
Comparison of Twelve Machine Learning Regression Methods for Spatial Decomposition of Demographic Data Using Multisource Geospatial Data: An Experiment in Guangzhou City, China


Abstract
:1. Introduction
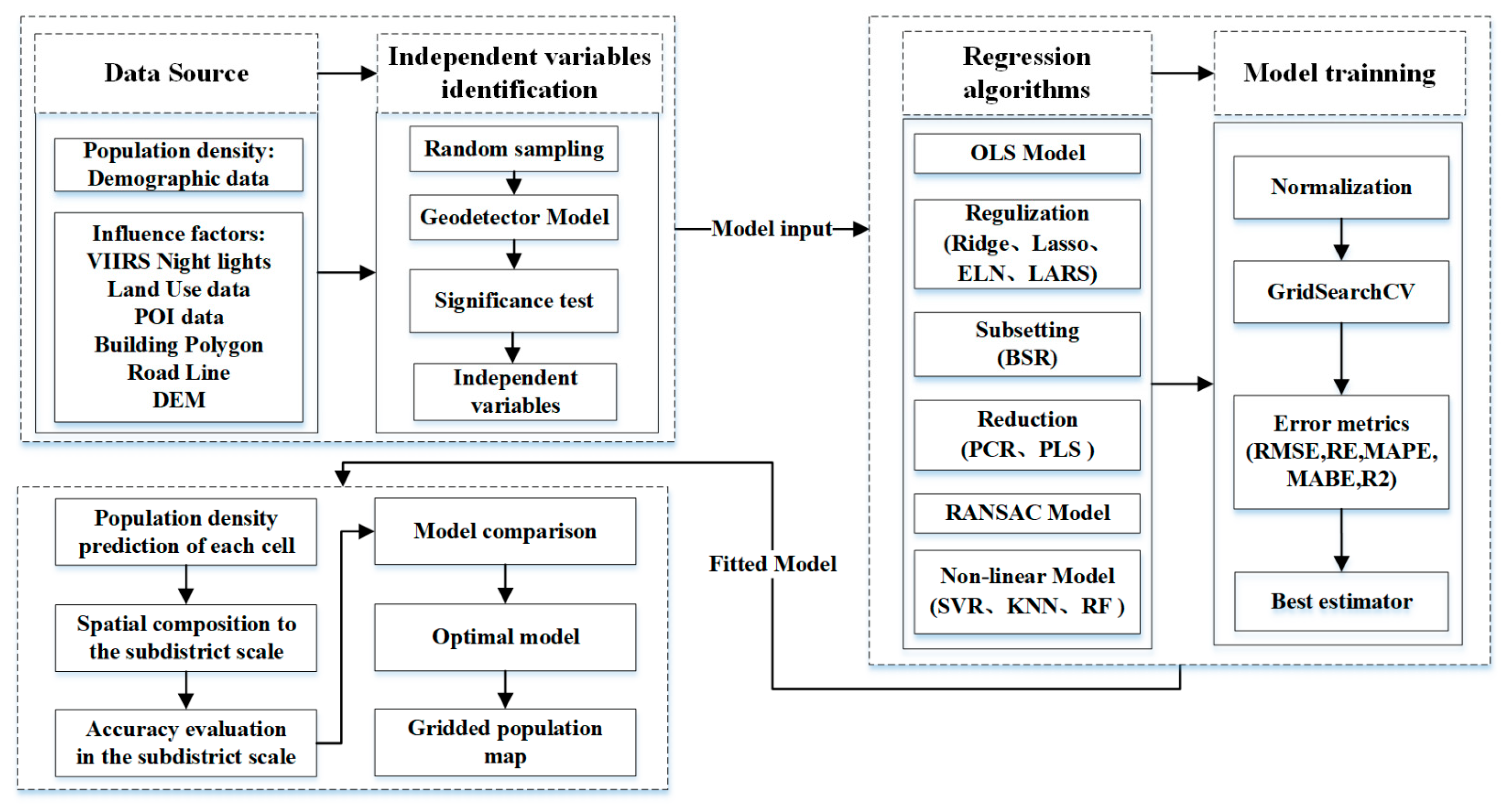
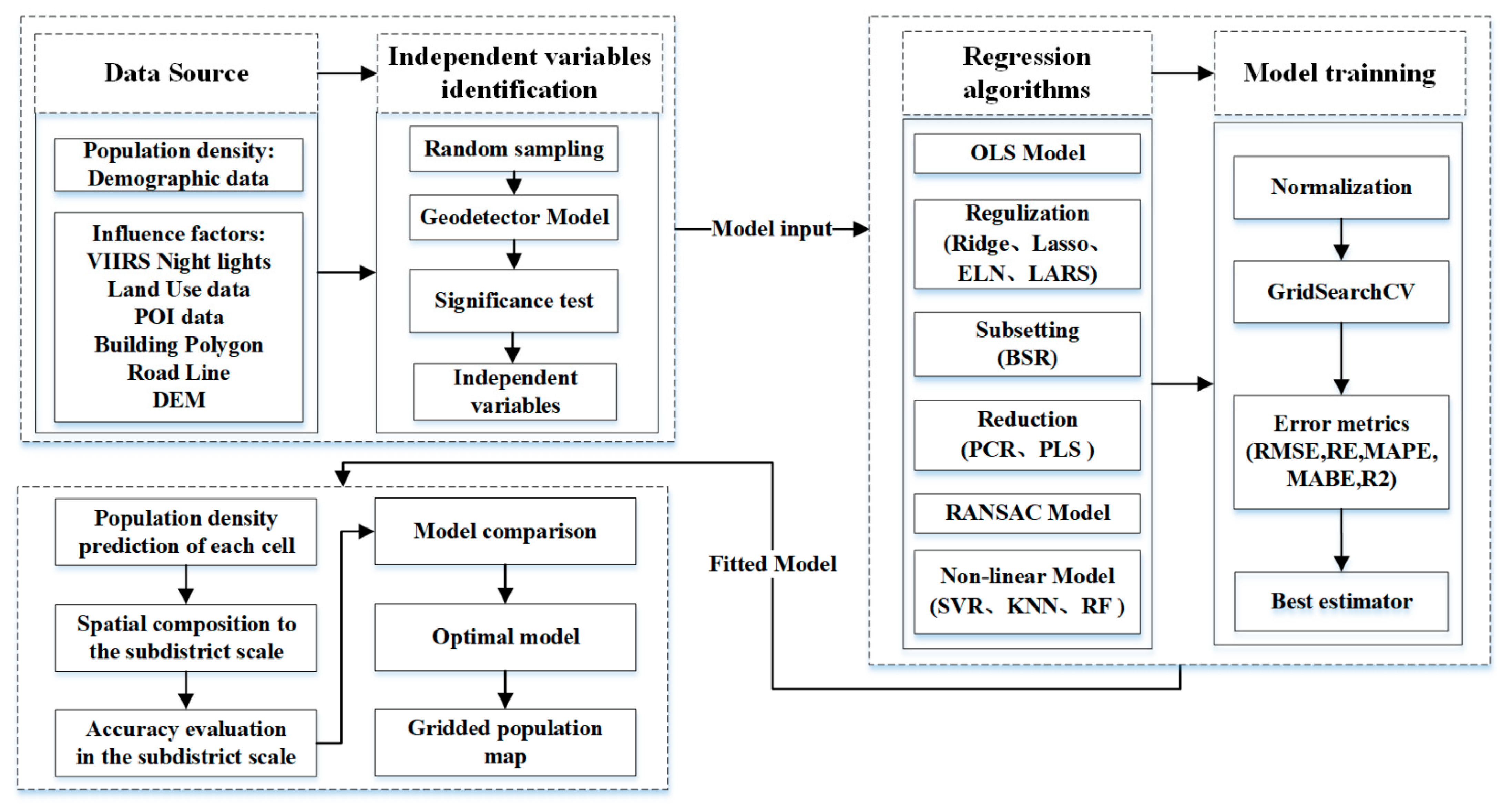
2. Materials and Methods
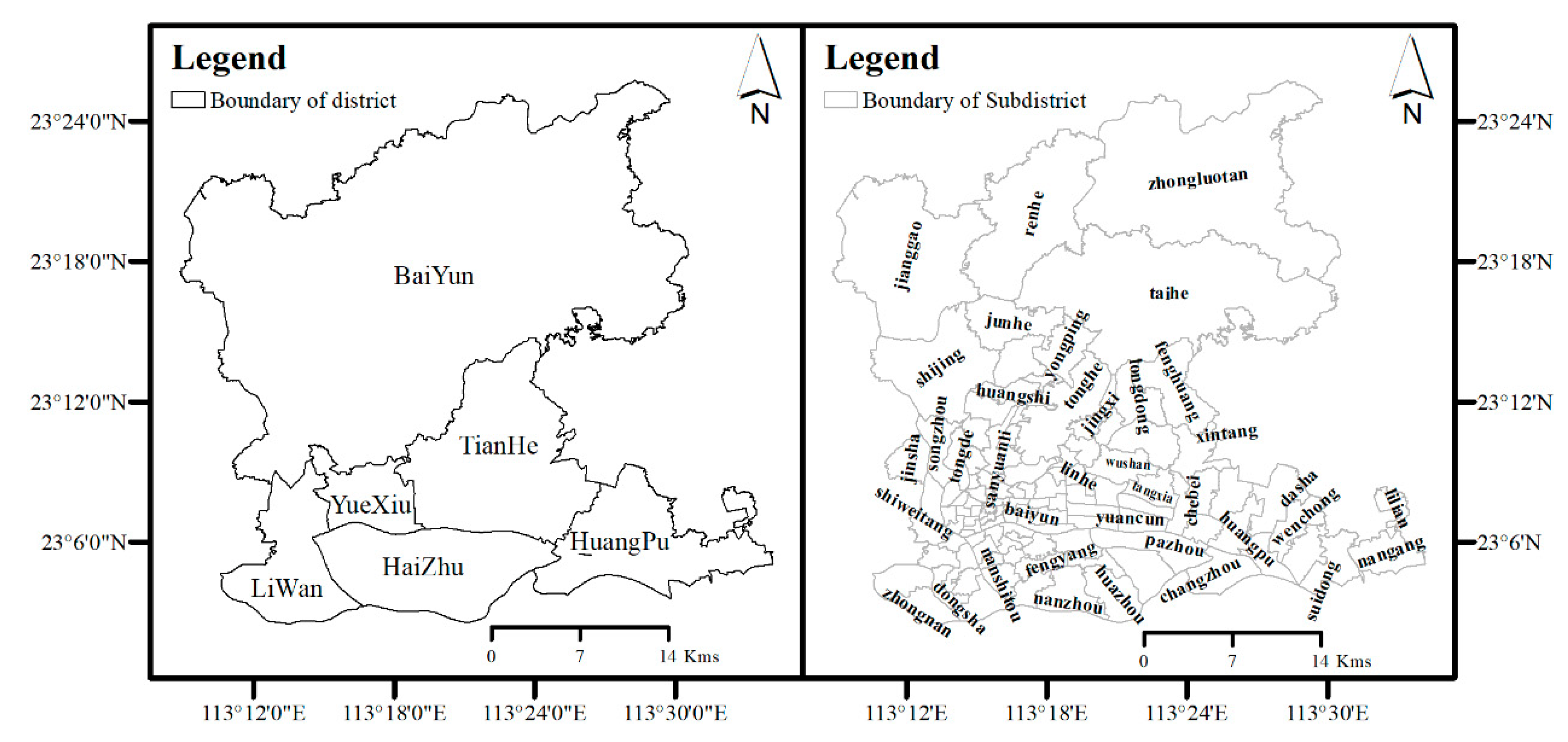
2.1. Study Area and Data Sources
2.2. Methods
2.2.1. Calculation of Initial Influence Factors in the Grid Scale
2.2.2. Selection of Independent Variables Based on Geographical Detector Model
2.2.3. Spatial Decomposition of Demographic Data Using Different Regression Algorithms
Machine Learning Training Method
Machine Learning Test Method
- Ordinary Least Squares (OLS) Regression Model
- 2.
