1. Introduction
Robots are used more and more frequently in inherently unpredictable outdoor environments: aerial search, rescue drones, deep-diving underwater AUVs, and even extra-terrestrial explorative probes. It is impossible to program autonomous robots for those tasks in a way that a priori accommodates all possible events that might occur during such missions. Thus, on-line and on-board learning, conducted for example by evolutionary computation and machine learning, becomes a significant aspect in those systems [
1,
2,
3,
4]. Evolutionary robotics has become a promising field of research to push forward the robustness, flexibility, and adaptivity of autonomous robots, which combines the software technologies of machine learning, evolutionary computation, and sensorimotor control with the physical embodiment of the robot in its environment.
We claim here that evolutionary robotics operating without a priori knowledge can fail easily because it suddenly hits an obscured “wall of complexity” with the current state-of-the-art of unsupervised learning. Extremely simple (trivial) tasks evolve well with almost every approach that was tested in literature [
2,
5,
6,
7]. However, already slightly more difficult tasks make all methods fail that are not a priori tailored to the properties that are needed to be able to evolve a solution for the software controller for the given task [
2,
7,
8]. However, these are often unknown for black-box problems where evolutionary computation and evolutionary robotics are applied most usefully. As is well known, there is no free lunch in optimization techniques [
9]. The more specifically an optimizer is tailored to a specific problem, the more probable it is that it will fail for other types of problems. Thus, only open-ended, uninformed evolutionary computation will allow for generality in problem solving as required in long-term autonomous operations in unpredictable environments. For example, many studies in the literature that have evolved complex tasks of cooperation and coordination in robots used pre-structured software controllers [
6,
10], while many studies that have evolved robotic controllers in an uninformed open-ended way produced only simple behaviors, such as coupled oscillators that generate gaits in robots [
11,
12,
13,
14] including simple reactive gaits [
15], homing, collision avoidance, area coverage, collective pushing/pulling, and similar straight-forward tasks [
16].
We hypothesize that one reason for the lack of success of evolving solutions for complex tasks is the improbable emergence of internal modularity [
17] in software controllers using open-ended evolution without explicitly enabling the evolution of modules. In an evolutionary approach, it is possible to push towards modularity by pre-defining a certain topology of Artificial Neural Networks (ANNs) [
18], by allowing evolving a potentially unlimited number of modules within a pre-defined modular ANN structure [
19,
20] or by switching between tasks on the time scale of generations [
21], which can then also be improved by imposing costs for links between neurons [
22]. However, if modularity is not pre-defined and not explicitly encouraged by a designer, then a modular software controller will not emerge from scratch even if modularity is directly required by the task. While nature is capable of evolving highly layered, modularized, and complex brain structures [
23] by starting from scratch, evolutionary computation fails to achieve similar progress within a reasonable time.
To support our claim, we searched for the most simple task that leads to the failure of plain-vanilla uninformed unsupervised evolutionary computation starting from a 100% randomized control software without any interference (guidance) by a designer during evolution and without any a priori mechanism or impetus to favor self-modularization. An easy way to define such a task is to construct it from two simple, but conflicting tasks that are both easily evolvable in isolation for almost any evolutionary computation and machine learning approach of today. However, we require that the behavior that solves Task 1 is the inverse of the behavior that solves Task 2 (e.g., positive and negative phototaxis). Hence, once one behavior has been evolved, the other behavior needs to be added together with an action selection mechanism. We propose a task that operates in one-dimensional space, and as it is shown in the paper, it can be solved by a very simple pseudo-code and also by hand-coded ANNs. Compared to the classification scheme of Braitenberg [
24], an agent that solves the Wankelmut (German, meaning roughly “whiffler”: a person who frequently changes opinions or course; see
https://www.merriam-webster.com/dictionary/whiffler (accessed on 29 January 2021)) task would be placed between Vehicle #4 and Vehicle #5 concerning the complexity of its behavior. Given that it operates in a one-dimensional space, this introduces a relation to Vehicle #1. We anticipate that searching to define the definition of such a “most simple task to fail” is a valuable effort benchmark for promoting future development in the fields of artificial intelligence, evolutionary robotics, and artificial life.
For simplicity, we suggest simple plain-vanilla ANNs as an evolvable runtime control software in combination with genetic algorithms [
25] or evolution strategies [
26] as an unsupervised adaptation mechanism. For our benchmark defined here, we accept either large fully-connected and randomized ANNs as initialization, as well as ANN implementations that allow restructuring (adding and removing of nodes and connections) as a starting point. However, we consider all implementations that have special implementations to facilitate or favored modular networks as “inapplicable for our focal research question” because the main challenge in our benchmark task is to evolve modularization from scratch as an emergent solution to the task.
2. Our Benchmark Task
For the sake of simplicity, we restrict ourselves to a very simple task that is hard to evolve in an open-ended, uninformed, and unguided way. As shown in
Figure 1, we assume an agent that moves in an environment expressing one single quality factor (e.g., height, water or air pressure, luminance, temperature) and that has to evolve a behavior that first makes the agent move uphill in this environmental gradient.
In the “uphill-walk” phase of the experiment, the agent always should move in the direction of the sensor that reports the higher value of the focal quality factor. As soon as the agent reaches an area of sufficiently high quality (above a threshold ), the agent should switch its behavioral mode and start to seek areas of low environmental quality. In this “downhill-walk” phase, the agent should always move towards the side where its sensor reports the lowest environmental quality value. After the agent has reached a sufficiently low quality area (below a threshold ), the agent should switch back to the “uphill-walk” behavior again.
We call the behavior that we aim to evolve “Wankelmut”, a term that expresses in German a character trait in which one always switches between two different goals as soon as one of the goals is reached. A “Wankelmut” agent is never satisfied and thus does not decide one thing and does not stick with it. It is a variant of “the grass is always greener,” a commonly found personality feature in natural agents (from humans to animals), and despite its negative perception in many cultural moral systems, it has its benefits. It keeps the agent going, being explorative, curious, and never satisfied. That is exactly the desired behavior of an autonomous probe on a distant planet that needs to be explored.
In summary, the task is to follow an environmental gradient up and down in an alternating way, hence maximizing the coverage (monitoring, observation, patrolling) of the areas between
and
. There are many examples that have been evolved by natural selection [
27]. In social insects (ants, termites, wasps, honeybees), foragers have first to go out of the nest, and after they encounter food, they switch their behavior and go back to the nest. After they have unloaded the food to other nest workers, they go outwards to forage again [
28]. Often, environmental cues and gradients are involved in the homing and in the foraging behaviors (sun compass, nest scent, pheromone marks) and are exploited differently by the workers in the outbound behavioral state compared to the inbound behavioral state [
29]. Other biological sources of inspiration are animals following a diurnal rhythm (day-walkers and night-walkers). In an engineering context, the rhythm might be imposed by energy recharging cycles, water depths, or aerial heights in transportation tasks by underwater vehicles or aerial drones.
Figure 1B shows that we de-complexified the benchmark task to a one-dimensional cellular space of
N cells in which always one cell of index
is occupied by the agent that has state
. The environmental gradient is produced by the Gauss error function:
whereby the quality of every cell
i is modeled as:
In every time step
, the agent has access to two lateral sensor readings, which are modeled as:
and:
The agent changes its position based on these sensor readings:
whereby the agent’s position is restricted by the boundaries of the simulated world. Its motion (
f) is restricted to a maximum of one step to the left or to the right of the agent’s current position.
Initially, the agent is in the uphill, state which means it should move uphill. If the agent’s local , then the state is changed to downhill, and if the agent’s local , then the agent’s state is changed back to uphill.
