
A Hybrid Deep Residual Network for Efficient Transitional Activity Recognition Based on Wearable Sensors




Abstract
:1. Introduction
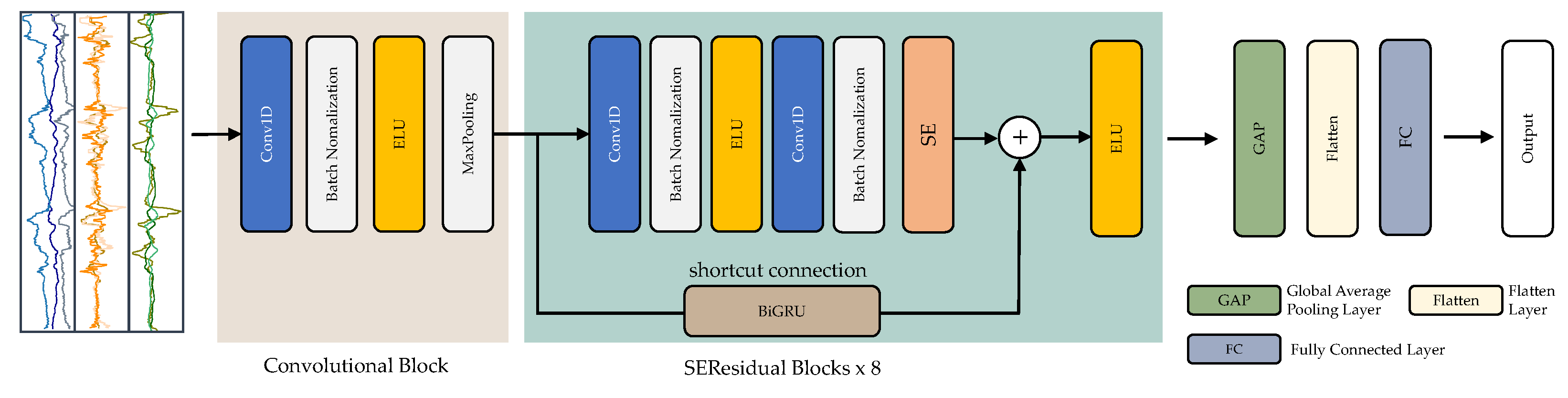
- This work presents a hybrid deep residual model based on convolutional layers and bidirectional gated recurrent unit layers that is capable of autonomously learning local features and modeling their temporal dependency. The proposed method augments the deep residual model with hybrid Squeeze-and-Excitation (SE) residual blocks, allowing for hierarchical extraction of deep spatio-temporal characteristics and effective separation of transitional activities.
- The proposed model achieved the recognition of transitional activities and basic ADL activities in short durations of continuous sensor data streams.
- We investigated the effects of recognizing transitional activities in various issues including segmentation techniques and multimodal sensors.
- We evaluated the exploratory findings in comparison to those obtained from other models using the same HAR dataset. The results indicate that the proposed strategy outperforms different sophisticated approaches.
2. Related Works
2.1. Basic ADL Recognition
2.2. Transitional Human Activity Recognition
2.3. Available Transitional HAR Datasets
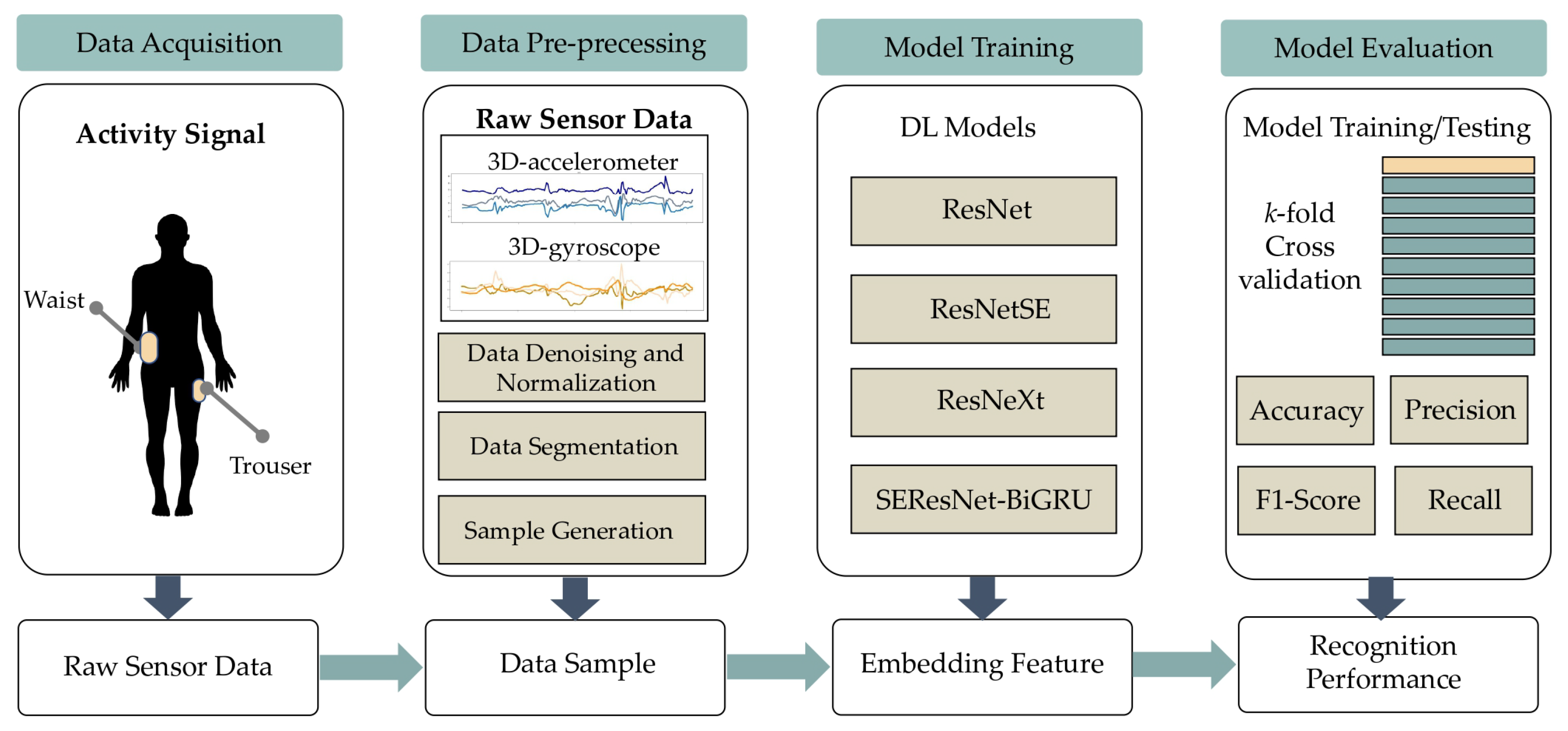
3. Proposed Methodology
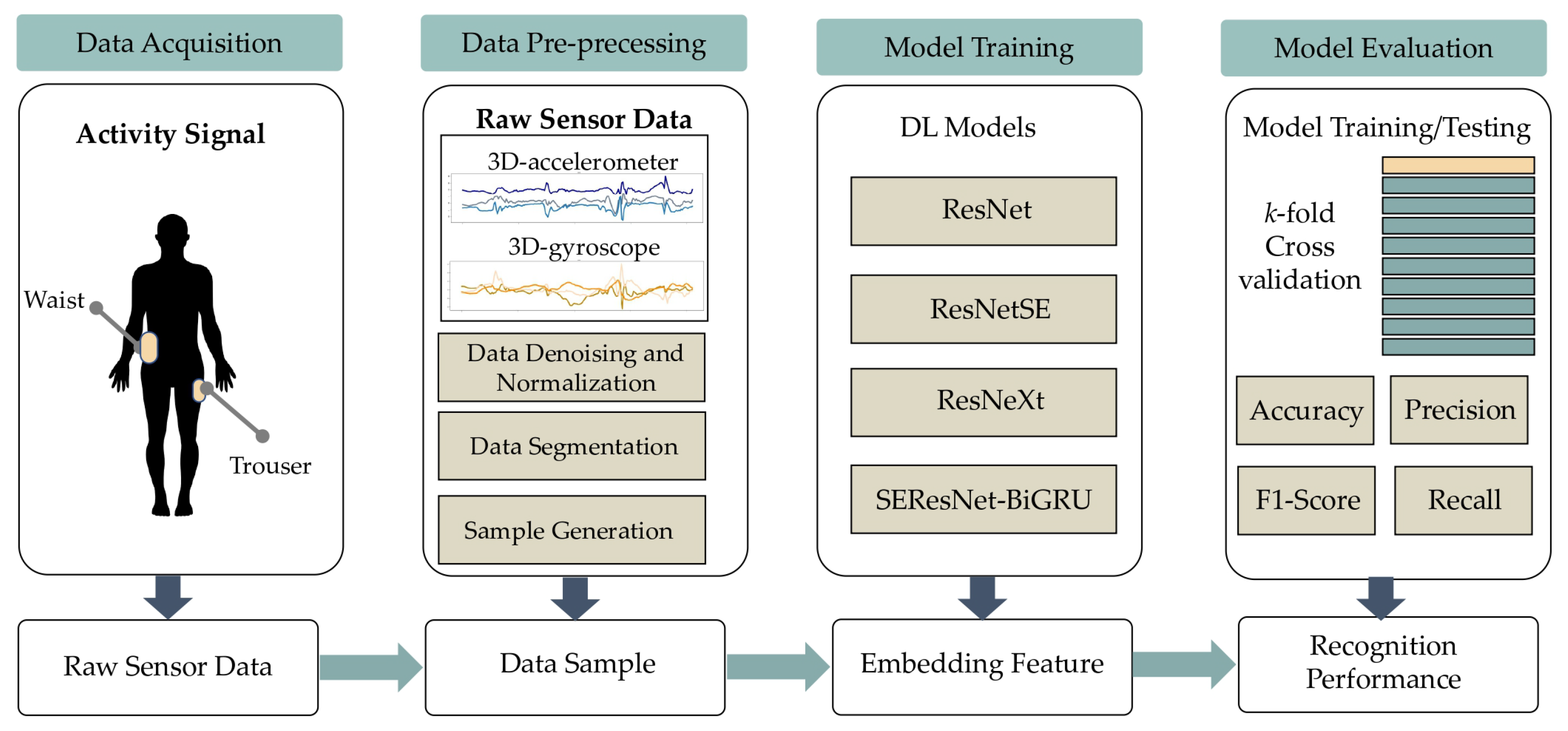
3.1. Overview of the HAR Framework Used in This Study
3.2. HAR Datasets
3.2.1. HAPT: Human Activities and Postural Transition Dataset
3.2.2. MobiAct v2.0 Dataset
3.3. Data Preprocessing
3.3.1. Data Denoising
3.3.2. Data Normalization
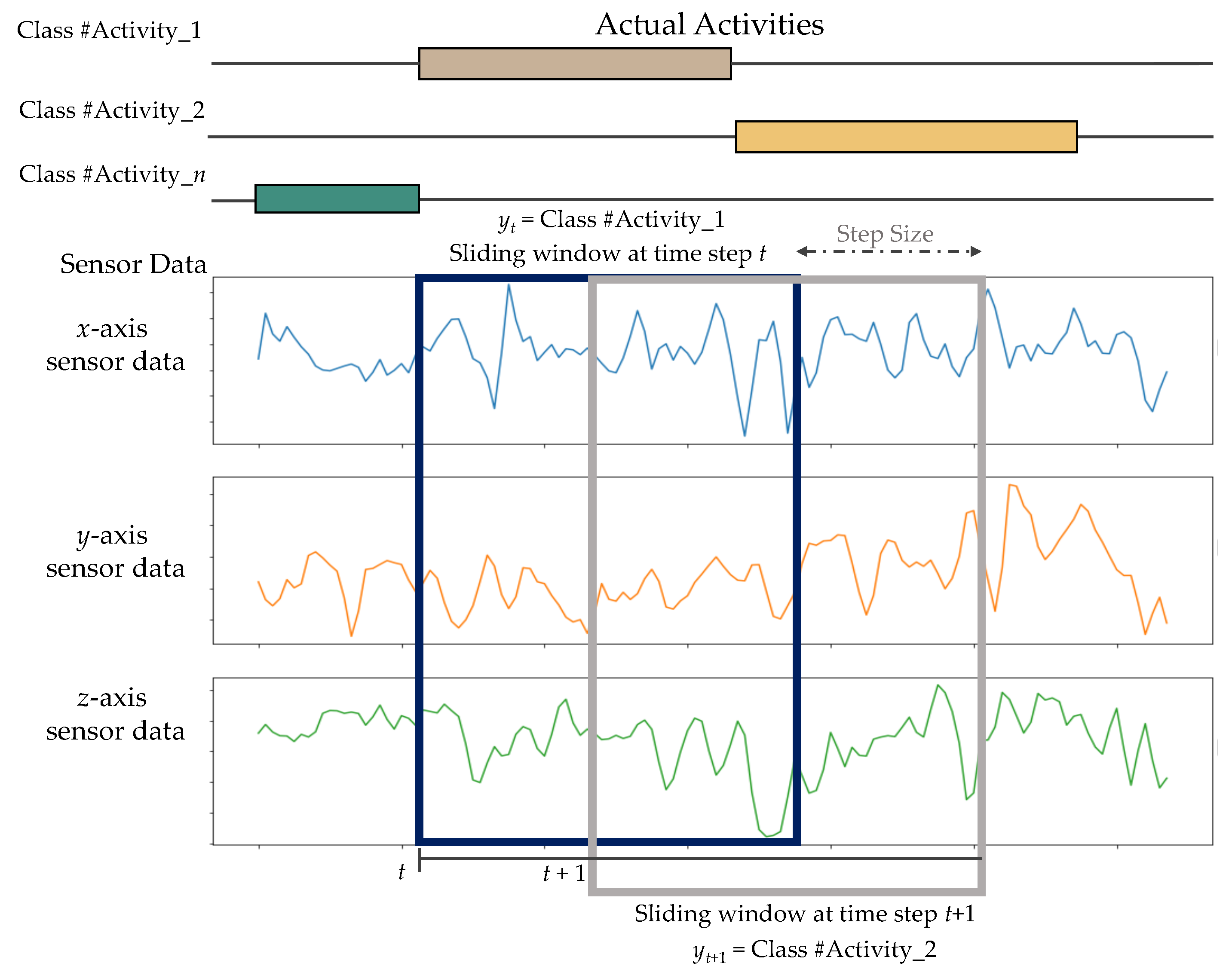
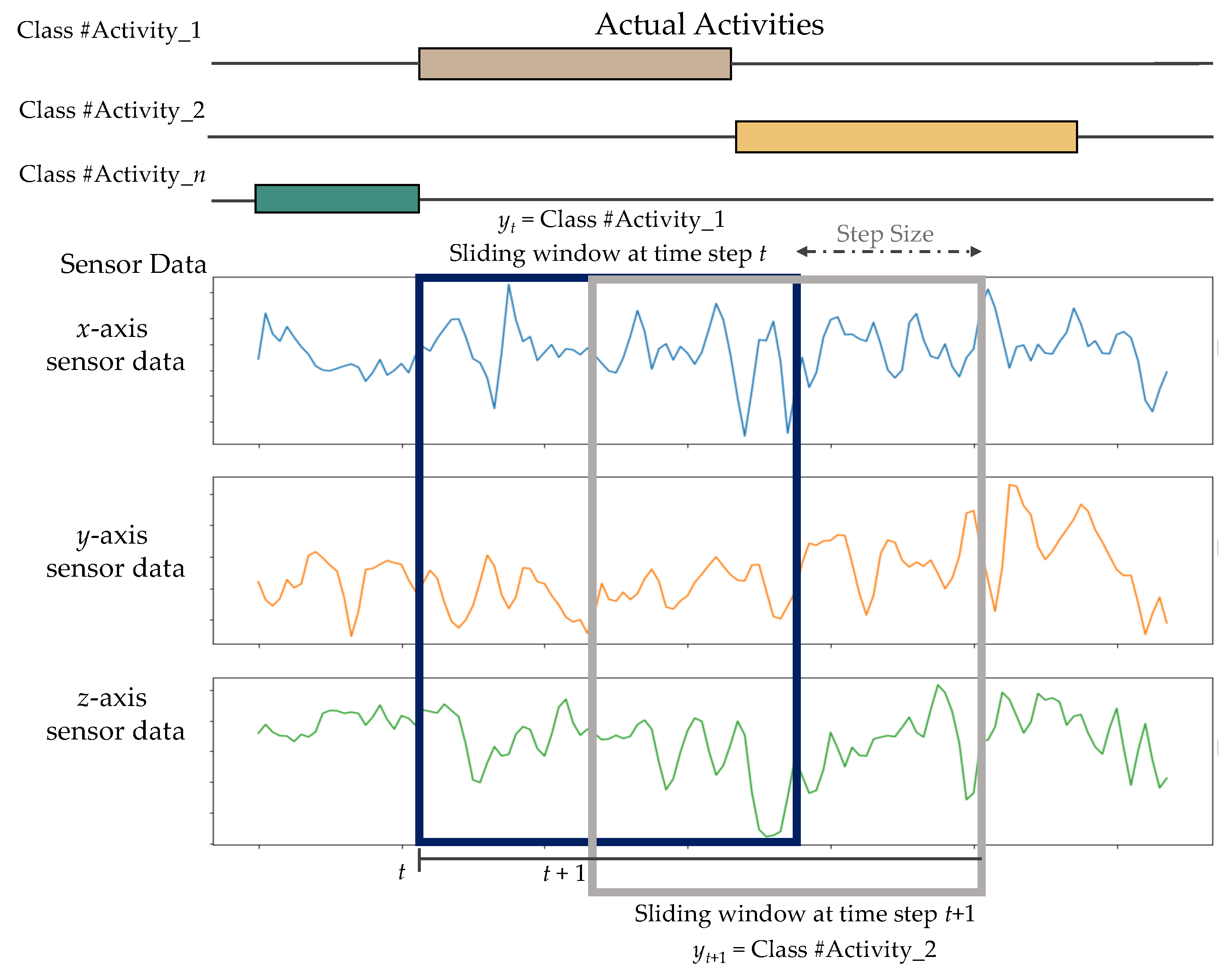
3.3.3. Data Segmentation
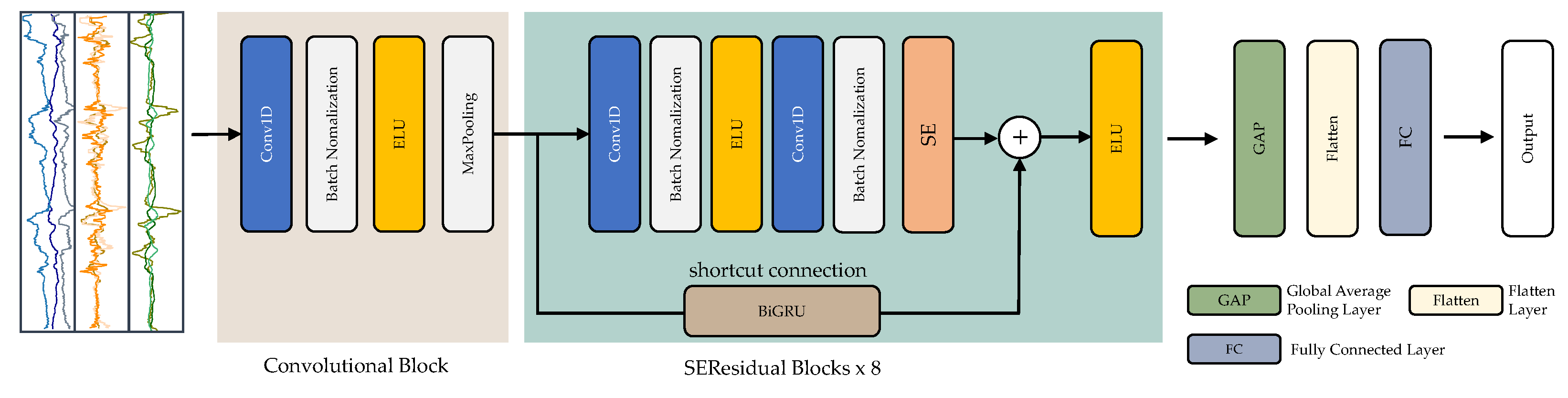
3.4. The Proposed SEResNet-BiGRU Model
3.4.1. Convolutional Block
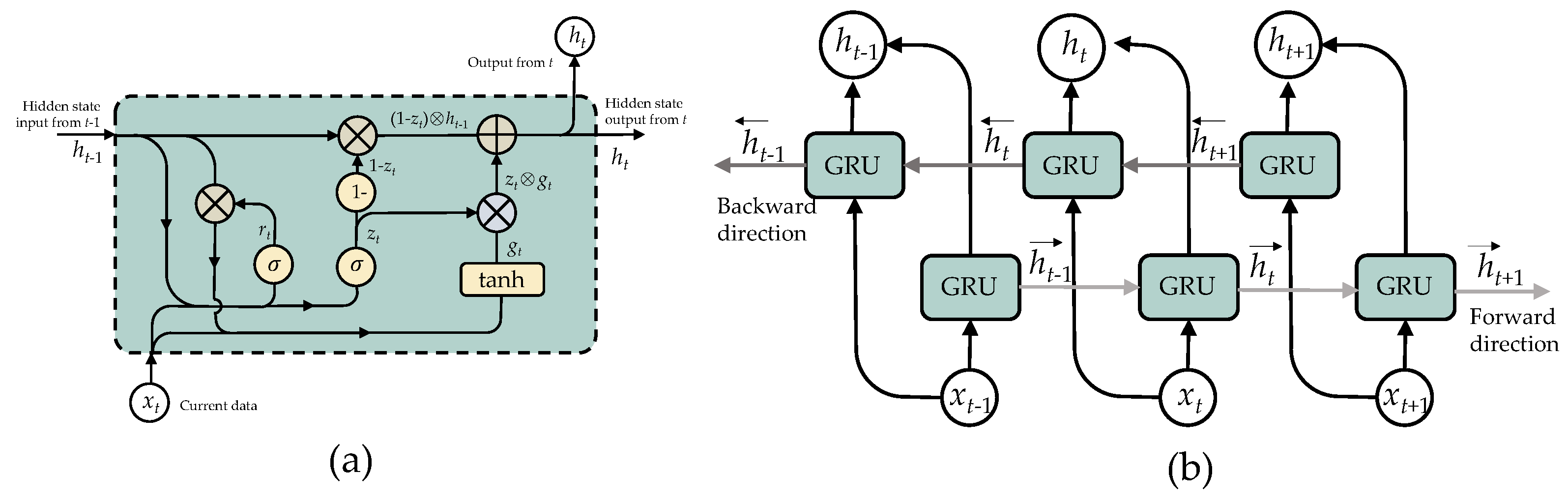
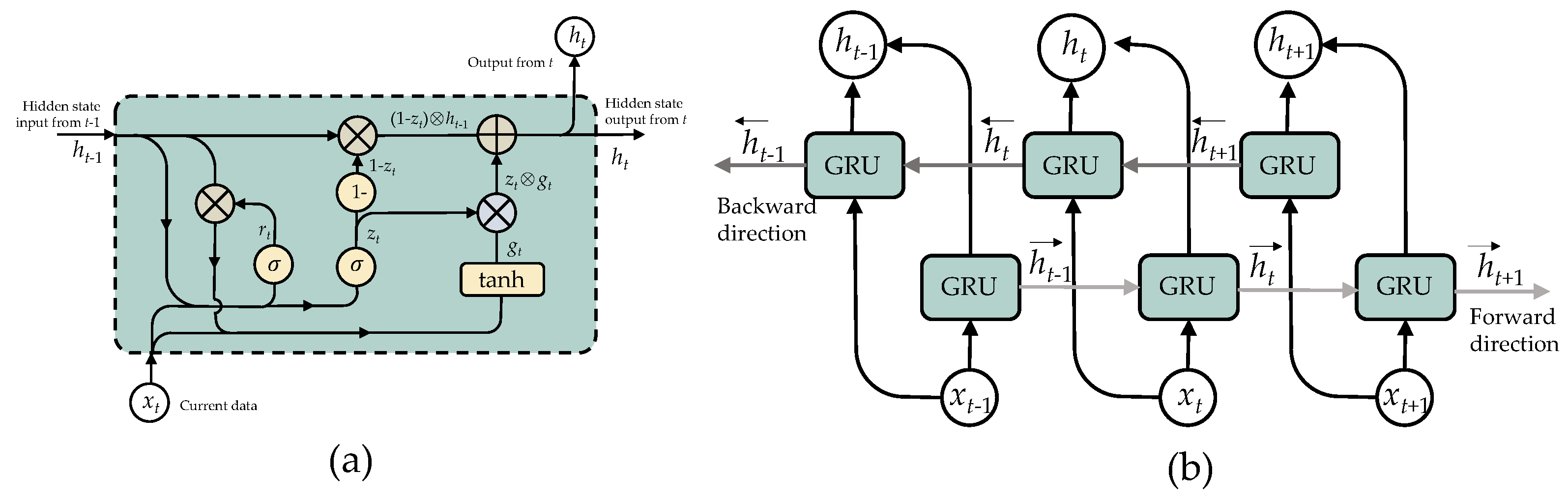
3.4.2. Structure of Gated Recurrent Unit
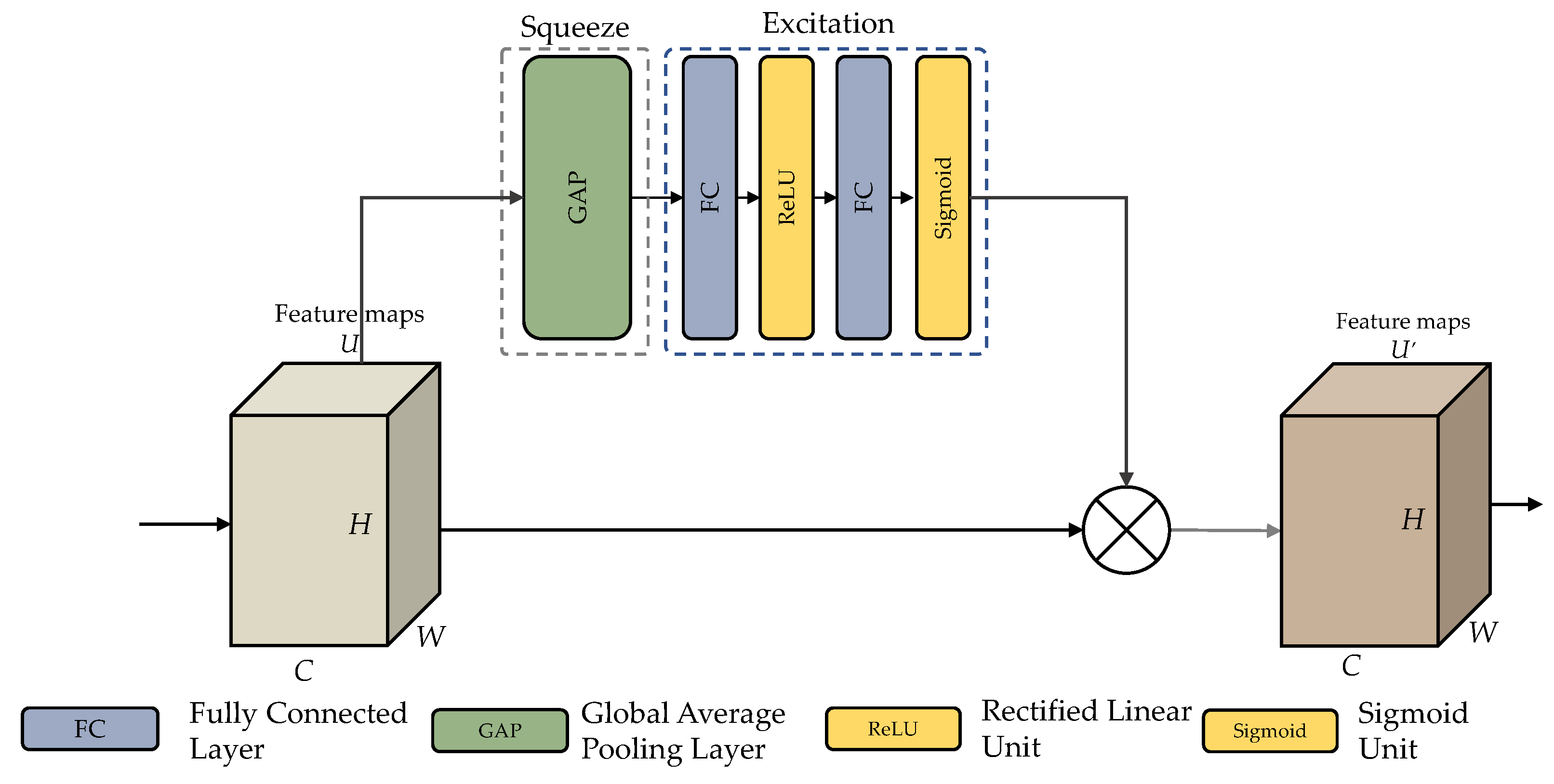
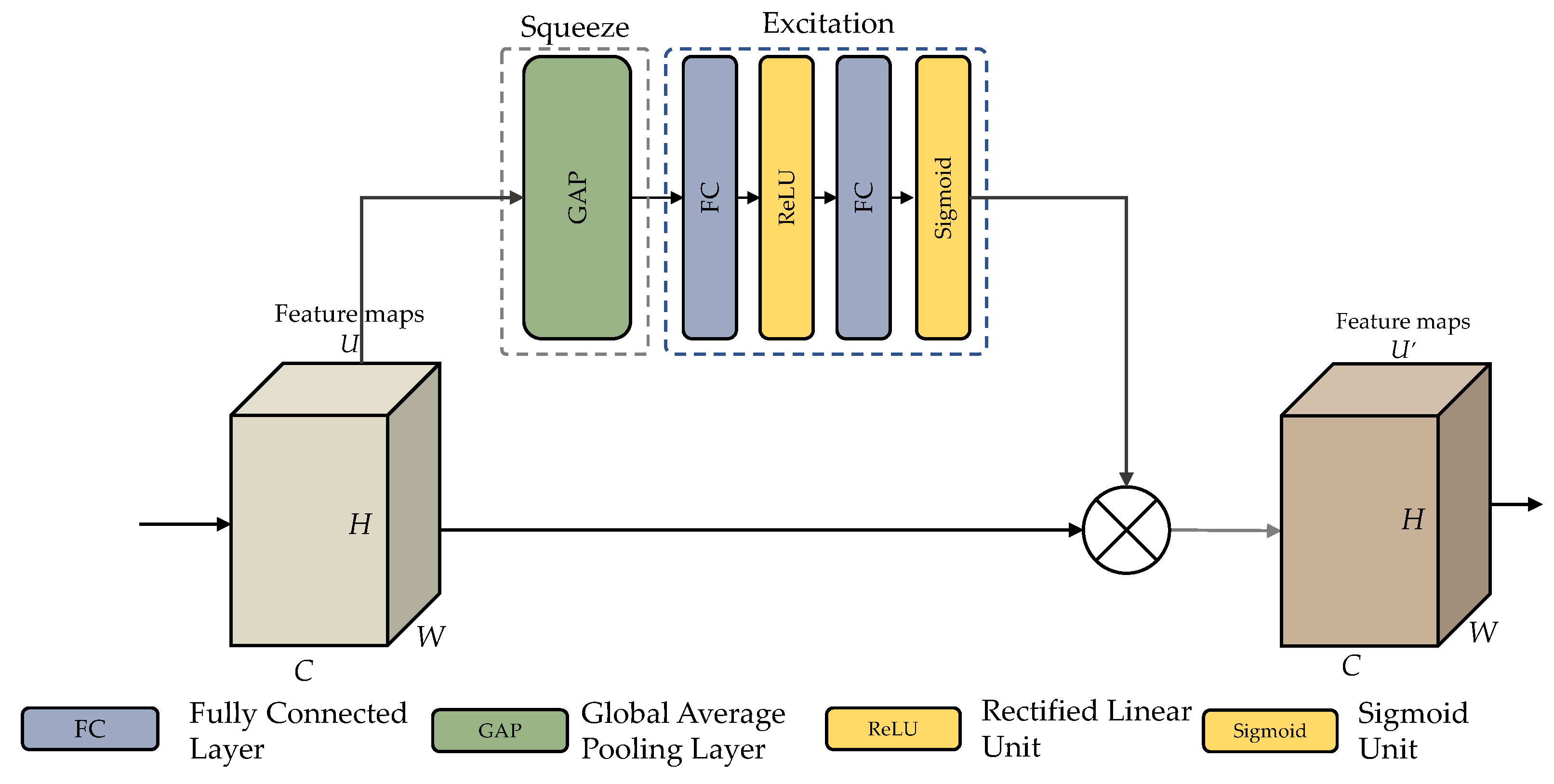
3.4.3. SEResidual Block
3.5. Hyperparameters
3.6. Model Training and Performance Evaluation
3.6.1. Training
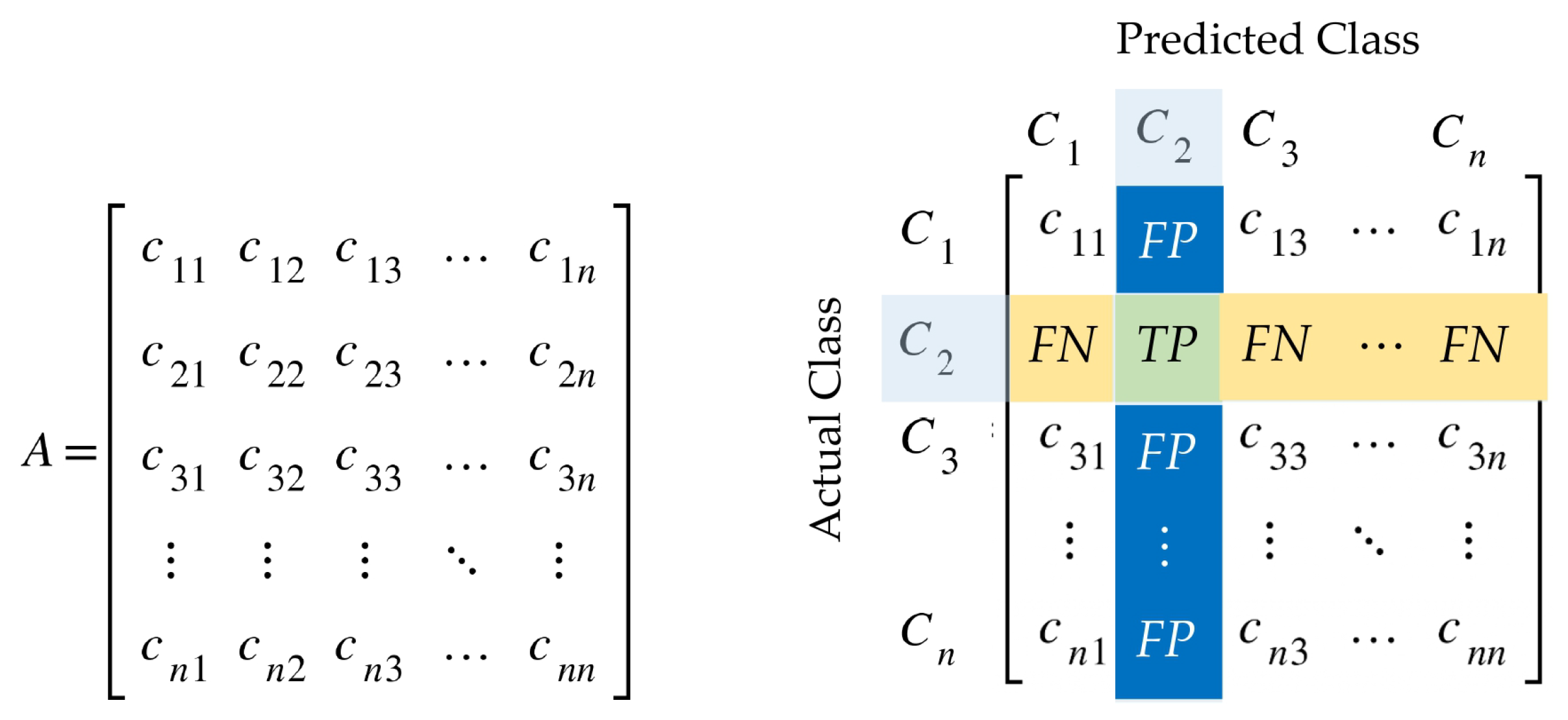
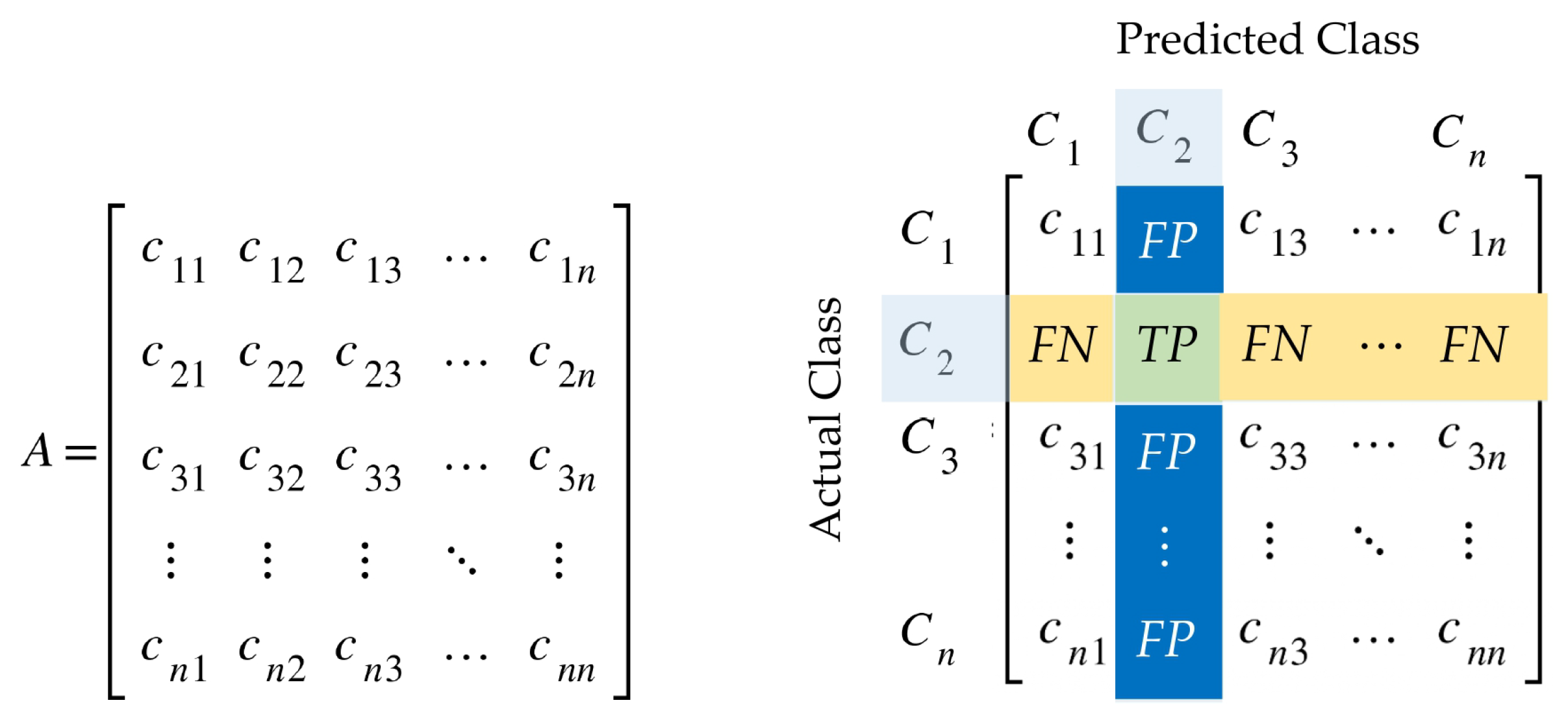
3.6.2. Evaluation Metrics
4. Experimental Results and Discussion
4.1. Experimental Setup
4.2. Experimental Results
4.3. Comparison of Results
4.4. Comparison of Results with Previous Works
4.5. Effect of SE and BiGRU Modules
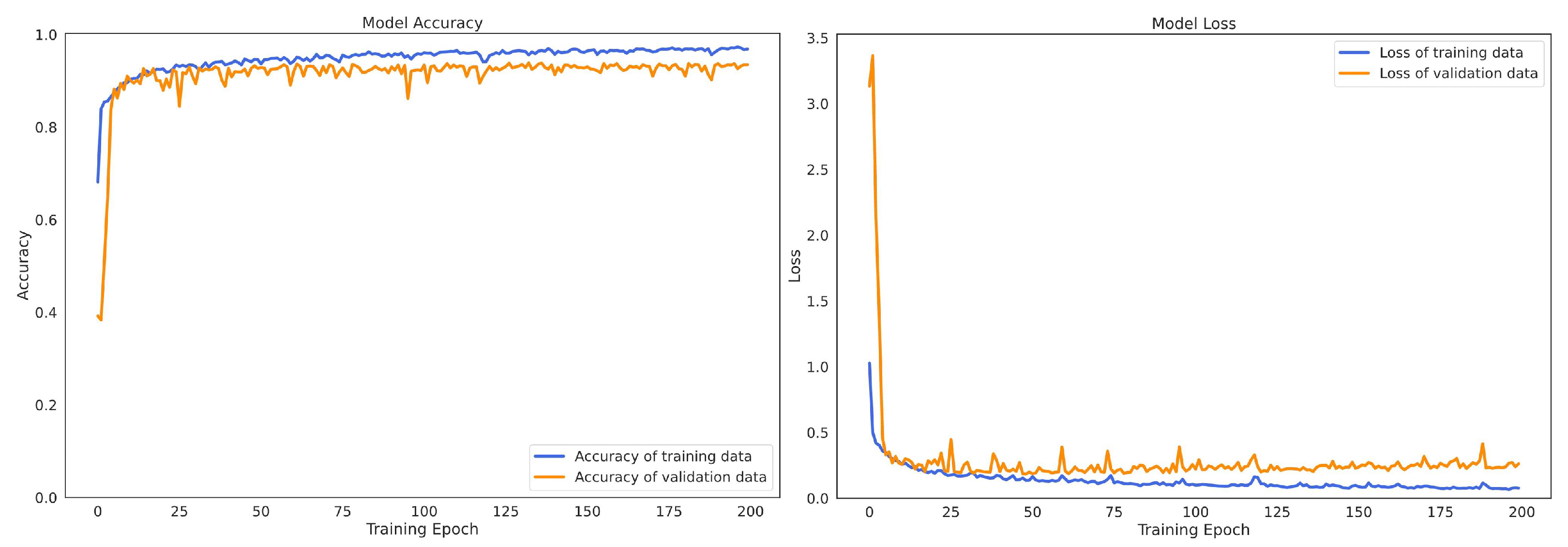
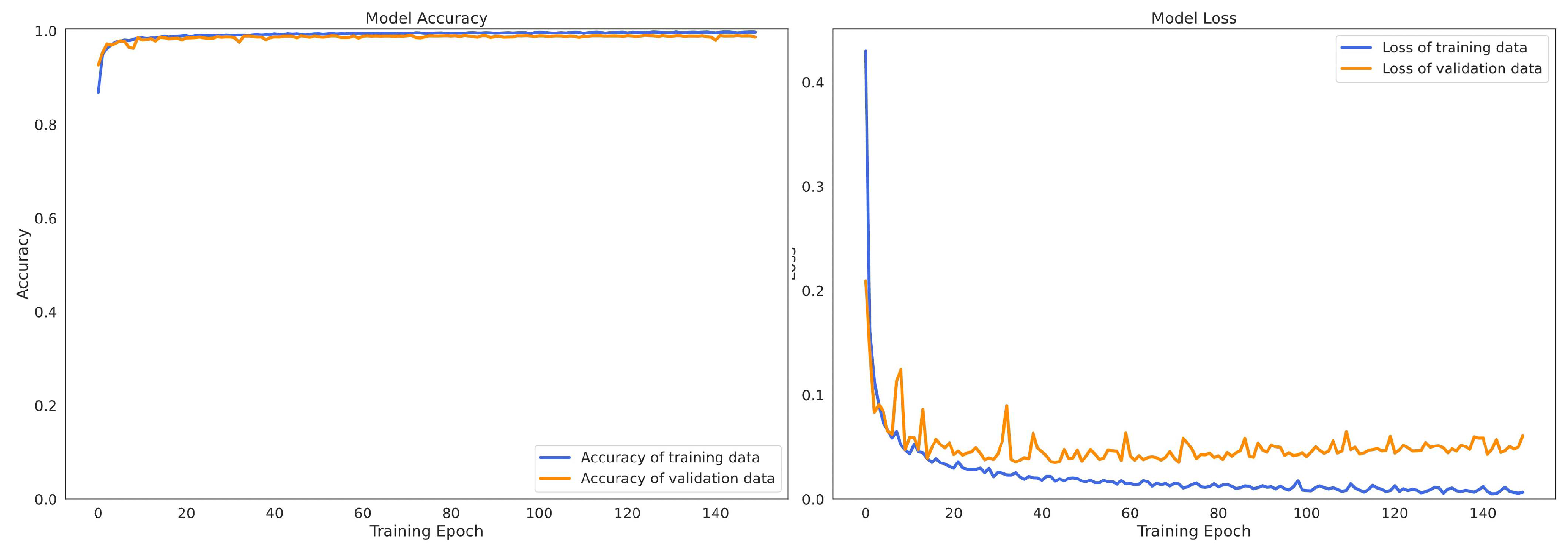
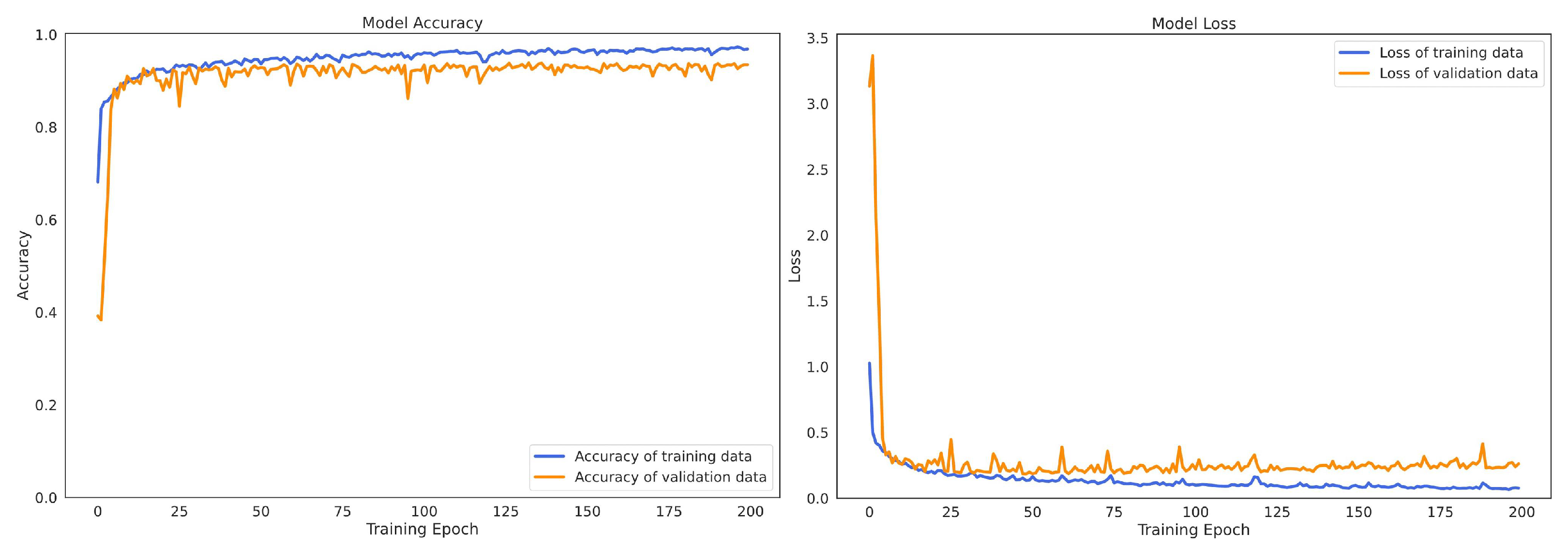
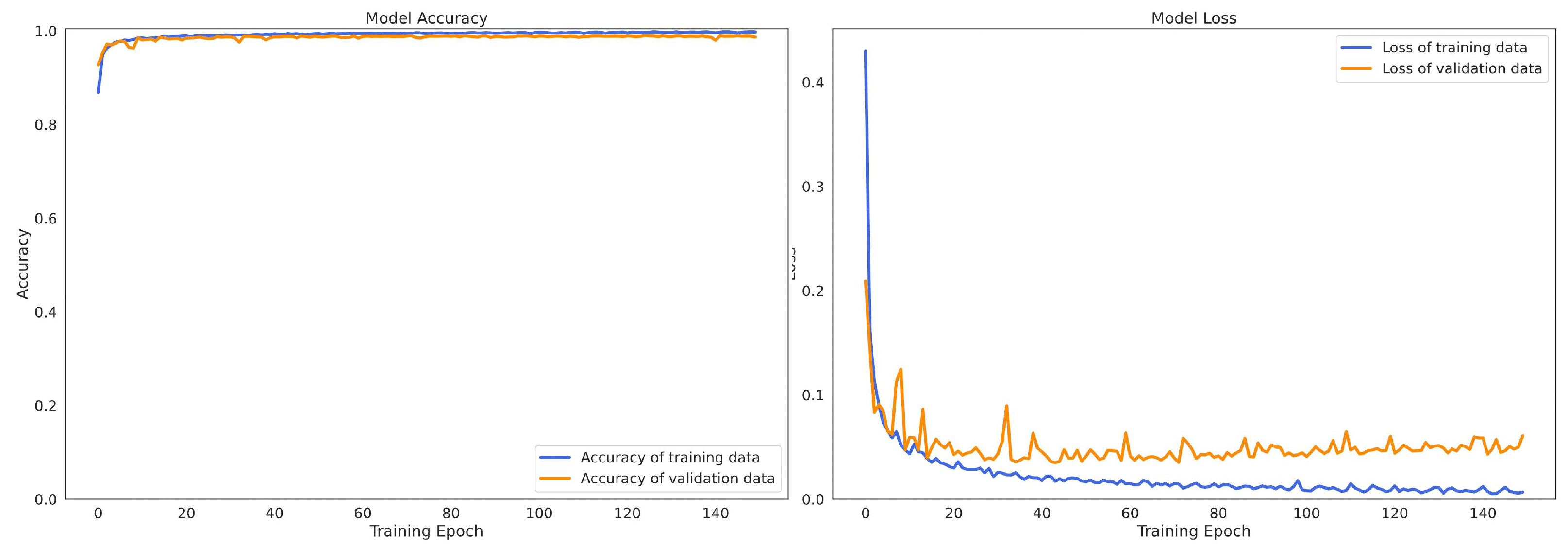
4.6. Convergence Process
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. The Summary of Hyperparameters

