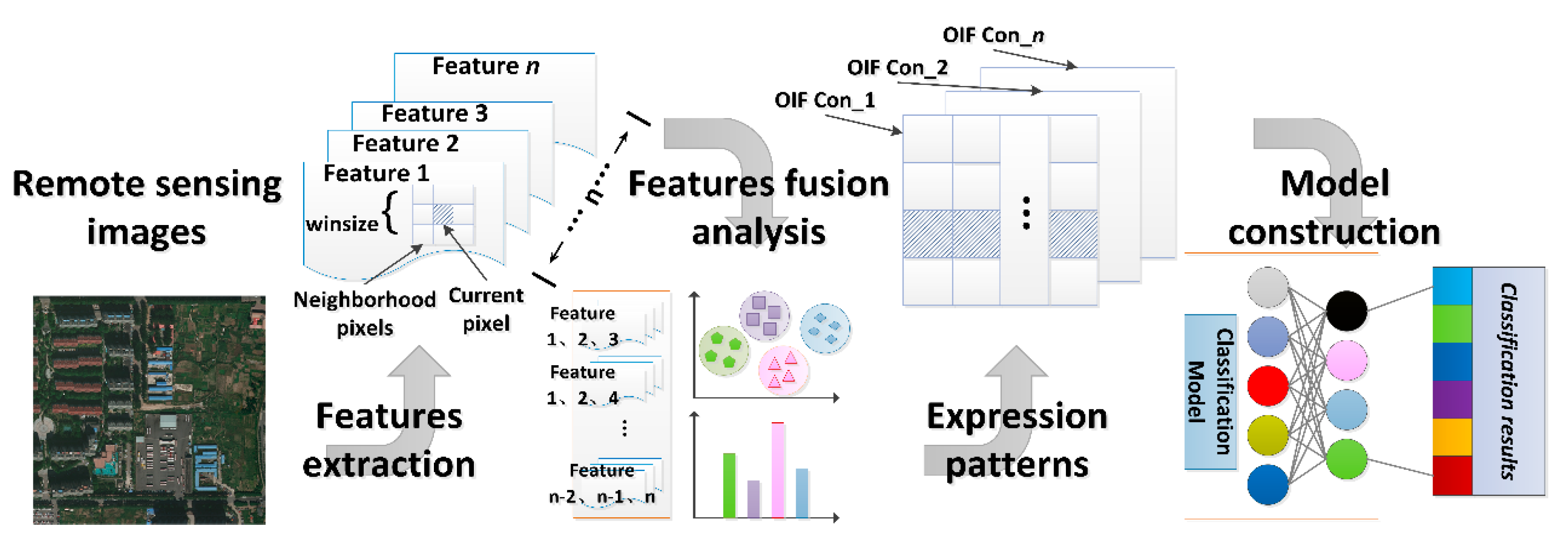
4.3.1. Pixel-Neighborhood-Window-Based Method
4.3.2. Object-Oriented Method
4.3.3. Rule-Partition-Based Method
4.3.4. Global Organization Method Based on Local Structure
5. Semantic Understanding of Concept Layer
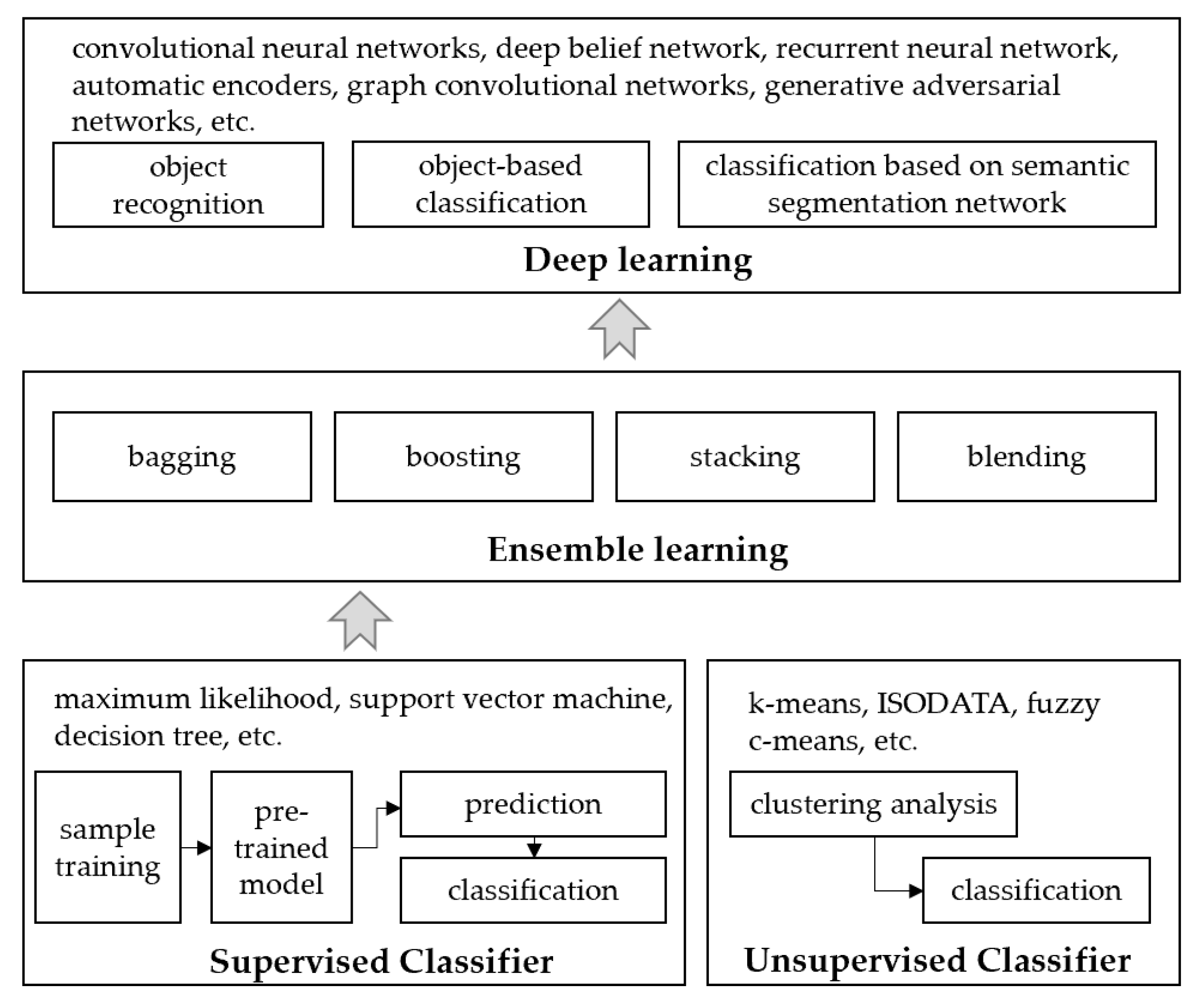
5.1. Visual Features Based Method
5.2. Object Semantics Based Method
5.2.1. Target-Recognition-Based Method
5.2.2. Local Semantics Based Method
- (1)
- Bag of visual words model
- (2)
- Probabilistic topic model
5.3. Feature-Learning-Based Method
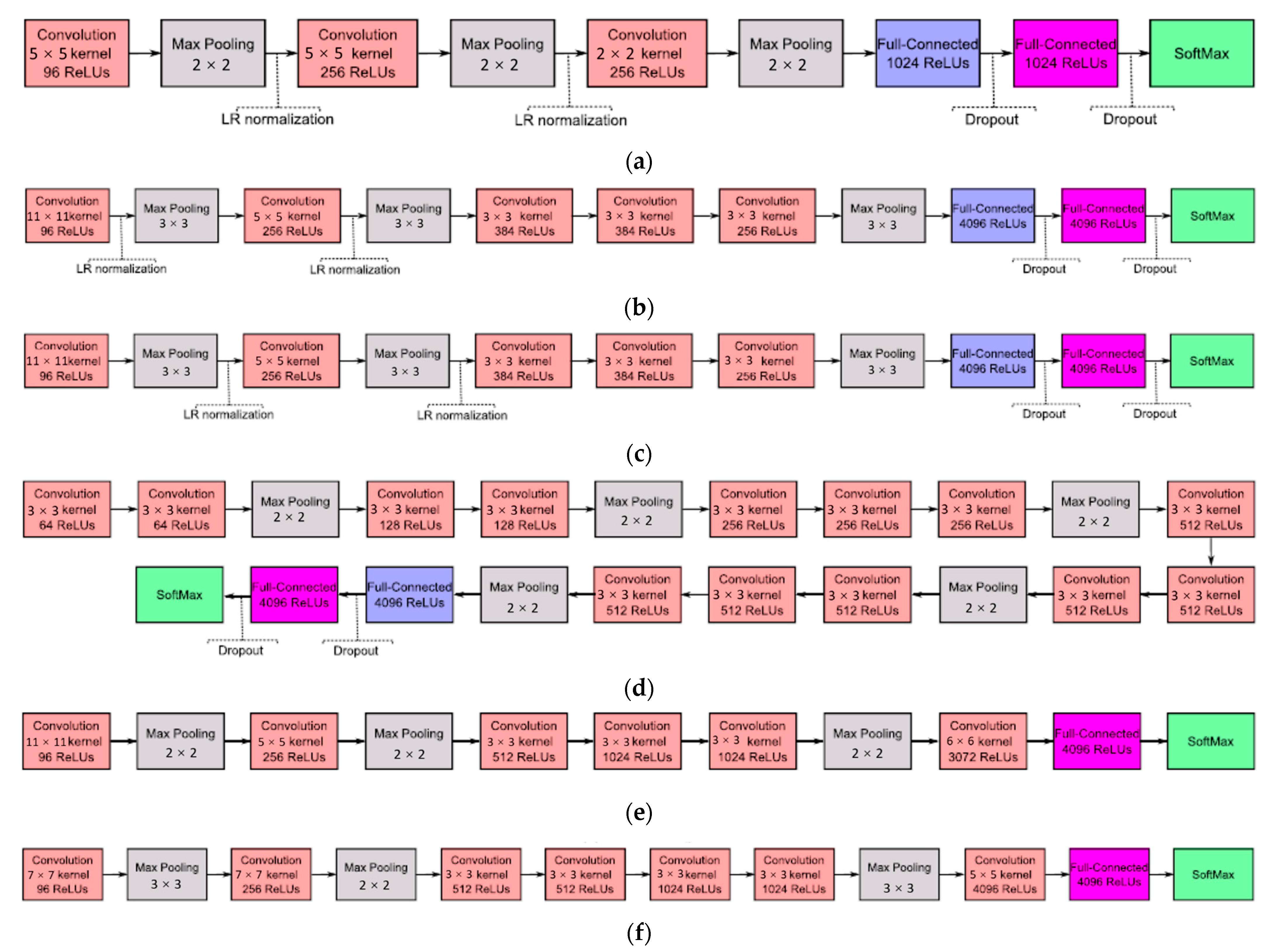
5.3.1. The Method Based on Fully Supervised Deep Learning
5.3.2. The Method Based on Semi-Supervised Deep Learning
5.3.3. The Method Based on Weak Supervised Deep Learning
- (1)
- In terms of training data, the success of a deep neural network is that it can fit large-scale samples without sacrificing generalization ability. In the field of geographic scene understanding, it is difficult to construct a large-scale, high-quality and complete HSR remote sensing image dataset for training. Firstly, from the perspective of time, a training sample can only represent the sampling of a time section. However, the interpretations of objects are dynamic in different periods. This time heterogeneity puts forward higher requirements for the quality, scale and completeness of sample annotation [196]. Secondly, from the perspective of space, due to the differences in climate and light conditions, the distribution of ground objects in different geographic scenes has natural heterogeneity [197]. This spatial heterogeneity leads to the imbalance of sample categories in the supervised learning process, whether within the training set or between the training set and the test set, which leads to “over-fitting” or “under-fitting” problems.
- (2)
- In terms of learning mechanisms, supervised learning mainly relies on semantic support provided by manual annotation as the only learning signal for model training. If human labeling is regarded as prior knowledge, the machine has been limited in knowledge in the process of labeling [198]. However, for the huge amount of image data, the intrinsic information should be much more abundant than the semantic information provided by sparse labels. Therefore, over-reliance on a manual annotation will cause the risk of “inductive bias” in the trained model. Moreover, the computational cost is high, especially for small samples. Most of the deep learning models are trained on the established network structure and are then fine-tuned to obtain better network parameters. This training pattern is not suitable for ever-expanding datasets.