- Best Subset Linear Regression (BSR) Model
- 3.
- Principal Component Regression (PCR) Model and Partial least squares (PLS) Regression Model
- 4.
- Lasso Regression Model, Ridge Regression Model, and Elastic Net Regression Model
- 5.
- Least Angle Regression (LARS) Model, and Random Sample Consensus (RANSAC) Regression Model
- 6.
- Support Vector Machine Regression (SVR) Model, K-Nearest Neighbors (KNN) Regression Model, and Random Forest (RF) Regression Model
2.2.4. Model Accuracy Evaluation Metrics
3. Results
3.1. Independent Variables Selection Results Based on Geodetector Model
3.2. Spatial Decomposition Results Based on Different Regression Models
3.2.1. Model Training Results for Population Density Regression on Subdistrict Scale
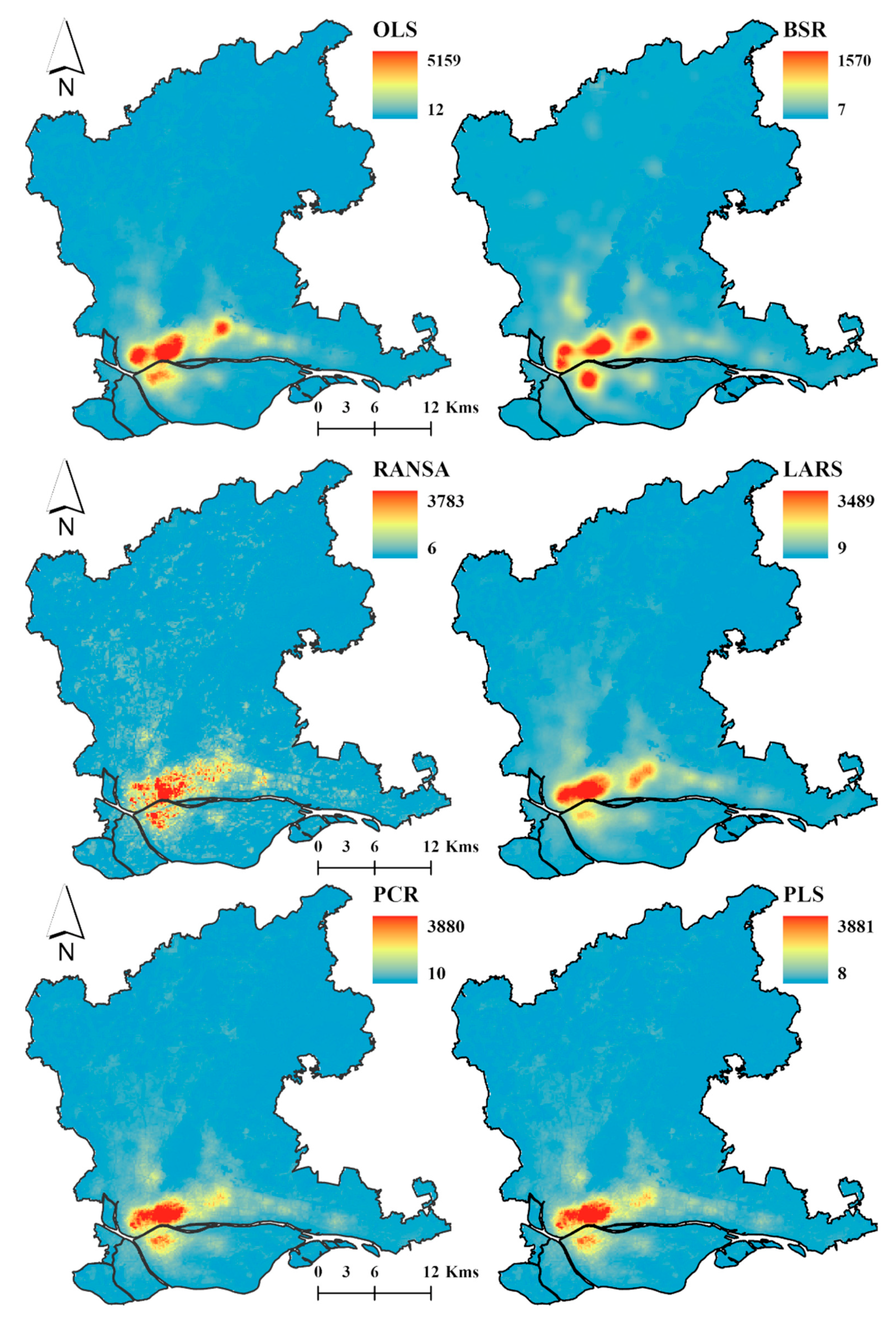
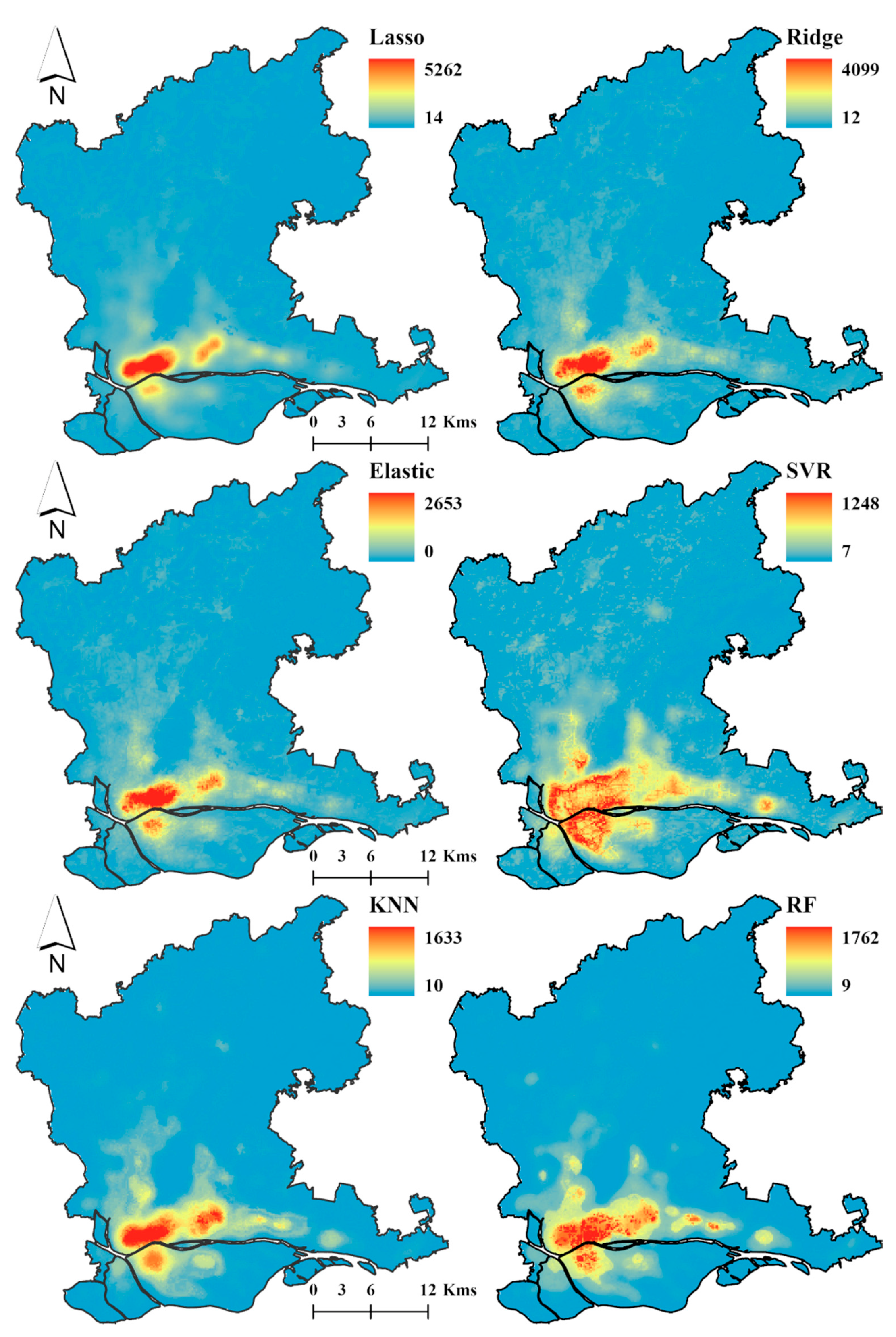
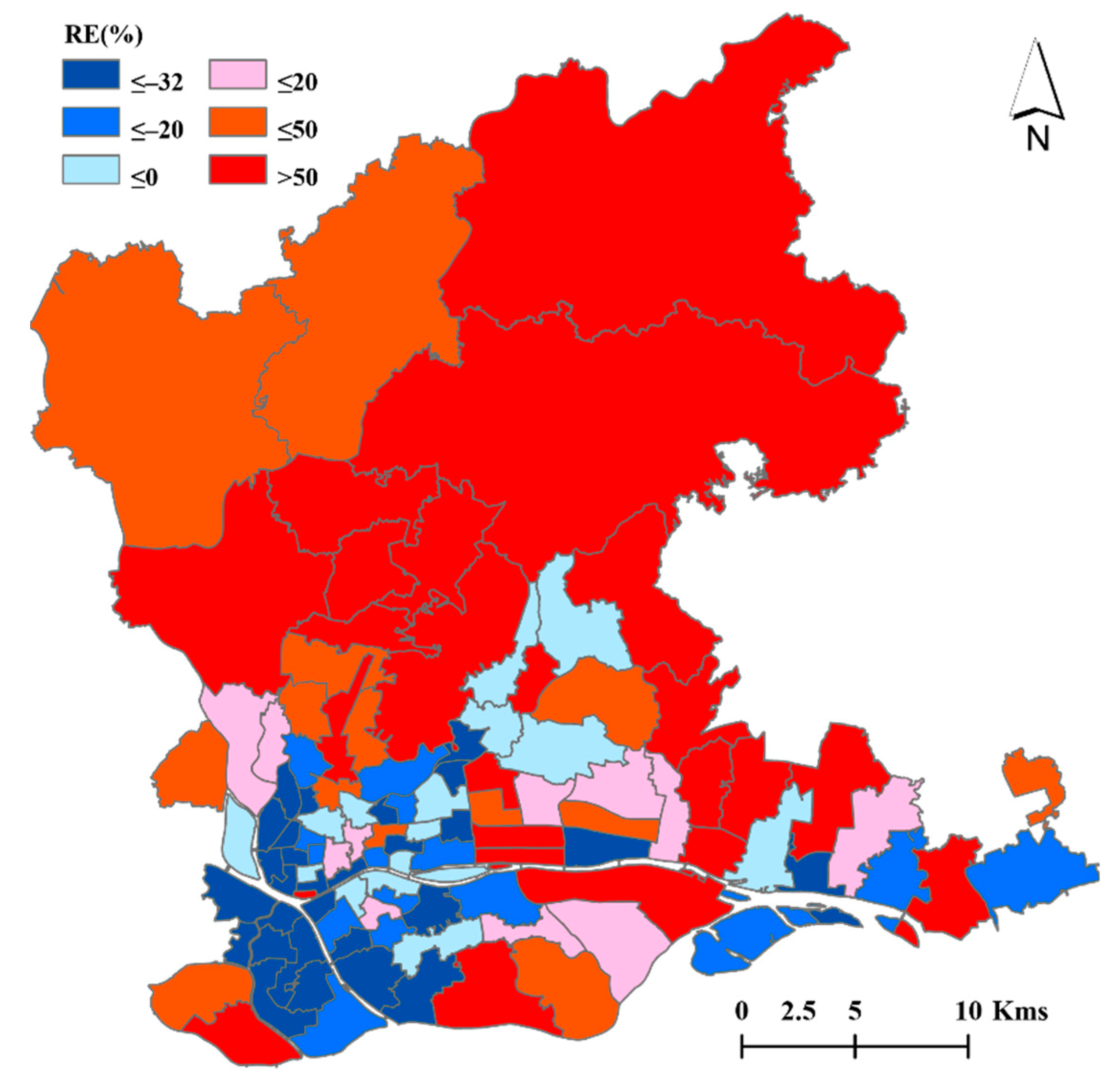
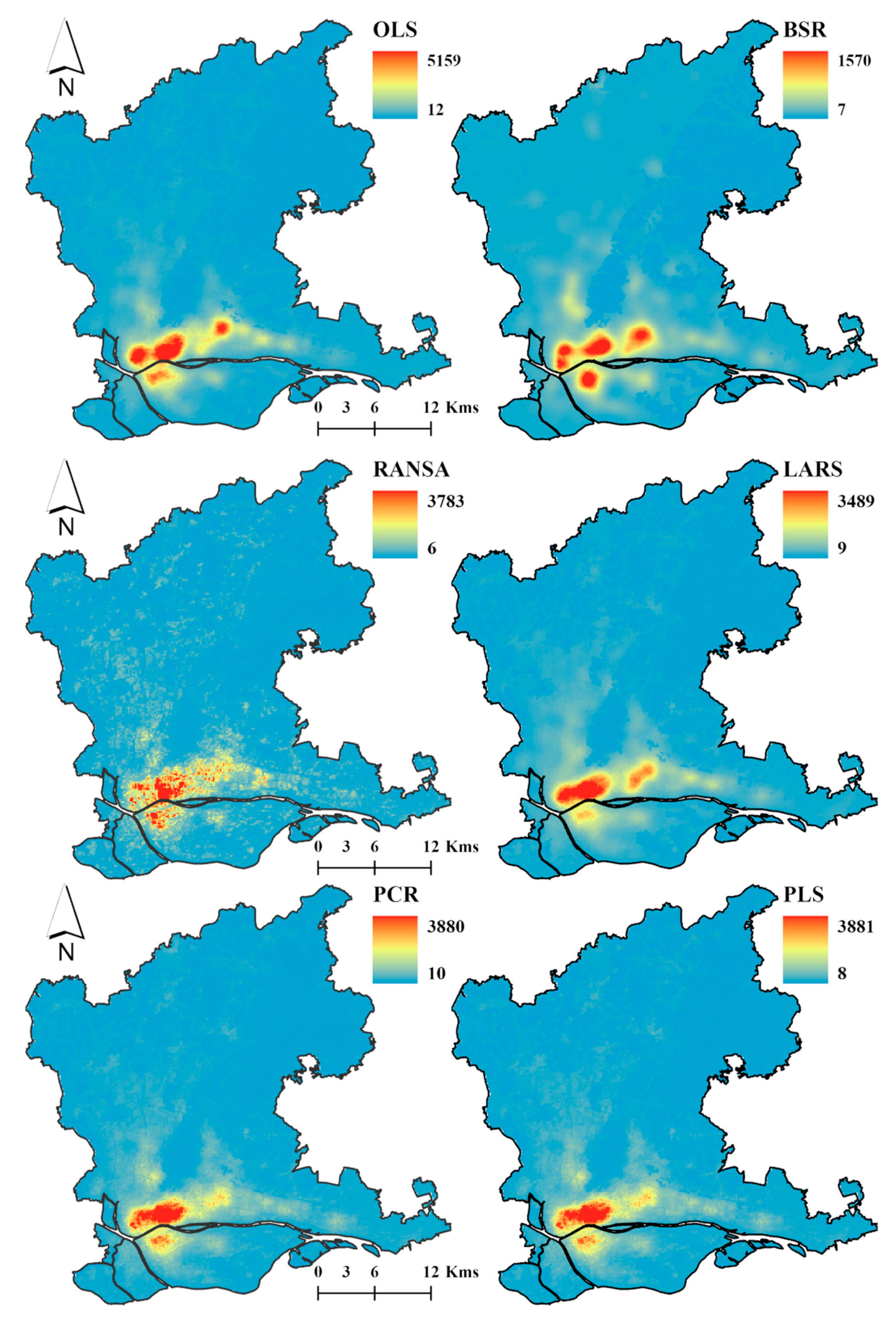
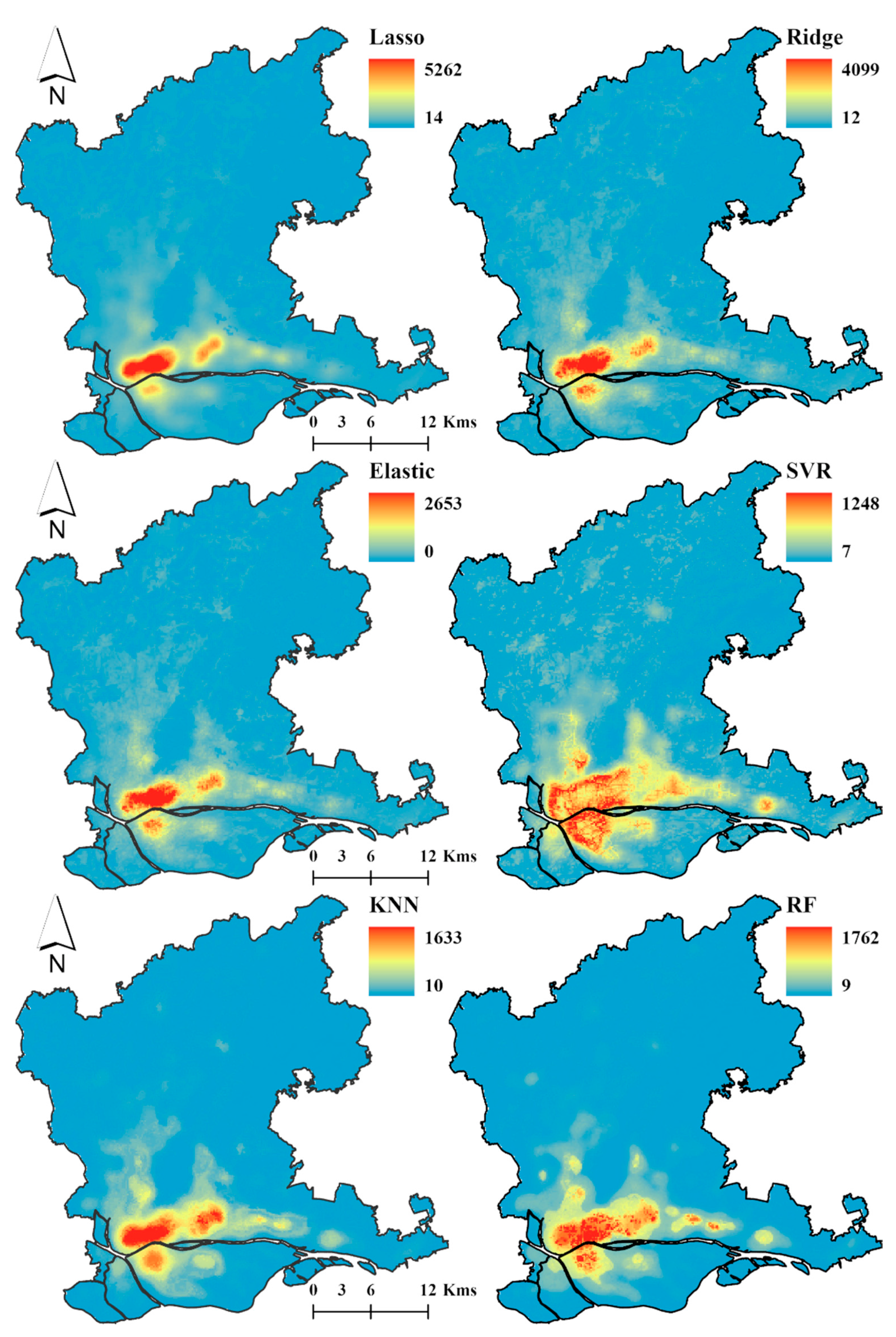
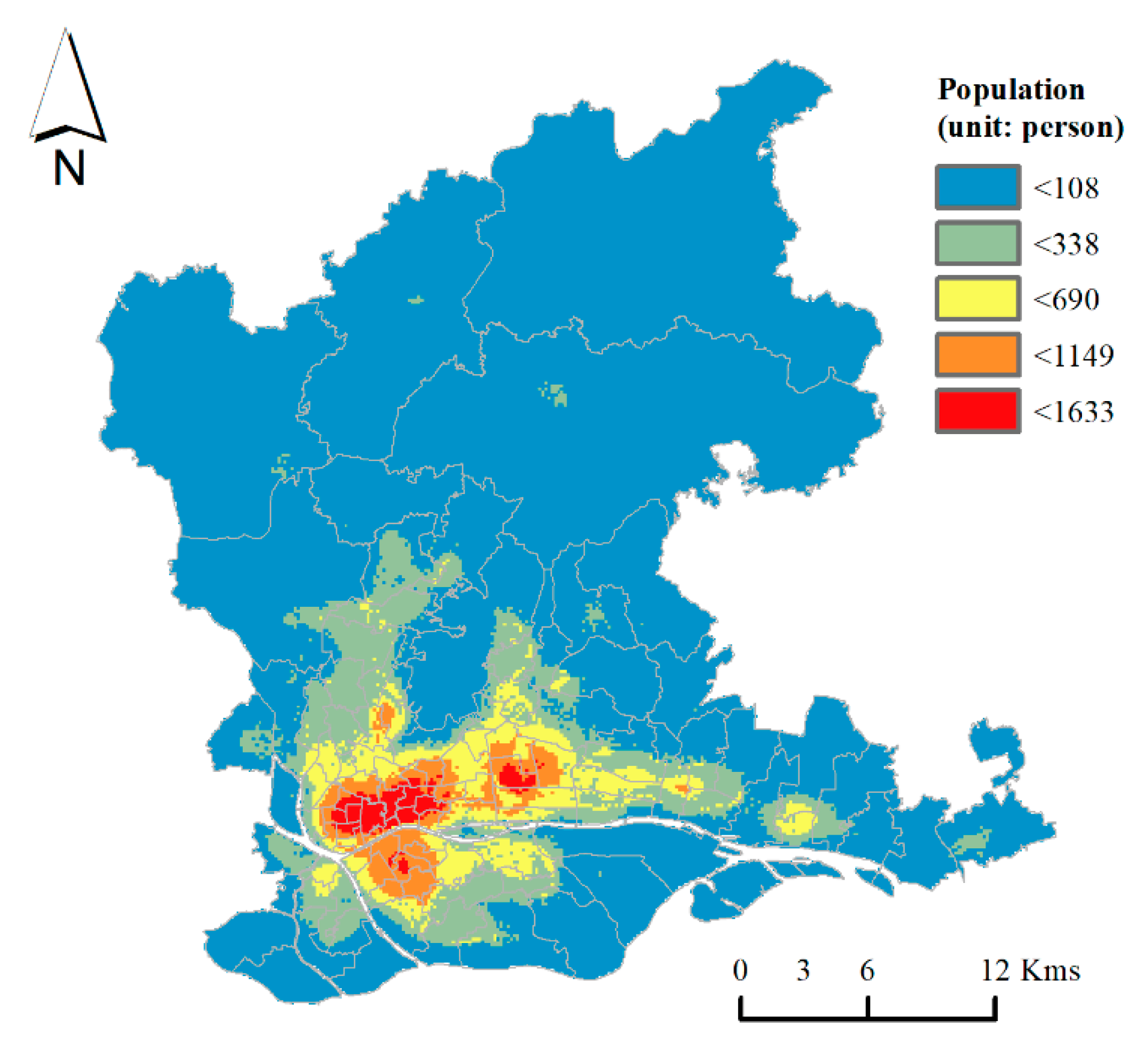
3.2.2. Spatial Decomposition Results of Demographic Data with Different Regression Models
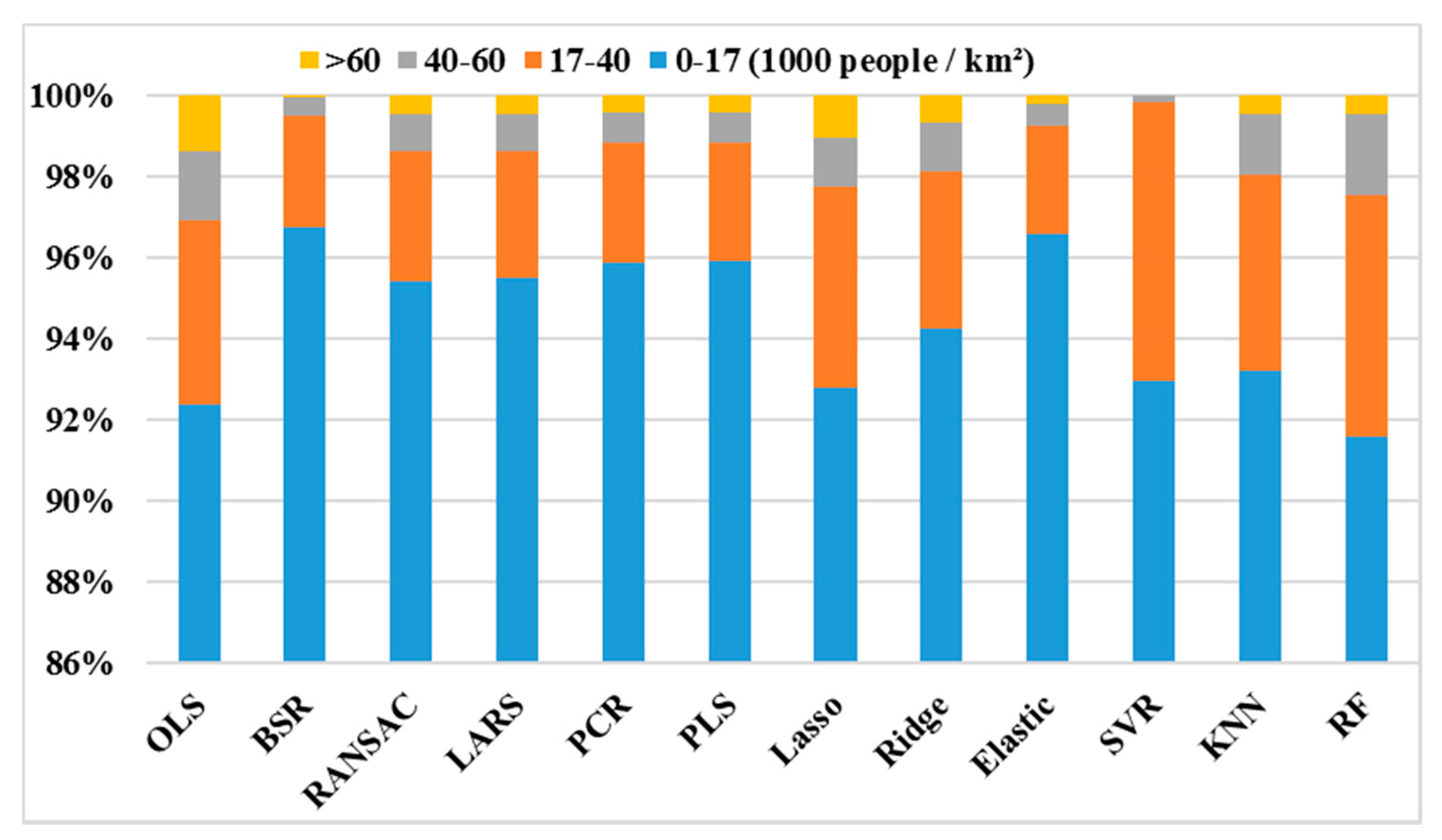
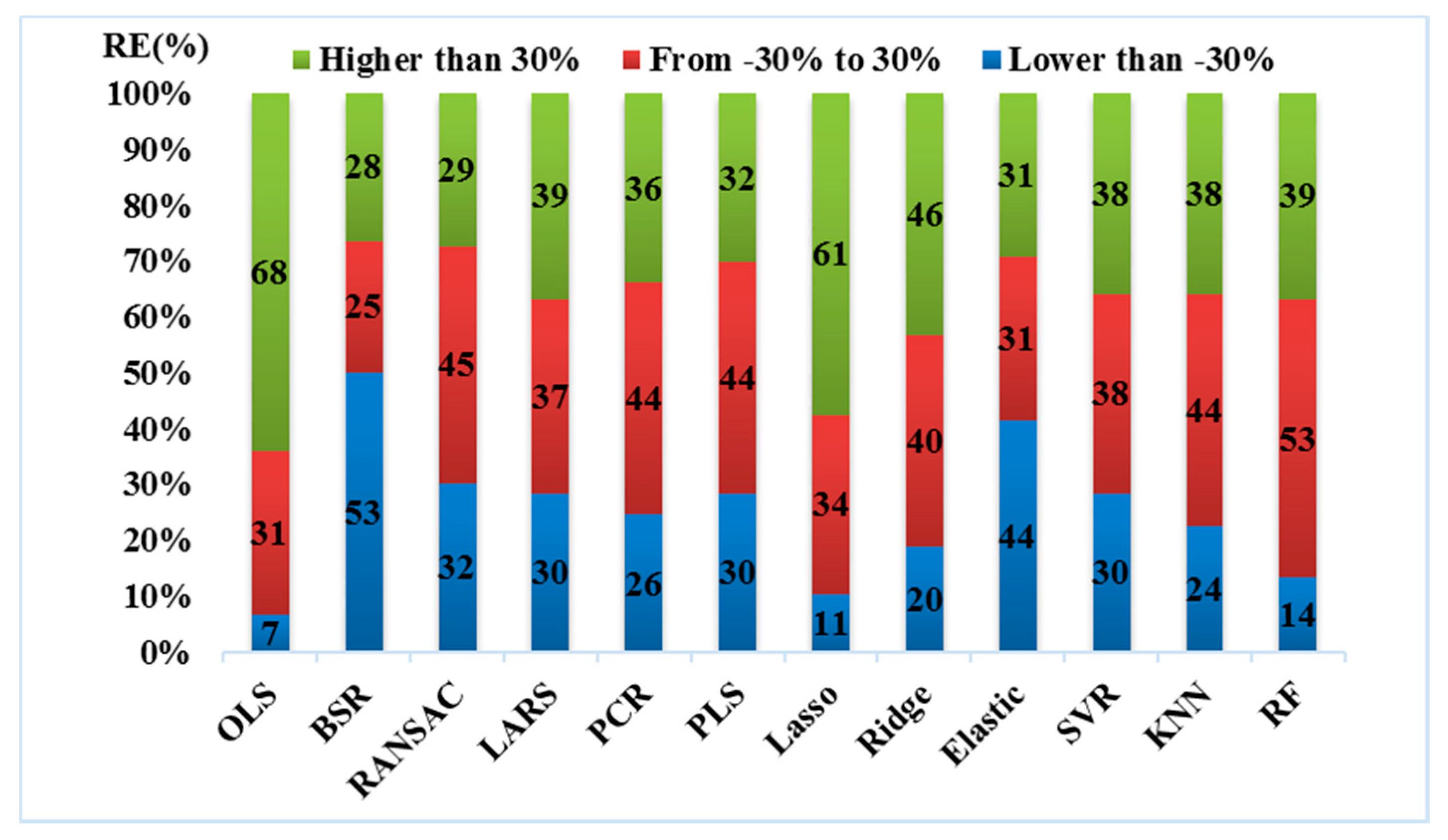
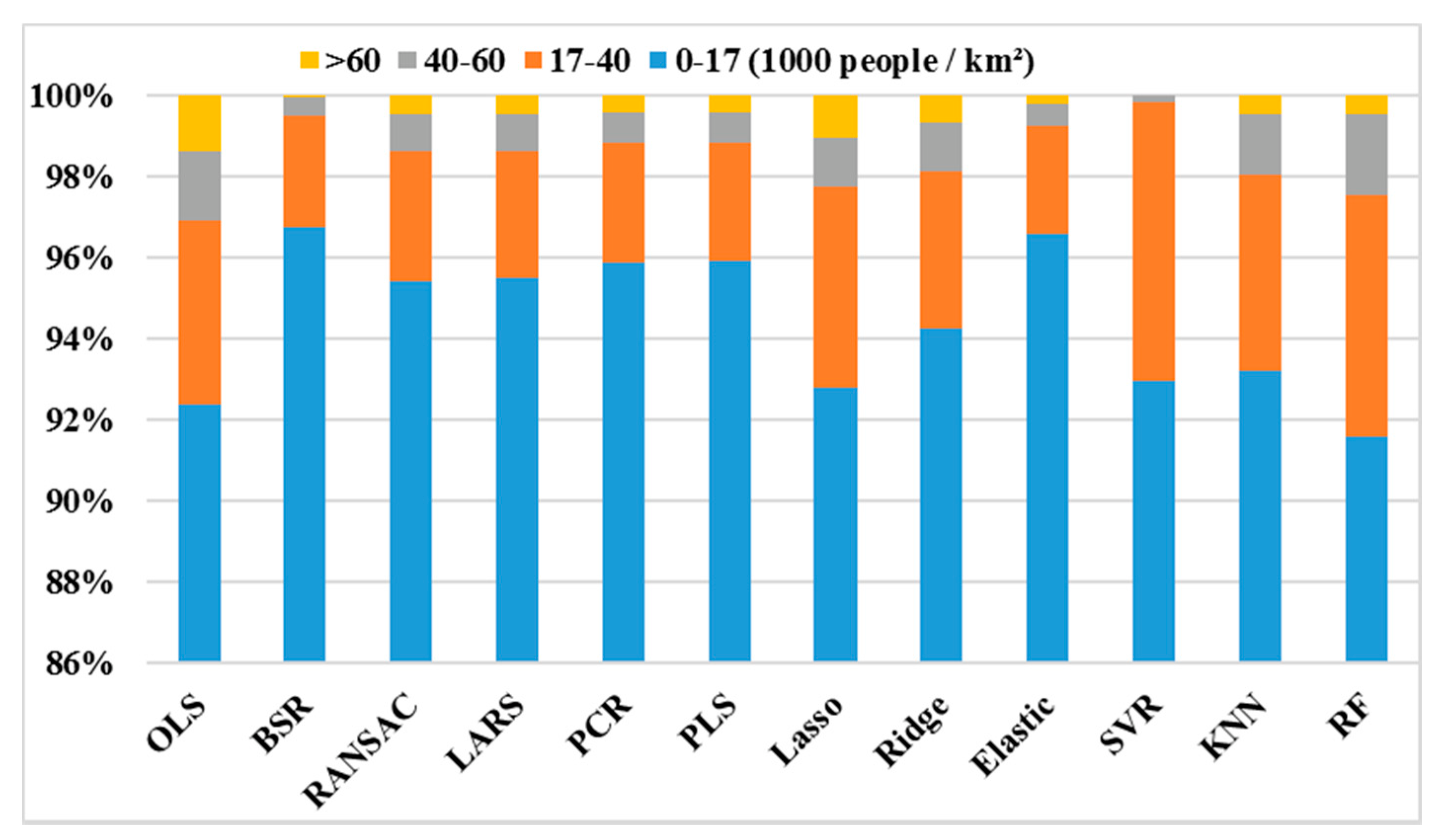
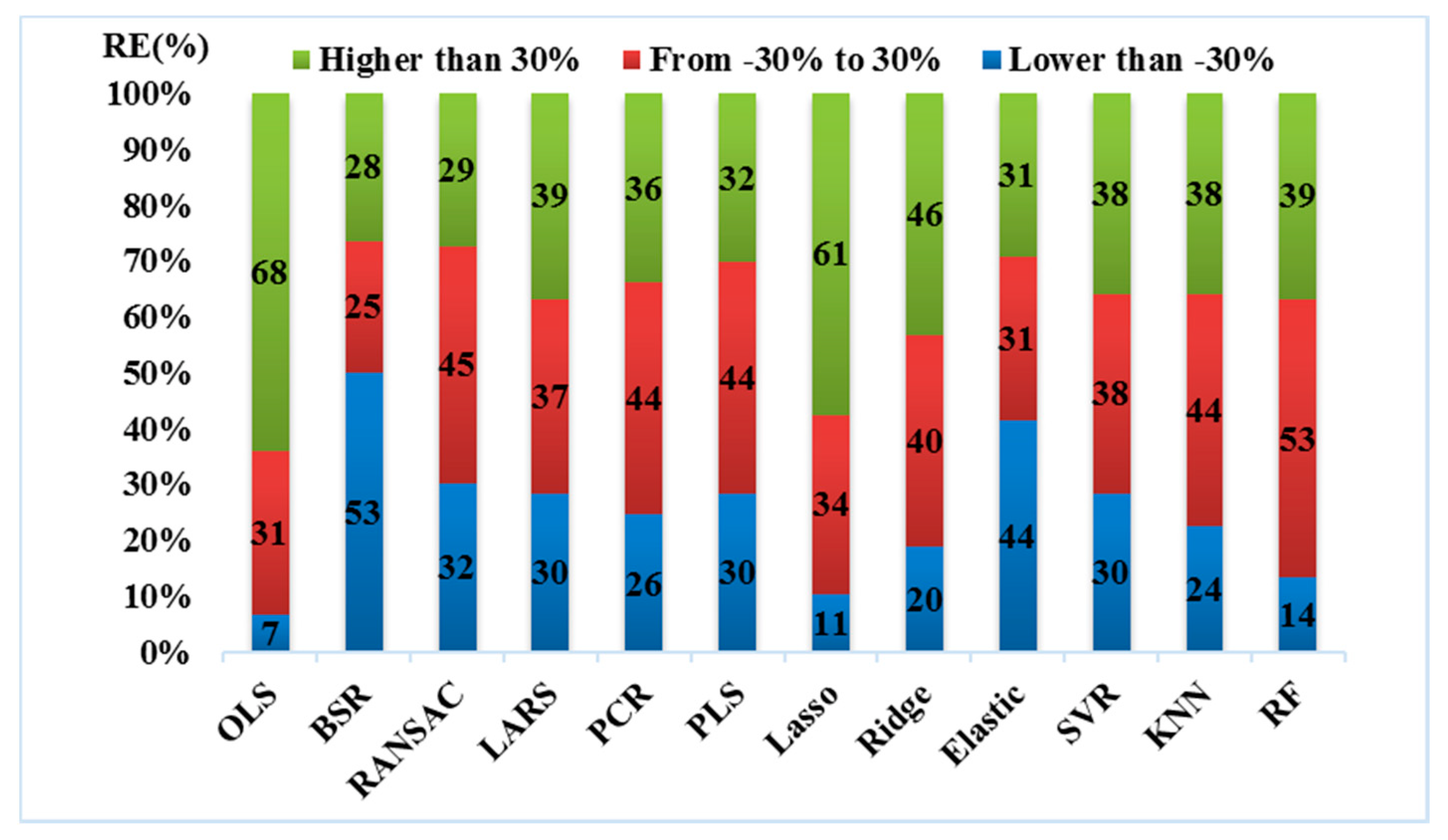
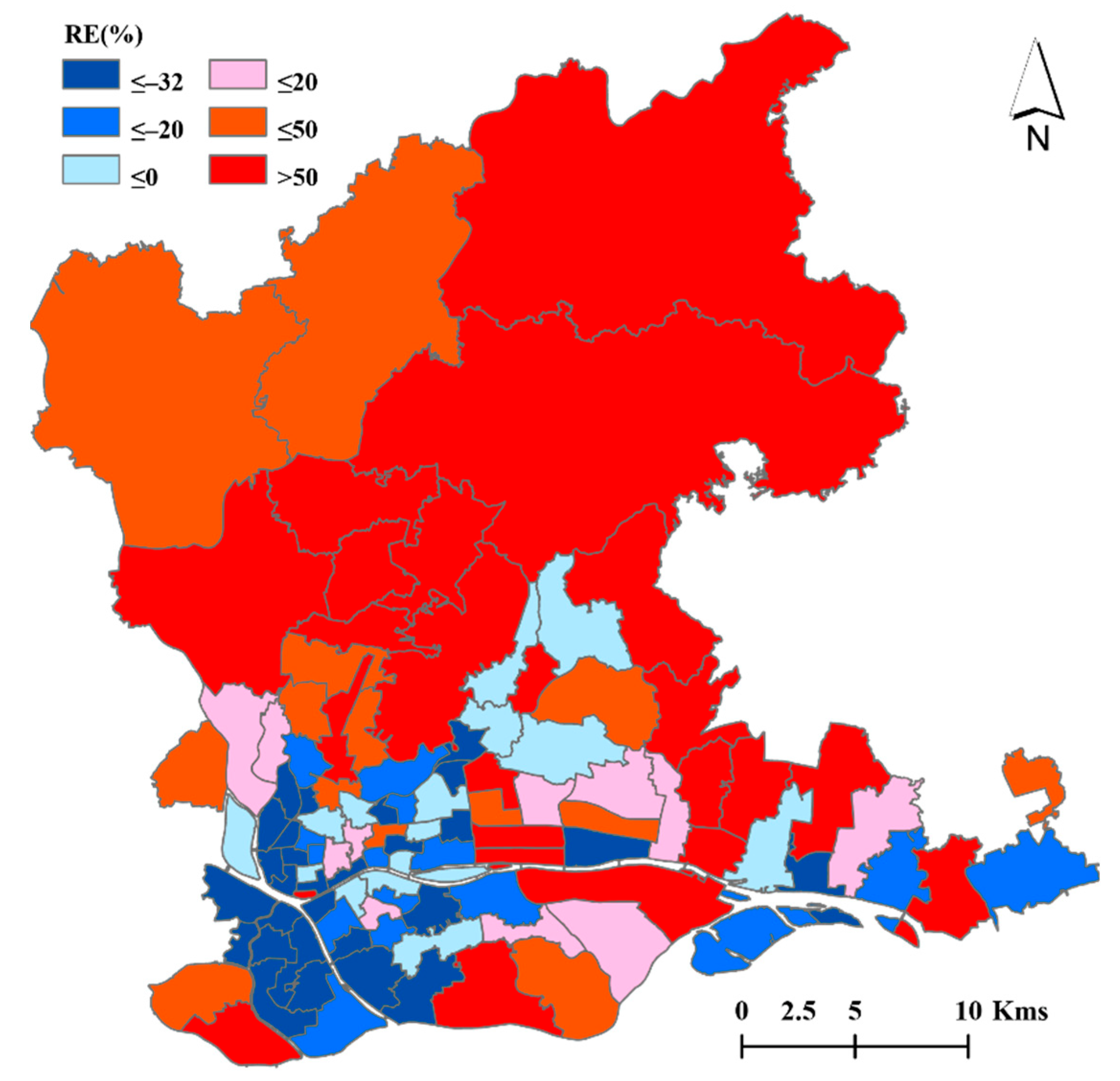
3.3. Accuracy Assessment of Spatial Decomposition Results Using Twelve Regression Models
4. Discussion and Conclusions
4.1. Discussion
4.1.1. Principal Findings and Meaningful Implication
- (1)
- The methodology framework proposed in this paper provides an effective and rapid approach to the fine spatial decomposition of demographic data. The auxiliary data from various sources can be combined for gridded population mapping via machine learning regression. It was demonstrated that location-based services (LBS) data, derived from mobile phones, Baidu map, Tencent LBS, Sina Weibo, and so on, offer the possibility of illustrating gridded population maps more accurately and finely in urban areas [11,22,64,65,66,67,68,69,70,71]. In particular, the accuracy of gridded population maps can be improved significantly through the integration of remote sensing data and LBS data [72]. The geographical detector model can quickly and effectively identify the factors influencing population density distributions. Three non-linear machine learning regression algorithms, including the SVR model, the RF model and the KNN model, were employed in the spatial decomposition of demographic data, which was demonstrated to be useful for mining implicit non-linear relationships. The proposed approach can provide very useful information to support future research on the spatial decomposition of demographic data with growing multi-source geospatial data [22,73].
