
Dual Auto-Encoder GAN-Based Anomaly Detection for Industrial Control System



Abstract
:1. Introduction
- A dual GAN model based on the “encoder–decoder–encoder” architecture is developed to accurately detect the outliers of the industrial control system without depending on any anomalous samples;
- A parameter-free dynamic strategy is designed to learn the marginal data distribution robustly and accurately through dynamic interaction between two GANs;
- Based on the learned marginal distribution and normal distribution, an anomaly score optimization strategy is used to enhance the accuracy and stability of anomaly detection from the feature space;
- Comparative experiments with five various networks on the DS2OST dataset and the SWAT dataset demonstrate the effectiveness of the DAGAN method.
2. Related Works
- Statistical model-based methods make up the first category, with Gaussian mixture model (GMM) [11] and independent component analysis (ICA) [12] as typical representatives. The idea behind this is to build a statistical model of system operation, which is used to calculate the probability that the observed value of a random variable is within a certain range, and treat data that exceed a certain preset threshold as outlier. For example, Zhang et al. [13] combined GMM and linear discriminant analysis (LDA) to build a feature distribution model, and then used SVM to obtain the outliers in the smart meters data. Once models are built, they can be mathematically evaluated quickly and easily implemented. However, since they rely heavily on prior knowledge, the quality of the results produced is mostly unreliable in practical applications, and they are generally not suitable for multidimensional schemes. Xie et al. [14] used bilateral principal component analysis (B-PCA) to build a time series feature distribution model for the anomaly detection of network traffic. However, ICS has many resource-constrained heterogeneous devices, complex and diverse working environments, and a lot of noise, so it is very difficult to model accurately.
