
Concept Drift Adaptation with Incremental–Decremental SVM


Abstract
1. Introduction
2. Related Work: Concept Drift with Adaptive Shifting Windows
3. Background: The Adaptive Window Model for Drift Detection and the Incremental–Decremental SVM
3.1. Concept Drift with Adaptive Window
3.2. Kuhn–Tucker Conditions and Vector Migration in Incremental–Decremental SVMs
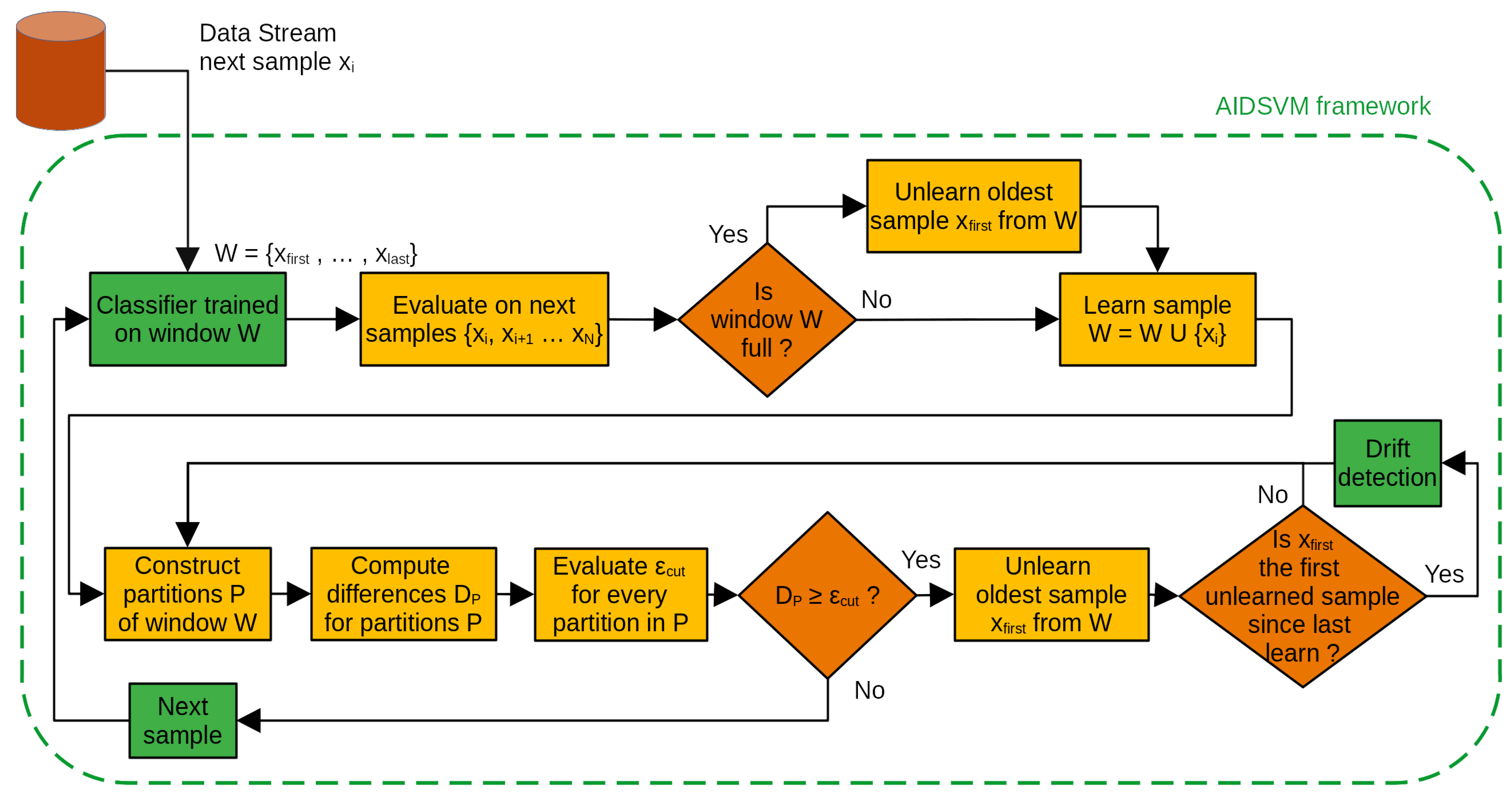
4. Adaptive-Window Incremental–Decremental SVM (AIDSVM)
| Algorithm 1 Concept drift AIDSVM learning and unlearning |
|
- 1.