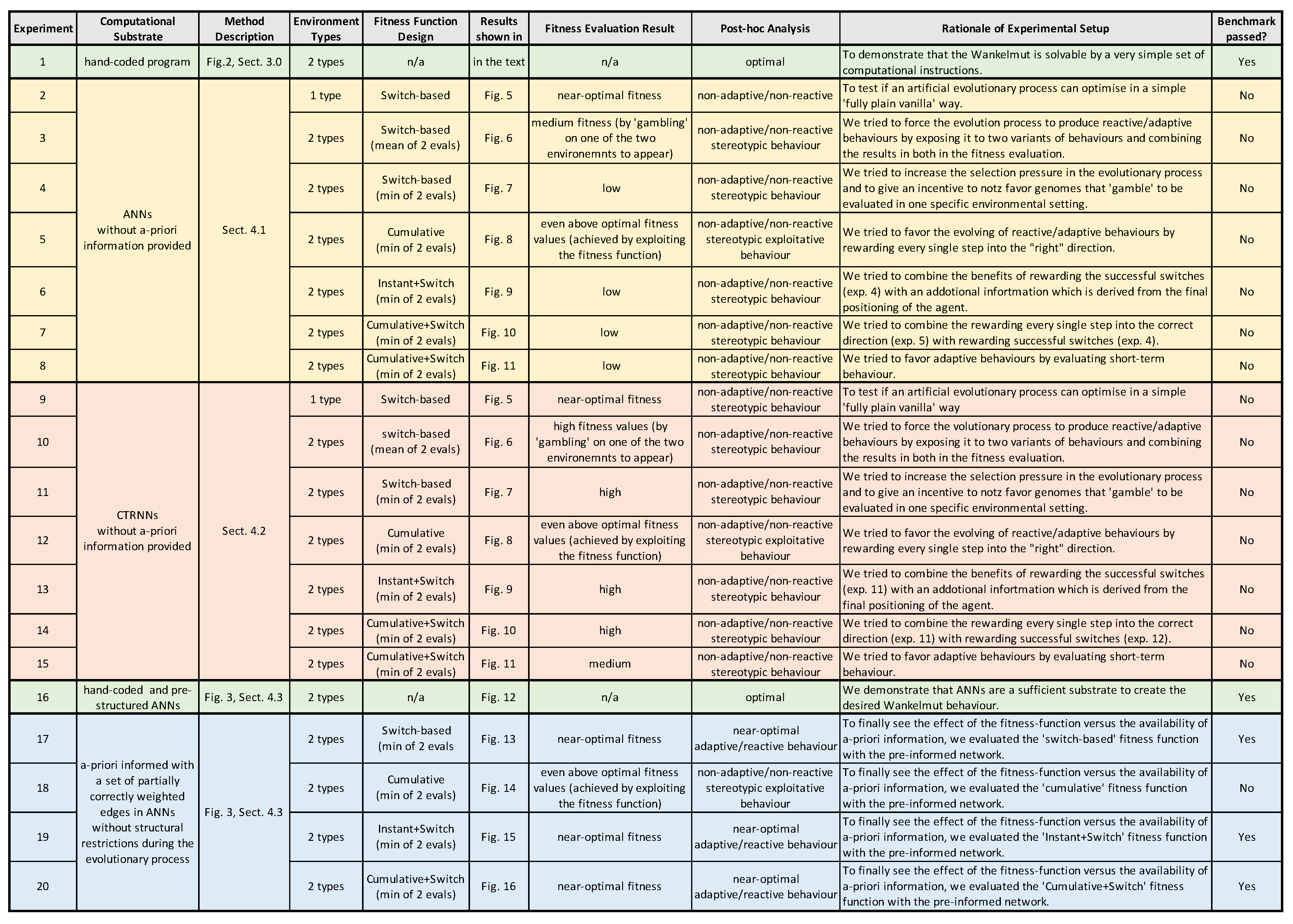
4. Evolvable Agent Controllers
In the following, we describe the different representations of robot controllers that we tested: simple artificial neural networks (
Section 4.1), continuous-time recurrent neural networks (
Section 4.2), and as a control experiment, also hand-coded artificial neural networks (
Section 4.3). In
Section 5, we present the results for all controller variants in two environments (mirrored gradient) for different fitness functions. For an overview, see
Figure 3.
4.1. Simple Artificial Neural Network
Our simple approach made use of recurrent artificial neural networks. The activation function used is a sigmoid function:
The network has eleven neurons distributed over the input layer (two), a first hidden layer (three), a second hidden layer (three), a third hidden layer (two), and the output layer (one). Each neuron in the second hidden layer has a link to itself (loop) and an input link from each of the neighboring nodes in addition to the links from the nodes in the previous layer. Weights were randomly initialized with a random uniform distribution from the interval .
4.2. Continuous-Time Recurrent Neural Networks
In a second approach, we used Continuous-Time Recurrent Neural Networks (CTRNNs), which are Hopfield continuous networks with an unrestricted weight matrix inspired by biological neurons [
30]. A neuron
i in the network is of the following general form:
where
is the state of the
ith neuron,
is the neuron’s time constant,
is the weight of the connection from the
jth to
ith neuron,
is a bias term,
is a gain term,
is an external input, and
is the standard logistic output function.
The weights were randomly initialized. By considering the study of the parameter space structure of the CTRNN by [
31], the values of the
s were set based on the weights in a way that the richest possible dynamics were achieved. We used 11 nodes where two nodes received the sensor inputs and one node was used as the output node determining the direction of the movement (right/left).
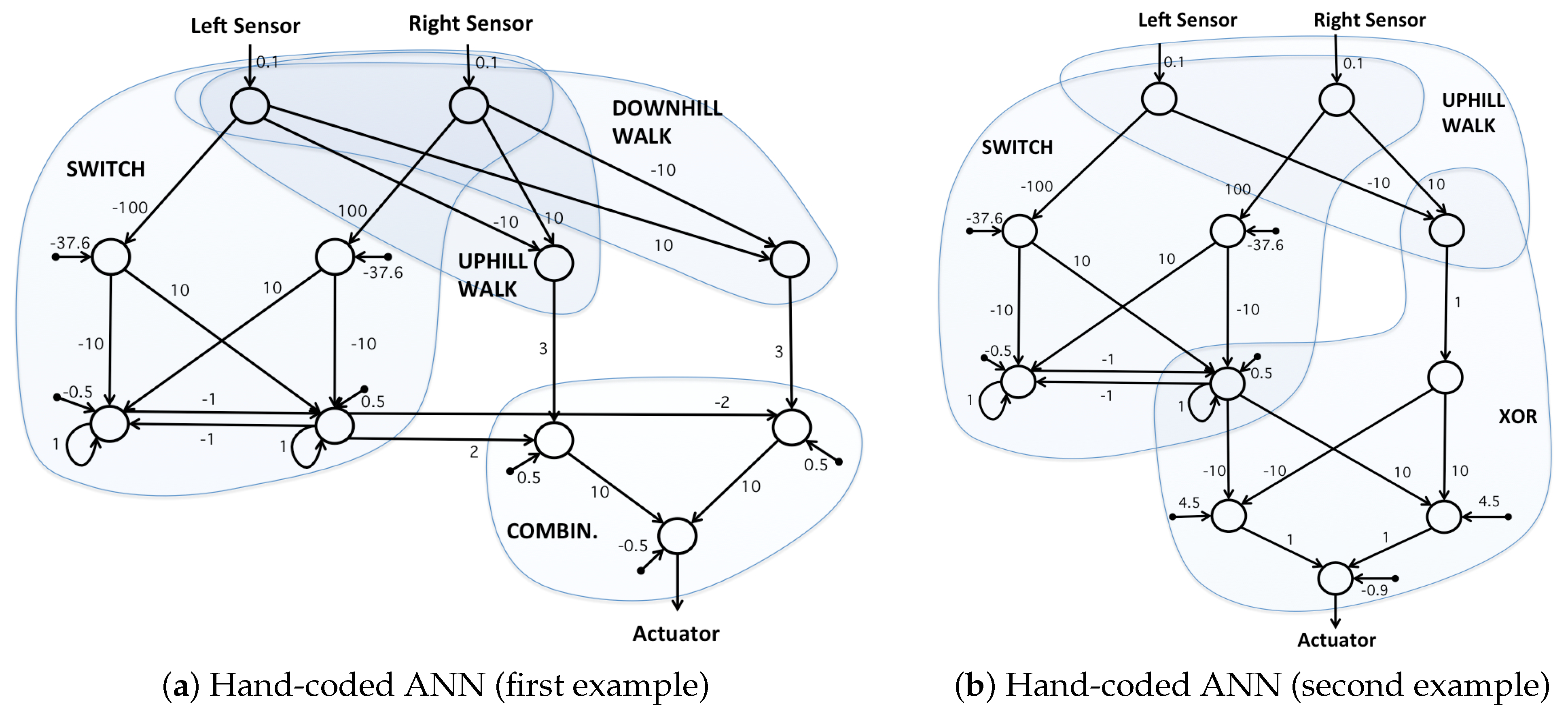
4.3. Hand-Coded Artificial Neural Network
In order to make sure that the topology of our evolved neural networks is sufficient for solving the problem, we designed hand-coded neural network solutions that are based on the same topology as at least one of the networks described above (ANN or CTRNN).
For the activation function, we used Equation (
6), as before.
Figure 4 shows two examples of hand-coded neural networks. The first example is topologically consistent with the CTRNN defined in the previous subsection. The second example is topologically consistent with both the ANN and CTRNN defined in the previous subsections. That means, in principle, it is possible for an evolutionary algorithm to evolve this problem from a population of the above ANNs or CTRNNs.
To design the hand-coded networks, we followed a logic based on subnetworks for various subtasks. In
Figure 4a, an uphill and a downhill walk subnetwork and a switch subnetwork are designed. The switch keeps the current state of the controller, and when the inputs pass the thresholds, it switches to the other state. Finally, in the last subnetwork, the information from the switch is used to choose between uphill and downhill walk.