- Machine learning-based methods make up the second category, with support vector machine (SVM) [15] and regression model as typical representatives. The idea behind this is to use traditional machine learning methods to learn a latent feature distribution from normal data, so that data that do not satisfy this distribution are regarded as outliers. However, due to the complex and diverse operating environments of ICS, this method cannot accurately learn the deep features of normal data and is sensitive to high-dimensional noise. For example, Ma et al. [16] combined kernel Support Vector Machine (KSVM) and LDA to learn the latent normal feature distribution of network traffic, and then find anomalies. The efficacy of the proposed anomaly detection model in network traffic is great. However, it requires a pre-existed corpus for data transformation and model training. Poornima et al. [17] established the Online Locally Linear Weighted Projection Regression (OLWPR) model to achieve more accurate anomaly detection through online learning and data dimensionality reduction. The advantage of this is that there is no need to store all training data in node memory; only the model remains in the node and performs predictions. However, as the dimensionality of the data increases, the performance of these models degrades. Chen et al. [18] proposed an efficient NBAD algorithm based on deep belief networks (DBN) and long short-term memory networks (LSTM). This algorithm can accurately and quickly detect abnormal network behavior. Moreover, due to the feature extraction implemented by DBN and the light structure of the method, the time consumption of the training and detection processes is drastically reduced. However, it is not ideal for categories with few records in the dataset. Forestiero [19] proposed an activity footprint-based method to detect anomalies in IoT by exploiting a multiagent algorithm. This method can be used to dynamically handle information changes and exhibit adaptive behavior, and the proposed meta-heuristic is fully decentralized.
