A Hybrid Machine-Learning-Based Method for Analytic Representation of the Vocal Fold Edges during Connected Speech

 ,
,  and
and {kind=link}
{kind=link}
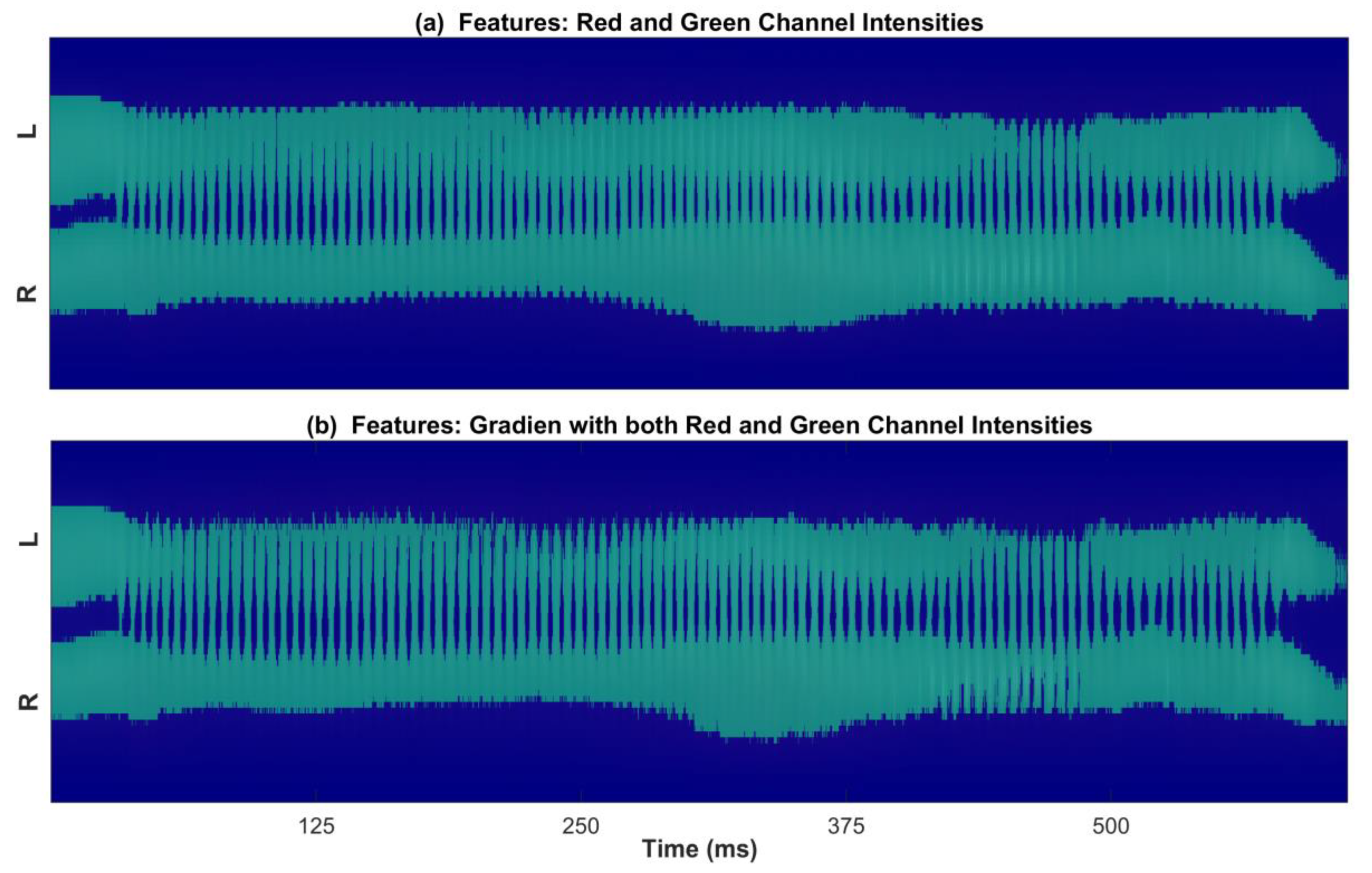{kind=link}
{kind=link}
{kind=link}
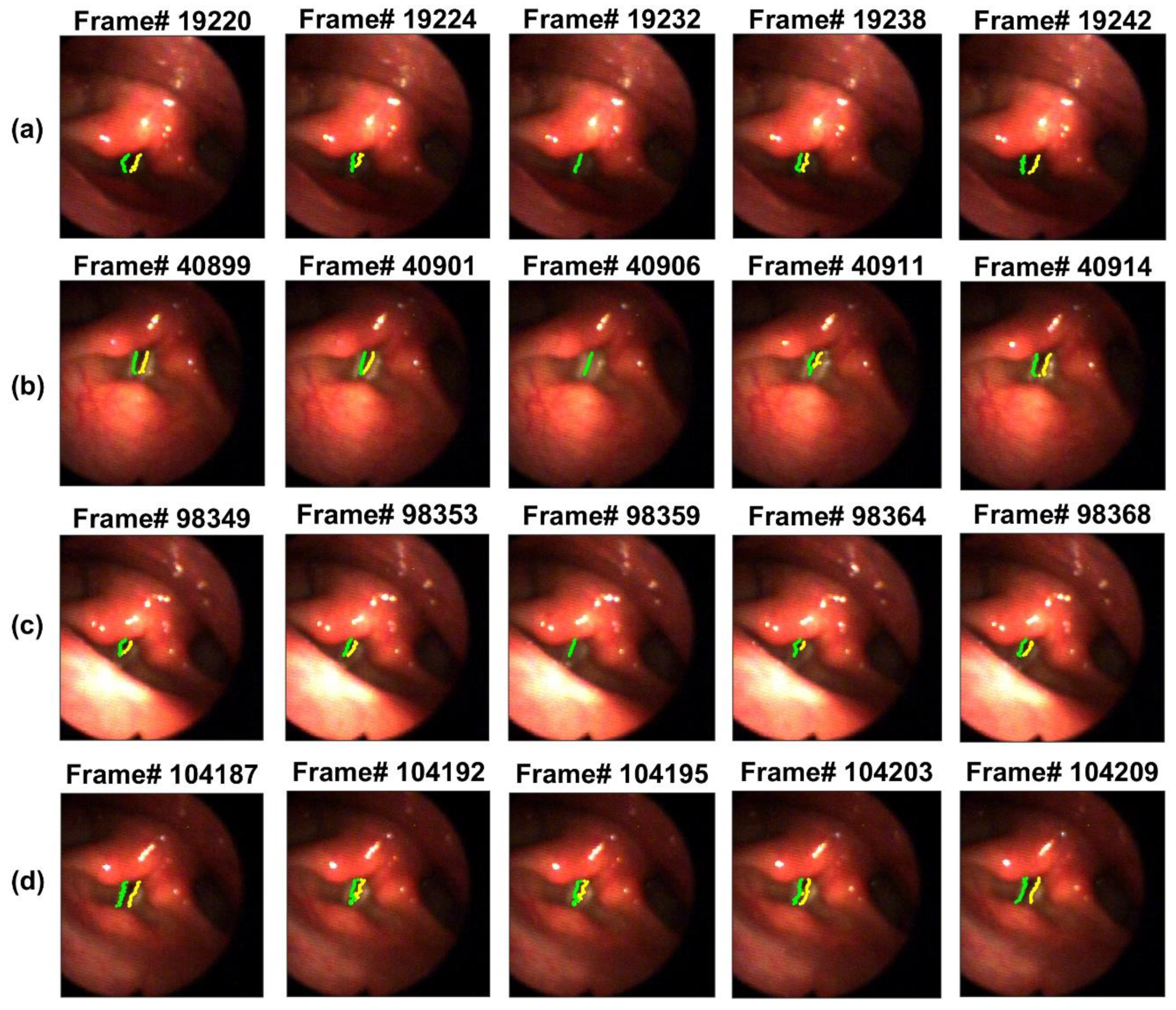{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Clinical Data
2.2. Data Analysis
2.2.1. Data Preprocessing
2.2.2. Feature Selection and Extraction
2.2.3. Unsupervised Clustering Method
2.2.4. Spatial Segmentation: The Hybrid Method
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mafee, M.F.; Valvassori, G.E.; Becker, M. Imaging of the Neck and Head, 2nd ed.; Thieme: Stuttgart, Germany, 2005. [Google Scholar]
- Uloza, V.; Saferis, V.; Uloziene, I. Perceptual and acoustic assessment of voice pathology and the efficacy of endolaryngeal phonomicrosurgery. J. Voice 2005, 19, 138–145. [Google Scholar] [CrossRef] [PubMed]
- Verikas, A.; Uloza, V.; Bacauskiene, M.; Gelzinis, A.; Kelertas, E. Advances in laryngeal imaging. Eur. Arch. Otorhinolaryngol. 2009, 266, 1509–1520. [Google Scholar] [CrossRef] [PubMed]
- Slonimsky, E. Laryngeal imaging. Oper. Tech. Otolaryngol. Head Neck Surg. 2019, 30, 237–242. [Google Scholar] [CrossRef]
- Kitzing, P. Stroboscopy–A pertinent laryngological examination. J. Otolaryngol. 1985, 14, 151–157. [Google Scholar] [PubMed]
- Bless, D.M.; Hirano, M.; Feder, R.J. Videostroboscopic evaluation of the larynx. Ear. Nose Throat J. 1987, 66, 289–296. [Google Scholar] [PubMed]
- Woo, P.; Casper, J.; Colton, R.; Brewer, D. Aerodynamic and stroboscopic findings before and after microlaryngeal phonosurgery. J. Voice 1994, 8, 186–194. [Google Scholar] [CrossRef]
- Stemple, J.C.; Glaze, L.E.; Klaben, B.G. Clinical Voice Pathology: Theory and Management; Cengage Learning; Plural Publishing: San Diego, MA, USA, 2000. [Google Scholar]
- Stojadinovic, A.; Shaha, A.R.; Orlikoff, R.F.; Nissan, A.; Kornak, M.F.; Singh, B.; Boyle, J.O.; Shah, J.P.; Brennan, M.F.; Kraus, D.H. Prospective functional voice assessment in patients undergoing thyroid surgery. Ann. Surg. 2002, 236, 823–832. [Google Scholar] [CrossRef]
- Mehta, D.D.; Hillman, R.E. Voice assessment: Updates on perceptual, acoustic, aerodynamic, and endoscopic imaging methods. Curr. Opin. Otol. Head Neck Surg. 2008, 16, 211–215. [Google Scholar] [CrossRef]
- Aronson, A.E.; Bless, D. Clinical Voice Disorders; Thieme: Stuttgart, Germany, 2011. [Google Scholar]
