SCCDNet: A Pixel-Level Crack Segmentation Network

 , ,
, ,
Abstract
1. Introduction
- We designed an end-to-end crack segmentation network based on the CNNs, which can determine whether each pixel in the image belongs to a crack.
- In order to improve the segmentation accuracy of the model, the Skip-Squeeze-and-Excitation (SSE) module we designed was introduced into the network, using Squeeze and Excitation to recalibrate the pixels of the feature map. This skip-connection strategy can enhance the gradient correlation between the layers, thereby enhancing the performance of the network.
- We designed a dense connection network in the Decoder module to reduce the number of channels of feature maps by considering the crack features learned by each layer of the network; the traditional convolution was replaced by depthwise separable convolution, which reduces the complexity of the model without affecting the segmentation accuracy.
- A public dataset with manual annotations was established, including 7169 crack images with a resolution of 448 × 448. This dataset includes labeled crack images of different scenes and different shapes, as well as non-crack images which are similar to crack images, which can enhance the generalization ability of the model.
2. Methods
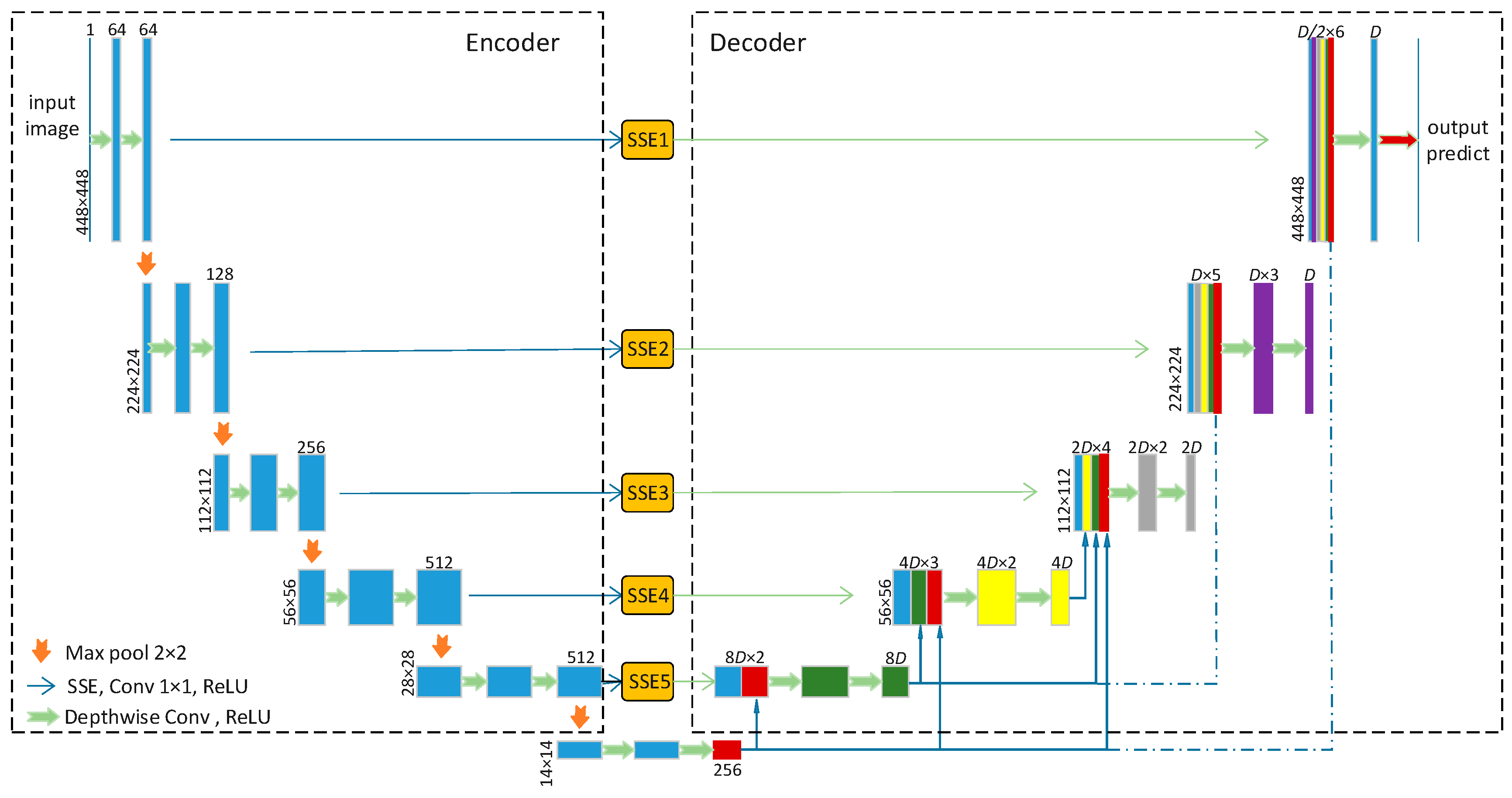
2.1. Model Architecture
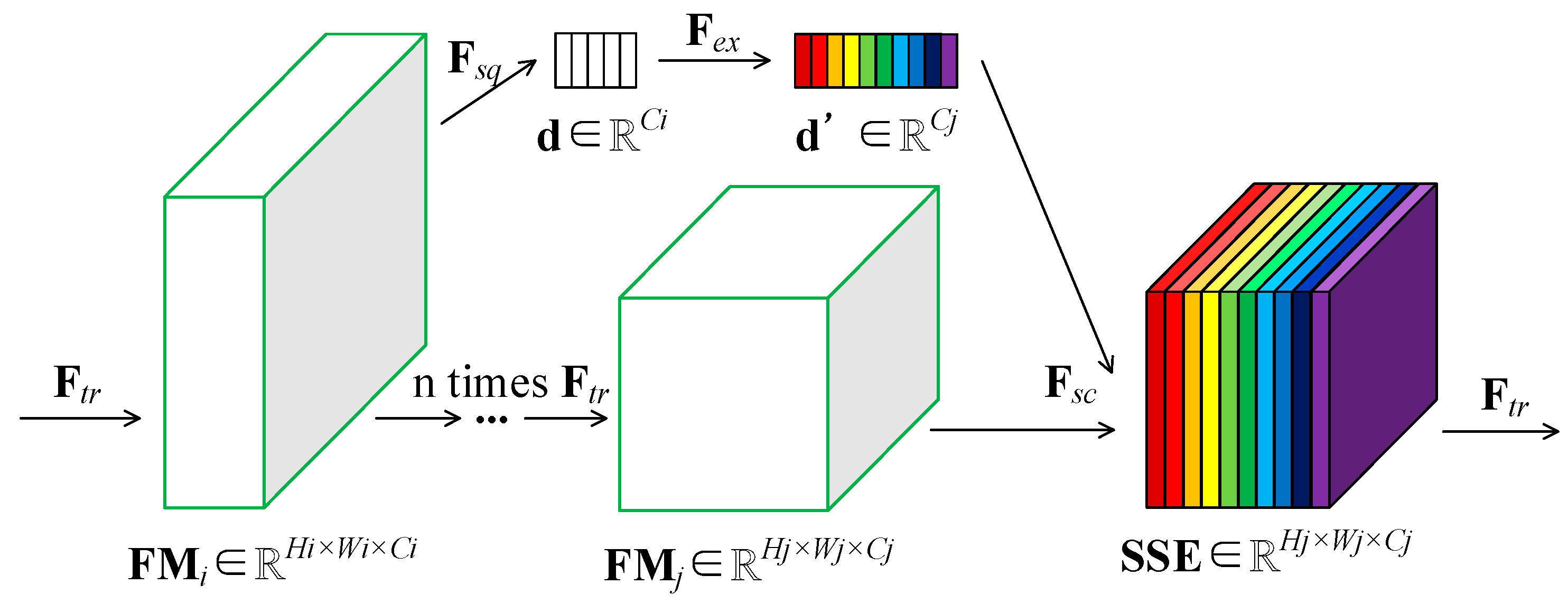
2.2. SSE Module
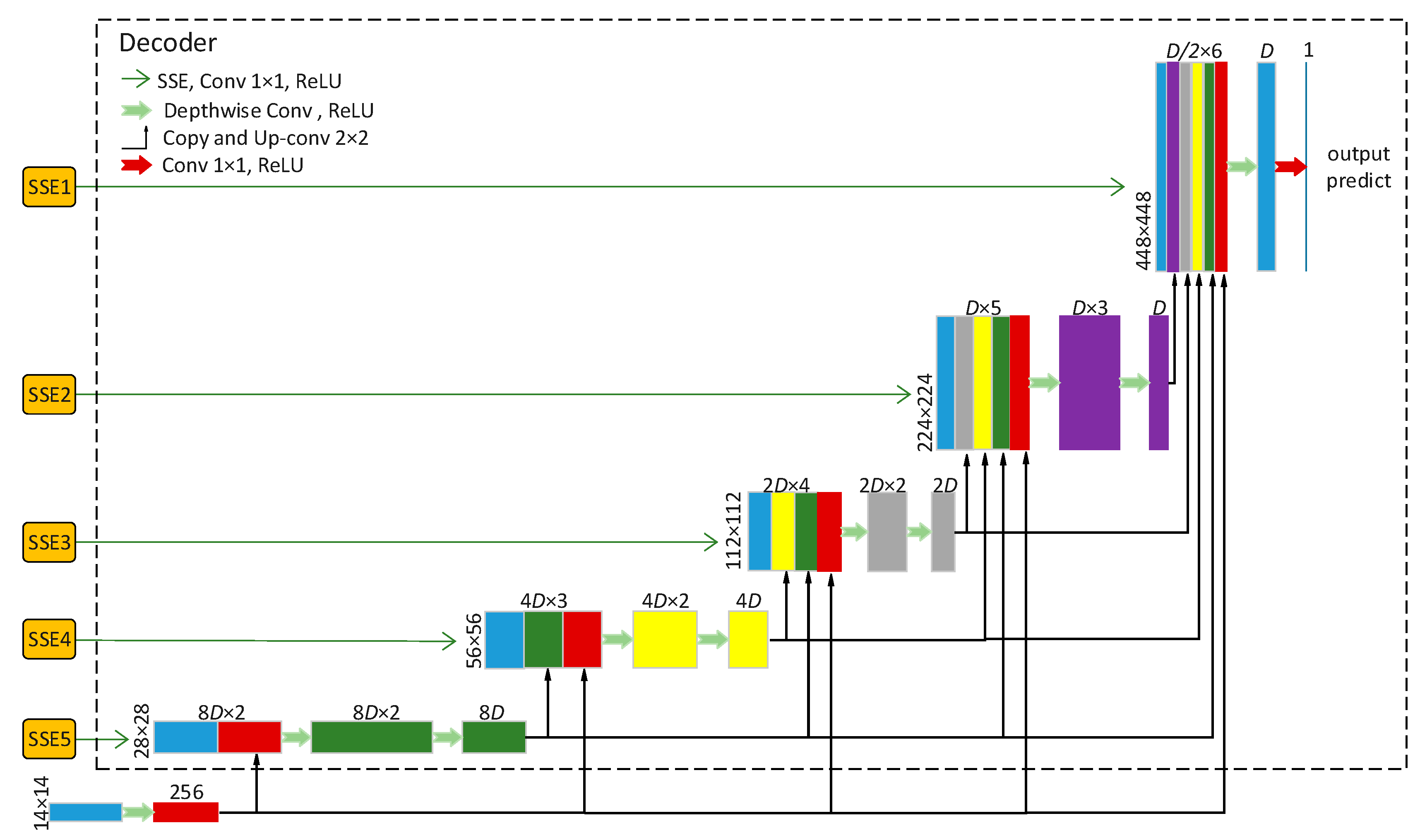
2.3. Decoder Module
2.4. Model Customization
2.5. Loss Function and Hyperparameters
3. Results and Experimental Evaluations
- (a)
- CPU: Intel(R) Core(TM) i9-7980XE;
- (b)
- GPU: NVIDIA 2080Ti GPU;
- (c)
- RAM: 32 GB.