6. Open Problems and Challenges
- (1)
- Integrated system engineering for geographic scene understanding

- (2)
- Comprehensive semantic representation of the geographic scene in HSR remote sensing image
- (3)
- Adaptability for large-scale complex geographic scenes
- (4)
- Fusion application of abundant multi-source data
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, D.; Zhang, L.; Xia, G. Automatic Analysis and Mining of Remote Sensing Big Data. Acta Geod. Cartogr. Sin. 2014, 43, 1211–1216. [Google Scholar]
- Dumitru, C.O.; Cui, S.; Schwarz, G.; Datcu, M. Information content of very-high-resolution sar images: Semantics, geospatial context, and ontologies. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 1635–1650. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zheng, X.; Liu, G.; Sun, X.; Wang, H.; Fu, K. Semi-Supervised Manifold Learning Based Multigraph Fusion for High-Resolution Remote Sensing Image Classification. IEEE Geosci. Remote Sens. 2014, 11, 464–468. [Google Scholar] [CrossRef]
- Liu, Q.; Hang, R.; Song, H.; Li, Z. Learning multiscale deep features for high-resolution satellite image scene classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 117–126. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W. Diversified deep structural metric learning for land use classification in remote sensing images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Zhang, L. Scene classfication based on the semantic-feature fusion fully sparse topic model for high spatial resolution remote sensing imagery. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B7, 451–457. [Google Scholar] [CrossRef] [Green Version]
- Biederman, I. Human image understanding: Recent research and theory. Comput. Vis. Graph. Image Process. 1985, 31, 400–401. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Eakins, J. Automatic image content retrieval—Are we getting anywhere? In Proceedings of the Third International Conference on Electronic Library and Visual Information Research (ELVIRA3), Milton Keynes, UK, 10–12 May 1996. [Google Scholar]
- Lv, G.; Chen, M.; Yuan, L.; Zhou, L.; Wen, Y.; Wu, M.; Hu, B.; Yu, Z.; Yue, S.; Sheng, Y. Geographic scenario: A possible foundation for further development of virtual geographic environments. Int. J. Digit. Earth 2018, 11, 356–368. [Google Scholar]
- Zhong, Y.; Fei, F.; Zhang, L. Large patch convolutional neural networks for the scene classification of high spatial resolution imagery. J. Appl. Remote Sens. 2016, 10, 025006. [Google Scholar] [CrossRef]
- Lin, B.; Liu, Q.; Li, C.; Ye, Z.; Hui, M.; Jia, X. Using Bag of Visual Words and Spatial Pyramid Matching for Object Classification Along with Applications for RIS. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar]
- Vyas, K.; Vora, Y.; Vastani, R. Bag-of-visual-words and spatial extensions for land-use classification. Procedia Comput. Sci. 2016, 89, 457–464. [Google Scholar] [CrossRef] [Green Version]
- Kasper, A.; Jäkel, R.; Dillmann, R. Using spatial relations of objects in real world scenes for scene structuring and scene understanding. In Proceedings of the 2011 15th International Conference on Advanced Robotics (ICAR), Tallinn, Estonia, 20–23 June 2011. [Google Scholar]
- Zhang, X.; Du, S. A Linear Dirichlet Mixture Model for decomposing scenes: Application to analyzing urban functional zonings. Remote Sens. Environ. 2015, 169, 37–49. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Y.; Li, Y. A Survey on Deep Learning-Driven Remote Sensing Image Scene Understanding: Scene Classification, Scene Retrieval and Scene-Guided Object Detection. Appl. Sci. 2019, 9, 2110. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Y.; Wu, S.; Zhao, B. Scene Semantic Understanding Based on the Spatial Context Relations of Multiple Objects. Remote Sens. 2017, 9, 1030. [Google Scholar] [CrossRef] [Green Version]
- Qin, K.; Chen, Y.; Gan, S.; Feng, X.; Ren, W. Review on methods of spatial structural feature modeling of high resolution remote sensing images. J. Image Graph. 2013, 18, 1055–1064. [Google Scholar]
- Hu, J. Multi-Level Feature Representation for Scene Classification with High Spatial Resolution Remote Sensing Images. Ph.D. Thesis, Wuhan University, Wuhan, China, 2019. [Google Scholar]
- Long, Y.; Xia, G.; Li, S.; Yang, W.; Yang, M.; Zhu, X.; Zhang, L.; Li, D. On Creating Benchmark Dataset for Aerial Image Interpretation: Reviews, Guidances, and Million-AID. IEEE J-STARS. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Shahriari, M.; Bergevin, R. Land-use scene classification: A comparative study on bag of visual word framework. Multimed. Tools Appl. 2017, 76, 23059–23075. [Google Scholar] [CrossRef]
- Xia, G.; Yang, W.; Delon, J.; Gousseau, Y.; Sun, H.; Maitre, H. Structural high-resolution satellite image indexing. In Proceedings of the ISPRS TC VII Symposium—100 Years ISPRS, Vienna, Austria, 5–7 July 2010; pp. 298–303. [Google Scholar]
- Nilakshi, D.; Bhogeswar, B. A novel mutual information-based feature selection approach forefficient transfer learning in aerial scene classification. Int. J. Remote sens. 2021, 2321–2325. [Google Scholar] [CrossRef]
- Zhao, L.; Ping, T.; Huo, L. Feature significance-based multibag-of-visual-words model for remote sensing image scene classification. J. Appl. Remote Sens. 2016, 10, 035004. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Xia, G.; Zhang, L. Dirichlet-Derived Multiple Topic Scene Classification Model for High Spatial Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2108–2123. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2017, 145, 197–209. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark data Set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. EuroSAT: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef] [Green Version]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Forssén, P.E. Maximally Stable Colour Regions for Recognition and Matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition., Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Sande, K.; Gevers, T.; Snoek, C. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1582–1596. [Google Scholar] [CrossRef]
- Tao, D.; Jin, L.; Zhao, Y.; Li, X. Rank Preserving Sparse Learning for Kinect Based Scene Classification. IEEE Trans. Cybern. 2013, 43, 1406–1417. [Google Scholar] [CrossRef]
- Banerji, S.; Sinha, A.; Liu, C. New image descriptors based on color, texture, shape, and wavelets for object and scene image classification. Neurocomputing 2013, 117, 173–185. [Google Scholar] [CrossRef]
- Iqbal, N.; Mumtaz, R.; Shafi, U.; Zaidi, S.M.H. Gray level co-occurrence matrix (GLCM) texture based crop classification using low altitude remote sensing platforms. PeerJ Comput. Sci. 2021, 7, e536. [Google Scholar] [CrossRef]