- Patel, R.; Dailey, S.; Bless, D. Comparison of high-speed digital imaging with stroboscopy for laryngeal imaging of glottal disorders. Ann. Otol. Rhinol. Laryngol. 2008, 117, 413–424. [Google Scholar] [CrossRef]
- Zacharias, S.R.C.; Myer, C.M.; Meinzen-Derr, J.; Kelchner, L.; Deliyski, D.D.; de Alarcón, A. Comparison of videostroboscopy and high-speed videoendoscopy in evaluation of supraglottic phonation. Ann. Otol. Rhinol. Laryngol. 2016, 125, 829–837. [Google Scholar] [CrossRef]
- Deliyski, D.D. Laryngeal high-speed videoendoscopy. In Laryngeal Evaluation: Indirect Laryngoscopy to High-Speed Digital Imaging; Thieme Medical Publishers: New York, NY, USA, 2010; pp. 243–270. [Google Scholar]
- Naghibolhosseini, M.; Deliyski, D.D.; Zacharias, S.R.; de Alarcon, A.; Orlikoff, R.F. Temporal segmentation for laryngeal high-speed videoendoscopy in connected speech. J. Voice 2018, 32, 256.e1–256.e12. [Google Scholar] [CrossRef] [PubMed]
- Zañartu, M.; Mehta, D.D.; Ho, J.C.; Wodicka, G.R.; Hillman, R.E. Observation and analysis of in vivo vocal fold tissue instabilities produced by nonlinear source-filter coupling: A case study. J. Acoust. Soc. Am. 2011, 129, 326–339. [Google Scholar] [CrossRef] [PubMed]
- Mehta, D.D.; Deliyski, D.D.; Zeitels, M.S.; Zañartu, M.; Hillman, R.E. Integration of transnasal fiberoptic high-speed videoendoscopy with time-synchronized recordings of vocal function. In Normal & Abnormal Vocal Folds Kinematics: High Speed Digital Phonoscopy (HSDP), Optical Coherence Tomography (OCT) & Narrow Band Imaging; Pacific Voice & Speech Foundation: San Fransisco, CA, USA, 2015; Volume 12, pp. 105–114. [Google Scholar]
- Naghibolhosseini, M.; Deliyski, D.D.; Zacharias, S.R.; de Alarcon, A.; Orlikoff, R.F. A method for analysis of the vocal fold vibrations in connected speech using laryngeal imaging. In Proceedings of the 10th International Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications MAVEBA; Manfredi, C., Ed.; Firenze University Press: Firenze, Italy, 2017; pp. 107–110. [Google Scholar]
- Naghibolhosseini, M.; Deliyski, D.D.; Zacharias, S.R.C.; de Alarcon, A.; Orlikoff, R.F. Studying vocal fold non-stationary behavior during connected speech using high-speed videoendoscopy. J. Acoust. Soc. Am. 2018, 144, 1766. [Google Scholar] [CrossRef]
- Yousef, A.M.; Deliyski, D.D.; Zacharias, S.R.C.; de Alarcon, A.; Orlikoff, R.F.; Naghibolhosseini, M. Spatial segmentation for laryngeal high-speed videoendoscopy in connected speech. J. Voice 2020. [Google Scholar] [CrossRef] [PubMed]