- Deep learning-based methods make up the third category, with auto-encoder, LSTM and Convolutional Neural Network (CNN) as typical representatives [20]. The basic idea behind this is to use deep neural networks to learn the deep features of normal data more accurately. For example, for discrete data, Kim et al. [21] constructed an auto-encoder model to map the data to a low-dimensional space to learn features, and then treat data that do not satisfy the features as anomalies. For time series data, Zhou et al. [22] used LSTM to learn deep features and anomaly detection. For image data, Zhang et al. [23] constructed a tensor-based convolutional neural network to learn the deep features of high-dimensional images and complete anomaly detection. Zhang et al. [24] combined a self-supervised learning module to learn general normal patterns and an adaptive memory fusion module to learn rich feature representations based on a convolutional auto-encoder structure. Although this method has good accuracy and robustness, it usually requires enough abnormal samples and heavily depends on the quality of training samples. It also has high time complexity.
- In recent years, GAN-based anomaly detection has become a hot research topic. AnoGAN [25] in 2017 is the first work to use GAN to discover anomalies in high-dimensional image data. The basic process is to build a CNN as a generator G to generate an image with a Gaussian noise Z, and then build a discriminator D to accurately classify the generated image and the real image, and finally observe the difference between a test image and its generated image to determine whether this image is an outlier. However, this method requires a lot of training in the testing phase, so its time complexity is high. Zentai et al. [26] further constructed the BiGAN model to complete anomaly detection from both the feature space and the data space, which is more stable and takes less training time. The FenceGAN model [4] is proposed to utilize a modified GAN to learn the marginal distribution of real data for better anomaly detection. However, this method requires a preset threshold and is not robust. Since it is difficult to obtain abnormal samples, the GANomaly model [5] combines auto-encoder and GAN to design a novel “encoder–decoder–encoder” architecture, which can realize anomaly detection without abnormal samples. In