
Effect of Subglottic Stenosis on Vocal Fold Vibration and Voice Production Using Fluid–Structure–Acoustics Interaction Simulation



Abstract
1. Introduction
2. Models
2.1. Numerical Algorithms
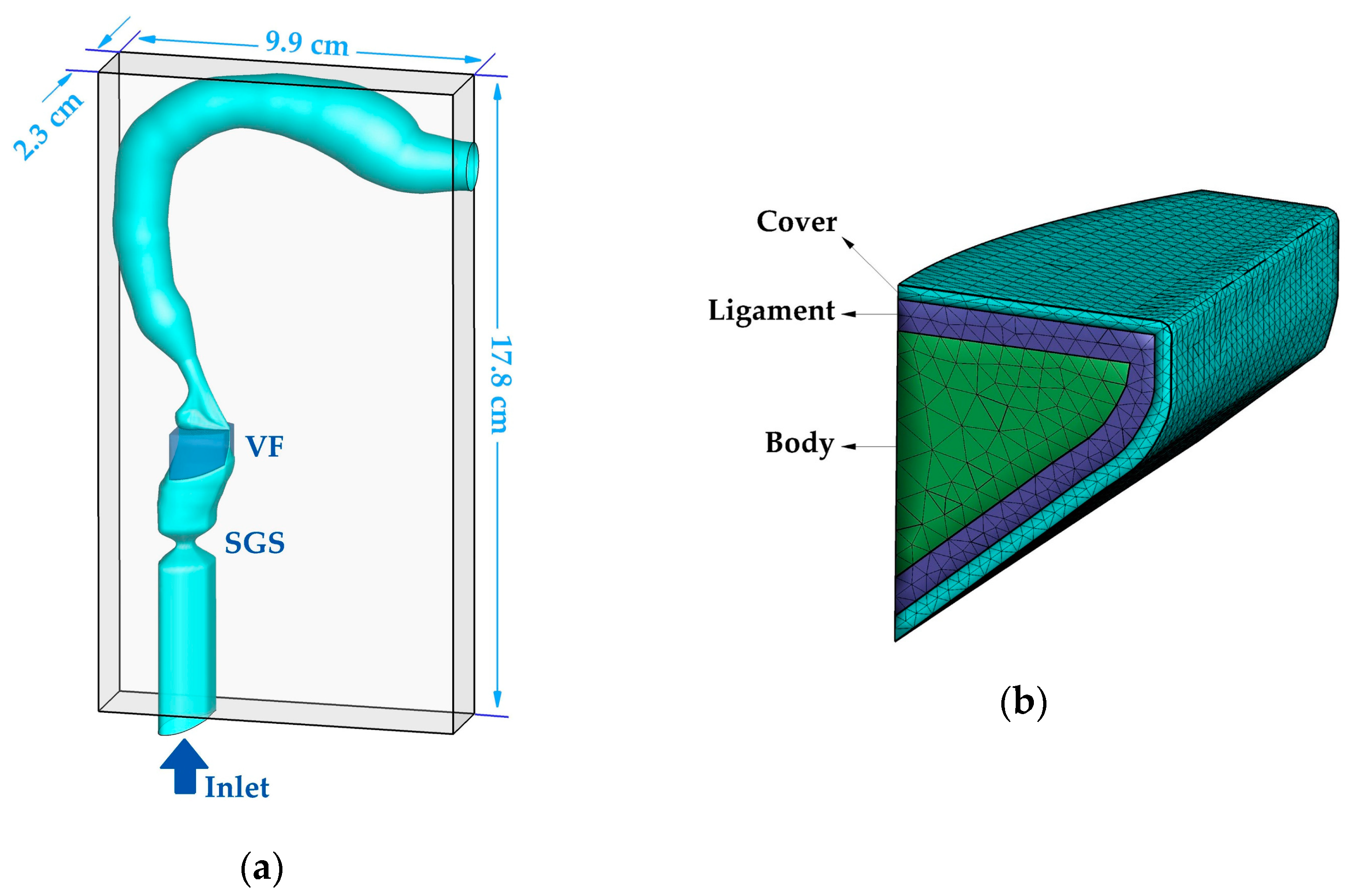
2.2. Geometric Models
2.3. Computational Domain and Boundary Conditions
3. Results and Discussion
3.1. Baseline Case Dynamics
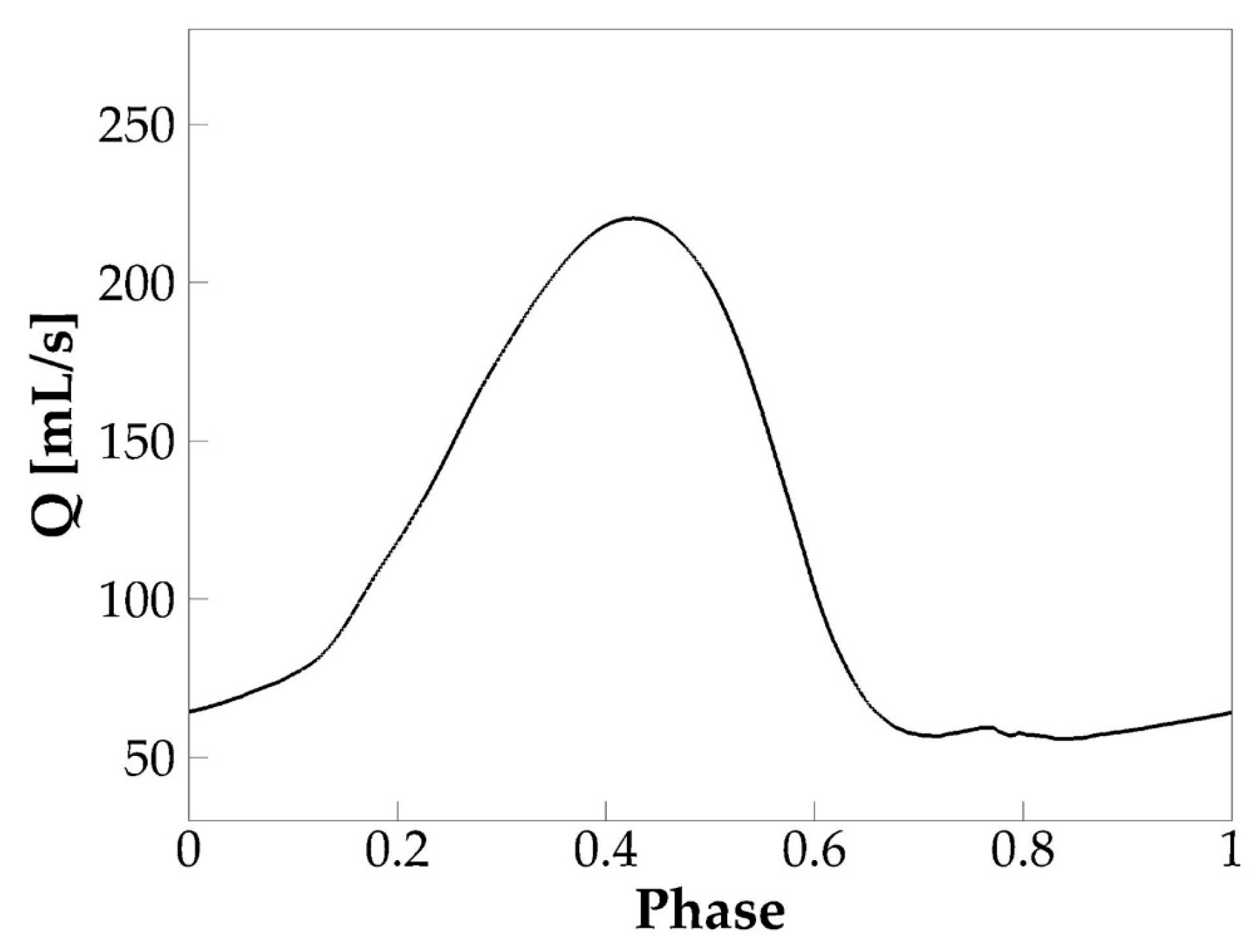
3.1.1. Glottal Flow Rate Waveform
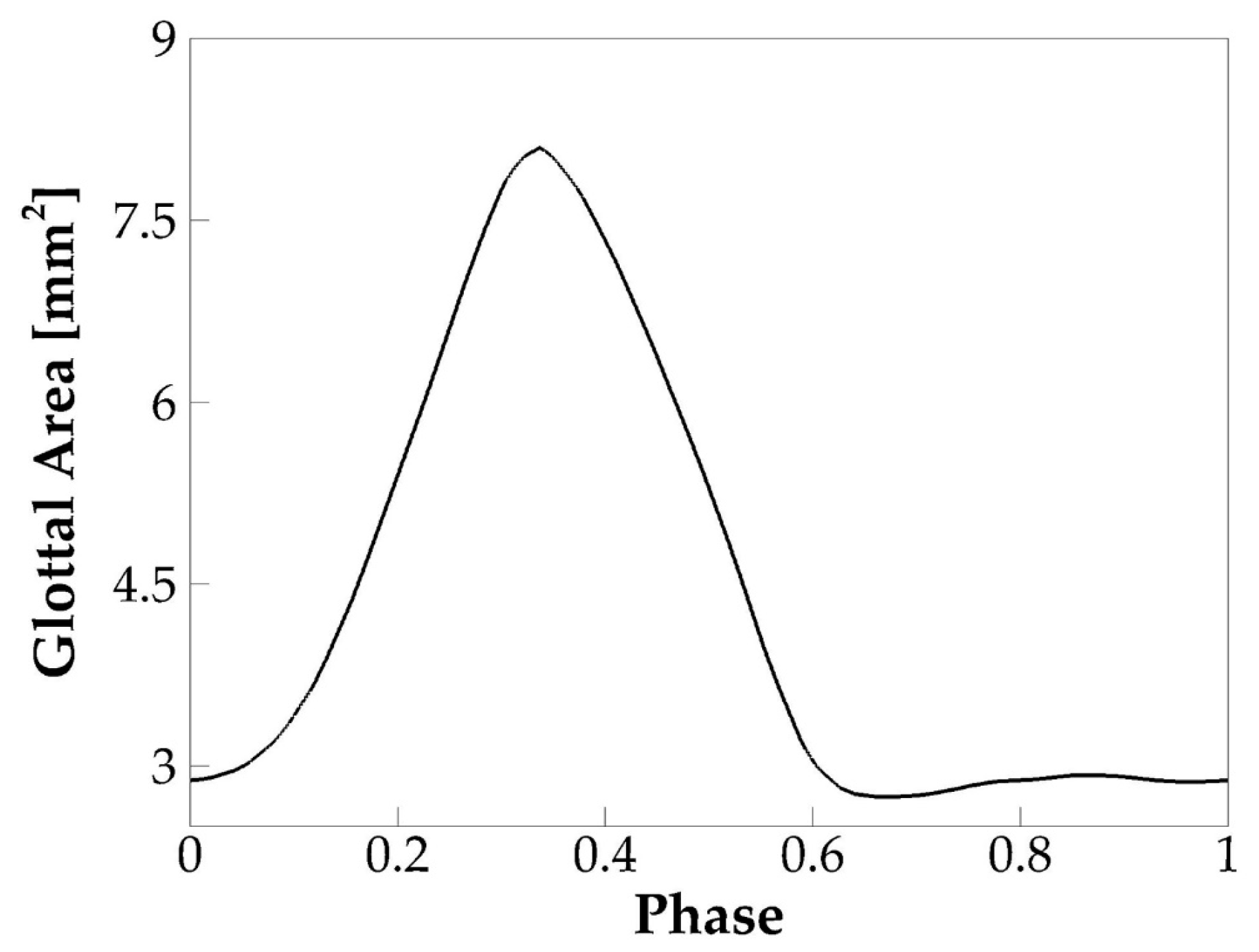
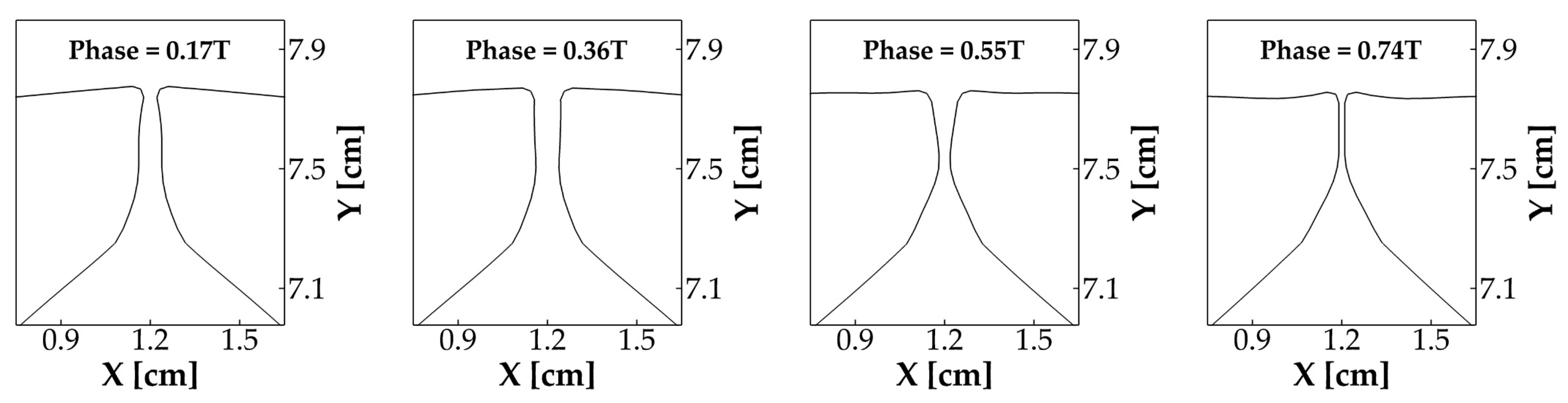
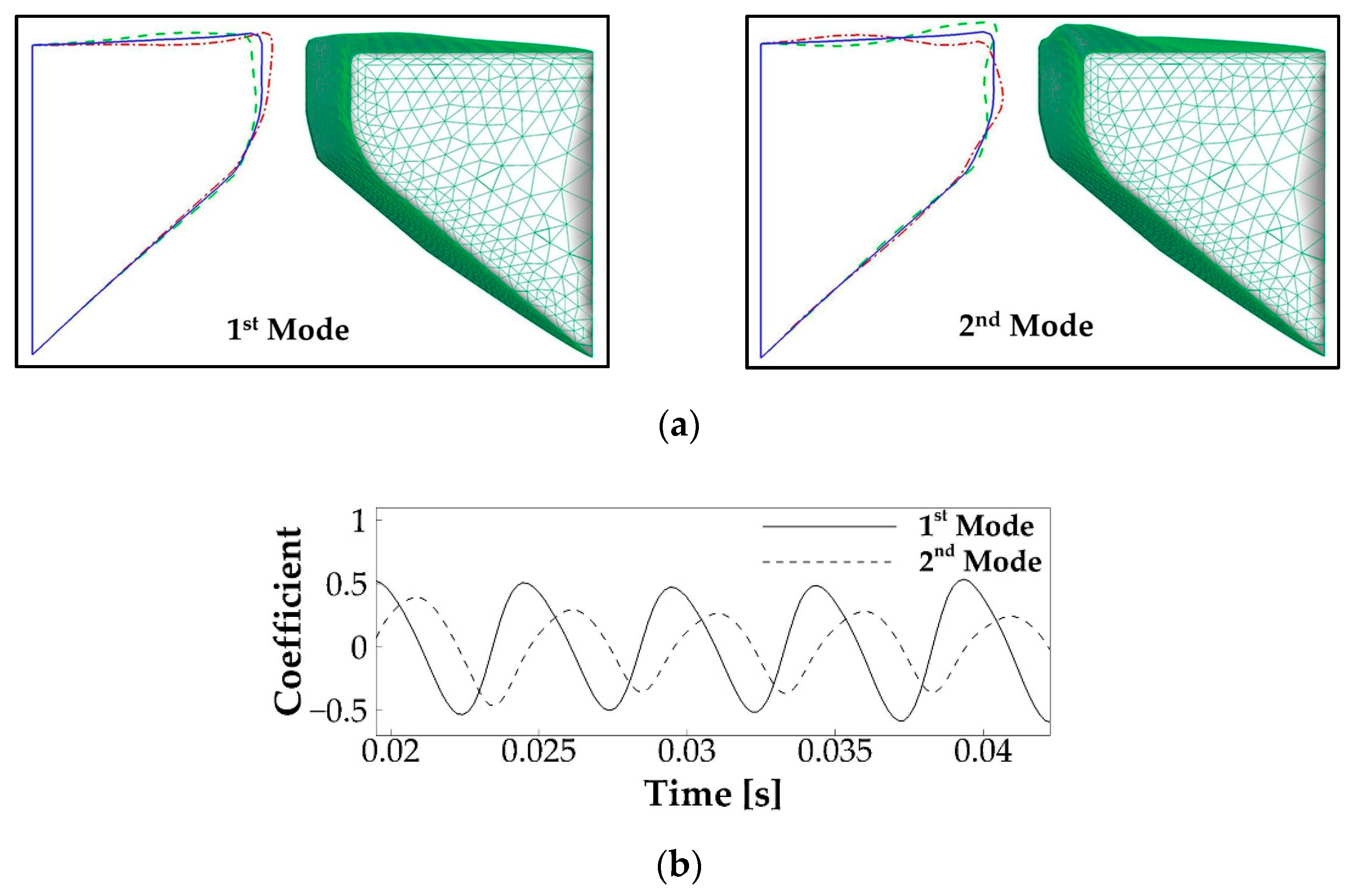
3.1.2. Vocal Fold Dynamics
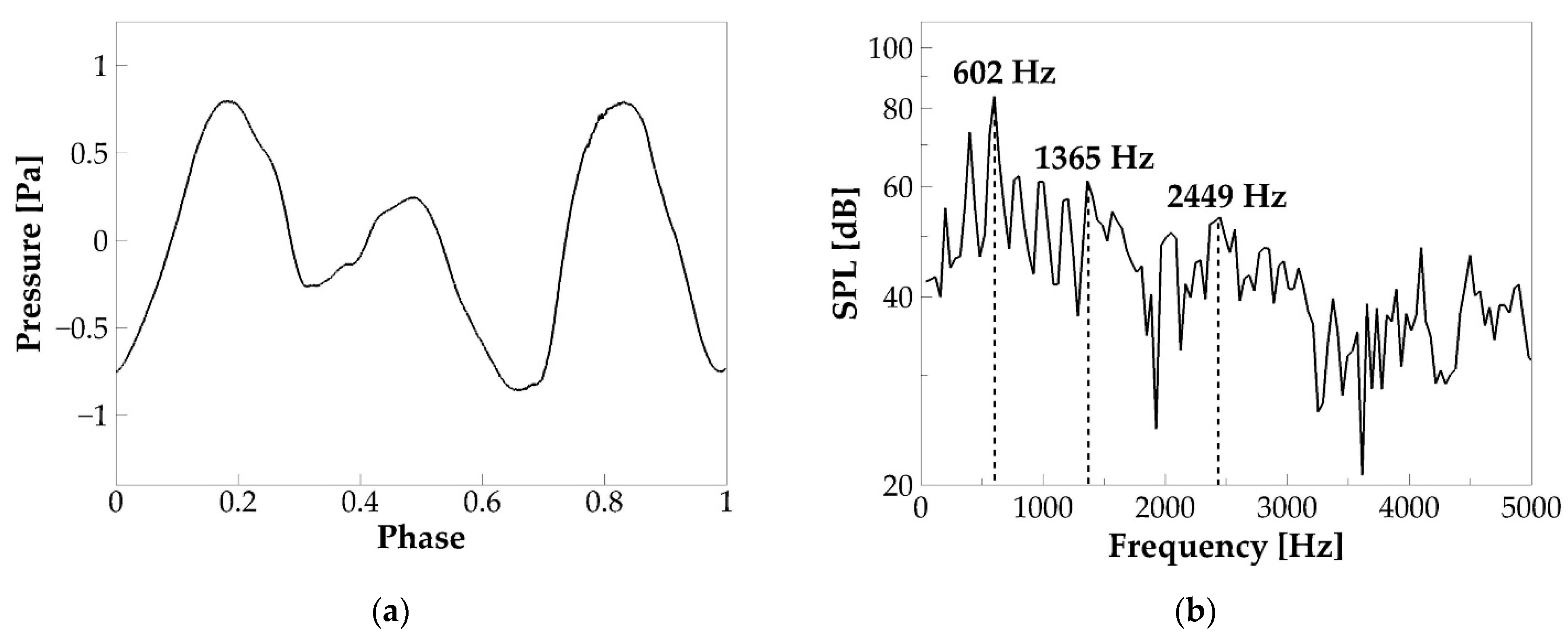
3.1.3. Acoustics
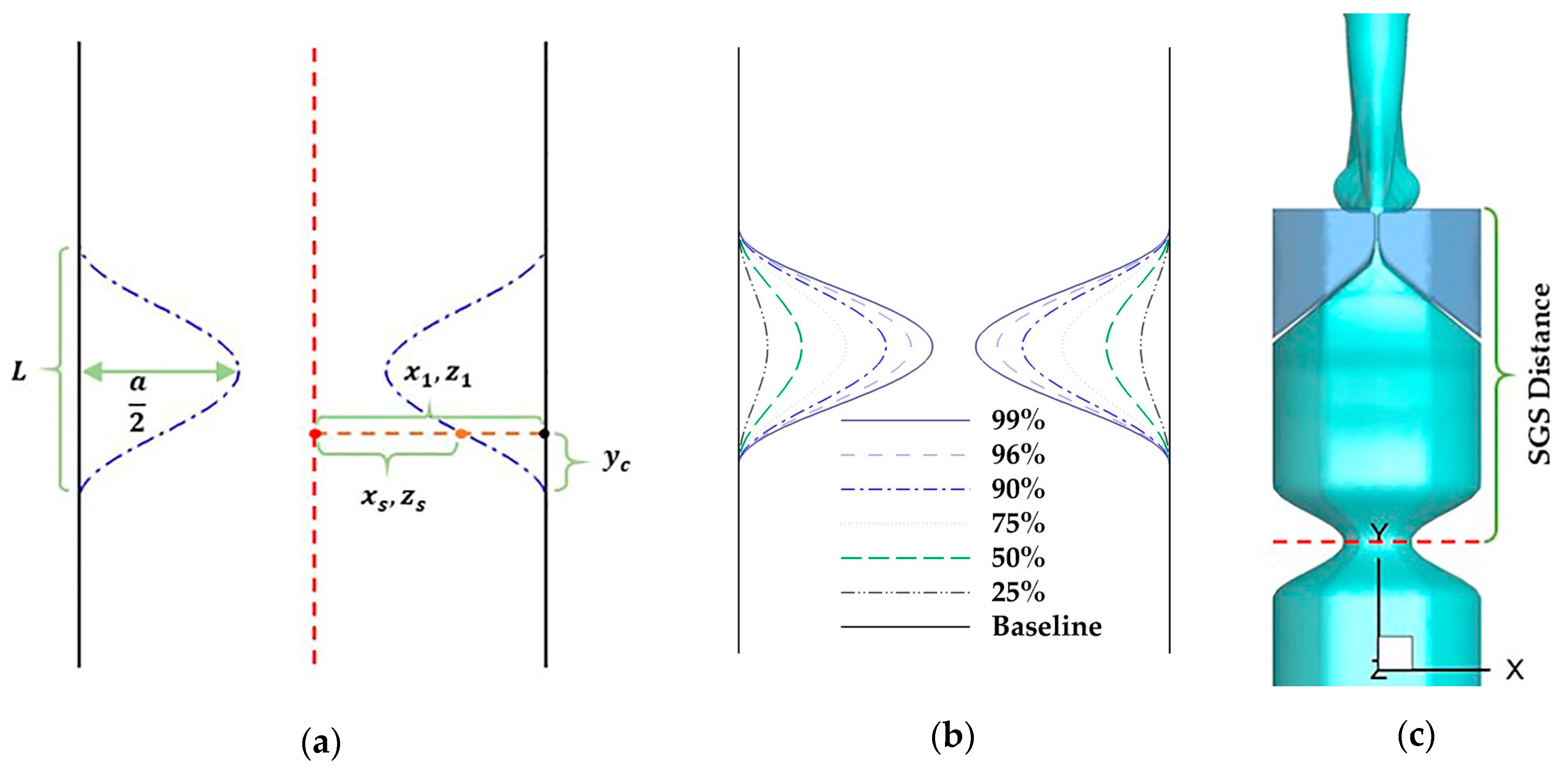
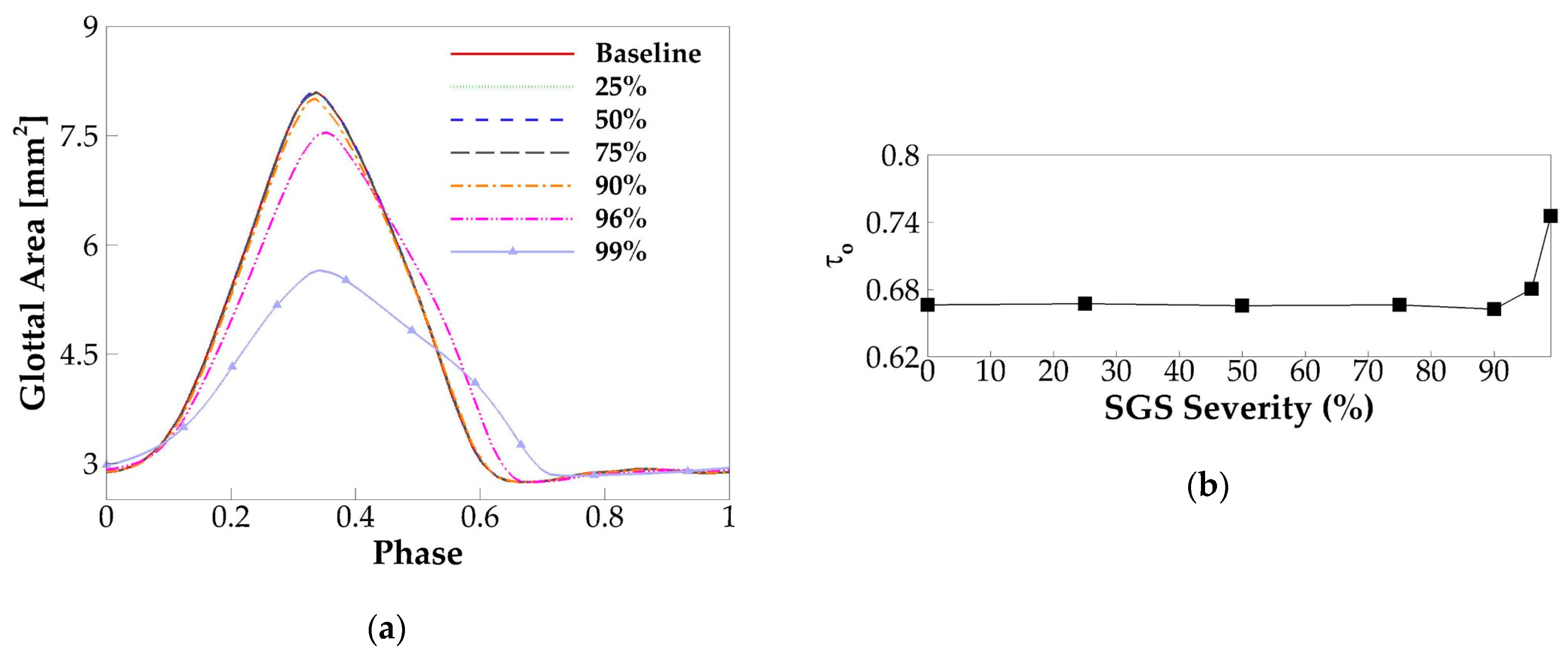
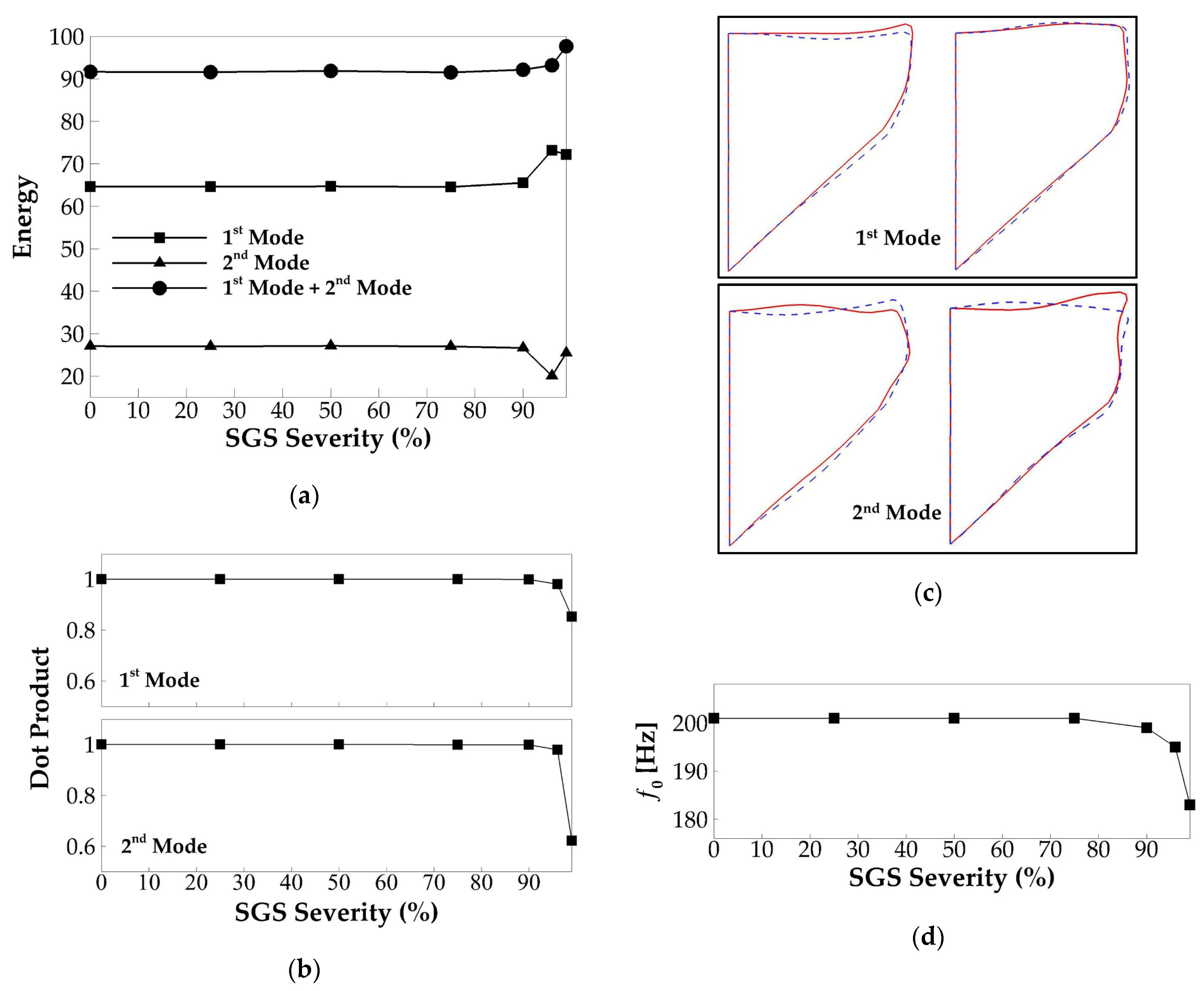
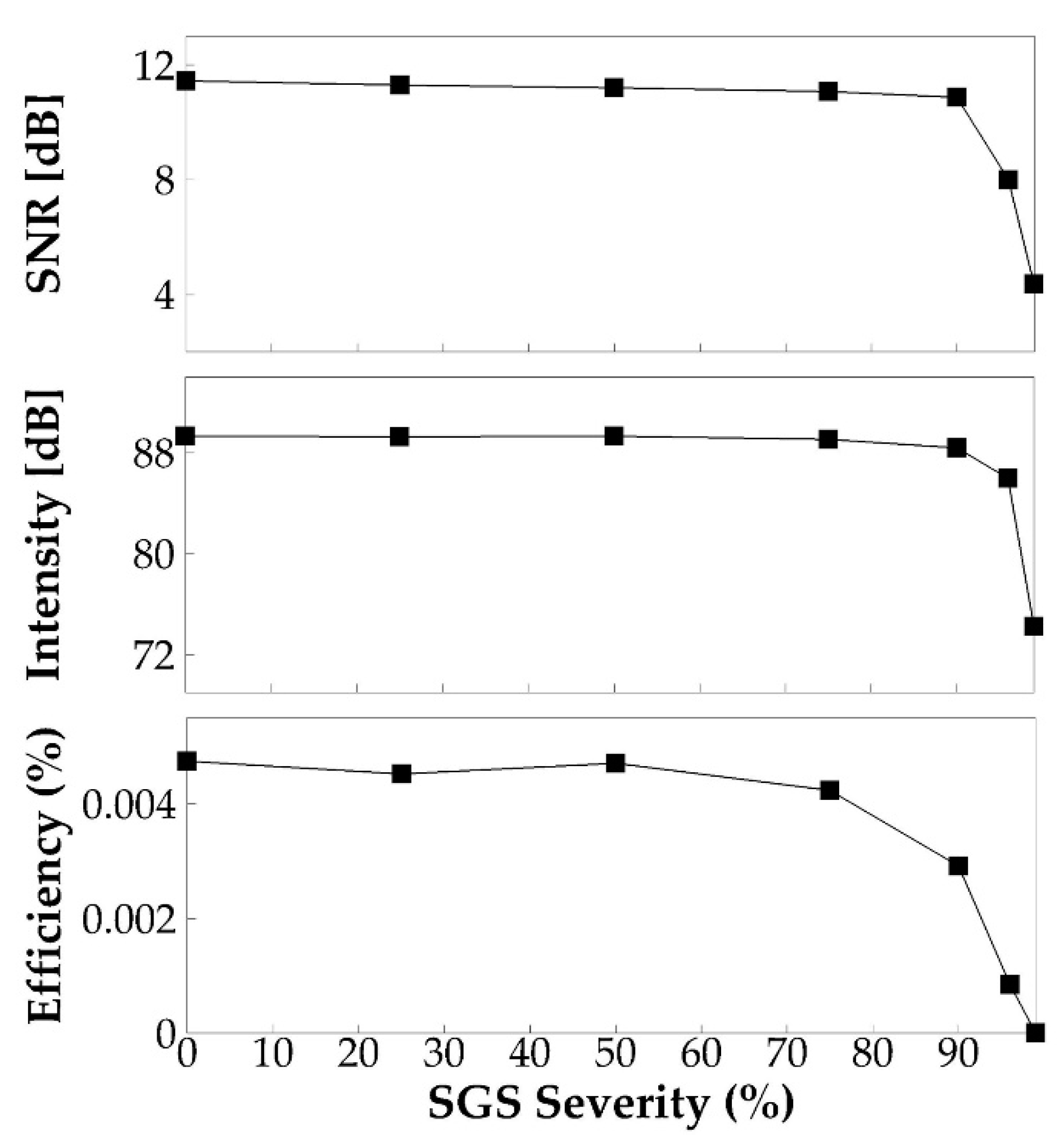
3.2. Effects of SGS Severity on Glottal Flow Dynamics, Vocal Fold Vibration, and Acoustics
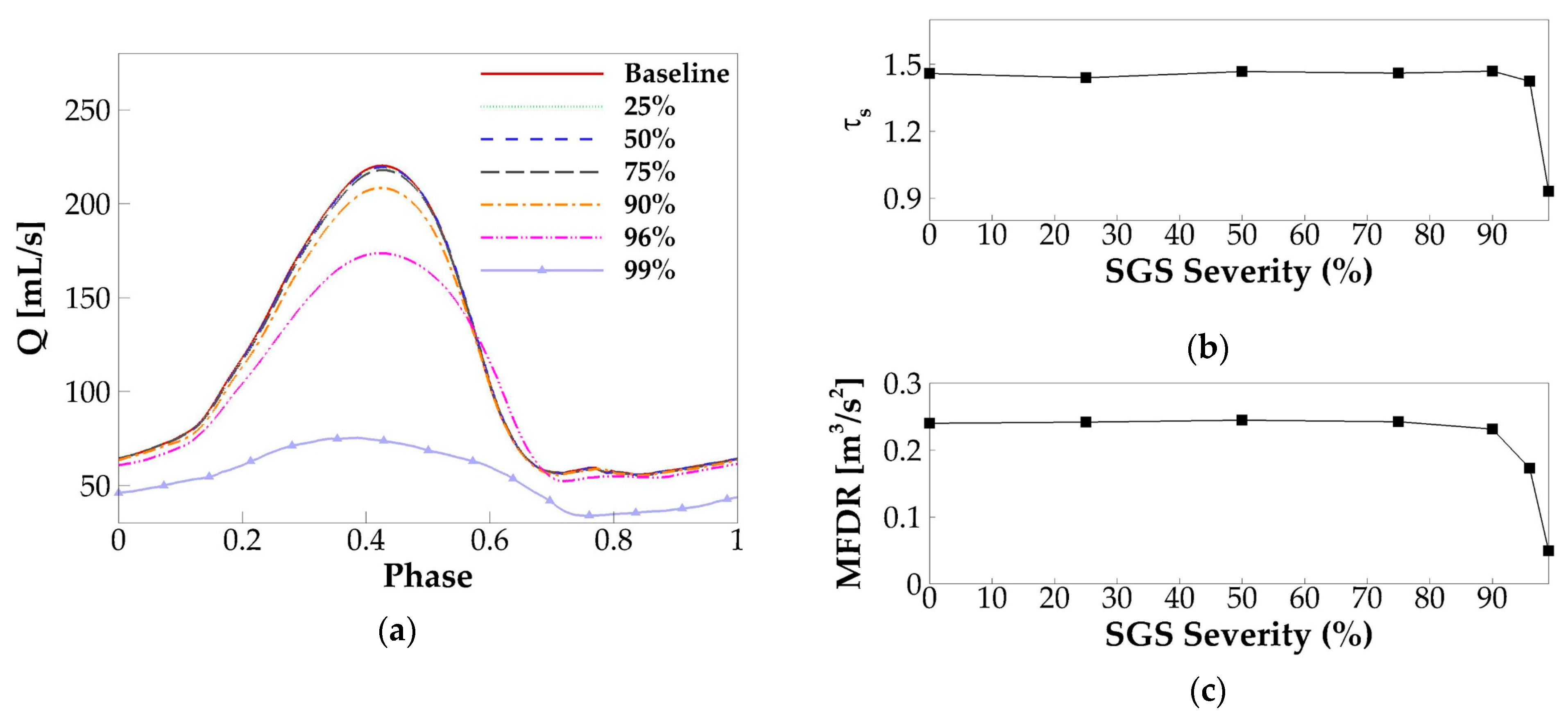
3.2.1. Glottal Flow Rate Waveform
3.2.2. Vocal Fold Dynamics
3.2.3. Acoustics
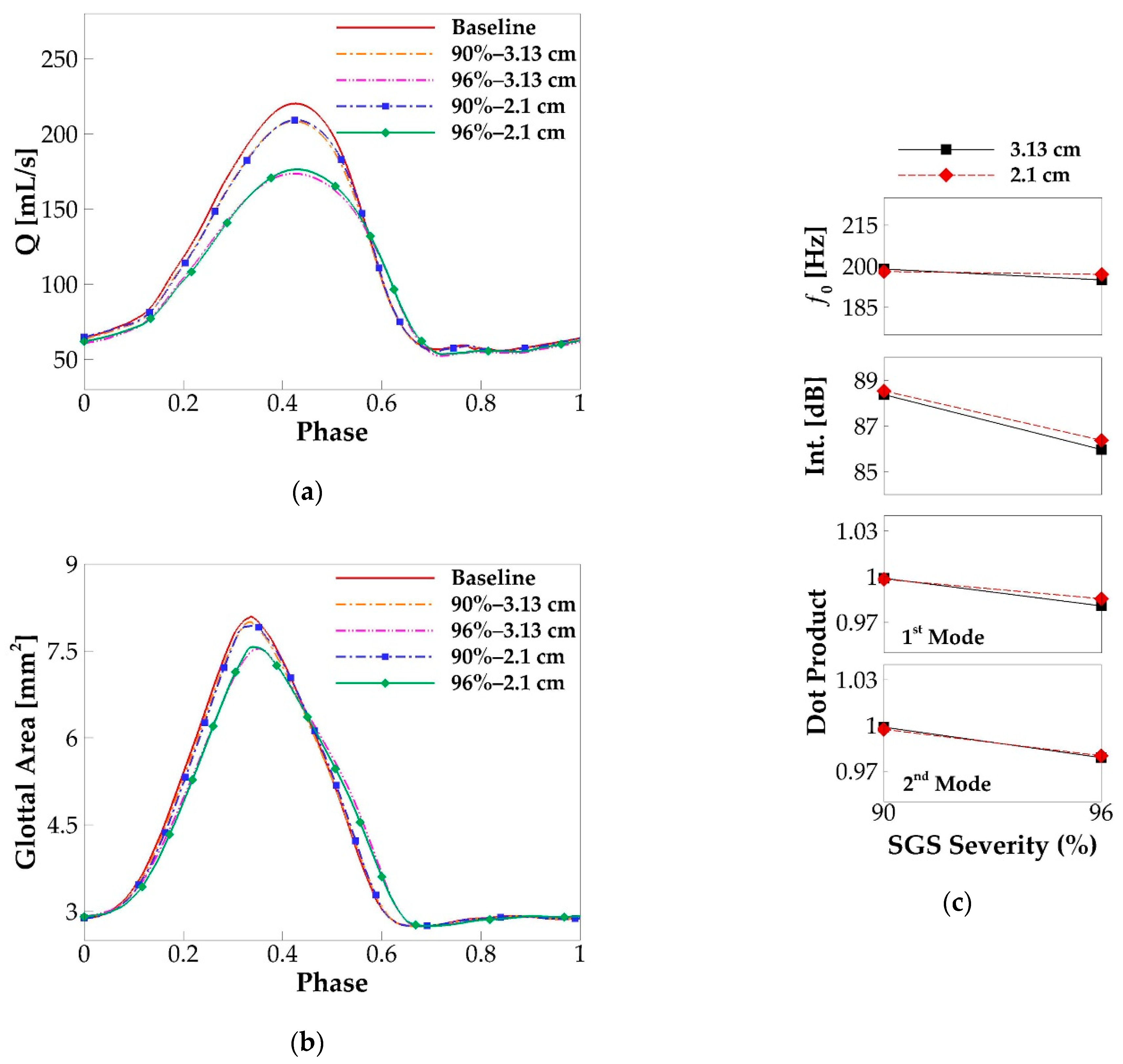
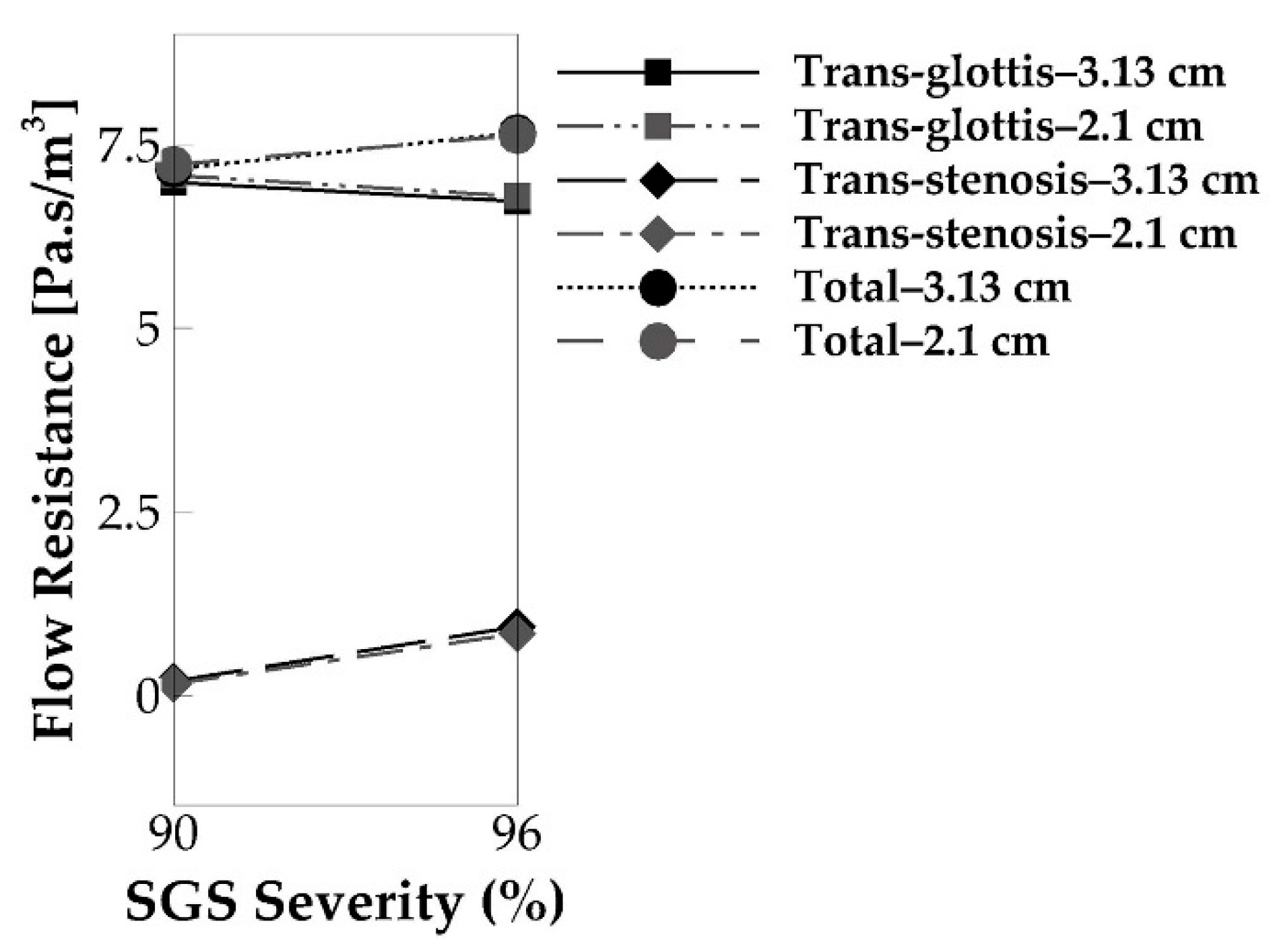
3.3. Effects of SGS Location on Glottal Flow Dynamics, Vocal Fold Vibration and Acoustics
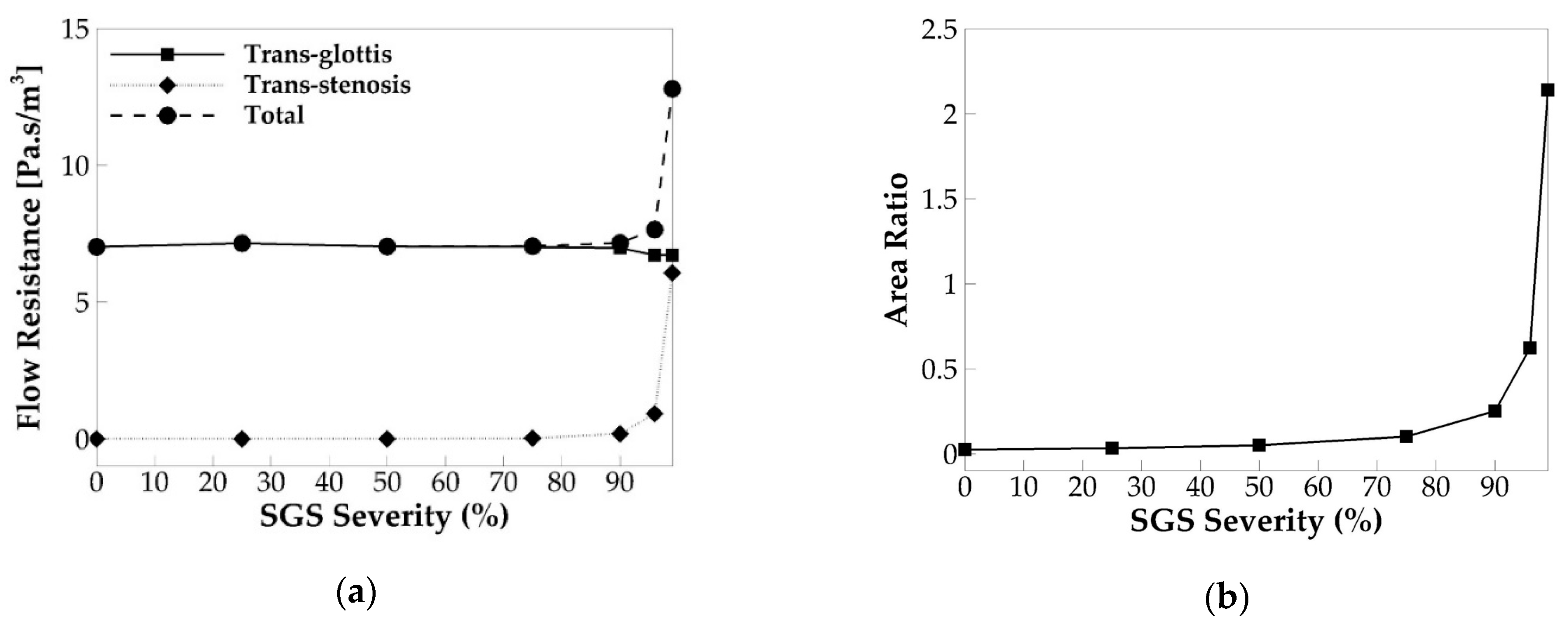
3.4. Underlying Mechanism—Correlation to the Flow Resistance
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Quiney, R.E.; Gould, S.J. Subglottic stenosis: A clinicopathological study. Clin. Otolaryngol. 1985, 10, 315–327. [Google Scholar] [CrossRef] [PubMed]