3.1. Dataset
3.2. Evaluation Matrix
3.3. Segmentation Result
3.4. 5-Fold Cross-Validation
3.5. Ablation Study and Discussion
3.5.1. Ablation Analysis of the SSE Module
3.5.2. Ablation Analysis of the Decoder Module
3.5.3. Ablation Analysis of the Depthwise Separable Convolution
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alipour, M.; Harris, D.K. Increasing the robustness of material-specific deep learning models for crack detection across different materials. Eng. Struct. 2020, 206, 110157. [Google Scholar] [CrossRef]
- Oliveira, H.; Correia, P.L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 17th European Signal Processing Conference (EUSIPCO 2009), Glasgow, Scotland, 24–28 August 2009; IEEE: New York, NY, USA, 2009; pp. 622–626. [Google Scholar]
- Elbehiery, H.; Hefnawy, A.; Elewa, M. Surface defects detection for ceramic tiles using image processing and morphological techniques. IJREAS 2005, 2, 1307–1322. [Google Scholar]
- Georgieva, K.; Koch, C.; König, M. Wavelet transform on multi-GPU for real-time pavement distress detection. In Computing in Civil Engineering; American Society of Civil Engineers (ASCE): Reston, VA, USA, 2015; pp. 99–106. [Google Scholar]
- Zhang, A.; Li, Q.; Wang, K.C.; Qiu, S. Matched filtering algorithm for pavement cracking detection. Transp. Res. Rec. J. Transp. Res. Board 2013, 2367, 30–42. [Google Scholar] [CrossRef]
- Li, Q.; Liu, X. In Novel approach to pavement image segmentation based on neighboring difference histogram method. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; IEEE: Washington, DC, USA, 2008; pp. 792–796. [Google Scholar]
- Chun, P.J.; Izumi, S.; Yamane, T. Automatic detection method of cracks from concrete surface imagery using two-step light gradient boosting machine. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 61–72. [Google Scholar] [CrossRef]
- Li, Q.; Zou, Q.; Zhang, D.; Mao, Q. FoSA: F* seed-growing approach for crack-line detection from pavement images. Image Vis. Comput. 2011, 29, 861–872. [Google Scholar] [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognit. Lett. 2012, 33, 227–238. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network. Comput. Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Sermanet, P.; Chintala, S.; LeCun, Y. Convolutional neural networks applied to house numbers digit classification. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; IEEE: Washington, DC, USA, 2012; pp. 3288–3291. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks: Towards good practices for deep action recognition. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 20–36. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Washington, DC, USA, 2015; pp. 3431–3440. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Washington, DC, USA, 2015; pp. 1529–1537. [Google Scholar]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O.J. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Washington, DC, USA, 2016; pp. 3708–3712. [Google Scholar]
- Soukup, D.; Huber-Mörk, R. Convolutional neural networks for steel surface defect detection from photometric stereo images. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 8–10 December 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 668–677. [Google Scholar]
- Kaseko, M.S.; Ritchie, S.G. A neural network-based methodology for pavement crack detection and classification. Transp. Res. Part C Emerg. Technol. 1993, 1, 275–291. [Google Scholar] [CrossRef]