- Perform an O(1) test to check if the associated is within the allowed limits, , while testing whether the penalty has either reached zero (due to migrating to support set) or a positive or negative value (due to migration to the rest/error sets);
- 2.
- Computation of Q is in ;
- 3.
- Computation of , given by Equation (11), is based on matrix inversion, so it is in , where is the number of support vectors;
- 4.
- Computation of is in as given by Equation (12);
- 5.
- Procedure compute_limits_for_support_and_rest_vectors() is in , computation of the maximum/minimum for values associated to support vectors is in , and for the rest vectors we have to compute the penalties h, which is ;
- 6.
- Procedure reassign_vectors_in_sets() has linear time.
5. Experiments
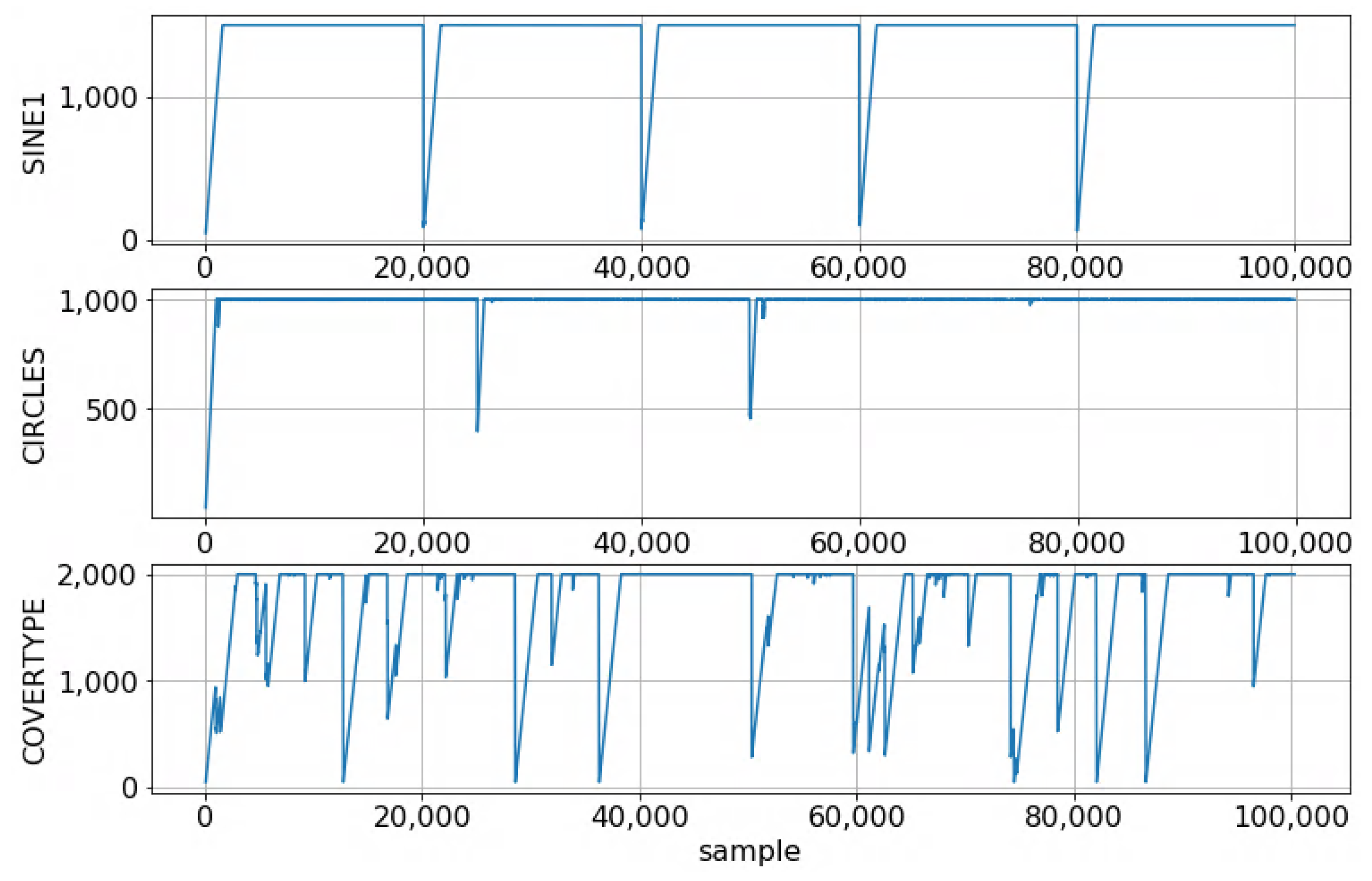
5.1. SINE1 Dataset
5.2. CIRCLES Dataset
5.3. COVERTYPE Dataset
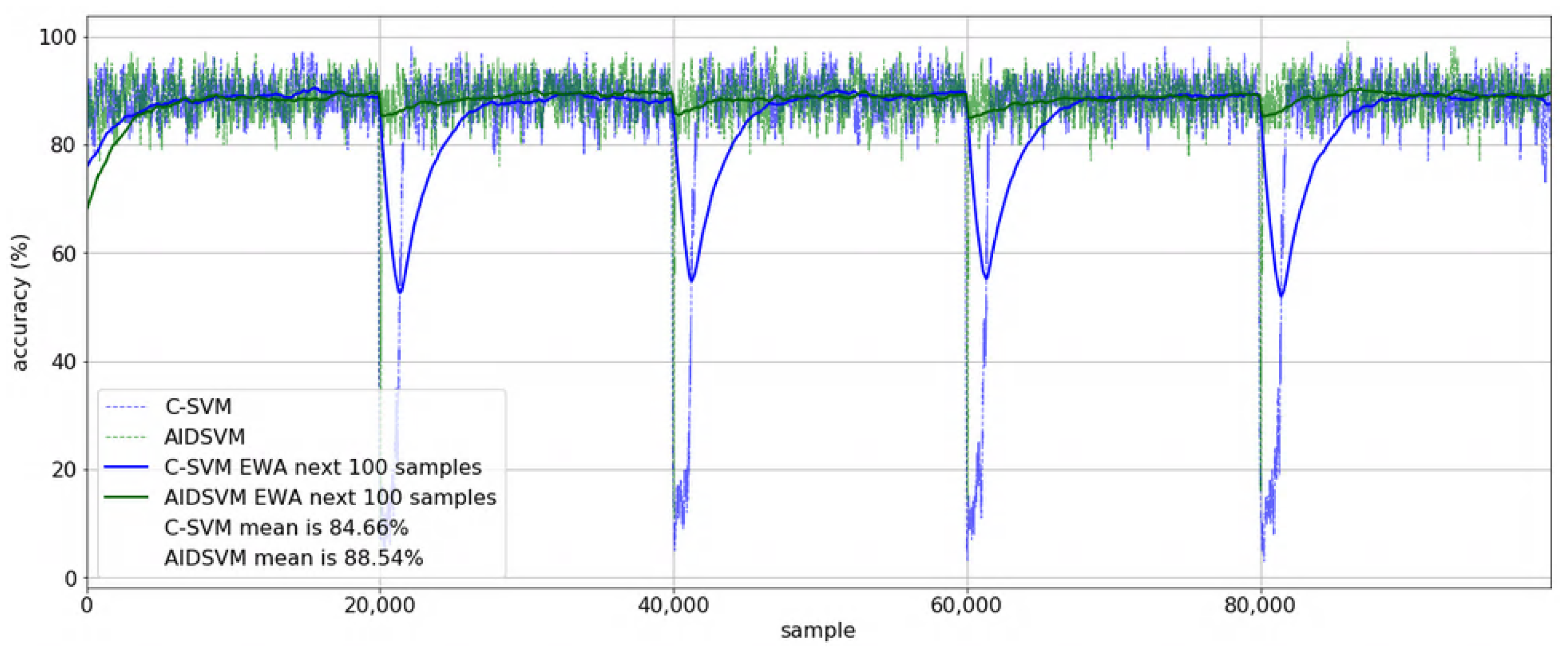
5.4. Performance Comparison
5.5. Qualitative Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Voosen, P. New climate models predict a warming surge. Science 2019, 364, 222–223. [Google Scholar] [CrossRef]
- Gama, J. Knowledge Discovery from Data Streams, 1st ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Lazarescu, M.M.; Venkatesh, S.; Bui, H.H. Using multiple windows to track concept drift. Intell. Data Anal. 2004, 8, 29–59. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Iwashita, A.S.; Papa, J.P. An overview on concept drift learning. IEEE Access 2019, 7, 1532–1547. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2019, 31, 2346–2363. [Google Scholar] [CrossRef]
- Farid, D.M.; Zhang, L.; Hossain, A.; Rahman, C.M.; Strachan, R.; Sexton, G.; Dahal, K. An adaptive ensemble classifier for mining concept drifting data streams. Expert Syst. Appl. 2013, 40, 5895–5906. [Google Scholar] [CrossRef]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in nonstationary environments: A survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Alippi, C.; Qi, W.; Roveri, M. Learning in nonstationary environments: A hybrid approach. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 11–15 June 2017; pp. 703–714. [Google Scholar]