- Garnett, J.D.; Meyers, A.D. Subglottic Stenosis in Adults; Emedicine, Medscape Otolaryngology and Facial Plastic Surgery: New York, NY, USA, 2018. [Google Scholar]
- Giudice, M.; Piazza, C.; Foccoli, P.; Toninelli, C.; Cavaliere, S.; Peretti, G. Idiopathic subglottic stenosis: Management by endoscopic and open-neck surgery in a series of 30 patients. Eur. Arch. Otol. Rhino Laryngol. 2003, 260, 235–238. [Google Scholar] [CrossRef] [PubMed]
- Poetker, D.M.; Ettema, S.L.; Blumin, J.H.; Toohill, R.J.; Merati, A.L. Association of airway abnormalities and risk factors in 37 subglottic stenosis patients. Otolaryngol. Head Neck Surg. 2005, 135, 434–437. [Google Scholar] [CrossRef]
- Axtell, A.L.; Mathisen, D.J. Idiopathic subglottic stenosis: Technique+s and results. Ann. Cardiothorac. Surg. 2018, 7, 299–305. [Google Scholar] [CrossRef] [PubMed]
- Myer, C.M.; O’Connor, D.M.; Cotton, R.T. Proposed grading system for subglottic stenosis based on endotracheal tube sizes. Ann. Otol. Rhinol. Laryngol. 1994, 103, 319–323. [Google Scholar] [CrossRef]
- Smith, M.E.; Marsh, J.H.; Cotton, R.T.; Myer, C.M. Voice problems after pediatric laryngotracheal reconstruction: Videolaryngostroboscopic, acoustic, and perceptual assessment. Int. J. Pediatric Otorhinolaryngol. 1993, 25, 173–181. [Google Scholar] [CrossRef]
