
Short-Term Prediction of COVID-19 Cases Using Machine Learning Models

 ,
,  ,
,  ,
,  ,
,  , , and
, , and 
Abstract
1. Introduction
- 1
- The number of COVID-19 infected people is currently still increasing inBangladesh but there are only incomplete data on the number and location of cases. There are many strategies for reducing the spread that could be implemented by the local authorities but a lack of understanding of the spreading pattern hinders their design and implementation. We therefore designed software based modeling that can be trained to perform short-term forecasting.
- 2
- Many previous studies have considered many epidemiological models where several pandemic parameters depended on the rate of social mixing of people. In the current circumstances in Bangladesh, we cannot determine or measure such parameters precisely. Therefore, various machine learning models can be a useful approach to forecast infectious cases without needing such parameter precision. However, it is important to note that predictions of infection levels are sensitive to non-linear changes of parameters so that long term prediction tends to give poor results. For this reason, we have focused on implementing short-term forecasting models where accuracy is more likely to be achieved.
- 3
- The analysis with different sliding windows (rounds) helps to estimate the prediction capability of individual machine learning models and assist in the exploration of the best models that provide the most accurate predictions. This model will assist governmental authorities to take more effective steps against COVID-19 spread and fatalities.
- 4
- Cloud based web mining makes it possible to achieve fast and feasible to get real-time outcomes.
2. Materials and Methods
2.1. Data Description
2.2. Regression Methods
Hyperparameter Tuning
2.3. Cloud Based Services
2.4. Evaluation Metrics
2.4.1. Root Mean Square Error (RMSE)
2.4.2. Mean Absolute Error (MAE)
2.4.3. R-Squared
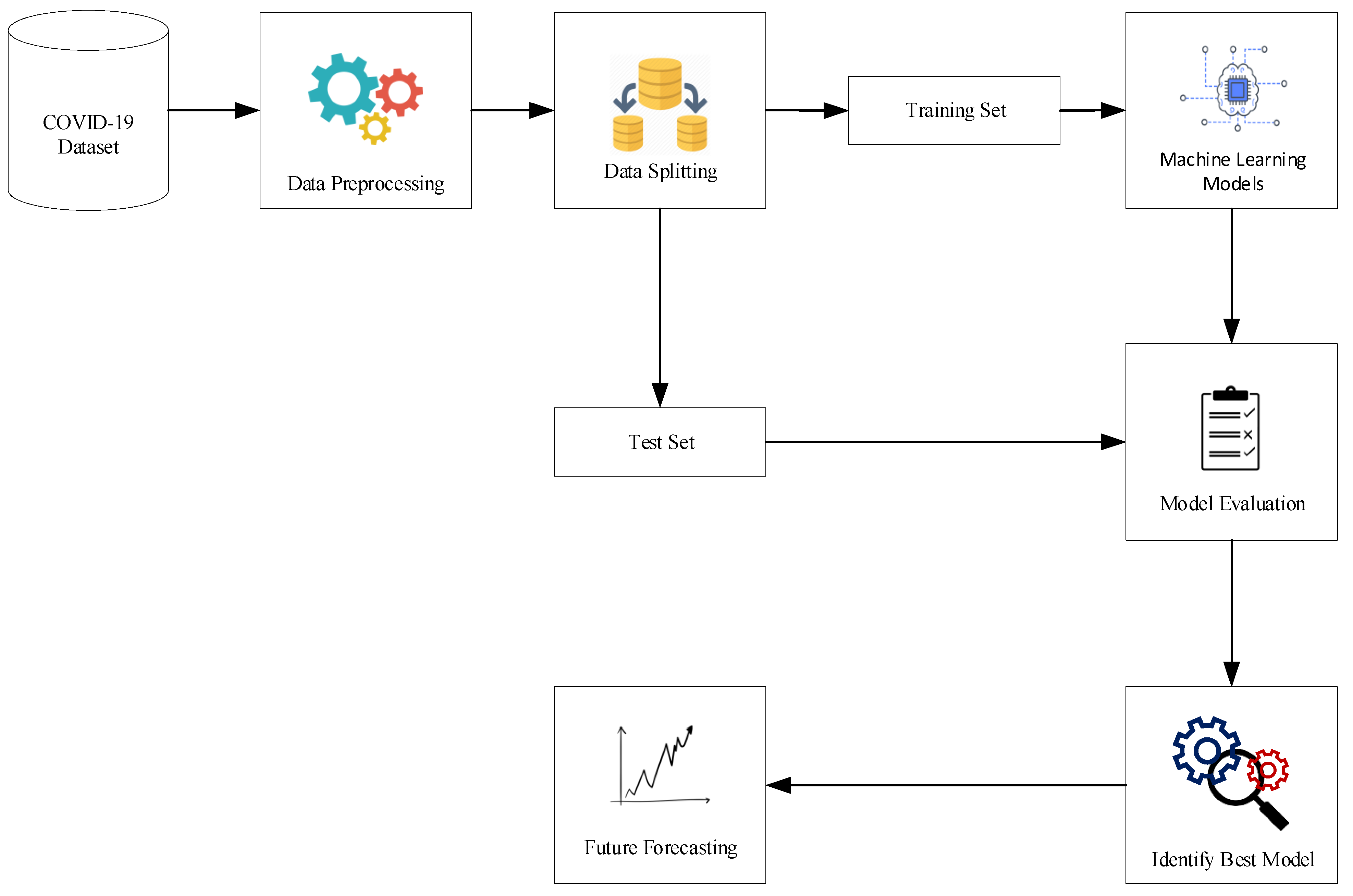
2.5. Cloud Based Short Term Forecasting Model: Epidemic Analysis
- Firstly, this web tool gathers the daily cumulative instances of confirmed infection and fatality cases of Bangladesh at the Github repository of the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University (see Section 2.1).