{kind=link}
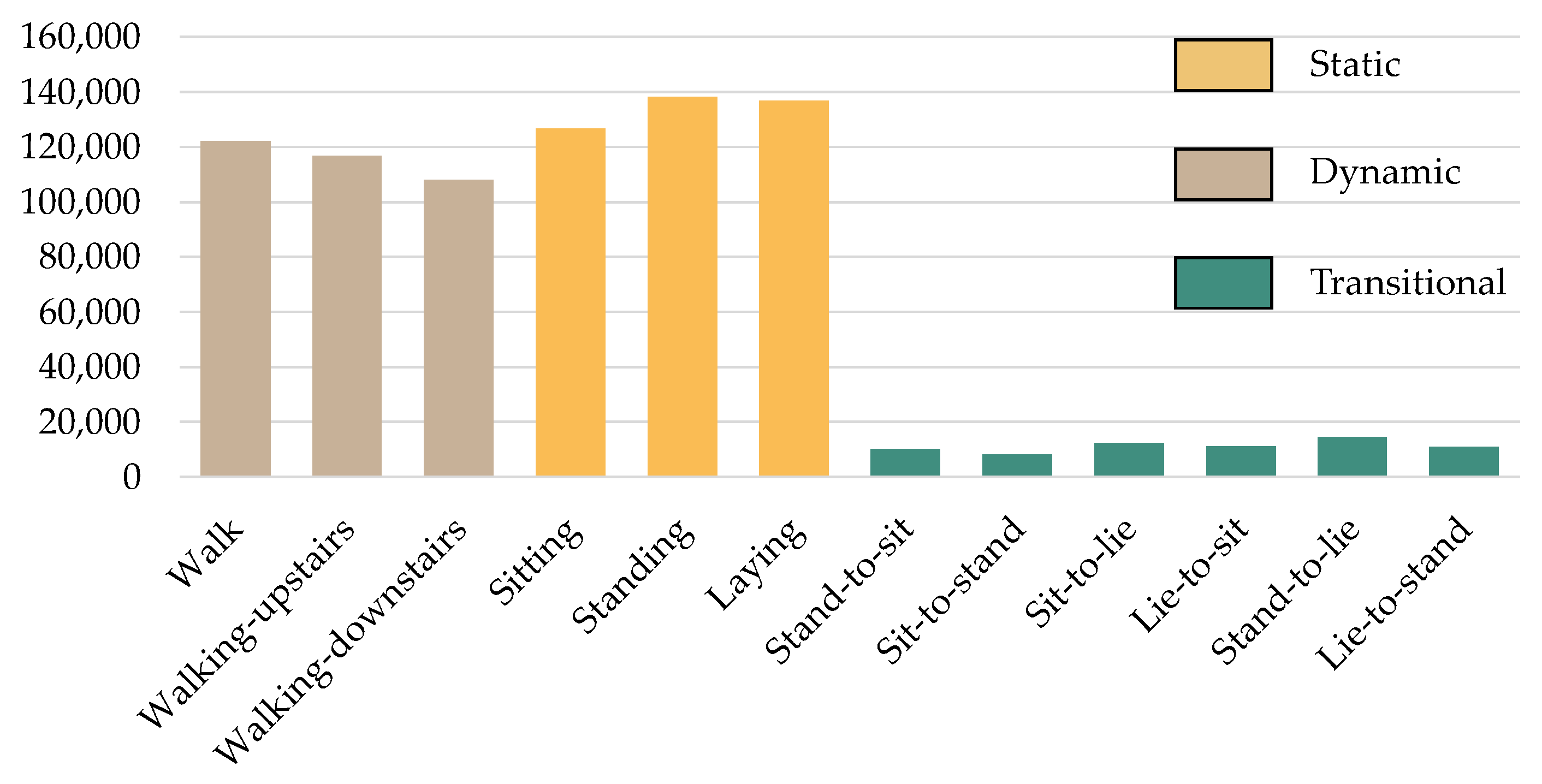{kind=link}
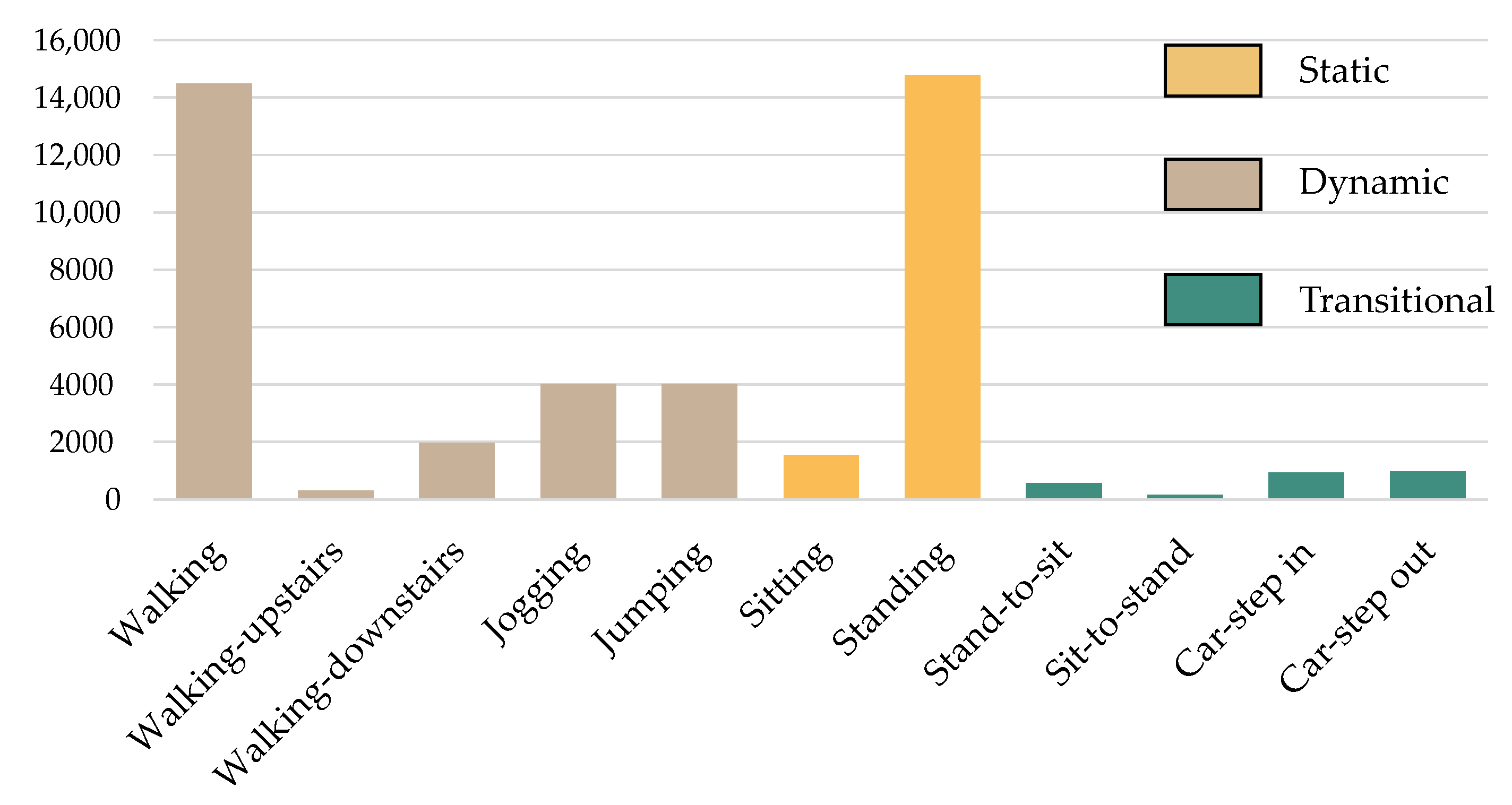{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Hyperparameters | Values | |
|---|---|---|---|
| Architecture | 1D-Convolution | Kernel Size | 5 |
| Stride | 1 | ||
| Filters | 64 | ||
| Dropout | 0.25 | ||
| Max Pooling | 2 | ||
| Flatten | - | ||
| Training | Loss Function | Cross-entropy | |
| Optimizer | Adam | ||
| Batch Size | 64 | ||
| Number of Epochs | 200 | ||
| Stage | Hyperparameters | Values |
|---|---|---|
| Architecture | LSTM Unit | 128 |
| Dropout | 0.25 | |
| Dense | 128 | |
| Training | Loss Function | Cross-entropy |
| Optimizer | Adam | |
| Batch Size | 64 | |
| Number of Epochs | 200 |
| Stage | Hyperparameters | Values |
|---|---|---|
| Architecture | BiGRU Unit | 128 |
| Dropout | 0.25 | |
| Dense | 128 | |
| Training | Loss Function | Cross-entropy |
| Optimizer | Adam | |
| Batch Size | 64 | |
| Number of Epochs | 200 |
| Stage | Hyperparameters | Values | |
|---|---|---|---|
| Architecture | Convolutional Block | ||
| 1D-Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 64 | ||
| Batch Normalization | - | ||
| Activation | ELU | ||
| Max Pooling | 2 | ||
| SE-ResNet Block × 8 | |||
| (Main Path) | |||
| 1D-Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 32 | ||
| Batch Normalization | - | ||
| Activation | ELU | ||
| 1D-Convolution | Kernel Size | 5 | |
| Stride | 1 | ||
| Filters | 64 | ||
| Batch Normalization | - | ||
| SE Module | - | ||
| (Parallel Path) | |||
| BiGRU Unit | 128 | ||
| Global Average Pooling | - | ||
| Flatten | - | ||
| Dense | 128 | ||
| Training | Loss Function | Cross-entropy | |
| Optimizer | Adam | ||
| Batch Size | 64 | ||
| Number of Epochs | 200 | ||
References
- Qi, J.; Yang, P.; Hanneghan, M.; Tang, S.; Zhou, B. A Hybrid Hierarchical Framework for Gym Physical Activity Recognition and Measurement Using Wearable Sensors. IEEE Internet Things J. 2019, 6, 1384–1393. [Google Scholar] [CrossRef] [Green Version]
- Asghari, P.; Soleimani, E.; Nazerfard, E. Online human activity recognition employing hierarchical hidden Markov models. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 1141–1152. [Google Scholar] [CrossRef] [Green Version]
- Minh Dang, L.; Min, K.; Wang, H.; Jalil Piran, M.; Hee Lee, C.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Wei, Z.; Nie, J.; Huang, L.; Wang, S.; Li, Z. A Review on Human Activity Recognition Using Vision-Based Method. J. Healthc. Eng. 2017, 2017, 3090343. [Google Scholar] [CrossRef]