- Smith, M.E.; Roy, N.; Stoddard, K.; Barton, M. How does cricotracheal resection affect the female voice. Ann. Otol. Rhinol. Laryngol. 2008, 117, 85–89. [Google Scholar] [CrossRef]
- Herrington, H.C.; Weber, S.M.; Andersen, P.E. Modern Management of Laryngotracheal Stenosis. Laryngoscope 2006, 116, 1553–1557. [Google Scholar] [CrossRef]
- Bailey, M.; Hoeve, H.; Monnier, P. Paediatric laryngotracheal stenosis: A consensus paper from three European centres. Eur. Arch. Oto-Rhino-Laryngol. 2003, 260, 118–123. [Google Scholar] [CrossRef]
- Ettema, S.L.; Tolejano, C.J.; Thielkes, R.J.; Toohill, R.J.; Merati, A.L. Perceptual voice analysis of patients with subglottic stenosis. Otolaryngol. Head Neck Surg. 2005, 135, 730–735. [Google Scholar] [CrossRef]
- Cebral, J.; Summers, R. Tracheal and central bronchial aerodynamics using virtual bronchoscopy and computational fluid dynamics. Ieee Trans. Med. Imaging 2004, 23, 1021–1033. [Google Scholar] [CrossRef] [PubMed]
- Brouns, M.; Jayaraju, S.T.; Lacor, C.; De Mey, J.; Noppen, M.; Vincken, W.; Verbanck, S. Tracheal stenosis: A flow dynamics study. J. Appl. Physiol. 2007, 102, 1178–1184. [Google Scholar] [CrossRef]
- Mihaescu, M.; Gutmark, E.; Elluru, R.; Willging, J.P. Large Eddy Simulation of the Flow in a Pediatric Airway with Subglottic Stenosis. In Proceedings of the 47th AIAA Aerospace Sciences Meeting including The New Horizons Forum and Aerospace Exposition, Orlando, FL, USA, 5–8 January 2009; p. 775. [Google Scholar]