- Chou, J.; O’Neill, W.A.; Cheng, H. Pavement distress classification using neural networks. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 2–5 October 1994; IEEE: Washington, DC, USA, 1994; pp. 397–401. [Google Scholar]
- Hsu, C.-J.; Chen, C.-F.; Lee, C.; Huang, S.-M. Airport pavement distress image classification using moment invariant neural network. In Proceedings of the 22nd Asian Conference on Remote Sensing and processing (CRISP), Singapore, 5–9 November 2001; pp. 200–250. [Google Scholar]
- Nguyen, T.S.; Avila, M.; Begot, S. Automatic detection and classification of defect on road pavement using anisotropy measure. In Proceedings of the 2009 17th European Signal Processing Conference, Glasgow, UK, 24–28 August 2009; IEEE: Washington, DC, USA, 2009; pp. 617–621. [Google Scholar]
- Moussa, G.; Hussain, K. A new technique for automatic detection and parameters estimation of pavement crack. In Proceedings of the 4th International Multi-Conference on Engineering Technology Innovation (IMETI), Orlando, FL, USA, 19–22 July 2011. [Google Scholar]
- Daniel, A.; Preeja, V. Automatic road distress detection and analysis. Int. J. Comput. Appl. 2014, 101, 18–23. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Yamane, T.; Chun, P. Crack detection from a concrete surface image based on semantic segmentation using deep learning. J. Adv. Concr. Technol. 2020, 18, 493–504. [Google Scholar] [CrossRef]
- Fei, Y.; Wang, K.C.; Zhang, A.; Chen, C.; Li, J.Q.; Liu, Y.; Yang, G.; Li, B. Pixel-level cracking detection on 3D asphalt pavement images through deep-learning-based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2019, 21, 273–284. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Choi, W.; Cha, Y.-J. SDDNet: Real-time crack segmentation. IEEE Trans. Ind. Electron. 2019, 67, 8016–8025. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. 2017. Available online: https://arxiv.org/abs/1704.04861 (accessed on 26 April 2021).
- Huang, G.; Liu, Z.; Van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Washington, DC, USA, 2017; pp. 4700–4708. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention u-net: Learning where to look for the pancreas. In Proceedings of the 1st Conference on Medical Imaging with Deep Learning (MIDL 2018), Amsterdam, The Netherlands, 4–6 July 2018. [Google Scholar]
- Nair, V.; Hinton, G.E. In Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Li, H.; Xu, H.; Tian, X.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. Bridge Crack Detection Based on SSENets. Appl. Sci. 2020, 10, 4230. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Washington, DC, USA, 2018; pp. 7132–7141. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. 2016. Available online: https://arxiv.org/abs/1608.03983 (accessed on 13 August 2016).
- Fan, R.; Bocus, M.J.; Zhu, Y.; Jiao, J.; Wang, L.; Ma, F.; Cheng, S.; Liu, M. Road crack detection using deep convolutional neural network and adaptive thresholding. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IVS), Paris, France, 9–12 June 2019; IEEE: Washington, DC, USA, 2019; pp. 474–479. [Google Scholar]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.-M. How to get pavement distress detection ready for deep learning? A systematic approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AL, USA, 14–19 May 2017; IEEE: Washington, DC, USA, 2017; pp. 2039–2047. [Google Scholar]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic road crack detection using random structured forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Precision | Recall | F-Score | Dice | IoU | FLOPs/G | Parameters/M |