- (2)
- The results of this study indicate that the OLS model is prone to overfitting in the spatial decomposition of demographic data. As we know, bias and variance are two key characteristics of estimators that must be considered in regression analysis; the former measures the accuracy of the model, while the latter measures the stability of the model. Clearly, ordinary least square linear regression is more affected by variance due to the excess of independent variables or collinearity. Both regularization and subsetting methods can effectively improve overfitting in the OLS model. Because all possible feature combinations are traversed, the features selected by the BSR model should, theoretically, offer an optimal combination. However, in this case, the improvement effect of the regularization methods on overfitting was better than in the BSR model, whether in the L1 regularization or the L2 regularization. These results again reflected the shortcomings of the BSR model. The reason why the BSR model is not the best in practical applications is still unclear; the unreasonable selection of independent variables, collinearity, and so on, are worth considering in this regard. In addition, another drawback of the BSR model is that it needs to fit 2p models, which is very computationally expensive (assuming the model includes p features). For this reason, we believe that for the spatial decomposition of demographic data, the regularization method is better than the subsetting method in improving overfitting.
- (3)
- The results of our case study demonstrate that for the spatial decomposition of demographic data, nonlinear regression models offer greater accuracy than linear regression models. The results may imply that the relationship between population density distribution and impact factors is complicated and non-linear. Since the nonlinear regression model can deal better with the collinearity of independent variables and other problems that easily lead to overfitting, we suggest that when conducting research on the spatial decomposition of demographic data, priority should be given to using nonlinear regression models to improve the accuracy of results. However, the results of regression models such as the KNN model, the SVR model and the RF model are non-parametric, and the interpretability of these models is very poor. Therefore, when the interpretability of the model needs to be taken into account, linear regression models based on the regularization method should be given priority.
4.1.2. Explanations for Further Research
4.2. Conclusions
- (1)
- The R2 values of the twelve regression algorithms discussed in this paper varied between 0.193 and 0.758. It can be said that besides the OLS algorithm, all the algorithms produced acceptable decomposition results by taking the R2 as the only evaluation metric. When all the algorithms were evaluated with the metric of MAPE, it was observed that the MAPE values of these models varied between 78.58% and 174.37%. That is, it can be concluded that all the decomposition results can be considered “reasonable”, apart from those of the OLS algorithm. Both the regularization method and the subsetting method can effectively alleviate overfitting in the OLS model. For the spatial decomposition of demographic data, the regularization method is better than the subsetting method in alleviating overfitting.
- (2)
- According to the model evaluation results, it can be seen that nonlinear regression algorithms offer greater accuracy than linear regression algorithms. Among the three nonlinear regression algorithms discussed in this study, the RF algorithm and the KNN algorithm both produced better results than the SVR algorithm, especially the KNN algorithm. Therefore, the KNN algorithm was recognized as a more suitable algorithm for this study. However, the accuracy of the KNN algorithm in other areas still needs to be evaluated. In addition, because the KNN algorithm does not provide a parameterized regression model, the interpretability of the decomposition model is very poor.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Azar, D.; Engstrom, R.; Graesser, J.; Comenetz, J. Generation of fine-scale population layers using multi-resolution satellite imagery and geospatial data. Remote Sens. Environ. 2013, 130, 219–232. [Google Scholar] [CrossRef]
- Balk, D.L.; Deichmann, U.; Yetman, G.; Pozzi, F.; Hay, S.I.; Nelson, A. Determining Global Population Distribution: Methods, Applications and Data. In Advances in Parasitology; Hay, S.I., Graham, A., Rogers, D.J., Eds.; Academic Press: London, UK, 2006; Volume 62, pp. 119–156. [Google Scholar]
- Weber, E.M.; Seaman, V.Y.; Stewart, R.N.; Bird, T.J.; Tatem, A.J.; McKee, J.J.; Bhaduri, B.L.; Moehl, J.J.; Reith, A.E. Census-independent population mapping in northern Nigeria. Remote Sens. Environ. 2018, 204, 786–798. [Google Scholar] [CrossRef]
- O’neill, B.C.; Dalton, M.; Fuchs, R.; Jiang, L.; Pachauri, S.; Zigova, K. Global demographic trends and future carbon emissions. Proc. Natl. Acad. Sci. USA 2010, 107, 17521–17526. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Huang, C.; Feng, Y.; Zhao, M.; Gu, J. Using Earth Observation for Monitoring SDG 11.3.1-Ratio of Land Consumption Rate to Population Growth Rate in Mainland China. Remote Sens. 2020, 12, 357. [Google Scholar] [CrossRef] [Green Version]
- Tuholske, C.; Gaughan, A.E.; Sorichetta, A.; de Sherbinin, A.; Bucherie, A.; Hultquist, C.; Stevens, F.; Kruczkiewicz, A.; Huyck, C.; Yetman, G. Implications for Tracking SDG Indicator Metrics with Gridded Population Data. Sustainability 2021, 13, 7329. [Google Scholar] [CrossRef]
- Gallopín, G.C. Human dimensions of global change: Linking the global and the local processes. Int. Soc. Sci. J. 1991, 43, 707. [Google Scholar]
- Zhou, Y.; Ma, M.; Shi, K.; Peng, Z. Estimating and Interpreting Fine-Scale Gridded Population Using Random Forest Regression and Multisource Data. ISPRS Int. J. Geo-Inf. 2020, 9, 369. [Google Scholar] [CrossRef]
- Wu, T.J.; Luo, J.C.; Dong, W.; Gao, L.J.; Hu, X.D.; Wu, Z.F.; Sun, Y.W.; Liu, J.S. Disaggregating County-Level Census Data for Population Mapping Using Residential Geo-Objects With Multisource Geo-Spatial Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1189–1205. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, X.; Li, X.; Zhang, J.; Liang, Z.; Mai, K.; Zhang, Y. Mapping fine-scale population distributions at the building level by integrating multisource geospatial big data. Int. J. Geogr. Inf. Sci. 2017, 31, 1220–1244. [Google Scholar] [CrossRef]
- Deville, P.; Linard, C.; Martin, S.; Gilbert, M.; Stevens, F.R.; Gaughan, A.E.; Blondel, V.D.; Tatem, A.J. Dynamic population mapping using mobile phone data. Proc. Natl. Acad. Sci. USA 2014, 111, 15888–15893. [Google Scholar] [CrossRef] [Green Version]
- Goodchild, M.F.; Anselin, L.; Deichmann, U. A Framework for the Areal Interpolation of Socioeconomic Data. Environ. Plan. A 1993, 25, 383–397. [Google Scholar] [CrossRef]
- Tobler, W.; Deichmann, U.; Gottsegen, J.; Maloy, K. World population in a grid of spherical quadrilaterals. Int. J. Popul. Geogr. 1997, 3, 203–225. [Google Scholar] [CrossRef]
- Lin, J.; Cromley, R.G. Evaluating geo-located Twitter data as a control layer for areal interpolation of population. Appl. Geogr. 2015, 58, 41–47. [Google Scholar] [CrossRef]
- Shi, X.; Li, M.; Hunter, O.; Guetti, B.; Andrew, A.; Stommel, E.; Bradley, W.; Karagas, M. Estimation of environmental exposure: Interpolation, kernel density estimation or snapshotting. Ann. GIS 2019, 25, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Qiu, F.; Cromley, R. Areal Interpolation and Dasymetric Modeling. Geogr. Anal. 2013, 45, 213–215. [Google Scholar] [CrossRef]
- Ye, T.; Zhao, N.; Yang, X.; Ouyang, Z.; Liu, X.; Chen, Q.; Hu, K.; Yue, W.; Qi, J.; Li, Z.; et al. Improved population mapping for China using remotely sensed and points-of-interest data within a random forests model. Sci. Total Environ. 2018, 658, 936–946. [Google Scholar] [CrossRef]
- Xu, M.; Cao, C.; Jia, P. Mapping Fine-Scale Urban Spatial Population Distribution Based on High-Resolution Stereo Pair Images, Points of Interest, and Land Cover Data. Remote Sens. 2020, 12, 608. [Google Scholar] [CrossRef] [Green Version]
- Balk, D.L.; Yetman, G. The Global Distribution of Population: Evaluating the Gains in Resolution Refinement; Columbia University: New York, NY, USA, 2004. [Google Scholar]
- Dobson, J.E.; Bright, E.A.; Coleman, P.R.; Durfee, R.C.; Worley, B.A. A Global Population Database for Estimating Population at Risk. Photogramm. Eng. Remote Sens. 2000, 66, 849–858. [Google Scholar]
- Freire, S.; Macmanus, K.; Pesaresi, M.; Doxsey-Whitfield, E.; Mills, J. Development of new open and free multi-temporal global population grids at 250 m resolution. In Proceedings of the Agile, Helsinki, Finland, 14–16 June 2016. [Google Scholar]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating Census Data for Population Mapping Using Random Forests with Remotely-Sensed and Ancillary Data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.; Yang, M. Urban Population Distribution Mapping with Multisource Geospatial Data Based on Zonal Strategy. ISPRS Int. J. Geo-Inf. 2020, 9, 654. [Google Scholar] [CrossRef]