- Mihaescu, M.; Gutmark, E.; Murugappan, S.; Elluru, R.; Cohen, A.; Willging, J.P. Modeling flow in a compromised pediatric airway breathing air and heliox. Laryngoscope 2008, 118, 2205–2211. [Google Scholar] [CrossRef] [PubMed]
- Mimouni-Benabu, O.; Meister, L.; Giordano, J.; Fayoux, P.; Loundon, N.; Triglia, J.M.; Nicollas, R. A preliminary study of computer assisted evaluation of congenital tracheal stenosis: A new tool for surgical decision-making. Int. J. Pediatric Otorhinolaryngol. 2012, 76, 1552–1557. [Google Scholar] [CrossRef] [PubMed]
- Lin, E.L.; Bock, J.M.; Zdanski, C.J.; Kimbell, J.S.; Garcia, G.J. Relationship between degree of obstruction and airflow limitation in subglottic stenosis. Laryngoscope 2018, 128, 1551–1557. [Google Scholar] [CrossRef]
- Smith, S.L.; Thomson, S.L. Influence of subglottic stenosis on the flow-induced vibration of a computational vocal fold model. J. Fluids Struct. 2013, 38, 77–91. [Google Scholar] [CrossRef]
- Titze, I.R. Theoretical Analysis of Maximum Flow Declination Rate Versus Maximum Area Declination Rate in Phonation. J. Speech Lang. Hear. Res. 2006, 49, 439–447. [Google Scholar] [CrossRef]
- Mittal, R.; Dong, H.; Bozkurttas, M.; Najjar, F.M.; Vargas, A.; Von Loebbecke, A. A versatile sharp interface immersed boundary method for incompressible flows with complex boundaries. J. Comput. Phys. 2008, 227, 4825–4852. [Google Scholar] [CrossRef]