- Lv, H.; Liu, Y.; Xue, X.; Ma, T. Methods and Experiments of Background Subtraction and Grayscale Stretch for Remote Sensing Images. Chin. J. Liq. Cryst. Disp. 2012, 27, 235. [Google Scholar]
- Li, Y.; Zhang, J.; Zhou, Y.; Niu, J.; Wang, L.; Meng, N.; Zheng, J. ISAR Imaging of Nonuniformly Rotating Targets with Low SNR Based on Coherently Integrated Nonuniform Trilinear Autocorrelation Function. IEEE Geosci. Remote Sens. Lett. 2020, 99, 1074–1078. [Google Scholar] [CrossRef]
- Ru, C.; Li, Z.; Tang, R. A Hyperspectral Imaging Approach for Classifying Geographical Origins of Rhizoma Atractylodis Macrocephalae Using the Fusion of Spectrum-Image in VNIR and SWIR Ranges (VNIR-SWIR-FuSI). Sensors 2019, 19, 2045. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, L.; Chen, C.; Li, W.; Du, Q. Remote Sensing Image Scene Classification Using Multi-Scale Completed Local Binary Patterns and Fisher Vectors. Remote Sens. 2016, 8, 483. [Google Scholar] [CrossRef] [Green Version]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2011, 42, 145–175. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Computer Vision—ECCV 2006; Lecture Notes in Computer Science; Proceedings of the 9th European Conference on Computer Vision (ECCV 2006), Graz, Austria, 7–13 May 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Wu, J.; Rehg, J. CENTRIST: A visual descriptor for scene categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1489–1501. [Google Scholar]
- Zou, C.; Lei, Z.; Lv, S. Remote Sensing Image Dam Detection Based on Dual Threshold Network. In Proceedings of the 2020 Chinese Control and Decision Conference (CCDC), Hefei, China, 23 August 2020. [Google Scholar]
- Horhan, M.; Eidenberger, H. An Efficient DCT template-based Object Detection Method using Phase Correlation. In Proceedings of the 2016 50th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 6–9 November 2017. [Google Scholar]
- Wu, Z.; Wan, Q.; Liang, J.; Zhou, Z. Line Detection in Remote Sensing Images Using Hough Transform Based on Granular Computing. Geomat. Inf. Sci. Wuhan Univ. 2007, 32, 860–863. [Google Scholar]
- Zhang, L.; Zhang, L.; Tao, D.; Xin, H.; Bo, D. Hyperspectral Remote Sensing Image Subpixel Target Detection Based on Supervised Metric Learning. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4955–4965. [Google Scholar] [CrossRef]
- Hermosilla, T.; Ruiz, L.A.; Recio, J.A.; Estornell, J. Evaluation of Automatic Building Detection Approaches Combining High Resolution Images and LiDAR Data. Remote Sens. 2011, 3, 1188–1210. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Xu, H.; An, S. Monitoring and assessment of intensive utilization of port area based on high spatial resolution remote sensing image with case study of five typical ports in the Bohai Sea. J. Appl. Oceanogr. 2019, 38, 126–134. [Google Scholar]
- Ai, S.; Yan, J.; Li, D.; Xu, J.; Shen, J. An Algorithm for Detecting the Airport Runway in Remote Sensing Image. Electron. Opt. Control 2017, 24, 43–46. [Google Scholar]
- Li, X.; Zhang, Z.; Lv, S.; Pan, M.; Yu, H. Road Extraction from High Spatial Resolution Remote Sensing Image Based on Multi-Task Key Point Constraints. IEEE Access 2021, 9, 95896–95910. [Google Scholar] [CrossRef]
- Wei, S.; Chen, H.; Zhu, X.; Zhang, H. Ship Detection in Remote Sensing Image based on Faster R-CNN with Dilated Convolution. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020. [Google Scholar]
- Wang, X.; Luo, G.; Ke, Q.; Chen, A.; Tian, L. A Fast Target Locating Method for Remote Sensing Images Based on Line Features. Int. J. Signal Process. Image Process. Pattern Recogn. 2017, 10, 61–72. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, Q.; Ming, G.; Li, J. Remote Sensing Image Analysis on Circulation Induced by the Breakwaters in the Huanghua Port. In Proceedings of the International Conference on Estuaries and Coasts, Hangzhou, China, 9–11 November 2003. [Google Scholar]
- Song, J.; Hu, W. Experimental Results of Maritime Target Detection Based on SVM Classifier. In Proceedings of the 2020 IEEE 3rd International Conference on Information Communication and Signal Processing (ICICSP), Shanghai, China, 12–15 September 2020. [Google Scholar]
- Huang, S.; Huang, W.; Zhang, T. A New SAR Image Segmentation Algorithm for the Detection of Target and Shadow Regions. Sci. Rep. 2016, 6, 38596. [Google Scholar] [CrossRef] [PubMed]
- Chaudhuri, D.; Agrawal, A. Split-and-merge Procedure for Image Segmentation using Bimodality Detection Approach. Def. Sci. J. 2010, 60, 290–301. [Google Scholar] [CrossRef]
- Sun, Y.J.; Lei, W.H.; Ren, X.D. Remote sensing image ship target detection method based on visual attention model. In Proceedings of the Lidar Imaging Detection and Target Recognition 2017; Lv, D., Lv, Y., Bao, W., Eds.; SPIE-Int. Soc. Optical Engineering: Bellingham, WA, USA, 2017; Volume 10605. [Google Scholar]
- Wu, J.; Rehg, J.M. Beyond the Euclidean distance: Creating effective visual codebooks using the Histogram Intersection Kernel. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Perronnin, F. Universal and Adapted Vocabularies for Generic Visual Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1243–1256. [Google Scholar] [CrossRef]
- Su, Y.; Allan, M.; Jurie, F. Improving Image Classification Using Semantic Attributes. Int. J. Comput. Vis. 2012, 100, 59–77. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Kai, Y.; Gong, Y.; Huang, T. Linear spatial pyramid matching using sparse coding for image classification. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Lee, H.; Battle, A.; Raina, R.; Ng, A.Y. Efficient sparse coding algorithms. In Advances in Neural Information Processing Systems 19, Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Yu, K.; Zhang, T. Improved Local Coordinate Coding using Local Tangents. In Proceedings of the International Conference on International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Wang, J.; Yang, J.; Kai, Y.; Lv, F.; Huang, T.; Gong, Y. Locality-constrained Linear Coding for image classification. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Pham, T.T.; Maisonnasse, L.; Mulhem, P.; Gaussier, E. Visual Language Model for Scene Recognition. In Proceedings of the Singaporean-French Ipal Symposium 2009, Singapore, 18–20 February 2009. [Google Scholar]
- Hofmann, T. Unsupervised Learning by Probabilistic Latent Semantic Analysis. Mach. Learn. 2001, 42, 177–196. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Wu, L.; Hu, Y.; Li, M.; Yu, N.; Hua, X. Scale-Invariant Visual Language Modeling for Object Categorization. IEEE Trans. Multimed. 2009, 11, 286–294. [Google Scholar] [CrossRef]
