
Fitmix: An R Package for Mixture Modeling of the Budding Yeast S. cerevisiae Replicative Lifespan (RLS) Distributions

Abstract
:1. Introduction
2. Materials and Methods
2.1. Survival Time Functions
2.1.1. Gompertz Distribution
2.1.2. Log-Logistic Distribution
2.1.3. Log-Normal Distribution
2.1.4. Weibull Distribution
2.2. General Case for the Mixture Model
2.3. An Example: Deriving Gompertz Mixture Model
2.4. Maximum Likelihood Estimations of the Parameters with EM Algorithm in Mixture of Distributions
2.5. Estimating the Parameters of Replicative Lifespan Datasets Fitted by Mixture Models
2.6. Goodness-of-Fit Measurement of Mixture Modeling
2.6.1. Akaike Information Criterion (AIC)
2.6.2. Bayesian Information Criterion (BIC)
2.6.3. Kolmogorov–Smirnov (KS)
2.6.4. The Log-Likelihood Test
3. Results
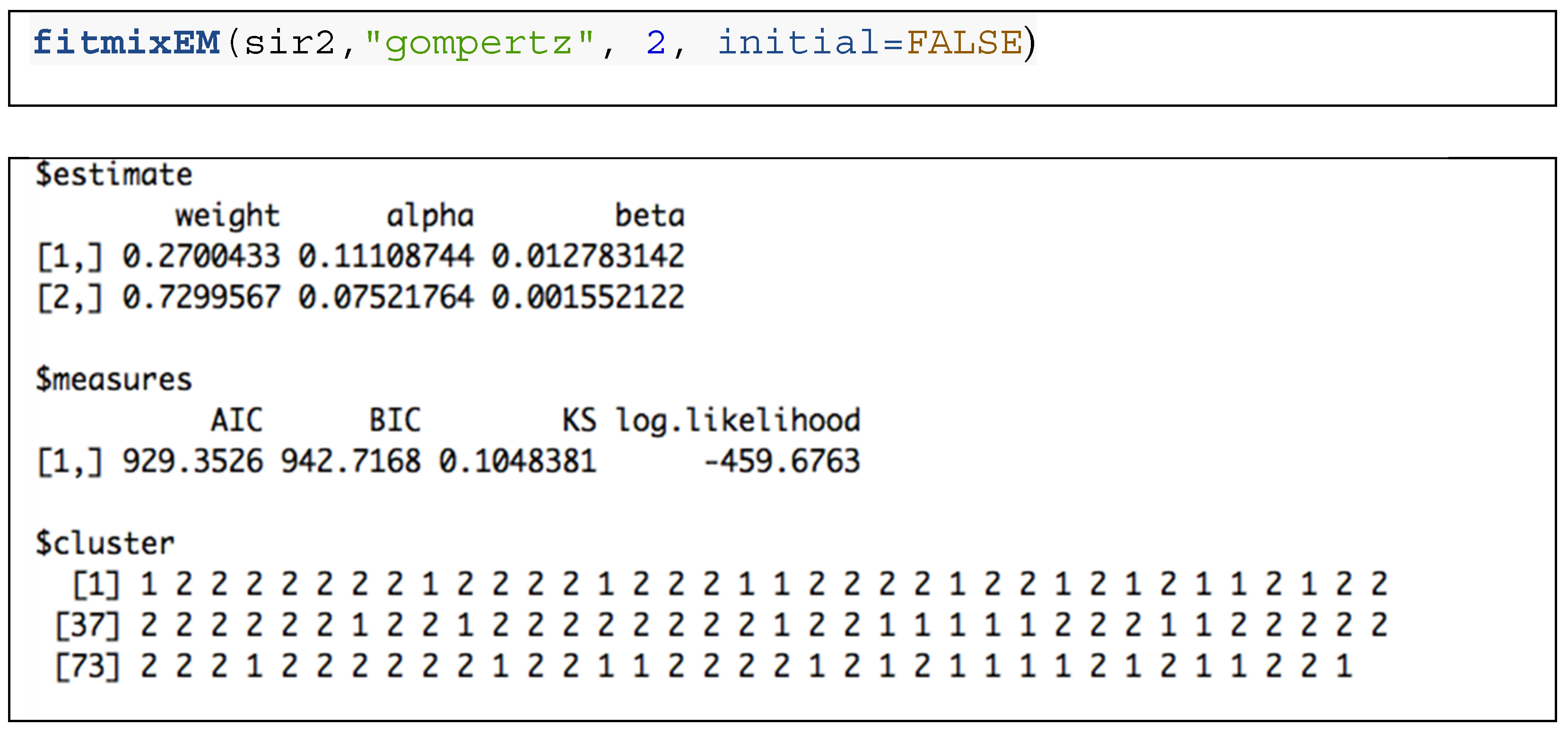
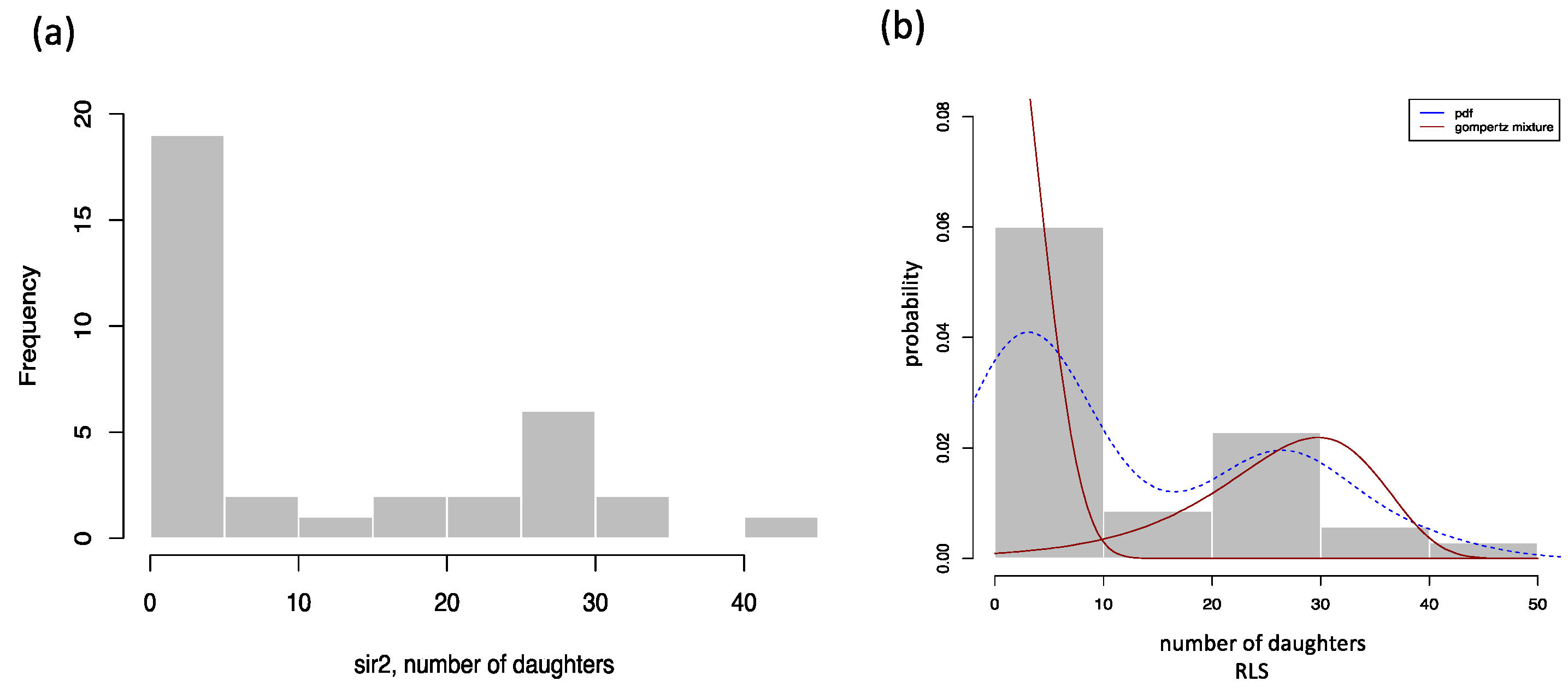
