
Online Textual Symptomatic Assessment Chatbot Based on Q&A Weighted Scoring for Female Breast Cancer Prescreening

 , , , ,
, , , , 

Abstract
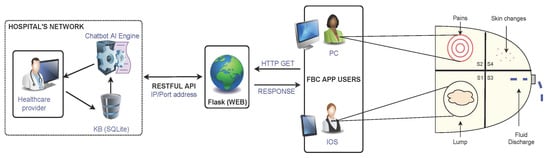
:
1. Introduction
- Benefit to users: SAC’s Q&A assessment raises the awareness of FBC ailment and encourages self examination of the breasts during dialog in the comfort of the users’ valued privacy, which will stimulate them to communicate freely and sincerely about their FBC symptoms. In congruence to this regard, an earlier study by Lucas et al. [15] revealed that patients are more comfortable responding honestly to computer-administered health assessments than that of human physicians due to the “intimate” nature of information usually required in such conversational contexts. On the other hand, SAC has the ability to promptly schedule medical appointment for the users scored with positive FBC symptoms in-order to expedite timely FBC diagnosis and early medical treatment.
- Benefit to hospitals: SAC offers the potential benefit of controlling undue and inundating influx of patients in FBC healthcare departments, most of whom may schedule FBC medical appointments while having unrelated symptoms (i.e., FBC false negative cases). According to Bibault et al. [14], dialog systems can allow physicians to spend more time in treating patients who need the most consultation. On this account, the healthcare sector of many countries are beginning to utilize the digital services of chatbots for patients’ disease prescreening assessment and triage in-order to reduce stress on health providers [16]. Therefore, by adopting SAC, hospitals can drastically minimize wastage of time, money, and other resource costs, and more importantly, doctors and other healthcare personnel will be enabled to work more productively to achieve effective patient-centric care service delivery.
2. Related Works
3. Methodology
3.1. The Symptomatic Assessment Process
3.1.1. Question and Answer Distribution
3.1.2. Knowledge-Base Data Structure
3.1.3. Weighing and Scoring Module
3.2. Natural Language Understanding
3.3. The Logic Reasoning Module
4. Experimental Results
4.1. Discussion
4.2. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ayaz, F.; Ayaz, S.B.; Farrukh, M. Reasons for Delayed Presentation of Women with Breast Cancer. J. Islamabad Med. Dent. Coll. 2016, 5, 187–191. [Google Scholar]
- Tesfaw, A.; Demis, S.; Munye, T.; Ashuro, Z. Patient Delay and Contributing Factors Among Breast Cancer Patients at Two Cancer Referral Centres in Ethiopia: A Cross-Sectional Study. J. Multidiscip. Healthc. 2020, 13, 1391–1401. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Wang, G.; Zhang, J.; Lu, Y.; Jiang, X. Patient delay and associated factors among Chinese women with breast cancer: A Cross-Sectional Study. J. Med. 2019, 98, e17454. [Google Scholar] [CrossRef]
- Anderson, B.; Aranda, S.; Chatamra, K.; Cheung, P.; Chiou, S.-T.; Crossing, S.; Dent, R.; Fan, Z.; Ginsburg, O.; Han, S.; et al. Breast Cancer in Asia: The Challenge and Response; The Economist Intelligence Unit: London, UK, 2016. [Google Scholar]
- Bhatia, H. Breast Cancer in Asia. General Reinsurance AG. November 2016. Available online: https://media.genre.com/documents/ri16-4-en.pdf (accessed on 28 January 2021).