- Jing, H.; Wei, H. Latent Dirichlet Allocation Based Image Retrieval. In Information Retrieval; Wen, J., Nie, J., Ruan, T., Liu, Y., Qian, T., Eds.; CCIR 2017, Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10390. [Google Scholar] [CrossRef]
- Kato, H.; Harada, T. Visual Language Modeling on CNN Image Representations. arXiv 2015, arXiv:1511.02872. [Google Scholar]
- Zhao, H.; Wang, Q.; Wang, Q.; Wu, W.; Yuan, N. SAR image despeckling based on adaptive neighborhood window and rotationally invariant block matching. In Proceedings of the 2014 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Guilin, China, 5–8 August 2014. [Google Scholar]
- Aytekin, Ö.; Koc, M.; Ulusoy, İ. Local Primitive Pattern for the Classification of SAR Images. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2431–2441. [Google Scholar] [CrossRef]
- Hudak, A.T.; Strand, E.K.; Vierling, L.A.; Byrne, J.C.; Eitel, J.; Martinuzzi, S.; Falkowski, M. Quantifying aboveground forest carbon pools and fluxes from repeat LiDAR surveys. Remote Sens. Environ. 2012, 123, 25–40. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Zhang, B.; Li, A.; Jia, X.; Gao, L.; Peng, M. Hyperspectral Imagery Clustering with Neighborhood Constraints. IEEE Geosci. Remote Sens. Lett. 2013, 10, 588–592. [Google Scholar] [CrossRef]
- Rahman, M.H.; Islam, H.; Neema, N. Compactness of Neighborhood Spatial Structure: A Case Study of Selected Neighborhoods of DNCC and DSCC Area. In Proceedings of the International Conference on Sustainability in Natural and Built Environment (iCSNBE 2019), Dhaka, Bangladesh, 19–22 January 2019. [Google Scholar]
- Guan, X.; Huang, C.; Yang, J.; Li, A. Remote Sensing Image Classification with a Graph-Based Pre-Trained Neighborhood Spatial Relationship. Sensors 2021, 21, 5602. [Google Scholar] [CrossRef]
- Sha, Z.; Bian, F. Object-Oriented Spatial Knowledge Representation and Its Application. J. Remote Sens. 2004, 19, 165–171. [Google Scholar]
- Wei, C.; Zheng, Z.; Zhou, Q.; Huang, J.; Yuan, Y. Application of a parallel spectral-spatial convolution neural network in object-oriented remote sensing land use classification. Remote Sens. Lett. 2018, 9, 334–342. [Google Scholar]
- Wang, Y.; Bao, W.; Yang, C.; Zhang, Y. A study on the automatic classification method on the basis of high resolution remote sensing image. In Proceedings of the 6th International Digital Earth Conference, Beijing, China, 9–12 September 2009. [Google Scholar]
- Liu, X. Object Oriented Information Classification of Remote Sensing Image Based on Segmentation and Merging. Appl. Mech. Mater. 2014, 568–570, 734–739. [Google Scholar] [CrossRef]
- Tan, Y.; Huai, J.; Tang, Z. An Object-Oriented Remote Sensing Image Segmentation Approach Based on Edge Detection. Spectrosc. Spect. Anal. 2010, 30, 1624–1627. [Google Scholar]
- Tong, X.; Jin, B.; Ying, W. A new effective Hexagonal Discrete Global Grid System: Hexagonal quad balanced structure. In Proceedings of the 8th International Conference on Geoinformatics, Beijing, China, 18–20 June 2010. [Google Scholar]
- Khromyk, V.; Khromykh, O. Analysis of Spatial Structure and Dynamics of Tom Valley Landscapes based on GIS, Digital Elevation Model and Remote Sensing. Procedia Soc. Behav. Sci. 2014, 120, 811–815. [Google Scholar] [CrossRef] [Green Version]
- Ding, Y.; Pan, S.; Chong, Y. Robust Spatial–Spectral Block-Diagonal Structure Representation with Fuzzy Class Probability for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1747–1762. [Google Scholar] [CrossRef]
- Gao, Y.; Zhang, Y.; Alsulaiman, H. Spatial structure system of land use along urban rail transit based on GIS spatial clustering. Eur. J. Remote Sens. 2021, 54, 438–445. [Google Scholar] [CrossRef]
- Wurm, M.; Taubenbck, H.; Dech, S. Quantification of urban structure on building block level utilizing multisensoral remote sensing data. In Proceedings of the Earth Resources and Environmental Remote Sensing/GIS Applications 2010, Toulouse, France, 25 October 2010. [Google Scholar]
- Chen, J.; Chen, S.; Chen, X.; Yang, Y.; Xing, L.; Fan, X.; Rao, Y. LSV-ANet: Deep Learning on Local Structure Visualization for Feature Matching. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Du, Z.; Li, X.; Lu, X. Local structure learning in high resolution remote sensing image retrieval. Neurocomputing 2016, 207, 813–822. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.; Zou, Z. Super-Resolution for Remote Sensing Images via Local-Global Combined Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Chen, J.; Fan, X.; Chen, S.; Yang, Y.; Bai, H. Robust Feature Matching via Hierarchical Local Structure Visualization. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Unsupervised Retraining of a Maximum Likelihood Classifier for the Analysis of Multitemporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 456–460. [Google Scholar] [CrossRef] [Green Version]
- Zeh, A.; Bezzateev, S. A New Bound on the Minimum Distance of Cyclic Codes Using Small-Minimum-Distance Cyclic Codes. Design. Code. Cryptogr. 2014, 71, 229–246. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Meng, Q. Polyp classification based on Bag of Features and saliency in wireless capsule endoscopy. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Guo, Y.; Ji, J.; Shi, D.; Ye, Q.; Xie, H. Multi-view feature learning for VHR remote sensing image classification. Multimed. Tools Appl. 2021, 80, 23009–23021. [Google Scholar] [CrossRef]
- Hu, J.; Li, M.; Xia, G.; Zhang, L. Mining the spatial distribution of visual words for scene classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016. [Google Scholar]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep Feature Fusion for VHR Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Li, L.; Su, H.; Xing, E.; Li, F. Object bank: A high-level image representation for scene classification & semantic feature sparsification. In Proceedings of the 23rd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 6–9 December 2010. [Google Scholar]
- Sadeghi, F.; Tappen, M.F. Latent Pyramidal Regions for Recognizing Scenes. In Computer Vision—ECCV 2012, Proceedings of the 12th European Conference on Computer Vision (ECCV 2012), Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Juneja, M.; Vedaldi, A.; Jawahar, C.; Zisserman, A. Blocks that shout: Distinctive parts for scene classification. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Wang, J.; Sun, X.; Nahavandi, S.; Kouzani, A.; Wu, Y.; She, M. Multichannel biomedical time series clustering via hierarchical probabilistic latent semantic analysis. Comput. Meth. Prog. Biol. 2014, 117, 238–246. [Google Scholar] [CrossRef] [PubMed]