- Deliyski, D.D. Clinical feasibility of high-speed videoendoscopy. In Perspectives on Voice and Voice Disorders; American Speech-Language-Hearing Association: Rockville, MD, USA, 2007; Volume 17, pp. 12–16. [Google Scholar]
- Deliyski, D.D.; Petrushev, P.P.; Bonilha, H.S.; Gerlach, T.T.; Martin-Harris, B.; Hillman, R.E. Clinical implementation of laryngeal high-speed videoendoscopy: Challenges and evolution. Folia Phoniatr. Logop. 2007, 60, 33–44. [Google Scholar] [CrossRef]
- Morrison, M.D.; Rammage, L.A. Muscle misuse voice disorders: Description and classification. Acta Oto-Laryngol. 1993, 113, 428–434. [Google Scholar] [CrossRef]
- Yiu, E.; Worrall, L.; Longland, J.; Mitchell, C. Analysing vocal quality of connected speech using Kay’s computerized speech lab: A preliminary finding. Clin. Linguist. Phon. 2000, 14, 295–305. [Google Scholar]
- Halberstam, B. Acoustic and perceptual parameters relating to connected speech are more reliable measures of hoarseness than parameters relating to sustained vowels. ORL 2004, 66, 70–73. [Google Scholar] [CrossRef]
- Roy, N.; Gouse, M.; Mauszycki, S.C.; Merrill, R.M.; Smith, M.E. Task specificity in adductor spasmodic dysphonia versus muscle tension dysphonia. Laryngoscope 2005, 115, 311–316. [Google Scholar] [CrossRef]
- Maryn, Y.; Corthals, P.; van Cauwenberge, P.; Roy, N.; de Bodt, M. Toward improved ecological validity in the acoustic measurement of overall voice quality: Combining continuous speech and sustained vowels. J. Voice 2010, 24, 540–555. [Google Scholar] [CrossRef]
- Lowell, S.Y. The acoustic assessment of voice in continuous speech. SIG 3 Perspect. Voice Voice Disord. 2012, 22, 57–63. [Google Scholar] [CrossRef]
- Brown, C.; Deliyski, D.D.; Zacharias, S.R.C.; Naghibolhosseini, M. Glottal attack and offset time during connected speech in adductor spasmodic dysphonia. In Proceedings of the the Virtual Voice Symposium: Care of the Professional Voice, Philadelphia, PA, USA, 27–31 May 2020. [Google Scholar]
- Naghibolhosseini, M.; Deliyski, D.D.; Zacharias, S.R.C.; de Alarcon, A.; Orlikoff, R.F. Glottal attack time in connected speech. In Proceedings of the 11th International Conference on Voice Physiology and Biomechanics ICVPB, East Lansing, MI, USA, 31 July–3 August 2018. [Google Scholar]
- Brown, C.; Naghibolhosseini, M.; Zacharias, S.R.C.; Deliyski, D.D. Investigation of high-speed videoendoscopy during connected speech in norm and neurogenic voice disorder. In Proceedings of the theMichigan Speech-Language-Hearing Association (MSHA) Annual Conference, East Lansing, MI, USA, 21–23 March 2019. [Google Scholar]