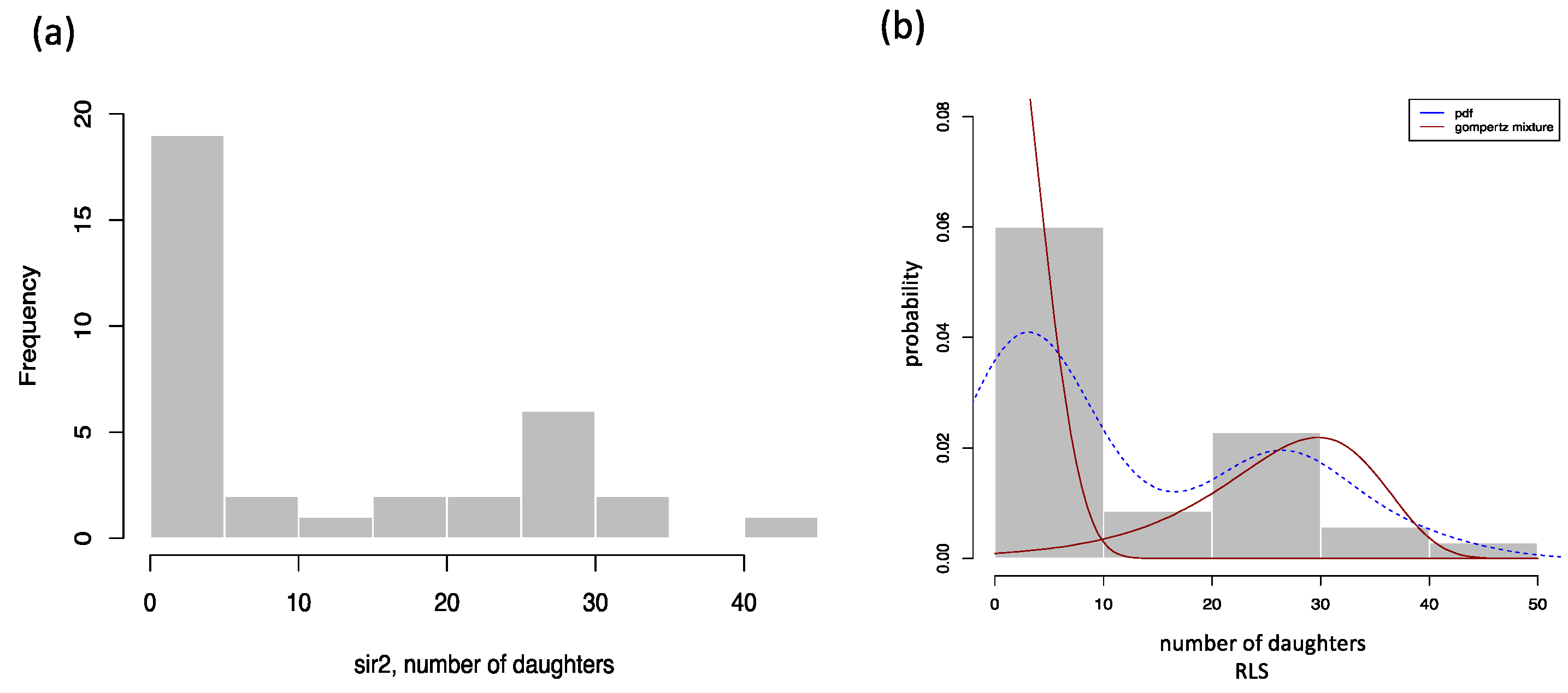
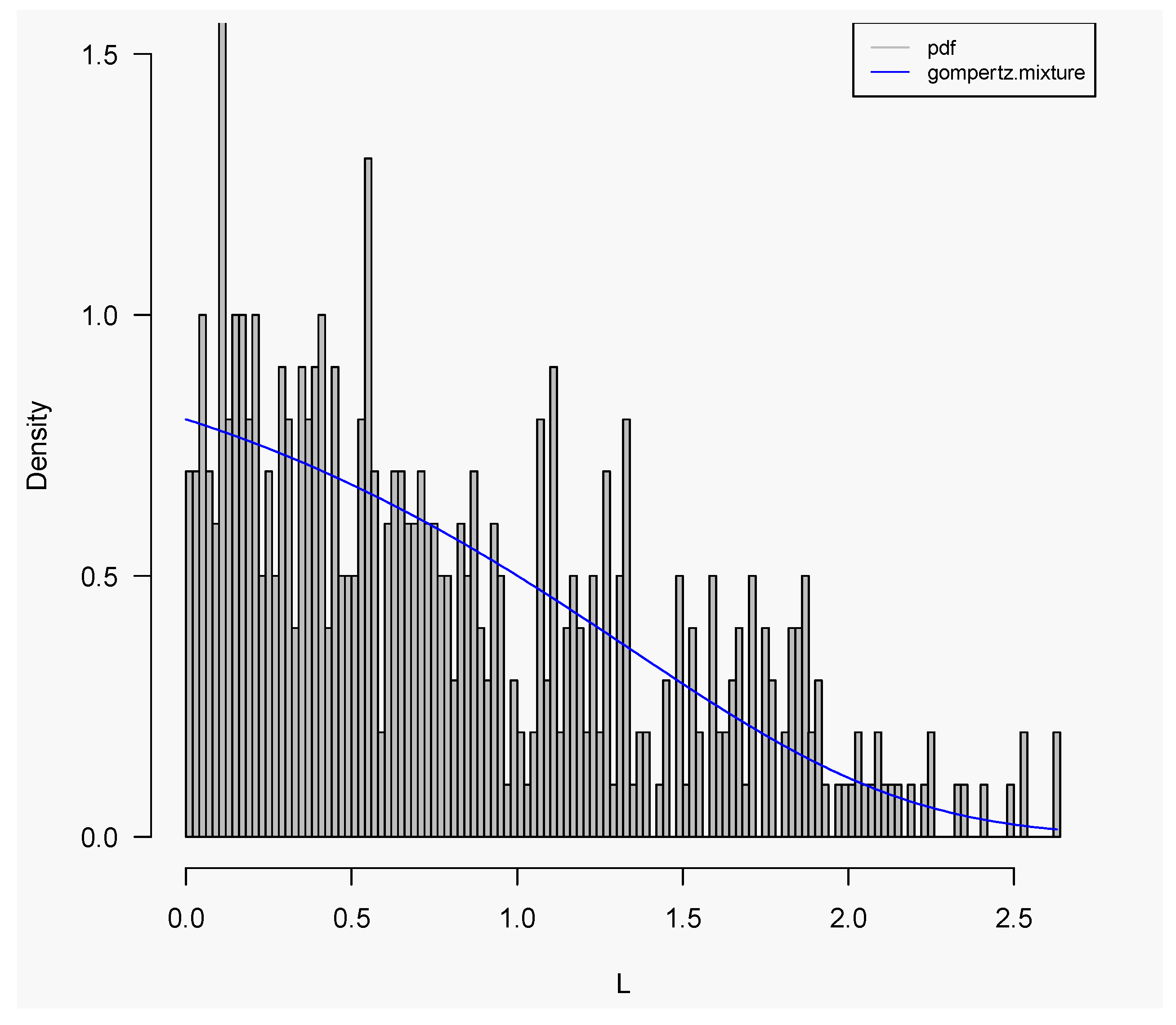
3.1. Working Examples: Fitting Finite Mixture Models to Lifespan Datasets

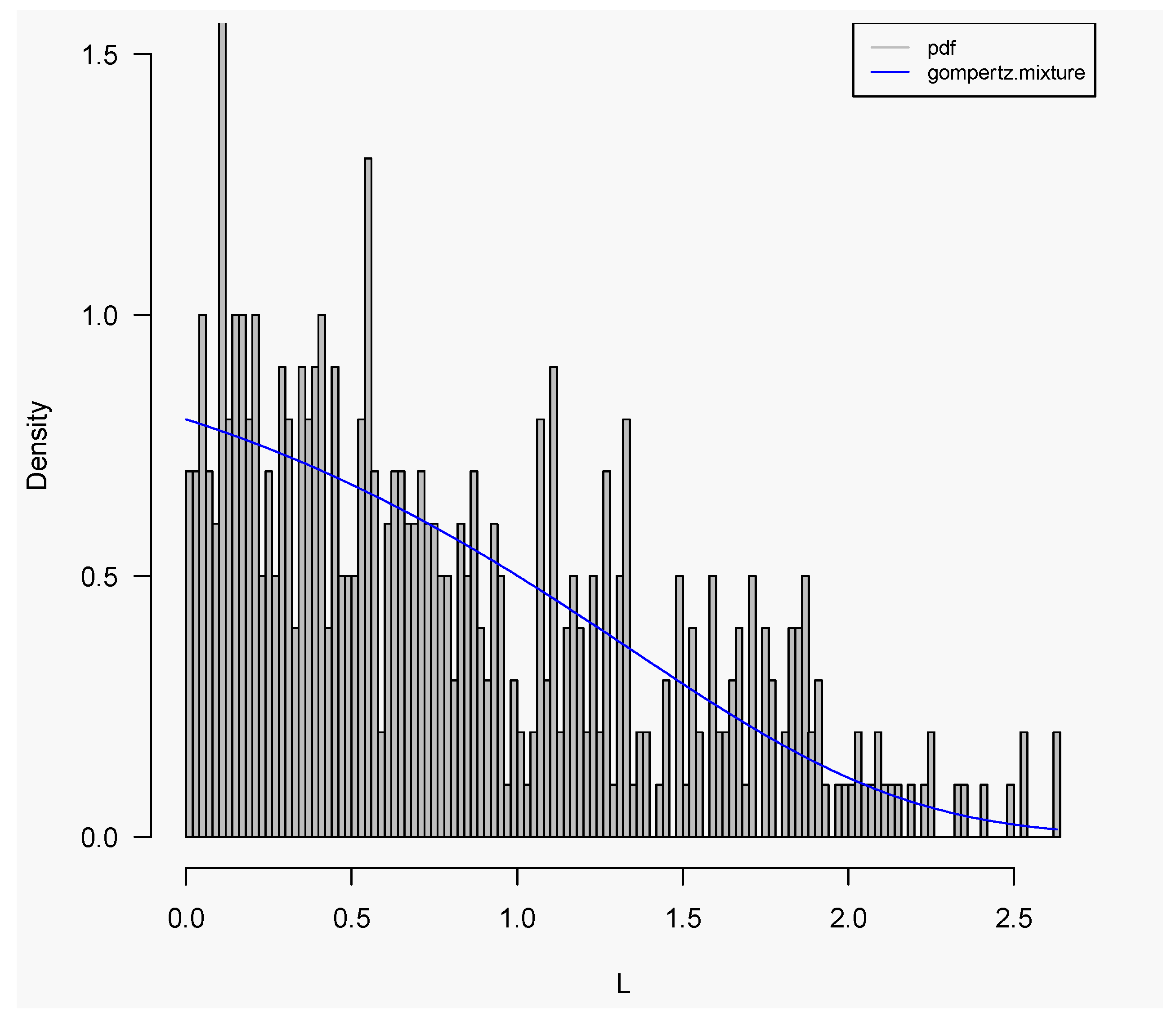
3.2. Distribution Functions for Finite Mixture Models


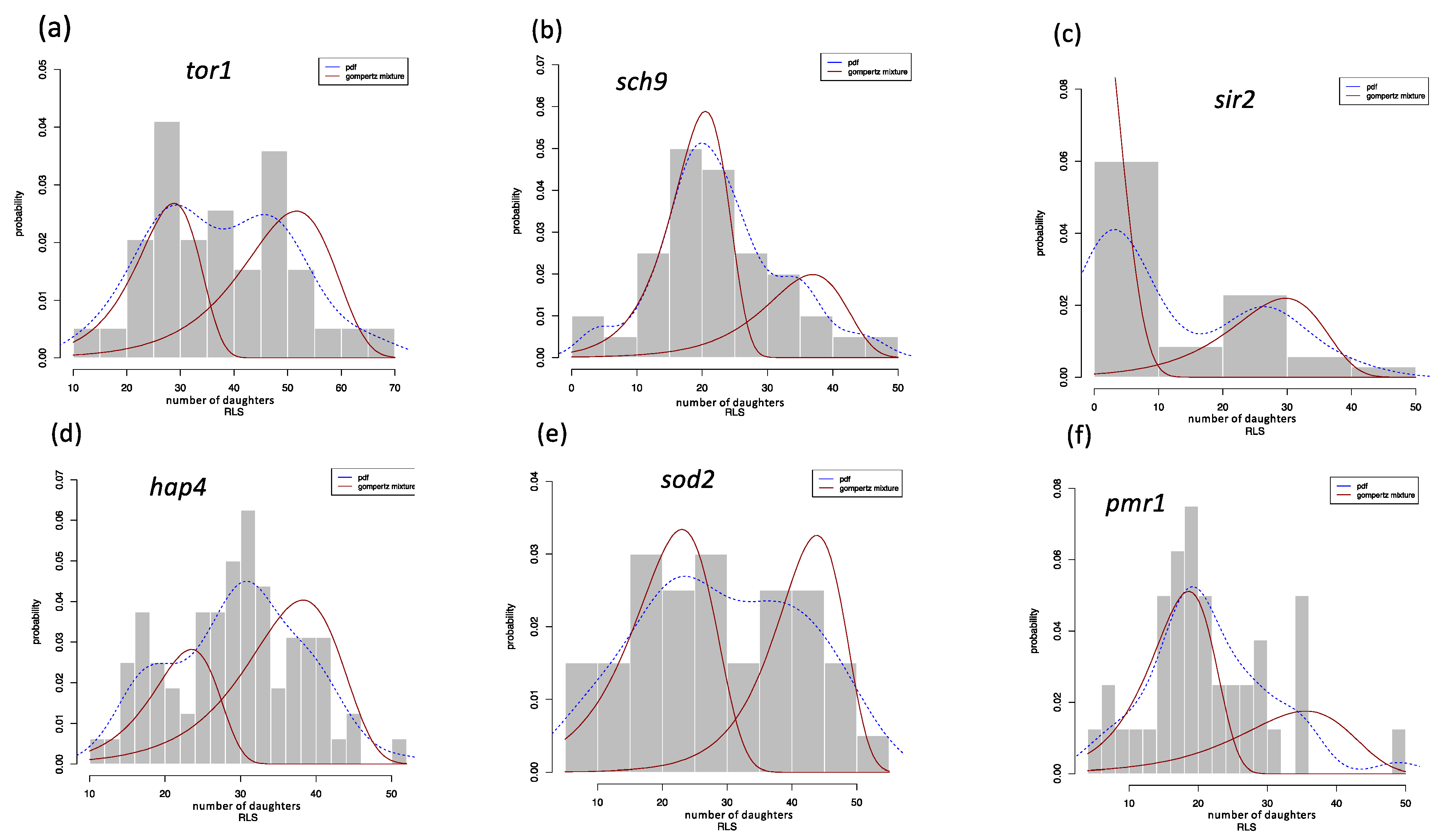
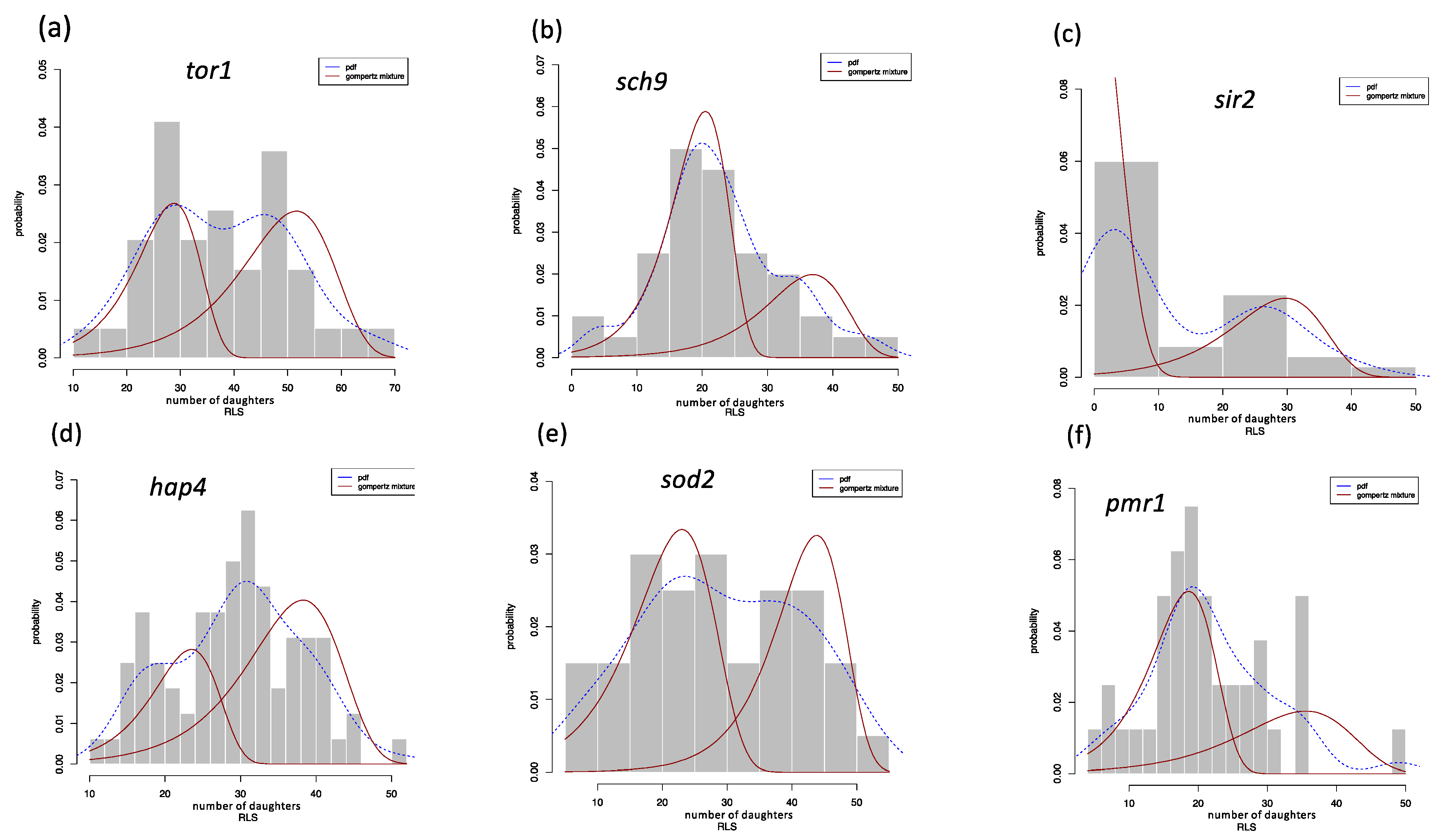
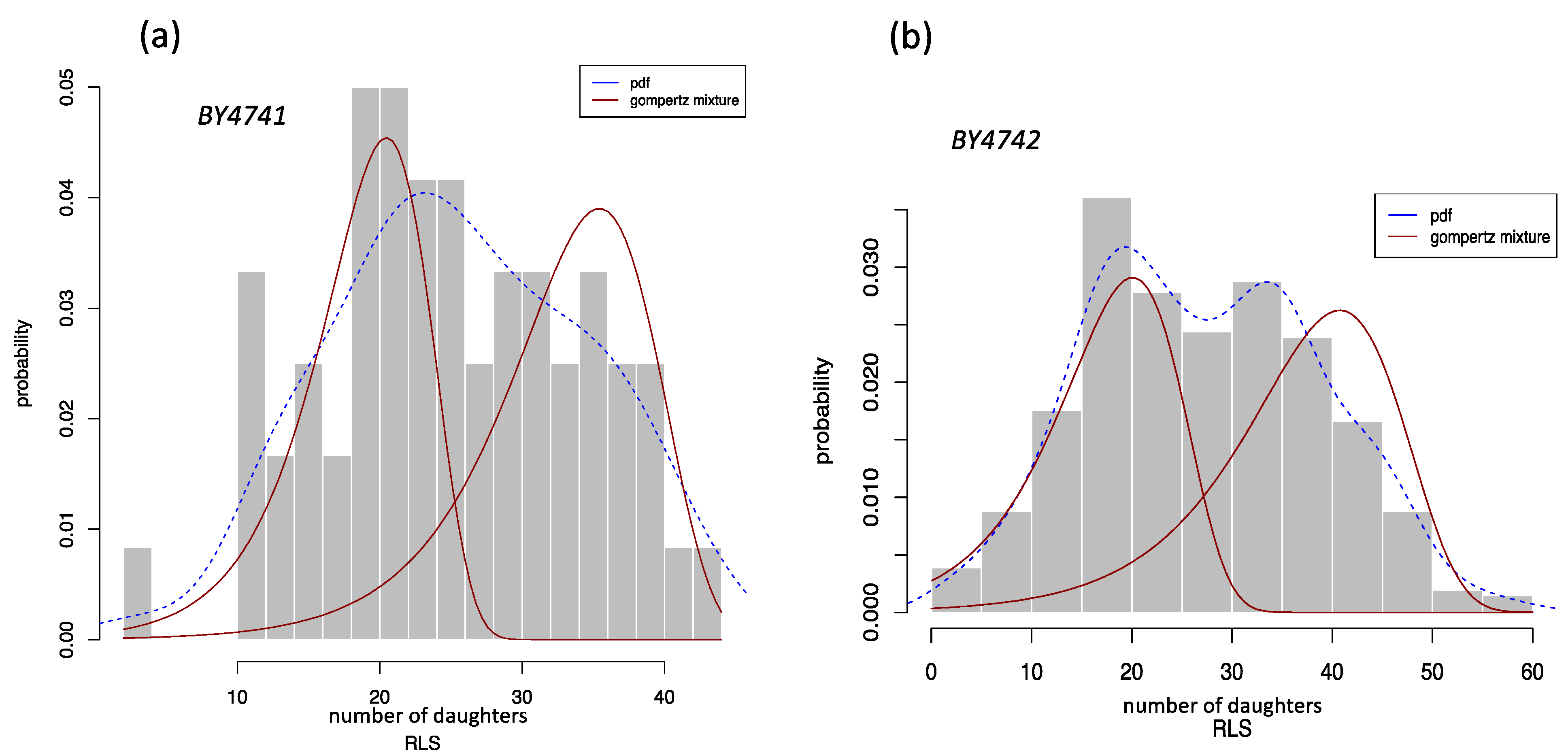
3.3. Finite Gompertz Mixture Model: Yeast Mutants with Known Effects on RLS Application
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Breitenbach, M.; Jazwinski, S.M.; Laun, P. Aging Research in Yeast; Springer Science & Business Media: Berlin, Germany, 2011; Volume 57, ISBN 94-007-2561-2. [Google Scholar]
- Longo, V.D.; Shadel, G.S.; Kaeberlein, M.; Kennedy, B. Replicative and Chronological Aging in Saccharomyces Cerevisiae. Cell Metab. 