|---|---|---|---|---|---|---|---|
| U-Net | 0.6953 | 0.8056 | 0.7464 | 0.7185 | 0.6002 | 111.632 | 44.021 |
| SegNet | 0.6483 | 0.7402 | 0.6912 | 0.6184 | 0.5015 | 30.703 | 29.444 |
| DeepCrack | 0.6761 | 0.4489 | 0.5396 | 0.3951 | 0.3166 | 61.280 | 58.858 |
| SCCD-D4 | 0.7336 | 0.7320 | 0.7328 | 0.6959 | 0.5773 | 61.590 | 30.161 |
| SCCD-D8 | 0.7114 | 0.8467 | 0.7732 | 0.7511 | 0.6362 | 61.817 | 30.302 |
| SCCD-D16 | 0.7234 | 0.8223 | 0.7697 | 0.7485 | 0.6324 | 62.533 | 30.663 |
| SCCD-D32 | 0.7294 | 0.8296 | 0.7763 | 0.7541 | 0.6402 | 65.004 | 31.705 |
| SCCD-D64 | 0.7302 | 0.8278 | 0.7760 | 0.7495 | 0.6372 | 74.108 | 35.066 |
| Models | m-Train_Loss | m-Valid_Loss | m-Precision | m-Recall | m-F-Score | m-Dice | m-IoU |
|---|---|---|---|---|---|---|---|
| U-Net | 0.0245 | 0.0284 | 0.6901 | 0.8069 | 0.7439 | 0.7160 | 0.5967 |
| SegNet | 0.0275 | 0.0404 | 0.6349 | 0.7592 | 0.6908 | 0.6226 | 0.5061 |
| SCCD-D16 | 0.0248 | 0.0363 | 0.7161 | 0.8246 | 0.7103 | 0.6462 | 0.5320 |
| SCCD-D32 | 0.0209 | 0.0270 | 0.7199 | 0.8300 | 0.7710 | 0.7457 | 0.6316 |
| SCCD-D64 | 0.0203 | 0.0270 | 0.7192 | 0.8320 | 0.7714 | 0.7441 | 0.6308 |
| Models | m-Precision | m-Recall | m-F-Score | m-Dice | m-IoU | FLOPs/G | Parameters/M |
|---|---|---|---|---|---|---|---|
| None-SSE | 0.7153 | 0.8024 | 0.7563 | 0.7364 | 0.6181 | 64.997 | 30.875 |
| SSE1 | 0.7192 | 0.8084 | 0.7612 | 0.7409 | 0.6230 | 64.997 | 31.269 |
| SSE2 | 0.7139 | 0.8046 | 0.7566 | 0.7379 | 0.6187 | 64.997 | 31.203 |
| SSE3 | 0.7126 | 0.8168 | 0.7612 | 0.7387 | 0.6211 | 64.998 | 30.957 |
| SSE4 | 0.7326 | 0.8017 | 0.7656 | 0.7489 | 0.6316 | 64.998 | 30.895 |
| SSE5 | 0.7313 | 0.8046 | 0.7662 | 0.7465 | 0.6297 | 65.000 | 30.880 |
| Fully-SSE | 0.7294 | 0.8296 | 0.7763 | 0.7541 | 0.6402 | 65.004 | 31.705 |
| Models | m-Precision | m-Recall | m-F-Score | m-Dice | m-IoU | FLOPs/G | Parameters/M |
|---|---|---|---|---|---|---|---|
| Normal Decoder | 0.6929 | 0.8150 | 0.7489 | 0.7232 | 0.6040 | 111.639 | 45.245 |
| Dense Decoder | 0.7294 | 0.8296 | 0.7763 | 0.7541 | 0.6402 | 65.004 | 31.705 |
| Models | m-Precision | m-Recall | m-F-Score | m-Dice | m-IoU | FLOPs/G | Parameters/M |
|---|---|---|---|---|---|---|---|
| Normal Conv | 0.7281 | 0.8112 | 0.7674 | 0.7485 | 0.6310 | 83.786 | 39.499 |
| D-S Conv | 0.7294 | 0.8296 | 0.7763 | 0.7541 | 0.6402 | 65.004 | 31.705 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Yue, Z.; Liu, J.; Wang, Y.; Cai, H.; Cui, K.; Chen, X. SCCDNet: A Pixel-Level Crack Segmentation Network. Appl. Sci. 2021, 11, 5074. https://doi.org/10.3390/app11115074
Li H, Yue Z, Liu J, Wang Y, Cai H, Cui K, Chen X. SCCDNet: A Pixel-Level Crack Segmentation Network. Applied Sciences. 2021; 11(11):5074. https://doi.org/10.3390/app11115074
Chicago/Turabian StyleLi, Haotian, Zhuang Yue, Jingyu Liu, Yi Wang, Huaiyu Cai, Kerang Cui, and Xiaodong Chen. 2021. "SCCDNet: A Pixel-Level Crack Segmentation Network" Applied Sciences 11, no. 11: 5074. https://doi.org/10.3390/app11115074
APA StyleLi, H., Yue, Z., Liu, J., Wang, Y., Cai, H., Cui, K., & Chen, X. (2021). SCCDNet: A Pixel-Level Crack Segmentation Network. Applied Sciences, 11(11), 5074. https://doi.org/10.3390/app11115074