- Seo, J.H.; Mittal, R. A high-order immersed boundary method for acoustic wave scattering and low-Mach number flow-induced sound in complex geometries. J. Comput. Phys. 2011, 230, 1000–1019. [Google Scholar] [CrossRef]
- Bodaghi, D.; Jiang, W.; Xue, Q.; Zheng, X. Effect of Supraglottal Acoustics On Fluid-Structure Interaction During Human Voice Production. ASME J. Biomech. Eng. 2021. [Google Scholar] [CrossRef]
- Zheng, X.; Xue, Q.; Mittal, R.; Beilamowicz, S. A Coupled Sharp-Interface Immersed Boundary-Finite-Element Method for Flow-Structure Interaction With Application to Human Phonation. J. Biomech. Eng. Trans. ASME 2010, 132, 111003. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Zheng, X.; Xue, Q. Computational Modeling of Fluid–Structure–Acoustics Interaction during Voice Production. Front. Bioeng. Biotechnol. 2017, 5, 7. [Google Scholar] [CrossRef] [PubMed]
- Story, B.H. A parametric model of the vocal tract area function for vowel and consonant simulation. J. Acoust. Soc. Am. 2005, 117, 3231–3254. [Google Scholar] [CrossRef] [PubMed]
- Story, B.H. Synergistic modes of vocal tract articulation for American English vowels. J. Acoust. Soc. Am. 2005, 118, 3834–3859. [Google Scholar] [CrossRef]
- Zheng, X.; Bielamowicz, S.; Luo, H.; Mittal, R. A Computational Study of the Effect of False Vocal Folds on Glottal Flow and Vocal Fold Vibration During Phonation. Ann. Biomed. Eng. 2009, 37, 625–642. [Google Scholar] [CrossRef]