- Tsai, H.Y.; Chang, Y.L.; Shen, C.T.; Chung, W.S.; Tsai, H.J.; Chen, F.M. Effects of the COVID-19 pandemic on breast cancer screening in Taiwan. Breast 2020, 54, 52–55. [Google Scholar] [CrossRef] [PubMed]
- Ataollahi, M.R.; Sharifi, J.; Paknahad, M.R.; Paknahad, A. Breast cancer and associated factors: A review. J. Med. Life 2015, 8, 6–11. [Google Scholar]
- Moser, E.C.; Narayan, G. Improving breast cancer care coordination and symptom managementby using AI driven predictive toolkits. Breast 2019, 50, 25–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fadhil, A.; Gabrielli, S. Addressing Challenges in Promoting Healthy Lifestyles: The AI-Chatbot Approach. In Proceedings of the 11th EAI international conference on pervasive computing technologies for healthcare, Barcelona, Spain, 23–26 May 2017; pp. 261–265. [Google Scholar]
- Siddique, S.; Chow, J.C.L. Machine Learning in Healthcare Communication. Encyclopedia 2021, 1, 220–239. [Google Scholar] [CrossRef]
- Hoermann, S.; McCabe, K.L.; Milne, D.N.; Calvo, R.A. Application of Synchronous Text-based Dialogue Systems in Mental Health Interventions: Systematic Review. J. Med. Internet Res. 2017, 19, e267. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Agbodike, O.; Wang, L. Memory-Based Deep Neural Attention (mDNA) for Cognitive Multi-Turn Response Retrieval in Task-Oriented Chatbots. Appl. Sci. 2020, 10, 5819. [Google Scholar] [CrossRef]
- Chang, K.-C.; Chang, H.-T. Is It Possible to Use Chatbot for the Chinese Word Segmentation? In Proceedings of the 2019 3rd International Conference on Natural Language Processing and Information Retrieval, Tokushima, Japan, 28–30 June 2019; pp. 20–24. [Google Scholar]
- Bibault, J.E.; Chaix, B.; Guillemassé, A.; Cousin, S.; Escande, A.; Perrin, M.; Pienkowski, A.; Delamon, G.; Nectoux, P.; Brouard, B. A Chatbot Versus Physicians to Provide Information for Patients With Breast Cancer: Blind, Randomized Controlled Noninferiority Trial. J. Med. Internet Res. 2019, 21, e15787. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lucas, G.M.; Gratch, J.; King, A.; Morency, L. It’s only a computer: Virtual humans increase willingness to disclose. Comput. Hum. Behav. 2014, 37, 94–100. [Google Scholar] [CrossRef]
- Martin, A.; Nateqi, J.; Gruarin, S.; Munsch, N.; Abdarahmane, I.; Zobel, M.; Knapp, B. An artificial intelligence-based first-line defence against COVID-19: Digitally screening citizens for risks via a chatbot. Nat. Sci. Rep. 2020, 10, 19012. [Google Scholar] [CrossRef]
- Majid, U.; Wasim, A. Patient-centric culture and implications for patient engagement during the COVID-19 pandemic. Patient Exp. J. 2020, 7, 5–16. [Google Scholar] [CrossRef]
- Koinis, A.; Giannou, V.; Drantaki, V.; Angelaina, S.; Stratou, E.; Saridi, M. The Impact of Healthcare Workers Job Environment on their Mental-emotional Health. Coping Strategies: The Case of a Local General Hospital. Health Psychol. Res. 2015, 3, 12–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Omoregbe, N.A.I.; Ndaman, I.O.; Misra, S.; Abayomi-Alli, O.O.; Damasevicius, R. Text Messaging-Based Medical Diagnosis Using Natural Language Processing and Fuzzy Logic. J. Healthc. Eng. 2020, 2020, 8839524. [Google Scholar] [CrossRef]
- Vaira, L.; Bochicchio, M.A.; Conte, M.; Casaluci, F.M.; Guillemasse, A.; Melpignano, A. MamaBot: A System based on ML and NLP for supporting Women and Families during Pregnancy. In Proceedings of the 22nd International Database Engineering & Applications Symposium 2018, Villa San Giovanni, Italy, 18–20 June 2018; pp. 273–277. [Google Scholar]
- Wang, L.; Wang, D.; Tian, F.; Peng, Z.; Zhang, X.; Ma, S.; Yu, M.; Ma, X.; Wang, H. CASS: Towards Building a Social-Support Chatbot for Online Health Community. ACM Hum.-Comput. Interact. 2021, 5, 1–31. [Google Scholar]
- Palanica, A.; Flaschner, P.; Thommandram, A.; Li, M.; Fossat, Y. Physicians’ Perception of Chatbots in Health Care: Cross-Sectional Web-Based Survey. J. Med. Internet Res. 2019, 21, e12887. [Google Scholar] [CrossRef] [PubMed]
- Chaix, B.; Bibault, J.E.; Pienkowski, A.; Delamon, G.; Guillemasse, A.; Nectoux, P.; Brouard, B. When Chatbots Meet Patients: One-Year Prospective Study of Conversations Between Patients with Breast Cancer and a Chatbot. JMIR Cancer 2019, 5, e12856. [Google Scholar] [CrossRef] [PubMed]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Shaikhina, T.; Khovanova, N.A. Handling limited datasets with neural networks in medical applications: A small-data approach. AI Med. 2017, 75, 51–63. [Google Scholar] [CrossRef] [PubMed]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. J. Healthc. Eng. 2017, 19, 1236–1246. [Google Scholar] [CrossRef] [PubMed]