- Raab, C.; Heusinger, M.; Schleif, F.M. Reactive Soft Prototype Computing for Concept Drift Streams. Neurocomputing 2020, 416, 340–351. [Google Scholar] [CrossRef]
- Saigal, P.; Khanna, V. Multi-category news classification using Support Vector Machine based classifiers. SN Appl. Sci. 2020, 2, 458. [Google Scholar] [CrossRef]
- Shamshirband, S.; Esmaeilbeiki, F.; Zarehaghi, D.; Neyshabouri, M.; Samadianfard, S.; Ghorbani, M.A.; Mosavi, A.; Nabipour, N.; Chau, K. Comparative analysis of hybrid models of firefly optimization algorithm with support vector machines and multilayer perceptron for predicting soil temperature at different depths. Eng. Appl. Comput. Fluid Mech. 2020, 14, 939–953. [Google Scholar] [CrossRef]
- Dabija, A.; Kluczek, M.; Zagajewski, B.; Raczko, E.; Kycko, M.; Al-Sulttani, A.H.; Tardà, A.; Pineda, L.; Corbera, J. Comparison of Support Vector Machines and Random Forests for Corine Land Cover Mapping. Remote Sens. 2021, 13, 777. [Google Scholar] [CrossRef]
- Flores, C.; Taramasco, C.; Lagos, M.E.; Rimassa, C.; Figueroa, R.A. Feature-Based Analysis for Time-Series Classification of COVID-19 Incidence in Chile: A Case Study. Appl. Sci. 2021, 11, 7080. [Google Scholar] [CrossRef]
- Zhu, H.; Woo, J.H. Hybrid NHPSO-JTVAC-SVM Model to Predict Production Lead Time. Appl. Sci. 2021, 11, 6369. [Google Scholar] [CrossRef]
- Shabani, S.; Samadianfard, S.; Sattari, M.T.; Mosavi, A.; Shamshirband, S.; Kmet, T.; Várkonyi-Kóczy, A.R. Modeling Pan Evaporation Using Gaussian Process Regression K-Nearest Neighbors Random Forest and Support Vector Machines. Comparative Analysis. Atmosphere 2020, 11, 66. [Google Scholar] [CrossRef]
- Klinkenberg, R.; Joachims, T. Detecting concept drift with support vector machines. In Proceedings of the Seventeenth International Conference on Machine Learning (ICML ’00), Stanford, CA, USA, 29 June–2 July 2000; ICML: San Diego, CA, USA, 2000; pp. 487–494. [Google Scholar]
- Klinkenberg, R. Learning drifting concepts: Example selection vs. example weighting. Intell. Data Anal. 2004, 8, 281–300. [Google Scholar] [CrossRef]