Figure 4b has a slightly different design where the output of the switch and an uphill walk subnetwork are combined by using a logical XOR subnetwork. The number of the nodes in both networks is the same; however, the number of weights used in the second example is lower.
The behaviors of an agent controlled by both networks are the same. The behaviors in two different environments are demonstrated in
Figure 5b,c.
Figure 5b shows the behavior when the quality of the environment is increasing from left to right.
Figure 5c shows the behavior when the quality of the environment is decreasing (the quality of the environments is represented in gray-scale).
In the next step, we allowed evolution to optimize the weights of the second hand-coded network. For that, we made a population of ANNs with the topology described in
Section 4.1. The connection weights of the population were initialized with the weights of the second hand-coded network. The non-existing weights in the hand-coded network were set to zero in the population. The evolutionary algorithm was then allowed to change the weights including the ones with zero value. The details of the evolutionary algorithm and the results are described in
Section 5.
4.4. What Do We Expect to See as a Solution to the Wankelmut Task?
Although the task might seem to be solved in a straight forward way, a number of different strategies can be taken by an optimal controller. Notice also that we tested our agents in two types of environments: one environment with the maximum at the left-hand side and another environment with the maximum at the right-hand side.
An intuitive solution is a controller that can go uphill or downhill along the gradient with a 1 bit internal memory for determining the current required movement strategy (uphill or downhill). The internal memory switches its state when the sensor values reach the extremes (defined thresholds). The initial state of the memory should indicate the uphill movement. Hence, a controller requires only this 1 bit internal memory. The comparison between the instant values of the sensors then determines the actual direction of the movement in each step. We would consider such a solution as a “correct” solution, as it basically resembles the pseudo-code given in
Figure 2. We assume that our chosen topology of the ANNs allows in principle to evolve the required behavior based on one internal binary state variable. Our simple ANN was a recurrent network and had two hidden layers with three nodes each. These two hidden layers should have provided enough options to evolve an independent (modular) uphill and downhill controller in combination with a 1 bit memory and an action selection mechanism. Similarly, for the CTRNN approach, we have nine neurons, and any topology between them was allowed.
Another solution to solve the task can be done in the following way: The controller starts by deciding about the initial direction of the agent’s movement to the right or left depending on the initial sensor value. Following this, it continues a blind movement (i.e., not considering the directional information of the sensor inputs) until extreme sensor values are perceived and then switches the direction of the agent. Here also, an internal 1 bit state variable is required to keep the direction of the agent’s movement.
There is even another solution possible. As our environment does not change in size, the controller does not even need to consider the sensor values at any time except the first time step: In this strategy, the robot has to initially classify the environment, and then, the remaining task can be completed correctly by choosing one of two “pre-programmed” trajectories. In this solution, the sensor information is only used at the first time step, but then, a more complicated memory (more than 1 bit) is needed to maintain the oscillatory movement between the two extremes. This is not a maximally reactive solution meaning that it partially replaces reactivity to sensor inputs with other mechanisms; i.e., using extra memory and pre-programmed behaviors. Such a solution would not work in the way we expect it to work in other environments (e.g., changed size of the gradient). Such a controller might achieve the optimal fitness in our evolutionary runs, but a post-hoc test in a slightly different environment would identify that it generates sub-optimal behavior. Thus, it does not represent a valid solution for the Wankelmut task. A post-hoc test that detects such a solution could be done by changing the size or the steepness of the environmental gradient or by using a Gaussian function (bell curve) instead of the Gauss error function (erf) with randomized starting positions: in this case, the agent should oscillate only in the left or in the right half of the environment, depending on its starting position, to implement a true reactive solution to the Wankelmut task.
Other solution strategies can also concern the switching condition, for example the switching may occur based on the extreme values of the sensors (defined thresholds), the difference between the two sensor values, or the fact that at the boundaries of the arena, the sensor values may not change even if the agent attempts to keep moving in the same direction, as we do not allow the agent to leave the arena.
Here, we are interested in controllers that are maximally reactive, meaning that they base their behaviors on reacting to sensor values instead of scheduling pre-programmed trajectories. The usage of memory in such controllers is minimized since memory is replaced by reactivity to sensors wherever possible. In our case, a valid controller is expected to need a sort of 1 bit memory (which is not replaceable by reactivity to sensors) to keep track of the direction of its movement. Solutions that use extra memory for scheduling their pre-programmed trajectories are considered invalid.
We are aware that the “creativity” of evolutionary computation cuts both ways. It can surprise the experimenter with the exploitation of Non-Adaptive Undesired Simple Solutions (NAUSSs) where it manages to maximize its fitness reward without producing the desired agent behavior, in a way that was initially not foreseen [
32]. Often, such a tendency can be a cause for trouble when applying evolutionary computation methods in simulators in order to evolve robot control software. Such an approach is often chosen due to a lack of hardware or due to the fact that it allows much higher generation and population numbers than real-world empirical experiments with robots. However, such simulators have a so-called “reality gap” [
5,
33] (e.g., simplified simulation of physics). The tendency of evolutionary computation to find simple-to-exploit solutions often detects features to produce well-performing desired behavioral control software in the simulation that do not perform in a similar way when the software is then executed on the real physically embodied robotic agent(s). Considering this, we designed the Wankelmut task in a way that such tricks would fail to perform well in the benchmark by setting the objective of the evolution towards adaptive behavior with respect to extrinsic environmental cues and with respect to intrinsic agent goals in dynamic combinations of each other. Only if the robot shows a behavior that satisfies its intrinsic goals in various static or in a dynamic environments can it achieve a high fitness value. There is no physics emulation involved in the simulator, in order to avoid the exploitation of numerical artifacts; thus, there has to be the evolution of an appropriate high-level behavioral control software in order to succeed in our Wankelmut benchmark. Post-hoc, low-performing software controllers produced by evolutionary computation are often considered to be a consequence of bad fitness function design [
7]. Therefore, we define several fitness functions and tested two software control techniques (ANN and CTRNN) using each fitness function in 30 evolutionary runs per setting, as is described in the following Quantitative Analysis Section.
6. Discussion and Conclusions
We propose the Wankelmut task, which is a very simple task. Compared to the classification scheme of Braitenberg [
24], an agent that solves the Wankelmut task would be placed between Vehicle #4 and Vehicle #5 concerning the complexity of its behavior. Given that it operates in a one-dimensional space introduces a relation to Vehicle #1. In the Wankelmut task, we evolve a controller that switches between two alternative conflicting tasks. Yet, there is no prioritizing between the two subtasks, and therefore, it is not a subsumption architecture. It also does not repeatedly alternate between two subtasks since the switching between the two tasks is based on the environmental clues. The simplicity of the pseudo-code shown in
Figure 2 clearly demonstrates the simplicity of the required controller that implements an optimal, flexible, and reactive Wankelmut agent.