- Casale, P.; Pujol, O.; Radeva, P. Human Activity Recognition from Accelerometer Data Using a Wearable Device. In Proceedings of the Pattern Recognition and Image Analysis; Vitrià, J., Sanches, J.M., Hernández, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 289–296. [Google Scholar]
- Romaissa, B.; Nini, B.; Sabokrou, M.; Hadid, A. Vision-based human activity recognition: A survey. Multimed. Tools Appl. 2020, 79, 30509–30555. [Google Scholar] [CrossRef]
- Li, J.H.; Tian, L.; Wang, H.; An, Y.; Wang, K.; Yu, L. Segmentation and Recognition of Basic and Transitional Activities for Continuous Physical Human Activity. IEEE Access 2019, 7, 42565–42576. [Google Scholar] [CrossRef]
- Ferreira, P.J.S.; Cardoso, J.M.P.; Mendes-Moreira, J. kNN Prototyping Schemes for Embedded Human Activity Recognition with Online Learning. Computers 2020, 9, 96. [Google Scholar] [CrossRef]
- Palaniappan, A.; Bhargavi, R.; Vaidehi, V. Abnormal human activity recognition using SVM based approach. In Proceedings of the 2012 International Conference on Recent Trends in Information Technology, Chennai, India, 19–21 April 2012; pp. 97–102. [Google Scholar] [CrossRef]
- Fan, L.; Wang, Z.; Wang, H. Human Activity Recognition Model Based on Decision Tree. In Proceedings of the 2013 International Conference on Advanced Cloud and Big Data, Nanjing, China, 13–15 December 2013; pp. 64–68. [Google Scholar] [CrossRef]
- Nurwulan, N.; Selamaj, G. Random Forest for Human Daily Activity Recognition. J. Phys. Conf. Ser. 2020, 1655, 012087. [Google Scholar] [CrossRef]
- Cheng, L.; Guan, Y.; Zhu, K.; Li, Y. Recognition of human activities using machine learning methods with wearable sensors. In Proceedings of the 2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Deep Residual Network for Smartwatch-Based User Identification through Complex Hand Movements. Sensors 2022, 22, 3094. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Deep Convolutional Neural Network with RNNs for Complex Activity Recognition Using Wrist-Worn Wearable Sensor Data. Electronics 2021, 10, 1685. [Google Scholar] [CrossRef]
- Li, W.; Liu, X.; Liu, J.; Chen, P.; Wan, S.; Cui, X. On Improving the accuracy with Auto-Encoder on Conjunctivitis. Appl. Soft Comput. 2019, 81, 105489. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. LSTM Networks Using Smartphone Data for Sensor-Based Human Activity Recognition in Smart Homes. Sensors 2021, 21, 1636. [Google Scholar] [CrossRef] [PubMed]