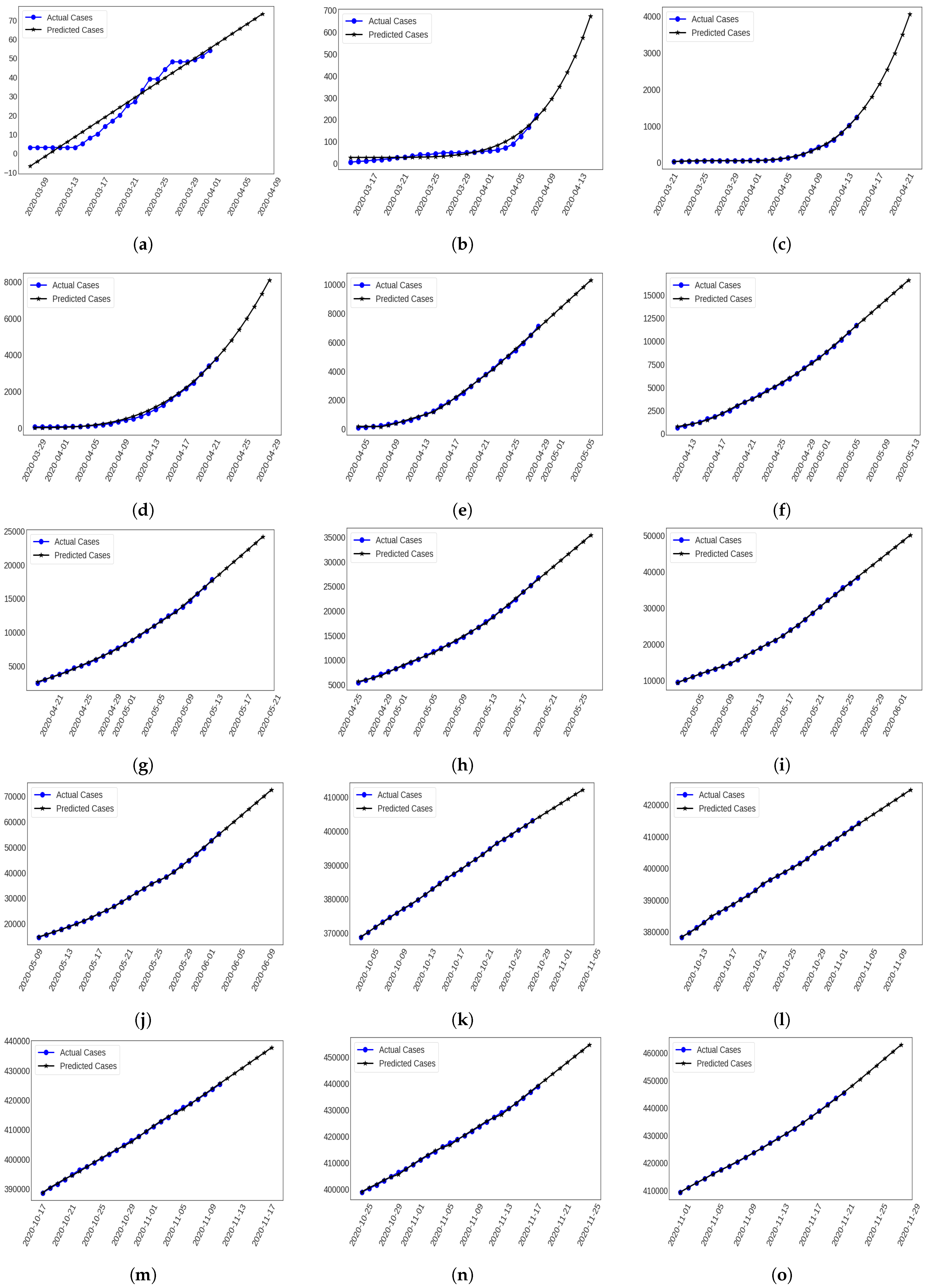
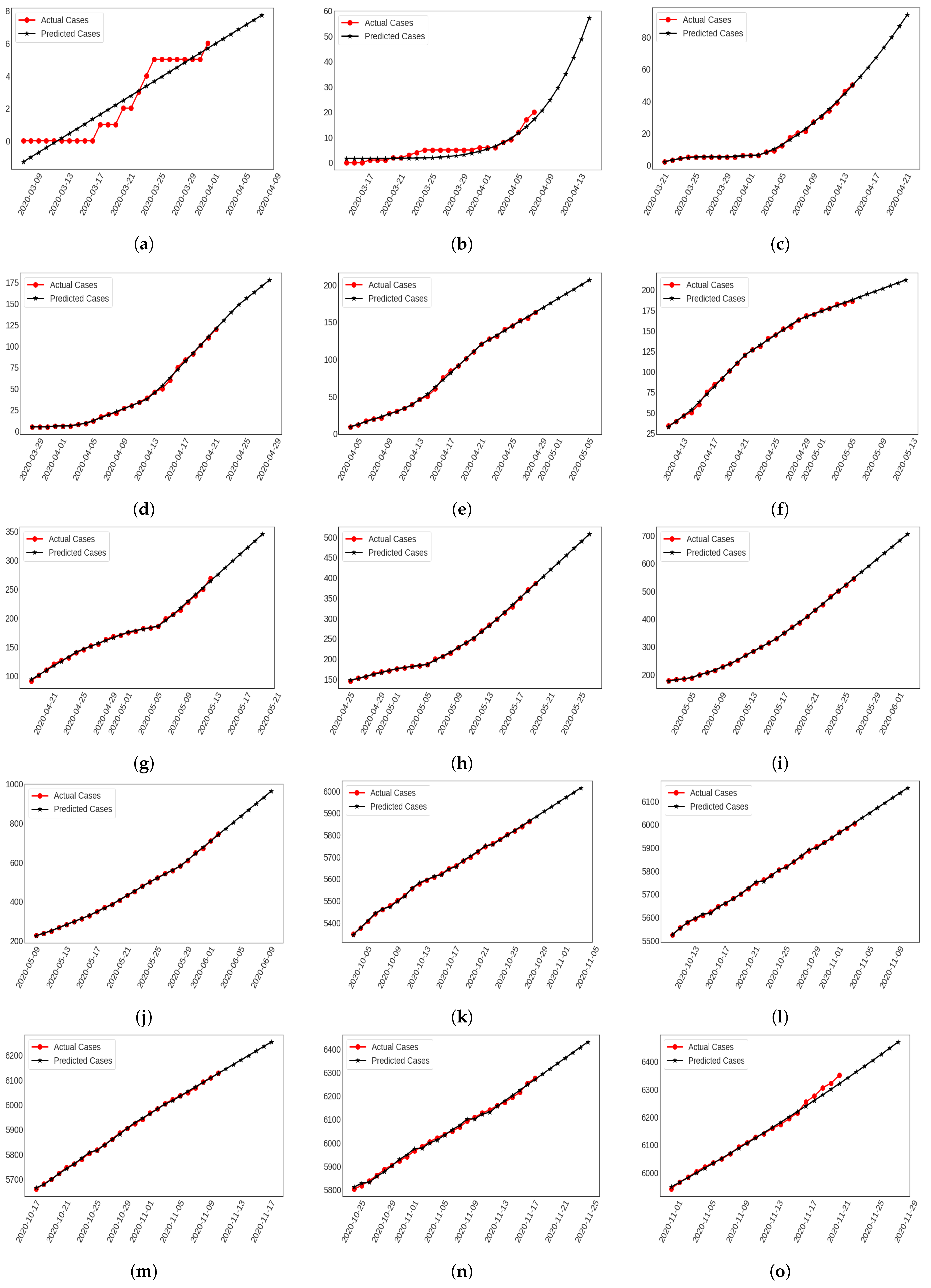
- In this work, we gathered the daily cumulative instances from 8 March 2020 to 28 November 2020 where the confirmed infection and fatality cases were investigated to assess the severity of the pandemic in Bangladesh. This whole period was split into several windows using sliding window techniques [40,41]. The size of sliding window was fixed (32 days) and each of them is called round. Instances were identified from the last 25 days where 85% of the data were used as the training set and 15% of the data were used for the the test set. Thus, it analyzes the confirmed infection and fatality cases and forecasts them for the next couple of days as a requirement. For instance, we predicted the next 7 days cases from the training period in this work. Besides this, we considered 35 rounds where the first 10 and last 5 rounds were presented for the next 7 days of future forecasting.
- The primary web mining model was executed on the Google Colab platform. Raw data were loaded and applied using different machine learning regression models which are described in Section 2.2. To explore the best results, parameters need to be estimated and the highest outcomes from them need to be found [27]. However, choosing the optimal parameters is a challenging task for any machine learning procedure. In this work, we manually trained models with various parameters and identified the best model from them.
- To evaluate the performance of different regression models, we used several metrics such as MAE, RMSE and values (see details in Section 2.4) for evaluating the test set and identifying the best model for predicting cumulative confirmed infection and fatality cases with the lowest error rate.
- All actual and predicted trajectories have been placed in our web tool which is uploaded by the local cloud host via plotly Chart Studio.