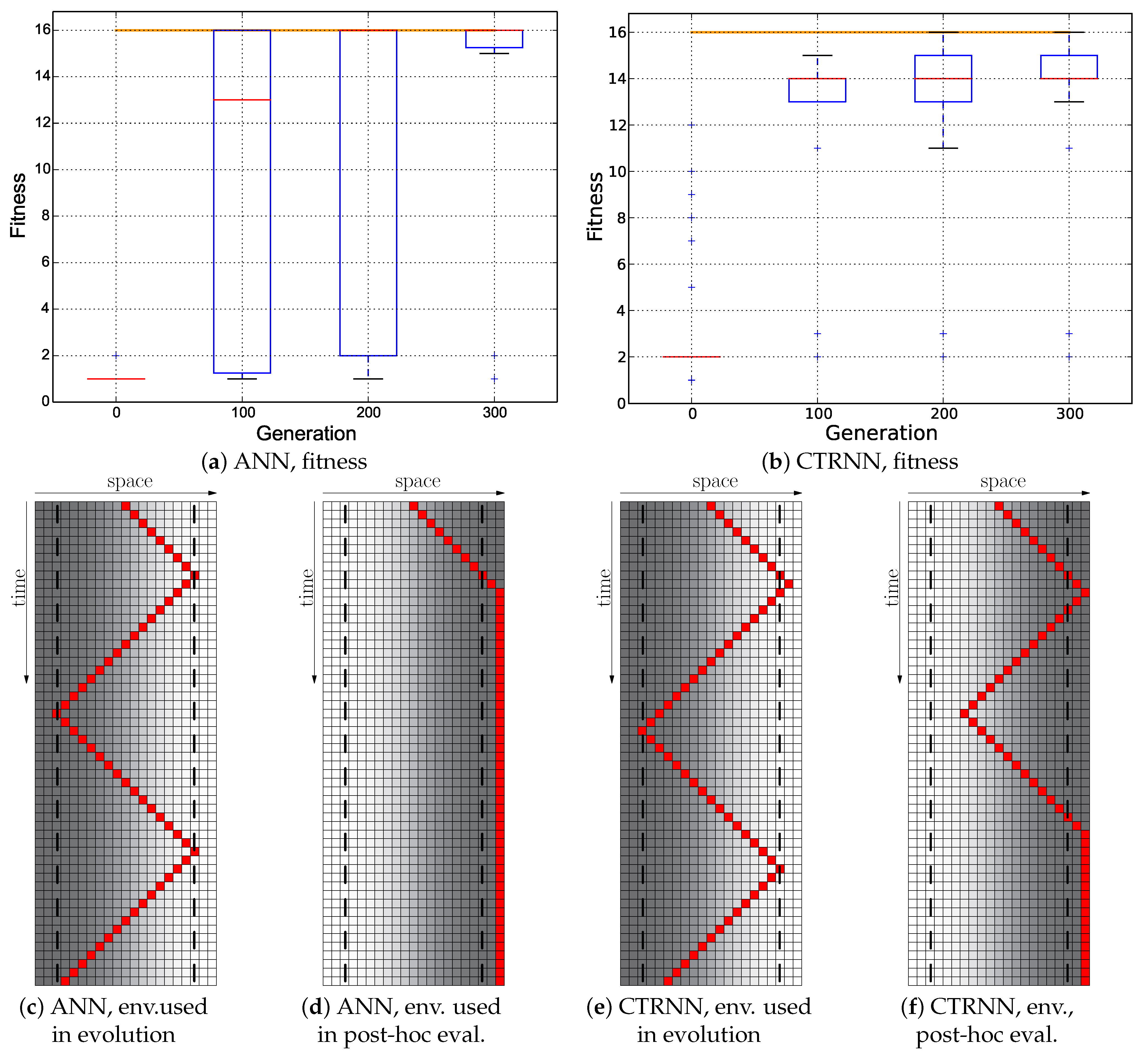
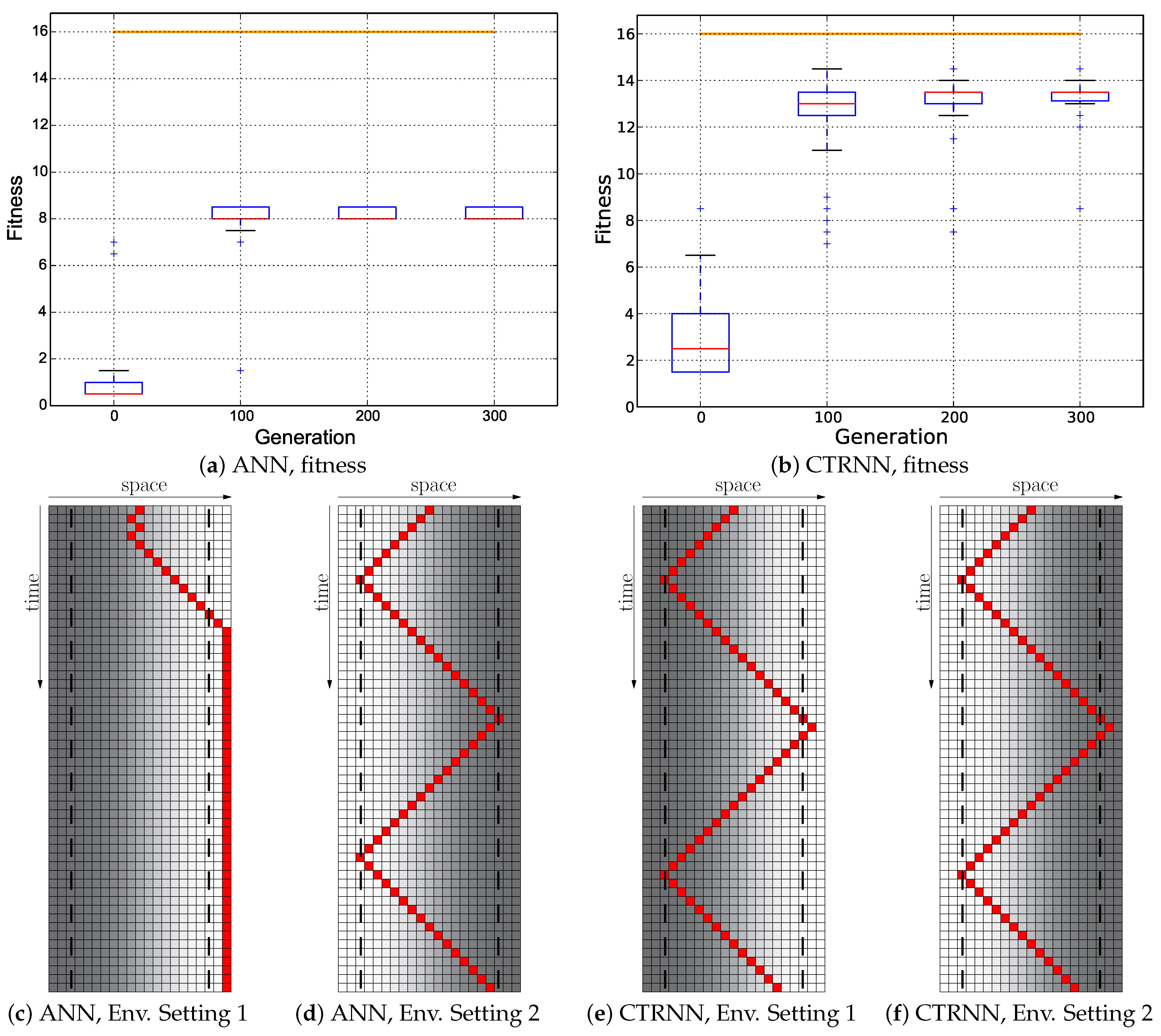
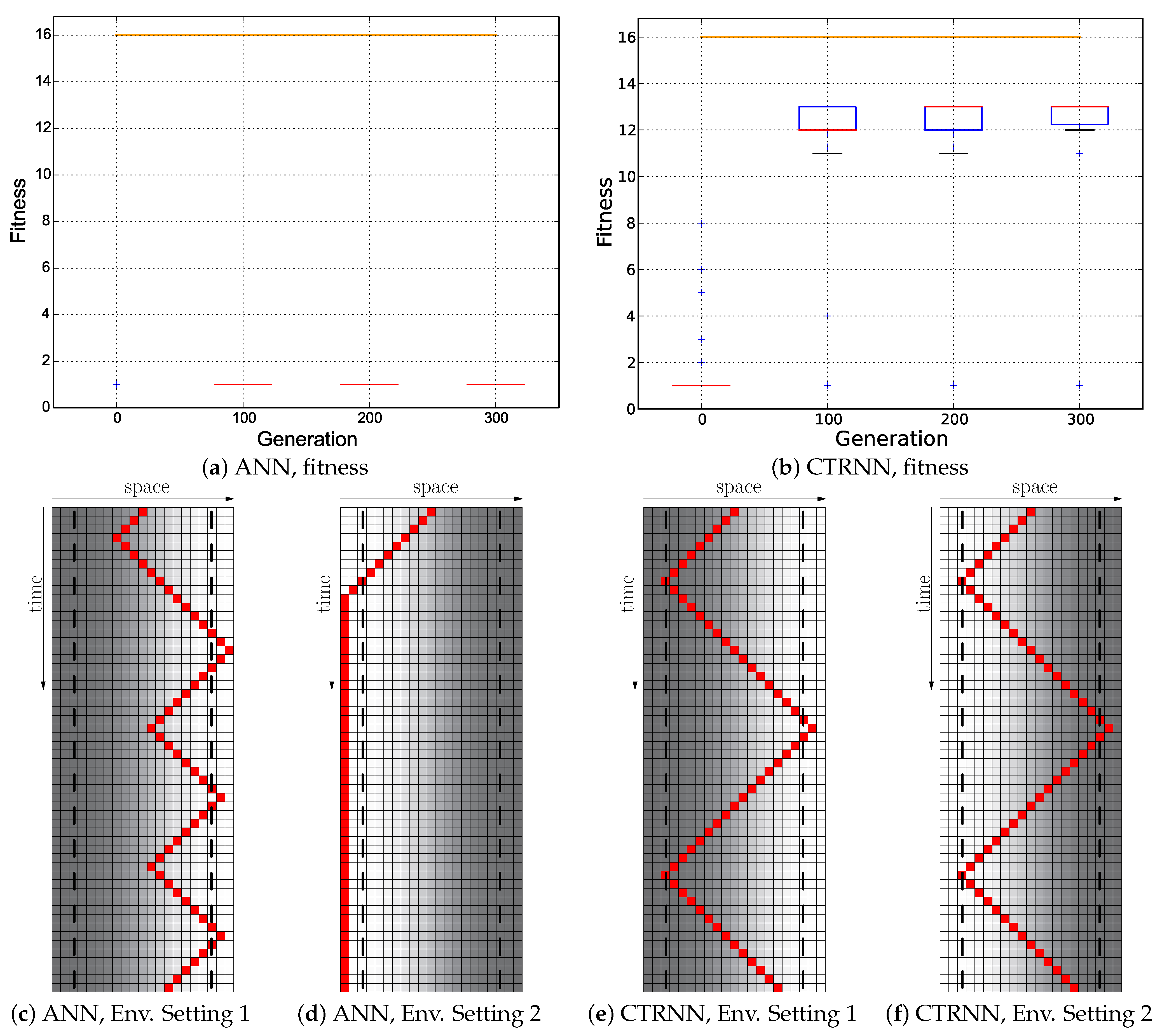
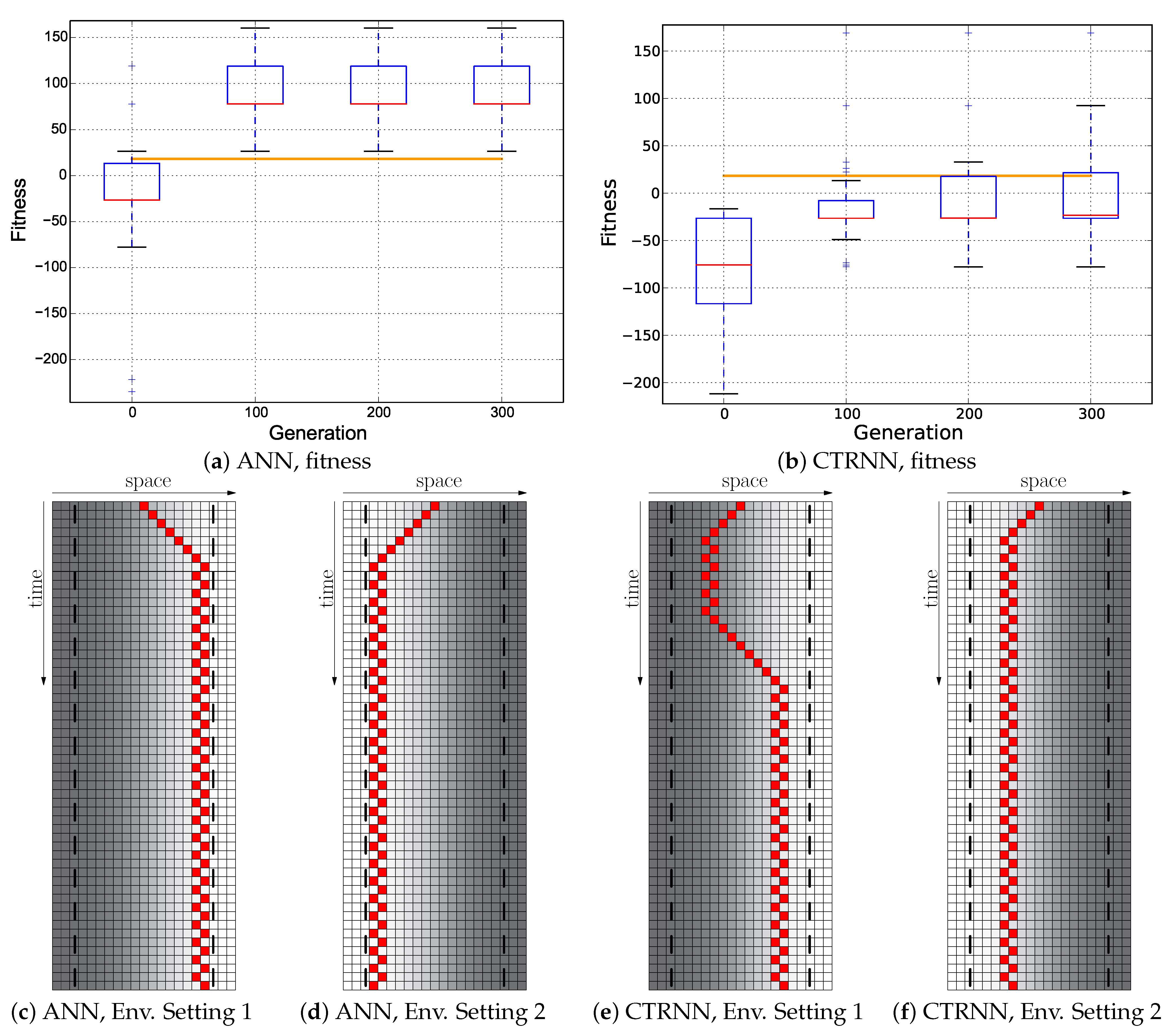
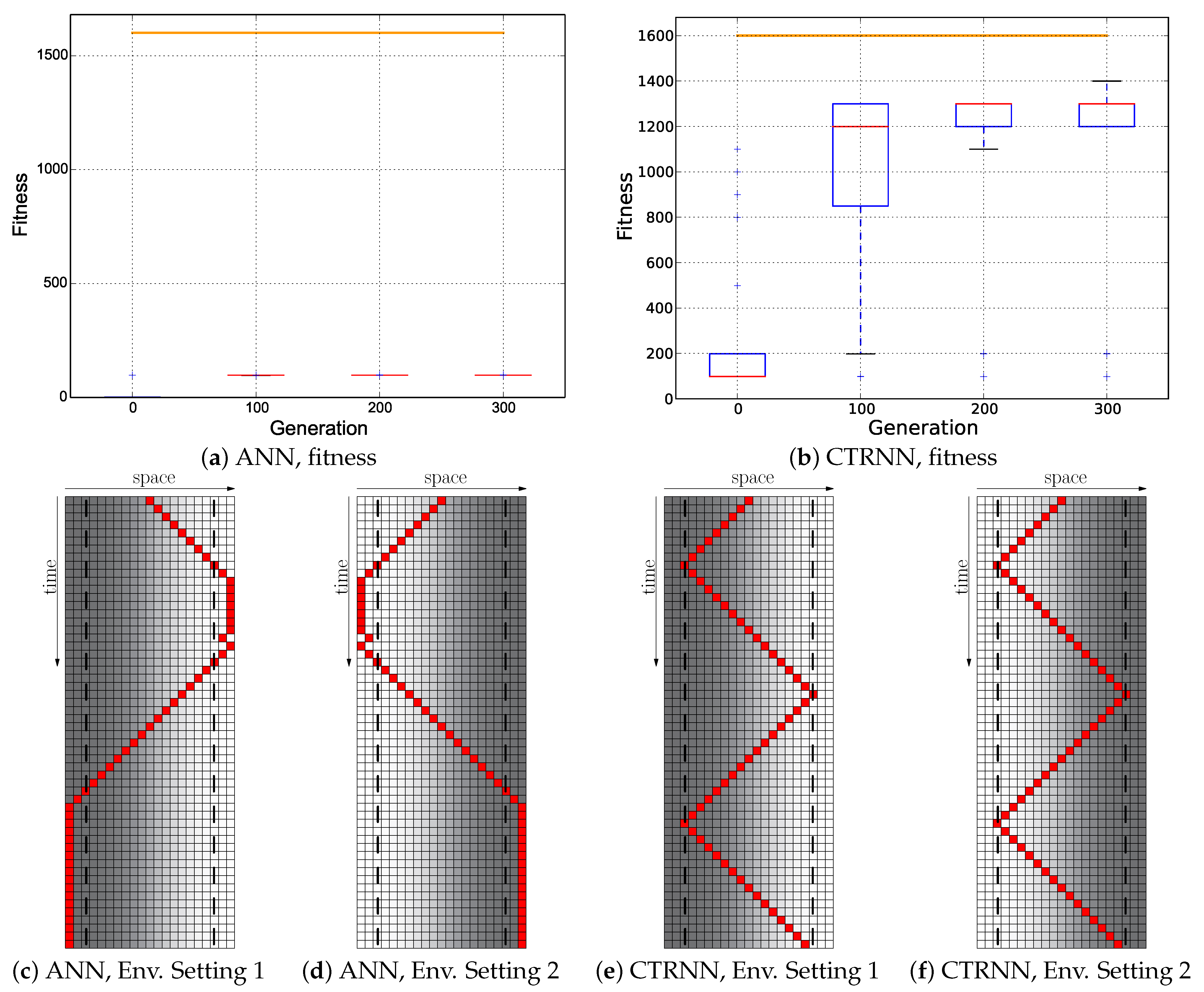
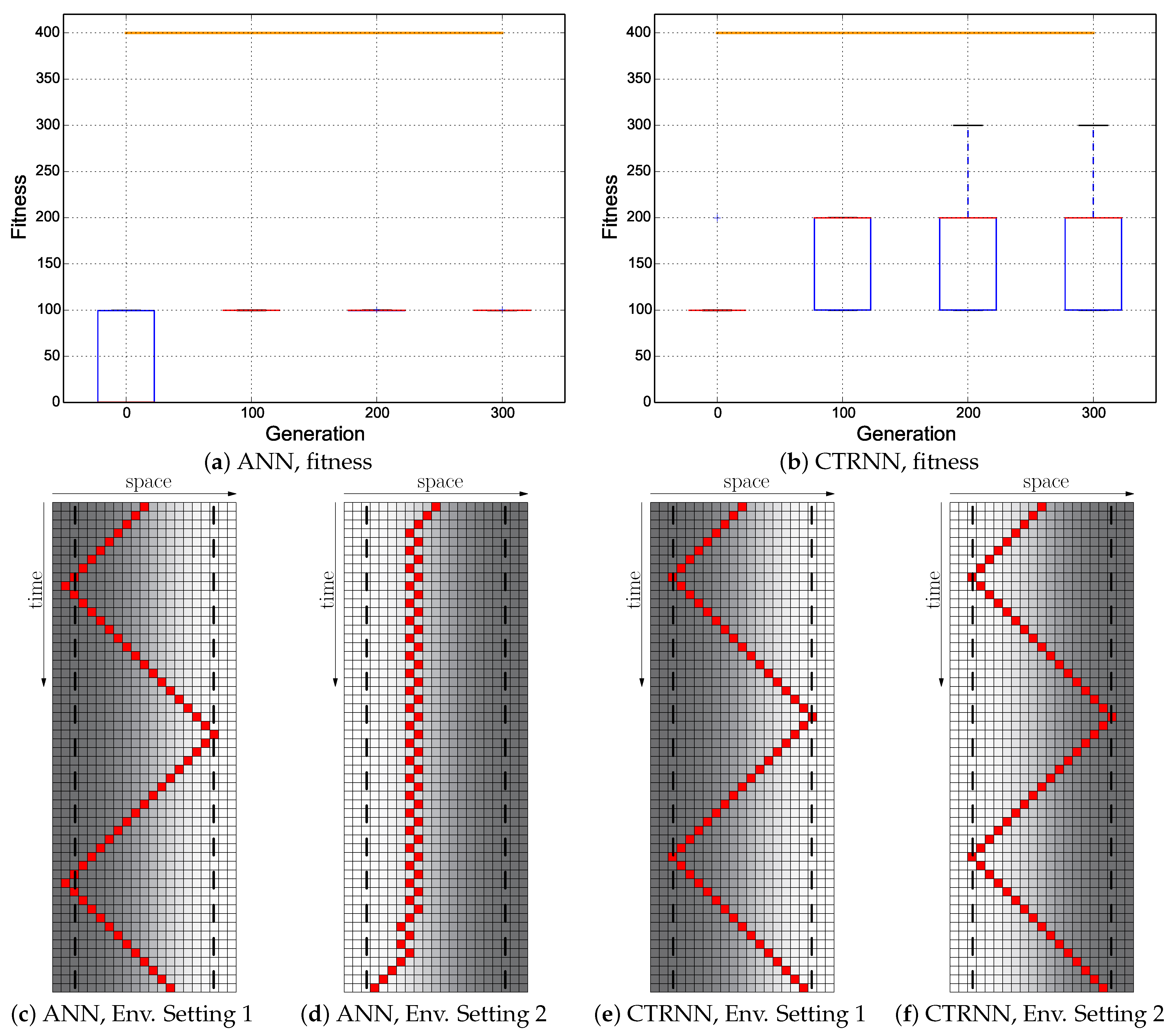
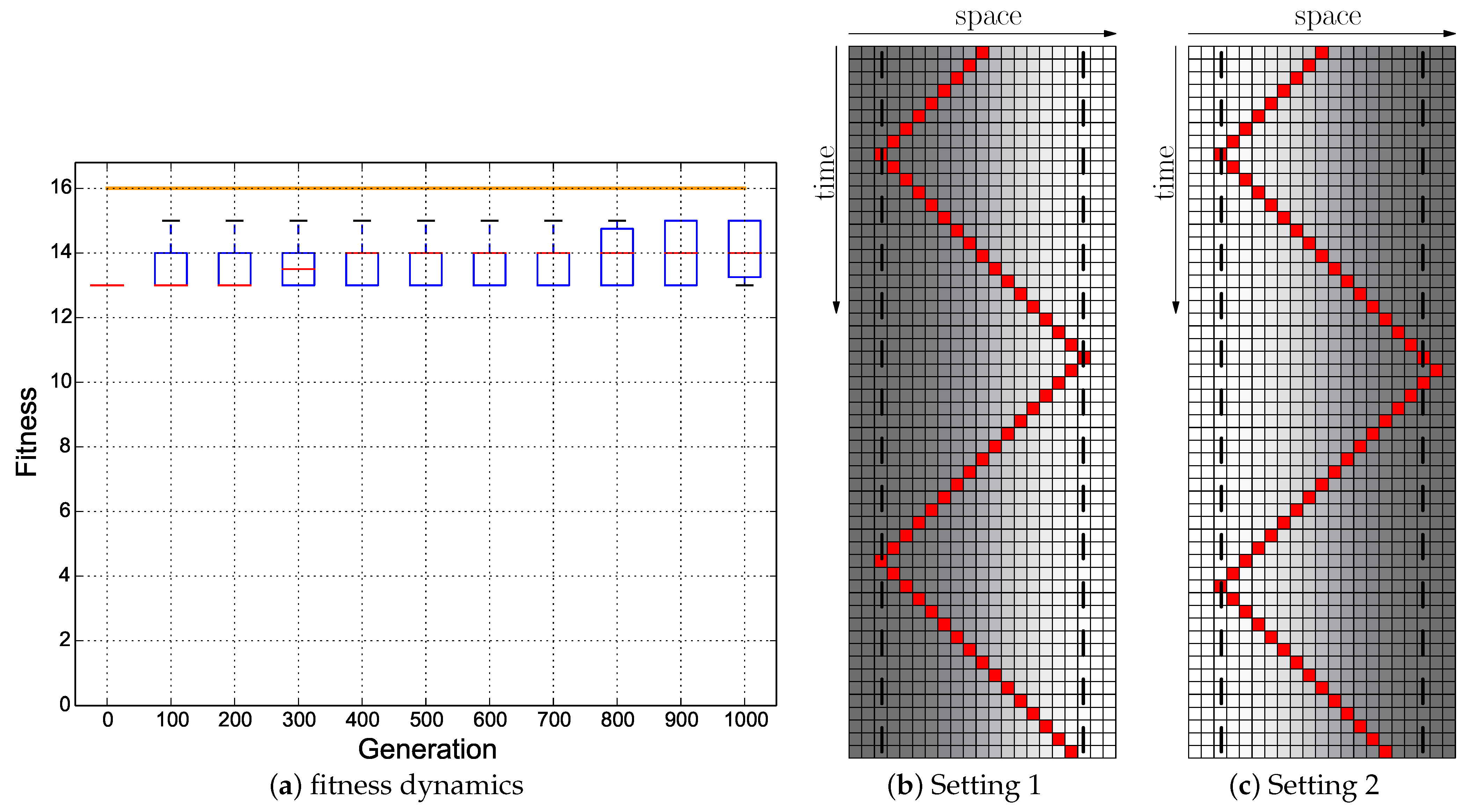