addition, this model makes full use of the reconstruction ability of the auto-encoder and the feature learning ability of GAN, so as to achieve a more accurate anomaly detection from the feature space. However, this model cannot reconstruct the complex and variable high-dimensional data well. In summary, GAN has a strong ability to learn the potential distribution of high-dimensional data, and has good adaptability to strong noise, which is a better means to achieve accurate anomaly detection.
3. Preliminaries on GAN for Anomaly Detection
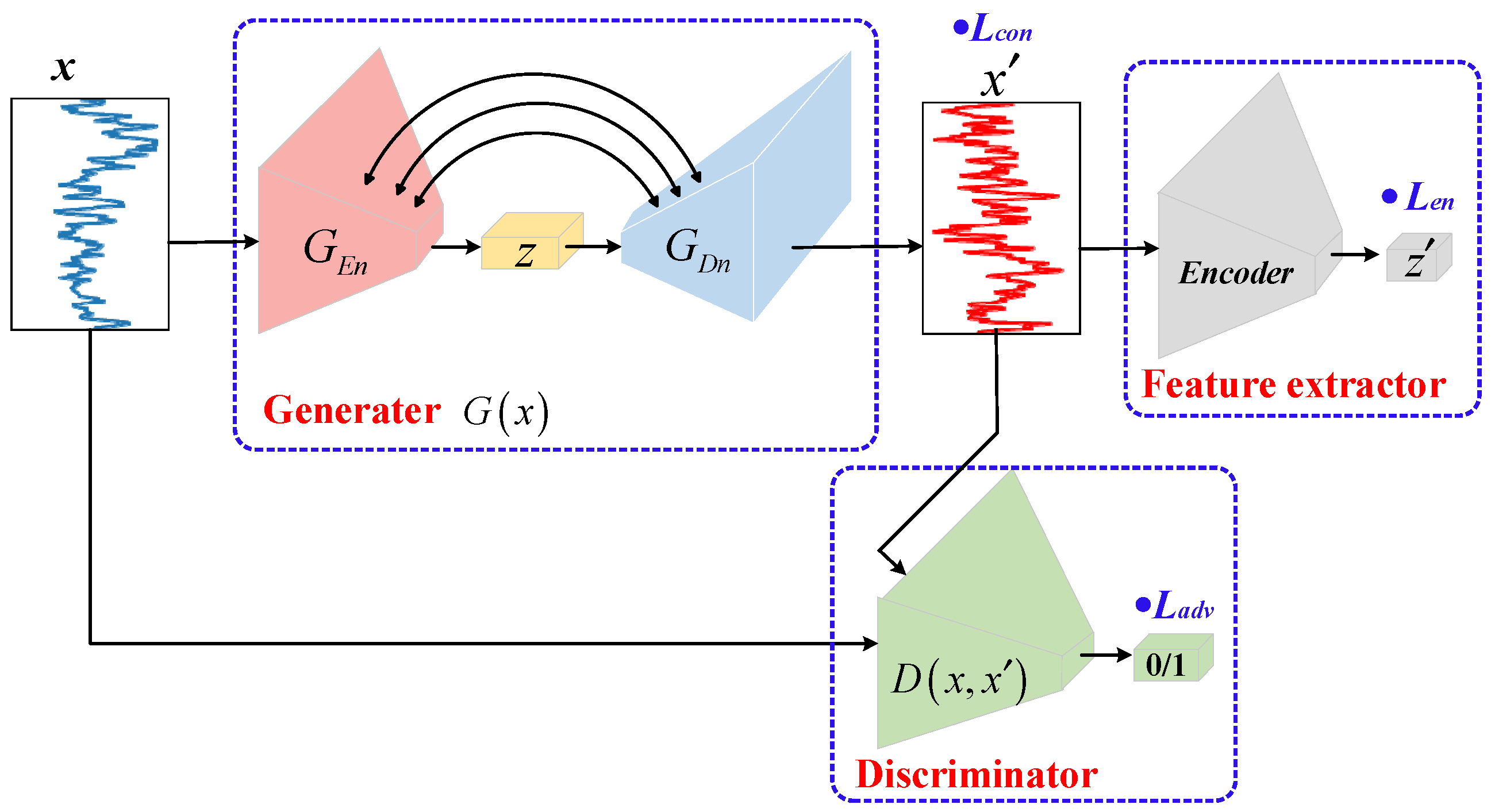
3.1. GAN-Based Unsupervised Normal Distribution Learning
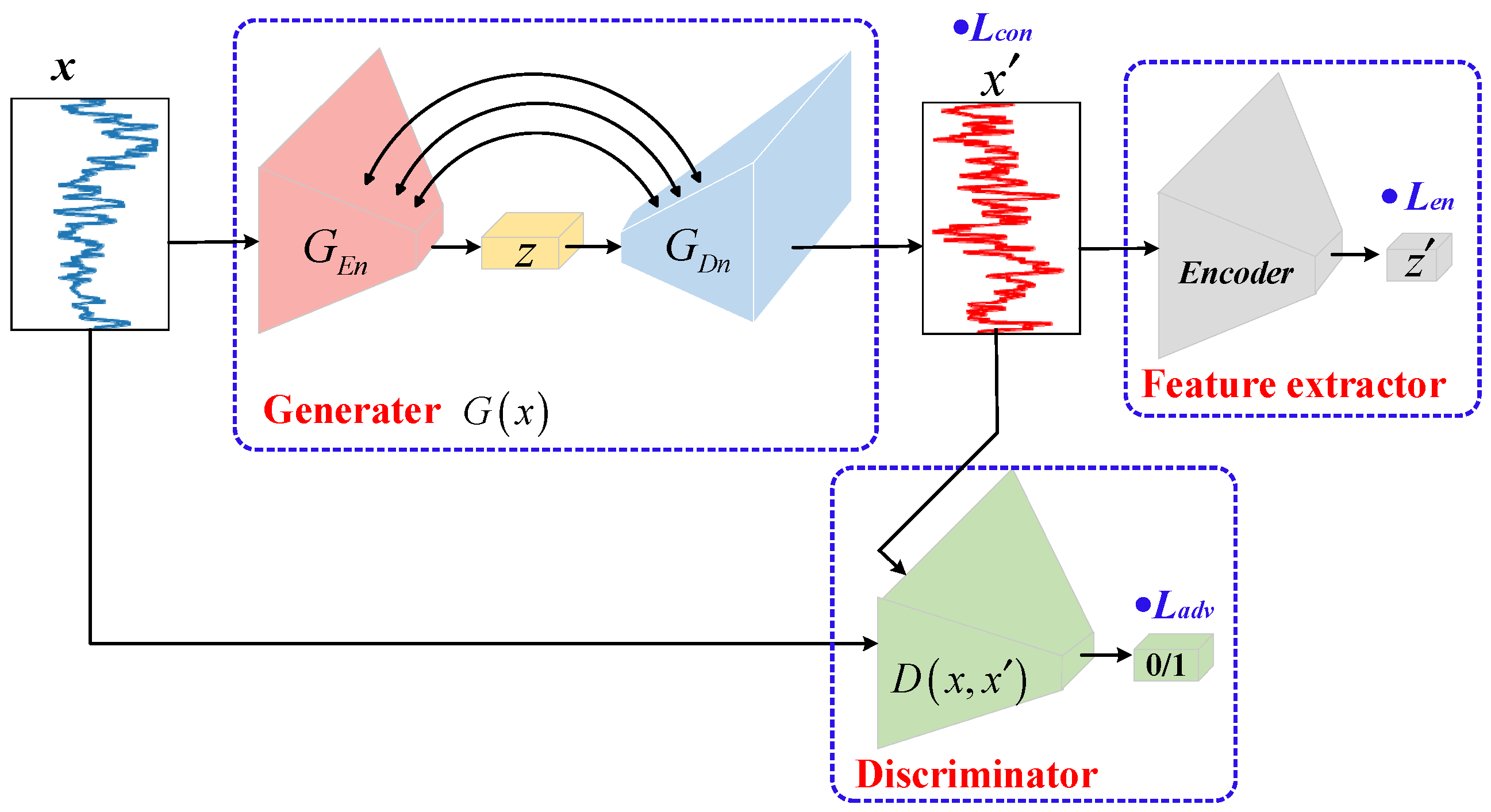
3.2. GANomaly-Based Anomaly Detection
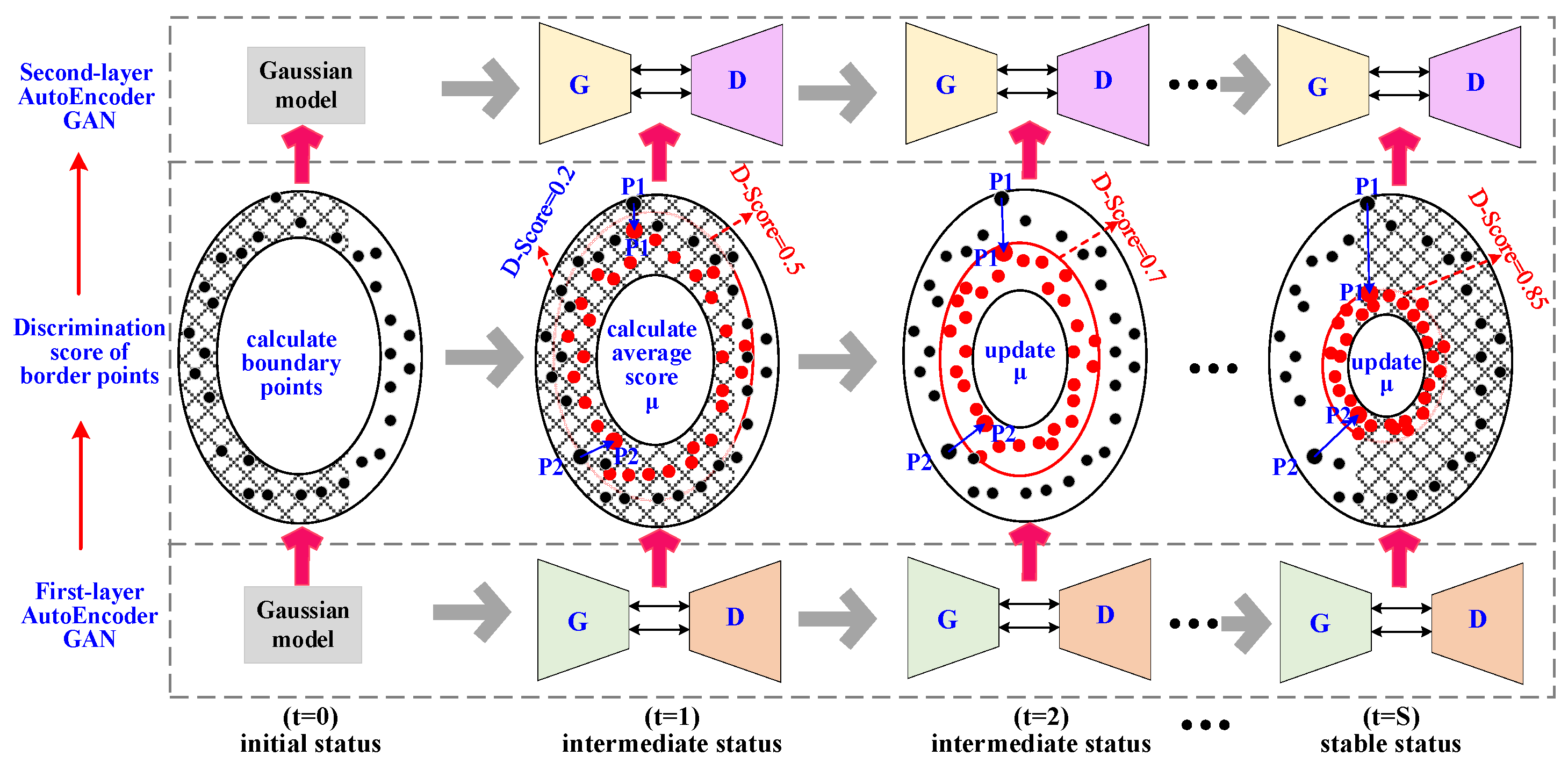
4. Dual Auto-Encoder GAN-Based Anomaly Detection for Industrial Control System (DAGAN)
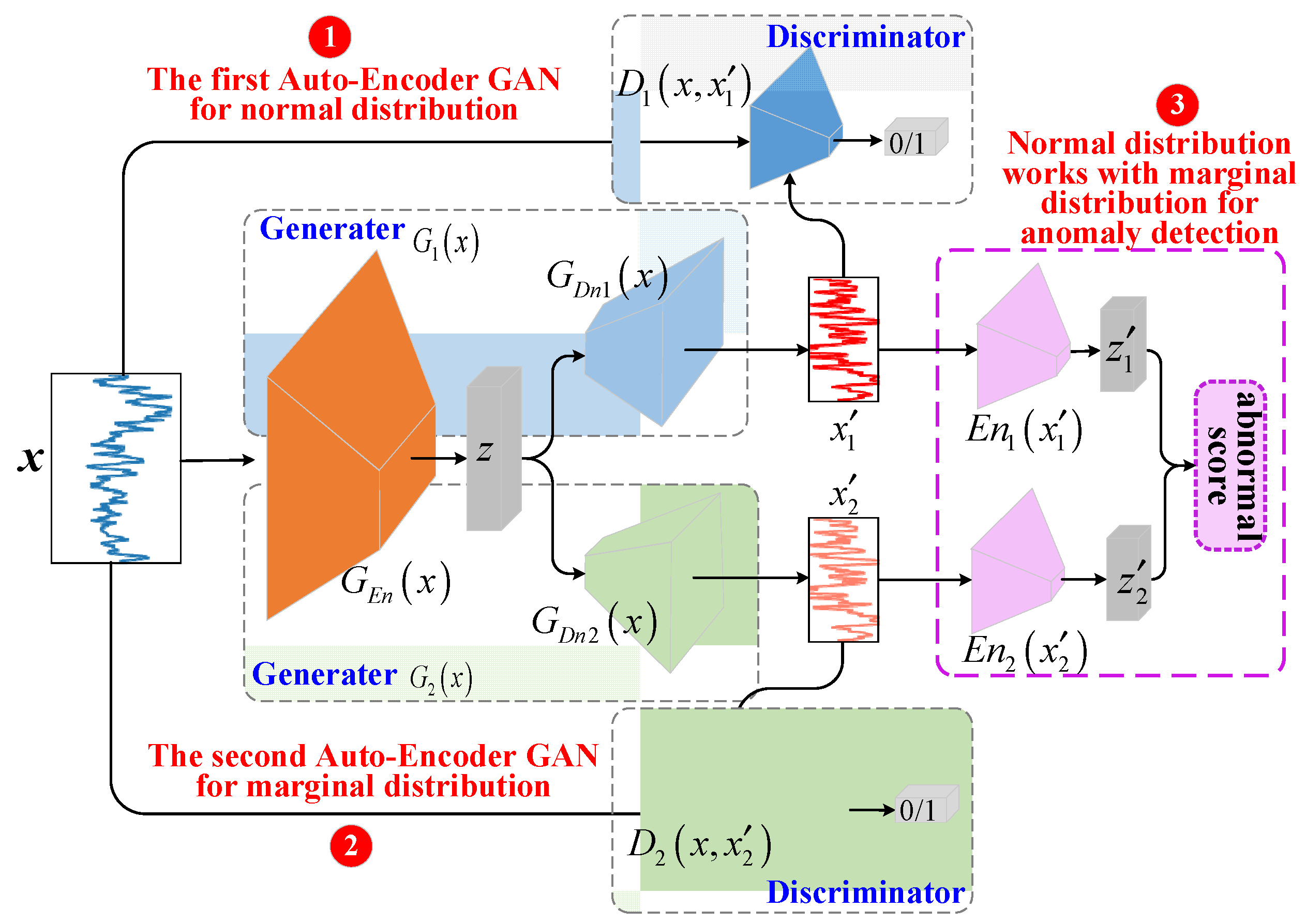
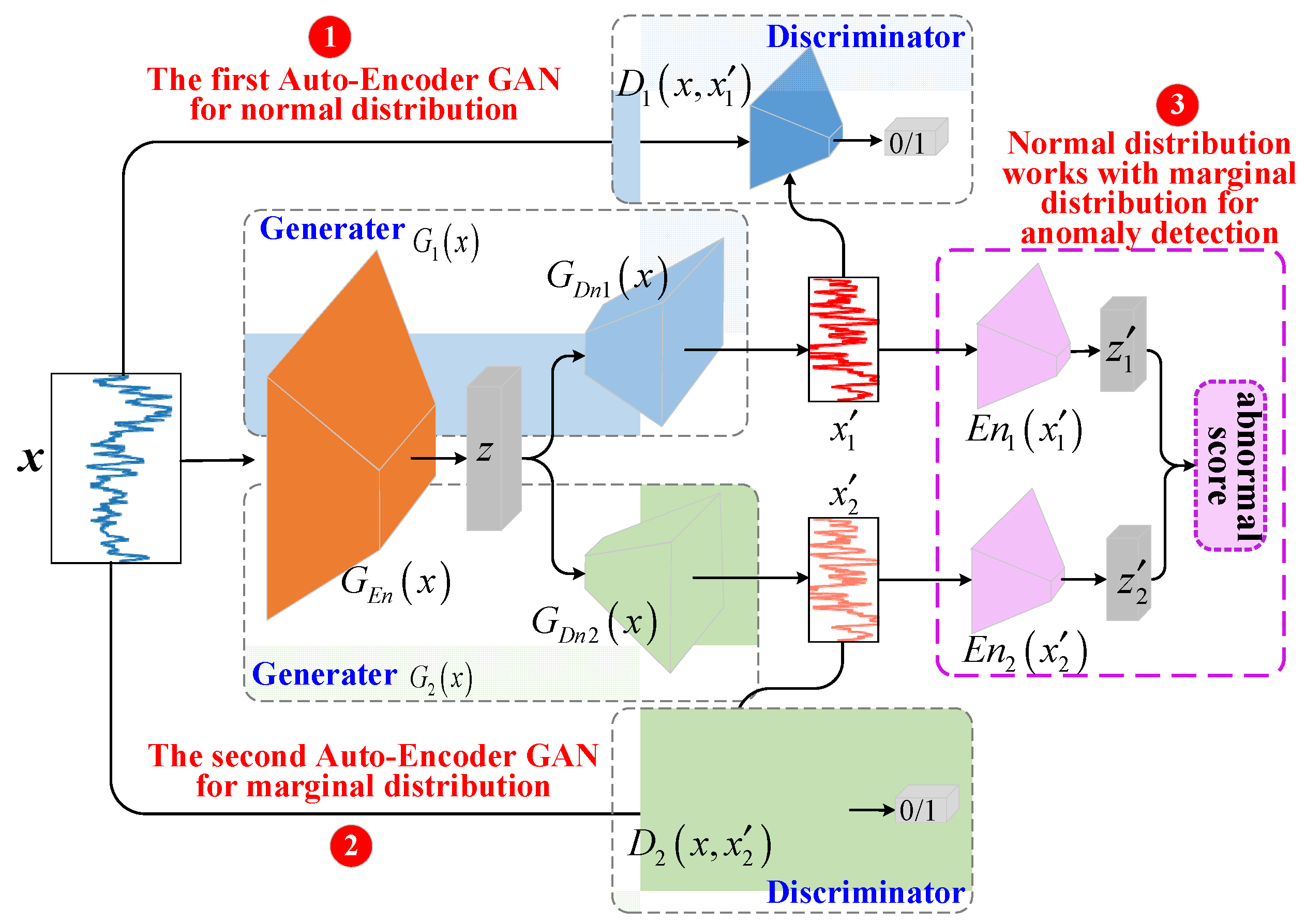
4.1. DAGAN Model
4.1.1. Problem Definition
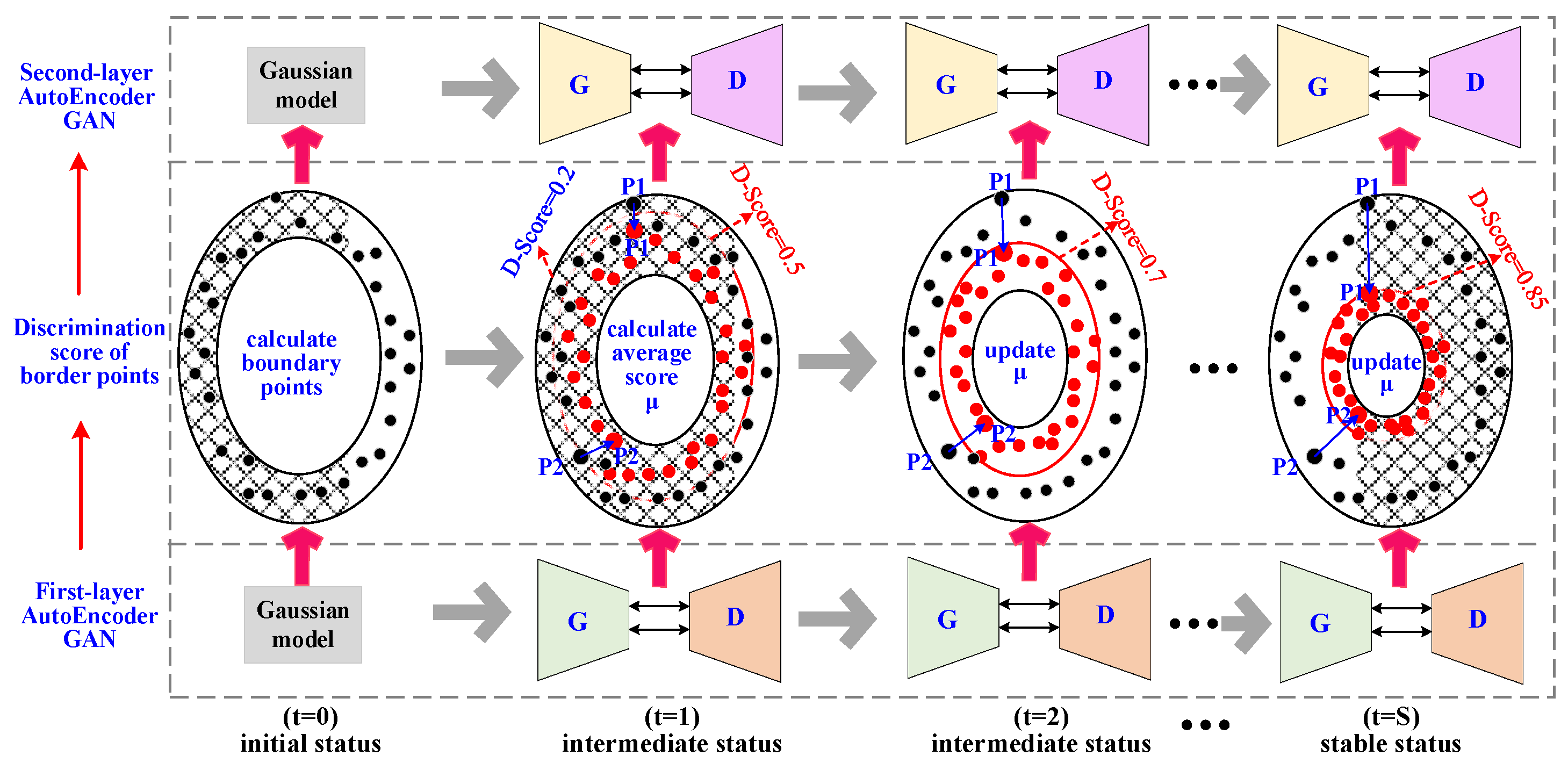
4.1.2. Model Pipeline
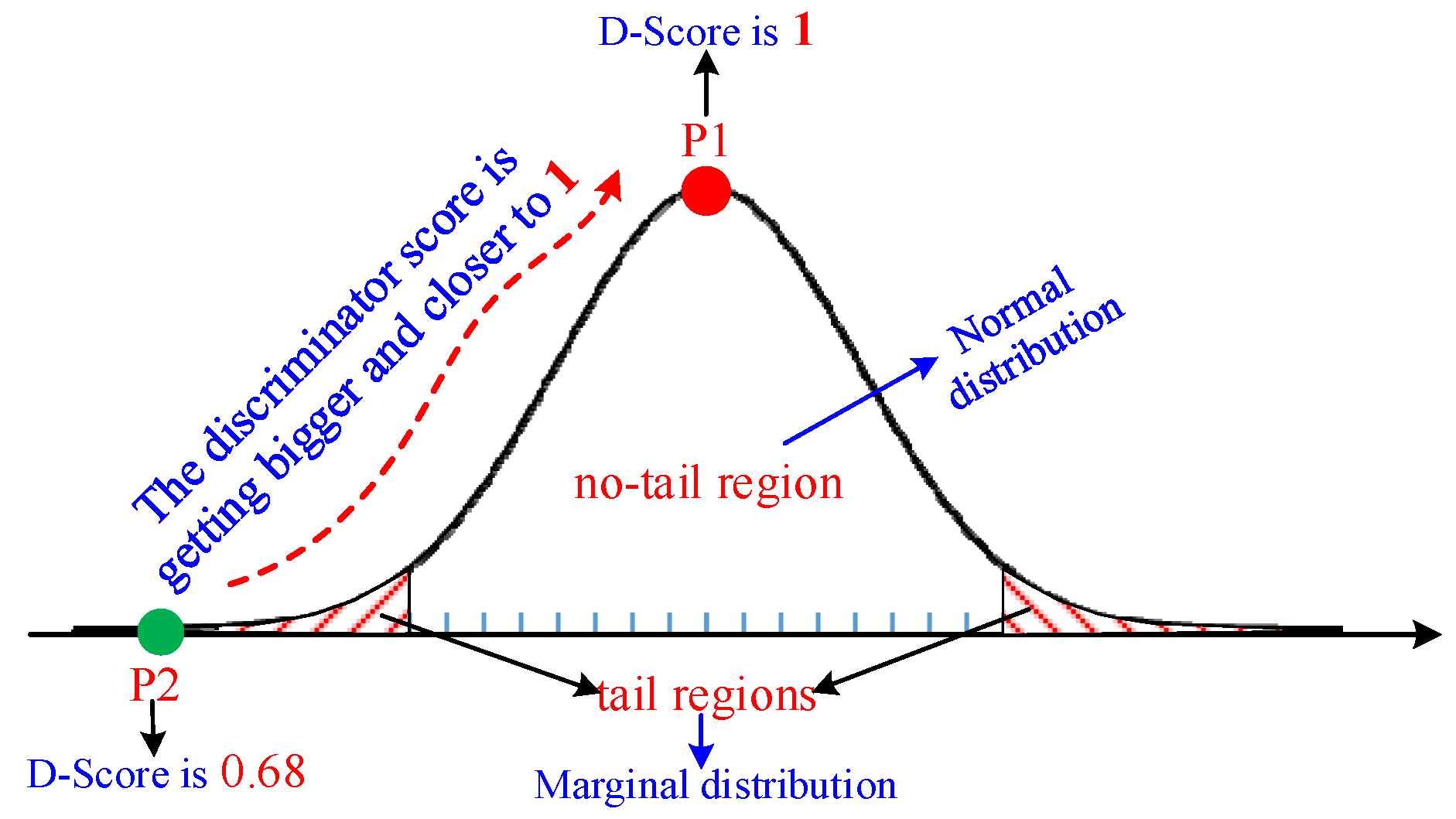
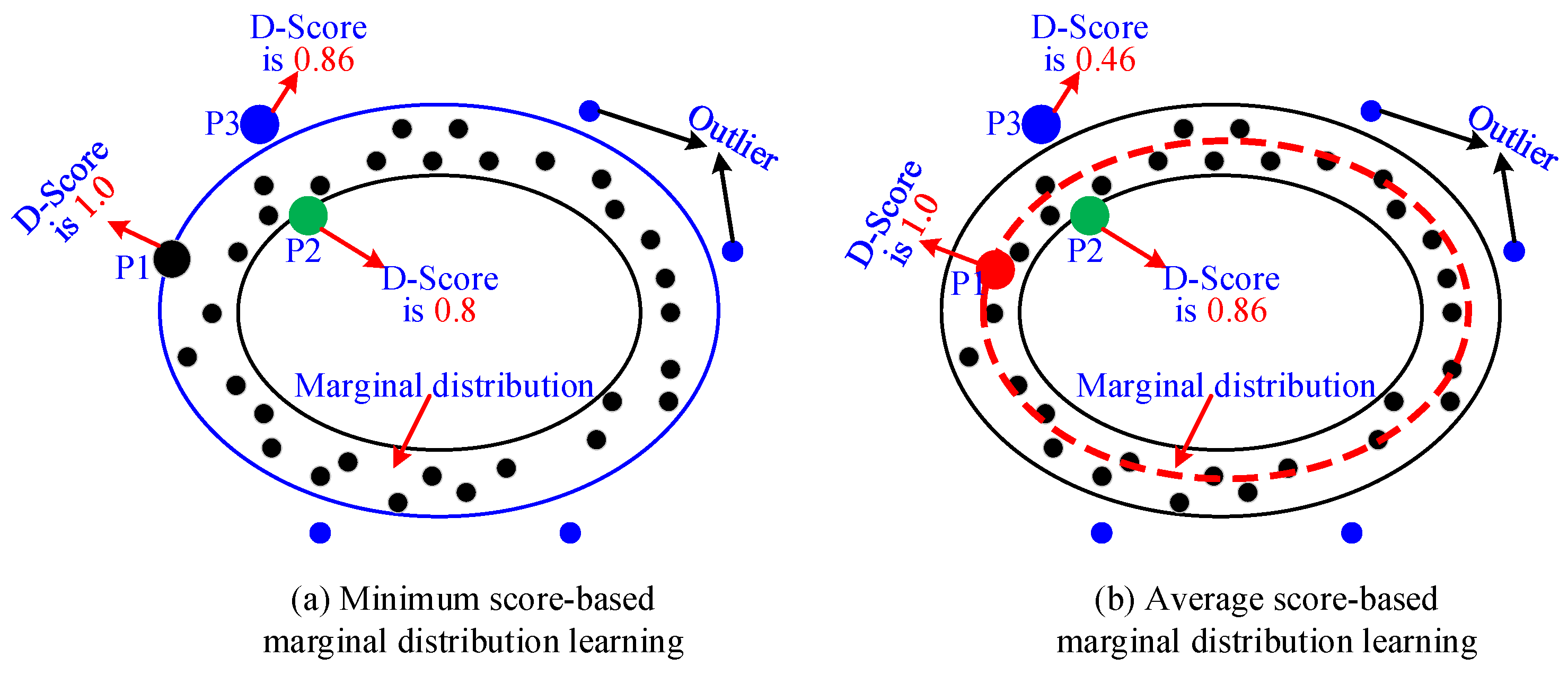
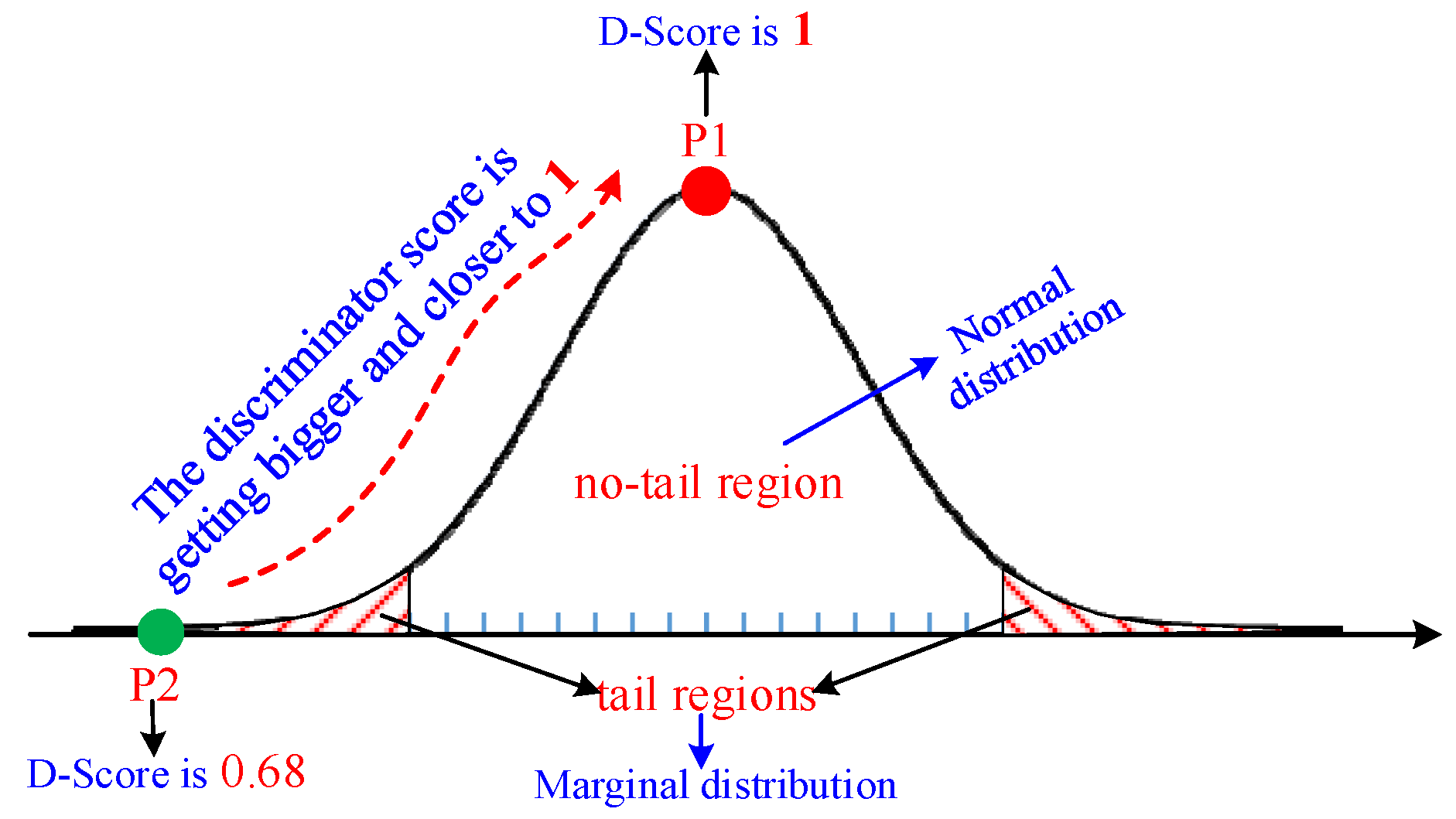
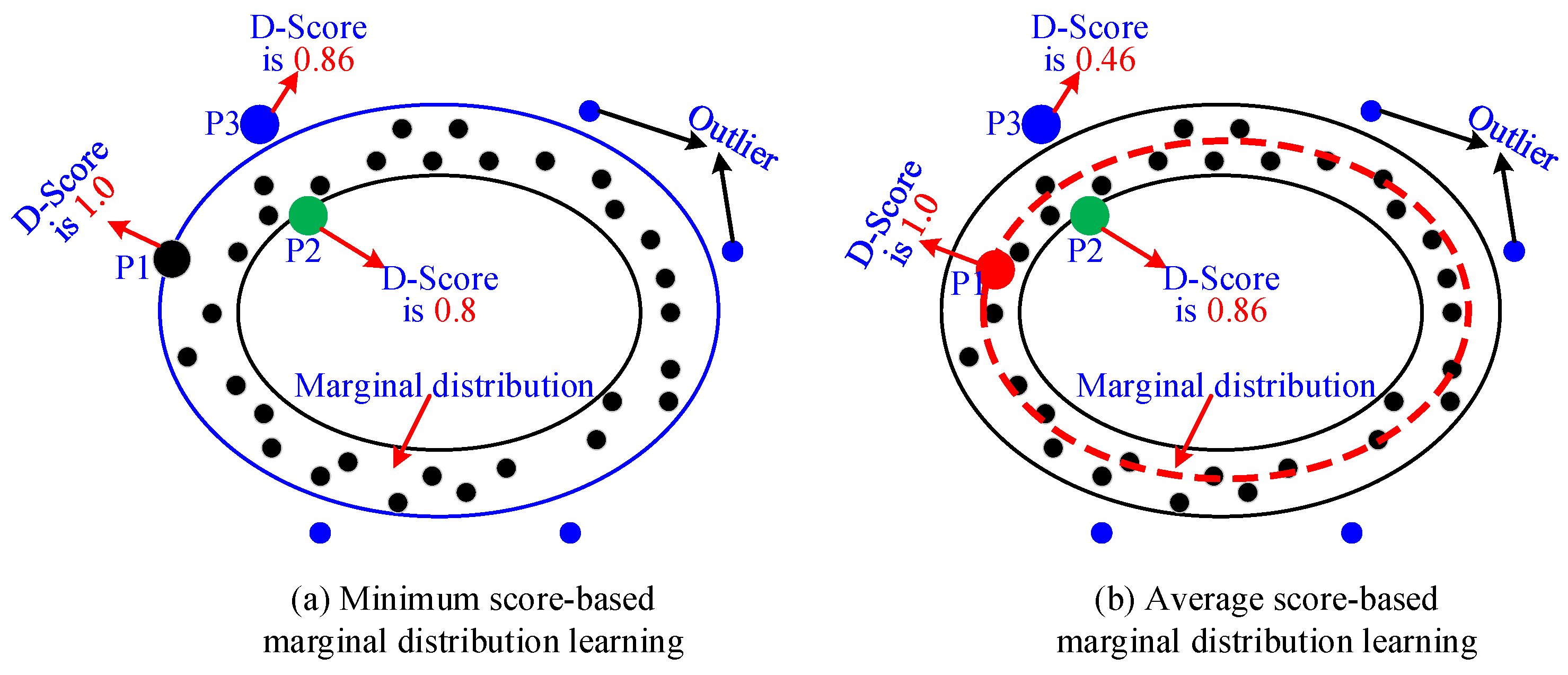
4.1.3. Parameter-Free Marginal Distribution Learning
4.2. Model Training
4.2.1. Training Objectives
- (1)
- The first GAN sub-network
- Adversarial Loss: This function is responsible for making the generated sample as real as possible, so that the discriminator D1 cannot correctly identify whether the samples are real or generated. The loss function is defined as follows:
- Reconstruction Loss: The purpose is to ensure that GDn1 can accurately learn the normal distribution of the training dataset by making the sample reconstructed by GDn1 as similar as possible to the original sample x. The loss function is defined as follows:
- Encoder Loss: This function is responsible for ensuring that the low-dimensional feature of obtained by the encoder En1 is as similar as possible to the low-dimensional feature z of the original sample x. The loss function is defined as follows:
- (2)
- The second GAN sub-network