- Sun, J.; Li, H.; Adeli, H. Concept Drift-Oriented Adaptive and Dynamic Support Vector Machine Ensemble With Time Window in Corporate Financial Risk Prediction. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 801–813. [Google Scholar] [CrossRef]
- Bifet, A.; Gavaldà, R. Learning from time-changing data with adaptive windowing. In Proceedings of the Seventh SIAM International Conference on Data Mining (SDM’07), Minneapolis, MN, USA, 26–28 April 2007; Volume 7, p. 6. [Google Scholar]
- Gemaque, R.N.; Costa, A.F.J.; Giusti, R.; dos Santos, E.M. An overview of unsupervised drift detection methods. WIREs Data Min. Knowl. Discov. 2020, 6, e1381. [Google Scholar] [CrossRef]
- Elwell, R.; Polikar, R. Incremental learning in nonstationary environments with controlled forgetting. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 771–778. [Google Scholar]
- Elwell, R.; Polikar, R. Incremental learning of concept drift in nonstationary environments. IEEE Trans. Neural Netw. 2011, 22, 1517–1531. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Zhu, Y.; Du, J.; Chen, Y. A Fast Learn++.NSE classification algorithm based on weighted moving average. Filomat 2018, 32, 1737–1745. [Google Scholar] [CrossRef]
- Gomes, H.M.; Bifet, A.; Read, J.; Barddal, J.P.; Enembreck, F.; Pfharinger, B.; Holmes, G.; Abdessalem, T. Adaptive random forests for evolving data stream classification. Mach. Learn. 2017, 106, 1469–1495. [Google Scholar] [CrossRef]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P.P. Learning with drift detection. In Proceedings of the 17th Brazilian Symposium on Artificial Intelligence (SBIA 2004), Sao Luis, Maranhao, Brazil, 29 September–1 October 2004. [Google Scholar]
- Baena-Garcıa, M.; del Campo-Ávila, J.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales-Bueno, R. Early drift detection method. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Data Streams, San Francisco, CA, USA; 2006; Volume 6, pp. 77–86. [Google Scholar]
- Pesaranghader, A.; Viktor, H.L. Fast Hoeffding drift detection method for evolving data streams. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2016; pp. 96–111. [Google Scholar]
- Pesaranghader, A.; Viktor, H.L.; Paquet, E. A framework for classification in data streams using multi-strategy learning. In International Conference on Discovery Science; Springer: Cham, Switzerland, 2016; pp. 341–355. [Google Scholar] [CrossRef]