3. Experiment Result
3.1. Cloud Based Short Term Forecasting
3.1.1. 1st Round (8 March 2020–8 April 2020)
3.1.2. 2nd Round (15 March 2020–15 April 2020)
3.1.3. 3rd Round (22 March 2020–22 April 2020)
3.1.4. 4th Round (29 March 2020–29 April 2020)
3.1.5. 5th Round (5 April 2020–6 May 2020)
3.1.6. 6th Round (12 April 2020–13 May 2020)
3.1.7. 7th Round (19 April 2020–20 May 2020)
3.1.8. 8th Round (26 April 2020–7 May 2020)
3.1.9. 9th Round (3 May 2020–3 June 2020)
3.1.10. 10th Round (10 May 2020–10 June 2020)
3.1.11. 31st Round (4 October 2020–4 November 2020)
3.1.12. 32nd Round (11 October 2020–11 November 2020)
3.1.13. 33rd Round (18 October 2020–18 November 2020)
3.1.14. 34th Round (25 October 2020–25 November 2020)
3.1.15. 35th Round (1 November 2020–28 November 2020)
4. Discussion
Implications
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Linear Regression (LR)
Appendix A.2. Polynomial Regression (PR)
Appendix A.3. Support Vector Machine-Regression (SVR)
Appendix A.4. Multi-Layer Perception (MLP)
Appendix A.5. Polynomial Multi-Layer Perception (Poly-MLP)
Appendix A.6. Prophet Model
References
- Sarkodie, S.A.; Owusu, P.A. Investigating the cases of novel coronavirus disease (COVID-19) in China using dynamic statistical techniques. Heliyon 2020, 6, e03747. [Google Scholar] [CrossRef]
- Shawni, D.; Bandyopadhyay, S.K. Machine learning approach for confirmation of COVID-19 cases: Positive, negative, death and release. Iberoam. J. Med. 2020, 2, 172–177. [Google Scholar] [CrossRef]
- Islam, M.T.; Talukder, A.K.; Siddiqui, M.N.; Islam, T. Tackling the COVID-19 pandemic: The Bangladesh perspective. J. Public Health Res. 2020, 9. [Google Scholar] [CrossRef] [PubMed]
- Ahamad, M.; Aktar, S.; Rashed-Al-Mahfuz, M.; Azad, A.; Uddin, S.; Alyami, S.A.; Sarker, I.H.; Liò, P.; Quinn, J.M.W.; Moni, M.A. Adverse effects of COVID-19 vaccination: Machine learning and statistical approach to identify and classify incidences of morbidity and post-vaccination reactogenicity. medrXiv 2021. [Google Scholar] [CrossRef]
- Uddin, S.; Imam, T.; Ali Moni, M. The implementation of public health and economic measures during the first wave of COVID-19 by different countries with respect to time, infection rate and death rate. In 2021 Australasian Computer Science Week Multiconference; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Rustam, F.; Reshi, A.A.; Mehmood, A.; Ullah, S.; On, B.; Aslam, W.; Choi, G.S. COVID-19 Future Forecasting Using Supervised Machine Learning Models. IEEE Access 2020, 8, 101489–101499. [Google Scholar] [CrossRef]
- Ahamad, M.M.; Aktar, S.; Rashed-Al-Mahfuz, M.; Uddin, S.; Liò, P.; Xu, H.; Summers, M.A.; Quinn, J.M.; Moni, M.A. A machine learning model to identify early stage symptoms of SARS-Cov-2 infected patients. Expert Syst. Appl. 2020, 160, 113661. [Google Scholar] [CrossRef]
- Satu, M.; Howlader, K.C.; Islam, S.M.S. Machine Learning-Based Approaches for Forecasting COVID-19 Cases in Bangladesh; SSRN Scholarly Paper ID 3614675; Social Science Research Network: Rochester, NY, USA, 2020. [Google Scholar] [CrossRef]
- Aktar, S.; Ahamad, M.; Rashed-Al-Mahfuz, M.; Azad, A.; Uddin, S.; Kamal, A.; Alyami, S.A.; Lin, P.I.; Islam, S.M.S.; Quinn, J.M.; et al. Predicting Patient COVID-19 Disease Severity by means of Statistical and Machine Learning Analysis of Blood Cell Transcriptome Data. arXiv 2020, arXiv:2011.10657. [Google Scholar]
- Kolhar, M.; Al-Turjman, F.; Alameen, A.; Abualhaj, M.M. A three layered decentralized IoT biometric architecture for city lockdown during COVID-19 outbreak. IEEE Access 2020, 8, 163608–163617. [Google Scholar] [CrossRef]
- Rahman, M.A.; Zaman, N.; Asyhari, A.T.; Al-Turjman, F.; Alam Bhuiyan, M.Z.; Zolkipli, M.F. Data-driven dynamic clustering framework for mitigating the adverse economic impact of Covid-19 lockdown practices. Sustain. Cities Soc. 2020, 62, 102372. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.M.; Garcia, N.M.; Trajkovik, V. Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote Sens. 2020, 12, 4142. [Google Scholar] [CrossRef]