- Gong, C.; Li, Z.; Yao, X.; Guo, L.; Wei, Z. Remote Sensing Image Scene Classification Using Bag of Convolutional Features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar]
- Hu, J.; Xia, G.-S.; Hu, F.; Zhang, L. A Comparative Study of Sampling Analysis in the Scene Classification of Optical High-Spatial Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14988–15013. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.; Tao, D.; Rui, Y.; Cheng, J. Pairwise constraints based multiview features fusion for scene classification. Pattern Recogn. 2013, 46, 483–496. [Google Scholar] [CrossRef]
- Wang, X.; Wang, B.; Bai, X.; Liu, W.; Tu, Z. Max-margin multiple-instance dictionary learning. In Proceedings of the 30th International Conference on International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Shen, L.; Wang, S.; Sun, G.; Jiang, S.; Huang, Q. Multi-level discriminative dictionary learning towards hierarchical visual categorization. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Oliveira, G.; Nascimento, E.; Vieira, A.; Campos, M. Sparse spatial coding: A novel approach for efficient and accurate object recognition. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.; Zhang, L. Bag-of-Visual-Words Scene Classifier with Local and Global Features for High Spatial Resolution Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 13, 747–751. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhong, Y.; Xu, K. Fast Binary Coding for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2016, 8, 555. [Google Scholar] [CrossRef] [Green Version]
- Kwitt, R.; Vasconcelos, N.; Rasiwasia, N. Scene recognition on the semantic manifold. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Wang, Z.; Feng, J.; Yan, S.; Xi, H. Linear distance coding for image classification. IEEE Trans. Image Process. 2013, 22, 537–548. [Google Scholar] [CrossRef]
- Xie, L.; Wang, J.; Guo, B.; Zhang, B.; Tian, Q. Orientational pyramid matching for recognizing indoor scenes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Singh, A.; Parmanand; Saurabh. Survey on pLSA based scene classification techniques. In Proceedings of the 2014 5th International Conference—Confluence the Next Generation Information Technology Summit (Confluence), Noida, India, 25–26 September 2014. [Google Scholar]
- Veeranjaneyulu, N.; Raghunath, A.; Devi, B.J.; Mandhala, V.N. Scene classification using support vector machines with LDA. J. Theor. Appl. Inf. Technol. 2014, 63, 741–747. [Google Scholar]
- Bosch, A.; Zisserman, A.; Muñoz, X. Scene classification via PLSA. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Wu, J. A fast dual method for HIK SVM learning. In Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010. [Google Scholar]
- Bosch, A.; Zisserman, A.; Muoz, X. Scene classification using a hybrid generative/discriminative approach. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 712–727. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Liu, H.; Wang, T.; Li, S.; Gao, G. Deep feature extraction and motion representation for satellite video scene classification. Sci. China Inf. Sci. 2020, 63, 140307. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Marcos, D.; Schindler, K.; Saux, B.L. Deep Learning-based Semantic Segmentation in Remote Sensing. In Deep Learning for the Earth Sciences: A Comprehensive Approach to Remote Sensing, Climate Science, and Geosciences; Camps-Valls, G., Tuia, D., Zhu, X., Reichstein, M., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 2021; Volume 5, pp. 46–66. [Google Scholar] [CrossRef]
- Lin, D. MARTA GANs: Deep Unsupervised Representation Learning for Remote Sensing Images. arXiv 2016, arXiv:1612.08879. [Google Scholar]
- Qi, K.; Zhang, X.; Wu, B.; Wu, H. Sparse coding-based correlation model for land-use scene classification in high-resolution remote-sensing images. J. Appl. Remote Sens. 2016, 10, 042005. [Google Scholar]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-Free Convolutional Neural Network for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Du, P.; Tan, K.; Xing, X. A novel binary tree support vector machine for hyperspectral remote sensing image classification. Opt. Commun. 2012, 285, 3054–3060. [Google Scholar] [CrossRef]
- Zhao, Z.; Luo, Z.; Li, J.; Chen, C.; Piao, Y. When Self-Supervised Learning Meets Scene Classification: Remote Sensing Scene Classification Based on a Multitask Learning Framework. Remote Sens. 2020, 12, 3276. [Google Scholar] [CrossRef]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J.; Zhang, L. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Risojevi, V.; Stojni, V. The Role of Pre-Training in High-Resolution Remote Sensing Scene Classification. arXiv 2021, arXiv:2111.03690. [Google Scholar]
- Boualleg, Y.; Farah, M.; Farah, I.R. Remote Sensing Scene Classification Using Convolutional Features and Deep Forest Classifier. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1944–1948. [Google Scholar] [CrossRef]
- Li, E.; Samat, A.; Du, P.; Liu, W.; Hu, J. Improved Bilinear CNN Model for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Deng, P.; Shi, G. Two-stream Feature Aggregation Deep Neural Network for Scene Classification of Remote Sensing Images. Inform. Sci. 2020, 539, 250–268. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1–5. [Google Scholar] [CrossRef]
- Liang, L.; Wang, G. Efficient recurrent attention network for remote sensing scene classification. IET Image Process. 2021, 15, 1712–1721. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J.; Han, J.; Guo, L.; Han, J. Auto-encoder-based shared mid-level visual dictionary learning for scene classification using very high resolution remote sensing images. IET Comput. Vis. 2015, 9, 639–647. [Google Scholar] [CrossRef]
- Liang, J.; Deng, Y.; Zeng, D. A Deep Neural Network Combined CNN and GCN for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4325–4338. [Google Scholar] [CrossRef]
- Duan, Y.; Tao, X.; Xu, M.; Han, C.; Lu, J. GAN-NL: Unsupervised Representation Learning for Remote Sensing Image Classification. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–29 November 2018. [Google Scholar]
- Yu, Y.; Li, X.; Liu, F. Attention GANs: Unsupervised Deep Feature Learning for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 519–531. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Adaptive deep sparse semantic modeling framework for high spatial resolution image scene classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6180–6195. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classification. IEEE T. Neur. Net. Lear. 2020, 31, 1461–1474. [Google Scholar] [CrossRef] [Green Version]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. BigEarthNet: A Large-Scale Benchmark Archive for Remote Sensing Image Understanding. arXiv 2019, arXiv:1902.06148. [Google Scholar]