- Pesaranghader, A.; Viktor, H.; Paquet, E. Reservoir of diverse adaptive learners and stacking fast Hoeffding drift detection methods for evolving data streams. Mach. Learn. J. 2018, 107, 1711–1743. [Google Scholar] [CrossRef]
- Pesaranghader, A. A Reservoir of Adaptive Algorithms for Online Learning from Evolving Data Streams. Ph.D. Dissertation, University of Ottawa, Ottawa, ON, Canada, 2018. [Google Scholar] [CrossRef]
- Yan, M.M.W. Accurate detecting concept drift in evolving data streams. ICT Express 2020, 6, 332–338. [Google Scholar] [CrossRef]
- ZareMoodi, P.; Siahroudi, S.K.; Beigy, H. A support vector based approach for classification beyond the learned label space in data streams. In Proceedings of the 31st Annual ACM Symposium on Applied Computing (SAC ’16), Pisa Italy, 4–8 April 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 910–915. [Google Scholar]
- Yalcin, A.; Erdem, Z.; Gurgen, F. Ensemble based incremental SVM classifiers for changing environments. In Proceedings of the 2007 22nd International Symposium on Computer and Information Sciences, Ankara, Turkey, 7–9 November 2007; pp. 1–5. [Google Scholar]
- Altendeitering, M.; Dübler, S. Scalable Detection of Concept Drift: A Learning Technique Based on Support Vector Machines. In Proceedings of the 30th International Conference on Flexible Automation and Intelligent Manufacturing (FAIM2021), Athens, Greece, 15–18 June 2021; Volume 51, pp. 400–407. [Google Scholar]
- Cauwenberghs, G.; Poggio, T. Incremental and decremental support vector machine learning. In Proceedings of the 13th International Conference on Neural Information Processing Systems (NIPS’00), Denver, CO, USA, 1 January 2000; MIT Press: Cambridge, MA, USA; 2000; pp. 388–394. [Google Scholar]
- Diehl, C.P.; Cauwenberghs, G. SVM incremental learning, adaptation and optimization. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; Volume 4, pp. 2685–2690. [Google Scholar]
- Laskov, P.; Gehl, C.; Krüger, S.; Mxuxller, K. Incremental support vector learning: Analysis, implementation and applications. J. Mach. Learn. Res. 2006, 7, 1909–1936. [Google Scholar]