- Wang, J. Analysis and design of a recurrent neural network for linear programming. IEEE Trans. Circuits Syst. Fundam. Theory Appl. 1993, 40, 613–618. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Michaelis, J.R.; Rupp, M.A.; Kozachuk, J.; Ho, B.; Zapata-Ocampo, D.; McConnell, D.S.; Smither, J.A. Describing the User Experience of Wearable Fitness Technology through Online Product Reviews. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2016, 60, 1073–1077. [Google Scholar] [CrossRef]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep Learning Models for Real-time Human Activity Recognition with Smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; Wang, K.I.K.; Wang, H.; Yang, L.T.; Jin, Q. Deep-Learning-Enhanced Human Activity Recognition for Internet of Healthcare Things. IEEE Internet Things J. 2020, 7, 6429–6438. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI Based Passive Human Activity Recognition Using Attention Based BLSTM. IEEE Trans. Mob. Comput. 2019, 18, 2714–2724. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, Z.; Soh, Y.C. A Novel Semisupervised Deep Learning Method for Human Activity Recognition. IEEE Trans. Ind. Inform. 2019, 15, 3821–3830. [Google Scholar] [CrossRef]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A Deep Neural Network for Complex Human Activity Recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Moufawad el Achkar, C.; Lenbole-Hoskovec, C.; Paraschiv-Ionescu, A.; Major, K.; Büla, C.; Aminian, K. Classification and characterization of postural transitions using instrumented shoes. Med. Biol. Eng. Comput. 2018, 56, 1403–1412. [Google Scholar] [CrossRef] [PubMed]
- Acampora, G.; Minopoli, G.; Musella, F.; Staffa, M. Classification of Transition Human Activities in IoT Environments via Memory-Based Neural Networks. Electronics 2020, 9, 409. [Google Scholar] [CrossRef] [Green Version]
- Uddin, M.T.; Billah, M.M.; Hossain, M.F. Random forests based recognition of human activities and postural transitions on smartphone. In Proceedings of the 2016 5th International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 13–14 May 2016; pp. 250–255. [Google Scholar] [CrossRef]
- Noor, M.H.M.; Salcic, Z.; Wang, K.I.K. Adaptive sliding window segmentation for physical activity recognition using a single tri-axial accelerometer. Pervasive Mob. Comput. 2017, 38, 41–59. [Google Scholar] [CrossRef]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-Aware Human Activity Recognition Using Smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef] [Green Version]
- Kozina, S.; Gjoreski, H.; Gams, M.; Lustrek, M. Three-layer Activity Recognition Combining Domain Knowledge and Meta- classification Author list. J. Med. Biol. Eng. 2013, 33, 406–414. [Google Scholar] [CrossRef]
- Gupta, P.; Dallas, T. Feature Selection and Activity Recognition System Using a Single Triaxial Accelerometer. IEEE Trans. Biomed. Eng. 2014, 61, 1780–1786. [Google Scholar] [CrossRef]