- Titze, I.R.; Talkin, D.T. A theoretical study of the effects of various laryngeal configurations on the acoustics of phonation. J. Acoust. Soc. Am. 1979, 66, 60–74. [Google Scholar] [CrossRef]
- Hirano, M. The structure of the vocal folds. Vocal Fold Physiol. 1981, 23, 33–41. [Google Scholar]
- Alipour, F.; Berry, D.A.; Titze, I.R. A finite-element model of vocal-fold vibration. J. Acoust. Soc. Am. 2000, 108, 3003–3012. [Google Scholar] [CrossRef]
- Xue, Q.; Mittal, R.; Zheng, X.; Bielamowicz, S. Computational modeling of phonatory dynamics in a tubular three-dimensional model of the human larynx. J. Acoust. Soc. Am. 2012, 132, 1602–1613. [Google Scholar] [CrossRef]
- Nouraei, S.A.R.; McPartlin, D.W.; Nouraei, S.M.; Patel, A.; Ferguson, C.; Howard, D.J.; Sandhu, G.S. Objective sizing of upper airway stenosis: A quantitative endoscopic approach. Laryngoscope 2006, 116, 12–17. [Google Scholar]
- Khadivi, E.; Zaringhalam, M.A.; Khazaeni, K.; Bakhshaee, M. Distance between Anterior Commissure and the First Tracheal Ring: An Important New Clinical Laryngotracheal Measurement. Iran. J. Otorhinolaryngol. 2015, 27, 193–197. [Google Scholar] [PubMed]
- Edgar, N.; Visbal, M. A General Buffer Zone-type Non-Reflecting Boundary Condition for Computational Aeroacoustics. In Proceedings of the 9th AIAA/CEAS Aeroacoustics Conference and Exhibit, Hilton Head, SC, USA, 12–14 May 2003; p. 3300. [Google Scholar]
- Seo, J.H.; Moon, Y.J. Linearized perturbed compressible equations for low Mach number aeroacoustics. J. Comput. Phys. 2006, 218, 702–719. [Google Scholar] [CrossRef]