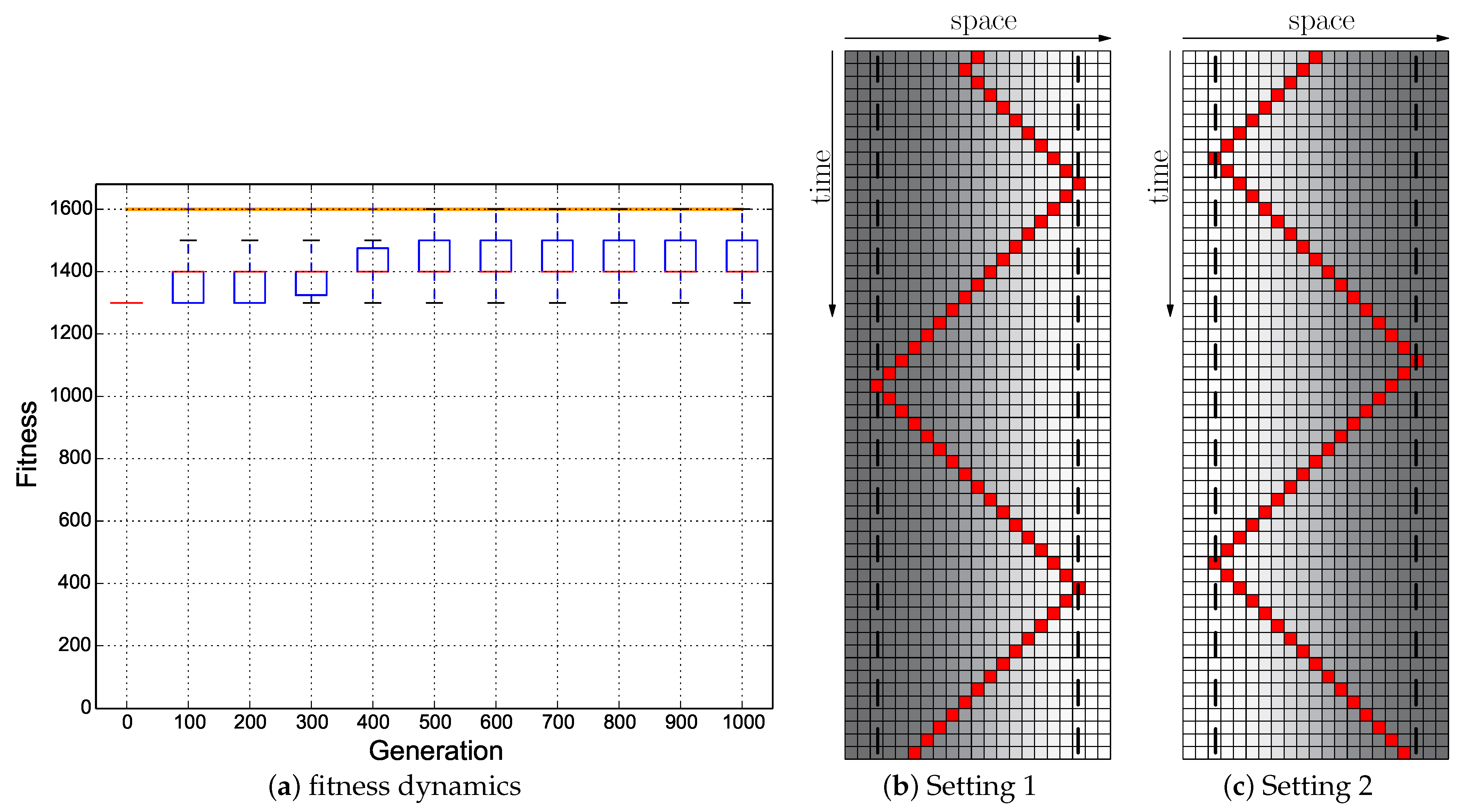
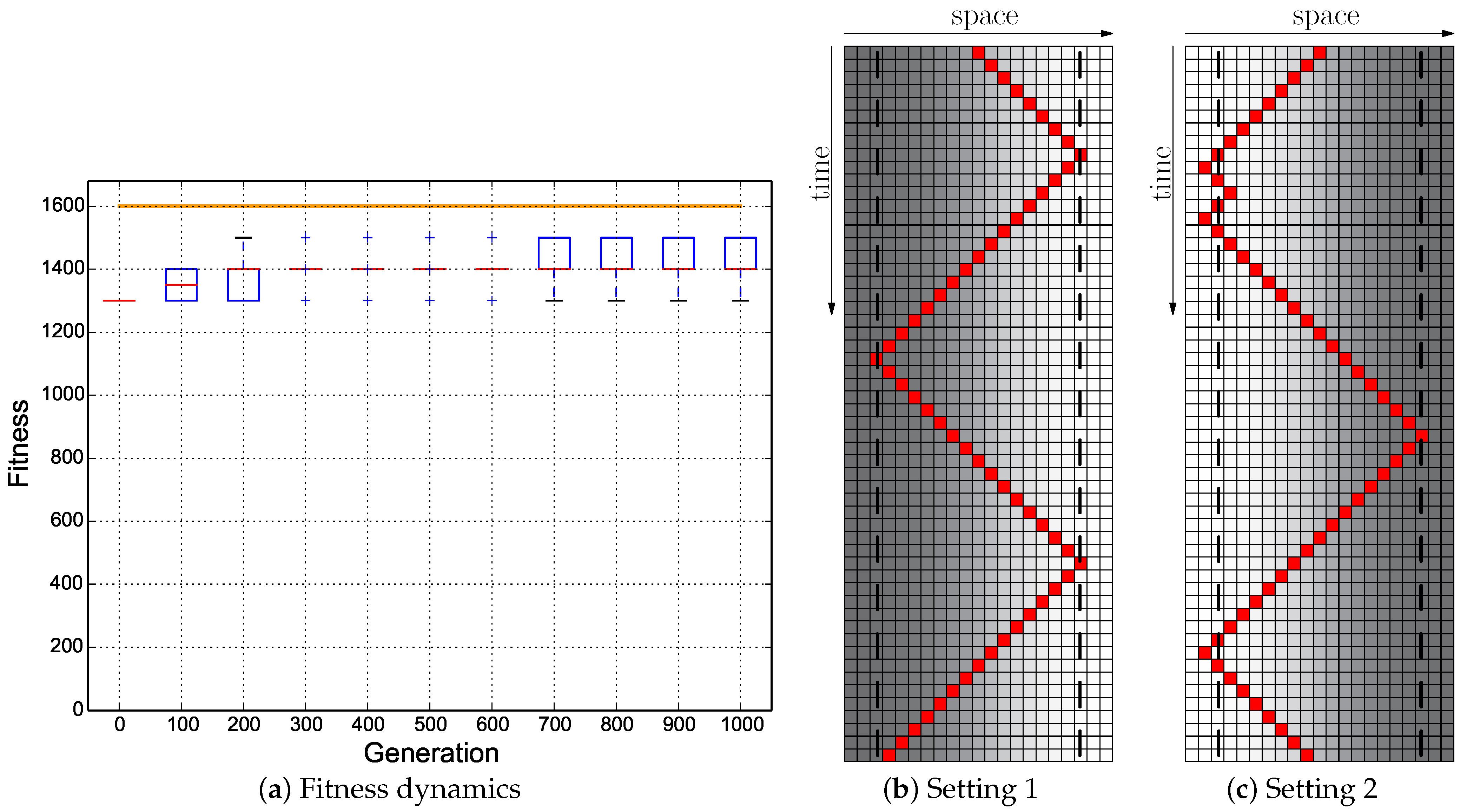
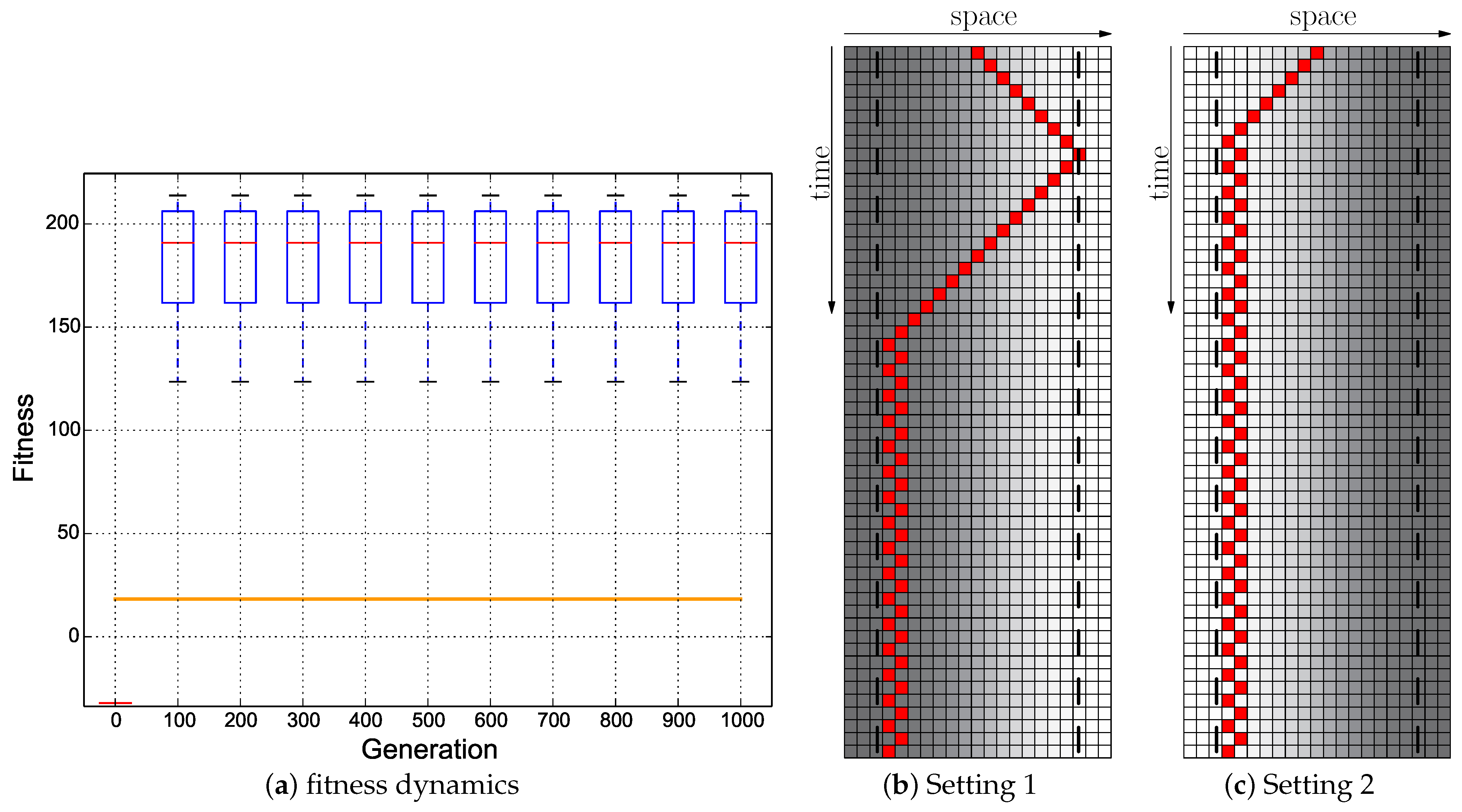
Our results indicate that plain-vanilla evolving ANNs easily can evolve the reactive uphill walk (see
Figure 6c). However, switching to the opposite behavior (downhill motion) and then flipping back was not found by any of our approaches, regardless of what fitness regime we used and regardless of which neuronal architecture we used as a substrate for the evolutionary process (ANN or CTRNN). In all tested fitness regimes, the desired behavior did not evolve. In one of these fitness regimes (
Cumulative regime), evolution found a “heap trick” to maximize the fitness with a surprising behavior; however, the desired reactive Wankelmut behavior did not evolve there.