- Liu, P.; Wang, J.; Sangaiah, A.K.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef]
- Ceci, M.; Corizzo, R.; Japkowicz, N.; Mignone, P.; Pio, G. ECHAD: Embedding-Based Change Detection From Multivariate Time Series in Smart Grids. IEEE Access 2020, 8, 156053–156066. [Google Scholar] [CrossRef]
- Aktar, S.; Ahamad, M.M.; Rashed-Al-Mahfuz, M.; Azad, A.; Uddin, S.; Kamal, A.; Alyami, S.A.; Lin, P.I.; Islam, S.M.S.; Quinn, J.M.; et al. Machine Learning Approach to Predicting COVID-19 Disease Severity Based on Clinical Blood Test Data: Statistical Analysis and Model Development. JMIR Med. Inf. 2021, 9, e25884. [Google Scholar] [CrossRef] [PubMed]
- Corizzo, R.; Ceci, M.; Fanaee-T, H.; Gama, J. Multi-aspect renewable energy forecasting. Inf. Sci. 2021, 546, 701–722. [Google Scholar] [CrossRef]
- Satu, M.S.; Khan, M.I.; Mahmud, M.; Uddin, S.; Summers, M.A.; Quinn, J.M.; Moni, M.A. TClustVID: A Novel Machine Learning Classification Model to Investigate Topics and Sentiment in COVID-19 Tweets. MedRxiv 2020. [Google Scholar] [CrossRef]
- Satu, M.S.; Ahammed, K.; Abedin, M.Z.; Rahman, M.A.; Islam, S.M.S.; Azad, A.; Alyami, S.A.; Moni, M.A. Convolutional Neural Network Model to Detect COVID-19 Patients Utilizing Chest X-ray Images. medRxiv 2021. [Google Scholar] [CrossRef]
- Aradhya, V.N.M.; Mahmud, M.; Guru, D.; Agarwal, B.; Kaiser, M.S. One-shot Cluster-Based Approach for the Detection of COVID–19 from Chest X–ray Images. Cogn. Comput. 2021, 1–8. [Google Scholar] [CrossRef]
- Depeursinge, A.; Chin, A.S.; Leung, A.N.; Terrone, D.; Bristow, M.; Rosen, G.; Rubin, D.L. Automated classification of usual interstitial pneumonia using regional volumetric texture analysis in high-resolution CT. Investig. Radiol. 2015, 50, 261. [Google Scholar] [CrossRef]
- Dey, N.; Rajinikanth, V.; Fong, S.J.; Kaiser, M.S.; Mahmud, M. Social Group Optimization–Assisted Kapur’s Entropy and Morphological Segmentation for Automated Detection of COVID-19 Infection from Computed Tomography Images. Cogn. Comput. 2020, 12, 1011–1023. [Google Scholar] [CrossRef]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. CovidGAN: Data Augmentation Using Auxiliary Classifier GAN for Improved Covid-19 Detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef]
- Aktar, S.; Talukder, A.; Ahamad, M.; Kamal, A.; Khan, J.R.; Protikuzzaman, M.; Hossain, N.; Quinn, J.M.; Summers, M.A.; Liaw, T.; et al. Machine Learning and Meta-Analysis Approach to Identify Patient Comorbidities and Symptoms that Increased Risk of Mortality in COVID-19. arXiv 2020, arXiv:2008.12683. [Google Scholar]
- Al-Turjman, F.; Deebak, B. Privacy-Aware Energy-Efficient Framework Using the Internet of Medical Things for COVID-19. IEEE Internet Things Mag. 2020, 3, 64–68. [Google Scholar] [CrossRef]
- Sujath, R.; Chatterjee, J.M.; Hassanien, A.E. A machine learning forecasting model for COVID-19 pandemic in India. Stoch. Environ. Res. Risk Assess. 2020, 34, 959–972. [Google Scholar] [CrossRef]
- Yadav, D.; Maheshwari, H.; Chandra, U.; Sharma, A. COVID-19 Analysis by Using Machine and Deep Learning. In Internet of Medical Things for Smart Healthcare: Covid-19 Pandemic; Chakraborty, C., Banerjee, A., Garg, L., Rodrigues, J.J.P.C., Eds.; Studies in Big Data; Springer: Singapore, 2020; pp. 31–63. [Google Scholar] [CrossRef]
- Ardabili, S.F.; Mosavi, A.; Ghamisi, P.; Ferdinand, F.; Varkonyi-Koczy, A.R.; Reuter, U.; Rabczuk, T.; Atkinson, P.M. COVID-19 Outbreak Prediction with Machine Learning. Algorithms 2020, 13, 249. [Google Scholar] [CrossRef]
- Zeroual, A.; Harrou, F.; Dairi, A.; Sun, Y. Deep learning methods for forecasting COVID-19 time-Series data: A Comparative study. Chaos Solitons Fractals 2020, 140, 110121. [Google Scholar] [CrossRef] [PubMed]