- Liu, K.C.; Hsieh, C.Y.; Chan, C.T. Transition-Aware Housekeeping Task Monitoring Using Single Wrist-Worn Sensor. IEEE Sens. J. 2018, 18, 8950–8962. [Google Scholar] [CrossRef]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Gusain, K.; Gupta, A.; Popli, B. Transition-aware human activity recognition using eXtreme gradient boosted decision trees. In Advanced Computing and Communication Technologies; Springer: Singapore, 2018; pp. 41–49. [Google Scholar] [CrossRef]
- Ahmed, N.; Rafiq, J.I.; Islam, M.R. Enhanced Human Activity Recognition Based on Smartphone Sensor Data Using Hybrid Feature Selection Model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Zuo, D.; Zhang, Z. Transition Activity Recognition System Based on Standard Deviation Trend Analysis. Sensors 2020, 20, 3117. [Google Scholar] [CrossRef] [PubMed]
- Setterquist, D. Using a Smartphone to Detect the Standing-to-Kneeling and Kneeling-to-Standing Postural Transitions. Master’s Thesis, School of Electrical Engineering and Computer Science (EECS), KTH Royal Institute of Technology, Stockholm, Sweden, 2018. [Google Scholar]
- Hoai Thu, N.T.; Han, D.S. HiHAR: A Hierarchical Hybrid Deep Learning Architecture for Wearable Sensor-Based Human Activity Recognition. IEEE Access 2021, 9, 145271–145281. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, J.; Li, J.; Tian, L.; Tu, P.; Cao, T.; An, Y.; Wang, K.; Li, S. Wearable sensor-based human activity recognition using hybrid deep learning techniques. Secur. Commun. Netw. 2020, 2020, 2132138. [Google Scholar] [CrossRef]
- Irfan, S.; Anjum, N.; Masood, N.; Khattak, A.S.; Ramzan, N. A Novel Hybrid Deep Learning Model for Human Activity Recognition Based on Transitional Activities. Sensors 2021, 21, 8227. [Google Scholar] [CrossRef]
- Chatzaki, C.; Pediaditis, M.; Vavoulas, G.; Tsiknakis, M. Human daily activity and fall recognition using a smartphone’s acceleration sensor. In Proceedings of the Information and Communication Technologies for Ageing Well and e-Health; Porto, Portugal, 28–29 April 2017, Röcker, C., O’Donoghue, J., Ziefle, M., Helfert, M., Molloy, W., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 100–118. [Google Scholar]
- Hassan, M.M.; Gumaei, A.; Aloi, G.; Fortino, G.; Zhou, M. A Smartphone-Enabled Fall Detection Framework for Elderly People in Connected Home Healthcare. IEEE Netw. 2019, 33, 58–63. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition using Smartphones. In Proceedings of the International Conference on European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Rong, L.; Jianzhong, Z.; Ming, L.; Xiangfeng, H. A Wearable Acceleration Sensor System for Gait Recognition. In Proceedings of the 2007 2nd IEEE Conference on Industrial Electronics and Applications, Harbin, China, 23–25 May 2007; pp. 2654–2659. [Google