- Adversarial Loss: The purpose is to help the generator G2 generate data with the discriminator score μ, so as to learn the marginal distribution of the real training set. The loss function is defined as follows:
- Dispersion Loss: The purpose is to supervise the data generated by G2 to be as evenly dispersed as possible in the marginal distribution, rather than fixed in some small regions. The loss function is defined as follows:
- Context Loss: This function is responsible for ensuring that the similarity between the marginal samples generated by G2 and the normal samples generated by G1 in the feature space is the same as the similarity between the discriminator scores. The loss function is defined as follows:
- Encoder Loss: This function is responsible for ensuring that the low-dimensional feature of obtained by the encoder En2 is as similar as possible to the low-dimensional feature z of the original sample x. The loss function is defined as follows:
4.2.2. Training Process
4.3. Anomaly Detection
5. Experimental Evaluation
5.1. Experimental Dataset
5.2. Experimental Setup
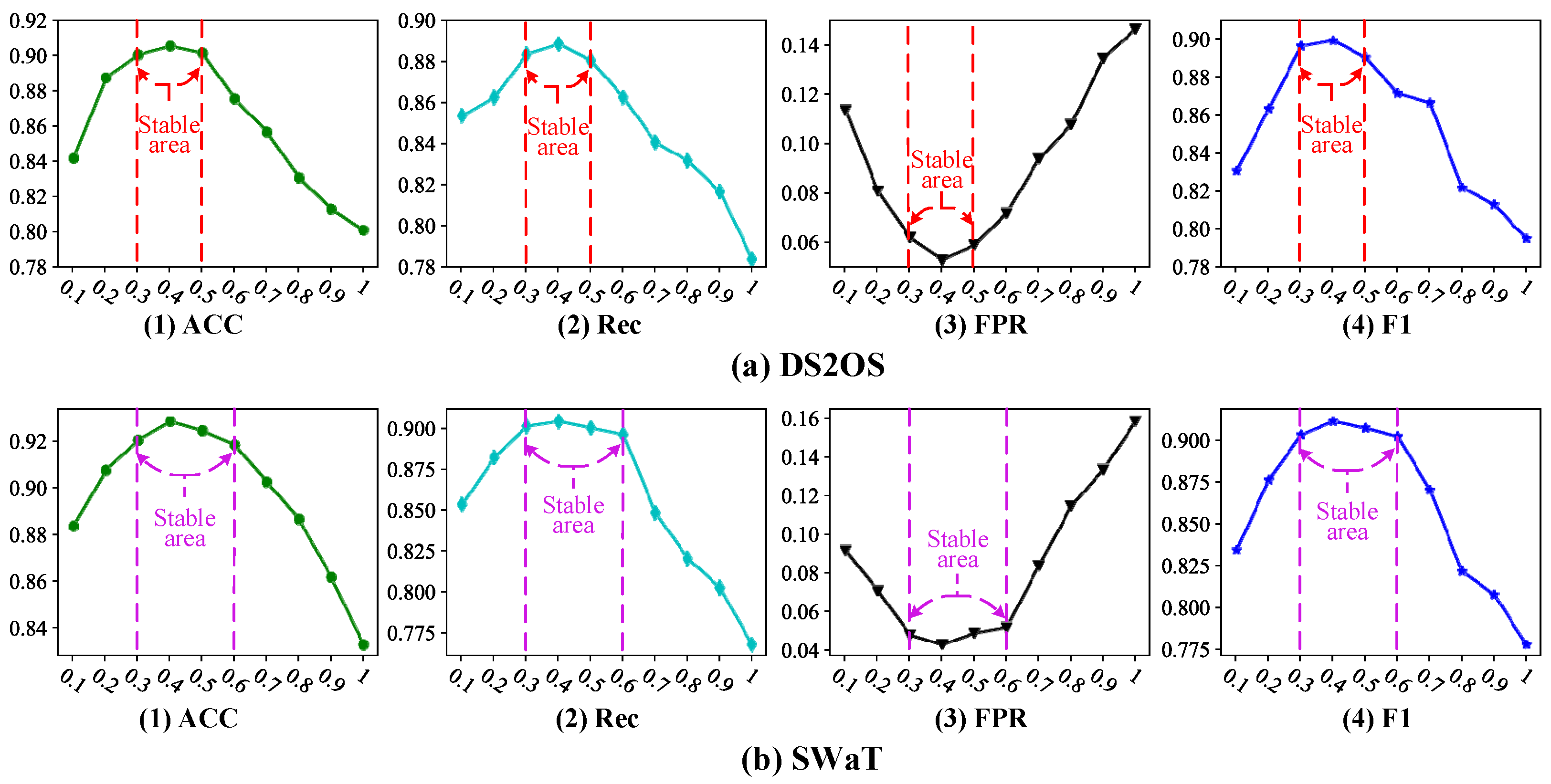
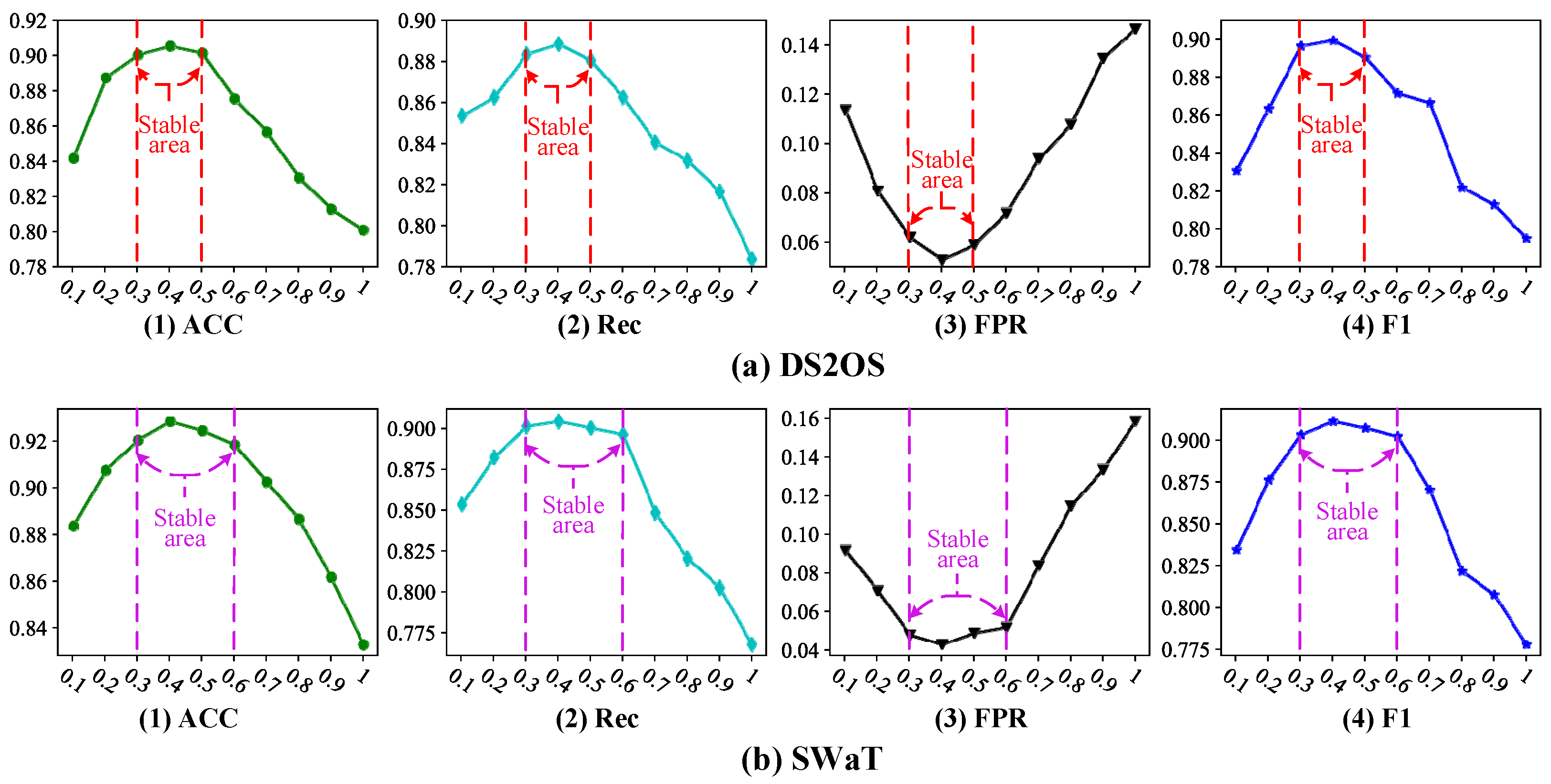
5.3. Sensitivity Analysis of the Hyper-Parameter γ
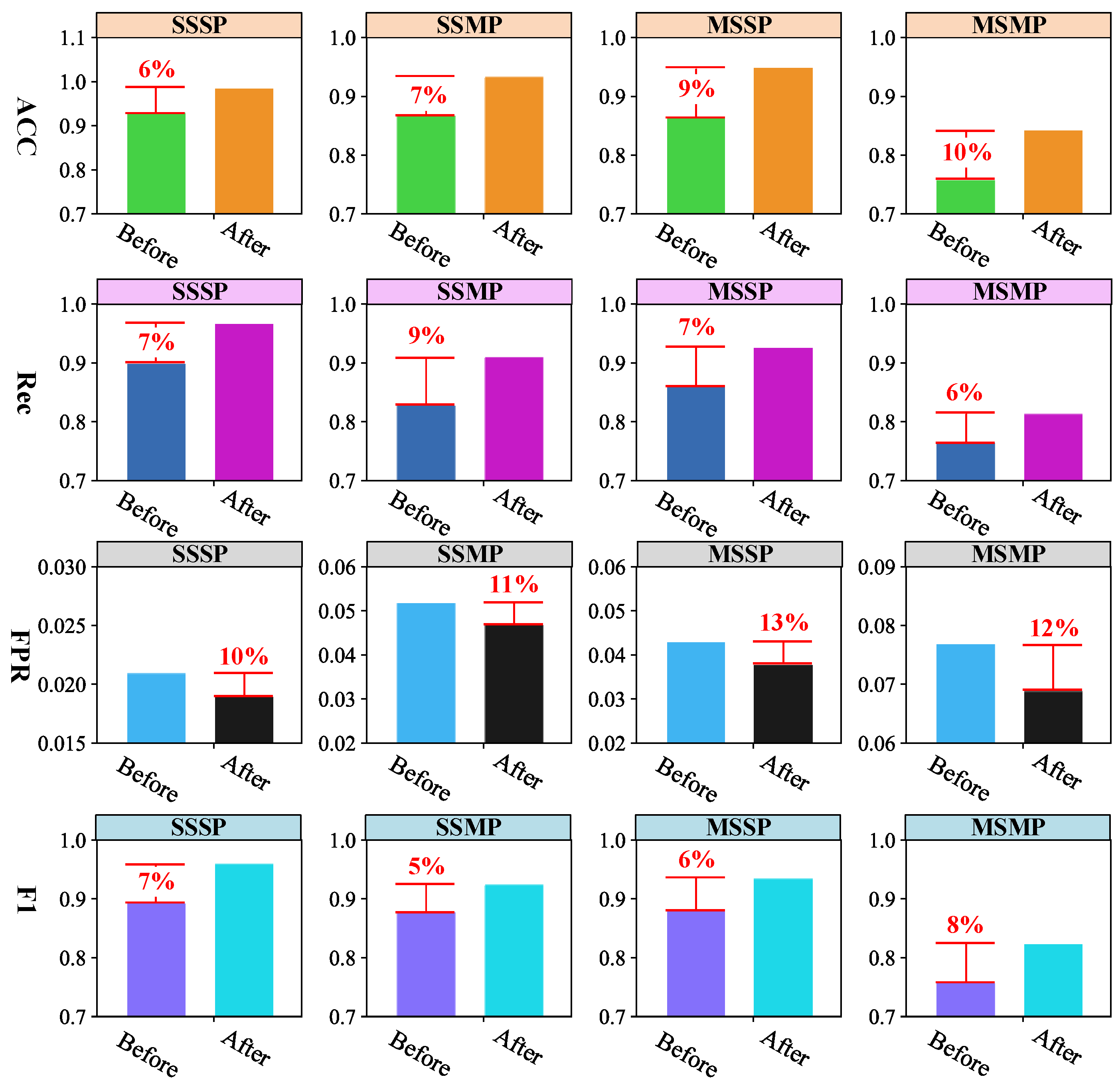
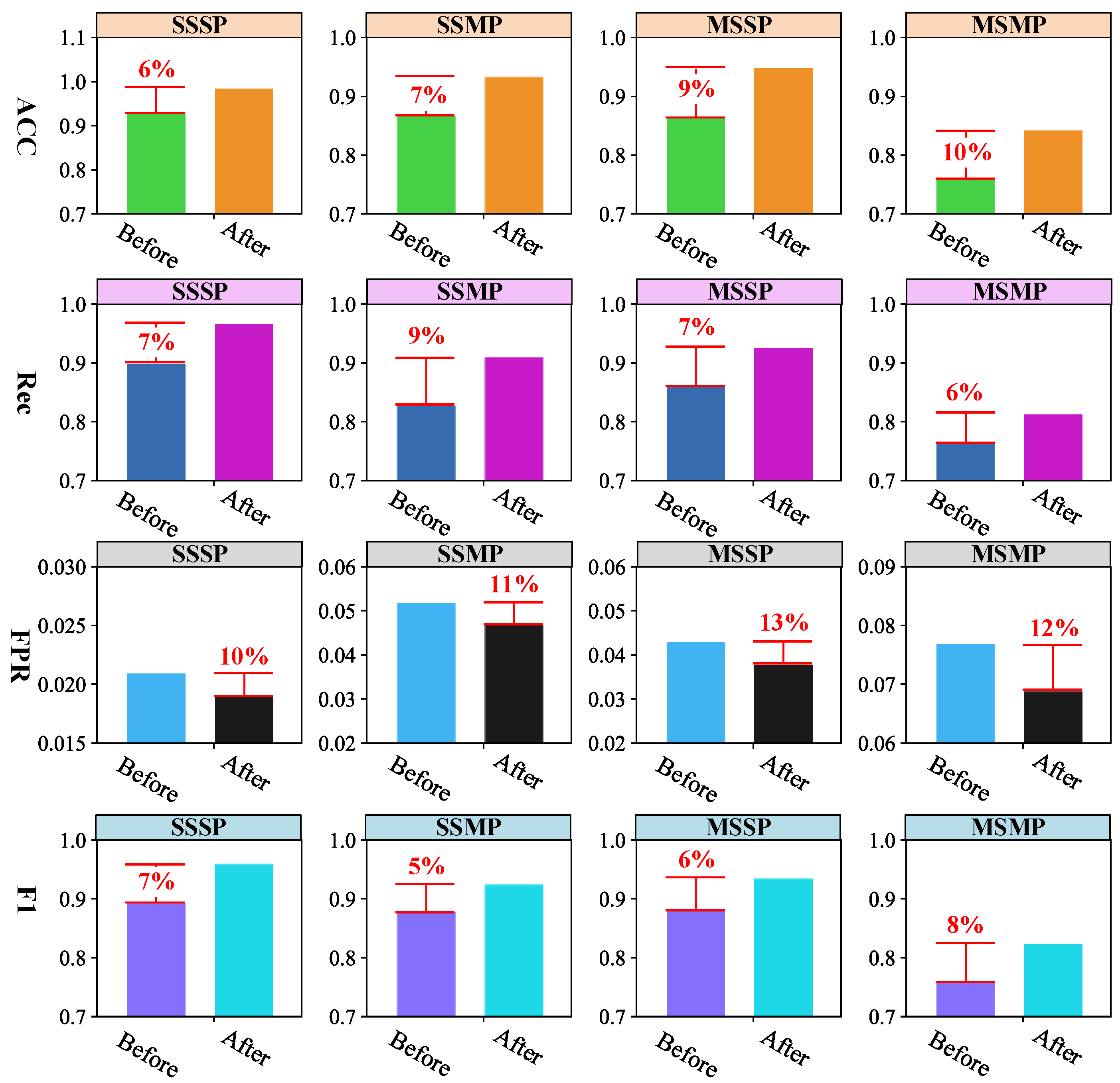
5.4. Performance Analysis of Optimization Strategy for the Marginal Distribution Learning
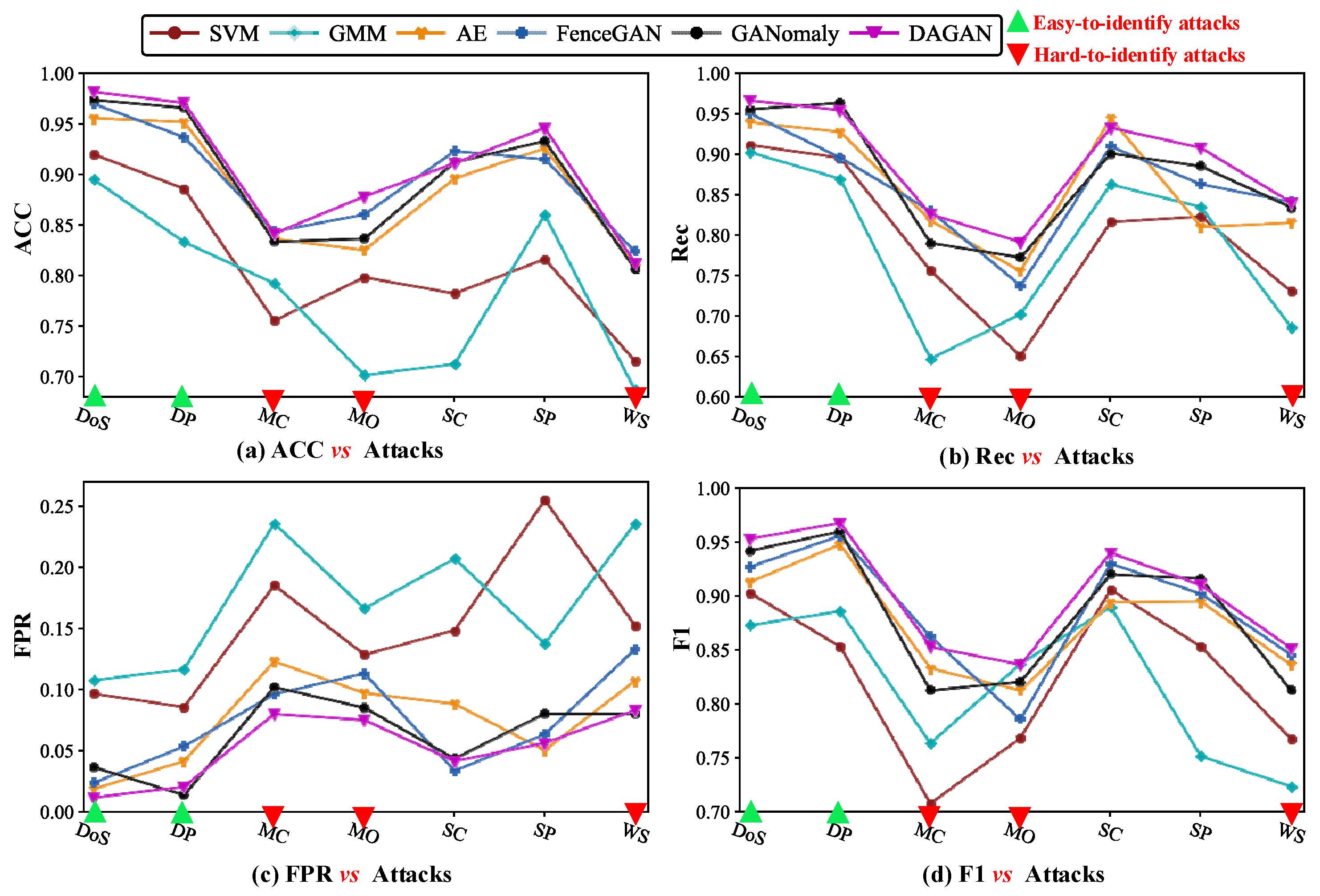
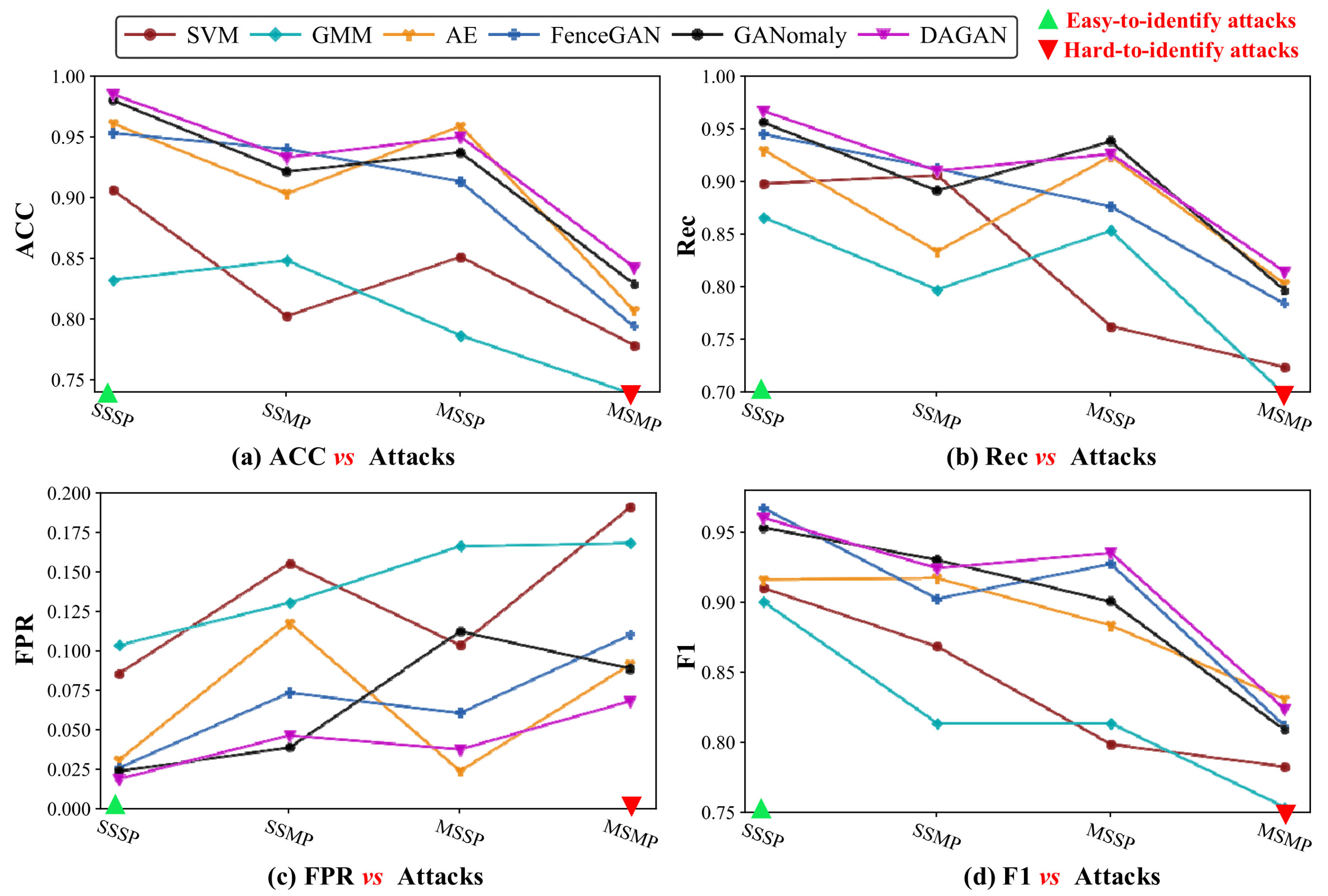
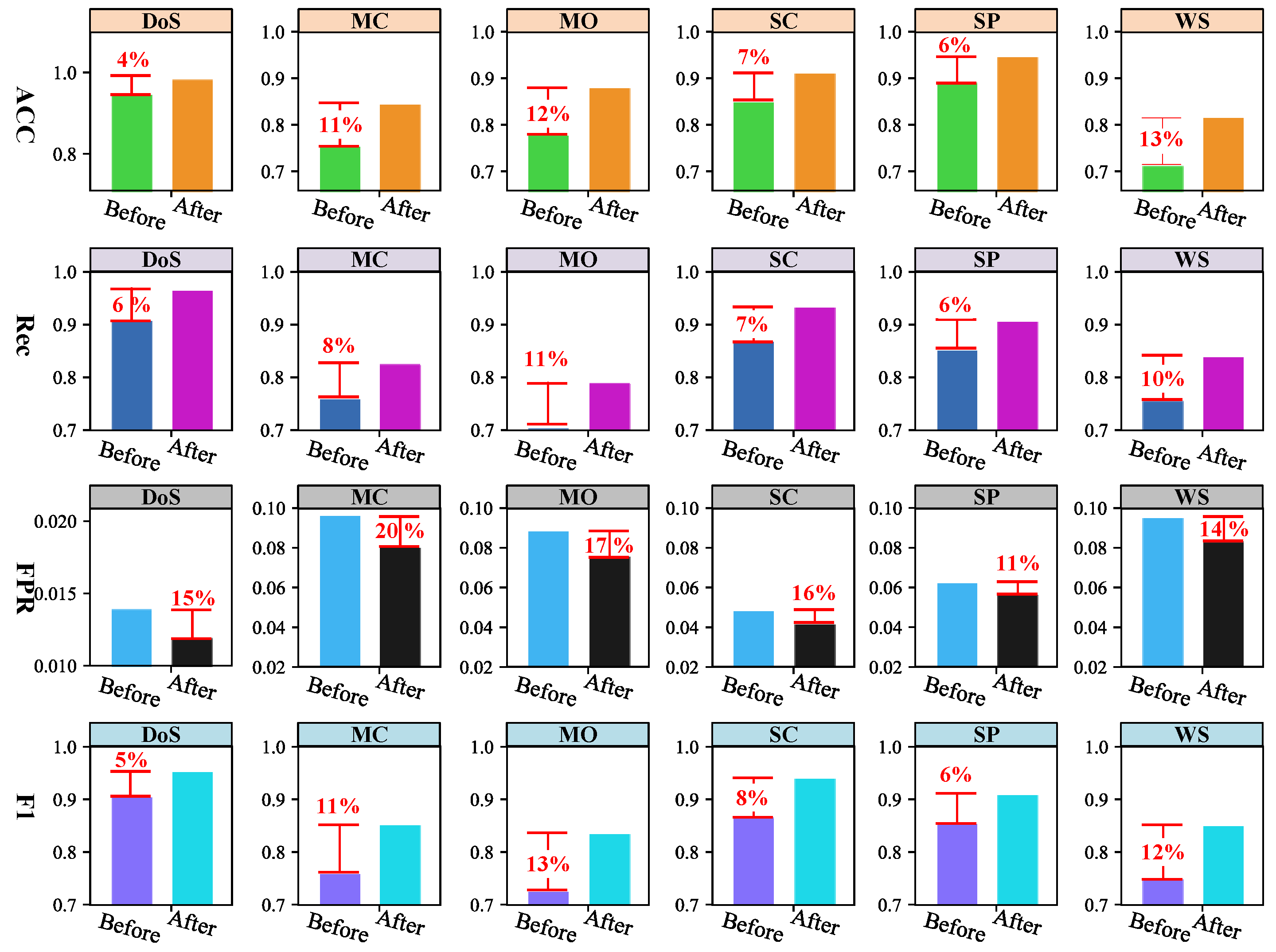
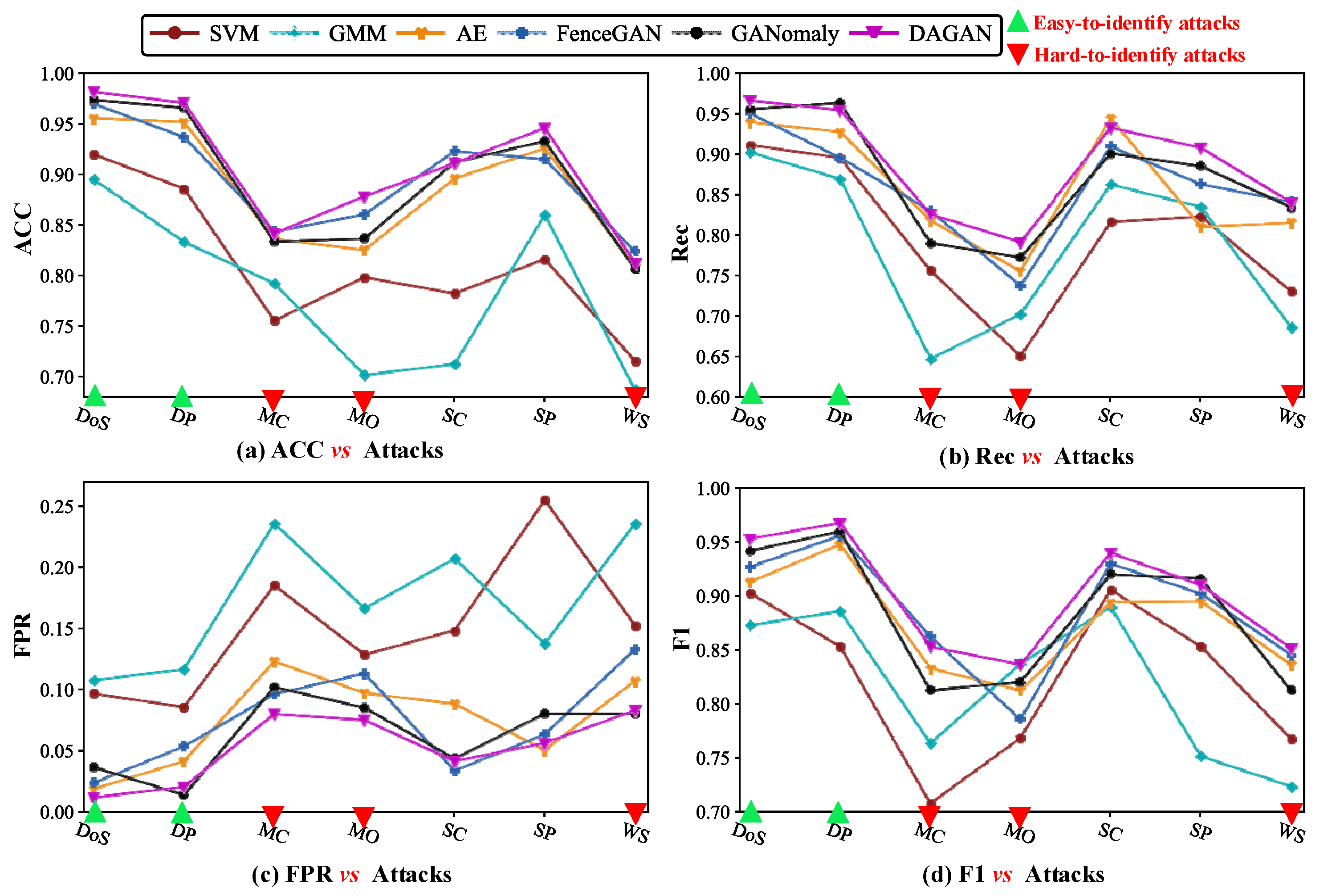
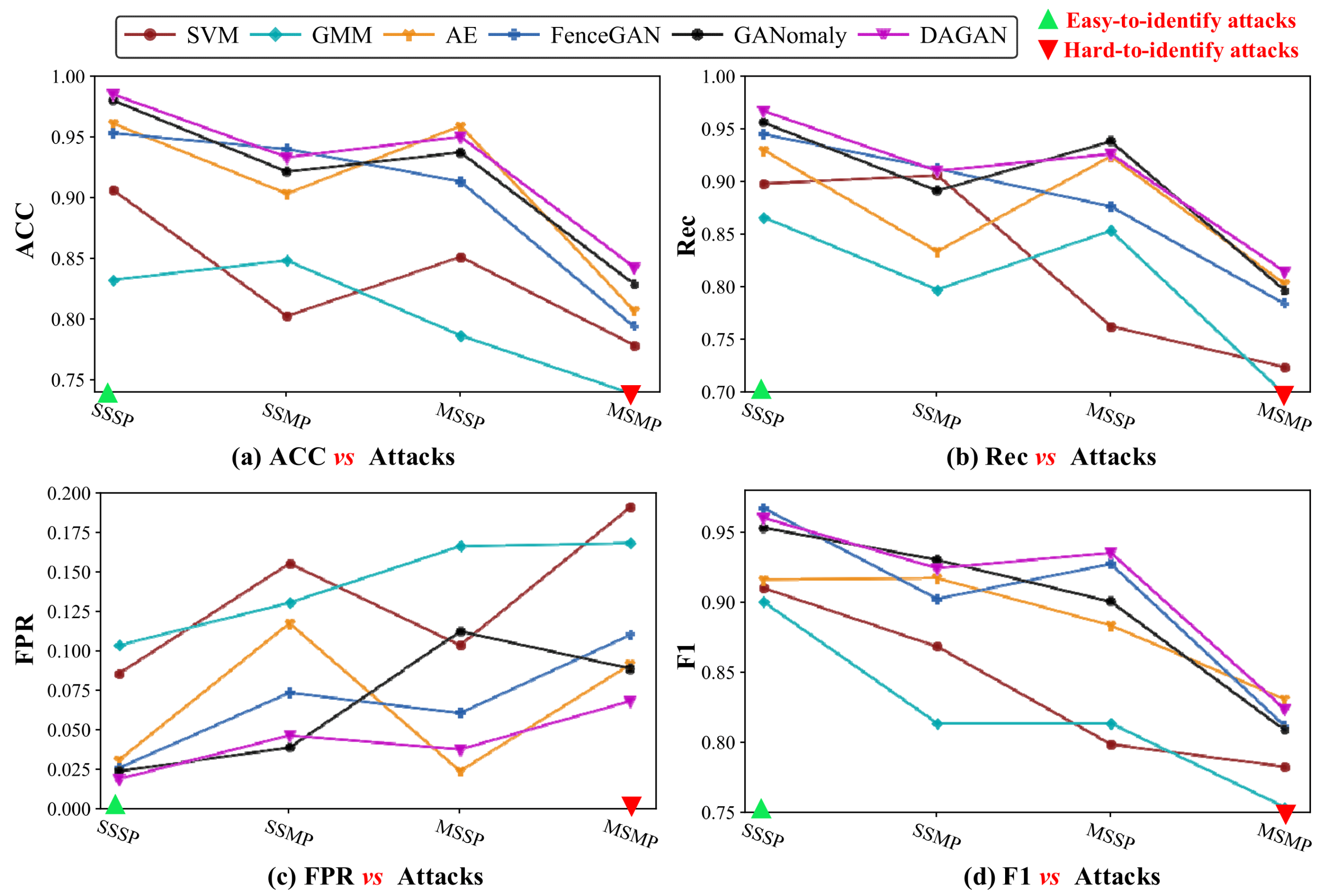
5.5. Performance Analysis of Anomaly Detection
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Asghar, M.R.; Hu, Q.; Zeadally, S. Cybersecurity in industrial control systems: Issues, technologies, and challenges. Comput. Netw. 2019, 165, 106946. [Google Scholar] [CrossRef]
- Rubio, J.E.; Alcaraz, C.; Roman, R.; Lopez, J. Current cyber-defense trends in industrial control systems. Comput. Secur. 2019, 87, 101561. [Google Scholar] [CrossRef]
- Feng, C.; Palleti, V.R.; Mathur, A.; Chana, D. A Systematic Framework to Generate Invariants for Anomaly Detection in Industrial Control Systems. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium 2019, San Diego, CA, USA, 24–27 February 2019. [Google Scholar] [CrossRef]