- Thomson, D.R.; Gaughan, A.E.; Stevens, F.R.; Yetman, G.; Elias, P.; Chen, R. Evaluating the Accuracy of Gridded Population Estimates in Slums: A Case Study in Nigeria and Kenya. Urban Sci. 2021, 5, 48. [Google Scholar] [CrossRef]
- Gaughan, A.E.; Stevens, F.R.; Catherine, L.; Peng, J.; Tatem, A.J.; Francesco, P. High Resolution Population Distribution Maps for Southeast Asia in 2010 and 2015. PLoS ONE 2013, 8, e55882. [Google Scholar] [CrossRef] [PubMed]
- Azar, D.; Graesser, J.; Engstrom, R.; Comenetz, J.; Leddy, R.M., Jr.; Schechtman, N.; Andrews, T. Spatial refinement of census population distribution using remotely sensed estimates of impervious surfaces in Haiti. Int. J. Remote Sens. 2010, 31, 5635–5655. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Tibshirani, R. Best Subset, Forward Stepwise or Lasso? Analysis and Recommendations Based on Extensive Comparisons. Stat. Sci. 2020, 35, 579–592. [Google Scholar] [CrossRef]
- Hocking, R.R.; Leslie, R.N. Selection of the Best Subset in Regression Analysis. Technometrics 1967, 9, 531–540. [Google Scholar] [CrossRef]
- Beale, E.M.L.; Kendall, M.G.; Mann, D.W. The Discarding of Variables in Multivariate Analysis. Biometrika 1967, 54, 357–366. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar] [CrossRef] [Green Version]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic Decomposition by Basis Pursuit. SIAM J. Sci. Comput. 1998, 20, 33–61. [Google Scholar] [CrossRef]
- Marquardt, D.W.; Snee, R.D. Ridge Regression in Practice. Am. Stat. 1975, 29, 3–20. [Google Scholar] [CrossRef]
- Dorugade, A.V.; Kashid, D.N. Alternative Method for Choosing Ridge Parameter for Regression. Appl. Math. Sci. 2010, 4, 447–456. [Google Scholar]
- Hans, C. Elastic Net Regression Modeling With the Orthant Normal Prior. J. Am. Stat. Assoc. 2011, 106, 1383–1393. [Google Scholar] [CrossRef]
- Zou, H.; Zhang, H.H. On the Adaptive Elastic-Net with a Diverging Number of Parameters. Ann. Stat. 2009, 37, 1733–1751. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, H.; Hastie, T. Regularization and Variable Selection via the Elastic Net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Mansfield, E.R.; Webster, J.T.; Gunst, R.F. An Analytic Variable Selection Technique for Principal Component Regression. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1977, 26, 34–40. [Google Scholar] [CrossRef]
- Greenberg, E. Minimum Variance Properties of Principal Component Regression. J. Am. Stat. Assoc. 1975, 70, 194–197. [Google Scholar] [CrossRef]
- Reiss, P.T.; Ogden, R.T. Functional Principal Component Regression and Functional Partial Least Squares. J. Am. Stat. Assoc. 2007, 102, 984–996. [Google Scholar] [CrossRef]
- Kaspi, O.; Yosipof, A.; Senderowitz, H. RANdom SAmple Consensus (RANSAC) algorithm for material-informatics: Application to photovoltaic solar cells. J. Cheminform. 2017, 9, 34. [Google Scholar] [CrossRef] [PubMed]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Wang, L.Y.; Fan, H.; Wang, Y.K. Improving population mapping using Luojia 1-01 nighttime light image and location-based social media data. Sci. Total Environ. 2020, 730, 139148. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.F.; Li, X.H.; Christakos, G.; Liao, Y.L.; Zhang, T.; Gu, X.; Zheng, X.Y. Geographical Detectors-Based Health Risk Assessment and its Application in the Neural Tube Defects Study of the Heshun Region, China. Int. J. Geogr. Inf. Sci. 2010, 24, 107–127. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C. Geodetector: Principle and prospective. Acta Geogr. Sin. 2017, 72, 116–134. (In Chinese) [Google Scholar] [CrossRef]
- Swami, A.; Jain, R. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2013, 12, 2825–2830. [Google Scholar]
- Oh, Y.J.; Park, H.S.; Min, Y. Understanding Location-Based Service Application Connectedness: Model Development and Cross-Validation. Comput. Hum. Behav. 2019, 94, 82–91. [Google Scholar] [CrossRef]
- Gholinejad, S.; Naeini, A.A.; Amiri-Simkooei, A.R. Robust Particle Swarm Optimization of RFMs for High-Resolution Satellite Images Based on K-Fold Cross-Validation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2594–2599. [Google Scholar] [CrossRef]
- Park, H.; Kim, N.; Lee, J. Parametric models and non-parametric machine learning models for predicting option prices: Empirical comparison study over KOSPI 200 Index options. Expert Syst. Appl. 2014, 41, 5227–5237. [Google Scholar] [CrossRef]
- Chunhua, Z.; Yingjie, T.; Naiyang, D. The new interpretation of support vector machines on statistical learning theory. Sci. China Math. 2010, 53, 151–164. [Google Scholar]
- Onel, M.; Kieslich, C.A.; Guzman, Y.A.; Floudas, C.A.; Pistikopoulos, E.N. Big Data Approach to Batch Process Monitoring: Simultaneous Fault Detection and Diagnosis Using Nonlinear Support Vector Machine-based Feature Selection. Comput. Chem. Eng. 2018, 115, 503–520. [Google Scholar] [CrossRef]
- Baseer, M.A.; Saidur, R. Application of support vector machine models for forecasting solar and wind energy resources: A review. J. Clean. Prod. 2018, 199, 272–285. [Google Scholar]
- Chapelle, O.; Vapnik, V.; Bousquet, O.; Mukherjee, S. Choosing Multiple Parameters for Support Vector Machines. Mach. Learn. 2001, 46, 131–159. [Google Scholar] [CrossRef]
- Hu, L.Y.; Huang, M.W.; Ke, S.W.; Tsai, C.F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, H.L.; Huang, C.C.; Yu, X.G.; Xu, X.; Sun, X.; Wang, G.; Wang, S.J. An efficient diagnosis system for detection of Parkinson’s disease using fuzzy k-nearest neighbor approach. Expert Syst. Appl. 2013, 40, 263–271. [Google Scholar] [CrossRef]
- Rodrigues, E.O. Combining Minkowski and Cheyshev: New Distance Proposal and Survey of Distance Metrics Using k-Nearest Neighbours Classifier. Pattern Recognit. Lett. 2018, 110, 66–71. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Cao, Q.; Yu, Y.; Liu, Y. Comparison of daily diffuse radiation models in regions of China without solar radiation measurement. Energy 2020, 191, 116571. [Google Scholar] [CrossRef]
- Rehman, S. Solar radiation over Saudi Arabia and comparisons with empirical models. Energy 1998, 23, 1077–1082. [Google Scholar] [CrossRef]
- Zang, H.; Cheng, L.; Ding, T.; Cheung, K.W.; Wang, M.; Wei, Z.; Sun, G. Application of functional deep belief network for estimating daily global solar radiation: A case study in China. Energy 2020, 191, 116502. [Google Scholar] [CrossRef]
- Ceylan, İ.; Gürel, A.E.; Ergün, A. The mathematical modeling of concentrated photovoltaic module temperature. Int. J. Hydrogen Energy 2017, 42, 19641–19653. [Google Scholar] [CrossRef]
- Gouda, S.G.; Hussein, Z.; Luo, S.; Yuan, Q. Model selection for accurate daily global solar radiation prediction in China. J. Clean. Prod. 2019, 221, 132–144. [Google Scholar] [CrossRef]
- Zhuo, L.; Ichinose, T.; Zheng, J.; Chen, J.; Shi, P.J.; Li, X. Modelling the population density of China at the pixel level based on DMSP/OLS non-radiance-calibrated night-time light images. Int. J. Remote Sens. 2009, 30, 1003–1018. [Google Scholar] [CrossRef]
- Patel, N.N.; Stevens, F.R.; Huang, Z.; Gaughan, A.E.; Elyazar, I.; Tatem, A.J. Improving Large Area Population Mapping Using Geotweet Densities. Trans. GIS 2017, 21, 317. [Google Scholar] [CrossRef]
- Bakillah, M.; Liang, S.; Mobasheri, A.; Arsanjani, J.J.; Zipf, A. Fine-resolution population mapping using OpenStreetMap points-of-interest. Int. J. Geogr. Inf. Syst. 2014, 28, 1940–1963. [Google Scholar] [CrossRef]
- Zhao, X.; Zhou, Y.; Chen, W.; Li, X.; Li, X.; Li, D. Mapping hourly population dynamics using remotely sensed and geospatial data: A case study in Beijing, China. GISci. Remote Sens. 2021, 58, 717–732. [Google Scholar] [CrossRef]
- Xu, Y.; Song, Y.; Cai, J.; Zhu, H. Population mapping in China with Tencent social user and remote sensing data. Appl. Geogr. 2021, 130, 102450. [Google Scholar] [CrossRef]
- Miao, R.; Wang, Y.; Li, S. Analyzing Urban Spatial Patterns and Functional Zones Using Sina Weibo POI Data: A Case Study of Beijing. Sustainability 2021, 13, 647. [Google Scholar] [CrossRef]
- Shang, S.; Du, S.; Du, S.; Zhu, S. Estimating building-scale population using multi-source spatial data. Cities 2021, 111, 103002. [Google Scholar] [CrossRef]
- Nong, D.H.; Fox, J.M.; Saksena, S.; Lepczyk, C.A. The Use of Spatial Metrics and Population Data in Mapping the Rural-Urban Transition and Exploring Models of Urban Growth in Hanoi, Vietnam. Environ. Urban Asia 2021, 12, 156–168. [Google Scholar] [CrossRef]
- Liu, J.; Ma, X.; Zhu, Y.; Li, J.; He, Z.; Ye, S. Generating and Visualizing Spatially Disaggregated Synthetic Population Using a Web-Based Geospatial Service. Sustainability 2021, 13, 1587. [Google Scholar] [CrossRef]
- Yang, X.; Ye, T.; Zhao, N.; Chen, Q.; Yue, W.; Qi, J.; Zeng, B.; Jia, P. Population Mapping with Multisensor Remote Sensing Images and Point-Of-Interest Data. Remote Sens. 2019, 11, 574. [Google Scholar] [CrossRef] [Green Version]