Scholar] [CrossRef]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window Size Impact in Human Activity Recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [Green Version]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. In Proceedings of the NIPS 2014 Workshop on Deep Learning, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Muqeet, A.; Iqbal, M.T.B.; Bae, S.H. HRAN: Hybrid Residual Attention Network for Single Image Super-Resolution. IEEE Access 2019, 7, 137020–137029. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- Rundo, L.; Han, C.; Nagano, Y.; Zhang, J.; Hataya, R.; Militello, C.; Tangherloni, A.; Nobile, M.S.; Ferretti, C.; Besozzi, D.; et al. USE-Net: Incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets. Neurocomputing 2019, 365, 31–43. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Janocha, K.; Czarnecki, W. On Loss Functions for Deep Neural Networks in Classification. arXiv 2017, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar] [CrossRef] [Green Version]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
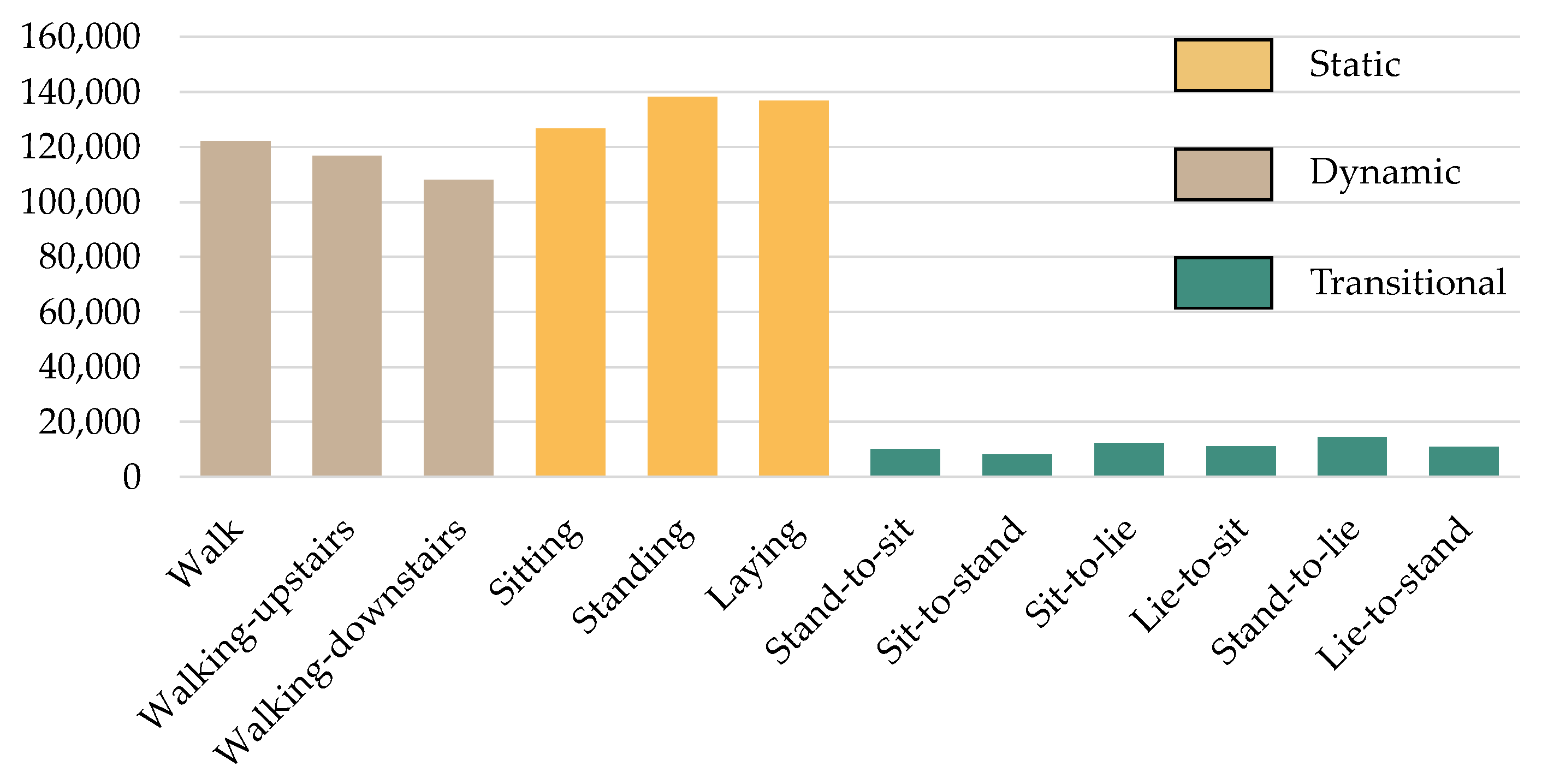
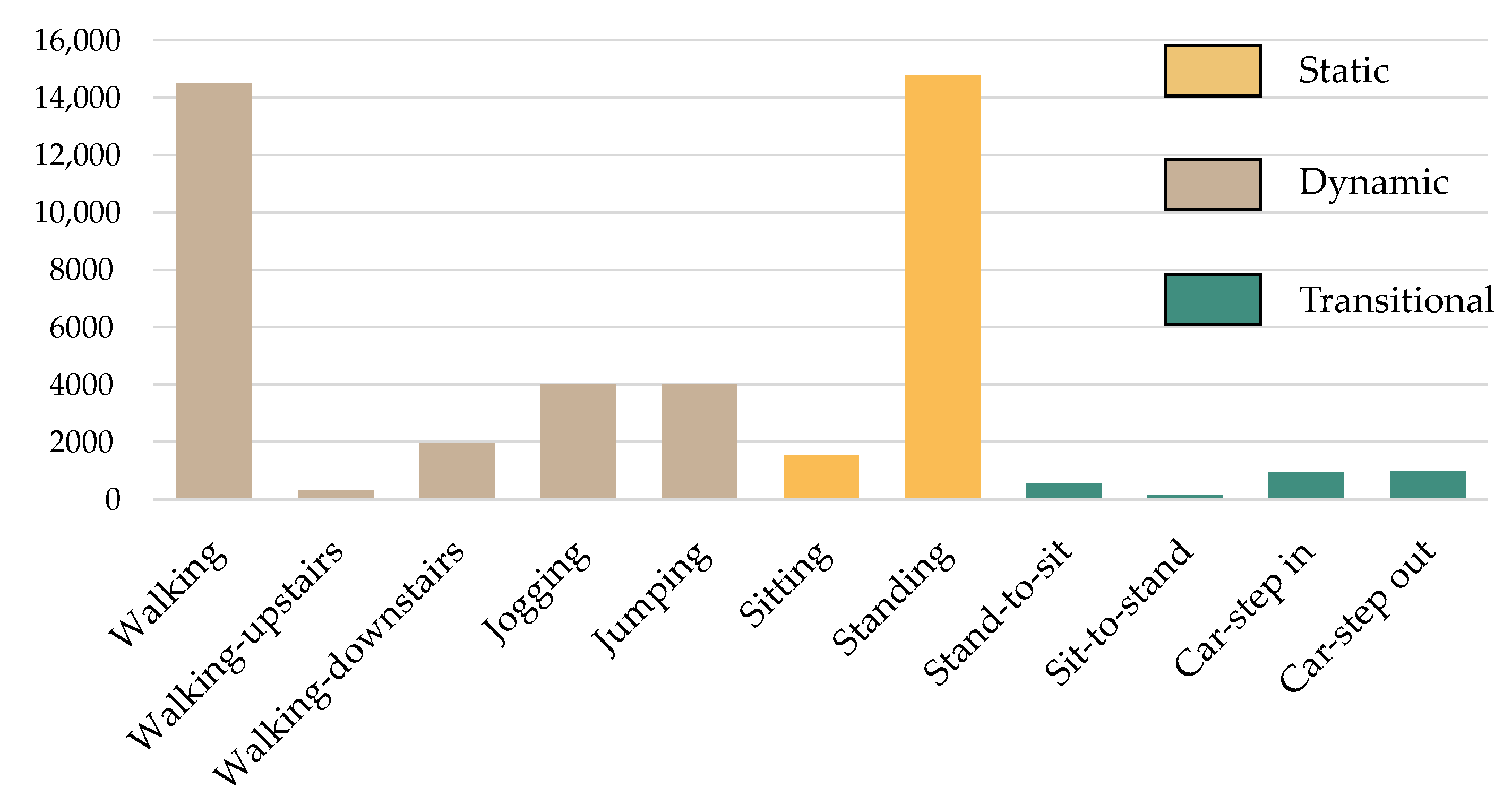
| Year | Model | Learning Algorithm | Accuracy (%) | Dataset | Weaknesses |
|---|---|---|---|---|---|
| 2016 | TAHAR [31] | ML | 96.44 | HAPT | An SVM with a heuristic filtering approach needs a feature mapping layer to achieved with a high accuracy. |
| 2018 | SVM-TED [34] | ML | 81.62 | own dataset | A conventional SVM with a transition occurrence detection module can detect postural transitions but lacks the precision essential for effective movement recognition. |
| 2018 | DBN [35] | DL | 95.80 | HAPT | DBN causes it more challenging to train the network design, and ReLu has substituted it, a more suitable lesson for the vanishing gradient issue. |
| 2018 | GBDT [36] | ML | 94.90 | HAPT | Provides the most excellent outcomes with smaller datasets, but accuracy declines as the size of the dataset increases. |
| 2020 | SVM + SFFS [37] | ML | 96.81 | HAPT | Increased accuracy with fewer datasets and increased data volume results in decreased accuracy. |
| 2020 | STD-TA [38] | ML | 80.0 | own dataset | A standard SVM with moderate accuracy extracts statistical information to distinguish between transitional and fundamental actions. |
| 2020 | Multi-LSTM [39] | DL | 89.00 | own dataset | Multiple pipelined LSTM units are employed in this strategy, which slows the network’s training and increases the model’s sophistication. Any flaw or inconsistency in a single LSTM unit affects the pipeline of LSTM units as a whole. |
| 2020 | CNN+LSTM [38] | DL | 95.80 | HAPT | The model is complicated, and the CNN utilized is a standard CNN with a simple three-layered construction that is not enhanced. No consideration was given to complex tasks and their transitions. |