- Gâlmeanu, H.; Andonie, R. Implementation issues of an incremental and decremental SVM. In Proceedings of the 18th International Conference on Artificial Neural Networks (ICANN ’08), Prague, Czech Republic, 3–6 September 2008; Part I; Springer: Berlin/Heidelberg, Germany, 2008; pp. 325–335. [Google Scholar]
- Gâlmeanu, H.; Andonie, R. A multi-class incremental and decremental SVM approach using adaptive directed acyclic graphs. In Proceedings of the 2009 International Conference on Adaptive and Intelligent Systems, Klagenfurt, Austria, 24–26 September 2009; pp. 114–119. [Google Scholar]
- Martin, M. On-line support vector machine regression. In Machine Learning: ECML 2002; Elomaa, T., Mannila, H., Toivonen, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 282–294. [Google Scholar]
- Ma, J.; Theiler, J.; Perkins, S. Accurate on-line support vector regression. Neural Comput. 2003, 15, 2683–2703. [Google Scholar] [CrossRef]
- Gâlmeanu, H.; Sasu, L.M.; Andonie, R. Incremental and decremental SVM for regression. Int. J. Comput. Commun. Control 2016, 11, 755–775. [Google Scholar] [CrossRef]
- Ma, Y.; Zhao, K.; Wang, Q.; Tian, Y. Incremental cost-sensitive Support Vector Machine with linear-exponential loss. IEEE Access 2020, 8, 149899–149914. [Google Scholar] [CrossRef]
- Pesaranghader, A. The Tornado Framework for Data Stream Mining (Python Implementation). Available online: https://github.com/alipsgh/tornado (accessed on 3 October 2021).
- Mahdi, O.A.; Pardede, E.; Ali, N.; Cao, J. Fast Reaction to Sudden Concept Drift in the Absence of Class Labels. Appl. Sci. 2020, 10, 606. [Google Scholar] [CrossRef]
- Huang, D.T.J.; Koh, Y.S.; Dobbie, G.; Bifet, A. Drift detection using stream volatility. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2015; pp. 417–432. [Google Scholar]
- Blackard, J.A.; Dean, D.J. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables. Comput. Electron. Agric. 2000, 24, 131–151. [Google Scholar] [CrossRef]
- Centre for Open Software Innovation, The University of Waikato. Datasets—MOA. 2019. Available online: https://moa.cms.waikato.ac.nz/datasets/ (accessed on 1 May 2020).