2012, 16, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Spivey, E.C.; Jones, S.K.; Rybarski, J.R.; Saifuddin, F.A.; Finkelstein, I.J. An Aging-Independent Replicative Lifespan in a Symmetrically Dividing Eukaryote. eLife 2017, 6, e20340. [Google Scholar] [CrossRef]
- Kaeberlein, M. Lessons on Longevity from Budding Yeast. Nature 2010, 464, 513–519. [Google Scholar] [CrossRef] [Green Version]
- Powers, R.W.; Kaeberlein, M.; Caldwell, S.D.; Kennedy, B.K.; Fields, S. Extension of Chronological Life Span in Yeast by Decreased TOR Pathway Signaling. Genes Dev. 2006, 20, 174–184. [Google Scholar] [CrossRef] [Green Version]
- Henderson, K.A.; Hughes, A.L.; Gottschling, D.E. Mother-Daughter Asymmetry of PH Underlies Aging and Rejuvenation in Yeast. Elife 2014, 3, e03504. [Google Scholar] [CrossRef]
- Minois, N.; Frajnt, M.; Wilson, C.; Vaupel, J. Advances in Measuring Lifespan in the Yeast Saccharomyces Cerevisiae. Proc. Natl. Acad. Sci. USA 2005, 102, 402–406. [Google Scholar] [CrossRef] [Green Version]