- Fehling, M.K.; Grosch, F.; Schuster, M.E.; Schick, B.; Lohscheller, J. Fully automatic segmentation of glottis and vocal folds in endoscopic laryngeal high-speed videos using a deep Convolutional LSTM Network. PLoS ONE 2020, 15, e0227791. [Google Scholar] [CrossRef] [PubMed]
- Gómez, P.; Kist, A.M.; Schlegel, P.; Berry, D.A.; Chhetri, D.K.; Dürr, S.; Echternach, M.; Johnson, A.M.; Kniesburges, S.; Kunduk, M.; et al. BAGLS, a multihospital benchmark for automatic glottis segmentation. Sci. Data 2020, 7, 186. [Google Scholar] [CrossRef] [PubMed]
- Kist, A.M.; Zilker, J.; Gómez, P.; Schützenberger, A.; Döllinger, M. Rethinking glottal midline detection. Sci. Rep. 2020, 10, 20723. [Google Scholar] [CrossRef]
- Kist, A.M.; Döllinger, M. Efficient biomedical image segmentation on EdgeTPUs at point of care. IEEE Access 2020, 8, 139356–139366. [Google Scholar] [CrossRef]
- Koç, T.; Çiloğlu, T. Automatic segmentation of high speed video images of vocal folds. J. Appl. Math. 2014, 2014, 16p. [Google Scholar] [CrossRef]
- Lohscheller, J.; Toy, H.; Rosanowski, F.; Eysholdt, U.; Döllinger, M. Clinically evaluated procedure for the reconstruction of vocal fold vibrations from endoscopic digital high-speed videos. Med. Image Anal. 2007, 11, 400–413. [Google Scholar] [CrossRef]
- Mehta, D.D.; Deliyski, D.D.; Quatieri, T.F.; Hillman, R.E. Automated measurement of vocal fold vibratory asymmetry from high-speed videoendoscopy recordings. J. Speech Lang. Hear. Res. 2011, 54, 47–54. [Google Scholar] [CrossRef]
- Karakozoglou, S.-Z.; Henrich, N.; D’Alessandro, C.; Stylianou, Y. Automatic glottal segmentation using local-based active contours and application to glottovibrography. Speech Commun. 2012, 54, 641–654. [Google Scholar] [CrossRef]
- Moukalled, H.J.; Deliyski, D.D.; Schwarz, R.R.; Wang, S. Segmentation of laryngeal high-speed videoendoscopy in temporal domain using paired active contours. In Proceedings of the 10th International Workshop on Models and Analysis of VocaL Emissions for Biomedical Applications MAVEBA; Manfredi, C., Ed.; Firenze University Press: Firenze, Italy, 2009; Volume 6, pp. 141–144. [Google Scholar]
- Mehta, D.D.; Deliyski, D.D.; Zeitels, S.M.; Quatieri, T.F.; Hillman, R.E. Voice production mechanisms following phonosurgical treatment of early glottic cancer. Ann. Otol. Rhinol. Laryngol. 2010, 119, 1–9. [Google Scholar] [CrossRef]