- Ngo, P.C.; Winarto, A.A.; Kou, C.K.L.; Park, S.; Akram, F.; Lee, H.K. Fence GAN: Towards better anomaly detection. In Proceedings of the 2019 IEEE 31St International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 141–148. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Computer Vision—ACCV 2018; Springer: Cham, Switzerland, 2018; pp. 622–637. [Google Scholar]
- Rousseeuw, P.J.; Hubert, M. Anomaly detection by robust statistics. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1236. [Google Scholar] [CrossRef] [Green Version]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Erhan, L.; Ndubuaku, M.; Di Mauro, M.; Song, W.; Chen, M.; Fortino, G.; Bagdasar, O.; Liotta, A. Smart anomaly detection in sensor systems: A multi-perspective review. Inf. Fusion 2021, 67, 64–79. [Google Scholar] [CrossRef]
- Cook, A.A.; Misirli, G.; Fan, Z. Anomaly Detection for IoT Time-Series Data: A Survey. IEEE Internet Things J. 2019, 7, 6481–6494. [Google Scholar] [CrossRef]
- Thudumu, S.; Branch, P.; Jin, J.; Singh, J.J. A comprehensive survey of anomaly detection techniques for high dimensional big data. J. Big Data 2020, 7, 1–30. [Google Scholar] [CrossRef]
- Priya, G.S.; Latha, M.; Manoj, K.; Prakash, S. Unusual Activity And Anomaly Detection In Surveillance Using GMM-KNN Model. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1450–1457. [Google Scholar]
- Zhang, R.; Dai, H. Independent component analysis-based arbitrary polynomial chaos method for stochastic analysis of structures under limited observations. Mech. Syst. Signal Processing 2022, 173, 109026. [Google Scholar] [CrossRef]
- Zhang, L.; Wan, L.; Xiao, Y.; Li, S.; Zhu, C. Anomaly Detection method of Smart Meters data based on GMM-LDA clustering feature Learning and PSO Support Vector Machine. In Proceedings of the 2019 IEEE Sustainable Power and Energy Conference (ISPEC), Beijing, China, 21–23 November 2019; pp. 2407–2412. [Google Scholar]
- Xie, K.; Li, X.; Wang, X.; Cao, J.; Xie, G.; Wen, J.; Zhang, D.; Qin, Z. On-Line Anomaly Detection With High Accuracy. IEEE/ACM Trans. Netw. 2018, 26, 1222–1235. [Google Scholar] [CrossRef]