- Wardrop, N.A.; Jochem, W.C.; Bird, T.J.; Chamberlain, H.R.; Clarke, D.; Kerr, D.; Bengtsson, L.; Juran, S.; Seaman, V.; Tatem, A.J. Spatially disaggregated population estimates in the absence of national population and housing census data. Proc. Natl. Acad. Sci. USA 2018, 115, 3529–3537. [Google Scholar] [CrossRef] [Green Version]
- Kang, C.; Liu, Y.; Ma, X.; Wu, L. Towards Estimating Urban Population Distributions from Mobile Call Data. J. Urban Technol. 2012, 19, 3–21. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Factors |
|---|---|
| Natural factors | (1) POI density: X1 (Government agencies), X2 (Public service facilities), X3 (Commercial residential facilities), X4 (Medical service facilities), X5 (Financial facilities), X6 (Transportation facilities), X7 (Educational, scientific, and cultural facilities), X8 (Sports and leisure facilities), X9 (Living service facilities), X10 (Catering facilities), X11 (Companies), X12 (Accommodation service facilities), X13 (Shopping facilities) (2) Night light intensity: X14 (Night light intensity index) (3) Building area: X17 (Building area index) (4) Road intensity: X20 (Road density index) |
| Socio-economic factors | (5) Land use: X15 (Index of urban land use), X18 (Index of arable land), X19 (Index of wood land), X21 (Index of rural land), X22 (Index of other construction land), X23 (Index of waters), X24 (Index of grass land) (6) Altitude: X16 (Elevation index) |
| The Implementation of the BSR Algorithm |
|---|
| # Loop over all possible numbers of features to be included for k in range (1, X_train.shape [1] + 1): # Loop over all possible subsets of size k for subset in itertools.combinations(range(X_train.shape[1]), k): subset = list(subset) # Traning the subset model linreg_model = LinearRegression().fit(X_train[:, subset], y_train) #Predict the dependent variable using the fitted subset model linreg_prediction = linreg_model.predict(X_test[:, subset]) #Accuracy evaluation on the results of the subset model linreg_mabe = np.mean(np.abs(y_test − linreg_prediction)) results = results.append(pd.DataFrame([{‘num_features’: k, ‘features’: subset, ‘MABE’: linreg_mabe}])) # Inspect the best combinations results = results.sort_values(‘MABE’).reset_index() # Fit the best subset model best_subset_model = LinearRegression(normalize=False).fit(X_train[:, results [‘features’][0]], y_train) |
| Metric | Equation | Description |
|---|---|---|
| MABE | MABE is the absolute value of the bias error that is as low as possible. MABE provides knowledge about the long-term performance of prediction models [58,59]. | |
| MAPE | As with MABE, MAPE is calculated in the form of a percentage. The smaller the MAPE value, the better the model performance [60,61]. | |
| RE | The relative error (RE) is the ratio of the absolute error of a measurement to the measurement being taken [23]. | |
| RMSE | RMSE is the square root of the ratio of the square of the deviation between the predicted value and the true value to the number of observations. A smaller RMSE value always represents a better performance [60]. | |
| R2 | R2 is an important metric reflecting the goodness of fit of the model, which is the ratio of the regression sum of squares to the total sum of squares. The value of R2 is between 0 and 1. The larger the value, the better the performance [62]. |
| Type | Factors |
|---|---|
| Natural factors | (1) POI density: X1 (Government agencies), X2 (Public service facilities), X3 (Commercial residential facilities), X4 (Medical service facilities), X5 (Financial facilities), X6 (Transportation facilities), X7 (Educational, scientific and cultural facilities), X8 (Sports and leisure facilities), X9 (Living service facilities), X10 (Catering facilities), X11 (Companies), X12 (Accommodation service facilities), X13 (Shopping facilities) (2) Night light intensity: X14 (Night light intensity index) (3) Building area: X17 (Building area index) (4) Roads intensity: X20 (Road density index) |
| Socio-economic factors | (5) Land use: X18 (Index of arable land), X19 (Index of wood land) (6) Altitude: X16 (Elevation index) |
| Algorithm | R2 | RMSE | MAPE (%) | MABE |
|---|---|---|---|---|
| OLS | 0.924 | 6471.913 | 48.063 | 4733.677 |
| BSR | 0.977 | 3547.13 | 34.667 | 2282.022 |
| RANSAC | 0.899 | 7421.336 | 59.307 | 5125.861 |
| LARS | 0.888 | 7838.545 | 69.02 | 5759.284 |
| PCR | 0.914 | 6868.028 | 102.96 | 6133.461 |
| PLS | 0.922 | 6535.272 | 89.433 | 5666.922 |
| Lasso | 0.924 | 6459.609 | 51.043 | 4819.67 |
| Ridge | 0.907 | 7128.09 | 76.27 | 5874.865 |
| Elastic Net | 0.915 | 6828.741 | 81.983 | 5814.385 |
| SVR | 0.876 | 8157.352 | 71.263 | 5924.128 |
| KNN | 0.925 | 6424.436 | 50.105 | 4711.419 |
| RF | 0.977 | 3606.155 | 21.562 | 2429.656 |
| Algorithm | Regression Coefficients |
|---|---|
| OLS | Intercept: 1901.1, X18: −2701.682, X19: 3361.864, X14: −18,485.94, X16: −2380.934, X10: −64,862.639, X2: 41,694.214, X11: −4371.515, X13: −1373.629, X6: −11,883.214, X5: −5818.896, X7: 350.947, X3: 62,982.759, X9: 38,206.661, X8: 1205.293, X4: −5115.524, X1: 4267.389, X12: 8741.203, X17: 23,840.905, X20: 326.614 |
| BSR | Intercept: −3403.922, X18: 5337.635, X19: −93,394.656, X14: 53,891.134, X16: 7504.77, X10: −25,863.081, X2: 86,852.708, X11: 20,344.519, X13: 21,736.836 |
| LARS | Intercept: −2900.887, X18: 0.0, X19: 0.0, X14: 0.0, X16: 0.0, X10: 0.0, X2: 30,624.587, X11: 0.0, X13: 0.0, X6: 0.0, X5: 0.0, X7: 0.0, X3: 7234.966, X9: 0.0, X8: 0.0, X4: 0.0, X1: 42,087.766, X12: 0.0, X17: 8925.469, X20: 0.0 |
| RANSAC | Intercept: 3153.065, X18: −2329.204, X19: −2244.842, X14: −15,134.735, X16: −680.564, X10: −68,444.646, X2: 62,309.348, X11: 8446.039, X13: −32,618.475, X6: −1115.962, X5: −70,222.187, X7: 1347.96, X3: 14,151.086, X9: 67,667.638, X8: 32,527.374, X4: 3245.049, X1: −9210.031, X12: 39,307.589, X17: 4264.226, X20: 6561.059 |
| PCR | Intercept: 21,141.643, PCA_comp_1: 22,453.882, PCA_comp_2: 13,210.932, PCA_comp_3: 34,922.859, PCA_comp_4: 4447.51, PCA_comp_5: −18,119.79, PCA_comp_6: 21368.82 |
| PLS | Intercept: 21,141.643, X18: 2373.471, X19: −2654.313, X14: −9015.102, X16: −448.029, X10: −8446.882, X2: 32,589.97, X11: −12,449.821, X13: −2399.885, X6: 3084.427, X5: −7366.366, X7: 10,634.243, X3: 21,308.299, X9: 48,67.91, X8: 6529.518, X4: 16,855.52, X1: 22,241.48, X12: −5143.745, X17: 18,142.841, X20: −7780.463 |
| Lasso | Intercept: 1964.62, X19: −1589.42, X14: 192.919, X16: −17,277.211, X10: 0.0, X2: −42,274.926, X11: 39,859.867, X13: −6965.692, X6: 0.0, X5: 0.0, X7: −3148.53, X3: 0.0, X9: 53,982.023, X8: 18,387.694, X4: 0.0, X1: −1408.461, X12: 10,624.522, X17: 551.24 |
| Ridge | Intercept: −564.43, X18: −463.238, X19: 6.035, X14: −11,254.556, X16: 294.123, X10: −12,849.21, X2: 27,474.343, X11: −10,941.451, X13: −971.068, X6: 3010.897, X5: −5240.741, X7: 8376.518, X3: 18,889.473, X9: 5893.067, X8: 9164.593, X4: 6572.182, X1: 29,686.551, X12: 1171.75, X17: 18,537.403, X20: −3996.295 |
| Elastic Net | Intercept: −2646.624, X18: 75.337, X19: −523.813, X14: −6518.326, X16: 1903.378, X10: −3420.06, X2: 18,940.878, X11: −6626.514, X13: 1211.34, X6: 3634.379, X5: −2755.817, X7: 8352.229, X3: 13,091.079, X9: 5572.288, X8: 7356.989, X4: 11,183.943, X1: 23,092.917, X12: 655.476, X17: 14,025.249, X20: −2551.125 |
| SVR | Non-parametric |
| KNN | Non-parametric |
| RF | Non-parametric |
| Algorithms | R2 | RMSE | MABE | MAPE (%) |
|---|---|---|---|---|
| OLS | 0.924 | 6471.913 | 48.063 | 4733.677 |
| BSR | 0.977 | 3547.13 | 34.667 | 2282.022 |
| RANSAC | 0.899 | 7421.336 | 59.307 | 5125.861 |
| LARS | 0.888 | 7838.545 | 69.02 | 5759.284 |
| PCR | 0.914 | 6868.028 | 102.96 | 6133.461 |
| PLS | 0.922 | 6535.272 | 89.433 | 5666.922 |
| Lasso | 0.924 | 6459.609 | 51.043 | 4819.67 |
| Ridge | 0.907 | 7128.09 | 76.27 | 5874.865 |
| Elastic Net | 0.915 | 6828.741 | 81.983 | 5814.385 |
| SVR | 0.876 | 8157.352 | 71.263 | 5924.128 |
| KNN | 0.925 | 6424.436 | 50.105 | 4711.419 |
| RF | 0.977 | 3606.155 | 21.562 | 2429.656 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, G.; Li, Z.; Yang, M. Comparison of Twelve Machine Learning Regression Methods for Spatial Decomposition of Demographic Data Using Multisource Geospatial Data: An Experiment in Guangzhou City, China. Appl. Sci. 2021, 11, 9424. https://doi.org/10.3390/app11209424
Zhao G, Li Z, Yang M. Comparison of Twelve Machine Learning Regression Methods for Spatial Decomposition of Demographic Data Using Multisource Geospatial Data: An Experiment in Guangzhou City, China. Applied Sciences. 2021; 11(20):9424. https://doi.org/10.3390/app11209424
Chicago/Turabian StyleZhao, Guanwei, Zhitao Li, and Muzhuang Yang. 2021. "Comparison of Twelve Machine Learning Regression Methods for Spatial Decomposition of Demographic Data Using Multisource Geospatial Data: An Experiment in Guangzhou City, China" Applied Sciences 11, no. 20: 9424. https://doi.org/10.3390/app11209424
APA StyleZhao, G., Li, Z., & Yang, M. (2021). Comparison of Twelve Machine Learning Regression Methods for Spatial Decomposition of Demographic Data Using Multisource Geospatial Data: An Experiment in Guangzhou City, China. Applied Sciences, 11(20), 9424. https://doi.org/10.3390/app11209424