- Larsson, H.; Hertegard, S.; Lindestad, P.A.; Hammarberg, B. Vocal fold vibrations: High-speed imaging, kymography, and acoustic analysis: A preliminary report. Laryngoscope 2000, 110, 2117–2122. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Chen, X.; Bless, D. Automatic tracing of vocal-fold motion from high-speed digital images. IEEE Trans. Biomed. Eng. 2006, 53, 1394–1400. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Damrose, E.; Bless, D. Functional analysis of voice using simultaneous high-speed imaging and acoustic recordings. J. Voice 2007, 21, 604–616. [Google Scholar] [CrossRef] [PubMed]
- Demeyer, J.; Dubuisson, T.; Gosselin, B.; Remacle, M. Glottis Segmentation with a High-Speed Glottography: A Fullyautomatic Method. In Proceedings of the 3rd Advanced Voice Function Assessment International Workshop; IEEE Press: Madrid, Spain, 2009; pp. 113–116. [Google Scholar]
- Shi, T.; Kim, J.H.; Murry, T.; Woo, P.; Yan, Y. Tracing vocal fold vibrations using level set segmentation method. Int. J. Numer. Methods Biomed. Eng. 2015, 31, e02715. [Google Scholar] [CrossRef] [PubMed]
- Osma-Ruiz, V.; Godino-Llorente, J.I.; Sáenz-Lechón, N.; Fraile, R. Segmentation of the glottal space from laryngeal images using the watershed transform. Comput. Med. Imaging Graph. 2008, 32, 193–201. [Google Scholar] [CrossRef]
- Manfredi, C.; Bocchi, L.; Bianchi, S.; Migali, N.; Cantarella, G. Objective vocal fold vibration assessment from videokymographic images. Biomed. Signal Process. Control 2006, 1, 129–136. [Google Scholar] [CrossRef]
- Schenk, F.; Aichinger, P.; Roesner, I.; Urschler, M. Automatic high-speed video glottis segmentation using salient regions and 3d geodesic active contours. Ann. BMVA 2015, 2015, 15p. [Google Scholar]
- Kass, M.; Witkin, A.; Terzopoulos, D. Snakes: Active contour models. Int. J. Comput. Vis. 1988, 1, 321–331. [Google Scholar] [CrossRef]
- Zhou, S.; Wang, J.; Zhang, S.; Liang, Y.; Gong, Y. Active contour model based on local and global intensity information for medical image segmentation. Neurocomputing 2016, 186, 107–118. [Google Scholar] [CrossRef]
- Sulong, G.; Abdulaali, H.; Hassan, S. Edge detection algorithms vs-active contour for sketch matching: Comparative study. Res. J. Appl. Sci. Eng. Technol. 2015, 11, 759–764. [Google Scholar] [CrossRef]
- Yan, Y.; Du, G.; Zhu, C.; Marriott, G. Snake based automatic tracing of vocal-fold motion from high-speed digital images. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP’12), Kyoto, Japan, 25–30 March 2012; pp. 593–596. [Google Scholar]