- Juckett, D.; Rosenberg, B. Comparison of the Gompertz and Weibull Functions as Descriptors for Human Mortality Distributions and Their Intersections. Mech. Ageing Dev. 1993, 69, 1–31. [Google Scholar] [CrossRef]
- Qin, H. Estimating Network Changes from Lifespan Measurements Using a Parsimonious Gene Network Model of Cellular Aging. BMC Bioinform. 2019, 20, 599. [Google Scholar] [CrossRef]
- Jin, M.; Li, Y.; O’Laughlin, R.; Bittihn, P.; Pillus, L.; Tsimring, L.S.; Hasty, J.; Hao, N. Divergent Aging of Isogenic Yeast Cells Revealed through Single-Cell Phenotypic Dynamics. Cell Syst. 2019, 8, 242–253.e3. [Google Scholar] [CrossRef] [Green Version]
- O’Laughlin, R.; Jin, M.; Li, Y.; Pillus, L.; Tsimring, L.S.; Hasty, J.; Hao, N. Advances in Quantitative Biology Methods for Studying Replicative Aging in Saccharomyces Cerevisiae. Transl. Med. Aging 2020, 4, 151–160. [Google Scholar] [CrossRef] [PubMed]
- Moustafa, H.M.; Ramadan, S.G. On MLE of a Nonlinear Discriminant Function from a Mixture of Two Gompertz Distributions Based on Small Sample Size. J. Stat. Comput. Simul. 2003, 73, 867–885. [Google Scholar] [CrossRef]
- Wilkinson, D.J. Stochastic Modelling for Quantitative Description of Heterogeneous Biological Systems. Nat. Rev. Genet. 2009, 10, 122–133. [Google Scholar] [CrossRef]
- Güven, E.; Akçay, S.; Qin, H. The Effect of Gaussian Noise on Maximum Likelihood Fitting of Gompertz and Weibull Mortality Models with Yeast Lifespan Data. Exp. Aging Res. 2019, 45, 167–179. [Google Scholar] [CrossRef]
- Everitt, B.S. Finite Mixture Distributions. In Encyclopedia of Statistics in Behavioral Science; American Cancer Society: Atlanta, GA, USA, 2005; ISBN 978-0-470-01319-9. [Google Scholar]