| 2021 | Multiple DL + Fusion Decision Module | DL | 96.11 | HAPT | The model contains many hyperparameters and spend lots of computation time. |
| 2021 | HiHAR [40] | DL | 97.98 | HAPT | The transitional activities were grouped into two classes to avoid |
| 96.16 | MobiAct | the class imbalanced problem. |
| Dataset | Sensors | Number of Subjects | Number of Activities | Activities | ||
|---|---|---|---|---|---|---|
| Static | Dynamic | Transition | ||||
| HAPT [31] | 3D-Acc. 3D-Gyro. | 30 | 12 | sitting standing laying | walking walking-upstairs walking-downstairs | stand-to-sit it-to-stand sit-to-lie lie-to-sit stand-to-lie lie-to-stand |
| MobiAct v2.0 [43] | 3D-Acc. 3D-Gyro. 3D-Ori. | 19 | 11 | sitting standing | walking walking-upstairs walling-downstairs jogging jumping | stand-to-sit sit-to-stand car-step in car-step out |
| Metrics | Formulas |
|---|---|
| Accuracy | |
| Recall of class | |
| Precision of class | |
| F1-score of class | |
| Recall | |
| Precision | |
| F1-score |
| Model | Acc. | Gyro. | Acc. and Gyro. | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy (%) (±SD (%)) | Loss (±SD) | F1-Score (%) (±SD (%)) | Accuracy (%) (±SD (%)) | Loss | F1-Score (%) (±SD) | Accuracy (%) (±SD (%)) | Loss | F1-Score (%) (±SD(%)) | |||
| ResNet | 96.97% (±0.44%) | 0.103 (±0.017) | 92.53% (±0.39%) | 89.16% (±6.39%) | 1.185 (±1.460) | 87.55% (±5.13%) | 97.87% (±0.125%) | 0.088 (±0.009) | 93.89% (±0.31%) | ||
| ResNetSE | 96.45% (±0.79%) | 0.107 (±0.016) | 92.62% (±0.55%) | 84.73% (±7.31%) | 1.895 (±1.970) | 85.59% (±5.28%) | 97.89% (±0.33%) | 0.095 (±0.018) | 93.81% (±0.43%) | ||
| ResNeXt | 96.38% (±0.35%) | 0.114 (±0.014) | 91.99% (±0.72%) | 96.05% (±0.36%) | 0.137 (±0.018) | 91.63% (±0.83%) | 97.43% (±0.30%) | 0.093 (±0.017) | 93.33% (±0.66%) | ||
| SEResNet-BiGRU | 97.01% (±0.30%) | 0.112 (±0.010) | 92.76% (±0.48%) | 93.69% (±1.95%) | 0.290 (±0.114) | 91.77% (±0.59%) | 98.03% (±0.17%) | 0.080 (±0.006) | 94.09% (±0.55%) | ||
| Model | Acc. | Gyro. | Acc.+ Gyro. | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy (%) (±SD (%)) | Loss (±SD) | F1-Score (%) (±SD (%)) | Accuracy (%) (±SD (%)) | Loss (±SD) | F1-Score (%) (±SD (%)) | Accuracy (%) (±SD (%)) | Loss (±SD) | F1-Score (%) (±SD (%)) | |||
| ResNet | 98.60% (±0.11%) | 0.057 (±0.007) | 94.33% (±0.46%) | 91.48% (±9.36%) | 0.751 (±1.184) | 86.73% (±5.69%) | 98.84% (±0.16%) | 0.058 (±0.014) | 95.50% (±0.42%) | ||
| ResNetSE | 98.65% (±0.18%) | 0.040 (±0.009) | 94.34% (±0.90%) | 96.93% (±0.33%) | 0.133 (±0.019) | 90.65% (±0.54%) | 98.90% (±0.09%) | 0.052 (±0.004) | 95.49% (±0.52%) | ||