- Titze, I.R. Principles of Voice Production; National Centre for Voice and Speech: Iowa City, IA, USA, 2000; ISBN 978-0137178933. [Google Scholar]
- Berry, D.A.; Herzel, H.; Titze, I.R.; Krischer, K. Interpretation of biomechanical simulations of normal and chaotic vocal fold oscillations with empirical eigenfunctions. J. Acoust. Soc. Am. 1994, 95, 3595–3604. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Mittal, R.; Xue, Q.; Bielamowicz, S. Direct-numerical simulation of the glottal jet and vocal-fold dynamics in a three-dimensional laryngeal model. J. Acoust. Soc. Am. 2011, 130, 404–415. [Google Scholar] [CrossRef] [PubMed]
- Qi, Y.; Hillman, R.E.; Milstein, C. The estimation of signal-to-noise ratio in continuous speech for disordered voices. J. Acoust. Soc. Am. 1999, 105, 2532–2535. [Google Scholar] [CrossRef] [PubMed]
- Šrámková, H.; Granqvist, S.; Herbst, C.T.; Švec, J.G. The softest sound levels of the human voice in normal subjects. J. Acoust. Soc. Am. 2015, 137, 407–418. [Google Scholar] [CrossRef]
- Engineering ToolBox. Available online: https://www.engineeringtoolbox.com/voice-level-d_938.html (accessed on 15 September 2020).
- Titze, I.R.; Maxfield, L.; Palaparthi, A. An Oral Pressure Conversion Ratio as a Predictor of Vocal Efficiency. J. Voice 2016, 30, 398–406. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ep (kPa) | Epz (kPa) | Gpz (kPa) | η (Pa·s) | |