- Anton, S.D.D.; Sinha, S.; Schotten, H.D. Anomaly-based intrusion detection in industrial data with SVM and random forests. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019; pp. 1–6. [Google Scholar]
- Ma, Q.; Sun, C.; Cui, B.; Jin, X. A novel model for anomaly detection in network traffic based on kernel support vector machine. Comput. Secur. 2021, 104, 102215. [Google Scholar] [CrossRef]
- Poornima, I.G.A.; Paramasivan, B. Anomaly detection in wireless sensor network using machine learning algorithm. Comput. Commun. 2020, 151, 331–337. [Google Scholar] [CrossRef]
- Chen, A.; Fu, Y.; Zheng, X.; Lu, G. An efficient network behavior anomaly detection using a hybrid DBN-LSTM network. Comput. Secur. 2022, 114, 102600. [Google Scholar] [CrossRef]
- Forestiero, A. Metaheuristic algorithm for anomaly detection in Internet of Things leveraging on a neural-driven multiagent system. Knowl.-Based Syst. 2021, 228, 107241. [Google Scholar] [CrossRef]
- Zhou, F.; Huang, Z.; Zhang, C. Carbon price forecasting based on CEEMDAN and LSTM. Appl. Energy 2022, 311, 118601. [Google Scholar] [CrossRef]
- Kim, S.J.; Jo, W.Y.; Shon, T. APAD: Autoencoder-based payload anomaly detection for industrial IoE. Appl. Soft Comput. 2020, 88, 106017. [Google Scholar] [CrossRef]
- Zhou, X.; Hu, Y.; Liang, W.; Ma, J.; Jin, Q. Variational LSTM Enhanced Anomaly Detection for Industrial Big Data. IEEE Trans. Ind. Inform. 2020, 17, 3469–3477. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, B. Transferred CNN Based on Tensor for Hyperspectral Anomaly Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 2115–2119. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Chen, Y.; Yu, H.; Qin, T. Adaptive Memory Networks with Self-supervised Learning for Unsupervised Anomaly Detection. IEEE Trans. Knowl. Data Eng. 2022, 1. [Google Scholar] [CrossRef]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery. In International Conference on Information Processing in Medical Imaging; Springer: Cham, Switzerland, 2017; pp. 146–157. [Google Scholar]
- Zenati, H.; Foo, C.S.; Lecouat, B.; Manek, G.; Chandrasekhar, V.R. Efficient gan-based anomaly detection. arXiv 2018, arXiv:1802.06222. [Google Scholar]