| ResNeXt | 98.12% (±0.31%) | 0.070 (±0.009) | 92.49% (±1.12%) | 94.98% (±0.46%) | 0.225 (±0.038) | 84.65% (±1.59%) | 98.64% (±0.16%) | 0.072 (±0.006) | 94.53% (±0.41%) | ||
| SEResNet-BiGRU | 98.79% (±0.11%) | 0.021 (±0.004) | 95.03% (±0.89%) | 97.08% (±0.16%) | 0.108 (±0.029) | 89.86% (±0.67%) | 98.92% (±0.09%) | 0.048 (±0.012) | 95.71% (±0.43%) | ||
| Model | Accuracy (%) ± SD (%) | |
|---|---|---|
| HAPT Dataset | MobiAct Dataset | |
| Basic DL models | ||
| CNN | 94.40 ± 0.36 | 93.69 ± 0.34 |
| LSTM | 91.02 ± 1.50 | 83.38 ± 2.95 |
| BiGRU | 94.40 ± 0.36 | 90.43 ± 1.48 |
| Proposed model | ||
| SEResNet-BiGRU | 98.03 ± 0.17 | 98.92 ± 0.09 |
| Model | Accuracy (%) ± SD (%) | |
|---|---|---|
| HAPT Dataset | MobiAct Dataset | |
| ML Models | ||
| KNNs (k = 7) [40] | 75.62 | 65.86 |
| SVM [40] | 89.26 | 63.60 |
| Hybrid DL models | ||
| LSTM-CNN [56] | 90.49 ± 1.01 | 91.15 ± 0.79 |
| InnoHAR [25] | 95.09 ± 0.49 | 93.70 ± 0.49 |
| HiHAR [40] | 97.98 ± 0.24 | 96.16 ± 0.22 |
| Proposed model | ||
| SEResNet-BiGRU | 98.03 ± 0.17 | 98.92 ± 0.09 |
| SE Module | BiGRU Module | Dataset | Accuracy (%) |
|---|---|---|---|
| - | - | HAPT | 97.87% |
| ✓ | - | HAPT | 97.89% |
| - | ✓ | HAPT | 97.95% |
| ✓ | ✓ | HAPT | 98.03% |
| - | - | MobiAct v2.0 | 98.84% |
| ✓ | - | MobiAct v2.0 | 98.90% |
| - | ✓ | MobiAct v2.0 | 98.89% |
| ✓ | ✓ | MobiAct v2.0 | 98.92% |
| SE Module | BiGRU Module | Dataset | Mean Prediction Time (ms.) |
|---|---|---|---|
| - | - | HAPT | 0.1304 |
| ✓ | - | HAPT | 0.3080 |
| - | ✓ | HAPT | 1.1696 |
| ✓ | ✓ | HAPT | 1.3208 |
| - | - | MobiAct v2.0 | 0.1276 |
| ✓ | - | MobiAct v2.0 | 0.2857 |
| - | ✓ | MobiAct v2.0 | 1.8489 |
| ✓ | ✓ | MobiAct v2.0 | 2.0047 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mekruksavanich, S.; Hnoohom, N.; Jitpattanakul, A. A Hybrid Deep Residual Network for Efficient Transitional Activity Recognition Based on Wearable Sensors. Appl. Sci. 2022, 12, 4988. https://doi.org/10.3390/app12104988
Mekruksavanich S, Hnoohom N, Jitpattanakul A. A Hybrid Deep Residual Network for Efficient Transitional Activity Recognition Based on Wearable Sensors. Applied Sciences. 2022; 12(10):4988. https://doi.org/10.3390/app12104988
Chicago/Turabian StyleMekruksavanich, Sakorn, Narit Hnoohom, and Anuchit Jitpattanakul. 2022. "A Hybrid Deep Residual Network for Efficient Transitional Activity Recognition Based on Wearable Sensors" Applied Sciences 12, no. 10: 4988. https://doi.org/10.3390/app12104988
APA StyleMekruksavanich, S., Hnoohom, N., & Jitpattanakul, A. (2022). A Hybrid Deep Residual Network for Efficient Transitional Activity Recognition Based on Wearable Sensors. Applied Sciences, 12(10), 4988. https://doi.org/10.3390/app12104988