- Qian, X.; Li, E.; Zhang, J.; Zhao, S.; Wu, Q.; Zhang, H.; Wang, W.; Wu, Y. Hardness recognition of robotic forearm based on semi-supervised generative adversarial networks. Front. Neurorobot. 2019, 13, 73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- Soto, P.J.; Bermudez, J.D.; Happ, P.N.; Feitosa, R. A comparative analysis of unsupervised and semi- supervised representation learning for remote sensing image categorization. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W7, 167–173. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Tan, H.; Lu, S. Multipath sparse coding for scene classification in very high resolution satellite imagery. In Proceedings of the SPIE 9643, Image and Signal Processing for Remote Sensing XXI, Toulouse, France, 15 October 2015. [Google Scholar]
- Othman, E.; Bazi, Y.; Melgani, F.; Alhichri, H.; Alajlan, N.; Zuair, M. Domain adaptation network for cross-scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4441–4456. [Google Scholar] [CrossRef]
- Gong, Z.; Zhong, P.; Yu, Y.; Hu, W. Diversity-promoting deep structural metric learning for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 371–390. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2014, arXiv:1312.6229. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. arXiv 2013, arXiv:1310.1531. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM international conference on Multimedia, New York, NY, USA, 3–7 November 2014. [Google Scholar]
- Chung, A.; Shafiee, M.; Wong, L. Random feature maps via a Layered Random Projection (LARP) framework for object classification. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Luus, F.P.; Salmon, B.P.; Van Den Bergh, F.; Maharaj, B.T.J. Multiview deep learning for land-use classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2448–2452. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Nogueira, K.; Penatti, O.; Santos, J. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recogn. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene classification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Penatti, O.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Li, B.; Su, W.; Wu, H.; Li, R.; Zhang, W.; Qin, W.; Zhang, S. Aggregated Deep Fisher Feature for VHR Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3508–3523. [Google Scholar] [CrossRef]
- Scott, G.; Hagan, K.; Marcum, R.; Hurt, J.; Anderson, D.; Davis, C. Enhanced Fusion of Deep Neural Networks for Classification of Benchmark High-Resolution Image Data Sets. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1451–1455. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL Internationa Conference on Advances in Geographic Information Systems (ACM 2010), San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Risojević, V.; Babić, Z. Aerial image classification using structural texture similarity. In Proceedings of the 2011 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Bilbao, Spain, 14–17 December 2011. [Google Scholar]
- Risojević, V.; Babić, Z. Orientation difference descriptor for aerial image classification. In Proceedings of the 2012 19th International Conference on Systems, Signals and Image Processing (IWSSIP), Vienna, Austria, 11–13 April 2012. [Google Scholar]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Processing 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Shao, W.; Yang, W.; Xia, G.; Liu, G. A hierarchical scheme of multiple feature fusion for high-resolution satellite scene categorization. In Proceedings of the 9th International Conference, ICVS 2013, Saint Petersburg, Russia, 16–18 July 2013. [Google Scholar]
- Zhao, L.; Tang, P.; Huo, L. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. A 2-D wavelet decomposition-based bag-of-visual-words model for land-use scene classification. Int. J. Remote Sens. 2014, 35, 2296–2310. [Google Scholar] [CrossRef]
- Cheriyadat, A.M. Unsupervised feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2013, 52, 439–451. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Negrel, R.; Picard, D.; Gosselin, P. Evaluation of second-order visual features for land-use classification. In Proceedings of the 2014 12th International Workshop on Content-Based Multimedia Indexing (CBMI), Klagenfurt, Austria, 18–20 June 2014. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2175–2184. [Google Scholar] [CrossRef]
- Chen, S.; Tian, Y. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhu, Q.; Zhang, L. Scene classification based on the multifeature fusion probabilistic topic model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6207–6222. [Google Scholar] [CrossRef]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Luo, J.; Kitamura, G.; Arefan, D.; Doganay, E.; Panigrahy, A.; Wu, S. Knowledge-Guided Multiview Deep Curriculum Learning for Elbow Fracture Classification. In Proceedings of the 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, 27 September 2021. [Google Scholar]
- Zhang, F.; Du, B.; Zhang, L. Scene classification via a gradient boosting random convolutional network framework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1793–1802. [Google Scholar] [CrossRef]
- Liu, Q.; Hang, R.; Song, H.; Zhu, H.; Plaza, J.; Plaza, A. Adaptive deep pyramid matching for remote sensing scene classification. arXiv 2016, arXiv:1611.03589. [Google Scholar]
- Han, X.; Zhong, Y.; Zhao, B.; Zhang, L. Scene classification based on a hierarchical convolutional sparse auto-encoder for high spatial resolution imagery. Int. J. Remote Sens. 2017, 38, 514–536. [Google Scholar] [CrossRef]
- Lin, D.; Fu, K.; Wang, Y.; Xu, G.; Sun, X. MARTA GANs: Unsupervised representation learning for remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2092–2096. [Google Scholar] [CrossRef] [Green Version]
- Shawky, O.A.; Hagag, A.; El-Dahshan, E.S.A.; Ismail, M. A very high-resolution scene classification model using transfer deep CNNs based on saliency features. Signal Image Video Processing 2021, 15, 817–825. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; Van De Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 138, 74–85. [Google Scholar] [CrossRef] [Green Version]
- Qi, K.; Guan, Q.; Yang, C.; Peng, F.; Shen, S.; Wu, H. Concentric Circle Pooling in Deep Convolutional Networks for Remote Sensing Scene Classification. Remote Sens. 2018, 10, 934. [Google Scholar] [CrossRef] [Green Version]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Wang, W.; Du, L.; Gao, Y.; Su, Y.; Wang, F.; Cheng, J. A Discriminative Learned CNN Embedding for Remote Sensing Image Scene Classification. arXiv 2019, arXiv:1911.12517. [Google Scholar]