- McLachlan, G.J.; Lee, S.X.; Rathnayake, S.I. Finite Mixture Models. Annu. Rev. Stat. Its Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Saka, K.; Ide, S.; Ganley, A.R.; Kobayashi, T. Cellular Senescence in Yeast Is Regulated by RDNA Noncoding Transcription. Curr. Biol. 2013, 23, 1794–1798. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marín, J.M.; Rodriguez-Bernal, M.; Wiper, M.P. Using Weibull Mixture Distributions to Model Heterogeneous Survival Data. Commun. Stat. Simul. Comput. 2005, 34, 673–684. [Google Scholar] [CrossRef] [Green Version]
- Tsionas, E.G. Bayesian Analysis of Finite Mixtures of Weibull Distributions. Commun. Stat. Theory Methods 2002, 31, 37–48. [Google Scholar] [CrossRef]
- Al-Hussaini, E.K.; Al-Dayian, G.R.; Adham, S.A. On Finite Mixture of Two-Component Gompertz Lifetime Model. J. Stat. Comput. Simul. 2000, 67, 20–67. [Google Scholar] [CrossRef]
- Güven, E. A Comparison between the Performance of Weibull and Log-Logistic Aging Models on Saccharomyces Cerevisiae Lifespan Data. Bilecik Şeyh Edebali Üniversitesi Fen Bilimleri Derg. 2020, 7, 123–132. [Google Scholar] [CrossRef]
- Blischke, W.R.; Murthy, D.P. Reliability: Modeling, Prediction, and Optimization; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 767, ISBN 1-118-15047-3. [Google Scholar]
- Peel, D.; McLachlan, G.J. Robust Mixture Modelling Using the t Distribution. Stat. Comput. 2000, 10, 339–348. [Google Scholar] [CrossRef]
- Wilson, D.L. The analysis of survival (mortality) data: Fitting Gompertz, Weibull, and logistic functions. Mech. Ageing Dev. 1994, 74, 15–33. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Krishnan, T.; Ng, S.K. The EM Algorithm. 2004. Available online: https://www.econstor.eu/bitstream/10419/22198/1/24_tk_gm_skn.pdf (accessed on 18 March 2021).