- Gupta, R.; Pandey, G.; Chaudhary, P.; Pal, S.K. Machine Learning Models for Government to Predict COVID-19 Outbreak. Digit. Gov. Res. Pract. 2020, 1, 1–6. [Google Scholar] [CrossRef]
- Wieczorek, M.; Siłka, J.; Woźniak, M. Neural network powered COVID-19 spread forecasting model. Chaos Solitons Fractals 2020, 140, 110203. [Google Scholar] [CrossRef] [PubMed]
- Amar, L.A.; Taha, A.A.; Mohamed, M.Y. Prediction of the final size for COVID-19 epidemic using machine learning: A case study of Egypt. Infect. Dis. Model. 2020, 5, 622–634. [Google Scholar] [CrossRef] [PubMed]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef]
- Srivastava, V.; Srivastava, S.; Chaudhary, G.; Al-Turjman, F. A systematic approach for COVID-19 predictions and parameter estimation. Pers. Ubiquitous Comput. 2020. [Google Scholar] [CrossRef]
- Kumar, S.; Viral, R.; Deep, V.; Sharma, P.; Kumar, M.; Mahmud, M.; Stephan, T. Forecasting major impacts of COVID-19 pandemic on country-driven sectors: Challenges, lessons, and future roadmap. Pers. Ubiquitous Comput. 2021. [Google Scholar] [CrossRef] [PubMed]
- Roosa, K.; Lee, Y.; Luo, R.; Kirpich, A.; Rothenberg, R.; Hyman, J.; Yan, P.; Chowell, G. Real-time forecasts of the COVID-19 epidemic in China from February 5th to February 24th, 2020. Infect. Dis. Model. 2020, 5, 256–263. [Google Scholar] [CrossRef]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Pandey, M.K.; Subbiah, K. Performance Analysis of Time Series Forecasting Using Machine Learning Algorithms for Prediction of Ebola Casualties. In International Conference on Application of Computing and Communication Technologies; Communications in Computer and Information Science; Deka, G.C., Kaiwartya, O., Vashisth, P., Rathee, P., Eds.; Springer: Singapore, 2018; pp. 320–334. [Google Scholar]
- Ribeiro, M.H.D.M.; da Silva, R.G.; Mariani, V.C.; dos Santos Coelho, L. Short-term forecasting COVID-19 cumulative confirmed cases: Perspectives for Brazil. Chaos Solitons Fractals 2020, 135, 109853. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Zheng, X.; Li, J.; Zhu, B. Prediction of epidemic trends in COVID-19 with logistic model and machine learning techniques. Chaos Solitons Fractals 2020, 139, 110058. [Google Scholar] [CrossRef]
- Alberg, D.; Last, M. Short-term load forecasting in smart meters with sliding window-based ARIMA algorithms. Vietnam. J. Comput. Sci. 2018, 5, 241–249. [Google Scholar] [CrossRef]
- Khan, I.A.; Akber, A.; Xu, Y. Sliding window regression based short-term load forecasting of a multi-area power system. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–5. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Khan, M.H.R.; Hossain, A. COVID-19 Outbreak Situations in Bangladesh: An Empirical Analysis. medRxiv 2020. [Google Scholar] [CrossRef]
- Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. COVID-19 Epidemic Analysis using Machine Learning and Deep Learning Algorithms. medRxiv 2020. [Google Scholar] [CrossRef]
- Ndiaye, B.M.; Tendeng, L.; Seck, D. Analysis of the COVID-19 pandemic by SIR model and machine learning technics for forecasting. arXiv 2020, arXiv:2004.01574. [Google Scholar]
- Satu, M.S.; Rahman, M.K.; Rony, M.A.; Shovon, A.R.; Adnan, M.J.A.; Howlader, K.C.; Kaiser, M.S. COVID-19: Update, Forecast and Assistant-An Interactive Web Portal to Provide Real-Time Information and Forecast COVID-19 Cases in Bangladesh. In Proceedings of the 2021 International Conference on Information and Communication Technology for Sustainable Development (ICICT4SD), Dhaka, Bangladesh, 27–28 February 2021; pp. 456–460. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Akter, T.; Satu, M.S.; Khan, M.I.; Ali, M.H.; Uddin, S.; Lio, P.; Quinn, J.M.; Moni, M.A. Machine learning-based models for early stage detection of autism spectrum disorders. IEEE Access 2019, 7, 166509–166527. [Google Scholar] [CrossRef]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inf. Decis. Mak. 2019, 19, 1–16. [Google Scholar] [CrossRef]