- Bifet, A.; Kirkby, R. Data Stream Mining: A Practical Approach; MOA, The University of Waikato, Centre for Open Software Innovation: Hamilton, New Zealand, 2009; Available online: https://www.cs.waikato.ac.nz/~abifet/MOA/StreamMining.pdf (accessed on 2 October 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Window Size | (gamma) | C |
|---|---|---|---|
| SINE1 | 1500 | 6.008484 | 10 |
| CIRCLES | 1000 | 7.797753 | 1 |
| COVERTYPE | 2000 | 0.241477 | 100 |
| Method on Dataset | SINE1 | CIRCLES | COVERTYPE |
|---|---|---|---|
| NB+FHDDM | 85.32% | 86.24% | 87.94% |
| NB+FHDDMS | 85.35% | 86.26% | 87.05% |
| NB+DDM | 85.06% | 86.06% | 88.43% |
| NB+EDDM | 82.50% | 84.81% | 84.92% |
| NB+ADWIN | 84.72% | 86.20% | 86.78% |
| HT+FHDDM | 86.37% | 87.16% | 89.16% |
| HT+FHDDMS | 86.36% | 87.19% | 87.58% |
| HT+DDM | 86.09% | 86.97% | 89.90% |
| HT+EDDM | 83.69% | 85.21% | 84.98% |
| HT+ADWIN | 84.09% | 86.74% | 87.02% |
| C-SVM | 84.83% | 87.17% | 91.79% |
| AIDSVM | 88.68% | 87.22% | 92.17% |
| Method on Dataset | SINE1 | CIRCLES | COVERTYPE |
|---|---|---|---|
| C-SVM | 154 ± 12 | 115 ± 8 | 119 ± 11 |
| AIDSVM | 117 ± 7 | 75 ± 9 | 73 ± 6 |
| Drifts Signalled | SINE1 | CIRCLES | COVERTYPE |
|---|---|---|---|
| NB+FHDDM | 20,048, 40,043, 60,048, 80,047 | 25,061, 50,063, 75,104 | 803, 1761, 2689, 3149, 3587 ... |
| NB+FHDDMS | 20,033, 40,035, 60,047, 80,037 | 25,061, 50,023, 75,104 | 803, 1607, 2009, 2644, 3129 ... |
| NB+DDM | 20,156, 40,138, 60,106, 80,171 | 25,339, 50,240, 75,676 | 839, 2105, 2717, 3149, 3588 ... |
| NB+EDDM | 93, 21,121, 40,949, 61,038, 61,165 ... | 110, 260, 31,163, 50,397, 50,629 ... | 116, 280, 364, 553, 703 ... |
| NB+ADWIN | 20,065, 26,178, 27,775, 29,924, 40,069 ... | 9537, 25,090, 27,843, 50,052, 75,205 ... | 1025, 2818, 3747, 4772, 5637 ... |
| HT+FHDDM | 20,054, 40,052, 41,756, 60,052, 80,051 | 25,061, 50,063, 75,066 | 816, 1673, 2031, 2700, 3146 ... |
| HT+FHDDMS | 20,036, 40,042, 41,765, 60,047, 80,038 | 25,061, 50,023, 75,066 | 816, 1607, 2009, 2706, 3123 ... |
| HT+DDM | 20,150, 40,144, 60,154, 80,164 | 25,304, 50,297, 75,559 | 853, 1924, 51,532, 51,741, 51,775 ... |
| HT+EDDM | 93, 20,899, 40,873, 60,951, 61,224 ... | 110, 260, 27,840, 31,500, 31,930 ... | 116, 280, 364, 553, 703 ... |
| HT+ADWIN | 2877, 4770, 6435, 8260, 12,869 ... | 1985, 5506, 25,091, 28,420, 50,053 ... | 993, 2786, 4675, 5636, 5797 ... |
| AIDSVM | 20,036, 40,041, 60,044, 80,038 | 25,055, 25,069, 50,023, 50,030, 50,037, 75,668 ... | 990, 996, 1006, 4715, 4751 ... |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gâlmeanu, H.; Andonie, R. Concept Drift Adaptation with Incremental–Decremental SVM. Appl. Sci. 2021, 11, 9644. https://doi.org/10.3390/app11209644
Gâlmeanu H, Andonie R. Concept Drift Adaptation with Incremental–Decremental SVM. Applied Sciences. 2021; 11(20):9644. https://doi.org/10.3390/app11209644
Chicago/Turabian StyleGâlmeanu, Honorius, and Răzvan Andonie. 2021. "Concept Drift Adaptation with Incremental–Decremental SVM" Applied Sciences 11, no. 20: 9644. https://doi.org/10.3390/app11209644
APA StyleGâlmeanu, H., & Andonie, R. (2021). Concept Drift Adaptation with Incremental–Decremental SVM. Applied Sciences, 11(20), 9644. https://doi.org/10.3390/app11209644