|---|---|---|---|---|
| Cover | 2.014 | 40 | 10 | 0.15 |
| Ligament | 3.306 | 66 | 40 | 0.225 |
| Body | 3.99 | 80 | 20 | 0.375 |
| Computed Value | Typical Range [31] | |
|---|---|---|
| f0 (Hz) | 201 | 65–260 |
| 1.45 | 1.1–3.4 | |
| 0.67 | 0.4–0.7 | |
| (mL/s) | 220 | 200–580 |
| (mL/s) | 113 | 110–220 |
| MFDR (L/s2) | 240 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bodaghi, D.; Xue, Q.; Zheng, X.; Thomson, S. Effect of Subglottic Stenosis on Vocal Fold Vibration and Voice Production Using Fluid–Structure–Acoustics Interaction Simulation. Appl. Sci. 2021, 11, 1221. https://doi.org/10.3390/app11031221
Bodaghi D, Xue Q, Zheng X, Thomson S. Effect of Subglottic Stenosis on Vocal Fold Vibration and Voice Production Using Fluid–Structure–Acoustics Interaction Simulation. Applied Sciences. 2021; 11(3):1221. https://doi.org/10.3390/app11031221
Chicago/Turabian StyleBodaghi, Dariush, Qian Xue, Xudong Zheng, and Scott Thomson. 2021. "Effect of Subglottic Stenosis on Vocal Fold Vibration and Voice Production Using Fluid–Structure–Acoustics Interaction Simulation" Applied Sciences 11, no. 3: 1221. https://doi.org/10.3390/app11031221
APA StyleBodaghi, D., Xue, Q., Zheng, X., & Thomson, S. (2021). Effect of Subglottic Stenosis on Vocal Fold Vibration and Voice Production Using Fluid–Structure–Acoustics Interaction Simulation. Applied Sciences, 11(3), 1221. https://doi.org/10.3390/app11031221