- Moula, F.E.; Guotai, C.; Abedin, M.Z. Credit default prediction modeling: An application of support vector machine. Risk Manag. 2017, 19, 158–187. [Google Scholar] [CrossRef]
- Hu, Y.C. Multilayer perceptron for robust nonlinear interval regression analysis using genetic algorithms. Sci. World J. 2014, 2014, 970931. [Google Scholar] [CrossRef] [PubMed]
- Taylor, S.J.; Letham, B. Forecasting at scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Round | Method | Hyperparameters | Method | Hyperparameters |
|---|---|---|---|---|
| 1st Round | Prophet | default | Prophet | default |
| 2nd Round | SVR | degree = 5 | SVR | degree = 5 |
| 3rd Round | PR | degree = 4 | Poly-MLP | degree = 2, neuron = 100 |
| 4th Round | PR | degree = 3 | Poly-MLP | degree = 1, neuron = 25,13,5 |
| 5th Round | Prophet | default | Prophet | default |
| 6th Round | Prophet | default | Prophet | default |
| 7th Round | Prophet | default | Prophet | default |
| 8th Round | Prophet | default | Prophet | default |
| 9th Round | Prophet | default | Prophet | default |
| 10th Round | Prophet | default | Prophet | default |
| 31st Round | Prophet | default | Prophet | default |
| 32nd Round | Prophet | default | Prophet | default |
| 33rd Round | Prophet | default | Prophet | default |
| 34th Round | Prophet | default | Prophet | default |
| 35th Round | Prophet | default | Prophet | default |
| Round | Date | Highest Factor | Date | Highest Factor | |
|---|---|---|---|---|---|
| Infected Cases | Fatality Cases | ||||
| 1st Round | 15-March | 1.6670 | 21-March | 2.0000 | |
| 2nd Round | 16-March | 1.6000 | 21-March | 2.0000 | |
| 3rd Round | 9-April | 1.5138 | 23-March | 1.5000 | |
| 4th Round | 9-April | 1.5138 | 7-April | 1.4167 | |
| 5th Round | 9-April | 1.5138 | 7-April | 1.4167 | |
| 6th Round | 13-April | 1.2930 | 17-April | 1.2500 | |
| 7th Round | 20-April | 1.2003 | 20-April | 1.1099 | |
| 8th Round | 29-April | 1.0992 | 13-May | 1.0760 | |
| 9th Round | 5-May | 1.0775 | 13-May | 1.0760 | |
| 10th Round | 18-May | 1.0772 | 13-May | 1.0760 | |
| 31st Round | 07-October | 1.0064 | 14-October | 1.0044 | |
| 32nd Round | 12-October | 1.0061 | 14-October | 1.0044 | |
| 33th Round | 05-November | 1.0044 | 29-October | 1.0054 | |
| 34th Round | 17-November | 1.0051 | 17-November | 1.0063 | |
| 35th Round | 19-November | 1.0054 | 17-November | 1.0063 | |
| Round | Method | RMSE | MAE | R2 | Method | RMSE | MAE | R2 | |
|---|---|---|---|---|---|---|---|---|---|
| Infected Cases | Fatality Cases | ||||||||
| 1st Round | LR | 1.0950 | 1.0489 | 0.7716 | LR | 0.2766 | 0.2500 | 0.5921 | |
| 2nd Round | SVR | 19.5371 | 17.4783 | 0.8372 | SVR | 2.0445 | 1.6569 | 0.7710 | |
| 3rd Round | PR | 13.2350 | 10.4837 | 0.9966 | Poly-MLP | 0.9218 | 0.8057 | 0.9777 | |
| 4th Round | Poly-MLP | 53.2986 | 43.5731 | 0.9882 | MLP | 0.7134 | 0.6773 | 0.9956 | |
| 5th Round | Prophet | 43.9722 | 39.9999 | 0.9951 | Prophet | 1.0051 | 0.8383 | 0.9758 | |
| 6th Round | Prophet | 13.0955 | 10.9061 | 0.9998 | Prophet | 0.5113 | 0.4621 | 0.9751 | |
| 7th Round | Prophet | 38.8117 | 32.6514 | 0.9989 | Prophet | 1.7241 | 1.5615 | 0.9870 | |
| 8th Round | Prophet | 59.5438 | 56.5706 | 0.9987 | Prophet | 1.8866 | 1.6031 | 0.9925 | |
| 9th Round | Prophet | 125.7346 | 105.7328 | 0.9946 | Prophet | 0.8403 | 0.5109 | 0.9988 | |
| 10th Round | Prophet | 151.9238 | 132.1162 | 0.9974 | Prophet | 2.8667 | 2.5618 | 0.9939 | |
| 31th Round | Prophet | 7.13 | 5.82 | 1.0000 | Prophet | 9.25 | 8.41 | 1.0000 | |
| 32th Round | Prophet | 2.10 | 1.46 | 1.0000 | Prophet | 4.55 | 2.27 | 1.0000 | |