- Zhang, Y.; Bieging, E.; Tsui, H.; Jiang, J.J. Efficient and effective extraction of vocal fold vibratory patterns from high-speed digital imaging. J. Voice 2010, 24, 21–29. [Google Scholar] [CrossRef] [PubMed]
- Rao, V.S.; Vidyavathi, S. Comparative Investigations and performance analysis of FCM and MFPCM algorithms on Iris data. Indian J. Comput. Sci. Eng. 2010, 1, 145–151. [Google Scholar]
- Kuruvilla, J.; Sukumaran, D.; Sankar, A.; Joy, S.P. A review on image processing and image segmentation. In Proceedings of the International Conference on Data Mining and Advanced Computing (SAPIENCE), Ernakulam, India, 16–18 March 2016; pp. 198–203. [Google Scholar]
- Deliyski, D.D. Endoscope motion compensation for laryngeal high-speed videoendoscopy. J. Voice 2005, 19, 485–496. [Google Scholar] [CrossRef] [PubMed]
- Hartigan, J.; Wong, M. A K-means Clustering Algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, Philadelphia, PA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Deliyski, D.D.; Petrushev, P. Methods for objective assessment of high-speed videoendoscopy. In Proceedings of the International Conference on Adances on Quantitative Laryngology Voice Speech Research (AQL) 2003, Hamburg, Germany, 3–5 April 2003; Volume 28, pp. 1–16. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yousef, A.M.; Deliyski, D.D.; Zacharias, S.R.C.; de Alarcon, A.; Orlikoff, R.F.; Naghibolhosseini, M. A Hybrid Machine-Learning-Based Method for Analytic Representation of the Vocal Fold Edges during Connected Speech. Appl. Sci. 2021, 11, 1179. https://doi.org/10.3390/app11031179
Yousef AM, Deliyski DD, Zacharias SRC, de Alarcon A, Orlikoff RF, Naghibolhosseini M. A Hybrid Machine-Learning-Based Method for Analytic Representation of the Vocal Fold Edges during Connected Speech. Applied Sciences. 2021; 11(3):1179. https://doi.org/10.3390/app11031179
Chicago/Turabian StyleYousef, Ahmed M., Dimitar D. Deliyski, Stephanie R. C. Zacharias, Alessandro de Alarcon, Robert F. Orlikoff, and Maryam Naghibolhosseini. 2021. "A Hybrid Machine-Learning-Based Method for Analytic Representation of the Vocal Fold Edges during Connected Speech" Applied Sciences 11, no. 3: 1179. https://doi.org/10.3390/app11031179
APA StyleYousef, A. M., Deliyski, D. D., Zacharias, S. R. C., de Alarcon, A., Orlikoff, R. F., & Naghibolhosseini, M. (2021). A Hybrid Machine-Learning-Based Method for Analytic Representation of the Vocal Fold Edges during Connected Speech. Applied Sciences, 11(3), 1179. https://doi.org/10.3390/app11031179