- Akaike, H. A New Look at the Statistical Model Identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Smirnov, N. Table for Estimating the Goodness of Fit of Empirical Distributions. Ann. Math. Stat. 1948, 19, 279–281. [Google Scholar] [CrossRef]
- Fisher, R.A. Two New Properties of Mathematical Likelihood. Proc. R. Soc. London. Ser. A Math. Phys. Sci. 1934, 144, 285–307. [Google Scholar]
- Kaeberlein, M.; Kirkland, K.T.; Fields, S.; Kennedy, B.K. Sir2-Independent Life Span Extension by Calorie Restriction in Yeast. PLoS Biol. 2004, 2, e296. [Google Scholar] [CrossRef]
- Qin, H. A Network Model for Cellular Aging. arXiv 2013, arXiv:1305.5784. [Google Scholar]
- Li, Y.; Jiang, Y.; Paxman, J.; O’Laughlin, R.; Klepin, S.; Zhu, Y.; Pillus, L.; Tsimring, L.S.; Hasty, J.; Hao, N. A Programmable Fate Decision Landscape Underlies Single-Cell Aging in Yeast. Science 2020, 369, 325–329. [Google Scholar] [CrossRef]
- El-Gohary, A.; Alshamrani, A.; Al-Otaibi, A.N. The Generalized Gompertz Distribution. Appl. Math. Model. 2013, 37, 13–24. [Google Scholar] [CrossRef] [Green Version]
- Jansen, R. Maximum Likelihood in a Generalized Linear Finite Mixture Model by Using the EM Algorithm. Biometrics 1993, 49, 227–231. [Google Scholar] [CrossRef]
- Benaglia, T.; Chauveau, D.; Hunter, D.; Young, D. Mixtools: An R Package for Analyzing Finite Mixture Models. J. Stat. Softw. 2009, 32, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Erisoglu, U.; Erisoglu, M.; Erol, H. MIXTURE MODEL APPROACH TO THE ANALYSIS OF HETEROGENEOUS SURVIVAL DATA. Pak. J. Stat. 2012, 28, 115–130. [Google Scholar]
- Karakoca, A.; Erisoglu, U.; Erisoglu, M. A Comparison of the Parameter Estimation Methods for Bimodal Mixture Weibull Distribution with Complete Data. J. Appl. Stat. 2015, 42, 1472–1489. [Google Scholar] [CrossRef]
- Erişoğlu, Ü.; Erişoğlu, M.; Erol, H. A Mixture Model of Two Different Distributions Approach to the Analysis of Heterogeneous Survival Data. Int. J. Comput. Math. Sci. 2011, 5, 75–79. [Google Scholar]
- Morin, A.J.S.; Litalien, D. Mixture Modeling for Lifespan Developmental Research. Available online: https://oxfordre.com/psychology/view/10.1093/acrefore/9780190236557.001.0001/acrefore-9780190236557-e-364 (accessed on 13 April 2021).
- Jackson, C. Flexsurv: A Platform for Parametric Survival Modeling in R. J. Stat. Softw. 2016, 70, 1–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimated | Parameters | |||||
|---|---|---|---|---|---|---|
| deletion mutants | ||||||
| tor1 | 0.58193 | 0.11853 | 0.00025 | 0.41806 | 0.17316 | 0.00118 |
| sch9 | 0.32569 | 0.16519 | 0.00037 | 0.67430 | 0.23548 | 0.00188 |
| sir2 | 0.41763 | 0.14042 | 0.00215 | 0.58236 | 0.15148 | 0.22705 |
| hap4 | 0.32934 | 0.23195 | 0.00099 | 0.67065 | 0.16322 | 0.00031 |
| sod2 | 0.49874 | 0.17351 | 0.0001 | 0.50125 | 0.17925 | 0.00353 |
| pmr1 | 0.37274 | 0.12604 | 0.00142 | 0.62725 | 0.22176 | 0.00377 |
| wildtypes | ||||||
| BY4741 | 0.57262 | 0.22899 | 0.00139 | 0.42737 | 0.21757 | 0.00007 |
| BY4742 | 0.48798 | 0.17110 | 0.00443 | 0.512012 | 0.13422 | 0.00053 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Güven, E.; Qin, H. Fitmix: An R Package for Mixture Modeling of the Budding Yeast S. cerevisiae Replicative Lifespan (RLS) Distributions. Appl. Sci. 2021, 11, 6114. https://doi.org/10.3390/app11136114
Güven E, Qin H. Fitmix: An R Package for Mixture Modeling of the Budding Yeast S. cerevisiae Replicative Lifespan (RLS) Distributions. Applied Sciences. 2021; 11(13):6114. https://doi.org/10.3390/app11136114
Chicago/Turabian StyleGüven, Emine, and Hong Qin. 2021. "Fitmix: An R Package for Mixture Modeling of the Budding Yeast S. cerevisiae Replicative Lifespan (RLS) Distributions" Applied Sciences 11, no. 13: 6114. https://doi.org/10.3390/app11136114
APA StyleGüven, E., & Qin, H. (2021). Fitmix: An R Package for Mixture Modeling of the Budding Yeast S. cerevisiae Replicative Lifespan (RLS) Distributions. Applied Sciences, 11(13), 6114. https://doi.org/10.3390/app11136114