| 33th Round | Prophet | 7.70 | 7.28 | 1.0000 | Prophet | 4.55 | 2.27 | 1.0000 | |
| 34th Round | Prophet | 2.93 | 2.49 | 1.0000 | Prophet | 1.36 | 1.14 | 1.0000 | |
| 35th Round | Prophet | 11.7169 | 9.0584 | 0.8144 | Prophet | 213.5905 | 201.4884 | 0.9923 | |
| Round | LR | PR | SVR | MLP | Poly-MLP | Prophet |
|---|---|---|---|---|---|---|
| 1st Round | 0.467 | 0.603 | 0.666 | 1.673 | 1.314 | 0.450 |
| 2nd Round | 0.468 | 0.431 | 0.483 | 1.201 | 1.201 | 0.433 |
| 3rd Round | 0.452 | 0.444 | 0.451 | 3.557 | 2.609 | 4.012 |
| 4th Round | 0.459 | 0.454 | 0.457 | 6.173 | 7.149 | 4.189 |
| 5th Round | 0.471 | 0.432 | 0.465 | 6.842 | 8.127 | 4.613 |
| 6th Round | 0.724 | 0.457 | 0.466 | 11.836 | 9.134 | 4.560 |
| 7th Round | 0.522 | 0.456 | 0.437 | 13.691 | 10.809 | 4.501 |
| 8th Round | 0.466 | 0.703 | 0.470 | 12.593 | 12.404 | 4.693 |
| 9th Round | 0.445 | 0.460 | 0.476 | 8.051 | 10.579 | 4.520 |
| 10th Round | 0.471 | 0.458 | 0.452 | 8.013 | 8.801 | 4.737 |
| 31st Round | 0.515 | 0.656 | 0.665 | 8.532 | 7.510 | 35.499 |
| 32nd Round | 0.471 | 0.483 | 0.459 | 8.657 | 8.002 | 30.286 |
| 33rd Round | 0.493 | 0.723 | 0.512 | 8.764 | 7.590 | 23.994 |
| 34th Round | 0.485 | 0.475 | 0.751 | 8.727 | 7.762 | 28.945 |
| 35th Round | 0.500 | 0.463 | 0.477 | 9.043 | 7.848 | 0.459 |
| Round | Method | RMSE | MAE | R2 | Method | RMSE | MAE | R2 |
|---|---|---|---|---|---|---|---|---|
| Confirmed Cases | Death Cases | |||||||
| 1st Round | Prophet | 3.5808 | 2.7740 | −0.5786 | Prophet | 0.5837 | 0.4524 | −1.7821 |
| 2nd Round | SVR | 24.8737 | 22.8440 | 0.8043 | SVR | 2.4589 | 2.2902 | 0.7660 |
| 3rd Round | PR | 55.1576 | 49.7568 | 0.9676 | Poly-MLP | 2.3675 | 2.1407 | 0.9394 |
| 4th Round | PR | 63.7025 | 57.3959 | 0.9928 | Poly-MLP | 5.8317 | 4.9376 | 0.9072 |
| 5th Round | Prophet | 36.9007 | 31.2751 | 0.9985 | Prophet | 1.3350 | 1.0758 | 0.9877 |
| 6th Round | Prophet | 10.9600 | 9.0326 | 0.9999 | Prophet | 0.7154 | 0.6148 | 0.9870 |
| 7th Round | Prophet | 38.8742 | 34.5744 | 0.9995 | Prophet | 1.5454 | 1.4078 | 0.9956 |
| 8th Round | Prophet | 51.7929 | 46.3280 | 0.9996 | Prophet | 1.4812 | 1.1691 | 0.9982 |
| 9th Round | Prophet | 117.2432 | 98.1062 | 0.9987 | Prophet | 0.8894 | 0.6813 | 0.9996 |
| 10th Round | Prophet | 155.8378 | 131.5769 | 0.9990 | Prophet | 2.2835 | 1.8957 | 0.9987 |
| 31st Round | Prophet | 6.22 | 4.99 | 1.0000 | Prophet | 9.27 | 8.71 | 1.0000 |
| 32nd Round | Prophet | 1.89 | 1.50 | 1.0000 | Prophet | 4.86 | 2.60 | 1.0000 |
| 33rd Round | Prophet | 7.93 | 7.48 | 1.0000 | Prophet | 4.86 | 2.60 | 1.0000 |
| 34th Round | Prophet | 3.11 | 2.63 | 1.0000 | Prophet | 1.33 | 1.17 | 1.0000 |
| 35th Round | Prophet | 4.40 | 3.33 | 1.0000 | Prophet | 8.21 | 7.04 | 1.0000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Satu, M.S.; Howlader, K.C.; Mahmud, M.; Kaiser, M.S.; Shariful Islam, S.M.; Quinn, J.M.W.; Alyami, S.A.; Moni, M.A. Short-Term Prediction of COVID-19 Cases Using Machine Learning Models. Appl. Sci. 2021, 11, 4266. https://doi.org/10.3390/app11094266
Satu MS, Howlader KC, Mahmud M, Kaiser MS, Shariful Islam SM, Quinn JMW, Alyami SA, Moni MA. Short-Term Prediction of COVID-19 Cases Using Machine Learning Models. Applied Sciences. 2021; 11(9):4266. https://doi.org/10.3390/app11094266
Chicago/Turabian StyleSatu, Md. Shahriare, Koushik Chandra Howlader, Mufti Mahmud, M. Shamim Kaiser, Sheikh Mohammad Shariful Islam, Julian M. W. Quinn, Salem A. Alyami, and Mohammad Ali Moni. 2021. "Short-Term Prediction of COVID-19 Cases Using Machine Learning Models" Applied Sciences 11, no. 9: 4266. https://doi.org/10.3390/app11094266
APA StyleSatu, M. S., Howlader, K. C., Mahmud, M., Kaiser, M. S., Shariful Islam, S. M., Quinn, J. M. W., Alyami, S. A., & Moni, M. A. (2021). Short-Term Prediction of COVID-19 Cases Using Machine Learning Models. Applied Sciences, 11(9), 4266. https://doi.org/10.3390/app11094266