- Wang, C.; Wang, B.; Liu, H.; Qu, H. Anomaly Detection for Industrial Control System Based on Autoencoder Neural Network. Wirel. Commun. Mob. Comput. 2020, 2020, 8897926. [Google Scholar] [CrossRef]
- Eskandarnia, E.; Al-Ammal, H.M.; Ksantini, R. An embedded deep-clustering-based load profiling framework. Sustain. Cities Soc. 2021, 78, 103618. [Google Scholar] [CrossRef]
- Ma, J.W.; Leite, F. Performance boosting of conventional deep learning-based semantic segmentation leveraging unsupervised clustering. Autom. Constr. 2022, 136, 104167. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Full Name | Implement |
|---|---|---|
| SVM [15] | Anomaly-based Intrusion Detection in Industrial Data with SVM and Random Forests. | Python |
| GMM [11] | Unusual Activity and Anomaly Detection in Surveillance Using GMM-KNN Model. | Python |
| AE [27] | Anomaly Detection for Industrial Control System based on Auto-encoder Neural Network. | Python |
| FenceGAN [4] | Fence GAN: Towards Better Anomaly Detection. | Python |
| GANomaly [5] | GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training. | Python |
| DAGAN | Dual Auto-Encoder GAN-Based anomaly detection for industrial control system. | Python |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Li, Y.; Deng, X.; Liu, Z.; Lv, M.; Zhang, H. Dual Auto-Encoder GAN-Based Anomaly Detection for Industrial Control System. Appl. Sci. 2022, 12, 4986. https://doi.org/10.3390/app12104986
Chen L, Li Y, Deng X, Liu Z, Lv M, Zhang H. Dual Auto-Encoder GAN-Based Anomaly Detection for Industrial Control System. Applied Sciences. 2022; 12(10):4986. https://doi.org/10.3390/app12104986
Chicago/Turabian StyleChen, Lei, Yuan Li, Xingye Deng, Zhaohua Liu, Mingyang Lv, and Hongqiang Zhang. 2022. "Dual Auto-Encoder GAN-Based Anomaly Detection for Industrial Control System" Applied Sciences 12, no. 10: 4986. https://doi.org/10.3390/app12104986
APA StyleChen, L., Li, Y., Deng, X., Liu, Z., Lv, M., & Zhang, H. (2022). Dual Auto-Encoder GAN-Based Anomaly Detection for Industrial Control System. Applied Sciences, 12(10), 4986. https://doi.org/10.3390/app12104986