In order to prove that the task is solvable by the encoding that we used here, we designed two hand-coded ANNs to solve the task. However, the hand-coded networks demonstrated a behavior that was quite good, but not optimal. To further improve this, we then evolved one of the hand-coded ANNs and achieved the optimal behavior showing that the encoding covers the solution and the evolution can evolve the behavior when it is searching in the vicinity of the solution (
Figure 5).
In summary, Wankelmut is an easy-to-implement benchmark task that can be solved by two simple hand-coded lines of code (see
Figure 2). Despite its simplicity, it was found to be a hard task for evolutionary algorithms to solve, as all our evolutionary trajectories without access to a priori information about how to solve the task failed to achieve the desired adaptive behaviors. To investigate the role of modularity in this process, we created pre-structured neural networks, where the weights were initialized to provide an appropriate adaptive, but still suboptimal solution, and allowed to be optimized by the evolutionary process, as shown in
Figure 3. These experiments yielded sub-optimal, but reactive behavioral controllers that produced a correct Wankelmut-like behavior, thus indicating a step forward concerning evolvability. By further hand-tuning of these evolved networks, we were able to implement an improvement that resulted in optimal adaptive behaviors, demonstrating that the offered computational substrate was capable of producing the desired behavior.
When looking at
Figure 3, it becomes clear that only the hand-coded controller depicted in
Figure 2 showed the desired Wankelmut behavior, as did also the hand-coded and pre-structured ANNs in an almost similar way. From all evolutionary runs that we performed, only those showed a close-to-optimal Wankelmut behavior that started the evolutionary process already with a pre-structured network and that then evolved this structure further with an appropriate fitness function (
Switch,
Instant + Switch, or
Cumulative + Switch).This stresses, on the one hand, the simplicity of computational structures that are required to fulfill the task and the need of having the evolutionary computation already informed about the path towards the solution, which is a structure consisting of three interconnected modules: two for each of the antagonistic behaviors and one as a higher order regulatory element that negotiates between those two other modules.
Based on these observations, we come to the interpretation that a pre-defined suitable modularity of the network helps, but is not sufficient for optimal results. A method to achieve optimal results needs to either have the required modules available from the beginning and then ensure that this modularity is used beneficially in the evolutionary process or, even more desired, be able to create the needed modularity during the evolutionary process by itself. We designed the Wankelmut task on purpose to consist of two opposing behaviors (uphill and downhill walk) that cannot be performed at the same time in order to generate a hard-to-learn task. Neural structures that are beneficial to create downhill behavior cannot be easily converted into structures that produce uphill behavior without “destroying” the previously learned network functionality, if there is no other higher level of control preventing it (cf. catastrophic forgetting [
34]). Thus, in order to evolve a combination of both, it would require a specific evolutionary framework that is designed to generate functional modules, to store (freeze) useful modules and then to combine them with more complex behaviors like the Wankelmut task. However, such a functionality was not found to evolve from scratch by itself in our system in an emergent way.
Given that the hand-coded solution is simple, a tree-based approach with exhaustive search or a Genetic Programming (GP) approach [
35] is expected to be able to find the desired behavior. However, we would expect also here to hit the same “wall of complexity”, as controllers that require a bit more complexity overwhelm the exhaustive tree-search, while the existing local optima, that already fooled the ANN + Evoapproach and the CTRNN + Evo approach, will also fool the stochastic GP search in a similar way. This remains to be tested in future experiments.
We point out that the target of evolving controllers for the Wankelmut task from scratch requires evolving a behavioral switch. However, the evolution of such a switch represents a chicken-egg problem. The switch is useless without the two motion modules (subnets) for uphill and downhill motion, while those sub-modules are useless without the switch.
In addition, we want to point out the fact that a similar behavior could be exerted by just switching the environment in an oscillatory way. This is not the same as our envisioned Wankelmut behavior, as our behavior intrinsically switches its behavioral pattern in reaction to a stable environment. Therefore, it is intrinsic dynamics exhibited in a global stable environment and not a fixed (stable) behavioral pattern in a globally dynamic environment.
The Wankelmut task might also prove to be an interesting benchmark for more sophisticated methods that push towards modularization. Examples are artificial epigenetic networks as reported by Turner et al. [
36]: they used the coupled inverted pendulums benchmark [
37], which requires the concurrent evolution of several behaviors similar to the Wankelmut task. However, the control of coupled inverted pendulums is more complex than the simple world of Wankelmut. Other methods alternate between different tasks on evolutionary time-scales [
21], and there are methods that, in addition, also impose costs on connections between nodes in neural networks [
22]. Other interesting approaches either pre-determine or push towards modularity [
18]. The approach of HyperNEAT was tested for its capability to generate modular networks with a negative result in the sense that modularity was not automatically generated [
38]. Bongard [
39] reported modularity by imposing different selection pressures on different parts of the network.
In fact, we propose here two challenges for the scientific community at once:
The first challenge is to find the most simple uninformed evolutionary computation algorithm that can solve the Wankelmut task presented here. Then, the community can search for the next simple task that is shown to be unsolvable for this new algorithm. This will yield iterative progress in the field.
The Wankelmut task is the simplest task found so far (concerning required memory size, number of modules, dimensionality of the world it operates in, etc.). Still, there might be even simpler tasks that already break plain-vanilla uninformed evolutionary computation, so we also pose the challenge to search for such simpler benchmark tasks.
It should be noted that there is no evidence that such walls of complexity are consistent in a way that breaking one wall may cause a new wall at a different position. This is quite similar to the reasoning behind the “no free lunch” theorem. Theoretically, an optimization algorithm cannot be optimal for all tasks. However, neither natural nor artificial evolution achieve in general optimal solutions. Instead, especially natural evolution has proven to be a great heuristic for which the walls might be fixed in a certain place but, definitely far away from the wall for state-of-the-art artificial evolution. Hence, we should try to search for that one heuristic that allows us to push all walls of many different tasks as far as possible forward (while still accepting the implications of no free lunch).
We think that either dismissing all pre-informed methods or finding minimally pre-informed methods to solve the Wankelmut task is important. Natural evolution has produced billions of billions of reactive and adaptive behaviors of organisms much more complex than the Wankelmut task, and it has achieved this without any information that promoted self-complexification and self-modularization. In contrast, the evolutionary process started from scratch and developed all of that due to evolution-intrinsic forces. We think that this can be a lesson for evolutionary computation: studying how an uninformed process that is neither pre-fabricated towards complexification or modularization and that is not specifically rewarded for complexification or modularization can still yield complex solutions. Nature has shown this, and evolutionary computation and biologists together should find out how this was achieved. Perhaps, this would then not be “evolutionary computation’ anymore, but rather “artificial evolution”, a real valid, yet still simple model of natural evolution. This might be achieved by incorporating the principles of biological growth, for example the mechanisms of Evolutionary Developmental biology, “EvoDevo” [
40], which might be the path to evolve future in silico neuromorphic computation systems [
41] and virtual brains [
42] via embryogenetic or morphogenetic algorithms [
43] that can develop the required capabilities of self-modularization and self-complexification, in order to break through the walls of complexity that we discovered.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}