- Yu, Y.; Liu, F. Dense Connectivity Based Two-Stream Deep Feature Fusion Framework for Aerial Scene Classification. Remote Sens. 2018, 10, 1158. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intel. Neurosc. 2018, 2018, 8639367. [Google Scholar] [CrossRef] [Green Version]
- Ye, L.; Wang, L.; Sun, Y.; Zhao, L.; Wei, Y. Parallel multi-stage features fusion of deep convolutional neural networks for aerial scene classification. Remote Sens. Lett. 2018, 9, 294–303. [Google Scholar] [CrossRef]
- Chen, J.; Wang, C.; Ma, Z.; Chen, J.; He, D.; Ackland, S. Remote Sensing Scene Classification Based on Convolutional Neural Networks Pre-Trained Using Attention-Guided Sparse Filters. Remote Sens. 2018, 10, 290. [Google Scholar] [CrossRef] [Green Version]
- Akodad, S.; Vilfroy, S.; Bombrun, L.; Cavalcante, C.C.; Germain, C.; Berthoumieu, Y. An ensemble learning approach for the classification of remote sensing scenes based on covariance pooling of CNN features. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019. [Google Scholar]
- Liu, Y.; Zhong, Y.; Qin, Q. Scene Classification Based on Multiscale Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7109–7121. [Google Scholar]
- Lu, X.; Ji, W.; Liu, W.; Zheng, X. Bidirectional adaptive feature fusion for remote sensing scene classification. Neurocomputing 2019, 328, 135–146. [Google Scholar] [CrossRef]
- He, H.; Garcia, E. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Spatial Resolution (m) | Image Size | Number of Categories | Number of Samples per Category | Total Number of Samples | Year of Publication |
|---|---|---|---|---|---|---|
| UC-Merced [23] | 0.3 | 256 × 256 | 21 | 100 | 2100 | 2010 |
| WHU-RS19 [24] | 0.5 | 600 × 600 | 12 | 50 | 950 | 2010 |
| RSSCN7 [25] | - | 400 × 400 | 7 | 400 | 2800 | 2015 |
| RSC11 [26] | 0.2 | 512 × 512 | 11 | About 100 | 1232 | 2016 |
| SIRI-WHU [27] | 2 | 200 × 200 | 12 | 200 | 2400 | 2016 |
| NWPU-RESISC45 [28] | 0.2–30 | 256 × 256 | 45 | 700 | 31,500 | 2017 |
| PatternNet [29] | 0.062–4.693 | 256 × 256 | 38 | 800 | - | 2017 |
| AID [30] | - | - | 30 | - | 10,000 | 2017 |
| EuroSAT [31] | - | 64 × 64 | 10 | 2000–3000 | 27,000 | 2019 |
| Name | Type | Output | Advantage | Disadvantage | Applicable |
|---|---|---|---|---|---|
| GIST | Global | Spectral information | Low computational complexity and easy to use | Poor performance in complex scenes with dense targets | Simple natural scenes |
| SIFT | Local | Neighborhood histogram | Suitable for translation, rotation, scale transformation | Poor performance in complex scenes with overall layout | Natural scenes |
| HOG | Vector | Representation of contours and edges | Poor performance in scenes with unstable shape structure | Scenes with global structural stability | |
| CENTRIST | Census transformed value | Highlight local characteristics and reflect position information | Poor performance in complex and volatile scenes | Scenes with clear layout and sparse target distribution |
| Name | Advantage | Disadvantage | Applicable |
|---|---|---|---|
| Object Bank | Identifiable targets and natural scenes | High computational complexity and high feature dimension | Natural scenes with landmark targets |
| Latent Pyramidal Regions | Good performance for regions with specific structures | Focus on the shape structure of the scene, lack of deep semantic understanding | Scenes with complex background and crowded targets |
| Bag of Parts | Good performance for areas with boundaries or corners | ||
| Latent Semantic Analysis | The synonym is characterized by dimensionality reduction, and the redundant data are used | Polysemous words have low discrimination and high computational complexity | Scenes with heterogeneous information and clear boundaries |
| Method | Accuracy (%) | Other Indicators | |
|---|---|---|---|
| Visual features-based method | Gabor texture [161] | 76.91 | - |
| Color-HLS [161] | 81.19 | - | |
| NN-STSIM [162] | 86 | - | |
| Quaternion orientation difference [163] | 85.48 ± 1.02 | - | |
| MS-CLBP [164] | 90.6 ± 1.4 | - | |
| Object-semantics-based method | BoVW [161] | 76.81 | - |
| BoVW + SCK [161] | 77.71 | - | |
| SPM [161] | 75.29 | - | |
| SPCK ++ [165] | 77.38 | - | |
| HMFF [166] | 92.38 ± 0.62 | - | |
| CCM-BoVW [167] | 86.64 ± 0.81 | - | |
| Wavelet BoVW [168] | 87.38 ± 1.27 | - | |
| UFL [169] | 81.67 ± 1.23 | - | |
| COPD [170] | 91.33 ± 1.11 | - | |
| FV [171] | 93.8 | - | |
| VLAT [171] | 94.3 | - | |
| SG-UFL [172] | 82.72 ± 1.18 | - | |
| PSR [173] | 89.1 | - | |
| UFL-SC [174] | 90.26 ± 1.51 | - | |
| SAL-PLSA [175] | 87.62 | - | |
| SAL-LDA [175] | 88.33 | - | |
| Feature-learning-based method | CaffeNet finetune [176] | 95.48 | - |
| GoogleNet finetune [176] | 97.1 | - | |
| Multiview DL [177] | 93.48 ± 0.82 | 84.35 (Sensitivity), 91.72 (Specificity) | |
| GBRCN [178] | 94.53 | - | |
| ADPM [179] | 94.86 | - | |
| HCSAE [180] | 97.14 ± 1.19 | - | |
| MARTA GANs [181] | 94.86 ± 0.80 | - | |
| Fusion by addition [182] | 97.42 ± 1.79 | - | |
| salM3LBP-CLM [183] | 95.75 ± 0.80 | - | |
| TEX-Nets [184] | 97.72 | - | |
| CCP-Net [185] | 97.52 ± 0.97 | - | |
| CNN (LOFs+GCFs) [186] | 99.00 ± 0.35 | - | |
| ARCNet-VGG16 [187] | 99.12 ± 0.40 | - | |
| D-CNN with VGG16 [188] | 98.93 ± 0.10 | - | |
| SAL-TS-Net [189] | 98.90 ± 0.95 | - | |
| Two-stream deep fusion [190] | 98.02 ± 1.03 | - | |
| PMS [191] | 98.81 | 8.32 × 106 (Number of neurons) | |
| SSF-AlexNet [192] | 92.43 ± 0.46 | - | |
| VGG16+MSCP+MRA [193] | 98.40 ± 0.34 | - | |
| MCNN [194] | 96.66 ± 0.90 | - | |
| Bidirectional adaptive feature fusion [195] | 95.48 | - | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, P.; Liu, G.; Huang, Y. Geographic Scene Understanding of High-Spatial-Resolution Remote Sensing Images: Methodological Trends and Current Challenges. Appl. Sci. 2022, 12, 6000. https://doi.org/10.3390/app12126000
Ye P, Liu G, Huang Y. Geographic Scene Understanding of High-Spatial-Resolution Remote Sensing Images: Methodological Trends and Current Challenges. Applied Sciences. 2022; 12(12):6000. https://doi.org/10.3390/app12126000
Chicago/Turabian StyleYe, Peng, Guowei Liu, and Yi Huang. 2022. "Geographic Scene Understanding of High-Spatial-Resolution Remote Sensing Images: Methodological Trends and Current Challenges" Applied Sciences 12, no. 12: 6000. https://doi.org/10.3390/app12126000
APA StyleYe, P., Liu, G., & Huang, Y. (2022). Geographic Scene Understanding of High-Spatial-Resolution Remote Sensing Images: Methodological Trends and Current Challenges. Applied Sciences, 12(12), 6000. https://doi.org/10.3390/app12126000