- Shaikhina, T.; Khovanova, N.A. A Review of Challenges and Opportunities in Machine Learning for Health. AMIA Summits Transl. Sci. Proc. 2020, 2020, 191–200. [Google Scholar]
- Kapočiūtė-Dzikienė, J. A Domain-Specific Generative Chatbot Trained from Little Data. Appl. Sci. 2020, 10, 2221. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Chen, H.; Huang, X. Chinese-English Mixed Text Normalization. In Proceedings of the 7th ACM international conference on Web search and data mining, New York, NY, USA, 24–28 February 2014; pp. 433–442. [Google Scholar]
- Shao, C.; Feng, Y.; Chen, X. Greedy Search with Probabilistic N-gram Matching for Neural Machine Translation. In Proceedings of the ACL Conference Empirical Methods in Natural Language Processing, Brussels Belgium, 31 October–4 November 2018; pp. 4778–4784. [Google Scholar]
- Ma, J.; Hinrichs, E. Accurate Linear-Time Chinese Word Segmentation via Embedding Matching. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, Beijing China, 26–31 July 2015; pp. 1733–1743. [Google Scholar]
- Cai, D.; Zhao, H.; Zhang, Z.; Xin, Y.; Wu, Y.; Huang, F. Fast and Accurate Neural Word Segmentation for Chinese. arXiv 2017, arXiv:1704.07047v1. [Google Scholar]
- Fu, J.; Liu, P.; Zhang, Q.; Huang, X. Rethink CWS: Is Chinese Word Segmentation a Solved Task? arXiv 2020, arXiv:2011.06858v2. [Google Scholar]
- Fadhil, A.; Schiavo, G. Designing for Health Chatbots. arXiv 2019, arXiv:1902.09022v1. [Google Scholar]
- Zhao, J.; Liu, H.; Bao, Z.; Bai, X.; Li, S.; Lin, Z. N-gram Model for Chinese Grammatical Error Diagnosis. In Proceedings of the 4th Workshop on Natural Language Processing Techniques for Educational Applications (NLPTEA 2017), Taipei, Taiwan, 1 December 2017; pp. 39–44. [Google Scholar]
- Zeng, D.; Wei, D.; Chau, M.; Wang, F. Domain-specific Chinese word segmentation using suffix tree and mutual information. Inf. Syst. Front. 2010, 13, 115–125. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Question Topic Categories | |||
|---|---|---|---|
| Index | Query | Index | Query |
| QC1 * | Did you feel any breast lumps? | QC9 | Have you ever had a breast ultrasound examination? |
| QC2 | Does the breast hurt? | QC10 | Have you ever had a mammogram? |
| QC3 * | Is there any discharge from the nipple? | QC11 | Have you ever had a breast tumor lab test or breast tumor removal surgery? |
| QC4 * | Is the appearance of the breast sunken, bulged, or wounded? | Q12 | Have you ever had an underarm examination or breast augmentation surgery? |
| QC5 | Is any of the breast skin itchy? | QC13 | Have you ever had a breast MRI examination? |
| QC6 * | Do you personally have a medical history of ovarian cancer, breast cancer, prostate cancer, or pancreatic cancer? | QC14 * | Have you had any other imaging tests in the past that show a problem with the breast? |
| QC7 | Do you have direct blood relatives or siblings suffering from metastatic prostate cancer or pancreatic cancer? | QC15 * | Have you ever had a blood or genetic test confirming you are in high-risk group for breast cancer? |
| QC8 | Do you have a family history of breast cancer or ovarian cancer? | QC16 * | Have you or any of your family members tested positive for breast cancer gene (BRCA)? |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.-H.; Agbodike, O.; Kuo, W.-L.; Wang, L.; Huang, C.-H.; Shen, Y.-S.; Chen, B.-H. Online Textual Symptomatic Assessment Chatbot Based on Q&A Weighted Scoring for Female Breast Cancer Prescreening. Appl. Sci. 2021, 11, 5079. https://doi.org/10.3390/app11115079
Chen J-H, Agbodike O, Kuo W-L, Wang L, Huang C-H, Shen Y-S, Chen B-H. Online Textual Symptomatic Assessment Chatbot Based on Q&A Weighted Scoring for Female Breast Cancer Prescreening. Applied Sciences. 2021; 11(11):5079. https://doi.org/10.3390/app11115079
Chicago/Turabian StyleChen, Jen-Hui, Obinna Agbodike, Wen-Ling Kuo, Lei Wang, Chiao-Hua Huang, Yu-Shian Shen, and Bing-Hong Chen. 2021. "Online Textual Symptomatic Assessment Chatbot Based on Q&A Weighted Scoring for Female Breast Cancer Prescreening" Applied Sciences 11, no. 11: 5079. https://doi.org/10.3390/app11115079